
Abstract
Due to environmental conditions, such as rainy days, foggy days, and dim lighting, objects in visible light images are not prominently displayed, leading to an easy loss of targets during tracking. In recent years, many RGB visible light trackers have achieved significant success in addressing visual tracking challenges. However, these trackers perform poorly when tracking targets under special conditions, such as occlusions and low-light scenarios. In contrast, objects in thermal infrared images are more distinct in poor lighting conditions. Given this characteristic, researchers have shown increased interest in the development of trackers that combine thermal infrared and visible light imagery. However, some mainstream RGBT (red–green–blue and thermal) algorithms, such as MANET and ADNET, are based on the anchor-based theory, requiring consideration of anchor box sizes and introducing a substantial number of hyperparameters. This can lead to suboptimal performance when tracking dynamically changing targets. Moreover, these models rely on convolutional neural networks for feature extraction, which have limitations in capturing global features. In this paper, we introduce a novel training network model called DAPAT, which combines the anchor-free concept with Transformer theory. DAPAT differs from previous models in several ways. Specifically, we have designed a straightforward model to extract precise global features from template and search images. We have also incorporated two enhancement modules into the model to improve template and search images of different sizes while suppressing the impact of non-target images. We employ a dual-stream feature fusion network to reduce the loss of image feature information due to feature correlation operations. Finally, we compare the performance of the tracking model proposed in this paper with some advanced RGBT trackers on three data sets (RGBT234, RGBT210, and GTOT). The test results demonstrate that our tracker exhibits improvements in robustness and success rate, among other performance aspects.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Visual tracking has drawn immense interest from the academic community due to its applicability in areas, such as self-driving vehicles and drone surveillance. Most recent advancements in this domain primarily revolve around RGB-based tracking. In previous years, a plethora of inventive tracking methods emerged [1,2,3]. Yet, strategies relying solely on RGB often falter in difficult environments. This largely stems from the tracker's dependence on comparing successive frames for consistency [4]. In instances of obstructions, poor lighting, or image blurriness, RGB visuals may provide inadequate data, complicating the tracking process. To overcome such hurdles, integrating visible light with thermal imagery, termed RGBT tracking, is being rigorously explored [5], driven by factors like:
-
1.
RGB and thermal captures, though from identical scenes, present diverse visual data, enabling a multifaceted feature insight.
-
2.
Technological advancements in computing and thermal imaging have led to sharper thermal visuals, bolstering the potential of RGBT tracking.
The introduction of several RGBT tracking solutions indicates ongoing issues in the field. Strengthening their precision and efficiency remains a priority. Diverse methods have emerged to merge data from RGB and thermal channels. Some scholars have integrated Siamese structures into RGBT systems for efficient data blending. For example, Zhang and team [6] modified SIAMRPN + + [7] to accommodate RGBT inputs. Beginning with an RGB-focused tracking mechanism, they then expanded the system to accommodate RGB-T pairs using a basic CONCAT method. Both Lu's team [8] and Xu's group [9] ventured down similar paths. Within Siamese models, positional forecasts hinge on analyzing the target against a reference image. Solely harnessing local data in this method could omit crucial broader context, complicating boundary identification and diminishing tracker effectiveness. Conversely, several experts have pursued alternative integration tactics. Li and associates' MANET [10] directly linked RGB and thermal features before processing them through a neural network. Wang's group [11] innovated on solo-mode trackers, formulating a dual-mode version. Zhu and colleagues [12] conceived an attention-driven fusion system, autonomously refining the neural sensitivity during the blending phase. Yet, such direct fusion might cap the model's capabilities, bypassing intricate image nuances, potentially undermining the tracker's efficiency.
Presently, a multitude of tracking systems amalgamate CNN designs with RGBT mechanisms, notable ones being APFNET [13], MDNET [14], and MANET + + [8]. These CNN-centric trackers might overlook comprehensive data insights. Given that they often fixate on the initial frame's configuration, discerning distinct target characteristics becomes tough. It implies a continuous hold on intricate details, presenting dilemmas when distinguishing between the subject and surrounding elements. In opposition, transformer designs with attention elements bypass such constraints, grasping data in its entirety. Plus, transformers' bidirectional structure fosters better inter-modal dialogues, showcasing exemplary performance across data sets. However, these systems often lean on the ANCHOR technique, mandating predefined anchor frames. This not only elevates hyperparameter count but also complicates predictions during notable target size alterations.
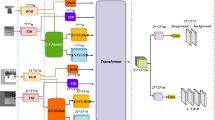
In this paper, we introduce a straightforward yet effective visual tracking framework to address the challenges of estimating the target's scale and predicting its position under poor lighting conditions. The proposed tracker primarily consists of four components: the backbone network, Transformer feature fusion network, attention network, and the prediction head network. As illustrated in Fig. 1, we use the backbone network to extract features separately from RGB images and thermal infrared images. The extracted features mainly encompass the target template features and search features from both types of images. To minimize the loss of crucial information during transmission, we feed the target template features into the FEM. To diminish the interference from non-target features on tracking, we have also incorporated an NNSM within the network. Given the successful application of attention theory in RGB trackers, we have added a Transformer module to our model to tackle various challenges in multi-modal tracking. This module substantially reduces image feature losses caused by cross-correlation operations. After fusing the extracted RGB and thermal infrared features through the Transformer module, we obtain a 25 × 25 feature map. Many cutting-edge algorithms (such as MANET, DAPNET, and ADNET) currently adopt the anchor-based approach. In this paper, we experiment with the anchor-free approach, creating both classification and regression modules. As depicted in Fig. 1, the primary purpose of the classification module is to categorize every point in the image, distinguishing them as target points or non-target points. The regression module is mainly utilized to predict the bounding box.

Overall frame construction
The efficacy of the proposed framework is validated on three benchmark data sets: GTOT, RGBT210, and RGBT234. On GTOT, compared to anchor-based methods (HMFT and CMPP), our approach achieves relative improvements of up to 5.4% and 5.8% on the crucial tracker evaluation metric SR (Success Rate). On RGBT234, relative to anchor-based methods (DMCNET and APFNET), our method achieves relative improvements of up to 3% and 5.4% on the SR metric. As demonstrated in Table 4, our tracker's performance is competitive compared to recent anchor-based advanced techniques on standard data sets. As shown in Table 4, our tracker can operate at a speed of 40.3 FPS (Frames Per Second). The test results demonstrate that our tracker, in terms of time efficiency, outperforms many advanced anchor-based trackers and is competitive.
Subsequently, to assess the tracker's robustness in various lighting conditions, we further carried out evaluations on the RGBT234 benchmark data set under 12 distinct lighting conditions (represented by the 12 metrics in Table 2). We juxtaposed its performance with other state-of-the-art trackers. In conclusion, given that different modules might impact the model's efficacy, we also undertook ablation studies to discern the influence of distinct modules on the tracker.
In summary, our main contributions are as follows:
-
(1)
We've designed an end-to-end anchor-free offline tracking training model. Traditional anchor-based approaches might generate an excessive number of overlapping candidates, leading to redundancy during detection. Our approach minimizes this redundancy, enhancing detection efficiency. Our tracker is adept at managing targets of various sizes and shapes, showcasing superior generalization capabilities. Furthermore, the model can dynamically adjust the predicted bounding box dimensions and shape, thereby honing in on the target more accurately. By merging transformers with anchor-free, we have addressed issues of imprecise localization.
-
(2)
We have devised the FEM and NNSM modules. The FEM module effectively enhances target features. The NNSM module aims to reduce the interference of non-target features on the overall tracking performance. Ablation studies confirm that our specially designed modules contribute to increased accuracy and success rates.
-
(3)
The tracker we propose employs a transformer model that differs structurally from previously advanced transformers. This model extracts features separately from RGB images and thermal infrared images, which aids in preserving global information, reducing the chance of local information loss that can lead to tracking failures. As a result, the success rate of target tracking has seen notable improvement, especially when confronting various challenging attributes.
-
(4)
We conducted a comparative analysis with other advanced models on the standard data sets GTOT, GBT210, and RGBT234. The outcomes indicate that, while our tracker shows some disparities when juxtaposed with certain cutting-edge RGBT algorithms, it demonstrates enhanced stability when faced with diverse environmental challenges, proving its competitive merit.
2 Related Work
2.1 The Theory of Anchor-Free-Based Methods
The anchor-free technique has gained considerable attention in the field of object detection due to its notable advantages in both design simplicity and performance [15,16,17]. However, such a technique is not new. In 2015, DENSEBOX [18] was the first to propose an FCN solution for face detection. Currently, numerous novel anchor-free detection methods have emerged.
On one hand, these methods are based on specific point object detection [16, 19, 20]. For instance, CORNERNET [16] advocates for identifying the scope of an object using a set of specific points, such as central positions [15] or corner points [16]. EXTREMENET [20], on the other hand, employs a conventional-specific point evaluation network to identify the four corners and center of the object. Some other methods adopt anchor-free detection means [17, 21], directly determining the scope of the target on each pixel without relying on anchors or specific points as reference standards. Another category is density-based detection [17, 22]. The widespread application of the anchor-free technique in the domain of object detection, as well as its method application in some single-mode RGB trackers [23], has greatly inspired us. We attempt to apply the anchor-free approach to the challenges of RGBT multi-modal trackers.
In object detection, the anchor-free detection strategy usually assumes the category of the target is known. However, at the start of object tracking, the target category is not yet determined. Therefore, our strategy requires the design of a classification module mechanism to distinguish between the target and non-target. In addition, our adopted anchor-free strategy was influenced by the method [17].
2.2 Transformer Tracking Methods
The Transformer, initially designed as a neural network architecture for addressing NLP problems (Vaswani et al. [24]), has been extensively applied to a variety of computer vision tasks in recent years, including object tracking. Carion [25] introduced an end-to-end object detection model fully based on the Transformer, abandoning traditional object detection methods, such as R-CNN and its variants. Through the use of the Transformer, DETR can directly output bounding boxes of objects and their corresponding classes on an image. Chen et al. [1] proposed a Transformer model applied directly to object tracking in Trans-T. Trans-T employs a lightweight Transformer structure, effectively addressing the object tracking problem. Zhou et al. [26] introduced a point-based object tracking model, but it laid a framework for subsequent use of the Transformer in multi-object tracking. This research emphasized the efficacy of detecting and tracking objects as points. The Transformer architecture has introduced new perspectives and possibilities for object tracking. Although it is a relatively new research field, the Transformer has already showcased its potential in object tracking. Inspired by the aforementioned studies, we aim to explore how to leverage the Transformer to enhance multi-modal features. Unlike previous Transformer models, we designed an enhanced feature fusion transformer module, composed of 2 encoders and 1 decoder, which can amplify modality-specific features.
3 Proposed Method
In this section, we provide a brief description of the proposed method. As depicted in Fig. 1, the model introduced in this paper primarily consists of four components. These are: the backbone network, Transformer feature fusion network, attention network, and the prediction head network.
As shown in Fig. 1, initially, due to the relatively large size of the benchmark data set images, we need to perform preprocessing on the images. Specifically, we convert the visible light images and thermal images from the benchmark data set into template images of 127 pixels and search images of 512 pixels, respectively. The visible light and thermal infrared images are separately processed by the feature extraction module of the backbone network to produce 7 × 7 template feature maps and 31 × 31 search feature maps. The 7 × 7 pixel visible light and thermal infrared template feature maps are input into the FEM (Feature Enhancement Module) module, which aims to minimize information loss during the transmission process. Then, the 31 × 31 pixel visible light and thermal infrared search feature maps are input into the NNSM (non-target feature suppression module), which aims to reduce the interference of background features on the target features.
After passing through the FEM and NNSM modules, the extracted feature maps are further enhanced. We incorporate a Transformer module in the model, specifically designed for target tracking. This module enables more precise extraction of global feature information, reducing the influence of local information on the results. In addition, it can replace cross-correlation operations, reducing the loss of image feature information caused by correlation operations. After further fusion of the feature maps using the Transformer module, we obtain enhanced feature maps of size 25 × 25 pixels.
Next, we will proceed with further operations on the 25 × 25 enhanced feature maps. The prediction head network consists of two parts: the classification module and the regression module. Since tracking tasks require classification before tracking, as shown in the diagram, the fused feature information is divided into tracking targets and non-tracking targets through the action of the classification module. This allows us to determine the tracking target for each frame. To obtain the position of the predicted object bounding box, we input the fused feature information into the regression module. Ultimately, we can obtain a relatively accurate prediction of the bounding box.
In the following subsections, we will provide detailed explanations of the main modules within the structure.
3.1 Design of the Backbone Network Model
As shown in Fig. 1, the backbone network requires the input of four sets of image information. Before training, we need to modify the dimensions of the images in the benchmark data set. The original size of the images in the benchmark data set is 630 × 460. Through the operations of the cropping module, we first categorize the images in the benchmark data set into target images and search images. Then, through resizing, we uniformly change the dimensions of our target information images to 127 × 127 and the dimensions of our search information images to 512 × 512. In this way, we obtain four sets of input image information, namely, GX (visible light search information image), GZ (visible light target information image), TX (thermal infrared search information image), and TZ (thermal infrared target information image).
Next, we input the four sets of input image information into the feature information pre-extraction network built with ResNet-50 [16]. CF [18] has demonstrated that designing a network to pre-extract feature information is beneficial for target localization. This part of the network mainly consists of a low-level information feature extraction network, Layers2, and a high-level information extraction network, Layers4. The Layers2 network is sensitive to the local features and details of the target, while the Layers4 network is helpful for understanding the overall features and semantics of the target. To enhance the resolution of the feature images, we also introduce the principle of dilated convolution [17] in the Layers2 and Layers4 networks. Dilated convolution can increase the receptive field. We design the dilation factors as 2 and 6, respectively.
As shown in Fig. 1, we input the feature information extracted by the Layers2 and Layers4 networks into the FFM (Feature Fusion Module) for the fusion of information from different layers. The FFM module can reduce the computational load of the model and improve tracking performance. The output features of the backbone network are labeled as Gz (7 × 7) and Tz (7 × 7), Gx (31 × 31) and Tx (31 × 31). The following equations represent the fusion of feature information:
where the appropriate weight values for each feature map are α and β.
3.2 Attention Module
Figure 2 illustrates the FEM (Feature Enhancement Module) we created. We take Gz and Tz, which are derived from the backbone network, and feed them as inputs into the FEM module. Using the CAT operation, we concatenate the features of Gz and Tz. Subsequently, we obtain a concatenated feature termed 'Unit'. The feature dimension of Unit is H × L × 2 M. As depicted in Fig. 2, first, we pool the Unit using δ and apply a fully connected operation ω. Then, we input the feature into the activation function ɛ. After undergoing a nonlinear transformation, we achieve an enhanced combined feature named Unit1. With both the enhanced combined feature Unit1 and the original Unit, we apply weights to each channel. Specifically, this involves executing the ⊗ operation on these multi-channel feature maps, which equates to the independent multiplication of values for each channel. By leveraging the interdependencies among the feature channels, we can enhance the features. Ultimately, we obtain a finalized enhanced feature map(H × L × 2 M). After performing the split operation 'sp', we acquire the outputs \(U_{RGB}\) and \(U_{TIR}\). The subsequent formula depicts the entire information flow process:

FEM model
Figure 3 illustrates the NNSM (non-target noise suppression module) we developed. We take URGB and UTIR, which are outputs from the FEM module, as inputs into the NNSM module. Similarly, using the CAT operation, we concatenate URGB and UTIR to produce a connected feature called \(Unit_{N}\). The feature dimension of Unit is also H × L × 2 M. As shown in Fig. 3, we first perform a max pooling operation denoted as "ϕ" on \(Unit_{N}\) to derive feature X with dimensions H × L × 1. Subsequently, we apply an average pooling operation, denoted as “ρ”, on \(Unit_{N}\) to obtain feature Y with dimensions H × L × 1. We then concatenate X and Y using the CAT operation to produce a feature with dimensions H × L × 2. Following this, through a 2-D convolution operation denoted as “φ”, we obtain an enhanced feature channel with dimensions H × L × 1, where "K" represents the weights. Next, we feed this feature into the activation function ε. After undergoing a nonlinear transformation, we obtain an enhanced combined feature called \(Unit1_{N}\). With both the enhanced \(Unit1_{N}\) and the original \(Unit_{N}\), we aim to exploit the spatial relationship between features to suppress non-target noise. By performing a broadcasting operation ("\(\odot\)"), we can apply the enhanced \(Unit1_{N}\) to every spatial position of the original \(Unit_{N}\), achieving spatial transformation of the image.

NNSM model
In the end, we obtain a final enhanced feature channel map. After the splitting operation denoted as "sp", we can derive outputs \(U_{RGB}^{N}\) and \(U_{TIR}^{N}\). The following formula represents the entire information flow process:
3.3 Transformer Feature Fusion Network
As shown in Fig. 4, we have designed a Transformer fusion network for feature extraction. The outputs \(U_{RGB}\),\(U_{TIR}\), \(U_{RGB}^{N}\), and \(U_{TIR}^{N}\) from FEM and NNSM serve as the input to this module. Feature vectors are fed into the Transformer module. First, \(U_{RGB}\) is used as input for k1 and v1, and \(U_{TIR}^{N}\) serves as the input for Q1, both of which are fed into the attention module (FCTM). After feature extraction by the FCTM module, we obtain the output Q. Next, \(U_{TIR}\) is used as input for k2 and v2, and \(U_{RGB}^{N}\) serves as the input for Q2, both of which are fed into the attention module (U-CTM). After feature extraction by the U-CTM module, we obtain the output KV. Finally, we input K, V, and Q into the BCTM, and the output is denoted as Y. The BCTM is used to fuse the feature vectors of the template and search branches.

Transformer model
For the readers to implement and understand our module structure, we will provide pseudocode for the Transformer module below.

The U-CTM and BCTM modules have the same structure as compared to the FCTM, with the only difference being the input and output data. In this paper, we provide a detailed explanation of the information processing process for the FCTM module. The structure of the FCTM module is shown in Fig. 5. This module is used for processing information from different input sequences and facilitating information transfer between sequences. First, the FCTM module takes two input sequences (values of K1, V1, and Q1) and computes the correlation scores with each element in the key-value sequence. By applying the attention scores to the corresponding elements of the value sequence, it assigns a weighted sum to each query element. "Multi-attention" represents multi-head attention, and through the concatenation or weighting of the multi-attention module, the final attention output Q is obtained. The dimension of Q is 7 × 7 × m.

Module is FCTM
Similarly, the U-CTM module takes two input sequences (values of K2, V2, and Q2) and undergoes the same feature extraction process, resulting in the output of K and V. The dimensions of K and V are 31 × 31 × m.
Finally, we input K, V, and Q into the BCTM module to fuse the previously extracted features. The fused output is denoted as Y, with dimensions of 25 × 25 × m.
The entire process of feature information flow in the CTM module is described by the following equations:
As shown in Fig. 5, \(T_{Q}\) and \(T_{KV}\) represent the inputs, \(e_{Q}\) and \(e_{KV}\) represent the positional encodings, and \(T_{out}\) represent the outputs.
3.4 Position Prediction Head and Loss Functions
As shown in Fig. 1, the prediction head module mainly consists of a classification module and a location prediction module. In this subsection, we will explain how the tracker performs classification and location prediction for the target separately.
Classification: Unlike object detection algorithms, we need to classify the target before tracking. We use the output obtained by fusing the Transformer module as input data to the prediction head module, resulting in a shape of \(T_{out}\)(*, 256, 25, 25).
Using the linear equations for ellipses, as shown in the following formula, we draw two elliptical regions, Y1 and Y2, on the feature map with the target template as the center. The Y2 region encompasses the Y1 region:
In the above, \(X_{x}\),\(X_{y}\),\(X_{w}\) and \(X_{h}\), respectively, represent the (x, y, w, h) of a certain point X in the feature map.
We consider the area within Y2 to be highly likely to contain the target, so we refer to the points within Y2 as target points. On the other hand, points outside the Y2 region are referred to as non-target points. Using the classification module, we obtain feature information with an output size of (*, 2, 25, 25).
3.4.1 Location Prediction
To start, using the formula mentioned earlier, it is straightforward to calculate the distance from a point within Y2 to its surrounding boundaries. As shown in the formula below, this allows us to obtain four coordinate points for predicting the bounding box:
where \(X_{{{\text{Lx}}}}\) and \(X_{Ly}\) represent the coordinates of the top-left corner of a certain point X, and \(X_{{{\text{r}}x_{{}} }}\) and \(X_{{{\text{r}}y}}\) represents the coordinates of the bottom-right corner of a certain point X.
We continuously compare the predicted bounding box with the actual bounding box and calculate the Intersection over Union (IOU) value between the two regions. Finally, we output the coordinate points with an IOU value close to 1. The output has dimensions of (*, 4, 25, 25).
In this paper, to better utilize the features from visible light and thermal infrared images and achieve complementarity between thermal infrared features and visible light features, we calculate the Intersection over Union (IOU) loss separately for both visible light and thermal infrared features. This enables accurate object tracking on both visible light and thermal infrared images.
We will set \(\lambda\) to be 0.5. Finally, the calculation of the loss function is as shown in the formula below:
We set the value of \(\eta\) and \(\delta\) to be 0.4 and 0.6. Finally, the calculation of the loss function is as shown in the following formula:
3.5 RGBT Tracker Testing
After offline model training, we need to test the model on benchmark data sets. Prior to testing, it is essential to perform uniform cropping on the images in the benchmark data set. After cropping, the target template image size is set to 127, and the search image size is 512. The key step in tracking is predicting the target's position. We input the benchmark data sets GTOT, RGBT234, and RGBT210 into the tracker shown in Image 1.
The image sequences in the benchmark data set are continuous. Predicting the target's position is achieved by extracting features from the search image based on the target's previous position in the current frame. Since there are no reference images before the first frame, the first frame does not participate in the calculation. We need to extract the features of the target's position from the first frame image based on the target template image. In the second frame, the search image is cropped and features are extracted based on the target's position obtained from the first frame image. This process is repeated for each subsequent frame, and the extracted features are mapped onto the search image for position prediction.
We can use Eq. 6 to obtain the coordinates of the top-right corner (\(X_{{{\text{Lx}}}}\) and \(X_{Ly}\)) and the bottom-right corner (\(X_{{{\text{r}}x_{{}} }}\) and \(X_{{{\text{r}}y}}\)) of the predicted box. Throughout the testing process, many prediction boxes are generated. We select the prediction box with the highest score and update its size through linear interpolation between the previous frame's position and the current frame's position. This interpolation method helps smooth out changes in the target's size, making the tracking more stable and accurate.
4 Experiments
This section presents the results of our tracker on three tracking benchmark data sets, and compares them with some of the advanced RGBT trackers available. In addition, we provide an ablation study analysis to evaluate the influence of each component in our model on the tracking results.
4.1 Implementation Details
4.1.1 Training
We have constructed a training sub-network centered around ResNet-50. This network has been pre-trained on ImageNet, and training weight parameters can be referred to in [27]. We chose our tracker to be trained separately on the GTOT [28] and RGBT234 data sets. For comparison purposes, the input size of the visible light image template is 127 pixels, and the input size of the search area is 256 pixels. The input size of the thermal image template is also 127 pixels, and the input size of the search area is also 256 pixels. Visible light images and thermal images are trained separately through their respective Stochastic Gradient Descent (SGD) networks. Considering the impact of different layers on image feature extraction, we froze other layers and only extracted image features from the second and fourth layers. We designed the training for 30 epochs. We used two GTX 3080-Ti graphics cards for training, with each GPU hosting 16 images, so the batch size for each iteration is 32 images. During training, the learning rate gradually increased from 0.001 to 0.005 in the first five epochs, while the main network parameters were frozen. In the remaining epochs, the main network was unfrozen, and the learning rate exponentially decayed from 0.005 to 0.00005.
Currently proposed trackers (such as MANET, DAPNET) often have different training settings. Comparing different trackers under unified training parameters is often challenging. To ensure fair comparisons, when comparing our tracker with others, we strive to have all trackers adopt the same training parameters.
4.1.2 Testing
For the offline model, we input visible light images and thermal images into their respective testing networks. Using a siamese network structure, the target object's features are computed once in the first frame and then continuously matched with subsequent search images. We can obtain the regression and classification losses of the visible light images and thermal images separately. In Eq. (7), the fusion weights \(\lambda\) for classification and regression are both set to 0.5. Finally, in Eq. (8), the classification weights \(\eta\) and \(\delta\) are set to 0.4 and 0.6. Our tracker is implemented using Python 3.6 and Pytorch 1.1.0. We ran the proposed model network five times, with a performance standard deviation of ± 0.3%, proving the stability of our tracker.
4.1.3 Evaluation Data Sets and Metrics
We used three benchmark data sets to evaluate tracking performance, including GTOT, RGBT210 [29], and RGBT234. The GTOT data set contains a total of 50 video sequences of visible light and thermal images. The RGBT210 data set has 210 video sequences, and the RGBT234 data set added 24 sequences to RGBT210, making it more challenging. Considering the large number of sequences in RGBT210 included in the RGBT234 data set, we used the GTOT data set for training and tested on RGBT210 and RGBT234 separately, avoiding the possibility of using the same data set for training and testing. The standardized evaluation data sets primarily use two metrics, accuracy (Prec.) and success rate (SR), as key performance indicators. Among them, SR is an essential performance metric, which is a critical indicator for comparing RGBT trackers. To test the robustness of the tracker under different lighting conditions, we further evaluated our tracker on the RGBT234 benchmark data set under 12 different lighting conditions (as indicated by the 12 metrics in Table 3). We compared its performance with that of other advanced trackers. Finally, since different modules might influence the model's performance, we also conducted ablation experiments to compare the effects of various modules on the tracker.
Compared to these benchmark data sets, RGBT234 has longer sequences, with an average of 2,500 frames per sequence. Different benchmark data sets have different video sequence lengths, and the number of frames in each sequence varies. The tracking environment challenges differ in different data sets, which affects the tracker's test results. The GTOT data set includes challenges in eight different environments, as shown in Table 1. The RGBT234 data set contains challenges in 12 different environments, as shown in Table 2. Under different challenge tasks, the same tracker's tracking effect is affected. In general, the more sequences a benchmark data set contains, the more challenge tasks it contains, the more complex the environment, the lower the tracker's success rate (SR) and accuracy (PC) scores.
4.2 Compared with SOTA RGB-T Trackers
4.2.1 Compared Methods
We conducted a comprehensive evaluation of our RGB-T tracker proposal, comparing it against several advanced existing trackers using a wide range of performance metrics and challenging characteristics. As illustrated in Tables 3 and , our choice of trackers included various supervised approaches with anchor-based methodologies, including HMFT [30], APFNET [31], DMCNET [32], JMMAC [33], CBPNET [9], MACNET [34], MANET [10], CMP [35], CMPP [36], MFGNET [37], DAPNET [29], MFDIMP [38], LTDA [39], DUSIAMRT [40], TCNN [5], JCDA [41] and SIAMDW [42]. To broaden the extent of our comparison, we also integrated non-deep RGB-T trackers, such as CMCF [43], NRCMR [44], CMR [45], SGTS [46], TMRM [47], CSR [28], CLGM [48], MEEM [49] and KCF [50]. Furthermore, in light of the incorporation of a TRANSFORMER model within our algorithm, we also conducted comparisons with various TRANSFORMER-based methods, including APFNET.
4.2.2 Results on GTOT
In this section, we will present the results of comparing our proposed tracker with other state-of-the-art algorithms on the GTOT benchmark data set. The GTOT benchmark data set consists of 50 video sequences, each of which is distinct from the others. This data set allows us to evaluate the performance of trackers under various challenging attributes. As shown in Table 1, the GTOT benchmark data set includes eight different challenging attributes under various conditions.
As shown in Fig. 6 and Table 4, we present the comparison results of our RGB-T tracker with other anchor-based trackers on the GTOT benchmark data set. To ensure fairness in the results, we employed the RGBT234 benchmark data set as the training set and GTOT benchmark data set as the test set, ensuring that the two sets contain distinct video sequences. According to the results presented in Table 4, our RGB-T tracker outperforms all non-deep learning-based RGB-T trackers in both success rate (SR) and precision rate (PR) metrics. When compared to anchor-based self-supervised RGB-T trackers, our tracker excels in SR performance.

Following are the findings of an experimental evaluation of GTOT: a Precision Plot; b Success Plot
In terms of the critical SR metric, our method achieves relative improvements of 5.4% and 5.8% when compared to the second- and third-ranked anchor-based methods (HMFT and CMPP, respectively). However, there is still a gap between our tracker's PR performance and that of some advanced trackers, such as HMFT, CMPP, APFNET, and DMCNET. The primary reason for this discrepancy might be their utilization of larger benchmark data sets for training and the use of more complex models.
4.2.3 Results on RGBT210
As shown in Fig. 7, we present the comparison results of our anchor-based RGB-T tracker on the RGBT210 benchmark data set. Similarly, to ensure fairness in the results, we used the GTOT benchmark data set as the training set and the RGBT210 benchmark data set as the test set, ensuring that the two sets contain distinct video sequences. The results displayed in Fig. 7 indicate that our RGB-T tracker outperforms other anchor-based trackers in both success rate (SR) and precision rate (PR) metrics. When compared to the second-ranked anchor-based method (HMFT), our approach achieves a remarkable relative improvement of up to 6.1% on the critical tracking evaluation metric SR (Success Rate).

Results of an experimental assessment of the RGBT210: maximum success rate and maximum precision rate, respectively
4.2.4 Results on RGBT234
As shown in Fig. 8 and Table 4, we present the comparison results of our anchor-based RGB-T tracker on the RGBT234 benchmark data set. To ensure fairness in the results, we used the GTOT benchmark data set as the training set and the RGBT234 benchmark data set as the test set, ensuring that the two sets contain distinct video sequences. According to the results displayed in Table 4, our RGB-T tracker outperforms other anchor-based trackers in both success rate (SR) and precision rate (PR) metrics. When compared to the second- and third-ranked anchor-based methods (DMCNET and ADFNET), our approach achieves relative improvements of 3% and 5.4%, respectively, on the critical tracking evaluation metric SR (Success Rate).

Following are the findings of an experimental evaluation of RGBT234: a Precision Plot; b Success Plot
Compared to the results on the GTOT data set, the improvements in SR scores and performance are notably lower on the RGBT234 data set. This is mainly due to the increased challenging attributes in the RGBT234 data set. In addition, the RGBT234 data set contains a significantly larger number of video sequences compared to GTOT.
4.2.5 Attribute-Based Results
As shown in Fig. 9 and Table 3, we conducted a performance comparison of our proposed tracker and other advanced trackers on the RGBT234 benchmark data set based on 12 challenging attributes.

Graph shows a comparison based on challenge attributes between the proposed tracker and other advanced trackers on the RGBT234 data set
In Table 3, we used red, blue, and purple to, respectively, represent the top-performing RGB-T trackers in each attribute. From the experimental results, we can observe that our tracker excels in NO and PO performance metrics compared to other trackers. Our tracker demonstrates high robustness when facing other challenging attributes. The ability to exhibit outstanding competitiveness in challenging attributes is mainly due to our anchor-free design-based modules. This model shows greater adaptability when facing large-scale changes in shape compared to anchor-based designs. In addition, we have incorporated the NNSM module into our model, significantly reducing the impact of non-target features on the tracker's results. In our future research, we will consider designing modules specifically tailored to address the challenges in NO and PO performance.
4.2.6 Qualitative Results
As shown in Fig. 10, we conducted a qualitative performance comparison of our proposed tracker on RGBT234 with a selection of anchor-based designed trackers, including KCF–RGBT, CSR–RGBT, SGT, SOWP–RGBT, MEEM, and SOWP–RGBT. Our proposed tracker is represented in red, while the other trackers are indicated in different colors. By marking the positions of the tracking boxes predicted by each tracker on the same image, the performance of our tracker can be visually demonstrated. The test results indicate that our tracker exhibits strong competitiveness compared to the other trackers. The images used for testing are extracted from the benchmark data set RGBT234 and have no financial interests or affiliations with any of the authors.

Qualitative performance analysis: a Balance bike b White car c Woman in black
4.3 Ablation Studies and Analysis
In this section, we conducted an ablation experiment to analyze the effects of different modules on the tracker's performance on the GTOT benchmark data set. As shown in Fig. 11, we performed ablation tests to assess the impact of different modules on our proposed tracker's results. First, we tested whether the FEM module and NNSM module would affect the tracking performance of the tracker. In Fig. 11, "ours-GTOT-F" represents our tracker model with only the FEM module, and "ours-GTOT-N" represents our tracker model with only the NNSM module. From the test results, it can be seen that when our tracker model only contains the FEM module, both the SR and PR scores of our tracker have decreased. However, in the case of having only the NNSM module, our tracker's SR and PR scores have improved, indicating that NNSM can enhance the tracking performance of the model. Next, we added both the FEM and NNSM modules to the tracker simultaneously. The tracking results we obtained, as shown in "ours-GTOT-(F-N)-NO(TS)," demonstrate a significant improvement in tracking performance when the two modules work together. To test whether the addition of the Transformer module can further enhance the model's tracking performance, we added the TS module to the tracker. The results, as shown in "ours-GTOT-(F-N-TS)," indicate that after adding the Transformer module, our proposed tracker achieved even better tracking performance in both PR and SR metrics.

We conducted ablation experiments on the tracker on the GTOT benchmark data set and presented the results
5 Conclusion
This article introduces a dual Siamese anchor points adaptive tracker (referred to as DAPAT) for RGBT tracking, incorporating the Transformer model. In this model, we have integrated the transformer's attention mechanism and anchor-free design, replaced candidate boxes, and removed redundant hyperparameters. Furthermore, to enhance the tracker's success rate, we have replaced the correlation algorithm in the Siamese network, minimizing feature loss from cross-correlation operations. In the experimental analysis section, the efficacy of our proposed framework is validated on three benchmark test sets: GTOT, RGBT210, and RGBT234. On the GTOT set, our method, compared to anchor-based methods, such as HMFT and CMPP, achieved relative improvements of 5.4% and 5.8%, respectively, on the vital tracker evaluation metric SR (Success Rate). On the RGBT210 data set, our approach showed up to an 6.1% relative increase in the SR metric when compared to the anchor-based method HMFT. Similarly, on the RGBT234 data set, relative improvements of 3% and 5.4% were observed when compared to DMCNET and APFNET, respectively. As shown in Table 4, our tracker achieved an SR of 79.6% on the GTOT benchmark data set, outperforming all anchor-based trackers. Similarly, on the RGBT234 benchmark data set, our tracker registered an SR of 62.3%, again surpassing all anchor-based trackers. The experimental results indicate that our tracker exhibits competitive performance compared to other trackers across different benchmark data sets.
As shown in Table 4, our tracker can operate at a speed of 40.3 FPS (Frames Per Second). The test results demonstrate that our tracker, in terms of time efficiency, outperforms many advanced anchor-based trackers and is competitive. However, there is still room for improvement in comparison with some high-speed trackers, and we hope that future research can focus on designing a faster model with respect to the speed metric.
The performance based on challenge attributes on the RGBT234 data set is illustrated in Fig. 9. It can be observed that our RGB-T tracker, being a lightweight tracker, achieves highly competitive performance in terms of FM, LR, HO, and SV. Notably, in the challenge attributes' MSR graph, our tracker surpasses other tracking algorithms in terms of MSR.
Target tracking algorithms, as a significant subfield of artificial vision, are gradually permeating various aspects of our lives. This technology is extensively applied in areas, such as security surveillance, autonomous vehicles, and health monitoring. However, it simultaneously raises several ethical and societal concerns. The ability of target tracking technology to continuously and real-time monitor-specific individuals or objects poses a potential threat to personal privacy. While such technology can enhance public safety, for instance, by monitoring suspicious activities in cities, it can also be exploited for illicit purposes, such as illegal surveillance or unwarranted tracking of innocent individuals. Consequently, striking a balance between safeguarding public safety and ensuring individual privacy becomes a paramount challenge we face.
In the future, we are contemplating integrating our algorithm into the design of RGBD trackers in the next research iteration. This will widen the application spectrum and might enhance performance in challenging scenarios. During our research, we will strive to ensure that appropriate regulatory measures are in place to prevent potential misuse of these technologies.
In conclusion, as researchers, we must possess foresight and a sense of responsibility, ensuring that our research not only advances technology but also aligns with societal values and expectations.
Availability of Data and Materials
The data sets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Change history
18 March 2024
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s44196-024-00447-2
Abbreviations
- RGB-T:
-
RGBT images refer to the fact that each set of images consists of a combination of images of both visible and thermal infrared light modes
References
Chen, X., Yan, B., Zhu, J., Wang, D., Yang, X., Lu, H.: Transformer tracking. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, pp. 8122–8131 (2021)
Martin, D., Goutam, B., Fahad, S.K., Michael, F.A.T.O.M.: Accurate tracking by over-lap maximization. CVPR 1, 6 (2019)
Li, Bo., Yan, J., Wei, Wu., Zhu, Z., Xiaolin, Hu.: High performance visual tracking with Siamese region proposal network. CVPR 1, 2 (2018)
Lu, H., Wang, D.: Introduction to visual tracking. In: Ch, M. (ed.) Online Visual Tracking. Springer, Singapore (2019). https://doi.org/10.1007/978-981-13-0469-9_1
Li, C., Xiaohao, Wu., Zhao, N., Cao, X., Tang, J.: Fusing two-stream convolutional neural networks for RGB-T object tracking. Neurocomputing 281(78–85), 1 (2018)
Tianlu, Z., Xueru, L., Qiang, Z., Jungong, H.: Siamcda: complementarity-and distractor-aware RGB-T tracking based on Siamese network. TCSVT 32(3), 1403–1417 (2021)
Bo, L., Wei, W., Qiang, W., Fangyi, Z., Junliang, X., Junjie, Y.: SiamRPN++: evolution of siamese visual tracking with very deep networks. In CVPR (2019)
Lu, A., et al.: RGBT tracking via multi-adapter network with hierarchical divergence loss. IEEE Trans. Image Process. 30, 5613–5625 (2021)
Xu, Q., et al.: Multimodal Cross-Layer Bilinear Pooling for RGBT Tracking. IEEE Trans. Multimed. 24, 567–580 (2022)
Li, C., Lu, A., Hua Zheng, A., Tu, Z., Tang, J.: Multi-adapter RGBT tracking. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (2019)
Xiao, W., Jianing, L., Lin, Z., Zhipeng, Z., Zhe, C., Xin, L., Yaowei, W., Yonghong, T., Feng, W.: Visevent: reliable object tracking via collaboration of frame and event flows. arXiv preprint arXiv:2108.05015 (2021)
Zhu, Y., Li, C., Tang, J., Luo, B.: Quality-aware feature aggregation network for robust RGBT tracking. IEEE Trans. Intell. Veh. 6(1), 121 (2021)
Xiao, Y., Yang, M., Li, C., Liu, L., Tang, J.: Attribute-based progressive fusion network for RGBT tracking. AAAI 36(3), 2831 (2022)
Nam, H., Han, B.: Learning multi-domain convolutional neural networks for visual tracking. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, pp. 4293–4302 (2016)
Duan, K., Bai, S., Xie, L., Qi, H., Huang, Q., Tian, Q.: Centernet: Keypoint triplets for object detection. In: ICCV, pp. 6569–6578 (2019)
Law, H., Deng, J.: Cornernet: detecting objects as paired keypoints. In: ECCV, pp. 734–750. Springer (2018)
Tian, Z., Shen, C., Chen, H., He, T.: FCOS: Fully convolutional one-stage object detection. In: ICCV, pp. 9627–9636 (2019)
Lichao, H., Yi Y., Yafeng, D., Yinan, Y.: Dense-Box: Unifying landmark localization with end to end object detection. arXiv preprint arXiv:1509.04874 (2015)
Ze, Y., Shaohui, L., Han, H., Liwei, W., Stephen, L.: RepPoints: point set representation for object detection. In: IEEE International Conference on Computer Vision, pp. 9657–9666 (2019)
Xingyi, Z., Jiacheng, Z., Philipp, K.: Bottom-up object detection by grouping extreme and center points. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 850–859 (2019)
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: CVPR, pp. 779–788 (2016)
Chenchen, Z., Yihui, H., Marios, S.: Feature selective anchor-free module for single-shot object detection. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 840–849 (2019)
Zhipeng, Z., Houwen, P., Jianlong, F., Bing, L., Weiming, H..: Ocean: object-aware anchor-free tracking. In: Computer Vision–ECCV (2020)
Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; Polosukhin, I.: Attention is all you need. In: Proceedings of the Advances in Neural Information Processing Systems, pp. 5998–6008 (2017)
Carion, N., Massa, F., Synnaeve, G., et al.: End-to-end object detection with transformers. In: European Conference on Computer Vision, pp. 213–229. Springer International Publishing (2020)
Zhou, X., Koltun, V., Krähenbühl, P.: Tracking objects as points. In: European Conference on Computer Vision, pp. 474–490. Springer International Publishing (2020)
Olga, R., Jia, D., Hao, S., Jonathan, K., Sanjeev, S., Sean, M., Zhiheng, H., Andrej, K., Aditya, K., Michael, B., et al.: Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 115(3), 211–252 (2015)
Li, C., Cheng, H., Hu, S., Liu, X., Tang, J., Lin, L.: Learning collaborative sparse representation for grayscale-thermal tracking. IEEE Trans. Image Process. 25(12), 5743–5756 (2016)
Yabin, Z., Chenglong, L., Bin, L., Jin, T., Xiao, W.: Dense feature aggregation and pruning for RGBT tracking. In: Proceedings of the 27th ACM International Conference on Multimedia. ACM (2019)
Zhang, P., Zhao, J., Wang, D., Lu, H., Ruan, X.: Visible thermal UAV tracking: a large-scale benchmark and new baseline. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8886– 8895 (2022)
Xiao, Y., Yang, M., Li, C., Liu, L., Tang, J.: Attribute based progressive fusion network for RGBT Tracking. Proc. AAAI Conf. Artif. Intell. (2022). https://doi.org/10.1609/aaai.v36i3.20187
Lu, A., Qian, C., Li, C., Tang, J., Wang, L.: Duality-gated mutual condition network for RGBT tracking. IEEE Trans. Neural Netw. Learn. Syst. (2022). https://doi.org/10.1109/TNNLS.2022.3157594
Zhang, P., Zhao, J., Bo, C., Wang, D., Lu, H., Yang, X.: Jointly modeling motion and appearance cues for robust RGBT tracking. IEEE Trans. Image Process. 30, 3335–3347 (2021)
Zhang, H., et al.: Object Tracking in RGB-T Videos Using Modal-Aware Attention Network and Competitive Learning. Sensors (Basel, Switzerland) 20(2), 393 (2020)
Yang, R., Wang, X., Li, C., Hu, J., Tang, J.: RGBT tracking via cross-modality message passing. Neurocomputing 462, 365–375 (2021)
Wang, C., Xu, C., Cui, Z., Zhou, L., Zhang, T., Zhang, X., Yang, J.: Cross-modal pattern-propagation for RGB-T tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7064–7073 (2020)
Wang, X., Shu, X., Zhang, S., Jiang, B., Wang, Y., Tian, Y., Wu, F.: MFGNet: dynamic modality-aware filter generation for RGB-T tracking. IEEE Trans. Multimed. (2022). https://doi.org/10.1109/TMM.2022.3174341
Zhang, L., Danelljan, M., Gonzalez-Garcia, A., van de Weijer, J., Shahbaz Khan, F.: Multi-modal fusion for end-to-end RGBT tracking. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (2019)
Yang, R., Zhu, Y, Wang, X., Li, C., Tang, J.: Learning target-oriented dual attention for robust RGB-T tracking. In: 2019 IEEE International Conference on Image Processing (ICIP). IEEE, pp. 3975–3979 (2019)
Guo, C., Yang, D., Li, C., Song, P.: Dual Siamese network for RGBT tracking via fusing predicted position maps. Vis. Comput. 38(7), 2555–2567 (2022)
Kang, B., Liang, D., Ding, W., Zhou, H., Zhu, W.-P.: Grayscale-thermal tracking via inverse sparse representation based collaborative encoding. IEEE Trans. Image Process. 29, 3401–3415 (2019)
Zhang, Z., Peng, H.: Deeper and wider siamese networks for real-time visual tracking. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE (2019)
Zhai, S., Shao, P., Liang, X., Wang, X.: Fast RGB-T tracking via cross-modal correlation filters. Neurocomputing 334, 172–181 (2019)
Li, C., Xiang, Z., Tang, J., Luo, B., Wang, F.: RGBT tracking via noise-robust cross-modal ranking. IEEE Trans. Neural Netw. Learn. Syst. 33, 5019–5031 (2021)
Li, C., Zhu, C., Huang, Y., Tang, J., Wang, L.: Cross-modal ranking with soft consistency and noisy labels for robust RGBT tracking. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 808–823. Springer (2018)
Li, C., et al.: Weighted sparse representation regularized graph learning for RGB-T object tracking. In: Proceedings of the 25th ACM international conference on Multimedia, ACM (2017)
Li, C., Zhu, C., Zheng, S., Luo, B., Tang, J.: Two-stage modality-graphs regularized manifold ranking for RGB-T tracking. Signal Process. 68, 207–217 (2018)
Shen, L., Wang, X., Liu, L., Hou, B., Jian, Y., Tang, J., Luo, B.: RGBT tracking based on cooperative low-rank graph model. Neurocomputing 492, 370–381 (2022)
Zhang, J., Ma, S., Sclaroff, S.: MEEM: robust tracking via multiple experts using entropy minimization. In: European Conference on Computer Vision, pp. 188–203. Springer (2014)
Henriques, J.F., Caseiro, R., Martins, P., Batista, J.: High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 37(3), 583–596 (2014)
Li, C., Liang, X., Lu, Y., Zhao, N., Tang, J.: RGB-T object tracking: Benchmark and baseline. Pattern Recognit. 96, 106977 (2019)
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
LF: conceptualization of this study. Methodology, Software. PK: as the corresponding author, Pyeoungkee Kim is primarily responsible for designing the research plan, planning the experiments, coordinating and communicating with the collaborators, and other related tasks.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethical Approval and Consent to Participate
Not applicable.
Consent for Publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s44196-024-00447-2
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fan, L., Kim, P. RETRACTED ARTICLE: Dual Siamese Anchor Points Adaptive Tracker with Transformer for RGBT Tracking. Int J Comput Intell Syst 16, 187 (2023). https://doi.org/10.1007/s44196-023-00360-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00360-0