
Abstract
We provide a new, flexible model called the Odd Kappa-Exponential (OK-E) distribution. The shape of its hazard rate function (hrf) might be constant, declining, growing, inverted-J, bathtub, or inverted-bathtub. The probability density function (pdf) and the cumulative distribution function (cdf) have both been expressed as linear expansions. Bonferroni and Lorenz curves, ordinary and incomplete moments, the quantile function, the mean residual life, the mean waiting time, and the entropy are all defined. The maximum likelihood method is used to estimate the values of the model’s unknown parameters. To verify the precision of the estimate, we ran a simulation study. The attractiveness and adaptability of the Odd Kappa-Exponential model were shown using four real-world examples from the fields of economics, engineering, and the environment.
Similar content being viewed by others

1 Introduction
In the fields of reliability modeling and life testing analysis, the univariate exponential distribution is by far the most popular and extensively utilized continuous one-parameter distribution. Independent events occur at a constant average rate in a Poisson point process, hence the time between them is assumed to follow an exponential distribution. This distribution may be thought of as a special case of the gamma distribution. This distribution may be thought of as a no-memory, continuous variant of the geometric distribution. It’s not only for studying Poisson point processes; there are many applications. The cdf and pdf for the exponential distribution are defined as:
where \(\beta >0\) is a rate parameter. Predictions of when something will happen are often made using the exponential distribution. It is often used to track radioactive decay in the field of physics; in engineering, time-to-defect analysis is used to determine how long a production line must wait to acquire a faulty product, and it is often used to predict the likelihood of a portfolio’s next default in finance. The exponential distribution is often used to estimate the time remaining before an event happens. For instance, an exponential distribution may be found in the period (from now on) until an earthquake occurs. Other examples are the life of a vehicle battery in months or the duration of a long-distance business call in minutes. New generalizations and applications of the exponential distribution include [2, 3, 18, 27]. These are but a few examples of when the exponential distribution might be handy. Additionally, owing to space limitations, further details related to exponential distribution cannot be given.; Readers interested in learning more might go to resources like [4, 17, 35] and the references found within them.
The Kappa distribution, suggested by [44] and [45], is a desirable positive-skew asymmetric distribution. Because it may be used to compare rainfall, streamflow, and wind speed data, this distribution is gaining increased interest in hydrological research. The well-known gamma and log-normal distributions have been used to fit historical rainfall data. However, these distributions are computationally problematic since there are no closed forms for computing their cdf and quantile functions. On the other hand, the Kappa distribution’s formulae are closed algebraic expressions that can be readily evaluated. The cdf of three-parameter Kappa(Kappa3) distribution ( [45]) is
where a and \(\lambda\) are shape parameters and b is a scale parameter. Furthermore, the pdf of three-parameter Kappa(Kappa3) distribution is
Keep in mind that the Kappa(Kappa3) distribution with three parameters becomes the Kappa(Kappa1) distribution with just one parameter if \(\lambda =b =1\). In addition, if \(\lambda =1\), the Kappa(Kappa3) distribution with three parameters becomes the Kappa(Kappa2) distribution with just two parameters.
Many fields, including demography, economics, finance, insurance, biological research, medicine, engineering, the environment, and actuarial science, have employed various classical distributions to model data throughout the last few decades. However, flexible distributions are constantly required to describe, explain, and predict the phenomena investigated in these areas. No one kind of distribution can adequately characterize skewed data under all conditions. The options for studying a variety of tail weights and skewnesses are widened when one or more shape parameters are added to the baseline distribution. Therefore, researchers have explored several methods for generating new families of distributions that are either more adaptable or better reflect certain practical situations.
An exciting method for creating a new, more versatile family of distributions was proposed by [42], which included adding a new parameter to an existing distribution. Their method results in an extended distribution that encompasses the baseline distribution as a special case and hence may be used to more precisely explain a wider range of data. Parameter addition by exponentiation, on the other hand, may be traced back to [31], who exponentiated the extreme value distribution to graduate mortality tables [5].
Reference [29] proposed a new family of distributions with roots in the beta distribution. By replacing the cdf of a normal distribution with \(F\left( x\right)\), they came up with the beta-normal distribution. Several new distributions have been defined and studied using this approach. Beta-generated distributions and other generalizations were summarized by [39]. References [24] and [36] expanded the beta-generated method by substituting the Kumaraswamy distribution [38] for the beta distribution. In addition, Ref. [8] used the Topp-Leone distribution to create the Topp-Leone family of distributions (for additional information, see see [49] and [62]). Additionally, Ref. [6] extended the beta and hypergeometric distributions to create new generalized statistical probability distributions.
Other popular generators, to mention a few, include Weibull-G by [19], logistic-G by [64], exponentiated half logistic generated family by [23], McDonald-G (Mc-G) by [9], gamma-G type 1 by [65], gamma-G type 2 by [55], gamma-G type 3 by [63] and log-gamma-G by [14], Transformed-Transformer (T-X) by [11], exponentiated (T-X) by [13], T-X\(\{\)Y\(\}\)-quantile based approach by [10], T-R\(\{\)Y\(\}\) by [12]. alpha power transformation introduced by [41]. For discussions of further examples of generators see [30, 37, 39, 60, 61].
Several modifications were made to the original Kappa distribution. Reference [33] proposed the Kumaraswamy generalized Kappa (KGK), the exponentiated generalized Kappa (EGK), and the McDonald generalized Kappa (McGK) as three generalized forms of the Kappa distribution. The author looked into the different statistical features of these innovative extended forms, used several methods to estimate their unknown parameters, and applied the models to real-world data. The Kumaraswamy generalized Kappa (KGK) distribution was suggested by [52] (derived from [33]), whereas [34] proposed the Marshall-Olkin Kappa (MOK) distribution. Many features were examined, unknown parameters were calculated, and examples from real-world data sets were given to show how their proposed allocations would work.
Although many studies have generalized some existing distributions, there is a lack of research on the extension of Kappa distribution. This research gap limits our understanding of the usefulness of Kappa extension. Reference [7] introduced a novel flexible family of distributions, the Odd Kappa-G family, with its cdf defined as:
Therefore, our contribution to this study aims to explore the flexibility of our Odd Kappa family of distributions by studying the Odd Kappa-Exponential (OK-E) distribution as a member of this family that can be applied to real-life phenomena. This study will present and extensively examine the OK-E distribution.
The remaining sections of the paper are structured as follows. The novel Odd Kappa-Exponential (OK-E) distribution is presented in Sect. 2. We show the asymptotic and shapes of this distribution’s pdf and hrf in Sect. 3. In Sect. 4, we provide an applicable linear form for the pdf and cdf of this distribution. This model’s quantile function is derived in Sect. 5. Moments, both ordinary and incomplete, as well as the mean residual life (MRL) and the mean waiting time (MWT), are reported in Sect. 6. Section 7 introduces the concept of entropy. Maximum likelihood parameter estimation is discussed in Sect. 8. In Sect. 9, we provide simulation results that evaluate the efficacy of the maximum likelihood estimation strategy. In Sect. 10, we show the flexibility of the new distribution with four examples drawn from actual data. In Sect. 11, we provide some concluding remarks.
2 Odd Kappa-Exponential (OK-E) Distribution
We assume an exponential distribution as the starting point, with the cdf and pdf specified by equations (1) and (2), respectively. In that case, the OK-E cdf, pdf, and hrf are as follows:
where\(\ x>0\) and \(a,b,\lambda ,\beta >0\).

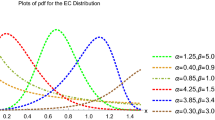
Plots of the pdf and hrf of the OK-E distribution, respectively, for the selected parameter values
Several different pdf types, such as unimodal, monotonically decreasing, symmetrical, and right-skewed, are shown in Fig. 1 to be generated by the OK-E distribution. The hrf shapes produced by this distribution may be constant, monotonically decreasing, increasing, bathtub, upside-down bathtub, or even reversed-J. Therefore, the OK-E distribution may be pretty effective in fitting various data sets.
3 Asymptotics and Shapes
Proposition 1
The asymptotics of cdf, pdf and hrf when \(x\rightarrow 0\) are given by
Proposition 2
The asymptotics of cdf, pdf and hrf when \(x\rightarrow \infty\) are given by
The Shapes of the pdf and hrf can be described analytically. The critical points of the OK-E’s pdf are the roots of the equation:
that corresponds to points where \(f^{\prime }\left( x\right) =0\). There may be more than one root to this equation.
Let \(\tau \left( x\right) =\frac{d^2 \log \left[ f\left( x\right) \right] }{{dx}^2}\). We get
If \(x=c\) is a root of the equation (8) then it refers to a local maximum if \(\tau \left( x\right) >0\) for all \(x<c\) and \(\tau \left( x\right) <0\) for all \(x>c\). In addition, it corresponds to a local minimum if \(\tau \left( x\right) <0\) for all \(x<c\) and \(\tau \left( x\right) >0\) for all \(x>c\). Moreover, it gives an inflexion point if either \(\tau \left( x\right) >0\) for all \(x\ne c\) or \(\tau \left( x\right) <0\) for all \(x\ne c\).
Similarly, the roots of the equation are the critical points of the OK-E’s hrf:
that corresponds to points where \(h^{\prime }\left( x\right) =0\). There may be more than one root to this equation.
Let \(\varphi \left( x\right) =\frac{d^2 \log \left[ h\left( x\right) \right] }{{dx}^2}\). We get
If \(x=d\) is a root of the equation (10) then it corresponds to a local maximum if \(\varphi \left( x\right) >0\) for all \(x<d\) and \(\varphi \left( x\right) <0\) for all \(x>d\). Moreover, it corresponds to a local minimum if \(\varphi \left( x\right) <0\) for all \(x<d\) and \(\varphi \left( x\right) >0\) for all \(x>d\). Furthermore, it refers to an inflexion point if either \(\varphi \left( x\right) >0\) for all \(x\ne d\) or \(\varphi \left( x\right) <0\) for all \(x\ne d\).
Most symbolic computing software platforms, such as Mathematica, Maple, Matlab, SageMath, Maxima, and others, may be used to find the local minimums and maximums, as well as inflexion points, for these equations.
The plots of equations (8)-(11) for the OK-E distribution are shown at (a) through (d) in Fig. 2. We observe that cases (1), (2) and (4) at (a) and (b) in Fig. 2 have \(\frac{d}{dx} \log \left[ f\left( x\right) \right] <0\) which implies f(x) is a decreasing function. However, case (4) starts with concave-up since \(\tau \left( x\right) =\frac{{d}^{2}}{{dx}^{2}} \log \left[ f\left( x\right) \right] >0\) for \(x < c\) then becomes concave-down since \(\tau \left( x\right) =\frac{{d}^{2}}{{dx}^{2}} \log \left[ f\left( x\right) \right] <0\) for \(x > c\) which implies that c is the inflection point and equals 0.5493. Moreover, curves of \(\frac{d}{dx} \log \left[ f\left( x\right) \right]\) in cases (3) and (5) at (a) and (b) in Fig. 2 cut the horizontal axis and \(\tau \left( x\right) =\frac{{d}^{2}}{{dx}^{2}} \log \left[ f\left( x\right) \right] <0\). This implies that f(x) is log-concave and unimodal with the existence of a local maximum equals 0.7815 for case (3) or 1.053 for case (5).
On the other hand, case (1) at (c) and (d) in Fig. 2 has \(\frac{d}{dx} \log \left[ h\left( x\right) \right] <0\) and \(\varphi \left( x\right) =\frac{{d}^{2}}{{dx}^{2}} \log \left[ h\left( x\right) \right] >0\) where this indicates that h(x) is a decreasing and concave up function, respectively. However, case (2) at (c) and (d) in Fig. 2 has \(\frac{d}{dx} \log \left[ h\left( x\right) \right] =0\) implying that h(x) is a constant for all x. Moreover, curves of \(\frac{d}{dx} \log \left[ h\left( x\right) \right]\) in cases (3) and (5) at (c) and (d) in Fig. 2 cut the horizontal axis and \(\varphi \left( x\right) =\frac{{d}^{2}}{{dx}^{2}} \log \left[ h\left( x\right) \right] <0\). In these cases, h(x) is log-concave and unimodal with the existence of a local maximum equals 1.3725 for case (3) or 1.754 for case (5). In addition, h(x) is log-convex with a local minimum equals 0.3155 in case (4) since the curve of \(\frac{d}{dx} \log \left[ h\left( x\right) \right]\) at (c) and (d) in Fig. 2 cuts the horizontal axis and \(\varphi \left( x\right) =\frac{{d}^{2}}{{dx}^{2}} \log \left[ h\left( x\right) \right] >0\).

Plots of the \({1}^{st}\) and \({2}^{nd}\) derivatives of the log of both pdf {(a) & (b)} and hrf {(c) & (d)} for the OK-E distribution, respectively
4 Expansions of Both cdf and pdf of OK-E
In the event that you round off numbers incorrectly, for instance, it might be difficult to determine some mathematical aspects of the OK-E distribution using numerical integration. Therefore, using established algebraic expansions to determine particular characteristics. In most practical situations, we may substitute a big positive integer, say ten or more, for the sum’s “infinite” limit. The following Proposition is derived from [7]’s work, specifically Sect. 5.
Proposition 3
The OK-E distribution’s cdf and pdf may be stated, respectively, as
Proof
Due to space limitations, all proofs have been excluded; nevertheless, interested readers may find them in [7] or by contacting the author personally. \(\square\)
Therefore, the main findings of this study are presented in Proposition 3. Thus, the OK-E distribution’s cdf and pdf may be expressed as an infinite linear combination of exponentiated-exponential cdf and pdf, respectively. The ordinary moments, incomplete moments, and residual life functions, among other mathematical aspects of the proposed distribution, may be derived from Proposition 3. Among others, [32, 47], and [50] address several features of the exp-G distributions.
5 Quantile Function
Proposition 4
The quantile function (qf) of the OK-E distribution is obtained as
where \(\tau \sim \text {uniform}\left( 0,1\right)\).
6 Moments
Several properties of the OK-E distribution are obtained in this section, including the (reversed) residual life, skewness, kurtosis, and ordinary and incomplete moments.
6.1 Ordinary Moments
Proposition 5
The \({r}^{th}\ (r=1,2,...)\) non-central moments of the OK-E distribution is given by
where \(p_{s,0}=1\,\ p_{s,k}=\frac{1}{k}\sum ^k_{m=1}{\left[ m\left( s+1\right) -k\right] \ q_m \ p_{s,k-m}}\ \ and\ \ q_m=\frac{{\left( -1\right) }^m}{m+1}\) and \(w_j\) is defined in equation (14).
Remark 1
The \({s}^{th}\) central moments of the OK-E distribution, say \({\mu }_s\), may be derived using the relationship between non-central and central moments as follows:
where \({\mu }^{\prime }_r\) is defined in Proposition 5. Furthermore, \({\mu }_0={\mu }^{\prime }_0=1\), \({\mu }_1=0\), \({\mu }_2={\mu }^{\prime }_2-{\left( {\mu }^{\prime }_1\right) }^2={\sigma }^2\), \({\mu }_3={\mu }^{\prime }_3-3{\mu }^{\prime }_2{\mu }^{\prime }_1+2{\left( {\mu }^{\prime }_1\right) }^3\), \({\mu }_4={\mu }^{\prime }_4-4{\mu }^{\prime }_3{\mu }^{\prime }_1+6{\mu }^{\prime }_2{\left( {\mu }^{\prime }_1\right) }^2-3{\left( {\mu }^{\prime }_1\right) }^4\), etc.
For some arbitrary choices of the distribution parameters, some numerical values for the mean(\(\mu ={\mu }^{\prime }_1\)) and variance(\({\sigma }^2={\mu }^{\prime }_2-{\left( {\mu }^{\prime }_1\right) }^2\)) of the OK-E(\(a,b,\lambda ,\beta\)) distribution are displayed in Table 1. As the values of the parameters(\(a,\lambda \ and\ \beta\)) increase, it is observed that both the mean and variance decrease. Whereas the values of the parameter(b) increase, the mean and variance increase as well.
6.2 Skewness and Kurtosis
To make skewness and kurtosis independent of data units, it is typically to divide \({\mu }_3\) and \({\mu }_4\) by \({\left( {\mu }_2\right) }^{\left( 3/2\right) }\) and \({\left( {\mu }_2\right) }^2\), respectively. Hence, kurtosis = \({\mu }_4/{\left( {\mu }_2\right) }^2\) and skewness = \({\mu }_3/{\left( {\mu }_2\right) }^{\left( 3/2\right) }\), see [22].
Figure 3 shows the behavior of the skewness and kurtosis of the OK-E(\(a,b,\lambda ,\beta\)) defined in equation (6) with respect to a and \(\lambda\) when \(b =2\) and \(\beta =1\). Based on this Figure, we can infer that changes in the parameters a and \(\lambda\) have a significant influence on the skewness and kurtosis of the OK-E distribution, indicating higher flexibility for OK-E.

Skewness and kurtosis plots for the Odd Kappa-exponential(\(a,b,\lambda ,\beta\)) when \(b =2\) and \(\beta =1\)
The Moors coefficient of kurtosis \(\left( K \right)\) and Bowley coefficient of skewness \(\left( S \right)\) are considered to be robust statistics. These coefficients are, respectively, given as
and
where the three quartiles of the OK-E distribution are defined by \(Q_1=Q_X\left( 1/4;a,b,\lambda ,\beta \right) ,\ Q_2=Q_X\left( 1/2;a,b,\lambda ,\beta \right) =Median(M)\ and\ Q_3=Q_X\left( 3/4;a,b,\lambda ,\beta \right)\) where \(Q_X\left( \cdot \right)\) is defined in equation (15). In addition, the inter-quartile range is given by \(IQR=Q_3-Q_1\).
See [20] and [46] for more details on these coefficients, respectively.
We observe in Table 2 that the effects of \(a,b,\lambda \ and\ \beta\) on the quartiles are significant. The spread of the distribution increases as the value of a, \(\lambda\) or \(\beta\) decreases. However, the spread of the distribution increases as the value of b increases. In addition, we always have moderate variations for K. Furthermore, the distribution is approaching negatively-skewed shape (i.e. \(S<0\)) when all values of the distribution parameters start to be greater than one; otherwise, the shape of the distribution becomes right-skewed.
6.3 Incomplete Moments
Proposition 6
the first incomplete moment of the OK-E distribution is given by
where \(w_j\) is defined in equation (14).
Remark 2
Empirical descriptions of the form of many distributions and measures of inequality, such as the Lorenz and Bonferroni curves, may benefit from incomplete moments. Because of this, the Lorenz and Bonferroni curves (see [25]) are thought to be the most widely utilized inequality indicators in the distribution of income and wealth. The following is the Lorenz curve for a certain probability, \(\pi\):
where
Also, the Bonferroni curve as follows:
Plots of the Lorenz and Bonferroni curves for some parameter values are depicted in Fig. 4.

Lorenz(\(L_X\left( \pi \right)\)) and Bonferroni(\(B_X\left( \pi \right)\)) curves for the Odd Kappa-exponential(\(a,b,\lambda ,\beta\)) for some parameter values
In economics, if \(\pi =F_{X}\left( q\right)\) is the proportion of units with incomes less than or equal to q, \(L_{X}\left( \pi \right)\) gives the proportion of total income volume accumulated by the set of units with an income lower than or equal to q. In a similar manner, the Bonferroni curve \(B_{X}\left( \pi \right)\) calculates the ratio of this group’s mean income to the population’s mean income.
6.4 (Reversed) Residual Life Function
The use of (reversed) residual life random variables is widespread in reliability analysis and risk theory. We propose mean residual life (MRL) and mean waiting time (MWT) as special cases in the following Proposition:
Proposition 7
Let X follows the OK-E distribution then the first moment of residual life of X, say \(M_1\left( t\right) =E\left[ X-t|X>t\right] \ for\ t>0\) and the first moment of reversed residual life of X, say \(M^*_1\left( t\right) =E\left[ t-X|X\le t\right] \ for\ t>0\), uniquely determine \(F\left( x\right)\) (see [51]) are expressed respectively as:
and
Remark 3
The extra life expectancy if a component survives until time t is reflected in the mean residual life (MRL) which is a function of t in equation (21). The following is one interpretation of the MRL: If anything survives this far, what is the estimated length of time for it to live? MRL provides an answer to this query.
Remark 4
The mean waiting time (MWT), which is sometimes referred to as the mean past lifetime, the mean reversed residual life function, or the mean inactivity time (MIT), may be expressed as follows in equation (22): Think about the following situation: We have discovered that a device has malfunctioned at some point in the past, let’s say t. When estimating the precise moment of a device breakdown, the MWT is a valuable metric. In biomedicine, the length of a patient’s remission, or disease-free survival time, is used to evaluate how effective a treatment is while dealing with recurrent diseases. The actual size of the remission is often uncertain since it takes a significant amount of money and time to maintain constant patient monitoring. In such cases, the real remission time may be estimated using a MWT function.
For some arbitrary choices of the OK-E distribution parameters at the time points \(t=1,\ 2,\ 3\) and 5, some numerical values for the mean residual life and the mean waiting time of the Odd Kappa-Exponential(\(a,b,\lambda ,\beta\)) distribution are, respectively, displayed in Tables 3 and 4. As the values of the parameters(\(a,b,\ \lambda\) and \(\beta\)) become smaller than one, it is observed in Table 3 that the mean residual life increases with increasing the time points t. However, the mean residual life decreases with increasing the time points t as the values of the parameters(\(a,b,\ \lambda\) and \(\beta\)) become equal or greater than one. On the other hand, Table 4 shows that the mean waiting time increases with increasing the time points t as the values of the parameters(\(a,b,\ \lambda\) and \(\beta\)) increase.
7 Entropy
Entropy is a measure of unpredictability or randomness used in many research fields, including engineering, hydrology, statistical mechanics, physics, molecular imaging of cancer, and sparse kernel density estimation. The Rényi entropy ( [54]) and the Shannon entropy ( [58]) are two standard entropy metrics. Creating a Rényi entropy expression is important because it allows one to compare the shapes and tails of many widely used densities and characterize the shape of a distribution (see [59] for more information).
Proposition 8
The Rényi entropy for the OK-E distribution is given by
where \(\delta>0\,\ \delta \ne 1 \, \ \omega \left( i,j\right) ={\left( -1\right) }^{i+j}\ {\lambda }^{\delta }\ {a }^{\left( \delta +i\right) } \ {\frac{\delta }{a} \atopwithdelims ()i} \ {-\delta \atopwithdelims ()j} \, \ j+ka\lambda +1>\delta \ >ka\lambda\), and \(Beta\left( s,t\right) =\int ^1_0{u^{s-1}\ {\left( 1-u\right) }^{t-1}}du\) for \(s>0\ and\ t>0\).
The Shannon entropy is a special case of the Rényi entropy in Proposition 8 when \(\delta \rightarrow 1\).
Proposition 9
The Shannon entropy for the OK-E distribution is given by
where \(a\lambda t<1 \, \ \psi \left( x\right) =\frac{d \log \left[ \Gamma \left( x\right) \right] }{dx}\) is the psi function or the digamma function which is the logarithmic derivative of the gamma function and \(w_j\) is defined in equation (14).
Some numerical values for the Rényi and Shannon entropies of the OK-E(\(a,b,\lambda ,\beta\)) distribution for some several choices of the distribution parameters are displayed in Table 5. We observe that the model parametrs have an important impact on the amount of information quantified by the entropy. Therefore, both the Rényi and Shannon entropies decrease as the values of the parameter(\(\beta\)) increase. Moreover, the Shannon entropy decreases as the values of the parameters(\(a \ or\ \lambda\)) increase. Whereas the values of the parameter(b) increase, both the Rényi and Shannon entropies increase, too. However, the Rényi entropy increases as the values of the parameter(a) increase toward 0.7 then it starts to decrease as the values of the parameter(a) become greater than 0.7 (holding \(b=0.5,\ \lambda =1\ and\ \beta =3\)). Similarly, the Rényi entropy increases as the values of the parameter(\(\lambda\)) increase toward 1.5 then it starts to decrease as the values of the parameter(\(\lambda\)) become greater than 1.5 (holding \(a=0.5,\ b=1\ and\ \beta =3\)). Some values of the entropy are negatives which may be interpreted as loss of information (see [56] and [16]).
8 Estimation
The most popular technique for estimating parameters is the maximum likelihood approach (see [22]). In this part, we use complete samples to get the maximum likelihood estimates (MLEs) of the unknown parameters in the OK-E distribution. Let \(x={\left( x_1,\dots ,x_n\right) }^T\) be a random sample of size n from the OK-E distribution with parameters a, b, \(\lambda\), and \(\beta\). Let the \(\mathrm {p\times 1}\) parameter vector be \(\varvec{\xi }\mathrm {=}{\left( a \mathrm {,\ }b,\lambda \mathrm {,\ }{\beta }\right) }^{\textrm{T}}\). The total log-likelihood function for \(\varvec{\xi }\) is \({\ell }_n={\ell }_n\left( \varvec{\xi }\right) =\sum ^n_{i=1}{{\ell }^{\left( i\right) }}\), where \({\ell }^{\left( i\right) }\) is the log likelihood for the ith observation (\(i=1,\dots ,n\)). Then, \({\ell }_n\) is given by
In order to maximize \({\ell }_n\), we must differentiate equation (24) and then solve the resulting nonlinear likelihood equations. However, it is not possible to solve these equations analytically. Because of this, they may be solved by statistical software employing iterative techniques like Newton-type algorithms. A few examples include the MaxBFGS in Ox (see [26]), the PROC NLMIXED Procedure in SAS/STAT (see [57]), and optim in R (see [53]).
The components of the score function \(U_n\left( \varvec{\xi }\right) ={\left( U_{a },\ U_{b },\ U_{\lambda },\ U_{\beta }\right) }^T=\) \({\left( \mathrm {\partial }{\ell }_n/\partial a \mathrm {,\ }\mathrm {\partial }{\ell }_n/\partial b \mathrm {,\ }\mathrm {\partial }{\ell }_n/\partial \lambda \textrm{,}\mathrm {\partial }{\ell }_n/\partial \beta \right) }^{\textrm{T}}\) are
Solving the equations \(U_n\left( \varvec{\xi }\right) ={\left( U_{a },\ U_{b },\ U_{\lambda },\ U_{\beta }\right) }^T=\textbf{0}\) simultaneously gives the maximum likelihood estimate (MLE) \(\widehat{\varvec{\xi }}\mathrm {=}{\left( {\widehat{a}},{\widehat{b}},\widehat{\lambda },{\widehat{\beta }}\right) } ^{\textrm{T}}\) of \(\varvec{\xi }\mathrm {=}{\left( a, b,\lambda ,\beta \right) }^{\textrm{T}}\).
The Fisher information matrix must be constructed to test hypotheses and provide parameter interval estimates, which may be done by utilizing the second partial derivatives of the log-likelihood function about each parameter (see 1). For parameter MLEs, the asymptotic variance-covariance matrix may be obtained by inverting the Fisher information matrix. This procedure’s evaluation might be challenging at times. Therefore, it may be estimated using the observed Fisher’s information matrix.
9 Simulation
We may evaluate the Odd Kappa-Exponential MLEs in terms of their performance as a function of sample size n by using these steps:
-
1.
Generate \(B=10000\) samples of size n by using the inversion method to get \(x_{\tau }=\frac{1}{\beta } \log \left[ 1+b {\left[ \frac{a \ {\tau }^{a }}{1-{\tau }^{a }}\right] }^{\left( \frac{1}{a\lambda }\right) }\right]\) where \(\tau\) is uniform(0,1) (see Proposition 4).
-
2.
Compute the MLEs for the B samples, say \({\widehat{\xi }}_i={{\widehat{a}}}_i,{{\widehat{b}}}_i,{\widehat{\lambda }}_i,{{\widehat{\beta }}}_i\) for \(i=1,\dots ,B\).
-
3.
Compute the standard errors of the MLEs by inverting the observed information matrices for the B samples, say \({se}_{{{\widehat{\xi }}}_i}\) for \(i=1,\dots ,B\).
-
4.
Compute the biases and the mean squared errors given by Bias(\({\widehat{\xi }}\))=\(\mathrm {\ }\frac{\textrm{1}}{\textrm{B}}\sum ^{\textrm{B}}_{\mathrm {i=1}}{\left( {\widehat{\xi }}_{\textrm{i}}\mathrm {-}\xi \right) }\) and MSE(\(\widehat{\xi }\))= \(\frac{\textrm{1}}{\textrm{B}}\sum ^{\textrm{B}}_{\mathrm {i=1}}{{\left( {\widehat{\xi }}_{\textrm{i}}\mathrm {-}\xi \right) }^{\textrm{2}}}\) Also, \(\overline{\widehat{\xi }}\mathrm {=}\frac{\textrm{1}}{\textrm{B}}\sum ^{\textrm{B}}_{\mathrm {i=1}}{{\widehat{\xi }}_{\textrm{i}}}\) where \(\xi =a,b,\lambda ,\beta\).
-
5.
Repeat steps(1-4) for the combinations of n and \(\xi\).
Table 6 gives empirical findings on the performance of model parameters, and from these results, we learn the following:
-
Biases decrease as sample size increases.
-
MSE decreases as sample size increases.
-
As sample sizes increases, estimates of model parameters are closer to true values.
10 Applications
This section examines the fitting of competing models and the odd Kappa-Exponential (OK-E) to four actual data sets. The first data set that is explained below and examined by [52, 34], and [45] provides the reason for selecting almost all of these competing models, as seen in Table 7. The exponential and attractive Weibull models are added to Table 7. Therefore, the thirteen selected models presented in Table 7 are: exponential(Exp(\(\beta\))), gamma(\(\alpha ,\beta\)), log-normal(lognormal(\(\alpha ,\beta\))) and weibull(\(\alpha ,\beta\)) distributions, one-parameter Kappa(Kappa1(\(\alpha\))), two-parameter Kappa(Kappa2 (\(\alpha ,\beta\))) and three-parameter Kappa(Kappa3(\(\alpha ,\beta ,\theta\))) distributions, exponentiated Kappa Lehmann type I (EK-L1(\(a,\alpha ,\beta ,\theta\))) and exponentiated Kappa Lehmann type II (EK-L2(\(b,\alpha ,\beta ,\theta\))) distributions, Marshall-Olkin Kappa(MOK (\(\lambda ,\alpha ,\beta ,\theta\))) distribution, Kumaraswamy generalized Kappa(KGK (\(a,b,\alpha ,\beta ,\theta\))), exponentiated generalized Kappa(EGK (\(b,\lambda ,\alpha ,\beta ,\theta\))) and McDonald generalized Kappa(McGK (a,b,\(\lambda\),\(\alpha\),\(\beta\),\(\theta\))) distributions.
To compare these models, the estimated negative log-likelihood values (\(-l\left( \cdot \right)\)), goodness of fit statistics based on empirical distribution function (Kolmogorov-Smirnov(KS), Anderson-Darling(A\({}^{*}\)), Cramer–von-Mises(W\({}^{*}\)), and Sum of Squares(SS)), and goodness of fit statistics based on information criteria (AIC, AICc, cAIC, BIC, and HQIC) will be used. Based on goodness-of-fit statistics across four actual data sets, these competitive models will be compared against the Odd Kappa-Exponential (OK-E(\(a,b,\lambda ,\beta\))).
Typically, the best model is characterized by possessing the highest p-value in KS and lower values for the \(-l\left( \cdot \right)\), AIC, AICc, cAIC, BIC, SS, W\({}^{*}\), A\({}^{*}\) and KS. All calculations are derived using the R program ( [53]).
10.1 Data Set 1: Stream Flow Amounts Data
The data set pertains to environmental or geological information and comprises 35 stream flow quantities (measured in 1000 acre-feet). These observations were gathered between 1936 and 1970 from the surface water records maintained by the US Geological Survey (USGS), specifically from the gaging station identified as 9-3425. The data obtained corresponds to the period spanning from April 1st to August 31st of each year (see [44]). This data set was also investigated by [34, 45], and [52]. For convenience, the data are 192.48, 303.91, 301.26, 135.87, 126.52, 474.25, 297.17, 196.47, 327.64, 261.34, 96.26, 160.52, 314.6, 346.3, 154.44, 111.16, 389.92, 157.93, 126.46, 128.58, 155.62, 400.93, 248.57, 91.27, 238.71, 140.76, 228.28, 104.75, 125.29, 366.22, 192.01, 149.74, 224.58, 242.19, 151.25.
The estimated values and their corresponding standard errors, included in parentheses, may be found in Table 8 for the parameters of the OK-E distribution and the competitive models. Table 9 presents the lowest values of the negative log-likelihood function \(-l\left( \cdot \right)\) and the goodness of fit statistics derived from both information criteria and the empirical distribution function. These values are obtained for all distributions examined using the first data set. In the study conducted by [34], the Anderson-Darling (A\({}^{*}\)) and Cramer–von-Mises (W\({}^{*}\)) statistics were used as metrics to assess the relative performance of different distributions. Other researchers in reputable scientific publications widely adopt this approach. By employing the same measures, as well as the negative log-likelihood function \(-l\left( \cdot \right)\), the sum of squares (SS), and the Kolmogorov-Smirnov (KS) statistic along with its corresponding p-value, it becomes evident that the OK-E distribution exhibits the lowest values for \(-l\left( \cdot \right)\), SS, W\({}^{*}\), A\({}^{*}\), and KS, as well as the highest p-value when compared to the other distributions listed in Table 9.
The total time on the test (TTT) and hrf plots are shown in Fig. 5. For more comprehensive information on using the TTT plot in data analysis, please see reference [1]. The concave shape of the TTT curve is seen in both graphs shown in Fig. 5, supporting the suitability of a monotonic increasing hrf, as suggested by [1]. Therefore, it can be concluded that the OK-E distribution is a suitable model for accurately representing this particular data set.

Empirical and fitted scaled TTT-transforms and hrf for the first data set, respectively
To demonstrate the existence of a singular solution in the parameters, we generate profile log-likelihood plots for the parameters of the OK-E distribution using the provided dataset. Figure 6 provides empirical evidence supporting the model’s distinctive characteristics under consideration.

The log-likelihood as a function of parameters of OK-E for the first data set
The relative histogram with the fitted densities and the empirical with the fitted distribution functions are shown in Fig. 7, respectively. The plots confirm the findings in Table 9 and show that the OK-E distribution is the best-fitting model out of all the models considered.

Plots of Estimated cdfs and pdfs for the first data set, respectively
As a result, the following is the estimated variance-covariance matrix for the OK-E\((a, b, \lambda , \beta )\) distribution:
The \(95\%\) confidence intervals for a, b, \(\lambda\), and \(\beta\) are \([0,\mathrm{3.518907\times }{10}^{-5}]\), [0, 3.9661], [0, 444973.9698], and [0, 0.0117], respectively.
The LR test statistic for testing \(H_0: OK-E(1,1,1,\beta ) \equiv Exp(\beta )\) against \(H_1: OK-E(a,b,\lambda ,\beta )\) is 34.3124 with the associated p-value = \(\mathrm{1.702032\times }{10}^{-7}\). Therefore, it is concluded that there is strongly significant difference between \(OK-E(a,b,\lambda ,\beta )\) and \(Exp(\beta )\) distributions.
The last three data sets, which will be discussed next, demonstrate the adaptability of OK-E as a member of this family of distributions and the effectiveness of our model (OK-E) in contrast to the other models listed in Table 7.
10.2 Data Set 2: Failure Times of 50 Components y
The provided data set pertains to electrical engineering and includes 50 observations about the failure times of 50 components measured per 1000 h. This information may be found in [48], page 180. [43, 15] and [28] also investigated this data collection. The data are 0.036, 0.058, 0.061, 0.074, 0.078, 0.086, 0.102, 0.103, 0.114, 0.116, 0.148, 0.183, 0.192, 0.254, 0.262, 0.379, 0.381, 0.538, 0.570, 0.574, 0.590, 0.618, 0.645, 0.961, 1.228, 1.600, 2.006, 2.054, 2.804, 3.058, 3.076, 3.147, 3.625, 3.704, 3.931, 4.073, 4.393, 4.534, 4.893, 6.274, 6.816, 7.896, 7.904, 8.022, 9.337, 10.940, 11.020, 13.880, 14.730, 15.080.
The table labeled "Table 10" presents the estimates and their corresponding standard errors in parentheses for the parameters of the OK-E distribution and the competitive models. Table 11 displays the lowest values of the negative log-likelihood function \(-l\left( \cdot \right)\), the goodness of fit statistics derived from the information criterion, and the empirical distribution function. Among all measures except cAIC, it is evident that the OK-E distribution exhibits the highest p-value for the KS. Additionally, the \(-l\left( \cdot \right)\), AIC, AICc, BIC, SS, W\({}^{*}\), A\({}^{*}\), and KS values for the OK-E distribution are comparatively less than those of the other distributions shown in Table 11. Hence, this model is deemed the most suitable for accurately representing the given data set. In contrast, it is worth noting that the remaining data sets consistently prefer the OK-E distribution across all measures without any exceptions, as will be shown subsequently.
The total time on the test (TTT) and hrf graphs are shown in Fig. 8. Figure 8 displays two charts that demonstrate the convexity of the TTT curve, suggesting that a hrf that decreases monotonically is sufficient. Due to the aforementioned reasons, the OK-E distribution may be considered a suitable model for the present data set.

Empirical and fitted scaled TTT-transforms and hrf for the second data set, respectively
To demonstrate the existence of only one solution in the parameters, we provide a graphical representation of the profile log-likelihood functions for the parameters associated with the OK-E distribution in the second data set. Figure 9 provides evidence supporting the uniqueness of the parameters within our model.

The log-likelihood as a function of parameters of OK-E for the second data set
Figure 10 displays the relative histogram with the fitted densities and the empirical with the fitted distribution functions. Therefore, the plots demonstrate that the OK-E distribution is the most suitable model among all the models under consideration, aligning with the findings in Table 11.

Plots of Estimated cdfs and pdfs for the second data set, respectively
Hence, the variance-covariance matrix for the OK-E\((a, b, \lambda , \beta )\) distribution may be expressed as:
The \(95\%\) confidence intervals for a, b, \(\lambda\), and \(\beta\) are \([0,\mathrm{1.061779\times }{10}^{-5}]\), [0, 0.8237], [0, 3615971.3572], and [0.1539, 0.8279], respectively.
The LR test statistic for testing \(H_0: OK-E(1,1,1,\beta ) \equiv Exp(\beta )\) against \(H_1: OK-E(a,b,\lambda ,\beta )\) is 25.5144 with the associated p-value = \(\mathrm{1.205227\times }{10}^{-5}\). Therefore, it may be inferred that there is a considerable difference in the distributions of \(OK-E(a,b,\lambda ,\beta )\) and \(Exp(\beta )\).
10.3 Data Set 3: Gross Domenstic Product Data
The provided dataset consists of 196 observations, including the gross domestic product (GDP) per capita of various nations worldwide in 2007. The World Bank facilitated the initial dissemination of this data via their database at http://data.worldbank.org/data-catalog/world-development-indicators. In addition, the R program ( [53]) offers a convenient means of acquiring the necessary information. This may be achieved by using the “gdp” data frame, which is included inside the R package “rpanel” ( [21]) and consists of 216 rows and 48 columns.
Table 12 presents the estimated parameters of the OK-E distribution and the competitive model and their corresponding standard errors included in parentheses. Table 13 displays the lowest values of the negative log-likelihood function \(-l\left( \cdot \right)\) for each distribution applied to the third data set. Additionally, the table includes goodness-of-fit statistics derived from information criteria and the empirical distribution function. Upon comparing the OK-E distribution with the other distributions listed in Table 13, it becomes evident that the former exhibits the highest p-value for the KS and the lowest values for the \(-l\left( \cdot \right)\), AIC, AICc, cAIC, BIC, SS, W\({}^{*}\), A\({}^{*}\), and KS metrics. This implies that the model under consideration is the most suitable choice for the given data set.
Figure 11 illustrates the hrf plots and the total time on the test (TTT). Both graphs shown in Fig. 11 demonstrate that the TTT curve has a convex form, providing more support for the notion that a nearly monotonically increasing or unimodal hrf is satisfactory. The OK-E distribution may suitably characterize the data collection.

Empirical and fitted scaled TTT-transforms and hrf for the third data set, respectively
Based on the third data set, the profile log-likelihood functions of the parameters of the OK-E distribution demonstrate that the likelihood equations possess a singular solution for the parameters. Figure 12 provides evidence of the parameters’ uniqueness in the OK-E model.

The log-likelihood as a function of parameters of OK-E for the third data set
Figure 13 shows the fitted distribution functions on the empirical and the fitted densities on the relative histogram. In line with the findings in Table 13, the plots demonstrate that the OK-E distribution provides the most excellent overall fit.

Plots of Estimated cdfs and pdfs for the third data set, respectively
Given this, we can write down the OK-E\((a, b, \lambda , \beta )\) distribution’s estimated variance-covariance matrix as
The \(95\%\) confidence intervals for a, b, \(\lambda\), and \(\beta\) are \([0,\mathrm{9.411654\times }{10}^{-5}]\), [0.0511, 0.2167], [0, 995056.467], and \([\mathrm{3.028068\times }{10}^{-5},\mathrm{7.934854\times }{10}^{-5}]\), respectively.
With a p-value of 0, the LR test statistic for comparing \(H_0: OK-E(1,1,1,\beta ) \equiv Exp(\beta )\) against \(H_1: OK-E(a,b,\lambda ,\beta )\) is 122.416. Therefore, we infer that the \(OK-E(a,b,\lambda ,\beta )\) and \(Exp(\beta )\) distributions are distinct from one another in a very significant way.
10.4 Data Set 4: Carbon Dioxide Data
The following dataset provides 196 observations of carbon dioxide (CO2) emissions, measured in metric tons per capita, for nations worldwide in 2003. Carbon dioxide (CO2) emissions are primarily generated via the production of cement and the combustion of fossil fuels. The emissions include carbon dioxide (CO2) generated from the combustion of gaseous, liquid, and solid fuels, as well as the process of gas flaring. The World Bank facilitated the initial provision of this data through the database accessible at http://data.worldbank.org/data-catalog/world-development-indicators. Moreover, the “co2.emissions” data frame, including 216 rows and 48 columns, may be readily accessed from the R program ( [53]) under the “rpanel” package ( [21]).
The parameter estimates and their corresponding standard errors for the OK-E distribution and the competitive models are shown in Table 14. Table 15 presents the lowest values of the negative log-likelihood function \(-l\left( \cdot \right)\) and goodness of fit statistics derived from information criteria and the empirical distribution function for all the investigated distributions under study on the fourth data set. After considering all metrics, it becomes evident that the OK-E distribution exhibits the highest p-value for the KS while displaying lowest values for the \(-l\left( \cdot \right)\), AIC, AICc, cAIC, BIC, SS, W\({}^{*}\), A\({}^{*}\), and KS in comparison to the other distributions shown in Table 15. Hence, it can be concluded that this model is the most optimal choice for accurately representing the given data set.
In this study, we offer empirical and fitted scaled TTT-transforms and hrf plots for the fourth data set, as seen in Fig. 14. Both figures demonstrate that the TTT curve is convex, proving that a monotonically declining hrf is appropriate. Hence, it can be concluded that the OK-E distribution is an approach suitable for fitting the given data set.

Empirical and fitted scaled TTT-transforms and hrf for the fourth data set, respectively
The profile log-likelihood functions of the parameters of the OK-E distribution for the fourth data set are shown in Fig. 15. This display demonstrates that the likelihood equations possess a unique solution in the parameters. Therefore, Fig. 15 provides evidence of the uniqueness in the parameter support for our OK-E model.

The log-likelihood as a function of parameters of OK-E for the fourth data set
The figure labeled 16 displays the empirical with the fitted distribution functions and the relative histogram with the fitted densities, respectively. The plots effectively illustrate that the OK-E distribution is the most suitable model among the several competing models, hence corroborating the findings shown in Table 15.

Plots of Estimated cdfs and pdfs for the fourth data set, respectively
Therefore, the estimated variance covariance matrix for the OK-E\((a, b, \lambda , \beta )\) distribution is given by:
The \(95\%\) confidence intervals for a, b, \(\lambda\), and \(\beta\) are [0, 0.0099], [0.1785, 1.1924], [0, 346.7002], and [0.2808, 0.5765], respectively.
The LR test statistic for testing \(H_0: OK-E(1,1,1,\beta ) \equiv Exp(\beta )\) against \(H_1: OK-E(a,b,\lambda ,\beta )\) is 50.7044 with the associated p-value = \(\mathrm{5.655454\times }{10}^{-11}\). Hence, it is concluded that there is very strongly significant difference between \(OK-E(a,b,\lambda ,\beta )\) and \(Exp(\beta )\) distributions.
11 Concluding Remarks
This research study presents a novel and adaptable distribution known as the Odd Kappa-Exponential (OK-E) distribution. This paper presents an introduction to certain mathematical features of the OK-E distribution. Through empirical evidence, we have established that this probability distribution may effectively simulate a diverse range of heavy-tailed, skewed, and extreme datasets across several domains. The OK-E model has proven to be a valuable tool for analyzing environmental, engineering, and economic data frequently encountered in practical scenarios. Hence, we use four real data sets to provide empirical evidence of the efficacy of our novel flexible distribution from this particular family compared to other existing models documented in the literature. In subsequent investigations, more distributions belonging to this specific family will be explored in the context of complete and censored data.
Data Availibility Statement
All data sets analyzed during this study are included in this article and no materials used.
Abbreviations
- pdf:
-
Probability density function
- cdf:
-
Cumulative distribution function
- sf:
-
Survival function
- hrf:
-
Hazard rate function
- AIC:
-
Akaike information criterion
- BIC:
-
Bayesian information criterion
- CAIC:
-
Consistent Akaike Information Criterion
- HQIC:
-
Hannan–Quinn information criterion
- CM:
-
Cramer–von Mises
- AD:
-
Anderson-Darling
- KS:
-
Kolmogorov-Smirnov
- mgf:
-
Moment generating function
- MLEs:
-
Maximum likelihood estimators
- MSE:
-
Mean square error
- OLS:
-
Ordinary least square
- pwm:
-
Probability weighted moment
References
Aarset, M.V.: How to identify a bathtub hazard rate. IEEE Trans. Reliab. R–36(1), 106–108 (1987). https://doi.org/10.1109/TR.1987.5222310
Abd El-Raheem, A.: Optimal design of multiple constant-stress accelerated life testing for the extension of the exponential distribution under type-ii censoring. J. Comput. Appl. Math. 382, 113094 (2021). https://doi.org/10.1016/j.cam.2020.113094
Adil Hussain, S., Ahmad, I., Saghir, A., Aslam, M., Almanjahie, I.M.: Mean ranked acceptance sampling plan under exponential distribution. Ain Shams Eng. J. (2021). https://doi.org/10.1016/j.asej.2021.03.008
Ahsanullah, M., Hamedani, G.: Exponential Distribution: Theory and Methods. Mathematics research developments. Nova Science Publishers (2010). https://books.google.com.sa/books?id=BkcRRgAACAAJ
Al-Hussaini, E.K., Ahsanullah, M.: Exponentiated Distributions. Springer, Berlin (2015)
Al-Shomrani, A.A.: New generalizations of extended beta and hypergeometric functions. Far East J. Theor. Stat. 54(4), 381–406 (2018). https://doi.org/10.17654/ts054040381
Al-Shomrani, A.A., Al-Arfaj, A.J.: A new flexible odd kappa-G family of distributions: theory and properties. Adv. Appl. Math. Sci. 21(1), 3443–3514 (2021)
Al-Shomrani, A.A., Arif, O.H., Shawky, A.I., Hanif, S., Shahbaz, M.Q.: Topp-Leone family of distributions: some properties and application. Pak. J. Stat. Oper. Res. 12(3), 443–451 (2016). https://doi.org/10.18187/pjsor.v12i3.1458
Alexander, C., Cordeiro, G.M., Ortega, E.M., Sarabia, J.M.: Generalized beta-generated distributions. Comput. Stat. Data Anal. 56(6), 1880–1897 (2012). https://doi.org/10.1016/j.csda.2011.11.015
Aljarrah, M.A., Lee, C., Famoye, F.: On generating T-X family of distributions using quantile functions. J. Stat. Distrib. Appl. 1(1), 1–17 (2014). https://doi.org/10.1186/2195-5832-1-2
Alzaatreh, A., Lee, C., Famoye, F.: A new method for generating families of continuous distributions. METRON 71(1), 63–79 (2013). https://doi.org/10.1007/s40300-013-0007-y
Alzaatreh, A., Lee, C., Famoye, F.: T-normal family of distributions: a new approach to generalize the normal distribution. J. Stat. Distrib. Appl. 1(1), 1–18 (2014). https://doi.org/10.1186/2195-5832-1-16
Alzaghal, A., Famoye, F., Lee, C.: Exponentiated T-X family of distributions with some applications. Int. J. Stat. Probab. 2(3), 31–49 (2013). https://doi.org/10.5539/ijsp.v2n3p31
Amini, M., MirMostafaee, S.M., Ahmadi, J.: Log-gamma-generated families of distributions. Statistics 48(4), 913–932 (2014). https://doi.org/10.1080/02331888.2012.748775
Aryal, G., Elbatal, I.: On the exponentiated generalized modified Weibull distribution. Commun. Stat. Appl. Methods 22(4), 333–348 (2015). https://doi.org/10.5351/CSAM.2015.22.4.333
Bakouch, H.S., Abd El-Bar, A.M.T.: A new weighted Gompertz distribution with applications to reliability data. Appl. Math. 62(3), 269–296 (2017). https://doi.org/10.21136/AM.2017.0277-16
Balakrishnan, K.: Exponential Distribution: Theory, Methods and Applications. Routledge, London (2019)
Bentoumi, R., El Ktaibi, F., Mesfioui, M.: A new family of bivariate exponential distributions with negative dependence based on counter-monotonic shock method. Entropy 23(5), 1–17 (2021). https://doi.org/10.3390/e23050548
Bourguignon, M., Silva, R.B., Cordeiro, G.M.: The Weibull-G family of probability distributions. J. Data Sci. 12(1), 53–68 (2014)
Bowley, A.L.: Elements of Statistics, vol. 2. PS King, London (1920)
Bowman, A., Crawford, E., Alexander, G., Bowman, R.W.: rpanel: simple interactive controls for r functions using the tcltk package. J. Stat. Softw. 17(1), 1–18 (2007)
Casella, G., Berger, R.: Statistical Inference, 2nd edn. Thomson Learning, Australia (2002)
Cordeiro, G.M., Alizadeh, M., Ortega, E.M.M.: The exponentiated half-logistic family of distributions: properties and applications. J. Probab. Stat. 2014, 1–22 (2014). https://doi.org/10.1155/2014/864396
Cordeiro, G.M., de Castro, M.: A new family of generalized distributions. J. Stat. Comput. Simul. 81(7), 883–898 (2011). https://doi.org/10.1080/00949650903530745
Dagum, C.: Specification and Analysis of Wealth Distribution Models with Applications, pp. 8–12. Business and Economic Statistic Section, American Statistical Association (2004)
Doornik, J.A.: An Object-Oriented Matrix Programming Language Ox 6. (2009)
Eghwerido, J.T., Nzei, L.C., Zelibe, S.C.: The alpha power extended generalized exponential distribution. J. Stat. Manag. Syst. (2021). https://doi.org/10.1080/09720510.2021.1872692
Eissa, F.H.: The exponentiated Kumaraswamy-Weibull distribution with application to real data. Int. J. Stat. Probab. 6(6), 167–182 (2017). https://doi.org/10.5539/ijsp.v6n6p167
Eugene, N., Lee, C., Famoye, F.: Beta-normal distribution and its applications. Commun. Stat. Theory Methods 31(4), 497–512 (2002). https://doi.org/10.1081/STA-120003130
Famoye, F., Lee, C., Alzaatreh, A.: Some recent developments in probability distributions. In: Proceedings of the 59th World Statistics Congress (2013). https://www.statistics.gov.hk/wsc/STS084-P3-S.pdf
Gompertz, B.: On the nature of the function expressive of the law of human mortality and on a new mode of determining the value of life contingencies. Philos. Trans. R. Soc. Lond. 115, 513–583 (1825). https://doi.org/10.1098/rstl.1825.0026
Gupta, R.C., Gupta, P.L., Gupta, R.D.: Modeling failure time data by Lehman alternatives. Commun. Stat. Theory Methods 27(4), 887–904 (1998). https://doi.org/10.1080/03610929808832134
Hussain, S.: Properties, extension and application of kappa distribution (m. phil thesis). Government College University, Faisalabad, Pakistan (2015)
Javed, M., Nawaz, T., Irfan, M.: The Marshall-Olkin kappa distribution: properties and applications. J. King Saud Univ. Sci. 31(4), 684–691 (2019). https://doi.org/10.1016/j.jksus.2018.01.001
Johnson, N.L., Kotz, S., Balakrishnan, N.: Continuous Univariate Distributions, vol. 1, 2nd edn. Wiley, New York (1994)
Jones, M.: Kumaraswamyś distribution: a beta-type distribution with some tractability advantages. Stat. Methodol. 6(1), 70–81 (2009). https://doi.org/10.1016/j.stamet.2008.04.001
Jones, M.C.: On families of distributions with shape parameters. Int. Stat. Rev. 83(2), 175–192 (2015). https://doi.org/10.1111/insr.12055
Kumaraswamy, P.: A generalized probability density function for double-bounded random processes. J. Hydrol. 46(1), 79–88 (1980). https://doi.org/10.1016/0022-1694(80)90036-0
Lee, C., Famoye, F., Alzaatreh, A.Y.: Methods for generating families of univariate continuous distributions in the recent decades. WIREs Comput. Stat. 5(3), 219–238 (2013). https://doi.org/10.1002/wics.1255
Lemonte, A.J., Barreto-Souza, W., Cordeiro, G.M.: The exponentiated Kumaraswamy distribution and its log-transform. Braz. J. Probab. Stat. 27(1), 31–53 (2013). https://doi.org/10.1214/11-BJPS149
Mahdavi, A., Kundu, D.: A new method for generating distributions with an application to exponential distribution. Commun. Stat. Theory Methods 46(13), 6543–6557 (2017). https://doi.org/10.1080/03610926.2015.1130839
Marshall, A.W., Olkin, I.: A new method for adding a parameter to a family of distributions with application to the exponential and Weibull families. Biometrika 84(3), 641–652 (1997). https://doi.org/10.1093/biomet/84.3.641
Merovci, F., Elbatal, I.: The Mcdonald modified Weibull distribution: properties and applications (2013). https://arxiv.org/abs/1309.2961
Mielke, P.W.: Another family of distributions for describing and analyzing precipitation data. J. Appl. Meteorol. Climatol. 12(2), 275–280 (1973). https://doi.org/10.1175/1520-0450(1973)012<0275:AFODFD>2.0.CO;2
Mielke, P.W., Johnson, E.S.: Three-parameter kappa distribution maximum likelihood estimates and likelihood ratio tests. Mon. Weather Rev. 101(9), 701–707 (1973). 10.1175/1520-0493(1973)101<0701:TKDMLE>2.3.CO;2
Moors, J.J.A.: A quantile alternative for kurtosis. J. R. Stat. Soc. Ser. D (Stat.) 37(1), 25–32 (1988). https://doi.org/10.2307/2348376
Mudholkar, G., Srivastava, D.: Exponentiated Weibull family for analyzing bathtub failure-rate data. IEEE Trans. Reliab. 42(2), 299–302 (1993). https://doi.org/10.1109/24.229504
Murthy, D.P., Xie, M., Jiang, R.: Weibull Models, vol. 505. Wiley, New York (2004)
Nadarajah, S., Kotz, S.: Moments of some j-shaped distributions. J. Appl. Stat. 30(3), 311–317 (2003). https://doi.org/10.1080/0266476022000030084
Nadarajah, S., Kotz, S.: The exponentiated type distributions. Acta Applicandae Mathematica 92(2), 97–111 (2006). https://doi.org/10.1007/s10440-006-9055-0
Navarro, J., Franco, M., Ruiz, J.: Characterization through moments of the residual life and conditional spacings. Sankhya A 60(3), 36–48 (1998)
Nawaz, T., Hussain, S., Ahmad, T., Naz, F., Abid, M.: Kumaraswamy generalized kappa distribution with application to stream flow data. J. King Saud Univ. Sci. 32(1), 172–182 (2020). https://doi.org/10.1016/j.jksus.2018.04.005
R Core Team: R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria (2020). https://www.R-project.org/
Rényi, A.: On measures of entropy and information. In: Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, pp. 547–561. University of California Press (1961)
Ristić, M.M., Balakrishnan, N.: The gamma-exponentiated exponential distribution. J. Stat. Comput. Simul. 82(8), 1191–1206 (2012). https://doi.org/10.1080/00949655.2011.574633
Saboor, A., Bakouch, H.S., Nauman Khan, M.: Beta Sarhan-Zaindin modified Weibull distribution. Appl. Math. Model. 40(13), 6604–6621 (2016). https://doi.org/10.1016/j.apm.2016.01.033
SAS, S.A.S.I.: The sas system for windows. release 9.0 (2002)
Shannon, C.E.: A mathematical theory of communication. SIGMOBILE Mob. Comput. Commun. Rev. 5(1), 3–55 (2001). https://doi.org/10.1145/584091.584093
Song, K.S.: Rényi information, loglikelihood and an intrinsic distribution measure. J. Stat. Plan. Infer. 93(1), 51–69 (2001). https://doi.org/10.1016/S0378-3758(00)00169-5
Tahir, M.H., Cordeiro, G.M.: Compounding of distributions: a survey and new generalized classes. J. Stat. Distrib. Appl. 3(1), 1–35 (2016). https://doi.org/10.1186/s40488-016-0052-1
Tahir, M.H., Nadarajah, S.: Parameter induction in continuous univariate distributions: well-established g families. Anais da Academia Brasileira de Ciências 87(2), 539–568 (2015). https://doi.org/10.1590/0001-3765201520140299
Topp, C.W., Leone, F.C.: A family of j-shaped frequency functions. J. Am. Stat. Assoc. 50(269), 209–219 (1955). 10.1080/01621459.1955.10501259
Torabi, H., Hedesh, N.M.: The gamma-uniform distribution and its applications. Kybernetika 48(1), 16–30 (2012)
Torabi, H., Montazeri, N.H.: The logistic-uniform distribution and its applications. Commun. Stat. Simul. Comput. 43(10), 2551–2569 (2014). https://doi.org/10.1080/03610918.2012.737491
Zografos, K., Balakrishnan, N.: On families of beta- and generalized gamma-generated distributions and associated inference. Stat. Methodol. 6(4), 344–362 (2009). https://doi.org/10.1016/j.stamet.2008.12.003
Acknowledgements
The authors would like to thank the editor and the anonymous referee for their insightful comments that helped to enhance the paper. This study is a part of the master thesis of the second author under supervision of the first author.
Funding
The authors received no funding for this research.
Author information
Authors and Affiliations
Contributions
The authors carried out this work and drafted the manuscript together. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no Conflict of interest.
Consent to participate
Not applicable.
Ethics approval
Not applicable.
Consent for publication
Not applicable.
Appendices
Appendix>
Second Partial Derivatives of the OddKappa-Exponential Distribution
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Al-Shomrani, A.A., Al-Arfaj, A. Properties and Applications of A New Attractive Distribution. J Stat Theory Appl 23, 67–112 (2024). https://doi.org/10.1007/s44199-024-00073-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s44199-024-00073-z