
Abstract
Background
Taking DMARDs as prescribed is an essential part of self-management for patients with Rheumatoid Arthritis. To date, the Compliance Questionnaire for Rheumatology (CQR) is the only self-report adherence measure created specifically for and validated in rheumatic diseases. However, the factor structure of the CQR has not been reported and it can be considered lengthy at 19 items. The aim of this study was to test the factor structure of the CQR and reduce the number of items whilst retaining robust explanation of non-adherence to DMARDs. Such a reduction would increase the clinical utility of the scale, to identify patients with sub-optimal adherence to DMARDs in the clinic as well as for research purposes.
Methods
An exploratory factor analysis was performed to reduce the number of items in the CQR and then a confirmatory factor analysis was run to establish the fit of a 5 item version (CQR5) to the data. A discriminant function analysis was performed to determine the optimal combination of questions to identify suboptimal adherence.
Results
The factor analyses identified a unidimensional 5 item model that explains 50.3% of the variance in adherence and has good internal consistency and fit to the data. Discriminant function analysis shows that the CQR5 can affectively detect 69% of low adherers to DMARDs using Fisher’s weighted regression equation.
Conclusion
A shortened version of the CQR increases the clinical utility by reducing the patient burden whilst maintaining a good level of reliability and validity for a short, self-administered, self-report questionnaire.
Similar content being viewed by others

Background
As Rheumatoid Arthritis (RA) is currently incurable, treatment is focused upon prevention of joint damage and loss of function with typical therapies including corticosteroids to reduce inflammation and DMARDs to prevent joint damage [1]. Since DMARDs have been shown to reduce disease activity and joint damage [2, 3] it is therefore essential to ensure that DMARDs are being taken regularly and correctly in accordance with the clinicians’ prescription to enhance efficacy for maintaining joint function. However, it is well established that DMARDs can take months to exhibit noticeable therapeutic benefits and can sometimes have unpleasant side-effects that prompt patients to stop taking them [4].
The extent to which a patient takes medication as prescribed is termed “adherence” [5]. A patient who is fully adherent never (or rarely) misses or changes doses of the prescribed medication. Suboptimal adherence can lead to disease progression [6], increasing the burden on the healthcare system due to GP and specialist appointments and hospitalisations as well as increased morbidity and mortality [7]. The apparent treatment “failure” caused by non-adherence can lead to unnecessary treatment escalation resulting in increased costs and decreased quality of life [6–8]. Medication non-adherence in various chronic illnesses is typically quoted at 30-50% [9, 10]; however, non-adherence rates for DMARDs in RA are often higher at 41% [11] and up to 75% for correct dosing [2, 12].
The “gold standard” for measuring adherence is currently electronic medication event monitoring (eMEMs). Medications are decanted into specialised pots with lids equipped with microchips that automatically record the time and date it was opened, thus inferring medication taking. This allows for more accurate data regarding the timing of doses than traditional methods such as pill counts. However, eMEMs is expensive and requires numerous resources from both the patient and researcher for it to be implemented effectively. In addition, it is not suitable for extended periods which can result in “white coat compliance” where patients are deliberately more adherent for a short period because they are aware that their medication taking behaviour is being measured [12]. This method is also unsuitable for polypharmacy, limiting the ecological validity of medication taking in RA where many patients are prescribed more than one DMARD, which in itself creates challenges to adherent behaviour. To increase the utility in large scale clinical studies, the most common methods of assessing medication adherence are self-report questionnaires. Questionnaires can measure attitudes, intentions and behaviours and although they are prone to biased results from socially desirable answering, if item construction and validation is carried out correctly, these problems can be overcome. An additional advantage of questionnaires is that they can help to establish how and why a patient is non-adherent which can then be addressed, whereas eMEMs gives only the number of doses missed. Garber, Nau, Erickson, Aikens & Lawrence [13] reviewed concordance between self-reported adherence and more objective measures such as pill counts or eMEMs and found that 55% of the questionnaires were highly concordant with the objective measure. Of the self-report measures that have been developed to monitor medication adherence, most have limited sensitivity and have not been specifically developed for rheumatic diseases, which present unique barriers and procedures for treatment [14]. For this reason, the Compliance Questionnaire for Rheumatology (CQR19) was developed by de Klerk et al.[12, 15]. This questionnaire has been validated against eMEMs [12] and has been shown to have good reliability and validity; however it can be considered lengthy for use in a clinical setting and the factor structure of the questionnaire has not been published which is necessary to aid reliability and interpretation.
Our aim therefore was to investigate whether it is possible to reduce the number of items in the CQR19 whilst retaining the internal reliability. The rationale for shortening the questionnaire was two-fold. Firstly, a condensed questionnaire would be quicker and easier to administer during a routine outpatient clinic appointment for strictly clinical uses and secondly, the reduction allows for the CQR to be incorporated more easily into a battery of questionnaires for research purposes.
Methods
Participants
Patients aged 18–80 years with a confirmed diagnosis of Rheumatoid Arthritis and prescribed at least 1 DMARD were opportunistically recruited from across rheumatology outpatient clinics in the UK. Patients who were not responsible for their own medication taking (i.e. relied on a carer) or could not consent for themselves were not eligible to participate.
The Compliance Questionnaire for Rheumatology (CQR19)
The CQR19 (Table 1) is a 19 item, self-administered questionnaire that was developed with the aim of correctly identifying patients that were classified as “low” adherers (taking <80% of their medication correctly) [12, 15]. The questions were identified through focus groups and clinician’s expert opinion of the likely barriers to medication taking. The four point Likert answering scale ranges from; “Definitely don’t agree” (scored 1) to “Definitely agree” (scored 4) with lower scores indicating lower levels of adherence. The CQR19 was validated against eMEMs and found to correctly identify 62% of low adherers without the extensive time and costs that are associated with “gold standard” medication monitoring techniques such as pill counting or blood chemistry levels. An additional advantage to the questionnaire is that the answers can provide some indication of the social or cognitive reasons behind non-adherence. When used in conjunction with specialised psychosocial measures, this provides the potential for healthcare professionals to address problems identified by the questionnaire as barriers to taking medication.
Methodology
All consecutive patients at 3 rheumatology clinics in the UK were approached and asked if they would consent to participate in a questionnaire study. Those that gave informed consent were provided with a booklet of questionnaires, of which the CQR19 was one. Factor analysis was then carried out on the responses in order to reduce the number of items in the CQR19. Ethical approval for this study has been given by the Hertfordshire Research Ethics Committee (REC) of the UK NHS.
Statistical analyses
Exploratory factor analysis (EFA)
An exploratory factor analysis (EFA) was carried out on the full CQR19 using SPSS v15 to identify the factor structure and to aid reduction of the number of items without losing reliability. The number of factors, the amount of variance explained by each factor and the amount of variance explained overall were each recorded in order to compare successive models to ensure that the explanatory ability of the questionnaire in a reduced form was not compromised. Items were selected for removal if they did not add explanatory power to the scale. One item was removed at a time, the EFA procedure repeated, and each of the criteria above inspected again to look for improvements in the reliability statistics. This procedure was continued until the internal reliability could no longer be improved by removing items.
The internal consistency measured by Cronbach’s α and percentage of variance explained of the final reduced model were evaluated against acceptable thresholds to ensure the model was stable before a confirmatory factor analysis was carried out.
Confirmatory factor analysis (CFA)
As the data were categorical, new polychoric and asymptotic covariance matrices were created from which the subsequent analyses were performed as there was a non-normal response pattern. Datascreening was then carried out in order to check for univariate and multivariate normality and missing cases.
In contrast to the EFA where the factor structure is dictated by the data, a confirmatory factor analysis (CFA) tests whether or not the data fits a predefined factor structure. Therefore, the CFA was testing whether the reduced questionnaire developed by the EFA provided a good model fit to measure medication adherence. The CFA was carried out using Lisrel 8. The reduced questionnaire was tested using Robust Maximum Likelihood and the fit to the data was evaluated using goodness of fit indices. These were chosen to include at least one index from each fit class; absolute, parsimony and comparative [16]. Taking into account the different but important ways in which these fit indices evaluate the model, including at least one of each gives the opportunity to fully consider the suitability of the model in question.
Model modification was carried out using modification indices provided by Lisrel and removing items with standardized correlated residuals higher than ±2.00 and R2 < 0.3 values indicating large error and little explanation of medication adherence respectively [17]. For each modification, the fit indices were again examined to determine whether further modification was required.
The items that were retained in the final model were checked to ensure that they explained more variance than by chance. In this case, each item should have a positive parameter estimate with a t value >1.96 (significant to α = 0.05). The final model was tested in a random sample of 500 created using the bootstrap test in Stata with the “cfa” command [18].
Discriminant function analysis of CQR5
In order to test the discriminant ability of the CQR5, each patient was classified as either a “high” or “low” adherer, based on the regression model given by de Klerk et al. [12]. A discriminant function analysis was then carried out using SPSS v15. This determined whether the model can reliably distinguish between high and low adherers. This test also gives the weights for each question to create a regression equation to be used with the reduced questionnaire to optimise classification.
Results
Participants
A total of 225 patients completed the CQR19. A total sample size of 225 gives a-cases-per-predictor ratio for the exploratory factor analysis of 12:1 which is in keeping with general rules of thumb suggested for this type of analysis [19]. The median age range was 50–59 years and 75.1% were female (see Table 2). Methotrexate was the most commonly prescribed DMARD (54%).
Exploratory factor analysis of CQR19
The initial EFA of the CQR19 showed 6 eigen-values >1 which accounted for 61.6% of the variance in adherence, which is somewhat higher than the original authors found at 46% [12]. The Kaiser-Meyer-Olkin Measure of Sampling Adequacy (KMO) = 0.79 which indicates a weak factor structure [20]. This can also be seen as the eigen-values of two of the factors were very low at 1.09 and 1.04, a trait which is enhanced by the fact that the factor matrix indicated that only one item loaded highly on each of factors 2–6 suggesting that the additional factors were the product of items that inadequately measure medication adherence (see Additional file 1: Table S1). A single factor is also suggested by the Scree Plot in Figure 1.

Scree plot of the CQR19.
The reduction of items led to a gradual increase in KMO and reduction in the number of factors, suggesting that the presence of more than one factor was an artefact of a few questions that in this case do not appear to be measuring the construct of medication adherence. This is supported by the fact that the percentage of variance in medication adherence explained by the questionnaire reduces by only 11% (from 61.6% to 50.3%) on removal of 8 items, and subsequently 4 factors. The results of the factor analyses are summarised in Table 3.
The final model that was identified from the EFA was the CQR11 which had only one factor. This showed both a good KMO (0.84) and Cronbach’s α (0.84), indicating a strong factor structure and reliable measure. This model explained 50.3% of the overall variance in medication adherence, and has the benefit of being short and robust. The items retained were; 2, 3, 5, 6, 7, 10, 13, 14, 15, 17, 18.
Confirmatory factor analysis of CQR11
Datascreening of the polychoric and asymptotic correlation matrices showed that there were 11 missing values and 1 missing case. Once listwise deletion had been implemented, the resulting effective sample size was N = 187 giving a cases per predictor ratio of 18:1. Of these 187 cases, there were 154 distinct response patterns, indicating that the majority of participants responded completely differently to everybody else. The two most common patterns were; i) answering “strongly agree” to every question (N = 17) and ii) answering “agree” to every question (N = 7). A similar pattern was not found with the “disagree” responses; therefore it is possible that these participants were showing social response bias as “agree” responses indicate high adherence rates. However, the bivariate normality appeared to hold with nearly all of the p values being non-significant and two being very close to non-significant (item 10 vs item 2, p = 0.01 and item 18 vs item 3, p = 0.03).
The CQR11 model that was identified from the Exploratory Factor Analysis showed a less than satisfactory fit as the Satorra-Bentler χ2 and Root Mean Square Error (RMSEA) were outside of the acceptable ranges (see Table 4 and footnote for recommended cut off values). Model modification was therefore carried out using modification indices provided by Lisrel and removal of items with residuals of more than ±2.00 or where R2 < 0.3, to improve the model fit. Through subsequent modifications, it was found that 6 items consistently had the highest standardised residuals and the lowest R2 values, indicating that these items produced the most error and explained little of the variance in medication adherence. For these reasons, they were removed from the model to produce the CQR5 (see Table 1 for items retained in the CQR5).
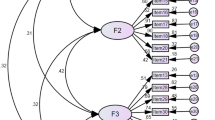
The fit indices for the CQR5 were much improved on the CQR11 and showed an acceptable model. The fit indices were all within acceptable parameters; RMSEA = 0.089 (95% CI, 0.036:0.15), NFI = 0.98, CFI = 0.99 and RMR = 0.054 indicating a good fit to the data. Although the χ2 values were beyond those acceptable for a good fit, these are susceptible to sample sizes >100 making p > 0.05 overly sensitive and so should be interpreted in conjunction with other indices [21]. All of the t-values for the parameter estimates were positive and highly significant, which is indicated by the large parameter estimates shown in Figure 2. The R2 values for the parameter estimates ranged from R2 = 0.65 (Q17) to R2 = 0.84 (Q6) showing that each of the items explained a large amount of variance in medication adherence. The internal reliability was acceptable as Cronbach’s α = 0.85. The goodness of fit indices remained adequate in a bootstrapped sample of 500 randomly selected samples from the dataset.

Path diagram for CQR5.
Discriminant function analysis
A discriminant function analysis was carried out using the CQR5 to identify the ideal weighted combination of items to identify high and low adherers measured by the full CQR19. The canonical linear discriminant analysis was highly significant, F(5, 228) = 45.10, p < 0.001, indicating that the CQR5 can effectively discriminate between high and low adherers. The effect size η2 was large at 0.50 and the explained variance was very high at 70.5%. The structure matrix indicates that Q3 (0.84), Q17 (0.30) and Q5 (0.20) were most strongly correlated with the function of adherence. This is supported by a one way ANOVA of the item means between groups which shows that these questions produce significantly lower means by patients classified as low adherers, indicating that they “do not agree” more often than those classified as high adherers.
The CQR5 correctly predicted group membership measured by the full CQR19 for 88.5% of cases, with sensitivity to predict low adherence of 69% and specificity of predicting high adherence of 97%.
The structure matrix gives the optimal linear combination of the CQR5 questions to maximise the discriminant ability. Fisher’s classification function coefficients result in the following equations:
Given the two parameters D0 and D1, if D0 is greater than D1 then the respondent should be classified as likely to be a low adherer. Conversely, if D1 is greater than D0 then the respondent should be classified as likely to be highly adherent. See Additional file 2.
Discussion
The present study found that reducing the CQR to just 5 items did not dramatically reduce its explanatory power and the sensitivity of identifying low adherers remained high. The exploratory factor analysis allowed for the factor structure to be made simpler and more robust with the removal of extraneous items. This reduces the burden on patients whilst completing the questionnaire, and makes interpretation easier as all items can be reliably considered to be related to adherence.
The confirmatory factor analysis confirms that the CQR5 fits the data well and explains 52.9% of variance in medication adherence which is good for a very short, self-administered questionnaire. The CQR5 also performed at a similar rate in a bootstrapped sample of 500 repetitions, confirming that the scale had not been over-fitted ad hoc to this particular dataset, but that it is likely to be applicable to the wider RA population.
Further evidence of this generalisability is shown by the fact that two of the items identified in the CQR5 (Q3 and Q5) correspond to two of the four items that the original authors found to explain 35% of the variance in their sample [12]. As the full CQR19 only explained 46% of the variance in their sample, these items are clearly contributing highly to the explanation of medication adherence.
It is interesting to note that all six of the reversed items were removed from the questionnaire by the EFA. This suggests that there was a fundamental problem with the delivery of these questions that led to them not explaining non-adherence in an adequate way. Four of these six items explore issues of medications in general and the patients’ expectations of their medications. These constructs are well measured in Horne et al.[22] Belief’s about Medications Questionnaire (BMQ) which has been tested and found to be reliable and valid across a number of illnesses including RA [23]. It could therefore be suggested that the BMQ should be used in conjunction with the CQR to specifically address this construct. The two other reversed items are concerned with reduced medication adherence on weekends and holidays. Unsurprisingly, it was found that these two items were strongly correlated, although neither of them correlated strongly with any other item. It was interesting to find that Q9; “When I am on vacation, it sometimes happens that I don’t take my medications” showed no correlation to Q14; “If I don’t take my anti-rheumatic medication regularly, the inflammation returns”. This could be due to the fact that either patients had not experienced taking a holiday whilst on their current DMARD, or that patients view their holidays as completely separate to their normal lives and develop a new routine that is unconcerned with their disease status. This possibly changing belief would be interesting to investigate in a more formal way, particularly if it leads to low levels of adherence whilst away from patients’ normal care teams.
The discriminant function analysis of the CQR5 suggests good specificity by identifying 97% of the high adherers classified by the full CQR19 and sensitivity of 69% at identifying low adherers. As the CQR5 is a nested model of the CQR19, which was used as the dependent variable to classify patients, good sensitivity and specificity would be expected. However, the good discriminatory power that the CQR5 shows provides more evidence that the other 14 items of the CQR19 are extraneous and are not providing additional explanatory power over and above the five retained items, demonstrating the clinical utility of the more parsimonious questionnaire. The CQR5 performs equally as well as the CQR19 at correctly classifying patients, but with only a quarter of the number of questions. However, as the CQR19 was used as the dependent variable for the discriminant function analysis, the sensitivity and specificity of the CQR5 should be interpreted with caution unless it is shown to be as good when using an objective measure of adherence (such as electronic medication event monitoring) as the dependent variable.
As was found by de Klerk et al.[12], the CQR5 is most predictive when used as a weighted discriminant equation. This is the optimum combination of weighted questions to classify patients as either high or low adherers, and is the function that should be used when implementing the CQR5. The structure matrix indicates that Q3; “I definitely don’t dare to miss my anti-rheumatic medication” is the most indicative of high or low adherence as high adherers tend to “agree” whereas low adherers tend to “disagree”. It may therefore be possible to get an indication of the overall result from the answer to this question with a positive (answer 3 or 4) response indicating high adherence and a negative (answer 1 or 2) response indicating low adherence. The main benefit of using self report questionnaires is to attempt to identify the determinants of non-adherence in order to target for intervention. Although the CQR is not designed for this purpose, it does allow for the latent variable of adherence to be measured alongside validated measures of adherence predictors. Questionnaires such as the revised Illness Perception Questionnaire (IPQ-R) [24] and the Beliefs about Medications Questionnaire (BMQ) [22] have shown promising strides in identifying determinants of non-adherence in many illnesses including Rheumatoid Arthritis [23–26]. The CQR5 can be used in future research as a short, parsimonious, unidimensional adherence scale to successfully identify the most useful areas for intervention with the ultimate aim of improving patient outcomes.
This study benefitted from having a large sample size and patients that had a wide range of disease and treatment experience as well as differing socio and geographic demographics and ages. Although the CQR5 performed well compared to the CQR19, the next step would be to validate the reduced version against a measure of adherence such as eMEMs to determine the sensitivity of identifying suboptimal adherence in a more objective manner. However, some support is given by the fact that within this sample of 225 patients, 24% (N = 53) were classified as being low adherers based on their CQR5 scores which is in accordance with previously published figures [5, 12, 23, 27] of medication non-adherence.
Conclusions
This study shows that it is possible to reduce the number of questions of the CQR19 without losing its explanatory properties, thus improving the clinical utility. The CQR5 is as good as the CQR19 at classifying patients as low adherers and is quick and easy enough to be widely used in the clinic without burdening patients. The simplified factor structure is also more parsimonious and gives an indication to the clinical care team of possible sub-optimal DMARD adherence which can then be addressed. This then has the potential to improve the prognosis for the patient and avoid unnecessary treatment escalations or delays.
References
ten Wolde S, Breedveld FC, Dijkmans BAC, Hermans J, Vandenbroucke JP, van de Laar MAFJ: Randomised placebo-controlled study of stopping second-line drugs in rheumatoid arthritis. Lancet (British edition). 1996, 347 (8998): 347-352. 10.1016/S0140-6736(96)90535-8.
Park DC, Hertzog C, Leventhal H, Morrell RW, Leventhal E, Birchmore D: Medication adherence in rheumatoid arthritis patients: older is wiser. J Am Geriatr Soc. 1999, 47: 172-183.
Young A: Current approached to drug treatment in rheumatoid arthritis. Prescriber. 2008, 19: 19-28.
Goodacre LJ, Goodacre JA: Factors influencing the beliefs of patients with rheumatoid arthritis regarding disease-modifying medication. Rheumatology. 2004, 43 (5): 583-586. 10.1093/rheumatology/keh116.
Treharne GJ, Lyons AC, Hale ED, Douglas KMJ, Kitas GD: ‘Compliance’ is futile but is ‘concordance’ between rheumatology patients and health professionals attainable?. Rheumatology. 2006, 45: 1-5. 10.1093/rheumatology/kei223.
Grijalva CG, Chung CP, Arbogast PG, Stein CM, Mitchel EF, Griffin MR: Assessment of adherence to and persistence on disease-modifying antirheumatic drugs (DMARDs) in patients with rheumatoid arthritis. Med Care. 2007, 45 (10): S66-
DiMatteo MR: Enhancing patient adherence to medical recommendations. JAMA. 1994, 271 (1): 79-10.1001/jama.271.1.79.
Hughes DA, Bagust A, Haycox A, Walley T: The impact of non-compliance on the cost-effectiveness of pharmaceuticals: a review of the literature. Health Econ. 2001, 10: 601-615. 10.1002/hec.609.
Steiner JF, Prochazka AV: The assessment of refill compliance using pharmacy records: methods, validity, and applications. J Clin Epidemiol. 1997, 50 (1): 105-116. 10.1016/S0895-4356(96)00268-5.
Barber N, Parsons J, Clifford S, Dattacott R, Horne R: Patients’ problems with new medication for chronic conditions. QSHC. 2004, 13: 172-175.
Viller F, Guillemin F, Briancon S, Moum T, Suurmeijer T, van den Heuvel W: Compliance to drug treatment of patients with rheumatoid arthritis: a 3 year longitudinal study. J Rheumatol. 1999, 26 (10): 2114-2122.
de Klerk E, van der Heijde D, Landewe R, van der Tempel H, van der Linden S: The compliance-questionnaire-rheumatology compared with electronic medication event monitoring: a validation study. J Rheumatol. 2003, 30 (11): 2469-2475.
Garber MC, Nau DP, Erikson SR, Aikens JE, Lawrence JB: The concordance of self report with other measures of medication adherence. a summary of the literature. Med Care. 2004, 42 (7): 649-652. 10.1097/01.mlr.0000129496.05898.02.
Neame R, Hammond A: Beliefs about medications: a questionnaire survey of people with rheumatoid arthritis. Rheumatology. 2005, 44: 762-767. 10.1093/rheumatology/keh587.
de Klerk E, van der Heijde D, van der Tempel H, van der Linden S: Development of a questionnaire to investigate patient compliance with antirheumatic drug therapy. J Rheumatol. 1999, 26 (12): 2635-2641.
Brown TA: Confirmatory Factor Analysis for Applied Research. 2006, New York: Guildford Press
Tabachnik BGF, Fidell LS: Using Multivariate Statistics. 1989, New York: Harper Collins
Kolenikov S: Confirmatory factor analysis using cfa. Stata J. 2009, 9 (3): 1-44.
MacCallum RC, Widaman KF, Zhang S, Hong S: Sample size in factor analysis. Psychol Methods. 1999, 4: 84-99.
Kaiser H: An index of factorial simplicity. Psychometrika. 1974, 39: 31-36. 10.1007/BF02291575.
Hu L, Bentler PM: Cut-off criteria for fit indexes in covariance structure analysis: conventional criteria versus new alternatives. Struct Equn Modeling. 1999, 6 (1): 1-55. 10.1080/10705519909540118.
Horne R, Weinman J, Hankins M: The beliefs about medicines questionnaire: the development and evaluation of a new method for assessing the cognitive representation of medication. Psychol Health. 1999, 14 (1): 1-24. 10.1080/08870449908407311.
Treharne GJ, Lyons AC, Kitas GD: Medication adherence in rheumatoid arthritis: effects of psychosocial factors. Psychol Health Med. 2004, 9 (3): 337-349. 10.1080/13548500410001721909.
Moss-Morris R, Weinman J, Petrie K, Horne R, Cameron LD, Buick D: The revised illness perceptions questionnaire (IPQ-R). Psychol Health. 2002, 17 (1): 1-16. 10.1080/08870440290001494.
de Thurah A, Norgaard M, Harder I, Stengaard-Petersen K: Compliance with Methotrexate treatment in patients with rheumatoid arthritis: influence of patients’ beliefs about the medicine. a prospective cohort study. Rheumatol Int. 2010, 30: 1441-1448. 10.1007/s00296-009-1160-8.
Hughes LD: Psychological Adjustment to the Onset of Rheumatoid Arthritis: a Longitudinal Evaluation of Perceptions of and Adherence to Medication. PhD thesis. 2011, University of Hertfordshire, School of Psychology
Treharne GJ, Lyons AC, Hale ED, Douglas KMJ, Kitas GD: Predictors of medication adherence in people with rheumatoid arthritis: studies are necessary but non-validated measures of medication adherence are of concern. Rheumatology. 2005, 44 (10): 1330-10.1093/rheumatology/kei001.
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1471-2474/14/286/prepub
Acknowledgements
The authors would like to thank Dr Gareth Treharne for recruiting patients for this study and for providing comments on a previous draft. This work was supported by an Economic & Social Research Council CASE studentship and the Early Rheumatoid Arthritis Network (ERAN) [ES/F035020/1 to LH].
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
LH designed the study, collected the data, carried out the analysis and wrote the draft of the manuscript. JD participated in the design of the study, provided assistance with data analysis and contributed to the draft of the manuscript. AY contributed to the design of the study, collected data and contributed to the draft of the manuscript. All authors have read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an open access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Hughes, L.D., Done, J. & Young, A. A 5 item version of the Compliance Questionnaire for Rheumatology (CQR5) successfully identifies low adherence to DMARDs. BMC Musculoskelet Disord 14, 286 (2013). https://doi.org/10.1186/1471-2474-14-286
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2474-14-286