
Abstract
The paper is devoted to scheduling in multiagent systems in the framework of the Flatland 3 competition. The main aim of this competition is to develop an algorithm for the effective control of dense traffic in complex railroad networks according to a given schedule. The proposed solution is based on reinforcement learning. To adapt this method to the particular scheduling problem, a novel approach based on structuring the reward function that stimulates an agent to adhere to its schedule was developed. The architecture of the proposed model is based on a multiagent version of centralized critic with proximal policy optimization (PPO) learning. In addition, a curriculum learning strategy was developed and implemented. This allowed the agent to cope with each level of complexity on time and train the model in more difficult conditions. The proposed solution won first place in the Flatland 3 competition in the reinforcement learning track.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 INTRODUCTION
High rates of industrialization in the modern world contribute to the increase in traffic volumes. This problem is especially important in the field of rail transportation because changing the railroad network infrastructure is quite labor-intensive and the problem of the optimal use of existing resources arises. The density of both freight and passenger traffic is increasing. As a result, the requirements for the execution of the traffic schedule increase, and any deviation from it can lead to significant penalties, for example, to an increase in train delays and their cancellation [1]. Therefore, the development of control systems for this area is an urgent and promising direction. In this area, there are high requirements for traffic safety, which lead to additional difficulties and restrictions. As a result, the task of effectively managing the railroad traffic becomes extremely difficult. This problem is faced by all transport and logistics companies around the world.
One of those who set out to create the most effective solution in this area based on the use of the most advanced approaches, including artificial intelligence, was the Swiss Federal Railways and Deutsche Bahn AG. For this purpose, they organized the Flatland competition on the AICrowd platform. In this competition, participants are provided with a simulator of the processes of train movement and the operation of the railroad infrastructure in order to perform experiments to test their implemented algorithms. In this competition, there are two tracks—one for solutions based on the use of classical algorithms and the other—for solutions based on multiagent reinforcement learning (RL) [1].
In the third version of the simulator, designed for Flatland version 3 (competition 2019), a functionality was added that also checks the punctuality of following the given schedule [2]. Each train has a set schedule with specific arrival and departure times at stations, as well as a window of time during which it must start and reach its destination. The schedule is designed so that each train has more time than theoretically necessary to arrive at its destination. Therefore, it is necessary to use this time margin in such a way that all trains arrive with a minimum delay, for example, by giving way to other trains.
The goal of the competition is to design and implement a train scheduling algorithm in which all trains will arrive at their destination with a minimum delay in relation to the required arrival time.
The problem of constructing efficient schedules is one of the most difficult problems in the field of railroad transport planning and management. When solving this problem, it is necessary to take into account various aspects of the organization of the transportation process [3]. This problem can be formulated as a classical operations research problem and as a problem of reinforcement learning. The solution presented in this paper was proposed to participate in the Flatland 3 competition in the reinforcement learning track, where it won first place [4].
The search for a solution in this area is associated with the problem of decision making when other agents appear on the way, the stochastic nature of breakdowns, and the response to a sparse reward function used in the simulator. This problem is related to the features of multiagent learning, and the main tool for solving it is the use of reinforcement learning methods with a centralized critic [5]. However, the proposed new concept of schedules creates special difficulties in learning and makes the construction of the reward function sensitive. In this regard, the implemented approach is based on the technique of structuring rewards, as well as a specially developed strategy of curriculum learning. A common way to adapt to new features of a problem is to convert new domain knowledge into additional rewards and train agents with a combination of original and new rewards [6, 7]. In this case, an additional component was developed that reflects the degree of delay of a train from its schedule. The results showed that the developed scheduling strategy is able to cope with each level of complexity on time, which made it possible to train the model in more complex environments. The proposed hybrid reward structure responds to the new aspects of the challenge and made it possible to effectively overcome the difficulties of the new edition of the Flatland 3 competition.
2 SIMULATOR FEATURES
Consider the features of the Flatland 3 environment for management in the field of transport communications [8].
2.1 Environment
Flatland is a simulator that simulates train dynamics and railroad infrastructure. This simulator generates levels that are a two-dimensional grid, where each cell has its own type: turn, road, fork, or inaccessible terrain. Each train occupies one cell of the grid and has a destination and a direction. As in real railroad networks, trains do not move at the same speed, but have different travel speeds according to the train type. For example, a freight train will move slower than a passenger train and, therefore, scheduling a fast train behind a slow one should be avoided. Also, each train has its own time window during which it must start and arrive at its destination. In the event of a train collision, a traffic jam occurs.
2.2 Observations
From the agent side, Flatland provides access to almost all information about the current state of the environment, on the basis of which you can build your own type of observations. The simulator has already implemented 3 types of observations [8]:
—The global observation is the simplest one. In this case, each agent is provided a global view of the entire environment.
—The observation on the local grid is similar to the global observation, but the size of the observed environment is limited.
—Tree observation is based on the fact that the railroad network is a graph, and therefore the observation is built only along the allowed transitions in the graph. An observation is created by spanning a 4 branched tree from the agent’s current position. Each branch follows the allowed transitions (backward branches are only allowed in dead ends) until a cell with multiple allowed transitions is reached. Here, the information gathered from the branch is stored as a node in the tree.
2.3 Actions
The simulation proceeds step by step. At each step, each train agent must determine what action to take. Trains in Flatland have a very limited set of actions as would be expected from a railroad simulator. This means that only a few actions are allowed, namely: turn left, turn right, move forward, continue the previous action, or stop.
In addition, the simulator simulates breakdowns with a given frequency. Unforeseen events are common in railroad networks. The original plan needs to be rescheduled in real time as minor events such as delayed departures from stations, train or infrastructure breakdowns, or even weather conditions cause trains to be late. The breakdown mechanism is implemented using the Poisson process, namely, the delay is simulated by stopping agents at random times for random periods of time. A train with such a fault cannot move for a certain number of simulation steps causing it to block the following trains, which often results in traffic jams.
2.4 Metric of the Agent Behavior
In Flatland 3, the reward response is provided only at the end of the episode, which makes the default reward function sparse. Decisions are evaluated by the total deviation of trains from their schedule.
An episode ends when all trains reach their destination or when the maximum number of time steps is reached. At the end of the episode, each train has the following options:
1. The train arrived at its destination:
0 if it arrived on time or earlier;
min(tl —ta, 0) if it was late, where tl is the simulation step before which or at which the agent is expected to arrive and ta is the actual time of the agent arrival.
2. The train did not reach its destination. If the train does not arrive at the destination at all, then in accordance with the general principles of railroads, additional penalties are taken into account. Then the reward is negative and proportional to the delay of the train and to the estimated amount of time required to reach the agent’s destination from its current position along the shortest path (\({{t}_{{{\text{sp}}}}}\)):
3. The train never moved. In this case, the train is considered canceled and the reward
(–1)* cancellation_factor * (\({{t}_{{{\text{sp}}}}}\) + cancellation_time_buffer)
is provided, where the cancellation_factor and cancellation_time_buffer are special parameters configured by the competition organizers.
This reward structure creates particular learning difficulties. Let us take a closer look at them and how to overcome them.
3 THE PROBLEM AND ITS FEATURES
The task of the competition is to score the maximum number of points according to two criteria. The decision making is based on the total reward function scored by all agents and on the percentage of agents that successfully reached their destination. The evaluation of the solution is organized in such a way that with each successfully closed level the structure of the next level of the railroad network becomes more complicated and the number of trains increases, so the agents have to solve problems of an ever larger scale. With each round, the complexity of the original environment also increases, and besides that, a new additional requirement is added, such as speed rate. The main task of the third edition of the competition is to create the best schedule in which all trains arrive at their destination with a minimum delay.
The problem is also complicated by unpredictable delays due to failures in train operation. Breakdowns force agents to quickly change their plans, which can lead to negative consequences. Thus, it is not easy to train an RL model in such conditions.
Consider the consequences of the problem complication.
The main difficulty is traffic jams—a poorly trained model cannot cope with multiagent train routing. However, even more successful models may not solve the problem of congestion due to concomitant factors, such as breakdowns or a large number of trains starting at the same time.
Another difficulty is the tendency for fast trains to follow slower trains along a convenient road, thus worsening the optimality of the final solution.
Finally, the already mentioned structure of the reward function turned out to be the most global and complex problem, which interfered with learning in many aspects. It could lead, for example, to the loss of a landmark, passing by the target, or intentionally getting into a traffic jam.
Consider the proposed model for solving the formulated and related problems.
4 ARCHITECTURE OF THE MODEL
The basic architecture of the proposed model is a fully connected network with proximal policy optimization (PPO) learning [9]. At runtime, this ensures that the agent makes a decision quickly. At the same time, during training, in addition to the first network, another, more complex network is used, which contributes to the gradients for training the agent’s network. This agent, called central critic, is provided with a more holistic view of the state of the environment, with the help of which it approximates an adequate response to one or another action of the agent in the current situation.
There are many variations of the centralized critic method [5, 10, 11]. The version we implemented does not use global observations, but combines the observations of the agent being trained with the observations of other agents. This approach was chosen in order to create a solution that is easily extensible for large-scale environments. Another addition to the multi-agent PPO algorithm with a centralized critic is that a transformer has been added to the architecture of the critic that allows the critic to effectively combine representations of his own and others’ observations [12]. This allows you to work with sparse observations and data heterogeneity, as well as with the possible invariance of permutations in the case of a change in the subset of agents included in the observation [8].
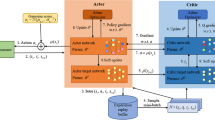
Figure 1 shows the architecture of the model, which consists of the Actor, which predicts the agent’s policy, that is, the probabilistic distribution of actions in a given state, and the Critic, which gives an approximation of the environment’s reward for one or another action of the agent (Q-value). Next, the model is trained to improve the Advantage from this action. To ensure the stability of the model, several parallel threads were used at once, which simultaneously collected experience for the Trainer object, while each thread interacted with several environments at once.

Architecture of the model.
During the experiments, an alternative model was also implemented with the transformer moved to the Actor. Here the main content has been placed in the Actor. It received information about the observations of the agent’s nearest neighbors and, converting them into vector representations (embeddings), together with the agent’s own representations, transferred them to the Multi Head Attention layer. The agent’s view layer was designed in such a way that it could be made both separate for the Critic and the Actor, or shared.
Unfortunately, there was not enough time for tuning this model, so it gave worse results and was not used in the final solution. In addition, it takes such a loaded Actor long time to perform calculations at runtime. In the future, we plan to study the potential of this alternative model architecture.
5 GENERAL STRATEGY OF THE SOLUTION
5.1 Developed Observations
For more efficient use of information received from the environment, the tree observation system [8] proposed by the simulator was modified. The main innovation took into account the peculiarities of working with train schedules. The information stored in the node was expanded—in addition to the basic information about the train route, its speed, network infrastructure and other trains encountered on the way—information was added on the temporary deviation from the schedule and on the potential conflicts on the considered branch of the motion.
5.2 Reward Structuring
To improve the efficiency of the developed algorithm and to overcome the difficulties described above, the process of interaction between the agent and the simulator was modified. Most of the environment wrappers (Fig. 3) were designed to modify the reward function, but some of them were also designed to make the learning process easier. So, one of significant changes was filtering of the training data with an emphasis on the position of the agent at or near intersections. The “action masking” technique was also applied, which helps to get rid of unacceptable actions during training [8].

Alternative model.

Environment wrappers.
Consider the last four wrappers designed to adjust the reward function. It has undergone significant changes. Additional components were developed that made it possible to cope with the consequences of its sparse structure, stimulated the agent who reached the goal, and punished it in the opposite case.
In the previous versions of the competition, the reward function was not sparse; that is, at each step, the agent received a penalty for not reaching the goal yet; in addition, a reward was also given at the ends for the overall state of affairs. This time, the organizers made the task more difficult, mainly in order to introduce the concept of a schedule into the overall problem statement. Therefore, the model was not trained in its original form (WITHOUT-ALL), whereas for the previous reward structure (old-evaluator), the same model produced good results (Fig. 4).

Differences in training the model for different versions of solution evaluation in Flatland.
For this reason, the structure of the reward function was significantly modified. In the general form, the reward formula can be written as
where r is the original reward function, F is the shaping reward function, and r' is the modified reward function.
In the basic solutions for the competition, a terminal version of the shaping reward function FDR was proposed, aimed at detecting and fighting against traffic jams. The proposed component added to the reward function a penalty for the behavior that caused path blocking (see Fig. 3, deadlock wrapper). This wrapper identifies an agent in a jam, penalizes it, and ends the episode for it. However, in combination with the new reward structure, it led to the fact that agents, instead of avoiding traffic jams, on the contrary sought to get into them. This behavior of agents can be explained by the fact that with large penalties for lateness, it was easier to finish the episode early and make a profit due to the fact that the episode ended before the arrival time.
Therefore, this idea was transformed into a more general form, namely, FAR (Fig. 3, Adjust wrapper) was used, which can be represented as follows:
Here FAR is the terminal correcting component of the reward shaping function F, rfin is the customizable reward for finishing the episode at the desired destination, and rnotfin is the customizable penalty for finishing the episode not at the desired destination.
In any case, this component waited for the end of the episode, and gave a penalty for a traffic jam or for non-arrival at the destination and additional reward for reaching the destination. It also normalized the step-by-step rewards, which should be discussed in more detail.
In order to reduce the consequences of the sparse reward function specified in the simulator, a stepwise reward was additionally introduced, reflecting the degree of train delay from the schedule (Fig. 3, Time wrapper). In general, it can be represented by the following formulas:
Here FTR is the time component of the shaping reward function, dmax is the given maximum possible delay of the agent according to its schedule, Pmax is the customizable maximum penalty, and tr is the remaining time until the scheduled arrival.
On one hand, this component of the shaping reward function meets the new requirements for taking into account the train schedule. On the other hand, it is reminiscent of the step-by-step punishment from the old Flatland reward structure for each time step made in the environment, as long as there is enough time before the last arrival of the agent. When the time until the last arrival expires, the penalty significantly increases. Its meaning is reflected in the plot in Fig. 5.

Additional time component of the reward function.
This modification of the reward function structure has radically improved the nature of the learning model. It encouraged the agent to stay on the road not too long and at the same time adhere to the given schedule.
For better orientation to the destination, the FDR component (Fig. 3, Distance wrapper) was developed, which added a reward for the agent’s approach to the destination and penalized it in case of downtime:
here FDR is the path component of the shaping reward function, σ is the coefficients for normalizing the path component of the reward, Δd is the distance traveled by the agent at the current step, \({{N}_{i}}\) the number of the agent’s last idle steps (in case of idle time), and \({{P}_{i}}\) is the downtime penalty. The downtime penalty increased as the downtime increased. This seemingly useful wrapper has one unpleasant nuance. It must be dosed in a minimum amount so that the agents do not have an unwholesome desire not to end the episode at all, but to “move towards the destination” as long as possible.
Thus, the total reward function was formed as follows:
where a, b, and c are coefficients for configuring the common behavior, R is the total reward function, and r is the original reward function.
5.3 Learning Strategy
For incremental learning at more complex simulation levels, a curriculum learning strategy was developed. A number of environments with different levels of complexity were constructed. Each level added to the environment a new feature of the problem, whether it was an increase in the number of breakdowns, speed rates, or a more complex ratio between cities and agents. Learning began with a very small environment of two agents and two cities, then gradually became more complex in accordance with the following rule: if the current environment did not grow to the next level of complexity, only the ratio of agents and cities changed, otherwise the transition to the next more complex environment was made.
The transition event to a new environment was based on the achievement of the following conditions in relation to the learning process:
—a sufficient number of learning steps have been performed since the last environment switch;
—the derivative of the reward regression line does not exceed the specified value;
—the current score of the solution and the percentage of completion exceed the specified thresholds.
This strategy, together with the proposed transition conditions, allowed the learning process to cope with each level of complexity in time and gradually adapt to new features of the environment.
Also, for regularization and prevention of premature convergence, a plot of a smooth decline in entropy was established. The entropy plot turned out to be a very significant factor in curriculum learning. By adjusting its smooth decline, we were able to train the model at more complex levels of the environment.
6 RESULTS
To evaluate the results of the proposed methods, we analyzed the learning plots for a number of characteristics, including the episode score mean and the percentage of successful agents (percentage done).
Figure 6 illustrates the effect of applying the reward structuring technique, namely learning without and with an additional time component (WITHOUTtimeRew and timeRewWrap0.7). As can be seen from the plot, adding the developed additional FTR function to the structure of the reward function makes a significant contribution to the success of the entire learning process. In addition, the application of action masking and the shaping reward functions FDR and FAR gave a minor improvement in the computation and convergence rate (skipNC-avAct-adj-dist01).

Plot of the episode score mean metric for learning using the reward structuring technique and without this technique.
Figure 7 shows the episode score mean for learning the model according to the developed schedule.

Curriculum learning.
Figure 8 shows learning in two different modes, in the dark blue plot the entropy decreases more sharply, and in blue it is slower. You can see that the dark blue plot, although it quickly reached an acceptable value of indicators at first, with further learning on a new environment it could not move to a new level of complexity because it began to converge prematurely to a local maximum.

Entropy decrease plot.
Setting the parameters of this model is illustrated in Fig. 9. More detailed information can be found in [13].

Adjustment of hyperparameters.
The extended agent observation mechanism showed slightly better results than the basic “Tree observation” observation, illustrating the special sensitivity of agents to observation components.
7 CONCLUSIONS
In this paper, we propose a strategy for solving the problem of multiagent planning of railroad transportation. The described solution, which is based on reinforcement learning, took the first place in the RL track of the Flatland 3 competition. The paper describes the task assigned to the participants of the competition, describes its main difficulties, and suggests methods for resolving them. To solve the problem, a new approach to the problem of train planning was developed based on a special reward structuring technique that stimulated the agent to follow the given schedule. This technique, together with further parameter tuning, made the greatest contribution to the performance of the model.
In addition, the curriculum learning strategy was developed that allowed the learning process to cope with each level of complexity in time and made it possible to train the model in more complex conditions with an increased level of breakdowns. The results obtained showed the effectiveness of the developed methods. However, there remains a large area for further improvement and research in regard of improving the speed and efficiency of the algorithm.
REFERENCES
Flatland Intro. https://flatland.aicrowd.com/intro.html. Cited June 6, 2022.
Flatland-3 Homepage. https://www.aicrowd.com/challenges/flatland-3. Cited June 6, 2022.
F. F. Paschchenko, N. A. Kuznetsov, E. M. Zakharova, I. K. Minashina, and A. K. Takmazian, “Intelligent control systems for the rolling equipment maintenance of rail transport,” IEEE 11th International Conference on Application of Information and Communication Technologies (AICT), 2017, IEEE, pp. 1–3.
Flatland-3 Winners. https://www.aicrowd.com/challenges/flatland-3/winners. Cited June 6, 2022.
S. Iqbal and F. Sha, “Actor-attention-critic for multi-agent reinforcement learning,” Int. Conf. on Machine Learning, PMLR, 2019, pp. 2961–2970.
A. Y. Ng, D. Harada, and S. Russell, “Policy invariance under reward transformations: Theory and application to reward shaping,” Proc. of the Sixteenth Int. Conf. on Machine Learning, ICML, vol. 99, 1999, pp. 278–287.
Y. Hu, W. Wang, H. Jia, et al., “Learning to utilize shaping rewards: A new approach of reward shaping,” 34th Conf. on Neural Information Processing Systems (NeurIPS 2020), Vancouver, Canada, 2020.
S. Mohanty et al., “Flatland-rl: Multi-agent reinforcement learning on trains,” arXiv:2012.05893, 2020. https://doi.org/10.48550/arXiv.2012.05893.
J. Schulman, A. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv: 1707.06347 [cs.LG], 2017. https://doi.org/10.48550/arXiv.1707.06347.
R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environments,” Adv. Neural Inf. Proc. Syst. (NIPS 2017), vol. 30, 2017.
J. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson, “Counterfactual multi-agent policy gradients,” AAAI Conference on Artificial Intelligence, vol. 28, no. 1, 2018.
E. Parisotto et al., “Stabilizing transformers for reinforcement learning,” Int. Conf. on Machine Learning, PMLR, 2020, pp. 7487–7498.
Weights & Biases. https://wandb.ai/innasviri/flatland-sub/reports/Shared-panel22-02-03-12-02-19–VmlldzoxNTE1OTgx. Cited June 7, 2022.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
The authors declare that they have no conflicts of interest.
Additional information
Translated by A. Klimontovich
Rights and permissions
Open Access. This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Minashina, I.K., Gorbachev, R.A. & Zakharova, E.M. Scheduling in Multiagent Systems Using Reinforcement Learning. Dokl. Math. 106 (Suppl 1), S70–S78 (2022). https://doi.org/10.1134/S1064562422060175
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1134/S1064562422060175