
Abstract
In this work, we are concerned with neural network guided goal-oriented a posteriori error estimation and adaptivity using the dual weighted residual method. The primal problem is solved using classical Galerkin finite elements. The adjoint problem is solved in strong form with a feedforward neural network using two or three hidden layers. The main objective of our approach is to explore alternatives for solving the adjoint problem with greater potential of a numerical cost reduction. The proposed algorithm is based on the general goal-oriented error estimation theorem including both linear and nonlinear stationary partial differential equations and goal functionals. Our developments are substantiated with some numerical experiments that include comparisons of neural network computed adjoints and classical finite element solutions of the adjoints. In the programming software, the open-source library deal.II is successfully coupled with LibTorch, the PyTorch C++ application programming interface.
Article Highlights
-
Adjoint approximation with feedforward neural network in dual-weighted residual error estimation.
-
Side-by-side comparisons for accuracy and computational cost with classical finite element computations.
-
Numerical experiments for linear and nonlinear problems yielding excellent effectivity indices.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
This work is devoted to an innovative solution of the adjoint equation in goal-oriented error estimation with the dual weighted residual (DWR) method [3,4,5] (based on former adjoint concepts [19]); we also refer to [1, 7, 22, 41] for some important early work. Since then, the DWR method has been applied to numerous applications such as variational inequalities [54], space-time adaptivity for parabolic problems [51], fluid-structure interaction [20, 23, 47, 57], Maxwell’s equations [12], worst-case multi-objective adaptivity [55], the finite cell method [53], surrogate models in stochastic inversion [37], model adaptivity in multiscale problems [36], mesh and model adaptivity for frictional contact [43], and adaptive multiscale predictive modeling [39]. A summary of theoretical advancements in efficiency estimates and multi-goal-oriented error estimation was recently made in [15]. An important part in these studies is the adjoint problem, as it measures the sensitivity of the primal solution with respect to a single or multiple given goal functionals (quantities of interest). This adjoint solution is usually obtained by global higher order finite element method (FEM) solutions or local higher order approximations [5]. In general, the former is more stable, see e.g. [18], but the latter works often sufficiently well in practice. As the adjoint solution is only required to evaluate the a posteriori error estimator, a cheap solution is of interest.
Consequently, in this work, the main objective is to explore alternatives for computing the adjoint. Due to the universal approximation property [42], a primer candidate are neural networks as they are already successfully employed for solving ordinary and partial differential equations (PDE) [6, 10, 24, 25, 30, 31, 33, 34, 44, 45, 50, 52, 58]. A related work in aiming to improve goal-oriented computations with the help of neural network data-driven finite elements is [9]. Moreover, a recent summary of the key concepts of neural networks and deep learning was compiled in [26]. The advantage of neural networks is a greater flexibility as they belong to the class of meshless methods. We follow the methodology of [44, 52] to solve PDEs by minimizing the residual using an L-BFGS (Limited memory Broyden-Fletcher-Goldfarb-Shanno) method [32]. We address both linear and nonlinear PDEs and goal functionals in stationary settings. However, a shortcoming in the current approach is that we need to work with strong adjoint formulations, which may limit extensions to nonlinear coupled PDEs such as multiphysics problems and coupled variational inequality systems. If such problems can be restated in an energy formulation, again neural network algorithms are known [14, 50]. Despite this drawback, namely the necessity of working with strong formulations, the current study provides useful insights whether at all neural network guided adjoints can be an alternative concept for dual weighted residual error estimation. For this reason, our resulting modified adaptive algorithm and related numerical simulations are compared side by side in all numerical tests to classical Galerkin finite element solutions (see e.g., [11]) of the adjoint. Our proposed algorithm is implemented in the open-source finite element library deal.II [2] coupled with LibTorch, the PyTorch C++ API [40].
The outline of this paper is as follows: In Sect. 2, we recapitulate the DWR method. Next, in Sect. 3 we gather the important ingredients of the neural network solution. This section also includes an extension of an approximation theorem from Lebesgue spaces to classical function spaces. The algorithmic realization is addressed in Sect. 4. Then, in Sect. 5 several numerical experiments are conducted. Our findings are summarized in Sect. 6.
2 Dual weighted residual method
2.1 Abstract problem
Let U and V be Banach spaces and let \({\mathcal {A}}: U \rightarrow V^*\) be a nonlinear mapping, where \(V^*\) denotes the dual space of V. With this, we can define the problem: Find \(u \in U\) such that
Additionally, we can look at an approximation of this problem. For subspaces \({\tilde{U}} \subset U\) and \({\tilde{V}} \subset V\) the problem reads: Find \({\tilde{u}} \in {\tilde{U}}\) such that
Remark 1
In the following the nonlinear mapping \({\mathcal {A}}(\cdot )(\cdot )\) will represent the variational formulation of a stationary partial differential equation with the associated function spaces U and V. We define the finite element approximation of the abstract problem as follows: Find \(u_h \in U_h\) such that
where \(U_h \subset U\) and \(V_h \subset V\) denote the finite element spaces. Here the operator is given by \({\mathcal {A}}(u_h)(\cdot ) := a(u_h)(\cdot ) - l(\cdot )\) with the linear forms \(a(u_h)(\cdot )\) and \(l(\cdot )\).
2.2 Motivation for adaptivity
In many applications we are not necessarily interested in the whole solution to a given problem but more explicitly only in the evaluation of a certain quantity of interest. This quantity of interest can often be represented mathematically by a goal functional \(J: U \rightarrow {\mathbb {R}}\). Here the main target is to minimize the approximation error between u and \(u_h\) measured in the given goal functional \(J(\cdot )\) and use the computational resources efficiently. This can lead to the approach of [4, 5], the DWR method, which this work will follow closely. We also refer to [1, 3] and the prior survey paper using duality arguments for adaptivity in differential equations [19]. We are interested in the evaluation of the goal functional J in the solution \(u \in U\) to the problem \({\mathcal {A}}(u)(v) = 0\) for all \(v \in V\) and its corresponding discrete problem \(u_h \in U_h\) to the problem \({\mathcal {A}}(u_h)(v_h) = 0\) for all \(v_h \in V_h\). Under the assumption that both problems yield unique solutions, the problem statement of minimizing the approximation error with respect to a given PDE from above can be rewritten into the equivalent optimization problem:
For this constrained optimization problem we can introduce the corresponding Lagrangian
with the adjoint variable \(z \in V\) acting as a Lagrange multiplier. For this, a stationary point needs to fulfill the first-order necessary conditions
where \(J^\prime , {\mathcal {A}}^\prime \) denote the Fréchet derivatives. We see that a defining equation for the adjoint variable arises therein. Find \(z \in V\) such that
which is known as the adjoint problem. In other words, the adjoint solution measures the variation of the primal solution u with respect to the goal functional \(J(\cdot )\). Similarly to Sect. 2.1, we apply an approximation (for instance a finite element discretization) and obtain as discrete adjoint problem: Find \({{\tilde{z}}} \in V\) such that
These preparations yield to the a posteriori error representation for the approximation distance between u and \({{\tilde{u}}}\) measured in terms of the goal functional \(J(\cdot )\), as derived in [46].
Theorem 1
Let \((u,z) \in U \times V\) solve (1) and (3). Further, let \({\mathcal {A}} \in {\mathcal {C}}^3(U,V^*) \) and \(J \in {\mathcal {C}}^3(U,{\mathbb {R}})\). Then for arbitrary approximations \(({\tilde{u}},{\tilde{z}}) \in U \times V\) the error representation
holds true and
With \(e = u-{\tilde{u}}, \ e^* = z - {\tilde{z}}\), the remainder term reads as follows:
Proof
The proof can be found in [46]. \(\square \)
Remark 2
If \({\tilde{u}} := u_h \in U_h \subset U\) is the Galerkin projection which solves (2) and \({\tilde{z}} := z_h \in V_h \subset V \) solving (4), then the iteration error \(\rho ( {\tilde{u}}) ({\tilde{z}})\) vanishes and yields the theorems presented in the early work [3]. Therefore, from now on we omit the iteration error. The remainder term is usually of third order [5] and can be omitted for which detailed computational evidence was demonstrated in [17]. In the case of a linear problem, it clearly holds that
Remark 3
Theorem 1 motivates the error estimator
This error estimator is exact but not computable. Therefore, the exact solutions u and z are now being approximated by higher-order solutions \(\left( u_h^{(2)},z_h^{(2)}\right) \in U_h^{(2)} \times V_h^{(2)}\). These higher-order solutions can be realised on a refined grid or by using higher-order basis functions. The practical error estimator reads
2.3 DWR algorithm
In principle, we need to solve four problems, where especially the computation of \(u_h^{(2)}\) is expensive. It is well-known that different possibilities exist such as global higher-order finite element solution or local interpolations [5, 7, 48]. Moreover, we only consider the primal part of the error estimator, which is justified for linear problems only, and yields a second order remainder term in nonlinear problems [5] [Proposition 2.3]:
For many nonlinear problems this version is used as it reduces to solving only two problems and yields for mildly nonlinear problems, such as incompressible flow in a laminar regime [8], excellent values. On the other hand, for quasi-linear problems, there is a strong need to work with the adjoint error parts \(\rho ^*\) as well [16, 17].
In our work, we employ solutions in enriched spaces. We compute the adjoint solution \(z_h^l = i_h z_h^{l,(2)} \in V_h^l \subset V_h^{l,(2)}\) via restriction. For nonlinear problems, we approximate the primal solution in the enriched space \(u_h^{l,(2)} = I_h^{(2)}u_h^l \in U_h^{l,(2)} \supset U_h^l\) via interpolation. Therefore, we only solve two problems in practice: the primal problem and the enriched adjoint problem.

2.4 Error localization
The error estimator \(\eta ^{(2)}\) must be localized to corresponding regions of error contribution. This can be either done by methods proposed in [3,4,5], which use integration by parts in a backwards manner and result in an element wise localization employing the strong form of the equations or the filtering approach using the weak form [7]. In this work we use another weak form technique proposed in [48], where a partition-of-unity (PU) \(\sum _i \psi _i \equiv 1\) was introduced, in which the error contribution is localized on a nodal level. To realize this partition-of-unity, one can simply choose piece-wise bilinear elements \(Q_1^c\) (see e.g., [11]) in a finite element space \(W_h = \text {span}\{\psi _1,\ldots , \psi _N\}\) with dim\((W_h) = N\). Then, the approximated error indicator reads
Some recent theoretical work on the effectivity and efficiency of \(\eta ^{(2), PU}\) can be found in [17, 48], respectively. The main objective of the remainder of this paper is to compute the adjoint solution with a feedforward neural network.
2.5 Effectivity index
To evaluate the accuracy of the error estimator we introduce the effectivity index
If J(u) is unknown, we approximate it by \(J({\hat{u}})\), where \({\hat{u}}\) is the solution of the PDE on a very fine grid. We desire that the effectivity index converges to 1, which signifies that our error estimator is a good approximation of the error in the goal functional.
3 Neural networks
In order to realize neural network guided DWR, we consider feedforward neural networks \(u_{NN}: {\mathbb {R}}^d \rightarrow {\mathbb {R}}\), where d is the dimension of the domain \(\Omega \) plus the dimension of u and the dimension of all the derivatives of u that are required for the adjoint problem. The neural networks can be expressed as
where \(T^{(i)}: {\mathbb {R}}^{n_{i-1}} \rightarrow {\mathbb {R}}^{n_{i}},{\varvec{y}} \mapsto W^{(i)} {\varvec{y}}\, +\, {\varvec{b}^{(i)}}\) are affine transformations for \(1 \le i \le L\), with weight matrices \(W^{(i)} \in {\mathbb {R}}^{n_i \times n_{i-1}}\) and bias vectors \({\varvec{b}^{(i)}} \in {\mathbb {R}}^{n_i}\). Here \(n_{i}\) denotes the number of neurons in the i.th layer with \(n_0 = d\) and \(n_L = 1\). \(\sigma : {\mathbb {R}} \rightarrow {\mathbb {R}}\) is a nonlinear activation function, which is the hyperbolic tangent function throughout this work. Derivatives of neural networks can be computed with back propagation (see e.g. [26, 49]), a special case of reverse mode automatic differentiation [38]. Similarly higher order derivatives can be calculated by applying automatic differentiation recursively.
3.1 Universal function approximators
Cybenko [13] and Hornik [27] proved a first version of the universal approximation theorem, which states that continuous functions can be approximated to arbitrary precision by single hidden layer neural networks. A few years later Pinkus [42] generalized their findings and showed that single hidden layer neural networks can uniformly approximate a function and its partial derivatives.
This theoretical result motivates the application of neural networks for the numerical approximation of partial differential equations.
3.2 Residual minimization with neural networks
Residual minimization with neural networks has become popular in the last few years by the works of Raissi, Perdikaris and Karniadakis on physics-informed neural networks (PINNs) [44] and the paper of Sirignano and Spiliopoulos on the “Deep Galerkin Method” [52]. For their approach one can consider the strong formulation of the stationary PDE
where \({\mathcal {N}}\) is a differential operator and \({\mathcal {B}}\) is a boundary operator. An example for the differential operator \({\mathcal {N}}\) is given by the semi-linear form \({\mathcal {A}}(u)(v)\) introduced in Sect. 2.1. The boundary operator \({\mathcal {B}}\) in case of Dirichlet conditions is realized in the weak formulation as usual in the function space U. One then needs to find a neural network \(u_{NN}\), which minimizes the loss function
where \({\varvec{x}}_1^\Omega , \dots , {\varvec{x}}_{n_\Omega }^\Omega \in \Omega \) are collocation points inside the domain and \({\varvec{x}}_1^{\partial \Omega }, \dots , {\varvec{x}}_{n_{\partial \Omega }}^{\partial \Omega } \in \partial \Omega \) are collocation points on the boundary. In [56] it has been shown that the two components of the loss function need to be weighted appropriately to yield accurate results. Therefore, we use a modified version of this method which circumvents these issues.
3.3 Our approach
Let us again consider the abstract PDE problem in its strong formulation (8). For simplicity, we only consider Dirichlet boundary conditions, i.e. \({\mathcal {B}}(u,{\varvec{x}}):=u({\varvec{x}}) - g({\varvec{x}})\). Additionally, in our work we use the approach of Berg and Nyström [6] shown in Fig. 1, who used the ansatz
to fulfill inhomogeneous Dirichlet boundary conditions exactly. Here \({\tilde{g}}\) denotes the extension of the boundary data g to the entire domain \({\bar{\Omega }}\), which is continuously differentiable up to the order of the differential operator \({\mathcal {N}}\). Berg and Nyström [6] used the distance to the boundary \(\partial \Omega \) as their function \(d_{\partial \Omega }\). However, it is sufficient to use a function \(d_{\partial \Omega }\) which is continuously differentiable up to the order of the differential operator \({\mathcal {N}}\) with the properties
Thus, \(d_{\partial \Omega }\) can be interpreted as a level-set function, since
Obviously, for this kind of ansatz for the solution of the PDE, it holds that
Therefore, in contrast to some previous works, we do not need to account for the boundary conditions in our loss function, which is a big benefit of our approach, since proper weighting of the different residual contributions in the loss function is not required. It might only be a little cumbersome to fulfill the boundary conditions exactly when dealing with mixed boundary condition, but the form of the ansatz function for such boundary conditions has been laid out in [35].

Section 3.3: Diagram of our ansatz \(u = d_{\partial \Omega }\cdot u_{NN} + {\tilde{g}}\) for the two dimensional Poisson problem. Here we used the abbreviations \(u_i := u(x_i, y_i)\) and \(f_i := f(x_i,y_i)\) for points \(\varvec{x}_i = (x_i,y_i) \in {\bar{\Omega }}\)
3.3.1 Approximation theorem
In the following, we prove that our neural network solutions approximate the analytical solutions well if their loss is sufficiently small. Our neural networks \(u_{NN}\) have been trained with the mean squared error of the residual of the PDE, i.e.
where n is the number of collocation points \({\varvec{x}}_i\) from the domain \(\Omega \). For the sake of generality, let us consider the generalized loss
for \(p \ge 1\). Then, the loss (10) is just the Monte Carlo approximation of the generalized loss for \(p = 2\). We briefly recall the approximation theorem from [56] and show that the classical solution of the Poisson problem satisfies the assumptions of the approximation theorem.
Lemma 2
(Approximation theorem [56]) Let \(2 \le p \le \infty \). We consider a PDE of the form (8) on a bounded, open domain \(\Omega \subset {\mathbb {R}}^m\) with Lipschitz boundary \(\partial \Omega \) and \({\mathcal {N}}(u,{\varvec{x}}) = N(u,{\varvec{x}}) - {\hat{f}}({\varvec{x}})\), where N is a linear, elliptic operator and \({\hat{f}} \in L^2(\Omega )\). Let there be a unique solution \({\hat{u}} \in H^1(\Omega )\) and let the following stability estimate
hold for \(u \in H^1(\Omega ), f \in L^2(\Omega )\) with \(N(u,{\varvec{x}}) = f({\varvec{x}})\) in \(\Omega \). Then we have for an approximate solution \(u\in H^1(\Omega )\) that
Proof
Let
Let \(u = d_{\partial \Omega }\cdot u_{NN} + {\tilde{g}} \in H^1(\Omega )\) be an approximate solution of the PDE with \({\hat{L}}_p(u) < \delta \), which means that there exists a perturbation to the right-hand side \(f_{\text {error}} \in L^2(\Omega )\) such that \(N(u,{\varvec{x}}) = {\hat{f}}({\varvec{x}}) + f_{\text {error}}({\varvec{x}})\). By the stability estimate and the linearity of N, we have
Applying the Hölder inequality to the norm of \(f_\text {error}\) and using \(2 \le p \le \infty \) yields
Combing the last two inequalities gives us the desired error bound
In the last inequality, we used that the generalized loss of our approximate solution is sufficiently small, i.e. \({\hat{L}}_p(u) < \delta \). \(\square \)
Let us recapitulate an important result from the Schauder theory [21], which yields the existence and uniqueness of classical solutions of the Poisson problem if we assume higher regularity of our problem, i.e. when we work with Hölder continuous functions and sufficiently smooth domains.
Lemma 3
(Solution in classical function spaces) Let \(0< \lambda < 1\) be such that \(\Omega \subset {\mathbb {R}}^m\) is a domain with \(C^{2,\lambda }\) boundary, \({\tilde{g}} \in C^{2,\lambda }({\bar{\Omega }})\) and \({\hat{f}} \in C^{0,\lambda }({\bar{\Omega }})\). Then Poisson’s problem, which is of the form (8) with \(N(u,{\varvec{x}}) := -\Delta u({\varvec{x}})\), has a unique solution \({\hat{u}} \in C^{2,\lambda }({\bar{\Omega }})\).
Proof
Follows immediately from [21][Theorem 6.14]. \(\square \)
With Lemma 3 we can now show that the approximation theorem holds for the Poisson problem in classical function spaces.
Theorem 4
Let \(0< \lambda < 1\) be such that \(\Omega \subset {\mathbb {R}}^m\) is a bounded, open domain with \(C^{2,\lambda }\) boundary, \({\tilde{g}} \in C^{2,\lambda }({\bar{\Omega }})\) and \({\hat{f}} \in C^{0,\lambda }({\bar{\Omega }})\). Then Poisson’s problem, which is of the form (8) with \(N(u,{\varvec{x}}) := -\Delta u({\varvec{x}})\), has a unique solution \({\hat{u}} \in H^1(\Omega )\). Furthermore, there exists \(u = d_{\partial \Omega }\cdot u_{NN} + {\tilde{g}} \in H^1(\Omega )\) with the estimate
Proof
From Lemma 3 it follows that there exists a unique solution \({\hat{u}} \in C^{2,\lambda }({\bar{\Omega }}) \subset H^1(\Omega )\). Analogously it holds that \(u = d_{\partial \Omega }\cdot u_{NN} + {\tilde{g}} \in H^1(\Omega )\). Furthermore, we have by the Lax-Milgram Lemma that \({\hat{u}} \in H^1(\Omega )\) is the unique weak solution and fulfills the stability estimate
By Lemma 2 the estimate
then also holds. \(\square \)
Remark 4
Theorem 4 implies that a low loss value of a neural network with high probability corresponds to an accurate approximation u of the exact solution \({\hat{u}}\) of the PDE, since the loss is a Monte Carlo approximation of the generalized loss, which for a large number of collocation points should be close in value.
3.3.2 Neural network solution of the adjoint PDE
To make a posteriori error estimates for our FEM solution of the primal problem (1), we now use neural networks to solve the adjoint PDE (3). In an FEM approach, the adjoint PDE would be solved in its variational form as described in Algorithm 1, but we minimize the residual of the strong form using neural networks and hence need to derive the strong formulation of the adjoint PDE first. After training, the neural network is then projected into the FEM ansatz function space of the adjoint problem. Finally, the a posteriori estimates can be made as usual with the DWR method following again Algorithm 1.
Remark 5
For linear goal functionals the Riesz representation theorem yields the existence and uniqueness of the strong formulation. Nevertheless, deriving the strong form of the adjoint PDE might be very involved for complicated PDEs, such as fluid structure interaction, e.g. [47, 57], and nonlinear goal functionals \(J: U \rightarrow {\mathbb {R}}\). In future works, we aim to extend to alternative approaches which do not require the derivation of the strong form.
4 Algorithmic realization
In this section, we describe our final algorithm for the neural network guided dual weighted residual method. In the algorithm, we work with hierarchical FEM spaces, i.e. \(U_h^{l} \subset U_h^{l,(2)}\) and \(V_h^{l} \subset V_h^{l,(2)}\).

Here we only consider the Galerkin method for which the ansatz function space and the trial function space coincide, i.e. \(U=V\), but \(U \ne V\) can be realized in a similar fashion. The novelty compared to the DWR method presented in Sect. 2 are step 4 and step 5 of the algorithm. In the following, we describe these parts in more detail.
In step 4, we solve the strong form of the adjoint problem, which for nonlinear PDEs or nonlinear goal functionals also depends on the primal solution \(u_h^{l,(2)}\). However, when the PDE and goal functional are both linear, the adjoint problem does not depend on the primal solution and it is sufficient to train the neural network only once. Otherwise, the neural network needs to be trained in each adaptive iteration. The strong form of the adjoint problem is of the form (8) and thus we can find a neural network based solution by minimizing the loss (10) with L-BFGS [32], a quasi-Newton method. To evaluate the partial derivatives of the neural network based solution \(z = d_{\partial \Omega } \cdot z_{NN} + {\tilde{g}}\) inside the loss function \(L(\cdot )\), e.g. the Laplacian of the solution, we employ automatic differentiation as mentioned at the beginning of Sect. 3. We observed that by using L-BFGS sometimes the loss exploded or the optimizer got stuck at a saddle point. Consequently, we restarted the training loop with a new neural network when the loss exploded or used a few steps with the Adam optimizer [29] when a saddle point was reached. Afterwards, L-BFGS can be used as an optimizer again. During training we used the coordinates of the degrees of freedom as our collocation points. We stopped the training when the loss did not decrease by more than \(TOL = 10^{-8}\) in the last \(n = 5\) epochs or when we reached the maximum number of epochs, which we chose to be 400. An alternative stopping criterion on fine meshes could be early stopping, where the collocation points are being split into a training and a validation set and the training stops when the loss on the validation set starts deviating from the loss on the training set, i.e. when the neural network begins to overfit on the training data.
In step 5, we projected the neural network based solution into the enriched FEM space by evaluating it at the coordinates of the degrees of freedom, which yields a unique function \(z_h^{l,(2)}\).
5 Numerical experiments
In this section, we consider three stationary problems (with in total five numerical tests) with our proposed approach. We consider both linear and nonlinear PDEs and goal functionals. The primal problem, i.e. the original PDE, is being solved with bilinear shape functions. The adjoint PDE is solved by minimizing the residual of our neural network ansatz (Sects. 3 and 4) and we project the solution into the biquadratic finite element space. For studying the performance, we also compute the adjoint problem with finite elements employing biquadratic shape functions. Finally, this neural network solution is being plugged into the PU DWR error estimator (7), which decides which elements will be marked for refinement. To realize the numerical experiments, we couple deal.II [2] with LibTorch, the PyTorch C++ API [40].
5.1 Poisson’s equation
At first we consider the two dimensional Poisson equation with homogeneous Dirichlet conditions on the unit square. In our ansatz (9), we choose the function
Poisson’s problem is given by
with \(f = -1\). For a linear goal functional \(J: V \rightarrow {\mathbb {R}}\) the adjoint problem then reads:
Find \(z \in H^1_0(\Omega )\) such that
Here \((\cdot ,\cdot )\) denotes the \(L^2\) inner product, i.e. \((f,g) := \int _{\Omega }\,f\cdot g\ \mathrm {d}{\varvec{x}}\).
5.1.1 Mean value goal functional
As a first numerical example of a linear goal functional, we consider the mean value goal functional
The adjoint PDE can be written as
and can be transformed into its strong form
We trained a fully connected neural network with two hidden layers with 32 neurons each and the hyperbolic tangent activation function for 400 epochs on 1,000 uniformly sampled points. In [44] it has been shown that wider and deeper neural networks can achieve a lower \(L^2\) error between the neural network and the analytical solutions. However, if we use the support points of the FEM mesh as the collocation points, we cannot use bigger neural networks, since we do not have enough training data. Therefore, we decided to use smaller networks.
We compared our neural network based error estimator with a standard finite element based error estimator:
In this numerical test the neural network refined in the same way as the finite element method and both error indicators yield effectivity indices \(I_{eff}\) of approximately 1.0, which means that the exact error and the estimated error were almost identical. The error reduction is of second order as to be expected and the overall results in Table 1 confirm well similar computations presented in [48][Table 1].
5.1.2 Regional mean value goal functional
In the second numerical example, we analyze the mean value goal functional which is only being computed on a subset \(D \subset \Omega \) of the domain. We choose \(D := \left[ 0,\frac{1}{4}\right] \times \left[ 0,\frac{1}{4}\right] \). For the regional goal function
the strong form of the PDE is given by
where \(1_D\) is the indicator function of D. The rest of the training setup is the same as for the previous goal functional.
The computational results for this example can be found in Table 2. Here we can observe that the finite element method and our approach end up with different grid refinements, see Fig. 2, however both methods have a similar performance and effectivity indices \(I_{eff}\) of approximately 1.0.

Section 5.1.2: Grid refinement with regional mean value goal functional
On the grids in Fig. 2, which have been refined with the different approaches, we can see that the finite element method creates a symmetrical grid refinement. This symmetry can not be observed in the neural network based refinement. Furthermore, our approach refined a few more elements than FEM, but overall our methodology still produced a reasonable grid adaptivity.
5.1.3 Mean squared value goal functional
In this third numerical test, an example of a nonlinear goal functional is the mean squared value, which reads
For a nonlinear goal functional the adjoint problem then needs to be modified to (see also (3) in Section 2): Find \(z \in H^1_0(\Omega )\) such that
Computing the Fréchet derivative of the mean squared value goal functional, we can rewrite the adjoint problem as
and can be transformed into its strong form
Our training setup also changed slightly. The problem statement has become more difficult and we decided to use slightly bigger networks to compute a sufficiently good solution of the adjoint solution. We used three hidden layers with 32 neurons and retrained the neural network on each grid, since the primal solution is part of the adjoint PDE.
In Table 3 it can be seen that our neural network approach consistently underestimates the error and produces slightly worse results than the FEM solution. Nevertheless, the effectivity index is still sufficiently close to 1 and the grid refinement, see Fig. 3, looks reasonable. Moreover as in the other previous tests, the effecitivity indices \(I_{eff}\) are stable without major oscillations.

Section 5.1.3: Grid refinement with mean squared value goal functional
5.2 Poisson’s problem with analytical primal and adjoint solutions
To be better able to assess our methodology, we now consider a Poisson problem with analytical primal and adjoint solutions.
5.2.1 Problem statement
For this we choose the source function of the primal Poisson problem to be
and we choose the goal functional \(J (u) = \int _\Omega f\cdot u\ \mathrm {d} {\varvec{x}}\). For this problem the strong form of the adjoint PDE is given by
Then it holds that the primal and adjoint solution read
5.2.2 Setups for performance analysis
In the following, we analyze the performance of our proposed approach, while varying the number of hidden layers and the number of neurons therein. Like in the previous numerical experiments, we consider fully connected neural networks with hyperbolic tangent activation function. For the hyper parameters of the neural networks, i.e. the number of hidden layers and the number of neurons, we applied a grid search to \(\lbrace 1,2,4,6,8 \rbrace \) hidden layers and \(\lbrace 10,20,40 \rbrace \) neurons.
For a fair comparison with the FEM guided adjoint computations, we chose to reuse the neural network and continue its training in each refinement cycle. However, since the PDE and the goal functional are linear, it would have been sufficient to train the neural network based adjoint solution once prior to the entire FEM simulations.
Furthermore, we investigated whether our method can lead to computational improvements over the finite element method on fine meshes, where the number of degrees of freedom is large and FEM simulations are computationally expensive. To reduce the computational effort when dealing with neural networks and a large number of degrees of freedom, we are reusing the neural network from the last refinement cycle. We expect the weights and biases from the last refinement cycle to be a good initial value for the weights and biases in the current refinement cycle. Additionally, instead of working with a large number of collocation points, on fine meshes we randomly sample 10,000 collocation points from the coordinates of the degrees of freedom. On the one hand, we chose this restriction since we are using L-BFGS to optimize the parameters of our neural network. This quasi-Newton scheme has a higher order of convergence than Adam or other gradient descent based schemes, but in its original formulation does not allow batch-wise optimization. Due to these memory limitations of the L-BFGS method, we decided to limit the number of collocation points. On the other hand, our neural network based ansatz is a meshless method, which might not require all coordinates of the degrees of freedom as collocation points to achieve a sufficient accuracy.
5.2.3 Discussion of our findings
To access the performance of our approach for different hyper parameters of the neural networks, we summarize the effectivity indices in Table 4. Here we start at refinement cycle 0 with 25 degrees of freedom and through adaptive mesh refinement end up with close to 500,000 degrees of freedom at refinement cycle 8. Taking a closer look at the effectivity indices of our simulations, we observe that the effectivity indices of the neural network mostly coincide with the effectivity indices from the finite element method computations independently of the number of hidden layers and the number of neurons. This indicates that our approach yields accurate solutions for all neural network hyper parameters from our experiment.
To investigate whether our method can lead to speed ups over the finite element method on fine meshes, we inspect the CPU times of the finite element method and the neural network based approach. The FEM based DWR method with 474,153 degrees of freedom in the 8th refinement cycle had a mean CPU time of 169.2 s and a standard deviation of 0.5 s in 10 independent runs. In Table 5 the CPU times for our approach with neural networks with different hyper parameters are being reported. We observe that the computational time increases with more hidden layers. Moreover, one hidden layer neural networks were on average twice as fast as the FEM simulations. Finally, neural networks with up to four hidden layers had on average a shorter CPU time than the FEM based approach. Note that the neural networks with 8 hidden layers with 10 neurons have a large mean and standard deviation due to a statistical outlier. Here in one of the runs the CPU time amounted to more than 3,000 seconds because of repeated failure to converge during the training procedure.

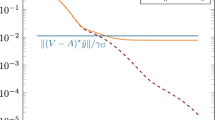
Section 5.2: Neuronal network training times (in seconds) per refinement cycle for 10 independent runs for the Poisson problem with analytical primal and adjoint solution
In Fig. 4, we display the training times of the neural networks in each refinement cycle. The solid lines and the shaded regions, which are bounded by dashed lines, represent the mean and one standard deviation of the training times. We observe that for all neural network hyper parameters the 0th refinement cycle is the most CPU time intensive and the remaining refinement cycles have a one order of magnitude shorter neural network training time. Moreover, deeper neural networks, i.e. models with more hidden layers, in general require a higher training time than shallow neural networks, i.e. models with fewer hidden layers, due to a higher number of weights and biases which need to be optimized. Note that the peak of the training time of 8 hidden layer neural networks at 3 refinement cycles has been caused by the aforementioned statistical outlier, which restarted training more than 100 times in the 3rd refinement cycle due to an explosion in the loss value or due to being stuck in a local minimum.

Section 5.2: Number of epochs per refinement cycle to train neural network for 10 independent runs for the Poisson problem with analytical primal and adjoint solution
In Fig. 5, the number of epochs for training the neural networks are shown for each refinement cycle. In each epoch the weights and biases of the neural network are trained on the full set of collocation points with the L-BFGS optimizer. Like before, the solid lines and the shaded regions, which are bounded by dashed lines, represent the mean and one standard deviation of the number of epochs. Analogous to our observations of the CPU times, the number of epochs after the 0th refinement cycle decreases by an order of magnitude. In the 0th refinement cycle more hidden layers lead to a higher number of training epochs. Deeper neural networks have a more complex loss surface and thus are more prone to an explosion of the loss or a stagnation of the loss at an suboptimal value. This is being reflected in the higher number of epochs in the 0th refinement cycle. Nevertheless, in the remaining refinement cycles the number of epochs does not seem to depend on the depth of the neural networks.
5.3 Nonlinear PDE and nonlinear goal functional
In the second numerical problem, we now consider the case were both the PDE and the goal functional are nonlinear. We add the scaled nonlinear term \(u^2\) to the previous equation, such that the new problem is given by
with \(\gamma > 0\) and \(f = -1\). For our nonlinear goal functional, we choose the mean squared value goal functional from the previous example. The adjoint problem thus reads:
Find \(z \in H^1_0(\Omega )\) such that
with corresponding strong form
The training setup is the same as for the mean squared value goal functional example. For \(\gamma = 50\) we obtain the results shown in Table 6.
Our neural network approach produces different results, see Fig. 6, than the finite element method, but at the efficiency indices and the refined grids we observe that our approach still works well for adaptive mesh refinement.

Section 5.3: Grid refinement for the nonlinear PDE
6 Conclusions and outlook
In this work, we proposed neural network guided a posteriori error estimation with the dual weighted residual method. Specifically, we computed the adjoint solution with feedforward neural networks with two or three hidden layers. To use existing FEM software we first solved the adjoint PDE with neural networks and then projected the solution into the FEM space of the adjoint PDE. We demonstrated experimentally that neural network based solutions of the strong formulation of the adjoint PDE yield excellent approximations for dual weighted residual error estimates. Therefore, neural networks might be an alternative way to compute adjoint sensitivities within goal-oriented error estimators for certain problems, when the number of degrees of freedom is high. Furthermore they admit greater flexibility being a meshless method and it would be interesting to investigate in future works how different choices of collocation points influence the quality of the error estimates. In the current work, we observed an advantage in computing times (in terms of CPU time) when using more than 400,000 degrees of freedom. Additionally, we could establish the same accuracies and robustness as for pure FEM problems. However, an important current limitation of our methodology is that we work with the strong formulation of the PDE, whose derivation from the weak formulation can be very involved for more complex problems, e.g. multiphysics. Hence, if an energy minimization formulation exists, this should be a viable alternative to our strong form of the adjoint PDE. This alternative problem can be solved with neural networks with the “Deep Ritz Method” [14, 50]. Nevertheless, the energy minimization formulation does not exist for all partial differential equations. For this reason in the future, we are going to analyze neural network based methods, which work with the variational formulation, e.g. VPINNs [28].
Data availability
The authors agree on open-source data and programming codes as the underlying finite element library deal.II [2] is itself open-source. However, the programming code of the current paper is under development and not yet well documented. Parts of the data and code can be obtained from the corresponding author upon request. The finite element implementations for both the linear and nonlinear test cases can be re-implemented using the template [59] with the code on github https://github.com/tommeswick/goal-oriented-fsi and replacing the equations, parameters, geometry, and boundary conditions by the respective data in this paper.
References
Ainsworth M, Oden JT (2000) A posteriori error estimation in finite element analysis. pure and applied mathematics (New York). Wiley-Interscience [John Wiley & Sons], New York. URL https://www.wiley.com/en-us/exportProduct/pdf/9780471294115
Arndt D, Bangerth W, Blais B, Clevenger TC, Fehling M, Grayver AV, Heister T, Heltai L, Kronbichler M, Maier M, Munch P, Pelteret J-P, Rastak R, Thomas I, Turcksin B, Wang Z, Wells D (2020) The deal.II library, version 9.2. J Numer Math 28(3):131–146. https://doi.org/10.1515/jnma-2020-0043
Bangerth W, Rannacher R (2003) Adaptive Finite Element Methods for Differential Equations. Birkhäuser Verlag. URL https://link.springer.com/book/10.1007/978-3-0348-7605-6
Becker R, Rannacher R (1996) A feed-back approach to error control in finite element methods: basic analysis and examples. East-West J Numer Math 4:237–264
Becker R, Rannacher R (2001) An optimal control approach to a posteriori error estimation in finite element methods. Acta Numerica 10:1–102. https://doi.org/10.1017/S0962492901000010
Berg J, Nyström K (2018) A unified deep artificial neural network approach to partial differential equations in complex geometries. Neurocomputing, 317:28–41. ISSN 0925-2312. https://doi.org/10.1016/j.neucom.2018.06.056
Braack M, Ern A (2003) A posteriori control of modeling errors and discretization errors. Multiscale Modeling Simul 1(2):221–238. https://doi.org/10.1137/S1540345902410482
Braack M, Richter T (2006) Solutions of 3D Navier–Stokes benchmark problems with adaptive finite elements. Comput Fluids 35(4):372–392. ISSN 0045-7930. https://doi.org/10.1016/j.compfluid.2005.02.001. URL http://www.sciencedirect.com/science/article/pii/S0045793005000381
Brevis I, Muga I, van der Zee KG (2020) A machine-learning minimal-residual (ML-MRes) framework for goal-oriented finite element discretizations. Comput Math Appl ISSN 0898-1221. https://doi.org/10.1016/j.camwa.2020.08.012. URL https://www.sciencedirect.com/science/article/pii/S0898122120303199
Chen F, Sondak D, Protopapas P, Mattheakis M, Liu S, Agarwal D, Giovanni MD (2020) NeuroDiffEq: a Python package for solving differential equations with neural networks. J Open Source Softw. https://doi.org/10.21105/joss.01931
Ciarlet P (2002) The finite element method for elliptic problems. Classics in Applied Mathematics. Soc Ind Appl Math. ISBN 9780898715149. URL https://books.google.de/books?id=isEEyUXW9qkC
Cilliers PI, Botha MM (2020) Goal-Oriented Error Estimation for the Method of Moments to Compute Antenna Impedance. IEEE Antennas Wireless Propag Lett 19(6):997–1001. https://doi.org/10.1109/LAWP.2020.2986169
Cybenko G (1989) Approximation by superpositions of a sigmoidal function. Math Control Signals Syst 2(4):303–314. ISSN 1435-568X. https://doi.org/10.1007/BF02551274
WE, Yu B (Mar 2018) The Deep Ritz Method: a deep learning-based numerical algorithm for solving variational problems. Commun Math Stat 6(1):1–12. ISSN 2194-671X. https://doi.org/10.1007/s40304-018-0127-z
Endtmayer B (2021) Multi-goal oriented a posteriori error estimates for nonlinear partial differential equations. PhD thesis, Johannes Kepler University Linz. URL https://epub.jku.at/obvulihs/content/titleinfo/5767444
Endtmayer B, Langer U, Wick T (2019) Multigoal-oriented error estimates for non-linear problems. J Numer Math 27(4):215–236. https://doi.org/10.1515/jnma-2018-0038
Endtmayer B, Langer U, Wick T (2020) Two-side a posteriori error estimates for the dual-weighted residual method. SIAM J Sci Comput 42(1):A371–A394. https://doi.org/10.1137/18M1227275
Endtmayer B, Langer U, Wick T (2021) Reliability and efficiency of dwr-type a posteriori error estimates with smart sensitivity weight recovering. Comput Methods Appl Math. https://doi.org/10.1515/cmam-2020-0036
Eriksson K, Estep D, Hansbo P, Johnson C (1995) Introduction to adaptive methods for differential equations. In: Iserles A (ed) Acta Numerica. Cambridge University Press, Cambridge, pp 105–158. https://doi.org/10.1017/S0962492900002531
Failer L, Wick T (2018) Adaptive time-step control for nonlinear fluid-structure interaction. J Comput Phys 366:448–477. ISSN 0021-9991. https://doi.org/10.1016/j.jcp.2018.04.021. URL https://www.sciencedirect.com/science/article/pii/S0021999118302377
Gilbarg D, Trudinger NS (2001) Elliptic partial differential equations of second order, classics in mathematics, vol 224. Springer, Berlin, Heidelberg
Giles M, Süli E (2002) Adjoint methods for pdes: a posteriori error analysis and postprocessing by duality. Acta Numerica 2002:145–236. https://doi.org/10.1017/S096249290200003X (A. Iserles, ed)
Grätsch T, Bathe K-J (2006) Goal-oriented error estimation in the analysis of fluid flows with structural interactions. Comput Methods Appl Mech Eng 195:5673–5684. https://doi.org/10.1016/j.cma.2005.10.020
Hartmann D, Lessig C, Margenberg N, Richter T (2020) A neural network multigrid solver for the Navier–Stokes equations, arXiv:2008.11520. URL https://arxiv.org/pdf/2008.11520.pdf
Hennigh O, Narasimhan S, Nabian MA, Subramaniam A, Tangsali K, Rietmann M, del Aguila Ferrandis J, Byeon W, Fang Z, Choudhry S (2020) NVIDIA \(\text{SimNet}^{TM}\): an AI-accelerated multi-physics simulation framework, arXiv:2012.07938. URL https://arxiv.org/abs/2012.07938
Higham C, Higham D (2019) Deep learning: an introduction for applied mathematicians. SIAM Rev 61(4):860–891. https://doi.org/10.1137/18M1165748
Hornik K (1991) Approximation capabilities of multilayer feedforward networks. Neural Netw 4(2):251–257. ISSN 0893-6080. https://doi.org/10.1016/0893-6080(91)90009-T. URL http://www.sciencedirect.com/science/article/pii/089360809190009T
Kharazmi E, Zhang Z, Karniadakis GE (2019) Variational physics-informed neural networks for solving partial differential equations, arXiv:1912.00873
Kingma DP, Ba J (2017) Adam: A Method for Stochastic Optimization, arXiv:1412.6980
Knoke T, Wick T (2021) Solving differential equations via artificial neural networks: Findings and failures in a model problem. Examples Counterexamples, 1:100035. ISSN 2666-657X. https://doi.org/10.1016/j.exco.2021.100035. URL https://www.sciencedirect.com/science/article/pii/S2666657X21000197
Li Z, Kovachki N, Azizzadenesheli K, Liu B, Bhattacharya K, Stuart A, Anandkumar A (2020) Fourier neural operator for parametric partial differential equations, arXiv:2010.08895
Liu DC, Nocedal J (Aug 1989) On the limited memory BFGS method for large scale optimization. Math Program 45(1):503–528. ISSN 1436-4646. https://doi.org/10.1007/BF01589116
Lu L, Jin P, Pang G, Zhang Z, Karniadakis GE (Mar 2021a) Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nat Mach Intell 3(3):218–229. ISSN 2522-5839. https://doi.org/10.1038/s42256-021-00302-5
Lu L, Meng X, Mao Z, Karniadakis GE (2021) DeepXDE: a deep learning library for solving differential equations. SIAM Rev 63(1):208–228. https://doi.org/10.1137/19M1274067
Lyu L, Wu K, Du R, Chen J (2020) Enforcing exact boundary and initial conditions in the deep mixed residual method, arXiv:2008.01491
Maier M, Rannacher R (2018) A duality-based optimization approach for model adaptivity in heterogeneous multiscale problems. Multiscale Modeling Simul 16(1):412–428. https://doi.org/10.1137/16M1105670
Mattis SA, Wohlmuth B (2018) Goal-oriented adaptive surrogate construction for stochastic inversion. Comput Methods Appl Mech Eng 339:36–60. ISSN 0045-7825. https://doi.org/10.1016/j.cma.2018.04.045. URL http://www.sciencedirect.com/science/article/pii/S0045782518302305
Nocedal J, Wright SJ (2006) Numerical optimization, 2nd edn. Springer, New York, NY, USA
Oden JT (2018) Adaptive multiscale predictive modelling. Acta Numerica 27:353–450. https://doi.org/10.1017/S096249291800003X
...Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, Killeen T, Lin Z, Gimelshein N, Antiga L, Desmaison A, Kopf A, Yang E, DeVito Z, Raison M, Tejani A, Chilamkurthy S, Steiner B, Fang L, Bai J, Chintala S (2019) Pytorch: An imperative style, high-performance deep learning library. In: Wallach H, Larochelle H, Beygelzimer A, d’Alché Buc F, Fox E, Garnett R (eds) Advances in neural information processing systems, vol 32. Curran Associates Inc, New York
Peraire J, Patera A (1998) Bounds for linear-functional outputs of coercive partial differential equations: local indicators and adaptive refinement. In: Ladeveze P, Oden J (eds) Advances in Adaptive Computational Methods in Mechanics. Elsevier, Amsterdam, pp 199–215. https://doi.org/10.1016/S0922-5382(98)80011-1
Pinkus A (1999) Approximation theory of the MLP model in neural networks. Acta Numerica 8:143–195. https://doi.org/10.1017/S0962492900002919
Rademacher A (2019) Mesh and model adaptivity for frictional contact problems. Numerische Mathematik 142:465–523. https://doi.org/10.1007/s00211-019-01044-8
Raissi M, Perdikaris P, Karniadakis GE (2019) Physics-informed neural networks: a deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J Comput Phys 378:686–707. https://doi.org/10.1016/j.jcp.2018.10.045
Raissi M, Yazdani A, Karniadakis GE (2020) Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations. Science. ISSN 0036-8075. https://doi.org/10.1126/science.aaw4741. URL https://science.sciencemag.org/content/early/2020/01/29/science.aaw4741
Rannacher R, Vihharev J (2013) Adaptive finite element analysis of nonlinear problems: balancing of discretization and iteration errors. J Numer Math 21(1):23–62. https://doi.org/10.1515/jnum-2013-0002
Richter T (2012) Goal-oriented error estimation for fluid-structure interaction problems. Comput Methods Appl Mech Eng 223–224:28–42. https://doi.org/10.1016/j.cma.2012.02.014
Richter T, Wick T (2015) Variational localizations of the dual weighted residual estimator. J Comput Appl Math 279:192–208. https://doi.org/10.1016/j.cam.2014.11.008
Rumelhart D, Hinton G, Williams R (1986) Learning representations by back-propagating errors. Nature 323:533–536. https://doi.org/10.1038/323533a0
Samaniego E, Anitescu C, Goswami S, Nguyen-Thanh V, Guo H, Hamdia K, Zhuang X, Rabczuk T (2020) An energy approach to the solution of partial differential equations in computational mechanics via machine learning: Concepts, implementation and applications. Comput Methods Appl Mech Eng 362:112790. ISSN 0045-7825. https://doi.org/10.1016/j.cma.2019.112790. URL https://www.sciencedirect.com/science/article/pii/S0045782519306826
Schmich M, Vexler B (2008) Adaptivity with dynamic meshes for space-time finite element discretizations of parabolic equations. SIAM J Sci Comput 30(1):369–393. https://doi.org/10.1137/060670468
Sirignano J, Spiliopoulos K (2018) DGM: A deep learning algorithm for solving partial differential equations. J Comput Phys, 375:1339–1364. ISSN 0021-9991. https://doi.org/10.1016/j.jcp.2018.08.029. URL https://www.sciencedirect.com/science/article/pii/S0021999118305527
Stolfo PD, Rademacher A, Schröder A (2019) Dual weighted residual error estimation for the finite cell method. J Numer Math 27(2):101–122. https://doi.org/10.1515/jnma-2017-0103
Suttmeier F (2008) Numerical solution of Variational Inequalities by Adaptive Finite Elements. Vieweg+Teubner. URL https://link.springer.com/book/10.1007/978-3-8348-9546-2
van Brummelen E, Zhuk S, van Zwieten G (2017) Worst-case multi-objective error estimation and adaptivity. Comput Methods Appl Mech Eng 313:723–743. ISSN 0045-7825. https://doi.org/10.1016/j.cma.2016.10.007. URL http://www.sciencedirect.com/science/article/pii/S0045782516301815
van der Meer R, Oosterlee C, Borovykh A (2020) Optimally weighted loss functions for solving PDEs with Neural Networks, arXiv:2002.06269
van der Zee K, van Brummelen E, Akkerman I, de Borst R (2011) Goal-oriented error estimation and adaptivity for fluid-structure interaction using exact linearized adjoints. Comput Methods Appl Mech Eng 200(37):2738–2757. ISSN 0045-7825. https://doi.org/10.1016/j.cma.2010.12.010. URL https://www.sciencedirect.com/science/article/pii/S0045782510003555. Special Issue on Modeling Error Estimation and Adaptive Modeling
Wessels H, Weißenfels C, Wriggers P (2020) The neural particle method—an updated Lagrangian physics informed neural network for computational fluid dynamics. Comput Methods Appl Mech Eng 368:113127. ISSN 0045-7825. https://doi.org/10.1016/j.cma.2020.113127. URL https://www.sciencedirect.com/science/article/pii/S0045782520303121
Wick T (2021) Adjoint-based methods for optimization and goal-oriented error control applied to fluid-structure interaction: implementation of a partition-of-unity dual-weighted residual estimator for stationary forward FSI problems in deal.II. In: Book of Extended Abstracts of the 6th ECCOMAS Young Investigators Conference 7th-9th (July 2021) Valencia. Spain. ECCOMAS 2021. https://doi.org/10.4995/YIC2021.2021.12332
Acknowledgements
This work is supported by the Deutsche Forschungsgemeinschaft (DFG) under Germany’s Excellence Strategy within the cluster of Excellence PhoenixD (EXC 2122, Project ID 390833453). Moreover, we thank the anonymous reviewers for several suggestions that helped to improve the paper.
Funding
Open Access funding enabled and organized by Projekt DEAL. The Funding was provided by Deutsche Forschungsgemeinschaft (Grant Number 390833453).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest. The authors have no relevant financial or non-financial interests to disclose. The authors have no conflicts of interest to declare that are relevant to the content of this article. All authors certify that they have no affiliations with or involvement in any organization or entity with any financial interest or non-financial interest in the subject matter or materials discussed in this manuscript. The authors have no financial or proprietary interests in any material discussed in this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Roth, J., Schröder, M. & Wick, T. Neural network guided adjoint computations in dual weighted residual error estimation. SN Appl. Sci. 4, 62 (2022). https://doi.org/10.1007/s42452-022-04938-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-022-04938-9