
Abstract
The western flower thrips Frankliniella occidentalis (Thysanoptera: Thripidae) is a global invasive species that causes increasing damage by direct feeding on crops and transmission of plant viruses. Here, we assemble a previously published scaffold-level genome into a chromosomal level using Hi-C sequencing technology. The assembled genome has a size of 302.58 Mb, with a contig N50 of 1533 bp, scaffold N50 of 19.071 Mb, and BUSCO completeness of 97.8%. All contigs are anchored on 15 chromosomes. A total of 16,312 protein-coding genes are annotated in the genome with a BUSCO completeness of 95.2%. The genome contains 492 non-coding RNA, and 0.41% of interspersed repeats. In conclusion, this high-quality genome provides a convenient and high-quality resource for understanding the ecology, genetics, and evolution of thrips.
Similar content being viewed by others


Background & Summary
Thrips are a group of tiny insects from the order Thysanoptera. Most thrips species feed on plants and fungi, while only a small number of species are predators of small invertebrates1. There are over 7000 species of thrips, with 150 of them being harmful to plants2. Pest thrips are causing increasing damage to crop production worldwide3,4. Thrips can be easily dispersed through transportation of host plants5. The western flower thrips (WFT) Frankliniella occidentalis is one of the most notorious thrips worldwide6,7. This species is native to America and has dispersed worldwide since the 1970s as an invasive species8. The invasion genetics of this species have been widely investigated9,10,11,12. Insecticides were frequently used to control this pest and thus causing pesticide resistance in the field13,14. However, resistant mechanisms of WFT to many insecticides remain to be explored14,15. In addition to directly feeding on plants, WFT can transmit plant viruses from the genus Tospovirus, making it an important species to understand insect-plant-virus interaction16,17. A genome assembly is crucial to understand the complex biology, ecology and genetic of the WFT. The WFT genome is the first that has been assembled in thrips and made publicly available18, providing invaluable resources for studying the genetic mechanisms governing pest and vector biology, feeding behaviours, ecology, and resistance to insecticides and development of novel control methods10,19,20. However, some genes are scattered across different scaffolds of the currently assembled genome, which hinders the functional genomics study of this species. An improved genome assembly of WFT to a chromosome level will benefit future studies of this important insect pest. Here, we assembled the previously published scaffold-level genome of WFT to a chromosomal level using chromosome conformation capture (Hi-C) technology18.
Methods
Sample collection and Hi-C library sequencing
The chromosome conformation of the genome was analysed to determine the order and orientation of the contigs using Hi-C technology. A strain of WFT was reared for approximately 10 generations and used for Hi-C library construction at the College of Forestry, Inner Mongolia Agricultural University, Hohhot, China. Approximately 1000 live adults of mixed sex were ground and then cross-linked in a fresh, ice-cold nuclear isolation buffer with a 2% formaldehyde solution for 10 minutes. The fixed cells were then digested using DpnII (NEB) enzymes, and further processed by cell lysis, incubation, DNA end labelling with biotin-14-dCTP, and blunt-end ligation of crosslinked fragments. The Hi-C library was amplified by 12–14 PCR cycles and sequenced on the Illumina NovaSeq 6000 platform. A total of 36.11 Gb of clean data were generated, representing 119.34X coverage of the genome.
Genome characteristics estimation
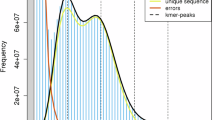
Genome characteristics were estimated based on Illumina short-reads. Raw reads of the whole genome sequencing of WFT were downloaded from the NCBI Sequence Read Archive database (accession number of SRR1300140). The raw sequences were trimmed using the software fastp21 with default parameters. The trimmed data was used to count the K-mer distribution histogram under 17, 21, 27, 31 and 41-mer using KMC v3.022 with parameters ‘-m96 -ci1 -cs10000’ and ‘-cx10000’. The genome size, heterozygosity rate, and duplication rate were estimated using GCE v2.023 with default parameters. The estimated genome size and genome duplication decreased as the K-mer increased, ranging from 281 Mb to 287 Mb and 1.75% to 2.65%, respectively. Each K-mer distribution showed single-peak, indicating that the genome of WFT is a simple one (Table 1, Fig. 1).

Estimated characteristics of Frankliniella occidentalis genome based on Illumina short-read data. Results were obtained in KMC v3.0 and GCE v2.0 with 17- (A), 21- (B), 27- (C), 31- (D) and 41- (E) mer. len, estimated genome size in bp; aa, homozygosity rate; ab, heterozygosity rate; dup, duplication rate.
Genome assembly and annotation
The scaffold-level genome was downloaded from NCBI database (accession number: GCF_000697945) and used for chromosomal-level genome assembly based on Hi-C sequencing data. Low-quality reads and adapters from the Hi-C library were filtered using Trimmomatic v0.3924 with default parameters and then mapped to the genome contigs using Juicer25 with default parameters. The reads were grouped into chromosomes using 3D de novo assembly (3D-DNA)26 with parameters ‘–editor_repeat_coverage = 15, -r 2’. Error joints were manually adjusted in Juicebox v2.16.00 (https://github.com/aidenlab/Juicebox), and the raw-chromosomes were updated using the script “run-asm-pipeline-post-review.sh” in 3D-DNA again.
The repeat-masked genome assembly was submitted to the online tool Helixer27 for genome structure annotation under the invertebrate lineage-specific mode. Helier is a novel tool for cross-species gene annotation of large eukaryotic genomes using deep learning algorithms. Functional annotation was performed by BLAST the proteins against the EggNOG v5.028 database using eggNOG-Mapper29. Additionally, the entire gene sets were functionally annotated by aligning protein sequences with the Nr database, Uniport_SwissProt, Uniref90, InterPro (-appl pfam, PRINTS, PANTHER, ProSiteProfiles, SMART, CDD, SFLD, AntiFam), KEGG and GO database using BLASTP and InterProScan version 5.59–91.0 (https://github.com/ebi-pf-team/interproscan) with an e-value cutoff of e < 10−5. The final genome assembly was consisted of 250,191 contigs, which were assembled into 15 chromosomes (Fig. 2). The chromosome sizes ranged from 15.116 Mb to 32.461 Mb, with a total length of 302.58 Mb, a contig N50 length of 1533 bp, and a scaffold N50 length of 19.071 Mb. We numbered the chromosomes in descending order of their size. Compared to the scaffold-level assembly with a size of 415.8 Mb and scaffold N50 of 948.9 kb, the genome size was reduced and became more approximated to the estimated genome size. In total, 16,312 protein-coding genes (PCGs) were identified, which is 547 genes fewer than the official gene set (OGS v1.0) of 16,859 for the scaffold-level assembly. The functionally annotated terms were discrepant according to the reference databases, ranged from 15619 PCGs for Nr database to 370 domains for InterPro database (Table 2). The G + C content of the final genome assembly was 50.75% (Table 1), which is similar to that of the published WFT genome18, lower than that of Frankliniella intonsa30,31, Megalurothrips usitatus32,33, Stenchaetothrips biformis34 and Thrips palmi35, while slightly higher than those of Frankliniella fusca36.

Genome-wide contact matrix of Frankliniella occidentalis generated using Hi-C data. Each blue square represents a chromosome, each green square represents a contig. Fifteen chromosomes were anchored under the default parameters of Juicer and 3D-DNA software. Numbers on the axes show the chromosome length in Mb. The numbers in bold at the bottom of the figure represents the chromosomes number.
Repeat elements and non-coding RNA predictions
The repetitive elements longer than 1000 bp were identified against the Insecta repeats within RepBase Update (20120418). The identification was performed using RepeatMasker version open-4.0.037 (-no_is -norna -xsmall -q) under the search engine RM-BLAST (v2.2.23+). De novo identification of transposable elements (TEs) was performed using RepeatModeler38. Non-coding RNAs were identified using Rfam39,40, ribosome RNAs (rRNAs) and transfer RNAs (tRNAs) were searched by tRNAscan-SE v2.041 and RNAmmer v1.242, both with default parameters. A total of 189159 transposable elements (TEs) were identified, including 5005 retroelements with a total length of 542068 bp, 8850 DNA transposons and 175304 Tandem Repeats (TRs) (Table 3). We identified 49 miRNAs, 19 snRNAs, 31 snoRNAs, 101 rRNAs and 292 tRNAs in WFT genome (Table 4).
Data Records
The genome project was deposited at NCBI under BioProject No. PRJNA1016120. The Hi-C sequencing data were deposited in the Sequence Read Archive at NCBI under accession SRR2610605943. The genome assembly, genome structure annotation and protein files were deposited in Figshare under a DOI of https://doi.org/10.6084/m9.figshare.24968679.v144. The final genome assembly was also deposited in GenBank at NCBI under the accession number GCA_035583395.145.
Technical Validation
Benchmarking Universal Single-Copy Orthologs (BUSCO) v5.4.546 was used to estimate the integrity and quality of the genome assembly and the annotated protein-coding genes based on the Eukaryota, Metazoa, Arthropoda and Insecta (odb_10, released on 2024-01-08) datasets. For the chromosome-level genome assembly, the BUSCO completeness was 97.7%, 98.7%, 98.5% and 97.8% based on the Eukaryota, Metazoa, Arthropoda and Insecta datasets, respectively. For the protein-coding gene set, the BUSCO completeness was 93.3%, 95.6%, 95.7% and 95.2% based on the Eukaryota, Metazoa, Arthropoda and Insecta datasets, respectively. To avoid the genetic differences of samples for assembly, we mapped the Illumina short-reads for scaffold-level assembly and Hi-C library sequencing reads obtained in our study to our assembled chromosome-level genomes using BWA version 0.7.17-r1198-dirty47. The mapping rate of Illumina short-reads and Hi-C sequencing data was 94.70% and 95.15%, respectively.
Code availability
No specific code or script were used in this study.
References
Zhang, S., Mound, L. & Feng, J. Morphological phylogeny of Thripidae (Thysanoptera: Terebrantia). Invertebr. Syst. 33, 671–696 (2019).
Mound, L. A., Wang, Z., Lima, E. F. B. & Marullo, R. Problems with the concept of “Pest” among the diversity of pestiferous thrips. Insects 13, https://doi.org/10.3390/insects13010061 (2022).
Rodriguez, D. & Coy-Barrera, E. Overview of updated control tactics for western flower thrips. Insects 14, 649, https://doi.org/10.3390/insects14070649 (2023).
Maurastoni, M., Han, J., Whitfield, A. E. & Rotenberg, D. A call to arms: novel strategies for thrips and tospovirus control. Curr. Opin. Insect Sci. 57, 101033, https://doi.org/10.1016/j.cois.2023.101033 (2023).
Reitz, S. R. Biology and ecology of the western flower thrips (Thysanoptera: Thripidae): the making of a pest. Fla. Entomol. 92, 7–13 (2009).
Reitz, S. R. et al. Invasion biology, ecology, and management of western flower thrips. Annu. Rev. Entomol. 65, 17–37 (2020).
Gao, Y. L., Lei, Z. R. & Reitz, S. R. Western flower thrips resistance to insecticides: detection, mechanisms and management strategies. Pest Manag. Sci. 68, 1111–1121 (2012).
Reitz, S. R., Gao, Y. L. & Lei, Z. R. Thrips: pests of concern to China and the United States. Agr. Sci. China 10, 867–892 (2011).
Sun, L. N. et al. Temporal decline of genetic differentiation among populations of western flower thrips across an invaded range. Biol. Invasions 25, 1921–1933, https://doi.org/10.1007/s10530-023-03024-4 (2023).
Cao, L. J. et al. Low genetic diversity but strong population structure reflects multiple introductions of western flower thrips (Thysanoptera: Thripidae) into China followed by human-mediated spread. Evol. Appl. 10, 391–401, https://doi.org/10.1111/eva.12461 (2017).
Yang, X. M. et al. Temporal genetic dynamics of an invasive species, Frankliniella occidentalis (Pergande), in an early phase of establishment. Sci. Rep-Uk 5, 11877, https://doi.org/10.1038/srep11877 (2015).
Yang, X. M., Sun, J. T., Xue, X. F., Li, J. B. & Hong, X. Y. Invasion genetics of the western flower thrips in China: evidence for genetic bottleneck, hybridization and bridgehead effect. PloS ONE 7, e34567, https://doi.org/10.1371/journal.pone.0034567 (2012).
Wan, Y. et al. Insecticide resistance increases the vector competence: a case study in Frankliniella occidentalis. J. Pest Sci. 94, 83–91, https://doi.org/10.1007/s10340-020-01207-9 (2020).
Guillen, J., Navarro, M. & Bielza, P. Cross-resistance and baseline susceptibility of spirotetramat in Frankliniella occidentalis (Thysanoptera: Thripidae). J.Econ. Entomol. 107, 1239–1244 (2014).
Sun, L. N. et al. Increasing frequency of G275E mutation in the nicotinic acetylcholine receptor alpha6 subunit conferring spinetoram resistance in invading populations of western flower thrips in China. Insects 13, 331, https://doi.org/10.3390/insects13040331 (2022).
Rotenberg, D., Jacobson, A. L., Schneweis, D. J. & Whitfield, A. E. Thrips transmission of tospoviruses. Curr. Opin. Virol. 15, 80–89, https://doi.org/10.1016/j.coviro.2015.08.003 (2015).
Whitfield, A. E., Ullman, D. E. & German, T. L. Tospovirus-thrips interactions. Annu. Rev. Phytopathol. 43, 459–489, https://doi.org/10.1146/annurev.phyto.43.040204.140017 (2005).
Rotenberg, D. et al. Genome-enabled insights into the biology of thrips as crop pests. BMC Biol. 18, 142, https://doi.org/10.1186/s12915-020-00862-9 (2020).
Wu, M. et al. Efficient control of western flower thrips by plastid-mediated RNA interference. Proc. Natl. Acad. Sci. USA 119, e2120081119, https://doi.org/10.1073/pnas.2120081119 (2022).
Han, J. & Rotenberg, D. Integration of transcriptomics and network analysis reveals co-expressed genes in Frankliniella occidentalis larval guts that respond to tomato spotted wilt virus infection. BMC Genomics 22, 810, https://doi.org/10.1186/s12864-021-08100-4 (2021).
Chen, S. F., Zhou, Y. Q., Chen, Y. R. & Gu, J. fastp: an ultra-fast all-in-one FASTQ preprocessor. Bioinformatics 34, i884–i890, https://doi.org/10.1093/bioinformatics/bty560 (2018).
Kokot, M., Dlugosz, M. & Deorowicz, S. KMC 3: counting and manipulating k-mer statistics. Bioinformatics 33, 2759–2761, https://doi.org/10.1093/bioinformatics/btx304 (2017).
Ranallo-Benavidez, T. R., Jaron, K. S. & Schatz, M. C. GenomeScope 2.0 and Smudgeplot for reference-free profiling of polyploid genomes. Nat. Commun. 11, 1432, https://doi.org/10.1038/s41467-020-14998-3 (2020).
Bolger, A. M., Lohse, M. & Usadel, B. Trimmomatic: a flexible trimmer for Illumina sequence data. Bioinformatics 30, 2114–2120, https://doi.org/10.1093/bioinformatics/btu170 (2014).
Durand et al. Juicer provides a one-click system for analyzing loop-resolution Hi-C experiments. Cell Syst. 3, 95–98 (2016).
Dudchenko et al. De novo assembly of the Aedes aegypti genome using Hi-C yields chromosome-length scaffolds. Science 356, 92–95 (2017).
Holst, F. et al. Helixer- de novo prediction of primary eukaryotic gene models combining deep learning and a hidden markov model. Bioinformatics 36, 5291–5298, https://doi.org/10.1101/2023.02.06.527280 (2023).
Huerta-Cepas, J. et al. eggNOG 5.0: a hierarchical, functionally and phylogenetically annotated orthology resource based on 5090 organisms and 2502 viruses. Nucleic Acids Res. 47, D309–D314, https://doi.org/10.1093/nar/gky1085 (2019).
Huerta-Cepas, J. et al. Fast genome-wide functional annotation through orthology assignment by eggNOG-Mapper. Mol. Biol. Evol. 34, 2115–2122, https://doi.org/10.1093/molbev/msx148 (2017).
Song, W. et al. A chromosome-level genome for the flower thrips Frankliniella intonsa. Sci. Data 11, 280, https://doi.org/10.1038/s41597-024-03113-6 (2024).
Zhang, Z. J. et al. Chromosome-level genome assembly of the flower thrips Frankliniella intonsa. Sci. Data 10, 1–6, https://doi.org/10.1038/s41597-023-02770-3 (2023).
Zhang, Z. J. et al. The chromosome-level genome assembly of bean blossom thrips (Megalurothrips usitatus) reveals an expansion of protein digestion-related genes in adaption to high-protein host plants. Int. J. Mol. Sci. 24, 11268, https://doi.org/10.3390/ijms241411268 (2023).
Ma, L. et al. Chromosome-level genome assembly of bean flower thrips Megalurothrips usitatus (Thysanoptera: Thripidae). Sci. Data 10, 252, https://doi.org/10.1038/s41597-023-02164-5 (2023).
Hu, Q. L., Ye, Z. X., Zhuo, J. C., Li, J. M. & Zhang, C. X. A chromosome-level genome assembly of Stenchaetothrips biformis and comparative genomic analysis highlights distinct host adaptations among thrips. Commun. Biol. 6, 813, https://doi.org/10.1038/s42003-023-05187-1 (2023).
Guo, S. K. et al. Chromosome-level assembly of the melon thrips genome yields insights into evolution of a sap-sucking lifestyle and pesticide resistance. Mol. Ecol. Resour. 20, 1110–1125, https://doi.org/10.1111/1755-0998.13189 (2020).
Catto, M. A. et al. Pest status, molecular evolution, and epigenetic factors derived from the genome assembly of Frankliniella fusca, a thysanopteran phytovirus vector. BMC Genomics 24, 343, https://doi.org/10.1186/s12864-023-09375-5 (2023).
Tarailo-Graovac, M. & Chen, N. S. Using RepeatMasker to identify repetitive elements in genomic sequences. Curr. Protoc. Bioinformatics Chapter 4, 1–14, https://doi.org/10.1002/0471250953.bi0410s25 (2009).
Flynn, J. M. et al. RepeatModeler2 for automated genomic discovery of transposable element families. Proc. Natl. Acad. Sci. USA 117, 9451–9457 (2020).
Gardner, P. P. et al. Rfam: Wikipedia, clans and the “decimal” release. Nucleic Acids Res. 39, D141–D145, https://doi.org/10.1093/nar/gkq1129 (2011).
Burge, S. W. et al. Rfam 11.0: 10 years of RNA families. Nucleic Acids Res. 41, D226–D232, https://doi.org/10.1093/nar/gks1005 (2013).
Schattner, P., Brooks, A. N. & Lowe, T. M. The tRNAscan-SE, snoscan and snoGPS web servers for the detection of tRNAs and snoRNAs. Nucleic Acids Res. 33, 686–689, https://doi.org/10.1093/nar/gki366 (2005).
Lagesen, K. et al. RNAmmer: consistent and rapid annotation of ribosomal RNA genes. Nucleic Acids Res. 35, 3100–3108, https://doi.org/10.1093/nar/gkm160 (2007).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26106059 (2023).
Song, W. & Jun, W. S. Genome assembly and annotation of the western flower thrips Frankliniella occidentalis. Figshare https://doi.org/10.6084/m9.figshare.24968679.v1 (2024).
NCBI GenBank https://identifiers.org/ncbi/insdc.gca:GCA_035583395.1 (2023).
Simao, F. A., Waterhouse, R. M., Ioannidis, P., Kriventseva, E. V. & Zdobnov, E. M. BUSCO: assessing genome assembly and annotation completeness with single-copy orthologs. Bioinformatics 31, 3210–3212, https://doi.org/10.1093/bioinformatics/btv351 (2015).
Li, H. & Durbin, R. Fast and accurate long-read alignment with Burrows-Wheeler transform. Bioinformatics 26, 589–595, https://doi.org/10.1093/bioinformatics/btp698 (2010).
Acknowledgements
This work is supported by the National Key R&D Program of China (2023YFD1401200), and the Programs of Beijing Academy of Agricultural and Forestry Sciences (KJCX20240306, JKZX202208).
Author information
Authors and Affiliations
Contributions
S.J.W. conceived the study. W.X.B. and J.C.C. prepared the samples. W.S. and L.J.C. analysed the data. W.S. and S.J.W. wrote and revised the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Song, W., Cao, LJ., Chen, JC. et al. Chromosome-level genome assembly of the western flower thrips Frankliniella occidentalis. Sci Data 11, 582 (2024). https://doi.org/10.1038/s41597-024-03438-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03438-2
- Springer Nature Limited