
Abstract
This paper proposes a new Topp-Leone Exponentiated Pareto (TLEtP) distribution. The new distribution family is derived by expanding the Topp Leone-G family of distributions with additional positive shape parameters. The corresponding density and distribution functions are derived and shown. Some of the derived mathematical properties of the distribution include quantile function, ordinary and incomplete moments generating function (mgf), hazard function, survival function, odd function, probability weighted moment, and distribution of order statistic. The parameters of the distribution are estimated using Maximum Likelihood method. The proposed distribution’s validity is demonstrated by fitting two sets of real data and comparing the results with two existing same-family distributions, the Topp-Leone Pareto type I(TLPI) and Pareto (P), with the Akaike Information Criteria (AIC) and Bayesian Information Criteria (BIC), respectively. The comparison of the proposed Topp-Leone Exponentiated Pareto (TLEtP) to the Topp-Leone Pareto type I(TLPI) and Pareto (P) distribution demonstrate that the TLEtP distribution offers a better fit for the data sets than the other two distributions.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Since the World Health Organization declared the Corona virus (COVID-19) pandemic outbreak a public health crisis and of international concern in 2020, approximately 704,241,673 cases and 7,006,177 deaths have been recorded worldwide as of 19 March 2024 [1]. Between 2020 and 2021, when the pandemic was at its peak, several efforts were made to develop and identify COVID-19 prevention methods. Despite global efforts to develop vaccines and cures, the primary strategy used to contain the spread was social distancing, isolation, personal and community hygiene, and mass testing. Prior to the advent of effective vaccines, a number of alternative methods were proposed to combat the pandemic. Most of these strategies were only able to reduce the spread of the disease through the use of personal hygiene measures such as face and nose masks, social distancing, patient quarantine, social isolation, mass testing and lockdown. Irrespective of the measures taken to limit the transmission of the pandemic, social distancing and isolation, as well as general lockdown measures, were all reported to be successful in reducing the spread of the virus [2,3,4].
The development and comparisons of life models (distributions) curves are always of key importance in modelling and predicting the outbreak of the disease. This is because if the data on the outbreak can be well modelled, the evolution of the disease can be traced, and then the spread can be prevented by studying the dynamics of the disease in the model. A good model in this resguard can be very helpful in decision-making by survival analysts and health authorities. The exponentiated-G class was first proposed by [5], who raised the cumulative distribution function (cdf) to a positive power parameter. Thus, becoming one of many methods proposed by statisticians where parameters are added to distributions. A number of techniques for creating new families of distributions have been investigated by [6]. New families of probability distributions that expand well-known distributions are frequently created to offer flexibility when modeling data in practice. In other words, distributions have been built by expanding popular families of continuous distributions. By enhancing the original model with at least one shape or scale parameter, these generalized distributions offer greater versatility. Additionally, statisticians create families of distributions so that distributions can be skewed to the right, left, unimodal, J or reversed J shape to provide consistently better fits, which equip other distributions with the same underlying model. In fact, a large number of families of continuous probability distributions have been developed with one or two parameters, such as the Marshall-Olkin-G [7], beta generalized-G [8], exponentiated generalized-G [9], exponentiated Gompertz using informative prior [10], Burr X-G distribution [11], generalized odd generalized exponential family [12], Lomax-G [13], mixture of Lomax distribution [14], Type I general exponential class of distributions by [15], transmuted Weibull-G family of distributions [16], and generalized odd generalized exponential family [17].
To obtain a better fit of the models, this article proposes the inclusion of new parameters and provides evidence that the use of two parameters provides a better fit compared to the original distributions. The Topp-Leone Exponentiated-G and Pareto distribution functions are used to generate a new distribution, the Topp-Leone Exponentiated Pareto (TLetP), and the mathematical properties are defined. The proposed Topp-Leone Exponentiated Pareto (TLEtP) distribution has an exceptional probability density function (pdf) due to its ability to model both positively and negatively skewed data with significant tails and symmetric data sets, making it a more flexible model. It can also be used to model increasing, decreasing and bathtub hazard and survival rates. These characteristics make the proposed model a novel distribution for modelling life data, including survival, reliability engineering and biomedical life testing. The proposed model is then applied to two real COVID-19 datasets to illustrate the properties and flexibility of the distribution. The first example is daily confirmed COVID-19 cases recorded in Pakistan and the results are compared with those obtained by [18] and the second example uses data from the COVID-19 pandemic in South Africa. The rest of the paper is organised as follows: Section 2 explains the procedure for generating the Topp Leonne Exponentiated Pareto (TLetP) distribution and develops its mathematical properties. Section 3 shows how the proposed distribution is applied to a real data set and section 4 contains the conclusion.
2 Methods
A four-parameter distribution, the Topp Leone Exponentiated-G Family of Distributions, is proposed by [19] with the probability density function (pdf) and cumulative distribution function (cdf) of the family are given as:
and
where \(\psi\) is the vector of parameters of the baseline distribution. The cdf and pdf of the baseline distribution correspond to the Pareto distribution.
and
Some properties like moments, moment generating function, quantile, hazard function, survival function, odd function, distribution of order statistics, and estimate of the parameters using the method of maximum likelihood are described.
2.1 The Proposed Topp-Leone Exponentiated Pareto (TLEtP) distribution
In this sub-section, a new Topp-Leone exponentiated Pareto distribution is derived. To obtain the the new distribution, (3) is inserted into (1) to give the cumulative distribution function (cdf) of TLEtP as:
On differentiation Eq. (3) with respect x, we have the pdf given as:
Therefore,
Where \(x \ge 0\), \(\beta > 0\) is the scale parameters and \(\alpha , \theta , \lambda > 0\) are the shape parameters.
We can represent the distribution using binomial expansion on (6) as:
Then,
Therefore,
and
We can also represent the distribution using binomial expansion on (5) as:
and
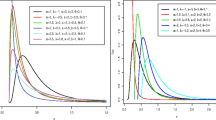
Figure 1a and b show the cdf and pdf of the proposed distribution with different simulated parameters.

The cdf and pdf of TLEtP distribution with different parameter values
Using Eqs. (7) and (8), various properties of the TLEtP distribution are presented in section (2.2).
2.2 Mathematical properties
2.2.1 Moments
2.3 Moment Generating Function (mgf)
The moment-generating function of X can be obtained using the following equation.
2.4 Quantile Function
The TLEtP distribution is simply approximated by inverting (5). If \(\mu\) has a uniform \(U \sim (0,1)\) distribution, then the equation’s solution is:
Equation (10) is the quantile function of the Topp-Leone exponentiated Pareto distribution and Eq. (11) is the median for the Topp-Leone exponential Pareto distribution.
2.5 Hazard Function
The hazard function is defined by:
Considering the definition above, the hazard function of TLEtP distribution is given as:
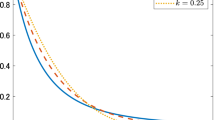
Figure 2 shows the hazard function with different parameter values.

Hazard function plot of TLEtP distribution with different parameter values
2.6 Survival Function
The survival function, which is the probability of an item not failing prior to some time, can be defined as:
So, the survival function for the TLEtP distribution is given as:
And, the survival function plot can be seen in Fig. 3.

Survival function plot of TLEtP distribution with different parameter values
2.7 Odds Function
The odds function is obtained using the relation:
The odds function of TLEtP distribution is given as:
2.8 Distribution of Order Statistics
Let \(X_{1}, X_{2}, \dots , X_{n}\) be n independent random variable from the TLEtP distribution and let \(X_{(1)}, X_{(2)}, \cdots , X_{(n)}\) be their corresponding order statistics. Let \(F_{r:n}(x)\) and \(f_{r:n}(x)\), \(r=1,2,3, \dots , n\) denote the cdf and pdf of the \(r^{th}\) order statistics \(X_{r:n}\) respectively. The pdf of the \(r^{th}\) order statistics of \(X_{r:n}\) is given as:
Where
and
The maximum order statistics is obtained by setting \(r = n\) in Eq. (13) as:
And, the minimum order statistics is obtained by setting \(r=1\) in Eq. (13).
Now
2.9 Parameter Estimation
Since maximum likelihood estimators give the maximum information about the population parameters, this section presents the maximum likelihood estimates (MLEs) of the parameters that are inherent within the distribution function.
Let \(X_{1}, X_{2}, \dots , X_{n}\) be random variables of the TLEtP distribution of size n. The log-likelihood function of the TLEtP distribution is obtained as:
Deriving the Eq. (16), we have:
Equations (17), (18), and (20) do not have a simple form and are intractable. As a result, we have to resort to using interactive procedures to estimate the parameters.
3 Application Using Real-Life Data Sets
The application of the TLEtP distribution is demonstrated using two data sets. The performance of the distribution with regards to providing reasonable parametric fit to the data sets was compared to Topp-Leone Pareto type I(TLPI) and Pareto (P) distributions using the Akaike information criterion (AIC) and Bayesian information criterion (BIC), respectively. The model with a minimum value of AIC and BIC is chosen as the best model to fit the data set.
3.1 Example 1
The first data set as listed in the Table 1 represents the daily confirmed COVID-19 cases recorded in Pakistan from March 24 to April 28, 2020, previously used by Al-Marzouki, et al. (2020).
The TLEtP distribution provides a better fit for the data set compared to the TLPI model. From Table 2, the TLEtP distribution has the highest log-likelihood and the smallest AIC and BIC values compared to the other fitted models. This fit can also be seen in Figs. 4 and 5.

Fitted pdfs for the TLEtP, TLPI, and Pareto distribution based on confirmed COVID-19 cases recorded in Pakistan from March 24 to April 28, 2020

Fitted cdf, pdf, Q-Q and P-P plots of confirmed COVID-19 cases recorded in Pakistan from March 24 to April 28, 2020 for the TLEtP distribution
3.1.1 Example 2
The second data set as listed in the Table 3 represents the active COVID-19 cases per day in South Africa from March 11 to August 31, 2020.
The analysis of the data from South Africa showed similar results that of Pakistan, i.e., the model with the TLEtP distribution showed a better fit compared to other models. From Table 4, the TLEtP distribution has the highest log-likelihood and the smallest AIC and BIC. This fit can be seen in Figs. 6 and 7.

Fitted pdfs for the TLEtP, TLPI, and Pareto distribution based on confirmed COVID-19 cases per day in South Africa from March 11 to August 31, 2020

Fitted cdf, pdf, Q-Q, and P-P plots of confirmed COVID-19 cases per day in South Africa from March 11 to August 31, 2020 for the TLEtP distribution
4 Conclusion
Recently, statisticians have increasingly created extended distributions from families of existing distributions. We have successfully created the novel Topp-Leone Exponentiated Pareto (TLEtP) family of distributions. Furthermore, some mathematical characteristics of the newly developed distribution are derived. By analyzing the COVID-19 outbreak in Pakistan and South Africa and comparing the data with two members of the Topp-Leone Pareto type I (TLPI) and Pareto (P) families of distributions, we show the adaptability and applicability of the new distributions. Compared to (TLPI) and (P) distributions, the proposed distribution (TLEtP) provides a better fit for the data set. As a result, we anticipate that the proposed distributions (TLEtP) will be useful in a variety of domains, particularly in reliability studies when the hazard rate is increasing.
Data Availability
The data is available in the article
References
COVID - Coronavirus Statistics - Worldometer. https://www.worldometers.info/coronavirus/ Accessed 2024-03-19
Anderson, R.M., Heesterbeek, H., Klinkenberg, D., Hollingsworth, T.D.: How will country-based mitigation measures influence the course of the COVID-19 epidemic? 395(10228), 931–934 (2020) https://doi.org/10.1016/S0140-6736(20)30567-5 . Accessed 2024-03-19
Mitjà, O., Arenas, A., Rodó, X., Tobias, A., Brew, J., Benlloch, J.M.: Experts’ request to the spanish government: move spain towards complete lockdown 395(10231), 1193–1194 (2020) https://doi.org/10.1016/S0140-6736(20)30753-4 . Accessed 2024-03-19
Saez, M., Tobias, A., Varga, D., Barceló, M.A.: Effectiveness of the measures to flatten the epidemic curve of COVID-19. the case of spain 727, 138761 (2020) https://doi.org/10.1016/j.scitotenv.2020.138761 . Accessed 2024-03-19
Gupta, R.C., Gupta, P.L., Gupta, R.D.: Modeling failure time data by lehman alternatives. Communications in Statistics - Theory and Methods 27(4), 887–904 https://doi.org/10.1080/03610929808832134 . Accessed 2023-09-17
Alzaatreh, A., Lee, C., Famoye, F.: A new method for generating families of continuous distributions. METRON 71(1), 63–79 https://doi.org/10.1007/s40300-013-0007-y . Accessed 2023-09-17
Marshall, A.W., Olkin, I.: A new method for adding a parameter to a family of distributions with applicatino to the exponental and weibull families. Biometrika 84(3), 641–652
Eugene, N., Lee, C., Famoye, F.: BETA-NORMAL DISTRIBUTION AND ITS APPLICATIONS. Communications in Statistics - Theory and Methods 31(4), 497–512 https://doi.org/10.1081/STA-120003130 . Accessed 2023-09-17
Cordeiro, G.M., Ortega, E.M.M., Cunha, D.C.C.D.: The exponentiated generalized class of distributions. Journal of Data Science 11(1), 1–27 https://doi.org/10.6339/JDS.2013.11(1).1086 . Accessed 2023-09-17
Aslam, M., Afzaal, M., Ishaq Bhatti, M.: A study on exponentiated gompertz distribution under bayesian discipline using informative priors. Statistics in Transition New Series 22(4), 101–119 (2021) https://doi.org/10.21307/stattrans-2021-040 . Accessed 2023-12-27
Yousof, H.M., Afify, A.Z., Hamedani, G.G., Aryal, G.: The burr x generator of distributions for lifetime data. Journal of Statistical Theory and Applications 16(3), 288 https://doi.org/10.2991/jsta.2017.16.3.2 . Accessed 2023-09-17
Alizadeh, M., Ghosh, I., Yousof, H.M., Rasekhi, M., Hamedani, G.G.: The generalized odd generalized exponential family of distributions: Properties, characterizations and application. Journal of Data Science 15(3), 443–466 https://doi.org/10.6339/JDS.201707_15(3).0005 . Accessed 2023-09-17
Cordeiro, G.M., Ortega, E.M.M., Popović, B.V., Pescim, R.R.: The lomax generator of distributions: Properties, minification process and regression model. Applied Mathematics and Computation 247, 465–486 https://doi.org/10.1016/j.amc.2014.09.004 . Accessed 2023-09-17
Younis, F., Aslam, M., Bhatti, M.I.: Preference of prior for two-component mixture of lomax distribution. Journal of Statistical Theory and Applications 20(2), 407 (2021). https://doi.org/10.2991/jsta.d.210616.002. Accessed 2023-12-27
Hamedani, D.G.G., Yousof, H.M., Rasekhi, M., Alizadeh, M., Najibi, S.M.: Type i general exponential class of distributions. Pakistan Journal of Statistics and Operation Research 14(1), 39 https://doi.org/10.18187/pjsor.v14i1.2193 . Accessed 2023-10-11
Mansour, M.M., Abd Elrazik, E.M., Afify, A.Z., Ahsanullah, M., Altun, E.: The transmuted transmuted-g family: properties and applications. Journal of Nonlinear Sciences and Applications 12(4), 217–229 https://doi.org/10.22436/jnsa.012.04.03 . Accessed 2023-10-11
Alizadeh, M., Cordeiro, G.M., Pinho, L.G.B., Ghosh, I.: The Gompertz-G family of distributions. Journal of Statistical Theory and Practice 11(1), 179–207 (2017). https://doi.org/10.1080/15598608.2016.1267668. Accessed 2023-04-19
Al-Marzouki, S., Jamal, F., Chesneau, C., Elgarhy, M.: Topp-leone odd frechet generated family of distributions with applicationsto COVID-19 data sets. Computer Modeling in Engineering & Sciences 125(1), 437–458 https://doi.org/10.32604/cmes.2020.011521 . Accessed 2023-09-17
Ibrahim, S., Doguwa, S.I., Audu, I., Muhammad, J.H.: On the topp leone exponentiated-g family of distributions: Properties and applications. Asian Journal of Probability and Statistics, 1–15 https://doi.org/10.9734/ajpas/2020/v7i130170 . Accessed 2023-10-05
Acknowledgements
The authors are grateful to the anonymous referee for a careful review and helpful comments, which improved this paper. We would like to thank the University of the Free State for paying the APC.
Funding
No funding was received to conduct this study.
Author information
Authors and Affiliations
Contributions
Conceptualization of the study was done by FMC, BJO, IS, and OAB, and all participated in its design and coordination. FMC, BJO, and IS were involved in the formal investigation, and FMC and OAB performed the statistical analysis. This was concluded with review and editing by FMC, BJO, IS, and OAB, and all authors read and approved the manuscript.
Corresponding author
Ethics declarations
Consent to participate
Not applicable
Ethics approval
The research work in this article is new and unique and it contains no ethics issues.
Consent for publication
Not applicable
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Correa, F.M., Odunayo, B.J., Sule, I. et al. Topp-Leone Exponentiated Pareto Distribution: Properties and Application to Covid-19 Data. J Stat Theory Appl (2024). https://doi.org/10.1007/s44199-024-00076-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44199-024-00076-w