
Abstract
Background
Artificial intelligence has been proven to improve the identification of various maxillofacial lesions. The aim of the current study is two-fold: to assess the performance of four deep learning models (DLM) in external root resorption (ERR) identification and to assess the effect of combining feature selection technique (FST) with DLM on their ability in ERR identification.
Methods
External root resorption was simulated on 88 extracted premolar teeth using tungsten bur in different depths (0.5 mm, 1 mm, and 2 mm). All teeth were scanned using a Cone beam CT (Carestream Dental, Atlanta, GA). Afterward, a training (70%), validation (10%), and test (20%) dataset were established. The performance of four DLMs including Random Forest (RF) + Visual Geometry Group 16 (VGG), RF + EfficienNetB4 (EFNET), Support Vector Machine (SVM) + VGG, and SVM + EFNET) and four hybrid models (DLM + FST: (i) FS + RF + VGG, (ii) FS + RF + EFNET, (iii) FS + SVM + VGG and (iv) FS + SVM + EFNET) was compared. Five performance parameters were assessed: classification accuracy, F1-score, precision, specificity, and error rate. FST algorithms (Boruta and Recursive Feature Selection) were combined with the DLMs to assess their performance.
Results
RF + VGG exhibited the highest performance in identifying ERR, followed by the other tested models. Similarly, FST combined with RF + VGG outperformed other models with classification accuracy, F1-score, precision, and specificity of 81.9%, weighted accuracy of 83%, and area under the curve (AUC) of 96%. Kruskal Wallis test revealed a significant difference (p = 0.008) in the prediction accuracy among the eight DLMs.
Conclusion
In general, all DLMs have similar performance on ERR identification. However, the performance can be improved by combining FST with DLMs.
Similar content being viewed by others

Introduction
Early detection of ERR is crucial as it may lead to progressive, irreversible damage and tooth loss in severe cases [1, 2]. ERR is commonly revealed incidentally during radiographic examination though the prevalence has been reported as high as 28.8% [3, 4]. The periapical radiograph is one of the radiographic examinations commonly used to identify ERR. Although it has a high resolution, this image has several limitations, such as superimposition of two-dimensional image that may underestimate the true extent of ERR [5, 6]. It has been reported that CBCT is superior to intra-oral periapical radiographs in detecting ERR because it permits three-dimensional evaluation [6,7,8,9,10]. However, assessment of ERR on CBCT can be influenced by observer performance and viewing condition. A computer-aided tool may improve the identification and reduce the time in identifying pathologies such as ERR [11].
In dentistry, machine learning (ML), a subfield of artificial intelligence (AI) based tools, has been developed to automate the identification of oral and maxillofacial pathologies such as ERR [12]. Random Forest (RF) and Support Vector Machine (SVM) classifiers were the high-performing ML algorithms commonly utilized for image classification tasks in dentistry [13,14,15]. The use of multilayer convolutional neural networks (CNN) contributes to deep learning (DL) methods that can learn image features and perform classification tasks [16,17,18]. However, CNN requires high computational costs and needs to adapt a considerable number of parameters [19]. To address this issue, several pre-trained models have been established with pre-defined network architectures. To overcome the issue of overfitting due to limited sample data for deep learning training, a transfer learning with CNN had been recommended for small sample size studies [20]. Transfer learning model based on Visual Geometry Group with 16-layer (VGG16) and EfficientNetB4 has been reported to achieve excellent performance on several image classification tasks [19, 21, 22]. The ensemble of pre-trained architectures such as VGG16 and EfficientNetB4 with machine learning algorithms (RF and SVM) have resulted in high performance of classification tasks [19].
The development of machine learning models that incorporate medical diagnostic images for disease classification has encountered significant challenges resulting from the complex and large number of features present in these images [23]. To address this challenge, a process known as the feature selection technique (FST) was introduced. The process is specifically designed to extract the most relevant and significant subset from the original set of features [24]. Feature selection technique has been implemented to classify carious cavities with a reported high accuracy of 96% [25]. Another study on FST for breast cancer classification found that using conventional FST improved classification accuracy by 51% [26]. A novel FST wrapper method (Boruta algorithm) has recently been implemented to improve the performance of RF classifiers in classification models [27]. Additionally, to improve the performance of SVM classifiers, the RFE algorithm was widely used as a feature selection method [28, 29].
The current study utilised an innovative approach that combines transfer learning using VGG16 and EFNetB4 architectures. This novel methodology incorporates the integration of Support Vector Machine (SVM) and Random Forest (RF) classifiers to improve the accuracy of ERR classification. In this study, four deep learning models, which consist of a hybrid between ML algorithms (RF and SVM) with pre-trained DL architectures (VGG16 and EfficientnetB4) were developed for the identification and classification of ERR. Feature selection methods were implemented on all models to optimize the classification performance of ERR resulting in four additional optimised models. Therefore, this study aims to (1) evaluate the accuracy of deep learning models (DLMs) in ERR identification, (2) assess the effect of FST on DLM performance.
Materials and methods
Study protocol
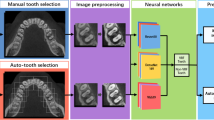
This study assessed the effect of feature selection technique (FST) on DLM performance in classifying ERR lesions. In the first stage of this study, image preprocessing was performed using Contrast-Limited Adaptive Histogram Equalization (CLAHE) filter. Then, image classification analysis was conducted using two pretrained deep convolutional neural networks (CNN), namely, EfficientNetB4 [30] and VGG16. These two deep CNNs were ensemble with two machine learning classifiers; Random Forest (RF) and Support Vector Machine (SVM) to perform ERR classification. As a result, four DLMs were developed; RF with VGG16 (RF + VGG), RF with EfficientnetB4 (RF + EFNET), SVM with VGG16 (SVM + VGG) and SVM with EfficientnetB4 (SVM + EFNET) in the first stage. In the second stage, a feature selection algorithm (Boruta and RFE) was employed to generate four new optimized DLMs (FS + RF + VGG, FS + RF + EFNET, FS + SVM + VGG and FS + SVM + EFNET) [30]. The block diagram of the proposed model as discussed in the study protocol is given in Fig. 1. The Institutional Review Board of the Medical Ethics Committee Faculty of Dentistry University of Malaya (DF RD2030/0139 (L)) has reviewed and approved this study protocol.

Proposed model block diagram
Dataset
A total of 88 extracted premolars were collected from the Faculty of Dentistry, University of Malaya. The inclusion criteria set for this study were absence of root destruction, complete root formation, absence of caries or abrasions in the cervical region, and no endodontic treatment [31]. Tungsten burrs of various sizes (0.5 mm, 1.0 mm, and 2.0 mm) were used to simulate different depths ERR on each tooth. All teeth were scanned with a CBCT machine (CS 9000 CBCT, Carestream Dental, Atlanta, GA). The acquisition settings were 65 kVp, 5 mA, 10.8 S 5 × 3 cm F.O.V., 0.076 mm isotropic voxel size. In total, 2125 2D slices of CBCT images were obtained. All CBCT datasets were converted to Digital Imaging and Communication in Medicine (DICOM) format. The sample size was calculated based on a previous comparable study [26] by a priori power analysis in G*power 3.1.9.7, assuming an independent t-test dataset with a power of 80% and significance of 5%.
Ground truth labelling
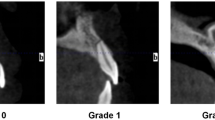
Data analysis for ERR detection and labelling were performed by an oral and maxillofacial radiologist with five years of experience analyzing CBCT images and was considered as the ground truth. Each annotation was further classified into four groups of depths. All CBCT data was visualized on a Dell laptop (1920 × 1080 pixels, Dell Latitude E7450; Dell, Austin, TX). The ground truths dataset was prepared by segmenting the CBCT images (DICOM format) using a third-party A.I. tool (Makesense.AI) [32]. Teeth were grouped as 0 (ERR depth = 0.5 mm), 1 (ERR depth = 1.0 mm), 2 (ERR depth = 2.0 mm), 3 (no ERR). Figure 2 shows sample images from the dataset collected from the Faculty of Dentistry, Universiti Malaya.

External root resorption sample images
AI Network architecture and training
Image preprocessing
In Phase 1, the extraction of region of interest (ROI) and image enhancement was performed (Fig. 3). A bounding box of 160 × 320 pixels was assigned to all 2D slices, with the tooth centered in the box and converted into Portable Network Graphic format. All sagittal slices were used to train and test (ROI) from these bounding boxes. The ROI obtained from a single tooth ranged from 17 to 80 slices resulting in a total of 2125 number of ROI extracted from the CBCT volumes (training and validation 1700, test 425). Then, the CLAHE filter was applied followed by an adjustment in image intensity before the pre-processing procedure.

CBCT data image processing
Image classification
In Phase 2, four main DLMs (RF + VGG, RF + EFNET, SVM + VGG, and SVM + EFNET) were implemented to classify ERR lesions (Fig. 1). Subsequently, all four models were optimized using FST to produce four new enhanced DLMs (FS + RF + VGG, FS + RF + EFNET, FS + SVM + VGG and FS + SVM + EFNET). Training and testing ratios of 70:30 was selected as an optimum ratio for images classification as adopted in previous DLMs studies [33, 34]. Two-dimensional CBCT images of ERR were entered into a transfer learning with CNN models. In addition, these images were randomly distributed into training (70%), validation (10%) and test (20%) dataset. Subsequently, the ERR lesions observed in the images were classified as 0, 1,2 or 3 as the output, according to the depth of ERR in the images. In VGG16 and EfficientnetB4 systems, 555,328 and 18,764,579 parameters were utilized (Tables 1 and 2) [30]. Multiclass classification was performed by all models using Tensorflow and Keras phyton deep learning library.
Performance evaluation
The model’s performance was evaluated based on the calculation of accuracy. A confusion matrix summarized the prediction results on a classification task [35]. Five metrics were used to demonstrate the classification model’s performance: classification accuracy, F1-score, precision, specificity, and error rate [36]. Consequently, 70 values (7 × 10) were measured. The mean values for each group were calculated. Due to the non-normal distribution of the data, the Kruskal Wallis test, a non-parametric method, was employed to evaluate the difference in accuracy among all DLMs. The analysis was conducted using a statistical package for social sciences software (SPSS) 27.0 (IBM Corporation, Armonk, NY, USA). Following the Kruskal Wallis test for overall group differences, post-hoc analyses were conducted to examine pairwise differences between groups. Dunn’s post-hoc test was employed to identify specific pairs of groups with significant differences. Additionally, an independent t-test was conducted to assess any significant difference between the results obtained with and without FST. The metric evaluation was performed according to the following formula using confusion matrix in Table 3.
Where, TP = True Positive, FN = False Negative, TN = True Negative and FP = False Positive.
Results
The multiclass classification models’ performances were presented in Table 4. The highest performance was achieved by FS + RF + VGG model with overall accuracy of 81.9%, weighted accuracy of 83% and 81.9% F1-score, precision, and specificity. The error rate for FS + RF + VGG was 18%, and AUC of 96%. In contrast the lowest performing model was RF + EFNET with an overall accuracy of 55.3%, weighted accuracy of 61%, and 55.3% F1-score, precision, specificity. The error rate of RF + EFNET was 45%, and AUC of 84%. Following the implementation of FST, the highest accuracy improvement was achieved by SVM + EFNET model (4.7%) while the lowest improvement was recorded by the SVM + VGG model (1.7%). Of all eight DLMs, the highest AUC was recorded by FS + RF + VGG (96%), while the lowest was by SVM + VGG (81%) (Fig. 4). The Kruskal Wallis test showed a significant difference, with the p-value for the H-test being 0.008, which is less than the significant level at α = 0.05 (p < 0.05). This study indicated that there is a significant difference in accuracy between different models (H (7) = 19.119; p < 0.05) (Table 5). In Table 6, pairwise comparisons using Dunn’s post-hoc test among DLMs indicated a significant difference only between RF + EFNET and FS + RF + VGG (p < 0.05). Subsequent comparisons across other DLMs revealed no significant differences (p > 0.05). Furthermore, independent t-test showed no significant difference in the classification accuracy among allDLMs before and after incorporating FST (Table 7). The prediction accuracy of all eight DLMs were summarized in 4 × 4 confusion matrices as shown in Fig. 5.

AUC of eight trained models

Confusion matrices showing prediction accuracy of all DLMS
Discussion
Precise detection of ERR lesions is crucial in preventing inaccurate management of this lesion which may subsequently result in irreversible root surface loss, discomfort, and non-vital tooth [1]. In this study, the performance of four DLMs on ERR identification were assessed using five parameters (classification accuracy, F1-score, precision, specificity, and AUC). Subsequently, the effect of FST on the DLMs performance was evaluated. The present study provides valuable insights into the potential of advanced machine learning techniques in improving ERR identification. To the best of our knowledge, the present study is the first to report the multiclass classification of ERR based on different depths of the lesions on CBCT images.
Deep learning-based algorithms play a significant role in developing an automated computer-aided diagnosis system for medical and dental radiographic image annotation, segmentation, and classification [19, 37,38,39]. Most deep learning algorithms require balance [40] and large data [41] to optimize an enormous number of weighting parameters in deep CNN. Hence, the current study introduced a transfer learning approach using pre-trained deep CNN algorithms to extract features from ERR lesions. Recent studies have reported that classification models incorporating pre-trained VGG16 and EfficientNetB4 architectures displayed robust performance in medical image analysis [19, 42]. The highest DLM accuracy of the current study was comparable to previous studies that had employed VGG16 for facial feature and jaw tumor classification [43, 44]. In the present study RF + EFNET demonstrated the lowest performance accuracy (0.55) than the other tested DLMs (RF + VGG, SVM + VGG, SVM + EFNET) i.e., more than 0.72. The performance of RF + EFNET in this study was even lower than previous ERR studies using panoramic radiograph [45, 46]. This can be attributed to a lack of compatibility between the RF classifier and the EfficientNetB4 algorithm used in this study. In general, DLMs had demonstrated a promising potential in assisting the identification and classification of ERR based on the lesion’s depth.
Feature selection technique (FST) can improve classification model performance by identifying and selecting the most informative features within the dataset [29, 47]. The utilization of FST, especially Burota and RFE, had decreased the risks associated with overfitting and improved the interpretability of medical image analysis [23, 48, 49]. The present study observed an increase in DLMs accuracy improvements (2–4.7%) when FST were combined during the post-processing phase. Similarly, high accuracy improvements (10% and 5.8%) were reported by previous studies using Burota [50] and RFE [29]. The low accuracy improvement that was observed in the current study might be due to imbalanced classes of the dataset, with a greater amount of data in 0.5 and 1.0 mm classes [51]. All DLMs in this study demonstrated improvement in classification accuracy. A study using FST on neurodegenerative lesions classification reported a selective DLM accuracy improvement (CfsSubsetEval, WrapperSubsetEval, ChiSquaredAttributeEval, and ClassifierAttributeEval) [52]. Therefore, it can be assumed that accuracy improvement might be influenced by the compatibility of FST and hybrid DLMs utilized in this study, as reported by Bhalaji et al. and Albashish et al. [53, 54].
In this present study, DLM systems have demonstrated considerable performance in identifying ERR. The main limitation was identified during conducting this study, namely the small CBCT dataset. To avoid overfitting due to small sample size, this study had utilized a high-quality training dataset specifically to emphasize ERR depths [55]. Furthermore, data augmentation [56] was performed to increase the training dataset, and transfer learning approach (VGG16 and EfficienNetB4) was implemented to enhance the performance of DLMs [57]. This study had exclusively utilized DLMs in identifying ERR on extracted premolar teeth. However, the ability of these newly developed models should be tested on real data before clinical applications. Although the experimental nature of this study might compromise the ability of these DLMs on real data [58], it allows standardized preparation techniques for ERR and CBCT scanning parameters [59]. Future research should focus on three main areas: expanding the dataset, exploring the ability of various FSTs, and conducting prospective clinical trials.
Conclusions
The present study explored the potential of eight newly developed DLMs in identifying ERR on CBCT images. The application of deep learning-based algorithms on CBCT images had demonstrated promising results for future automated ERR identification. Integrating compatible FST with deep learning-based models may enhance the performance of all DLMs in identifying ERR lesions.
Availability of data and materials
The datasets used and analysed during the current study are available from the corresponding author on reasonable request.
References
Heboyan A, Avetisyan A, Karobari MI, Marya A, Khurshid Z, Rokaya D, Zafar MS. Fernandes GVdO: tooth root resorption: a review. Sci Prog. 2022;105(3):00368504221109217.
Villefrance JS, Wenzel A, Kirkevang L-L, Væth M, Christensen J, Matzen LH. Early detection of external cervical resorption in posterior teeth: a radiographic, cross-sectional study of an adolescent population. Dentomaxillofacial Radiol, 0(0):20220223.
Tsesis I, Fuss Z, Rosenberg E, Taicher S. Radiographic evaluation of the prevalence of root resorption in a Middle Eastern population. Quintessence Int. 2008;39(2):e40-4.
Dao V, Mallya SM, Markovic D, Tetradis S, Chugal N. Prevalence and characteristics of Root Resorption Identified in Cone-Beam Computed Tomography scans. J Endod. 2023;49(2):144–54.
Matny LE, Ruparel NB, Levin MD, Noujeim M, Diogenes A. A volumetric assessment of external cervical resorption cases and its correlation to classification, treatment planning, and expected prognosis. J Endod. 2020;46(8):1052–8.
de Souza DV, Schirru E, Mannocci F, Foschi F, Patel S. External cervical resorption: a comparison of the diagnostic efficacy using 2 different cone-beam computed tomographic units and periapical radiographs. J Endod. 2017;43(1):121–5.
Creanga AG, Geha H, Sankar V, Teixeira FB, McMahan CA, Noujeim M. Accuracy of digital periapical radiography and cone-beam computed tomography in detecting external root resorption. Imaging Sci Dentistry. 2015;45(3):153–8.
Yi J, Sun Y, Li Y, Li C, Li X, Zhao Z. Cone-beam computed tomography versus periapical radiograph for diagnosing external root resorption: a systematic review and meta-analysis. Angle Orthod. 2016;87(2):328–37.
Jawad Z, Carmichael F, Houghton N, Bates C. A review of cone beam computed tomography for the diagnosis of root resorption associated with impacted canines, introducing an innovative root resorption scale. Oral Surg Oral Med Oral Pathol Oral Radiol. 2016;122(6):765–771.
Hellyer P. Root resorption. Br Dent J. 2023;234(7):517–7.
Yang P, Guo X, Mu C, Qi S, Li G. Detection of vertical root fractures by cone-beam computed tomography based on deep learning. Dentomaxillofacial Radiol. 2023;52(3):20220345.
Alqahtani KA, Jacobs R, Shujaat S, Politis C, Shaheen E. Automated three-dimensional quantification of external root resorption following combined orthodontic-orthognathic surgical treatment. A validation study. J Stomatol Oral Maxillofac Surg. 2023;124(1S):101289.
Arsiwala-Scheppach LT, Chaurasia A, Müller A, Krois J, Schwendicke F. Machine learning in Dentistry: a scoping review. J Clin Med. 2023;12(3):937.
Hung KF, Ai QYH, Wong LM, Yeung AWK, Li DTS, Leung YY. Current applications of Deep Learning and Radiomics on CT and CBCT for Maxillofacial diseases. Diagnostics. 2023;13(1):110.
Hung M, Voss MW, Rosales MN, Li W, Su W, Xu J, Bounsanga J, Ruiz-Negrón B, Lauren E, Licari FW. Application of machine learning for diagnostic prediction of root caries. Gerodontology. 2019;36(4):395–404.
Xue Y, Zhang R, Deng Y, Chen K, Jiang T. A preliminary examination of the diagnostic value of deep learning in hip osteoarthritis. PLoS ONE. 2017;12(6):e0178992.
Ayidh Alqahtani K, Jacobs R, Smolders A, Van Gerven A, Willems H, Shujaat S, Shaheen E. Deep convolutional neural network-based automated segmentation and classification of teeth with orthodontic brackets on cone-beam computed-tomographic images: a validation study. Eur J Orthod. 2022;45(2):169–74.
Ishtiaq U, Abdullah ERMF, Ishtiaque Z. A hybrid technique for Diabetic Retinopathy Detection based on ensemble-optimized CNN and texture features. Diagnostics. 2023;13(10):1816.
Albashish D, Al-Sayyed R, Abdullah A, Ryalat MH, Almansour NA. Deep CNN Model based on VGG16 for Breast Cancer Classification. In: 2021 International Conference on Information Technology (ICIT): 14–15 July 2021 2021; 2021: 805–810.
Tammina S. Transfer learning using vgg-16 with deep convolutional neural network for classifying images. Int J Sci Res Publications (IJSRP). 2019;9(10):143–50.
Ye Z, Qian JM, Hosny A, Zeleznik R, Plana D, Likitlersuang J, Zhang Z, Mak RH, Aerts HJ, Kann BH. Deep learning–based detection of Intravenous contrast Enhancement on CT scans. Radiology: Artif Intell. 2022;4(3):e210285.
Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, Van Der Laak JA, Van Ginneken B. Sánchez CI: A survey on deep learning in medical image analysis. Med Image Analysis. 2017;42:60–88.
Remeseiro B, Bolon-Canedo V. A review of feature selection methods in medical applications. Comput Biol Med. 2019;112:103375.
Cai J, Luo J, Wang S, Yang S. Feature selection in machine learning: a new perspective. Neurocomputing. 2018;300:70–9.
Lakshmi MM, Chitra P. Classification of Dental Cavities from X-ray images using Deep CNN algorithm. In: 2020 4th International Conference on Trends in Electronics and Informatics (ICOEI)(48184): 15–17 June 2020 2020; 2020: 774–779.
Lindqvist N, Price T. Evaluation of feature selection methods for machine learning classification of breast Cancer. In.; 2018.
Kursa MB, Rudnicki WR. Feature selection with the Boruta package. J Stat Softw. 2010;36:1–13.
Xia J, Sun L, Xu S, Xiang Q, Zhao J, Xiong W, Xu Y, Chu S. A Model Using Support Vector Machines Recursive Feature Elimination (SVM-RFE) Algorithm to Classify Whether COPD Patients Have Been Continuously Managed According to GOLD Guidelines. Int J Chron Obstruct Pulmon Dis. 2020;15:2779-86.
Lu X, Yang Y, Wu F, Gao M, Xu Y, Zhang Y, Yao Y, Du X, Li C, Wu L, et al. Discriminative analysis of schizophrenia using support vector machine and recursive feature elimination on structural MRI images. Med (Baltim). 2016;95(30):e3973.
Tan M, Le Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In: International conference on machine learning: 2019: PMLR; 2019: 6105–6114.
Deliga Schröder ÂG, Westphalen FH, Schröder JC, Fernandes Â, Westphalen VPD. Accuracy of Digital Periapical Radiography and cone-beam computed tomography for diagnosis of natural and simulated External Root Resorption. J Endod. 2018;44(7):1151–8.
Desai M, Mewada H. A novel approach for yoga pose estimation based on in-depth analysis of human body joint detection accuracy. PeerJ Comput Sci. 2023;9:e1152.
Liu H, Cocea M. Semi-random partitioning of data into training and test sets in granular computing context. Granul Comput. 2017;2:357–86.
Emara HM, Shoaib MR, Elwekeil M, El-Shafai W, Taha TE, El‐Fishawy AS, El‐Rabaie ESM, Alshebeili SA, Dessouky MI. Abd El‐Samie FE: deep convolutional neural networks for COVID‐19 automatic diagnosis. Microsc Res Tech. 2021;84(11):2504–16.
Caffo B. Developing Data products in R. R Softw. 2015;52.
Lian L, Zhu T, Zhu F, Zhu H. Deep learning for caries detection and classification. Diagnostics. 2021;11(9):1672.
Alkurdy NH, Aljobouri HK, Wadi ZK. Ultrasound renal stone diagnosis based on convolutional neural network and vgg16 features. Int J Electr Comput Eng. 2023;13(3):3440–8.
Anwar SM, Majid M, Qayyum A, Awais M, Alnowami M, Khan MK. Medical Image Analysis using Convolutional neural networks: a review. J Med Syst. 2018;42(11):226.
Khan HA, Haider MA, Ansari HA, Ishaq H, Kiyani A, Sohail K, Muhammad M, Khurram SA. Automated feature detection in dental periapical radiographs by using deep learning. Oral Surg Oral Med Oral Pathol Oral Radiol. 2021;131(6):711–20.
Sun Y, Wong AK, Kamel MS. Classification of imbalanced data: a review. Int J Pattern Recognit Artif Intell. 2009;23(04):687–719.
Wiestler B, Menze B. Deep learning for medical image analysis: a brief introduction. Neuro-oncology Adv. 2020;2(Supplement4):iv35–iv41.
Chhabra M, Kumar R. An advanced VGG16 architecture-based deep learning model to detect pneumonia from medical images. In: Emergent Converging Technologies and Biomedical Systems: Select Proceedings of ETBS 2021 edn.: Springer; 2022: 457–471.
Lin H-H, Chiang W-C, Yang C-T, Cheng C-T, Zhang T, Lo L-J. On construction of transfer learning for facial symmetry assessment before and after orthognathic surgery. Comput Methods Programs Biomed. 2021;200:105928.
Poedjiastoeti W, Suebnukarn S. Application of Convolutional Neural Network in the Diagnosis of Jaw Tumors. hir. 2018;24(3):236–241.
Tamura K, Kamiya T, Oda M, Tanaka T, Morimoto Y. Detection of the root resorption from panoramic X-ray images using deep metric learning. In: 2021 21st International Conference on Control, Automation and Systems (ICCAS): 12–15 Oct. 2021 2021; 2021: 1800–1803.
Tamura K, Kamiya T, Oda M, Morimoto Y. Classification the Root Resorption from Panoramic X-ray Image Using Center Loss Redefined in Angle Space. In: 2022 22nd International Conference on Control, Automation and Systems (ICCAS): 27 Nov.-1 Dec. 2022 2022; 2022: 570–573.
Chen R-C, Dewi C, Huang S-W, Caraka RE. Selecting critical features for data classification based on machine learning methods. J Big Data. 2020;7(1):52.
Tang R, Zhang X. CART decision tree combined with Boruta feature selection for medical data classification. In: 2020 5th IEEE International Conference on Big Data Analytics (ICBDA): 2020: IEEE; 2020:80–84.
Gupta YS, Finkelstein M, Manna S, Toussie D, Bernheim A, Little BP, Concepcion J, Maron SZ, Jacobi A, Chung M, et al. Coronary artery calcification in COVID-19 patients: an imaging biomarker for adverse clinical outcomes. Clin Imaging. 2021;77:1–8.
Ali NM, Aziz N, Besar R. Comparison of microarray breast cancer classification using support vector machine and logistic regression with LASSO and boruta feature selection. Indones J Electr Eng Comput Sci. 2020;20(2):712–9.
Thabtah F, Hammoud S, Kamalov F, Gonsalves A. Data imbalance in classification: experimental evaluation. Inf Sci. 2020;513:429–41.
Álvarez JD, Matias-Guiu JA, Cabrera-Martín MN, Risco-Martín JL, Ayala JL. An application of machine learning with feature selection to improve diagnosis and classification of neurodegenerative disorders. BMC Bioinformatics. 2019;20(1):1–12.
Bhalaji N, Kumar KS, Selvaraj C. Empirical study of feature selection methods over classification algorithms. Int J Intell Syst Technol Appl. 2018;17(1–2):98–108.
Albashish D, Hammouri AI, Braik M, Atwan J, Sahran S. Binary biogeography-based optimization based SVM-RFE for feature selection. Appl Soft Comput. 2021;101:107026.
Cho J, Lee K, Shin E, Choy G, Do S. How much data is needed to train a medical image deep learning system to achieve necessary high accuracy? arXiv Preprint arXiv:151106348 2015.
Shorten C, Khoshgoftaar TM. A survey on image data augmentation for deep learning. J big data. 2019;6(1):1–48.
Zhang P, Zhong Y, Deng Y, Tang X, Li X. A survey on deep learning of small sample in biomedical image analysis. arXiv Preprint arXiv:190800473 2019.
Keek SA, Leijenaar RT, Jochems A, Woodruff HC. A review on radiomics and the future of theranostics for patient selection in precision medicine. Br J Radiol. 2018;91(1091):20170926.
Yip SS, Aerts HJ. Applications and limitations of radiomics. Phys Med Biol. 2016;61(13):R150.
Acknowledgements
The authors would like to thank the Faculty of Dentistry, Universiti Malaya, Kuala Lumpur and the Centre of Oral and Maxillofacial Diagnostic and Medicine Studies, Faculty of Dentistry, Universiti Teknologi MARA, Sungai Buloh, Malaysia.
Funding
This work was supported by Fundamental Research Grant Scheme (FRGS), Ministry of Higher Education, Malaysia (Grant: FP1212020/FRGS/1/2020/SKK0/UM/02/23).
Author information
Authors and Affiliations
Contributions
N.I. developed the concept and design of the study and N.R. conducted sample collection, data acquisition, analysis and writing the manuscript. S.M. was responsible for performing model development, training, and validation of the classification models. E.R. supervised the classification model development and R.R was involved in drafting the manuscript. N. I. and A.A. secured the funding for the study. M.G. assisted during data analysis. All authors revised and approved the manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Ethical approval for this study was obtained from the Institutional Review Board of the Medical Ethics Committee Faculty of Dentistry University of Malaya (DF RD2030/0139 (L)).
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Reduwan, N.H., Abdul Aziz, A.A., Mohd Razi, R. et al. Application of deep learning and feature selection technique on external root resorption identification on CBCT images. BMC Oral Health 24, 252 (2024). https://doi.org/10.1186/s12903-024-03910-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12903-024-03910-w