
Abstract
Purpose
To predict the 1p/19q molecular status of Lower-grade glioma (LGG) patients nondestructively, this study developed a deep learning (DL) approach using radiomic to provide a potential decision aid for clinical determination of molecular stratification of LGG.
Methods
The study retrospectively collected images and clinical data of 218 patients diagnosed with LGG between July 2018 and July 2022, including 155 cases from The Cancer Imaging Archive (TCIA) database and 63 cases from a regional medical centre. Patients' clinical data and MRI images were collected, including contrast-enhanced T1-weighted images and T2-weighted images. After pre-processing the image data, tumour regions of interest (ROI) were segmented by two senior neurosurgeons. In this study, an Ensemble Convolutional Neural Network (ECNN) was proposed to predict the 1p/19q status. This method, consisting of Variational Autoencoder (VAE), Information Gain (IG) and Convolutional Neural Network (CNN), is compared with four machine learning algorithms (Random Forest, Decision Tree, K-Nearest Neighbour, Gaussian Neff Bayes). Fivefold cross-validation was used to evaluate and calibrate the model. Precision, recall, accuracy, F1 score and area under the curve (AUC) were calculated to assess model performance.
Results
Our cohort comprises 118 patients diagnosed with 1p/19q codeletion and 100 patients diagnosed with 1p/19q non-codeletion. The study findings indicate that the ECNN method demonstrates excellent predictive performance on the validation dataset. Our model achieved an average precision of 0.981, average recall of 0.980, average F1-score of 0.981, and average accuracy of 0.981. The average area under the curve (AUC) for our model is 0.994, surpassing that of the other four traditional machine learning algorithms (AUC: 0.523–0.702). This suggests that the model based on the ECNN algorithm performs well in distinguishing the 1p/19q molecular status of LGG patients.
Conclusion
The deep learning model based on conventional MRI radiomic integrates VAE and IG methods. Compared with traditional machine learning algorithms, it shows the best performance in the prediction of 1p/19q molecular co-deletion status. It may become a potentially effective tool for non-invasively and effectively identifying molecular features of lower-grade glioma in the future, providing an important reference for clinicians to formulate individualized diagnosis and treatment plans.
Similar content being viewed by others

Introduction
Glioma is the most common primary malignant tumor in the central nervous system. Although it accounts for less than 2% of all cancers, it is closely related to a high mortality rate [1, 2]. With the update of the fifth edition of the central nervous system tumor classification by the World Health Organization (WHO) in 2021, we can see that molecular markers/genes have played an increasingly important role in the diagnosis and treatment of gliomas in recent years [3]. In the past, low-grade gliomas usually were referred to grade 2 diffuse gliomas, and high-grade gliomas were referred to grade 3 and 4 gliomas. In 2019, the Society for Neuro-Oncology (SNO) and the European Association of Neuro-Oncology (EANO) proposed a new term"lower grade glioma"(LGG), which refers to gliomas graded 2 and 3 by WHO [4, 5]. Specifically, LGG includes astrocytoma and oligodendroglioma, where IDH mutation with 1p/19q nocodeletion is considered a characteristic molecular marker of astrocytoma, while 1p/19q codeletion is regarded as a characteristic marker of oligodendroglioma.
The 1p/19q codeletion refers to the simultaneous loss of the short arm (1p) of chromosome 1 and the long arm (19q) of chromosome 19. Previous studies have shown that glioma patients with 1p/19q codeletion are more sensitive to radiotherapy and chemotherapy and have significantly prolonged overall survival compared to those without this genetic abnormality [2, 6, 7]. Therefore, determining the molecular phenotype is important for the treatment of glioma patients. Obtaining pathological tissue samples through surgical resection or stereotactic biopsy carries certain safety risks, and further genetic testing can be time-consuming and expensive. Therefore, using non-invasive imaging techniques as a preoperative diagnostic method to predict the molecular subtype of brain gliomas has become a hot research topic in recent years [8,9,10].
Radiomics is an emerging interdisciplinary field that combines traditional imaging, computer science, and precision medicine. It uses specific algorithms to transform medical imaging data into a wide range of radiomic features. These features are further used to establish models and applied to clinical decision-making, ultimately assisting in precise diagnosis and prognosis evaluation of various diseases [11,12,13]. Typically, genomic sequencing only utilizes partial biopsy samples of tumors, while radiomics data comes from the entire tumor lesion, providing more comprehensive and accurate information to assist clinical decision-making. In recent years, many studies have developed machine learning algorithm-based models to predict the molecular status of 1p/19q in gliomas [14,15,16,17]. Most studies choose traditional ML models for model selection, which usually require complex feature extraction processes and show significant differences in accuracy on different datasets, with unstable performance. Compared to traditional machine learning algorithms, DL has been proven to have better performance in analyzing image feature data and is increasingly widely used in the medical imaging field [18,19,20].
This study aimed to explore the use of imaging omics methods based on conventional MRI to construct a CNN algorithm integrated with spontaneous data augmentation, combined with the information gain feature selection method, for predicting the molecular co-deletion status of 1p/19q in LGGs.
Materials and methods
Study design and participants
The data in this study were sourced from a public dataset and the Affiliated Hospital of Xuzhou Medical University. Ethical approval for the study was obtained from the Human Science Ethics Committee of the Affiliated Hospital of Xuzhou Medical University. The requirement for informed consent from patients was waived due to the study’s retrospective nature.The study procedures were in line with the guidelines laid out in the Declaration of Helsinki.
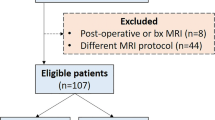
The internal dataset included 111 patients who underwent craniotomy for tumor resection at the Department of Neurosurgery of the Affiliated Hospital of Xuzhou Medical University between July 2018 and July 2022, and were diagnosed with LGG based on postoperative pathological examination. Inclusion criteria were: (1) adult patients (≥ 18 years old); (2) primary grade 2 or 3 glioma confirmed by postoperative histopathology; (3) postoperative pathology specimens with the molecular status of 1p/19q obtainable; (4) first-time diagnosis of glioma and no previous treatment, including biopsy, surgery or chemotherapy; (5) complete preoperative MRI imaging data available; (6) images without obvious artifacts as jointly determined by experienced neuro-radiologists and neurosurgeons. Based on these criteria, 63 patients were finally selected after screening, as shown in Fig. 1. Fluorescence in situ hybridization (FISH) was used to determine the 1p/19q co-deletion status for key molecular markers.

Patient screening process. TCIA: The cancer imaging archive; T2WI:T2 weighted imaging; T2 FLAIR: T2 fluid-attenuated inversion recovery
The imaging data of the public dataset were sourced from the Cancer Imaging Archive (TCIA), a large open archive of cancer medical images that provides a wealth of radiographic images and related supporting data for cancer research. Our study collected MRI and segmentation datasets of patients from the set named LGG-1p19q deletion in TCIA [21,22,23]. We downloaded the data using the NBIA Data Retriever software provided by the TCIA database. The original dataset contained a total of 159 LGG patients with histopathological and genomic features, and we obtained and confirmed the 1p/19q mutation status of all patients from the corresponding supporting data. Among them, 102 patients had co-deletion of 1p/19q (dd), and 57 patients did not have co-deletion of 1p/19q (nn). The TCIA provided complete regions of interest (ROI) for tumors based on the T2WI sequence, including three segmentation slices for each tumor. The final segmentation slice was determined by taking one slice above and one below the maximum slice at the center of the tumor. Due to poor image quality, the imaging data of four patients were discarded. Eventually, we included 155 patients from the public dataset and 63 patients from the internal dataset in this study.
MRI image acquisition
All patients whose internal data was collected underwent scanning with a 3.0 Tesla MRI scanner (GE Healthcare Systems, Signa HD, Waukesha, WI, USA) using an 8-channel head coil. The brain MRI scan orientations included T1-weighted imaging (T1WI), T2-weighted imaging (T2WI), fluid-attenuated inversion recovery (FLAIR) axial, coronal, and sagittal planes, and contrast-enhanced T1WI axial, sagittal and coronal planes. The contrast agent used for the enhanced scans was gadopentetate dimeglumine (Gd-DPTA, Bayer Healthcare LLC, Germany) at a dose of 0.2 mmol/kg, injected at a controlled rate of 3.0 ml/s. During the MRI scan, a comfortable foam cushion was used to stabilize the head of each subject to minimize head movement, and all subjects wore earplugs to reduce noise from the MRI machine. The 3.0 TMR scan parameters were as follows: T1WI (TR 200ms, TE 15ms); T2WI (TR 4300ms, TE 120ms); T2W-FLAIR (TR 8000ms, TE 150ms); Contrast-enhanced T1WI axial, sagittal and coronal planes: same parameters as in non-enhanced scans. Field of view (FOV) = 240 mm × 240 mm, slice thickness = 6.0mm, inter-slice gap = 1.0mm, number of excitations (NEX) = 2.0, matrix: 256 × 256.
Image preprocessing
Firstly, the LGG-1p19q deletion dataset in the public database TCIA includes images of CE-T1WI and T2WI sequences, so only these sequences were included in this study for analysis. Considering the differences in images between different hospitals, we preprocessed the images by registering the CE-T1WI sequence to either the T2WI sequence first. After registration, to reduce the influence of feature extraction by different MRI scanners, we adjusted the resolution of all images, resampling them to a uniform voxel resolution size of 1 × 1 × 1mm3, with a layer thickness of 1.0 mm. Furthermore, we used the N4BiasFieldCorrectionImageFilter method from the SimpleITK library to eliminate image bias caused by different MRI scanner models and technologies. This method is capable of estimating the bias field in the image and correcting it to remove the impact of scanner-related inhomogeneities. We first loaded each patient's MRI imaging into ITK-SNAP (3.6.0) (http://www.itksnap.org) and used the T2WI sequence for delineation.
Tumor segmentation
The internal dataset was segmented by two neurosurgeons with more than 10 years of experience in a blind manner to delineate the tumor regions of interest. Before tumor segmentation, the two physicians were not aware of the histopathological results of gliomas. If there was a disagreement in the segmentation area, it was jointly determined with a senior neuroradiologist, and the ROI obtained combined the delineation results of multiple physicians. The final ROI range was defined by a neurosurgeon with 30 years of experience in diagnosing neuro-oncology cases. Because LGG lesions may sometimes present as non-mass-like lesions, and peritumoral edema may also have infiltration of tumor cells, the delineation of tumor boundaries should include cystic, calcified, necrotic, and peritumoral edematous areas.
Feature extraction
We extract features from medical imaging based on Radiomics [24] (pyradiomic: 3.0.1, https://github.com/Radiomics/pyradiomics). The computer language is Python. The extracted features are aligned with Biomarker Standardization Initiative (IBSI) [25]. In this paper, the features extracted from magnetic resonance images mainly include three categories: (1)18 first-order features;(2)14 shape features (3) texture features: 24 Gy level cooccurrence matrix (GLCM) features, 16 Gy level size zone matrix (GLSZM) features, 16 Gy level run length matrix (GLRLM) features, 5 adjacent gray tone difference matrix (NGTDM) features, 14 Gy level dependence matrix (GLDM) features.Based on past research experience, models that extract features from a single sequence typically have lower prediction accuracy than those based on multiple sequences. Therefore, we will merge the features extracted from T1-contrast and T2 images into one dataset for the next step of analysis.
Model building under model construction
Data enhancement
In this study, we chose to use VAE [26] to capture internal structure and key information within the input data and utilize these information to generate data correlated with the input data, aiming to achieve data augmentation. VAE, consisting of an encoder and a decoder, is a variant of autoencoder (AE). As an unsupervised learning model, VAE can learn the implicit information of samples from a large amount of unlabeled data. VAEs train by maximizing the evidence lower bound (ELBO) on the marginal log-likelihood: \(logp\left(x\right)\ge ELBO= {E}_{q\left(z|x\right)}[log\frac{p(x,z)}{q(z|x)}]\). Let \(x\) denote the value of the sample variable. \(Z\) denotes the latent variable. \(X\) and \(Z\) represent the set of all samples, consisting of cases of disease. The encoder network defines the approximate posterior distribution \(q(z|x)\), which takes as input an observation and outputs a set of parameters for specifying the conditional distribution of the latent representation \(z\). The decoder network defines the approximate posterior distribution \(p(x,z)\), which takes a latent sample \(z\) as input and outputs the approximate value for a conditional distribution of the observation. The basic example framework of VAE is shown in Fig. 2. The detailed parameters of neurons are illustrated in the repository (https://github.com/sailorlee97/medicalMLsystem).

Framework diagram of the variational autoencoder
Feature extraction
Feature selection is an important task for eliminating noise variables and removing redundant and useless variables. In this study, we employ the Information Gain (IG) method to assess the contribution of features to the predictive model.IG is one of the filtered methods [27], where appropriate feature values are selected by comparing the magnitude of the information gain.During the feature selection process, we prioritize those features with higher information gain, as they provide more information about the target variable.
Model building
This paper uses a common pattern: several stacks of Conv1D, Maxpool1D, and Dense layers. Assuming that the input function is \(\text{x}\left(\text{t}\right)\), the kernel function is \(\text{k}\left(\text{t}\right)\), and the output function is \(\text{y}\left(\text{t}\right)\), then the convolution operation in the CNN can be expressed: \(\text{y}\left(\text{t}\right)=\text{x}\left(\text{t}\right)*\text{k}\left(\text{t}\right)\). Specifically, the model first extracts initial features through two convolution layers with 64 kernels of size 3, using the ReLU activation function to introduce non-linearity. Then, a max-pooling layer (with a pooling window size of 2) is applied for downsampling, reducing the feature dimensions and preventing overfitting. Next, the model further extracts more complex features through two convolution layers with 128 kernels, again using the ReLU activation function, followed by another max-pooling layer for downsampling [28]. After all convolution and pooling operations are completed, a flattening layer is used to convert the multi-dimensional feature maps into a one-dimensional vector, which is then integrated through a fully connected layer with 128 neurons [29]. Finally, the output layer is a fully connected layer with a Softmax activation function, converting the model output into a probability distribution of two classes, suitable for binary classification tasks. The model is compiled using the RMSprop optimizer with a low learning rate (0.0001) to ensure stable training and employs cross-entropy as the loss function while monitoring accuracy as the evaluation metric. The entire model is assessed during training using a validation set to ensure effective prevention of overfitting, and is trained with a batch size of 64 for 50 epochs to optimize classification performance. The design flow of this study is shown in Fig. 3. The parameters of the CNN model used in this study are described in the repository.

Flowchart of the method design. A MRI data acquisition, image preprocessing, and tumor segmentation. B Radiomics feature extraction, data augmentation, and feature selection. C Construction of CNN models and analysis of different model performances. ROI: Region of interest. VAE: Variational autoencoder. KNN:K-nearest neighbor. CNN: Convolutional Neural Network. ROC:Receiver operating characteristic
Statistical analysis
We propose an ECNN model comparing the performance of different algorithms, including K-Nearest Neighbor (KNN), Decision Tree (DT); Gaussian Naive Bayes (GNB); Random Forest (RF). The machine learning based classification calculations were performed using the Python platform.
The present investigation concerns binary classification, thus necessitating the implementation of several performance metrics to evaluate the efficacy of each machine learning model. Specifically, accuracy, F1-score, precision, and recall were utilized in conjunction with AUC to provide a comprehensive assessment of each model's overall performance. Furthermore, confusion matrices were employed to visualize the evaluation of model effectiveness. To ensure optimal training and validation, fivefold cross-validation was conducted on the entire dataset consisting of 218 patients.
Results
Clinical characteristics of patients
According to the screening criteria, a total of 218 patients were included, with 146 patients (67.0%) graded as level 2 and 72 patients (33.0%) graded as level 3; 100 patients (45.9%) were diagnosed with astrocytoma and 118 patients (54.1%) were diagnosed with oligodendroglioma. Among all patients, 118 cases (54.1%) had co-deletion mutations of 1p/19q, while 100 cases (45.9%) did not have co-deletion of 1p/19q. As shown in Table 1, there was a statistically significant difference in WHO tumor grading between the two groups of patients (P < 0.05).
Feature selection
The IG method was used to select the next step of extracted imaging omics features, and finally, 23 features were screened out. These included 4 shape features, 5 first-order features, 7 GLCM features, 1 GLDM feature, and 6 GLSZM features. In addition, we also screened all the quantitative radiomics features extracted and sorted them by importance weight. Figure 4 shows the ranking of feature importance.

Ranking the importance of features by using the method of IG
Classification performance and model comparison
The integrated CNN model proposed in this study is an end-to-end algorithm. Firstly, the outlined image is input into the model, and Radiomics features are extracted from it. Then, data augmentation is performed spontaneously, followed by the use of the information gain method to select useful features for model training and results retrieval. Additionally, the performance of the model is evaluated and compared with four other machine learning (ML) models. The performance results of the model are shown in Table 2. Eventually, the integrated CNN model outperforms the other four traditional ML algorithms with a precision of 0.981, recall of 0.980, F1-score of 0.981, and accuracy of 0.981. Moreover, the performance of the RF model is second only to that of the integrated CNN model, with a precision of 0.718 and accuracy of 0.674, while the accuracy of KNN, DT, and GNB is not quite satisfactory, at 0.620, 0.636, and 0.546, respectively. In this study, fivefold cross-validation was used, and AUC was used as an evaluation standard. All models were trained in each round of experiments, and false positive rates and true positive rates were saved for each round. Since the number of validation data varied in each round, interpolation was used to complete the data, and the final AUC value was obtained based on the expected results of all data after five rounds of validation. ROC curves were plotted, and the AUC values of 5 different models were displayed, as shown in Fig. 5. The AUC of CNN is 0.994, KNN is 0.600, DT is 0.614, GNB is 0.523, and RF is 0.702. The result indicates that the integrated CNN model exhibits the best predictive performance and can be considered an ideal model for predicting the 1p/19q molecular state, with the 23 features being optimal Radiomics features. Figure 6 shows the confusion matrix for the prediction of the missing 1p/19q molecular status in the experimental data using the integrated CNN model.

The ROC curve of the model plotted after fivefold cross-validation and the area under the curve values. KNN:K-nearest neighbor. CNN: Convolutional Neural Network. ROC:Receiver operating characteristic

Confusion matrix of the ECNN model for predicting the codeleted status of 1p/19q molecular in gliomas
Discussion
The CNN model proposed in this study predicts the molecular co-deletion status of 1p/19q in LGGs by extracting radiomic features from preoperative routine MRI images of patients. The data is processed through spontaneous data augmentation, and the information gain method is used to select radiomic features. Among all ML classification models, our proposed CNN model has the highest prediction accuracy with a receiver operating characteristic area under the curve (ROC-AUC) of 0.994. The performance of the model is superior to traditional machine learning models. This indicates that DL-based radiomic models have excellent performance in predicting the molecular status of 1p/19q in LGG.
In the classification of adult diffuse gliomas, the genetic features of glioblastoma typically do not include 1p/19q codeletion status. Furthermore, since 1p/19q codeletion status is primarily associated with the treatment and prognosis of low-grade gliomas, its guiding value for glioblastoma is limited. Therefore, our study focuses on astrocytomas and oligodendrogliomas, both of which IDH mutations are present. Thus, in our study, glioblastomas with wild-type IDH were excluded.The biological behavior of LGG is complex and diverse. grade 2 gliomas classified by WHO have no specific characteristics on MRI and can easily develop into grade 3 gliomas. Additionally, 8.8% ~ 10% of secondary glioblastoma multiforme are derived from LGG [1, 3, 30]. The molecular subtypes of gliomas are closely related to clinical prognosis. The oligodendroglial tumor with co-deletion of 1p/19q has the best prognosis in LGG, with a median survival period of 8.0 years. In contrast, astrocytoma without co-deletion of 1p/19q has a poorer prognosis, with a median survival period of 6.3 years [31, 32]. Recent research results indicate that maximizing the extent of resection (EOR) may not be the best choice for tumor removal because of the inertness and chemosensitivity of oligodendroglioma compared to astrocytoma [33, 34]. Overall, non-invasive molecular detection through preoperative MRI imaging is of great significance for the personalized treatment of glioma patients who are older, have other diseases, or have tumors invading important neural functional areas and are not suitable for surgery.
In previous studies, many radiomic methods have been used to predict the co-deletion status of 1p/19q in gliomas. Chia-Feng Lu et al. [14] developed a machine learning model with multiple binary classifiers to predict the molecular status of IDH and 1p/19q in gliomas. However, the number of LGGs in the test set was very limited, which reduced the reliability of the classification model. Quang-Hien Kha et al. [15] proposed a model based on the extreme gradient boosting (XGBoost) algorithm to predict the co-deletion status of 1p/19q. However, the model relied only on seven radiomic features for prediction, and further research is needed to determine its general applicability. In comparison, this study screened more features and achieved a higher average AUC score. Some of the previous prediction studies included only datasets from a single center, which may lack persuasiveness because patients from different countries and regions may differ. Many studies included glioblastomas in their dataset, but according to the latest WHO CNS classification standard, the diagnosis of glioblastomas is not directly related to the molecular status of 1p/19q. In addition, considering that LGGs have more similar biological characteristics, only grade 2 and 3 gliomas were included in the study, which has more practical clinical significance. Although whole-volume segmentation can obtain information about the entire tumor, it may consume a lot of time in practical operations, and it is difficult to perform accurate segmentation on parts close to the tumor boundary. This study used a small number of tumor slice segmentation layers as ROI and also achieved good prediction results, which will be an effective alternative to full-layer segmentation. Finally, compared with the cumbersome preprocessing process of traditional radiomics, our model realizes an"end-to-end"process, covering all aspects from raw input data to final output data, giving the model space to adjust automatically according to the specific situation of the data.
DL has stronger learning ability and wider coverage than traditional machine learning, and it is increasingly being used to predict the molecular genetic status in gliomas [35, 36]. However, the application of DL faces a common problem—it requires a large amount of data for training. The number of cases obtained from public medical datasets is limited, so most research data usually comes from a specific region, which may not collect enough imaging data [37]. In recent years, a data augmentation technique called VAE has been proposed as one solution to the problem of data volume limitation. VAE inherits the architecture of traditional autoencoders and is used to learn the generating distribution of data, allowing us to randomly extract samples from the latent space and decode these random samples to generate output samples that are very similar to the input samples. Because the sample size is imbalanced in this study, using data generated by VAE can effectively supplement the dataset during the construction of DL models. By adding variants generated by VAE to the training data, it can help the model learn and thereby improve its robustness when facing novel or unseen data.Therefore, we can enhance synthetic training data based on existing data to help improve the generalization performance of the model [38]. A large number of radiomic features can be extracted from the initial image, but the impact of these features on the model output is uncertain. Feature selection methods have been widely used in previous studies on glioma radiogenomics [15, 21, 40]. IG used in this study belongs to a univariate feature filter, also known as maximum mutual information, which is a very effective feature selection method. It measures the importance of features by their correlation with the category label. The criterion for measuring importance is how much information a feature can bring to the classification system. The more information it brings, the more important the feature is. Therefore, we only need to consider feature correlation, and we can completely ignore feature redundancy [27, 39, 41]. In this study, we constructed an"end-to-end"DL model that can directly learn important information from raw data to output results. The end-to-end model reduces the need for manual design steps, simplifies the entire development process, and integrates the processing steps into a unified whole.
To better explain the radiomic features, this study analyzed the 23 highest-scoring features in the average feature importance ranking, of which 14 were texture features. Previous studies found that first-order features and some texture features such as GLSZM and GLDM are important for predicting the co-deletion status of 1p/19q among all features, while other texture features such as GLRLM and GLCM are also considered to have good effects on predicting the molecular status of 1p/19q [14, 42, 43]. Our results also show that most of the selected features are texture features, with first-order features and shape features accounting for only about 30%, indicating that texture features representing tumor spatial intensity changes play an important role in predicting the molecular status of 1p/19q in LGGs.
There are still some limitations in our study. Firstly, this study relies solely on conventional MRI sequences; however, related studies have shown that advanced MRI sequences such as Magnetic Resonance Spectroscopy (MRS) and Diffusion Weighted Imaging (DWI) can provide richer microstructural information, which may lead to more significant improvements in the prediction of glioma molecular status [44, 45]. Therefore, future research will consider incorporating more MRI sequences to enhance the model's predictive performance. This would not only provide the model with more detailed structural and functional information but also help us explore the contributions of different imaging data to the model's performance. We look forward to further improving the model's clinical application potential by integrating these advanced imaging data. Second, considering the importance of IDH, EGFR, and MGMT methylation status, as well as other relevant genes in the diagnosis and prognosis of gliomas, our future studies will include all types of adult diffuse gliomas. We will establish a stratified and progressive predictive model to predict multiple key genes, thus better assisting clinical diagnosis and treatment. The limitation of using data from a single center is also an issue we need to consider. The model needs to be validated across different geographical locations, ethnic groups, and treatment backgrounds. This will help us understand how the model performs across diverse patient populations. We anticipate that in future studies, we will be able to collect more data from different regions and populations, and through cross-center validation, further enhance the model's robustness, laying a solid foundation for its clinical application.Finally, the challenge of applying DL technology in medical imaging lies in the"black box"nature of the output results, making it difficult to understand and interpret the internal decision-making process.In the future, we will consider trying to combine radiomics with genomics, and use visualization techniques to explore the mechanisms behind the black box from multiple dimensions.
Conclusion
An algorithm model based on DL can effectively predict the molecular status of 1p/19q in LGG patients. The combination of spontaneous data augmentation and information gain feature selection methods can significantly improve the performance of the model. We hope that this work can provide important clinical assistance value for the non-invasive identification of molecular subtypes and customized individualized treatment plans for glioma patients in the future.
Data availability
Data will be made available on request.
References
Ostrom QT, Cioffi G, Waite K, et al. CBTRUS Statistical Report: Primary Brain and Other Central Nervous System Tumors Diagnosed in the United States in 2014–2018. Neuro Oncol. 2021;23(12 Suppl 2):iii1–105.
Jiang T, Nam DH, Ram Z, et al. Clinical practice guidelines for the management of adult diffuse gliomas. Cancer Lett. 2021;499:60–72.
Louis DN, Perry A, Wesseling P, et al. The 2021 WHO Classification of Tumors of the Central Nervous System: a summary. Neuro Oncol. 2021;23(8):1231–51.
Cancer Genome Atlas Research Network; Brat DJ, Verhaak RG, et al. Comprehensive, Integrative Genomic Analysis of Diffuse Lower-Grade Gliomas. N Engl J Med, 2015, 372(26):2481–98.
Schiff D, Van den Bent M, Vogelbaum MA, et al. Recent developments and future directions in adult lower-grade gliomas: Society for Neuro-Oncology (SNO) and European Association of Neuro-Oncology (EANO) consensus. Neuro Oncol. 2019;21(7):837–53.
Franceschi E, Mura A, De Biase D, et al. The role of clinical and molecular factors in low-grade gliomas: what is their impact on survival?. Future Oncol. 2018;14(16):1559–67.
Tom MC, Varra V, Leyrer CM, et al. Risk Factors for Progression Among Low-Grade Gliomas After Gross Total Resection and Initial Observation in the Molecular Era[J]. Int J Radiat Oncol Biol Phys. 2019;104(5):1099–105.
Darlix A, Deverdun J, Menjot de Champfleur N, et al. IDH mutation and 1p19q codeletion distinguish two radiological patterns of diffuse low-grade gliomas. J Neurooncol, 2017, 133(1):37–45.
Smits M, van den Bent MJ. Imaging Correlates of Adult Glioma Genotypes. Radiology. 2017;284(2):316–31.
Lee MK, Park JE, Jo Y, et al. Advanced imaging parameters improve the prediction of diffuse lower-grade gliomas subtype, IDH mutant with no 1p19q codeletion: added value to the T2/FLAIR mismatch sign. Eur Radiol. 2020;30(2):844–54.
Lambin P, Rios-Velazquez E, Leijenaar R, et al. Radiomics: extracting more information from medical images using advanced feature analysis. Eur J Cancer. 2012;48(4):441–6.
Afshar P, Mohammadi A, Plataniotis KN, et al. From handcrafted to deep-learning-based cancer radiomics: challenges and opportunities. IEEE Signal Process Mag. 2019;36(4):132–60.
Aerts HJ, Velazquez ER, Leijenaar RT, et al. Decoding tumour phenotype by noninvasive imaging using a quantitative radiomics approach[J]. Nat Commun. 2014;5:4006.
Lu CF, Hsu FT, Hsieh KL, et al. Machine Learning-Based Radiomics for Molecular Subtyping of Gliomas. Clin Cancer Res. 2018;24(18):4429–36.
Kha QH, Le VH, Hung TNK, et al. Development and Validation of an Efficient MRI Radiomics Signature for Improving the Predictive Performance of 1p/19q Co-Deletion in Lower-Grade Gliomas. Cancers (Basel). 2021;13(21):5398.
van der Voort SR, Incekara F, Wijnenga MMJ, et al. Predicting the 1p/19q Codeletion Status of Presumed Low-Grade Glioma with an Externally Validated Machine Learning Algorithm. Clin Cancer Res. 2019;25(24):7455–62.
van der Voort SR, Incekara F, Wijnenga MMJ, et al. Combined molecular subtyping, grading, and segmentation of glioma using multi-task deep learning. Neuro Oncol. 2023;25(2):279–89.
Nadeem MW, Ghamdi MAA, Hussain M, et al. Brain Tumor Analysis Empowered with Deep Learning: A Review, Taxonomy, and Future Challenges. Brain Sci. 2020;10(2):118.
Kocher M, Ruge MI, Galldiks N, et al. Applications of radiomics and machine learning for radiotherapy of malignant brain tumors. Strahlenther Onkol. 2020Oct;196(10):856–67.
Xu J, Meng Y, Qiu K, et al. Applications of Artificial Intelligence Based on Medical Imaging in Glioma: Current State and Future Challenges. Front Oncol. 2022;12: 892056.
Akkus Z, Ali I, Sedlář J, et al. Predicting Deletion of Chromosomal Arms 1p/19q in Low-Grade Gliomas from MR Images Using Machine Intelligence. J Digit Imaging. 2017;30(4):469–76.
Clark K, Vendt B, Smith K, et al. The Cancer Imaging Archive (TCIA): maintaining and operating a public information repository. J Digit Imaging. 2013;26(6):1045–57.
Akkus Z, Ali I, Sedlář J, et al. Predicting Deletion of Chromosomal Arms 1p/19q in Low-Grade Gliomas from MR Images Using Machine Intelligence. J Digit Imaging. 2017;30(4):469-476.
Van Griethuysen JJM, Fedorov A, Parmar C, et al. Computational Radiomics System to Decode the Radiographic Phenotype. Cancer Res. 2017;77(21):e104–7.
Zwanenburg A, Vallières M, Abdalah MA, et al. The Image Biomarker Standardization Initiative: Standardized Quantitative Radiomics for High-Throughput Image-based Phenotyping. Radiology. 2020;295(2):328–38.
Cinelli LP, Marins MA, Da Silva EAB, et al. Variational Methods for Machine Learning with Applications to Deep Networks [M]. Vol. 15. Cham: Springer, 2021.
Jović A, Brkić K, Bogunović N. A review of feature selection methods with applications[C]//2015 38th international convention on information and communication technology, electronics and microelectronics (MIPRO). IEEE, 2015: 1200–1205.
Gu J, Wang Z, Kuen J, et al. Recent advances in convolutional neural networks. Pattern Recogn. 2018;77:354–77.
Soffer S, Ben-Cohen A, Shimon O, et al. Convolutional Neural Networks for Radiologic Images: A Radiologist’s Guide. Radiology. 2019;290(3):590–606.
Ohgaki H, Kleihues P. The definition of primary and secondary glioblastoma. Clin Cancer Res. 2013;19(4):764–72.
Delev D, Heiland DH, Franco P, et al. Surgical management of lower-grade glioma in the spotlight of the 2016 WHO classification system. J Neurooncol. 2019;141(1):223–33.
Suzuki H, Aoki K, Chiba K, et al. Mutational landscape and clonal architecture in grade II and III gliomas. Nat Genet. 2015;47(5):458–68.
Ding X, Wang Z, Chen D, et al. The prognostic value of maximal surgical resection is attenuated in oligodendroglioma subgroups of adult diffuse glioma: a multicenter retrospective study. J Neurooncol. 2018;140(3):591–603.
Wijnenga MMJ, French PJ, Dubbink HJ, et al. The impact of surgery in molecularly defined low-grade glioma: an integrated clinical, radiological, and molecular analysis. Neuro Oncol. 2018;20(1):103–12.
Ali MB, Gu IY, Berger MS, et al. Domain Mapping and Deep Learning from Multiple MRI Clinical Datasets for Prediction of Molecular Subtypes in Low Grade Gliomas. Brain Sci. 2020;10(7):463.
Buda M, Saha A, Mazurowski MA. Association of genomic subtypes of lower-grade gliomas with shape features automatically extracted by a deep learning algorithm. Comput Biol Med. 2019;109:218–25.
Wiens J, Guttag J, Horvitz E. A study in transfer learning: leveraging data from multiple hospitals to enhance hospital-specific predictions. J Am Med Inform Assoc. 2014;21(4):699–706.
Pouyanfar S, Sadiq S, Yan Y, et al. A survey on deep learning: Algorithms, techniques, and applications. ACM Computing Surveys (CSUR). 2018;51(5):1–36.
Li J, Cheng K, Wang S, et al. Feature selection: A data perspective. ACM computing surveys (CSUR). 2017;50(6):1–45.
Lam LHT, Chu NT, Tran TO, et al. A Radiomics-Based Machine Learning Model for Prediction of Tumor Mutational Burden in Lower-Grade Gliomas. Cancers (Basel). 2022;14(14):3492.
Ross BC. Mutual information between discrete and continuous data sets. PLoS ONE. 2014;9(2): e87357.
Li Y, Ammari S, Lawrance L, et al. Radiomics-Based Method for Predicting the Glioma Subtype as Defined by Tumor Grade, IDH Mutation, and 1p/19q Codeletion. Cancers (Basel). 2022;14(7):1778.
Kocak B, Durmaz ES, Ates E, et al. Radiogenomics of lower-grade gliomas: machine learning-based MRI texture analysis for predicting 1p/19q codeletion status. Eur Radiol. 2020;30(2):877–86.
Maynard J, Okuchi S, Wastling S, et al. World Health Organization Grade II/III Glioma Molecular Status: Prediction by MRI Morphologic Features and Apparent Diffusion Coefficient. Radiology. 2020;296(1):111–21.
Kim M, Jung SY, Park JE, et al. Diffusion- and perfusion-weighted MRI radiomics model may predict isocitrate dehydrogenase (IDH) mutation and tumor aggressiveness in diffuse lower grade glioma. Eur Radiol. 2020;30(4):2142–51.
Acknowledgements
Not applicable.
Funding
The paper is sponsored by National Natural Science Fundation (General Program) Grant 61972211, China, andNational Key Research and Development Project Grant.2020YFB1804700, China.This work was also supported by Natural Science Foundation of Jiangsu Province (BK20181152), China Postdoctoral Science Foundation Funded Project (2019M661942), Jiangsu Province University Key Laboratory Open Project (XZSYSKF2021017), Development Foundation Project of Affiliated Hospital of Xuzhou Medical University (XYFM2021009), Pengcheng Talent Medical Youth Reserve Talent Training Project of Xuzhou City (XWRCHT20220039).
Author information
Authors and Affiliations
Contributions
FL, and ZL completed the study design. HX, GK and ZZ performed the study and analyzed the data. FL and ZL drafted the manuscript. KC and LH provided expert consultations and suggestions. FL, ZL, and LG conceived the study, participated in its design and coordination, and helped to embellish the language. All authors reviewed the final version of the manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. This study was approved by an Institutional Review Board approval from the Affiliated Hospital of Xuzhou Medical University prior to the commencement of this study (XYFY2022-KL233), and informed consent was waived because of the study design.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, F., Li, Z., Xu, H. et al. Prediction of 1p/19q state in glioma by integrated deep learning method based on MRI radiomics. BMC Cancer 25, 1228 (2025). https://doi.org/10.1186/s12885-025-14454-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1186/s12885-025-14454-9