
Abstract
In recent years, many RGB-THERMAL tracking methods have been proposed to meet the needs of single object tracking under different conditions. However, these trackers are based on ANCHOR-BASED algorithms and feature cross-correlation operations, making it difficult to improve the success rate of target tracking. We propose a siamAFTS tracking network, which is based on ANCHOR-FREE and utilizes a fully convolutional training network with a Transformer module, suitable for RGB-THERMAL target tracking. This model addresses the issue of low success rate in current mainstream algorithms. We also incorporate channel and channel spatial attention modules into the network to reduce background interference on predicted bounding boxes. Unlike current ANCHOR-BASED trackers such as MANET, DAPNet, SGT, and ADNet, the proposed framework eliminates the use of anchor points, avoiding the challenges of anchor hyperparameter tuning and reducing human intervention. Through repeated experiments on three datasets, we ultimately demonstrate the improved success rate of target tracking achieved by our proposed tracking network.
Similar content being viewed by others


Introduction
In order to predict and track the next location of a target, target tracking algorithms typically start with a specific initial target position feature, establish it as a reference, and then perform correlation operations with consecutive frames. Most tracking trackers are based on RGB images. However, in some challenging conditions such as fog, rain, and darkness, where the target is not clearly visible in RGB images, the tracker often fails to successfully track the target. In recent years, there has been increasing research interest in multi-modal trackers that combine other modalities with RGB images, such as RGB-T tracking, to address this limitation. To enhance tracking performance, Li et al. proposed a method based on the fusion of grayscale and thermal image categories1. Furthermore, they publicly shared their dataset in the paper. RGB-THERMAL trackers are more competitive as they leverage the complementary advantages of the fused RGB and thermal modes. In this approach, thermal infrared images are unaffected by lighting conditions, while RGB photographs capture detailed information pertaining to the target.
Since Li2 successfully improved the accuracy of target tracking by using Siamese networks, which extract features from two identical branching networks, this Siamese network has been widely applied in the design of RGB-THERMAL target tracking6,7,8,9 and10. all demonstrate that Siamese networks can effectively improve the accuracy and success rate of target tracking. In this study, we recommend the twin network for RGB-THERMAL fusion tracking, primarily for the tracking network's stability consideration.
In recent years, several different RGB-THERMAL tracking techniques have been introduced. Xingchen Zhang et al.3 employed a fully convolutional network and multilayer feature fusion to enhance thermal tracking performance. Guo et al.4 utilized a deep network model and combined RGB and thermal heat score maps to increase tracking speed. Zhu5 proposed a novel concept that emphasizes the importance of layers capturing key features and combined the separately collected layers to produce better prediction results.
The mentioned RGB-T trackers and many advanced RGB-T models11,12,13,14 are inspired by the Siam RPN8 model, which primarily involves predefining anchor frames of different sizes6,9 that each sample must match, leading to increased computation and processing time. These anchor frames are artificially designed and have a significant impact on the effectiveness of the tracking model, requiring a considerable amount of manual intervention during the experimental process. How to enable network models to learn autonomously without human intervention is also a current direction of development in artificial intelligence.
Currently, Siamese networks are widely used in advanced RGBT tracking algorithms. Siamese networks typically perform correlation operations on image features extracted from the target template and search region, and determine their similarity based on the similarity score. The target object is considered successfully tracked if the similarity score is high. However, correlation operations, which involve convolving two feature maps, may result in significant information loss, leading to a low success rate in target tracking. Recently, in the field of RGB-based target tracking, many researchers have incorporated Transformer technology into the design of tracking algorithms and achieved promising results. However, there are few studies that apply Transformer technology to RGBT-based target tracking, and the accuracy and success rate of RGBT trackers using Transformer are not high. Inspired by the application of Transformer in target tracking, we aim to design a new model with a Transformer framework to improve the accuracy and success rate of RGBT target tracking.
This study proposes an end-to-end trainable tracker based on Transformer for robust RGBT tracking. Firstly, we extract features from RGB and thermal infrared images separately. Then, we employ spatial and channel attention modules to enhance these features and improve the resolution of fused features, effectively reducing the discrepancies between modality features and eliminating background interference. Finally, by fusing these image features, we obtain a response map through our newly designed Transformer module. Our novel model predicts the target's position and bounding box using only one response map. In summary, our main contributions include:
-
1)
We designed an end-to-end offline tracking training model by using convolutional neural networks. Previous RGBT designs have been anchor-based; in this case, our model is anchor-free, which does not depend on pre-defined boxes and can be trained on well-annotated datasets and achieve good results.
-
2)
We have designed a new Transformer module specifically for RGBT target tracking. Experimental results demonstrate that the use of this module significantly improves the accuracy and success rate of target tracking. Our designed tracker takes into account the contributions of both RGB and TIR modes in modeling the target. It effectively utilizes the feature information to enhance the robustness of the model.
-
3)
We conducted an in-depth analysis of the GTOT, GBT210, and RGBT234 datasets. The results show that our proposed method exhibits some gaps when compared to the latest supervised RGBT algorithms. However, our tracker demonstrates highly competitive performance in many aspects.
Proposed method
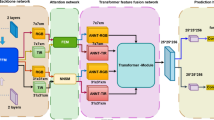
Figure 1 depicts the overall frame construction. We outline each part of our technique separately in this section.

The frame construction.
Backbone
As shown in Fig. 1 as the input of 4 images, our input consists of a visible light branch and a thermal infrared branch. The target branch in turn contains visible input Z1 and thermal infrared input Z2, and the search area branch is divided into visible input X1 and thermal infrared input X2. Since it is a Siamese model, both the visible and thermal infrared branches use the same ResNet50 model to extract feature maps. After backbone network feature extraction, the visible branch will get feature maps \(\varphi (Z1)\) and feature maps \(\varphi (X1)\),and the thermal infrared branch will get feature maps \(\varphi (Z2)\) and feature maps \(\varphi (X2)\). Then, we obtain the feature maps \(\varphi (Z1)\),\(\varphi (X1)\),\(\varphi (Z2)\),and \(\varphi (X2)\), where a portion is directly fed as input to the Transformer module for the next step of computation, while another portion is enhanced by passing through the SA and CA modules to augment the feature maps before being transmitted to the Transformer module for further computation.
During the object tracking process, we aim to include more image feature information in the response map. Inspired by reference7, we consider extracting feature maps from different layers as outputs during the process of feature extraction. Deep features and shallow features have different roles in target tracking. First, deep features have good discrimination of the required speech properties, which are enhanced for our classification task. In contrast, shallow features are rich in information about visual attributes such as edges and colors, which are enhanced for the target localization task. Inspired by references7,15, We modify the last module of ResNet50 to obtain feature maps from layers 6, 7, and 8. We obtain F6(X1), F7(X1), F8(X1). And we also get F6(X2), F7(X2), F8(X2). Here 6, 7, and 8 indicates the feature values we extracted from layer 6 layer 7, and layer 8. There are 256 channels in F6(X2), F7(X2), F8(X2).
Module for spatial attention
The channel attention mechanism can enhance the predictive capability of the network. To improve the information transfer capability between the two modes, we designed a Channel Attention Feature Enhancement module (CA module) as shown in Fig. 2.

CA model architecture.
In the CA module Fig. 2, we take the feature map \(\varphi (Z1)\) and \(\varphi (Z2)\) extracted through the backbone network as input to the CA module and obtain the joint feature as \(U^{{{\text{ca}}}}\). denoting the output as \(x_{rgb}^{ca}\) , \(x_{tir}^{ca}\), and the overall CA module can be described as follows:
where \(\delta\) represents the full set, \(\omega\) is the fully connected layer, \(\varepsilon\) denotes Sigmoid, \(\otimes\) is the product of channel-wise, and Split is the operation of extracting features along the channel dimension.
In order to suppress the effect of background noise on the classification task, we designed a spatial attention (SA module) module. It is shown in Fig. 3. This module mainly utilizes the spatial inter-relationship of features. We take \(\varphi (X1)\) and \(\varphi (X2)\) extracted through the backbone network as the input feature maps, and by using the SA module, we finally obtain the feature map \(U^{{{\text{ca}}}}\) using the following mathematical expression as:
where \(\rho\) is for the average set, \(\phi\) or the largest set, Cat stands for the process of stringing features along the channel dimension, \(\varphi\) stands for the two-dimensional convolution operation, H stands for a collection of kernel weights, and \(\varepsilon\) stands for the Sigmoid function.

SA model architecture.
The output is then represented as \(x_{rgb}^{sa} ,x_{tir}^{sa}\), and SA module as seen below:
\(\odot\) denotes connecting a CA module to an SA module, and finally, we get the final SA module.
Transformer network
Inspired by reference16, we designed a Transformer Network as shown in Fig. 4.

Illustration of the features fusion network based on the transformer.
From Fig. 4, we can see that the template feature and search feature extracted by the backbone network first pass through the CA and SA channel modules respectively, and obtain \(x_{rgb}^{sa}\),\(x_{tir}^{sa}\),\(\widehat{zf}_{rgb}^{ca}\) and \(\widehat{zf}_{{{\text{tir}}}}^{ca}\). Then, the feature vectors are fed into the Transformer module, as shown in Fig. 4. First, \(x_{rgb}^{sa}\) and \(\widehat{zf}_{rgb}^{ca}\) pass through a Transformer attention module (BCTM). Then, \(x_{tir}^{sa}\) and \(\widehat{zf}_{{{\text{tir}}}}^{ca}\) pass through another Transformer attention module (BCTM). BCTM is used to fuse different branch information. To make the fusion information more accurate, the fusion process is repeated four times. Finally, an extra Transformer module (ACTM) is added to fuse the feature vectors of the template and search branches. BCTM and ACTM have the same network structure. Here, we will provide a detailed explanation using BCTM as an example.
Figure 5 shows the BCMT module for transformers. The BCMT module utilizes positional encoding to distinguish position information of feature sequences and utilizes a residual-based multi-head cross-attention to integrate feature vectors from different inputs. Additionally, a residual-based feed-forward network (FFN) is employed to obtain the final output. The specific calculation process of the BCMT module is as follows:

Illustration of the transformer cross transformer module.
The calculation process of the CMT module involves \(W \in R^{{{\text{d}} \times N_{x} }}\) and \(W_{KV} \in R^{{{\text{d}} \times N_{KV} }}\) as two inputs from different branches, while \(P_{Q} \in R^{{{\text{d}} \times N_{Q} }}\) and \(P_{KV} \in R^{{{\text{d}} \times N_{KV} }}\) represent spatial positional encodings of \(W_{Q}\) and \(W_{KV}\). The output of the residual multi-head cross-attention and the final output are represented by \(W_{CF}{\prime}\) and \(W_{CF}\), respectively.
After ACTM, we obtain enhanced image features R1 of size 25*25*256. Next, referring to the lower part of Fig. 4, we observe that the image features that have not undergone the CA and SA modules are initially fused separately. For example, fusion of features \(\varphi (X1)\) and \(\varphi (X2)\) results in image feature \(\varphi (X)\) of size 31*31*m. Fusion of features \(\varphi (Z1)\) and \(\varphi (Z2)\) results in image feature \(\varphi (Z)\) of size 7*7*m. Firstly, \(\varphi (X)\) passes through a Transformer attention module (STM). Then, \(\varphi (Z)\) also passes through a Transformer attention module (STM). Finally, we transmit the obtained Q, K, and V to the Transformer attention module (BCTM), from which we can obtain image features R2 of the original image. We perform a CAT operation on R1 and R2, resulting in R:
In Fig. 6, we can observe the self-attention modules for the transformer (STM). These modules begin by incorporating a positional encoding technique to accurately differentiate the position information within feature sequences. Next, they utilize multi-head self-attention to consolidate the feature vectors from various positions. Lastly, a residual form is employed to obtain the output. The specific calculation process of the TS module is described below.
where \(P_{K} \in R^{{{\text{d}} \times N_{x} }}\) denotes the spatial positional encoding obtained through the application of a sine function. \(W \in R^{{{\text{d}} \times N_{x} }}\) represents the input to the TS module, while \(W_{SF} \in R^{{{\text{d}} \times N_{x} }}\) denotes the resulting output after the TS module's operations.

Illustration of the transformer self transformer module.
Anchor-free based bounding box prediction
a. Position prediction head
The location prediction head in Fig. 1 includes classification and regression modules. After passing through the Transformer attention module, we obtain image features of size (*, 256, 25, 25). These features are subsequently used in the location prediction head to generate image features of size (*, 2, 25, 25) and (*, 4, 25, 25) for classification and regression branches, respectively.
b. Training loss
Firstly, we classify the input samples into positive and negative samples. Since negative samples have a lower probability of representing the target, we only perform regression operations on positive samples.
We will determine whether a sample is positive or negative by drawing two ellipses, S1 and S2, around the target. We may obtain an ellipse S1 as illustrated in the equation that follows.
Likewise, we can obtain an ellipse S2:
If a sample point (k, j) lies outside the ellipse S1, it is defined as a negative sample. Conversely, if it lies inside S2, it is defined as a positive sample.
For the coordinates of positive samples, we perform regression operations. In anchor-based regression, we typically compare predicted boxes with ground truth boxes. However, in the anchor-free regression algorithm we employ, we use the following equation for regression calculations.
where \(d_{l}\), \(d_{{\text{t}}}\), \(d_{{\text{r}}}\), \(d_{{\text{b}}}\) and are the distances from that place to the four edges of the surrounding box. For the calculation of the loss function, we use IOU (Intersection over Union). By modifying the coordinates of the predicted bounding box's top-left corner and bottom-right corner, we can obtain the predicted bounding box for each point on the feature map corresponding to the search image. IOU represents the ratio of the intersection area between the ground truth and the predicted bounding box.
If the regression value exceeds 0 and the point (x, y) marked as a positive sample lies within the ellipse S2, then the IOU value falls between 0 and 1.
Tracking
The RGBT series consists of visible light and thermal infrared images. The visible light photos and thermal infrared images undergo a cropping process. The size of the search image is adjusted to 255 × 255 pixels, while the size of the template image is adjusted to 127 × 127 pixels. From these images, two sets are selected, each containing 60 samples (40 negative samples and 20 positive samples), which are the visible light and thermal infrared images.
The first step of the prediction process is to set up the tracker, which handles the first frame. Then, we save the image information of the first frame. The search image (second frame) is processed through the backbone to extract feature maps from the 6th, 7th, and 8th layers, which are then resized to 7 × 7. The feature maps extracted from the visible light and thermal infrared images are separately processed using the SA and CA channel attention mechanisms, preparing them for the next step of operations.
We separately input the extracted unenhanced and enhanced visible light and thermal infrared feature maps into the Transformer Network. Then, after undergoing transformation in the Transformer Network, we perform classification and regression operations on the obtained outputs. By performing regression operations using the following equation:
The top and bottom right corners of the prediction box are (\(P_{x1}\),\(P_{x2}\)) and (\(P_{y1}\),\(P_{y2}\)), respectively, while (\(d_{l}^{reg}\), \(d_{t}^{reg}\),\(d_{r}^{reg}\) and \(d_{b}^{reg}\)) denote the projected values of the regression box. The optimal tracking box is chosen from the generated prediction boxes, and the tracking box coordinates are updated through linear interpolation with the previous frame's state to achieve tracking. After generating the prediction boxes, cosine windows are applied to mitigate significant displacements, and penalties are introduced to discourage substantial changes in size and scale. Through the aforementioned series of operations, we ultimately obtain the best predicted bounding box.
Experiments
Data set and device description
In this study, we will evaluate our model by testing it on two datasets, GTOT1 , RGBT21016 and RGBT234.
Using PyTorch and two GTX 3080-Ti cards for training, the algorithm is put into practice. The search region's input size was 255 pixels, whereas the template's input size was 127 pixels for comparison's sake. we build a training subnetwork with the ResNet-50 as its core. Using ImageNet, the network had already been trained. The pre-trained weights served as an initialization for our model's further training.
Compared with SOTA RGB-T tackers
Compared anchor-based methods
We carefully selected a series of Anchor-Based supervised RGB-T trackers for comparison. These include HMFT22, CMPP23, DMCNet27, JMMAC26, CBPNet33, MaCNet25, MANet34, CMP35, MFGNet36, DAPNet37, mfDiMP38, LTDA31, DuSiamRT39, TCNN29, JCDA-InvSR30, and SiamDW47 + RGBT.
To broaden the scope of comparison, we also included transformer-based method APFNet48 and non-deep RGB-T trackers, such as CMCF40, NRCMR32, CMR41, SGT42, the method proposed by Li et al.43, CSR32,44, MEET45 + RGBT, and KCF46 + RGBT. This selection encompasses a wide range of RGB-T methods across various categories.
Results on GTOT
The method of this study further concludes the tracking on the GTOT dataset, which contains 50 different video sequences and considers different environmental conditions, as shown in Table 1
Figure 7 shows the comparison results of our proposed model with other anchor-based models on the GTOT datasets.

The results of our proposed model compared to other Anchor-Based models on the GTOT datasets, (a) Precision Rate; (b) Success Rate.
Table 3 displays the tracking results on the GTOT dataset. In terms of these two metrics, our RGB-T tracker achieves almost superior success rates compared to all Anchor-Based RGB-T trackers. However, we also notice that our results in accuracy are not high. The performance gap between our supervised RGB-T tracker and the state-of-the-art can be attributed to their usage of large-scale annotated RGB-T image pairs for training. Additionally, these trackers employ more complex models. In the future, we will modify our model to improve accuracy.
Results on RGBT210
The tracking outcomes of this technique using the RGBT210 data set are shown in Fig. 8. 210 real-label visible and thermal infrared video clips are included in RGBT210. This data collection takes a lot of difficult cases into account, as illustrated in Table 25.

The results of our proposed model compared to other Anchor-Based models on the RGBT210 datasets. (a) Precision Rate; (b) Success Rate.
By performing validation on the RGBT210 dataset, Fig. 8 shows that our tracker beats all trackers.
Results on RGBT234
The results on the RGBT234 dataset, presented in Table 3, demonstrate that our proposed RGB-T tracker outperforms both supervised and non-learning-based RGB-T trackers in terms of MSR. However, its performance on RGBT234 is relatively weaker compared to the GTOT dataset. This discrepancy can be attributed to the increased challenges posed by RGBT234, which comprises 234 images and encompasses 12 challenging attributes, surpassing the 7 attributes of GTOT. On the RGBT234 dataset, our model was compared to other Anchor-Based models. The comparison results show that we have achieved almost superior performance compared to all algorithms. However, it is worth noting that we have lower accuracy in certain aspects. To address this performance gap, our future work aims to explore better backbone trackers and larger training datasets.
By performing validation on the RGBT234 dataset, Fig. 9 shows that our tracker beats all trackers.

The results of our proposed model compared to other Anchor-Based models on the RGBT234 datasets. (a) Precision Rate; (b) Success Rate.
Attribute-based results
The performance of the challenging attributes on the RGBT234 dataset is shown in Figs. 10 and 11.


The figure illustrates the comparison of our model's accuracy against other state-of-the-art Anchor-Based models on 12 challenging attributes in the RGBT234 dataset.


The figure demonstrates the comparison of our model's success rate against other state-of-the-art Anchor-Based models on 12 challenging attributes in the RGBT234 dataset.
It can be observed that our RGB-T tracker achieves highly competitive performance in various aspects. In the MSR graph of the challenging attributes, our model performs well in most attributes except for TC, PO, NO, and LI, where it is not as effective as other models. However, our model performs well in the remaining attributes. In the MPR graph of the challenging attributes, our model performs poorly in SV, PO, and NO, but demonstrates excellent performance in the other nine attributes. Overall, our model faces challenges in dealing with PO and NO, indicating areas for improvement in our future work.
Qualitative results
As shown in Fig. 12, our RGB-T tracker is compared qualitatively with other anchor-based RGB-T trackers on the RGBT210 dataset. The images in Fig. 12 are sourced from the RGBT210 dataset17. We would like to express our gratitude to LI17 for making the dataset publicly available. We selected several RGB-T trackers, including SOWP18, SOWP + RGBT, KCF19 + RGBT, CSR20, SGT, and MEEM21 + RGBT. It can be seen from the figure that our RGB-T tracker performs better on these three sequences (Baketballwaliking , Balancebike, car41).

Results of an experimental assessment of the RGBT210.
Ablation studies and analysis
As shown in Fig. 13, these are the results of our ablation experiment. In this experiment, we used the RGBT234 dataset as the training set and the GTOT dataset as the test set. From the graph, we can obtain the following information: the experimental results without adding any module are significantly worse compared to the experimental results with the modules added. In the PR score graph, the experimental results of "ours-GTOT-SA" and " ours-GTOT-CA" are significantly better than the experimental results of "ours-GTOT-no (CA-SA-TS)", indicating that adding the SA and CA modules helps improve the accuracy of the tracker. In the SR score graph, we found that the experimental results of "ours-GTOT-SA" are better than those of " ours-GTOT-no (CA-SA-TS)". However, the experimental results of "our-ca" have decreased compared to "ours-GTOT-no (CA-SA-TS)", indicating that adding the CA module does not help improve the success rate of the tracker, but it still has an effect on improving the accuracy of the tracker. In this experiment, the experimental results of "ours-AFTS" are the highest, indicating that the TS module has a significant impact on improving the success rate of the tracker.

Results of Ablation experiment. ours-GTOT–SA represents the experimental results with only the SA module adds ours-GTOT–CA represents the experimental results with only the CA module added. ours-GTOT–no (CA–SA–TS) represents the experimental results without adding any module; ours-GTOT–(CA–SA)-no (TS) represents the experimental results with only the SA and CA module added. ours-AFTS represents the model with all modules included.
Conclusion
This paper introduces a novel approach for RGBT tracking, specifically an adaptive tracker based on the Transformer model with dual-Siamese architecture and anchor-free design.
The proposed method incorporates Transformer attention mechanism to replace the correlation operation in the Siamese network, leading to improved tracking success rate. By eliminating candidate boxes and reducing human-induced interference, our approach effectively addresses the limitations of Anchor-Based methods while eliminating the need for many hyperparameters. Experimental results demonstrate the reliability of the proposed algorithm, which successfully exploits the complementary information from visible light and thermal infrared modalities. As part of our future work, we are exploring the integration of RGBD tracking design, aiming to expand the application scope and enhance the performance in challenging scenarios.
Data availability
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- Siam AFTS:
-
we propose that we build a new tracker for RGB-T target tracking based on the siamese network, called Anchor-Free based Transformer network System (Siam AFTS)
- RGB-T:
-
RGB-T images refer to the fact that each set of images consists of a combination of images of both visible and thermal infrared light modes
References
Li, C. et al. Learning collaborative sparse representation forgrayscale-thermal tracking. IEEE Trans. Image Process. 25(12), 5743–5756 (2016).
Li, C., Xiaohao, Wu., Zhao, N., Cao, X. & Tang, J. Fusing two-stream convolutional neural networks for RGB-t object tracking. Neurocomputing 281, 78–85 (2018).
Zhang, X. et al. Corrections to “SiamFT: An RGB-infrared fusion tracking method via fully convolutional siamese networks”. IEEE Access 7, 144799–144799 (2019).
Guo, C., Yang, D., Li, C. & Song, P. Dual siamese network for RGBT tracking via fusing predicted position maps. Vis. Comput. 38(7), 2555–2567 (2021).
Zhu, Y., Li, C., Luo, B., Tang, J. and Wang X. Dense feature aggregation and pruning for RGBT tracking. in Proceedings of the 27th ACM International Conference on Multimedia. ACM, 2019.
He, A., Luo, C., Tian, X. and Zeng, W. A twofold Siamese network for real-time object tracking. in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2018.
Li, B., Wu, W., Wang, Q., Zhang, F., Xing, J. and Yan, J. SiamRPN: Evolution of Siamese visual tracking with very deep networks. in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019.
Li, B., Yan, J., Wu, W., Zhu, Z., and Hu, X. High performance visual tracking with siamese region proposal network. in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2018.
Valmadre, J., Bertinetto, L., Henriques, J., Vedaldi, A. and Philip, H. S. Torr. End-to-end representation learning for correlationfilter based tracking. in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017.
Zhu, Z., Wang, Q., Li, B., Wu, W., Yan, J. and Hu, W. Distractor-aware siamese networks for visual object tracking. in Computer Vision – ECCV 2018, pages 103–119. Springer Inter-national Publishing, 2018.
Shen, L. et al. RGBT tracking based on cooperative low-rank graph model. Neurocomputing 492, 370–381 (2022).
Zhang, X., Ye, P., Peng, S., Liu, J. & Xiao, G. DSiamMFT: An RGB-t fusion tracking method via dynamic siamese networks using multi-layer feature fusion. Signal Proc. Image Commun. 84, 115756 (2020).
Zhu, Y., Li, C., Tang, J. & Luo, B. Quality-aware feature aggregation network for robust RGBT tracking. IEEE Trans. Intell. Veh. 6(1), 121–130 (2021).
Feng, M., Song, K., Wang, Y., Liu, J. & Yan, Y.-H. Learning discriminative update adaptive spatial-temporal regularized correlation filter for RGB-t tracking. J. Vis. Commun. Image Represent. 72, 102881 (2020).
Ma, C., Huang, J.-B., Yang, X. & Yang, M.-H. Robust visual tracking via hierarchical convolutional features. IEEE Trans. Pattern Anal. Mach. Intell. 41(11), 2709–2723 (2019).
X. Chen, B. Yan, J. Zhu, D. Wang, X. Yang, H. Lu, Transformer tracking, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8126–8135.
Chenglong Li, Nan Zhao, Yijuan Lu, Chengli Zhu, and Jin Tang. Weighted sparse representation regularized graph learning for RGBT object tracking. In Proceedings of the 25th ACM international conference on Multimedia. ACM, 2017.
Han-Ul Kim, Dae-Youn Lee, Jae-Young Sim, and Chang-Su Kim. SOWP: Spatially ordered and weighted patch descriptor for visual tracking. in 2015 IEEE International Conference on Computer Vision(ICCV). IEEE, 2015.
Henriques, J. F., Caseiro, R., Martins, P. & Batista, J. High-speed tracking with Kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 37(3), 583–596 (2015).
Li, C., Sun, X., Wang, X., Zhang, L. & Tang, J. Grayscale-thermal object tracking via multitask Laplacian sparse rep-resentation. IEEE Trans. Syst. Man Cybern. Syst. 47(4), 673–681 (2017).
Zhang, J., Ma, S. and Sclaroff, S. MEEM: Robust tracking via multiple experts using entropy minimization. In Com-puter Vision – ECCV 2014, pages 188–203. Springer International Publishing, 2014.
P . Zhang, J. Zhao, D. Wang, H. Lu, and X. Ruan, “VisibleThermal UA V Tracking: A large-scale benchmark and new baseline,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8886– 8895.
C. Wang, C. Xu, Z. Cui, L. Zhou, T. Zhang, X. Zhang, and J. Yang, “Cross-modal pattern-propagation for RGB-T tracking,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 7064–7073
Xiao, Y., Yang, M., Li, C., Liu, L. and Tang, J. “Attributebased progressive fusion network for RGBT tracking,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2022.
Zhang, H., Zhang, L., Zhuo, L. & Zhang, J. Object tracking in RGB-T videos using modal-aware attention network and competitive learning. Sensors 20(2), 393 (2020).
Zhang, P. et al. Jointly modeling motion and appearance cues for robust RGBT tracking. IEEE Trans. Image Process. 30, 3335–3347 (2021).
Lu, A., Qian, C., Li, C., Tang, J. & Wang, L. Dualitygated mutual condition network for RGBT tracking. IEEE Trans. Neural Netw. Learn. Syst. https://doi.org/10.1109/TNNLS.2022.3157594 (2022).
Li, C. et al. Learning collaborative sparse representation for grayscale-thermal tracking. IEEE Trans. Image Process. 25(12), 5743–5756 (2016).
Li, C., Wu, X., Zhao, N., Cao, X. & Tang, J. Fusing two-stream convolutional neural networks for RGB-T object tracking. Neurocomputing 281, 78–85 (2018).
Kang, B., Liang, D., Ding, W., Zhou, H. & Zhu, W.-P. Grayscale-thermal tracking via inverse sparse representationbased collaborative encoding. IEEE Trans. Image Process. 29, 3401–3415 (2019).
Yang, R., Zhu, Y., Wang, X., Li, C. and Tang, J. “Learning target-oriented dual attention for robust RGB-T tracking,” in 2019 IEEE International Conference on Image Processing (ICIP). IEEE, 2019, pp. 3975–3979.
Li, C., Xiang, Z., Tang, J., Luo, B. & Wang, F. RGBT tracking via noise-robust cross-modal ranking. IEEE Transactions on Neural Networks and Learning Systems 33(5019), 5031 (2021).
Xu, Q., Mei, Y., Liu, J. & Li, C. Multimodal cross-layer bilinear pooling for RGBT tracking. IEEE Trans. Multimedia 24, 567–580 (2021).
Li, C., Lu, A., Hua Zheng, A., Tu, Z. and Tang, J. “Multi-adapter RGBT tracking,” in Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019, pp. 0–0.
Yang, R., Wang, X., Li, C., Hu, J. & Tang, J. RGBT tracking via cross-modality message passing. Neurocomputing 462, 365–375 (2021).
Wang, X., Shu, X., Zhang, S., Jiang, B., Wang, Y., Tian, Y. and Wu, F. “MFGNet: Dynamic modality-aware filter generation for RGB-T tracking,” IEEE Trans. Multimedia, 2022.
Zhu, Y., Li, C., Luo, B., Tang, J. and Wang, X. “Dense feature aggregation and pruning for RGBT tracking,” in Proceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 465–472.
L. Zhang, M. Danelljan, A. Gonzalez-Garcia, J. van de Weijer, and F. Shahbaz Khan, “Multi-modal fusion for end-to-end RGBT tracking,” in Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019, pp. 0–0.
Guo, C., Yang, D., Li, C. & Song, P. Dual Siamese network for RGBT tracking via fusing predicted position maps. Vis. Comput. 38(7), 2555–2567 (2022).
Zhai, S., Shao, P., Liang, X. & Wang, X. Fast RGB-T tracking via cross-modal correlation filters. Neurocomputing 334, 172–181 (2019).
Li, C., Zhu, C., Huang, Y., Tang, J. and Wang, L. “Cross-modal ranking with soft consistency and noisy labels for robust RGBT tracking,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 808–823.
Li, C., Zhao, N., Lu, Y., Zhu, C. and Tang, J. “Weighted sparse representation regularized graph learning for RGB-T object tracking,” in Proceedings of the 25th ACM international conference on Multimedia, 2017, pp. 1856–1864.
Li, C., Zhu, C., Zheng, S., Luo, B. & Tang, J. Two-stage modality-graphs regularized manifold ranking for RGB-T tracking. Signal Process. Image Commun. 68, 207–217 (2018).
Shen, L. et al. RGBT tracking based on cooperative low-rank graph model. Neurocomputing 492, 370–381 (2022).
Zhang, J., Ma, S. and Sclaroff, S. “MEEM: robust tracking via multiple experts using entropy minimization,” In European conference on computer vision. Springer, 2014, pp. 188–203.
Henriques, J. F., Caseiro, R., Martins, P. & Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 37(3), 583–596 (2014).
Zhang, Z. and Peng, H. “Deeper and wider siamese networks for real-time visual tracking,” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4593–4610.
Li, C., Liang, X., Lu, Y., Zhao, N. & Tang, J. RGB-T object tracking: Benchmark and baseline. Pattern Recogn. 96, 106977 (2019).
Author information
Authors and Affiliations
Contributions
L.F.: Conceptualization of this study, Methodology, Software. P.K.: As the corresponding author, P.K. is primarily responsible for designing the research plan, planning the experiments, coordinating and communicating with the collaborators, and other related tasks.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fan, L., Kim, P. Anchor free based Siamese network tracker with transformer for RGB-T tracking. Sci Rep 13, 13294 (2023). https://doi.org/10.1038/s41598-023-39978-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-39978-7
- Springer Nature Limited
This article is cited by
-
Retraction Note: Dual Siamese Anchor Points Adaptive Tracker with Transformer for RGBT Tracking
International Journal of Computational Intelligence Systems (2024)