
Abstract
At-site flood frequency analysis is a direct method of estimation of flood frequency at a particular site. The appropriate selection of probability distribution and a parameter estimation method are important for at-site flood frequency analysis. Generalized extreme value, three-parameter log-normal, generalized logistic, Pearson type-III and Gumbel distributions have been considered to describe the annual maximum steam flow at five gauging sites of Torne River in Sweden. To estimate the parameters of distributions, maximum likelihood estimation and L-moments methods are used. The performance of these distributions is assessed based on goodness-of-fit tests and accuracy measures. At most sites, the best-fitted distributions are with LM estimation method. Finally, the most suitable distribution at each site is used to predict the maximum flood magnitude for different return periods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Floods are natural hazards and cause extreme damages throughout the world. The main reasons of floods are extreme rainfall, ice and snow melting, dam breakage and the lack of capacity of the river watercourse to convey the excess water. Floods are natural phenomena which cause disasters like destruction of infrastructure, damages in environmental and agricultural lands, mortality and economic losses. Many frequency distribution models have been developed for determination of hydraulic frequency, but none of the distribution models is accepted as a universal distribution to describe the flood frequency at any gauging site. The selection of a suitable distribution usually depends on the characteristics of available data at a particular site. We need to estimate the flood magnitude at a particular site for various purposes including construction of hydraulic structures (barrages, canals, bridges, dams, embankments, reservoirs and spillways), insurance studies, planning of flood management and rescue operations. We come across a number of methods which are available in the literature for flood magnitude estimation, but at-site flood frequency analysis remains the most direct method of estimation of flood frequency at a particular site.
To describe the flood frequency at a particular site, the choice of an appropriate probability distribution and parameter estimation method are of immense importance. The probability distributions used in this study include the generalized extreme value (GEV) distribution, Pearson type-III (P3) distribution, generalized logistic (GLO) distribution, Gumbel (GUM) distribution and three-parameter log-normal (LN3) distribution. These distributions are recommended for at-sight flood frequency analysis in various countries [2, 4, 24]. Furthermore, these distributions are most commonly traced in the hydrological literature for at-site and regional flood frequency analysis.
Cicioni et al. [3] conducted at-site flood frequency analysis in Italy by using 107 stations. They identified LN3 and GEV as best-fitting distributions based on the Kolmogorov–Smirnov (KS), Anderson–Darling (AD) and Cramer–von Mises (CVM) goodness-of-fit tests. Saf [23] found the GLO as the most suitable distribution for Upper-West Mediterranean subregion in Turkey. Mkhandi et al. [17] used annual maximum flood data of 407 stations from 11 countries of Southern Africa to conduct the regional frequency analysis. They identified Pearson type-III (P3) distribution with probability weighted moment (PWM) method and log-Pearson type-III (LP3) with a method of moment (MOM) as the most suitable distributions for the regions. Młyński et al. [18] identified log-normal distribution as the most suitable for the upper Vistula Basin region (Poland). There have been many studies in the past literature on the comparison of various probability distributions with different parameter estimation methods for at-site flood frequency analysis, e.g. see [1, 5, 7, 22] (Fig. 1).

Locations of gauging stations used in this study
The most commonly used methods for estimation of parameters in flood frequency analysis are the maximum likelihood estimation (MLE) method, the method of moments (MOM), the L-moments (LM) method and the probability weighted moments method (PWM). The MLE method is an efficient and most widely used method for estimation of parameters. Recently, the LM method has gained more attention in the hydrological literature for estimation of parameters of probability distributions. In this research study, we used LM and MLE methods for estimation of parameters of the candidate probability distribution.
The methods usually use for selection of the best distribution are goodness-of-fit (GOF) tests (e.g. Anderson–Darling and Cramér–von Mises), accuracy measures (e.g. root mean square error and root mean squared percentage error), goodness-of-fit indices (e.g. AIC and BIC) and graphical methods (e.g. Q–Q plot and L-moment ratio diagram). In the hydrological literature, researchers have used different methods in order to find the best probability distribution. To identify the best-suited distribution at each site of Torne River, we have used goodness-of-fit (GOF) test and accuracy measures. The GOF tests are used to test that the data come from a specific distribution. The accuracy measures provide a term by term comparison of the deviation between the hypothetical distribution and the empirical distribution of the data. The details about accuracy measures and goodness-of-fit test used in this study are described in Sect. 3.
The estimation of flood frequency of the high return period is of great interest in flood frequency analysis. The flood frequency estimation of return periods is always associated with uncertainties. Uncertainty in flood frequency analysis arises from many sources. Uncertainties included in water resources management can be distinguished in data uncertainties, structural uncertainties and model/parameters uncertainties, see e.g. [13, 14]. Furthermore, there is uncertainty in the estimation of flood frequency of return periods much larger than the actual records, particularly in the type of probability density function (PDF) and its parameters. This is particularly true on the right tail of the PDF, the region of interest for flooding. In addition, there is uncertainty in the measurements. For example, see [15] for an in-depth discussion on epistemic uncertainty (reducible uncertainty) and natural uncertainty (irreducible uncertainty). The flood estimation on high return periods are always associated with high uncertainties. In this study, we quantify the uncertainty of a given quantile estimate for a specific fitted distribution by using the parametric bootstrap method.
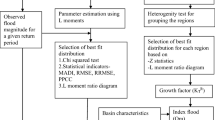
In this research paper, the flood frequency calculation, using statistical distribution, is addressed for gauged catchments, for which we dispose a respectively long-term hydrological time series. The choice of an appropriate probability distribution and associated parameter estimation method is vital for at-site flood frequency analysis. The core objective of this study is to find the best-fit distribution among the candidate probability distributions with a particular method of estimation (MLE or LM) for annual maximum peak flow data at each site of the Torne River by using goodness-of-fit (GOF) tests and accuracy measures. We are also interested to look that, is there any best overall distribution and fitting method for these five sites of Torne River?. Finally, to estimate the quantiles of flood magnitude for the return period of 5, 10, 25, 50, 100, 200 and 500 years with non-exceedance probability at each site of the river using the best-fit probability distribution. To address the uncertainty of flood estimations, we estimate standard error of estimated quantiles and construct 95% confidence interval of flood quantile for the return period using the parametric bootstrap method. This is a first study for at-site flood frequency analysis of Torne River.
This paper is organized as follows: Sect. 2 describes the study area and available data for the analysis. Section 3 deals with the model description, parameter estimation method and model comparison methods. Section 4 provides the results and discussion of the application of L-moments and maximum likelihood estimation method based flood frequency analysis of five gauging sites on the Torne River. Finally, Sect. 5 concludes the article.
2 Study area and data
The Torne River works as a border between northern Sweden and Finland, with total catchment area 40157 km\(^2\) of which 60% is within Swedish border and the remaining area is in Finland. The Muonio River, which is the biggest contributor of the Torne River, joins shortly after Pajala Pumphus. Another contributor river Lainio (259.74 km long) joins the Torne river shortly after Junosuando. In springtime, water flow is above average level, which converts into flood and this flood causes the damages to the waterfront constructions and buildings [6]. Therefore, Torne River is frequently affected by flooding problem [Swedish meteorological and hydrological institute (SMHI)]. The data of annual maximum flow of five gauging sites of Torne River (Swedish: Torneälven) are considered in this study. The data have been collected from SMHI (www.smhi.se). The length of the data series varies from 34 to 108 years. The summary of Torne River gauging sites characteristics is presented in Table 1.
3 Methodology
3.1 Candidate probability distributions
To describe the flood frequency at a particular site, the selection of an appropriate probability distribution is always important. We have considered generalized extreme value (GEV), Pearson type-III (P3) distribution, generalized logistic (GLO) distribution, Gumbel (GUM) distribution and three-parameter log-normal (LN3) distribution for the analysis of flood frequency at five gauging sites of the Torne River. The probability density function (pdf) and quantile function y(F) of these distributions are summarized in Table 2. These distributions are common in the literature and are recommended distributions for flood frequency analysis in many countries (see e.g. [2, 4, 21, 22]). We explain the detail of parameter estimation method (MLE and LM) in the following subsection.
3.2 Maximum likelihood estimation (MLE) method
The MLE method estimates the parameters by maximizing the log-likelihood function of a probability distribution. Suppose we have n independent and identically distributed observations \({y_1},\,{y_2}, \ldots ,\,{y_n}\). Each \(y_i\) has a pdf given by \(f(y_i;\varvec{\mu })\). Here, \(\varvec{\mu } = ({\mu _1},\;{\mu _2},\ldots ,{\mu _k})\) is a vector of unknown parameters to be estimated. Then, the log-likelihood function is defined as \(l\varvec{\left( \mu \right) } = \sum \nolimits _{i = 1}^n {\log f\left( {{y_i};\varvec{\mu } } \right) }\). The maximum likelihood estimate of \(\varvec{\mu }\) is the value of the parameter vector \(\varvec{\mu }\) that maximize the \(l\varvec{\left( \mu \right) }\) for given data Y. We use numerical optimization methods in order to search \(\varvec{\mu }\) which give the maximum value of \(l\varvec{\left( \mu \right) }\). Many numerical optimization methods, e.g. Newton–Raphson method, Nelder and Mead, differential evolution, etc. are found in the literature. We have used Nelder and Mead method for numerical optimization proposed by Nelder and Mead [19].
3.3 Theory of L-moments (LM)
L-moments are introduced by Hosking [9, 10], which are linear functions of probability weighted moments (PWM’s). L-moments are alternative to the conventional moments, but computed from linear combinations of order statistics. L-moments can be defined for any random variable Y whose mean exists [10]. The rth-order PWM (\(\beta _r\)) is defined as
where F(y) is a cumulative probability distribution and y(F) is a quantile function of distribution. The first four L-moments in terms of linear combination of PWM are defined as
The first L-moment (\(\lambda _1\)) is a measure of location (mean), while the second L-moment represents the dispersion. Finally, the L-moment ratios defined by Hosking [10] are given below
The unbiased sample estimators of \(\beta _i\) of the first four PWMs for any distribution can be computed as follows
where the data (\(y_{1:n}\)) are an ordered sample in ascending order from 1 to n. The parameters with L-moments estimation method are obtained by equating the sample L-moments with distribution L-moments.
3.4 Standard error of estimated parameters
The standard errors (SE) of estimated parameters indicate a measure of reliability of estimates and performance of estimation technique. In this study, we have obtained SE of estimated parameters by Monte Carlo simulation method. The description of this method is given as
We use estimated parameters with MLE and LM method at each gauging site and draw 1000 samples of size equal to the length of data from each probability distribution.
For each simulated sample, we obtain the MLE and LM estimates for the parameters of the distribution.
For each gauging site, the standard errors are obtained by taking the standard deviation of these 1000 MLE and LM estimates of the parameters of each distribution.
3.5 Goodness-of-fit (GOF) tests
The goodness-of-fit tests are used to test that the observed data follow a particular distribution. We consider the Anderson–Darling (AD) test for the study. This test is often used in flood frequency analysis and has shown good performance in case of small sample size and heavy-tailed distributions [12, 20]. The test statistic for AD test is defined as
where \({\sum \nolimits _{i = 1}^n {\left[ {\frac{{2i - 1}}{n}\left( {\log (1 - F({y_{n - i + 1}})) + \log (F({y_i}))} \right) } \right] } }\)
where \(F({y_i})\,\) represents the cumulative distribution function (CDF) of the specified distribution.
3.6 Accuracy measure method
In accuracy measure (AM) methods, we have used the mean absolute error (MAE), mean absolute percentage error (MAPE), root mean square error (RMSE), root mean squared percentage error (RMSPE) and correlation coefficient (\(R^2\)) to evaluate how adequately a given distribution fits the observed data. These measures are defined as
where \({\bar{F}}({y_i}) = \frac{{\sum \nolimits _{i = 1}^n {F({{{\hat{y}}}_i})} }}{n}\) and n represents the size of the data series. In all above accuracy measures, \(F({y_i})\) is the empirical cumulative distribution function (CDF) of the data (observed ordered values) and \(F({{\hat{y}}_i})\) indicates the theoretical CDF of the distribution (ordered estimated values from the distribution).
3.7 Quantile estimation
After selection of the best probability distribution, the main goal of flood frequency analysis is to estimate the quantile \({y_T}\) for a return period (T) of scientific relevance. \(P(Y \geqslant {y_T}) = \frac{1}{T}\) indicates the probability of exceedance from flood level \({y_T}\) once in T years. The cumulative probability of non-exceedance is defined as
The distribution function \(F({y_T})\) can be expressed in inverse form as \({y_T} = y(F)\), and we can directly evaluate estimated quantile \({y_T}\) by replacing F. Sometimes, inverse of \(F({y_T})\) does not exist analytically, and then, the numerical method is used to evaluate \({y_T}\) for the given value of F. The expressions of quantile function of candidate distributions are summarized in Table 2. The quantile estimate for T years is calculated by substituting the value of \(F =(1-\frac{1}{T})\) in the expressions of quantile in Table 2. The standard error of estimated quantiles represents the uncertainty in the estimation of flood frequency of return periods. The confidence interval of flood quantile gives an estimated range of values which is likely to include the flood frequency of return periods. We use a parametric bootstrap method for estimation of standard error of estimated quantiles and confidence interval of flood quantiles of return periods. This method is more precise than an asymptotic computation when n is small [16, p. 133]. The detail of procedure involves in parametric bootstrap method is given in [16, p. 133].
4 Result and discussion
We summarized the basic statistics of five gauging sites in Table 5. All data on gauging sites in the table are in cubic metre per second. It is observed that all data at these sites are skewed. This is a enough evidence to model the data with non-normal distribution. In flood frequency analysis, the basic statistical assumptions are independence, randomness and stationarity of the data series (see e.g. [8, 11]). The independence and randomness of the data series at given site are tested by using correlation coefficient (r) at lag-1 and Wald–Wolfowitz (WW) test, respectively. To check the stationarity of the data series, Mann–Kendall (MK) test has been applied. The assumptions verification results are summarized in Table 3. The results in Table 3 indicate that the data series at each gauging site of Torne River are suitable for flood frequency analysis and probability density estimation.
The estimated parameters for each distribution at each gauging site by using MLE and LM method of estimation along with standard error (SE) are reported in Table 4. To identify the best distribution at each site, we use GOF tests and accuracy measures. Each distribution with parameter estimation method is ranked in each GOF test and accuracy measure in Table 6. The distribution is assigned a rank score between 1 and 10 in GOF test and accuracy measures, rank score 10 for the best-fitted and 1 for the worse fitted distribution. The rank score scheme is based on the relative magnitude of accuracy measures and AD test P value. The distribution with the lowest RMSE, lowest MAE, lowest RMSEP, lowest MAEP or the highest \(R^2\) has the highest rank score value 10. In AD test, the distribution with the highest P value has the highest rank score value 10. The best distribution with estimation method at each site is identified based on the total rank score in GOF tests and accuracy measures methods. The total rank score in Table 6 indicates that GLO with MLE estimation method is best for Junosuando. For site Pajala Pumphus and Abisko, the LN3 distribution is performed better than other distributions with the LM method. The GEV and PE3 distribution with the LM method are best-fit distributions for gauging site Kukkolankoski Övre and Övre Abiskojokk, respectively.
In this study, a single distribution has not emerged as the best distribution for all gauging sites. This was also the case in [1, 5]. Overall, the LM estimation method performed better for identifying the suitable distribution (also see, [1]). The most suited distribution with MLE estimation method is identified at gauging site which has the highest CV and skewness, see Tables 5 and 6. It seems that the sites having extreme average of annual maxima of flood and catchment area (either very large or very small) are in favour of the LM method of estimation, see Tables 1, 5 and 6. If we look the landscape setting, the gauging sites which are at an extreme position (close and far away) to the Gulf of Bothnia are in favour of the LM estimation method. The sample size of the time series does not seem to be an important factor in favour of particular distribution or estimation method in this study.
One major objective of flood frequency analysis is to estimate the quantiles in the extreme upper tail of the best-fitted distribution at each gauging site. The quantiles estimate for the return periods 5, 10, 25, 50, 100, 200 and 500 years are calculated by using quantile function and parameters value of the best-fitted distributions. Quantile estimate \({y_T}\) with non-exceedance probability F for the best-fitted distributions is given in Table 7. The estimate of uncertainty (\(\sigma _{\mathrm{s}}\)) in quantile estimates and 95% confidence intervals of quantiles of flood for different return period are also presented in Table 7. The SE indicates that longer return periods have more uncertainty around the flood quantile estimates.
5 Conclusion
In this study, the annual maximum steam flow series of five gauging sites of Torne River are examined. Flood frequency analysis is performed by using GEV, P3, GUM, GLO and LN3 distributions. The MLE and LM parameter estimation techniques are used to estimate the distribution’s parameters. The study investigates the selection of best-fit probability distribution and estimation method for at-site flood frequency analysis of Torne river. The best-fit frequency distribution is identified at each gauging site based on the highest total rank score in goodness-of-fit tests and accuracy measures.
The results indicate that the GLO distribution using MLE for gauging site Junosuando and the LN3 distribution with a LM method for Pajala Pumphus and Abisko perform better than other distributions of this study. The GEV and P3 distributions using the LM method are the most suitable distribution at Kukkolankoski Övre and Övre Abiskojokk, respectively. At most gauging sites, the best distributions using LM estimation method are identified as the best-suited distributions.
The results found in this research study for flood frequency analysis of Torne River can be used in flood study, water resource planning and designing of hydraulic structures within the same basin and similar catchments. The best-fitted distributions used in this study could be considered as candidate distributions for regional flood frequency analysis of Torne River basin or at-site flood frequency analysis on other rivers in Sweden as well.
Data availability
The data that support the findings of this study are openly available at SMHI [25].
References
Ahmad I, Fawad M, Mahmood I (2015) At-site flood frequency analysis of annual maximum stream flows in Pakistan using robust estimation methods. Pol J Environ Stud 24(6):2345–2353
Castellarin A, Kohnová S, Gaál L, Fleig A, Salinas JL, Toumazis A, Kjeldsen TR, Macdonald N (2012) Review of applied-statistical methods for flood-frequency analysis in Europe. Technical report, (NERC) Centre for Ecology & Hydrology
Cicioni G, Giuliano G, Spaziani FM (1973) Best fitting of probability functions to a set of data for flood studies. In: Floods and droughts
Cunnane C (1989) Statistical distributions for flood frequency analysis. Operational Hydrology Report (WMO)
Drissia TK, Jothiprakash V, Anitha AB (2019) Flood frequency analysis using L moments: a comparison between at-site and regional approach. Water Resour Manag 33(3):1013–1037
Elfvendahl S, Liljaniemi P, Salonen N (2006) The River Torne international watershed: common Finnish and Swedish typology, reference conditions and a suggested harmonised monitoring program: results from the TRIWA project. County Administrative Board of Norrbotten [Länsstyrelsen i Norrbottens län]
Haddad K, Rahman A (2011) Selection of the best fit flood frequency distribution and parameter estimation procedure: a case study for Tasmania in Australia. Stoch Environ Res Risk Assess 25(3):415–428
Hamed K, Rao AR (1999) Flood frequency analysis. CRC Press, Boca Raton
Hosking JRM (1986) The theory of probability weighted moments. IBM Research Rep RC12210, IBM, Yorktown Heights, NY Google Scholar
Hosking JRM (1990) L-moments: analysis and estimation of distributions using linear combinations of order statistics. J R Stat Soc Ser B (Methodol) 52(1):105–124
Kite GW (2019) Frequency and risk analyses in hydrology. Water Resour Publications, LLC. https://books.google.se/books?id=b9OKxAEACAAJ
Laio F (2004) Cramer–von Mises and Anderson–Darling goodness of fit tests for extreme value distributions with unknown parameters. Water Resour Res 40(9):W09308
Leandro J, Leitão JP, de Lima JLMP (2013) Quantifying the uncertainty in the soil conservation service flood hydrographs: a case study in the Azores Islands. J Flood Risk Manag 6(3):279–288
Leandro J, Gander A, Beg MNA, Bhola P, Konnerth I, Willems W, Carvalho R, Disse M (2019) Forecasting upper and lower uncertainty bands of river flood discharges with high predictive skill. J Hydrol 576:749–763
Merz B, Thieken AH (2005) Separating natural and epistemic uncertainty in flood frequency analysis. J Hydrol 309(1–4):114–132
Meylan P, Favre AC, Musy A (2012) Predictive hydrology: a frequency analysis approach. CRC Press, Boca Raton
Mkhandi SH, Kachroo RK, Gunasekara TAG (2000) Flood frequency analysis of Southern Africa: II. Identification of regional distributions. Hydrol Sci J 45(3):449–464
Młyński D, Wałęga A, Stachura T, Kaczor G (2019) A new empirical approach to calculating flood frequency in ungauged catchments: a case study of the upper Vistula basin, Poland. Water 11(3):601
Nelder JA, Mead R (1965) A simplex method for function minimization. Comput J 7(4):308–313
Önöz B, Bayazit M (1995) Best-fit distributions of largest available flood samples. J Hydrol 167(1–4):195–208
Opere AO, Mkhandi S, Willems P (2006) At site flood frequency analysis for the Nile Equatorial basins. Phys Chem Earth Parts A/B/C 31(15–16):919–927
Rahman AS, Rahman A, Zaman MA, Haddad K, Ahsan A, Imteaz M (2013) A study on selection of probability distributions for at-site flood frequency analysis in Australia. Nat Hazards 69(3):1803–1813
Saf B (2009) Regional flood frequency analysis using L-moments for the West Mediterranean region of Turkey. Water Resour Manag 23(3):531–551
Sevruk B, Geiger H (1981) Selection of distribution types for extremes of precipitation (No. 551.577). Secretariat of the World Meteorological Organization
The Swedish Meteorological and Hydrological Institute (2019) Hydrologiska observationer. Data files retrieved from SMHI hydrological observations. https://vattenwebb.smhi.se/station/. Accessed 20 Mar 2019
Acknowledgements
Open access funding provided by Stockholm University.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Ul Hassan, M., Hayat, O. & Noreen, Z. Selecting the best probability distribution for at-site flood frequency analysis; a study of Torne River. SN Appl. Sci. 1, 1629 (2019). https://doi.org/10.1007/s42452-019-1584-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-019-1584-z