
Abstract
The goal of this research is to create a new general family of Topp-Leone distributions called the Topp-Leone Cauchy Family (TLC), which is exceedingly versatile and results from a careful merging of the Topp-Leone and Cauchy distribution families. Some of the new family’s theoretical properties are investigated using specific results on stochastic functions, quantile functions and associated measures, generic moments, probability weighted moments, and Shannon entropy. A parametric statistical model is built from a specific member of the family. The maximum likelihood technique is used to estimate the model’s unknown parameters. Furthermore, to emphasize the new family’s practical potential, we applied our model to two real-world data sets and compared it to existing rival models.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Statistical distributions have long been used to represent data for goals such as prediction and decision-making. Life cycle analysis, reliability, life expectancy, insurance, engineering, finance, economics, biological sciences, extreme events, medicine, agricultural engineering, actuarial science, demography, administration, sports, and materials science are all examples of their applications. Numerous statistical distributions consist of additional parameters to well-established continuous distributions in order to provide them new and intriguing functions. The most notorious of these families are Exponential-G family [1], beta-G family [2], gamma-G family [3]. Recent promising families include the Kumaraswamy-G family [4], half-logistic-G family of type II [5], generalized odd log-logistic Poisson family [6], odd Frechet-G family of distributions [7], Garhy-generated family of distributions [8], generalized transmuted Poisson-G family [9], Topp-Leone family [10, 11], Topp-Leone-Weibull [12], power Lambert uniform distribution [13], Gemeay–Zeghdoudi distribution [14], step stress and partially accelerated life testing [15], Burr III-Topp-Leone-G family of distributions [16], Fréchet Topp-Leone-G [17], Topp-Leone G transmuted [18], Topp-Leone Inverse Lomax [19], new power Topp-Leone-G Family [20], Generalized Topp-Leone-Weibull [12], Topp-Leone-Marshall-Olkin-G family [21], Topp-Leone generalized Rayleigh distribution [22, 23], Topp-Leone inverse Rayleigh distribution [24], truncated exponential Topp Leone Rayleigh distribution [25]. In addition to these previous works, recent advancements in the field of statistical distributions have introduced promising newcomers, including a novel extension of the Fréchet distribution [26], an efficient estimators of population variance in two-phase successive sampling under random non-response [27], and the half-normal model using informative priors under Bayesian Structure [28].
Most statistical distributions face limitations when it comes to adapting to various types of data sets. Indeed, certain datasets exhibit specific characteristics like high skewness, kurtosis, heavy tails, inverted J-shapes, multimodality, and more. Distribution generators offer the capability to manage and manipulate these dataset characteristics effectively. In this research, our objective is to create a novel set of distributions by merging the Topp-Leone and Cauchy distribution families, and showing how distributions from the created family offer a large possibility of adapting to real life data. The Topp-Leone distributions are extensively employed due to their advantageous attributes, such as mathematical simplicity and the versatility of their probabilistic functions. Its cumulative distribution function (CDF) is given by:
where \(\alpha >0\) and \(0\le x \le 1\) and the pdf is:
The Topp-Leone-G distribution family emerges from the fusion of (1) and P, where P represents a CDF. It is precisely this CDF that defines the distinguishing features of this distribution family.
\(P( x; \tau ) \in \left[ 0, 1 \right] , \alpha > 0 \), and \(P( x; \tau )\) is a basic continuous distribution’s CDF depending on \(\tau =( \tau _1,\ldots, \tau _n)\).
One way to define the Cauchy distribution is by its CDF, which is given by:
where \(a>0\) represents a scale parameter, b a position parameter, and \(x \in \left] 0; +\infty \right[\). By combining \(P(x, \tau )\) and the Cauchy distribution’s CDF (4), we get:
By merging the Topp-Leone distribution family (3) with the Cauchy distribution (5), we will create the new family. The representation of the CDF of the Topp-Leone distribution family (3) can be restated as:
By combining expressions (5) and (6), we get the new family’s CDF which is defined by:
\(\nu = (\alpha , a, b, \tau, m )\) and \(\alpha , a,\tau, m >0\) and \(x\in \,-\infty;+\infty \).
The development of this novel distribution family is driven by several motivations. First, it aims to offer increased flexibility compared to traditional statistical distributions like the normal or exponential, which often have limited parameters, making them less suitable for modeling highly variable real-world data. This new family introduces more parameters, enhancing its ability to adapt to complex phenomena. Second, it extends beyond the restricted value ranges commonly seen in classic distributions, making it applicable to a wider range of fields where data may lack predefined bounds. Additionally, it seeks to model diverse real-world phenomena more accurately, accounting for behaviors such as heavy tails, asymmetries, and extreme values. Finally, its versatility allows for application across various disciplines, from environmental sciences to medicine and engineering. Ultimately, the overarching goal is to improve the quality of statistical model fitting to real data, leading to more precise and reliable results across diverse research and application domains.
From this new family of distributions, several are the special members with very interesting properties. Within this family, we have introduced a distinct member where the basic distribution is represented by the CDF G. This yields the Topp-Leone Cauchy Rayleigh distribution, which encompasses four parameters. To evaluate its effectiveness, we have applied this distribution to two actual datasets and compared its performance against other existing competing models.
2 A Special Member: The TLCAR Distribution
The TLCA-G family encompasses various distributions, and the process of discovering a new distribution within this family parallels the process of discovering a new base distribution. In this work, the TLCAR distribution is established by utilizing the Rayleigh distribution with a positive shape parameter \(\theta\) as the foundational distribution. The CDF of the Rayleigh distribution can be expressed as:
where \(\theta > 0\) et \(x \in [ 0,+\infty [.\)
The associated probability density function (PDF) and hazard rate function (HRF) are given respectively, by:
and
The CDF that defines the TLCAR distribution is expressed as follows:
where \(\alpha , a, \theta > 0\). The associated PDF and HRF of (8) are respectively:
and
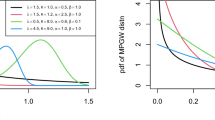
Figure 1 displays a graphical representation of the PDF of the TLCAR distribution, while Fig. 2 illustrates its HRF. Notably, Fig. 1 highlights the potential for the PDF to display a positive asymmetry and a shape of type J inverted. The PDF can exhibit diverse shapes, including increasing, decreasing, inverted, or bathtub-shaped patterns. This observation aligns with previous findings documented in the literature. These curvature characteristics are well known to be useful for developing versatile statistical models.

Probability density functions of the TLCAR distribution

TLCAR distribution’s hazard rate functions
3 Several Mathematical Properties of the TLCAR Distribution
This section highlights several important mathematical characteristics of the TLCAR distribution.
3.1 Serial Development of f
Proposition 1
The serial development of f is given by:
where
and
Proof
According to (8), \(F(x;\nu )=\left[ 1-\left( \frac{1}{2}-\frac{1}{\pi }\arctan \frac{1-e^{\frac{-x^2}{2\theta ^2}} -b}{a}\right) ^2\right] ^\alpha\),
Considering \(K(x;\nu ) =\arctan \left( \frac{1-e^{\frac{-x^2}{2\theta ^2}}-b}{a}\right)\),
and
Using the binomial formula, we have:
and
So we get:
By deriving the expression (16) of F(x) with x, we obtain the serial development (11) of f(x). \(\square\)
3.2 Rényi Entropy
The Rényi entropy associated with the distribution is given by:
where
and
Proof
The Rényi entropy of X for a continuous random variable can be defined by:
So we have:
Therefore, the Renyi entropy is given by:
\(\square\)
3.3 Moments
At this point, we will take a closer look at the moments of our distribution. Moment is a key statistical measure that allows us to characterize the shape of the distribution and to better understand its properties and behavior.
Proposition
The moment of order s associated with our distribution is given by:
where \(T_{i,j}\) is defined in (12)
Proof
The moment of order s of a variable is determined by:
so
By using the serial development (11), we have:
where \(S_s(x;\nu )\) is defined in (23). \(\square\)
3.4 Moment Generating Function
Proposition
The moment generating function is given by:
Proof
The moment generating function is determined by:
By using the serial development of exponential function, we have:
So we can write:
\(\mathbb {E}(x^r)\) represents the order moment r of the distribution. So,
By replacing (26) in (25), we obtain:
where
\(\square\)
3.5 Incomplete Moments
The incomplete moment of TLCAR distribution can be obtained as:
By considering the expression obtained with the moment in (22), we have:
where \(T_{i,j}\) is defined in (12)
3.6 Moment-Weighted Probabilities (MWP)
The MWP is defined by:
where
and
Proof
Let put \(\varphi (x)=f(x) \times F^s(x)\),
so
By using the binomial formula, we have:
The moment generating function is determined by:
Therefore:
where \(J_{i,j,s}\) and \(I_j(x;\nu )\) are defined respectively in (27) and (28). \(\square\)
3.7 Quantile Function
In this section, we will give with justification the quantile function.
Proposition
The quantile function associated with the distribution is defined by:
Proof
Let us put
Then by the definition of the quantile function, \(x_y\) satisfies the nonlinear equation:
So
By raising each member of Eq> (31) to the power \(\frac{1}{\alpha }\) we have:
Let put
We get:
Considering the expression (32), we can write:
In our case, \(P(x;\theta )= 1-e^{\left( \frac{-x^2}{2\theta ^2}\right) }\),
So we have:
Therefore, the quantile function is given by:
\(\square\)
3.8 Survival Function
The survival function of TLCAR distribution is given by:
3.9 Hazard Function
The hazard function of TLCAR distribution is defined as:
3.10 Cumulative Hazard Function (Cf)
The cumulative hazard function is defined by the following expression:
So, the TLCAR distribution’s cumulative hazard function is given by:
3.11 Reserve Hazard Function
We use the following expression to determine the reserve hazard function:
Therefore, the reserve hazard function of TLCAR distribution is given by:
3.12 Mean Waiting Time
The mean waiting time refers to the average time one has to wait for an event or an outcome to occur. It is a measure of central tendency that quantifies the typical or average duration of waiting. It is defined as:
By using the expression (11) of f(x), we have:
So, the mean waiting time of TLCAR distribution is given by:
where
3.13 Mean Residual Life
The mean residual life is a concept that pertains to survival analysis and the study of lifetime or duration data. It is a measure that provides information about the average remaining lifetime of an individual or system given that it has already survived up to a certain point. The mean residual life function (mr) is defined as:
By using the serial development (11) of f(x), we have:
So, the mean residual life of TLCAR distribution is given by:
where
3.14 Mean Deviation About Mean
The mean deviation about the mean (also known as the mean absolute deviation or simply the average deviation) is a measure of the average distance between each data point in a dataset and the mean of that dataset. It provides a measure of the dispersion or spread of the data. Suppose X has TLCAR distribution with a mean of \(\mu\). The mean absolute deviation is expressed as follows:
By using (34), we have:
So, the mean absolute deviation is given by:
where
3.15 Mean Deviation About Median
The mean deviation about the median is a measure of the average distance between each data point in a dataset and the median of that dataset. It is similar to the mean deviation about the mean, but instead of using the mean as the central measure, the median is used. Let consider the TLCAR distribution’s random variable X has a median value of Me. The mean deviation about median can be expressed as:
By using (35), we have:
So, the mean absolute deviation is given by:
where
4 Estimation
Let \(x_1, x_2,\ldots, x_n\) be a random sample of size n of a variable X. Then, using the pdf in (9), the likelihood function is given by:
So we have:
The log-likelihood function is defined as:
We obtain:
Defining the maximum likelihood estimators \(\hat{\alpha }\), \(\hat{a}\), \(\hat{b}\) and \(\hat{\theta }\), we satisfy:
\(l(\hat{\alpha },\hat{a},\hat{b},\hat{\theta })= max_{ (\alpha ,a,b,\theta ) \in \left[ 0,+\infty \right] ^{4}} l(\alpha ,a,b,\theta )\)
Let’s put:
We have:
The log-likelihood function can therefore be rewritten as follows:
The first partial derivatives of \(l(\hat{\alpha },\hat{a},\hat{b},\hat{\theta })\) to be set to zero are provided as follows:
5 Simulation Study
To assess the consistency of maximum likelihood estimators (MLEs) within the context of our hybrid TLCAR distribution, a comprehensive simulation study is conducted in this section using the R package ’stats4.’ We generate one thousand independent samples, each with varying sizes of \(n=80, 100, 200, 300\), and 400, drawn from the TLCAR distribution. For each of the 1000 replications, we computed the MLEs for the parameters of interest. Subsequently, we assessed two fundamental statistical metrics: the average bias (Bias) and the root mean square error (RMSE). These metrics were used to evaluate the precision and consistency of the estimated parameters. The results of these calculations are documented in Table 1. This simulation-based approach provides a robust framework for scrutinizing the performance of MLEs and offers valuable insights into their consistency under various sample size scenarios within the unique context of the TLCAR distribution.
6 Data Analysis
To test the performance of our distribution in real life situations, we will apply it with two appropriate data sets and compare its performance to the existing competing models below:
-
1.
Topp-Leone Compound Rayleigh (TLCR) [29].
-
2.
On Type II Topp Leone Inverse Rayleigh Distribution (TIITIR) [30].
-
3.
Rayleigh distribution [31].
We used Mathematica to determine the estimated values of the density function parameters and Matlab to plot them. The analysis of the results will allow us to determine whether the distribution lives up to its promise in real-life situations.
Dataset I:
The provided dataset exhibits failure times (measured in hours) obtained from an accelerated life test involving 59 conductors. The data are presented below [32, 33]: 6.545, 9.289, 7.543, 6.956, 6.492, 5.459, 8.120, 4.706, 8.687, 2.997, 8.591, 6.129, 11.038, 5.381, 6.958, 4.288, 6.522, 4.137, 7.459, 7.495, 6.573, 6.538, 5.589, 6.087, 5.807, 6.725, 8.532, 9.663, 6.369, 7.024, 8.336, 9.218, 7.945, 6.869, 6.352, 4.700, 6.948, 9.254, 5.009, 7.489, 7.398, 6.033, 10.092, 7.496, 4.531, 7.974, 8.799, 7.683, 7.224, 7.365, 6.923, 5.640, 5.434, 7.937, 6.515, 6.476, 6.071, 10.941, 5.923. Table 2 displays the estimated values for the dataset I. The information criteria obtained from different models on the dataset I are presented in Table 3. Moreover, empirical PDFs and CDFs for dataset I can be visualized in Fig. 3.

Visualization of Empirical PDFs and CDFs for dataset I
Dataset II:
The dataset consists of observations on the fracture toughness of silicon nitride, measured in units of MPa \(m^{\frac{1}{2}}\) [16]. The set is consisted of 119 observations which are: 5.5, 5, 4.9, 6.4, 5.1, 5.2, 5.2, 5, 4.7, 4, 4.5, 4.2, 4.1, 4.56, 5.01, 4.7, 3.13, 3.12, 2.68, 2.77, 2.7, 2.36, 4.38, 5.73, 4.35, 6.81, 1.91, 2.66, 2.61, 1.68, 2.04, 2.08, 2.13, 3.8, 3.73, 3.71, 3.28, 3.9, 4, 3.8, 4.1, 3.9, 4.05, 4, 3.95, 4, 4.5, 4.5, 4.2, 4.55, 4.65, 4.1, 4.25, 4.3, 4.5, 4.7, 5.15, 4.3, 4.5, 4.9, 5, 5.35, 5.15, 5.25, 5.8, 5.85, 5.9, 5.75, 6.25, 6.05, 5.9, 3.6, 4.1, 4.5, 5.3, 4.85, 5.3, 5.45, 5.1, 5.3, 5.2, 5.3, 5.25, 4.75, 4.5, 4.2, 4, 4.15, 4.25, 4.3, 3.75, 3.95, 3.51, 4.13, 5.4, 5, 2.1, 4.6, 3.2, 2.5, 4.1, 3.5, 3.2, 3.3, 4.6, 4.3, 4.3, 4.5, 5.5, 4.6, 4.9, 4.3, 3, 3.4, 3.7, 4.4, 4.9, 4.9, 5. Table 4 displays the estimated values for the dataset II. The information criteria obtained from different models on the dataset II are presented in Table 5. From Fig. 4, we can see the empirical PDFs and CDFs for dataset II.

Visualization of empirical PDFs and CDFs for dataset II
After analyzing the Tables 2, 3, 4, 5, and Figs. 3, 4, it can be deduced that the TLCAR model demonstrates a more robust compatibility with the datasets I and II examined in comparison to the rival models. The TLCAR model possesses the advantage of flexibility, enabling its application to both industrial and artificial intelligence data. Hence, it can be concluded that the TLCAR model is the preferable option for modeling these datasets, owing to its superior performance and versatility in accommodating diverse data types.
7 Conclusion
Our study focused on the creation and use of a distribution to simulate data. We implemented a rigorous methodology and were able to create a reliable distribution based on empirical data and precise statistical calculations. The simulations performed with this distribution showed results very close to the real data, thus demonstrating the relevance and efficiency of our approach.
Furthermore, we emphasized the relevance of assessing the suitability of statistical models to the data by comparing simulation outcomes to real-world data and employing visualization tools like histograms and density functions.
Finally, our study has shown that the creation of custom distributions can be an efficient approach to simulate data in different fields such as finance, biology, industry or physics.
We hope that our work will serve as a foundation for future research and contribute to the advancement of knowledge in these areas.
8 Future Work and Coming
This research intends to focus on various areas of exploration in the future. One of these topics will include investigating transformations as TX among others in order to create a new distribution for predicting unknown lifetime occurrences. This new distribution will provide a more sophisticated statistical model for studying and predicting lifetimes, as well as it has the potential to be employed in a wide range of applications. Another area of research will be the creation of a bivariate distribution, which will allow us to evaluate and forecast the interaction of two variables. We will also investigate copulas and other aspects of this novel distribution to better understand its behavior and applicability.
Last but not least, we also intend to use the new distribution with engineering and accelerated data to investigate the reliability function’s behavior utilizing calibrated data. This will help to establish the new distribution’s potential utility in industry and other sectors by providing insights into how it might be utilized in real-world circumstances. Overall, our future research will concentrate on the development of advanced statistical models and the analysis of their behavior in a variety of applications. We are excited about the possible insights and breakthroughs that these investigations may yield.
Availability of data and materials
Data are provided within the paper.
Change history
03 January 2024
A Correction to this paper has been published: https://doi.org/10.1007/s44199-023-00069-1
References
Elbatal, I., Ozel, G., Cakmakyapan, S.: Odd extended exponential-g family: properties and application on earthquake data. J. Stat. Manag. Syst. 25 1751–1765 (2022)
Olanrewaju, R.O.: On the application of generalized beta-g family of distributions to prices of cereals. J. Math. Finance 11, 670–685 (2021)
Hosseini, B., Afshari, M., Alizadeh, M.: The generalized odd gamma-g family of distributions: properties and applications. Austrian J. Stat. 47, 69–89 (2018)
Nofal, Z.M., Altun, E., Afify, A.Z., Ahsanullah, M.: The generalized kumaraswamy-g family of distributions. J. Stat. Theory Appl. 18, 329–342 (2019)
Soliman, A. H., Elgarhy, M. A. E., Shakil, M.: Type ii half logistic family of distributions with applications. Pak. J. Stat. Oper. Res. 13, 245–264 (2017)
Alizadeh, M., Yousof, H.M., Rasekhi, M., Altun, E.: The odd log-logistic poisson-g family of distributions. J. Math. Ext. 12, 81–104 (2018)
ul Haq, M. A., Elgarhy, M.: The odd frechet-g family of probability distributions. J. Stat. Appl. Probab. 7,189–203 (2018)
Elgarhy, M., Hassan, A.S., Rashed, M.: Garhy-generated family of distributions with application. Math. Theory Model. 6, 1–15 (2016)
Yousof, H., Afify, A. Z., Alizadeh, M., Hamedani, G., Jahanshahi, S., Ghosh, I.: The generalized transmuted poisson-g family of distributions: Theory, characterizations and applications. Pak. J. Stat. Oper. Res. 14, 759–779 (2018)
Al-Shomrani, A., Arif, O., Shawky, A., Hanif, S., Shahbaz, M. Q.: Topp–leone family of distributions: Some properties and application. Pak. J. Stat. Oper. Res. 12, 443–451 (2016)
Atchadé, M. N., N’bouké, M., Djibril, A. M., Shahzadi, S., Hussam, E., Aldallal, R., Alshanbari, H. M., Gemeay, A. M., El-Bagoury, A.-A. H.: A new power topp–leone distribution with applications to engineering and industry data. PLoS One 18, e0278225 (2023)
Ashraf-Ul-Alam, M., Khan, A.A.: Generalized topp-leone-weibull aft modelling: A Bayesian analysis with mcmc tools using r and stan. Austrian J. Stat. 50, 52–76 (2021)
Gemeay, A. M., Karakaya, K., Bakr, M., Balogun, O. S., Atchadé, M. N., Hussam, E.: Power lambert uniform distribution: statistical properties, actuarial measures, regression analysis, and applications. AIP Adv. 13, 095319 (2023)
Belili, M. C., Alshangiti, A. M., Gemeay, A. M., Zeghdoudi, H., Karakaya, K., Bakr, M., Balogun, O. S., Atchadé, M. N., Hussam, E.: Two-parameter family of distributions: Properties, estimation, and applications, AIP Adv. (2023). https://doi.org/10.1063/5.0173532
Rahman, A., Kamal, M., Khan, S., Khan, M. F., Mustafa, M. S., Hussam, E., Atchadé, M. N., Al Mutairi, A.: Statistical inferences under step stress partially accelerated life testing based on multiple censoring approaches using simulated and real-life engineering data. Sci. Reports 13, 12452 (2023)
Chipepa, F., Oluyede, B., Peter, P.O.: The burr iii-topp-leone-g family of distributions with applications. Heliyon 7, e06534 (2021)
Reyad, H., Korkmaz, M.Ç., Afify, A.Z., Hamedani, G., Othman, S.: The fréchet topp leone-g family of distributions: properties, characterizations and applications. Ann. Data Sci. 8, 345–366 (2021)
Yousof, H.M., Alizadeh, M., Jahanshahi, S., Ghosh, T.G.R.I., Hamedani, G.: The transmuted topp-leone g family of distributions: theory, characterizations and applications. J. Data Sci. 15, 723–740 (2017)
Soliman, A., Ismail, D.: Estimation of parameters of topp-leone inverse lomax distribution in presence of right censored samples, Gazi Univ. J. Sci. 34 (2021) 1193–1208
Bantan, R.A., Jamal, F., Chesneau, C., Elgarhy, M.: A new power topp-leone generated family of distributions with applications. Entropy 21, 1177 (2019)
Chipepa, F., Oluyede, B., Makubate, B., et al.: The topp-leone-marshall-olkin-g family of distributions with applications. Int. J. Stat. Probab. 9, 15–32 (2020)
Nanthaprut, P., Patummasut, M., Bodhisuwan, W.: Topp-leone generalized Rayleigh distribution and its applications. Songklanakarin J. Sci. Technol. 40, 1186–1202 (2018)
Ahmad, A., Alsadat, N., Atchade, M. N., ul Ain, S. Q., Gemeay, A. M., Meraou, M. A., Almetwally, E. M., Hossain, M. M., Hussam, E.: New hyperbolic sine-generator with an example of rayleigh distribution: simulation and data analysis in industry. Alexandria Eng. J. 73, 415–426 (2023)
Mohammed, H., Yahia, N.: On type II topp-leone inverse Eayleigh distribution. Appl. Math. Sci. 13, 607–615 (2019)
Hilal, O. A., Al-Noor, N. H.: Theory and applications of truncated exponential topp leone rayleigh distribution. AIP Conf. Proc. 2414, 040055 (2023)
Suleiman, A.A.: A novel extension of the fréchet distribution: Statistical properties and application to groundwater pollutant concentrations. J. Data Sci. Insights 1, 8–24 (2023)
Basit, Z., Bhatti, M.I.: Efficient classes of estimators of population variance in two-phase successive sampling under random non-response. Statistica 82, 177–198 (2022)
Kiani, S.K., Aslam, M., Bhatti, M.I.: Investigation of half-normal model using informative priors under Bayesian structure. Stat. Transit 24, 19–36 (2023)
Rasheed, N.: Topp-leone compound Rayleigh distribution: properties and applications. Res. J. Math. Stat. Sci. 7, 51–58 (2019)
Yahia, N., Mohammed, H.: The type ii topp-leone generalized inverse rayleigh distribution. Int. J. Contemp. Math. Sci 14, 113–122 (2019)
Beckmann, P.: Rayleigh distribution and its generalizations. Radio Sci. J. Res. NBS/USNC-URSI 68, 927–932 (1964)
Nasiri, P., Pazira, H.: Bayesian approach on the generalized exponential distribution in the presence of outliers. J. Stat. Theory Pract. 4, 453–475 (2010)
Schafft, H.A., Staton, T.C., Mandel, J., Shott, J.D.: Reproducibility of electromigration measurements. IEEE Trans. Electron Devices 34, 673–681 (1987)
Acknowledgements
The authors would like to thank the Editor-in-Chief, the Associate Editor and the reviewers for their comments which improved the paper. We also thank Mr. Marcel Vitouley, an independent researcher, who helped us in the proofreading of this paper.
Funding
This work was carried out with the aid of a grant to Mintodê Nicodème Atchadé from UNESCO TWAS and the Swedish International Development and Cooperation Agency, (Sida). The views expressed herein do not necessarily represent those of UNESCO TWAS, Sida or its Board of Governors.
Author information
Authors and Affiliations
Contributions
MNA: Conceptualization, Resources, Visualization, Formal analysis, Writing, Review, Editing, Validation, Supervision. MJB: Formal analysis, Visualization, Writing, Review, Editing. AMD Formal analysis, Visualization, Review, Editing. MN: Writing, Review, Editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare they have no competing interest.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Atchadé, M.N., Bogninou, M.J., Djibril, A.M. et al. Topp-Leone Cauchy Family of Distributions with Applications in Industrial Engineering. J Stat Theory Appl 22, 339–365 (2023). https://doi.org/10.1007/s44199-023-00066-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s44199-023-00066-4