
Abstract
Deep Reinforcement Learning has made significant progress in multi-agent systems in recent years. The aim of this review article is to provide an overview of recent approaches on Multi-Agent Reinforcement Learning (MARL) algorithms. Our classification of MARL approaches includes five categories for modeling and solving cooperative multi-agent reinforcement learning problems: (I) independent learners, (II) fully observable critics, (III) value function factorization, (IV) consensus, and (IV) learn to communicate. We first discuss each of these methods, their potential challenges, and how these challenges were mitigated in the relevant papers. Additionally, we make connections among different papers in each category if applicable. Next, we cover some new emerging research areas in MARL along with the relevant recent papers. In light of MARL’s recent success in real-world applications, we have dedicated a section to reviewing these applications and articles. This survey also provides a list of available environments for MARL research. Finally, the paper is concluded with proposals on possible research directions.

Similar content being viewed by others


Notes
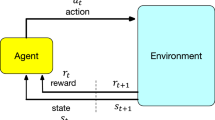
A policy can be deterministic or stochastic. Action at is the direct outcome of a deterministic policy, i.e., at = π(st). In stochastic policies, the outcome of the policy is the probability of choosing each of the actions, i.e., π(a|st) = Pr(at = a|st), and then an additional method is required to choose an action among them. For example, a greedy method chooses the action with the highest probability. In this paper, when we refer to an action resulted from a policy we mostly use the notation for the stochastic policy, \(a \sim \pi (.|s)\).
GTD algorithm is proposed to stabilize the TD algorithm with linear function approximation in an off-policy setting.
Arrow-Hurwicz is a primal-dual optimization algorithm that performs the gradient step on the Lagrangian over the primal and dual variables iteratively
Semi-cooperative environments are those that each agent looks for its own goal while all agents also want to maximize a common goal.
References
Monireh A, Nasser M, Ana LC B (2011) Traffic light control in non-stationary environments based on multi agent q-learning. In: 2011 14th international IEEE conference on intelligent transportation systems (ITSC), pp 1580–1585. https://doi.org/10.1109/ITSC.2011.6083114
Alekh A, Sham M K, Jason D L, Gaurav M (2020) Optimality and approximation with policy gradient methods in markov decision processes. In: Conference on learning theory. PMLR, pp 64–66
Adrian K A, Kagan T (2004) Unifying temporal and structural credit assignment problems
Kyuree A, Jinkyoo P (2021) Cooperative zone-based rebalancing of idle overhead hoist transportations using multi-agent reinforcement learning with graph representation learning. IISE Trans 0(0):1–17. https://doi.org/10.1080/24725854.2020.1851823https://doi.org/10.1080/24725854.2020.1851823
Aimsun (2019) Aimsun next 8.4 user’s manual. In: Aimsun SL
Andreas J, Rohrbach M, Darrell T, Klein D (2016) Neural module networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 39–48
Andriotis CP, Papakonstantinou KG (2019) Managing engineering systems with large state and action spaces through deep reinforcement learning. Reliab Eng Syst 191:106483
Arel I, Liu C, Urbanik T, Kohls AG (2010) Reinforcement learning-based multi-agent system for network traffic signal control. IET Intell Transp Syst 4(2):128–135
Arora S, Prashant D (2021) A survey of inverse reinforcement learning Challenges, methods and progress. Artif Intell, pp 103500
Arrow JA, Hurwicz L, Uzawa H (1958) Studies in linear and non-linear programming. Stanford University Press
Steffen B (2015) Tecnomatix plant simulation: Modeling and programming by means of examples. In: Springer
Wenhang B, Xiao-yang L (2019) Multi-agent deep reinforcement learning for liquidation strategy analysis. In: Workshops at the Thirty-Sixth ICML Conference on AI in Finance
Nolan B, Jakob N F, Sarath C, Neil B, Marc L, H F S, Emilio P, Vincent D, Subhodeep M, Edward H et al (2020) The hanabi challenge: a new frontier for ai research. Artif Intell 280:103216
Max B, Guni S, Roni S, Ariel F (2014) Suboptimal variants of the conflict-based search algorithm for the multi-agent pathfinding problem. In: Seventh annual symposium on combinatorial search. Citeseer
Charles B, Joel Z L, Denis T, Tom W, Marcus W, Heinrich K, Andrew L, Simon G, Víctor V, Amir S et al (2016) Deepmind lab. arXiv:1612.03801
Bellemare MG, Naddaf Y, Veness J, Bowling M (2013) The arcade learning environment: an evaluation platform for general agents. J Artif Intell Res 47:253–279
Richard B (1957) A markovian decision process. J Math Mech, pp 679–684
Bernstein DS, Givan R, Immerman N, Zilberstein S (2002) The complexity of decentralized control of markov decision processes. Math Oper Res 27(4):819–840
Dimitri P B, John N T (1996) Neuro-Dynamic Programming. Athena Scientific, Belmont, MA
Bhatnagar S, Precup D, Silver D, Sutton RS, Maei HR, Szepesvári C. (2009) Convergent temporal-difference learning with arbitrary smooth function approximation. In: Advances in neural information processing systems, pp 1204–1212
David B, Xiangyu Z, Dylan W, Deepthi V, Rohit C, Jennifer K, Ahmed S Z (2021) Powergridworld: a framework for multi-agent reinforcement learning in power systems arXiv:2111.05969
Bianchi P, Jakubowicz J (2012) Convergence of a multi-agent projected stochastic gradient algorithm for non-convex optimization. IEEE Trans Autom Control 58(2):391–405
Jan B, Steven Morad JG, Qingbiao L, Amanda P (2021) A framework for real-world multi-robot systems running decentralized gnn-based policies. arXiv:2111.01777
Borkar VS, Meyn SP (2000) The o.d.e. method for convergence of stochastic approximation and reinforcement learning. SIAM J Control Optim 38(2):447–469
Bouton M, Farooq H, Forgeat J, Bothe S, Shirazipour M, Karlsson P (2021) Coordinated reinforcement learning for optimizing mobile networks, arXiv:2109.15175
Bowling M, Veloso M (2002) Multiagent learning using a variable learning rate. Artif Intell 136(2):215–250
Marc B, Peng W (2019) Autonomous air traffic controller: a deep multi-agent reinforcement learning approach. In: Reinforcement learning for real life workshop in the 36th international conference on machine learning, long beach
Greg B, Vicki C, Ludwig P, Jonas S, John S, Jie T, Wojciech Zaremba (2016) Openai gym
Lucian B, Robert B, Bart De S et al (2008) A comprehensive survey of multiagent reinforcement learning. IEEE Trans Syst, Man, Cybern, Part C (Appl Rev) 38(2):156–172
Buşoniu L, Babuška R, Bart DS (2010) Multi-agent reinforcement learning: An overview. In: Innovations in multi-agent systems and applications-1. Springer, pp 183–221
Cáp M, Novák P, Seleckỳ M, Faigl J, Jiff V. (2013) Asynchronous decentralized prioritized planning for coordination in multi-robot system. In: IEEE/RSJ international conference on intelligent robots and systems. IEEE, pp 3822–3829
Cassano L, Yuan K, Sayed AH (2021) Multiagent fully decentralized value function learning with linear convergence rates. IEEE Trans Auto Cont 66(4):1497–1512. https://doi.org/10.1109/TAC.2020.2995814
Chen HWC, Nan X u, Zheng G, Yang M, Xiong Y, Kai X, Li Z (2020) Toward a thousand lights: decentralized deep reinforcement learning for large-scale traffic signal control. In: Proceedings of the thirty-fourth AAAI conference on artificial intelligence
Chen J, Sayed AH (2012) Diffusion adaptation strategies for distributed optimization and learning over networks. IEEE Trans Signal Process 60(8):4289–4305
Chen Y, Liu Y u, Xiahou T (2021) A deep reinforcement learning approach to dynamic loading strategy of repairable multistate systems. IEEE Trans Reliability
Yu Fan C, Miao L, Michael E, How JP (2017) Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning. In: 2017 IEEE international conference on robotics and automation (ICRA). IEEE, pp 285–292
Kyunghyun C, Bart van M, Gülçehre Ç, Dzmitry B, Fethi B, Holger S, Yoshua B (2014) Learning phrase representations using rnn encoder-decoder for statistical machine translation. In: EMNLP, pp 1724–1734. http://aclweb.org/anthology/D/D14/D14-1179.pdf. Accessed 28 July 2019
Jinyoung C, Beom-Jin L, Byoung-Tak Z (2017) Multi-focus attention network for efficient deep reinforcement learning. In: Workshops at the thirty-first AAAI conference on artificial intelligence
Chu T, Wang J, Codecà L, Li Z (2019) Multi-agent deep reinforcement learning for large-scale traffic signal control. IEEE Trans Intell Transp Syst 21(3):1086–1095
Chu X, Ye H (2017) Parameter sharing deep deterministic policy gradient for cooperative multi-agent reinforcement learning. arXiv:1710.00336
Kamil C, Shimon W (2020) Expected policy gradients for reinforcement learning. http://jmlr.org/papers/v21/18-012.html. Accessed 28 Feb 2021, vol 21, pp 1–51
Cui R, Bo G, Ji G (2012) Pareto-optimal coordination of multiple robots with safety guarantees. Auton Robot 32(3):189–205
Silva FLD, Costa AHR (2019) A survey on transfer learning for multiagent reinforcement learning systems. J Artif Intell Res 64:645–703
Dandanov N, Al-Shatri H, Klein A, Poulkov V (2017) Dynamic self-optimization of the antenna tilt for best trade-off between coverage and capacity in mobile networks. Wirel Pers Commun 92(1):251–278
Das A, Kottur S, Moura José MF, Lee S, Batra D (2017) Learning cooperative visual dialog agents with deep reinforcement learning. In: Inproceedings of the IEEE international conference on computer vision, pp 2951–2960
Abhishek D, Théophile G, Joshua R, Dhruv B, Devi P, Mike R, Joelle P (2019) TarMAC: Targeted multi-agent communication. In: Kamalika Chaudhuri, Ruslan Salakhutdinov (eds) Proceedings of the 36th international conference on machine learning, volume 97 of proceedings of machine learning research. PMLR, long beach, California, pp 1538–1546, 09–15 Jun, http://proceedings.mlr.press/v97/das19a.html. Accessed 28 Oct 2019
Sam D, Daniel K (2011) Theoretical considerations of potential-based reward shaping for multi-agent systems. In: The 10th international conference on autonomous agents and multiagent systems-volume 1. International foundation for autonomous agents and multiagent systems, pp 225–232
Devlin S, Yliniemi L, Kudenko D, Kagan T (2014) Potential-based difference rewards for multiagent reinforcement learning
Lorenzo PD, Scutari G (2016) Next: in-network nonconvex optimization. IEEE Trans Signal Inf Process Over Netw 2(2):120–136
Raghuram Bharadwaj D, D Sai Koti R, Prabuchandran KJ, Shalabh B. (2019) Actor-critic algorithms for constrained multi-agent reinforcement learning. In: Proceedings of the 18th international conference on autonomous agents and multiagent systems. Richland, SC, AAMAS?19. International foundation for autonomous agents and multiagent systems, pp 1931–1933
Ding Z, Huang T, Zongqing L u (2020) Learning individually inferred communication for multi-agent cooperation. Adv Neural Inf Process Syst 33:22069–22079
Dittrich M-A, Fohlmeister S (2020) Cooperative multi-agent system for production control using reinforcement learning. CIRP Ann 69(1):389–392
Eck A, Soh L-K, Devlin S, Kudenko D (2016) Potential-based reward shaping for finite horizon online pomdp planning. Auton Agent Multi-Agent Syst 30(3):403–445
William F, Prajit R, Rishabh A, Yoshua B, Hugo L, Mark R, Will D (2020) Revisiting fundamentals of experience replay. In: International conference on machine learning. PMLR, pp 3061–3071
Fitouhi M-C, Nourelfath M, Gershwin SB (2017) Performance evaluation of a two-machine line with a finite buffer and condition-based maintenance. Reliab Eng Syst 166:61–72
Foerster J, Assael IA, Freitas Nando de, Whiteson S (2016) Learning to communicate with deep multi-agent reinforcement learning. Adv Neural Inf Process Syst:2137–2145
Jakob F, Nantas N, Gregory F, Triantafyllos A, Philip HS T, Pushmeet K, Shimon W (2017) Stabilising experience replay for deep multi-agent reinforcement learning. In: Proceedings of the 34th international conference on machine learning-volume 70. JMLR. org, pp 1146–1155
Jakob NF, Gregory F, Triantafyllos A, Nantas N, Shimon W (2018) Counterfactual multi-agent policy gradients. In: Thirty-second AAAI conference on artificial intelligence
Freed B, Sartoretti G, Jiaheng H, Choset H (2020) Communication learning via backpropagation in discrete channels with unknown noise. In: Proceedings of the AAAI conference on artificial intelligence, vol 34, pp 7160–7168
Fuji T, Ito K, Matsumoto K, Yano K (2018) Deep multi-agent reinforcement learning using dnn-weight evolution to optimize supply chain performance. In: Proceedings of the 51st Hawaii international conference on system sciences, vol 8
Fujimoto S, Hoof H, Meger D (2018) Addressing function approximation error in actor-critic methods. In: International conference on machine learning. PMLR, pp 1587–1596
Gabel T, Riedmiller M (2007) On a successful application of multi-agent reinforcement learning to operations research benchmarks. In: 2007 IEEE international symposium on approximate dynamic programming and reinforcement learning. IEEE, pp 68–75
Gao Q, Hajinezhad D, Zhang Y, Kantaros Y, Zavlanos MM (2019) Reduced variance deep reinforcement learning with temporal logic specifications. In: Proceedings of the 10th ACM/IEEE international conference on cyber-physical systems. ACM, pp 237–248
Garcıa J, Fernández F (2015) A comprehensive survey on safe reinforcement learning. J Mach Learn Res 16(1):1437–1480
Glavic M, Fonteneau R, Ernst D (2017) Reinforcement learning for electric power system decision and control: past considerations and perspectives. IFAC-PapersOnLine 50(1):6918–6927
Gong Y, Abdel-Aty M, Cai Q, Md SR (2019) Decentralized network level adaptive signal control by multi-agent deep reinforcement learning. Transp Res Interdiscip Perspect 1:100020
Haarnoja T, Zhou A, Abbeel P, Levine S (2018) Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In: International conference on machine learning. PMLR, pp 1861–1870
Hado VH (2010) Double q-learning. In: Advances in neural information processing systems, pp 2613–2621
Hausknecht M, Stone P (2015) Deep recurrent q-learning for partially observable mdps. In: 2015 AAAI fall symposium series
Hernandez-Leal P, Kartal B, Taylor ME (2019) A survey and critique of multiagent deep reinforcement learning. Auton Agent Multi-Agent Syst 33(6):750–797
Hestenes MR, Stiefel E et al (1952) Methods of conjugate gradients for solving linear systems. NBS Washington, DC, vol 49
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural comput 9(8):1735–1780
HolmesParker C, Taylor ME, Zhan Y, Tumer K (2014) Exploiting structure and agent-centric rewards to promote coordination in large multiagent systems. In: Adaptive and learning agents workshop
Hong M, Hajinezhad D, Zhao M-M (2017) Prox-pda: the proximal primal-dual algorithm for fast distributed nonconvex optimization and learning over networks. In: Proceedings of the 34th international conference on machine learning-volume 70. JMLR. org, pp 1529–1538
Yedid H (2017) Vain: attentional multi-agent predictive modeling. In: Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, Garnett R (eds) Advances in neural information processing systems 30. Curran Associates, Inc., pp 2701–2711. http://papers.nips.cc/paper/6863-vain-attentional-multi-agent-predictive-modeling.pdfhttp://papers.nips.cc/paper/6863-vain-attentional-multi-agent-predictive-modeling.pdf. Accessed 28 Oct 2019
Huang G, Liu Z, Maaten LVD, Weinberger KQ (2017) Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4700–4708
Huang J, Chang Q, Chakraborty N (2019) Machine preventive replacement policy for serial production lines based on reinforcement learning. In: 2019 IEEE 15th international conference on automation science and engineering (CASE). IEEE, pages 523–528
Huang J, Chang Q, Arinez J (2020) Deep reinforcement learning based preventive maintenance policy for serial production lines. Expert Syst Appl 160:113701
Shariq I, Fei S (2019) Actor-attention-critic for multi-agent reinforcement learning. In: Chaudhuri K, Salakhutdinov R (eds) Proceedings of the 36th international conference on machine learning, volume 97 of proceedings of machine learning research. PMLR, long beach, California, USA, 09–15 Jun, pp 2961–2970. http://proceedings.mlr.press/v97/iqbal19a.html
Eric J, Gu S, Poole B (2016) Categorical reparameterization with gumbel-softmax. In: ICLR
Natasha J, Angeliki L, Edward H, Caglar G, Pedro O, Dj S, Joel ZL, Nando DF (2019) Social influence as intrinsic motivation for multi-agent deep reinforcement learning. In: Chaudhuri K, Salakhutdinov R (eds) Proceedings of the 36th international conference on machine learning, volume 97 of proceedings of machine learning research. PMLR, long beach, California, USA, 09–15 Jun pp 3040–3049. http://proceedings.mlr.press/v97/jaques19a.html. Accessed 28 Oct 2019
Jiang J, Zongqing L u (2018) Learning attentional communication for multi-agent cooperation. In: Advances in neural information processing systems, pp 7254–7264
Jiang J, Chen D, Tiejun H, Zongqing L (2020) Graph convolutional reinforcement learning. In: International conference on learning representations. https://openreview.net/forum?id=HkxdQkSYDB. Accessed 15 May 2020
Shuo J (2019) Multi-Agent Reinforcement Learning Environment. https://github.com/Bigpig4396/Multi-Agent-Reinforcement-Learning-Environmenthttps://github.com/Bigpig4396/Multi-Agent-Reinforcement-Learning-Environment Accessed 2019-07-28
Jiang S, Amato C (2021) Multi-agent reinforcement learning with directed exploration and selective memory reuse. In: Proceedings of the 36th annual ACM symposium on applied computing, pp 777–784
Jing G, Bai H, George J, chakrabortty A, Piyush K S (2022) A scalable graph-theoretic distributed framework for cooperative multi-agent reinforcement learning. arXiv:2202.13046
Johnson M, Hofmann K, Hutton T, Bignell D (2016) The malmo platform for artificial intelligence experimentation. In: IJCAI, pp 4246–4247
Jorge E, Kågebäck M, Johansson FD, Gustavsson E (2016) Learning to play guess who? and inventing a grounded language as a consequence. arXiv:1611.03218
Arthur J, Berges V-P, Vckay E, Gao Y, Henry H, Mattar M, Lange D (2018) Unity: a general platform for intelligent agents. arXiv:1809.02627
Kar S, Moura José MF, H Vincent P (2013a) \({\mathcal {QD}}\)-learning: a collaborative distributed strategy for multi-agent reinforcement learning through consensus + innovations. IEEE Trans Signal Process 61(7):1848–1862
Kar S, Moura MFJ, Poor HV (2013b) Distributed reinforcement learning in multi-agent networks. In: 2013 5th IEEE international workshop on computational advances in multi-sensor adaptive processing (CAMSAP). IEEE, pp 296–299
Kasai T, Tenmoto H, Kamiya A (2008) Learning of communication codes in multi-agent reinforcement learning problem. In: IEEE conference on soft computing in industrial applications. IEEE, pp 1–6
Kempka M, Wydmuch M, Runc G, Toczek J, Jaśkowski W (2016) ViZDoom: A Doom-based AI research platform for visual reinforcement learning. In: IEEE conference on computational intelligence and games. IEEE, Santorini, The best paper award, pp 341–348
Kim D, Moon S, Hostallero D, Kang WJ, Lee T, Son K, Yi Y (2019) Learning to schedule communication in multi-agent reinforcement learning. In: International conference on learning representations. https://openreview.net/forum?id=SJxu5iR9KQ. Accessed 07 March 2020
Kober J, Andrew Bagnell J, Jan P (2013) Reinforcement learning in robotics a survey. Int J Robot Res 32(11):1238–1274
Kroese DP, Rubinstein RY (2012) Monte carlo methods. Wiley Interdiscip Rev Comput Stat 4(1):48–58
Kulkarni TD, Narasimhan K, Saeedi A, Josh T. (2016) Hierarchical deep reinforcement learning: integrating temporal abstraction and intrinsic motivation. In: Advances in neural information processing systems, pages 3675–3683
Lanctot M, Zambaldi V, Gruslys A, Lazaridou A, Tuyls K, Pérolat J, Silver D, Graepel T (2017) A unified game-theoretic approach to multiagent reinforcement learning. In: Advances in neural information processing systems, pp 4190– 4203
Lanctot M, Lockhart E, Lespiau J-B, Zambaldi V, Upadhyay S, Pérolat J, Srinivasan S, Timbers F, Tuyls K, Omidshafiei S et al (2019) Openspiel: a framework for reinforcement learning in games. arXiv:1908.09453
Lauer M, Riedmiller M (2000) An algorithm for distributed reinforcement learning in cooperative multi-agent systems. In: Proceedings of the seventeenth international conference on machine learning. Citeseer
LaValle SM (2006) Planning algorithms. Cambridge university press
Lazaric A (2012) Transfer in reinforcement learning: a framework and a survey. In: Reinforcement learning. Springer, pp 143–173
Lazaric A, Restelli M, Bonarini A (2008) Reinforcement learning in continuous action spaces through sequential monte carlo methods. In: Advances in neural information processing systems, pp 833–840
Lazaridou A, Peysakhovich A, Baroni M (2017) Multi-agent cooperation and the emergence of (natural) language. In: ICLR
Donghwan L, Hyung-Jin Y, Naira H (2018) Primal-dual algorithm for distributed reinforcement learning: distributed GTD. 2018 IEEE Conf Decis Control (CDC):1967–1972
Lee J, Park J, Jangmin O, Lee J, Hong E (2007) A multiagent approach to q-learning for daily stock trading. IEEE Trans Syst Man Cybern A: Syst Hum 37(6):864–877
Leibo JZ, Zambaldi V, Lanctot M, Marecki J, Graepel T (2017) Multi-agent reinforcement learning in sequential social dilemmas. In: Proceedings of the 16th conference on autonomous agents and multiagent systems. International foundation for autonomous agents and multiagent systems, pp 464?473
Leroy S, Laumond J-P, Siméon T (1999) Multiple path coordination for mobile robots A geometric algorithm. In: IJCAI, vol 99 pp 1118–1123
Li Q, Lin W, Liu Z, Prorok A (2021) Message-aware graph attention networks for large-scale multi-robot path planning. IEEE Robot Autom Lett 6(3):5533–5540
Yuxi L (2017) Deep reinforcement learning: an overview. arXiv:1701.07274
Liang E, Liaw R, Nishihara R, Moritz P, Fox R, Gonzalez J, Goldberg K, Stoica I (2017) Ray RLlib: a composable and scalable reinforcement learning library. In: Deep reinforcement learning symposium (DeepRL @ NeurIPS)
Liang E, Liaw R, Nishihara R, Moritz P, Fox R, Goldberg K, Gonzalez J, Jordan M, Stoica I (2018) RLlib: abstractions for distributed reinforcement learning. In: Dy J, Krause A (eds) Proceedings of the 35th international conference on machine learning, volume 80 of proceedings of machine learning research. PMLR, 10–15 Jul, pp 3053–3062. http://proceedings.mlr.press/v80/liang18b.html. Accessed 23 Nov 2019
Lillicrap T, Hunt JJ, Pritzel A, Heess N, Erez T, Tassa Y, Silver D, Wierstra D (2016) Continuous control with deep reinforcement learning. In: ICLR (Poster)
Lin K, Zhao R, Zhe X, Zhou J (2018) Efficient large-scale fleet management via multi-agent deep reinforcement learning. In: Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. ACM, pp 1774–1783
Lin L-J (1992) Self-improving reactive agents based on reinforcement learning, planning and teaching. Mach Learn 8(3-4):293–321
Lipton ZC, Gao J, Li L, Li X, Ahmed F, Li D (2016) Efficient exploration for dialog policy learning with deep bbq networks & replay buffer spiking. coRR abs/1608.05081
Liu B, Cai Q, Yang Z, Wang Z (2019) Neural trust region/proximal policy optimization attains globally optimal policy. In: Wallach H, Larochelle H, Beygelzimer A, d’ Alché-Buc F, Fox E, Garnett R (eds) Advances in neural information processing systems. Curran Associates Inc., volume 32. https://proceedings.neurips.cc/paper/2019/file/227e072d131ba77451d8f27ab9afdfb7-Paper.pdf. Accessed 12 Apr 2020
Ruishan L, James Z (2018) The effects of memory replay in reinforcement learning. In: 2018 56th annual allerton conference on communication, control, and computing (Allerton). IEEE, pp 478–485
Liu Y, Logan B, Liu N, Zhiyuan X, Tang J, Wang Y (2017) Deep reinforcement learning for dynamic treatment regimes on medical registry data. In: 2017 IEEE international conference on healthcare informatics (ICHI). IEEE, pp 380–385
Liu Y, Chen Y, Jiang T (2020) Dynamic selective maintenance optimization for multi-state systems over a finite horizon: a deep reinforcement learning approach. Eur J Oper Res 283(1):166–181
Lowe R, Yi W, Tamar A, Harb J, Abbeel OpenAI P., Mordatch I (2017) Multi-agent actor-critic for mixed cooperative-competitive environments. In: Advances in neural information processing systems, pp 6382–6393
Lussange J, Lazarevich I, Bourgeois-Gironde S, Palminteri S, Gutkin B (2021) Modelling stock markets by multi-agent reinforcement learning. Comput Econ 57(1):113–147
Xueguang L, Yuchen X, Brett D, Chris A (2021) Contrasting centralized and decentralized critics in multi-agent reinforcement learning. In: AAMAS
Ma H, Tovey C, Sharon G, Kumar TK, Koenig S (2016) Multi-agent path finding with payload transfers and the package-exchange robot-routing problem. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 30
Ma H, Harabor D, Stuckey PJ, Li J, Koenig S (2019) Searching with consistent prioritization for multi-agent path finding. In: Proceedings of the AAAI conference on artificial intelligence, vol 33, pp 7643–7650
Sergio Valcarcel M, Jianshu C, Santiago Z, Ali H S (2015) Distributed policy evaluation under multiple behavior strategies. IEEE Trans Auto Cont 60(5):1260–1274. https://doi.org/10.1109/TAC.2014.2368731
Macua SV, Tukiainen A, Hernández DG-O, Baldazo D, de Cote EM, Zazo S (2018) Diff-dac: Distributed actor-critic for average multitask deep reinforcement learning. In: Adaptive learning agents (ALA) conference
Makar R, Mahadevan S, Ghavamzadeh M (2001) Hierarchical multi-agent reinforcement learning. In: Proceedings of the fifth international conference on autonomous agents. ACM, pp 246–253
Mao H, Zhang Z, Xiao Z, Gong Z (2019) Modelling the dynamic joint policy of teammates with attention multi-agent ddpg. In: Proceedings of the 18th international conference on autonomous agents and multiagent systems. International foundation for autonomous agents and multiagent systems, pp 1108–1116
Matignon L, Laurent G, Fort-Piat NL (2007) Hysteretic q-learning: an algorithm for decentralized reinforcement learning in cooperative multi-agent teams. In: IEEE/RSJ international conference on intelligent robots and systems. IROS’07, pp 64– 69
Matignon L, Laurent GJ, Fort-Piat NL (2012) Independent reinforcement learners in cooperative markov games: a survey regarding coordination problems. Knowl Eng Rev 2(1):1–31
Mguni D, Jennings J, Macua SV, Ceppi S, de Cote EM (2018) Controlling the crowd: inducing efficient equilibria in multi-agent systems. In: Advances in neural information processing systems 2018 MLITS workshop
Mirhoseini A, Goldie A, Yazgan M, Jiang J, Songhori E, Wang S, Lee Y-J, Johnson E, Pathak O, Nazi A et al (2021) A graph placement methodology for fast chip design. Nature 594(7862):207–212
ML2 (2021) Marlenv, multi-agent reinforcement learning environment. http://github.com/kc-ml2/marlenv. Accessed 12 March 2020
Mnih V, Kavukcuoglu K, Silver D, Graves A, Antonoglou I, Wierstra D, Riedmiller M (2013) Playing atari with deep reinforcement learning. Adv Neural Inf Process Syst. Deep learning workshop
Mnih V, Kavukcuoglu K, Silver D, Rusu AA, Veness J, Bellemare MG, Graves A, Riedmiller M, Fidjeland AK, Ostrovski G et al (2015) Human-level control through deep reinforcement learning. Nature (7540):529–533
Mnih V, Badia AP, Mirza M, Graves A, Lillicrap T, Harley T, Silver D, Kavukcuoglu K (2016) Asynchronous methods for deep reinforcement learning. In: International conference on machine learning, pp 1928–1937
Moerland TM, Broekens J, Jonker CM (2020) Model-based reinforcement learninga survey. arXiv:2006.16712
Mohanty S, Nygren E, Laurent F, Schneider M, Scheller C, Bhattacharya N, Watson J, Egli A, Eichenberger C, Baumberger C et al (2020) Flatland-rl: Multi-agent reinforcement learning on trains. arXiv:2012.05893
Mordatch I, Abbeel P (2018a) Emergence of grounded compositional language in multi-agent populations. In: Proceedings of the AAAI conference on artificial intelligence, vol 32
Mordatch I, Abbeel P (2018b) Emergence of grounded compositional language in multi-agent populations. In: Thirty-second AAAI conference on artificial intelligence
Moritz P, Nishihara R, Wang S, Tumanov A, Liaw R, Liang E, Elibolm M, Yang Z, Paul W, Jordan M et al (2018) Ray: a distributed framework for emerging fAIg applications. In: 13th {USENIX} symposium on operating systems design and implementation (fOSDIg 18), pp 561–577
Mousavi HK, Nazari M, Takáč M, Motee N (2019) Multi-agent image classification via reinforcement learning. In: 2019 IEEE/RSJ international conference on intelligent robots and systems (IROS), pp 5020–5027. https://doi.org/10.1109/IROS40897.2019.8968129https://doi.org/10.1109/IROS40897.2019.8968129
Mousavi HK, Liu G, Yuan W, Takác M, Munoz-Avila H, Motee N (2019) A layered architecture for active perception: Image classification using deep reinforcement learning. CoRR, arXiv:1909.09705
Nazari M, Oroojlooy A, Snyder L, Takác M. (2018) Reinforcement learning for solving the vehicle routing problem
Ng AY, Harada D, Russell SJ (1999) Policy invariance under reward transformations: theory and application to reward shaping. In: Proceedings of the sixteenth international conference on machine learning, ISBN 1-55860-612-2. ICML ’99, pp 278–287. http://dl.acm.org/citation.cfm?id=645528.657613. Morgan Kaufmann Publishers Inc., CA. Accessed 28 July 2019.
Nguyen TT, Nguyen ND, Nahavandi S (2020) Deep reinforcement learning for multiagent systems: a review of challenges, solutions, and applications. IEEE Trans Cybern 50(9):3826–3839
Norén JFW (2020) Derk gym environment. https://gym.derkgame.com. Accessed 01 Sept 2021
Omidshafiei S, Pazis J, Amato C, How JP, Vian J (2017) Deep decentralized multi-task multi-agent reinforcement learning under partial observability. In: Proceedings of the 34th international conference on machine learning-volume 70. JMLR. org, pp 2681–2690
Oroojlooyjadid A, Nazari M, Snyder L, Takáč M (2017) A deep q-network for the beer game: deep reinforcement learning for inventory optimization. Manuf Serv Oper Manag 0(0):null, 0. https://doi.org/10.1287/msom.2020.0939.
Padullaparthi VR, Nagarathinam S, Vasan A, Menon V, Sudarsanam D (2022) Falcon-farm level control for wind turbines using multi-agent deep reinforcement learning. Renew Energy 181:445–456
Pan L, Cai Q, Meng Q, Chen W, Huang L (2020) Reinforcement learning with dynamic boltzmann softmax updates. In: Christian Bessiere (ed) Proceedings of the twenty-ninth international joint conference on artificial intelligence. International joint conferences on artificial intelligence organization, IJCAI-20, Main track, pp 1992–1998. https://doi.org/10.24963/ijcai.2020/276
Panerati J, Zheng H, Zhou SQ, Xu J, Prorok A, Schoellig AP (2021) Learning to fly–a gym environment with pybullet physics for reinforcement learning of multiagent quadcopter control. In: 2021 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, pp 7512– 7519
Papoudakis G, Christianos F, Schäfer L, Albrecht SV (2021) Benchmarking multi-agent deep reinforcement learning algorithms in cooperative tasks. In: Thirty-fifth conference on neural information processing systems datasets and benchmarks track (Round 1). https://openreview.net/forum?id=cIrPX-Sn5n. Accessed 21 Nov 2021
Bei P, Tabish R, Christian Schroeder de W, Pierre-Alexandre K, Philip T, Wendelin B, Shimon W (2021) Facmac: Factored multi-agent centralised policy gradients. Adv Neural Inf Process Syst, vol 34
Peng P, Wen Y, Yang Y, Yuan Q, Tang Z, Long H, Wang J (2017) Multiagent bidirectionally-coordinated nets: emergence of human-level coordination in learning to play starcraft combat games
Pennesi P, Paschalidis IC (2010) A distributed actor-critic algorithm and applications to mobile sensor network coordination problems. IEEE Trans Auto Cont 55(2):492–497. ISSN 0018-9286. https://doi.org/10.1109/TAC.2009.2037462
Petersen K (2012) Termes: an autonomous robotic system for three-dimensional collective construction. Robot: Sci Syst VII, pp 257
Prabuchandran KJ, Hemanth Kumar AN, Bhatnagar S (2014) Multi-agent reinforcement learning for traffic signal control. In: 17th international IEEE conference on intelligent transportation systems (ITSC). IEEE, pp 2529–2534
Prashanth LA, Bhatnagar S (2010) Reinforcement learning with function approximation for traffic signal control. IEEE Trans Intell Transp Syst 12(2):412–421
Guannan Q, Na L (2017) Harnessing smoothness to accelerate distributed optimization. IEEE Trans Cont Netw Syst 5(3):1245–1260
Rabinowitz N, Perbet F, Song F, Zhang C, Eslami SMA, Botvinick M (2018) Machine theory of mind. In: Dy J, Krause A (eds) Proceedings of the 35th international conference on machine learning, volume 80 of proceedings of machine learning research. PMLR, Stockholmsmassan, Stockholm Sweden, 10–15 Jul, pp 4218–4227. http://proceedings.mlr.press/v80/rabinowitz18a.html
Rangwala M, Williams R (2020) Learning multi-agent communication through structured attentive reasoning. Adv Neural Inf Process Syst 33:10088–10098
Rashid T, Samvelyan M, Schroeder C, Farquhar G, Foerster J, Whiteson S (2018) QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning. In: Dy J, Krause A (eds) Proceedings of the 35th international conference on machine learning, volume 80 of proceedings of machine learning research. PMLR, Stockholmsmassan, Stockholm Sweden, 10–15 Jul, pp 4295–4304. http://proceedings.mlr.press/v80/rashid18a.html. Accessed 27 Feb 2019
Ryu H, Shin H, Park J (2018) Multi-agent actor-critic with generative cooperative policy network. arXiv:1810.09206
Samvelyan M, Rashid T, de Witt CS, Farquhar G, Nardelli N, Rudner TGJ, Hung Ch-M, Torr PHS, Foerster J, Whiteson S (2019a) The StarCraft multi-agent challenge. arXiv:1902.04043
Samvelyan M, Rashid T, De Witt CS, Farquhar G, Nardelli N, Rudner TGJ, Hung C-M, Torr PHS, Foerster J, Whiteson S (2019b) The starcraft multi-agent challenge. arXiv:1902.04043
Sanchez G, Latombe J-C (2002) Using a prm planner to compare centralized and decoupled planning for multi-robot systems. In: Proceedings 2002 IEEE international conference on robotics and automation (Cat. No. 02CH37292), vol 2, pp 2112–2119
Sartoretti G, Kerr J, Shi Y, Wagner G, Kumar TKS, Koenig S, Choset H (2019a) Primal: pathfinding via reinforcement and imitation multi-agent learning. IEEE Robot Auto Lett 4 (3):2378–2385
Guillaume S, Yue W, William P, TK SK, Sven K, Howie C (2019b) Distributed reinforcement learning for multi-robot decentralized collective construction. In: Distributed Autonomous Robotic Systems. Springer, pp 35–49
Savva M, Chang AX, Dosovitskiy A, Funkhouser T, Koltun V (2017) MINOS: multimodal indoor simulator for navigation in complex environments. arXiv:1712.03931
Schaul T, Quan J, Antonoglou I, Silver D (2016) Prioritized experience replay. In: ICLR (Poster)
Schmidt M, Roux NL, Bach F (2017) Minimizing finite sums with the stochastic average gradient. Math Program 162(1-2):83–112
de Witt CS, Foerster J, Farquhar G, Torr P, Boehmer W, Whiteson S (2019) Multi-agent common knowledge reinforcement learning. Adv Neural Inf Process Syst 32:9927–9939
Schulman J, Levine S, Abbeel P, Jordan M, Moritz P (2015) Trust region policy optimization. In: International conference on machine learning, pp 1889–1897
Schulman J, Levine S, Abbeel P, Jordan M, Moritz P (2015) Trust region policy optimization. In: International conference on machine learning, pp 1889–1897
Seth A, Sherman M, Reinbolt JA, Delp SL (2011) Opensim: a musculoskeletal modeling and simulation framework for in silico investigations and exchange. Procedia Iutam 2:212–232
Shalev-Shwartz S, Shammah S, Shashua A (2016) Safe, multi-agent, reinforcement learning for autonomous driving. arXiv:1610.03295
Sharon G, Stern R, Felner A, Sturtevant NR (2015) Conflict-based search for optimal multi-agent pathfinding. Artif Intell 219:40–66
Shu T, Tian Y (2019) M3RL: mind-aware multi-agent management reinforcement learning. In: International conference on learning representations. https://openreview.net/forum?id=BkzeUiRcY7. Accessed 18 Jan 2020
Silva MAL, de Souza SR, Souza MJF, Bazzan ALC (2019) A reinforcement learning-based multi-agent framework applied for solving routing and scheduling problems. Expert Syst Appl 131:148–171
David S, Guy L, Nicolas H, Thomas D, Daan W, Martin R (2014) Deterministic policy gradient algorithms. In: Xing EP, Jebara T (eds) Proceedings of the 31st international conference on machine learning, volume 32 of proceedings of machine learning research. PMLR, Bejing, 22–24 Jun, pages 387–395, http://proceedings.mlr.press/v32/silver14.html. Accessed 28 July 2019
David S, Huang A, Maddison CJ, Guez A, Sifre L, Den Driessche GV, Schrittwieser J, Antonoglou I, Panneershelvam V, Lanctot M et al (2016) Mastering the game of go with deep neural networks and tree search. Nature 529(7587):484
Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, Hubert T, Baker L, Lai M, Bolton A et al (2017) Mastering the game of go without human knowledge. Nature 550(7676):354
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: International conference on learning representations
Singh A, Jain T, Sukhbaatar S (2018) Learning when to communicate at scale in multiagent cooperative and competitive tasks. In: ICLR
Smierzchalski R, Michalewicz Z (2005) Path planning in dynamic environments. In: Innovations in robot mobility and control. Springer, pp 135–153
Son K, Kim D, Kang WJ, Hostallero ED, Yi Y (2019) Qtran: learning to factorize with transformation for cooperative multi-agent reinforcement learning. In: Proceedings of the 31st international conference on machine learning, proceedings of machine learning research. PMLR
Song Y, Wojcicki A, Lukasiewicz T, Wang J, Aryan A, Xu Z, Xu M, Ding Z, Wu L (2020) Arena: a general evaluation platform and building toolkit for multi-agent intelligence. Proc AAAI Conf Artif Intell 34(05):7253–7260. https://doi.org/10.1609/aaai.v34i05.6216. https://ojs.aaai.org/index.php/AAAI/article/view/6216
Sorensen J, Mikkelsen R, Henningson D, Ivanell S, Sarmast S, Andersen S (2015) Simulation of wind turbine wakes using the actuator line technique. Philosophical Trans Series Math Phys Eng Sci. vol 373(02). https://doi.org/10.1098/rsta.20140071
Stanković M, Stanković S (2016) Multi-agent temporal-difference learning with linear function approximation: weak convergence under time-varying network topologies. In: 2016 American control conference (ACC), pp 167–172. https://doi.org/10.1109/ACC.2016.7524910
Stone P, Veloso M (2000) Multiagent systems: a survey from a machine learning perspective. Auton Robot 8(3):345– 383
Su J, Adams S, Beling PA (2021) Value-decomposition multi-agent actor-critics. In: Proceedings of the AAAI conference on artificial intelligence, vol 35, pp 11352–11360
Su J, Huang J, Adams S, Chang Q, Beling PA (2022) Deep multi-agent reinforcement learning for multi-level preventive maintenance in manufacturing systems. Expert Syst Appl 192:116323
Suarez J, Du Y, Isola P, Mordatch I (2019) Neural mmo: a massively multiagent game environment for training and evaluating intelligent agents. arXiv:1903.00784
Sukhbaatar S, Szlam A, Synnaeve G, Chintala S, Fergus R (2015) Mazebase: a sandbox for learning from games. arXiv:1511.07401
Sukhbaatar S, Fergus R et al (2016) Learning multiagent communication with backpropagation
kthankar G, Rodriguez-Aguilar JA (2017) Autonomous agents and multiagent systems. In: AAMAS 2017 workshops, best papers, São Paulo, Brazil, 8-12 May 2017. Revised selected papers, vol 10642. Springer
Sun W, Jiang N, Krishnamurthy A, Agarwal A, Langford J (2019) Model-based rl in contextual decision processes: pac bounds and exponential improvements over model-free approaches. In: Conference on learning theory. PMLR, pp 2898–2933
Sunehag P, Lever G, Gruslys A, Czarnecki WM, Zambaldi V, Jaderberg M, Lanctot M, Sonnerat N, Leibo JZ, Tuyls K et al (2018) Value-decomposition networks for cooperative multi-agent learning based on team reward. In: Proceedings of the 17th international conference on autonomous agents and multiagent systems, pp 2085–2087. International foundation for autonomous agents and multiagent systems
Suttle W, Yang Z, Zhang K, Wang Z, Başar T, Liu J (2020) A multi-agent off-policy actor-critic algorithm for distributed reinforcement learning. IFAC-PapersOnLine. ISSN 2405-8963. 21th IFAC World Congress 53(2):1549–1554. https://doi.org/10.1016/j.ifacol.2020.12.2021. https://www.sciencedirect.com/science/article/pii/S2405896320326562
Sutton RS, Barto AG (2018) Reinforcement learning: an introduction. MIT Press
Sutton RS, McAllester DA, Singh SP, Mansour Y (2000) Policy gradient methods for reinforcement learning with function approximation. In: Advances in neural information processing systems, pp 1057–1063
Sutton RS, Maei HR, Precup D, Bhatnagar S, Silver D, Szepesvári C, Wiewiora E (2009) Fast gradient-descent methods for temporal-difference learning with linear function approximation. In: Proceedings of the 26th annual international conference on machine learning, ICML ’09, pages 993–1000, New York. ACM. ISBN 978-1-60558-516-1. https://doi.org/10.1145/1553374.1553501
Sutton RS, Rupam Mahmood A, White M (2016) An emphatic approach to the problem of off-policy temporal-difference learning. J Mach Learn Res 17(1):2603–2631
Tampuu A, Matiisen T, Kodelja D, Kuzovkin I, Korjus K, Aru J, Aru J, Vicente R (2017) Multiagent cooperation and competition with deep reinforcement learning. Plos one 12(4):e0172395
Tan M (1993) Multi-agent reinforcement learning: independent vs. cooperative agents. In: Proceedings of the tenth international conference on machine learning, pp 330–337
Tang H, Hao J, Lv T, Chen Y, Zhang Z, Jia H, Ren CYZ, Fan C, Wang L (2018) Hierarchical deep multiagent reinforcement learning. arXiv:1809.09332
Tasfi N (2016) Pygame learning environment. https://github.com/ntasfi/PyGame-Learning-Environment. Accessed 28 July 2019
Terry JK, Black BJ, Grammel N, Jayakumar M, Hari A, Sullivan R, Santos L, Dieffendahl C, Horsch C, Perez-Vicente RDL, Williams NL, Lokesh Y, Ravi P (2021) Pettingzoo: gym for multi-agent reinforcement learning. In: Beygelzimer A, Dauphin Y, Liang P, Wortman Vaughan J (eds) Advances in neural information processing systems. https://openreview.net/forum?id=fLnsj7fpbPI. Accessed 17 March 2022
Todorov E, Erez T, Tassa Y (2012) Mujoco: a physics engine for model-based control. In: 2012 IEEE/RSJ international conference on intelligent robots and systems, pp 5026–5033
Usunier N, Synnaeve G, Lin Z, Chintala S (2017) Episodic exploration for deep deterministic policies for starcraft micromanagement. In: International conference on learning representations. https://openreview.net/forum?id=r1LXit5ee. Accessed 28 July 2019
Berg JVD, Guy SJ, Lin M, Manocha D (2011) Reciprocal n-body collision avoidance. In: Robotics research. Springer pp 3–19
Van Hasselt H, Guez A, Silver D (2016) Deep reinforcement learning with double q-learning. In: Thirtieth AAAI conference on artificial intelligence
Seijen HV, Fatemi M, Romoff J, Laroche R, Barnes T, Tsang J (2017) Hybrid reward architecture for reinforcement learning. In: Advances in Neural Information Processing Systems, pp 5392–5402
Varshavskaya P, Kaelbling LP, Rus D (2019) Efficient distributed reinforcement learning through agreement. In: Distributed autonomous robotic systems 8. Springer, pp 367–378
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Łukasz K, Polosukhin I (2017) Attention is all you need. In: Advances in neural information processing systems, pp 5998–6008
Vezhnevets AS, Osindero S, Schaul T, Heess N, Jaderberg M, Silver D, Kavukcuoglu K (2017) Feudal networks for hierarchical reinforcement learning. In: Proceedings of the 34th international conference on machine learning-vol 70. JMLR. org, pp 3540–3549
Wagner G, Choset H (2015) Subdimensional expansion for multirobot path planning. Artif Intell 219:1–24
Wai HT, Yang Z, Wang PZ, Hong M (2018) Multi-agent reinforcement learning via double averaging primal-dual optimization. In: Advances in neural information processing systems, pp 9649–9660
Wang B, Liu Z, Li Q, Prorok A (2020a) Mobile robot path planning in dynamic environments through globally guided reinforcement learning. IEEE Robotics and Automation Letters 5(4):6932–6939
Wang H, Wang X, Hu X, Zhang X, Gu M (2016a) A multi-agent reinforcement learning approach to dynamic service composition. Inf Sci 363:96–119
Wang J, Xu W, Gu Y, Song W, Green TC (2021) Multi-agent reinforcement learning for active voltage control on power distribution networks. In: Beygelzimer A, Dauphin y , Liang P, Vaughan JW (eds) Advances in neural information processing systems. https://openreview.net/forum?id=hwoK62_GkiT. Accessed 23 Jan 2022
Wang L, Cai Q, Yang Z, Wang Z (2020b) Neural policy gradient methods: Global optimality and rates of convergence. In: International conference on learning representations. https://openreview.net/forum?id=BJgQfkSYDS. Accessed 02 July 2020
Wang RE, Everett M, How JP (2019a) R-maddpg for partially observable environments and limited communication. In: Reinforcement learning for real life workshop in the 36th international conference on machine learning, Long Beach
Wang RE, Everett M, How JP (2019b) R-maddpg for partially observable environments and limited communication. ICML 2019 Workshop RL4reallife
Wang S, Wan J, Zhang D, Li D, Zhang C (2016b) Towards smart factory for industry 4.0: a self-organized multi-agent system with big data based feedback and coordination. Comput Netw 101:158–168
Wang X, Wang H, Qi C (2016c) Multi-agent reinforcement learning based maintenance policy for a resource constrained flow line system. J Intell Manuf 27(2):325–333
Wang Y, Han B, Wang T, Dong H, Zhang C (2020c) Dop: Off-policy multi-agent decomposed policy gradients. In: International conference on learning representations
Wang Z, Schaul T, Hessel M, Hasselt H, Lanctot M, Freitas N (2016d) Dueling network architectures for deep reinforcement learning. In: Balcan MF, Weinberger KQ (eds) Proceedings of The 33rd international conference on machine learning, vol 48 of Proceedings of machine learning research, pp 1995–2003, New York, New York, USA, 20–22 Jun. PMLR. http://proceedings.mlr.press/v48/wangf16.html. Accessed 28 July 2019
Watkins CJ, Dayan P (1992) Q-learning. Mach Learn 8(3-4):279–292
Wei H, Chen C, Zheng G, Kan W, Gayah V, Xu K, Li Z (2019a) Presslight: learning max pressure control to coordinate traffic signals in arterial network. In: Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, KDD ’19, pp 1290–1298
Wei H, Nan X u, Zhang H, Zheng G, Zang X, Chen C, Zhang W, Zhu Y, Xu K, Li Z (2019b) Colight: Learning network-level cooperation for traffic signal control. In: Proceedings of the 28th ACM international conference on information and knowledge management, pp 1913–1922
Wei H, Zheng G, Gayah V, Li Z (2019c) A survey on traffic signal control methods. arXiv:1904.08117
Weiß G (1995) Distributed reinforcement learning. In: Luc Steels (ed) The Biology and technology of intelligent autonomous agents, pp 415–428. Berlin, Heidelberg. Springer Berlin Heidelberg
Williams R (1992) Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach Learn 8(3-4):229–256
Wu C, Kreidieh A, Parvate K, Vinitsky E, Bayen AM (2017) Flow: Architecture and benchmarking for reinforcement learning in traffic control. arXiv:1710.05465
Wu J, Xu X (2018) Decentralised grid scheduling approach based on multi-agent reinforcement learning and gossip mechanism. CAAI Trans Intell Technol 3(1):8–17
Wu J, Xu X, Zhang P, Liu C (2011) A novel multi-agent reinforcement learning approach for job scheduling in grid computing. Futur Gener Comput Syst 27(5):430–439
Wu Y, Wu Y, Gkioxari G, Tian Y (2018) Building generalizable agents with a realistic and rich 3d environment. https://openreview.net/forum?id=rkaT3zWCZ. Accessed 28 July 2019
Ian X (2018) A distributed reinforcement learning solution with knowledge transfer capability for a bike rebalancing problem. arXiv:1810.04058
Yang J, Nakhaei A, Isele D, Fujimura K, Zha H (2020) Cm3: Cooperative multi-goal multi-stage multi-agent reinforcement learning. In: International conference on learning representations. https://openreview.net/forum?id=S1lEX04tPr. Accessed 08 Nov 2020
Yang Y, Wang J (2020) An overview of multi-agent reinforcement learning from game theoretical perspective. arXiv:2011.00583
Yang Y, Luo R, Li M, Zhou M, Zhang W, Wang J (2018a) Mean field multi-agent reinforcement learning. In: Dy J, Krause A (eds) Proceedings of the 35th international conference on machine learning, vol 80. of Proceedings of machine learning research, pp 5571–5580. Stockholmsmassan, Stockholm Sweden, 10–15 Jul PMLR
Yang Z, Zhang K, Hong M (2018b) Tamer başar. A finite sample analysis of the actor-critic algorithm. In: IEEE Conference on decision and control (CDC). IEEE, pp 2759–2764
Dayong Y, Zhang M, Yang Y (2015) A multi-agent framework for packet routing in wireless sensor networks. Sensors 15(5):10026–10047
Ying B, Yuan K, Sayed AH (2018) 2018 Convergence of variance-reduced learning under random reshuffling. In: IEEE International conference on acoustics, speech and signal processing (ICASSP). IEEE, pp 2286–2290
Yousefi N, Tsianikas S, Coit DW (2020) Reinforcement learning for dynamic condition-based maintenance of a system with individually repairable components. Qual Eng 32(3):388–408
Yu H (2015) On convergence of emphatic temporal-difference learning. In: Conference on learning theory, pp 1724–1751
Zawadzki E, Lipson A, Leyton-Brown K (2014) Empirically evaluating multiagent learning algorithms. arXiv:1401.8074
Zhang C, Li X, Hao J, Chen S, Tuyls K, Xue W, Feng Z (2018a) Scc-rfmq learning in cooperative markov games with continuous actions. In: Proceedings of the 17th international Conference on Autonomous Agents and MultiAgent systems. International foundation for autonomous agents and Multiagent systems, pp 2162–2164
Zhang C, Lesser V, Shenoy P (2009) A multi-agent learning approach to online distributed resource allocation. In: Twenty-first international joint conference on artificial intelligence
Zhang H, Jiang H, Luo Y, Xiao G (2017) Data-driven optimal consensus control for discrete-time multi-agent systems with unknown dynamics using reinforcement learning method. IEEE Trans Ind Electron 64(5):4091–4100. https://doi.org/10.1109/TIE.2016.2542134
Zhang H, Feng S, Liu C, Ding Y, Zhu Y, Zhou Z, Zhang W, Yong Y u, Jin H, Li Z (2019) Cityflow: A multi-agent reinforcement learning environment for large scale city traffic scenario. In: The world wide web conference. ACM, pp 3620–3624
Zhang K, Yang Z (2018b) Tamer Basar Networked multi-agent reinforcement learning in continuous spaces. In: 2018 IEEE Conference on decision and control (CDC), IEEE. pp 2771–2776
Zhang K, Yang Z, Liu H, Zhang T, Basar T (2018c) Fully decentralized multi-agent reinforcement learning with networked agents. In: Dy J, Krause A (eds) Proceedings of the 35th international conference on machine learning, vol 80. of proceedings of machine learning research. PMLR, 10–15 Jul, Stockholmsmassan, Stockholm Sweden pp 5872–5881
Zhang K, Koppel A, Zhu H, Basar T (2020a) Global convergence of policy gradient methods to (almost) locally optimal policies. SIAM J Control Optim 58(6):3586–3612
Zhang K, Yang Z, Basar T (2021) Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms, pp 321–384. Springer, Cham. https://doi.org/10.1007/978-3-030-60990-0_12
Ke Z, He F, Zhang Z, Xi L, Li M (2020b) Multi-vehicle routing problems with soft time windows: A multi-agent reinforcement learning approach. Transp Res C: Emerg Technol 121:102861
Zhang S, Sutton RS (2017) A deeper look at experience replay. arXiv:1712.01275
Zhang Y, Zavlanos MM (2019) Distributed off-policy actor-critic reinforcement learning with policy consensus. In: 2019 IEEE 58th Conference on decision and control (CDC), pp 4674–467. https://doi.org/10.1109/CDC40024.2019.9029969
Zheng G, Xiong Y, Zang X, Feng J, Wei H, Zhang H, Li Y, Kai XU, Li Z (2019) Learning phase competition for traffic signal control. In: Proceedings of the 28th ACM international conference on information and knowledge management, pp 1963–1972
Zuo X (2018) Mazelab: a customizable framework to create maze and gridworld environments. https://github.com/zuoxingdong/mazelab. Accessed 28 July 2019
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Oroojlooy, A., Hajinezhad, D. A review of cooperative multi-agent deep reinforcement learning. Appl Intell 53, 13677–13722 (2023). https://doi.org/10.1007/s10489-022-04105-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-022-04105-y