
Abstract
In this paper, we present the result of the analysis made on the Virtual Atomic and Molecular Data Centre infrastructure, following the FAIR Data Maturity Model framework defined by the Research Data Alliance. After recalling the technical architecture of the VAMDC e-infrastructure (Sect. 1.1), we will introduce the RDA FAIR evaluation framework (Sect. 2) and define the methodology we adopt to perform our analysis (Sect. 2.1). In Sect. 2.2, we will present the result of this analysis (the fine-grained granularity analysis from which Sect. 2.2 is discussed in “Appendix A”). After having identified some lines of work aimed at improving the FAIRness of VAMDC (Sect. 3), we will conclude with some ideas for further developments of this work (Sect. 4).
Graphical Abstract






Similar content being viewed by others



Data Availability Statement
This manuscript has associated data in a data repository. Data sharing not applicable to this article as no datasets were generated during the current study. The data and metadata analyzed during the current study are publicly available through the VAMDC infrastructure, following the HTML links systematically cited in the text.
Notes
The VAMDC SQL Subset, see https://standards.vamdc.eu.
we will use the same numbering convention introduced in [16].
cf. https://github.com/mservillat/voprov/blob/master/tutorials/voprov_tutorial.ipynb for an example of how provenance information formatted using IVOA-prov appears to end users.
Requestable, returnable and restrictables ( https://standards.vamdc.eu/dictionary/index.html) are three controlled vocabularies containing specific terms that clients may use to interact with the data nodes.
These are codes of processes historically defined by the Data Centre Network initiative at the IAEA (the legacy web site is https://www-amdis.iaea.org/DCN/). Today the activity is led by the AMD unit (https://amdis.iaea.org/databases/processes/).
A standard dictionary built for the semantic web, cf. https://www.iso.org/standard/71339.html and https://www.dublincore.org/specifications/dublin-core/dcmi-terms/.
References
M.L. Dubernet, V. Boudon, J.L. Culhane, M.S. Dimitrijevic, A.Z. Fazliev, C. Joblin, F. Kupka, G. Leto, P. Le Sidaner, P.A. Loboda, H.E. Mason, N.J. Mason, C. Mendoza, G. Mulas, T.J. Millar, L.A. Nuñez, V.I. Perevalov, N. Piskunov, Y. Ralchenko, G. Rixon, L.S. Rothman, E. Roueff, T.A. Ryabchikova, A. Ryabtsev, S. Sahal-Bréchot, B. Schmitt, S. Schlemmer, J. Tennyson, V.G. Tyuterev, N.A. Walton, V. Wakelam, C.J. Zeippen, Virtual atomic and molecular data centre. JQSRT 111, 2151–2159 (2010). https://doi.org/10.1016/j.jqsrt.2010.05.004
M.L. Dubernet, B.K. Antony, Y.A. Ba, Y.L. Babikov, K. Bartschat, V. Boudon, B.J. Braams, H.-K. Chung, F. Daniel, F. Delahaye, G. Del Zanna, J. de Urquijo, M.S. Dimitrijević, A. Domaracka, M. Doronin, B.J. Drouin, C.P. Endres, A.Z. Fazliev, S.V. Gagarin, I.E. Gordon, P. Gratier, U. Heiter, C. Hill, D. Jevremović, C. Joblin, A. Kasprzak, E. Krishnakumar, G. Leto, P.A. Loboda, T. Louge, S. Maclot, B.P. Marinković, A. Markwick, T. Marquart, H.E. Mason, N.J. Mason, C. Mendoza, A.A. Mihajlov, T.J. Millar, N. Moreau, G. Mulas, Y. Pakhomov, P. Palmeri, S. Pancheshnyi, V.I. Perevalov, N. Piskunov, J. Postler, P. Quinet, E. Quintas-Sánchez, Y. Ralchenko, Y.-J. Rhee, G. Rixon, L.S. Rothman, E. Roueff, T. Ryabchikova, S. Sahal-Bréchot, P. Scheier, S. Schlemmer, B. Schmitt, E. Stempels, S. Tashkun, J. Tennyson, V.G. Tyuterev, V. Vujčić, V. Wakelam, N.A. Walton, O. Zatsarinny, C.J. Zeippen, C.M. Zwölf, The virtual atomic and molecular data centre (VAMDC) consortium. J. Phys. B Atom. Mol. Phys. 49(7), 074003 (2016). https://doi.org/10.1088/0953-4075/49/7/074003
D. Albert, B.K. Antony, Y.A. Ba, Y.L. Babikov, P. Bollard, V. Boudon, F. Delahaye, G. Del Zanna, M.S. Dimitrijević, B.J. Drouin, M.-L. Dubernet, F. Duensing, M. Emoto, C.P. Endres, A.Z. Fazliev, J.-M. Glorian, I.E. Gordon, P. Gratier, C. Hill, D. Jevremović, C. Joblin, D.-H. Kwon, R.V. Kochanov, E. Krishnakumar, G. Leto, P.A. Loboda, A.A. Lukashevskaya, O.M. Lyulin, B.P. Marinković, A. Markwick, T. Marquart, N.J. Mason, C. Mendoza, T.J. Millar, N. Moreau, S.V. Morozov, T. Möller, H.S.P. Müller, G. Mulas, I. Murakami, Y. Pakhomov, P. Palmeri, J. Penguen, V.I. Perevalov, N. Piskunov, J. Postler, A.I. Privezentsev, P. Quinet, Y. Ralchenko, Y.-J. Rhee, C. Richard, G. Rixon, L.S. Rothman, E. Roueff, T. Ryabchikova, S. Sahal-Bréchot, P. Scheier, P. Schilke, S. Schlemmer, K.W. Smith, B. Schmitt, I.Y. Skobelev, V.A. Srecković, E. Stempels, S.A. Tashkun, J. Tennyson, V.G. Tyuterev, C. Vastel, V. Vujčić, V. Wakelam, N.A. Walton, C. Zeippen, C.M. Zwölf, A decade with VAMDC: results and ambitions. Atoms 8(4), 76 (2020). https://doi.org/10.3390/atoms8040076
N. Moreau, C.-M. Zwolf, Y.-A. Ba, C. Richard, V. Boudon, M.-L. Dubernet, The VAMDC portal as a major enabler of atomic and molecular data citation. Galaxies 6(4), 105 (2018). https://doi.org/10.3390/galaxies6040105
S. Regandell, T. Marquart, N. Piskunov, Inside a VAMDC data node-putting standards into practical software. Phys. Scr. 93(3), 035001 (2018). https://doi.org/10.1088/1402-4896/aaa268
C.M. Zwölf, N. Moreau, M.-L. Dubernet, New model for datasets citation and extraction reproducibility in VAMDC. J. Mol. Spectrosc. 327, 122–137 (2016). https://doi.org/10.1016/j.jms.2016.04.009
N. Walton, Meeting the user science challenge for a virtual universe, in Toward an International Virtual Observatory (Springer), pp. 187–192. https://doi.org/10.1007/10857598_29
S.R. Heller, A. McNaught, I. Pletnev, S. Stein, D. Tchekhovskoi, InChI, the IUPAC international chemical identifier. J. Cheminform. (2015). https://doi.org/10.1186/s13321-015-0068-4
C.M. Zwölf, N. Moreau, Y.-A. Ba, M.-L. Dubernet, Implementing in the VAMDC the new paradigms for data citation from the research data alliance. Data Sci. J. (2019). https://doi.org/10.5334/dsj-2019-004
P. Wittenburg, M Hellström, C-M Zwölf, H. Abroshan, A. Asmi, G. Di Bernardo, D. Couvreur, T. Gaizer, P. Holub, R. Hooft, I. Häggström, M. Kohler, D. Koureas, W. Kuchinke, L. Milanesi, J. Padfield, A. Rosato, C. Staiger, D. van Uytvanck, T. Weigel, Persistent identifiers: consolidated assertion. Res. Data Alliance (2017). https://doi.org/10.15497/RDA00027
A. Rauber, B. Gößwein, C.M. Zwölf, C. Schubert, F. Wörister, J. Duncan, K. Flicker, K. Zettsu, K. Meixner, L.D. McIntosh, S. Pröll, T. Miksa, M.A. Parsons, Precisely and persistently identifying and citing arbitrary subsets of dynamic data. Harvard Data Sci. Rev. (2021). https://doi.org/10.1162/99608f92.be565013
A. Burton, A. Aryani, H. Koers, P. Manghi, S.L. Bruzzo, M. Stocker, M. Diepenbroek, U. Schindler, M. Fenner, The Scholix framework for interoperability in data-literature information exchange. D-Lib Mag. (2017). https://doi.org/10.1045/january2017-burton
M. Dubernet, L. Nenadovic, N. Doronin, Spectcol: a new software to combine spectroscopic data and collisional data within VAMDC. Astron. Data Anal. Softw. Syst. XXI 461, 335 (2012)
T. Möller, C. Endres, P. Schilke, eXtended CASA line analysis software suite (XCLASS). Astron. Astrophys. 598, 7 (2017). https://doi.org/10.1051/0004-6361/201527203
M.D. Wilkinson, M. Dumontier, I.J. Aalbersberg, G. Appleton, M. Axton, A. Baak, N. Blomberg, J.-W. Boiten, L.B.da Silva Santos, P.E. Bourne, J. Bouwman, A.J. Brookes, T. Clark, M. Crosas, I. Dillo, O. Dumon, S. Edmunds, C.T. Evelo, R. Finkers, A. Gonzalez-Beltran, A.J.G. Gray, P. Groth, C. Goble, J.S.Grethe, J. Heringa, P.A.C ’t Hoen, R. Hooft, T. Kuhn, R. Kok, J. Kok, S.J. Lusher, M.E. Martone, A. Mons, A.L. Packer, B. Persson, P. Rocca-Serra, M. Roos, R. van Schaik, S.-A. Sansone, E. Schultes, T. Sengstag, T. Slater, G. Strawn, M.A. Swertz, M. Thompson, J. van der Lei, E. van Mulligen, J. Velterop, A. Waagmeester, P. Wittenburg, K. Wolstencroft, J. Zhao, B. Mons, The FAIR guiding principles for scientific data management and stewardship. Sci. Data 3(1), 1 (2016). https://doi.org/10.1038/sdata.2016.18
C. Bahim, C. Casorrán-Amilburu, M. Dekkers, E. Herczog, N. Loozen, K. Repanas, K. Russell, S. Stall, The FAIR data maturity model: an approach to harmonise FAIR assessments. Data Sci. J. (2020). https://doi.org/10.5334/dsj-2020-041
A. Devaraju, R. Huber, M. Mokrane, P. Herterich, L. Cepinskas, J. de Vries, H. L’Hours, J. Davidson, A. White, FAIRsFAIR data object assessment metrics. Zenodo (2022). https://doi.org/10.5281/zenodo.6461229
B. Mons, C. Neylon, J. Velterop, M. Dumontier, L.O.B. da Silva Santos, M.D. Wilkinson, Cloudy, increasingly FAIR; revisiting the FAIR data guiding principles for the European open science cloud. Inf Serv Use 37(1), 49–56 (2017). https://doi.org/10.3233/isu-170824
W. Steinhoff, V. Tykhonov, F. Aguilar, FAIR Metrics SKOS Mapping. https://doi.org/10.5281/zenodo.7113227. EOSC-synergy receives funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 857647. https://zenodo.org/record/7113227#.Y85KOS_pMeY
C.M. Zwölf, G. Rixon, Authentication, Authorisation and Accounting strategy. Zenodo (2015). https://doi.org/10.5281/zenodo.3936606
M. Servillat, F. Bonnarel, C. Boisson, M. Louys, J.E. Ruiz, M. Sanguillon, Towards a Provenance Management System for Astronomical Observatories (Springer, Berlin, 2021). https://doi.org/10.1007/978-3-030-80960-7_20
C. Goble, S. Cohen-Boulakia, S. Soiland-Reyes, D. Garijo, Y. Gil, M.R. Crusoe, K. Peters, D. Schober, Fair computational workflows. Data Intell. 2(1–2), 108–121 (2020). https://doi.org/10.1162/dint_a_00033
M.D. Wilkinson, M. Dumontier, S.A. Sansone, L.O.B. da Silva Santos, M. Prieto, D. Batista, P. McQuilton, T. Kuhn, P. Rocca-Serra, M. Crosas, E. Schultes, Evaluating FAIR maturity through a scalable, automated, community-governed framework. Sci. Data (2019). https://doi.org/10.1038/s41597-019-0184-5
A. Devaraju, M. Mokrane, L. Cepinskas, R. Huber, P. Herterich, J. de Vries, V. Akerman, H. L’Hours, J. Davidson, M. Diepenbroek, From conceptualization to implementation: FAIR assessment of research data objects. Data Sci. J. (2021). https://doi.org/10.5334/dsj-2021-004
C. Sun, V. Emonet, M. Dumontier, A comprehensive comparison of automated FAIRness evaluation tools, pp. 44–53. http://ceur-ws.org/Vol-3127/#paper-6
A. Masson, G. D. Marchi, B. Merin, M. H. Sarmiento, D. L. Wenzel, B. Martinez, Google dataset search and DOI for data in the ESA space science archives. Adv. Space Res. 67(8), 2504–2516 (2021). https://doi.org/10.1016/j.asr.2021.01.035
R.V. Guha, D. Brickley, S. MacBeth, Schema.org: evolution of structured data on the web. Queue 13(9), 10–37 (2015). https://doi.org/10.1145/2857274.2857276
S.-A. Sansone, P. McQuilton, P. Rocca-Serra, A. Gonzalez-Beltran, M. Izzo, A.L. Lister, M. Thurston, FAIRsharing as a community approach to standards, repositories and policies. Nat. Biotechnol. 37(4), 358–367 (2019). https://doi.org/10.1038/s41587-019-0080-8
Y.-A. Ba, M.-L. Dubernet, N. Moreau, C.M. Zwölf, Basecol 2020 new technical design. Atoms (2020). https://doi.org/10.3390/atoms8040069
L. Lannom, D. Broeder, G. Manepalli, RDA data type registries working group output. Zenodo (2015). https://doi.org/10.15497/A5BCD108-ECC4-41BE-91A7-20112FF77458
Acknowledgements
The authors thank Prof. M.L. Dubernet, previous chair of VAMDC, for suggesting the investigation of FAIR principles in VAMDC. They also thank the authors of [16] for their ready availability to answer questions related to the interpretation of indicators and the anonymous reviewers for their advice, which helped to improve the manuscript considerably. Part of this work was supported by the European project FAIR-IMPACT - GA 101057344.
Additional information
Guest editors: Annarita Laricchiuta, Iouli E. Gordon, Christian Hill, Gianpiero Colonna, Sylwia Ptasinska.
Appendix A: Details of the evaluation
Appendix A: Details of the evaluation
-
RDA-F1-01 M—Essential
- \({\mathcal {D}}\) :
-
Metadata are identified by a persistent identifier;
- \({\mathcal {A}}\) :
-
VAMDC federates heterogeneous databases, and each one of those has its own PID strategy and procedure for metadata. Moreover, these databases are dynamic. To address the issue of persistently identifying metadata associated with VAMDC data extractions, we implemented the RDA Dynamic Data Citation recommendation [9]: The Query Store achieves the persistent identification of both metadata and data extracted from the VAMDC infrastructure;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-F1-01D—Essential
- \({\mathcal {D}}\) :
-
Data are identified by a persistent identifier;
- \({\mathcal {A}}\) :
-
The analysis is the same as in the case of the indicator RDA-F1-01 M;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-F1-02 M—Essential
- \({\mathcal {D}}\) :
-
Metadata are identified by a globally unique identifier;
- \({\mathcal {A}}\) :
-
The Query Store assigns to any extracted digital object (i.e., the data together with its relevant metadata) a UUIDFootnote 17 and, upon user request, a DOI. These identifiers are unique by construction;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-F1-02D—Essential
- \({\mathcal {D}}\) :
-
Data are identified by a globally unique identifier;
- \({\mathcal {A}}\) :
-
The analysis is the same as in the case of RDA-F1-02 M;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-F2-01 M—Essential
- \({\mathcal {D}}\) :
-
Rich metadata are provided to allow discovery;
- \({\mathcal {A}}\) :
-
As we discussed in Sect. 2.1, VAMDC provides rich metadata to describe its data. We identified three different sets of metadata within the infrastructure, each set being associated with a particular infrastructure component:
- 1.:
-
The metadata associated with the served queries characterize the queries (e.g., the query execution time, the query text string, the version of nodes having generated the data, the version of the standard used to format the output data, etc.). These metadata are stored on the Query Store;
- 2.:
-
The metadata associated with the available resources (e.g., list of supported requestable, returnable and restrictables,Footnote 18 node capabilities, supported access protocols, names of node maintainers, contacts, etc.). These metadata constitute the data stored into the Registry;
- 3.:
-
The metadata about the species and processes available for each node. These metadata constitute the data stored into the Species database;
These three sets of metadata help users in discovering which database may contain interesting information.
- \({\mathcal {L}}\) :
-
= 4
- \({\mathcal {I}}\) :
-
A better integration between the Species database information and those from the Registry is encouraged. Users should have a single access point giving all the information on a given node, without having to use two different services. Today the information is fragmented.
-
RDA-F3-01 M—Essential
- \({\mathcal {D}}\) :
-
Metadata include the identifier for the data;
- \({\mathcal {A}}\) :
-
- 1.:
-
In the case of the Query Store, the PID associated with the query resolves to a Digital Object containing both the metadata and the underlying data. These are accessible for both human and machines;
- 2.:
-
In the case of the Registry, the underlying data associated with the metadata are the resources (e.g., nodes and processors). These are clearly identified by their IVOID (cf. Table 1) and their service endpoint;
- 3.:
-
In the case of the Species database, the underlying data associated with the metadata are the nodes and the processes supported by the nodes. In the web–human interface, these are clearly identified (by a direct link to the autonomous version of the database, not the VAMDC IVOID or TAP endpoint), whereas in the Excel machine-oriented interface,Footnote 19 the IVOID of resources is provided. The link with the processes is a simple text string (only human-readable information in the web interface) and is missing in the machine-actionable interface;
- \({\mathcal {L}}\) :
-
= 4
- \({\mathcal {I}}\) :
-
In the case of the Species database, improve the machine actionability of the information, by putting, for example, links to the VAMDC IVOID of ressources in the human–web interface. Also pointers to processes should be machine-actionable.
-
RDA-F4-01 M—Essential
- \({\mathcal {D}}\) :
-
Metadata are offered in such a way that they can be harvested and indexed;
- \({\mathcal {A}}\) :
-
The above-described three sets of metadata are offered in a way which may be indexed. VAMDC itself indexes those metadata and provides discipline-oriented (atomic and molecular data community) services and portal. However, it does not seem that the metadata from VAMDC are harvested and/or indexed outside VAMDC (e.g., Google or other indexing services). From the technical point of view, there are no particular barriers to achieve a better integration between indexing services and VAMDC, following an approach similar to the one described in [26];
- \({\mathcal {L}}\) :
-
= 3
- \({\mathcal {I}}\) :
-
VAMDC experts may define strategies to improve metadata harvesting and indexing from outside their data services. Two different strategies may be sketched: prepare metadata in formats that may be directly ingested by indexing services [27], or register VAMDC endpoints and standards in public catalogues of services (e.g., EOSC Portal,Footnote 20 FAIRsharing [28], etc.) so that harvesting services may discover and interact with VAMDC resources.
-
RDA-A1-01 M—Important
- \({\mathcal {D}}\) :
-
Metadata contain information to enable the user to get access to the data;
- \({\mathcal {A}}\) :
-
The data in VAMDC are completely free and open. In the case of the Query Store, the digital object may be accessed directly by resolving a given PID. In all the other cases, data are accessible following classic https links. Since the access to the data is straightforward (in the sense that no authentication or particular procedure is required to use the services), VAMDC does not require specific metadata to enable users to get access to the data.
- \({\mathcal {L}}\) :
-
= 0
- \({\mathcal {I}}\) :
-
It could be useful for users to systematically provide information about the conditions of usage for VAMDC services, personal data and privacy policy and licenses on data. Those conditions are already defined for the Portal and for the Query Store. These should be extended to the Species database and to the Registry cf. indicator RDA-R1.1-01 M.
-
RDA-A1-02 M—Essential
- \({\mathcal {D}}\) :
-
Metadata can be accessed manually (i.e., with human intervention);
- \({\mathcal {A}}\) :
-
The core central services of VAMDC (cf. Sect. 1.1) have a web interface designed for humans. All the metadata are accessible through those interfaces;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-A1-02D—Essential
- \({\mathcal {D}}\) :
-
Data can be accessed manually (i.e., with human intervention);
- \({\mathcal {A}}\) :
-
The VAMDC portal [4] has a web interface designed for humans. All the data are accessible through those interfaces;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-A1-03 M—Essential
- \({\mathcal {D}}\) :
-
Metadata identifier resolves to a metadata record;
- \({\mathcal {A}}\) :
-
- 1.:
-
In the case of the Query Store, the PID resolves directly to a digital object where the metadata and the underlying data are packed together. Resolving a Query Store PID gives access both to query metadata and query produced data;
- 2.:
-
In the case of the registries, a resolution service is implemented which, starting from the resources IVOID (cf. Table 1) resolves to the underlying Registry node resource record;
- 3.:
-
In the case of the Species database, a resolution service is implemented which, starting from a given species identifier resolves to the underlying metadata;
- \({\mathcal {L}}\) :
-
= 4
- \({\mathcal {I}}\) :
-
The endpoints of machine-oriented resolution services for the Species database and the Registry should be advertised and indexed in some ad hoc service, so everybody may discover these endpoints.
-
RDA-A1-03D—Essential
- \({\mathcal {D}}\) :
-
Data identifier resolves to a digital object;
- \({\mathcal {A}}\) :
-
In the case of the Query Store, the PID resolves directly to a digital object where the metadata and underlying data are packed together. Resolving a Query Store PID gives access both to query metadata and to the extracted data;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-A1-04 M—Essential
- \({\mathcal {D}}\) :
-
Metadata are accessed through standardized protocol;
- \({\mathcal {A}}\) :
-
All the communications between the VAMDC web services are built over the http protocol (and its secured version https), which is free and standard. All the data and metadata are accessed using http. If we go deeply into details, the messages encapsulated into this http envelope also follow standard and open protocols: The Registry relies over the IVOA recommendation,Footnote 21 and the data nodes implements the TAP protocol for data extractionFootnote 22and accepts queries formatted into a standard query languageFootnote 23;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-A1-04D—Essential
- \({\mathcal {D}}\) :
-
Data are accessible through standardized protocol;
- \({\mathcal {A}}\) :
-
The analysis is the same as in the case of RDA-A1-04 M;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-A1-05D—Important
- \({\mathcal {D}}\) :
-
Data can be accessed automatically (i.e., by a computer program);
- \({\mathcal {A}}\) :
-
The architecture of VAMDC infrastructure relies on web services designed for machine-to-machine interaction. The web interfaces and tools designed for humans are an overlay to those services. Data extraction and handling are fully machine-actionable;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-A1.1-01 M—Essential
- \({\mathcal {D}}\) :
-
Metadata are accessible through a free access protocol;
- \({\mathcal {A}}\) :
-
The analysis is the same as in the case of RDA-A1-04 M;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-A1.1-01D—Important
- \({\mathcal {D}}\) :
-
Data are accessible through a free access protocol;
- \({\mathcal {A}}\) :
-
The analysis is the same as in the case of RDA-A1-04 M;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-A1.2-01D—Useful
- \({\mathcal {D}}\) :
-
Data are accessible through an access protocol that supports authentication and authorization;
- \({\mathcal {A}}\) :
-
As previously mentioned, all the VAMDC data and services are open and free. However, as discussed in [20], the protocols may support authentication and authorization;
- \({\mathcal {L}}\) :
-
= 2
-
RDA-A2-01 M—Essential
- \({\mathcal {D}}\) :
-
Metadata are guaranteed to remain available after data are no longer available;
- \({\mathcal {A}}\) :
-
The Species database and the Registry are services describing the real-time state of the infrastructure. The legacy service for VAMDC data is the Query Store. Its metadata are kept permanently, even after the data deletion;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-I1-01 M—Important
- \({\mathcal {D}}\) :
-
Metadata use knowledge representation expressed in standardized format;
- \({\mathcal {A}}\) :
-
- 1.:
-
The DOI associated with a query in the Query Store resolves to a Digital Object whose metadata follow the DataCite metadata format.Footnote 24 The metadata, obtained while resolving the PID on the Query Store side, are formatted in JSON text, but do not follow any specific standard;
- 2.:
-
The metadata in the Registry follow the IVOA standards already cited, and the information provided is built over standard dictionariesFootnote 25;
- 3.:
-
The metadata in the Species database do not use specific standards to express knowledge;
- \({\mathcal {L}}\) :
-
= 3
- \({\mathcal {I}}\) :
-
- 1.:
-
The format of the metadata returned by the Query Store while resolving a PID should be documented (in both human-readable and machine-actionable way) and published both through the VAMDC standards and in metadata registries, such as FAIRsharingFootnote 26[28];
- 2.:
-
In the Registry, when a specific term is used (for example, a given value for a restrictable or returnable) there should be a pointer, under the form of a PID, resolving to the definition of the term itself. A less desirable solution should be to point to the VAMDC dictionary repository from the Registry. Also, the version of standards should contain a PID resolving to the standards definition. Up to now, the links between the access protocol, the dictionaries and the other components are explained in human-readable documentations but not explicitly expressed in machine interfaces;
- 3.:
-
A dictionary specific to the knowledge representation of the Species database should be introduced and published (both in human-readable and machine-actionable way), both on the VAMDC standard page and in metadata registries such as FAIRsharing.
-
RDA-I1-01D—Important
- \({\mathcal {D}}\) :
-
Data use knowledge representation expressed in standardized format;
- \({\mathcal {A}}\) :
-
The data extracted from VAMDC are formatted using the community-specific XSAMS standard. The XSAMS standard is documented in a human-readable form and in a machine-actionable form via an XSD schema;
- \({\mathcal {L}}\) :
-
= 4
- \({\mathcal {I}}\) :
-
Three aspects may improve the interoperability of the XSAMS standard:
- 1.:
-
Register the XSAMS standard as a standard format into registries of types such as FAIRsharing;
- 2.:
-
The VAMDC format contains enumerations of terms which are defined neither in the scheme, nor in an external dictionary: for example, CategoryType in Methods object, dataDescription values in DataSets object;
- 3.:
-
For codes of processes, PID resolving to the definition of the codes should be introduced. In particular for IAEA DCN codes,Footnote 27 the relevant metadata associated with each code is resolvable at as a JSON object (e.g., https://amdis.iaea.org/databases/processes/HCX/).
-
RDA-I1-02 M—Important
- \({\mathcal {D}}\) :
-
Metadata use machine-understandable knowledge representation;
- \({\mathcal {A}}\) :
-
- 1.:
-
The DOI associated with a query in the Query Store resolves to a Digital Object whose metadata follow the DataCite metadata format, which is machine-actionable. The metadata obtained while resolving the PID on the Query Store side are formatted in JSON text, but do not follow any specific standard. Metadata are machine-readable but not machine-understandable;
- 2.:
-
Metadata in registry are built to be machine-understandable;
- 3.:
-
Metadata in the Species database are formatted in JSON text, but do not follow any specific standard. Metadata are machine-readable but not machine-understandable;
- \({\mathcal {L}}\) :
-
= 3
- \({\mathcal {I}}\) :
-
Improve the machine understandability of the information from the Query Store and from the Species database.
-
RDA-I1-02D—Important
- \({\mathcal {D}}\) :
-
Data use machine-understandable knowledge representation;
- \({\mathcal {A}}\) :
-
The XSAMS standard (cf. Sect. 1.1) is, as its name indicates, an XML schema which is designed to be machine-understandable. VAMDC provides several tools and converter to automatically interact with XSAMS data;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-I2-01 M—Important
- \({\mathcal {D}}\) :
-
Metadata use FAIR-compliant vocabularies;
- \({\mathcal {A}}\) :
-
- 1.:
-
The DOIs related to query store resolve to Digital Objects which use DataCite metadata (cf. Tables 1, 2), and as a consequence dictionaries that are compliant with the Dublin Core extended dictionary.Footnote 28 The PIDs of the Query Store use no FAIR dictionaries;
- 2.:
-
The registries use elements from VAMDC dictionaries to define capacities of nodes (e.g., restrictables and returnables). However, only the label of the term is used. There is no pointer to a PID resolving to the term definition. Moreover, the VAMDC dictionaries are not fully FAIR since they are not designed for machine but only for human fruition (e.g., there is just a web site and no API to access the terms and their definition);
- 3.:
-
The species DB does not use dictionaries to define the nature of metadata;
- \({\mathcal {L}}\) :
-
= 2
- \({\mathcal {I}}\) :
-
Make the VAMDC dictionaries more FAIR by improving machine actionability and term identification. Introduce dictionaries for the Species database.
-
RDA-I2-01D—Useful
- \({\mathcal {D}}\) :
-
Data use FAIR-compliant vocabularies;
- \({\mathcal {A}}\) :
-
The VAMDC format contains enumeration of terms which are defined neither in the scheme, nor in an external dictionary, e.g., CategoryType in Methods object or dataDescription values in DataSet object. The codes for processes (including IAEA DCN codes) are simple text strings;
- \({\mathcal {L}}\) :
-
= 2
- \({\mathcal {I}}\) :
-
Improvements identified at item \({\mathcal {I}}\)-2 and \({\mathcal {I}}\)-3 of indicator RDA-I1-01D apply also here.
-
RDA-I3-01 M—Important
- \({\mathcal {D}}\) :
-
Metadata include references to other metadata;
- \({\mathcal {A}}\) :
-
- 1.:
-
The Query Store provides information about the node generating the query and the version of the standard. These references are only human-readable text string;
- 2.:
-
In the Registry, the records of data nodes contain some references to other metadata (services endpoints, curators, versions of standard) in a machine-understandable way, but not necessary machine-actionable: Those references cannot be resolved, as, for example, in the registry entry for BasecolFootnote 29 [29] one can find these two fields:
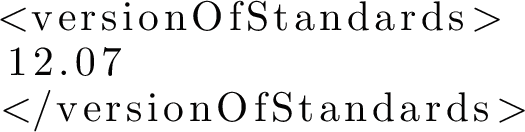
and

We see that we have no direct link to the definition of the cited standard, nor to the repository for the cited software. The two text strings enclosed by the XML tags may be understood only by expert users;
- 3.:
-
The Species database contains references to the nodes providing a given species. By now this points directly to the historical web sites of databases as they existed (and still exist) before the building of VAMDC and not to the VAMDC data node versions (i.e., to the corresponding data node resources, as defined in the Registry);
- \({\mathcal {L}}\) :
-
= 2
- \({\mathcal {I}}\) :
-
- 1.:
-
The Query Store should provide references pointing to the node record in the registries and to definition of standards;
- 2.:
-
In the Registry, the metadata should point to definition of standards or to the software repositories in a machine-actionable way;
- 3.:
-
The Species database should have a link to the Registry record of each node.
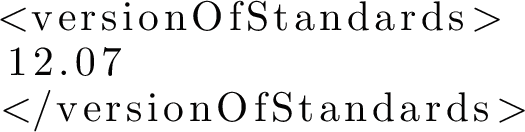

-
RDA-I3-01D—Useful
- \({\mathcal {D}}\) :
-
Data include references to other data;
- \({\mathcal {A}}\) :
-
In the XSAMS schema, the Source object may be used to reference other data and/or papers playing the role of source for the current data;
- \({\mathcal {L}}\) :
-
= 4
- \({\mathcal {I}}\) :
-
By now it does not exist a mechanism to reference connected data (e.g., similar data, previous version of the same data, etc.) directly inside XSAMS. VAMDC should investigate if such a need exists in its community.
-
RDA-I3-02 M—Useful
- \({\mathcal {D}}\) :
-
Metadata include references to other data;
- \({\mathcal {A}}\) :
-
The DOIs assigned by the Query Store are versioned. The filiation of data with previous version are a typical example of “metadata include references to other data.” In all the other cases this indicator is not applicable;
- \({\mathcal {L}}\) :
-
= 0
-
RDA-I3-02D—Useful
- \({\mathcal {D}}\) :
-
Data include qualified references to other data;
- \({\mathcal {A}}\) :
-
The analysis is the same as for indicator RDA-I3-01D. The references are qualified in a machine-readable way (but not necessarily-actionable since the DOI is not mandatory in the XSAMS Source object) as “sources for the data”;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-I3-03 M—Important
- \({\mathcal {D}}\) :
-
Metadata include qualified references to other metadata;
- \({\mathcal {A}}\) :
-
The references described while evaluating RDA-I3-01 M are all qualified in a human-oriented way and in a machine-readable way;
- \({\mathcal {L}}\) :
-
= 4
- \({\mathcal {I}}\) :
-
Metadata references to other metadata should be machine-actionable, cf. the analysis of RDA-R1-01 M.
-
RDA-I3-04 M—Important
- \({\mathcal {D}}\) :
-
Metadata include qualified references to other data;
- \({\mathcal {A}}\) :
-
The analysis is the same as for indicator RDA-I3-02 M;
- \({\mathcal {L}}\) :
-
= 0
-
RDA-R1-01 M—Essential
- \({\mathcal {D}}\) :
-
Plurality of accurate and relevant attributes are provided to allow reuse;
- \({\mathcal {A}}\) :
-
As explained while evaluating the previous indicators, VAMDC uses a wide number of metadata to describe its data. The quality of those metadata is high;
- \({\mathcal {L}}\) :
-
= 4
- \({\mathcal {I}}\) :
-
Use standards and norm for all metadata to get them machine-actionable.
-
RDA-R1.1-01 M—Essential
- \({\mathcal {D}}\) :
-
Metadata include information about the license under which the data can be reused;
- \({\mathcal {A}}\) :
-
There are no metadata describing the license on data. Data in VAMDC are free, but the consortium never discussed about a license to apply on VAMDC extracted data. As of today, there are no metadata field defined to specify the adopted license;
- \({\mathcal {L}}\) :
-
= 1
- \({\mathcal {I}}\) :
-
Define a license for all the data/metadata in VAMDC (cf. Sect. 3.1).
-
RDA-R1.1-02 M—Important
- \({\mathcal {D}}\) :
-
Metadata refer to a standard reuse license;
- \({\mathcal {A}}\) :
-
Since there is no license (and no metadata field to provide license information), we cannot point to a standard reuse license;
- \({\mathcal {L}}\) :
-
= 1
- \({\mathcal {I}}\) :
-
The adopted license for data/metadata should be a widely adopted and accepted one (e.g., one from the Creative Commons ecosystemFootnote 30).
-
RDA-R1.1-03 M—Important
- \({\mathcal {D}}\) :
-
Metadata refer to a machine-understandable reuse license;
- \({\mathcal {A}}\) :
-
The analysis is the same as for indicator RDA-R1.1-02 M;
- \({\mathcal {L}}\) :
-
= 1
- \({\mathcal {I}}\) :
-
The adopted license should be machine-actionable.
-
RDA-R1.2-01 M—Important
- \({\mathcal {D}}\) :
-
Metadata include provenance information according to community-specific standards;
- \({\mathcal {A}}\) :
-
We recall that provenance metadata in the XSAMS is well defined using the Source element;
- 1.:
-
Provenance of data in the Query Store is clearly stated, since all the metadata of a landing page are about provenance. This information does not follow any particular standard but are human-readable;
- 2.:
-
Provenance of data in the registries is well defined. The information follows IVOA standard;
- 3.:
-
Provenance in the Species database is well defined. (We know from which node the information comes.) However, we miss the time stamp information about the databases that provide the species information.
- \({\mathcal {L}}\) :
-
= 3
- \({\mathcal {I}}\) :
-
Adopt standards for provenance in the Query Store and in the Species database.
-
RDA-R1.2-02 M—Useful
- \({\mathcal {D}}\) :
-
Metadata include provenance information according to a cross-community language;
- \({\mathcal {A}}\) :
-
Cross-community standard from provenance (W3CFootnote 31 or IVOA-provFootnote 32) are not used (cf. Sect. 3.2 for a discussion);
- \({\mathcal {L}}\) :
-
= 1
-
RDA-R1.3-01 M—Essential
- \({\mathcal {D}}\) :
-
Metadata comply with a community standard;
- \({\mathcal {A}}\) :
-
- 1.:
-
The DOIs assigned by the Query Store use metadata compliant with the DataCite metadata standard;
- 2.:
-
The metadata constituting the registries follows the IVOA standard for registries;
- 3.:
-
In the Species database, we use Inchi and InchiKey chemical standards for species identifications. The other information do not follow any particular standard;
- \({\mathcal {L}}\) :
-
= 3
-
RDA-R1.3-01D—Essential
- \({\mathcal {D}}\) :
-
Data comply with a community standard;
- \({\mathcal {A}}\) :
-
Data extracted from VAMDC are formatted using the XSAMS standard;
- \({\mathcal {L}}\) :
-
= 4
-
RDA-R1.3-02 M—Essential
- \({\mathcal {D}}\) :
-
Metadata are expressed in compliance with a machine-understandable community standard;
- \({\mathcal {A}}\) :
-
- 1.:
-
The DOIs assigned by the Query Store use metadata compliant with the DataCite standard, which are machine-actionable;
- 2.:
-
Metadata constituting the Registry follow the IVOA standard for registries, which are machine-understandable and machine-actionable;
- 3.:
-
The Species database metadata do not follow any particular standard;
- \({\mathcal {L}}\) :
-
= 3
- \({\mathcal {I}}\) :
-
Use machine-actionable standards for the information returned by the Query Store and by the Species database.
-
RDA-R1.3-02D—Important
- \({\mathcal {D}}\) :
-
Data are expressed in compliance with a machine-understandable community standard;
- \({\mathcal {A}}\) :
-
Data extracted from VAMDC are formatted using the XSAMS standard, which is fully machine-understandable;
- \({\mathcal {L}}\) :
-
= 4
- \({\mathcal {I}}\) :
-
Register XSAMS into registries of types [30], such as FAIRsharing [28].
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zwölf, C.M., Moreau, N. Assessment of the FAIRness of the Virtual Atomic and Molecular Data Centre following the Research Data Alliance evaluation framework. Eur. Phys. J. D 77, 70 (2023). https://doi.org/10.1140/epjd/s10053-023-00649-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjd/s10053-023-00649-x