
Abstract
The spatially averaged inhomogeneous Universe includes a kinematical backreaction term \({\mathcal {Q}}_{\mathcal {D}}\) that is relate to the averaged spatial Ricci scalar \({\langle \mathcal {R}} \rangle _{\mathcal {D}}\) in the framework of general relativity. Under the assumption that \({\mathcal {Q}}_{\mathcal {D}}\) and \({\langle \mathcal {R}} \rangle _{\mathcal {D}}\) obey the scaling laws of the volume scale factor \(a_{\mathcal {D}}\), a direct coupling between them with a scaling index n is remarkable. In order to explore the generic properties of a backreaction model for explaining the accelerated expansion of the Universe, we exploit two metrics to describe the late time Universe. Since the standard FLRW metric cannot precisely describe the late time Universe on small scales, the template metric with an evolving curvature parameter \(\kappa _{\mathcal {D}}(t)\) is employed. However, we doubt the validity of the prescription for \(\kappa _{\mathcal {D}}\), which motivates us apply observational Hubble parameter data (OHD) to constrain parameters in dust cosmology. First, for FLRW metric, by getting best-fit constraints of \(\varOmega ^{{\mathcal {D}}_0}_m = 0.25^{+0.03}_{-0.03}\), \(n = 0.02^{+0.69}_{-0.66}\), and \(H_{\mathcal {D}_0} = 70.54^{+4.24}_{-3.97}\ \mathrm{km \ s^{-1} \ Mpc^{-1}}\), the evolutions of parameters are explored. Second, in template metric context, by marginalizing over \(H_{\mathcal {D}_0}\) as a prior of uniform distribution, we obtain the best-fit values of \(n=-1.22^{+0.68}_{-0.41}\) and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.12^{+0.04}_{-0.02}\). Moreover, we utilize three different Gaussian priors of \(H_{\mathcal {D}_0}\), which result in different best-fits of n, but almost the same best-fit value of \({{\varOmega }_{m}^{\mathcal {D}_{0}}}\sim 0.12\). Also, the absolute constraints without marginalization of parameter are obtained: \(n=-1.1^{+0.58}_{-0.50}\) and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.13\pm 0.03\). With these constraints, the evolutions of the effective deceleration parameter \(q^{\mathcal {D}}\) indicate that the backreaction can account for the accelerated expansion of the Universe without involving extra dark energy component in the scaling solution context. Nevertheless, the results also verify that the prescription of \(\kappa _{\mathcal {D}}\) is insufficient and should be improved.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The universe is homogeneous and isotropic on very large scales. According to Einstein’s general relativity, one can obtain a homogeneous and isotropic solution of Einstein’s field equations, which is called Friedmann–Lemaitre–Robertson–Walker (FLRW) metric. Since on smaller scales, the universe appears to be strongly inhomogeneous and anisotropic, Larena et al. [1] doubt that the FLRW cosmology describes the averaged inhomogeneous universe at all times. They assume that FLRW metric may not hold at late times especially when there are large matter inhomogeneities existed, even though it may be suitable at early times. Therefore they introduce a template metric that is compatible with homogeneity and isotropy on large scales of FLRW cosmology, and also contains structure on small scales. In other words, this metric is built upon weak, instead of strong, cosmological principle.
The observations of type Ia supernovae (SNe Ia) [2, 3] suggest that the universe is in a state of accelerated expansion, which implies that there exists a latent component so called dark energy (DE) with negative pressure that causes the accelerated expansion of the universe. There are many scenarios proposed to account for the observations. The simplest one is the positive cosmological constant in Einstein’s equations, which in common assumption is equivalent to the quantum vacuum. Since the measured cosmological constant is much smaller than the particle physics predicted, some other scenarios are proposed, such as the phenomenological models which explained DE as a late time slow rolling scalar field [4] or the Chaplygin gas [5], and the modified gravity models. Recently, a new scenario [6, 7] is raised to consider DE as a backreaction effect of inhomogeneities on the average expansion of the universe. Here we specifically focus on the backreaction model without involving perturbation theory.
According to Buchert [8], the averaged equations of the averaged spatial Ricci scalar \({\langle \mathcal {R}} \rangle _{\mathcal {D}}\) and the ‘backreaction’ term \({\mathcal {Q}}_{\mathcal {D}}\) can be solved to obtain the exact scaling solutions in which a direct coupling between \({\langle \mathcal {R}} \rangle _{\mathcal {D}}\) and \({\mathcal {Q}}_{\mathcal {D}}\) with a scaling index n is significant. With that solution, a domain-dependent Hubble function (effective volume Hubble parameter) \(H_{\mathcal {D}}\) can be expressed with the scaling index n and the present effective matter density parameter \({{\varOmega }_{m}^{\mathcal {D}_{0}}}\). Also, as mentioned in [1], the pure scaling ansatz is not what we expected in a realistic evolution of backreaction.
So as to explore the generic properties of a backreaction model for explaining the observations of the Universe, we, in this paper, exploit two metrics to describe the late time Universe. Although the template metric proposed by Larena et al. [1] is reasonable, the prescription of the so-called “geometrical instantaneous spatially-constant curvature” \(\kappa _{\mathcal {D}}\) is skeptical, based on the discrepancies between our results and theirs. Comparing the FLRW metric with the smoothed template metric, we use observational Hubble parameter data (OHD) to constrain the scaling index n (corresponding to constant equation of state for morphon field \(w^{\mathcal {D}}_{\Phi }\) [9]) and the present effective matter density parameter \({{\varOmega }_{m}^{\mathcal {D}_{0}}}\) without involving perturbation theory. In the latter case, according to [10], we choose to marginalize over both the top-hat prior of \(H_{{\mathcal {D}}_0}\) with a uniform distribution in the interval [50, 90] and three different Gaussian priors of \(H_{{\mathcal {D}}_0}\), where we also obtain the absolute constraint results without the marginalization of the parameters. Combining both the FLRW geometry and the template metric with the backreaction model, we obtain the fine relation between effective Hubble parameter \(H_{\mathcal {D}}\) and effective scale factor \(a_{\mathcal {D}}\) by utilizing Runge–Kutta method to solve the differential equations of the latter, in order to acquire the link between \(a_{\mathcal {D}}\) and effective redshift \(z_{\mathcal {D}}\). At last, a conflict, as expected, arises. Our results show that it needs a higher instead of lower amount of backreaction to interpret the effective geometry, even though accelerated expansion of \(a_{\mathcal {D}}\) still remains. The power law prescription of \(\kappa _{\mathcal {D}}\) certainly need to be improved, since it only evolves from 0 to \(-1\), which is insufficient. Of course, we should point out that the power law ansatz is not the realistic case and the results are expected to be inaccurate. For simplicity, we only deliberate the situation under the assumption of power-law ansatz here.
The paper is organized as follows. The backreaction context is demonstrated in Sect. 2. In Sect. 3, we introduce the template metric and computation of observables along with the effective Hubble parameter \(H_{\mathcal {D}}\), and demonstrate how to relate effective redshift \({z_{\mathcal {D}}}\) to effective scale factor \(a_{\mathcal {D}}\). We also refer to overall cosmic equation of state \(w^{\mathcal {D}}_\mathrm{eff}\) [9] and how it differs from constant equation of state w. In Sect. 4, according to the effective Hubble parameter, we apply OHD with both the FLRW metric and the template metric, and make use of Metropolis–Hastings algorithm of the Markov-Chain-Monte-Carlo (MCMC) method and mesh-grid method, respectively, to obtain the constraints of the parameters. In former case, we employ the best-fits to illustrate the evolutions of \({q}^{\mathcal {D}}\), \(w^{\mathcal {D}}_\mathrm{eff}\), \(\kappa _{\mathcal {D}}\) and density parameters. In latter case, we test the effective deceleration parameter with the best-fit values. After analysis of the results in Sect. 4, we summarize our conclusion and discussion in Sect. 5.
We use the natural units \(c = 1\) throughout the paper, and assign that Greek indices such as \(\alpha \), \(\mu \) run through \(0\cdots 3\), while Latin indices such as i, j run through \(1\cdots 3\).
2 The backreaction model
Buchert [8] introduced a model of dust cosmologies, which leads to two averaged equations, the averaged Raychaudhuri equation
and the averaged Hamiltonian constraint
where \(\langle \rho \rangle _{\mathcal {D}}\), G, and \(\Lambda \) represent averaged matter density in the domain \({\mathcal {D}}\), gravitational constant, and cosmological constant, respectively. The over-dot represents partial derivative with respect to proper time t here after. A effective scale factor is introduced via volume (normalized by the volume of the initial domain \(V_{\mathcal {D}_i}\)),
The averaged spatial Ricci scalar \(\langle {\mathcal {R}}\rangle _{\mathcal {D}}\) and the ‘backreaction’ \({\mathcal {Q}}_{\mathcal {D}}\) are domain-dependent constants, which yet are time-dependent functions. The ‘backreaction’ term is expressed as
with two scalar invariants
and
where \(\varTheta _{ij}\) is the expansion tensor, with the trace-free symmetric shear tensor \(\sigma _{ij}\), the rate of shear \({\sigma }^2=\frac{1}{2}{\sigma }^i_{\ j}{\sigma }^j_{\ i}\) and the expansion rate \(\theta \). Substituting Eqs. (1) into (2), one can get
where the dot over the parentheses represents partial derivative over time t, and the scaling solutions are
where n and m are real numbers. As mentioned in [8], there are two types of solutions to be considered. The first type is \(n=-2\) and \(m=-6\), which corresponds to a quasi-FLRW universe at late times, i.e., backreaction is negligible. The second type is a direct coupling between \(\langle {\mathcal {R}}\rangle _{\mathcal {D}}\) and \({\mathcal {Q}}_{\mathcal {D}}\), i.e., \(m=n\), which reads
and
A domain-dependent Hubble function is defined to be \(H_{\mathcal {D}}=\dot{a_{\mathcal {D}}}/{a_{\mathcal {D}}}\), and dimensionless (‘effective’) averaged cosmological parameters are also given respectively by
and
Thus, according to Eq. (2), one can have
The components that are not included in Friedmann equation read
If \(\varOmega ^{\mathcal {D}}_\Lambda =0\), then \(\varOmega ^{\mathcal {D}}_X\) is considered to be the DE contribution, and usually dubbed as X-matter. Considering Eqs. (9) and (10), one can get
Furthermore, one can easily obtain
where \({{\mathcal {D}}_0}\) denotes the domain at present time, and \(a_{{\mathcal {D}}_0}=1\) here after.
In comparison with the deceleration parameter q in standard cosmology, an effective volume deceleration parameter \({q}^{\mathcal {D}}\) is interpreted as
3 Effective geometry
3.1 The template metric
Larena et al. [1] proposed the template metric (space-time metric) as follows,
where \(a_{{\mathcal {D}}_0}L_{H_0}=1/H_{{\mathcal {D}}_0}\) is introduced as the size of the horizon at present time, so that the coordinate distance is dimensionless, and the domain-dependent effective 3-metric reads
with solid angle element \(\mathrm{d}\varOmega ^2=r^2(\mathrm{d}\theta ^2+sin^2\theta \mathrm{d}\phi ^2)\). Under their assumption, the template 3-metric is identical to the spatial part of a FLRW space-time at any given time, except for the time-dependent scalar curvature. According to their discussion, \(\kappa _{\mathcal {D}}\) must be related to \(\langle {\mathcal {R}}\rangle _{\mathcal {D}}\), thus in analogy with a FLRW metric, the correlation can be given by
Notice that this template metric does not need to be a dust solution of Einstein’s equations, since Einstein’s field equations are satisfied locally for any space-time metric. Nevertheless, this prescription is insufficient, as \(\kappa _{\mathcal {D}}\) cannot be positive in this case, which is assertive and skeptical.
3.2 Computation of observables
The computation of effective distances along the approximate smoothed light cone associated with the travel of light is very different from general that of distances [11]. Firstly, an effective volume redshift \(z_{\mathcal {D}}\) is defined as
where the O and the S represent the evaluation of the quantities at the observer and source, respectively, \(g_{\mu \nu }\) is the template effective metric, \(u^{\mu }\) is the 4-velocity of the matter content (\(u^{\mu }u_{\mu }=-1\)) with respect to comoving reference, and \(k^{\mu }\) is the wave vector of a light ray that travels from the source S to the observer O (\(k^{\mu }k_{\mu }=1\)). Normalizing the wave vector \((k^{\mu }u_{\mu })_O=-1\) and defining the scaled vector \(\hat{k}^{\mu }={a^2_{\mathcal {D}}}k^{\mu }\), we can obtain the following relation
where \(\hat{k}^0\) obeys the null geodesics equation \(\hat{k}^{\mu }\nabla _{\mu }\hat{k}^{\nu }=0\), which can lead to
As light travels along null geodesic, we have
which is slightly different from Eq. (30) of [1], since \(r(0)=0\) they choose is actually \(r(a_{{\mathcal {D}}_0}=1)=0\). (Note: this should be just a typo and does not affect the results.) By solving Eq. (26) we can get the coordinate distance \(\bar{r}(a_{\mathcal {D}})\), and then substitutes it into Eq. (25) to find the relation between \(z_{\mathcal {D}}\) and \(a_{\mathcal {D}}\). Combining equations in Sects. 2 and 3, we can obtain
Note that there are also typos in Eq. (41) of [1], and the correct one is Eq. (28). As shown in Fig. 1, panels (a) and (d) are identical to Larena’s Fig. 1, and panels (b) and (c) have same evolutionary trends but different limits on the left, where when \(a_{\mathcal {D}}=10^{-3}\), \(z_\mathrm{FLRW}/z_{\mathcal {D}}\approx 1.86\) for our work here, but \(z_\mathrm{FLRW}/z_{\mathcal {D}}\approx 2.63\) for their work. Since panels (c) and (d) are obtained with the same method and just different equations, we are certain about the precisions of our results.

The evolutions of the coordinate distance \(cr/H_{{\mathcal {D}}_0}\) (a), the redshift (b) and the ratio between the FLRW redshift and the effective redshift, \(1/(a_{\mathcal {D}}(1+z_{\mathcal {D}}))\), in the averaged model as function of the effective scale factor \(z_{\mathcal {D}}\) with \(n = -1\), \(\varOmega ^{{\mathcal {D}}_0}_m = 0.3\), \(H_{{\mathcal {D}}_0} = 70\ \mathrm{km \ s^{-1} \ Mpc^{-1}}\) (dashed line). The flat FLRW model with same parameters are the solid lines shown in (a) and (b), respectively. d \(1/(a_{\mathcal {D}}(1+z_{\mathcal {D}}))\) for Larena’s best-fit averaged model with \(n=0.12\), \(\varOmega ^{{\mathcal {D}}_0}_m = 0.38\), \(H_{{\mathcal {D}}_0} = 78.54\ \mathrm{km \ s^{-1} \ Mpc^{-1}}\)
In DE context, a constant equation of state w is correlated with the component n as \(w^{\mathcal {D}}=-(n+3)/3\). However, as for the time-dependent curvature of the backreaction model, due to [9], the overall ‘cosmic equation of state’ \(w^{\mathcal {D}}_\mathrm{eff}\) is given by
where \(w^{\mathcal {D}}_{\Phi }\), the constant equation of state for the morphon field, represents the effect of the averaged geometrical degrees of freedom.
4 Constraints with OHD
4.1 The flat FLRW model
In flat FLRW model, we can have
where \(z_{\mathcal {D}}\), \(a_{{\mathcal {D}}_0}\) and \(a_{\mathcal {D}}\) are assumed to be identical to z, \(a_0\) and a, respectively. As a result, Eq. (18) becomes
where \(\varOmega ^{{\mathcal {D}}_0}_X=1-\varOmega ^{{\mathcal {D}}_0}_m\), and the unknown parameters are n, \(\varOmega ^{{\mathcal {D}}_0}_m\), and \(H_{{\mathcal {D}}_0}\). We consider all prior distributions of these parameters to be uniform distributions with ranges of n, \(\varOmega ^{{\mathcal {D}}_0}_m\), \(H_{{\mathcal {D}}_0}\) from \(-3\) to 3, 0.0 to 0.7, and 50.0 to 90.0, respectively. The constraints on (\(n, \varOmega ^{{\mathcal {D}}_0}_m\)) can be obtained by minimizing \(\chi ^2_H(n, \varOmega ^{{\mathcal {D}}_0}_m, H_{{\mathcal {D}}_0})\),
Here we assume that each measurement in \(\{H_\mathrm{obs}(z_i)\}\) is independent. However, we note that the covariance matrix of data is not necessarily diagonal, as discussed in [12], and if not, the case will become complicated and should be treated by means of the method mentioned by [12]. Despite that, if interested in the constraint of n and \(\varOmega ^{{\mathcal {D}}_0}_m\), we could still marginalize \(H_{{\mathcal {D}}_0}\) to obtain the probability distribution function of n and \(\varOmega ^{{\mathcal {D}}_0}_m\), i.e., the likelihood function is
where \(P(H_{{\mathcal {D}}_0})\) is the prior distribution function for the present effective volume Hubble constant. Table 1 [13] shows all 38 available OHD and reference therein, which includes data obtained by both the differential ages method and the radial Baryon acoustic oscillation (BAO) method.

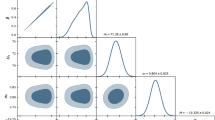
The 1\(\sigma \), 2\(\sigma \) and 3\(\sigma \) confidence regions of the effective parameters n, \(\varOmega ^{{\mathcal {D}}_0}_m\), and \(H_{{\mathcal {D}}_0}\) for the backreaction model, along with their own probability density function
The confidence regions are shown in Fig. 2, where the best fits are \(\varOmega ^{{\mathcal {D}}_0}_m = 0.25^{+0.03}_{-0.03}\), \(n = 0.02^{+0.69}_{-0.66}\), and \(H_{\mathcal {D}_0} = 70.54^{+4.24}_{-3.97}\ \mathrm{km \ s^{-1} \ Mpc^{-1}}\). As opposed to Fig. 2 of [1], the degeneracy direction [26] of the contour (\(n, \varOmega ^{{\mathcal {D}}_0}_m\)) is different in our Fig. 2. In this paper, the best-fit values of \(\varOmega ^{{\mathcal {D}}_0}_m=0.25\) and \(n=0.03\), while in [1], \(\varOmega ^{{\mathcal {D}}_0}_m = 0.26\) and \(n = 0.24\) were given for the flat FLRW model. The best-fits of \(\varOmega ^{{\mathcal {D}}_0}_m\) are almost the same, however, the values of n are variant, the reason of which may be the lack of precision caused by the insufficient amount of OHD. Nevertheless, as for best-fit of \(\varOmega ^{{\mathcal {D}}_0}_m\), in comparison with [27], \(\varOmega _m = 0.263^{+0.042}_{-0.042}(1\sigma \ \mathrm stat)^{+0.032}_{-0.032}(\mathrm sys)\) for a flat \(\Lambda \)CDM model, and with [2], \(\varOmega ^{flat}_m = 0.28^{+0.09}_{-0.08}(1\sigma \ \mathrm stat)^{+0.05}_{-0.04}(\mathrm sys)\) for a flat cosmology, the proportions of matter density are not much of differences.
The evolutions of \(\kappa _{\mathcal {D}}(z)\) and the dimensionless averaged cosmological parameters are illustrated in Fig. 3c, d, respectively, with the best fits of \(n = 0.03\), and \(\varOmega ^{{\mathcal {D}}_0}_m = 0.25\). The former obviously evolves from 0 to \(-1\), which is biased due to the prescription. Furthermore, we substitute the best-fits into the effective volume deceleration parameter \(q^{\mathcal {D}}\)
where
Consequently, Fig. 3a illustrates how the volume deceleration parameter \(q^{\mathcal {D}}\) evolves over redshift z with best-fit values of n and \(\varOmega ^{{\mathcal {D}}_0}_m\). The transition redshift \(z_t\), when the universe transited from a deceleration to accelerated expansion phase, is around 0.815, and the present value of the volume deceleration parameter \(q^{{\mathcal {D}}_0}\) is about \(-0.636\). While the transition value in [28] is constrained to be \(z_t = 0.46 \pm 0.13\), and in [29] is \(z_t = 0.68^{+0.10}_{-0.09}\) with the present value of the deceleration parameter \(q_0 = -0.48^{+0.11}_{-0.14}\), we find that our values of \(z_t\) and \(q^{{\mathcal {D}}_0}\) are both higher than them. Of course, since the flat FLRW metric does not fit averaged model, the result is predetermined. As shown in Fig. 3b, the present value \(w^{{\mathcal {D}}_0}_\mathrm{eff}\) is approximately \(-0.758\).
4.2 The template metric model
In the template metric context, as mentioned above, we cannot directly constrain parameters with the expression of Eq. (18). However, by using Runge–Kutta method to solve Eq. (28), Eq. (25) and subsequently Eq. (24) with given values of n and \(\varOmega ^{{\mathcal {D}}_0}_m\), we can form a one-to-one correspondence of \(a_{\mathcal {D}}\) and \(z_{\mathcal {D}}\), and then the constraint on parameters of Eq. (18) with OHD could be performed. Thus, we can rewrite Eq. (18) as follows
After marginalizing the likelihood function over \(H_{{\mathcal {D}}_0}\), we can obtain parameter constraints in (n, \(\varOmega ^{{\mathcal {D}}_0}_m\)) subspace. As Ma et al. [10] stated, with top-hat prior of \(H_{{\mathcal {D}}_0}\) over the interval [x, y], the posterior probability density function (PDF) of parameters given the dataset {\(H_i\)} by Bayes’ theorem reads

a The evolution of \(q^{\mathcal {D}}\) with best-fit values of n = 0.03, and \(\varOmega ^{{\mathcal {D}}_0}_m\) = 0.25; b The evolution of \(w^{\mathcal {D}}_\mathrm{eff}(z)\) with the same best-fit values as in (a); c The relation between \(\kappa _{\mathcal {D}}(z)\) and z with the same best-fit values as in (a); d The evolution of \(\varOmega ^{\mathcal {D}}_m\) (solid line) and \(\varOmega ^{\mathcal {D}}_X\) (dashed line) with the same best fits as in (a)
where
and
where \(x=50.0\), \(y=90.0\), and erf represents the error function. In the process here, we utilize so called mesh-grid method to scan spots of (\(n, \varOmega ^{{\mathcal {D}}_0}_m\)) subspace with the range of n, and \(\varOmega ^{{\mathcal {D}}_0}_m\) to be [\(-3, 3\)] and [0.0, 0.7], respectively. Note that the range of n is not randomly chosen. Since at first, we are not sure for the specific region, due to the symmetrical purpose and ranging from large to small, we gradually narrow down the regions into the possible region that is enough for all the constraining cases. Eventually, as shown in Fig. 4, we attain the constraints with \(n=-1.22^{+0.68}_{-0.40}\), and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.12^{+0.04}_{-0.02}\). Apparently, our results are quite different from Larena’s results of \(\varOmega ^{{\mathcal {D}}_0}_m = 0.397\) and \(n = 0.5\) for averaged model. Since these are all based on the power law ansatz of \(a_{\mathcal {D}}\), the issues might be the wrong prescription of \(\kappa _{\mathcal {D}}\), the chosen prior of \(H_{{\mathcal {D}}_0}\), or the lack of amount for OHD.

The 1\(\sigma \), 2\(\sigma \) and 3\(\sigma \) confidence regions of the effective parameters n, \(\varOmega ^{{\mathcal {D}}_0}_m\), marginalizing \(H_{{\mathcal {D}}_0}\) over the interval [50, 90], where the best-fits are \(n=-1.22\), and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.12\)

The 1\(\sigma \), 2\(\sigma \) and 3\(\sigma \) confidence regions of the effective parameters n, \(\varOmega ^{{\mathcal {D}}_0}_m\) with Gaussian prior of \(H_{{\mathcal {D}}_0}=69.32\pm 0.80\ \mathrm km \ s^{-1} \ Mpc^{-1}\), where the best-fits are \(n=-0.88\), and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.12\)
To test the probability of the second issue, we select three different Gaussian prior distributions of \(H_{{\mathcal {D}}_0}\). Thus, as described in [10], the posterior PDF of parameters becomes
where
where \(\mu _H\) and \(\sigma ^2_H\) denote prior expectation and deviation of \(H_{{\mathcal {D}}_0}\), respectively. First, we make use of \(H_{{\mathcal {D}}_0}=69.32\pm 0.80\ \mathrm km \ s^{-1} \ Mpc^{-1}\) [30] to obtain the constraints. As a result, Fig. 5 illustrates the confidence regions with 1\(\sigma \) constraints \(n=-0.88^{+0.26}_{-0.23}\), and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.12^{+0.03}_{-0.03}\). Second, as shown in Fig. 6, we acquire the constraints \(n=-1.04^{+0.27}_{-0.31}\) and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.13^{+0.02}_{-0.03}\) with \(H_{{\mathcal {D}}_0}=67.3\pm 1.2\ \mathrm km \ s^{-1} \ Mpc^{-1}\) [31]. Last, we attain the constraints with Gaussian prior of \(H_{{\mathcal {D}}_0}=73.24\pm 1.74\ \mathrm km \ s^{-1} \ Mpc^{-1}\) [32], as depicted in Fig. 7, \(n=-0.58^{+0.36}_{-0.34}\) and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.12^{+0.02}_{-0.03}\). As a result, we find that although three Gaussian priors lead to different best-fit values of n, the best-fits of \({{\varOmega }_{m}^{\mathcal {D}_{0}}}\) are compatible with the result of top-hat prior.
Furthermore, we constrain the model without marginalization of the Hubble constant. The absolute best-fit results are plotted in Fig. 8, where the 1\(\sigma \) best-fit values are (\(n=-1.2^{+0.61}_{-0.58}, {{H}_{\mathcal {D}_{0}}}=66^{+5.3}_{-4.2}\ \mathrm km\ s^{-1}\ Mpc^{-1}\)), (\({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.13\pm 0.03, {{H}_{\mathcal {D}_{0}}}=67^{+5.1}_{-4.4}\ \mathrm km\ s^{-1}\ Mpc^{-1}\)), and (\(n=-1.1^{+0.58}_{-0.50},{{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.13\pm 0.03\)). The best-fits results, \(n=-1.1\) and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.13\), are consistent with both the ones with the Gaussian prior of \(H_{{\mathcal {D}}_0}=67.3\pm 1.2\ \mathrm km \ s^{-1}\ Mpc^{-1}\) and the ones with top-hat prior of \(H_{{\mathcal {D}}_0}\), and also in contrary with the absolute constraint results of Larena et al., i.e., \(n=0.12\) and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.38\). Therefore, the prior issue can be ruled out.

Same as Fig. 5, but with Gaussian prior of \(H_{{\mathcal {D}}_0}=67.3\pm 1.2\ \mathrm km \ s^{-1} \ Mpc^{-1}\), where the best-fits are \(n=-1.04\), and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.13\)

Same as Fig. 5, but with Gaussian prior of \(H_{{\mathcal {D}}_0}=73.24\pm 1.74\ \mathrm km \ s^{-1} \ Mpc^{-1}\), where the best-fits are \(n=-0.58\), and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.12\)

The likelihood contour without marginalization of the parameters, where the best-fit pairs are \((n, {{H}_{\mathcal {D}_{0}}})=(-1.2, 66)\), \(({{\varOmega }_{m}^{\mathcal {D}_{0}}}, {{H}_{\mathcal {D}_{0}}})=(0.13, 67)\), and \((n, {{\varOmega }_{m}^{\mathcal {D}_{0}}})=(-1.1, 0.13)\)
Since the same set of data shared by FLRW case results in a reasonable conclusion, the lack of amount for OHD can also be neglected. Therefore, the prescription of \(\kappa _{\mathcal {D}}\) should be modified, or some other scenarios should be introduced. In fact, based on Sect. 4.3 of [1], the most probable value of \(n-m\) should be \(-1\), i.e., the prescription should be modified as follows,
This form can also guarantee that \(\kappa _{\mathcal {D}}\) inherits the sign of \(\langle {\mathcal {R}}\rangle _{\mathcal {D}}\), as the sign of \(a_{\mathcal {D}}\) is positive. Moreover, since the backreaction is considered, \(\kappa _{\mathcal {D}}\) can be related to both \({\mathcal {Q}}_{\mathcal {D}}\) and \(\langle {\mathcal {R}}\rangle _{\mathcal {D}}\). In this context, the following form can be evaluated
However, because of the coupling between \({\mathcal {Q}}_{\mathcal {D}}\) and \(\langle {\mathcal {R}}\rangle _{\mathcal {D}}\), there is not much difference for the above two forms. But if \({\mathcal {Q}}_{\mathcal {D}}\) and \(\langle {\mathcal {R}}\rangle _{\mathcal {D}}\) are not following the scaling solutions, then the difference would be significant. Note that even if we choose the \(n\cong m\) case, the form of \(\kappa _{\mathcal {D}}\) should be
instead of Eq. (22). Besides, in order to compensate the fact that \(\kappa _{\mathcal {D}}\) can only be changed from zero to negative numbers, we can add a positive constant to the expression of \(\kappa _{\mathcal {D}}\).
Our results show that it demands lower values of \(\varOmega ^{\mathcal {D}_0}_m\) for the models to be compatible with data, and on the contrary with Larena’s conclusion, a larger amount of backreaction is required to account for effective geometry. As mentioned in [1], a DE model in FLRW context with \(n=-1\) is compatible with the data at 1\(\sigma \) for \(\varOmega ^{\mathcal {D}_0}_m \sim 0.1\), and as calculated in [33, 34], the leading perturbative model (\(n=-1\)) is marginally at 1\(\sigma \) for \(\varOmega ^{\mathcal {D}_0}_m \sim 0.3\). As expected, purely perturbative estimate of backreaction could not provide sufficient geometrical effect to account for observations. What is not expected is that the values of \(\varOmega ^{\mathcal {D}_0}_m\) is higher or lower compared to the standard DE models with a FLRW geometry. The following subsection will explore the effective deceleration parameter \(q^{\mathcal {D}}\) evolves over \(a_{\mathcal {D}}\) in many cases, in order to pinpoint the hinge of the issue.
4.3 Testing the effective deceleration parameter
Figure 9 shows the evolutions of \(q^{\mathcal {D}}\) over effective scale factor \(a_{\mathcal {D}}\) with our best-fit values. We can gain the information that in each case \(q^{\mathcal {D}}\) tends to 0.5 as \(a_{\mathcal {D}}\) becomes smaller, and they all have sufficient backreaction to meet the observations, at leat in this perspective, which indicates that the observational data do not disfavour the constraints. However, we also illustrate the same evolutions by using the absolute and the marginalized best-fits of Larena et al. and our absolute ones, as shown in Fig. 10, where the same conclusions are found. The only differences lie in the different turning points for the slow evolutions and present values of \(q^{\mathcal {D}_0}\). The larger n becomes, the earlier the evolutionary curves change from fast to slow. This further favours our doubt about the prescription of \(\kappa _{\mathcal {D}}\).

The evolutions of \(q^{\mathcal {D}}\) over effective scale factor \(a_{\mathcal {D}}\) with best-fit values of a \(n = -1.22\), \(\varOmega ^{{\mathcal {D}}_0}_m = 0.12\), b \(n = -0.88\), \(\varOmega ^{{\mathcal {D}}_0}_m = 0.12\), c \(n = -1.04\), \(\varOmega ^{{\mathcal {D}}_0}_m = 0.13\), and d \(n = -0.58\), \(\varOmega ^{{\mathcal {D}}_0}_m = 0.12\), respectively

Same as Fig. 9, but for best-fit values of a \(n = 0.12\), \(\varOmega ^{{\mathcal {D}}_0}_m = 0.38\), b \(n = 0.5\), \(\varOmega ^{{\mathcal {D}}_0}_m = 0.397\), and c \(n = -1.1\), \(\varOmega ^{{\mathcal {D}}_0}_m = 0.13\)
5 Conclusions and discussions
In this paper, we delve the backreaction model of dust cosmology with both FLRW metric and smoothed template metric to constrain parameters with observational Hubble parameter data (OHD), the purpose of which is to explore the generic properties of a backreaction model for explaining the observations of the Universe. Unlike the work [35], first, in the FLRW model, we constrain two of three parameters with MCMC method by marginalizing the likelihood function over the rest one parameter, and obtain the best-fits: \(\varOmega ^{{\mathcal {D}}_0}_m = 0.25^{+0.03}_{-0.03}\), \(n = 0.02^{+0.69}_{-0.66}\), and \(H_{\mathcal {D}_0} = 70.54^{+4.24}_{-3.97}\ \mathrm km \ s^{-1} \ Mpc^{-1}\). We employ these best-fit values of n and \(\varOmega ^{{\mathcal {D}}_0}_m\) to study the evolutions of \(q^{\mathcal {D}}\), \(w^{\mathcal {D}}_\mathrm{eff}\), \(\kappa _{\mathcal {D}}\), and effective density parameters. The results compared with other models are slightly biased, which is natural as for the inconsistency between FLRW geometry and averaged model. Second, with template metric and the specific method for computing the observables along null geodesic, we choose a top-hat prior, i.e., uniform distribution of \(H_{{\mathcal {D}}_0}\) to be marginalized, in order to attain the posterior PDF of parameters. By making use of classical mesh-grid method, we plot the likelihood contour in the subspace of \((n,\varOmega _m^{\mathcal {D}_0})\), and obtain the best-fit values, which are \(n=-1.22^{+0.68}_{-0.41}\) and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.12^{+0.04}_{-0.02}\). The value of \({{\varOmega }_{m}^{\mathcal {D}_{0}}}\) is considerably small in comparison with the one of Larena et al. [1].
Our results show that it demands lower values of \(\varOmega ^{\mathcal {D}_0}_m\) for the models to be compatible with data, which means that on the contrary with Larena’s conclusion, a larger amount of backreaction is required to account for effective geometry. The reasons for this discrepancy may be the wrong prescription of \(\kappa _{\mathcal {D}}\), the chosen prior of \(H_{{\mathcal {D}}_0}\), or the lack of amount for OHD. To test the probability of the second reason, we select three different Gaussian prior distributions of \(H_{{\mathcal {D}}_0}\), where the three sets of best-fits are: \(n=-\,0.88^{+0.26}_{-0.23}\), and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.12^{+0.03}_{-0.03}\), for \(H_{{\mathcal {D}}_0}=69.32\pm 0.80\ \mathrm km \ s^{-1} \ Mpc^{-1}\) [30]; \(n=-1.04^{+0.27}_{-0.31}\), and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.13^{+0.02}_{-0.03}\) with \(H_{{\mathcal {D}}_0}=67.3\pm 1.2\ \mathrm km \ s^{-1} \ Mpc^{-1}\) [31]; \(n=-\,0.58^{+0.36}_{-0.34}\), and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.12^{+0.02}_{-0.03}\), related to \(H_{{\mathcal {D}}_0}=73.24\pm 1.74\ \mathrm km \ s^{-1} \ Mpc^{-1}\) [32]. As a result, we find out that although three Gaussian priors lead to different best-fit values of n, the best-fits of \({{\varOmega }_{m}^{\mathcal {D}_{0}}}\) are still compatible with the result of top-hat prior. In addition, we also constrain the parameters without marginalization of any parameter, and obtain the best-fit values: (\(n=-1.2^{+0.61}_{-0.58}, {{H}_{\mathcal {D}_{0}}}=66^{+5.3}_{-4.2}\ \mathrm km\ s^{-1}\ Mpc^{-1}\)), (\({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.13\pm 0.03, {{H}_{\mathcal {D}_{0}}}=67^{+5.1}_{-4.4}\ \mathrm km\ s^{-1}\ Mpc^{-1}\)), and (\(n=-1.1^{+0.58}_{-0.50},{{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.13\pm 0.03\)). The best-fits results, \(n=-1.1\) and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.13\), are consistent with both the ones with the Gaussian prior of \(H_{{\mathcal {D}}_0}=67.3\pm 1.2\ \mathrm km \ s^{-1} \ Mpc^{-1}\) and the ones with top-hat prior of \(H_{{\mathcal {D}}_0}\), and also in contrary with the absolute constraint results of [1], i.e., \(n=0.12\) and \({{\varOmega }_{m}^{\mathcal {D}_{0}}}=0.38\). Therefore, the prior issue can be excluded. Since the same set of data shared by FLRW case result in a reasonable conclusion, the lack of amount for OHD can also be neglected.
Finally, we believe that the prescription of \(\kappa _{\mathcal {D}}\) should be modified, or some other scenarios should be considered. On the one hand, we can modify the prescription into the forms of Eqs. (38) and (39), which are not different from each other in this context but are distinct beyond the scaling solutions. On the other hand, we can add an appropriate positive constant to the expression of \(\kappa _{\mathcal {D}}\) for complimenting the problem of not including positive possibility.
In order to further pinpoint the hinge of the issue, we explore the evolutions of \(q^{\mathcal {D}}\) over effective scale factor \(a_{\mathcal {D}}\) with best-fit values of both us and Larena et al. It turns out that both results are similar in the tendency of the evolutions. The only differences lie in the different turning points for the slow evolutions and the present values of \(q^{\mathcal {D}_0}\). The larger n becomes, the earlier for the evolutionary curves change from fast to slow. In other words, despite of the constraints of the effective parameters, there are not much differences, which leaves both the constraints for mutual contradiction. It just proves our point that we must remain skeptical on the prescription of \(\kappa _{\mathcal {D}}\) and consider other options as mentioned above.
References
J. Larena, J.M. Alimi, T. Buchert, M. Kunz, P.S. Corasaniti, Phys. Rev. D Part. Fields Gravit. Cosmol. 79(8), 1 (2009). https://doi.org/10.1103/PhysRevD.79.083011
S. Perlmutter, G. Aldering, G. Goldhaber et al., Astrophys. J. 517, 565 (1999). https://doi.org/10.1086/307221
A.G. Riess, A.V. Filippenko, P. Challis et al., Astron. J. 116(3), 1009 (1998). https://doi.org/10.1086/300499
E.J. Copeland, M. Sami, S. Tsujikawa, Int. J. Mod. Phys. D 15, 1753 (2006). https://doi.org/10.1142/S021827180600942X
V. Gorini, A.Y. Kamenshchik, U. Moschella, O.F. Piattella, A.A. Starobinsky, Phys. Rev. D Part Fields Gravit. Cosmol. 80(10), 104038 (2009). https://doi.org/10.1103/PhysRevD.80.104038
S. Räsänen, J. Cosmol. Astropart. Phys. 2(02), 003 (2004). https://doi.org/10.1088/1475-7516/2004/02/003
E.W. Kolb, S. Matarrese, A. Riotto, New J. Phys. 8, 322 (2006). https://doi.org/10.1088/1367-2630/8/12/322
T. Buchert, Gen. Relativ. Gravit. 32(8), 105 (2000). https://doi.org/10.1023/A:1001800617177
T. Buchert, J. Larena, J.M. Alimi, Class. Quantum Gravity 23, 6379 (2006). https://doi.org/10.1088/0264-9381/23/22/018
C. Ma, T.J. Zhang, Astrophys. J. 730, 74 (2011). https://doi.org/10.1088/0004-637X/730/2/74
C. Bonvin, R. Durrer, M.A. Gasparini, Phys. Rev. D Part Fields Gravit. Cosmol. 73(2) (2006). https://doi.org/10.1103/PhysRevD.73.023523
H.R. Yu, S. Yuan, T.J. Zhang, Phys. Rev. D 88(10), 103528 (2013). https://doi.org/10.1103/PhysRevD.88.103528
X.W. Duan, M. Zhou, T.J. Zhang, arXiv e-prints (2016). arXiv:1605.03947
C. Zhang, H. Zhang, S. Yuan, S. Liu, T.J. Zhang, Y.C. Sun, Res. Astron. Astrophys. 14, 1221 (2014). https://doi.org/10.1088/1674-4527/14/10/002
R. Jimenez, L. Verde, T. Treu, D. Stern, Astrophys. J. 593(2), 622 (2003). https://doi.org/10.1086/376595
J. Simon, L. Verde, R. Jimenez, Phys. Rev. D Part Fields Gravit. Cosmol. 71(12), 123001 (2005). https://doi.org/10.1103/PhysRevD.71.123001
M. Moresco, L. Verde, L. Pozzetti, R. Jimenez, A. Cimatti, J. Cosmol. Astropart. Phys. 2012(07), 053 (2012). https://doi.org/10.1088/1475-7516/2012/07/053
E. Gaztañaga, A. Cabré, L. Hui, Mon. Not. R. Astron. Soc. 399, 1663 (2009). https://doi.org/10.1111/j.1365-2966.2009.15405.x
X. Xu, A.J. Cuesta, N. Padmanabhan, D.J. Eisenstein, C.K. McBride, Mon. Not. R. Astron. Soc. 431(3), 2834 (2013). https://doi.org/10.1093/mnras/stt379
M. Moresco, L. Pozzetti, A. Cimatti et al., J. Cosmol. Astropart. Phys. 5, 014 (2016). https://doi.org/10.1088/1475-7516/2016/05/014
C. Blake, S. Brough, M. Colless et al., Mon. Not. R. Astron. Soc. 425(1), 405 (2012). https://doi.org/10.1111/j.1365-2966.2012.21473.x
D. Stern, R. Jimenez, L. Verde et al., J. Cosmol. Astropart. Phys. 2, 8 (2010). https://doi.org/10.1088/1475-7516/2010/02/008
L. Samushia, B.A. Reid, M. White et al., Mon. Not. R. Astron. Soc. 429(2), 1514 (2013). https://doi.org/10.1093/mnras/sts443
M. Moresco, Mon. Not. R. Astron. Soc. Lett. 450(1), L16 (2015). https://doi.org/10.1093/mnrasl/slv037
T. Delubac, J.E. Bautista, N.G. Busca et al., Astron. Astrophys. 574, A59 (2015). https://doi.org/10.1051/0004-6361/201423969
H.Y. Teng, Y. Huang, T.J. Zhang, Res. Astron. Astrophys. 16, 50 (2016). https://doi.org/10.1088/1674-4527/16/3/050
P. Astier, J. Guy, N. Regnault et al., Astron. Astrophys. 447(1), 31 (2006). https://doi.org/10.1051/0004-6361:20054185
A.G. Riess, L.G. Strolger, J. Tonry et al., Astrophys. J. 607(2), 665 (2004). https://doi.org/10.1086/383612
M. Vargas dos Santos, R.R.R. Reis, I. Waga, J. Cosmol. Astropart. Phys. 02, 13 (2016). https://doi.org/10.1088/1475-7516/2016/02/066
C.L. Bennett, D. Larson, J.L. Weiland et al., Astrophys. J. Suppl. 208, 20 (2013). https://doi.org/10.1088/0067-0049/208/2/20
Planck Collaboration, P.A.R. Ade, N. Aghanim et al. Astron. Astrophys. 571, A16 (2014). https://doi.org/10.1051/0004-6361/201321591
A.G. Riess, L.M. Macri, S.L. Hoffmann et al., Astrophys. J. 826, 56 (2016). https://doi.org/10.3847/0004-637X/826/1/56
N. Li, D.J. Schwarz, Phys. Rev. D 76(8), 083011 (2007). https://doi.org/10.1103/PhysRevD.76.083011
N. Li, M. Seikel, D.J. Schwarz, Fortschritte der Physik 56, 465 (2008). https://doi.org/10.1002/prop.200710521
M. Chiesa, D. Maino, E. Majerotto, J. Cosmol. Astropart. Phys. 2014(12), 049 (2014). https://doi.org/10.1088/1475-7516/2014/12/049
Acknowledgements
This work was supported by the National Science Foundation of China (Grants nos. 11573006, 11528306), National Key R&D Program of China (2017YFA0402600), the Fundamental Research Funds for the Central Universities and the Special Program for Applied Research on Super Computation of the NSFC-Guangdong Joint Fund (the second phase).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funded by SCOAP3
About this article

Cite this article
Cao, SL., Teng, HY., Wan, HY. et al. Testing backreaction effects with observational Hubble parameter data. Eur. Phys. J. C 78, 170 (2018). https://doi.org/10.1140/epjc/s10052-018-5616-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-018-5616-4