
Abstract
Systems biology is defined in this review as ‘an iterative process of computational model building and experimental model revision with the aim of understanding or simulating complex biological systems’. We propose that, in practice, systems biology rests on three pillars: computation, the omics disciplines and repeated experimental perturbation of the system of interest. The number of ethical and physiologically relevant perturbations that can be used in experiments on healthy humans is extremely limited and principally comprises exercise, nutrition, infusions (e.g. Intralipid), some drugs and altered environment. Thus, we argue that systems biology and environmental physiology are natural symbionts for those interested in a system-level understanding of human biology. However, despite excellent progress in high-altitude genetics and several proteomics studies, systems biology research into human adaptation to extreme environments is in its infancy. A brief description and overview of systems biology in its current guise is given, followed by a mini review of computational methods used for modelling biological systems. Special attention is given to high-altitude research, metabolic network reconstruction and constraint-based modelling.
Similar content being viewed by others


Review
Introduction
The term ‘systems biology’ is suddenly everywhere. One could be forgiven for believing, therefore, that it is something new, yet this would be misleading. The application of general system theory to living organisms dates back, at least, to Ludwig von Bertalanffy's pioneering work in the 1920s and perhaps earlier still (see [1] and references therein). To appreciate exactly what systems biology is, at least in theory and philosophy, one could do worse than von Bertalanffy's own description of a system and why general system theory rose to prominence in the last century. He contrasted system theory with the analytical, reductionist approach to science that had characterised the scientific method from Francis Bacon onward, thus, “Application of the analytical procedure depends on two conditions. The first is that interactions between ‘parts’ be… weak enough to be neglected … Only under this condition, can the parts be ‘worked out,’ actually, logically and mathematically, and then be ‘put together.’ The second condition is that the relations describing the behaviour of the parts be linear” [1].
The first condition is clear enough. The second can be better expressed mathematically. If each ‘part’ of the whole can be described by a function (say f1, f2 etc.), then condition two states that the behaviour of the whole (say w) can be written as a linear combination of the parts, i.e. w = x1f1 + x2f2 + x3f3… where x1, x2… etc. are constants. For von Bertalanffy, violation of either or both of these conditions defined a system [1]. Few with any experience of biological research would argue that these conditions are true of living things. Life is, by its very nature, awesomely complex and chaotic. To cite von Bertalanffy one final time, ‘The then prevalent mechanistic approach just mentioned appeared to neglect or actively deny just what is essential in the phenomena of life.’
This, then, helps define the theory and philosophy of systems biology. Yet, what does it mean in practice? That is the focus and purpose of this review. To some extent, this review will be biased by the authors' own experiences of working together in this area. Thus, examples will be drawn from high-altitude research and the use of metabolic network reconstructions. Yet, these perspectives, we hope, will be broadly generalisable, and we aim to provide a basic introduction to systems biology for the non-expert. We also propose that systems biology and environmental and exercise physiology are particularly complementary. We will also briefly discuss some of the challenges that lie ahead.
What is (and is not) systems biology?
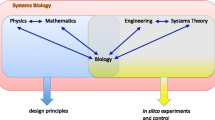
If then it is nothing new, why is systems biology suddenly so visible? Some have implicitly argued that systems biology is a mirage, no more than a rebranding of the type of holistic thinking that some biologists and integrative physiologists have been using for decades [2]. Yet, systems biology in its current guise is different to these earlier disciplines. It stems from advances in technology, particularly in genome sequencing, computing and in analytical platforms such as mass spectrometry and nuclear magnetic resonance. In order to truly study a large system in its entirety, one requires the ability to model and measure it in its entirety (or at least make an effective attempt to do so). Until the advent of whole genome sequencing, this was an insurmountable experimental challenge for biologists. With the advancements in computing power, genomics, transcriptomics, proteomics, metabolomics and fluxomics, it is becoming possible to ‘profile’ and model a complete biological system or subsystem.
Yet, another common misconception is that systems biology and the so-called omics disciplines are one and the same. This, too, is misleading. An omics discipline is defined by its methods, as an attempt to measure every instance of a species in a specific class. Thus, proteomics is an attempt to measure every protein in a cell or tissue. Systems biology, while leveraging much of the data these experiments generate, transcends the methods. Reconstructions of cell metabolic networks not only undoubtedly leverage data from genomics, proteomics and metabolomics, but also use data from traditional enzyme assays and measures of physiological function. Indeed, a key test of any reconstruction is whether it has the capacity to recapitulate the normal physiological functions of the system of interest [3]. Another feature that distinguishes systems biology from omics disciplines is recursivity. Systems biology as defined herein (and elsewhere [4]) comprises an iterative cycle of experiment and modelling rather than a single experiment and modelling cycle. In this respect, systems biology is similar to traditional biological practice, in which statistics are used to ‘process’ experimental data before the ‘filtered’ observations are compared with a biological model, leading to progressive model revision. This has been described as the ‘model as hypothesis’ [4].
In practice, perhaps the single feature that distinguishes systems biology from both the omics disciplines and other relatives such as integrative physiology is the central role of mathematical modelling and computer simulations—a distinction that has been overlooked by previous commentators [5]. Yet, we are not alone in emphasising the central role of computation in systems biology [6–8]. Therefore, we propose defining systems biology (for the purposes of this review) as ‘an iterative process of computational model building and experimental model revision with the aim of understanding or simulating complex biological systems’ (Figure 1). Although there has been substantial variation in how systems biology has been defined previously, we believe that our definition here is consistent with the emerging consensus [4, 6, 9]. Given the huge amounts of data generated by the trademark techniques of genomics, transcriptomics, proteomics and metabolomics, unaided human interpretation is utterly inadequate, and systems biology, as defined here and elsewhere, arises spontaneously. Yet, typical omics experiments (in isolation) fail this test; most involve the de novo building of multivariate statistical models to the data from each experiment in isolation rather than progressive model refinement (statisticians who specialise in multivariate modelling are well aware of the problems associated with this approach; instead, they recommend that such statistical models are confirmed using newly acquired data or bootstrapping procedures [10]).

The iterative cycle of systems biology (image of climber courtesy of Caudwell Xtreme Everest).
There are many in the biological sciences who continue to hold that the very phrase ‘biological modelling’ is an oxymoron. To them, we argue that model building itself is an indispensible (yet often tacit) part of biological thinking. Whether the model is descriptive only (as is found in the discussion section of virtually every biological paper ever published), graphic (i.e. a figure or drawing) or fully quantitative, all models are nothing more than descriptions of biological reality that one believes to be correct. Adding numbers to a model simply makes its validity easier to assess; computers are required if the complexity of a quantitative (or even semi-quantitative) model passes beyond a certain point.
Approaches to modelling biological systems
If mathematical modelling and computer simulations are the distinguishing features of systems biology, which methods are currently used? This review is too limited a forum for examining such a broad topic in any depth; fortunately, many excellent books and reviews already exist (see [4, 11–13]). Nevertheless, a brief introduction follows, preceding a more in-depth description of one particular method: genome-scale biochemical modelling.
Approaches to modelling biological systems can broadly be divided into two, often described as ‘top-down’ and ‘bottom-up’ (Figure 2). Top-down methods start with data and fit models to them. Traditional statistics is therefore a top-down method, as are machine learning, pattern recognition and (broadly) bioinformatics. These methods can discern meaningful biological relationships and sometimes even quite complex networks; in such cases, they are often referred to as ‘reverse-engineering’. For example, Algorithm for the Reconstruction of Accurate Cellular Networks (ARACNE) uses statistical methods to reconstruct transcriptional networks by extracting correlated transcripts across a series of biological perturbations [14]. ARACNE successfully predicted 11 out of 12 targets of the MYC transcription factor, based on perturbation experiments, which were subsequently experimentally validated [15]. Of the multivariate statistical methods currently in fashion, perhaps the most popular is principal component analysis (PCA) and its relatives (such as orthogonal projection onto latent spaces). These techniques are regularly used to process omics data, especially metabolomics.

‘Top-down’ vs. ‘bottom-up’ approaches to modelling biological systems viewed in the context of biological hierarchies.
In contrast to top-down methods, such as ARACNE and PCA, are bottom-up methods that attempt to build models based on existing or acquired knowledge of network behaviour and connectedness (or topology). These include traditional kinetic models (based on a system of differential equations, cf. [16]) and stochastic methods [17]. However, both these approaches (kinetic and stochastic) are presently limited to relatively small systems. An exciting new approach to bottom-up modelling is the reconstruction of biochemical networks combined with a suite of modelling tools that fall under the heading of constraint-based modelling [18]. The reconstruction process is well established for metabolism and has been applied to a growing number of organisms, including mouse [19] and human [20]. The same approach can also be applied for other cellular functions, such as signalling [21, 22] and macromolecular synthesis [23]. The reconstruction process has been reviewed by numerous groups [24–26], and more recently, a standard operating procedure has been formulated that describes the necessary steps in great detail [3].
Lastly, it should be noted that the distinction between top-down and bottom-up modelling is not one of biological hierarchical level. For example, one might use metabolomics data acquired from cells and build a statistical model from it—this would be top-down modelling of a system. Equally, one could build a model of signal transduction (from organ to organ) in the blood using theories of flow and diffusion and anatomical measurements. This would be a bottom-up model.
Metabolic network reconstruction
We will briefly introduce the general approach to reconstructing metabolic networks; a more detailed description can be found elsewhere [3]. First, a draft reconstruction is generated based on an annotated genome (for example, from NCBI). Biochemical databases such as Kyoto Encyclopedia Of Genes And Genomes (KEGG) [27] and Braunschweig Enzyme Database [28] are used to link genes to function and thus metabolic reactions. However, the resulting draft reconstruction will be incomplete and will contain numerous missing or wrong annotations. The refinement and expansion of the draft reconstruction is performed through manual curation and extensive use of biochemical literature specific for the target organism. Particular attention needs to be paid to substrate and coenzyme specificity, which can differ between organisms and may require additional biochemical data. As a third step, the conversion of the manually curated metabolic reconstruction into a mathematical model follows, which includes the addition of physico-chemical and physiological balances and bounds (or constraints). Balances in biochemical networks can be, for example, mass and energy conservation, and the majority of modelling applications of metabolic models assume the system to be in quasi-steady state. Bounds on metabolic reactions can include maximal reaction rates based on the catalysing enzyme's properties (or measured in vivo metabolite uptake rates, for example VO2max) and thermodynamic information (e.g. reaction directionalities [29, 30]). Network debugging and evaluation comprise the fourth stage and ensure that the metabolic model has similar phenotypic properties as the target organism. This includes evaluation of dead-end metabolites (metabolites that are only either produced or consumed in the network, but not both) to identify whether they can be connected to the remaining network by adding one or more reactions to the reconstruction. Also, the model's capability to produce its own biomass is evaluated. This process may lead to the identification of yet more network gaps. This stage also includes further quality tests; these will depend on the properties of the target organism as well as the availability of experimental data (for example, phenotyping data, knock-out data etc.). The fifth and final stage is undoubtedly the most exciting: study of the biological system of interest. Network reconstructions have been put to numerous uses over the last decade or so, including biological discovery [31], metabolic engineering [32, 33], prediction of the outcome of adaptive evolution [34, 35], network topology [36, 37] and the assessment of phenotypic behaviour [38–41]. Some of these applications have been summarised in excellent recent reviews [42–44].
The human metabolic reconstruction
The genome-scale metabolic reconstruction process described above was applied to human metabolism, and the subsequent reconstruction, published in 2007, was named Recon 1 [20]. Recon 1 accounts for the functions of 1,496 open reading frames, 2,766 metabolites and 3,311 reactions distributed over eight cellular compartments (the cytoplasm, mitochondria, nucleus, endoplasmic reticulum, Golgi apparatus, lysosome, peroxisome and the extracellular environment). This first comprehensive, genome-scale human metabolic reconstruction captures most of the known central metabolic pathways occurring in any human cell. This reconstruction has been employed for numerous biomedical studies (reviewed in [43]). Moreover, the generic human metabolic reconstruction serves as a starting point for tissue- and cell-type specific reconstructions, many of which are generated using omics data (e.g. transcriptomic and proteomic data) as well as some manual curation. These reconstructions include macrophages [45], hepatocytes [46], myocytes [47] and adipocytes [47]. Recently, a core cancer cell network has also been compiled by mapping the NCI-60 cancer cell line transcriptomic data onto Recon 1 [48].
The next pressing challenge is the need to generate multi-network and ‘trans-hierarchical’ (multi-scale) models. Examples of these are recent models that describe the metabolism of two human cell (or tissue) types and their interactions [47, 49]. In these cases, the model comprises genome-scale metabolic networks at one level and a most basic two-node model of cell-cell interaction at the other. The complexity of even these simple models highlights the awesome task ahead if we wish to model the interactions between multiple cell types, tissues and organs, even before we have considered the physical complications of anatomy and physiology. Other important multi-system models are those attempting to reconcile metabolism with, for example, transcriptional control (cf. [50–52]) and those that combine gross models of physiology with detailed models of enzyme kinetics [53]. Again, an excellent recent review has addressed the challenges associated with multi-scale modelling [13].
Two final notes on bottom-up reconstructions: first, although these models are termed bottom-up, they are, inevitably, middle-up. This is because they rest on an arbitrarily defined lowest level; one could almost always model from a lower level (say atomic or subatomic). This, however, raises a serious philosophical point—is it possible to predict complex biological functions from the very lowest hierarchical levels or are we prevented from ever doing this (perhaps by a form of Gödel's completeness theorem as suggested previously [4])? Second, the level of detail (sometimes called fine- or coarse-graining) in a model is very important. Although it seems as though increasing detail would always be desirable, it may not be [6]. Parameter fitting (i.e. estimating parameters from in vivo data) is hazardous and can lead to mistaken confidence, especially where an unknown and unmeasured molecule (or other influence) may be acting simultaneously on multiple points in a system (as may very often be the case [7]). Another practical constraint on the degree of detail in a bottom-up model is computing power; there is no point having a model that includes single molecule dynamics if it is completely unusable.
Systems biology at work—filling gaps in human metabolism
Figure 1 shows the iterative cycle of systems biology: model building and computation generate hypotheses that are tested experimentally, leading to further model refinement. For example, a common and important question when reconstructing metabolic networks is as follows: is the reconstruction complete? Given that metabolic network reconstructions leverage all the currently available data regarding human metabolism, this question is equivalent to asking whether our knowledge of human metabolism is complete, yet in a completely thorough and systematised way. One can identify missing reactions in a network reconstruction by comparing model simulations with experimental data [31]. This method is generally called gap filling, and numerous computational algorithms have been published [31, 54, 55]. Similarly, metabolomics data from cells, tissues and biofluids [56–58] could be used to identify missing knowledge in human metabolism; the presence of a metabolite in a biofluid, which is absent from the reconstruction, indicates a knowledge gap. There are a number of different computational approaches [31, 55] that could be used in these cases to identify candidate missing reactions and corresponding genes [59, 60]. These computational methods ‘borrow’ one or more reactions, known to be present in other species, from a universal reaction database (for example, the KEGG ligand database [27]) and add them to the metabolic model, thus potentially filling the gap. If no existing experimental support can be found in the literature, then the predicted missing genes and reactions are hypotheses that require experimental validation.
Systems biology and extreme physiology research
How can these methods help the extreme physiology researcher (and what use are data on humans in extreme environments to the systems biologist)? Central to the practice of systems biology, at least in cells, is the concept of perturbing a biological system [6]. Thus, one might very reasonably argue that the three pillars of systems biology are (1) the ability to measure all the variables of interest (omics), (2) a conceptual framework within which to understand the data (a model) and (3) a way of perturbing the system under interrogation (the experiment). However, the list of methods available to perturb the biological homeostasis of a healthy human is relatively short and comprises exercise, drugs (subject to ethical constraints), dietary manipulation, infusions (for example, lipid emulsions such as Intralipid [58]) and environmental challenges including extreme temperature and hypoxia. Therefore, extreme environments represent one of only a handful of techniques to perturb healthy human biology in a systems biology experiment. As we stated at the outset, we believe therefore that environmental physiology and systems biology are natural symbionts. The usefulness of exercise in this role has, to a limited extent, already been recognised by a small number of systems biology researchers [61, 62]. For those whose research focus is environmental adaptation, they will be well aware that the patterns of human cell, organ and physiological adaptation to extreme environments are astonishingly complex. Reductionist methods have led to a number of ‘paradoxes’ (for example, the lactate paradox in hypoxia). As suggested previously [63], resolving these paradoxes may require systems biology methods. For example, computational modelling suggests that molecular overcrowding in cells may be an important, yet overlooked, factor when attempting to explain limits to cell oxidative metabolism (and hence lactate production under various conditions) [61]. Thus, collaborations between environmental physiologists and systems biologists (with an interest in human physiology) would appear to make good sense for both parties.
Although there is currently a shortage of systems biology studies (as defined here and elsewhere [4, 8]) on human environmental physiology, excellent work has been conducted in the areas of high-altitude genetics and proteomics. Several studies have shown convincingly that human populations at high altitude have experienced a degree of genetic divergence. For example, two recent studies showed that Tibetans, whose ancestors have resided at high altitude for over 10,000 years, have acquired and maintained novel mutations in the gene encoding the oxygen-sensing hypoxia-inducible factor (HIF) molecule [64, 65]. Two-dimensional gel electrophoresis-based proteomics, conducted on skeletal muscle biopsies acquired from subjects exposed for 1 week at 4,500 m [66], showed a number of proteins (related to iron transport and oxidative metabolism) whose abundance was significantly different in experienced climbers after exposure to extreme high altitude. Other investigators have studied the human urinary peptidome [67] and plasma proteome [68] in response to altitude exposure, in the latter case, with particular attention to identifying biomarkers of high-altitude pulmonary oedema. These and similar studies will provide the building blocks for a concerted systems biology effort to model and understand the human physiological response to high altitude. What is required now is a computational framework within which these disparate data can be unified and examined together, most probably a network reconstruction such as that outlined above [69]. There is also a substantial literature on experimental hypoxia (and related issues such as HIF signalling) in humans and animals, including genuine systems biology research, much of which would be relevant to those with an interest in high-altitude acclimatization (cf. [70–77]).
Building bridges between disciplines
Finally, here is a word regarding the challenges ahead. There is increasing interest, driven to some extent by a systems biology agenda within the major funding agencies, in building collaborations between scientists from the life scientists and their colleagues from the physical sciences (including physicists, computer scientists, chemists and mathematicians). Thus, the authors' own collaboration, between a systems biologist/bioengineer and a human physiologist, will become increasingly common. Yet, simply putting physical and life scientists ‘in the same room’ is not enough. Life scientists with poor mathematics will struggle to grasp much of what is possible, while physical scientists with little experience or knowledge of biology will fail to instinctively see both new applications and potential limitations. A perhaps neglected aspect of this interaction is that a lack of knowledge of each others' disciplines limits the scope of the conversation.
There is also a recognition that a new breed of trans-disciplinary scientists will be needed. At present, the focus is on retraining physical scientists and mathematicians in life sciences, with the tacit assumption that this is an easier task than retraining life scientists in mathematics and computation. This, we believe, is a hazardous course of action. Years of experience in any field is never wasted, and life scientists bring with them an innate understanding of the ‘logic of life’ that is impossible to gain in a few short weeks (or even years). We are not alone in this viewpoint; to paraphrase Ideker et al., ‘cross-disciplinary scientists’ contributions will be proportional to their understanding of biology[6]. Thus, physiologists and life scientists must be prepared to rise to the challenge, by expanding their knowledge of computation and (especially) mathematics to a level that will allow them to be productive systems biologists and to engage with scientists from other areas in an informed and productive manner. No longer can biology be considered a science for those who ‘cannot do maths’.
Conclusions
Systems biology is everywhere, yet true applications of systems biology in human physiological research are surprisingly rare. This review has attempted to provide a brief overview of systems biology for the non-expert, while also attempting to describe some ways in which these new approaches can be used to further our understanding of how humans respond to extreme environments. Indeed, we argue that environmental physiology and systems biology are natural bedfellows. Environmental and exercise challenges provide a unique platform for the study of human physiology from a systems perspective, by allowing scientists to challenge homeostasis in a manner that is both ethical and evolutionarily appropriate (in other words, by challenging human physiology with challenges that it has evolved to withstand). Ultimately, the hope is that the relationship between physiology and systems biology will develop and grow, leading us to a more mature and profound understanding of healthy human biology.
Abbreviations
- ARACNE:
-
Algorithm for the Reconstruction of Accurate Cellular Networks
- HIF:
-
Hypoxia-inducible factor
- KEGG:
-
Kyoto Encyclopedia of Genes and Genomes
- PCA:
-
Principal components analysis
- Recon 1:
-
Human metabolic network reconstruction v1
- VO2max:
-
Maximal oxygen uptake.
References
von Bertalanffy L: General System Theory. Foundations, Development, Applications. 1969, New York: George Braziller, Inc
Hargreaves M: Fatigue mechanisms determining exercise performance: integrative physiology is systems biology. J Appl Physiol. 2008, 104: 1541-1542. 10.1152/japplphysiol.00088.2008.
Thiele I, Palsson BO: A protocol for generating a high-quality genome-scale metabolic reconstruction. Nat Protoc. 2010, 5: 93-121.
Palsson B: Systems Biology. 2008, Cambridge: Cambridge University Press
Greenhaff PL, Hargreaves M: ‘Systems biology’ in human exercise physiology: is it something different from integrative physiology?. J Physiol. 2011, 589: 1031-1036. 10.1113/jphysiol.2010.201525.
Ideker T, Galitski T, Hood L: A new approach to decoding life: systems biology. Annu Rev Genomics Hum Genet. 2001, 2: 343-372. 10.1146/annurev.genom.2.1.343.
Westerhoff HV: Systems biology left and right. Methods Enzymol. 2011, 500: 3-11.
Shublaq N, Sansom C, Coveney PV: Patient-specific modelling in drug design, development and selection including its role in clinical decision making. Chem Biol Drug Des. 2012, 10.1111/j.1747-0285.2012.01444.x.
Wanjek C: Systems biology as defined by NIH: an intellectual resource for integrative biology. The NIH Catalyst. 2011, 19: 1-
Hawkins DM, Kraker J: Deterministic fallacies and model validation. J Chemom. 2010, 24: 188-193. 10.1002/cem.1311.
Fall CP, Marland ES, Wagner JM, Tyson JJ: Computational Cell Biology. 2002, New York: Springer
Edelstein-Keshet L: Mathematical Models in Biology. 2005, Philadelphia: SIAM
Qu Z, Garfinkel A, Weiss JN, Nivala M: Multi-scale modeling in biology: how to bridge the gap between scales?. Prog Biophys Mol Biol. 2011, 107: 21-31. 10.1016/j.pbiomolbio.2011.06.004.
Margolin AA, Wang K, Lim WK, Kustagi M, Nemenman I, Califano A: Reverse engineering cellular networks. Nat Protoc. 2006, 1: 662-671. 10.1038/nprot.2006.106.
Basso K, Margolin AA, Stolovitzky G, Klein U, Dalla-Favera R, Califano A: Reverse engineering of regulatory networks in human B cells. Nat Genet. 2005, 37: 382-390. 10.1038/ng1532.
Edwards LM, Ashrafian H, Korzeniewski B: In silico studies on the sensitivity of myocardial PCr/ATP to changes in mitochondrial enzyme activity and oxygen concentration. Mol Biosyst. 2011, 7: 3335-3342. 10.1039/c1mb05310h.
Gillespie DT: A general method for numerically simulating the stochastic time evolution of coupled chemical reactions. J Comput Phys. 1976, 22: 404-434.
Lewis NE, Nagarajan H, Palsson BO: Constraining the metabolic genotype-phenotype relationship using a phylogeny of in silico methods. Nat Rev Microbiol. 2012, 10: 291-305.
Sigurdsson MI, Jamshidi N, Steingrimsson E, Thiele I, Palsson BO: A detailed genome-wide reconstruction of mouse metabolism based on human Recon 1. BMC Syst Biol. 2010, 4: 140-10.1186/1752-0509-4-140.
Duarte NC, Becker SA, Jamshidi N, Thiele I, Mo ML, Vo TD, Srivas R, Palsson BO: Global reconstruction of the human metabolic network based on genomic and bibliomic data. Proc Natl Acad Sci U S A. 2007, 104: 1777-1782. 10.1073/pnas.0610772104.
Li F, Thiele I, Jamshidi N, Palsson BO: Identification of potential pathway mediation targets in Toll-like receptor signaling. PLoS Comput Biol. 2009, 5: e1000292-10.1371/journal.pcbi.1000292.
Papin JA, Palsson BO: The JAK-STAT signaling network in the human B-cell: an extreme signaling pathway analysis. Biophys J. 2004, 87: 37-46. 10.1529/biophysj.103.029884.
Thiele I, Jamshidi N, Fleming RM, Palsson BO: Genome-scale reconstruction of Escherichia coli's transcriptional and translational machinery: a knowledge base, its mathematical formulation, and its functional characterization. PLoS Comput Biol. 2009, 5: e1000312-10.1371/journal.pcbi.1000312.
Feist AM, Herrgard MJ, Thiele I, Reed JL, Palsson BO: Reconstruction of biochemical networks in microorganisms. Nature reviews. 2009, 7: 129-143.
Durot M, Bourguignon PY, Schachter V: Genome-scale models of bacterial metabolism: reconstruction and applications. FEMS Microbiol Rev. 2009, 33: 164-190. 10.1111/j.1574-6976.2008.00146.x.
Notebaart RA, van Enckevort FH, Francke C, Siezen RJ, Teusink B: Accelerating the reconstruction of genome-scale metabolic networks. BMC Bioinforma. 2006, 7: 296-10.1186/1471-2105-7-296.
Kanehisa M, Goto S, Hattori M, Aoki-Kinoshita KF, Itoh M, Kawashima S, Katayama T, Araki M, Hirakawa M: From genomics to chemical genomics: new developments in KEGG. Nucleic Acids Res. 2006, 34: D354-357. 10.1093/nar/gkj102.
Barthelmes J, Ebeling C, Chang A, Schomburg I, Schomburg D: BRENDA, AMENDA and FRENDA: the enzyme information system in 2007. Nucleic Acids Res. 2007, 35: D511-514. 10.1093/nar/gkl972.
Jankowski MD, Henry CS, Broadbelt LJ, Hatzimanikatis V: Group contribution method for thermodynamic analysis of complex metabolic networks. Biophys J. 2008, 95: 1487-1499. 10.1529/biophysj.107.124784.
Fleming RM, Thiele I: von Bertalanffy 1.0: a COBRA toolbox extension to thermodynamically constrain metabolic models. Bioinformatics (Oxford, England). 2011, 27: 142-143. 10.1093/bioinformatics/btq607.
Reed JL, Patel TR, Chen KH, Joyce AR, Applebee MK, Herring CD, Bui OT, Knight EM, Fong SS, Palsson BO: Systems approach to refining genome annotation. Proc Natl Acad Sci U S A. 2006, 103: 17480-17484. 10.1073/pnas.0603364103.
Fong SS, Burgard AP, Herring CD, Knight EM, Blattner FR, Maranas CD, Palsson BO: In silico design and adaptive evolution of Escherichia coli for production of lactic acid. Biotechnol Bioeng. 2005, 91: 643-648. 10.1002/bit.20542.
Lee SY, Kim JM, Song H, Lee JW, Kim TY, Jang YS: From genome sequence to integrated bioprocess for succinic acid production by Mannheimia succiniciproducens. Appl Microbiol Biotechnol. 2008, 79: 11-22. 10.1007/s00253-008-1424-3.
Ibarra RU, Edwards JS, Palsson BO: Escherichia coli K-12 undergoes adaptive evolution to achieve in silico predicted optimal growth. Nature. 2002, 420: 186-189. 10.1038/nature01149.
Fong SS, Marciniak JY, Palsson BO: Description and interpretation of adaptive evolution of Escherichia coli K-12 MG1655 by using a genome-scale in silico metabolic model. J Bacteriol. 2003, 185: 6400-6408. 10.1128/JB.185.21.6400-6408.2003.
Schilling CH, Letscher D, Palsson BO: Theory for the systemic definition of metabolic pathways and their use in interpreting metabolic function from a pathway-oriented perspective. J Theor Biol. 2000, 203: 229-248. 10.1006/jtbi.2000.1073.
Almaas E, Kovacs B, Vicsek T, Oltvai ZN, Barabasi AL: Global organization of metabolic fluxes in the bacterium Escherichia coli. Nature. 2004, 427: 839-843. 10.1038/nature02289.
Thiele I, Price ND, Vo TD, Palsson BO: Candidate metabolic network states in human mitochondria: impact of diabetes, ischemia, and diet. J Biol Chem. 2005, 280: 11683-11695. 10.1074/jbc.M409072200.
Teusink B, Wiersma A, Molenaar D, Francke C, de Vos WM, Siezen RJ, Smid EJ: Analysis of growth of Lactobacillus plantarum WCFS1 on a complex medium using a genome-scale metabolic model. J Biol Chem. 2006, 281: 40041-40048. 10.1074/jbc.M606263200.
Reed JL, Palsson BO: Genome-scale in silico models of E. coli have multiple equivalent phenotypic states: assessment of correlated reaction subsets that comprise network states. Genome Res. 2004, 14: 1797-1805. 10.1101/gr.2546004.
Joyce AR, Reed JL, White A, Edwards R, Osterman A, Baba T, Mori H, Lesely SA, Palsson BO, Agarwalla S: Experimental and computational assessment of conditionally essential genes in Escherichia coli. J Bacteriol. 2006, 188: 8259-8271. 10.1128/JB.00740-06.
Feist AM, Palsson BO: The growing scope of applications of genome-scale metabolic reconstructions using Escherichia coli. Nat Biotechnol. 2008, 26: 659-667. 10.1038/nbt1401.
Bordbar A, Palsson BO: Using the reconstructed genome-scale human metabolic network to study physiology and pathology. J Intern Med. 2012, 271: 131-141. 10.1111/j.1365-2796.2011.02494.x.
Oberhardt MA, Palsson BO, Papin JA: Applications of genome-scale metabolic reconstructions. Mol Syst Biol. 2009, 5: 320-
Bordbar A, Lewis NE, Schellenberger J, Palsson BO, Jamshidi N:Insight into human alveolar macrophage andM. tuberculosisinteractions via metabolic reconstructions. Mol Syst Biol. 2010, 6: 422-
Gille C, Bolling C, Hoppe A, Bulik S, Hoffmann S, Hubner K, Karlstadt A, Ganeshan R, Konig M, Rother K, Weidlich M, Behre J, Holzhütter HG: HepatoNet1: a comprehensive metabolic reconstruction of the human hepatocyte for the analysis of liver physiology. Mol Syst Biol. 2010, 6: 411-
Bordbar A, Feist AM, Usaite-Black R, Woodcock J, Palsson BO, Famili I: A multi-tissue type genome-scale metabolic network for analysis of whole-body systems physiology. BMC Syst Biol. 2011, 5: 180-10.1186/1752-0509-5-180.
Folger O, Jerby L, Frezza C, Gottlieb E, Ruppin E, Shlomi T: Predicting selective drug targets in cancer through metabolic networks. Mol Syst Biol. 2011, 7: 517-
Lewis NE, Schramm G, Bordbar A, Schellenberger J, Andersen MP, Cheng JK, Patel N, Yee A, Lewis RA, Eils R, König R, Palsson BØ: Large-scale in silico modeling of metabolic interactions between cell types in the human brain. Nat Biotechnol. 2010, 28: 1279-1285. 10.1038/nbt.1711.
Chandrasekaran S, Price ND: Probabilistic integrative modeling of genome-scale metabolic and regulatory networks in Escherichia coli and Mycobacterium tuberculosis. Proc Natl Acad Sci U S A. 2010, 107: 17845-17850. 10.1073/pnas.1005139107.
Lee JM, Gianchandani EP, Eddy JA, Papin JA: Dynamic analysis of integrated signaling, metabolic, and regulatory networks. PLoS Comput Biol. 2008, 4: e1000086-10.1371/journal.pcbi.1000086.
Covert MW, Xiao N, Chen TJ, Karr JR: Integrating metabolic, transcriptional regulatory and signal transduction models in Escherichia coli. Bioinformatics (Oxford, England). 2008, 24: 2044-2050. 10.1093/bioinformatics/btn352.
Willmann S, Thelen K, Lippert J: Integration of dissolution into physiologically-based pharmacokinetic models III: PK-Sim((R)). J Pharm Pharmacol. 2012, 64: 997-1007. 10.1111/j.2042-7158.2012.01534.x.
Satish Kumar V, Dasika MS, Maranas CD: Optimization based automated curation of metabolic reconstructions. BMC Bioinforma. 2007, 8: 212-10.1186/1471-2105-8-212.
Kumar VS, Maranas CD: GrowMatch: an automated method for reconciling in silico/in vivo growth predictions. PLoS Comput Biol. 2009, 5: e1000308-10.1371/journal.pcbi.1000308.
Illig T, Gieger C, Zhai G, Romisch-Margl W, Wang-Sattler R, Prehn C, Altmaier E, Kastenmuller G, Kato BS, Mewes HW, Meitinger T, de Angelis MH, Kronenberg F, Soranzo N, Wichmann HE, Spector TD, Adamski J, Suhre K: A genome-wide perspective of genetic variation in human metabolism. Nat Genet. 2010, 42: 137-141. 10.1038/ng.507.
Suhre K, Wallaschofski H, Raffler J, Friedrich N, Haring R, Michael K, Wasner C, Krebs A, Kronenberg F, Chang D, Meisinger C, Wichmann HE, Hoffmann W, Völzke H, Völker U, Teumer A, Biffar R, Kocher T, Felix SB, Illig T, Kroemer HK, Gieger C, Römisch-Margl W, Nauck M: A genome-wide association study of metabolic traits in human urine. Nat Genet. 2011, 43: 565-569. 10.1038/ng.837.
Edwards LM, Lawler NG, Nikolic SB, Peters JM, Horne J, Wilson R, Davies NW, Sharman JE: Metabolomics reveals increased isoleukotoxin diol (12,13-DHOME) in human plasma after acute Intralipid infusion. J Lipid Res. 2012, 53 (9): 1979-86. 10.1194/jlr.P027706.
Orth JD, Palsson BO: Systematizing the generation of missing metabolic knowledge. Biotechnol Bioeng. 2010, 107: 403-412. 10.1002/bit.22844.
Rolfsson O, Palsson BO, Thiele I: The human metabolic reconstruction Recon 1 directs hypotheses of novel human metabolic functions. BMC Syst Biol. 2011, 5: 155-10.1186/1752-0509-5-155.
Vazquez A, Oltvai ZN: Molecular crowding defines a common origin for the Warburg effect in proliferating cells and the lactate threshold in muscle physiology. PLoS One. 2011, 6: e19538-10.1371/journal.pone.0019538.
van Beek JH, Supandi F, Gavai AK, de Graaf AA, Binsl TW, Hettling H: Simulating the physiology of athletes during endurance sports events: modelling human energy conversion and metabolism. Philos Transact A Math Phys Eng Sci. 2011, 369: 4295-4315. 10.1098/rsta.2011.0166.
Murray AJ: Metabolic adaptation of skeletal muscle to high altitude hypoxia: how new technologies could resolve the controversies. Genome Med. 2009, 1: 117-10.1186/gm117.
Beall CM, Cavalleri GL, Deng L, Elston RC, Gao Y, Knight J, Li C, Li JC, Liang Y, McCormack M, Montgomery HE, Pan H, Robbins PA, Shianna KV, Tam SC, Tsering N, Veeramah KR, Wang W, Wangdui P, Weale ME, Xu Y, Xu Z, Yang L, Zaman MJ, Zeng C, Zhang L, Zhang X, Zhaxi P, Zheng YT: Natural selection on EPAS1 (HIF2alpha) associated with low hemoglobin concentration in Tibetan highlanders. Proc Natl Acad Sci U S A. 2010, 107: 11459-11464. 10.1073/pnas.1002443107.
Yi X, Liang Y, Huerta-Sanchez E, Jin X, Cuo ZX, Pool JE, Xu X, Jiang H, Vinckenbosch N, Korneliussen TS, Zheng H, Liu T, He W, Li K, Luo R, Nie X, Wu H, Zhao M, Cao H, Zou J, Shan Y, Li S, Yang Q, Asan Ni P, Tian G, Xu J, Liu X, Jiang T, Wu R: Sequencing of 50 human exomes reveals adaptation to high altitude. Science. 2010, 329: 75-78. 10.1126/science.1190371.
Vigano A, Ripamonti M, De Palma S, Capitanio D, Vasso M, Wait R, Lundby C, Cerretelli P, Gelfi C: Proteins modulation in human skeletal muscle in the early phase of adaptation to hypobaric hypoxia. Proteomics. 2008, 8: 4668-4679. 10.1002/pmic.200800232.
Mainini V, Gianazza E, Chinello C, Bilo G, Revera M, Giuliano A, Caldara G, Lombardi C, Piperno A, Magni F, Parati G: Modulation of urinary peptidome in humans exposed to high altitude hypoxia. Mol Biosyst. 2012, 8: 959-966. 10.1039/c1mb05377a.
Ahmad Y, Shukla D, Garg I, Sharma NK, Saxena S, Malhotra VK, Bhargava K: Identification of haptoglobin and apolipoprotein A-I as biomarkers for high altitude pulmonary edema. Funct Integr Genomics. 2011, 11: 407-417. 10.1007/s10142-011-0234-3.
Edwards LM, Thiele I: Studying the effects of hypoxia on mitochondrial metabolism in human heart using a genome-wide metabolic network model. Proc Aus Phys Soc. 2011, 42: 33-
Lai X, Nikolov S, Wolkenhauer O, Vera J: A multi-level model accounting for the effects of JAK2-STAT5 signal modulation in erythropoiesis. Comput Biol Chem. 2009, 33: 312-324. 10.1016/j.compbiolchem.2009.07.003.
Turan N, Kalko S, Stincone A, Clarke K, Sabah A, Howlett K, Curnow SJ, Rodriguez DA, Cascante M, O'Neill L, Egginton S, Roca J, Falciani F: A systems biology approach identifies molecular networks defining skeletal muscle abnormalities in chronic obstructive pulmonary disease. PLoS Comput Biol. 2011, 7: e1002129-10.1371/journal.pcbi.1002129.
Stefanini MO, Qutub AA, Mac Gabhann F, Popel AS: Computational models of VEGF-associated angiogenic processes in cancer. Math Med Biol. 2012, 29: 85-94. 10.1093/imammb/dqq025.
Baumann K, Carnicer M, Dragosits M, Graf AB, Stadlmann J, Jouhten P, Maaheimo H, Gasser B, Albiol J, Mattanovich D, Ferrer P: A multi-level study of recombinant Pichia pastoris in different oxygen conditions. BMC Syst Biol. 2010, 4: 141-10.1186/1752-0509-4-141.
Schmierer B, Novak B, Schofield CJ: Hypoxia-dependent sequestration of an oxygen sensor by a widespread structural motif can shape the hypoxic response - a predictive kinetic model. BMC Syst Biol. 2010, 4: 139-10.1186/1752-0509-4-139.
Mac Gabhann F, Qutub AA, Annex BH, Popel AS: Systems biology of pro-angiogenic therapies targeting the VEGF system. Wiley Interdiscip Rev Syst Biol Med. 2010, 2: 694-707. 10.1002/wsbm.92.
Kojima T, Ueda Y, Adati N, Kitamoto A, Sato A, Huang MC, Noor J, Sameshima H, Ikenoue T: Gene network analysis to determine the effects of antioxidant treatment in a rat model of neonatal hypoxic-ischemic encephalopathy. J Mol Neurosci. 2010, 42: 154-161. 10.1007/s12031-010-9337-x.
Selivanov VA, Votyakova TV, Zeak JA, Trucco M, Roca J, Cascante M: Bistability of mitochondrial respiration underlies paradoxical reactive oxygen species generation induced by anoxia. PLoS Comput Biol. 2009, 5: e1000619-10.1371/journal.pcbi.1000619.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
LME and IT contributed equally to the writing of this article. Both authors read and approved the final manuscript
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Edwards, L.M., Thiele, I. Applying systems biology methods to the study of human physiology in extreme environments. Extrem Physiol Med 2, 8 (2013). https://doi.org/10.1186/2046-7648-2-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/2046-7648-2-8