
Abstract
In this work, we reconstruct the Hubble diagram using various data sets, including correlated ones, in artificial neural networks (ANN). Using ReFANN, that was built for data sets with independent uncertainties, we expand it to include non-Guassian data points, as well as data sets with covariance matrices among others. Furthermore, we compare our results with the existing ones derived from Gaussian processes and we also perform null tests in order to test the validity of the concordance model of cosmology.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The standard model of cosmology is almost universally accepted as the concordance model for explaining cosmological observations [1, 2]. This is based on the incorporation of cold dark matter (CDM) to explain aspects of clustering [3, 4] while the late time accelerated expansion of the Universe [5, 6] is described through the action of a cosmological constant [7]. While theoretical problems [8] of the cosmological constant description and the direct measurability of CDM [9, 10] have been in question for decades, the recent problems of cosmological tensions [11,12,13,14,15,16,17,18] have brought into question the predictability of \(\varLambda \)CDM concordance model.
The cosmological tensions issue is most pronounced with the Hubble constant tension, which has shown a growing discrepancy between direct and indirect determinations of the \(H_0\) parameter [19]. The indirect approaches rely on assuming a \(\varLambda \)CDM cosmology [20] which is part of the reason why this model is being possibly reconsidered as the standard model of cosmology. In terms of indirect measurements, the latest reported values from the Planck and ACT collaborations are respectively \(H_0^\textrm{P18} = 67.4 \pm 0.5\) \(\mathrm{km\, s}^{-1} \textrm{Mpc}^{-1}\) [21] and \(H_0^\mathrm{ACT-DR4} = 67.9 \pm 1.5\) \(\mathrm{km\, s}^{-1} \textrm{Mpc}^{-1}\) [22], which point to a generically lower Hubble constant. On the other end of the spectrum, direct measurements of the Hubble constant have come from various different phenomenological sources. The strongest determination of the constant has come from the SH0ES team who have determined a best value of \(H_0^\textrm{R20} = 73.2 \pm 1.3\) \(\mathrm{km\, s}^{-1} \textrm{Mpc}^{-1}\) [23]. This is based on observations of Type Ia Supernovae (SN-Ia) that are calibrated using Cepheid stars in their host galaxies. In this spirit, strong lensing measurements by quasar systems has also produced a consistent direct result of \(H_0^\textrm{HW} = 73.3^{+1.7}_{-1.8}\) \(\mathrm{km\, s}^{-1} \textrm{Mpc}^{-1}\) which is due to the H0LiCOW Collaboration [24]. On the other hand, there is a direct result using the Tip of the Red Giant Branch (TRGB) technique which results in a lower value of the Hubble constant which gives \(H_0^\textrm{F20} = 69.8 \pm 1.9 \,\mathrm{km\, s}^{-1} \textrm{Mpc}^{-1}\) [25]. While systematics feature in every experiment, the Hubble tension appears to appear in several independent surveys and has now been present in several studies in the literature for some years.
The community has responded in several ways to this pressing problem. While work on understanding whether systematics may be the source of this tension will be ongoing for years to come, there is a growing body of work that is considering modifications to our standard picture of cosmology. The Hubble tension has been confronted with several interesting approaches in the literature including modifications to early Universe dark energy [20], as well as the neutrino sector [26], and renewed interest in modifications to gravitational models [27,28,29,30,31,32,33]. These approaches all offer interesting paths to new physics either through revisiting the foundations of cosmological models or by adding unknown components to the cosmological framework. However, many of these models are degenerate with each other in terms of current observational approaches which may require a new way of investigating new physics in the observational sector. One such approach is to consider the class of so-called model-independent methods. In this work, we aim to extend the current implementation of artificial neural networks (ANN) [34] in terms of the Hubble diagram so that there will eventually be a way to perform reconstruction of cosmological models.
Through ANNs, real-world observational data can be used for undertaking reconstructions and inferences that are independent of any underlying physical models. They are also free of many of the statistical assumptions that appear in many of the other techniques. In this work, we reconstruct the Hubble diagram from various combined data sets where we fully incorporate the information in the data, specifically the covariance matrix. We do this by building on ReFANNFootnote 1 [35] which was originally designed for reconstructing the Hubble diagram for data sets with independent uncertainties, based on PyTorch.Footnote 2 We ran this code on GPUs which significantly reduced the computational time as compared with CPU runs. In Sect. 2, we briefly introduce the data sets and discuss the reconstruction methodology adopted. We show the outputs for these analyses in Sect. 3. We compared and contrast our ANN outputs against their GP analogues in Sect. 4. The null tests for these outputs are performed in Sect. 5, while in Sect. 6 we discuss our main results and make some concluding remarks.
2 Observational data sets and methodology
In this part of the work we present the reconstruction methods used with a particular emphasis on ANNs and their architecture. We also discuss the data sets under investigation together with the priors used from the literature.
2.1 Methodology
The most popular approach to using model-independent techniques to study cosmology is through Gaussian processes (GP) [36] since they offer an integrated way to produce cosmological parameters together with their associated uncertainties. GP is based on a covariance function, or kernel, that characterizes the relationship between pairs of data points in a distribution. The kernel is functionally dependent on non-physical hyperparameters which can be fit using ordinary methods. The literature contains numerous works based on using this approach to reconstructing cosmological parameters [37,38,39,40,41,42,43,44,45,46,47,48,49,50]. Most recently, GPs have been used to reconstruct cosmological models [29,30,31,32,33] from a foundational perspective. However, GP suffer from two major drawbacks, namely (i) they have an overfitting issue for low redshifts which can artificially constrain the Hubble constant at the level of its uncertainties; (ii) there is an over-reliance on the choice of kernel which may affect the profile of the reconstructed parameters.
An alternative approach to reconstructed cosmological parameters is through ANNs, which also open the way to the use of more complex data such as non-Gaussian data points and correlated data sets. Here, artificial neurons are modeled to mimic their biological counterpart, which are then organized into layers through which input signals are transformed into output signals. One example that this is formulated is input redshifts giving Hubble parameter and uncertainty outputs [51,52,53]. An ANN is generally composed of a huge number of neurons that undergo training to optimize their associated hyperparameter values. A recent study in which this is performed is Ref. [35] which was further studied in Ref. [54] using null tests. Now, GP are a very attractive as an approach because they organically give higher order derivatives of their reconstructed function, and given that most cosmological models include such derivatives, they enter into the range of models that can be reconstructed in this way. In the recent work Ref. [55], the Hubble diagram ANN reconstruction method was extended to higher order derivatives using a Monte Carlo approach. This has opened the way for performing reconstructions of cosmological models. However. this work is based on using independent data points whereas most real world data is correlated in some way. This is normally contained in some covariance matrix. In Markov chain Monte Carlo analyses, this covariance matrix would feature in the log-likelihood of the sampler. Our main aim in the current work is to extend the reconstruction approach of the Hubble diagram to include covariance information. Together with the reconstruction of higher derivatives of the Hubble parameter this means that more complex reconstruction programmes of cosmological models can be considered.

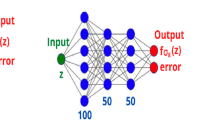
The general structure of the adopted ANN, where the input is the redshift of a cosmological parameter \(\varUpsilon (z)\), and the outputs are the corresponding value and error of \(\varUpsilon (z)\)
To do this, consider the mechanics of ANN systems in which an input layer is connected to an output layer through a series of hidden internal layers where the majority of neurons are located. These neurons each feature hyperparameters which are set by training with the aim of having new inputs produce outcomes that real observations would. In our setup, the input signal simply consists of a redshift value while the output layer gives the mean Hubble parameter at that redshift together with the uncertainty at that point. This system is depicted in Fig. 1 for a generalized scenario where each redshift value z results in a generic cosmological parameter \(\varUpsilon (z)\) together with its corresponding uncertainty \(\sigma _\varUpsilon ^{}(z)\).
The ANN architecture is composed of each neuron possessing an activation function which calibrates the impact each neuron will have on the output for a particular input signal. Each neuron depends on hyperparameters (weights and biases) which during the training of the ANN take an optimal value. The layers are then structured as the input and output connections between each neuron. In this way, a signal traverses the whole network to produce an output signal in a structured way. In this work, we consider the exponential linear unit (ELU) [56] as the activation function, specified by
where \(\alpha \) is a positive hyperparameter that scales the value to which negative inputs are calibrated to, while positive inputs continue to traverse the network. Thus, complexity in the data would be incorporated through differently optimized hyperparameter values.
The hyperparameter values are set in the training process where real data is inputted through the system and hyperparameter values are optimized against real-world data. This is characterized by a loss function which measures the difference between predicted and ground truth values in \(\varUpsilon \). By minimizing the loss function, the ANN hyperparameters are optimized for particular data sets. An example of this process is the gradient descent combined with the back-propagation algorithm, while Adam’s algorithm [57] represents a slightly better version of this optimization algorithm. The L1 loss function is the simplest and most direct way of assessing the difference between the predicted and observed values of some parameter, where the absolute difference between observed and predicted values of the Hubble parameter at the observation redshift points are each summed, that is
where \(H_\textrm{obs}(z)\) and \(H_\textrm{pred}(z)\) are observed and ANN predicted values of the Hubble parameter at observation redshifts z. This is akin to the MCMC log-likelihood for independent data sets (less the uncertainties). Other loss functions exist but they do not generally incorporate more complexity in the data. In this work, we consider a native way to incorporate more complexity in the observed data sets by defining a new loss function analogous to the MCMC log-likelihood for correlated data sets. We do this by defining the following \(\chi ^2\) loss function
where \(\textrm{C}_{ij}\) is the total noise covariance matrix of the data, which includes the statistical noise and systematics. In this way, we will be able to naively use correlated data in our ANN architecture. While the exact details of the training process are contained in Sect. 3, this loss function assures that the ANN will infer Hubble expansion values that reflect both the mean observational values as well as the covariance matrix relationships between these points. To ensure the fidelity of this process, we employ a batch size that is equal to the Pantheon compilation sample size. On the other hand, one could divide this matrix and utilize smaller batch sizes if the whole data set were to be unmanageable larger.

Plots showing the reduced \(\chi ^2\) (left panel), and the evolution of the \(\chi ^2\) loss function (right panel), for configuring the optimal neural network architecture using the Pantheon SN-Ia \(d_L\) compilation
In order to configure and train our network, we undertake the following steps:
-
1.
Designing the neural network: After sorting the observational data sets from low to high redshifts, we use simple ANN, with one input layer (to feed the training redshifts) and one output layer (to predict the reconstructed function). We take into account network models with 1 and 2 hidden layers. The dropout rate is set to 0.2 to prevent it from over-fitting. The number of neurons in the hidden layers is chosen as \(2^n\) where \(2 \le n \le 13\). So the ANN architectures are \(1,~ 2^n,~ 1\) for ANN with 1 hidden layer and \(1,~ 2^n,~ 2^n,~ 1\) for those with two hidden layers.
-
2.
Determining the optimal network configuration: The hyperparameters (weights and biases) of the network are initialized with fixed values. All the ANN configurations are trained after \(10^5\) iterations, to ensure that the loss function no longer decreases. We set the initial learning rate to 0.01 which goes on decreasing with the number of iterations and compute the averaged loss of the last 100 iterations. The predictions are made at the training redshifts and evaluate reduced \(\chi ^2\) for all the architectures considered. The ANN architecture with the least averaged loss of the last 100 iterations, and reduced \(\chi ^2\) just less than 1 is chosen as the optimal configuration. The optimal network architecture for Pantheon \(d_L\) compilation is found to be 1, 64, 64, 1 (see Fig. 2 and Table 1). On proceeding in a similar fashion, we get 1, 1024, 1 as the optimal network structure for the Hubble H(z) data.
-
3.
Monte Carlo approach for final predictions: This optimal network architecture is now iterated over 500 times, for random initialization of hyperparameters along with the dropout effect. Thus, we get 500 samples of the reconstructed functions at the corresponding test redshifts, from which we compute the mean function and the respective uncertainties.
-
4.
Derivative predictions: With the 500 realizations of the predicted functions, we compute numerical derivatives as, \( f'(z_i) \simeq \frac{f(z_{i+1}) - f(z_{i-1})}{z_{i+1} - z_{i-1}} \). From the reconstructed \(f'(z)\) samples, we obtain the mean values of reconstructed \(f'(z)\) along with the associated confidence levels using another MC routine [55].
-
5.
Batch size: For determining the optimal network configuration, we employ a batch size that is equal to the data size. During the final predictions, the batch size adopted for the Pantheon compilation is 40 (equal to the size of the binned Pantheon data), and half the number of available measurements for the Hubble data.
These are also illustrated in Fig. 3 where the different processes in the construction, training and eventual reconstruction procedures are connected together.

Flow of ANN architecture design and reconstruction process
2.2 Data sets
We now employ ANNs to reconstruct the Hubble diagram, considering three sources of data. These include the cosmic chronometers (CC) and baryonic acoustic oscillation (BAO) measurements of the Hubble parameter, as well as the type Ia supernovae (SN) apparent magnitude data. Furthermore, keeping in mind the rising \(H_0\) tension, we consider the most precise Cepheid calibration result of \(H_0 = 73.3 \pm 1.04\) km Mpc\(^{-1}\) s\(^{-1}\) [58] by the SH0ES team (hereafter referred to as R21), recently inferred \(H_0 = 69.7 \pm 1.9\) km Mpc\(^{-1}\) s\(^{-1}\) [59] via the Tip of the Red Giant Branch (TRGB) calibration technique (hereafter referred to as TRGB) and the most precise early-time determination of \(H_0 = 67.4 \pm 0.5\) km Mpc\(^{-1}\) s\(^{-1}\) [21] inferred from the Cosmic Microwave Background (CMB) sky by the Planck 2018 survey (hereafter referred to as P18). In our analysis, we assume Gaussian prior distributions with the mean and variances corresponding to the central and 1\(\sigma \) reported values of each prior above.

Marginalized posteriors for the calibrated values of supernovae apparent magnitude \(M_B\) in the Pantheon compilation considering the R21, TRGB, and P18 \(H_0\) priors (in units of km Mpc\(^{-1}\) s\(^{-1}\)), respectively. The constraints obtained are \(M_B\) = \(-19.302 \pm 0.031\), \(-19.369 \pm 0.037\) and \(-19.425\pm 0.017\) corresponding to the R21, TRGB and P18 \(H_0\) priors
For the SN data, we take into account the full Pantheon [60] compilation consisting of 1048 supernovae. We attempt to reconstruct the comoving distances from the Pantheon compilation. To begin with, we convert the apparent magnitudes m(z) from the full supernova sample to the respective luminosity distances (in units of Mpc), as
where \(M_B\) is the absolute magnitude of supernovae. We obtain the marginalized constraints on \(M_B\) assuming vanilla \(\varLambda \)CDM, considering a uniform prior \(M_B \in [-35, -5]\) via a Markov Chain Monte Carlo (MCMC) analysis using emceeFootnote 3 [61] python library. The calibrated constraints obtained are \(M_B\) = \(-19.302 \pm 0.031\), \(-19.369 \pm 0.037\) and \(-19.425\pm 0.017\) corresponding to the R21, TRGB and P18 \(H_0\) priors, respectively, are shown in Fig. 4 using GetDistFootnote 4 [62].
Again, we make use of the latest 32 CC Hubble parameter measurements [63,64,65,66,67,68,69], covering the redshift range up to \(z \sim 2\). These data do not assume any particular cosmological model but depend on the differential ages technique between galaxies, where we consider the full covariance matrix including the systematic and calibration errors [70]. We also take into account the BAO Hubble distance \(\frac{d_H(z)}{r_d}\) measurements [71,72,73,74,75,76,77] from different galaxy surveys like Sloan Digital Sky Survey (SDSS), the Baryon Oscillation Spectroscopic Survey (BOSS) and the extended Baryon Oscillation Spectroscopic Survey (eBOSS), such that
Note that, the BAO H(z) data assumes a fiducial value for the radius of the comoving sound horizon \(r_d\). To investigate the effect of the sound horizon scale on the reconstruction when using the BAO data, we consider the following constraint on \(r_d h = 102.56 \pm 1.87\) obtained by Camarena and Marra [78], keeping in mind the degeneracy between \(H_0\) and \(r_d\).
3 Neural network reconstruction
After preparation of the \(d_L\) data, we train a network model to learn to mimic the complex relationships between z, \(d_L(z)\) and \(\sigma _{d_L}(z)\). With this trained model, any arbitrary number of \(d_L(z)\) samples can be reconstructed by feeding a sequence of redshifts to this network model. Before training the network model on real data, we structure the optimal network configuration of our network model, i.e. determining the optimal number of neurons and layers according to Sec. A of [55].
Now, for the given sample of reconstructed \(d_L(z)\), we can arrive at the evolution of the normalized transverse comoving distance, D, from the Pantheon sample as

Plots for the reconstructed (i) D(z) (left panel), and (ii) \(D^\prime (z)\) (right panel), using neural networks from the Pantheon SN data considering R21, TRGB, and P18 \(H_0\) priors

Plots for the reconstructed reduced Hubble parameter E(z) from the (i) Pantheon SN compilation (left panel) and (ii) combined CC+BAO Hubble data set (right panel), using neural networks considering R21, TRGB, and P18 \(H_0\) priors
The plot for the reconstructed D is shown in the left panel of Fig. 5. In this setting, the reconstruction is produced by feeding a number of redshift points into the ANN so that values of D and its associated uncertainty can be obtained. The observational covariance information will have been imprinted on the ANNs through the training process due to the form of the loss function, while the reconstructed diagram will simply be composed of mean values and uncertainties at specific redshift points. We also undertake the simultaneous reconstruction of \(D^\prime (z)\), the first order derivative of D(z), where this prime denotes derivative with respect to the redshift z, via an MC routine on multiple \(d_L(z)\) realizations, such that \(D^\prime (z) = \frac{H_0}{c(1+z)} ~d_L^\prime (z)\). This compounding effect of MC with ANNs is undertaken following the methodology described in Ref. [55]. The plot for the reconstructed \(D^\prime (z)\) is shown in the right panel of Fig. 5. Finally, one can plot the evolution of the reduced Hubble parameter E(z) from the supernovae data as, \(E(z) = 1/D^\prime (z)\), given in the left panel of Fig. 6.
For a comparison between the Hubble and supernovae data sets, we next utilize the ANN method to reconstruct the reduced Hubble parameter,
directly from the combined CC+BAO Hubble data. The uncertainty associated with the reconstructed E(z) is obtained via the Monte Carlo method. Plots for the reconstructed E(z) from the Hubble data are shown in the right panel of Fig. 6.

Plots for the reconstructed (i) D(z) (left panel), and (ii) \(D^\prime (z)\) (right panel), using Gaussian processes from the Pantheon SN data considering R21, TRGB, and P18 \(H_0\) priors

Plots for the reconstructed reduced Hubble parameter E(z) from the (i) Pantheon SN compilation (left panel) and (ii) combined CC+BAO Hubble data set (right panel), using Gaussian processes considering R21, TRGB, and P18 \(H_0\) priors
4 Comparison with Gaussian processes reconstruction
In this section, we will discuss the work done in this paper using ANN-based reconstruction techniques, compared to the ones from Gaussian Processes. We recall that the methods by which these two reconstruction strategies function are fundamentally different. While GP requires some constraints on the type of data that it can be applied to, ANNs make vastly fewer assumptions and feature a much higher number of hyperparameters, which are then fit during the training of the neural network. Thus, one would expect an ANN to be much less constrained by the complexity of the data, and to have wider uncertainties. On the other hand, since GP does have some information about the behavior of the data, it can obtain smaller uncertainties.
We start by comparing the normalized transverse comoving distance D(z) (6) which quantifies the comoving distance for an object of relatively small characteristic length with respect to the Hubble flow. This is an appropriate way in which to interpret the SN data, since it does not require a fully determined cosmological model on which to perform numerical integrals. In our case, we first show the reconstruction for D(z) in Fig. 5 where the evolution is shown for a wider range of redshifts with means being shown for the \(\varLambda \)CDM model, as well as reconstructions for various literature priors. Given our reconstruction approach, we can also show the reconstruction of the redshift derivative of D(z) for the same priors. This can be contrasted with the analogous plot Fig. 7 which is the GP reconstruction of the same plots. In both cases, the reconstructions have very low uncertainties for most of the evolution of both D(z) and its first derivative. This happens because there is such a volume of data for the Pantheon sample. Thus, both methods will function quite well in the reconstruction of this particular data set.
The other comparison that provides an important dimension to the performance of GP and ANNs is that of the reduced Hubble parameter described in Eq. (7) which is a rescaled Hubble parameter that features a theoretical prior in that \(E(0) = 1\). This rescaled Hubble parameter is used for both the Pantheon data set as well as for Hubble data in the form of CC+BAO. For the ANN reconstruction, the reduced Hubble parameter gives Fig. 6 in which the reconstruction based on the Pantheon data set shows good behavior for low to medium values of redshift but then becomes numerically unbounded for much larger redshifts, while the same parameter is well behaved for the whole data range in the CC+BAO case. On the other hand, the GP reconstruction, shown in Fig. 8 has associated uncertainties that increase at slightly lower redshifts for the Pantheon data set case. Also, the CC+BAO reconstruction with is in mild tension with \(\varLambda \)CDM at comparatively lower redshifts.
GP and ANN both have positive features in reconstructing cosmological data sets. However, ANN shows greater promise in that they rely on less rigid training data and can model more complex structures of data sets.
5 Null tests
We now introduce some null tests, namely the \(\mathscr {O}m\) diagnostics [79,80,81], followed by the \(H_0\) diagnostics [82], to test the validity of the concordance model of cosmology.
5.1 \(\mathscr {O}m\) diagnostics
The \(\mathscr {O}m\) diagnostic [79,80,81] serves as a null test to distinguish the \(\varLambda \)CDM model from alternative dark energy and modified gravity models, defined as
where \(E (z) = {H(z)}/{H_0}\) is the reduced Hubble parameter. It works on the principle that different models have different evolutionary trajectories in \(z-\mathscr {O}m(z)\) plane. Being a function of H(z) only, which can be directly reconstructed from observational data, it is independent of the cosmic equation of state. Moreover, there is no dependence on any theory of gravity. So, this exercise serves as an alternative route towards understanding the late-time cosmic acceleration in the absence of any convincing physical theory [83,84,85,86].
For a universe with an underlying expansion history E(z), given by the \(\varLambda \)CDM model, \(\mathscr {O}m(z)\) will essentially be a constant, exactly equal to \(\varOmega _{m0}\), the matter density parameter at the present epoch. The slope of \(\mathscr {O}m(z)\) can differentiate between different dark energy and modified gravity models even if the \(\varOmega _{m0}\) is not accurately known. Therefore, any possible deviation of \(\mathscr {O}m(z)\) from \(\varOmega _{m0}\) can be used to draw inferences on the dynamics of the universe. For the phenomenological wCDM model, where the dark energy component is described by a constant equation of state parameter w, a positive slope of the \(\mathscr {O}m(z)\) indicates a phantom behaviour of dark energy, whereas a negative slope points towards a quintessence dark energy model.

Plots for the reconstructed \(\mathscr {O}m\) diagnostics using (i) neural networks (left panel) and (ii) gaussian processes (right panel), from the Pantheon SN data considering R21, TRGB, and P18 \(H_0\) priors

Plots for the reconstructed \(\mathscr {O}m\) diagnostics using (i) neural networks (left panel) and (ii) gaussian processes (right panel), from the combined CC+BAO Hubble data considering R21, TRGB, and P18 \(H_0\) priors
We plot the \(\mathscr {O}m\) diagnostics, as a function of the redshift z, using the reconstructed E(z) in Figs. 9 and 10 from the Pantheon SN and combined CC+BAO Hubble data respectively. The uncertainties associated with the reconstructed \(\mathscr {O}m\) diagnostics are obtained by an MC error propagation technique. We also show a comparison between the two methods of reconstruction, i.e. implementation with neural networks in the left panel, and employing Gaussian processes in the right panel. Figures 9 and 10 show that the reconstructed values are not well constrained at lower redshifts \(z < 0.2\). The mean reconstructed \(\mathscr {O}m\) curves in both the figures show evolution with increasing redshift. In Fig. 9, we find that the mean curves are characterised by a significant positive slope for \(z > 1\), nonetheless the \(\varLambda \)CDM model assuming the Planck best-fit \(\varOmega _{m0}= 0.315\) [21] is consistent with the \(\mathscr {O}m\) reconstruction at the 2\(\sigma \) confidence level. Whereas, the reconstruction profile in Fig. 10 tends to be characterised by a negative slope for \(z > 1\), excluding \(\varLambda \)CDM at 2\(\sigma \) confidence level for \(z>2\). This deviation from the concordance model possibly arises from the inclusion of high redshift Ly-\(\alpha \) BAO measurements which calls for further investigation.
5.2 \(H_0\) diagnostics
The Hubble tension, routinely presented as a mismatch between the Hubble constant \(H_0\) determined from local measurements and a value inferred from the CMB sky assuming \(\varLambda \)CDM cosmology, essentially boils down to a disagreement between two numbers. Assuming this tension is cosmological in origin, the authors in [82] explore the possibility of other inferred values of \(H_0\), predicting that a “running of \(H_0\) with z” may be expected within the concordance model. Similar possibilities of a steadily varying trend in the inferred \(H_0\) as one moves from low to high redshift data have also been studied [87,88,89,90,91,92,93,94]. Such a phenomenological evolution of \(H_0\) with the z could be a straightforward alternative in resolving the tension without any direct investigation of the fundamental framework. One such diagnostic that flags possible deviations from \(\varLambda \)CDM is the \(H_0\) diagnostics \(\mathbf {{H0}}\), defined as
This quantity \(\textbf{H0}\) provides us with a null test for the concordance model and a non-constancy of \(\textbf{H0}\) suggests evidence for new physics beyond \(\varLambda \)CDM.

Plots for the reconstructed \(\mathrm {H_0}\) diagnostics using (i) neural networks (left panel) and (ii) gaussian processes (right panel), from the Pantheon SN data considering R21, TRGB, and P18 \(H_0\) priors

Plots for the reconstructed \(\mathrm {H_0}\) diagnostics using (i) neural networks (left panel) and (ii) gaussian processes (right panel), from the combined CC+BAO Hubble data considering R21, TRGB, and P18 \(H_0\) priors
In this section, we plot the evolution of \(\textbf{H0}\) with respect to the redshift z from the reconstructed E(z) in Figs. 11 and 12 from the Pantheon SN and combined CC+BAO Hubble data respectively. The left panels correspond to the reconstruction with ANNs, whereas the right panel represents the reconstruction using GPs. We make use of the employed \(H_0\) priors to obtain the numerator \(H(z) = H_0 E(z)\), in the RHS of 9. The denominator has been fixed by sampling \(\varOmega _{m0}\) directly via an MCMC analysis with the combined CC+BAO+SN data sets assuming \(\varLambda \)CDM cosmology. The constraints obtained on \(\varOmega _{m0}\) are \(0.290 \pm 0.016\), \(0.298 \pm 0.017\) and \(0.303 \pm 0.016\) considering the R21, TRGB and P18 \(H_0\) priors. The uncertainties associated with the parameter \(\varOmega _{m0}\) and reconstructed H(z) are propagated using the MC error propagation technique.
Our results show that the mean reconstructed \(\textbf{H0}\) curves in both the figures show a non-monotonic evolution with respect to z. In Fig. 11, \(\textbf{H0}\) progressively increases with increasing z, but on going beyond \(z>2\) we observe a dip in the reconstruction profile. The presence of such a dip is apparent in the right panel when employing GPs. We also plot the R21, TRGB, and P18 \(H_0\) values in black solid, dashed and dotted lines to simultaneously compare them with the obtained \(\textbf{H0}(z)\) respectively. We find that the reconstructed errors accommodate \(\varLambda \)CDM within a \(2\sigma \) level. The non-monotonic nature of \(\textbf{H0}\) is clearly visible in Fig. 12, when the Hubble data is taken into consideration. The reconstructed \(\textbf{H0}\) profile indicates a clear deviation from \(\varLambda \)CDM at the 2\(\sigma \) confidence level, driven by Lyman-\(\alpha \) BAO leading to a significant dip in \(\textbf{H0}\) for \(z>2\). However, if we restrict our attention to \(z < 1\), where the quality of available data is much better, one finds little evidence for any deviation from \(\varLambda \)CDM cosmology.
6 Conclusion
Even though reconstruction techniques have been a very popular topic of research the last few years in cosmology, the majority of the studies focus on GP to reconstruct dark energy and its potential theoretical foundations. GP, however, suffer from various problems among which are overfitting at low redshifts, meaning that the reconstructed function is too closely aligned to low redshift data points, as well as the selection of a kernel which introduces a statistical bias.
ANNs have been proposed as a promising alternative to GPs, but in contrast to GPs, one can reconstruct only the cosmological parameters without their derivatives. There has been a recent work on the reconstruction of higher derivatives of the Hubble function in [55], where the authors use an MC approach. Even though, this helps with the testing of cosmological models, up to now there have been used only independent data points, while the most realistic data sets are correlated somehow.
In this work, our goal was to include covariance information in the reconstruction approach in order to be able to use more realistic data sets. Once we reconstruct a cosmological parameter, we can use the Monte Carlo approach to reconstruct its higher derivatives and thus reproduce or test the viability of various cosmological models with better accuracy than before.
In greater detail, we reconstructed the Hubble diagram for various combinations of Cosmic Chronometers, Baryon Acoustic Oscillations, as well as the 1048 data points of Supernovae type Ia of Pantheon, which are correlated. To do this, we expanded ReFANN, that was initially formed based on PyTorch, using only independent data points.
The type of data that ANNs can use is not as constrained as in GP. Specifically, ANNs make much less assumptions, because the many more hyperparameters they use, imitate in a better way the natural process compared to GP. For this reason, one would expect that, ANNs would produce higher uncertainties, however this is not the case here. Because of the large volume of data in the Pantheon set, both GP and ANNs perform in a similar way in terms of error bars. Thus, comparison between the two techniques shows more potential for the latter, since it does on exact training data and also can represent more complicated structures of data sets.
Last but not least, apart from the reconstruction of the Hubble function, we performed null tests in order to test the consistency of our results. In particular, through the \(\mathscr {O}m\) and the \(\textbf{H0}\) diagnostics we tried to identify possible deviations from the \(\varLambda \)CDM model. Both diagnostics indicate a deviation from the concordance model at \(z>2\), most probably because of the inclusion of the high redshift BAO data points. However, they both can accommodate \(\varLambda \)CDM at \(2\sigma \) confidence level.
What would interesting to see from now on, is not only to forecast observations for experiments in progress that are about to publish their results, but also to use the reconstructed Hubble parameter and its derivative to constrain or even eliminate alternative cosmological models.
Data availability
This manuscript has no associated data or the data will not be deposited. [Authors’ comment: The Authors confirm that all relevant source data from the public domain are included in the manuscript, and/or duly cited.]
References
P.J.E. Peebles, B. Ratra, Rev. Mod. Phys. 75, 559 (2003). https://doi.org/10.1103/RevModPhys.75.559
E.J. Copeland, M. Sami, S. Tsujikawa, Int. J. Mod. Phys. D 15, 1753 (2006). https://doi.org/10.1142/S021827180600942X
L. Baudis, J. Phys. G 43(4), 044001 (2016). https://doi.org/10.1088/0954-3899/43/4/044001
E. Aprile et al., Phys. Rev. Lett. 121(11), 111302 (2018). https://doi.org/10.1103/PhysRevLett.121.111302
A.G. Riess et al., Astron. J. 116, 1009 (1998). https://doi.org/10.1086/300499
S. Perlmutter et al., Astrophys. J. 517, 565 (1999). https://doi.org/10.1086/307221
V. Mukhanov, Physical Foundations of Cosmology (Cambridge Univ. Press, Cambridge, 2005). https://doi.org/10.1017/CBO9780511790553. https://cds.cern.ch/record/991646
S. Weinberg, Rev. Mod. Phys. 61, 1 (1989). https://doi.org/10.1103/RevModPhys.61.1
D.S. Akerib et al., Phys. Rev. Lett. 118(2), 021303 (2017). https://doi.org/10.1103/PhysRevLett.118.021303
R.J. Gaitskell, Ann. Rev. Nucl. Part. Sci. 54, 315 (2004). https://doi.org/10.1146/annurev.nucl.54.070103.181244
E. Di Valentino et al., Astropart. Phys. 131, 102606 (2021). https://doi.org/10.1016/j.astropartphys.2021.102606
E. Di Valentino et al., Astropart. Phys. 131, 102605 (2021). https://doi.org/10.1016/j.astropartphys.2021.102605
E. Di Valentino et al., Astropart. Phys. 131, 102604 (2021). https://doi.org/10.1016/j.astropartphys.2021.102604
D. Staicova, in 16th Marcel Grossmann Meeting on Recent Developments in Theoretical and Experimental General Relativity, Astrophysics and Relativistic Field Theories (2021)
E. Di Valentino, O. Mena, S. Pan, L. Visinelli, W. Yang, A. Melchiorri, D.F. Mota, A.G. Riess, J. Silk, Class. Quantum Gravity 38(15), 153001 (2021). https://doi.org/10.1088/1361-6382/ac086d
L. Perivolaropoulos, F. Skara, New Astron. Rev. 95, 101659 (2022). https://doi.org/10.1016/j.newar.2022.101659
E. Di Valentino, W. Giarè, A. Melchiorri, J. Silk, Phys. Rev. D 106(10), 103506 (2022). https://doi.org/10.1103/PhysRevD.106.103506
M.S. Athar et al., Prog. Part. Nucl. Phys. 124, 103947 (2022). https://doi.org/10.1016/j.ppnp.2022.103947
E. Abdalla et al., JHEAP 34, 49 (2022). https://doi.org/10.1016/j.jheap.2022.04.002
V. Poulin, T.L. Smith, T. Karwal, arXiv:2302.09032 [astro-ph.CO] (2023). https://doi.org/10.48550/arXiv.2302.09032
N. Aghanim et al., Astron. Astrophys. 641, A6 (2020). https://doi.org/10.1051/0004-6361/201833910. [Erratum: Astron. Astrophys. 652, C4 (2021)]
S. Aiola et al., JCAP 12, 047 (2020). https://doi.org/10.1088/1475-7516/2020/12/047
A.G. Riess, S. Casertano, W. Yuan, J.B. Bowers, L. Macri, J.C. Zinn, D. Scolnic, Astrophys. J. Lett. 908(1), L6 (2021). https://doi.org/10.3847/2041-8213/abdbaf
K.C. Wong et al., Mon. Not. R. Astron. Soc. 498(1), 1420 (2020). https://doi.org/10.1093/mnras/stz3094
W.L. Freedman, B.F. Madore, T. Hoyt, I.S. Jang, R. Beaton, M.G. Lee, A. Monson, J. Neeley, J. Rich (2020). https://doi.org/10.3847/1538-4357/ab7339
E. Di Valentino, A. Melchiorri, Astrophys. J. Lett. 931(2), L18 (2022). https://doi.org/10.3847/2041-8213/ac6ef5
A. Addazi et al., Prog. Part. Nucl. Phys. 125, 103948 (2022). https://doi.org/10.1016/j.ppnp.2022.103948
E.N. Saridakis et al., arXiv:2105.12582 [gr-qc] (2021). https://doi.org/10.48550/arXiv.2105.12582
Y.F. Cai, M. Khurshudyan, E.N. Saridakis, Astrophys. J. 888, 62 (2020). https://doi.org/10.3847/1538-4357/ab5a7f
X. Ren, S.F. Yan, Y. Zhao, Y.F. Cai, E.N. Saridakis, Astrophys. J. 932, 131 (2022). https://doi.org/10.3847/1538-4357/ac6ba5
R.C. Bernardo, J.L. Said, JCAP 09, 014 (2021). https://doi.org/10.1088/1475-7516/2021/09/014
R. Briffa, S. Capozziello, J.L. Said, J. Mifsud, E.N. Saridakis, Class. Quantum Gravity 38(5), 055007 (2020). https://doi.org/10.1088/1361-6382/abd4f5
J.L. Said, J. Mifsud, J. Sultana, K.Z. Adami, JCAP 06, 015 (2021). https://doi.org/10.1088/1475-7516/2021/06/015
Željko Ivezić, A.J. Connolly, J.T. VanderPlas, A. Gray, Statistics, Data Mining, and Machine Learning in Astronomy: A Practical Python Guide for the Analysis of Survey Data, stu-student edn. (Princeton University Press, 2014). http://www.jstor.org/stable/j.ctt4cgbdj
G.J. Wang, X.J. Ma, S.Y. Li, J.Q. Xia, Astrophys. J. Suppl. 246(1), 13 (2020). https://doi.org/10.3847/1538-4365/ab620b
C.E. Rasmussen, C.K.I. Williams, Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning) (The MIT Press, Cambridge, 2005)
V.C. Busti, C. Clarkson, M. Seikel, IAU Symp. 306, 25 (2014). https://doi.org/10.1017/S1743921314013751
V.C. Busti, C. Clarkson, M. Seikel, Mon. Not. R. Astron. Soc. 441, 11 (2014). https://doi.org/10.1093/mnrasl/slu035
M. Seikel, C. Clarkson, arXiv:1311.6678 [astro-ph.CO] (2013). https://doi.org/10.48550/arXiv.1311.6678
R.C. Bernardo, J.L. Said, JCAP 08, 027 (2021). https://doi.org/10.1088/1475-7516/2021/08/027
S. Yahya, M. Seikel, C. Clarkson, R. Maartens, M. Smith, Phys. Rev. D 89(2), 023503 (2014). https://doi.org/10.1103/PhysRevD.89.023503
M. Seikel, C. Clarkson, M. Smith, JCAP 2012(6), 036 (2012). https://doi.org/10.1088/1475-7516/2012/06/036
A. Shafieloo, A.G. Kim, E.V. Linder, Phys. Rev. D 85, 123530 (2012). https://doi.org/10.1103/PhysRevD.85.123530
D. Benisty, Phys. Dark Univ. 31, 100766 (2021). https://doi.org/10.1016/j.dark.2020.100766
D. Benisty, J. Mifsud, J.L. Said, D. Staicova, Phys. Dark Univ. 39, 101160 (2023). https://doi.org/10.1016/j.dark.2022.101160
R.C. Bernardo, D. Grandón, J. Levi Said, V.H. Cárdenas, Phys. Dark Univ. 40, 101213 (2023). https://doi.org/10.1016/j.dark.2023.101213
C. Escamilla-Rivera, J. Said, J.L. Mifsud, JCAP 10, 016 (2021). https://doi.org/10.1088/1475-7516/2021/10/016
R.C. Bernardo, D. Grandón, J.L. Said, V.H. Cárdenas, Phys. Dark Univ. 36, 101017 (2022). https://doi.org/10.1016/j.dark.2022.101017
P. Mukherjee, N. Banerjee, Eur. Phys. J. C 81, 36 (2021). https://doi.org/10.1140/epjc/s10052-021-08830-5
P. Mukherjee, N. Banerjee, Phys. Dark Univ. 36, 100998 (2022). https://doi.org/10.1016/j.dark.2022.100998
C. Aggarwal, Neural Networks and Deep Learning: A Textbook (Springer International Publishing, 2018). https://books.google.com.mt/books?id=achqDwAAQBAJ
Y.C. Wang, Y.B. Xie, T.J. Zhang, H.C. Huang, T. Zhang, K. Liu, Astrophys. J. Supp. 254(2), 43 (2021). https://doi.org/10.3847/1538-4365/abf8aa
I. Gómez-Vargas, J.A. Vázquez, R.M. Esquivel, R. García-Salcedo, Eur. Phys. J. C 83, 304 (2023). https://doi.org/10.1140/epjc/s10052-023-11435-9
K. Dialektopoulos, J.L. Said, J. Mifsud, J. Sultana, K.Z. Adami, JCAP 02(02), 023 (2022). https://doi.org/10.1088/1475-7516/2022/02/023
P. Mukherjee, J.L. Said, J. Mifsud, JCAP 12, 029 (2022). https://doi.org/10.1088/1475-7516/2022/12/029
D.A. Clevert, T. Unterthiner, S. Hochreiter, (2015). arXiv:1511.07289
D.P. Kingma, J. Ba, (2014). arXiv:1412.6980
A.G. Riess et al., Astrophys. J. Lett. 934(1), L7 (2022). https://doi.org/10.3847/2041-8213/ac5c5b
W.L. Freedman, Astrophys. J. 919(1), 16 (2021). https://doi.org/10.3847/1538-4357/ac0e95
D.M. Scolnic et al., Astrophys. J. 859(2), 101 (2018). https://doi.org/10.3847/1538-4357/aab9bb
D. Foreman-Mackey, D.W. Hogg, D. Lang, J. Goodman, Publ. Astron. Soc. Pac. 125, 306 (2013). https://doi.org/10.1086/670067
A. Lewis, arXiv:1910.13970 [astro-ph.IM] (2019). https://doi.org/10.48550/arXiv.1910.13970
D. Stern, R. Jimenez, L. Verde, M. Kamionkowski, S.A. Stanford, JCAP 02, 008 (2010). https://doi.org/10.1088/1475-7516/2010/02/008
M. Moresco et al., JCAP 08, 006 (2012). https://doi.org/10.1088/1475-7516/2012/08/006
M. Moresco, L. Pozzetti, A. Cimatti, R. Jimenez, C. Maraston, L. Verde, D. Thomas, A. Citro, R. Tojeiro, D. Wilkinson, JCAP 05, 014 (2016). https://doi.org/10.1088/1475-7516/2016/05/014
N. Borghi, M. Moresco, A. Cimatti, Astrophys. J. Lett. 928(1), L4 (2022). https://doi.org/10.3847/2041-8213/ac3fb2
A.L. Ratsimbazafy, S.I. Loubser, S.M. Crawford, C.M. Cress, B.A. Bassett, R.C. Nichol, P. Väisänen, Mon. Not. R. Astron. Soc. 467(3), 3239 (2017). https://doi.org/10.1093/mnras/stx301
M. Moresco, Mon. Not. R. Astron. Soc. 450(1), L16 (2015). https://doi.org/10.1093/mnrasl/slv037
C. Zhang, H. Zhang, S. Yuan, T.J. Zhang, Y.C. Sun, Res. Astron. Astrophys. 14(10), 1221 (2014). https://doi.org/10.1088/1674-4527/14/10/002
M. Moresco, R. Jimenez, L. Verde, A. Cimatti, L. Pozzetti, Astrophys. J. 898(1), 82 (2020). https://doi.org/10.3847/1538-4357/ab9eb0
S. Alam et al., Mon. Not. R. Astron. Soc. 470(3), 2617 (2017). https://doi.org/10.1093/mnras/stx721
J.E. Bautista et al., Mon. Not. R. Astron. Soc. 500(1), 736 (2020). https://doi.org/10.1093/mnras/staa2800
H. Gil-Marin et al., Mon. Not. R. Astron. Soc. 498(2), 2492 (2020). https://doi.org/10.1093/mnras/staa2455
R. Neveux et al., Mon. Not. R. Astron. Soc. 499(1), 210 (2020). https://doi.org/10.1093/mnras/staa2780
J. Hou et al., Mon. Not. R. Astron. Soc. 500(1), 1201 (2020). https://doi.org/10.1093/mnras/staa3234
V. de Sainte Agathe et al., Astron. Astrophys. 629, A85 (2019). https://doi.org/10.1051/0004-6361/201935638
M. Blomqvist et al., Astron. Astrophys. 629, A86 (2019). https://doi.org/10.1051/0004-6361/201935641
D. Camarena, V. Marra, Mon. Not. R. Astron. Soc. 495(3), 2630 (2020). https://doi.org/10.1093/mnras/staa770
V. Sahni, A. Shafieloo, A.A. Starobinsky, Phys. Rev. D 78, 103502 (2008). https://doi.org/10.1103/PhysRevD.78.103502
C. Zunckel, C. Clarkson, Phys. Rev. Lett. 101, 181301 (2008). https://doi.org/10.1103/PhysRevLett.101.181301
A. Shafieloo, C. Clarkson, Phys. Rev. D 81, 083537 (2010). https://doi.org/10.1103/PhysRevD.81.083537
C. Krishnan, E.O. Colgáin, M.M. Sheikh-Jabbari, T. Yang, Phys. Rev. D 103(10), 103509 (2021). https://doi.org/10.1103/PhysRevD.103.103509
C. Clarkson, B. Bassett, T.H.C. Lu, Phys. Rev. Lett. 101, 011301 (2008). https://doi.org/10.1103/PhysRevLett.101.011301
J.Z. Qi, M.J. Zhang, W.B. Liu, arXiv:1606.00168 [gr-qc] (2016). https://doi.org/10.48550/arXiv.1606.00168
J.Z. Qi, S. Cao, M. Biesiada, T. Xu, Y. Wu, S. Zhang, Z.H. Zhu, Res. Astron. Astrophys. 18(6), 066 (2018). https://doi.org/10.1088/1674-4527/18/6/66
C.A.P. Bengaly, C. Clarkson, M. Kunz, R. Maartens, Phys. Dark Univ. 33, 100856 (2021). https://doi.org/10.1016/j.dark.2021.100856
C. Krishnan, R. Mondol, arXiv:2201.13384 [astro-ph.CO] (2022). https://doi.org/10.48550/arXiv.2201.13384
E.O. Colgáin, M.M. Sheikh-Jabbari, R. Solomon, G. Bargiacchi, S. Capozziello, M.G. Dainotti, D. Stojkovic, Phys. Rev. D 106(4), L041301 (2022). https://doi.org/10.1103/PhysRevD.106.L041301
E.O. Colgáin, M.M. Sheikh-Jabbari, R. Solomon, M.G. Dainotti, D. Stojkovic, arXiv:2206.11447 [astroph.CO] (2022). https://doi.org/10.48550/arXiv.2206.11447
E.O. Colgáin, M.M. Sheikh-Jabbari, R. Solomon, Phys. Dark Univ. 40, 101216 (2023). https://doi.org/10.1016/j.dark.2023.101216
M.G. Dainotti, B. De Simone, T. Schiavone, G. Montani, E. Rinaldi, G. Lambiase, Astrophys. J. 912(2), 150 (2021). https://doi.org/10.3847/1538-4357/abeb73
M.G. Dainotti, B. De Simone, T. Schiavone, G. Montani, E. Rinaldi, G. Lambiase, M. Bogdan, S. Ugale, Galaxies 10(1), 24 (2022). https://doi.org/10.3390/galaxies10010024
T. Schiavone, G. Montani, M.G. Dainotti, B. De Simone, E. Rinaldi, G. Lambiase, in 17th Italian-Korean Symposium on Relativistic Astrophysics (2022)
M. Malekjani, R.M. Conville, E.O. Colgáin, S. Pourojaghi, M.M. Sheikh-Jabbari, (2023)
Acknowledgements
This paper is based upon work from COST Action CA21136 Addressing observational tensions in cosmology with systematics and fundamental physics (CosmoVerse) supported by COST (European Cooperation in Science and Technology). PM thanks ISI Kolkata for computational facilities and financial support through Research Associateship under project A/C No. 5756 H. JLS and JM would like to acknowledge funding from “The Malta Council for Science and Technology” through the “FUSION R &I: Research Excellence Programme”. The work was supported by the PNRR-III-C9-2022-I9 call, with project number 760016/27.01.2023 and by the Hellenic Foundation for Research and Innovation (H.F.R.I.) under the ”First Call for H.F.R.I. Research Projects to support Faculty members and Researchers and the procurement of high-cost research equipment grant” (Project Number: 2251).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dialektopoulos, K.F., Mukherjee, P., Said, J.L. et al. Neural network reconstruction of cosmology using the Pantheon compilation. Eur. Phys. J. C 83, 956 (2023). https://doi.org/10.1140/epjc/s10052-023-12124-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-023-12124-3