
Abstract
Real driving scenarios, due to occlusions and disturbances, provide disordered and noisy measurements, which makes the task of multi-object tracking quite challenging. Conventional approach is to find deterministic data association; however, it has unstable performance in high clutter density. This paper proposes a novel probabilistic tracklet-enhanced multiple object tracker (PTMOT), which integrates Poisson multi-Bernoulli mixture (PMBM) filter with confidence of tracklets. The proposed method is able to realize efficient and robust probabilistic association for 3D multi-object tracking (MOT) and improve the PMBM filter’s continuity by smoothing single target hypothesis with global hypothesis. It consists of two key parts. First, the PMBM tracker based on sets of tracklets is implemented to realize probabilistic fusion of disordered measurements. Second, the confidence of tracklets is smoothed through a smoothing-while-filtering approach. Extensive MOT tests on nuScenes tracking dataset demonstrate that the proposed method achieves superior performance in different modalities.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
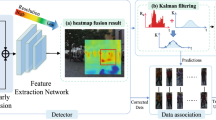
For automated vehicles, an accurate detection of single frame alone is not enough, instead of a fluent and coherent comprehension of continuous-time series of perception data is required. Therefore, most autonomous driving perception systems have implemented the online multiple object tracking (MOT) algorithm, which is responsible for tracking multiple targets of interest, recording their trajectories and maintaining their labels [1]. The output of a MOT algorithm generally contains two parts: trajectory and label of each tracked object. The task of MOT becomes extremely challenging in noisy and crowded environment, where data association between measurements and states is hard to achieve. Without correct association, the quality of state update can barely be guaranteed [1]. Figure 1 shows a general widely used measure-state matching tracking framework.

General multi-object tracking framework based on measurement-state matching data association paradigm. Matched pairs of measurement and state are filled into motion prediction module in a filtering process and finally managed by trajectory manager, while unmatched states are judged birth or death by lifetime manager
Data association is the process of matching individual observation and state. Much research has been conducted in this area. The most commonly implemented approach to deal with data association is global nearest neighbor (GNN) algorithm [2], whose main idea is to convert the matching of observations and states into obtaining the minimum distance of two sets. Popular applications of GNN include greedy algorithm, implemented in CenterPoint [3] CenterTrack[4] and Hungarian algorithm, implemented in AB3DMOT [5], StanfordTRI Mahalanobis 3D [6]. These GNN-based tracking methods are quite efficient and have achieved great performance. However, GNN shows degraded performance in environments of high clutter density. To overcome this problem, Joint Probability Data Association (JPDA) [7] is proposed. However, due to its exponential complexity, JPDA is rarely implemented in the tracking system of automated vehicles. In summary, both GNN and JPDA methods try to solve the optimal matching at a given observation and provide a deterministic matching result.
Unlike GNN and JPDA, the random finite set (RFS) framework, first proposed in Ref. [8], is a probabilistic approach to realize data association. RFS-based tracker is able to estimate the states and cardinality of multiple targets from a set of observations with clutter. Due to the application of Bayesian probability, the RFS-based tracker can associate the measurements and states while at the same time avoiding high-complexity deterministic data association [9]. Some closed-form realizations of RFS include the probability hypothesis density (PHD) [10], the cardinalized probability hypothesis density (CPHD) [11], labeled multi-Bernoulli (LMB) [12] and Poisson multi-Bernoulli mixture (PMBM) [13]. PMBM has been proved to have superior performance and simpler parameterization than GLMB. PMBM filter has been implemented for visual-based tracking in KITTI dataset [14] , and lidar tracking in Argoverse and Waymo datasets [15].
Probabilistic approach of tracking, like RFS-based tracker, with the advantage of higher efficiency in data association. Nevertheless, this approach may cause frequent track fragmentation and track discontinuity, because early RFS research does not consider the constraint on the continuity of the trajectory. There is a tendency to extend the state of RFS tracker when considering the trajectories of a target [16]. Xia et al. extend the concept of PMBM to multi-scan PMBM based on sets of trajectories. However, computing the probability density of trajectories has a high computational complexity and takes considerable computation time [17]. How to perform trajectory PMBM in an environment with strong real-time requirements remains under-explored.
The constraint of a trajectory requires to consider the continuity among states over a period of time. In a contrast, classic filtering method only considers the states and observations of two frames, the frame before and after. To consider more consecutive frames during online tracking, there is a growing tendency to analyze the update of short trajectory, called tracklet. PC-TCNN [18] detects tracklets directly from raw point clouds and performs data association between tracklets. In the concept of tracklet, the forward filtering considers multiple frames of historical information, while the backward smoothing estimates the possibility of the tracklet existence. This possibility of existence is defined as confidence. Different from traditional count-based methods, the method of estimating confidence is called the confidence-based method. CBMOT [19] originates scores from detection scores and performs score decay through tracklets. PC-3T[20] performs score update via prediction confidence model. ByteTrack [21] designs a simple structure “BYTE”, which can associate detections with either high-confidence tracklets or low-confidence ones. In summary, the score imposed on a tracklet indicates a kind of intuition that targets observed in the long-term field of vision will not suddenly disappear. Existing methods design different hand-crafted processes to manage the change of confidence of each tracklet. Explanation of the meaning of confidence, quantification and utilization of confidence remain under-explored.
This paper proposes PTMOT, a confidence-based probabilistic tracklet multi-object tracker, aiming to realize probabilistic association between tracklets and measurements to reduce calculation burden and integrate confidence-based estimation in RFS framework. Moreover, this paper adopts a confidence-based approach to adjust the confidence of tracklets.
Compared with the deterministic association method, due to the estimation of multiple association assumptions, the proposed method can correct occasional errors in certain frames. Prior RFS-based methods are prone to high ID switches due to the switching of multiple hypotheses, which damages the tracking continuity. The proposed method adopts the approach of combining the confidence estimation method and the PMBM model, which greatly improves the tracking continuity of the random finite set method. The proposed tracker achieves high performance in nuScenes tracking challenge, using different modalities lidar, cameras and radars. Precisely, the contributions of this paper are as follows:
-
(1)
A probabilistic MOT tracker which maintains both trajectory and label is developed by integrating PMBM filter and tracklet confidence estimation method. The proposed probabilistic MOT tracker is applicable to different detection inputs and achieves satisfactory performance.
-
(2)
A confidence-based method which is able to continuously estimate and update the confidence of the tracklets. The single target hypotheses (STHs) of a target at different moments update the confidence of the leaf nodes following a bottom-up tree structure. Global hypotheses are remapped to enhance the most likely STHs’ confidence.
The rest of this paper is organized as follows: Sect. 2 introduces the architecture of the proposed tracker. Section 3 presents the process of the tracking algorithm and details of modules. Section 4 discusses the experiment, quantitative results and ablation study on datasets. Section 5 concludes this paper.
2 Probabilistic Tracker Architecture
The multi-object tracker jointly estimates the position and label of each target of attention, while filtering out false detection and supplementing missed detection. By correlating the targets in the time series, the past trajectory of one target is obtained, and its velocity is computed. Organization of past trajectories is the most important input for trajectory prediction; therefore, multi-object tracking is the foundation of trajectory prediction.
The pipeline of the proposed probabilistic 3D multi-object tracker has the structure shown in Fig. 2. The three core modules are the Poisson process for tracking position, the multi-Bernoulli mixture process for tracking label and the confidence estimation module. The pipeline consists of five stages: input formatting, Poisson process, multi-Bernoulli mixture process, confidence estimation and output formatting. Compared to deterministic trackers, the proposed tracker only replaces the original deterministic observation-track matching process, without changing the underlying operation of the filtering-based tracking method, including matching metrics and filtering methods. It can work on any filtering algorithm, such as the Kalman filter, extended Kalman filter, or unscented Kalman filter and any matching metrics, such as the 3D-IOU, Mahalanobis distance or distance in embedded feature space.

Pipeline of the probabilistic multiple object tracker. After formatting detection results as point targets, the proposed tracker executes Poisson process for initialization of possible new tracklets. Then, the MBM process searches several most likely GHs and updates STHs. The confidence module refines the confidence score of STHs. The targets and unique labels of the most likely hypothesis are formatted as tracking outputs
2.1 Probabilistic Tracking of Position
In the beginning, a standard tracking-by-detection approach is adopted. At each time step, the 3D object detector gives out detection results of n objects \(Z=\left( D_1,D_2,\ldots ,D_n\right)\). The detection results are encoded as point targets and fed into the tracker. Note that the detection results contain clutter, and the position tracking part is responsible for distinguishing and extracting true targets and their initial confidence from noisy measurements with clutter.
Poisson component is responsible for tracking position of newly initiated targets. It considers the density of undetected targets, manages the number of hypotheses of potential targets and gives birth to new-born detected targets. Poisson intensity is defined as:
In Eq. 1, \(f^\mathrm {p}\left( X\right)\) denotes the posterior of Poisson intensity, \(\mu (x)\) denotes a Poisson density and X denotes the whole set of undetected objects.
For the sake of closed-form solution, Poisson intensity is often modeled as multi-modal Gaussian distribution. Figure 3 illustrates an example of the Poisson process graphically. At last timestamp, there are four intensity components. At the current timestamp, they are updated with several point measurements, and new tracklets are initialized at the peaks of updated intensity. The predicted Poisson intensity and birth intensity update in a quasi-convolutional manner, i.e., every intensity component interacts with every birth intensity component. The tracklets are spawned at the peaks of Gaussian distribution. In this way, no explicit one-to-one data association is required, and new targets are spawned based on the mixture of multiple Gaussian distributions.

A simple example of the Poisson process of tracking location and spawning new tracks. First, generate intensity according to detection scores from measurements, then, correlate with predicted intensity to get the updated intensity, and finally initialize new tracklets whose confidence is beyond an adaptive threshold
2.2 Probabilistic Tracking of Label
The multi-Bernoulli mixture(MBM) process considers the data association global hypotheses and single target hypotheses. The MBM density is defined as sum of j global hypotheses:
In Eq. 2, \(f^{\mathrm {mbm}}(X)\) is the posterior of MBM intensity, X is the whole set of detected objects, \(w_{j,i}\) denotes the weight of a Bernoulli component \(X_i\) in global hypothesis (GH) j, and \(f_{j,i}\left( X_i\right)\) is the probability density of single Bernoulli component \(X_i\) in global hypothesis j:
In Eq. 3, \(r_{j,i}\) denotes the existence probability of object x in STH X. Each STH has missed detection or one object detected.
The multi-Bernoulli process predicts the existing tracklets, updates the possibility of multiple data associations, proposes single target hypotheses and multiple global hypotheses. An illustration of MBM process is shown in Fig. 4. The tracking results of the current frame are selected from the most likely GH.

Multi-Bernoulli mixture process of tracking labels
2.3 Tracklet Confidence Estimation
Unlike traditional count-based methods, confidence-based methods manage the birth and death of tracklets based on confidence score. Confidence-based methods enable a continuous estimation of tracklets. A target is able to have a continuous existence probability, even if the detector occasionally loses the observation of the target. The tracklet is smoothed in terms of confidence.
Confidence serves the data association process. The confidence is defined as the Bernoulli parameter \(r_i\). The initial value originates from detection score. The confidence changes in the process of generating new child STHs in a tree structure. The confidence is filled into elements in the cost matrix.
Confidence estimation needs two important function, score update and score decay. The score decay module performs a tree-structured backward smoothing of confidence to maintain a continuous estimation. The score update module enhances the confidence of existing STHs with most likely GHs.
3 Proposed Confidence-Based Tracker
3.1 Overall Process
The proposed tracker adopts the Bayesian filtering theory to formalize the multi-object tracking process. MOT can be modeled as a multi-variable estimation problem. \(x_t^i\) represents the state of the i-th object at the t-th timestamp, \(\varvec{X_t} =(x_t^1,x_t^2,\ldots ,x_t^{M_t})\) is the state of all targets in the t-th frame.\(z_t^i\) represents the observation of the i-th target at the t-th timestamp. \(\varvec{Z_t} =(z_t^1,z_t^2,\ldots ,z_t^{M_t} )\) represents the observation sequence of all targets under the t-th frame.
The pseudo-code of the implementation of the proposed tracker at a timestamp k is shown in Algorithm 1. The whole process is divided into six stages. They are prediction, update, reduction, score decay, score update and targets estimation.

The main difference between the proposed tracker and typical PMBM filter lies in the prediction step. Unlike typical PMBM, the proposed tracker does not marginalize out the previous states. In general, the prediction step follows the Chapman–Kolmogorov equation:
In Eq. 4, \(f_{k+1 \mid k}(x_{k+1})\) is the prediction of the next timestamp, \(g_{k+1}(x_{k+1} \mid x)\) is the single-target transition density at time \(k+1\) and the previous state is marginalized out to obtain the state \(x_{k+1}\) at timestamp \(k+1\).
The state variable tracklet in PMBM tracker is a concatenation of object states at consecutive timestamps in sliding windows. For real-time requirements of online tracking, the tracklet is approximately a series of multiple first-order Markovian aggregations and only the state of multiple frames is considered when estimating the confidence of the tracklet.
The smoothing of confidence is implemented through online smoothing-while-filtering approach. The definition and usage of confidence are illustrated in Sect. 3.3.1. Two important functions in score decay process are introduced in Sect. 3.3.2, while score update is introduced in Sect. 3.3.3.
3.2 PMBM Modules
3.2.1 PMBM Prediction
The prediction of PMBM consists of two stages, the prediction of Poisson components and the Bernoulli components.
Each Poisson component follows the state transition function \(g(p_{k+1}\mid p_k)\) and its weight \(w_i\) is multiplied by probability of survival \(P_{\mathrm {s}}\):
The prediction of each Bernoulli component \(f_{j,i}\left( X_i\right)\) follows the state transition function \(g(x_{k+1}\mid x_k)\), while the confidence is multiplied by probability of survival \(P_{\mathrm {s}}\):
The STHs after prediction are written to the current timestamp of the state sequence.
The state transition function \(g(x_{k+1}\mid x_k)\) follows a first-order constant velocity and constant turning rate (CVCT) motion model and Kalman filter. The important state variables concerned in 3D MOT include position \(p_x\),\(p_y\), scale, orientation \(\theta\), velocity \(v_x\), \(v_y\) and yaw rate \(\dot{\theta }\). The state is expressed as
State-of-the-art detectors predict the velocity of each target, so the observations include velocity prediction \(v_x\) and \(v_y\).
The state transition equation is:
Given random measurement noise \({v}_k\), the observation model follows
The position and orientation of 3D bounding boxes are tracked, while the dimensions and other properties are inherited from measurements.
3.2.2 PMBM Update

The pseudo-code of PMBM update is shown in Algorithm 2. Similar to prediction stage, the PMBM update consists of two stage, the Poisson and Bernoulli update. Each Poisson density weakens the weights of undetected objects w that stay undetected by the detection probability \(P_\mathrm {d}\).
Poisson update is also in charge of the initialization of new tracklets. First, perform gating for each measurement to Poisson densities and select the neighboring Poisson components. Next, perform merging for selected components and get the mixed state \(X_{\mathrm {mix}}\). Last, spawn a new track whose first STH is the Bernoulli component \(f_{\mathrm {ini}}\left( X\right)\). The initial state of \(f_{\mathrm {ini}}\left( X\right)\) is \(X_{\mathrm {mix}}\), and the initial confidence is set to be the detection score.
Core hypothesis-based data association method is proceeded in Bernoulli update. First, for each STH, perform gating to measurements and the STH, then update each STH with neighboring possible measurements and become several child STHs. Second, if there is no GH, spawn the first one using current STHs. If there are already GH, spawn new global hypotheses recursively based on current ones. For each current GH who has j STHs and current number of measurements i, create a cost matrix \(C_{mn}\) with the size \([i,i+j]\). Fill in each element with the opposite number of the cost of child STH. Last, perform Murty solver to get weight for each GH.
3.2.3 PMBM Reduction
Reduction is a necessary step for PMBM to prune low-confidence candidate targets and keep the target candidate pool from overflowing. The pruning process is divided into three stages. First, prune the STHs whose confidence is below a certain threshold, instead, the pruned states are recycled back to the Poisson mixture density. Second, prune global hypotheses whose weight is under a certain threshold, as well as hypotheses which include the removed STHs. Third, prune STHs that are not included in any global hypotheses. Since a recursive approach is adopted to produce new global hypotheses, that is, to create new GH based on one global hypothesis in the last timestamp, the STH will no longer appear if it is not included in this timestamp.
3.3 Confidence-Based Operations
3.3.1 Confidence in Probabilistic Data Association
Confidence is defined as the Bernoulli parameter \(r_i\) in each STH which is the form of a Bernoulli component. The confidence serves as an important reference for data association. In PMBM structure, the probabilistic data association lies in the update process in Sect. 3.2.2. The initial confidence \(r_i^0\) of a newly spawned tracklet comes from the detection score \(s_{\mathrm {D}}\):
The confidence \(r_{i,j}^t\) of new STH \(s_{i,j}^t\) matching with one observation \(z_j\) generates from the confidence \(r_i^{t-1}\) of its parent STH \(s_i^{t-1}\) and considers the likehood between observation \(z_j\) and state \(x_i\):
The likelihood function computes the normalized likelihood according to a certain matching metrics. The confidence \(r_{i}^t\) of new STH \(s_{i}^t\) indicates the target misses only generates from the confidence \(r_{i}^{t-1}\) of its parent STH \(s_{i}^t\) with detection probability \(P_\mathrm {d}\):
The cost matrix \(\varvec{C_{M\times N}}\) is responsible for finding several optimal association alternatives. M is the number of measurements, and N is the number of tracklets. The matrix is divided into two sub-matrices. \(\varvec{C_{{1:M}, {1:N-M}}}\) stands for the cost for targets detected in the previous time step, while \(\varvec{C_{{1:M}, {M-N+1:N}}}\) stands for the cost for newly detected target, for elements in sub-matrix \(\varvec{C_{{1:M}, {1:N-M}}}\):
for elements in sub-matrix \(\varvec{C_{{1:M}, {M-N+1:N}}}\):
The Murty solver is responsible for solving several best paths in the cost matrix. The opposite of confidence in the formula is because the Murty solver generally needs to search for the shortest path. In this process, the comparison of confidence in different tracklets is relative. Confidence has a great impact on probabilistic data association procedure in the tracker.
3.3.2 Score Decay
The pseudo-code of score decay process is shown in Algorithm 3.

The score decay performs in the form of tracklet smoothing. The tracklets’ confidence is smoothed near online through re-scoring STHs in a temporal window. Basically, the state of a tracklet is defined as a tuple:
where \(\beta\) denotes the discrete-time of the tracklet’s most recent state and \(\alpha\) denotes the timestamp when the tracklet starts to be estimated. Here only the tracklets that are currently activated are taken into consideration, then the sequence of states is \([x_\alpha ,x_{\alpha +1},\ldots ,x_{\beta -1},x_\beta ]\). Each state has a corresponding confidence score, and the approach is to get an average score during the tracklet and assign this score to the most current state as well as perform a certain score decay to the last several states.
The main difference between prior confidence-based tracker and the proposed tracker is that one tracklet has more than one STHs at one time. That means the tracklet needs to be managed in a tree-structure manner rather than a list-structure manner. An simple example of score decay is illustrated in Fig. 5. Given the decay factor \(\eta =0.75\), the score estimation is that \(r=(1/4)\cdot (0.60+0.75\cdot 0.15+0.75^2\cdot 0.25+0.75^3\cdot 0.95)=0.31\).
In Eq. 20, N is the length of the tracklet, \(Pa(\cdot )\) denotes the parent of current STH, \(r_{j,i}\) is the confidence rate of the leaf STH node. In this manner, the meaning of the decay is the choice of previous timestamps in this tracklet. The scores of the state sequence in the tracklet are smoothed and later utilized in data association.

An example of tracing parents nodes and to perform tracklet smoothing of confidence
3.3.3 Score Update

In typical PMBM filter, the process of computing GH with various STHs is a one-way route. The consequent most likely global hypothesis is chosen for target estimation. This section aims to render a two-way influence between STH and GH, i.e., remap the weight of GHs to the weight of each STH. The pseudo-code of score update is shown in Algorithm 4.
Each Bernoulli component is controlled by two parameters \({r_i,p_i}\), where \(r_i\) stands for the probability of existence of the target. The score update process is:
In Eq. 21, \(G_j\) stands for the j-th GH and \(w_j\) is its weight. In the pseudo-code, add a remapping attribute \(\delta _i\) to each STH. For each Bernoulli component, query its existence in the top 5 likely GHs whose weights have been normalized. If the STH is included in one GH \(G_j\) with weight \(w_j\), add the weight to the remapping attribute.
For example, if the STH appears in all top 5 global hypotheses, the remapping attribute reaches the maximum 1. Next, multiply the Bernoulli confidence \(r_i\) with \(\delta _i\) and become the new enhanced confidence. The new confidence rate will affect the element of cost matrix in the next data association process. During this process, most of the STH is weakened, but since the data association considers the relative cost of different STHs, the remapping process can greatly distinguish the STHs that are frequently considered in different global hypotheses.
4 MOT Tests
4.1 Dataset and Evaluation Metrics
Dataset for MOT tests is nuScenes tracking dataset [22], which contains the diverse sensor data from top lidar, radars and cameras. The dataset consists of 700 scenes in split train, 150 scenes in split val and 150 scenes in split test. Each scene lasts for 20 s. These frames include annotated samples (every 0.5s) and unannotated sweeps. For the sake of evaluation, detectors and the proposed multi-object tracker run between samples, which means the sampling time is 0.5 s. Input data include lidar and radar point clouds, images accompanied with GPS/IMU localization.
Evaluation metric of nuScenes tracking challenge follows the widely used CLEAR MOT metrics [23] (including AMOTA, AMOTP, IDS and FRAG), Mostly Tracked (MT) / Mostly Lost (ML) metrics and new proposed metrics in Ref. [22]. Note that nuScenes evaluates AMOTP based on Euclidean distance between each center point of ground truth bounding box and predicted bounding box; therefore, a smaller distance in AMOTP represents a higher accuracy.
4.2 Implementation Details
4.2.1 Environmental Setup
The test is implemented using Python3 on a laptop Dell Inspiron 7591 with Intel Core i7-9750H CPU, RAM 8GB and GeForce GTX 1650 on a standard operating system Ubuntu 18.04LTS. The average latency of the proposed tracker in unaccelerated python code is less than 100ms, which meets the requirement of real-time online tracking.
4.2.2 3D Object Detection
A tracking-by-detection approach is adopted. The key information of one 3D bounding box includes:
In Eq. 22, [x, y, z] are the positions of the center of each bounding box in the global coordinate. [h, w, l] denote its height, width and length. The yaw angle denotes the orientation, while the pitch angle and roll angle are not considered. The detection method shall provide a detection score and semantic object type identification for each detected object. \([v_x,v_y]\) denotes the velocity of plane movement of the center point in the global frame. CenterPoint [3] is used as a 3D detector using lidar, and CenterFusion [24] is used as another detector using cameras and radars.
4.2.3 Parameter Setting
An optimal parameter setting is shown in Table 1. The matching metric of affinity applies the Mahalanobis distance. The parameter settings are mostly based on empirical study. The hyper-parameters in the table have little influence on the results given a \(\pm 20\%\) fluctuation.
4.3 Tracking Performance Evaluation
The proposed tracker is evaluated on nuScenes val and test subset. The evaluation is divided into modalities using lidar and modalities without lidar. Qualitative results of the proposed tracker using CenterPoint detection are shown in Fig. 6. Six typical scenes from the test subset of nuScenes are selected, each having three consecutive samples, to show the effectiveness of the tracker to handle difficult cases like occasional detection loss. Different colors indicate identical labels and instances.

Visualization of 3D tracking results of the proposed tracker. Different colors of the bounding boxes indicate unique labels of tracked objects
4.3.1 Baseline Evaluation
Since the method uses only motion features of 3D bounding boxes but not appearance features from feature extraction backbone network, a standard realization of AB3DMOT[5] and Mahalanobis3D [6] is used as baselines. Table 2 shows comparison of the proposed tracker with baselines methods. For the sake of fairness, all trackers share the same object detection results from CenterPoint [3] implemented in mmdetection3D [25]. Baseline methods are implemented in open-source codes provided by Mahalanobis 3D [6].
Table 2 shows the improvement of the proposed tracker against other motion-only methods. A significant improvement of 4.5% in AMOTA score against the lidar-based Mahalanobis 3D tracker is achieved. Compared to standard PMBM filter, the proposed tracker enhances the AMOTP with an average precision increase of 0.1m.
The standard PMBM filter suffers a major problem of high ID switch and fragmentation because PMBM does not provide explicit continuity between time steps. The proposed method considers the STHs in a sliding window and remaps global hypotheses to STHs, so it strengthens the impression of a trajectory. It decreases 28% of IDS and 47% of FRAG. It achieves the least FRAG among the mentioned motion-only filtering methods. The results prove that the proposed tracker successfully tackles the problem of track fragmentation.
Similarly, on the nuScenes test subset, the proposed tracker decreases 27.4% of IDS and 46.3% of FRAG compared to standard PMBM filter, which proves the proposed tracker achieves an enhanced track continuity. The improvement also indicates more mostly tracked trajectories and more true positives.
4.3.2 Comparison Regarding Modalities Radar-Camera
Measuring whether a multi-object tracker can get a satisfactory output given an inaccurate detector shows the generality of the tracker. As an typical detector using cameras and radars, CenterFusion performs about half of superior accuracy compared to lidar detectors in terms of nuScenes Detection Score (NDS). The proposed tracker is compared with other trackers using modalities camera and radar-based in Table 3. Only modalities including cameras and/or radars are considered. The tracker proposed in this paper uses centerfusion detection input generated from open-source code. Results of other trackers are from leaderboard of Eval.AI. In terms of modalities, ‘C’ denotes camera, ‘R’ denotes radar, and ‘R-C’ denotes Radar-Camera.
In Table 3, the proposed method is compared with CenterTrack [4], the best camera-based tracker QD-3DT [26] and CFTrack [27]. A considerable improvement of 3.9% in AMOTA score against the camera-based tracker QD-3DT and 5.6% against CFTrack which is also based on CenterFusion detection results is achieved. Moreover, the method has the least track fragmentation FRAG of 2116 compared to other methods. These results prove that the proposed tracker has a satisfactory generality for domain adaption. In summary, the proposed tracker achieves superior tracking performance given low-cost sensors like cameras and radars.
4.3.3 Ablation Study
The ablation study of the proposed method is implemented on nuScenes val set. An ablation analysis of the three modules described in Sect. 2 to better understand their contribution to the proposed tracker is provided. The three modules are the Poisson position tracking module, MBM label tracking module and confidence estimation module. The ablation study is shown in Table 4. “P” denotes Poisson position tracking module, “M” denotes MBM label tracking module and “C” denotes confidence estimation module, “N” denotes the length of a tracklet.
The MBM module is the core module of the proposed method. The Poisson module yields consistent improvement in precision, while the confidence module greatly improves the track continuity over the baseline. Moreover, longer tracklets lead to fewer fragmentation, while shorter tracklets are prone to get higher accuracy.
4.4 Discussion
One of the most important advances of the proposed tracker lies in the track continuity, which is reflected in the reduction of track fragmentation to half compared with the typical PMBM filter. Less track fragmentation and improved continuity lead to better AMOTP precision.
Here is a brief discussion about the parameter setting of the proposed method with data-driven methods. Two advantages of the proposed approach over data-driven approaches are highlighted, generality for different detectors and physically defined hyper-parameters which can be tuned according to some guidelines. Data-driven methods have advantages over inference-based methods in the number of learnable parameters, but still need to manually modulate certain hyper-parameters, which brings challenges to the domain adaption of the model if not given enough training data. In contrast, the proposed method does not need training data because the hyper-parameters of the method have very well-defined physical meanings and it achieves satisfactory performance given different detector input with a similar parameter setting.
5 Conclusion
The RFS-based tracking algorithms are attracting growing attention because they are able to automatically manage the birth and death of trajectories as well as manage the data association problem in an online multi-hypothesis tracking manner. This paper proposes PTMOT, a probabilistic tracklet multi-object tracker, which introduces confidence-based methods to PMBM filter. The confidence estimation of STHs and GHs is handled by “score update” and “score decay” function. The experiments demonstrate that the track fragmentation of the proposed tracker decreases significantly. The proposed tracker is able to ensure the continuity of the trajectory over sliding windows. It has also achieved superior performance in tracking with modality radar camera. In the future, the authors will extend the research of RFS-based tracker to multi-modalities MOT algorithms.
Data Availability
Some data that support the findings of this study are available from the corresponding author upon reasonable request.
Abbreviations
- GH:
-
Global hypothesis
- GNN:
-
Global nearest neighbor
- JPDA:
-
Joint probability data association
- MBM:
-
Multi-Bernoulli mixture
- MOT:
-
Multi-object tracking
- PHD:
-
Probability hypothesis density
- PMBM:
-
Poisson multi-Bernoulli mixture
- RFS:
-
Random finite set
- STH:
-
Single target hypothesis
References
Luo, W., Xing, J., Milan, A., Zhang, X., Liu, W., Kim, T.K.: Multiple object tracking: a literature review. Artif. Intell. 293, 103448 (2021). https://doi.org/10.1016/j.artint.2020.103448
Konstantinova, P., Udvarev, A., Semerdjiev, T.: A study of a target tracking algorithm using global nearest neighbor approach. In: Proceedings of the International Conference on Computer Systems and Technologies (CompSysTech’03), pp. 290–295 (2003)
Yin, T., Zhou, X., Krahenbuhl, P.: Center-based 3d object detection and tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11784–11793 (2021)
Zhou, X., Koltun, V., Krähenbühl, P.: Tracking objects as points. In: European Conference on Computer Vision, pp. 474–490. Springer (2020)
Weng, X., Wang, J., Held, D., Kitani, K.: 3D multi-object tracking: a baseline and new evaluation metrics. IEEE/RSJ Int. Conf. Intell. Robots Syst pp. 10359–10366 (2020)
Chiu, H.K., Li, J., Ambruş, R., Bohg, J.: Probabilistic 3d multi-modal, multiobject tracking for autonomous driving. In: 2021 IEEE International Conference on Robotics and Automation (ICRA), pp. 14227–14233 (2021). https://doi.org/10.1109/ICRA48506.2021.9561754
Fortmann, T.E., Bar-Shalom, Y., Scheffe, M.: Multi-target tracking using joint probabilistic data association. In: 1980 19th IEEE Conference on Decision and Control Including the Symposium on Adaptive Processes, pp. 807–812 (1980). https://doi.org/10.1109/CDC.1980.271915
Mahler, R.P.S.: Multitarget bayes filtering via first-order multitarget moments. IEEE Trans. Aerosp. Electron. Syst. 39, 1152–1178 (2003). https://doi.org/10.1109/TAES.2003.1261119
Vo, B.N., Vo, B.T., Beard, M.: Multi-sensor multi-object tracking with the generalized labeled multi bernoulli filter. IEEE Trans. Signal Process 67(23), 5952–5967 (2019)
Vo, B.N., Ma, W.K.: The Gaussian mixture probability hypothesis density filter. IEEE Trans. Signal Process 54(11), 4091–4104 (2006). https://doi.org/10.1109/TSP.2006.881190
Vo, B.T., Vo, B.N., Cantoni, A.: The cardinalized probability hypothesis density filter for linear Gaussian multi-target models. In: 2006 IEEE Conference on Information Sciences and Systems, CISS 2006—Proceedings, pp. 681–686 (2006). https://doi.org/10.1109/CISS.2006.286554
Reuter, S., Vo, B., Vo, B., Dietmayer, K.: The labeled multi-bernoulli filter. IEEE Trans. Signal Process 62(12), 3246–3260 (2014). https://doi.org/10.1109/TSP.2014.2323064
García-Fernández, A., Williams, J., Granström, K., Svensson, L.: Poisson multi-bernoulli mixture filter: direct derivation and implementation. IEEE Trans. Aerosp. Electron. Syst. (2017). https://doi.org/10.1109/TAES.2018.2805153
Scheidegger, S., Benjaminsson, J., Rosenberg, E., Krishnan, A., Granström, K.: Mono-camera 3d multi-object tracking using deep learning detections and pmbm filtering. In: 2018 IEEE Intelligent Vehicles Symposium (IV), pp. 433–440. IEEE (2018)
Pang, S., Radha, H.: Multi-object tracking using poisson multi-bernoulli mixture filtering for autonomous vehicles. In: ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 7963–7967 (2021). https://doi.org/10.1109/ICASSP39728.2021.9415072
García-Fernández, A.F., Svensson, L., Williams, J.L., Xia, Y., Granström, K.: Trajectory multi-bernoulli filters for multi-target tracking based on sets of trajectories. In: 2020 IEEE 23rd International Conference on Information Fusion (FUSION), pp. 1–8 (2020). https://doi.org/10.23919/FUSION45008.2020.9190554
Xia, Y., Granström, K., Svensson, L., García-Fernández, A.F., Williams, J.L.: Extended target poisson multi-bernoulli mixture trackers based on sets of trajectories. In: 2019 22th International Conference on Information Fusion (FUSION), pp. 1–8 (2019)
Wu, H., Li, Q., Wen, C., Li, X., Fan, X., Wang, C.: Tracklet proposal network for multi-object tracking on point clouds. In: Zhou, Z. (ed.) Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, pp. 1165–1171 (2021). https://doi.org/10.24963/ijcai.2021/161
Benbarka, N., Schröder, J., Zell, A.: Score refinement for confidence-based 3d multi-object tracking. In: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 8083–8090. IEEE (2021)
Wu, H., Han, W., Wen, C., Li, X., Wang, C.: 3d multi-object tracking in point clouds based on prediction confidence-guided data association. IEEE Trans. Intell. Transp. Syst. 23(6), 5668–5677 (2022). https://doi.org/10.1109/TITS.2021.3055616
Zhang, Y., Sun, P., Jiang, Y., Yu, D., Yuan, Z., Luo, P., Liu, W., Wang, X.: Bytetrack: multi-object tracking by associating every detection box (2021). arXiv preprint arXiv:2110.06864
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: Nuscenes: a multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11621–11631 (2020)
Bernardin, K., Stiefelhagen, R.: Evaluating multiple object tracking performance: the clear mot metrics. J. Image Video Process. 2008, 246309 (2008). https://doi.org/10.1155/2008/246309
Nabati, R., Qi, H.: Centerfusion: center-based radar and camera fusion for 3d object detection (2020). arXiv preprint arXiv:2011.04841
MMDetection3D Contributors: MMDetection3D Open-MMLab next-generation platform for general 3D object detection (2022). https://github.com/open-mmlab/mmdetection3d
Hu, H.N., Yang, Y.H., Fischer, T., Yu, F., Darrell, T., Sun, M.: Monocular quasi-dense 3d object tracking (2021). ArXiv:2103.07351
Nabati, R., Harris, L., Qi, H.: CFTrack: center-based radar and camera fusion for 3D multi-object tracking (2021). ArXiv:2107.05150
Acknowledgements
This work was supported by International Science and Technology Cooperation Program of China (2019YFE0100200), in part by National Natural Science Foundation of China (61903220) and National Natural Science Foundation of China (U1864203).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author declares that they have no conflict of interest.
Additional information
Academic Editor: Xipeng Wang
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jiang, K., Shi, Y., Zhou, T. et al. PTMOT: A Probabilistic Multiple Object Tracker Enhanced by Tracklet Confidence for Autonomous Driving. Automot. Innov. 5, 260–271 (2022). https://doi.org/10.1007/s42154-022-00185-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42154-022-00185-1