
Abstract
In this article, a large class of univriate Birnbaum–Saunders distributions based on the scale shape mixture of skew normal distributions is introduced which generates suitable subclasses for modeling asymmetric data in a variety of settings. The moments and maximum likelihood estimation procedures are disscused via an ECM-algorithm. The observed information matrix to approximate the asymptotic covariance matrix of the parameter estimates is then derived in some subclasses. A simulation study is also performed to evaluate the finite sample properties of ML estimators and finally, a real data set is analyzed for illustrative purposes.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The two-parameter Birnbaum Saunders (BS) distribution, as a life type distribution, was originally introduced by Birnbaum and Saunders [8] in a failure model due to cracks, see Miner [31]. This distribution is related with normal distribution by means of a very simple functional relationship, and is based on a physical argument of cumulative damage that produces fatigue in the materials. The BS distribution, as a skew distribution, has been frequently applied in last few years; to biological model by Desmond [14], to medical field by Leiva et al. [26] and Barros et al. [5], to the forestry and environmental sciences by Podaski [32], Leiva et al. [28] and Vilca et al. [37], to fatigue life model by Cordeiro et al. [12], and to genetic model by Hassani et al. [20].
However, the BS model may suffer from a lack of robustness in the presence of extreme outlying observations. To allay this problem, several extensions of the BS distribution have been proposed in the literature, see e.g. Diaz-Garcia and Leiva [15], Sanhueza et al. [36], Leiva et al. [27], Gomez et al. [17], Vilca et al. [38], Hashemi et al. [25], Poursadeghfard et al. [33], Reyes et al.[34], and Mahbudi et al. [29], Benkhalifa [7],
The skew normal (SN) distribution proposed by Azzalini [2, 3] has been widely used in many applications to accommdate data with skewness. For more flexibilities, several extension of the SN model have been still considered. Branco and Dey [9] discussed the family of scale mixtures the skew-normal (SMSN) distributions. The random variable Y is said to have the univariate SMSN model when it has the following representation
where \(\tau\) is a positive random variable with cumulative distribution function (cdf) \(H(\tau ;\upsilon ).\) The cdf \(H(\tau ;\upsilon )\) is known as the mixing scale distribution. The univarite skew-t ([4]) and skew-slash ([39]) distributions are two special cases of SMSN distributions. Jammalizadeh et al. (2017) consider a more general class of scale-shape mixtures of skew normal (SSMSN) distributions and applied the EM-type algorithm for the computation of maximum likelihood estimates of parameters. This model includes SMSN model as a special case. Further, any model of the form \(\frac{2}{\sigma }f\left( \frac{y-\xi }{\sigma }\right) G\left( \lambda \left( \frac{y-\xi }{\sigma }\right) \right) ,\) for which f and G are scale mixtures of the normal distributions, belongs to this class. For example, the skew t normal (STN) distribution discussed by Gomez et al. [18] and Cabral et al. [11] is a special case of SSMSN distributions.
In this paper, we introduce a new extension class of the BS distributions based on the SSMSN class, named the scale shape mixture of skew nomal- Birnbaum Saunders (SSMSN-BS) class. It includes the STN-BS distributions in Poursadeghfard et al. [33], the SNT-BS distributions in Hashemi et al. [25] and the SN-BS distributions in Vilca et al. (38) as the special cases. According to more felxibility of the class of SSMSN-BS distributions, they are attractive for modeling skewed and positive data sets in a much wider range, and we hope they have a better fit to compare the gamma, lognormal, weibull and exponential distributions as the lifetime distributions. However, a direct likelihood maximization for this class is dificult to compute due to the complexity of the likelihood function. To overcome this hurdle, we propose the ECM algorithm to estimate the parameters based on a convenient stochastic representation.
The rest of this paper is structured as follows. In Sect. 2, a useful stochastic representation of the SSMSN-BS class and its subclasses is presented, and basic properties of them are studied. In Sect. 3, the ECM-type algorithms for calculating ML estimates of parameters are provided. The information matrix for obtaining the asymptotic covariance matrix of the ML estimates are calculated in Sect. 4. Finally, a simulation study is presented in Sect. 5, where the proposed methodology through a real data set is also illustrated.
2 The Class of SSMSN-BS Distributions
In this section, we present the definition and some simple properties of the SSMSN-BS distributions. Some important asymmetric distributions generated from SSMSN-BS are also studied. Suppose \(Z_{1}\) and \(Z_{2}\) be two independent copies from \(N\left( 0,1\right)\), and \(\varvec{\tau } =\left( \tau _{1},\tau _{2}\right) ^{T}\) be a positive bivariate random variable, i.e. \(P\left( \tau _{1}>0,\tau _{2}>0\right) =1,\) with probability density function (pdf) \(h\left( \varvec{\tau ,\eta }\right)\) where \(\varvec{\eta }\) is a vector of parameters. Further, we assume that both \(\mathbf {Z}=\left( Z_{1},Z_{2}\right) ^{T}\) and \(\varvec{\tau }=\left( \tau _{1},\tau _{2}\right) ^{T}\) are independent. A random variable Y is said to have the scale shape mixture of skew normal \(\left( SSMSN\right)\) distribution, denoted by \(Y\thicksim SSMSN\left( \lambda ,\varvec{\eta } \right)\), if
By using the stochastic representation in \(\left( 1\right)\) the random variable Y has following useful representation
with \(f=\frac{\tau _{1}}{\tau _{2}}.\) Denoting by \(\gamma =\sqrt{\tau _{1}^{-1}\left( f+\lambda ^{2}\right) }\left| Z_{1}\right| ,\) a further hierarchical representation of the SSMSN distribution can be written as
where TN \(\left( \mu ,\sigma ^{2};\left( a,b\right) \right)\) represents the truncated normal distribution for \(N\left( \mu ,\sigma ^{2}\right)\) lying within the truncated interval \(\left( a,b\right) ,\) see Jammalizadeh and Lin (2017) for more details.
The cdf and pdf of a BS random variable, denoted by T \(\thicksim BS\left( \alpha ,\beta \right) ,\) are given by
where
and \(\alpha >0\) and \(\beta >0\) are shape and scale parameters, and \(\Phi\) and \(\phi\) denote the cdf and pdf of the standard normal distribution, respectively.
The stochastic representation of T is
See Birnbaum and Saunders [8].
Definition 2.1
If \(Z\thicksim SSMSN\left( \lambda ,\varvec{ \eta }\right)\) in (6), then T is said to have a BS distribution based on SSMSN distribution with parameter\(\left( \alpha ,\beta ,\lambda , \varvec{\eta }\right) .\) It is denoted by \(T\thicksim \text {SSMSN-BS}\left( \alpha ,\beta ,\lambda ,\varvec{\eta }\right) .\)
From (3), (5) and (6), the joint pdf T, \(\gamma\) and \(\varvec{\tau } =\left( \tau _{1},\tau _{2}\right)\) is given by
By integrating on \(\gamma\) in (7), we get
The marginal density of T is then given by
implying that \(\gamma\) and \(\tau _{1}\) are conditionally independent given \(T=t\) and \(\tau _{2}.\) From (10), it is clear that
The conditional pdf of \(\varvec{\tau }=\left( \tau _{1},\tau _{2}\right)\) given \(T=t\) is also given by
Proposition 2.1
Let \(T\thicksim \text {SSMSN-BS}\), then the mean, variance, coefficient of variation, skewness and kurtosis of T are given by
respectively, where
with \(T^{*}\left( \upsilon _{1}\right) \overset{d}{=}\tau _{1}^{-\frac{1 }{2}}\left( \upsilon _{1}\right) Z\left( 0,1\right) ,ET^{*2}=E\tau _{1}^{-1},ET^{*4}=3E\tau _{1}^{-2},ET^{*6}=15E\tau _{1}^{-3},ET^{*^{8}}=105E\tau _{1}^{-4},\) and
In the following subsections, some asymmetric distributions generated by \(SSMSN-BS\) are studied.
2.1 The Skew t\(_{1}\)t\(_{2}\)-BS Distribution
Let \(\tau _{1}\) and \(\tau _{2}\) be two independent gamma random variables with shape and rate parameters equal to \(\frac{\upsilon _{i}}{2},\) namely \(\Gamma \left( \frac{\upsilon _{i}}{2},\frac{\upsilon _{i}}{2}\right)\) for \(i=1,2,\) with the following joint density
where \(\varvec{\eta }=\left( \upsilon _{1},\upsilon _{2}\right)\) and f denotes the pdf of the gamma distribution, then Y in (2) and (3), is said to have the skew t\(_{\text {1}}\)t\(_{\text {2}}\) distribution with parameter \(\left( \lambda ,\varvec{\eta }\right) ,\) and will be denoted by \(Y\sim ST_{\upsilon _{1}}T_{\upsilon _{2}}\left( \lambda ,\upsilon _{1},\upsilon _{2}\right) .\) Now we define the skew
t\(_{\text {1}}\)t\(_{\text {2}}\)-BS distribution as follows:
Definition 2.2
If \(Y\overset{d}{=}Z\sim ST_{\upsilon _{1}}T_{\upsilon _{2}}\left( \lambda ,\upsilon _{1},\upsilon _{2}\right)\) in (6), we say that the random variable T follows the \(ST_{\upsilon _{1}}T_{\upsilon _{2}}\text {-BS}\) distribution with the following pdf
where \(t\left( .;\upsilon _{1}\right) ,\) \(T\left( .;\upsilon _{2}\right)\) denote the pdf and cdf of the Student-t distribution with degree of freedom \(\upsilon _{1},\) \(\upsilon _{2}\) respectively.
We shall write \(T\sim ST_{\upsilon _{1}}T_{\upsilon _{2}}\text {-BS}(\alpha ,\beta ,\lambda ,\upsilon _{1},\upsilon _{2})\) to denote that T follows the \(ST_{\upsilon _{1}}T_{\upsilon _{2}}\text {-BS}\) distribution with pdf in (17). The mean, variance and measures of skewness and kurtosis coefficients of T follows from the equations in (13)–(15), for which, we have
with
From (12), the conditional pdf of \(\tau _{1}\) given \(T=t\) is
and the conditional pdf of \(\tau _{2}\) given \(T=t\) is
So, we have
where \(DG\left( x\right) =\frac{\Gamma ^{\prime }\left( x\right) }{\Gamma \left( x\right) }\) is the digamma function.
Remark: If \(\upsilon _{1}=\upsilon _{2}=\upsilon ,\) then \(T\sim ST_{\upsilon }T_{\upsilon }\thicksim BS(\alpha ,\beta ,\lambda ,\upsilon ).\)
It should be noted that SSMSN-BS class includes some special distributions. In the following, some special cases are given.
(I) The skew t normal-BS (STN-BS) distribution formulated by taking \(\tau _{1}\thicksim \Gamma \left( \frac{\upsilon }{2},\frac{\upsilon }{2}\right)\) and \(\tau _{2}=1\) with probability 1. The pdf is
See Poursadeghfard et al. (2016).
(II) The skew normal t-BS (SNT-BS) distribution formulated by \(\tau _{1}=1\) with probability 1 and \(\tau _{2}\thicksim \Gamma \left( \frac{ \upsilon }{2},\frac{\upsilon }{2}\right) .\) The pdf is
See Hashemi et al. [25].
(III) The skew normal-BS (SN-BS) distribution obtained by taking \(\tau _{1}=\tau _{2}=1\) with probability 1. The pdf is
See Vilca et al. [38].
Figure 1 displays the graph of the densities, BS, SN-BS, STN-BS, SNT-BS, \(ST_{\upsilon }T_{\upsilon }\text {-BS}\) with \(\alpha =0.5,\) \(\beta =0.8\), \(\lambda =3\) and four different degrees of freedom \(\upsilon =1,\) 3, 5 and 15.

The graph of densities, BS, SN-BS, STN-BS, SNT-BS, and \(ST_{ \upsilon }T_{\upsilon }\text {-BS}\), for the selected of values of parameters
2.2 The Skew t-BS Distribution
Let \(\tau _{1}=\tau _{2}=\tau\) with probability 1 be a one gamma random variable with shape and rate parameters equal to \(\frac{\upsilon }{2},\) with the following pdf
Then Y in (2) is said to have the skew t distribution with parameter \(\left( \lambda ,\upsilon \right) ,\) and will be denoted by Y \(\sim ST\left( \lambda ,\upsilon \right) .\)
Definition 2.3
If \(Y\overset{d}{=}Z\sim ST\left( \lambda ,\upsilon \right)\) in (6) we say that the random variable T follows the ST-BS distribution with pdf
we shall write T \(\sim ST-BS(\alpha ,\beta ,\lambda ,\upsilon )\) to denote that T follows the \(ST-BS\) distribution.
The mean, variance and measures of skewness and kurtosis coefficients of T follows equations in (13)–(15), (18). In addition \(Y\sim ST\left( \lambda ,\upsilon \right) .\)
From (12), the conditional pdf of \(\tau\) given \(T=t\) is
and so the conditional expectation of \(\tau\) and \(\log \tau\) given \(T=t\) are
respectively, where \(g\left( x;\upsilon \right) =DG\left( \frac{\upsilon +2}{ 2}\right) -DG\left( \frac{\upsilon +1}{2}\right) -\log \left( 1+\frac{x^{2}}{ \upsilon +1}\right) +\frac{\left( \upsilon +1\right) x^{2}-\upsilon -1}{ \left( \upsilon +1\right) \left( \upsilon +1+x^{2}\right) }.\) Also
Note that in the case of \(\tau =1\) with probability 1, the SN-BS distribution is obtained. Figure 2 displays the graph of the densities, BS, ST-BS with \(\alpha =0.5,\) \(\beta =0.8,\) \(\lambda =3\) and four different degrees of freedom \(\upsilon =1,\) 3, 5, 15.

The graph of densities, BS, ST-BS, for the selected of values of parameters
2.3 The Skew Generalized Laplace Normal-BS Distribution
A random variable Y is said to have a generalized Laplace \(\left( GL\right)\) distribution, denote by \(Y\sim GL\left( \upsilon \right) ,\) if it has the pdf
where \(k_{r}\left( x\right)\) denotes the modified Bessel function of third kind of order \(r\in R\) defined by
The first derivative of (30) with respect to r is
Let \(\tau _{1}\sim \frac{1}{\chi _{\left( 2\upsilon \right) }^{2}},\) \(\tau _{2}=1\) with probability 1 in (2) , where \(\chi _{\left( 2\upsilon \right) }^{2}\) denotes the chi squared distribution with df \(2\upsilon ,\) then Y is said to have the skew generalized Laplace normal distribution with pdf given by
and will be denoted by \(Y\sim SGLN\left( \lambda ,\upsilon \right)\). See Jammalizadeh and Lin (2016).
Definition 2.4
If \(Y\overset{d}{=}Z\sim SGLN\left( \lambda ,\upsilon \right)\) in (6), we say that the random variable T follows the SGLN-BS distribution with pdf
We write \(T\sim \text {SGLN-BS}\left( \alpha ,\beta ,\lambda ,\upsilon \right)\) to denote that T follows the \(SGLN-BS\) distribution. The mean, variance and measures of skewness and kurtosis coefficients of T follows from equation in (13)–(15), for which, we have
with
From (12), we can show that the conditional pdf of \(\tau\) given \(T=t\) is
where GIG is the Generalized Inverse Gaussian distribution, see Jørgensen [21].
So we obtain
Figure 3 displays several density functions of T with \(\alpha =0.5,\) \(\beta =0.8,\) \(\lambda =3\) and four different \(\upsilon =1,\) 3, 5 and 15.

The graph of densities, SGLN-BS, for the selected of values
Remark: Some special cases are as follows:
(I) If \(\tau _{1\text { }}=1\) with probability 1 and \(\tau _{2\text { }}\sim \frac{1}{\chi _{\left( 2\upsilon \right) }^{2}},\) then \(T\sim \text {SNGL-BS}\left( \alpha ,\beta ,\lambda ,\upsilon \right)\) with density function
(II) If \(\tau _{1\text { }}\sim \frac{1}{\chi _{\left( 2\upsilon _{1}\right) }^{2}},\) \(\tau _{2\text { }}\sim \Gamma \left( \frac{\upsilon _{2}}{2},\frac{ \upsilon _{2}}{2}\right) ,\) then \(T\sim SGLT-BS\left( \alpha ,\beta ,\lambda ,\upsilon _{1},\upsilon _{2}\right)\) with density function
(III) If \(\tau _{1\text { }}\sim \Gamma \left( \frac{\upsilon _{1}}{2},\frac{ \upsilon _{1}}{2}\right) ,\) \(\tau _{2\text { }}\sim \frac{1}{\chi _{\left( 2\upsilon _{1}\right) }^{2}},\) then \(T\sim STGL-BS\left( \alpha ,\beta ,\lambda ,\upsilon _{1},\upsilon _{2}\right)\) with density function
where \(F_{GL}(.;\upsilon _{2})\) is the cdf of the generalized Laplace distribution.
2.4 The Skew Slash Normal-BS Distribution
Let \(\tau _{1}\sim\) \(Beta\left( \frac{\upsilon }{2},1\right) ,\) \(\tau _{2}=1\) with probability in (2), then we obtain the pdf of the skew slash normal distribution with shape parameter \(\upsilon\) and skewness parameter \(\lambda ,\) denoted by Y \(\sim SSN\left( \upsilon ,\lambda \right) .\) The pdf is given by
where \(f_{s}\left( .;\upsilon \right)\) is the pdf of the slash distribution with shape parameter \(\upsilon .\)
where \(G(.;\alpha )\) denotes the cdf of gamma distribution with scale parameter 1 and shape parameter \(\alpha .\) See Rogers and Tukey [35].
Definition 2.5
If \(Y\overset{d}{=}Z\sim SSN\left( \upsilon ,\lambda \right)\) in (6), we say that the random variable T follows the SSN-BS with pdf
We write \(T\sim \text {SSN-BS}\left( \alpha ,\beta ,\lambda ,\upsilon \right)\) to denote that T follows the SSN-BS distribution.
Figure 4 displays several density functions of T \(\sim \text {SSN-BS}\left( \alpha ,\beta ,\lambda ,\upsilon \right)\) with \(\alpha =0.5,\) \(\beta =0.8,\) \(\lambda =3\) and four different \(\upsilon =1,\) 3, 5, 15.

The graph of the densities, SSN-BS, for selected values of parameters
The mean, variance and measures of skewness and kurtosis coefficients of T follows equations in (13), (14), (15), for which we have
From (12), we can show that the conditional pdf of \(\tau\) given \(T=t\) is
and the conditional expectation of \(\tau\) and \(\log \left( \tau \right)\) given \(T=t\) is
3 Maximum Likelihood Estimation
In this section, we derive the ML estimation parameters of SSMSN-BS distributions via modification of the EM-algorithm (ECM-algorithm). The ECM algorithm modifies the EM Algorithm by replacing its Maximization step by a sequence of conditional maximization steps. For more details about EM and ECM algorithms, see Dempster et al. [13] and Meng and Rubin [30].
3.1 The General Case
Let \(T_{1},\) \(T_{2},\) \(\ldots ,\) \(T_{n}\) are random samples from \(SSMSN-BS\left( \alpha ,\text { }\beta ,\text { }\lambda ,\text { }\varvec{\eta }\right)\) with the following hierarchical formulation
where \(\gamma _{i}=\sqrt{\tau _{1i}\left( f_{i}+\lambda ^{2}\right) } \left| Z_{1}\right| ,\) \(f_{i}=\frac{\tau _{1i}}{\tau _{2i}},\) and \(\varvec{\tau }_{i}=\left( \tau _{1i},\tau _{2i}\right) ^{T}\) are n bivariate positive random samples with pdf \(h\left( \tau _{1i},\tau _{2i}; \varvec{\eta }\right) .\)
Set the observed data by \(\mathbf {t}=\left( t_{1},\ldots ,\text { } t_{n}\right) ^{T},\) the missing data \(\varvec{\gamma }=\left( \gamma _{1},\ldots ,\text { }\gamma _{n}\right) ^{T}\) and \(\varvec{\tau } =\left( \varvec{\tau }_{1},\ldots ,\text { }\varvec{\tau } _{n}\right) ^{T}\) and the complete data by \(\mathbf {t}^{c}=\left( \mathbf {t} ^{T},\varvec{\gamma }^{T},\varvec{\tau }^{T}\right) ^{T}\). Then from (43), and \(h\left( \varvec{\tau }_{i}\varvec{,\eta }\right)\) we can construct the complete data log-likelihood function of \(\varvec{\theta } =\left( \alpha ,\beta ,\lambda ,\varvec{\eta }\right)\) given complete data \(\mathbf {t}^{c}=\left( t,\gamma ,\tau _{1},\tau _{2}\right) .\) By ignoring the additive constant terms, the log-likelihood function is given by
where \(\varepsilon (t_{i};\beta )=\sqrt{\frac{t_{i}}{\beta }}-\sqrt{\frac{ \beta }{t_{i}}}.\) Suppose \(\widehat{\varvec{\theta }}^{(r)}=( \widehat{\alpha }^{(r)},\widehat{\beta }^{(r)},\widehat{\lambda }^{(r)}, \widehat{\varvec{\eta }}^{(r)})\) is the current estimate (in the rth iteration) of \(\varvec{\theta }\). Based on the ECM algorithm principle, in the E-step, we should first form the following conditional expectation
where
Then the ECM algorithm is done as follows:
E-step: Given \(\varvec{\theta }=\widehat{ \varvec{\theta }}^{(r)}\), compute \(\widehat{S}_{1i}^{(r)},\widehat{S} _{2i}^{(r)},\widehat{S}_{3i}^{(r)}\), for \(i=1,\ldots ,n.\)
CM-step 1: Fix \(\beta =\widehat{\beta }^{(r)}\) and update \(\widehat{ \alpha }^{(r)},\widehat{\lambda }^{(r)}\) by maximizing (45) over \(\alpha\) and \(\lambda\), which leads to
CM-step 2: Updating \(\widehat{\varvec{\eta }}^{(r)}\) is strongly related to form of the \(h\left( \tau _{1i},\tau _{2i};\varvec{ \eta }\right)\) said to the next section.
CM-step 3: Fix \(\alpha =\widehat{\alpha }^{(r+1)},\lambda =\widehat{ \lambda }^{(r+1)},\mathbf {\eta }=\widehat{\varvec{\eta }}^{(r+1)}\) and update \(\widehat{\beta }^{(r)}\) using
Note that the CM-step 3 requires a one-dimensional search for the root of \(\beta ,\) which can be easily obtained by using the optimize function in the statistical software R.
3.2 ECM-Estimation for the \(ST_{\upsilon _{1}}T_{ \upsilon _{2}}\text {-BS}\) Distribution
For the \(ST_{\upsilon _{1}}T_{\upsilon _{2}}\text {-BS}\) distribution, we recall equation (16)
from (45), the E-step involves the calculation of two additional conditional expectations, given by
which can be calculated by using (21). Now, rewrite
CM-step 2: Fix \(\alpha =\widehat{\alpha }^{(r+1)},\lambda =\widehat{ \lambda }^{(r+1)},\) \(\beta =\widehat{\beta }^{(r)}\) and update \(\widehat{ \upsilon }_{1}^{(r)}\) and \(\widehat{\upsilon }_{2}^{(r)}\) by maximizing (45) over \(\upsilon _{1},\) \(\upsilon _{2}\) which leads to solve the root of the following equations
3.3 ECM-Estimation for the ST-BS Distribution
For the ST-BS distribution, we recall equation (25)
The E-step (46) converts to
and one additional conditional expectation, given by
which can be calculated by using (26). Now, we rewrite
CM-step 2: Updating \(\widehat{\upsilon }^{(r)}\) leads to solve the root of the following equation
3.4 ECM-Estimation for the SGLN-BS Distribution
As mentioned in Sect. 2.3, the SGLN-BS distribution can be generated from SSMSN-BS by taking \(\tau _{1i}=\tau _{i}\overset{d}{=}\frac{1}{\chi _{\left( 2\upsilon \right) }^{2}}\) and \(\tau _{2i}=1\) with probability 1 for \(i=1,\) \(\ldots ,\) n. and so we have
Then the E-step (46) converts to
and additional conditional expectation
which can be calculated via (36). Now we rewrite
CM-step 2: Updating \(\widehat{\upsilon }^{(r)}\) leads to solve the root of the following equation
3.5 ECM-Estimation for the SSN-BS Distribution
As shown in Sect. 2.4, the SSN can be considered as a special case of SSMSN-BS by taking
\(\tau _{1i}=\tau _{i}\overset{d}{=}Beta\left( \upsilon ,1\right)\) and \(\tau _{2i}=1\) with probability 1 for \(i=1,\) \(\ldots ,\) \(n.\) So we have
The E-step (46) converts to
and additional conditional expectation
which can be calculated via (42). Now we rewrite
CM-step 2: Update \(\widehat{\upsilon }^{(r)}\) by
3.6 The Information Matrix
Under some regularity condition, the asymptotic covariance matrix of the ML estimates can be approximated by inverse of the observed information matrix, given by
where \(\ell (\varvec{\theta }\mid t)\) is the observed log-likelihood function on the basis of observations \(T=\left( t_{1},\ldots ,t_{n}\right) ^{T}.\)
Following Basford et al. [6], we obtain
where
is the individual score statistic corresponding to the single observation \(t_{i}\) \(\left( i=1,\ldots ,n\right) .\) Explicit expression for the elements of \(\widehat{\mathbf {S}}_{i}\) are summerized below.
\(\left( i\right)\) For the \(ST_{\upsilon _{1}}T_{\upsilon _{2}}-BS\) distribution, the elements of \(\widehat{\mathbf {S}}_{i}\) contain
In the case of \(\upsilon _{1}=\upsilon _{2}=\upsilon ,\) we have \(\widehat{ \mathbf {S}}_{i,\upsilon }=\widehat{\mathbf {S}}_{i,\upsilon _{1}}+\widehat{ \mathbf {S}}_{i,\upsilon _{2}}.\)
\(\left( ii\right)\) For the ST-BS distribution, the elements of \(\widehat{ \mathbf {S}}_{i}\) are obtained by
\(\left( iii\right)\) For the SGLN-BS distribution, the elements of \(\widehat{\mathbf {S}}_{i}\) are obtained by
\(\left( iv\right)\) For the SSN-BS distribution, the elements of \(\widehat{ \mathbf {S}}_{i}\) are obtained by
The covariance matrix can be useful for studying the asymptotic behavior of \(\widehat{\varvec{\theta }}=[\widehat{\alpha },\widehat{\beta }, \widehat{\lambda },\widehat{\upsilon }]\) by its asymptotic normality. The statistical inference about \(\varvec{\theta }=\left[ \alpha ,\beta ,\lambda ,\upsilon \right]\) can be then made.
4 Simulation Study and an Illustrative Example
4.1 Simulation Study
We perform a simulation study to evaluate the finite sample properties of ML estimators described in Sect. 3. To conduct the experimental study, we generate different sample of sizes \(n=50,\) 100, 200, 400, 800 from the STN-BS, SGLN-BS, SSN-BS models. The true parameters are supposed to b \(\varvec{\theta }=\left[ \alpha ,\beta ,\lambda ,\upsilon \right] =\left[ 1,1,2,2\right]\) and \(\varvec{\theta }=\left[ \alpha ,\beta ,\lambda ,\upsilon \right] =\left[ 0.5, 1, 2, 2\right] .\) Each simulate data set was fitted via the ECM algorithm under the same generated model using \(M=5000\) replications. To examine the performance of the ML estamates, for each sample size and for each estimate, \(\widehat{\varvec{\theta }}=[\widehat{\alpha },\widehat{\beta },\widehat{\lambda },\widehat{ \upsilon }],\) we compute the mean, \(E[\widehat{\theta }_{i}],\) the root mean square error, \(\sqrt{MSE},\) and the relative bias in absolute value, RB, defined as
respectively, such that \(\theta _{1}=\alpha ,\) \(\theta _{2}=\beta ,\) \(\theta _{3}=\lambda ,\) \(\theta _{4}=\upsilon .\) Tables 1, 2, 3 present the mean, \(\% RB,\) and \(\sqrt{MSE}\) of the ML estimates of the parameters \(\theta _{i}\) \(i=1,2,3,4\) for STN-B, SGLN-BS and SSN-BS models.
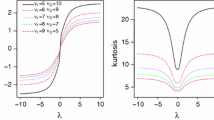
Figures 5, 6, 7 and 8 show the graphical representations of RB and \(\sqrt{ MSE}\) of the four parameter estimates as a function of sample size n, respectively. Clearly, the \(\sqrt{MSE}\) and RB values converge to zero when n increases.

RB values in parameter estimates when \(\alpha =0.5,\) \(\beta =1,\) \(\lambda =2,\) \(\upsilon =2\)

MSE root values in parameter estimates when \(\alpha =0.5,\) \(\beta =1,\) \(\lambda =2,\) \(\upsilon =2\)

RB values in parameter estimates when \(\alpha =1,\) \(\beta =1,\) \(\lambda =2,\) \(\upsilon =2\)

MSE root values in parameter estimates when \(\alpha =1,\) \(\beta =1,\) \(\lambda =2,\) \(\upsilon =2\)
4.2 An Illustrative Example
In this section, we consider the results in preceding sections by analyzing a data set originally reported by Bjerkedal [10] and analyzed by Kundu et al. [23]. Table 4 displays the summary of these data including sample median, mean, standard deviation (SD), coefficient of variation (CV), coefficient of skewness (CS), coefficient of kurtosis (CK), range, minimum, maximum and the sample size (n). As it is observed, the data comes from a positively skewed distribution with a kurtosis greater than three. So we propose that these data set can be suitable to modeling some kind of SSMSN-BS distributions listed in Table 5.
Estimation and model checking are provided in Table 5. We first obtain the ML estimation of the parameters via ECM algorithm described in Sect. 3. Then to assess the fitting performance, we use the maximized log-likelihood \(\mathbf {\ell }\left( \widehat{\varvec{\theta }}\right) ,\) the Akaike \(\left( AIC\right)\) and AIC with a correction (AICc) information criteria which defined as
where m is the number of the model parameters.
According to the AIC and AICc we find that the \(ST_{\upsilon _{1}}T_{\upsilon _{2}}-BS\) distribution provides the best fit.
The PP plots and empirical and theoretical cdf plots given in Figures 9, 10, 11, 12, 13, 14, 15, 16, 17, 18 confirm again the appropriateness of the \(ST_{\upsilon _{1}}T_{\upsilon _{2}}-BS\) distribution.

The PP plot (left) and empirical versus theoretical c.d.f. (right) for the BS model

PP plot (left) and empirical versus theoretical c.d.f. (right) for the T-BS model

PP plot (left) and empirical versus theoretical c.d.f. (right) for the SGLNT-BS model

PP plot (left) and empirical versus theoretical c.d.f. (right) for the SSN-BS model

PP plot (left) and empirical versus theoretical c.d.f. (right) for the ST-BS model

PP plot (left) and empirical versus theoretical c.d.f. (right) for the SN-BS model

PP plot (left) and empirical versus theoretical c.d.f. (right) for the SNT-BS model

PP plot (left) and empirical versus theoretical c.d.f. (right) for the STN-BS model

PP plot (left) and empirical versus theoretical c.d.f. (right) for the \(\text {ST}_{ \upsilon }T_{ \upsilon }\text {-BS}\) model

PP plot (left) and empirical versus theoretical c.d.f. (right) for the \(\text {ST}_{ \upsilon _{1}}T_{ \upsilon _{2}}\text {-BS}\) model
Also we use known distributions such as gamma, lognormal, weibull, exponential to compare the competition models. For the ML estimates we use fitdistr function in package MASS in the statistical software R. see Table 6. Again \(\text {ST}_{\upsilon _{1}}T_{\upsilon _{2}}\text {-BS}\) distribution seems to be the best.
5 Concluding Remarks
In this paper, an extension of the Birnbaum-Saunders distribution, called scale shape mixture of skew normal Birnbaum–Saunders (SSMSN-BS) distribution and its subclasses, are introduced. The parameters estimation via ECM algorithm are discussed and the utility of models is shown by means of simulation and real data set. The SSMSN-BS distributions can be in modeling different types of data due to their properties and their flexibility.
The study of the bivariate SSMSN-BS class (see [22]), or more general, the study of the multivariate \(SSMSN-BS\) class (see [1]) are interesting problems that remain to be studied. These works are currently under progress and we hope to report our findings in a future paper.
Abbreviations
- SSN-BS:
-
Skew slash normal Birnbaum Saunders
- BS:
-
Birnbaum Saunders
- SNN-BS:
-
Skew slash normal Birnbaum Saunders
- SN:
-
Skew normal (SN)
- SMSN:
-
Scale mixture the skew normal (SMSN)
- STN:
-
Skew t normal
- SSMSN:
-
Scale shape mixture of skew normal
- SSMSN-BS:
-
Scale shape mixture of skew normal-Birnbaum Saunders
- \(\text {ST}_{\upsilon }T_{\upsilon }\text {-BS}\) :
-
Skew t t-Birnbaum Saunders
- SGLN-BS:
-
Skew generalized laplace normal-Birnbaum Saunders
References
Arellano-Valle, R.B., Ferreira, C.S., Genton, M.G.: Scale and shape mixtures of multivariate skew-normal. J. Multivar. Anal. 166, 98–110 (2018)
Azzalini, A.: A class of distribution which includes the normal ones. Scand. J. Stat. 12, 171–178 (1985)
Azzalini, A.: Further results on a class of distribution which includes the normal ones. Statistica 46, 199–208 (1986)
Azzalini, A., Capitanio, A.: Distributions generated by perturbation of symmetry with emphasis on a multivariate skew t-distribution. J. R. Stat. Soc. Ser. B. 65, 367–389 (2003)
Barros, M., Paula, G.A., Leiva, V.: A new class of survival regression models with heavy tailed errors: roubustness and diagnostics. Lifetime Data Anal. 14, 316–332 (2008)
Basford, K.E., Greenway, D.R., McLachlan, G.J., Peel, D.: Standard error of fitted means under normal mixture. Comput. Stat. 12, 1–17 (1997)
Benkhalifa, L.: The Weibull Birnbaum–Saunders distribution and its applications. Stat. Optim. Inform. Comput. 9, 61–81 (2021)
Birnbaum, Z.W., Saunders, S.C.: A new family of life distribution. J. Appl. Probab. 6, 319–327 (1969)
Branco, M.D., Dey, D.K.: A general class of multivariate skew-elliptical distribution. J. Multivar. Anal. 79, 99–113 (2001)
Bjerkedal, T.: Acquisition of resistance in guinea pigs infected with different doses of virulent tubercle baclli. Am. J. Hyg. 72, 130–148 (1960)
Cabral, C.R.B., Bolfarine, H., Pereira, J.R.G.: Bayesian density estimation using skew student-t-normal mixtures. Comput. Stat. Data Anal. 52, 5075–5090 (2008)
Cordeiro, G.M., Lemonte, A.J.: The \(\beta\) Birnbaum–Saunders distribution: an improved distribution for fatigue life modeling. Comput. Stat. Data Anal. 55, 1445–1461 (2011)
Dempster, A.P., Laird, N.M., Rubin, D.B.: Maximum likelihood from incomplete data via the EM algorithm (with discussion). J. R. Stat. Soc. Ser. B 39, 1–38 (1977)
Desmond, A.: Stochastic models of failure in random environments. Can. J. Stat. 13, 171–183 (1985)
Diaz-Garcia, J.A., Leiva-Sanchez, V.: A new family of life distribution based on the elliptically contoured distributions. J. Stat. Plan. Inference 128, 445–457 (2005)
Gokhale, S., Khare, M.: Statistical behavior of carbon monoxide from vehicular exhausts in urban environments. Environ. Model. Softw. 22, 526–535 (2007)
Gomez, H.W., Olinares, J., Bolfarine, H.: An extension of the generalized Birnbaum–Saunders distribution. Stat. Probab. Lett. 79, 331–338 (2009)
Gomez, H.W., Venegas, O., Bolfarine, H.: Skew-symmetric distributions generated by the distribution function of the normal distribution. Environmetrics 18, 395–407 (2007)
Gomez, H.W., Olivares, J., Bolfarine, H.: An extension of the generalized Birnbaum–Saunders distribution. Stat. Probab. Lett. 79, 331–338 (2009)
Jamlizadeh, A., Lin, T.I.: A general class of scale-shape mixtures of skew-normal distributions: properties and estimation. Comput. Stat. 32, 451–474 (2017)
Jørgensen, S.: Statistical properties of the generalized inverse Gaussian distribution. Springer-Verlag, New York (1982)
Kundu, D., Balakrishnan, N., Jamalizadeh, A.: Bivariate Birnbaum–Saunders distribution and associate inference. J. Multivar. Anal. 101, 113–125 (2010)
Kundu, D., Kannan, N., Balakrishnan, N.: On the hazard function of Birnbaum–Saunders distribution and associate inference. Comput. Stat. Data Anal. 52, 2692–2702 (2008)
Hassani, H., Kalantari, M., Entezarian, M.R.: A new five-parameter Birnbaum–Saunders distribution for modeling bicoid gene expression data. Math. Biosci. 319, 108–275 (2020)
Hashemi, F., Amirzadeh, V., Jamalizadeh, A.: An extension of the Birnbaum–Saunders distribution based on skew-normal-t distribution. Stat. Res. Train. Cent. 12, 1–37 (2015)
Leiva, V., Barros, M., Paula, G.A., Galea, M.: Influence diagnostics in log-Birnbaum–Saunders regression models with censored data. Comput. Stat. Data Anal. 51, 5694–5707 (2007)
Leiva, V., Riquelme, M., Balakrishnan, N., Sanhueza, A.: Lifetime analysis based on the generalized Birnbaum–Saunders. Comput. Stat. Data Anal. 52, 2079–2097 (2008)
Leiva, V., Vilca, F., Balakrishnan, N., Sanhueza, A.: A skewed Sinh-normal distribution and its properties and application to air pollution. Commun. Stat. Theory Methods 39, 426–443 (2010)
Mahbudi, S., Jamalizadeh, A., Farnoosh, R.: Use of finite mixture models with skew-t-normal Birnbaum–Saunders components in the analysis of wind speed: case studies in Ontario, Canada. Renew. Energy 162, 196–211 (2020)
Meng, X.-L., Rubin, D.B.: Maximum likelihood estimation via the ECM algorithm: a general framework. Biometrika 80, 267–278 (1993)
Miner, M.A.: Cumulative damage in fatigue. J. Appl. Mech. 12, 159–164 (1945)
Podaski, R.: Characterization of diameter data in near-natural forests using the Birnbaum–Saunders distribution. Can. J. For. Res. 38, 518–527 (2008)
Poursadeghfard, T., Jamalizadeh, A., Nematollahi, A.: On the extended Birnbaum–Saunders distribution based on the skew-t-normal distribution. Iran. J. Sci. Technol. Trans. A Sci. 43, 1689–1703 (2018)
Reyes, J., Barranco-Chamorro, I., Gallardo, D., Gomez, H.: Generalized modified slash Birnbaum–Saunders distribution. Symmetry 10, 724–742 (2018)
Rogers, W.H., Tukey, J.W.: Understanding some long-tailed symmetrical distribution. Stat. Neerl. 26, 211–226 (1972)
Sanhueza, A., Leiva, V., Balakrishnan, N.: The generalized Birnbaum–Saunders distribution and its theory, methodology and application. Commun. Stat. Theory Methods 37, 645–670 (2008)
Vilca, F., Sanhueza, A., Leiva, V., Christakos, G.: An extended Birnbaum–Saunders model ad it application in the study of environmental quality quality in Santiago, Chile. Stoch. Environ. Res. Risk Assess. 24, 771–782 (2010)
Vilca, F., Santana, L., Leiva, V., Balakrishnan, N.: Estimation of extreme percentiles in Birnbaum–Saunders distribution. Comput. Stat. Data Anal. 55, 1665–1678 (2011)
Wang, J., Genton, M.G.: The multivariate skew-slash distribution. J. Stat. Plan. Inference 136, 209–220 (2006)
Acknowledgements
The authors would like to express their sincere thanks to the editor and referees for their encouragements, suggestions and valuable comments. They gratefully acknowledge the support of this work by Research Council of Shiraz University
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Author information
Authors and Affiliations
Contributions
The order of authorship is assigned based on contributions of authors. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare they have no conflicts of interest.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Poursadeghfard, T., Nematollahi, A. & Jamalizadeh, A. The Extended Birnbaum–Saunders Distribution Based on the Scale Shape Mixture of Skew Normal Distributions. J Stat Theory Appl 20, 481–517 (2021). https://doi.org/10.1007/s44199-021-00037-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s44199-021-00037-7
Keywords
- Scale shape mixtures of skew normal (SSMSN)
- Scale shape mixtures of skew normal-Birnbaum Saunders (SSMSN-BS)
- Skew t t-Birnbaum Saunders \(\left( \text {ST}_{\upsilon }T_{\upsilon }\text {-BS}\right)\)
- Skew generalized Laplace normal-Birnbaum Saunders (SGLN-BS)
- Skew slash normal-Birnbaum Saunders (SSN-BS)