
Abstract
In this paper, we perform a short-run Electricity Price Forecast (EPF) with a Recurrent Neural Network (RNN), namely Long Short-Term Memory (LSTM), using an algorithm that selects the variables and optimizes the hyperparameters. The results are compared with one of the standout machine learning algorithms, namely eXtreme Gradient Boosting (XGB). Apart from other EPF solutions, in this paper, we focus on the interval before and after the pandemic and the conflict in Ukraine. Furthermore, compared to the previous papers that mainly approached German, Austrian, Australian, Spanish, Nordic electricity Day Ahead Markets (DAM), we emphasize on the EPF for one of the East-European countries—Romania whose market rules closely align with the rules of the European Union electricity DAM. The contribution of this study consists in creating a data set that spans from January 2019 to August 2022 and providing an algorithm to identify the best stacked LSTM architecture to cope with a challenging short-term EPF. The proposed algorithm identifies the most relevant variables using a correlation threshold and performs a combination of three parameters—hidden layer size, dropout and learning rate generating the best EPF results.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Electricity prices have been significantly affected in recent years. Several events such as pandemic, conflict in Ukraine, prolonged drought, CO2 emissions taxes, European Union policy towards a clean environment etc. led to a roller coaster electricity price evolution [9, 28]. The COVID-19 pandemic started in the first week of December 2019 when several cases of pneumonia of unknown cause have been reported. Later, based on the way it spread and manifested, the virus was identified as one of the family of coronaviruses, but not one that was known until that time. These viruses usually circulate among animals, but they can also be transmitted to humans in a respiratory chain from person to person. The first official cases were reported on December 31, 2019, but not knowing exactly what they were going to face, the authorities did not take action until January 1, 2020, when the market in the Wuhan area was closed and people were isolated. This measure was taken, however, late when the power of spread was very high, the virus also reaching other regions of China. In the second half of January, the first cases outside of China were reported, specifically in Thailand, South Korea, Japan, Taiwan, Macau, Hong Kong and the United States.
The first critical moment in history marked by this virus was set on January 30, 2020, when the World Health Organization declared it a global health emergency. The virus spread with great power throughout the world, in a very short time, which put pressure and led the National Health Organization to declare on March 11, 2020 the new outbreak generated by COVID-19 as a global pandemic. Throughout history, there have been several such situations, with humanity dealing with plague, smallpox, cholera, tuberculosis, typhus, yellow fever, influenza, and now the coronavirus.
Lockdowns and other restrictions were imposed to limit the spread. Electricity consumption moved from schools and offices to households. Some economic and industrial activities were partially closed. However, these measures influenced electricity consumption, markets and, subsequently, the entire economy. Then gradually in 2021, the restrictions were removed, but the request for commodities and travelling was much higher than the offer leading to higher prices and interest rates.
Another event that has influenced the electricity prices is the conflict in Ukraine that outburst in February 2022 and has drastically challenged the markets that were highly depended on Russian primary resources such as gas and oil. In March 2022, 45–50% of the continent natural gas came through Russian pipelines. Immediately after Russia’s invasion in Ukraine, the stock markets were seriously disturbed. The waves of shock were soon felt on the spot electricity markets. Thus, more diversification, consumption flexibility and RES [11, 14] especially at the prosumers’ side, are encouraged to diminish the need for conventional resources and fulfill the European Union vision towards a clean environment for its citizens [17, 31]. The prolonged drought in Europe and the EU-ETS CO2 emission taxes additionally burdened the electricity price.
Analyzing the historical data from 2019 until 2022, one can notice that the two major events: pandemic and the conflict in Ukraine have influenced the electricity price and the capacity to accurately predict it. Its prediction is important as the producers and suppliers use DAM to adjust their necessities and fulfill long-term contracts provisions. Thus, if they succeed in predicting the electricity price and buy/sell the necessary quantities on DAM, significant costs due to imbalances are avoided. However, previous studies on EPF focused on different intervals, most of them were performed before pandemic times. Furthermore, they mostly focused on the West-European (Spain [1], Germany and Austria [21, 25], France and Germany [48]) and Nordic electricity markets [27], Denmark [32], Australian [28], Canadian [44] and Independent System Operators’ markets in the U.S.A. [53], probably due to the facile availability of the data sets.
In this paper, we create a data set that spans from January 2019 until August 2022 and consists of several time series. Our aim is to provide a thoughtful analysis of the generous interval from the electricity price evolution point of view.
The contribution of this paper consists of:
-
Providing a systematic insight on electricity prices (focused on a country from the East-European region) that were recorded before and after COVID-19 pandemic times and conflict in Ukraine;
-
Creating a data set with electricity prices, traded quantity and other economic variables (inflation rates in Romania and Europe, interest rates, gas prices and traded quantities on gas DAM, brent crude oil prices) that is available for further analysis;
-
Proposing a Recurrent Neural Network (RNN), namely a Long Short-Term Memory (LSTM) architecture to perform EPF, considering the capacity of the LSTM to store spikes and remember/make use of the long-run dependencies;
-
A heuristic algorithm that consists of a selection of variables using a correlation threshold and a combination of hyperparameters—layer size, dropout and learning rate—enhance the results. Based on this algorithm, we select the best stacked LSTM architecture that can improve the results considering the disruptive economic and geopolitical context;
-
Comparing the results of the proposed method with one of the standout machine learning algorithms, namely eXtreme Gradient Boosting (XGB).
We identified several research gaps, such as:
-
Ready-to-use input data was not available to perform short-term EPF in comparison with other studies that benefit from existing input data that is just processed. Therefore, we identified and collected several economic variables from open data sources, such as inflation, interest rate, prices of utilities, etc. They were initially merged to form one dataframe for further analyses;
-
Most previous studies related to the spot market EPF were performed before COVID-19 and the conflict in Ukraine that are two significant events that influenced the evolution of the electricity price;
-
Most previous studies related to the spot market EPF were focused on the West-European countries DAM, Australia, Nordic countries, Canada, and Independent System Operators from U.S.A.;
The research question that motivated us to analyze more recent data from the electricity DAM and perform this study is: How does the current disruptive economic and geopolitical context influence the electricity price and its prediction?
The remainder of this manuscript is structured as follows: the most relevant studies that focus on LSTM applications and EPF are presented in Sect. 2; the input data (time-series) analyses are performed in Sect. 3; in Sect. 4, the EPF methodology is presented; in Sect. 5, we provide the results comparing the performance indicators for prediction: Root Mean Squared Error (RMSE), Mean Absolute Error (MAE) and Mean Squared Error (MSE); discussion on the research question emphasizing on the spot price relevance, market design, insights and policy implications in Sect. 6; and final conclusion in Sect. 7.
2 Literature Review
Most of the previous analyses on electricity prices were not influenced by pandemic and invasion in Ukraine. To the best of our knowledge, an EPF performed using economic features such as inflation in Romania and in Europe, interest rate, hourly prices of gas and oil, traded volumes of electricity and gas on DAM, has not been analyzed yet. LSTM is a type of RNN that is particularly well-suited for tasks involving sequential data, such as time series forecasting. It can maintain a “memory” of past inputs by using gates to control the flow of information through the network, which allows it to effectively capture long-term dependencies in the data [15, 29]. LSTM is a highly popular architecture that has been employed in a plethora of research fields. A survey on deep learning and its applications is proposed in [10]. Due to its state-of-the-art performance on a multitude of forecasting tasks, LSTM is still one of the most used architectures in both industry and academia. The range of research areas that have seen the use of LSTM based models is highly varied. There are papers that tackle traffic and employ prediction techniques to help solve this problem [7, 50, 52, 57]. Traffic flow prediction is an important part of Intelligent Transportation Systems, an essential component of smart cities [23, 41]. Smart cities aim to improve the quality of life in urban areas, by tackling problems like the mitigating traffic congestions, including fuzzy logic strategies for priority control of the EV charging stations [24].
Thus, the LSTM architecture is used to help researchers in this field solve an essential problem for modern day human life. For instance, pedestrian trajectory prediction [39] is another topic that researchers are studying to improve the traffic problem. By accurately predicting where pedestrians would go, the number of traffic injuries could decrease, and pedestrian safety could increase. Akin to pedestrian trajectory prediction, cyclist trajectory prediction [18] has also popularized as a topic of research. These tasks are important in the context of self-driving vehicles, to lower the accident rate and develop safer technologies.
Another field that has seen the utilization of LSTM based architectures is healthcare, especially during the COVID-19 pandemic [4, 22]. Models that predict cardiovascular diseases [20] or predict blood pressure [33] that aim to identify issues in a timely manner to improve people’s lives have been proposed. Besides these examples, the pandemic has triggered a new wave of research on virus and disease transmission, besides many other topics. A lot of research was conducted that aimed to predict the number of patients and trend of the pandemic [19, 30, 45], to better equip the healthcare system to respond to the crisis. LSTM has again shown its popularity, being selected by many researchers as the architecture for their models. Researchers have also predicted the human-virus protein–protein interactions [49], to gain a better understanding of viral infections.
The financial sector has also seen the employment of the LSTM architecture, where correctly predicting the future could provide net record profits [38, 40]. LSTM based models have been used to predict stocks for quantitative trading [58], to optimize portfolios [46], predict financial time series [3], or predict the evolution of the entire stock market [5]. Predictive models are often used in financial and economics research, and the prowess of the LSTM architecture has ensured its frequent use in the field.
Other interesting applications of the LSTM architecture can be noted. Researchers have applied it for workload prediction for large scale computing systems to adequately manage resources [47], software defect detection to improve the production of high-quality software [34], the prediction of ship motion to help keep the equipment always stable [56], stream prediction of small and medium sized watersheds [51], marine temperature prediction to better monitor global climate change and marine ecosystems [26], pollution level prediction to improve environmental quality and human life in urban areas [54] are just a few of the interesting papers that highlight the versatility and popularity of the LSTM architecture.
To contextualize the LSTM architecture in the scope of our paper, works of interest in the energy research area will be presented. Zhou et al. [59] have applied an LSTM based architecture to wind power prediction. Wind power spot prediction and fluctuation interval information are essential to improve the stability, security and economic operation of the power grid. The authors propose K-Means-long short-term memory that leverages the strong memory function of the LSTM network in conjunction with the K-Means clustering method to improve prediction accuracy. The authors report that the proposed solution has superior results to other models, like support vector regression, Elman neural networks and conventional LSTM network models.
Delgado and Fahim [8] introduce a data analysis framework to visualize the data from the supervisory control and data acquisition (SCADA) system and the LSTM based prediction. The framework is aimed toward management teams, to aim them in better operate and generate more power from wind turbines. Another interesting topic in energy prediction is the forecasting of battery remaining useful life. This task, Remaining Useful Life (RUL) prediction, reduces the risk [12] of battery failure by accurately predicting the end of life, therefore avoiding accidents and reduce unexpected maintenance.
Park et al. [36] propose an LSTM based architecture that leverages many-to-one structure to substantially reduce the number of parameters for better generalization and to be flexible for various input types. This is an improvement over the traditional LSTM architecture, which matches the input layer with the output layer as one-to-one structure. The authors report increased performance of the proposed approach when compared to the conventional LSTM architecture. Ren et al. [42] propose an LSTM based model, that also leverages the Convolutional Neural Network architecture. The authors also employ an autoencoder to augment the data and produce a more effective training process. The authors reported superior results when comparing with other commonly used techniques.
Energy-related data is a form of real-world data that is susceptible to various types of drift. To address concept drift in machine learning, a study by Goel and Batra introduces a novel data stream framework called the Dynamically Adaptive and Diverse Dual Ensemble (DA-DDE) [13]. To respond to various types of drift in incoming data streams, the DA-DDE combines online and block-based ensemble techniques and makes use of an adaptive weight setting method and a dual voting system. On 24 synthetic and 11 real datasets, the framework outperforms 14 cutting-edge algorithms, proving its ability to handle various types of drift.
Using a high-dimensional dataset from the Residential Energy Consumption Survey, a paper by Burnett and Kiesling investigates various machine learning techniques to estimate household energy demand [2]. The random forest algorithm outperforms other approaches, such as the step-wise Akaike Information Criterion, partial least squares, ordinary least squares, k-nearest neighbors, penalized regression, and gradient boosting, according to the study, which compares various algorithms to find the one that best fits the data. The study also discusses how machine learning can forecast household energy consumption and inform residential energy policies.
Furthermore, extensive work has been done in the field of applying machine learning prediction techniques for electricity-based pricing. In a study conducted by Zhang et al. [55], four modules—feature pre-processing, deep learning-based point prediction, error compensation, and probabilistic prediction—are proposed as a novel hybrid deep-learning framework for day-ahead electricity price forecasting. The framework uses methods like quantile regression, isolation forest, Lasso, deep belief network, and LSTM neural network to handle the high volatility and nonlinearity of electricity prices. The outcomes of case studies that made use of Pennsylvania New Jersey and Maryland (PJM) market data show that it has an edge over other comparison techniques.
Another study conducted by Peng et al. uses LSTM and the Differential Evolution (DE) algorithm and combines the two to produce the DE-LSTM model for predicting electricity prices [37]. The LSTM’s hyperparameters are optimized by the DE algorithm to address problems with nonlinear regression and time series problems. Tests of the DE-LSTM model's performance on electricity prices in New South Wales, Germany/Austria, and France show that it performs better than existing models in terms of forecasting accuracy.
Using five uncertainty measures—COVID-Induced Uncertainty (CIU), Economic Policy Uncertainty (EPU), Global Fear Index (GFI), Volatility Index (VIX), and Misinformation Index of Uncertainty (MIU)—a study by Olubusoye et al. investigates the effects of uncertainties on energy pricing during the COVID-19 pandemic [35]. According to the study, these uncertainty measures have a significant impact on energy prices, with EPU during the pandemic having the biggest effect. Global energy sources can be predicted using VIX, CIU, and MIU.
To assist with investment decisions, a paper by Sadorsky explores machine learning techniques for forecasting clean energy stock prices. In terms of prediction accuracy, the study discovers that random forests, extremely randomized trees, stochastic gradient boosting, and support vector machines outperform Lasso and Naïve Bayes, achieving over 85% accuracy for forecasts of 10 to 20 days [43]. While EPU is typically less important, technical indicators like the MA200, MA50, and WAD, as well as non-technical indicators like the VIX and OVX, are significant in predicting the direction of the price of stocks. Extremely random trees are notable for their high precision and quick computation.
To better assess the work in the field, a quantitative analysis is be conducted for the identified papers that tackle the application of machine learning models for energy-based pricing. For each relevant paper, the dataset, models and reported performance are be presented in Table 1.
Table 1 highlights the various approaches taken by energy market forecasting researchers, who use a variety of datasets and machine learning models to predict various energy market variables. Different studies have focused on unique regional energy markets and employed distinct models to meet their specific needs, demonstrating that there is no one-size-fits-all solution.
Zhang et al. [55] tackled the PJM market data using advanced deep learning techniques such as DBN, LSTM, and CNN. Their MAPE error rates are relatively low, indicating the effectiveness of these deep learning models in this context. Peng et al. [37], on the other hand, used the DE-LSTM model, which produced a broader range of MAPE values for the New South Wales and French data, implying that the performance of the model varied significantly between the two datasets. On the other hand, Sadorsky [43] took a more comprehensive approach, comparing the performance of various machine learning models on PBW, ICLN, and QCLN datasets, including ET, Lasso, RF, GBM, Naïve Bayes, and SVM. The F1 scores were consistently high, indicating that these models were effective at predicting the energy market variables under consideration. This implies that a comparative approach could be beneficial in determining the best model for a given dataset. Olubusoye et al. [35] used the MARS model on energy prices from investing.com, which produced a narrow range of MAE values. This could imply that the MARS model is a viable option for accurately forecasting energy prices.
Table 1 puts into perspective the dissonance between energy market prediction research efforts. No two of the presented studies employed the same dataset or very similar techniques, with only Zhang et al. and Peng et al. choosing to employ similar architectures based on LSTM networks. As the field of ML is highly dependent on the quality and quantity of data that is available, it is very difficult to assess which option is the best or if a model is superior to others, as long as unity in the datasets is not achieved.
3 Input Data Analysis
The input date was extracted for interval January 2019—August 2022, from the Romanian market operator (OPCOM)Footnote 1—hourly electricity price and traded quantities, Romanian Commodities ExchangeFootnote 2—gas price on DAM and quantity, National Statistics InstituteFootnote 3—inflation, interest rateFootnote 4 in Romania, inflation rate in Europe,Footnote 5 oil price.Footnote 6 Descriptive statistics at the year level are showcased in Appendix 1. The data set overlaps the period before and after the pandemic and the invasion in Ukraine. Electricity price standard deviation and average prices on DAM are graphically represented in Figs. 1 and 2.

Standard deviation in the electricity price on DAM from January 2019 to August 2022 (X—Month, Y—Euro/MWh, Z—Year)

Average prices on DAM from January 2019 to August 2022 (X—Hour, Y—Euro/MWh, Z—Year-Month)
The increase in electricity prices was accompanied by the increase of price index and interest rate (ROBOR 3M). This evolution is shown in Fig. 3.

Monthly average electricity price, inflation, interest rate in Romania, 2019-Aug. 2022 (X—Year and Month, Y—Euro/MWh, Z—Percent)
Although the electricity prices significantly increased from 2019 to 2022, the traded volume on DAM was almost the same in 2019, 2020 and 2021, 2022. A slight increase was noticed between the more stable years (2019, 2020) and more turbulent years (2021, 2022). On average, the traded volume increased by 350–500 MWh, especially at peak and off-peak hours, whereas the prices increased by seven times at evening peak. Furthermore, we noticed a more humped electricity price curve in 2022 compared with 2019 and 2020 (Fig. 4).

Average hourly electricity price and traded volume from 2019 to 2022 (X—Hour, Y—Euro/MWh and MWh, Z—Year)
The electricity prices increase was also accompanied by the price increase of the primary resources (as in Fig. 5) such as gas/oil and their scarcity. We have introduced the prices of gas and oil in our analysis on the assumption that they are driven by the volatility of the energy market, and we could use the signals provided by their evolution to better predict the volatility of electricity price.

Price evolution for electricity, gas and oil between January 2019 to August 2022 (X—Date, Time, Y—Price in Euro/MWh)
To better understand the relationship between data, the correlation matrix was computed. First, the correlations for day level data were calculated. Analyzing the matrix shown in Fig. 6, it can be seen that day-ahead day Price (Price_1) is highly correlated with multiple other variables like Inflation, Gas Price, Oil Price and its own price from the previous day. The ROBOR 3M (interest rate) shows a high value of correlation, 69%, with the day-ahead price, signaling that interest rates exert a certain level of pressure. This is to be expected, as interest rates are connected with Inflation Rate, which has shown strong correlation with Price, and the dynamic between the three of them is not a surprising phenomenon. Another interesting observation to be made is the lack of correlation between the Quantity and the Price. It presents sign of a highly stable or regulated market, where the transaction quantity is somewhat constant, and it plays a small role in determining the price. Looking at the correlation matrix for hour level data, presented in Fig. 6, a similar behavior can be observed. Next, as our study spans a 4-year period (2019–2022), the correlation matrix for each year was computed, to analyze how the relationships between data change from year to year. This analysis is especially of interest due to the high volatility of the studied interval, from a stable 2019 to a pandemic period 2020–2021 and then to a major geopolitical event (conflict in Ukraine). By studying how the market reacts to such random events, a better understanding could lead to a performing prediction model.

Correlation matrix
Beginning with 2019, stark differences can be observed in Fig. 7. The only strong correlation that remains when compared with the entire 4-year period is that between the future and present price, and even it has seen a decrease (92 to 71%). The other variables present lower values, mostly negative, as the relationship is reversed. As such, Inflation, Oil price and Interest rate (ROBOR 3M) were negatively correlated in 2019 with Price. Additionally, Quantity and Price present a stronger correlation. These observations point toward a stable state of the market, where quantity drives price and where oil and energy present substitute product characteristics, as their prices are negatively correlated.

Correlation matrix 2019–2020
Moving to 2020, a shift of the market is observed. The correlations begin to move toward the 4-year period values and the behavior is therefore changed. The relationship between price and inflations changes, as the correlation drastically reduces in value, becoming insignificant. This could point to a change in nature, shifting from negative to positive. It also points to a highly volatile 2020, where prices were mostly determined in conditions of uncertainty. As the market swung, trying to reach an equilibrium point, the only reference point for the price of electricity are the prices of the other energy commodities. However, gas and oil seem to fair better, as their price is still determined by quantity or influenced by ROBOR 3M. However, it is clear that 2020 is a highly volatile and uncertain market, that has produced drastic changes for years to come.
Looking at 2021, the effects of the pandemic seem to be in full swing (as in Fig. 8). The price is now highly correlated with almost all the variables present in the study. Furthermore, the matrix presents strong, positive, correlations throughout. The only negatively correlated variable is quantity and presents the same behavior with all the other variables, except gas quantity. The information presented in Fig. 9 points toward a highly consolidated market that moves in the same direction. There could be multiple explanations for this unity shown by the market, from regulatory measures to players becoming accustomed to a pandemic world. What is certain is that the market present before the pandemic has completely changed and it has had a strong reaction to the shock that was produced by 2020.

Correlation matrix 2021–2022

LSTM cell
Lastly, January–August 2022 interval is studied. It must be mentioned that 2022 is not a complete year. Until August 31st, the final day that is studied, 2022 presents signs of a return to a pre-pandemic state. The strong correlations present in 2021 seem to lessen and a transition towards the original nature of the correlations seems to occur. However, 2022 is also an eventful year, with the emergence of the war in Ukraine. This event has sent shockwaves throughout the world, shockwaves that have also been felt by the energy sector. This can be most easily observed when studying the correlation between price and quantity. Akin to 2020, the strength of the correlation has decreased significantly, becoming mostly irrelevant. As in the case of the first pandemic year, this can point toward a high destabilization of the market, where quantity has no influence in determining the price and where exogenous factors play a role in determining the price behavior. Interesting insights can be extracted from Figs. 7 and 8. Some exogenous variables lost their importance such as the traded quantity, while others (interest rate, gas and oil price, price index) gained importance.
In order to reflect the impact of the COVID-19 pandemic and the Ukrainian crisis, we thoroughly investigate correlation matrices between electricity prices on DAM and multiple exogenous variables. To understand its trend and the changes, we analyze them year by year and depict the results in Figs. 6, 7 and 8. Exogenous variables, such as inflation, interest rate, price of gas, price of oil and traded quantity, are tracked for several years before and after the two major events. Based on the results, one can notice that the electricity price evolution has been significantly influenced by these events.
4 Methodology
In this section, we focus on XGB and LSTM to forecast the electricity price and propose an algorithm. The purpose of the algorithm is to enhance the most significant hyperparameters of the LSTM model and obtain the best forecasting results. In the following paragraphs, the advantages of XGB and LSTM as well as a comparison between the two methods are provided.
We elected to use the vanilla LSTM network for our study because we consider that better attention must be paid to correct data handling and model tuning before more complex models must be used. While different variations to the LSTM network have appeared in literature, we consider that not enough care was given to the model tuning process and performance was lost as a result. As such, we intend to demonstrate that comparable performance to a superior architecture can be achieved by a more conventional network like LSTM, if more effort and thought are given to the data handling and model tuning steps.
On the other hand, XGB is a powerful and widely used tool for performing gradient boosting on structured data [6]. It is a ML technique that has been used to achieve state-of-the-art results on a variety of tasks, including classification, regression, and ranking. At its core, gradient boosting is an ensemble learning method that combines weak prediction models, typically decision trees, to form a strong overall model. The weak models are trained sequentially, with each model attempting to correct the errors of the previous model. This is done by fitting the residuals of the previous model, rather than the original response variable. The final model is a weighted sum of the individual weak models. One of the key features of XGB is its ability to handle missing values and to deal with large-scale data efficiently. It also supports several regularization techniques to prevent overfitting, such as shrinkage, subsampling, and column subsampling. XGB has a few other useful features that make it a popular choice for machine learning tasks. One such feature is its support for a wide range of well-known objective functions. It also supports the use of custom objective functions, allowing users to define their own loss functions for specialized tasks.
Another important feature of XGB is its support for parallelization. It can be run on multiple CPU cores and distributed across multiple machines, allowing it to scale to large datasets. This makes it well-suited for tasks that require the processing of large amounts of data, such as recommendation systems and big data analytics. XGB also provides several advanced features for tuning and optimizing model performance. These include the ability to specify different booster types (such as linear models or tree-based models) and the ability to tune hyperparameters (such as the learning rate or the maximum depth of decision trees).
XGB and LSTM are both machine learning techniques, but they are used for different types of tasks and operate in different ways. LSTM is a type of recurrent neural network (RNN) that is particularly well-suited for tasks involving sequential data, such as time series forecasting. It can maintain a “memory” of past inputs by using gates to control the flow of information through the network, which allows it to effectively capture long-term dependencies in the data [16]. While XGB can be used for time series forecasting, it is not specifically designed for sequential data and may not be as effective as LSTM in capturing long-term dependencies. One advantage of LSTM over XGB for time series forecasting is its ability to learn and use long-term dependencies in the data. This is particularly important for these tasks, where the prediction of future values may depend on past values over a long period of time.
The ability of LSTM to capture and use long-term dependencies allows it to effectively model complex temporal patterns in the data, which can be challenging for other types of models. LSTM for an EPF problem consists of a many-to-many architecture. A data record \({x}^{t}\in X\), where \(X\) is the input data set. The hidden layer output for step t is calculated as following:
where \({a}_{h}\) is the activation function for \({h}^{t}\); \({h}^{t-1}\) is the hidden layer output at step t − 1; \({x}^{t}\) is the input value at step t composed by the following features:
\({b}_{h}\) is the bias for the activation value h; \({\theta }_{h},{\theta }_{x}\) is the two matrix parameters to calculate activation value a that is multiplied by h at step t − 1 and x at step t.
The output or the prediction of the electricity price is:
where \({a}_{y}\) is the activation function for \(\widehat{y}\); \({h}^{t}\) is the hidden layer output at step t; \({b}_{y}\) is the bias for the output \(\widehat{y}\); \({\theta }_{y}\) is the matrix parameter to calculate the output y that is multiplied by the hidden layer output h.
Compressing \({\theta }_{h}, {\theta }_{x}\) into one matrix of weights \(\theta\) and \(\left[\begin{array}{c}{h}^{t-1}\\ {x}^{t}\end{array}\right]=\left[{h}^{t-1},{x}^{t}\right]\), we obtain:
And Eq. (1) becomes:
The objective of LSTM algorithm is to minimize the loss or the cost function that is:
To solve the vanishing gradient problem, LSTM contains a cell memory variable c to keep information about spikes and remember them using gates. In the Gated Recurrent Unit (GRU) model that is a simpler version of LSTM, the memory cell is equal to the hidden layer output value:
where \({a}_{c}\) is the activation function for the memory cell; \({\widetilde{c}}^{t}\) is a candidate to replace \({c}^{t}\) when it is no more needed depending on the update gate that has an important role in deciding when \({c}^{t}\) is updated with the candidate memory cell. The input or update gate \({i}^{t}\) can be defined as:
where \({a}_{i}\) is the activation function for the update gate and it can be a sigmoid function. \({i}^{t}\) tends to 0 or 1. \({i}^{t}\) stores the relevant information about spikes in the memory cell to pass long sequences of data until it is used, then it can be forgotten. Therefore, the memory cell is defined as:
Thus, if the update gate is zero (\({i}^{t}=0\)), then the old value of the memory cell remains stored in the memory cell \({c}^{t}={c}^{t-1}\) until the update gate is one (\({i}^{t}=1\)), when the candidate replaces the actual memory cell: \({c}^{t}={\widetilde{c}}^{t}\). A relevance gate \({r}^{t}\) can be added to the model to store the relevance of the previous memory cell components.
But for LSTM \({c}^{t}\ne {a}^{t}\). Therefore, the candidate memory cell \({\widetilde{c}}^{t}\) at step t becomes:
Furthermore, the second component of Eq. (11), \((1-{i}^{t})\) is a new gate noted \({f}^{t}\), known as foregate gate. It can be calculated as:
The output gate \({o}^{t}\) allows the calculation of activation value at each step t:
Thus, the memory cell is defined as:
Using separate gates: \({i}^{t}\) and \({f}^{t}\), the memory cell keeps the previous value of the memory cell \({c}^{t-1}\) as well as the candidate value \({\widetilde{c}}^{t}\). The hidden layer output is equal to the output gate multiplied by memory cell at step t:
In Fig. 9, one of the LSTM cells is showcased. With the hidden layer output from previous step t − 1, \({h}^{t-1}\) and the input data at step t, \({x}^{t}\), the values of gates and the candidate memory cell \({\widetilde{c}}^{t}\) are calculated using various activation functions (sigmoid \(\sigma\), tanh, etc.). Using the previous memory cell and wise operators, the value of memory cell at step t is obtained.
Different configurations of the prediction model can be designed. The challenge is to identify the best configuration of the stacked LSTM architecture in order to enhance the results of EPF. The proposed algorithm for the best variable combination identification is presented in Table 2.
To evaluate the performance of the trained models and identify the best one, we elected to use RMSE, MSE, MAE and MAE/Average Price as performance metrics. Their use in the context of energy price prediction provides a comprehensive evaluation of the models’ accuracy and robustness. Both RMSE and MSE are useful for quantifying large deviations because the squaring operation penalizes larger errors more heavily. RMSE is sensitive to large differences, making it useful when minimizing such errors that is critical. MAE, on the other hand, provides a more interpretable and robust error measure because it computes the average absolute differences between predicted and actual values and is less sensitive to outliers. Finally, the MAE to Average Price ratio normalizes the error based on the average price, making it easier to compare model performance across datasets, time periods, or regions. Using these metrics in combination allows for a thorough examination of the model’s strengths and weaknesses, allowing for more informed improvements and refinements to increase its predictive capabilities.
The algorithm aims to identify the combination of parameters that will generate the best results. It works as follows: for three thresholds set \(thr\) for correlation with the day-ahead price, the variables that will be used by the model are selected, starting from the strongest correlation, over 90%, to the weakest threshold, over 70%. After this selection, the train and test sets are created and the input for the neural network is generated.
Each parameter influences the performance of the model in different ways. The threshold limits the quantity of data that is fed to the model, going from more to less restrictive. We use this parameter to identify the ideal informational cut-off for our experiments and determine which are the independent variables that must be used to determine the best performing model. The hidden layer size determines the size of our LSTM network. Larger networks have proven to deliver better performance for large quantities of data. This parameter starts small and increases as we intend to identify the ideal size of our network, given the presented data. Dropout and learning rate are important concepts in deep learning model training because they help to improve generalization and convergence speed. Dropout is a regularization technique that prevents overfitting by deactivating a proportion of neurons in a layer at random during training, forcing the model to learn more robust features and generalize better to unobserved data. In contrast, the learning rate is a critical hyperparameter that controls the step size at which the model updates its weights during gradient descent. An appropriate learning rate is critical for efficient training, balancing convergence speed and stability, and techniques, such as learning rate scheduling or adaptive learning rates can further optimize the process. Dropout and learning rate work together to improve the accuracy and efficiency of deep learning models. These parameters go from less to more aggressive, with an increase of dropout and decrease of learning rate, to help the model in the training process.
5 Results
The experiments were run on an Intel I7 3930 k CPU and an Nvidia GTX 1070 8 GB GPU machine. The Python version used was 3.9.12 and Tensorflow version 2.6.0.
According to the algorithm depicted in Table 2, 75 models are generated for each \(thr\), by adjusting the \(hls\), \({\varvec{d}}{\varvec{r}}{\varvec{o}}{\varvec{p}}{\varvec{o}}{\varvec{u}}{\varvec{t}}\) and \(lr\). After each model is generated, its results are computed and the metrics are stored, so they can be benchmarked, and the best parameter combination can be identified. As such, there were 225 models trained for each time step, day and hour, for a total of 550 models.
The models were trained for 150 periods, using the Adam optimizer and a batch size of 32. The models were trained with an 80/20 split of the data set. As such, they were trained using the 2019–2021 data, until July 12th, 2021. Therefore, the second half of 2021 and the entirety of 2022 are used for testing the performance of the models. The values of the different parameters are presented in Table 3.
The best architecture for LSTM at the day and hour level is shown in Fig. 10.

LSTM model
To better understand the variables related to each threshold, they are presented in Table 4. These variables are selected based on the entire 4-year period, as the intent is to develop a model that can predict market disturbances and black swan events, like the war or the pandemic.
The metrics of the best performing models, along with the parameters used to generate these models, are presented in Table 5. The Hour model achieves superior results compared to the Day model. This could be a consequence of the volume of data, as the Hour model was trained on 24 times more data points and deep learning models are known to be data hungry. However, both models generate good results and display the ability for generalization. Going forward, it is recommended to use as much data as possible as shown to improve results. The granularity of the data must also be prioritized, with hourly data displaying a good reference point.
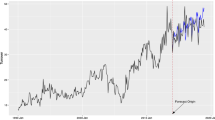
To visually assess the performance of the best identified models, the actual vs predicted curves were plotted in Figs. 11 and 12. Again, the increased performance of the Hour model can be observed, better following the value of the actual price, especially on the downturns. However, both models struggle when predicting price spikes. The models correctly identify the increase in price. However, they underestimate the increase of the price, with predicted prices plateauing around the 2500 mark. This is caused by the training data that the model has seen, as the maximum value from the train sample is 2000, while the maximum value from the test sample is over 4000. We chose to treat the data as time series and price as an auto-regressive variable. The previous value of price was the main influencer of present value of price. However, this methodology presents limitations, as the one identified in this study. To improve performance, the data can be shuffled, to ensure the models see as great of a variance as possible. Therefore, the ability of the model to predict the significance of a price swing can improve. However, models are still dependent on observed, historical data. As such, their ability to predict the occurrence of unpredictable events is significant, but the ability to assess the impact of those events still leaves a lot to be desired. Given these circumstances, our models display great performance on the collected data set and they represent a good point of reference for future research.

Actual vs predicted day (a); actual vs predicted hour (last 30 days) (b)

Actual vs predicted hour (last 268 days)
Furthermore, we develop models for each year in the study, trained on a smaller sample. The selected train period was January 15th to April 15th of each year, and the test period was the next 7 days, April 16th to April 22nd. To better assess the performance of LSTM model, we benchmarked the results with the results of an XGB Regressor model, trained on the same period, without using the correlation threshold. The best performing model, using the stated methodology, for each year is presented in Table 6.
Analyzing the yearly models that were trained on a small sample, it can be noticed that the XGB model achieves superior results in 3 of the 4 years, with 2019 being the only year in which the PA outclasses the standard model. This result is most likely determined by the small data sample used for training, as neural networks are known to require a great volume of data to display their performance. This argument is further approved when we train the models for the entire 4-year period and the PA achieves superior results to the XGB model, improving on the MAE/Average Price metric by more than 33%. The results are presented in Tables 7 and 8.
The superior performance of the PA when compared to the XGB model is again observed when the Hour time step is used for training. Using a larger data set enables the LSTM based architecture to better learn the relationship between the target, the day-ahead price, and the other selected variables and it leads to a substantial increase in performance. As such, the PA nets superior results, up to 243% improvement, to the benchmarking model and is the preferred option when using larger datasets. A graphical comparison for each year is shown in Fig. 13.

Actual prices versus prediction using XGB (left) and LSTM (right)
Besides benchmarking the performance of our solution with a baseline model, we have also benchmarked the performance of the PA with results reported in the literature. The comparison can be found in Table 9.
The results reinforce the conclusion drawn in the literature review section, where these papers were first introduced, there is no one size fits all solution. It can be observed that various datasets, with all the papers selecting to use a different dataset, and the dependence of the metrics to the distribution of the data make it difficult to correctly benchmark such solutions. For this reason, we have chosen to also report the MAE/average price metric, to provide a data agnostic result and better present the performance of our model. However, it can be observed when compared to other approaches from literature that PA nets good results, in accordance with the latest efforts. This proves that more attention must be given to data selection, processing, and good model selection. While ensemble methods or variations to traditional models could prove superior, much work must still be conducted on conventional models to extract as much value from them as possible. As such, the PA stands as evidence that conventional architectures, like LSTM, can generate comparable results to other, superior, methods, if enough effort and time is allocated to the data handling and model tuning processes.
6 Discussion on the Research Question
After performing input data analytics and EPF, coming back to the research question (How does the current disruptive economic and geopolitical context influence the electricity price and its prediction?) that motivated us to analyze more recent data from the electricity DAM and perform this study, several insights and policy implications are identified.
First, COVID-19 significantly influenced the inflation and the interest rates in Romania and Europe. All European electricity markets were heavily influenced by price fluctuations. The rapid grow of request for commodities and business recovery immediately after lockdowns also impacted the electricity markets especially the auctioning systems as they proved to be fragile. The market participants (producers and traders) speculated about the fact that the request for electricity was still high even if the prices were gradually increasing. The price-takers transformed into price-makers as they tested the market increasing the prices day by day to find out the market saturation level.
Considering this speculative behavior of sellers on DAM, several policy implications are revealed. First, the current pricing mechanism on DAM is Uniform Price (UP) that favorizes sellers that bid a lower price by offering them the clearing market price that is usually higher. A different pricing mechanism such as Pay-as-Bid (PAB) or Generalized Second Price (GSP) is more appropriate especially during disruptive economic and geopolitical context. Second, even if it distorts competition, another policy measure that can be imposed in the short run is a cap price for sellers. This measure could be applied until the economic context is less disruptive. Therefore, the market design of European coupled DAM should be reconsidered to avoid speculative behavior. This was additionally increased by the pedologic drought in Europe and planned maintenance intervals of the large nuclear units that were speculated by the sellers.
A drop in the competitiveness at the sellers’ level was noticed starting from May 2022 that also led to the higher prices in the following months. Herfindahl–Hirschman Index (HHI) on DAM increased from a low concertation level of 435 in December 2021 to almost 1482 in June 2022, then the HHI increased to moderate concentration level disturbing the competitiveness. Furthermore, C3—that is the sum of market shares of the biggest three market players showed a low competitiveness level on DAM. This indicated that the dominant sellers might use their market power, leading to higher electricity prices. Therefore, there is a strong relationship between DAM concentration and prices.
On top of that, the conflict in Ukraine increased the request for more commodities due to the war necessities in the proximity of the Black Sea border. Inflation additionally increased, generating higher interest rates and higher electricity prices. The size of the snowball effect could be seen in August 2022 when the electricity prices went to the highest level ever. The invasion in Ukraine came with sanctions and the fear that the prices would go up due to the primary resources’ scarcity. The crisis that followed the war in Ukraine again impacted the electricity prices as gas and oil were provided by Russia and the electricity markets in most European countries are coupled. Therefore, they were shaken by the first waves of shock of the invasion. The high level of migration also had a negative impact on the electricity markets.
In 2019 and 2020, we could notice more stability on DAM, but in 2021 and 2022, the influence of the input variables on the electricity price drastically changed. 2019 and 2020 presents signs of a stable market, where the transaction quantity is somewhat constant, and it plays a small role in determining the price. Inflation, oil price and interest rate were negatively correlated in 2019 with the price. Additionally, quantity and price present a stronger correlation. These observations point towards a stable state of the market, where quantity drives price and where oil and energy present substitute product characteristics, as their prices are negatively correlated. Higher price fluctuations were recorded in the 2nd semester of 2021 and in 2022. The price was highly correlated with almost all the variables and inversely correlated with quantity. The market before the pandemic has completely changed. The standard deviation of the electricity price on DAM increased from 17 in 2020 to 81 in 2021 and 147 in 2022. The mean hourly prices per month were around 0–100 Euro/MWh until mid of 2021, and they rapidly increased and went up to 600–700 Euro/MWh at peak hours by mid-2022. Fundamental features like traded quantity on DAM lost importance in 2021 and 2022 when gas, oil prices and inflation gained more importance according to the correlation maps.
The traded quantities on DAM did not increase following the same pace as prices. Therefore, the significant increase of the prices (that went up to 7 times) was not caused by the increase of the request on DAM that spanned from 350 to 500 MW. The small increase of the traded quantities was more determined by RES that are more predictable on short-term and preferred DAM. Therefore, the RES owners tried to avoid long-term bilateral contracts that are less flexible for RES. From this point of view, the Bilateral Contracts Market (BCM) design for RES is not appropriate. More flexibility is required to support RES owners to approach this market that offers a more stable market framework. The actual products (characterized by fixed quantities at certain hours of peak or off-peak and at certain week or weekend days) that can be traded on the BCM are rigid and are not likely to fit RES operational particularities due to their volatile output.
Electricity forecast is also significantly influenced by the disruptive economic and geopolitical context. The prediction errors doubled with both methods that enabled us to perform EPF. In comparison with XGB, LSTM reduced the level of errors but even with LSTM, the errors in 2022 were 2–3 times higher than errors in 2019. LSTM was able to capture and use long-term dependencies modelling complex temporal patterns in data, which can be challenging for other types of models. Results proved that a RNN architecture (the proposed LSTM architecture) is therefore more adequate to provide EPF than one of the most standout machine leaning algorithms (XGB).
7 Conclusion
In this paper, we have analyzed the predictive capability of the LSTM architecture on a constructed dataset consisting of some Romanian economy variables (such as: inflation, interest rate) and market data (electricity and gas prices and traded quantities on DAM), brent crude oil prices and inflation in Europe in the current economic and geopolitical context. We proposed a framework for data selection and model parametrization that has displayed superior results when compared to the XGBoost baseline model, while taking less time to train. The reported results are encouraging, achieving a high level of performance with a small margin of error.
One limitation of the proposed method is the data volume it requires to provide reliable results. Therefore, at least six months of data collection are necessary to train the LSTM model and obtain accurate results. For shorter intervals, the performance of LSTM model is lower. Another limitation of our study is regarding the time window selected for the analysis. If more robust models are to be trained, different and longer time periods should be analyzed. The architecture of the selected model could prove to be another limitation of this study. While we have proven that even a conventional LSTM-based model can achieve respectable results, variations have been shown to bring improvements. As such, a variation of a LSTM network in tandem with the PA for data handling and hyperparameter tuning could net superior results.
Going forward, we look to expand on the research presented in this paper by improving our data collection process and introducing more data in our experiments, like sentiment data collected from social networks, and by improving our model, expanding on the LSTM architecture by implementing better parametrization techniques or developing more complex architectures.
By developing a highly accurate predictive model on a dataset constructed for a under researched market, the Romanian energy market, on a time span of almost four years where high volatility has been present, we conclude that the aim of our research was achieved. The research performed in this paper can serve as a foundation for future research to explore the Romanian energy market, forecasting on high volatility intervals or employing a data selection and parametrization technique in conjunction with a state-of-the-art forecasting models like LSTM.
Availability of Data and Material
The data can be available upon reasonable request.
Notes
References
Beltrán, S., Castro, A., Irizar, I., Naveran, G., Yeregui, I.: Framework for collaborative intelligence in forecasting day-ahead electricity price. Appl. Energy (2022). https://doi.org/10.1016/j.apenergy.2021.118049
Burnett, J.W., Kiesling, L.L.: “How do machines predict energy use? Comparing machine learning approaches for modeling household energy demand in the United States. Energy Res. Soc. Sci. 91, 102715 (2022). https://doi.org/10.1016/j.erss.2022.102715
Cao, J., Li, Z., Li, J.: Financial time series forecasting model based on CEEMDAN and LSTM. Phys. A Stat. Mech. Appl. (2019). https://doi.org/10.1016/j.physa.2018.11.061
Chang, A.Y., Cowling, K., Micah, A.E., Chapin, A., Chen, C.S., Ikilezi, G., Sadat, N., et al.: Past, present, and future of global health financing: a review of development assistance, government, out-of-pocket, and other private spending on health for 195 countries, 1995–2050. Lancet (2019). https://doi.org/10.1016/S0140-6736(19)30841-4
Chen, S., Ge, L.: Exploring the attention mechanism in LSTM-based Hong Kong stock price movement prediction. Quant. Finance (2019). https://doi.org/10.1080/14697688.2019.1622287
Chen, T., Guestrin, C.: XGBoost: a scalable tree boosting system. In: Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Vol. 13–17-August-2016, doi: https://doi.org/10.1145/2939672.2939785 (2016).
Dai, S., Li, L., Li, Z.: Modeling vehicle interactions via modified LSTM models for trajectory prediction. IEEE Access (2019). https://doi.org/10.1109/ACCESS.2019.2907000
Delgado, I., Fahim, M.: Wind turbine data analysis and lstm-based prediction in scada system. Energies (2021). https://doi.org/10.3390/en14010125
Dobrowolski, Z., Sułkowski, Ł, Panait, M.: Using the business model canvas to improve audit processes. Probl. Perspect. Manag. 20(3), 142–152 (2022)
Dong, S., Wang, P. and Abbas, K. (2021), “A survey on deep learning and its applications”, Computer Science Review, Elsevier, Vol. 40, p. 100379, doi: https://doi.org/10.1016/J.COSREV.2021.100379.
Gabrielli, P., Wüthrich, M., Blume, S., Sansavini, G.: Data-driven modeling for long-term electricity price forecasting. Energy 244, 123107 (2022). https://doi.org/10.1016/J.ENERGY.2022.123107
Georgescu, I.: A possibilistic approach to risk aversion. Soft. Comput. (2011). https://doi.org/10.1007/s00500-010-0634-7
Goel, K., Batra, S.: Dynamically adaptive and diverse dual ensemble learning approach for handling concept drift in data streams. Comput. Intell. 38(2), 463–505 (2022). https://doi.org/10.1111/coin.12475
Hashemipour, N., Aghaei, J., Granado, P.C.D., Kavousi-Fard, A., Niknam, T., Shafie-Khah, M., Catalao, J.P.S.: Uncertainty modeling for participation of electric vehicles in collaborative energy consumption. IEEE Trans. Veh. Technol. (2022). https://doi.org/10.1109/TVT.2022.3184514
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997). https://doi.org/10.1162/neco.1997.9.8.1735
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. (1997). https://doi.org/10.1162/neco.1997.9.8.1735
Holz, F., Scherwath, T., Crespo del Granado, P., Skar, C., Olmos, L., Ploussard, Q., Ramos, A., et al.: A 2050 perspective on the role for carbon capture and storage in the European power system and industry sector. Energy Econ. (2021). https://doi.org/10.1016/j.eneco.2021.105631
Huang, Z., Wang, J., Pi, L., Song, X., Yang, L.: LSTM based trajectory prediction model for cyclist utilizing multiple interactions with environment. Pattern Recognit. (2021). https://doi.org/10.1016/j.patcog.2020.107800
Iqbal, M., Al-Obeidat, F., Maqbool, F., Razzaq, S., Anwar, S., Tubaishat, A., Khan, M.S., et al.: COVID-19 patient count prediction using LSTM. IEEE Trans. Comput. Soc. Syst. (2021). https://doi.org/10.1109/TCSS.2021.3056769
Junwei, K., Yang, H., Junjiang, L., Zhijun, Y.: Dynamic prediction of cardiovascular disease using improved LSTM. Int. J. Crowd Sci. (2019). https://doi.org/10.1108/IJCS-01-2019-0002
Keles, D., Scelle, J., Paraschiv, F., Fichtner, W.: Extended forecast methods for day-ahead electricity spot prices applying artificial neural networks. Appl. Energy (2016). https://doi.org/10.1016/j.apenergy.2015.09.087
Kovacs Erik-Robert, L.-A., Cotfas, D.C.: COVID-19 vaccination opinions in education-related tweets. In: Huseyin, B.M., Danis, H.D.E. (eds.) Eurasian business and economics perspectives, pp. 21–41. Springer International Publishing, Cham (2022)
Lazaroiu, C., Roscia, M., Saatmandi, S.: Blockchain strategies and policies for sustainable electric mobility into Smart City, in 2020 International Symposium on Power Electronics, Electrical Drives, Automation and Motion, SPEEDAM 2020, doi: https://doi.org/10.1109/SPEEDAM48782.2020.9161832 (2020).
Lazaroiu, G.C., Roscia, M.: Fuzzy logic strategy for priority control of electric vehicle charging. IEEE Trans. Intell. Transp. Syst. 23(10), 19236–19245 (2022). https://doi.org/10.1109/TITS.2022.3161398
Lehna, M., Scheller, F., Herwartz, H.: Forecasting day-ahead electricity prices: a comparison of time series and neural network models taking external regressors into account. Energy Econ. (2022). https://doi.org/10.1016/j.eneco.2021.105742
Liu, J., Zhang, T., Han, G., Gou, Y.: TD-LSTM: Temporal dependence-based LSTM networks for marine temperature prediction. Sensors (Switzerland) (2018). https://doi.org/10.3390/s18113797
Loutfi, A.A., Sun, M., Loutfi, I., Solibakke, P.B.: “Empirical study of day-ahead electricity spot-price forecasting: insights into a novel loss function for training neural networks. Appl. Energy 319, 119182 (2022). https://doi.org/10.1016/J.APENERGY.2022.119182
Lu, X., Qiu, J., Lei, G., Zhu, J.: Scenarios modelling for forecasting day-ahead electricity prices: case studies in Australia. Appl. Energy (2022). https://doi.org/10.1016/j.apenergy.2021.118296
Lungu, I., Căruţaşu, G., Pîrjan, A., Oprea, S.V., Bâra, A.: A two-step forecasting solution and upscaling technique for small size wind farms located on hilly terrain in Romania. Studies Info. Control J. 25(1), 77–86 (2016). https://doi.org/10.24846/v25i1y201609
Ma, R., Zheng, X., Wang, P., Liu, H., Zhang, C.: The prediction and analysis of COVID-19 epidemic trend by combining LSTM and Markov method. Sci. Rep. (2021). https://doi.org/10.1038/s41598-021-97037-5
Marneris, I.G., Ntomaris, A.V., Biskas, P.N., Baslis, C.G., Chatzigiannis, D.I., Demoulias, C.S., Oureilidis, K.O., et al.: Optimal participation of RES aggregators in energy and ancillary services markets. IEEE Trans. Ind. Appl. (2023). https://doi.org/10.1109/TIA.2022.3204863
Meng, A., Wang, P., Zhai, G., Zeng, C., Chen, S., Yang, X., Yin, H.: Electricity price forecasting with high penetration of renewable energy using attention-based LSTM network trained by crisscross optimization. Energy 254, 124212 (2022). https://doi.org/10.1016/J.ENERGY.2022.124212
Mou, H., Yu, J.: Cnn-lstm prediction method for blood pressure based on pulse wave. Electronics (Switzerland) (2021). https://doi.org/10.3390/electronics10141664
Munir, H.S., Ren, S., Mustafa, M., Siddique, C.N., Qayyum, S.: Attention based GRU-LSTM for software defect prediction. PLoS ONE (2021). https://doi.org/10.1371/journal.pone.0247444
Olubusoye, O.E., Akintande, O.J., Yaya, O.S., Ogbonna, A.E., Adenikinju, A.F.: Energy pricing during the COVID-19 pandemic: predictive information-based uncertainty indexes with machine learning algorithm. Intell. Syst. Appl. 12, 200050 (2021). https://doi.org/10.1016/j.iswa.2021.200050
Park, K., Choi, Y., Choi, W.J., Ryu, H.Y., Kim, H.: LSTM-based battery remaining useful life prediction with multi-channel charging profiles. IEEE Access (2020). https://doi.org/10.1109/ACCESS.2020.2968939
Peng, L., Liu, S., Liu, R., Wang, L.: Effective long short-term memory with differential evolution algorithm for electricity price prediction. Energy 162, 1301–1314 (2018). https://doi.org/10.1016/j.energy.2018.05.052
Popescu, C., Hysa, E. and Panait, M.: Perspectives of Responsible Management in Today’s VUCA World, in Akkaya, B., Guah, M.W., Jermsittiparsert, K., Bulinska-Stangrecka, H., Kaya, Y. (Eds.), Agile Management and VUCA-RR: Opportunities and Threats in Industry 4.0 towards Society 5.0, Emerald Publishing Limited, pp. 57–71, https://doi.org/10.1108/978-1-80262-325-320220005 (2022).
Quan, R., Zhu, L., Wu, Y., Yang, Y.: Holistic LSTM for pedestrian trajectory prediction. IEEE Trans. Image Process. (2021). https://doi.org/10.1109/TIP.2021.3058599
Raimi, L., Panait, M., Grigorescu, A., Vasile, V.: Corporate social responsibility in the telecommunication industry-driver of entrepreneurship. Resources (2022). https://doi.org/10.3390/resources11090079
Ramirez, A., Lazaroiu, G.C.: Fast steady-state computation of electrical networks involving nonlinear and photovoltaic components. IEEE Trans. Smart Grid (2021). https://doi.org/10.1109/TSG.2021.3053488
Ren, L., Dong, J., Wang, X., Meng, Z., Zhao, L., Deen, M.J.: A data-driven auto-CNN-LSTM prediction model for lithium-ion battery remaining useful life. IEEE Trans. Ind. Inform. 17(5), 102 (2021). https://doi.org/10.1109/TII.2020.3008223
Sadorsky, P.: Using machine learning to predict clean energy stock prices: how important are market volatility and economic policy uncertainty. J. Clim. Finance 1, 100002 (2022). https://doi.org/10.1016/j.jclimf.2022.100002
Sandhu, H.S., Fang, L., Guan, L.: Forecasting day-ahead price spikes for the Ontario electricity market. Electric Power Syst. Res. (2016). https://doi.org/10.1016/j.epsr.2016.08.005
Shahid, F., Zameer, A., Muneeb, M.: Predictions for COVID-19 with deep learning models of LSTM, GRU and Bi-LSTM. Chaos Solitons Fractals (2020). https://doi.org/10.1016/j.chaos.2020.110212
Ta, V.D., Liu, C.M., Tadesse, D.A.: Portfolio optimization-based stock prediction using long-short term memory network in quantitative trading. Appl. Sci. (Switzerland) (2020). https://doi.org/10.3390/app10020437
Tang, X.: Large-scale computing systems workload prediction using parallel improved LSTM neural network. IEEE Access (2019). https://doi.org/10.1109/ACCESS.2019.2905634
Tschora, L., Pierre, E., Plantevit, M., Robardet, C.: Electricity price forecasting on the day-ahead market using machine learning. Appl. Energy (2022). https://doi.org/10.1016/j.apenergy.2022.118752
Tsukiyama, S., Hasan, M.M., Fujii, S., Kurata, H.: LSTM-PHV: prediction of human-virus protein-protein interactions by LSTM with word2vec. Briefings Bioinform. 22(6), 102 (2021). https://doi.org/10.1093/bib/bbab228
Wei, W., Wu, H., Ma, H.: An autoencoder and LSTM-based traffic flow prediction method. Sensors (Switzerland) (2019). https://doi.org/10.3390/s19132946
Yan, L., Chen, C., Hang, T., Hu, Y.: A stream prediction model based on attention-LSTM. Earth Sci. Inform. (2021). https://doi.org/10.1007/s12145-021-00571-z
Yang, B., Sun, S., Li, J., Lin, X., Tian, Y.: Traffic flow prediction using LSTM with feature enhancement. Neurocomputing (2019). https://doi.org/10.1016/j.neucom.2018.12.016
Yang, H., Schell, K.R.: QCAE: a quadruple branch CNN autoencoder for real-time electricity price forecasting. Int. J. Electric. Power Energy Syst. 141, 108092 (2022). https://doi.org/10.1016/J.IJEPES.2022.108092
Zhang, M., Wu, D., Xue, R.: Hourly prediction of PM2.5 concentration in Beijing based on Bi-LSTM neural network. Multimed. Tools Appl. (2021). https://doi.org/10.1007/s11042-021-10852-w
Zhang, R., Li, G., Ma, Z.: A deep learning based hybrid framework for day-ahead electricity price forecasting. IEEE Access 8, 143423–143436 (2020). https://doi.org/10.1109/ACCESS.2020.3014241
Zhang, T., Zheng, X.Q., Liu, M.X.: Multiscale attention-based LSTM for ship motion prediction. Ocean Eng. (2021). https://doi.org/10.1016/j.oceaneng.2021.109066
Zheng, H., Lin, F., Feng, X., Chen, Y.: A hybrid deep learning model with attention-based conv-LSTM networks for short-term traffic flow prediction. IEEE Trans. Intell. Transport. Syst. (2021). https://doi.org/10.1109/TITS.2020.2997352
Zhichao Zou, Z.Q.: Using LSTM in stock prediction and quantitative trading. Deep Learning (2022)
Zhou, B., Ma, X., Luo, Y., Yang, D.: Wind power prediction based on LSTM networks and nonparametric kernel density estimation. IEEE Access (2019). https://doi.org/10.1109/ACCESS.2019.2952555
Acknowledgements
This paper was supported by Academy of Romanian Scientists, Ilfov 3, 050044 Bucharest, Romania, project title: Soluții informatice pentru analiza impactului rețelelor de social media asupra instrumentelor investiționale cu grad ridicat de risc: cryptomonede și bursă.
Author information
Authors and Affiliations
Contributions
S-VO: conceptualization, software, validation, formal analysis, investigation, resources, data curation, writing—original draft, writing—review and editing, visualization, supervision, project administration. AB: conceptualization, methodology, validation, formal analysis, investigation, writing—original draft, writing—review and editing, visualization. A-CB: conceptualization, methodology, validation, formal analysis, investigation, writing—original draft, writing—editing, visualization.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bâra, A., Oprea, SV. & Băroiu, AC. Forecasting the Spot Market Electricity Price with a Long Short-Term Memory Model Architecture in a Disruptive Economic and Geopolitical Context. Int J Comput Intell Syst 16, 130 (2023). https://doi.org/10.1007/s44196-023-00309-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00309-3