
Abstract
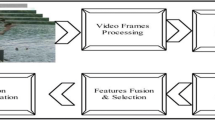
Recognizing human actions from unconstrained videos turns to be a major challenging task in computer visualization approaches due to decreased accuracy in the feature classification performance. Therefore to improve the classification performance it is essential to minimize the ‘classification’ errors. Here, in this work, we propose a hybrid CNN-GWO approach for the recognition of human actions from the unconstrained videos. The weight initializations for the proposed deep Convolutional Neural Network (CNN) classifiers highly depend on the generated solutions of GWO (Grey Wolf Optimization) algorithm, which in turn minimizes the ‘classification’ errors. The action bank and local spatio-temporal features are generated for a video and fed into the ‘CNN’ classifiers. The ‘CNN’ classifiers are trained by a gradient descent algorithm to detect a ‘local minimum’ during the fitness computation of GWO ‘search agents’. The GWO algorithms ‘global search’ capability as well as the gradient descent algorithms ‘local search’ capabilities are subjected for the identification of a solution which is nearer to the global optimum. Finally, the classification performance can be further enhanced by fusing the classifiers evidences produced by the GWO algorithm. The proposed classification frameworks efficiency for the recognition of human actions is evaluated with the help of four achievable action recognition datasets namely HMDB51, UCF50, Olympic Sports and Virat Release 2.0. The experimental validation of our proposed approach shows better achievable results on the recognition of human actions with 99.9% recognition accuracy.















Similar content being viewed by others


References
Ballas N, Yang Y, Lan Z-Z, Delezoide B, Preteux F, Hauptmann A (2013) Space-time robust representation for action recognition. In: The IEEE International Conference on Computer Vision (ICCV)
Bengio Y (2009) Learning deep architectures for AI. Found Trends Mach Learn 2(1):1–127
Bengio Y, Delalleau O (2011) On the expressive power of deep architectures. In: Proceedings of the 22nd International Conference on Algorithmic Learning Theory, ALT’11, Springer-Verlag, Berlin, pp 18–36
Bengio Y, Simard P, Frasconi P (2000) Learning long-term dependencies with gradient descent is difficult. IEEE Trans Neural Netw 5(2):157–166
Bergstra J, Bengio Y (2013) Random search for hyper-parameter optimization. J Mach Learn Res 13:281–305
Chetlur S, Woolley C, Vandermersch P, Cohen J, Tran J, Catanzaro B,Shelhamer E cudnn: efficient primitives for deep learning, CoRR abs/1410.0759,720 URL http://arxiv.org/abs/1410.0759
Dahl GE, Sainath TN, Hinton GE (2013) Improving deep neural networks for lvcsr using rectified linear units and dropout. In: Proceedings of the 2013 International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, pp. 8609–8613
Ding S, Li H, Su C, Yu J, Jin F (2013) Evolutionary artificial neural networks: a review. Artif Intell Rev 39(3):251–260. https://doi.org/10.1007/s10462-011-9270-6
Dollar P, Rabaud V, Cottrell G, Belongie S (2005) Behavior recognition via sparse spatio-temporal features. In: 2nd Joint IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, pp. 65–72. IEEE, Beijing
Emary E, Zawbaa HM, Hassanien AE (2016) Binary grey wolf optimization approaches for feature selection. J Neurocomput 172:371–381
Erhan D, Bengio Y, Courville A, Manzagol P-A, Vincent P, Bengio S (2010) Why does unsupervised pre-training help deep learning? J Mach Learn Res 11:625–660
Glorot X, Bengio Y (2010) Understanding the difficulty of training deep feed forward neural networks. In: Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS10), Journal on Society for Artificial Intelligence and Statistics
Herath S, Harandi M, Porikli F (2017) Going deeper into action recognition: a survey. J Image Vision Comput 60:4–21
Hinton GE, Osindero S, Teh Y-W (2006) A fast learning algorithm for deep belief nets. Neural Comput 18(7):1527–1554
Huang HJ, Serre T, Wolfand L, Poggio T (2007) A biologically inspired system for action recognition. In: Proceedings of ICCV, pp 1–8
Ignatov A (2017) Real-time human activity recognition from accelerometer data using Convolutional Neural Networks. Appl Soft Comput 62:915–922
Ji S, Xu W, Yang M, Yu K (2013) 3D convolutional neural networks for human action recognition. IEEE Trans Pattern Anal Mach Intell 35(1):221–231
Jones S, Shao L (2013) Content-based retrieval of human actions from realistic video databases. J Inf Sci 236:56–65
Kuehne H, Jhuang H, Garrote E, Poggio T, Serre T (2011) HMDB: a large video database for human motion recognition. In: IEEE International Conference on Computer Vision (ICCV), 2011 pp 2556–2563
Laptev I, Lindeberg T (2003) Space-time interest points. In: Proceedings of ICCV, pp 432–439
Laptev I, Lindeberg T (2003) Space-time interest points, ICCV
Larochelle H, Bengio Y, Louradour J, Lamblin P (2009) Exploring strategies for training deep neural networks. J Mach Learn Res 10:1–40
Lim MK, Tang S, Chan CS (2014) iSurveillance: intelligent framework for multiple events detection in surveillance videos. Expert Syst Appl 41(10):4704–4715
Liu AA, Xu N, Nie WZ, Su YT, Wong Y, Kankanhalli M (2017) Benchmarking a multimodal and multiview and interactive dataset for human action recognition. IEEE Transactions on Cybernetics 47(7):1781–1794
Lu Y, Boukharouba K, Boonært J, Fleury A, Lecoeuche S (2014) Application of an incremental SVM algorithm for on-line human recognition from video surveillance using texture and color features. J Neurocomput 126:132–140
Ma S, Bargal SA, Zhang J, Sigal L, Sclaroff S (2016) Do less and achieve more: training CNNs for action recognition utilizing action images from the web. Pattern Recogn 68:334–345
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey wolf optimizer. Adv Eng Softw 69:46–61
Mohammadi E, Wu QMJ, Saif M (2016) Human action recognition by fusing the outputs of individual classifiers. In: IEEE 13th Conference on Computer and Robot Vision (CRV) 2016 pp 335–341
Niebles JC, Chen C-W, Fei-Fei L (2010) Modeling temporal structure of decomposable motion segments for activity classification. In: European conference on computer vision, Springer, Berlin, pp 392–405
Oh S, Hoogs A, Perera A, Cuntoor N, Chen C-C, Lee JT, Mukherjee S et al (2011) A large-scale benchmark dataset for event recognition in surveillance video. In: IEEE conference on computer vision and pattern recognition (CVPR), pp 3153–3160
Oikonomopoulos A, Patras I, Pantic M (2006) Spatio-temporal salient points for visual recognition of human actions. IEEE Trans Syst, Man Cybern 36(3):710–719
Prechelt L (2000) Early stopping - but when? In: Neural Networks: Tricks of the Trade, volume 1524 of LNCS, Springer-Verlag, pp 55–69
Qiu Q, Jiang Z, Chellappa R (2011) Sparse dictionary-based representation and recognition of action attributes. In: IEEE International Conference on Computer Vision (ICCV), 2011, pp 707–714
Reddy KK, Shah M (2013) Recognizing 50 human action categories of web videos. Mach Vis Appl 24(5):971{981. https://doi.org/10.1007/s00138-012-0450-4
Rodriguez M, Orrite C, Medrano C, Makris D (2016) A time flexible kernel framework for video-based activity recognition. J Image Vision Comput 48:26–36
Sadanand S, Corso JJ (2012) Action bank: A high-level representation of activity in video. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp 1234–1241
Schaffer J, Whitley D, Eshelman L (1992) Combinations of genetic algorithms and neural networks: a survey of the state of the art. In: International Workshop on Combinations of Genetic Algorithms and Neural Networks (COGANN-92), pp 1–37. doi:https://doi.org/10.1109/COGANN.1992.273950
Schuldt C, Laptev I, Caputo B (2004) Recognizing human actions: A local SVM approach. In: IEEE International Conference on Pattern Recognition vol. 3, pp 32–36
Shen J (2009) Stochastic modeling western paintings for effective classification. Pattern Recogn 42(2):293–301
Shen J, Deng RH, Cheng Z, Nie L, Yan S (2015) On robust image spam filtering via comprehensive visual modeling. Pattern Recogn 48(10):3227–3238
Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R (2014) Dropout: a simple way to prevent neural networks from overfitting. J Mach Learn Res 15(1):1929–1958
Vinu Sundararaj (2016) An efficient threshold prediction scheme for wavelet based ECG signal noise reduction using variable step size firefly algorithm. Int J Intell Eng Syst 9(3):117–126
Sutskever I, Martens J, Dahl GE, Hinton GE (2013) On the importance of initialization and momentum in deep learning. In: Proceedings of the 30th International Conference on Machine Learning (ICML-13), Vol. 28, pp 1139–1147
Vinothini J, Ashok Bakkiyaraj R (2012) Grey wolf optimization algorithm for color image enhancement considering brightness preservation constraint. IEEE Conf Comput Vis Pattern Recognit 482:1234–1241
Wang H, Schmid C (2013) Action recognition with improved trajectories. In: Proceedings of the IEEE International Conference on Computer Vision, pp 3551–3558
Wang L, Yu Q, Tang X (2014) Latent hierarchical model of temporal structure for complex activity classification. IEEE Trans Image Process 23(2):810–822
Xie L, Shen J, Han J, Zhu L, Shao L (2017) Dynamic multi-view hashing for online image retrieval. In: Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, pp 3133–3139. IJCAI, Melbourne
Yao X (1999) Evolving artificial neural networks. Proc IEEE 87(9):1423–1447. https://doi.org/10.1109/5.784219.
Yuan F, Xia G-S, Sahbi H, Prinet V (2012) Mid-level features and spatio-temporal context for activity recognition. Pattern Recogn 45(12):4182–4191
Zhang E, Chen W, Zhang Z, Zhang Y (2016) Local surface geometric feature for 3D human action recognition. J Neurocomput 208(5):281–289
Zhen X, Shao L, Li X (2014) Action recognition by spatio-temporal oriented energies. J Inform Sci 281:295–309
Acknowledgements
This work was partially supported by my supervisor Dr.U.Srinivasulu Reddy, Assistant professor/ Department of Computer Applications, NIT Trichy, Tamilnadu, India.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Kumaran, N., Vadivel, A. & Kumar, S.S. Recognition of human actions using CNN-GWO: a novel modeling of CNN for enhancement of classification performance. Multimed Tools Appl 77, 23115–23147 (2018). https://doi.org/10.1007/s11042-017-5591-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-5591-z