
Abstract
Background
Clinical ethics support, in particular Moral Case Deliberation, aims to support health care providers to manage ethically difficult situations. However, there is a lack of evaluation instruments regarding outcomes of clinical ethics support in general and regarding Moral Case Deliberation (MCD) in particular. There also is a lack of clarity and consensuses regarding which MCD outcomes are beneficial. In addition, MCD outcomes might be context-sensitive. Against this background, there is a need for a standardised but flexible outcome evaluation instrument. The aim of this study was to develop a multi-contextual evaluation instrument measuring health care providers’ experiences and perceived importance of outcomes of Moral Case Deliberation.
Methods
A multi-item instrument for assessing outcomes of Moral Case Deliberation (MCD) was constructed through an iterative process, founded on a literature review and modified through a multistep review by ethicists and health care providers. The instrument measures perceived importance of outcomes before and after MCD, as well as experienced outcomes during MCD and in daily work. A purposeful sample of 86 European participants contributed to a Delphi panel and content validity testing. The Delphi panel (n = 13), consisting of ethicists and ethics researchers, participated in three Delphi-rounds. Health care providers (n = 73) participated in the content validity testing through ‘think-aloud’ interviews and a method using Content Validity Index.
Results
The development process resulted in the European Moral Case Deliberation Outcomes Instrument (Euro-MCD), which consists of two sections, one to be completed before a participant’s first MCD and the other after completing multiple MCDs. The instrument contains a few open-ended questions and 26 specific items with a corresponding rating/response scale representing various MCD outcomes. The items were categorised into the following six domains: Enhanced emotional support, Enhanced collaboration, Improved moral reflexivity, Improved moral attitude, Improvement on organizational level and Concrete results.
Conclusions
A tentative instrument has been developed that seems to cover main outcomes of Moral Case Deliberation. The next step will be to test the Euro-MCD in a field study.
Similar content being viewed by others

Background
Traditionally, clinical ethics support has been conducted by Clinical Ethics Committees and/or Clinical Ethics Consultation [1, 2]. A more recent form of clinical ethics support is Moral Case Deliberation (MCD) [3, 4]. MCD is a facilitator-led collective moral inquiry by health care providers into a concrete moral question connected to a real case in their practice [5, 6]. Often, MCD implies using a specific conversation method (such as the Dilemma method or the Socratic Dialogue) [6–10]. For the development of the instrument in this study, we use the term MCD as an umbrella term in line with the definition above excluding the specific conversation methods. Related terms that might be used instead of MCD are: Ethics rounds [9–13], Ethical case discussion [14, 15] and Ethics reflection groups [16, 17]. The MCD facilitator does not function as an ethics expert or consultant [5, 6, 10]. The expertise of the MCD facilitator supports the joint reasoning process, fostering a sincere, systematic and constructive dialogue and keeping in focus the moral dimension of the case [6].
The main goal of MCD is to support health care providers to manage ethically difficult situations in everyday clinical practice. Empirical investigations are needed to evaluate in which sense this main goal is reached and to understand what outcomes are produced by MCD. Previous literature reveals four gaps that hamper further empirical evaluation.
First, there is a lack of MCD evaluation research in general using validated instruments [2, 18, 19].
Second, existing quantitative MCD evaluation research using predetermined evaluation criteria have failed to detect any outcomes [11, 20]. The only previous MCD questionnaire published is the Dutch ‘Maastricht Moral Deliberation Evaluation Questionnaire’ [21]. However, this questionnaire was study-specific for a process evaluation of an implementation of MCD in a specific healthcare setting.
Third, the few available qualitative MCD evaluation studies have merely focused on the evaluation of the MCD sessions and little on the perceived outcomes of the MCD on everyday clinical work [7–10, 21].
Fourth, there is a lack of clarity and consensus on which outcomes ideally should be reached. This requires a more thorough consideration [2, 22]. A lack of consensus does not have to be a problem in itself, since goals of MCD can change in different contexts and over time. At the same time, this complicates selecting outcomes for MCD and developing an instrument. The contextual nature of MCD sessions prevents simple standardisation [22, 23]. Therefore, there is a need to study how outcomes differ and in which ways they are context sensitive (for example influenced by workplace, group dynamic behaviour, facilitator, patient cases and culture). This variety regarding outcomes stresses the need for an instrument that takes into account a broad range of different aspects. Results from using such an instrument can further inform and stimulate the discussion of beneficial outcomes of MCD, and thereby stimulate the professional development of MCD (even if a final consensus will not and need not be reached).
In sum, there is both a lack and need for a standardised outcome evaluation instrument for MCD that is developed according to rigid methodological standards and at the same time able to capture outcomes in different contexts. The fact that there is no consensus on MCD outcomes does not diminish the importance of developing a standardized instrument. Instead it makes it even more important to develop an instrument that allows for variety of different MCD outcomes in different contexts. Information on the outcomes of MCD informs about the quality of MCD which, in the end, will be beneficial for the health care providers. Thus, the aim of this study was to develop a multi-contextual evaluation instrument measuring health care providers’ experiences and perceived importance of outcomes of Moral Case Deliberation.
Methods
A multi-item instrument was developed with the following method of measurement: literature review, collection of items, categorization, a Delphi approach [24] and content validity testing [25–27]. The construct being measured was attitudes and experiences regarding possible outcomes of Moral Case Deliberation, measured through a reflective model [28]. The development process was inductive and did not emanate from predetermined aspects of the construct. An advisory statement including no objection to test the instrument was given by Swedish Regional Ethical Review Board (dnr 2012/34).
Participants
Overall, 86 participants contributed to the development process of the instrument (Tables 1 and 2). A purposeful sampling strategy was used. First, a Delphi panel of 13 key informants was selected consisting of clinical ethicists and/or ethics researchers from six different countries. Members of the European Clinical Ethics Network (ECEN) [29] were approached, as well as other clinical ethicists, in order to foster variation (Table 1).
Second, 73 participants were approached as representatives of the target population, including healthcare professions collaborating in patient care as well as social scientists, knowledgeable in MCD practice and the everyday English clinical language. They were asked to participate in the process of cognitive and content validity testing. Variation was sought for different professional backgrounds, medical field, countries and level of experience with MCD (Table 2).
Literature review
An explorative literature review search was conducted by MS to identify possible outcomes of clinical ethics support in general. The review functioned as an inspiration source and was aimed at generating a list of items and identifying outcome domains. A PUBMED search was performed with the MESH term ‘Ethics Consultation’, published 2002 to 2012 and the words ‘Moral Case Deliberation’ or ‘Ethics rounds’ in title or abstracts. Papers were included if they concerned (1) empirical studies of evaluation of Clinical Ethics Consultation, Clinical Ethics Committees or MCD, and (2) conceptual papers about aims of supporting health care providers concerning clinical ethical issues. Reasons for including papers on Clinical Ethics Consultation and Clinical Ethics Committees were that these outcome measures could also be relevant for MCD and also as a response to reported critique by participants of MCDs being too much reflexivity oriented instead of action oriented [10, 21].
Articles were excluded if they concerned only ethics consultation for individual physicians, patients and families, research design issues about clinical ethics support and education. No quality assessment of the involved papers was performed since the aim was only to develop a list of possible outcomes.
Categorization
MS and BM started the categorisation process with the purpose to build a preliminary conceptual model with three measurement levels: items, subdomains and domains. First, MS and BM grouped the various items into domains, independent from each other. This was a bottom up process (rather than top down or theoretically driven). Next, similarities and differences between the two categorizations as a heuristic tool were used until agreement on the measurement levels existed (see Table 3). Similar items were merged or grouped together and then coded into higher abstraction levels of subdomains and domains [30].
Delphi approach
A Delphi approach of three rounds of structured questionnaires to the expert panel was used in order to gain consensus without dominance on the process from specific experts [24]. The purpose was to further test the categorisation of the selected outcome items and the content validity of the items. Consensus was primarily sought for categorisation and relevance of items, but also for the structure of the instrument.
Delphi round 1
The Delphi panel was asked to independently categorise the various items into subdomains, and subdomains into domains. The participants were also asked to assess the relevance of all items collected from the literature review (both the items included in the categorisation and the items discarded by MS and BM) on a four-point scale; irrelevant to high relevance. In the light of the result, items, subdomains, and domains were merged, discarded or reformulated by MS and BM.
Delphi round 2
The panel received information on the categorisations and opinions of all members (anonymously) and a questionnaire on the appropriateness of the new version of the categorisation. A four point scale: not (1), somewhat (2), quite (3) and very appropriate (4) was used. In addition respondents were requested to make comments and suggestions of re-categorisation. On the basis of the Delphi categorization rounds, a draft instrument was constructed for content validity testing. Effort was put into reducing ambiguity in item wording and formulating items into everyday language [26].
Delphi round 3
The panel received nine closed questions regarding adequacy and clarity of the instruction, the questions and the grading of the draft instrument, with possibilities for comments.
Content validity testing on target population
Cognitive understanding and relevance of the items were tested on 73 persons from the target population (see Table 2). The testing was conducted through seven steps with different groups of participants at each step, using ratings of content validity index (CVI) and audio recorded ‘think-aloud’ interviews. Revisions were made between each step.
Content Validity Index testing
The inter-rater agreement of clarity of the items was measured by CVI using the four-point scale according to Yaghmaie: Not clear (1), Item needs some revision (2), Clear but needs minor revision (3) and Very clear (4). The relevance was measured on a four-point scale from irrelevant to high relevance [31]. The rater also had the opportunity to add comments. The questions on simplicity and ambiguity were discarded, after a ‘think-aloud’ pilot test that showed that the respondents gave identical answers on these two aspects, compared to the answers on clarity. Both the appropriateness of categorisation and the CVI was computed according to Polit et al. as universal agreement (S-CVI). An item-CVI (I-CVI) lower than .78 for was considered as a reason for revision [27].
‘Think-aloud’ interviews
The cognitive method ‘think-aloud’ [25, 26] was used while respondents simultaneously filled in the CVI- Through. individual- and focus group interviews [30], the understanding was tested for consistence and in accordance with the way the items were intended to be perceived [25, 26]. The interviewers read the items aloud and encouraged the informants to express their meaning with the question: ‘Can you rephrase this item in your own words?’ Furthermore, the participants were encouraged to express opinions on the relevance of the items.
Results
The European Moral Case Deliberation Outcome Instrument (Euro-MCD) was developed in accordance with the following steps.
Literature review
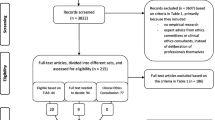
The literature search yielded 1378 articles. After reviewing titles according to the inclusion criteria, the number was reduced to 352 papers. After reading the abstract or, in case of insufficient information, the full text, 87 papers which fulfilled the relevant criteria were included for further analysis. The major content of these papers were conceptual and empirical studies on Clinical Ethics Consultation and 15 addressed MCD (umbrella term). At the end of the development process, the final items referred to 21 papers, where nine addressed MCD (Table 4).
Collection of items
A total of 96 preliminary items were collected from the contents of 53 of the 87 papers. In the first reduction step, items were reduced by MS and BM to 48 (Table 3) based on six criteria: similar items, not relevant enough for MCD, too academic, too vague, too unspecific to be categorised to only one domain, too abstract or difficult to measure (Table 5).
First categorization
The resulting 48 items were sorted into 12 subdomains, which were attributed into four overarching thematic domains: ‘Enhanced ethical climate’, ‘Enhanced moral competence’, ‘Reduced moral distress’ and ‘Concrete resolution’. For agreement, item reduction and domain revision see the tracking matrix in Table 3.
Delphi approach
Delphi round 1
The first round resulted in low agreement on the categorisation of the 48 items. Several of the Delphi-members had categorised items into several subdomains. For example the item ‘Moral consensus for care achieved in the patient cases’ was sorted into the following subdomains, depending on the Delphi-member: ‘Concrete steps taken in the patient cases’, ‘Organisation consistent with ethical standards’ and ‘Enhanced collaboration’. This led to the decision to discard these initial domains and create new ones. In order to gain clarity, all subdomains were discarded and the main domains were made less abstract. The second step of item reduction resulted in 33 items (Table 3).
Regarding the question of relevance of the items, there was also great variability of opinions of the 48 items in the categorisation and of the 54 items discarded by MS and BM from literature review. There was only agreement of high relevance for 10 items and agreement of low relevance for 37 items. No differences of judgments were detected between professions or countries.
Delphi round 2
In the second round, the appropriateness of the revised set of 33 items and the new categorisation was tested. The agreement between Delphi-members proved to be better (Table 3). The most important change after the second round was that the name of the domain ‘Improved moral skills’ was changed into ‘Improved moral reflexivity’, including moving one item into this domain and discarding two others from it. The fourth and final step of item reduction resulted in 26 items (Table 4).
Delphi round 3
The third round resulted in 100% agreement regarding the structure of the instrument; adequacy and clarity of the content of instruction, questions and also the response alternatives. After content validity testing, an additional question in both the Euro-MCD I and II was added: ‘Please list five of the most important outcomes’. This was done since the majority of items were viewed as “very important”.
Content validity testing
The Content Validity Index testing
The CVI, tested mostly on the target population (Table 2) through seven steps, showed that clarity increased from 0.71 to 0.96 and relevance from 0.70 to 0.95, although the change in relevance was less in France ( 0.77) (Table 6). The think-aloud interviews mainly provided input on clarity for everyday language, highlighted ambiguities and questioning of relevance of certain items. The testing led to 35 major reformulations and 65 minor reformulations and the discarding of two items (Table 6). No differences of judgments were detected between professions or specialties.
The ‘think-aloud’ interviews and comments
The interviews and comments led to reformulations of the items, since vague items with ambiguous meanings were pointed out (Table 6). When the informants were uncertain of the meaning of an item, they often gave suggestions for reformulations. See summaries of the interviews in Table 6.
Translation and CVI
The original language of the instrument is English. Euro-MCD I and II were literally translated into Swedish, Dutch, French and Norwegian by two independent translators for each of the languages. CVI and ‘think-aloud’ interviews were then tested in each country (Table 6). Next, the versions were back-translated into English by other translators [41]. Finally, all the back-translations were compared regarding literal translation and cultural adaption and then harmonized against the English source [41, 42]. The back-translations showed high agreement, except for the two items in the domain Impact on organizational level. The the terms ‘practice/policies’ were culturally translated in France and Norway, but literally in Sweden and Netherlands.
The final instrument
The Euro-MCD consists of two sections. Section I is to be used before MCD and consists of an open question on important outcomes in general, followed by one closed question regarding the importance of the 26 pre-formulated outcomes (the items). Section II is to be used after multiple MCDs. It starts with open questions on experiences of outcomes, followed by a series of closed questions on both the importance and the experience of outcomes (Table 7). A four-point response scale is used for measuring the importance and the experience of outcomes: none, somewhat, quite high and high.
The measurement model comprises 26 items and six domains: Enhanced emotional support, Enhanced collaboration, Improved moral reflexivity, Improved moral attitude, Impact on organizational level and Concrete results (Table 4). Some domains are complex and thus need more items, such as ‘Enhanced emotional support’, containing five items. More simple and concrete domains, such as ‘Concrete results’, contain three items.
Discussion
Through a systematic process, an instrument was developed measuring a wide range of possible outcomes associated with Moral Case Deliberation in different countries: The Euro-MCD.
The six domains in the final version - Enhanced emotional support, Enhanced collaboration, Improved moral reflexivity, Improved moral attitude, Impact on organizational level and Concrete results - seem to cover main outcomes of MCD. The domains in the initial development process contained only aspects that are directly related to ethics (Table 4). In the final version, the domains: Enhanced emotional support and Enhanced collaboration demonstrate that reflecting (in MCD) on the morally good thing to do also involves dealing with emotions and collaboration. Furthermore, outcomes need not always be of a strictly ethical nature in order to be considered important and relevant by MCD users. This is also described in the literature on MCD [43, 44].
Domains similar to those in the Euro-MCD are to be found in other validated instruments, developed outside the area of clinical ethics support. Examples are instruments concerning moral distress [45–47], nurse-physician collaboration [48], ethical climate [46] and team reflexivity [49]. However, all these instruments measure only one specific domain. With the Euro-MCD instrument we want to combine several domains and relate them specifically to MCD. Furthermore, we first want to know if there is a systematic pattern of MCD outcomes within the Euro-MCD, and if so, which MCD outcomes are most relevant. After testing the Euro-MCD in various countries, and further improving its validity, existing validated instruments mentioned above might be used in combination with the Euro MCD in order to evaluate to what degree the other instruments and the Euro MCD measure the same construct.
A crucial aspect of the instrument is that it measures both what the health care providers’ perceive as important and what they actually experience. It assumes that changes in daily work after MCD sessions, reported by respondents, are related to the participation in the MCD sessions. Again, this is the subjective experience of the respondents, and not in any way objectively observed. We think, however, that this in itself is valuable and informative, because the outcomes from the Euro-MCD are experiential phenomena.
A strong point of the instrument is the multinational and multi contextual development process [42] and thus can be applied in a wide variety of contexts. It might even be used in a wider sense, such as evaluating classic ethics consultation. Furthermore, the instrument can be used to measure changes over time through analysing differences in perceived importance before and after multiple MCDs.
We think the instrument can be useful, not only for those who facilitate MCD, but also for those who implement it (e.g. managers, board of directors). The information about the MCD outcomes could be an indicator of the effectiveness and indirectly also of the quality of the MCD at the local and institutional level. We think sharing the results of the Euro-MCD with participants is important for testing the validity and the meaning of these results but also, and especially, to empower MCD participants to use the MCD for their specific interests (i.e. to make them responsible and active owners of MCD).
Results of the Euro-MCD might also be used to develop new ways of facilitation, since low ratings on questions on experiencing certain outcomes during the MCD sessions can stimulate the facilitator to change focus when facilitating future MCD’s. When for example, the rating on ‘better mutual understanding of each other’s reasoning and acting’ receives a low rating, the facilitator could focus more on whether participants understand each other.
Methodological considerations
The development of the Euro-MCD was a complex, iterative process with continuous revision of items and domains. Refering to Brod’s parable of the GPS system [30], the initial course was plotted by the literature review, but the Delphi-panel and especially the content validity testing corrected the wrong turns in order to make the final destination. Five recommended steps out of six steps in the development of a measurement instrument, as described by de Vet et al. [28] was followed. The last step, field-testing will be conducted with the current version of the Euro-MCD. The study’s strength lies in the comprehensive methodology in developing the Euro-MCD and the use of standard statistical assessment at each stage. However, it might be considered as a weakness that this instrument does not measure objective outcomes (e.g. related to sick leave, turnover rates of employees, and patient related outcomes). Objective outcomes are important, but seem to be more difficult to capture and require another kind of research instrument and research design.
We selected a Delphi panel of members with high levels of expertise [27], since the members were MCD facilitators and/or ethics researchers from different countries and with different professional backgrounds. There was also a wide variation in respondents for the content validity process. However, a potential bias might has been caused by the fact that most respondents were Swedish, lacked experience of MCD and were middle-aged. When testing the instrument before and after multiple MCDs in the coming field study, we will also capture younger respondents with experience of MCD from four European countries.
The process of categorization was complicated by the diversity of opinions of the Delphi expert panel. As a consequence, this process did not give sufficient guidance for the categorization and item reduction. On the one hand, this is an interesting result in itself: experts on clinical ethics support vary on what kind of outcomes they consider appropriate for MCD. On the other hand, the low agreement between the Delphi-expert panel in the first round could be a result from the open and imprecise nature of the assignment given to them. In hindsight, we should have informed the Delphi expert panel more clearly that the domains were seen as reflections of the items (reflective model), not as predictions of the items (formative model) [28]. In Delphi round 2, the agreement of the categorization made by MS and BM was higher and the comments were much more distinct and helpful. It might be concluded that the first round was too open, and the second one too narrow.
The development of the Euro-MCD is not finished. In the coming field-study, health care providers have the opportunity to add items through the open questions in the instrument. This provides the opportunity for considering possible neglected but important outcomes in the next version. The open questions also fit with our contextual and pragmatic viewpoint that the specific context should have a say in which specific goals and outcomes of MCD are important. However, we are aware of that the number of items is too extensive and our goal is to decrease them after the field-study. In this phase it could be hazardous to limit them too much.
The content validity process was successful. This indicates that we have captured and formulated clear and relevant items, even though it was tested in only fiveWestern European countries. According to Brod et al., combining focus-groups and individual interviews support the content validity [30]. The focus group interview with healthcare professions working both clinically and as researchers was especially successful. The open and vivid communication enabled participants to equally express their opinions. Thus, a rich variation of relevance judgments and substantial suggestions for reformulations were generated. The discussion of the relevance of the item focusing on reaching consensus was especially salient. There were both strong opinions against, in that the consensus reached may be unethical, and strong opinions in favor, in that consensus are needed for a concrete problem in a particular patient situation.
We reached the recommended goal of a mean Content Validity Index over .90, as recommended by Polit et al. [27]. This means that the validity of the current items can be considered as high. However, questions can be raised concerning discriminative validity, since some items overlap. However, different respondents perceived different items as similar. After the results of the field study, items that overlap will be merged or deleted.
Conclusions
A tentative measurement model was developed that seems to cover main outcomes of Moral Case Deliberation. Both the process and the result of the content validity procedures seem high. The Euro-MCD is unique since it is flexible enough to be tailored to the specific needs of local MCD groups, but general enough to capture relevant MCD outcomes across multiple contexts.
However, a broader field study is needed to further develop and validate the Euro-MCD, collecting data from participants who have experienced multiple MCDs. Such a study will be conducted in France, Netherlands, Norway and Sweden. Psychometric testing will be used to evaluate the construct validity of the measurement model. This testing might lead to further reduction of items, but also to addition of new ones. Further aims are to find out whether systematic patterns of experienced outcomes and perceived importance can be found, or whether the results will be context sensitive.
In order to further develop and validate the instrument, those who want to use the Euro-MCD, please contact the first or last author.
References
Fox E, Myers S, Pearlman RA: Ethics consultation in United States hospitals: a national survey. Am J Bioeth. 2007, 7: 13-25.
Schildmann J, Gordon J, Vollman J: Clinical Ethics Consultation: theories - methods - evaluation. 2010, Surrey: Ashgate Publishers, Farnham
Dauwerse L, Abma T, Molewijk B, Widdershoven G: Need for ethics support in healthcare institutions: views of Dutch board members and ethics support staff. J Med Ethics. 2011, 37: 456-460. 10.1136/jme.2010.040626.
Dauwerse L, Abma TA, Molewijk B, Widdershoven G: Goals of Clinical Ethics Support: Perceptions of Dutch Healthcare Institutions. Health Care Anal. 2011, 21 (4): 323-337.
Molewijk B, Kleinlugtenbelt D, Widdershoven G: The role of emotions in moral case deliberation: theory, practice, and methodology. Bioethics. 2011, 25: 383-393. 10.1111/j.1467-8519.2011.01914.x.
Molewijk AC, Abma T, Stolper M, Widdershoven G: Teaching ethics in the clinic. The theory and practice of moral case deliberation. J Med Ethics. 2008, 34: 120-124. 10.1136/jme.2006.018580.
Weidema FC, Molewijk AC, Widdershoven GA, Abma TA: Enacting Ethics: Bottom-up Involvement in Implementing Moral Case Deliberation. Health Care Anal. 2012, 20 (1): 1-19.
van der Dam SS, Abma TA, Molewijk AC, Kardol MJ, Schols JM, Widdershoven GA: Organizing moral case deliberation experiences in two Dutch nursing homes. Nurs Ethics. 2011, 18: 327-340. 10.1177/0969733011400299.
Svantesson M, Anderzen-Carlsson A, Thorsen H, Kallenberg K, Ahlstrom G: Interprofessional ethics rounds concerning dialysis patients: staff's ethical reflections before and after rounds. J Med Ethics. 2008, 34: 407-413. 10.1136/jme.2007.023572.
Svantesson M, Lofmark R, Thorsen H, Kallenberg K, Ahlstrom G: Learning a way through ethical problems: Swedish nurses' and doctors' experiences from one model of ethics rounds. J Med Ethics. 2008, 34: 399-406. 10.1136/jme.2006.019810.
Kälvemark Sporrong S, Arnetz B, Hansson MG, Westerholm P, Hoglund AT: Developing ethical competence in health care organizations. Nurs Ethics. 2007, 14: 825-837. 10.1177/0969733007082142.
Hansson MG: Imaginative ethics–bringing ethical praxis into sharper relief. Med Health Care Philos. 2002, 5: 33-42. 10.1023/A:1014257603144.
Libow LS, Olson E, Neufeld RR, Martico-Greenfield T, Meyers H, Gordon N, Barnett P: Ethics rounds at the nursing home: an alternative to an ethics committee. J Am Geriatr Soc. 1992, 40: 95-97.
Gracia D: Ethical case deliberation and decision making. Med Health Care Philos. 2003, 6: 227-233. 10.1023/A:1025969701538.
Reiter-Theil S, Mertz M, Schurmann J, Stingelin Giles N, Meyer-Zehnder B: Evidence - competence - discourse: the theoretical framework of the multi-centre clinical ethics support project METAP. Bioethics. 2011, 25: 403-412. 10.1111/j.1467-8519.2011.01915.x.
Børslett H: Lillemoen, Pedersen [Let the ethics flourish - a book of systematic reflection in clinical practice] La etikken blomstre i praksis - en bok om systematisk refleksjon i arbeidshverdagen. 2011, UIO Norway: SME
Olofsson B: Opening up: psychiatric nurses' experiences of participating in reflection groups focusing on the use of coercion. J Psychiatr Ment Health Nurs. 2005, 12: 259-267. 10.1111/j.1365-2850.2005.00827.x.
Pedersen P, Hurst SA, Schildmann J, Schuster S, Molewijk B: The development of a descriptive evaluation tool for clinical ethics case consultations. Clinical Ethics. 2010, 5: 136-141. 10.1258/ce.2010.010025.
Schildmann J, Molewijk B, Benaroyo L, Forde R, Neitzke G: Evaluation of clinical ethics support services and its normativity. J Med Ethics. 2013, 39 (11): 681-685. 10.1136/medethics-2012-100697.
Forsgärde M, Westman B, Nygren L: Ethical discussion groups as an intervention to improve the climate in interprofessional work with the elderly and disabled. J Interprof Care. 2000, 14: 351-361. 10.1080/13561820020003900.
Molewijk B, Verkerk M, Milius H, Widdershoven G: Implementing moral case deliberation in a psychiatric hospital: process and outcome. Med Health Care Philos. 2008, 11: 43-56. 10.1007/s11019-007-9103-1.
Pfafflin M, Kobert K, Reiter-Theil S: Evaluating clinical ethics consultation: a European perspective. Camb Q Healthc Ethics. 2009, 18: 406-419. 10.1017/S0963180109090604.
Craig JM, May T: Evaluating the outcomes of ethics consultation. J Clin Ethics. 2006, 17: 168-180.
Keeney S, Hasson F, McKenna HP: A critical review of the Delphi technique as a research methodology for nursing. Int J Nurs Stud. 2001, 38: 195-200. 10.1016/S0020-7489(00)00044-4.
Collins D: Pretesting survey instruments: an overview of cognitive methods. Qual Life Res. 2003, 12: 229-238. 10.1023/A:1023254226592.
Patrick DL, Burke LB, Gwaltney CJ, Leidy NK, Martin ML, Molsen E, Ring L: Content validity–establishing and reporting the evidence in newly developed patient-reported outcomes (PRO) instruments for medical product evaluation: ISPOR PRO Good Research Practices Task Force report: part 2–assessing respondent understanding. Value Health. 2011, 14: 978-988. 10.1016/j.jval.2011.06.013.
Polit DF, Beck CT, Owen SV: Is the CVI an acceptable indicator of content validity? Appraisal and recommendations. Res Nurs Health. 2007, 30: 459-467. 10.1002/nur.20199.
De Vet H, Terwee C, Mokkink L, Knol D: Measurement in Medicine. A practical guide. 2011, Cambridge: Cambridge University Press
Molewijk B, Widdershoven G: Report of the Maastricht meeting of the European Clinical Ethics Network. Clinical Ethics. 2007, 2: 42-45.
Brod M, Tesler LE, Christensen TL: Qualitative research and content validity: developing best practices based on science and experience. Qual Life Res. 2009, 18: 1263-1278. 10.1007/s11136-009-9540-9.
Yaghmaie F: Content validity and its estimation. J Med Educ. 2003, 3 (1): 25-27.
Erlen JA: Ethical practice in nursing: doing the right thing. Pa Nurse. 2007, 62: 20-21.
Silva DS, Gibson JL, Sibbald R, Connolly E, Singer PA: Clinical ethicists' perspectives on organisational ethics in healthcare organisations. J Med Ethics. 2008, 34: 320-323. 10.1136/jme.2007.020891.
Pedersen R, Akre V, Forde R: What is happening during case deliberations in clinical ethics committees? A pilot study. J Med Ethics. 2009, 35: 147-152. 10.1136/jme.2008.026393.
Forde R, Pedersen R, Akre V: Clinicians' evaluation of clinical ethics consultations in Norway: a qualitative study. Med Health Care Philos. 2008, 11: 17-25. 10.1007/s11019-007-9102-2.
Schneiderman LJ, Gilmer T, Teetzel HD, Dugan DO, Blustein J, Cranford R, Briggs KB, Komatsu GI, Goodman-Crews P, Cohn F, Young EW: Effect of ethics consultations on nonbeneficial life-sustaining treatments in the intensive care setting: a randomized controlled trial. JAMA. 2003, 290: 1166-1172. 10.1001/jama.290.9.1166.
Cohn F, Goodman-Crews P, Rudman W, Schneiderman LJ, Waldman E: Proactive ethics consultation in the ICU: a comparison of value perceived by healthcare professionals and recipients. J Clin Ethics. 2007, 18: 140-147.
Steinkamp NL: European debates on ethical case deliberation. Med Health Care Philos. 2003, 6: 225-226. 10.1023/A:1025921818376.
Finder SG, Bliton MJ: Responsibility after the apparent end: 'following-up' in clinical ethics consultation. Bioethics. 2011, 25: 413-424. 10.1111/j.1467-8519.2011.01910.x.
Slowther A: Ethics case consultation in primary care: contextual challenges for clinical ethicists. Camb Q Healthc Ethics. 2009, 18: 397-405. 10.1017/S0963180109090598.
Wild D, Grove A, Martin M, Eremenco S, McElroy S, Verjee-Lorenz A, Erikson P: Principles of Good Practice for the Translation and Cultural Adaptation Process for Patient-Reported Outcomes (PRO) Measures: report of the ISPOR Task Force for Translation and Cultural Adaptation. Value Health. 2005, 8: 94-104. 10.1111/j.1524-4733.2005.04054.x.
Van Widenfelt BM, Treffers PD, De Beurs E, Siebelink BM, Koudijs E: Translation and cross-cultural adaptation of assessment instruments used in psychological research with children and families. Clin Child Fam Psychol Rev. 2005, 8: 135-147. 10.1007/s10567-005-4752-1.
Molewijk B, Van Zadelhoff E, Lendemeijer B, Widdershoven G: Implementing moral case deliberation in Dutch health care; improving moral competency of professionals and the quality of care. Bioethica Forum. 2008, 1: 57-65.
Molewijk B, Kleinlugtenbelt D, Pugh SM, Widdershoven G: Emotions and clinical ethics support. A moral inquiry into emotions in moral case deliberation. HEC Forum. 2011, 23: 257-268. 10.1007/s10730-011-9162-9.
Glasberg AL, Eriksson S, Dahlqvist V, Lindahl E, Strandberg G, Soderberg A, Sorlie V, Norberg A: Development and initial validation of the Stress of Conscience Questionnaire. Nurs Ethics. 2006, 13: 633-648. 10.1177/0969733006069698.
Silen M, Svantesson M, Kjellstrom S, Sidenvall B, Christensson L: Moral distress and ethical climate in a Swedish nursing context: perceptions and instrument usability. J Clin Nurs. 2011, 20: 3483-3493. 10.1111/j.1365-2702.2011.03753.x.
Sporrong SK, Hoglund AT, Arnetz B: Measuring moral distress in pharmacy and clinical practice. Nurs Ethics. 2006, 13: 416-427. 10.1191/0969733006ne880oa.
Dougherty MB, Larson E: A review of instruments measuring nurse-physician collaboration. J Nurs Adm. 2005, 35: 244-253.
Schippers M, Den Hartog DN: Refelexivity in Teams: A Measure and Correlates. Applied Psychology. 2007, 56: 189-211. 10.1111/j.1464-0597.2006.00250.x.
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1472-6939/15/30/prepub
Acknowledgements
The authors are especially indebted to Julie Bucher Andary, Lazare Benaroyo, Jean-Philippe Cobbault, Dick Kleinlugtenbelt, Suzanne Metselaar, Rouven Porz, Anne Stewart, Wike Seekles, Margreet Stolper, Berit Store Brinchmann, Ingemar Svantesson, Håkan Thorsén, Göril Ursin and Agneta Waller for valuable input in the Delphi-panel, the content validity process or the translations of the instrument. Also thanks to Anne Slowther and Dita Wickins-Drazilova for valuable comments and helpfulness in the recruitment of responders, as well as to AFA-Insurance in Sweden for financial support. Furthermore, we want to thank the European Clinical Ethics Network for their feedback and the participants of the research meeting on evaluation of clinical ethics support at VUmc in Amsterdam (8th of January 2013). We also want to thank the constructive and helpful comments from the reviewers of BMC Medical Ethics. Last but not least, we want to thank those health care providers who participated in earlier pilots when testing the instrument.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
MS and BM initiated and coordinated the study. MS carried out the literature review, categorization, Delphi approach and content validity testing and drafted the manuscript. BM participated in the design of study, the categorization, the data-collection, and drafting the manuscript. All authors read and approved the final manuscript. JK participated substantially in the design of the study and writing the manuscript. PB participated in the data-collection, the Delphi rounds, made substantial contributions to the categorisation and also gave comments on the writing of the manuscript. JS and LD participated in all the Delphi rounds and contributed with substantial comments in the writing of the manuscript. GW and MH made contributions to the design of the study and made substantial contributions to the manuscript. RP participated in one Delphi round and made substantial contributions to the writing of the manuscript.
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly credited.
About this article
Cite this article
Svantesson, M., Karlsson, J., Boitte, P. et al. Outcomes of Moral Case Deliberation - the development of an evaluation instrument for clinical ethics support (the Euro-MCD). BMC Med Ethics 15, 30 (2014). https://doi.org/10.1186/1472-6939-15-30
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1472-6939-15-30