
Abstract
Optimal measurements for the discrimination of quantum states are useful tools for classification problems. In order to exploit the potential of quantum computers, feature vectors have to be encoded into quantum states represented by density operators. However, quantum-inspired classifiers based on nearest mean and on Helstrom state discrimination are implemented on classical computers. We show a geometric approach that improves the efficiency of quantum-inspired classification in terms of space and time acting on quantum encoding and allows one to compare classifiers correctly in the presence of multiple preparations of the same quantum state as input. We also introduce the nearest mean classification based on Bures distance, Hellinger distance and Jensen–Shannon distance comparing the performance with respect to well-known classifiers applied to benchmark datasets.
Similar content being viewed by others

Introduction
The mathematical formulation of quantum mechanics can be used to devise machine learning algorithms that do not require any quantum hardware in the sense that the quantum formalism is applied to define data representations that are managed by classical computers. The so-called quantum-inspired machine learning is based on particular kinds of information storing and processing defined by means of the mathematical objects from the quantum theory that do not necessarily relates to physical quantum systems. This work is devoted to study some quantum-inspired classification algorithms from a geometric perspective and their comparison with well-known classical classifiers.
An interesting quantum-inspired binary classification algorithm has been introduced in terms of a nearest mean classifier based on the trace distance between density operators encoding feature vectors1. Another proposed quantum-inspired classifier is based on the Helstrom quantum state discrimination2 used for binary classification3. Both algorithms are structured on an encoding of the feature vectors into density operators and on techniques for estimating the distinguishability of quantum states like a distance in the space of the quantum states and the Helstrom measurement. Classification accuracy of these quantum-inspired classifiers can be improved by increasing, in terms of tensor products, the number of copies of the quantum states that encode the feature vectors, at the cost of dramatically increasing the computational space and time. However, in the present work, we argue that the geometric approach for representing data into quantum states provides a description of the quantum encoding that allows to implement feature maps saving space and time resources.
In this paper, we introduce the quantum encoding in terms of Bloch vectors applied to the execution of some quantum-inspired classifiers. In particular we run the Helstrom classifier representing data with different quantum encodings (i.e. different feature maps), then we define quantum-inspired nearest mean classifiers using Bures, Hellinger and Jensen–Shannon distances. In the experimental part, we present a comparison of the performances of the quantum-inspired classifiers against well-known classical algorithms.
The work is structured as follows: In “Quantum encoding” section , we introduce the representation of density operators in terms of Bloch vectors in arbitrary dimension and the basics of quantum encoding. “Quantum-inspired classifiers” section is a short description of the considered quantum-inspired algorithms that are the Helstrom classifier and the nearest mean classifiers based on several operator distances. In “Geometric approach to quantum-inspired classifications” section, we discuss how the encoding of feature vectors into Bloch vectors is useful to obtain a data representation that scales efficiently increasing the dimension of the feature space. In this section we define the classifiers based on Bures, Hellinger and Jensen–Shannon distances. In “Method and experimental results” section, there are the experimental results obtained running the quantum-inspired classifiers and the comparison with classical algorithms over some benchmark dataset. In “Conclusions” section, we draw the conclusion remarking the impact of adopting the geometric viewpoint in devising novel classification algorithms based on quantum structures.
Quantum encoding
A quantum encoding is any procedure to encode classical information (e.g., a list of symbols) into quantum states. In this paper, we consider encodings of vectors in \({\mathbb {C}}^n\) and \({\mathbb {R}}^n\) into density matrices on a Hilbert space \({\mathsf {H}}\) whose dimension depends on n, in particular we use different quantum encodings to implement different feature maps for data representation.
The set of density matrices on the (finite-dimensional) Hilbert space \({\mathsf {H}}\) is given by \({\mathfrak {S}}({\mathsf {H}})=\{\rho \in {\mathscr {B}}^+({\mathsf {H}}): {\mathrm{tr}}\rho =1\}\), where \({\mathscr {B}}^+({\mathsf {H}})\) is the set of positive semidefinite operators on \({\mathsf {H}}\). The set \({\mathfrak {S}}({\mathsf {H}})\) is convex and its extreme elements, the pure states, are rank-1 orthogonal projectors. A pure state has general form \(\rho =\left \vert {\psi } \right \rangle \left \langle {\psi }\right \vert \), and it can then be directly identified with the unit vector \(\left \vert {\psi } \right \rangle \in {\mathsf {H}}\) up to a phase factor. The bases of the real space of Hermitian matrices on \({\mathbb {C}}^d\) can be used to decompose density matrices associated with states of a quantum system described in a d-dimensional Hilbert space. A fundamental basis for qubits (\(\dim {\mathsf {H}}=2\)) is formed by the three Pauli matrices and the \(2\times 2\) identity matrix. In this case, any density matrix can be represented by a three-dimensional vector, the Bloch vector, that lies within the unit ball in \({\mathbb {R}}^3\) whose boundary is the Bloch sphere. The points on the spherical surface are in bijective correspondence with the pure states. In higher dimensions, the set of quantum states is a convex body with a much more complicated geometry and it is no longer simply represented as a unit ball. In general, for any j, k, l such that \(1\le j\le d^2-1\), \(0\le k<l\le d-1\), the generalized Pauli matrices on \({\mathbb {C}}^d\) can be defined as follows4:
where \(\left\{ \big \vert {\frac{k}{d-1}} \big \rangle \right\} _{k=0,\ldots ,d-1}\) denotes the canonical basis of \({\mathbb {C}}^d\). The generalized Pauli matrices \(\{\sigma _j\}_{j=1,\ldots ,d^2-1}\) are the standard generators of the special unitary group SU(d). Together with the \(d\times d\) identity matrix \(\mathtt {I}_d\), the generalized Pauli matrices form an orthogonal (the orthogonality is with respect to the Hilbert–Schmidt product \((A,B)_{HS}={\mathrm{tr}}(A^\dagger B)\)) basis of the real space of \(d\times d\) Hermitian matrices. Let \(\rho \) be a density operator on \({\mathbb {C}}^d\), the expansion of \(\rho \) with respect to the orthogonal basis \(\{\mathtt {I}_d,\sigma _j:1\le j\le d^2-1\}\) is:
where \(b^{(\rho )}_j=\sqrt{\frac{d}{2(d-1)}}{\mathrm{tr}}(\rho \,\sigma _j)\in {\mathbb {R}}\). The coordinates \({\mathbf{b}}^{(\rho )}=(b^{(\rho )}_1,\ldots ,b^{(\rho )}_{d^2-1})\) represent the Bloch vector associated to \(\rho \) with respect to the basis \(\{\mathtt {I}_d,\sigma _j:1\le j\le d^2-1\}\), which lies within the hypersphere of radius 1. For \(d>2\), the points contained in the unit hypersphere of \({\mathbb {R}}^{d^2-1}\) are not in bijective correspondence with quantum states on \({\mathbb {C}}^d\) such as in the case of a single qubit. However, any vector within the closed ball of radius \(\frac{2}{d}\) gives rise to a density operator5.
A complex vector can be encoded into a pure state in the following way:
where \(\{\big \vert {\alpha } \big \rangle \}_{\alpha =0,\ldots ,n}\) is the computational basis of the \((n+1)\)-dimensional Hilbert space \({\mathsf {H}}\), identified as the standard basis of \({\mathbb {C}}^{n+1}\). The map defined in (3), called amplitude encoding, encodes \({\mathbf{x}}\) into the density matrix \(\rho _{\mathbf{x}}=\big \vert {\mathbf{x}} \big \rangle \big \langle {\mathbf{x}}\big \vert \) where the additional component of \(\big \vert {\mathbf{x}} \big \rangle \) stores the norm of \({\mathbf{x}}\). Nevertheless the quantum encoding \({\mathbf{x}}\mapsto \rho _{\mathbf{x}}\) can be realized in terms of the Bloch vectors \({\mathbf{x}}\mapsto {\mathbf{b}}^{(\rho _{\mathbf{x}})}\). As shown in “Geometric approach to quantum-inspired classifications” section, encoding data into Bloch vectors is useful for saving space resources. The improvement of memory occupation within the Bloch representation is evident when we consider multiple copies of quantum states as tensor products to enlarge the dimension of the representation space (kernel trick). For instance, given two copies of a density operator \(\rho _{\mathbf{x}}\otimes \rho _{\mathbf{x}}\) on \({\mathbb {C}}^3\otimes {\mathbb {C}}^3\) (encoding a real feature vector \({\mathbf{x}}\in {\mathbb {R}}^2\)), instead of using a matrix of 81 real elements one can store a vector of just 20 entries obtained deleting redundant and null components from the Bloch vector.
Quantum-inspired classifiers
In this section we introduce the quantum-inspired classifiers that we consider in the present work. The classifier based on Helstrom state discrimination3,6 and some nearest mean classifiers based on operator distances among density matrices encoding data. Let us focus on the case of binary classification of n-dimensional complex feature vectors, the Helstrom classifier (or Helstrom Quantum Centroid) is based on the following three ingredients: (1) a quantum encoding of the feature vectors into density operators \({\mathbb {C}}^n\ni {\mathbf{x}}\mapsto \rho _{\mathbf{x}}\in {\mathfrak {S}}({\mathsf {H}})\); (2) the construction of the quantum centroids of the two classes \(C_1\) and \(C_2\) of training points:
(3) application of the Helstrom discrimination on the two quantum centroids in order to assign a label to a new data instance.
Let us briefly introduce the notion of quantum state discrimination. Given a set of arbitrary quantum states with respective a priori probabilities \(R=\{(\rho _1, p_1),\ldots ,(\rho _N, p_N)\}\), in general there is no a measurement process that discriminates the states without errors. More formally, there does not exist a POVM, i.e. a collection \(E=\{E_i\}_{i=1,\ldots ,N}\subset {\mathscr {B}}^+({\mathsf {H}})\) such that \(\sum _{i=1}^N E_i =\mathtt {I}\), satisfying the following property: \({\mathrm{tr}}(E_i\rho _j)=0\) when \(i\not =j\) for all \(i,j=1,\ldots ,N\). The probability of a successful state discrimination of the states in R performing the measurement E is:
An interesting and useful task is finding the optimal measurement that maximizes the probability (5). Helstrom provided a complete characterization of the optimal measurement \(E_{opt}\) for \(R=\{(\rho _1,p_1), (\rho _2,p_2)\}\)2. \(E_{opt}\) can be constructed as follows. Let \(\Lambda :\) = \(p_1\rho _1-p_2\rho _2\) be the Helstrom observable whose positive and negative eigenvalues are, respectively, collected in the sets \(D_+\) and \(D_-\). Consider the two orthogonal projectors:
where \(P_\lambda \) projects onto the eigenspace of \(\lambda \). The measurement \(E_{opt}:\) \(=\{P_+, P_-\}\) maximizes the probability (5) that attains the Helstrom bound \(h_b(\rho _1,\rho _2)=p_1{\mathrm{tr}}(P_+\rho _1)+p_2{\mathrm{tr}}(P_-\rho _2)\).
Helstrom quantum state discrimination can be used to implement a binary classifier6. Let \(\{({\mathbf{x}}_1, y_1),\ldots ,({\mathbf{x}}_M, y_M)\}\) be a training set with \(y_i\in \{1,2\}\) \(\forall i=1,\ldots ,M\). Once a quantum encoding \({\mathbb {C}}^n\ni {\mathbf{x}}\mapsto \rho _{\mathbf{x}}\in {\mathfrak {S}}({\mathsf {H}})\) has been selected, one can construct the quantum centroids \(\rho _1\) and \(\rho _2\) as in (23) of the two classes \(C_{1,2}=\{{\mathbf{x}}_i: y_i=1,2\}\). Let \(\{P_+, P_-\}\) be the Helstrom measurement defined by the set \(R=\{(\rho _1,p_1),(\rho _2,p_2)\}\), where the probabilities attached to the centroids are \(p_{1,2}=\frac{|C_{1,2}|}{|C_1|+|C_2|}\). The Helstrom classifier applies the optimal measurement for the discrimination of the two quantum centroids to assign the label y to a new data instance \({\mathbf{x}}\), encoded into the state \(\rho _{\mathbf{x}}\), as follows:
A strategy to increase the accuracy in classification is given by the construction of the tensor product of k copies of the quantum centroids \(\rho _{1,2}^{\otimes k}\) enlarging the Hilbert space where data are encoded. The corresponding Helstrom measurement is \(\{P_+^{\otimes k}, P_-^{\otimes k}\}\), and the Helstrom bound satisfies6:
Enlarging the Hilbert space of the quantum encoding, one increases the Helstrom bound obtaining a more accurate classifier. Since the Helstrom classifier is similar to a support vector machine with linear kernel7, considering many copies of the encoding quantum states give rise to a kernel trick. The corresponding computational cost is evident; however, in the following, we observe that in the case of real input vectors, the space can be enlarged saving time and space by means of the encoding into Bloch vectors.
Generally speaking, quantum state discrimination approaches consider global measurements or local measurements with classical feed-forward8. Unambiguous state discrimination requires more measurement outcomes than the dimension of the Hilbert space, the measurement takes the form of a POVM and identifies the state with certainty or gives an inconclusive outcome. States must have non-overlapping supports (i.e. the space spanned by the eigenvectors with non-zero eigenvalues for each state must not overlap with that of any other state in the ensemble). Maximum confidence sometimes yields incorrect answers9. Contrary, the minimum-error measurement strategy is to correctly identify the state as often as possible. For minimum error and unambiguous discrimination, optimization can be treated as a semi-definite program and particular instances can be solved efficiently numerically .
Helstrom provided an analytic closed-form solution for two states with the minimum probability of error and arbitrary prior probabilities. The square-root measurement, also known as Pretty Good measurement, defined by:
where \(\rho =\sum _i p_i\rho _i\), is the optimal minimum-error when states satisfy certain symmetry properties10. Clearly to distinguish between n centroids we need a measurement with at most n outcomes. It is sometimes optimal to avoid measurement and simply guess that the state is the a priori most likely state.
The optimal POVM \(\{E_i\}_i\) for minimum-error state discrimination over \(R=\{(\rho _1, p_1),\ldots ,(\rho _N, p_N)\}\) satisfies the following necessary and sufficient Helstrom conditions11:
where the Hermitian operator, also known as Lagrange operator, is defined by \(\Gamma :=\sum _i p_i\rho _i\, E_i\). It is also useful to consider the following properties which can be obtained from the above conditions:
For each i the operator \(\Gamma -p_i\rho _i\) can have two, one, or no zero eigenvalues, corresponding to the zero operator, a rank-one operator, and a positive-definite operator, respectively. In the first case, we use the measurement \(\{E_i=\mathtt {I}, E_{i \not = j}=0\}\) for some i where \(p_i \ge p_j\) \(\forall j\), i.e. the state belongs to the a priori most likely class. In the second case, if \(E_i\not = 0\), it is a weighted projector onto the corresponding eigenstate. In the latter case, it follows that \(E_i=0\) for every optimal measurement.
Given the following Bloch representations:
in order to determine the Lagrange operator in \({\mathbb {C}}^d\) we need \(d^2\) independent linear constraints:
A measurement with more than \(d^2\) outcomes can always be decomposed as a probabilistic mixture of measurements with at most \(d^2\) outcomes. Therefore, if the number of classes is greater than or equal to \(d^2\) and we get \(d^2\) linearly independent equations, we construct the Lagrange operator and derive the optimal measurements. From the geometric point of view, we obtain the unit vectors corresponding to the rank-1 projectors \(E_i=\frac{1}{d}\Big (\mathtt {I}_d+\sqrt{\frac{d(d-1)}{2}}\sum _{j=1}^{d^2-1}n^{(i)}_j\sigma _j\Big )\):
It is also possible to further partition the classes in order to increase the number of centroids and of the corresponding equations. An unlabelled point \({{\widehat{{\mathbf{x}}}}}\) is associated with the first label y such that \({\mathbf{b}}^{({\hat{{\mathbf{x}}}})}\cdot \mathbf{n }^{(y)}=\max _i {\mathbf{b}}^{({\hat{{\mathbf{x}}}})}\cdot \mathbf{n }^{(i)}\), where \(d=\lceil \sqrt{length({\mathbf{x}})+2}\rceil \). Such a geometric construction of the minimum-error state discrimination will be tested over a case-study of medical relevance as reported in “Method and experimental results” section.
The quantum-inspired nearest mean classifiers that we consider in this paper are essentially based on the following general observation: once encoded data into density matrices one can use an operator distance, suitable for quantum state distinguishability, to perform nearest mean classification. In1, the authors consider the trace distance that can be computed in terms of Euclidean distance among Bloch vectors. Here we focus on the Bures distance, the Hellinger distance and the Jensen–Shannon distance respectively defined as:
In the next section we explicitly define the nearest mean classifiers, based on the distances (15), (16), (17), within the data encoding into Bloch vectors of density operators in order to take advantage of the geometric approach.
Geometric approach to quantum-inspired classifications
In this section we discuss the encoding of real feature vectors into Bloch vectors of density operators in order to perform quantum-inspired classification. In particular we observe how the Bloch representation turns out to be a useful tool to reduce memory consumption in defining feature maps into higher dimensional spaces.
Within the quantum encoding (3), a real vector \({\mathbf{x}}\in {\mathbb {R}}^{d-1}\) is encoded in a projector operator \(\rho _{{\mathbf{x}}}=\big \vert {\mathbf{x}} \big \rangle \big \langle {\mathbf{x}}\big \vert \), on a d-dimensional Hilbert space where \(d\ge 2\). For simplicity, we consider an input vector \([x_1,x_2]\in {\mathbb {R}}^2\) and the corresponding projector operator \(\rho _{[x_1,x_2]}\) on \({\mathbb {C}}^3\). By easy computations, one can see that the Bloch vector of \(\rho _{[x_1,x_2]}\) has null components:
Instead of using a matrix with nine real elements to represent \(\rho _{[x_1,x_2]}\), memory occupation can be improved by considering only the non-zero components of the Bloch vector. In general, the technique of removing the components that are zero or repeated several times allows reducing the space and the calculation time considering only the significant values that allow to carry out the classification.
Generally speaking, defining a quantum encoding is equivalent to select a feature map to represent feature vectors into a space of higher dimension. In this sense data representation into quantum states can be considered a way to perform kernel tricks. In the case of the considered quantum encoding \({\mathbb {R}}^2\ni [x_1,x_2]\mapsto \rho _{[x_1,x_2]}\in {\mathfrak {S}}({\mathbb {C}}^3)\), in view of (18) the nonlinear explicit injective function \(\varphi :{\mathbb {R}}^2\rightarrow {\mathbb {R}}^5\) to encode data into Bloch vectors can be defined as follows:
From a geometric point of view, the mapped feature vectors are indeed points on the surface of a hyper-hemisphere. Within this representation, the centroids for classification can be calculated as:
In general, such centroids are points inside the hypersphere that do not have an inverse image in terms of density operators, however they can be rescaled to a Bloch vector as discussed below.
Data points can also be encoded in a smaller space using the following encoding from \({\mathbb {R}}^2\) to density operators of \({\mathbb {C}}^2\):
where the Bloch vector \({\mathbf{b}}=\varphi ([x_1,x_2])\in {\mathbb {R}}^3\) and \(\varphi ([x_1,x_2]):=\frac{1}{\sqrt{x_1^2+x_2^2+1}}[x_1,x_2,1]\). In this case, if the quantum centroids are calculated as in (20), they are points inside the Bloch sphere of a qubit then correspond to density operators. As shown below, considering Helstrom classifier, within this quantum encoding it is less accurate than the encoding into \({\mathbb {C}}^3\) as expected by any representation of data in a space of lower dimension.
In order to improve the accuracy of the classification, one can increase the dimension of the representation space providing k copies of the quantum states, in terms of a tensor product, encoding data instances and centroids. According to the quantum formalism, multiple copies of the states are described in a tensor product Hilbert space with a strong impact in terms of computational space (from dimension \(d-1\) to \(d^{2 k}\)) and time. Following the geometric approach, considering the significant values that allow to carry out the classification, the explicit function \(\varphi :{\mathbb {R}}^2\rightarrow {\mathbb {R}}^{20}\) for two copies of the density operators on \({\mathbb {C}}^3\) can be defined as follows:
In particular, removing null and multiple entries, we consider only 20 values instead of 81 for two copies, 51 values instead of 729 for three copies and so on. However, one must also take into account high-precision numbers and track the propagation of the numerical error.
Consider the quantum amplitude encoding of d-dimensional real feature vectors into pure states as introduced in “Quantum encoding” section:
where \(\{\big \vert {\alpha } \big \rangle \}_{\alpha =0,\ldots ,d}\) is the computational basis of the considered \((d+1)\)-dimensional Hilbert space. The quantum centroids of the classes \(C_1,\ldots , C_M\) of training points are defined by the mixed states:
Since any density operator \(\rho _{\mathbf{x}}\) can be represented in terms of its Bloch vector \({\mathbf{b}}^{({\mathbf{x}})}\), we can adopt the Bloch representation of data \({\mathbf{x}}\mapsto {\mathbf{b}}^{({\mathbf{x}})}\) so the centroids can be calculated in terms of Bloch vectors:
noting that \({\mathbf{b}}^{(i)}\) does not correspond to the Bloch vector of the quantum centroid \(\rho _i\) calculated in (23). In fact, \({\mathbf{b}}^{(i)}\) lies inside the hypersphere in \({\mathbb {R}}^{d^2+2d}\) then it is not necessarily the Bloch vector of a density operator for \(d>1\). However it can be contracted into the hypersphere of radius \(\frac{2}{d+1}\) to individuate a Bloch vector of a density operator, thus we define the contracted centroid \({\widehat{{\mathbf{b}}}}^{(i)}:=\frac{2}{d+1}{\mathbf{b}}^{(i)}\). Obviously, not even \({\widehat{{\mathbf{b}}}}^{(i)}\) is the Bloch vector of the quantum centroid \(\rho _i\) however it represents a valid density operator, say \({{\widehat{\rho}}}_{i}\), on \({\mathbb {C}}^{d+1}\) that can be adopted as an alternative definition of centroid.
Given the class \(C_i\) of data points, let us list different notions of centroid of \(C_i\) that we can define within a fixed quantum encoding \({\mathbf{x}}\mapsto \rho _{\mathbf{x}}\):
-
(1)
Quantum centroid \(\rho _{i}:=\frac{1}{|C_{i}|}\sum _{{\mathbf{x}}\in C_{i}}\rho _{\mathbf{x}}\);
-
(2)
Quantum encoding \(\rho _{{\overline{{\mathbf{x}}}}_i}\) of the classical centroid \({\overline{{\mathbf{x}}}}_i:=\frac{1}{|C_{i}|}\sum _{{\mathbf{x}}\in C_{i}}{\mathbf{x}}\);
-
(3)
Mean of the Bloch vectors \({\mathbf{b}}^{(i)}:=\frac{1}{|C_i|}\sum _{{\mathbf{x}}\in C_i} {\mathbf{b}}^{({\mathbf{x}})}\);
-
(4)
Contracted centroid \({\widehat{{\mathbf{b}}}}^{(i)}:=\frac{2}{d+1}{\mathbf{b}}^{(i)}\) that is a Bloch vector itself.
In general, we have that \(\rho _i\not =\rho _{{\overline{{\mathbf{x}}}}_i}\) and \({\widehat{{\mathbf{b}}}}^{(i)}\) is not the Bloch vector of \(\rho _i\) or \(\rho _{{\overline{{\mathbf{x}}}}_i}\). In the construction of the nearest mean classifiers with operator distances we choose \({\widehat{{\mathbf{b}}}}^{(i)}\) as definition of centroid in order to select the encoding that is less memory consuming and to represent centroids by quantum states so that the calculation of the considered operator distances is meaningful in terms of distinguishability of quantum states.
Let us consider a binary classification problem (the multi-class generalization is straightforward). As suggested in7, we can define a classification algorithm that evaluates the Bures distance between the pure state encoding a test point and the centroids that correspond to mixed states. The fidelity between density operators, defined as \({\mathscr {F}}(\rho _1,\rho _2)=\left( {\mathrm{tr}}\sqrt{\sqrt{\rho _1}\rho _2\sqrt{\rho _1}}\right) ^2\), reduces to \({\mathscr {F}}(\rho _1,\rho _2)=\langle \psi _1|\rho _2|\psi _1\rangle \) when \(\rho _1=\big \vert {\psi _1} \big \rangle \big \langle {\psi _1}\big \vert \). Therefore the Bures distance between the pure state \(\rho _1\) and the generic state \(\rho _2\) can be expressed in term of the Bloch representation as follows:
where \({\mathbf{b}}^{(1)}\) and \({\mathbf{b}}^{(2)}\) are the Bloch vectors of \(\rho _1\) and \(\rho _2\) respectively and n is the dimension of the Hilbert space of the quantum encoding. The formula (25) can be directly derived from
that is an immediate consequence of the fact that the generalized Pauli matrices are traceless and satisfy \({\mathrm{tr}}(\sigma _i\sigma _j)=2\delta _{ij}\). Thus a quantum-inspired nearest mean classifier based on Bures distance for binary classification can be defined by Algorithm 1.

Algorithm 1: Quantum-inspired nearest mean classifier based on Bures distance.
Now let us consider the Hellinger distance (16). Assuming that \(\rho _1\) is a pure state in a n-dimensional Hilbert space, so \(\sqrt{\rho _1}=\rho _1\), then the distance can be written as:
where \({\mathbf{b}}^{(1)}\) is the Bloch vector of the state \(\rho _1\) and \(\mathbf{d }^{(2)}\) is the Bloch vector of the operator \(\sqrt{\rho _2}\). Therefore a nearest mean classifier based on Hellinger distance, within the Bloch representation, can be defined by Algorithm 2 which provides the square roots of the density operators corresponding to the centroids. A standard calculation is done solving the corresponding eigenvalue problem. Given a density operator, let Diag be the function returning a unitary matrix U and a diagonal matrix \(\Lambda \) such that \(\rho =U\Lambda U^{-1}\). Obviously \(\sqrt{\rho }=U\sqrt{\Lambda }U^{-1}\) where \(\sqrt{\Lambda }\) is the diagonal matrix given by the square roots of the eigenvalues of \(\rho \).
In Algorithm 2, the function BlochVector returns the Bloch vector of a given density operator and \(BlochVector^{-1}\) is its inverse. On the one hand, the centroids are computed in terms of Bloch vectors but they are translated into operators to compute the Hellinger distance. On the other hand the training points are processed directly in terms of their Bloch representation.
In the case of feature vectors in \({\mathbb {R}}^2\), quantum-inspired classification can also be applied in a smaller space than \({\mathbb {C}}^3\) using the encoding (21). In other words, data points are encoded into Bloch vectors of pure states of a single qubit, so a centroid calculated as in (24) is a vector inside the Bloch sphere then always represents a quantum state \(\rho _i\). In this low-dimensional case, Hellinger distance and Jensen–Shannon distance between dataset elements and the centroids can be calculated with the following simplified formulas:
where \(r=|{\mathbf{b}}^{(i)}|\) and \(s=|{\mathbf{b}}^{({\mathbf{x}})}+{\mathbf{b}}^{(i)}|\). Thus the corresponding near mean classifiers can be defined by Algorithm 1 with (28) and (29) in place of the Bures distance.

Algorithm 2: Quantum-inspired nearest mean classifier based on Hellinger distance.
Method and experimental results
In this section, we present some numerical results obtained by the implementation of the Helstrom classifier and the considered quantum-inspired nearest mean classifiers compared to classical algorithms. We run the Helstrom classifier and the nearest mean classifiers with several distances (Euclidean, Bures, Hellinger, Jensen–Shannon) compared to the following well-known classifiers that we list with respective parameters, settings and main characteristics:
-
K-Nearest Neighbors: number of neighbors \(K=3\), Euclidean distance as distance measure, uniform weights in each neighborhood;
-
Gaussian Process: kernel \(1.0*RBF(1.0)\), maximum number of iterations in Newton’s method \(=100\);
-
Linear SVM: regularization parameter \(=0.025\), no limit on iterations within solver;
-
RBF SVM: regularization parameter \(=1.0\), kernel coefficient for RBF \(\gamma =2\), no limit on iterations within solver;
-
Neural Network (multi-layer perceptron classifier): number of hidden layers \(=1\), number of neurons in the hidden layer \(=100\), activation function \(f(x)=\max (0,x)\), L2 penalty parameter \(=1\), learning rate \(=0.001\), maximum number of epochs in weight optimization \(=1000\), weight optimization performed by stochastic gradient;
-
Quadratic Discriminant Analysis: tolerance for a singular value to be considered significant \(=0.0001\).
-
Decision Tree: maximum depth of the tree \(=5\), minimum number of samples required to split an internal node \(=2\), Gini impurity for evaluating the quality of a split.
-
Random Forest: maximum depth \(=5\), number of trees in the forest \(=10\), minimum number of samples required to split an internal node \(=2\), Gini impurity for evaluating the quality of a split.
-
AdaBoost12: Decision Tree as base classifier, maximum number of estimators \(=50\), learning rate \(=1.0\),
-
Naive Bayes: Portion of the largest variance of all features that is added to variances for calculation stability \(=10^{-9}\);
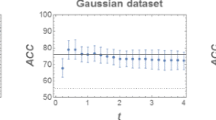
In order to compare the results with previous papers, we consider the following toy data and benchmark datasets from PMLB public repository13: moons, cicles, linearly separable, analcatdata aids, analcatdata asbestos, analcatdata boxing2, Hill Valley with noise, Hill Valley without noise, lupus, prnn synth. For each dataset we randomly select \(80\%\) of the data to create a training set and use the residual \(20\%\) for the evaluation.
For simplicity, we only consider the first two features of the datasets, i.e., an input vector \([x_1,x_2]\in {\mathbb {R}}^2\) and quantum-inspired classifiers in \({\mathbb {C}}^2\) within the encoding (21). We repeated the same procedure 100 times and calculated the average accuracy in Table 1. The results w.r.t. the F1-score are reported in Table 2. Since the Jensen and Hellinger distances generally do not provide better results than the Euclidean and Bures distances, even in the presence of more preparations of the same state, we will consider only the latter (Tables 3, 4, 5, 6, 7).
To correctly compare quantum-inspired classifiers in \({\mathbb {C}}^3\) with the well-known classifiers it is useful to map two features into a higher dimensional feature space \({\mathbb {R}}^5\) with the following explicit function \(\varphi :{\mathbb {R}}^2\rightarrow {\mathbb {R}}^5\):
For quantum-inspired classifiers in \({\mathbb {C}}^3\otimes {\mathbb {C}}^3\) with two preparations of the same quantum state it is useful the following explicit function \(\varphi _2:{\mathbb {R}}^2\rightarrow {\mathbb {R}}^{20}\):
The dimension of the feature space can be further increased considering multiple copies of the encoding quantum states as density operators in \(({\mathbb {C}}^3)^{\otimes 3}\) and \(({\mathbb {C}}^3)^{\otimes 4}\) implementing corresponding feature maps that are respectively given by explicit functions \(\varphi _3:{\mathbb {R}}^2\rightarrow {\mathbb {R}}^{81}\) and \(\varphi _4:{\mathbb {R}}^2\rightarrow {\mathbb {R}}^{122}\).
In the presented experiments we consider the average accuracy and the F1-score (Tables 2 and 7) as figures of merit to test and compare the performances of the quantum-inspired classifiers. However F-measures do not take true negative into account then average accuracy is considered better for the performance comparison of the classifier. Certainly, it is possible to compare the performances based on different statistic indices including balanced accuracy, sensitivity, specificity, precision, F-measure, Cohen’s k parameter3.
Helstrom classifier has been applied and compared with classical algorithms over the following datasets provided by the Wolfram data repository:
-
(1)
Death times of male laryngeal cancer patients: https://doi.org/10.24097/wolfram.61527.data.
-
(2)
Locations of cancer cases in North Liverpool, UK, annotated with subject type (case or control) marks: https://datarepository.wolframcloud.com/resources/Sample-Data-Liverpool-Cancer.
State discrimination using the Pretty Good measurement and the geometric Helstrom state discrimination introduced in “Quantum-inspired classifiers” section have been tested over the dataset:
-
(3)
Case-control study of esophageal cancer https://doi.org/10.24097/wolfram.41634.data.
The obtained results are reported in Tables 8 and 9 and discussed in the next section.
Discussion
The low-dimensional experiments, whose results are reported in Table 1, are performed encoding feature vectors of \({\mathbb {R}}^2\) into quantum states on \({\mathbb {C}}^2\) by means of (21). In this case, we observe that the performances of the Helstrom classifier are comparable to those of the linear SVM as expected7, except for the datasets moons and prnn_synth where the SVM turns out to be definitely more accuarate. However, for the linearly_separable dataset, Helstrom reaches a high average accuracy and for the datasets analcatdata_boxing2 and lupus it is the most accurate classifier, with a tiny margin, over the classical and the quantum-inspired ones. In particular, for analcatdata_boxing2, Helstrom presents an average accuracy that is only 0.1% higher than the Bures’. The considered quantum-inspired nearest mean classifiers present comparable accuracies between them and w.r.t. Helstrom, except for moons and prnn_synth datasets where they definitely outperform Helstrom and for circles and analcatdata_asbestos datasets where the nearest mean classifiers present an average accuracy that is over 10% higher than Helstrom’s. Over the considered datasets, the nearest mean classifier based on the Bures distance turns out to be the quantum-inspired algorithm with the highest average accuracy for five datasets: moons, linearly_separable, analcatdata_asbestos, Hill_Valley_with_noise, Hill_Valley_without_noise.
Within the encoding of real data points into density matrices on \({\mathbb {C}}^3\), the performance of the Helstrom classifier gets better and approaches the average accuracy of the linear SVM over the moons and prnn_synth datasets (Table 3) and outperforms the linear SVM over the cicles dataset. Thus, within this encoding, the performance of Helstrom classifier over the considered datasets is comparable to that of the quantum-inspired nearest mean classifiers. The Euclidean and the Bures classifiers improve their accuracy for the cicles dataset. The considered three quantum-inspired classifiers worsen the already poor performance over the analcatdata_aids w.r.t. the lower-dimensional encoding. As shown in Table 4, increasing the dimension of the feature space, from 5 to 20, by the preparation of two copies of the quantum states in \({\mathbb {C}}^3\otimes {\mathbb {C}}^3\), the Helstrom classifier outperforms the linear SVM over moons, cicles, linearly separable, lupus, prnn_synth datasets presenting a comparable average accuracy to the SVM’s over the other datasets except for analcatdata_aids where the performances of the quantum-inspired classifiers remain poor. Considering higher dimensional feature spaces (Tables 5 and 6) the performances of the quantum-inspired classifiers improve except for the analcatdata_aids dataset where there is a worsening of average accuracy increasing the dimension. In particular, the Helstrom classifier improves its performance w.r.t. the linear SVM becoming a definitely more accurate classifier.
In Table 9, we observe that all the classifiers presents low values of average accuracy over the data set iii). However the geometric Helstrom, that is the classifier based on the minimum-error measurement determined by (13), performs better than the classical competitors, except Random Forest and Naive Bayes, and the classifier based on state discrimination by means of the Pretty Good measurement defined in (9). In particular, geometric Helstrom outperforms the Nearest neighbor classifier.
Conclusions
The present paper is focused on some methods of quantum-inspired machine learning, in particular classification algorithms based on quantum state discrimination. We adopted a geometric approach in defining quantum encodings of classical data in terms of Bloch vectors of density operators. The geometry of quantum encoding has been analyzed in relation to the construction of feature maps and to the execution of the quantum-inspired classifiers. We considered algorithms based on the construction of an optimal measurement for state discrimination: the Helstrom classifier based on the well-known Helstrom’s theory of quantum discrimination2, a classifier based on the so-called Pretty Good measurement10 and a classifier based on the geometric construction of the minimum-error measurement11. Moreover we considered quantum-inspired nearest mean classifiers based on the encoding of data into density operators and the calculation of distances which quantify the distinguishability of quantum states in the spirit of other works on this subject1,7. The considered operator distances were: trace distance, Bures distance, Hellinger distance, Jensen–Shannon distance. The first two are particularly convenient in terms of the execution of a classifier within the Bloch encoding because the trace distance can be computed as the Euclidean distance among the Bloch vectors and the Bures distance allows the definition of a simple algorithm, reported in Algorithm 1, that perform the classification task entirely within the Bloch representation of the quantum states taking a full advantage by the geometric description. On the other hand, we do not find a satisfactory formulations of classification algorithms based on Hellinger and Jensen–Shannon distances that can executed entirely within the geometric description of the quantum states. Nevertheless, the experiments performed in the low-dimensional case (data encoding into qubit states) show that the classification done with the Hellinger and the Jensen–Shannon distances do not provide an average accuracy that is significantly different from that of the classifiers with trace and Bures distances, so we focused only on the latter for the experiments in higher dimension.
In “Geometric approach to quantum-inspired classifications” section, we clarified the adopted geometric approach. Within the encoding of real feature vectors into the amplitudes of pure quantum states w.r.t. a computational basis, the density operators are expressed as Bloch vectors and the centroids of data classes are directly calculated in terms of Bloch vectors. However, the mean of a set of Bloch vectors is not a Bloch vector in general (except in the case of qubit states). In order to identify the centroid as a proper density operator on \({\mathbb {C}}^d\) the obtained Bloch vector is re-scaled into the real sphere with radius \(\frac{2}{d+1}\). The advantage in considering such a Bloch representation is given by data compression allowed suppressing null and repeated components in Bloch vectors removing redundancy in the representation. This simple property is useful when many copies of the considered quantum state \(\rho \) are processed in order to increase the dimension of the feature space (kernel trick). In fact, the saving of spatial resources in representing \(\rho \otimes \cdots \otimes \rho \) by means of the Bloch vectors balances the exponential cost due to processing the tensor product. Thus the Bloch representation turns out to be a useful tool to efficiently increase the dimension of the feature space in quantum-inspired machine learning.
In the experiments over different datasets, described in “Method and experimental results” section, the effects of the kernel tricks on the accuracy of the Helstrom classifier are evident. Moreover, the obtained results show that the performances of the quantum-inspired classifiers are comparable, and sometimes better, to those of well-known classical algorithms. We observed that the classification based on the minimum-error measurement for state discrimination can be carried on by the Pretty Good measurement or by the so-called geometric Helstrom. A comparison over the dataset case-control study of esophageal cancer show that the geometric Helstrom is definitely more accurate w.r.t. the classifier based on Pretty Good measurement. Moreover, in Table 9 the results show that geometric Helstrom outperforms also the classical support vectors machines, the KNN, and the logistic regression.
Description and characterization of the quantum-inspired classifiers considered in the present work suggest that quantum structures can be a valuable resource in classical machine learning, in particular the geometric approach considering the Bloch representation of density matrices is suitable to efficiently implement feature maps in quantum-inspired classification. The adopted geometric approach and the obtained experimental results reveal that quantum encoding of data into density operators and quantum state discrimination allow the definition of new efficient classification algorithms that can be run on classical computers.
Code availability
The code is also at the following repository: https://github.com/leporini/classification (accessed on: December 9, 2021).
References
Sergioli, G., Bosyk, G., Santucci, E. & Giuntini, R. A quantum-inspired version of the classification problem. Int. J. Theor. Phys. 56, 3880–3888. https://doi.org/10.1007/s10773-017-3371-1 (2017).
Helstrom, C. Quantum detection and estimation theory. J. Stat. Phys. 1, 231–252. https://doi.org/10.1007/BF01007479 (1969).
Sergioli, G., Giuntini, R. & Freytes, H. A new quantum approach to binary classification. PLoS One. https://doi.org/10.1371/journal.pone.0216224 (2019).
Bertlmann, R. A. & Krammer, P. Bloch Vectors for Qudits. arXiv:0806.1174v1 (2008).
Kimura, G. & Kossakowski, A. The Bloch-vector space for n-level systems: The spherical-coordinate point of view. Open Syst. Inf. Dyn.https://doi.org/10.1007/s11080-005-0919-y (2005).
Giuntini, R. et al. Quantum State Discrimination for Supervised Classification. arXiv:2104.00971v1 (2021).
Leporini, R. & Pastorello, D. Support vector machines with quantum state discrimination. Quantum Rep.https://doi.org/10.3390/quantum3030032 (2021).
Croke, S., Barnett, S. & Graeme, W. Optimal sequential measurements for bipartite state discrimination. Phys. Rev. Ahttps://doi.org/10.1103/PhysRevA.95.052308 (2017).
Croke, S., Andersson, E., Barnett, S., Gilson, C. & Jeffers, J. Maximum confidence quantum measurements. Phys. Rev. Lett.https://doi.org/10.1103/PhysRevLett.96.070401 (2006).
Mochon, C. Family of generalized pretty good measurements and the minimal-error pure-state discrimination problems for which they are optimal. Phys. Rev. Ahttps://doi.org/10.1103/PhysRevA.73.032328 (2006).
Bae, J. Structure of minimum-error quantum state discrimination. New J. Phys.https://doi.org/10.1088/1367-2630/15/7/073037 (2013).
Freund, Y. & Schapire, R. E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 55, 119–139. https://doi.org/10.1006/jcss.1997.1504 (1997).
Romano, J. et al. Pmlb v1.0: An Open Source Dataset Collection for Benchmarking Machine Learning Methods. arXiv:2012.00058 (2020).
Acknowledgements
This work was supported by Q@TN, the joint lab between University of Trento, FBK-Fondazione Bruno Kessler, INFN-National Institute for Nuclear Physics and CNR-National Research Council.
Author information
Authors and Affiliations
Contributions
Conceptualization, R.L. and D.P.; software, R.L.; validation, D.P.; formal analysis, D.P.; writing—original draft preparation, R.L. and D.P.; writing—review and editing, D.P. All authors have read and agreed to this version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Leporini, R., Pastorello, D. An efficient geometric approach to quantum-inspired classifications. Sci Rep 12, 8781 (2022). https://doi.org/10.1038/s41598-022-12392-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-12392-1
- Springer Nature Limited