
Abstract
A new lifetime distribution has been defined. This distribution is obtained from a transformation of a random variable with beta distribution and is called here the kagebushin-beta distribution. Some mathematical properties such as mode, quantile function, ordinary and incomplete moments, mean deviations over the mean and median and the entropies of Rényi and Shannon are demonstrated. The maximum likelihood method is used to obtain parameter estimates. Monte Carlo simulations are carried out to verify the accuracy of the maximum likelihood estimators. Applications to real data showed that the kagebushin-beta model can be better than the Weibull, gamma and exponentiated exponential distributions.
Similar content being viewed by others

Introduction
A random variable Y having beta distribution has cumulative distribution function (cdf) and probability density function (pdf) given by
and
respectively, where \(a>0\) and \(b>0\) are shape parameters and \(B(a,b)=\int _0^1 z^{a-1}(1-z)^{b-1}\textrm{d}z\) denotes the beta function.
Taking the transformation \(X=-\log Y\), the cdf and pdf of X are given by
and
respectively. Here, we refer to a as a scale parameter and b as a shape parameter. The random variable X with pdf (2) is said to have kagebushin-beta (KB) distribution and is denoted as \(X\sim \text {KB}(a,b)\).
The beta function admits the following relation
where \(\Gamma (p)=\int _0^\infty z^{p-1}\textrm{e}^{-z}\textrm{d}z\) denotes the gamma function. Under these results, for \(b=1\), the Equation (2) becomes
that corresponds to the pdf of the exponential distribution. Thus, the KB distribution has the exponential distribution as special case.
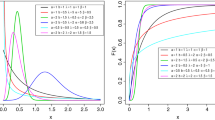
Figure 1 displays plots of the density function of X, for some values of the parameters.

Some pdfs of the KB distribution
This paper is organized as follows. In Sect. Properties, mathematical properties and entropy measures are described. In Sect. Estimation, the maximum likelihood method and Monte Carlo simulations are presented. In Sect. Applications, applications to real data are considered. Section Conclusions concludes the paper.
Properties
The first derivative of the log-density (2) is
The mode is obtained by solution of \(\eta (x)=0\). So, the mode of X is
By inverting \(F(x;a,b)=u\), the quantile function of X is
where \(Q_1(\cdot ;a,b)\) is the inverse function of the Equation (1). Using the quantile function, the random variable
has density function (2), where V is a uniform random variable over the interval (0, 1).
The rth moment of X is obtained as
Consider the following convergent expansion in power series
Using the expansion above, the rth moment of X can be written as
Taking \(w=(a+k)x\), we have
So, the rth moment of X is given by
For \(s>0\), the rth incomplete moment of X is obtained as
Taking \(t=(a+k)x\), we have
where \(\gamma (p,x)=\int _0^x z^{p-1}\textrm{e}^{-z}\textrm{d}z\) denotes the lower incomplete gamma function.
Then, the rth incomplete moment of X is given by
An entropy is a measure of variation or uncertainty of a random variable. Two popular entropy measures are the Rényi and Shannon entropies. For \(\rho >0\) and \(\rho \ne 1\), the Rényi entropy of a random variable having pdf \(f(\cdot )\) with support in (a, b) is given by
For KB distribution, the Rényi entropy is
Setting \(v=\textrm{e}^{-x}\), we have
Thus, the Rényi entropy of X becomes
The Shannon entropy is given by \(\mathcal {I}_s=\mathbb {E}[-\log f(X)]\). So, for KB distribution, the Shannon entropy is
From the maximum likelihood method, we can show that \(\mathbb {E}[X]=\psi (a+b)-\psi (a)\) and \(\mathbb {E}[\log (1-\textrm{e}^{-X})]=\psi (b)-\psi (a+b)\), where \(\psi (p)=d\log \Gamma (p)/dp\) is the digamma function.
Thus, the Shannon entropy is of X is
Thus, we see that for KB distribution, the Rényi and Shannon entropies can be easily computed.
The mean deviations of X about the mean and about the median are given as
and
respectively, where \(\mu ^1=\mathbb {E}[X]\) and \(\omega =F^{-1}(0.5; a,b)\) and \(m_1(\cdot )\) is defined in (4).
Estimation
Let the random variables \(X_i,\cdots ,X_n\sim \text {KB}(a,b)\) with observed values \(x_i,\cdots ,x_n\). From Equation (2), the log-likelihood for \((a,b)^\top\) is given by
The components of the score vector \(U(a,b)=(U_a,U_b)^\top\) of \(\mathcal {L}(a,b)\) are given by
The maximum likelihood estimates (MLEs) of a and b, say \({\hat{a}}\) and \({\hat{b}}\), are the simultaneous solutions of \(U_a=U_b=0\), which has no closed forms. Thus, this problem can be solved via iteractive numerical methods, such that Newton--Raphson algorithmic. Statistical packages such as R [1] and Ox [2] can be used for this purpose.
The Fisher expected information matrix is
in which
where \(\psi ^\prime (p)=d^2\log \Gamma (p)/dp^2\) is the trigamma function.
Under general regularity conditions, we have the result
where \(\mathcal {K}(a,b)^{-1}\) is the inverse matrix of \(\mathcal {K}(a,b)\) and \({\mathop {\sim }\limits ^{a}}\) denotes asymptotic distribution. This multivariate normal approximation for \(({\hat{a}},{\hat{b}})\) can be used for construing approximate confidence intervals for the model parameters. The LR statistics can be used for testing hypotheses on these parameters.
Simulation study
To show the accuracy of MLEs for the two parameters of the KB model, Monte Carlo simulations with 15, 000 replications were performed. Two scenarios are considered and the sample sizes chosen are \(n=\{25, 50, 75,100,200,400\}\). The random numbers are generated using Equation (3). The true parameters are: \(a=1.9\) and \(b=1.5\) in scenario 1 and \(a=4.5\) and \(b=2.5\) in scenario 2. The simulations were carried out using the matrix programming language Ox [2].
Tables 1 and 2 list the average estimates (AEs), biases and mean squared errors (MSEs), for scenarios 1 and 2, respectively. As expected, the MLEs converge to the true parameters and the biases and MSEs decrease when the sample size n increases.
Applications
In this section, we compare the results of fitting of the KB distribution with three others well-known distributions, for two datasets.
The data are:
-
(Dataset 1) The data refer to remission times (in months) of 128 bladder cancer patients. These data were also analyzed by [3].
-
(Dataset 2) The data consist of the waiting time between 64 consecutive eruptions of the Kiama Blowhole [4].
We compare the KB model (2) with the Weibull, gamma and exponentiated exponential [5] distributions. The pdfs of the Weibull (W), gamma (G) and exponentiated exponential (EE) distributions are
and
respectively, where \(\lambda >0\) is scale parameter and \(\beta >0\) is shape parameter. Note that for \(\beta =1\), all these pdfs become the density function of the exponential distribution.
The goodness-of-fit measures adopted are: Cramér-von Mises (\(W^*\)), Anderson Darling (\(A^*\)), Akaike information criterion (AIC), consistent Akaike information criterion (CAIC), Bayesian information criterion (BIC) and Hannan-Quinn information criterion (HQIC) for model comparisons. The lower the value of these statistics, more evidence we have for a good fit. The graphical analysis is also important to identify the best fitted model. All the computations were done using the Ox language [2].
Tables 3 and 5 list the MLEs with standard errors in parentheses (SEs) for datasets 1 and 2, respectively. Note that, in both applications, all MLEs of all models are significant, since their standard errors are low, when compared to the respective MLE.
The information criteria for datasets 1 and 2 are presented in Tables 4 and 6 , respectively. In both datasets, all information criteria point to the KB distribution as the best model, followed later by the EE distribution.
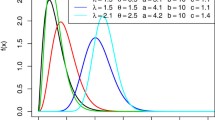
Figures 2 and 3 show the estimated pdfs and cdfs for datasets 1 and 2, respectively, considering the two best fitted models.

Estimated a pdfs and b cdfs for data 1

Estimated a pdfs and b cdfs for data 2
Conclusions
A new lifetime distribution has been defined. This distribution is obtained from a transformation of a random variable with beta distribution and is called here the kagebushin-beta distribution. Some mathematical properties such as mode, quantile function, ordinary and incomplete moments, mean deviations over the mean and median and the entropies of Rényi and Shannon are demonstrated.
The method used to estimate the parameters was maximum likelihood. Fisher’s expected information matrix has closed form. Monte Carlo simulations showed that the maximum likelihood estimators of the new model are valid, being in accordance with the asymptotic theory.
The usefulness of the kagebushin-beta model is shown with applications to real data. The results of these applications showed that the kagebushin-beta model is better than the Weibull, gamma and exponentiated exponential distributions.
Availability of data and materials
Ok.
References
R Core Team: R: A language and environment for statistical computing. R foundation for statistical computing, Vienna, Austria (2020). R foundation for statistical computing. https://www.R-project.org/
Doornik, J.A.: Ox: an Object-Oriented Matrix Programming Language. Timberlake Consultants and Oxford, London (2018)
Elbatal, I., Muhammed, H.Z.: Exponentiated generalized inverse Weibull distribution. Appl. Math. Sci. 8(81), 3997–4012 (2014)
da Silva, R.V., de Andrade, T.A.N., Maciel, D.B.M., Campos, R.P.S., Cordeiro, G.M.: A new lifetime model: the gamma extended Fréchet distribution. J. Stat. Theory Appl. 12(1), 39–54 (2013)
Gupta, R.D., Kundu, D.: Exponentiated exponential family: an alternative to gamma and Weibull distributions. Biomet. J. J. Mathemat. Methods Biosci. 43(1), 117–130 (2001)
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
The author produced the entire paper
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Ok
Competing interests
The authors declare that they have no competing interests.
Consent for publication
Ok.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ribeiro-Reis, L.D. The kagebushin-beta distribution: an alternative for gamma, Weibull and exponentiated exponential distributions. J Egypt Math Soc 30, 24 (2022). https://doi.org/10.1186/s42787-022-00158-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s42787-022-00158-7
Keywords
- Kagebushin-beta distribution
- Rényi entropy
- Shannon entropy
- Mean deviations
- Ordinary and incomplete moments