
Abstract
The primal-dual method of Chambolle and Pock is a widely used algorithm to solve various optimization problems written as convex-concave saddle point problems. Each update step involves the application of both the forward linear operator and its adjoint. However, in practical applications like computerized tomography, it is often computationally favourable to replace the adjoint operator by a computationally more efficient approximation. This leads to an adjoint mismatch in the algorithm. In this paper, we analyze the convergence of Chambolle–Pock’s primal-dual method under the presence of a mismatched adjoint in the strongly convex setting. We present an upper bound on the error of the primal solution and derive stepsizes and mild conditions under which convergence to a fixed point is still guaranteed. Furthermore we show linear convergence similar to the result of Chambolle–Pock’s primal-dual method without the adjoint mismatch. Moreover, we illustrate our results both for an academic and a real-world inspired application.
Similar content being viewed by others
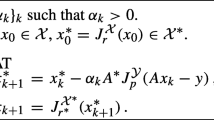


Avoid common mistakes on your manuscript.
1 Introduction
Inverse problems occur whenever unknown quantities are measured indirectly and in many cases the measurement process introduces measurement noise. Nevertheless, these inverse problems appear in many practical applications and are often approached by solving minimization problems, which can be formulated as the minimization of an expression
on a Hilbert space X with a linear and bounded operator \(A: X \rightarrow Y\). Sometimes these kind of problems are hard to solve and it can be beneficial to examine the equivalent dual problem
on the Hilbert space Y or the saddle point problem
with the Fenchel conjugates \(G^*, F^*\) of G, F instead of the primal problem above. If both \(G: X \rightarrow \overline{\mathbb {R}}\) and \(F^*: Y \rightarrow \overline{\mathbb {R}}\) are proper, convex, lower semicontinuous functionals defined on Hilbert spaces X, Y, the primal-dual algorithm of Chambolle and Pock [1], defined as
for all \(i \in \mathbb {N}\), with positive stepsizes \(\tau _i\) and \(\sigma _i\) and extrapolation parameter \(\omega _i\) has proven to be a simple and effective solution method. Using constant stepsizes, this method converges weakly, if \(F^*\) and G are convex and lower semi continuous functionals. Furthermore linear convergence is proven in [1], if both functionals are strongly convex. If only one of the functionals is strongly convex, while the other is convex, an accelerated version of the algorithm with varying stepsizes is proven in [1] to converge with rate of \(\Vert {x^{N}-{\hat{x}}} \Vert ^{2} = \mathcal {O}{(N^{-2})}\) where \({\hat{x}}\) is a solution of (1).
In practical applications, however, it can happen that the operator and its adjoint are given as two seperate implementations of discretizations of a continuous operator and its adjoint. If the implementations use the “first dualize, then discretize” approach, it may happen, that the discretizatons are not adjoint to each other. Sometimes, this even happens on purpose, for example to save computational time or to impose certain structure for the image of the adjoint operator [2,3,4]. The influence of such a mismatch has been studied for various algorithms [4,5,6,7,8,9].
In this paper we examine the convergence of the Chambolle–Pock method in the case of a mismatched adjoint, i.e., we examine the algorithm
with a linear operator \(V: X \rightarrow Y\) instead of A for convergence to a fixed point of (4) in the case where both G and \(F^{*}\) are strongly convex.
Example 1.1
(Counterexample for convergence) Here is a simple example that shows that the mismatched iteration does not necessarily converge. We consider the problem \(\min _{x} \Vert {x} \Vert _{1}\) on \(\mathbb {R}^{n}\), which is of the form (1), and model this with \(A = I\), \(F(y) = \Vert {y} \Vert _1\), and \(G\equiv 0\). We consider the most basic form of Chambolle–Pock’s method with constant \(\tau ,\sigma > 0\) and \(\omega =1\), i.e. the mismatched iteration is
If we consider the mismatch \(V = -\alpha I\) with \(\alpha >0\) (instead of I), the iteration becomes
If we initialize with \(x^{0} > 0\) and \(y^{0} > 0\) (component-wise), we get that the entries in \(x^{i}\) are strictly increasing and hence, will not converge to the unique solution \(x=0\).
Note that \((x,y) = (0,0)\) is both a saddle point and a fixed point of the mismatched iterations in this case.
Before we analyze the convergence of the mismatched iteration (4) we provide a result that shows that fixed points of (4) are close to the true solution of (3) if the norm \(\Vert {A-V} \Vert \) is small.
Theorem 1.2
If G is a \(\gamma _G\)-strongly convex function, \((x^*, y^*)\) is the fixed point of the original Chambolle–Pock method (3) and \((\hat{x},\hat{y})\) is the fixed point of the Chambolle–Pock method with mismatched adjoint (4), it holds that
Proof
Since \(\partial G\) is \(\gamma _{G}\)-strongly monotone and \(\partial F^*\) is monotone, we can conclude for \(-A^* y^* \in \partial G(x^*), -V^*\hat{y} \in \partial G(\hat{x}), A x^* \in \partial F^*(y^*), A \hat{x} \in \partial F^*(\hat{y})\) that
and
These sum up to
Furthermore, it is
which shows
\(\square \)
Notably, we cannot show that the mismatched algorithm will converge to the original solution (a situation which possible for other mismatched iterations [7]). However, since we can bound the difference of fixed points up to a multiplicative constant by the norm of the difference between the correct and the mismatched adjoint, the analysis of the Chambolle–Pock method with mismatched adjoint can be of interest in practical applications. Moreover, in applications in computerized tomography, mismatched adjoints are also used on purpose [4,5,6,7].
The rest of the paper is structured as follows. In Sect. 2 we reformulate (4), introduce the concept of test operators from [10] and provide some technical lemmas that we need to prove convergence of the mismatched iteration in Sect. 3. In Sect. 4, we present numerical examples and Sect. 5 concludes the paper.
Throughout this paper, we will use \(\langle {x},{x'}\rangle _T := \langle {Tx},{x'}\rangle \) and the seminorm \(\Vert {x} \Vert _T ^{2}:= \langle {x},{x}\rangle _T\) for a (not necessarily symmetric) positive semidefinite operator T.Footnote 1 In case of having \(T = I\), we will denote the Hilbert space norm as \(\Vert {x} \Vert \) without the subscripts. Additionally, we will use the notation \(\mathcal {L}(\mathcal {U},\mathcal {V})\) for the space of bounded linear operators \(L: \mathcal {U} \rightarrow \mathcal {V}\) between Hilbert spaces \(\mathcal {U}\) and \(\mathcal {V}\) with the corresponding operator norm \(\Vert {L} \Vert = \inf \{c \ge 0: \Vert {Lx} \Vert \le c \Vert {x} \Vert \text { for all } x \in \mathcal {U}\}\). Furthermore, we will write \(A \ge B\) for operators \(A,B \in \mathcal {L}(\mathcal {U},\mathcal {U})\), if \(A-B\) is positive semidefinite.
2 Preliminaries
In this section we present the reformulation of the mismatched iteration as a preconditioned proximal point method, recall the results from [10] on which our analysis relies and provide the necessary technical estimates needed for the convergence proof. Note that we do not prove the existence of a fixed point of the mismatched iteration, but take its existence for granted.
2.1 Subdifferential Reformulation
Since the original proof of Chambolle and Pock in [1] relies on having the exact adjoint, we use a different approach, namely the reformulation of the method as a preconditioned proximal point method from [11] (see also [12]). Recall that the proximal operator of a proper, convex and lower semicontinuous functional \(f: X \rightarrow \overline{\mathbb {R}}\) is defined as \({{\,\textrm{prox}\,}}_{f}(x) = \arg \min _{y \in X} f(y) + \tfrac{1}{2}\Vert {y-x} \Vert ^{2}\) and that it holds
One sees that each stationary point \({\hat{u}} = \begin{pmatrix} {\hat{x}}\\ {\hat{y}} \end{pmatrix}\) of iteration (4) fulfills \(0 \in H\hat{u}\) with
With \(\bar{x}^{i+1} = (1+\omega _i) x^{i+1} - \omega _i x^i\), we rewrite the update steps of algorithm (4) as
We rewrite this inclusion with the help of the operator \({\tilde{H}}_{i+1}\) defined by
the preconditioner
and the step length operator
as the following preconditioned proximal point iteration
which is exactly the mismatched iteration (6).
For this formulation of the iteration we can apply results from [10] and [12]. We quote this (slightly modified) general theorem of [12, Theorem 2.1]:
Theorem 2.1
Let \(\mathcal {U}\) be a Hilbert space, \(\tilde{H}_{i+1}: \mathcal {U} \rightrightarrows \mathcal {U}\) and let \(M_{i+1}, W_{i+1}, Z_{i+1} \in \mathcal {L}(\mathcal {U},\mathcal {U})\) for \(i \in \mathbb {N}\). Suppose that
is solvable for \(\{u^{i+1}\}_{i \in \mathbb {N}} \subset \mathcal {U}\) and let \(\hat{u} \in \mathcal {U}\) be a stationary point of the iteration.
If \(Z_{i+1}M_{i+1}\) is self-adjoint and for some \(\Delta _{i+1} \in \mathbb {R}\) the condition
holds for all \(i \in \mathbb {N}\), then so does the descent inequality
The maps \(\tilde{H}_{i}\), \(M_{i}\), and \(W_{i}\) from (7), (8), and (9) are defined on \(\mathcal {U} = X \times Y\). Then the iteration (11) is exactly the iteration (4). The operator \(Z_{i}\) and the number \(\Delta _{i}\) are yet to be defined and are used to establish inequality (12) and the final descent inequality. The operator \(Z_{i}\) is called test operator and the \(\Delta _{i}\) can be used to further quantify the descent.
We will introduce the test operator \(Z_{i}\) and the quantities \(\Delta _{i}\) in the next subsection and aim for non-positive \(\left( \Delta _{i}\right) _{i \in \mathbb {N}}\), but also want that the operators \(Z_{i+1}M_{i+1}\) grow as fast as possible to obtain fast convergence.
Consequently, our next aim is to show that
-
with the right step length choices an operator \(Z_{i+1}\) with \(Z_{i+1} M_{i+1}\) being self-adjoint exists, and
-
for some non-positive \(\Delta _{i+1}\) the inequality (12) can be obtained.
2.2 Test Operator and Step Length Bounds
We choose the test operator as
for \(i \in \mathbb {N}\) and show that with this choice we can fulfill the assumptions in Theorem 2.1 for appropriate \(\varphi _{i}\) and \(\psi _{i+1}\). First, we need that \(Z_{i+1}M_{i+1}\) is self adjoint. Since this operator is
we assume that the values \(\varphi _{i},\psi _{i+1}\) of the test operator fulfill
Next we introduce the “tested dual stepsize” \(\psi _{i}\sigma _{i}\)
and define the extrapolation constant \(\omega _{i}\) as
Consequently, the “tested primal stepsize” \(\tau _{i}\varphi _{i}\) also fulfills
Furthermore, Theorem 2.1 needs \(Z_{i+1} M_{i+1}\) to be positive semidefinite which we show now.
Lemma 2.2
([12, Lemma 3.4]) Let \(i \in \mathbb {N}\) and suppose that conditions (15), (16) and (17) hold. Then we have that \(Z_{i+1} M_{i+1}\) is self-adjoint and satisfies
for all \(\delta \in [0,\kappa ]\) with \(\kappa \in (0,1)\).
Proof
First note that from (14), (15), (16), (17), and (18) we get
For the second claim we observe
Since \(1 > \kappa \ge \delta \) and \((1-\kappa ) \varphi _i > 0\), we derive the positive semidefiniteness of M. \(\square \)
Hence, we can ensure that \(Z_{i+1}M_{i+1}\) is positive semidefinite if we assume
Note that by \(\eta _i = \varphi _i \tau _i = \psi _i \sigma _i\) and \(\eta _{i+1} = \eta _{i} \omega _{i}^{-1}\) we get that condition (20) enforces
similar to the widely known stepsize bounds in [1].
Next we investigate the operator \(Z_{i+2} M_{i+2} - Z_{i+1} M_{i+1}\) and show that it is easy to evaluate \(\Vert {u} \Vert _{Z_{i+2} M_{i+2} - Z_{i+1} M_{i+1}}^{2}\).
Lemma 2.3
([12, Lemma 3.5]) Let \(i \in \mathbb {N}\) and assume that conditions (15), (16), (17) and (20) are fulfilled and define
If the constants \(\mu _{G}\) and \(\mu _{F^{*}}\) are chosen such that
then it holds that
Proof
We use the expression for \(Z_{i+1}M_{i+1}\) from (19) and the conditions (15), (16), (22), (23) and (17) to get
This shows that \(Z_{i+1} M_{i+1} + Z_{i+1} \Xi _{i+1} - Z_{i+2} M_{i+2}\) is skew-symmetric, and hence, it holds for all u that \(\Vert {u} \Vert ^2_{Z_{i+1} ( M_{i+1} + \Xi _{i+1} ) - Z_{i+2} M_{i+2} } = 0\) from which the statement follows. \(\square \)
2.3 Technical Estimates
With the preparations from the previous subsection we are in position to estimate the term
which appears in Theorem 2.1. Recall that the operator \({\tilde{H}}_{i}\) is given by (7), the preconditioner \(M_{i}\) is given by (8), the step length operator \(W_{i}\) is given by (9), the test operator \(Z_{i}\) is defined in (13), and the operator \(\Xi _{i}\) is defined in (21). In order to estimate D, we assume that both \(F^*\) and G are strongly convex functionals and choose the step length appropriately, and state the following estimate for D.
Theorem 2.4
Let \(i \in \mathbb {N}\). Suppose that the conditions (15), (16), (17), (22), and (23) hold,
that \(G, F^*\) are \(\gamma _G\)/\(\gamma _{F^{*}}\)-strongly convex, respectively, with
for some \(\epsilon >0\). Then it holds that
Proof
We observe
which gives, by definition of \({\tilde{H}}_{i+1}\) in (7) and H in (5),
Now we estimate the first term on the right hand side: Since \(\hat{u} \in H^{-1}(0)\) with \(\hat{u} = \begin{pmatrix} \hat{x} \\ \hat{y} \end{pmatrix}\), we have
Hence we get
Now the strong convexity of G and \(F^*\) with constants \(\gamma _{G}\) and \(\gamma _{F^{*}}\), respectively, results in the inequality
Plugging this into the definition of D in (25) and collecting terms gives
We use the extrapolation \(\bar{x}^{i+1} - x^{i+1} = \omega _i (x^{i+1} - x^i)\) to get for every \(\epsilon >0\)
by Young’s inequality. Similarly we derive
With these two estimates we continue to lower bound D and arrive at
\(\square \)
The next lemma provides an estimate for \(-\Delta _{i+1}\).
Lemma 2.5
Let \(i \in \mathbb {N}\), the assumptions of Theorem 2.4 be fulfilled and assume furthermore that (20), (24) and
hold with \(0<\delta \le \kappa <1\). Define
and assume that
is fulfilled. Then it holds that
Proof
In the first step, we rewrite
so Lemma 2.2 gives
Hence
which shows the claim since Theorem 2.4 shows that the last two terms are a lower bound for D. \(\square \)
Now we state the following abstract convergence result which concludes this section:
Theorem 2.6
Suppose that the step length conditions (15), (16), (17), (20)–(23) and (26) hold with \(\epsilon >0\), \(0< \delta \le \kappa < 1\) and for all \(i \in \mathbb {N}\). Additionally suppose that \(G, F^*\) are \(\gamma _G\)/\(\gamma _{F^{*}}\)-strongly convex, respectively, and that (24) holds. Furthermore, let \(S_{i+1}\) be defined by (27) and \({\hat{u}} = \begin{pmatrix} {\hat{x}}\\ {\hat{y}} \end{pmatrix}\) fulfill \(0\in {\tilde{H}}({\hat{u}})\). Then it holds
for every \(\Delta _{i}\) which fulfills
Proof
We recognize from Lemma 2.5 that
Using the equality
we get
Rearranging these terms leads to
and thus all conditions of Theorem 2.1 are satisfied, and the result follows. \(\square \)
3 Convergence Rates
With the results from the previous section, we are in position to prove convergence of (4) under easily verifiable conditions. We assume that both G as well as \(F^*\) are proper, strongly convex, and lower-semicontinuous functions, and that the stepsizes can be chosen such that we obtain linear convergence. We proceed as follows: First we derive conditions under which we can guarantee linear convergence, and then we show how to select the parameters in order to obtain a choice of the stepsizes that is simply to apply in practice.
Theorem 3.1
Choose \(\mu _G> 0, \mu _{F^*} > 0\) and suppose that G is \(\gamma _G\)-strongly convex and \(F^*\) is \(\gamma _{F^*}\)-strongly convex with
for some \(\epsilon > 0\). Furthermore let \(u^{N} = (x^{N},y^{N})^{T}\) be generated by the Chambolle–Pock method with mismatched adjoint (4) and \({\hat{u}} = ({\hat{x}},{\hat{y}})^{T}\) be a fixed point of this iteration. Then with constant step lengths
for some \(0 \le \delta \le \kappa < 1\) it holds that \(\Vert {u^N - \hat{u}} \Vert ^2 =\mathcal {O}(\omega ^N)\).
Proof
We set \(\varphi _0 := \frac{1}{\tau }\) and \(\psi _0 := \frac{1}{\sigma }\) and by (22) we get
Hence, again by (16), we get
and, by (17)
Now we claim that the matrix \(S_{i+1}\) defined in (27) is positive semidefinite, which is equivalent to the conditions \(\delta \varphi _{i} - \eta _{i}\epsilon \Vert {A-V} \Vert \ge 0\) and \(\psi _{i+1}\ge \eta _{i}^{2}\Vert {V} \Vert ^{2}/(\varphi _{i}(1-\kappa ))\). The first condition is fulfilled since \(\tau \le \delta /(\epsilon \Vert {A-V} \Vert )\) holds by the assumption in the theorem. The second condition follows from the assumption \(\tau ^2 \le (1-\kappa )\mu _{F^{*}}/(\Vert {V} \Vert ^{2}\mu _{G})\), since
Consequently, \(S_{i+1}\) is positive semidefinite, so we can choose \(\Delta _{i+1} = 0\) for \(i \in \mathbb {N}\). As a result, Theorem 2.6 and Lemma 2.5 results in
Using the properties \(\eta _N = \tau \varphi _N = \sigma \psi _N\) and \(\eta _{N+1} = \omega \eta _N\) we arrive at
which proves the claim. \(\square \)
This above theorem is not immediately practical, since it is unclear, if all parameters can be chosen such that all conditions are fulfilled. Hence, we now derive a method that allows for a feasible choice of the parameters.
If we plug the definition of \(\omega \) into conditions (28), we get
Since \(\tfrac{1}{2}\le \tfrac{1+t}{1+2t}\le 1\) for \(t>0\) , (30) is fulfilled, if
We express the quantities \(\mu _{G}\) and \(\mu _{F^{*}}\) by \(\mu _{F^{*}} = a\gamma _{F^{*}},\ \mu _{G} = b\gamma _{G}\) with \(0\le a,b\le 1\). Then, we can use (31) to get a valid value for \(\epsilon \), namely
Furthermore, we observe that it is always beneficial to choose \(\delta \) as large as possible, i.e. we set \(\delta =\kappa \). Additionally, using this \(\epsilon \) and \(\mu _{G}\) in (29), we get
which gives the inequality
On the other hand, we plug in \(\delta =\kappa \), and the values for \(\epsilon \), \(\mu _{F^{*}}\) and \(\mu _{G}\) into the definition of \(\tau \) in Theorem 3.1 and get
For all choices of \(\kappa \) and a, there exists a small \(b \in (0,1)\), such that the minimal value is attained at the left expression in minimum. Hence, by choice, we choose our parameters in such a way, that
so we have that
must hold in the definition. Hence, we have to find a, b and \(\kappa \), such that
which is equivalent to
Clearly, the upper bound increases with decreasing the value of b. Hence, we restrict ourselves to \(b \le \tfrac{1}{2}\) and use our degrees of freedom to set \(a = \tfrac{1}{2}\). Now (33) turns into
which is equivalent to the condition
on b. To satisfy (34), we require \(b \le \frac{1}{2}\) and
The later is positive, whenever
is fulfilled. So by (37) we are able to find a small enough b for every \(\kappa \in (0,1)\), such that the corresponding inequality holds. In conclusion, we have proven:
Theorem 3.2
Suppose that \(G, F^*\) are \(\gamma _G/\gamma _{F^*}\)-strongly convex functions fulfilling
Define
for some arbitrary \(\kappa \in (0,1)\). Furthermore let \(\hat{u} = ({\hat{x}},{\hat{y}})^{T}\) be a fixed point of the Chambolle–Pock method with mismatched adjoint and constant step lengths
Then the iterates \((u^{N})_{N \in \mathbb {N}}\) converge with \(\Vert {u^N - \hat{u}} \Vert ^2\) decaying to zero at the rate \(\mathcal {O}(\omega ^N)\).
As a consequence of the freedom of choice for the value of \(\kappa \in (0,1)\), we can choose \(\kappa \le \frac{1}{2}\) small enough such that b in Theorem 3.2 equals \(\frac{1}{2}\). This leads to the following corollary.
Corollary 3.3
Suppose that \(G, F^*\) are \(\gamma _G/\gamma _{F^*}\)-strongly convex functions fulfilling
Let
Furthermore let \(\hat{u} = ({\hat{x}},{\hat{y}})^{T}\) be a fixed point of the Chambolle–Pock method with mismatched adjoint and constant step lengths
Then the iterates converge with \(\Vert {u^N - \hat{u}} \Vert ^2\) decaying to zero at the rate \(\mathcal {O}(\omega ^N)\).
Proof
By choosing \(\kappa \) as stated, one shows by a routine calculation that one gets \(b=1/2\) in Theorem 3.2. \(\square \)
As a consequence of Corollary 3.3 we get a simple parameter choice method. For fast convergence one needs small \(\omega \), i.e. one wants a large \(\tau \). Hence, smaller \(\kappa \) is better and thus, one chooses \(\kappa \) positive but small (e.g. \(\kappa =10^{-5}\)). Note that \(\kappa =0\) is not covered by our theory.
Since many problems involve only one strongly convex function while the other function only remains to be convex we investigate if we can prove convergence of the Chambolle–Pock method with mismatch with the approach in this paper. To that end, we start again at inequality (12) and investigate under which conditions we have non-positivity of \(\Delta _{i+1}\). Using the definition of \({\tilde{H}}\) from (7), H from (5), the definition of \(Z_{i+1}\) from (13), the one of \(W_{i+1}\) from (9) and the relations for \(\eta ,\tau ,\sigma ,\xi ,\varphi ,\psi \) from Sect. 2 we get from the monotonicity of the subgradient
Using the abbreviations
as well as the Cauchy-Schwarz inequality, we can finally bound
This is a quadratic polynomial in the four variables a, b, c, d and hence, non-negativity of this expression is implied by positiv semidefiniteness of the quadratic form \((a,b,c,d) Q (a,b,c,d)^T\) with
However, the conditions for positive semidefiniteness of Q involve the inequality
and if we have \(\Vert {A-V} \Vert \ne 0\), i.e. there is mismatch, then this implies that \(\gamma _{G},\gamma _{F^{*}}>0\) is necessary for \(\mu _{G},\mu _{F^{*}}\) to exist. Hence, we can not prove convergence of the Chambolle–Pock method with mismatch with the techniques of this paper if G or \(F^{*}\) is not strongly convex.
Here is a counterexample, that the Chambolle–Pock method with mismatch may actually diverge if there is mismatch and one of the functions is strongly convex while the other is not.
Example 3.4
Let \(A = \begin{pmatrix} 1&1 \end{pmatrix}\in \mathbb {R}^{1\times 2}\), \(F(y) = (y-z)^{2}/2\) for some \(z\in \mathbb {R}\) and \(G\equiv 0\) in problem (1), i.e., we consider the minimization problem
We consider the accelerated Chambolle–Pock method (Algorithm 2 in [1]) which is (with mismatch)
We initialize the stepsizes with \(\tau _{0}\sigma _{0}<1/\Vert {A} \Vert ^{2}\) and the iterates with
For the mismatch we take \(V = \begin{pmatrix} 1&-1 \end{pmatrix} \). A standard calculation shows that one gets
The sequence \(\tau _{i}\) fulfills
from which we deduce
Hence, it holds that \(1/\tau _{i+1}\le i+1\), i.e. \(\tau _{i}\ge 1/i\) and thus, the iterates \(x^{i}\) do diverge if \(z\ne 0\).
If we use the non-accelerated variant (Algorithm 1 from [1])) we can show divergence of the \(x^{i}\) as well.
4 Numerical Examples
In this section we report some numerical experiments to illustrate the results.
4.1 Convex Quadratic Problems
As examples where all quantities and solutions can be computed exactly, we consider convex quadratic problems of the form
with \(\alpha ,\beta >0\), \(A\in \mathbb {R}^{m\times n}\) and \(z\in \mathbb {R}^{m}\). With \(G(x) = \tfrac{\alpha }{2}\Vert {x} \Vert _{2}^{2}\) and \(F(\zeta ) = \tfrac{1}{2\beta }\Vert {\zeta -z} \Vert _{2}^{2}\) this is of the form (1). The conjugate functions are \(G^{*}(\xi ) = \tfrac{1}{2\alpha }\Vert {x} \Vert _{2}^{2}\) and \(F^{*}(y) = \tfrac{\beta }{2}\Vert {y} \Vert _{2}^{2} + \langle {y},{z}\rangle \) and the respective proximal operators are readily computed as
and the optimal primal solution is
Note that G is strongly convex with constant \(\gamma _{G} = \alpha \) and \(F^{*}\) is strongly convex with constant \(\gamma _{F^{*}} = \beta \) and hence, for \(\alpha ,\beta >0\) we can use Theorem 3.2 to obtain valid stepsizes. For a numerical experiment we choose \(n=400\), \(m=200\), a random matrix \(A\in \mathbb {R}^{m\times n}\) and a perturbation \(V\in \mathbb {R}^{m\times n}\) by adding a small random matrix to A, i.e.
The resulting algorithm is
We check the condition \(\gamma _{G}\gamma _{F^{*}}>2\Vert {A-V} \Vert ^{2}\) numerically and use Theorem 3.2 to obtain feasible stepsizes. For constant stepsizes, we get as limit the unique fixed points
while the true primal solution is
For our experiment we used \(\alpha = \gamma _G=0.15\) and \(\beta = \gamma _{F^{*}}=1\) and \(\kappa =0.01\) in Theorem 3.2.
Figure 1 illustrates that the method with mismatched adjoint behaves as expected: We observe linear convergence towards the fixed point \({\hat{x}}\) and the iterates reach the error to the true minimizer \(x^{*}\) that has been predicted by Theorem 1.2.

Convergence of iteration (40). Here \({\hat{x}}\) is the fixed point (41) of the iteration with mismatch and \(x^{*}\) is the original primal solution (42). The solid orange plot is the distance of the primal iterates \(x^{k}\) of (40) to the fixed point of the iteration, and the dashed purple line is the distance of the iterates \(x^{k}\) to the original primal solution. As predicted, the latter distance falls below the value given in Theorem 1.2
4.2 Computerized Tomography
To illustrate a real-world application of our results, we consider the problem of computerized tomography (CT) [13]. In computerized tomography one aims to reconstruct a slice of an object from x-ray measurements taken in different directions. The x-ray measurements are stored as the so-called sinogram and the map of the image of the slice to the sinogram is modeled by a linear map which is referred to as Radon transform or forward projection. The adjoint of the map is called backprojection. There exist various inversion formulas which express the inverse of the Radon transform explicitly, but since the Radon transform is compact (when modeled as a map between the right function spaces [14]), any inversion formula has to be unstable. One popular stable, approximate inversion method is the so called filtered backprojection (FBP) [13]. The method gives good approximate reconstruction when the number of projections is high and when the data is not too noisy. However, the quality of the reconstruction quickly gets worse when the number of projections decreases. There are numerous efforts to increase reconstruction quality from only a few projections, as this lowers the x-ray dose for a CT scan. One successful approach uses total variation (TV) regularization as a reconstruction method [15] and solves the respective minimization problem with the Chambolle–Pock method. Usually, the method takes a large number of iterations. Moreover, there are many ways to implement the forward and the backward projection. In applications it sometimes happens that a pair of forward and backward projections are chosen that are not adjoint to each other, either because this importance of adjointness is not noted, or on purpose (speed of computation, special choice of backprojector to achieve a certain reconstruction quality, see also [4, 6, 7, 16]).
We describe a discrete image with \(m\times n\) pixels as \(x\in \mathbb {R}^{m\times n}\). Its discrete gradient \(\nabla x = u\in \mathbb {R}^{m\times n\times 2}\) is a tensor and for such a tensor we define the pixel-wise absolute value in the pixel \((i_{1},i_{2})\) as \(|{u} |_{i_{1},i_{2}}^2 = \sum _{k=1}^2 u_{i_{1},i_{2},k}^2\), cf. [17, p. 416]. For images \(x\in \mathbb {R}^{m\times n}\) we denote by \(\Vert {x} \Vert _{p} = \left( \sum _{i_{i},i_{2}}|{x} |_{i_{1},i_{2}}^{p} \right) ^{1/p}\) the usual pixel-wise p-norm. With R we denote the discretized Radon transform taking an \(m\times n\)-pixel image to a sinogram of size \(s\times t\). We aim to solve the problem
for a given sinogram z and constants \(\lambda _{0},\lambda _1,\lambda _{2}>0\). This can be expressed as the saddle point problem
With \(F^*(q,p) = \frac{1}{2 \lambda _0}\Vert q\Vert _{2}^{2} + \langle q, z \rangle + I_{\Vert {\cdot } \Vert _{\infty } \le \lambda _1}(p)\), \(G(x) = \frac{\lambda _2}{2} \Vert {x} \Vert _2^2\) and \(A = \left( \begin{array}{l} R \\ \nabla \end{array}\right) \) the saddle point formulation is exactly of the form (1). The function G is strongly convex, however, \(F^{*}\) is not. Hence, we regularize further by adding \(\epsilon \Vert p\Vert _{2}^{2}/2\) with \(\epsilon >0\) to \(F^{*}\) which amounts to a Huber-smoothing of the total variation term in the primal problem.
In our experiment we want to recover the Shepp Logan phantom \(\hat{x}\) with \(400 \times 400\) pixels from measurement with just 40 equispaced angles and 400 bins for each angle and a parallel bean geometry, and added 15% relative Gaussian noise. Hence, the resulting sinogram z is of the shape \(40 \times 400\). To implement the mismatch we used non-adjoined implementations of the forward and back-projection (we used the Astra toolbox [18] and took as forward operator A the parallel strip beam projector and as backward projection \(V^{*}\) the adjoint of the parallel line beam projector, see https://www.astra-toolbox.com/docs/proj2d.html for the documentation). All experiments are done in Python 3.7.
We use the algorithm from Theorem 3.1 where we used \(V^{*} = \begin{pmatrix} S^{*}&-{\text {div}} \end{pmatrix} \) instead of \(A^{*}\) and replace the correct adjoint \(S^{*}\) by the computationally more efficient adjoint of the parallel line projector. To achieve a fair comparison, we vary the regularization parameter \(\lambda _1\) of the total variation penalty from 0.6 to 2.4. The remaining parameters are set to \(\lambda _0 = 1\) and \(\lambda _2 = \epsilon = 0.01\). The initial stepsizes are set according to Theorem 3.1 for the mismatched adjoint and [1, Algorithm 3] in the non-mismatched case, respectively. The operator norm of the adjoint operator \(S^{*}\) is computed numerically and the operator norm of the gradient is estimated like in (cf. [17, Lemma 6.142]).
In Fig. 2 we show the original image (the famous Shepp-Logan phantom), the reconstruction by filtered backprojection and the best results of the Chambolle–Pock iteration for TV regularized reconstruction with the exact and with the mismatched adjoint. One notes that the use of a mismatched adjoint leads to a good reconstruction, comparable to the result with [1, Algorithm 3].

Reconstruction (Rec.) of the Shepp Logan phantom. From left to right: Reconstruction with adjoint mismatch with fixed grayscale, the absolute reconstruction error towards the original image, the reconstruction with the exact adjoint and the corresponding absolute error. All images have a fixed grayscale with values reaching from 0.0 to 1.0
Figure 3 shows the distance of the iteration to the exact reconstruction (i.e. the true, noise-free Shepp-Logan phantom). Naturally, the Chambolle–Pock iteration does not drive the error to the noise-free solution to zero (for both exact and mismatched adjoint). There are at least three different reasons: There is some error in the sinogram, we only use few projections and there is TV regularization involved. However, the non-mismatched Chambolle–Pock method gets admittedly closer to the original image than the mismatched method. Figure 4 shows the primal objective. We note that in this example the iteration with mismatch yields results comparable to the non-mismatched Chambolle–Pock method. Moreover, it can be seen that, as expected, the use of a mismatched adjoint prevents the true minimization of the objective. With the computationally more efficient parallel line projector as adjoint, we are able to decreases the computation time significantly with approximately \(15\%\) average time saving per iteration on a 2020 M1 MacBook Air running macOS Big Sur. However, the non-mismatched method takes less iterations to retrieve a good result, so the no computational advantage can be shown by this experiment.

Relative distance to the exact reconstruction over iterations

Decay of the primal objective function value
5 Conclusion
We have established stepsizes, for which the Chambolle–Pock method converges, even if the adjoint is mismatched. Additionally, we presented results that showed, that not only strong convergence can be preserved under strong convexity assumptions, and also that the convergence rate is in a similar region. Furthermore, as a broad class of problems are in the scope of this paper, we established an upper bound on the distance between the original solution and the fixed point of iteration with mismatch. Thus, approximating the adjoint with a computationally more efficient algorithm can be done as long as the assumptions are respected. One of these assumptions is, that the iteration with mismatch still possesses a fixed point and more work is needed to understand when this is guaranteed. Furthermore, we discussed advantages and disadvantages of our analysis and illustrated our results on an example from computerized tomography, in which the mismatched adjoint was obtained using different discretization schemes for the forward operator and the mismatched adjoint.
Notes
In the case that T is not positive semidefinite, the expression \(\Vert {x} \Vert _{T}\) will not be used, however, its square \(\Vert {x} \Vert _{T}^{2}\) will (but may be a negative number.)
References
Chambolle, A., Pock, T.: A first-order primal-dual algorithm for convex problems with applications to imaging. J. Math. Imaging Vis. 40, 120–145 (2011). https://doi.org/10.1007/s10851-010-0251-1
Buffiere, J., Maire, E., Adrien, J., Masse, J., Boller, E.: In situ experiments with X ray tomography: an attractive tool for experimental mechanics. Exp. Mech. 50, 289–305 (2010)
Riddell, C., Bendriem, B., Bourguignon, M., Kernévez, J.: The approximate inverse and conjugate gradient: non-symmetrical algorithms for fast attenuation correction in SPECT. Phys. Med. Biol. 40(2), 269–81 (1995)
Zeng, G.L., Gullberg, G.T.: Unmatched projector/backprojector pairs in an iterative reconstruction algorithm. IEEE Trans. Med. Imaging 19(5), 548–555 (2000). https://doi.org/10.1109/42.870265
Savanier, M., Chouzenoux, É., Pesquet, J., Riddell, C., Trousset, Y.: Proximal gradient algorithm in the presence of adjoint mismatch. 2020 28th European Signal Processing Conference (EUSIPCO), pp. 2140–2144 (2021)
Chouzenoux, E., Pesquet, J.-C., Riddell, C., Savanier, M., Trousset, Y.: Convergence of proximal gradient algorithm in the presence of adjoint mismatch. Inverse Probl. 37(6), 065009–29 (2021). https://doi.org/10.1088/1361-6420/abd85c
Lorenz, D.A., Rose, S.D., Schöpfer, F.: The randomized Kaczmarz method with mismatched adjoint. BIT Numer. Math. 58, 1079–1098 (2018)
Dong, Y., Hansen, P., Hochstenbach, M., Riis, N.A.B.: Fixing nonconvergence of algebraic iterative reconstruction with an unmatched backprojector. SIAM J. Sci. Comput. 41, 1822–1839 (2019)
Elfving, T., Hansen, P.: Unmatched projector/backprojector pairs: perturbation and convergence analysis. SIAM J. Sci. Comput. (2018). https://doi.org/10.1137/17M1133828
Valkonen, T.: Testing and non-linear preconditioning of the proximal point method. Appl. Math. Optim. 82(2), 591–636 (2020). https://doi.org/10.1007/s00245-018-9541-6
He, B.-S., You, Y., Yuan, X.: On the convergence of primal-dual hybrid gradient algorithm. SIAM J. Imaging Sci. 7, 2526–2537 (2014). https://doi.org/10.1137/140963467
Clason, C., Mazurenko, S., Valkonen, T.: Acceleration and global convergence of a first-order primal-dual method for nonconvex problems. SIAM J. Optim. 29, 933–963 (2019)
Buzug, T.M.: Computed Tomography. Springer, Berlin, Heidelberg (2008)
Natterer, F.: The mathematics of computerized tomography. Classics Appl. Math. (2001). https://doi.org/10.1137/1.9780898719284. (Reprint of the 1986 original)
Sidky, E.Y., Jorgensen, J.H., Pan, X.: Convex optimization problem prototyping for image reconstruction in computed tomography with the Chambolle–Pock algorithm. Phys. Med. Biol. 57(10), 3065 (2012)
Palenstijn, W.J., Batenburg, K., Sijbers, J.: Performance improvements for iterative electron tomography reconstruction using graphics processing units (GPUs). J. Struct. Biol. 176(2), 250–3 (2011)
Bredies, K., Lorenz, D.: Mathematical Image Processing. Birkhäuser, Cham (2018). https://doi.org/10.1007/978-3-030-01458-2
Van Aarle, W., Palenstijn, W.J., Cant, J., Janssens, E., Bleichrodt, F., Dabravolski, A., De Beenhouwer, J., Batenburg, K.J., Sijbers, J.: Fast and flexible x-ray tomography using the astra toolbox. Opt. Express 24(22), 25129–25147 (2016)
Acknowledgements
This work has received funding from the European Union’s Framework Programme for Research and Innovation Horizon 2020 (2014-2020) under the Marie Skłodowska-Curie Grant Agreement No. 861137.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lorenz, D.A., Schneppe, F. Chambolle–Pock’s Primal-Dual Method with Mismatched Adjoint. Appl Math Optim 87, 22 (2023). https://doi.org/10.1007/s00245-022-09933-5
Accepted:
Published:
DOI: https://doi.org/10.1007/s00245-022-09933-5