
Abstract
Given the importance and interest of buildings in the urban environment, numerous studies have focused on automatically extracting building outlines by exploiting different datasets and techniques. Recent advancements in unmanned aerial vehicles (UAVs) and their associated sensors have made it possible to obtain high-resolution data to update building information. These detailed, up-to-date geographic data on the built environment are essential and present a practical approach to comprehending how assets and people are exposed to hazards. This paper presents an effective method for extracting building outlines from UAV-derived orthomosaics using a semantic segmentation approach based on a U-Net architecture with a ResNet-34 backbone (UResNet-34). The novelty of this work lies in integrating a grey wolf optimiser (GWO) to fine-tune the hyperparameters of the UResNet-34 model, significantly enhancing building extraction accuracy across various localities. The experimental results, based on testing data from four different localities, demonstrate the robustness and generalisability of the approach. In this study, Locality-1 is well-laid buildings with roads, Locality-2 is dominated by slum buildings in proximity, Locality-3 has few buildings with background vegetation and Locality-4 is a conglomeration of Locality-1 and Locality-2. The proposed GWO-UResNet-34 model produced superior performance, surpassing the U-Net and UResNet-34. Thus, for Locality-1, the GWO-UResNet-34 achieved 94.74% accuracy, 98.11% precision, 84.85% recall, 91.00% F1-score, and 88.16% MIoU. For Locality-2, 90.88% accuracy, 73.23% precision, 75.65% recall, 74.42% F1-score, and 74.06% MioU was obtained.The GWO-UResNet-34 had 99.37% accuracy, 90.97% precision, 88.42% recall, 89.68% F1-score, and 90.21% MIoU for Locality-3, and 95.30% accuracy, 93.03% precision, 89.75% recall, 91.36% F1-score, and 88.92% MIoU for Locality-4.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Buildings are a significant element of the urban environment and the most vital areas for human production and living, making them the leading indicators of urban expansion and the size of population centres [1]. Given the importance and interest of buildings in the urban environment, numerous studies have focused on automatically extracting building outlines by exploiting different datasets and techniques [2, 3]. These detailed, up-to-date geographic data on the built environment are essential and present a practical approach to comprehending how assets and people are exposed to environmental hazards such as floods, erosion, and coastal storms [4].
With significant advances in diverse platforms and sensors such as Light Detection and Ranging (LiDAR), cameras mounted on satellites, aerial platforms, and unmanned aerial vehicles (UAVs), it is now easier to acquire 2D images and generate 3D point clouds for building extraction purposes [5,6,7]. Existing studies have shown that satellite and aerial imageries [8,9,10], as well as LiDAR [11,12,13], have been extensively used for building segmentation purposes, and these data sources have achieved outstanding results. However, these data sources are costly to acquire, and the freely available ones are also temporally devoid for most developing countries in Africa.
Several techniques have been developed for building segmentation over the past decades and can loosely be categorised as traditional and deep learning (DL) based methods [14]. The traditional-based methods involve experts manually digitising building footprints or utilising the geometric features or contextual properties of buildings, such as shape [15, 16], edge [17, 18] and shadow [19] to extract the building outlines. However, these techniques are arduous, onerous, and economically expensive [20]. In view of the foregoing, there has been a fostering interest in implementing DL approaches for automatic building extraction after several advancements were achieved in a diversity of computer vision projects, such as classification [21], object detection [22], and semantic segmentation [23, 24]. Thus, the DL-based methods seek to do away with expert intervention as much as possible to increase productivity gain.
It is acknowledged that the DL-based building extraction process is a semantic segmentation problem that involves pixel-wise labelling of image pixels to categorise such pixels as either buildings or not. Among the different DL architectures used, the encoder-decoder is the most effective and solves most end-to-end issues encountered by other DL architectures [20]. One typical example of such encoder-decoder architecture is the U-Net built on a fully connected network (FCN) which has gained traction as a cutting-edge architecture for building extraction. The U-Net utilises a skip connection that enables a decoder to accept low-sampled features from the encoder to create outputs with minimum information loss [25]. To improve the accuracy and increase the performance of the U-Net, some works [26,27,28] proposed replacing the encoder part with a pre-trained network via transfer learning. Of the various pre-trained models, the residual network with 34 deep layers (ResNet—34) provides a good balance between performance and accuracy and hence was adopted in this paper.
The hyperparameters of DL networks significantly influence the network’s performance, as they serve as control agents for the network’s training process. Designing an optimal DL architecture for efficient learning and achieving optimum results depends on adjusting the hyperparameters, such as the number of convolutional layers, filter size, batch size, and convolutional filters. This implies exploring a vast and intricate search space and experimenting with diverse combinations and manually finding the best configuration and fine-tuning hyperparameter is computationally expensive [29]. Also, selecting the appropriate hyperparameters to achieve optimum training results is imperative. For example, choosing a lower learning rate implies that the network learns slowly and requires increasing the epochs to attain superior performance. By contrast, a higher learning rate would lead to early convergence whereby the network reaches sub-standard performance speedily and fails to improve further. Therefore, there is the need to optimise the DL hyperparameters for proper training and ideal performance results.
Existing studies [30,31,32] revealed that the grid and random search optimisation techniques are the most conventional ones used to fine-tune DL hyperparameters. Grid search, a systematic approach, exhaustively explores hyperparameter combinations, suitable for models with a limited number of hyperparameters [33, 34]. For instnace, Jiang and Xu [35] used grid search to optimise hyperparameters for various deep feedforward neural networks and machine learning models, achieving promising results in predicting breast cancer metastasis. Priyadarshini and Cotton [36] also applied grid search to develop a long short term memory-convolutional neural network (LSTM-CNN)based model for sentiment analysis. Ngoc et al. [37] utlised grid search within the walk-forward validation methodology to search for the optimal hyperparameters of a multilayer perceptron model. Although these approaches attained promising results, Bacanin et al. [34] argued that grid search is a trial-and-error technique that necessitates a strong understanding of the specific domain. Its efficiency diminishes as the number of hyperparameters expands, leading to exponential growth in computational demands [34]. On the contrary, the random search surpasses the grid search in effectiveness by allowing parallelisation and random sampling from a search space to identify the best hyperparameters [38, 39]. Rodríguez et al. [40] utilised random search for fine-tuning the hyperparameters of a CNN to recognise images over an augmented reality sandbox, and Jekova and Krasteva [41] exploited it to fine-tune an end-to-end CNN to analyse out-of-hospital cardiac arrest rhythms during cardiopulmonary resuscitation. Likewise, Ragab et al. [42] utilised it to optimise a one-dimensional CNN to recognise human activity. Nonetheless, a notable limitation of this random search technique is its failure to incorporate previously obtained results, potentially leading to repeated searches with the same hyperparameters [43]. As such, deep neural networks (DNNs) optimised with random search techniques tend to converge to local optima, distant from the global best hyperparameter configurations. Furthermore, hyperparameters vary in type, and can be continuous, categorical or discrete values, making these random search techniques sometimes inadequate [38, 44].
To address such problem, many researchers have tackled hyperparameter tuning of DL models as a hyperparameter optimisation (HPO) problem and proposed the use of advanced optimisation techniques such as metaheuristics [29, 34, 45]. Different from the other optimisation strategies, metaheuristics are designed to efficiently explore a large space, make use of previous searches, and strike a balance between exploration and exploitation [38, 46]. Moreover, these algorithms are capable of escaping local optima; thus, providing a more efficient way to find close-to-optimal [47]. These metaheuristic optimisation algorithms have demonstrated exceptional performance and their ease of implementation have made them preferential for tackling a wide array of complex optimisation problems spanning engineering, communications, industrial settings, and social sciences [48]. Furthermore, their versatility and robustness make them valuable tools for consistently delivering effective solutions to intricate optimisation tasks across various domains such as biological information analysis [49], chemical information optimisation [50], task scheduling within cloud computing environments [51], feature selection [52], image segmentation tasks [53], and even cost-effective emission dispatch problems [54], among others. One of such algorithms is the grey wolf optimisation (GWO) technique [55], a novel population-based metaheuristic that has proven to be a strong fit for handling numerous benchmark optimisation challenges. GWO is capable of learning in iteration and identifying the best-fit value in each iteration. Additionally, the mathematical framework of GWO makes it possible to identify solutions in an \(n\)-dimensional search space, mimicking the grey wolves hunting technique [56]. Moreover, GWO is computationally less expensive as it utilises only one position while reserving the three best solutions for enhanced exploration [57]. Coupled with its computational advantages, GWO has been utilised to tackle various issues such as feature extraction [58], weight initialisation of CNN [59, 60], and hyperparameter optimisation of CNNs for classification problems [45, 61]. Despite its vast application areas, the GWO has been underexplored to verify its authenticity in hyperparameter optimisation of DL segmentation architectures such as the U-Net and its associated variants for image segmentation problems.
In view of the enumerated benefits, this research proposes a hybrid intelligent building segmentation model of grey wolf and UResNet-34 called GWO-UResNet-34. The principal idea is to employ GWO to find the optimal hyperparameters of UResNet-34 in terms of activation function, learning rate, loss function, and epoch. This is necessary because choosing any hyperparameter configuration for the UResNet-34 can lead to local optimum solution, slow convergence and manual tasking. Therefore, to improve the UResNet-34 building segmentation performance, a suitable objective or fitness function was constructed and evaluated using the GWO by computing the fitness value in the form of mean intersection over union (MIoU) and F-1 score metric. The experimental results, when compared with U-Net and UResNet-34, illustrated the superiority of the proposed GWO-UResNet-34 approach. This study provides the first comprehensive assessment of the applicability of GWO as a reliable hyperparameter optimisation algorithm to enhance the performance of UResNet-34.The significant contributions of this paper to existing literature are to:
-
Investigate the performance of utilising GWO to fine-tune the adjustable hyperparameters of UResNet-34 for building segmentation.
-
Conduct extensive experiments on different localities to ascertain the proposed GWO-UResNet-34 versatility.
-
Evaluate and compare the results of the proposed GWO-UResNet-34 architecture with conventional U-Net and UResNet-34-based building segmentation approaches.
2 Related works
2.1 U-Net-Based building extraction
This section examines relevant literature on building extraction and segmentation techniques that utilise the U-Net model and its variations. This is crucial as the GWO-UResNet-34 model is a U-Net variant. A search was conducted on Google Scholar and Science Direct websites to gather information on U-Net-based building segmentation studies. The search employed keywords such as U-Net, building extraction, building, and modified U-Net. Initially, many papers were retrieved, but a selection process was implemented to include only studies that utilised U-Net or its associated variants for building segmentation. To further narrow down the selection, studies conducted between 2018 and 2022 were considered.
The literature review revealed that although scholars have reported promising results for U-Net-based models in semantic segmentation, its applicability to building extraction is still challenging and complex, even with high-quality images. This challenge is attributed to buildings with varied characteristics, while many urban and environmental factors can cause occlusion [62]. Hence, various U-Net models have been developed to automatically extract building footprints for different building properties and environments. Similarly, diverse U-Net architectures have been developed for building segmentation using remotely sensed images and have achieved good results. For instance, Wu et al. [63] proposed a multi-constraint FCN in performing building segmentation from aerial images by introducing additional constraints to the immediate layers of the basic U-Net model. Using transfer learning, Adibah et al. [27] developed a U-Net architecture based on ResNet-34 for building extraction and outperformed previous works on the INRIA dataset.
Liu et al. [64] replaced the encoder section of a U-Net model with a ResNet encoder to segment buildings in open-sourced remote sensing data. Delibasoglu and Cetin [65] modified the original U-Net model using inception blocks to improve building segmentation accuracy. AMUNet, a U-Net with multi-loss and an attention block was presented by Guo et al. [66] to overcome the insensitivity of DL models to small buildings and subdue the background noise for a better segmentation outcome. He et al. [14] proposed a hybrid first and second-order attention network (HFSA) to explore the connection between the intermediate layers for building delineation in remotely sensed images. Erdem and Avdan [26] compared various U-Net models for building extraction by replacing the encoder portion of the original U-Net with VGG-16, InceptionResNetV2, and DenseNet121 CNNs. Pan et al. [67] investigated the feasibility and accuracy of U-Net for extraction and classification in high-density areas. Rastogi et al. [68] presented a UNet-AP, a model that introduces an atrous spatial pyramid pooling (ASPP) capable of incorporating contextual information in the bottom neck of the original U-Net.
The approach by Chen et al. [69] attempts to overcome the biases encountered by the encoder and decoder parts of DL models by combining a self-attention module with the reconstruction-bias strategy for efficient building segmentation. Li et al. [70] developed an attention-enhanced U-Net by utilising a ResNet to add a spatial-channel attention mechanism and a multi-scale fusion module to improve small-building extraction. Jin et al. [71] presented a boundary-aware refined network (BARNet) based on U-Net and DeepLab-v3 to address the incomplete segmentation of large buildings and refine the accuracy of building extraction. Abdollahi and Pradhan [72] proposed a MultiRes-UNet network that utilises a MultiRes block to assimilate learned features while replacing the skip connections of the original U-Net network with the shortest path called the Res path. Xu et al. [73] designed a Holistically-Nested Attention U-Net (HA U-Net) that exploits an influential attention mechanism unit to incorporate multi-scale path information proficiently. Ye et al. [74] introduced a context-transfer-UNet (CT-UNet) to address the inter-class similarity between buildings and backgrounds by constructing a dense boundary block (DBB) capable of employing the reuse process to enhance attributes and proliferate recognition proficiencies.
These works demonstrated a collective effort to improve the accuracy and efficiency of the U-Net model by exploring various strategies and modifying the architecture. However, the existing studies reviewed did not explore the effect of hyperparameter selection and its effect on the sensitivity of the varying U-Net-based building segmentation models.
2.2 Metaheuristic-based hyperparameter optimisation
Metaheuristic algorithms are stochastic approximations that aim to find solutions close to the global optimum. They comprise two key phases: exploration (diversification) for global search and exploitation (intensification) focused on refining current best solutions. These two mechanisms dictate the generation of new candidate solutions based on the previous ones, enabling the algorithms to have global exploration and efficient search [34, 46]. Various metaheuristics have been developed over the past decade and are broadly classified into four groups [75]:
-
Evolutionary algorithms (EAs): These mimic biological processes such as reproduction, mutation, crossover and selection to solve complex programs. EAs can be subdivided into various categories, each having its unique characteristics. Evolutionary programming (EP) [76] is one category that focuses on evolving computer programs or representations, and it is well-suited for problems where the solutions can be represented as programs or symbolic expressions. The Evolution strategies (ES) [77] pay attention to parameter adaptation and are often used for numerical optimisation problems. Differential evolution (DE) [78] uses mutation and crossover to generate new solutions to estimate the differences in fitness values between target individuals and others in the population. Biogeography-based optimisation (BBO) [79] is inspired by the principles of biogeography, such as immigration and emigration between different regions, to model the flow of solutions between habitats. Genetic algorithms (GAs) [80] are arguably the most utilised subset of EAs. They use a population-based approach and employ selection, crossover, and mutation operators to evolve and improve solutions.
-
Swarm intelligence (SI) algorithms: These algorithms draw inspiration from the behaviours of animals and plants. For instance, particle swarm optimisation (PSO) [81] is inspired by the foraging process of bird flocks, cuckoo search (CS) [82] is influenced by the brood parasitic behaviour of certain cuckoo species, grey wolf optimiser (GWO) [55] is based on the leadership hierarchy and hunting mechanisms of grey wolves, salp swarm algorithm (SSA) [83] emulates the swarming behaviour of salps, and whale optimisation algorithm (WOA) [84] is inspired by the social behaviour of humpback whales, among others.
-
Physics-based algorithms (PAs): These algorithms are rooted in various physical phenomena. Common among these is the simulated annealing algorithm (SA) [85], which is based on the principle of solid annealing.
-
Human Activity-Related Algorithms (HA): These algorithms take cues from human activities. Popular algorithms in the subclass include teaching–learning-based optimisation (TLBO) [86] which is influenced by the traditional teaching mode, passing vehicle search (PVS) [87] which is inspired by the vehicle passing mechanisms on two-lane highways, and sine cosine algorithm (SCA) [88] which incorporates sine and cosine waves.
In recent years, metaheuristic algorithms have become prominent as practical alternatives for optimising hyperparameters of DL networks in various domains. For instance, Bouktif et al. [89] adopted GA and PSO to optimise LSTM hyperparameters for load forecasting. The results showed that the multi-sequence DL model tuned by these metaheuristic algorithms outperformed benchmark machine learning models and naive LSTM configurations. Somua et al. [90] introduced the “eDemand” model which utilised an improved sine cosine optimisation algorithm (ISCOA) to optimise the hyperparameters of LSTM for accurate and robust energy consumption forecasting. In addition, a Haar wavelet-based mutation operator was introduced to enhance ISCOA’s ability to converge towards global optimal solutions. A case study using real-time energy consumption data indicated that the proposed model outperformed state-of-the-art energy consumption forecast models across various performance metrics. Similarly, Peng et al. [90] proposed “FOA-LSTM”, a model that combined LSTM with the fruit fly optimisation algorithm (FOA) to determine optimal hyperparameters. Experimental results using various datasets, including the USA’s NN3 time series and monthly energy consumption data, demonstrated the FOA-LSTM model’s effectiveness. The proposed model outperformed other forecasting models, reducing the symmetric mean absolute percentage error (SMAPE) by up to 11.44% in some instances. Nadeem et al. [91] presented the “SHO-CNN” model, which leverages the spotted hyena optimiser (SHO) metaheuristic optimisation algorithm to fine-tune hyperparameters critical for CNN performance such as the learning rate, momentum, number of epochs, batch size, dropout, number of nodes, and activation function. Experimental results on various news datasets demonstrated that SHO-CNN outperformed baseline CNNs and other optimisation approaches, achieving high accuracy levels in multi-label news classification.
Challapalli and Devarakonda [92] used a hybrid particle swarm grey wolf (HPSGW) algorithm to fine-tune hyperparameters of a CNN, including batch size, number of hidden layers, number of epochs, and filter size, to achieve optimal network performance. The proposed method is tested on benchmark datasets like MNIST and CIFAR and applied to classifying 8 Indian classical dances. The experimental results revealed significant performance improvements compared to previous methods, achieving high accuracy levels for image classification tasks. Tuba et al. [46] addressed the problem of tuning hyperparameters for CNNs) using the bare-bones fireworks algorithm. The proposed method was tested on benchmark datasets, including CIFAR-10 and MNIST, and compared to other optimisation techniques. The results indicated that the proposed method outperforms previous methods, achieving high classification accuracy on both datasets. Tsai and Fang [47] introduced a novel metaheuristic algorithm called “search economics for hyperparameter optimisation” to improve the accuracy of prediction systems. This algorithm assigns search agents to different subspaces based on their potential for optimisation. Compared to methods such as Bayesian, random forest, support vector regression, DNN, and DNN with different hyperparameter search algorithms and based on data from Taipei City, Taiwan, the proposed method obtained lower mean absolute percentage error. Similarly, Tsai et al. [93] tackled the problem of predicting bus passengers using deep learning and optimizing hyperparameters based on simulated annealing (SA) to enhance accuracy. The proposed method was compared to other machine learning techniques, including support vector machines, random forests, and gradient boosting. Simulation results showed that the SA-based approach outperformed the other methods, achieving high accuracy in forecasting bus passenger numbers.
Nematzadeh et al. [94] proposed a method that utilises GWO and GA metaheuristics to fine-tune hyperparameters DNN for biomedical and biological purposes. The authors experimented on 11 biomedical, biological, and natural datasets, and the results demonstrated that metaheuristic methods, especially GWO, outperform other optimisation methods and showed faster convergence. Houssein et al. [48] introduced an optimised model called “IMPA-ResNet50” that used the improved marine predators algorithm (IMPA) for hyperparameter optimisation of a CNN model. A comparative assessment using mammographic datasets and compared to state-of-the-art approaches showed the superiority of IMPA-ResNet50, achieving high accuracy, sensitivity, and specificity, making it a promising tool for breast cancer diagnosis. Lee et al. [95] proposed using GA to optimise the network architecture and hyperparameters of CNNs. The authors applied this approach to an amyloid brain image dataset for Alzheimer’s disease diagnosis. The evaluation results demonstrated that their algorithm outperformed baseline CNN by a significant margin, achieving an 11.73% improvement on a classification task. Gülcü and Kus [96] presented the microcanonical optimisation algorithm (MOA), a variant of SA, for hyperparameter optimisation and architecture selection. The generated network was compared with networks generated by other optimisation-based approaches using six widely used image recognition datasets. The results indicated that the proposed method achieved competitive classification results. Utama et al. [97] explored PSO to tune hyperparameters and the architecture of a CNN for multivariate time-series analysis. The proposed network, PSO-CNN, was evaluated using electronic journal visitor datasets, and experimental results showed that PSO-CNN attained better performance than a standard CNN.
The literature review demonstrates metaheuristics’ versatility and efficacy in optimising DNN hyperparameters across different application domains, enhancing model performance and effectiveness in addressing real-world challenges. Nevertheless, while these studies collectively exemplify the success of metaheuristic algorithms in DNN hyperparameter optimisation, the need to explore new metaheuristics remains crucial. The No Free Lunch (NFL) theorem [98] champions that no single metaheuristic algorithm universally outperforms all others across diverse problem domains. As such, researchers continue to introduce novel metaheuristic algorithms, variants, and hybridization techniques that have the potential to outperform existing methods or exhibit unique capabilities. Moreover, the diversity of problems, sensitivity to problem characteristics, resource constraints, and comprehensive benchmarking further necessitate the continuous investigation of different metaheuristics tailored to specific challenges and problem characteristics.
3 Data and methodology
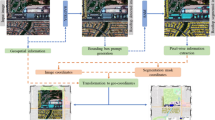
This work utilises GWO to optimise the hyperparameters of a modified U-Net with a ResNet-34 (UResNet-34) backbone for building segmentation purposes. The overall methodology of the study is illustrated in Fig. 1 and includes the input datasets and data pre-processing, model fitting and testing, and post-processing. The input dataset was high-resolution images obtained from a UAV survey and pre-processed into a DL readable format. The UResNet-34 model was subsequently developed and optimised with the GWO to create the GWO-UResNet-34 for training and prediction. Five commonly used evaluation metrics, accuracy, precision, recall, F-1 score, and mean intersection over union (MIoU), were utilised to evaluate the trained models. Detailed descriptions of the steps employed are given in the subsequent sections.

Schematic of the Proposed Methodology
3.1 Dataset description and study area
The dataset used as input for training the various models (GWO-UResNet-34, U-Net, and UResNet-34) employed in this study were three spectral bands (red, green, and blue) UAV orthomosaics of Accra and Tarkwa in Ghana, depicted in Fig. 2. Accra is the capital city, while Tarkwa is a mining hub in Ghana, making both areas associated with rapid developments and high urbanisation. These factors have led to ascendancy in the construction of various structures to cater for accommodation and office spaces. The Accra UAV orthomosaics was obtained in 2019 for a pilot phase of the national electrical grid connection project, had a 3 cm spatial resolution, and covered an area of 163.36 ha. It had 2531 manually digitised polygons representing structures (Fig. 2a). The UAV orthomosaic of Tarkwa was acquired in 2021 for an academic project, had a 5 cm spatial resolution, and covered an area of approximately 79.66 ha, with 494 structures annotated as polygons (Fig. 2b). This difference in resolutions between the two orthomosaics was to achieve a more generalised model. Compared to the Accra orthomosaic, the Tarkwa orthomosaic consisted of more slum structures.

UAV Orthomosaics of (a) Accra, Ghana, and (b) Tarkwa, Ghana
For the testing data, orthomosaics of four different localities were utilised. Locality-1 is associated with well-laid buildings with roads, while Locality-2 is dominated by slum buildings in proximity. In contrast, Locality-3 has a few buildings but has a substantial area of background vegetation, while Locality-4 is a conglomeration of Locality-1 and Locality-2. The geometrical variance (varying sizes, colours, and architectural designs) of the buildings depicted in Fig. 3 was to assess if the model can effectively segment buildings in other areas worldwide.

Test Localities with Varying Building Attributes
3.2 Grey wolf optimiser
GWO was inspired by the rigid leadership, pecking order, and group hunting behaviour of grey wolves, a species of the Canidae family [61]. Grey wolves are regarded as elite predators and are at the pinnacle of the trophic level, habitually living in packs of 5 to 12 wolves. The population of a pack is split into four distinct hierarchies consisting of the alpha (α), beta (β), delta (δ), and omega(ω). The alpha is the most powerful and makes judgments about hunting and sleeping. Beta wolves come second in the pecking order, and they support the alpha wolf in administration and convey information to and manage the subordinate groups. Omega wolves are the lowest in the hierarchy and typically fulfil sacrificial duties, albeit they are allowed to feed after the top hierarchies have finished feeding. Delta wolves lead the omega wolves and are usually scouts, sentinels, and guardians by assisting the alphas and betas when searching for and hunting prey. They also protect the territorial borders of the pack and nurse the frail and injured wolves. As expounded in the original work by Mirjalili et al. [55], the hunting tactic of the grey wolf is in four phases: encircling, hunting, attacking, and searching for the prey. The GWO algorithm is modelled according to the hunting strategy, with each wolf denoting a randomly initialised solution with the highest fittest score represented by the α – the first optimum solution, followed by the β – the second-best and δ – the third-best. Simultaneously, ω delineates the residual solutions. The three fittest wolves (α, β, and δ) are considered to be knowledgeable about the possible position of the prey, followed by ω. During hunting, the wolves generally encircle their prey, and this behaviour is delineated mathematically in Eqs. (1) and (2) [55].
where \(\overrightarrow{X}\left(t\right)and {\overrightarrow{X}}_{p}\left(t\right)\) denote the grey wolves and the prey’s location, respectively, at the tth iteration. \(\overrightarrow{D}\) denotes the position alteration element. \(\overrightarrow{A} and \overrightarrow{C}\) are coefficient vectors and are computed as shown in Eqs. (3) and (4) [55].
where \({\overrightarrow{r}}_{1} and {r}_{2}\) are vectors with values between 0 and 1 that are generated randomly, and \(\overrightarrow{a}\) is a moderating entity that linearly diminishes from 2 to 0.
In the GWO algorithm, the positions of the fittest solutions, that is, α, β, and δ, are updated first, followed by the re-positioning of the other search agents (ω) based on Eqs. (5), (6) and (7) [55].
where \({\overrightarrow{D}}_{\alpha }\), \({\overrightarrow{D}}_{\beta }\), and \({\overrightarrow{D}}_{\delta }\) denotes the step size of ω with regards to α, β, and δ, with their respective as \({\overrightarrow{X}}_{\alpha }\), \({\overrightarrow{X}}_{\beta }\), and \({\overrightarrow{X}}_{\delta }\). \({\overrightarrow{C}}_{1}\), \({\overrightarrow{C}}_{2}\) and \({\overrightarrow{C}}_{3}\) are randomly initiated vectors and \(\overrightarrow{X}\) is the current solution location.
After the distances are defined, \(\overrightarrow{X}\left(t+1\right)\) which denotes the final position of the current solution is subsequently computed by Eqs. (8), (9), (10) and (11) [55].
The capabilities of GWO enhanced due to the random adaptiveness of \(\overrightarrow{A}\) and \(\overrightarrow{C}.\) These parameters enable the algorithm to balance when exploring and exploiting a search space. Thus, \(\overrightarrow{A}\) initiates the exploration of search space and \(\left|\overrightarrow{A}\right|>1\) prompts candidate solutions to diverge from a weaker prey in search of a fitter one. Similarly, candidate solutions converge toward the prey when \(\left|\overrightarrow{A}\right|<1 \overrightarrow{C}=\left[0, 2\right]\left[\mathrm{0,2}\right]\). which a random vector secondarily specifies weights for the prey considering its location from the wolf [55]. Table 1 presents the pseudo-code for the GWO algorithm.
3.3 U-Net Architecture
U-Net was proposed initially by Ronneberger et al. [99] for semantic segmentation of biomedical images. The technique is built upon the FCN and is composed of two symmetrical parts that form a U shape with skip connections to help concatenate feature maps that provide localisation information, as depicted in Fig. 4. The first part is the contracting path, usually referred to as the encoder. In contrast, the second part, usually termed the decoder, is an expansive path. The encoder path seeks to learn what objects are in the input images and consists of several convolutions and max-pooling layers that gradually decrease input image size while increasing the network’s depth. The encoder part comprises two repeated 3 × 3 convolution kernels and a down-sampling layer of 2 × 2 window size combined with a rectified linear unit (ReLU) activation function. The decoder part operates similarly but utilises a 2 × 2 transpose convolution strategy to up-sample the images and concatenate the corresponding down-sample feature map from the encoder part. Finally, a convolution with a 1 × 1 kernel and a sigmoid function is utilised to map every feature map into the desired outputs. Regarding building segmentation with U-Net, the encoding process refers to building identification and separating buildings from non-buildings. On the other hand, the expansive process refers to building localisation and involves determining the spatial existence of the buildings [100].

UNet Architecture
3.4 U-Net with ResNet backbone
The residual network (ResNet) was introduced by He et al. [101] to solve the vanishing gradient problem encountered by most DL networks. The layers of ResNet are organised in “residual blocks” capable of learning residual functions regarding input layers instead of learning unreferenced functions. ResNet utilises skip connections between layers, thereby reducing the layers, simplifying the network, and speeding the learning. Fewer layers also imply less propagation and a reduction in the impact of the vanishing gradient. The pros of ResNet have made it suitable to be utilised in several deep networks, such as super-resolution, generative adversarial networks (GANs), and semantic segmentation, among others. ResNet variants comprise ResNet-18, ResNet-34, ResNet-50, and ResNet-101; however, the ResNet-34 has proven to provide a good balance between performance and accuracy when performing semantic segmentation tasks as demonstrated in literature [27, 64].
3.5 Hyperparameter optimization of UResNet-34 using GWO
In this work, the hyperparameters of UResNet-34 were optimised using GWO. This is necessary because choosing the appropriate hyperparameters impacts the accuracy and convergence of the DL model significantly. The learning rate, training epoch, optimiser, activation function, and loss function are notable DL training hyperparameters that are usually optimised. The learning rate regulates how much the DL model changes each time the model weights are updated in response to an estimated error. The training epoch expresses the number of times the complete dataset is distributed through the model. The optimiser alters the characteristics of a neural network, such as its weights and learning rate, and aids in reducing total loss and improving accuracy. The activation function helps the DL network to learn sophisticated patterns in the data. The loss function measures the difference between an estimated and true value, from which gradients are derived to update the DL network’s weight. Therefore, identifying the optimal hyperparameters is regarded as an optimisation problem. Some hyperparameters, mainly the optimisers, activation, and loss functions, are encoded into integers for the objective function. However, these are inverse transformed into their original values, so the model does not encounter an error. Since the objective function aims to ascertain the best hyperparameter combination to attain greater accuracy, the objective function is defined to achieve maximum fitness values with specific lower and upper bounds set for each hyperparameter. The overall design for the GWO-optimised UResNet-34 is illustrated in Fig. 5.

Overall design for the GWO-optimized UResNet-34
3.6 Evaluation metrics
Five standard metrics (recall, precision, accuracy, F-1 score, and MIoU) [102] were adopted to assess the proposed GWO-UResNet-34 model against U-Net and UResNet-34. The recall defines how complete a model is and is expressed as the ratio of the number of the positively detected targets to the total number of positive targets, as shown in Eq. (12). Precision is an indication of how exact or correct a model is and is defined as the ratio of the number of the positively detected targets to the total number of targets detected as positive. The mathematical expression for precision is presented in Eq. (13). Accuracy is the ratio of the correctly detected targets to the total number of detected targets and is computed as shown in Eq. (14). F1 is the harmonic mean of precision and recall (Eq. (15), and MIoU provides a balance between recall rate and accuracy as defined in Eq. (16).
where \(\mathrm{TP}\), \(\mathrm{TN}\), \(\mathrm{FP}\), and \(\mathrm{FN}\) represent the true positive (pixels precisely predicted as buildings), true negative (pixels precisely predicted as non-building), false positive (pixels erroneously predicted as buildings but are not), and false negative (pixels not predicted as non-building but are), respectively. \(K\) is the number of classes, which in this research is 2, \(P\) denotes the predicted buildings, while \(G\) represents the ground truth. MIoU ranges between 0 and 1, with 0 being the worst prediction and 1 being the best.
4 Experimental results
4.1 Dataset pre-processing
The dataset was manually labelled into two classes, building or non-buildings, and subsequently converted to binary mask (0,1) to serve as ground truth data, with 1 representing buildings and 0 representing non-buildings. A sample image tile with its corresponding mask in the dataset is given in Fig. 6. The orthomosaics were in tiles of 5000 × 5000 pixels, and as these sizes were too big for computer memory, they were divided into 256 × 256 patches, resulting in 10,624 images and masks each. Image patches not having at least 5% of building information were removed from the dataset to prevent bias towards the background. The remaining dataset (5045 images and masks each) was randomly divided into training (80%) and validation (20%) datasets. The purpose of the training dataset is to provide the model with the necessary information and visual properties of the buildings. The validation data, on the other hand, aids in verifying and improving the model’s performance during training. Data augmentation techniques such as vertical flip, \({90}^{0}\) random rotation, horizontal flip, transpose, and grid distortion were randomly applied to only the train images and their corresponding masks. This procedure produced 12,000 samples each for the training images and their corresponding masks.

Sample (a) Training Image and (b) Corresponding Mask Tiles
For the test data, each orthomosaic was of a tile size of \(5000\times 5000\) pixels and was directly fed to the trained model during the prediction stage. However, a modified version of the Smoothly-Blend-Image-Patches code (https://github.com/Vooban/Smoothly-Blend-Image-Patches) was employed for the models to ensure smooth and efficient predictions. The code works by first appropriately padding the input image to accommodate potential sampling beyond the image’s boundaries during the prediction process. Subsequently, the image is divided into patches, forming a 5D NumPy array. These patches, represented initially as 3D arrays, are ordered in spatial dimensions, necessitating the addition of two extra dimensions. These spatially ordered patches are then reshaped into 4D arrays, aligning along a single batch size dimension. This arrangement facilitated batch predictions, optimising GPU memory usage by simultaneously loading all patches into memory. The prediction function incorporates the trained models and is employed to predict buildings in each patch. The predicted results are restructured back into a 5D array following batch predictions. Lastly, a spline interpolation is applied to merge the patch predictions into a cohesive 3D image array. The benefit of this approach is that it capitalises on batch size for efficient GPU utilisation while ensuring smooth predictions.
4.2 Experimental design
The experiment was implemented using Python programming language using open-source libraries such as TensorFlow, OpenCV, NumPy, Segmentation Models, and Mealpy. The models were developed, trained, and evaluated on a Windows operating system using a GeForce RTX 2060 GPU with 16GB RAM. The training process involved utilising a data generator with a batch size of 16 to read both the images and their corresponding masks for the training and validation datasets. The data was subsequently fed to the UResNet-34 model 6, formulated as an objective function for the GWO. The GWO parameters were initialised to solve for the best hyperparameter combination for UResNet-34 to achieve maximum model accuracy. The parameters for the GWO settings are presented in Table 2.
4.3 Performance comparison
The proposed GWO-UResNet-34 model efficacy is validated by comparing it against the U-Net and UResNet-34 models on four distinct localities using the evaluation metrics (recall, precision, accuracy, F-1 score, and MIoU). Both U-Net and UResNet-34 were trained and validated using the same data as the proposed GWO-UResNet-34 model. The findings of the evaluation are discussed in the subsequent sections.
4.3.1 Results on locality-1 test data
Table 3 shows the performance outcomes of each model when utilised to segment the buildings in Locality-1. Based on Table 3, UResNet-34 achieved better results than U-Net. However, when GWO was utilised to optimise UResNet-34, there were general improvements in all the metric scores except for precision. Nevertheless, GWO-UResNet-34 was able to find a balance between recall and precision, which UResNet-34 failed. This resulted in better F1 and MIoU values for GWO-UResNet-34, the superior and comprehensive metrics for semantic image segmentation tasks. Compared to UResNet-34, GWO-UResNet-34 had 10.39% and 13.20% improvements in F1 score and MIoU, respectively.
A graphical evaluation was conducted to illustrate each model’s segmentation outcomes, depicted in Fig. 7. The first and second columns represent the test image and its corresponding mask, while the final three columns represent the segmentation results of U-Net, UResNet-34, and GWO-UResNet-34 accordingly. From Fig. 7, it is noticeable that the proposed GWO-UResNet-34 model had only a few inaccurately predicted buildings (false positives) and could extract the geometries of building more efficiently than the U-Net and UResNet-34. This could be attributed to the GWO enhanced learning dynamics achieved by the UResNet-34 model by directing the model towards more promising regions of the hyperparameter space. As such, the proposed model is better equipped to converge to a solution that minimises the segmentation error.

Building segmentation results for Locality-1. a UAV orthomosaic; (b) mask; (c)U-Net; (d) UResNet-34; (e) GWO-UResNet-34
4.3.2 Results on locality-2 test data
Locality-2 test data was challenging since it largely comprised a slum with buildings having no noticeable boundaries, thus making them difficult to identify and segment. Regardless, the findings for the quantitative comparison among the models presented in Table 4 indicate the superiority of the proposed GWO-UResNet-34 model. The proposed model had 0.77%, 8.49%, 0.79%, and 1.83% improvements in accuracy, precision, F1 score, and MIoU values over UResNet-34. Compared to U-Net, the corresponding improvements were 8.96%, 1.15%, 25.57%, 15.32%, and 13.48%, respectively.
Figure 8 illustrates the visual comparison of the segmentation results achieved by each model. All the models had issues extracting the imperceptible gaps between dense buildings. However, the segmentation output from the proposed GWO-UResNet-34 was comparable to the ground truth.

Building segmentation results for Locality-2. a UAV orthomosaic; (b) mask; (c)U-Net; (d) UResNet-34; (e) GWO-UResNet-34
4.3.3 Results on locality-3 test data
This test data was selected to assess how the model can segment buildings in areas with more vegetation than buildings. It is evident in Table 5 that the proposed GWO-UResNet-34 model achieved the best results. U-Net had a high precision of 0.9059 but a lower recall rate of 0.2810, and a similar situation was encountered for UResNet-34. However, the proposed model could find a balance between precision and recall with scores of 0.9097 and 0.8842, respectively. This balance improved F1 and MIoU values of 46.7% and 31.12%, and 17.25% and 13.26% over U-Net and UResNet-34, respectively.
A visual comparison is formulated and conveyed in Fig. 9 to demonstrate the segmentation results achieved by the proposed and compared models. From Fig. 9, the enhanced learning of the proposed model enabled it to achieve segmentation outputs that are similar to the mask. Thus, the geometry of the segmented buildings, to a greater extent, is akin to that of masks with almost no false positives.

Building segmentation results for Locality-3. a UAV orthomosaic; (b) mask; (c)U-Net; (d) UResNet-34; (e) GWO-UResNet-34
4.3.4 Results on locality-4 test data
The Locality-4 dataset encompasses a diverse range of building types, including commercial, residential, and slum structures. This dataset was explicitly employed to evaluate the model’s capability to learn and identify buildings in a complex setting. The quantitative evaluation results for the three models are provided in Table 6. The results in the table reveal an overall improvement in all evaluation metrics achieved by the GWO-UResNet-34 model. This model demonstrated a well-balanced performance with higher F1 scores of 9.20% and 4.96% and improved MIoU values of 10.99% and 6.08% compared to U-Net and UResNet-34, respectively.
The schematic diagram in Fig. 10 illustrates the visual assessment of the models. The outlines of buildings segmented by the proposed GWO-UResNet-34 model are well-defined and comparable to the mask. Overall, GWO-UResNet-34 could segment buildings with more detailed information and less noise (false positives). U-Net and UResNet-34 achieved similar results for large buildings but struggled with smaller buildings.

Building segmentation results for Locality-4. a UAV orthomosaic; (b) mask; (c)U-Net; (d) UResNet-34; (e) GWO-UResNet-34
4.4 Strengths and limitations of the study
The results from the comparative assessment indicated the superiority of the GWO-UResNet-34 for building extraction from different urban layouts. The GWO-UResNet-34 repetitively outperformed U-Net and UResNet-34 in almost all evaluation metrics across the four test datasets. Moreover, unlike the U-Net and UResNet-34, GWO-UResNet-34 could find a good balance between precision and recall. This balance is vital for semantic image segmentation tasks, ensuring accurate identification and comprehensive coverage of building segments. This improvement implies that the GWO-UResNet-34 model had good generalisation capabilities and demonstrated continual improvements across different test datasets, including areas with dense vegetation, challenging slum areas, and diverse building types.
However, although the GWO-UResNet-34 model exhibited great potential in segmenting buildings from different localities, some limitations exist. First, the computational cost of the GWO-UResNet-34 must be improved. Thus, the hyperparameter selection took considerable time before an optimal model could be attained, and this can limit the scalability and practicality of the approach for large and complex datasets. Also, although satisfactory results have been achieved, the study only utilised the GWO algorithm. It is recommended that other standalone metaheuristics (e.g., PSO and WOA), hybrid, or improved metaheuristic algorithms must be investigated to assess their performance in building segmentation. In addition, the study was limited to just four different localities. Therefore, future work can test the efficiency of the proposed GWO-UResNet-34 in other localities with different building and roof configurations, such as condensed slums, rural settings, and complex and non-uniform architecture.
4.5 Research implication
This work has demonstrated the use and highlighted the importance of metaheuristic algorithms, notably the GWO algorithm, as an alternative for optimum hyperparameter selection and combination. The accurate and efficient building segmentation achieved by the model can support a variety of applications, such as urban planning and infrastructure monitoring. Moreover, this study will encourage further exploration and refinement of other optimisation techniques for optimising the selection of DL network hyperparameters.
5 Conclusions and future works
This work proposed a GWO-UResNet-34 for building extraction from high-resolution UAV orthomosaics. The GWO algorithm was utilised to fine-tune the adjustable hyperparameters of the UResNet-34 DL model. The hyperparameters comprised the activation function, optimiser, learning rate, loss function, and epoch. The proposed GWO-UResNet-34 model was evaluated using four different location-based testing datasets with distinct building layouts and shapes and compared with two other segmentation models namely, U-Net and UResNet-34. Five evaluation metrics were used to assess the model’s efficiency, specifically accuracy, precision, recall, F1 score, and MIoU. The following key conclusions were drawn from the study:
-
i.
The results indicated that the proposed GWO-UResNet-34 model was more robust, achieved state-of-the-art performance, and outperformed the other two models.
-
ii.
One notable strength of the GWO-UResNet-34 was its ability to balance precision and recall, which is vital for accurate and comprehensive building segmentation tasks.
-
iii.
Overall, the GWO-UResNet-34 had a better generalisation capability across the four different locations tested, thus demonstrating the potential of metaheuristic algorithms, particularly the Grey Wolf Optimiser (GWO), for optimising hyperparameter selection of DL networks for building segmentation from UAV orthomosaics.
-
iv.
As a limitation, the computational cost and scalability of the approach need to be carefully probed as the hyperparameter selection process took considerable time and may pose challenges for large and complex datasets.
-
v.
Future studies could explore other metaheuristic algorithms to assess their performance in optimising hyperparameters of DNNs for building segmentation.
Availability of data and materials
The data is available with the corresponding author and can be shared with the public upon reasonable request.
References
Ding Z, Wang XQ, Li YL, Zhang SS (2018) Study on Building Extraction from High-Resolution Images Using MBI. Int Archives Photogrammetry, Remote Sensing Spatial Information Scie - ISPRS Archives 42:283–287. https://doi.org/10.5194/isprs-archives-XLII-3-283-2018
Awrangjeb, M.; Fraser, C. S. An Automatic and threshold-free performance evaluation system for building extraction techniques from Airborne LIDAR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 2014;7(10):4184–4198. https://doi.org/10.1109/JSTARS.2014.2318694
Chen, K.; Fu, K.; Gao, X.; Yan, M.; Sun, X.; Zhang, H. Building extraction from remote sensing images with deep learning in a supervised manner. In International Geoscience and Remote Sensing Symposium (IGARSS); Fort Worth, TX, USA, 2017; Vol. 2017-July, pp 1672–1675. https://doi.org/10.1109/IGARSS.2017.8127295
Luo X, Li J, Zhu S, Xu Z, Huo Z (2020) Estimating the Impacts of Urbanization in the Next 100 Years on Spatial Hydrological Response. Water Resour Manag 34(5):1673–1692. https://doi.org/10.1007/s11269-020-02519-2
Gomes Pessoa G, Caceres Carrilho A, Takahashi Miyoshi G, Amorim A, Galo M (2021) Assessment of UAV-Based Digital Surface Model and the Effects of Quantity and Distribution of Ground Control Points. Int J Remote Sens 42(1):65–83. https://doi.org/10.1080/01431161.2020.1800122
Julge K, Ellmann A, Köök R (2019) Unmanned Aerial Vehicle Surveying for Monitoring Road Construction Earthworks. Balt J Road Bridg Eng 14(1):1–17. https://doi.org/10.7250/bjrbe.2019-14.430
He H, Zhou J, Chen M, Chen T, Li D, Cheng P (2019) Building extraction from UAV images jointly using 6D-SLIC and multiscale siamese convolutional networks. Remote Sens 11(9):1–33. https://doi.org/10.3390/rs11091040
Cui S, Yan Q, Reinartz P (2012) Complex building description and extraction based on hough transformation and cycle detection. Remote Sens Lett 3(2):151–159. https://doi.org/10.1080/01431161.2010.548410
Lefèvre, S.; Weber, J.; Sheeren, D. Automatic Building Extraction in VHR Images Using Advanced Morphological Operators. In Proceedings of the 2007 Urban Remote Sensing Joint Event, URS; 2007; pp 1–5. https://doi.org/10.1109/URS.2007.371825
Peng J, Zhang D, Liu Y (2005) An improved snake model for building detection from urban aerial images. Pattern Recognit Lett 26:587–595. https://doi.org/10.1016/j.patrec.2004.09.033
Cai Z, Ma H, Zhang L (2019) A building detection method based on semi-suppressed Fuzzy C-means and restricted region growing using airborne LiDAR. Remote Sens 11(7):1–18. https://doi.org/10.3390/RS11070848
Ekhtari, N.; Sahebi, M. R.; Valadan Zoej, M. J.; Mohammadzadeh, A. Building Detection from LIDAR Point Cloud Data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci., 2018, 38, 473–478. https://doi.org/10.1109/ICCES45898.2019.9002555
Liu, C.; Shi, B.; Yang, X.; Li, N.; Wu, H. Automatic Buildings Extraction from Lidar Data in Urban Area by Neural Oscillator Network of Visual Cortex. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 2013, 6 (4), 1–12. https://doi.org/10.1109/JSTARS.2012.2234726
He N, Fang L, Plaza A (2020) Hybrid first and second order attention unet for building segmentation in remote sensing images. Sci China Inf Sci 63(4):1–12. https://doi.org/10.1007/s11432-019-2791-7
Huertas A, Nevatia R (1988) Detecting buildings in aerial images. Comput Vision Graph. Image Process 41(2):131–152. https://doi.org/10.1016/0734-189X(88)90016-3
McGlone, J. C.; Shufelt, J. A. Projective and Object Space Geometry for Monocular Building Extraction. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 1994;54–61. https://doi.org/10.1109/cvpr.1994.323810
Ahmadi S, Zoej MJV, Ebadi H, Abrishami H, Mohammadzadeh A (2010) Automatic urban building boundary extraction from high resolution Aerial images using an innovative model of active contours. Int J Appl Earth Obs Geoinf 12(3):150–157. https://doi.org/10.1016/j.jag.2010.02.001
Yari D, Mokhtarzade M, Ebadi H, Ahmadi S (2014) Automatic reconstruction of regular buildings using a shape-based balloon snake model. Photogramm Rec 29(146):187–205. https://doi.org/10.1111/phor.12060
Huang X, Zhang L (2012) Morphological Building/Shadow Index for Building Extraction from High-Resolution Imagery over Urban Areas. IEEE J Sel Top Appl Earth Obs Remote Sens 5(1):161–172. https://doi.org/10.1109/JSTARS.2011.2168195
Daranagama S, Witayangkurn A (2021) Automatic building detection with polygonizing and attribute extraction from high-resolution images. ISPRS Int J Geo-Information 10(9):1–23. https://doi.org/10.3390/ijgi10090606
Zhang C, Sargent I, Pan X, Li H, Gardiner A, Hare J, Atkinson PM (2018) An Object-Based Convolutional Neural Network (OCNN) for urban land use classification. Remote Sens Environ 216:57–70. https://doi.org/10.1016/j.rse.2018.06.034
Deng Z, Sun H, Zhou S, Zhao J, Lei L, Zou H (2018) Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J Photogramm Remote Sens 145:3–22. https://doi.org/10.1016/j.isprsjprs.2018.04.003
Kemker R, Salvaggio C, Kanan C (2018) Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J Photogramm Remote Sens 145:60–77. https://doi.org/10.1016/j.isprsjprs.2018.04.014
Mohammadimanesh F, Salehi B, Mahdianpari M, Gill E, Molinier M (2019) A new fully convolutional neural network for semantic segmentation of polarimetric SAR imagery in complex land cover ecosystem. ISPRS J Photogramm Remote Sens 151:223–236. https://doi.org/10.1016/j.isprsjprs.2019.03.015
Liu W, Yang MY, Xie M, Guo Z, Li EZ, Zhang L, Pei T, Wang D (2019) Accurate building extraction from fused DSM and UAV images using a chain fully convolutional neural network. Remote Sens 11(24):1–18. https://doi.org/10.3390/rs11242912
Erdem F, Avdan U (2020) Comparison of Different U-Net Models for Building Extraction from High-Resolution Aerial Imagery. Int J Environ Geoinformatics. 7(3):221–227. https://doi.org/10.30897/ijegeo.684951
Adiba A, Hajji H, Maatouk M (2019) Transfer Learning and U-Net for Buildings Segmentation. In ACM International Conference Proceeding Series. https://doi.org/10.1145/3314074.3314088
Ye H, Liu S, Jin K, Cheng H (2021) CT-UNet: context-transfer-unet for building segmentation in remote sensing images. Neural Process Lett 53(6):4257–4277. https://doi.org/10.1007/s11063-021-10592-w
Aufa, B. Z.; Suyanto, S.; Arifianto, A. Hyperparameter Setting of LSTM-Based Language Model Using Grey Wolf Optimizer. In Proceedings from 2020 International Conference on Data Science and Its Applications, ICoDSA 2020; 2020; pp 6–10. https://doi.org/10.1109/ICoDSA50139.2020.9213031
Kunang YN, Nurmaini S, Stiawan D, Suprapto BY (2021) Attack classification of an intrusion detection system using deep learning and hyperparameter optimization. J Inf Secur Appl 58:1–15. https://doi.org/10.1016/j.jisa.2021.102804
Gaspar A, Oliva D, Cuevas E, Zaldívar D, Pérez M, Pajares G (2021) Hyperparameter optimization in a convolutional neural network using metaheuristic algorithms. Studies Computational Intelligence 967:37–59. https://doi.org/10.1007/978-3-030-70542-8_2
Nazir S, Patel S, Patel D (2020) Assessing hyper parameter optimization and speedup for convolutional neural networks. Int J Artif Intell Mach Learn 10(2):1–17. https://doi.org/10.4018/ijaiml.2020070101
Bibaeva, V. Using Metaheuristics for Hyper-Parameter Optimization of Convolutional Neural Networks. In IEEE International Workshop on Machine Learning for Signal Processing, MLSP; IEEE, 2018; Vol. 2018-Septe, pp 1–6. https://doi.org/10.1109/MLSP.2018.8516989
Bacanin N, Bezdan T, Tuba E, Strumberger I, Tuba M (2020) Optimizing Convolutional Neural Network Hyperparameters by Enhanced Swarm Intelligence Metaheuristics. Algorithms 13(3):1–33. https://doi.org/10.3390/a13030067
Jiang X, Xu C (2022) Deep learning and machine learning with grid search to predict later occurrence of breast cancer metastasis using clinical data. J Clin Med 11(19). https://doi.org/10.3390/jcm11195772
Priyadarshini I, Cotton C (2021) A Novel LSTM–CNN–Grid search-based deep neural network for sentiment analysis. J Supercomput 77(12):13911–13932. https://doi.org/10.1007/s11227-021-03838-w
Ngoc TT, van Dai L, Phuc DT (2021) Grid search of multilayer perceptron based on the walk-forward validation methodology. Int. J. Electr. Comput. Eng 11(2):1742–1751. https://doi.org/10.11591/ijece.v11i2.pp1742-1751
Abbas F, Zhang F, Ismail M, Khan G, Iqbal J, Alrefaei AF, Albeshr MF (2023) Optimizing machine learning algorithms for landslide susceptibility mapping along the Karakoram highway, Gilgit Baltistan, Pakistan: a comparative study of baseline, bayesian, and metaheuristic hyperparameter optimization techniques. Sensors 23(15):1–31. https://doi.org/10.3390/s23156843
Hutter F, Lücke J, Schmidt-Thieme L (2015) Beyond manual tuning of hyperparameters. KI - Kunstl Intelligenz 29(4):329–337. https://doi.org/10.1007/s13218-015-0381-0
Rodríguez AOR, Mateus DEC, García PAG, Marín CEM, Crespo RG (2018) Hyperparameter optimization for image recognition over an ar-sandbox based on convolutional neural networks applying a previous phase of segmentation by Color-Space. Symmetry (Basel) 10(12). https://doi.org/10.3390/sym10120743
Jekova, I.; Krasteva, V. Optimization of end-to-end convolutional neural networks for analysis of out-of-hospital cardiac arrest rhythms during cardiopulmonary resuscitation. Sensors. 2021;21(12). https://doi.org/10.3390/s21124105
Ragab, M. G.; Abdulkadir, S. J.; Aziz, N. Random Search One Dimensional CNN for Human Activity Recognition. 2020 Int. Conf. Comput. Intell. ICCI 2020, 2020, No. October, 86–91. https://doi.org/10.1109/ICCI51257.2020.9247810
Yang L, Shami A (2020) On hyperparameter optimization of machine learning algorithms: theory and practice. Neurocomputing 415:295–316. https://doi.org/10.1016/j.neucom.2020.07.061
Guo Y, Li JY, Zhan ZH (2020) Efficient hyperparameter optimization for convolution neural networks in deep learning: a distributed particle swarm optimization approach. Cybern Syst 52(1):36–57. https://doi.org/10.1080/01969722.2020.1827797
Mohakud R, Dash R (2022) Designing a grey wolf optimization based hyper-parameter optimized convolutional neural network classifier for skin cancer detection. J King Saud Univ Comput Inf Sci 34(8):6280–6291. https://doi.org/10.1016/j.jksuci.2021.05.012
Tuba I, Veinovic M, Tuba E, Hrosik RC, Tuba M (2022) Tuning Convolutional Neural Network Hyperparameters by Bare Bones Fireworks Algorithm. Stud Informatics Control 31(1):25–35. https://doi.org/10.24846/v31i1y202203
Tsai CW, Fang ZY (2021) An Effective Hyperparameter Optimization Algorithm for DNN to Predict Passengers at a Metro Station. ACM Trans. Internet Technol 21(2). https://doi.org/10.1145/3410156
Houssein EH, Emam MM, Ali AA (2022) An optimized deep learning architecture for breast cancer diagnosis based on improved marine predators algorithm. Neural Comput Appl 34(20):18015–18033. https://doi.org/10.1007/s00521-022-07445-5
Hashim FA, Houssein EH, Hussain K, Mabrouk MS, Al-Atabany W (2020) A modified henry gas solubility optimization for solving motif discovery problem. Neural Comput Appl 32(14):10759–10771. https://doi.org/10.1007/s00521-019-04611-0
Houssein EH, Neggaz N, Hosney ME, Mohamed WM, Hassaballah M (2021) Enhanced harris hawks optimization with genetic operators for selection chemical descriptors and compounds activities. Neural Comput Appl 33(20):13601–13618. https://doi.org/10.1007/s00521-021-05991-y
Houssein EH, Gad AG, Wazery YM, Suganthan PN (2021) Task scheduling in cloud computing based on meta-heuristics: review, taxonomy, open challenges, and future trends. Swarm Evol Comput 62:1–41. https://doi.org/10.1016/j.swevo.2021.100841
Gunasundari S, Janakiraman S, Meenambal S (2016) Velocity bounded boolean particle swarm optimization for improved feature selection in liver and kidney disease diagnosis. Expert Syst Appl 56:28–47. https://doi.org/10.1016/j.eswa.2016.02.042
Ilunga-Mbuyamba E, Cruz-Duarte JM, Avina-Cervantes JG, Correa-Cely CR, Lindner D, Chalopin C (2016) Active contours driven by cuckoo search strategy for brain tumour images segmentation. Expert Syst Appl 56:59–68. https://doi.org/10.1016/j.eswa.2016.02.048
Hassan MH, Houssein EH, Mahdy MA, Kamel S (2021) An improved manta ray foraging optimizer for cost-effective emission dispatch problems. Eng Appl Artif Intell 100:1–20. https://doi.org/10.1016/j.engappai.2021.104155
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey wolf optimizer. Adv Eng Softw 69:46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007
Jalali, S. M. J.; Ahmadian, S.; Khosravi, A.; Shafie-khah, M.; Nahavandi, S.; Catalao, J. P. S. A Novel Evolutionary-Based Deep Convolutional Neural Network Model for Intelligent Load Forecasting. IEEE Trans. Ind. Informatics, 2021, 3203 (c), 1–10. https://doi.org/10.1109/TII.2021.3065718
Buabeng A, Simons A, Frempong NK, Ziggah YY (2021) A Novel hybrid predictive maintenance model based on clustering, smote and multi-layer perceptron neural network optimised with grey wolf algorithm. SN Appl Sci 3(5):1–24. https://doi.org/10.1007/s42452-021-04598-1
Garg S, Kaur K, Kumar N, Kaddoum G, Zomaya AY, Ranjan R (2019) A hybrid deep learning-based model for anomaly detection in cloud datacenter networks. IEEE Trans Netw Serv Manag 16(3):924–935. https://doi.org/10.1109/TNSM.2019.2927886
Kumaran N, Vadivel A, Kumar SS (2018) Recognition of human actions using cnn-gwo: a novel modeling of cnn for enhancement of classification performance. Multimed Tools Appl 77(18):23115–23147. https://doi.org/10.1007/s11042-017-5591-z
Chen, X.; Kopsaftopoulos, F.; Wu, Q.; Ren, H.; Chang, F. K. A Self-Adaptive 1D Convolutional Neural Network for Flight-State Identification. Sensors, 2019;19(2). https://doi.org/10.3390/s19020275
Goel T, Murugan R, Mirjalili S, Chakrabartty DK (2021) OptCoNet : an optimized convolutional neural network for an automatic diagnosis of COVID-19. Appl Intell 51:1351–1366
Mishra A, Pandey A, Baghel AS ( 2016) Building Detection and extraction techniques: a review. In proceedings of the 10th INDIACom; 2016 3rd international conference on computing for sustainable global development, INDIACom 2016. pp 3816–3821
Wu G, Shao X, Guo Z, Chen Q, Yuan W, Shi X, Xu Y, Shibasaki R (2018) Automatic building segmentation of aerial imagery usingmulti-constraint fully convolutional networks. Remote Sens 10(3):1–18. https://doi.org/10.3390/rs10030407
Liu, Z.; Chen, B.; Zhang, A. Building Segmentation from Satellite Imagery Using U-Net with ResNet Encoder. In Proceedings - 2020 5th International Conference on Mechanical, Control and Computer Engineering, ICMCCE 2020; 2020; pp 1967–1971. https://doi.org/10.1109/ICMCCE51767.2020.00431
Delibasoglu I, Cetin M (2020) improved u-nets with inception blocks for building detection. J Appl Remote Sens 14(04):1–15. https://doi.org/10.1117/1.jrs.14.044512
Guo M, Liu H, Xu Y, Huang Y (2020) Building extraction based on u-net with an attention block and multiple losses. Remote Sens 12(9):1–17. https://doi.org/10.3390/RS12091400
Pan Z, Xu J, Guo Y, Hu Y, Wang G (2020) Deep learning segmentation and classification for urban village using a worldview satellite image based on u-net. Remote Sens 12(10):1–17. https://doi.org/10.3390/rs12101574
Rastogi K, Bodani P, Sharma SA (2020) Automatic building footprint extraction from very high-resolution imagery using deep learning techniques. Geocarto Int 37(5):1501–1513. https://doi.org/10.1080/10106049.2020.1778100
Chen Z, Li D, Fan W, Guan H, Wang C, Li J (2021) Self-attention in reconstruction bias u-net for semantic segmentation of building rooftops in optical remote sensing images. Remote Sens 13(13):1–27. https://doi.org/10.3390/rs13132524
Li C, Fu L, Zhu Q, Zhu J, Fang Z, Xie Y, Guo Y, Gong Y (2021) Attention enhanced u-net for building extraction from farmland based on google and worldview-2 remote sensing images. Remote Sens 13(21):1–15. https://doi.org/10.3390/rs13214411
Jin Y, Xu W, Zhang C, Luo X, Jia H (2021) Boundary-aware refined network for automatic building extraction in very high-resolution urban aerial images. Remote Sens 13(4):1–20. https://doi.org/10.3390/rs13040692
Abdollahi A, Pradhan B (2021) Integrating semantic edges and segmentation information for building extraction from aerial images using unet. Mach Learn with Appl 6:1–10. https://doi.org/10.1016/j.mlwa.2021.100194
Xu L, Liu Y, Yang P, Chen HAO, Zhang H, Wang DAN, Zhang XIN (2021) HA U-Net : improved model for building extraction from high resolution remote sensing imagery. IEEE Access 9:101972–101984. https://doi.org/10.1109/ACCESS.2021.3097630
Ye, H.; Liu, S.; Jin, K.; Cheng, H. CT-UNET: An improved neural network based on u-net for building segmentation in remote sensing images. in proceedings - international conference on pattern recognition, Milan, Italy, Jan 10–15, 2021; 2020; pp 166–172. https://doi.org/10.1109/ICPR48806.2021.9412355
Zhang Y, Jin Z, Chen Y (2019) Hybridizing grey wolf optimization with neural network algorithm for global numerical optimization problems. Neural Comput Appl 32(14):10451–10470. https://doi.org/10.1007/s00521-019-04580-4
Fogel DB (2006) Evolutionary Computation: Toward a New Philosophy of Machine Intelligence, 3rd edn. John Wiley & Sons, NJ, USA
Beyer HG, Schwefel HPE (2022) Fast evolution strategies. Nat Comput 1:3–52. https://doi.org/10.1007/bfb0014808
Rahnamayan S, Tizhoosh HR, Salama MMA, Evolutionary A (2008) Opposition-based differential evolution. IEEE Trans Evol Comput 12(1):64–79
Simon D (2008) Biogeography-based optimization. IEEE Trans Evol. Comput. 12(6):702–713. https://doi.org/10.1109/TEVC.2008.919004
Goldberg DE, Holland JH (1988) Genetic Algorithms and Machine Learning. Mach. Learn. No. 3, 95–99
Kennedy J, Eberhart R (1995) Particle Swarm Optimization. In Proceedings of ICNN’95—international conference on neural networks. pp. 1942–1948
Yang X, Deb S, Behaviour ACB (2009) Cuckoo Search via Lévy flights. In 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC). pp. 210–214
Mirjalili S, Gandomi AH, Mirjalili SZ, Saremi S, Faris H, Mirjalili SM (2017) Salp swarm algorithm: a bio-inspired optimizer for engineering design problems. Adv Eng Softw 114:163–191. https://doi.org/10.1016/j.advengsoft.2017.07.002
Mirjalili S, Lewis A (2016) The whale optimization algorithm. Adv Eng Softw 95:51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008
Kirkpatrick, S.; Gelatt, C. D.; Vecchi, M. P. Optimization by Simulated Annealing. Science (80-. )., 1983, 220, 671–680. https://doi.org/10.1126/science.220.4598.671
Rao RV, Savsani VJ, Vakharia DP (2011) Teaching-learning-based optimization: a novel method for constrained mechanical design optimization problems. CAD Comput Aided Des 43(3):303–315. https://doi.org/10.1016/j.cad.2010.12.015
Savsani P, Savsani V (2016) Passing Vehicle Search (PVS): a novel metaheuristic algorithm. Appl Math Model 40(5–6):3951–3978. https://doi.org/10.1016/j.apm.2015.10.040
Mirjalili S (2016) SCA: a Sine Cosine Algorithm for solving optimization problems. Knowledge-Based Syst 96:120–133. https://doi.org/10.1016/j.knosys.2015.12.022
Bouktif S, Fiaz A, Ouni A, Serhani MA (2020) Multi-Sequence LSTM-RNN deep learning and metaheuristics for electric load forecasting. Energies 13(2):1–21. https://doi.org/10.3390/en13020391
Peng L, Zhu Q, Lv SX, Wang L (2020) effective long short-term memory with fruit fly optimization algorithm for time series forecasting. Soft Comput 24(19):15059–15079. https://doi.org/10.1007/s00500-020-04855-2
Nadeem MI, Ahmed K, Li D, Zheng Z, Naheed H, Muaad AY, Alqarafi A, Abdel Hameed H (2023) SHO-CNN: a metaheuristic optimization of a convolutional neural network for multi-label news classification. Electron 12(1):1–24. https://doi.org/10.3390/electronics12010113
Challapalli JR, Devarakonda N (2022) A novel approach for optimization of convolution neural network with hybrid particle swarm and grey wolf algorithm for classification of Indian classical dances. Knowl Inf Syst 64(9):2411–2434. https://doi.org/10.1007/s10115-022-01707-3
Tsai CW, Hsia CH, Yang SJ, Liu SJ, Fang ZY (2020) Optimizing hyperparameters of deep learning in predicting bus passengers based on simulated annealing. Appl Soft Comput J 88:106068. https://doi.org/10.1016/j.asoc.2020.106068
Nematzadeh S, Kiani F, Torkamanian-Afshar M, Aydin N (2021) Tuning hyperparameters of machine learning algorithms and deep neural networks using metaheuristics: a bioinformatics study on biomedical and biological cases. Comput Biol Chem 2022(97):107619. https://doi.org/10.1016/j.compbiolchem.2021.107619
Lee S, Kim J, Kang H, Kang DY, Park J (2021) Genetic algorithm based deep learning neural network structure and hyperparameter optimization. Appl Sci 11(2):1–12. https://doi.org/10.3390/app11020744
Gulcu A, Kus Z (2020) Hyper-parameter selection in convolutional neural networks using microcanonical optimization algorithm. IEEE Access 8:52528–52540. https://doi.org/10.1109/ACCESS.2020.2981141
Putra Utama, A. B.; Wibawa, A. P.; Muladi, M.; Nafalski, A. PSO Based Hyperparameter Tuning of CNN Multivariate Time- Series Analysis. J. Online Inform., 2022;7(2):193–202. https://doi.org/10.15575/join.v7i2.858
Ho YC, Pepyne DL (2002) Simple explanation of the no-free-lunch theorem and its implications. J Optim Therory Appl 115(3):549–570
Ronneberger O, Fischer P, Brox T (2015) U-Net: Convolutional Networks for Biomedical Image Segmentation. In: Navab, N., Hornegger, J., Wells, W., Frangi, A. (eds) Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. MICCAI 2015. Lecture Notes in Computer Science, vol 9351. Springer, Cham. https://doi.org/10.1007/978-3-319-24574-4_28
Temenos, A.; Protopapadakis, E.; Doulamis, A.; Temenos, N. Building Extraction from RGB Satellite Images Using Deep Learning: A U-Net Approach. In ACM International Conference Proceeding Series; 2021; pp 391–395. https://doi.org/10.1145/3453892.3461320
He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition; 2016; Vol. 2016-Decem, pp 770–778. https://doi.org/10.1109/CVPR.2016.90
Zhang P, Du P, Lin C, Wang X, Li E, Xue Z, Bai X (2020) A Hybrid Attention-Aware Fusion Network (Hafnet) for building extraction from high-resolution imagery and lidar data. Remote Sens 12(22):1–20. https://doi.org/10.3390/rs12223764
Acknowledgements
The authors thank the University of Mines and Technology, Tarkwa, Ghana, for this research.
Funding
No funding was received for this research.
Author information
Authors and Affiliations
Contributions
Richmond Akwasi Nsiah: Conceptualisation, Methodology, Investigation, Software and Scripting, Data Curation, Validation, Writing—original draft preparation, Writing—review and editing, Visualisation Yao Yevenyo Ziggah: Conceptualisation, Methodology, Investigation, Validation, Writing—original draft preparation, Writing—review and editing, Visualisation Supervision. Saviour Mantey: Conceptualisation, Methodology, Investigation, Validation, Writing—original draft preparation, Writing—review and editing, Visualisation Supervision. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no conflict of interest/competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nsiah, R.A., Mantey, S. & Ziggah, Y.Y. Building segmentation from UAV orthomosaics using unet-resnet-34 optimised with grey wolf optimisation algorithm. Smart Constr. Sustain. Cities 1, 21 (2023). https://doi.org/10.1007/s44268-023-00019-x
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44268-023-00019-x