
Abstract
Multi-Object Tracking (MOT) is an important topic in computer vision. Recent MOT methods based on the anchor-free paradigm trade complicated hierarchical structures for tracking performance. However, existing anchor-free MOT methods ignore the noise in detection, data association, and trajectory reconnection stages, which results in serious problems, such as missing detection of small objects, insufficient motion information, and trajectory drifting. To solve these problems, this paper proposes Noise-Control Tracker (NCT), which focuses on the noise-control design of detection, association, and reconnection. First, a prior depth denoise method is introduced to suppress the fusion feature redundant noise, which can recover the gradient information of the heatmap fusion features. Then, the Smoothing Gain Kalman filter is designed, which combines the Gaussian function with the adaptive observation coefficient matrix to stabilize the mutation noise of Kalman gain. Finally, to address the drift noise issue, the gradient boosting reconnection context mechanism is designed, which realizes adaptive trajectory reconnection to effectively fill the gaps in trajectories. With the assistance of the plug-and-play noise-control method, the experimental results on MOTChallenge 16 &17 datasets indicate that the NCT can achieve better performance than other state-of-the-art trackers.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Multi-target tracking (MOT) plays an important role in computer vision tasks, such as video monitoring, robot navigation, etc. [40]. It aims to trace the trajectory of multiple objects simultaneously according to the given specific identification (ID). MOT generates the trajectories by associating per-frame detection results. This process can be divided into three stages: detection, data association, and trajectory generation. Although some trackers [23, 26, 32, 43, 44, 48] have achieved preferable performances, the missing detection of small objects, insufficient motion information [2], and track drifting [21, 29] caused by occlusion, ambiguity, or vibration are still significant challenges. To address these issues, some advanced methodologies are proposed, such as heatmap, Kalman filter, and trajectory reconnection.
CenterTrack [64] proposed a new Joint Detection and Tracking (JDT) paradigm by generating the central points of the object according to the gradient of the fusion of heatmap and image features. It can extract the offset from the central points to alleviate the missing detection caused by object occlusion. In recent years, many studies [53, 62] improve CenterTrack using Reid, transformer, or other methods. However, these studies ignore the redundancy of semantic information in feature fusion. The additive fusion of heatmap and image features will introduce feature-redundant noises [3]. Meanwhile, blurred features and offset errors are caused by feature gradient deviation, which greatly weakens the characterization performance of each modal [3]. From the “Fusion Result“ part in Fig. 1(a), it can be seen that the central points in the red frame are not distinct compared to the original heatmap. These feature-redundant noises generated by additive fusion will decrease the accuracy of detecting small objects.
In the data association stage of the MOT algorithm, DeepSort [52] first introduced the Kalman filter for stable prediction of the object motion information to mitigate the track drifting problem. SDE [51] and FairMOT [62] enhance motion information to the Kalman filter by improving motion feature embedding, but the scale information of the detection noise is still ignored. GIAOTracker [10] proposed the NSA Kalman filter, which introduces confidence deviation as the observation noise scale variable. However, the adaptive observation noise mutation causes abrupt changes in the Kalman gain, which reduces the stability of Kalman filter prediction in GIAOTracker and leads to unstable predictions of the Kalman filter, thus decreasing the acquisition of motion information. As shown in part (b) of Fig. 1, the introduction of adaptive observation noise (\(R_k\)) results in large fluctuations in the originally stable Kalman gain (K), which hinders the acquisition of motion information. Therefore, it is necessary to develop a solution to stabilize the Kalman gain while introducing adaptive observation noise to improve the prediction performance of the Kalman filter.
Trajectory interruption will cause track noise problems such as tracking fragments and track drifting. Linear interpolation and spatial–temporal information strategy interpolation are two widely used methods to solve the trajectory interruption problem. Recent methods [27, 36] use binary linear interpolation with adaptive coefficients to quickly fill track gaps. However, the existing linear interpolation methods [61] ignore the motion information, which limits the accuracy of the restored bounding boxes. For the spatio-temporal information strategy, MAT [15] collects the motion information of the object by adopting a cyclic pseudo-observation trajectory filling strategy, which achieves superior tracking performance. MAATrack [46] reconnects the trajectories with an extra camera motion compensation (CMC) model [13]. However, these methods all introduce additional modules, which greatly increases the computational complexity. Recently, StrongSORT [11] proposed a method to mitigate this problem by modeling nonlinear motions through a Gaussian Process Regression (GPR) algorithm. The above interpolation methods fail to consider the actual trajectory of ground truth. The object associated with the video frames does not move in a smooth curve. As shown in part (c) of Fig. 1, the ground truth of the motion trajectory is a progressive fold with the motion direction. The current interpolation method does not conform to the ground-truth trajectory trend.

Noise limitation in MOT
As the discussion above, the existing studies have three limitations about noise: (1) fusion noise: redundant information in the fusion of heatmap and image features; (2) mutation noise: kalman filter gain mutation; (3) trajectory noise: trajectory reconnection inappropriate for the ground truth. The current noise-alleviating methods cannot process heatmap fusion, Kalman filter, and trajectory reconnection effectively. In this paper, Noise-Control Multi-Object Tracking (NCT) is proposed to improve the detection, association, and reconnection based on a suitable noise-control mechanism.
In detail, our NCT framework consists of five steps. First, feature extraction is performed separately for the heatmap and image frames, and additive fusion is performed on the extracted features to establish an anchor-free tracking structure. Then, the heatmap feature prior to the denoiser module is employed to eliminate the redundant information introduced by additive fusion, which enhances the semantic characterization of the fusion results. Afterward, the smoothing gain Kalman filter is applied to the detection results, and the Gaussian function is combined with the detection confidence to obtain the smoothing adaptive observation noise matrix. Meanwhile, the smoothing gain is derived to obtain the object motion information. Subsequently, the object trajectory is correlated by data association with the motion information between frames. Finally, the gradient boosting reconnection context mechanism is designed to reconnect the fragment tracks with trajectory drifting noise to obtain accurate tracking results.
The contributions of this paper are summarized as follows:
-
An Heatmap Feature Prior Denoiser (HFPD) method is proposed. HFPD is a prior denoise network that eliminates redundant noises from the fusion process of heatmap and image features. It enhances the semantic characterization information of fusion features and improves the detection of small objects.
-
The Smoothing Gain Kalman filter (SG Kalman) is proposed. It is an adaptive observation noise Kalman filter that combines the Gaussian function with the adaptive observation coefficient matrix to stabilize the mutation noise of Kalman gain. SG Kalman increases the motion information obtained by Kalman filtering.
-
The Gradient Boosting Reconnection Context (GBRC) mechanism is developed to realize gradient-adaptive reconnection of the fragment tracks with trajectory drifting noise. GBRC achieves a good trade-off between accuracy and efficiency for long-range motion-based reconnection through gradient boosting decision trees.
-
Extensive experiments are conducted on two public datasets to verify the performance and generalization ability of our methods, and the above methods are combined to form the Noise-Control Tracker (NCT) framework. It is a plug-and-play solution and can be easily embedded into other anchor-free MOT trackers with great performance. The codes of the HFPD, SG Kalman, and GBRC modules are available at https://github.com/Autoyou/Noise-control-multi-object-tracking.
The rest of this paper is organized as follows: the “Related works” presents a brief review of related works. Then, the “Methods” illustrates our proposed methods, including the HFPD, SG Kalman, and GBRC. In the “Experiments”, the feasibility and effectiveness of the proposed methods are verified by experimental evaluation and analysis on MOT16 and MOT17 benchmarks [33]. Finally, our work is concluded in the “Conclusion”.
Related works
In this section, the methodologies of the heatmap, Kalman filter, and trajectory reconnection for MOT are reviewed, respectively.
Heatmap in MOT
In the scenarios of ambient object occlusion or inter-object occlusion, setting a threshold to associate objects directly from the detection results can seriously impair tracking performance [35, 40, 55]. In recent years, anchor-free MOT [64] is proposed, which effectively solves the problem of occlusion using the heatmap central point offset as an association indicator. Based on heatmap central points, OUTrack [26] proposed a new occlusion estimation module, which can effectively recognize and track occluded objects when they are missed by the detector, thus achieving an excellent tracking performance. FairMOT [62] combines an anchor-free framework with improved Reid features for MOT and balances the semantic relationship between detection features and Reid features. Based on heatmap central point offsets, TraDes [53] proposes a cost–volume-based association (CVA) module and a motion-guided feature warner (MFW) module to effectively solve the occlusion problem in the before-and-after frame association process.
However, the above methods all directly merge heatmaps with image features through early feature fusion approaches, which add the two modal features directly. These fusion approaches introduce redundant information noise of image features, which greatly weakens the characterization performance of each heatmap. Fusion noise will cause detection problems such as missing detection of small objects, which undermines the tracking accuracy. By considering the fusion feature as a type of image, in the field of addressing image noise problems, DPDNN [9] proposed a multi-scale redundant noise reducer for processing noise images based on deep convolutional neural networks (DNN). However, DPDNN can only handle low noise levels and cannot restore images with a high noise level. DnCNN [57] uses a residual learning strategy to implicitly remove the potential noise in the hidden layer, which can handle noise-level models but ignores the prior information of the observed model. Thus, it is necessary to construct a denoiser that can combine the model prior information with a denoising depth network to solve the fusion noise problem.
Kalman filtering for data association
In the early stage, data association strategies build trajectories sequentially based on frame-by-frame association through greedy schemes [39] and Hungarian algorithms [22]. Unfortunately, these methods cannot avoid missing detections caused by occlusion, which results in short fragment trajectories and track drifting. To address this issue, DeepSort [52] first proposed to use the Kalman filter to forecast the object traces stably, and it introduced the motion information of the tracked object to alleviate the track fragmentation and drifting problem [8, 12]. For Kalman filter design, K-ADWIN [6] studied the combination of Kalman filter and dynamically maintaining a sliding window to achieve a retentive Kalman filter; MCKF [7] based on the maximum correntropy criterion and a fixed-point iterative algorithm to improve the robustness of Kalman filter; the argument Kalman filter[20] used the mathematical expectation of factors error and modeling dynamic equality to reduce the computational complexity of Takagi–Sugeno fuzzy models. All these design methods aim to reduce the noise of Kalman filter and improve its robustness. To obtain a more accurate motion state, GIAOTracker [10] proposed a Noise Scale Adaptive Kalman algorithm (NSA Kalman), which adaptively modulates the noise scale according to the quality of object detection.
However, there are strong fluctuations in the adaptive observation noise introduced by NSA Kalman through the detection confidence. The fluctuations of the adaptive observation noise will cause the mutation noise of the Kalman gain to weaken the prediction stability of the Kalman filter, which impairs motion information acquisition. Therefore, it is significant to design a new Kalman filter method that can improve the accuracy by combining with adaptive observation noise to ensure the gain stability.
Trajectory reconnection
When severe occlusion or blur occurs, the detector will inevitably cause a large number of missing detections and force the trajectories to be deactivated temporally. To ensure the robustness of long-range tracking, trajectory reconnection methods are proposed. The mainstream trajectory reconnection methods are divided into two categories: linear interpolation and interpolation based on spatio-temporal information strategy. Tubetrack [36], bytetrack [61], etc. [14, 31] use linear interpolation to fill the gaps of interrupted trajectories caused by missing detections. However, linear interpolation ignores the motion information of the trajectory, which extends the gap between the connected trajectory and the ground truth. This shortcoming limits the accuracy of linear trajectory reconnection. Some studies [15, 17] alleviate this problem by introducing the camera motion compensation (CMC) model that trades efficiency for performance improvement. The GSI algorithm proposed by StrongSORT [11] transforms the fragment trajectory into a smooth curve by Gaussian nonlinear interpolation, which achieves a good trade-off between accuracy and efficiency.
However, these trajectory reconnection methods do not consider the real situation of motion trajectory, so they cannot appropriately adjust the tracking drift noise. The ground truth of the motion trajectory is a progressive polyline with the direction of motion. Thus, it is essential to develop a new context reconnection algorithm based on the ground truth of the motion trajectory to make the predicted trajectory closest to the ground truth.
Methods
In this section, an overview of the proposed NCT is presented. In the following subsections, the HFPD, SG Kalman, and GBRC methods are introduced in detail.
Overall framework of NCT
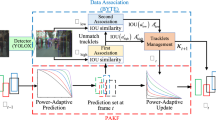
In this work, an intensive MOT framework called NCT is proposed, which is a plug-and-play solution focusing on the noise control for anchor-free trackers. The architecture of our noise-control MOT is illustrated in Fig. 2. First, the HFPD module is adopted to eliminate the feature redundancy noise introduced by fusion features. Then, to ensure the robustness of data association, the smoothness of the Gaussian function is exploited to make the Kalman filter stable while introducing adaptive observation noise. Finally, to process the tracking fragments caused by occlusion or blur, the GBRC mechanism can correctly track the ground-truth trajectory trend through adaptive gradient adjustment. Similar to Centertrack [64], our network takes the current frame, the previous frame, and the heatmap rendered from tracked object centers as input, so it is an anchor-free tracker. The noise-control MOT paradigm is independent of the overall tracking algorithm, so it can enhance and cooperate with anchor-free trackers.

Illustration of our NCT architecture

The architecture of the proposed HFPD module
Heatmap Feature Prior Denoiser (HFPD)
When the tracked object is obvious and the interference of ambient light factors is not serious, the anchor-free MOT method can obtain tracking results well. However, when facing small objects and complex illumination conditions, the anchor-free MOT method does not work well due to the redundant information fused by the heatmap and image features. The redundant information blurs the object, weakens the heatmap feature gradient calculation, and causes errors in the object’s central point offset. Thus, the proposed HFPD module aims to eliminate redundant information noise from the fused features.
Inspired by the image restoration (IR) method [58,59,60], the HFPD module combines the prior information of the model with a feed-forward denoising depth network, and the architecture of this module is illustrated in Fig. 3. U-Net [42] is efficient for inter-image transformation, while ResNet [16] is advantageous in increasing the modeling capability by stacking multiple residual blocks. HFPD combines the advantages of U-Net and ResNet and integrates residual blocks for noise control of heatmap fusion features.
As shown in Fig. 3, the HFPD module consists of four scales, each with an identity skip connection between the \(2\times 2\) strided convolution (SConv) down-transform and \(2\times 2\) transposed convolution (TConv) up-transform operations. The construction from the first scale to the fourth scale has 64, 128, 256, and 512 channels per level, respectively. According to the experimental conclusion of EDSR [24] on residual blocks, the HFPD module contains only one ReLU activation function per residual block. Meanwhile, no bias is used in the Conv, SConv, and TConv layers. Let the bias-free network \(F_bf\) be a feed-forward neural network with ReLU activation functions and no additive constant terms in any layer [34]. Then, Eq. (1) can be obtained
where x is the network input variable; \(\alpha \) is a non-negative constant; \(W_i\) is the weight matrix of each layer of an unbiased neural network with L layers, and \(i\in (1,L)\); R is the correction operator, which is a kind of nonlinear function to complete the nonlinear transformation of data.
Any negative term in the input is zero due to the activation function. Since multiplication with a non-negative constant does not change the sign of the vector, \(R(\alpha z)\) = \(\alpha R(z)\) holds for any input variable z with the correct dimension. Thus, Eq. (1) is derivable. It shows that if the CNN uses ReLU activation, the denoising mapping is locally homogeneous, and the increase in bias destroys this property. Besides, for biased networks, the size of the bias will be much larger than that of the filter, which in turn impairs the generalization of the model. This is the key reason for developing the bias-free network.
To trade-off between accuracy and speed, according to the experimental results shown in Fig. 3, this paper chooses to use \(C\_256\) and \(C\_128\) of the fused features as the input of the HFPD module. As depicted in Fig. 3, the noise feature containing redundant information is input to the left side. In the scenario of small object tracking, the feature affected by redundant information cannot highlight the heatmap central points. In contrast, with the HFPD module, the denoise feature on the right side of Fig. 3 successfully restores information of the heatmap central points, especially inside the blue circle where the apparent object central points can be seen.
Smoothing gain Kalman filter (SG Kalman)
In the MOT framework, Kalman filter was first applied to multi-target tracking in DeepSort[52], and has become a classic basic theory of MOT data association stage. The Kalman filter based on Gaussian distribution based is used to model object motion in two steps: state estimation and state update.
In state estimation, the observations are influenced by the observation noise. The measurement noise covariance R is used to represent the noise scale of the measurements. In Kalman’s algorithm, the noise scale is a constant matrix. However, as proposed by GIAOTracker [10], different measurements contain multiple scales of noise, and the noise scale of the measurement should vary with the confidence of the detection. Eq. (2) proposes an adaptive formula for calculating the noise covariance called NSA \(\tilde{R_k}\)
where \(R_k\) is the preset constant measurement noise covariance, and \(c_k\) is the detection confidence score at state k. This method represents the observation noise scale using the deviation of the observed value from the true value by \(1-c_k\).
However, the detection confidence score is affected by the detection result, and it will change abruptly when encountering object occlusion and complex illumination conditions. Then, the detection confidence score will mutate. The simple multiplication of the confidence score and the previous constant matrix in Eq. (2) leads to the mutation in \(\tilde{R_k}\), which will cause serious chain reactions.

Effects of system noise and observation noise for Kalman filter results
The system noise covariance matrix Q and the observed noise covariance matrix R jointly determine the Kalman prediction filtering output. As shown in Fig. 4, the variation of Q and R determines whether the prediction is closer to the system observation or the system prediction
Combining Eq. (3) with Fig. 4, it can be seen that the proportion of the system noise covariance matrix Q and the observation noise covariance matrix R determines the change in the system gain K, which determines the output of the system. The mutation of \(R_k\) leads to the mutation of the system gain K, which leads to the mutation noise in the output and destroys the original stable prediction of the Kalman filter. To ensure a stable change in K, inspired by the Gaussian function used as a pre-smoothing kernel in image processing [1], similar to the fading factor design[4, 28] in the field of neuro-fuzzy systems, this paper proposes the Smoothing Gain Kalman filter. It smooths the gain K by introducing a one-dimensional Gaussian function. Smoothing Gain \(\tilde{R_k}\) (\(SG\_\tilde{R_k}\)) is shown in Eq. (4)
where \(c_k\) is the detection confidence score at state k. The Gaussian radius \(\sigma \) is a hyperparameter used to control the smoothness of system observation noise, and it is set to 3 in the experiment. The expectation \(\mu \) represents the probability that the confidence score differs from the expectation, and it is set to 1 to reasonably introduce adaptive observation noise covariance.

Illustration of the difference between linear interpolation (LI), Gaussian smoothed interpolation (GSI), and the proposed Gradient boosting reconnection context (GBRC)
The whole process of our SG Kalman filter is shown in Algorithm 1, where the SG step is marked by a box.

Gradient boosting reconnection context (GBRC)
Interfered by target occlusion and environmental noise, trajectory interruption and fragmented trajectory are essential problems to be solved in MOT. Interpolation is widely used to fill the trajectory gaps caused by missing detections [31]. Linear interpolation is the mainstream trajectory reconnection method, which can be easily integrated into various tracking algorithms to improve performance. However, the recovered trajectories still have large deviations from the actual trajectories, because the linear interpolation limits the accuracy of the restored bounding boxes.
Gaussian smoothing interpolation (GSI) models nonlinear motion through Gaussian process regression [11]. It can smooth the curve to be close to the true trajectory, but it still ignores the trajectory trend of the ground truth. As shown in Fig. 5(a), the ground-truth trajectory on the left is not a smooth curve after zooming in, and the ground truth of the object trajectory is a progressive fold with direction affected by the frame rate and object motion direction. Based on this, our GBRC module adaptively approximates the ground-truth trajectory in the direction of residual reduction through the Gradient Boost Decision Tree (GBDT), thus achieving a good trade-off between accuracy and efficiency.
Based on interpolation theory, the proposed GBRC model for the \(i_th\) trajectory is formulated as follows:
where \(p_t\) is the position coordinate variate at frame t, and \(\xi \sim N(0,{\sigma }^{2})\) is the Gaussian noise.
Before performing gradient boosting reconnection context, linear interpolation is first performed on the interrupt trajectory. The interpolation trajectory is \(T^{(i)}=\{t^{(i)},p_{t}^{(i)}\}_{t=1}^{l}\), where l is the trajectory length, and it determines the efficiency of the module. \(GB^{(i)}(t)\) represents GBDT regression. After the trajectory \({(t_i,y_i)}_{1}^{n}\) is input into Eq. (6), the reconnection trajectory can be obtained through residual reduction iteration and recursion
where \(\gamma _{i}\) is the fit regression tree value, \(R_i\) is the terminal region, and L is the differentiable loss function. \(GB^{(i)}(t)\) uses an additive model and a forward step-by-step algorithm to achieve an iterative optimization toward the ground truth.
Figure 5b shows the difference between GBRC, LI, and GSI. The results of the original trace (yellow) usually include noise jitter, while LI (blue) ignores motion information with a significant gap to the true trajectory (green). GSI (orange) smooths the interpolated trajectory, but the result still does not match the true trajectory. Our GBRC adaptively approximates the true trajectory by learning the residual regression tree through distributed iterations, and the result is highly consistent with the ground truth.
Experiments
In this section, the experimental settings are introduced first. Then, some experiments are designed to validate the effectiveness of the proposed HFPD module, SG Kalman module, and GBRC module.
Experimental settings
Dataset: The proposed method is evaluated on the standard MOTChallenge datasets: MOT16 and MOT17 [33]. MOT16 is a collection of existing and new data and contains 14 challenging real-world videos of both static scenes and moving scenes (7 for training and 7 for testing). It is a large-scale dataset, composed of 110407 bounding boxes in the training set and 182326 bounding boxes in the test set. All video sequences are annotated following strict standards, and their ground truths are highly accurate, making the evaluation meaningful. MOT17 provides detection of objects in video frames with three detectors, namely SDP, Faster-RCNN, and DPM. These benchmarks involve many challenges, such as frequent occlusion, heavily crowded scenes, and variation in the frame rates.
Metrics: This paper adopts the standard metrics of MOTChallenge for performance evaluation, including Multi-Object Tracking Accuracy (MOTA), Number of identity Switches (IDs), ID F1 Score (IDF1), Higher Order Tracking Accuracy (HOTA), Association (AssA), Detection Accuracy (DetA), and Frames Per Second (FPS) [5, 30, 41]. Among the indicators, the MOTA is calculated by Eq. (8)
where FP and FN represent the number of false-positive samples and false-negative samples, respectively. GT is the total number of actual bounding boxes.
IDF1 is proposed to evaluate the MOT accuracy and recall rate based on the trajectory IDs, which can be calculated through Eq. (9)
where IDTP, IDFP, and IDFN represent the number of ID-based true-positive, false-positive, and false-negative samples, respectively.
MOTA focuses more on detection performance. By comparison, IDF1 better measures the consistency of ID matching [41]. HOTA explicitly combines the detection score DetA and association score AssA, which integrates the effects of performing accurate detection and association into a single unified metric.
Implementation details: The experiments were conducted on a server equipped with a Tesla V100 GPU, and the operating system is Ubuntu 20.04. Our implementation is based on CenterNet [63]. Deep Layer Aggregation (DLA) [56] is taken as the network backbone, and it is optimized with Adam with a learning rate of 1.16e-4 and a batch size of 3. Data augmentations include random horizontal flipping, random resized cropping, and color jittering. For all experiments, the networks are trained for 150 epochs. The learning rate is dropped by a factor of 10 at the 60th epoch.
Ablation study
Several ablation studies were conducted to demonstrate the effectiveness of the proposed HFPD module, SG Kalman module, and GBRC module through quantitative and qualitative analyses. Without losing generality, an ablation study is conducted on the MOT17 dataset, and the work in CenterTrack [64] is taken as the baseline. Since no validation data are provided in the MOTChallenge, a common practice is to split each video in the training set into two halves, where the first part is for training and the second part is for validation. No external dataset is used if not specified.
Noise-control MOT
In this subsection, the compatibility and universality of Noise-Control MOT is verified through the ablation study of the HFPD module, SG Kalman module, and GBRC module. First, the effect of the HFPD module is tested. As shown in Table 1, the baseline model with the HFPD module can obtain an MOTA of 70.79%, which is improved by 3.85%. After the SG Kalman module is added, the MOTA is increased to 72.18%. Then, the GBRC module is added to evaluate the effectiveness of our trajectory reconnection method, and the MOTA increases by 1.13%. Compared with adding the GBRC module alone, the combination of the GBRC module with other modules leads to better performance improvement for the tracker, indicating that the GBRC module has a good effect on general fragment track reconnection. After the three models are added, the HOTA, MOTA, and IDF1 of our Noise-Control MOT is improved by 6.7%, 6.37%, and 9.96%, proving that our Noise-Control MOT can effectively improve the performance of the whole tracker. The experimental results show that these modules have good compatibility and universality.
Heatmap feature prior denoiser
In this subsection, the effectiveness of the proposed HFPD module is verified through quantitative and qualitative analyses. DLANet is used as the backbone to add the HFPD module. To achieve a trade-off between accuracy and speed, this paper chooses to use the fusion features \(C\_256\) and \(C\_128\) as the input of the HFPD module. First, the model is quantitatively analyzed, as shown in Table 2. Our HFPD module has greatly improved the HOTA, MOTA, and DetA of the tracker. More specifically, after adding the HFPD module, the HOTA, MOTA, and DetA of the model are improved by 0.8%, 3.85%, and 3.84% respectively, which indicates that the detection accuracy and tracking accuracy of the tracker are greatly improved.

Visualized heatmap fusion features for the identities in the MOT17 validation set. From the left to right are: a Image frame features for preliminary feature extraction at time. t b Heatmap of preliminary feature extraction at time t. c The result of the additive fusion of heatmap and image frame features. d The fusion feature after noise reduction by the HFPD module

Visualized heatmap fusion features for the identities in the MOT17 validation set. From the left to right are: a Image frame features for preliminary feature extraction at time t. b Heatmap of preliminary feature extraction at time t. c Fusion features used to calculate gradients. d The fusion feature after noise reduction by the HFPD module

Visual comparison of the HFPD module on MOT17 dataset
As shown in Fig. 6, additive fusion introduces redundant information, especially for the heatmap central points of the small objects that are difficult to highlight. After noise control through the HFPD module, it can be seen that the original unrecognizable heatmap central points in the red frames are restored well, thus improving the original detection results. Figure 7(c) presents the fusion feature used to calculate the gradient. It can be seen that the heatmap central points of the objects in the red frames are seriously affected by redundant information. In Fig. 7(d), after noise control by the HFPD module, the heatmap central points of the small objects are restored, and the overall redundant information of the feature is also reduced. Since effective detection of small objects increases the number of detection objects, it also increases the cardinality of IDs, which can be reflected by the values of IDs and FP.
In addition, as shown in Fig. 8, after the object in the orange circle in the first column is blocked, the tracking interruption and ID switch problems in the baseline are well resolved by our HFPD module. Meanwhile, the unrecognized small objects in the red circles in the second and third columns of Fig. 8 are successfully tracked after using the HFPD module, which proves that the HFPD module can effectively overcome the difficulty in tracking small objects. In Fig. 8, the video has proceeded to frame 1191, and the multi-object tracking has ID tagging for the tracked objects starting from 1. The objects are tagged to 444 in the baseline, while there are 312 tagged objects after the HFPD module is added. This experiment result shows that the problem of IDs in the baseline is serious and causes a large number of ID tags, and the proposed HFPD module can solve this problem well.
Smoothing Gain Kalman filter
In the data association stage, it is necessary to collect motion information to predict the motion state of objects. Therefore, a stable Kalman filter model is crucial for predicting the motion state of objects. Table 3 compares the performance of the Kalman module, NSA Kalman module, and our SG Kalman module on the MOT17 dataset. As shown in Table 3, adding the Kalman module increases the HOTA of the model by 4.66%, indicating that the detection and association of the tracker are greatly improved by the Kalman module. The addition of the NSA Kalman module shows no significant improvement in the tracker affected by the observation covariance mutation, and it performs even worse in terms of IDF1 and FP. In contrast, our SG Kalman module stabilizes the Kalman gain while introducing an adaptive observation covariance, and the metric of HOTA, MOTA, and DetA are improved by 4.89%, 0.55%, and 8.97%, respectively, compared to the baseline. This experiment result indicates that our SG Kalman module further enhances the acquisition of motion information of the tracker.
A discussion has been given on the value of Gaussian radius \(\sigma \). As mentioned before, the Gaussian radius \(\sigma \) is used to control the smoothness of system observation noise. If \(\sigma \) is set too small, the mutation gain cannot be smoothed, and the original function of the SG Kalman module will be lost. However, when \(\sigma \) is set too large, the system gain noise will be too smooth to be close to a constant. As shown in Table 4, the adaptive system observation noise loses its effect and leads to the degradation of the tracker performance. From Table 3, it can be seen that HOTA, MOTA, and DetA achieve the best results when \(\sigma \) is set to 3. Therefore, the Gaussian radius \(\sigma \) is set to 3 for the subsequent experiments.

The observed covariance matrix R for iterative images
Finally, to verify the effectiveness of the SG Kalman filter, the observed covariance matrix R for multiple rounds of iterations is plotted. As shown in Fig. 9, although NSA \(R_k\) introduces adaptive observation noise, it also leads to mutation of \(R_k\). In contrast, as shown in the red circle in the figure, our SG Kalman filter introduces adaptive observation noise, which ensures the smooth change of Rk and controls the noise of Kalman gain.
Gradient boosting reconnection context
To efficiently fill the gaps in trajectories caused by missing detections, an efficient trajectory reconnection method is essential. Table 5 compares the performance of the GSI module and GBRC module on the MOT17 dataset. As shown in Table 5, adding the GSI module does not significantly improve the HOTA of the tracker, and the MOTA even drops. This result indicates that using nonlinear interpolation for overly fragmented trajectories cannot realize effective trajectory reconnection. When the tracker accuracy is low, the trajectory will further deviate from the ground truth. In contrast, our GBRC module effectively improves the tracking metrics through adaptive trajectory reconnection, and the result is consistent with the ground truth. As shown in Table 5, after adding the GBRC module, the HOTA and DetA of the tracker are improved by 0.26% and 0.2%, respectively, indicating the improvement of the tracking performance by the GBRC module.
Besides, the mean absolute error (MAE) of the GSI module and GBRC module are compared to verify the validity of the model, and the MAE is calculated in Eq. (10)

MAE of the GSI module and GBRC module
As shown in Fig. 10, the MAE of the GSI module and GBRC module is compared in six scenes of the MOT17 dataset. The comparison result shows that the MAE of the GBRC module is much smaller than that of the GSI module, indicating that our GBRC module is closer to the ground-truth trajectory and solves the track drifting problem.
MOT results
Results on MOTChallenge
NCT devotes to enhancing both the detection part and the tracking part of a tracker, so it can easily cooperate with the public or private detector. Meanwhile, it can be regarded as a near-online (denoted using NO) tracker.
Here, the comprehensive performance of our NCT approach is evaluated on the test sets of MOT16 and MOT17, using both the public and private detectors. Also, NCT is compared with other state-of-the-art (SOTA) public and private trackers that have been officially published or peer-reviewed with results on these benchmarks. The comparison results are shown in Tables 6 and 7, where the SOTA offline, online, and near-online MOT methods are all included. The offline trackers (denoted using Off) include ApLift [19], Lif_T [18], and QD [37]. The online trackers (denoted as O) like OUTrack [26], Hugmot [49], TMOH [47], MPTC [45], TraDes [53], CTTrack [64], GSDT [50], HTA [25], CTracker [38], and Tube_TK [36]. The near-online trackers (denoted as NO) include MAT [15].
As demonstrated in Tables 6 and 7, our NCT significantly outperforms all these SOTA MOT methods by a large margin, especially in terms of HOTA and MOTA. Meanwhile, NCT achieves almost the best results in IDF1 and DetA, no matter using the public or private detector.
Visualization results
In this subsection, the validity of noise-control MOT is verified through visualization results. Figure 11 shows the visual comparison with previous state-of-the-art methods, including MAT [15], TransCtr [54], and TMOH [47] in frame 100, frame 200, and frame 450 of MOT17-01. In Fig. 11(e), the red frame represents the objects successfully tracked by NCT but not recognized by other trackers. According to the comparison results, our NCT achieves superior tracking performance in the primary metrics.
The outstanding tracking performance of our proposed NCT is attributed to the combination of the HFPD module, SG Kalman module, and GBRC module. The HFPD module effectively controls the redundant noise of the model and improves the detection accuracy of the tracker. The SG Kalman module controls the mutation noise of the adaptive observation noise covariance matrix and achieves stable data association. Additionally, by further employing the GBRC module, the continuity and purity of trajectories are ensured. Thus, based on the good compatibility and universality of these modules, NCT can achieve superior tracking performance.

Visual comparison with previous state-of-the-art methods on the MOT17 dataset
Discussion about comparison
The validation results on the two datasets indicate that the proposed NCT has excellent universality and generalization ability. The existing anchor-free multi-target tracking methods simply fuse the heatmap with image features through additive fusion. Since the fused features contain redundant information noise, the gradient of the heatmap cannot be effectively calculated. Our HFPD module models the fused features as prior information and retrieves the degraded heatmap features through unbiased feature extraction and reconstruction, which improves the performance of the detector. This approach enhances the detection of small objects by the detector. Our SG Kalman module stabilizes the abrupt noise of the Kalman gain by combining a Gaussian function with an adaptive observation coefficient matrix. It improves the acquisition of motion information in data association and stabilizes the data association of the tracker. Traditional trajectory reconnection methods reconnect general fragment trajectories through linear interpolation, but they ignore the trend of the ground-truth trajectories. Our GBRC module proposes an adaptive trajectory reconnection that effectively complements the fragmented trajectories, thus alleviating the trajectory drift problem and improving the tracking accuracy.
Conclusion
In this paper, a new noise-control tracking framework is proposed, which consists of three key modules: the HFPD module, SG Kalman module, and GBRC module. Inspired by the image restoration method, the HFPD module is proposed to control the redundant noise of the heatmap and image feature fusion. The SG Kalman module ensures the stability of Kalman gain while introducing the adaptive observation coefficient matrix. It enhances the motion information and is more friendly to complex data association. The GBRC module effectively complements the fragmented trajectories by adaptive trajectory reconnection that approaches the ground-truth trajectories, thus eliminating trajectory drift noise. Extensive experiments conducted on the MOT challenging benchmarks demonstrate that our framework achieves outstanding performance. However, this study can be further improved, e.g., other image restoration of the heatmap feature can be investigated. Also, a new anchor-free method can be developed to reduce the reliance on heatmaps and improve the overall performance of the tracker.
Data Availability
All data included in this study are available upon request by contact with the corresponding author.
Code Availability
References
Babaud J, Witkin AP, Baudin M et al (1986) Uniqueness of the gaussian kernel for scale-space filtering. IEEE Trans Pattern Anal Mach Intell PAMI–8:26–33. https://doi.org/10.1109/TIP.2018.2839891
Balcazar R, de Jesús Rubio J, Orozco E et al (2022) The regulation of an electric oven and an inverted pendulum. Symmetry 14:759. https://doi.org/10.3390/sym14040759
Baltruaitis T, Ahuja C, Morency LP (2019) Multimodal machine learning: A survey and taxonomy. IEEE Trans Pattern Anal Mach Intell 41:423–443. https://doi.org/10.1109/TPAMI.2018.2798607
Bao R, Rong H et al (2018) Correntropy-based evolving fuzzy neural system. IEEE Trans Fuzzy Syst 26:1324–1338. https://doi.org/10.1109/TFUZZ.2017.2719619
Bernardin K, Stiefelhagen R et al (2008) Evaluating multiple object tracking performance: The clear mot metrics. J Image Video Process 2008:1–10. https://doi.org/10.1155/2008/246309
Bifet A, Gavaldà R (2006) Kalman filters and adaptive windows for learning in data streams. In: Discovery Science, 9th International Conference, vol. 4265. Springer, pp. 29–40, https://doi.org/10.1007/11893318_7
Chen B, Liu X et al (2017) Maximum correntropy kalman filter. Automatica 76:70–77. https://doi.org/10.1016/j.automatica.2016.10.004
Dai P, Wang X, Zhang W et al (2019) Instance segmentation enabled hybrid data association and discriminative hashing for online multi-object tracking. IEEE Trans Multimedia 21:1709–1723. https://doi.org/10.1109/TMM.2018.2885922
Dong W, Wang P, Yin W (2019) Denoising prior driven deep neural network for image restoration. IEEE Trans Pattern Anal Mach Intell 41:2305–2318. https://doi.org/10.1109/TPAMI.2018.2873610
Du Y, Wan JJ, Zhao Y et al. (2021) Giaotracker: A comprehensive framework for mcmot with global information and optimizing strategies in visdrone 2021. In: Proceedings of the IEEE International Conference on Computer Vision Workshops, pp 2809–2819, https://doi.org/10.1109/ICCVW54120.2021.00315
Du Y, Song Y, Yang B (2022) Strongsort: Make deepsort great again. ArXiv:2202.13514
Emami P, Elefteriadou L, Ranka S et al (2022) Long-range multi-object tracking at traffic intersections on low-power devices. IEEE Trans Intell Transport Syst 23:2482–2493. https://doi.org/10.1109/TITS.2021.3115513
Evangelidis GD, Psarakis Emmanouil Z et al (2008) Parametric image alignment using enhanced correlation coefficient maximization. IEEE Trans Pattern Anal Mach Intell 30:1858–1865. https://doi.org/10.1109/TPAMI.2008.113
Gündüz G, Acarman T (2019) Efficient multi-object tracking by strong associations on temporal window. IEEE Trans Intell Veh 4:447–455. https://doi.org/10.1109/TIV.2019.2919473
Han S, Huang P, Wang H et al (2022) MAT: motion-aware multi-object tracking. Neurocomputing 476:75–86. https://doi.org/10.1016/j.neucom.2021.12.104
He K, Zhang X, Ren S et al. (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778, https://doi.org/10.1109/CVPR.2016.90
He Q, Sun X, Yan Z et al (2022) Multi-object tracking in satellite videos with graph-based multitask modeling. IEEE Trans Geosci Remote Sens 60:1–13. https://doi.org/10.1109/TGRS.2022.3152250
Hornáková A, Henschel R, Rosenhahn B et al. (2020) Lifted disjoint paths with application in multiple object tracking. In: Proceedings of the International Conference on Machine Learning, pp 4364–4375
Hornáková A, Kaiser TB, Swoboda P et al. (2021) Making higher order mot scalable: An efficient approximate solver for lifted disjoint paths. In: Proceedings of the IEEE international conference on computer vision, pp 6310–6320, https://doi.org/10.1109/ICCV48922.2021.00627
de Jesús Rubio J, Lughofer E et al (2018) Neural network updating via argument kalman filter for modeling of takagi-sugeno fuzzy models. J Intell Fuzzy Syst 35:2585–2596. https://doi.org/10.3233/JIFS-18425
Rubio de Jesús J, Orozco E et al (2022) Modified linear technique for the controllability and observability of robotic arms. IEEE Access 10:3366–3377. https://doi.org/10.1109/ACCESS.2021.3140160
Kuhn HW (2010) The hungarian method for the assignment problem. Naval Res Logist 52:29–47. https://doi.org/10.1007/978-3-540-68279-0_2
Liang C, Zhang Z, Lu Y (2022) Rethinking the competition between detection and reid in multiobject tracking. IEEE Trans Image Process 31:3182–3196. https://doi.org/10.1109/TIP.2022.3165376
Lim B, Son S, Kim H et al. (2017) Enhanced deep residual networks for single image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 1132–1140, https://doi.org/10.1109/CVPRW.2017.151
Lin X, Li CT, Sanchez V (2021) On the detection-to-track association for online multi-object tracking. Pattern Recogn Lett 146:200–207. https://doi.org/10.1016/j.patrec.2021.03.022
Liu Q, Chen D, Qi Chu et al (2022) Online multi-object tracking with unsupervised re-identification learning and occlusion estimation. Neurocomputing 483:333–347. https://doi.org/10.1016/j.neucom.2022.01.008
Liu S, Liu D (2020) Deep learning in multi-object detection and tracking: state of the art. Complex Intell Syst. https://doi.org/10.1007/s40747-020-00161-4
Lughofer E (2021) Improving the robustness of recursive consequent parameters learning in evolving neuro-fuzzy systems. Inf Sci 545:555–574. https://doi.org/10.1016/j.ins.2020.09.026
Lughofer ED, Skrjanc I (2022) Evolving error feedback fuzzy model for improved robustness under measurement noise. IEEE Trans Fuzzy Syst. https://doi.org/10.1109/TFUZZ.2022.3193451
Luiten J, Osep A, Patrick Dendorfer et al (2021) Hota: A higher order metric for evaluating multi-object tracking. Int J Comp Vis 129:548–578. https://doi.org/10.1007/s11263-020-01375-2
Luo W, Stenger B, Zhao X et al (2019) Trajectories as topics: Multi-object tracking by topic discovery. IEEE Trans Image Process 28:240–252. https://doi.org/10.1109/TIP.2018.2866955
Meda-Campaña JA, Rodríguez-Manzanarez RA et al (2022) An algebraic fuzzy pole placement approach to stabilize nonlinear mechanical systems. IEEE Trans Fuzzy Syst 30:3322–3332. https://doi.org/10.1109/TFUZZ.2021.3113560
Milan A, Leal-Taixé L, et al. IDR (2016) Mot16: A benchmark for multi-object tracking. ArXiv:1603.00831
Mohan S, Kadkhodaie Z, Simoncelli EP et al. (2020) Robust and interpretable blind image denoising via bias-free convolutional neural networks. In: Proceedings of the International Conference on Learning Representations. OpenReview.net
Ong J, Vo BT, Vo BN (2022) A bayesian filter for multi-view 3d multi-object tracking with occlusion handling. IEEE Trans Patt Anal Mach Intell 44:2246–2263. https://doi.org/10.1109/TPAMI.2020.3034435
Pang B, Li Y, Zhang Y (2020) Tubetk: Adopting tubes to track multi-object in a one-step training model. In: Proceedings of the IEEE International Conference Computer Vision, pp 6307–6317, https://doi.org/10.1109/CVPR42600.2020.00634
Pang J, Qiu L, Li X et al. (2021) Quasi-dense similarity learning for multiple object tracking. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 164–173, https://doi.org/10.1109/CVPR46437.2021.00023
Peng J, Wang C, Wan F (2020) Chained-tracker: Chaining paired attentive regression results for end-to-end joint multiple-object detection and tracking. In: Proceedings of the European Conference on Computer Vision, vol 12349. Springer, pp. 145–161, https://doi.org/10.1007/978-3-030-58548-8_9
Pirsiavash H, Ramanan D, Fowlkes CC et al. (2011) Globally-optimal greedy algorithms for tracking a variable number of objects. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1201–1208, https://doi.org/10.1109/CVPR.2011.5995604
Ren W, Wang X, Tian J et al (2021) Tracking-by-counting: Using network flows on crowd density maps for tracking multiple targets. IEEE Trans Image Process 30:1439–1452. https://doi.org/10.1109/TIP.2020.3044219
Ristani E, Solera F, RSZ et al. (2016) Performance measures and a data set for multi-target, multi-camera tracking. In: Proceedings of the European Conference on Computer Vision, pp. 17–35, https://doi.org/10.1007/978-3-319-48881-3_2
Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Proceedings of the Medical Image Computing and Computer-Assisted Intervention, vol 9351. Springer, pp 234–241, https://doi.org/10.1007/978-3-319-24574-4_28
Silva-Ortigoza R, Hernández-Márquez E et al. (2021) Sensorless tracking control for a “full-bridge buck inverter-dc motor” system: Passivity and flatness-based design. IEEE Access 9:132,191–132,204. https://doi.org/10.1109/ACCESS.2021.3112575
Soriano LA, Zamora E, Vazquez-Nicolas J et al (2020) PD control compensation based on a cascade neural network applied to a robot manipulator. Frontiers Neurorobotics 14(577):749. https://doi.org/10.3389/fnbot.2020.577749
Stadler D, Beyerer J et al. (2021a) Multi-pedestrian tracking with clusters. In: Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance, pp. 1–10, https://doi.org/10.1109/AVSS52988.2021.9663829
Stadler D, Beyerer J et al. (2022) Modelling ambiguous assignments for multi-person tracking in crowds. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision Workshops, pp. 133–142, https://doi.org/10.1109/WACVW54805.2022.00019
Stadler DS, Beyerer J et al. (2021b) Improving multiple pedestrian tracking by track management and occlusion handling. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 10,953–10,962, https://doi.org/10.1109/CVPR46437.2021.01081
Sun S, Akhtar N, Song H (2021) Deep affinity network for multiple object tracking. IEEE Trans Pattern Anal Mach Intell 43:104–119. https://doi.org/10.1109/TPAMI.2019.2929520
Wan X, Zhou S, Wang J et al. (2021) Multiple object tracking by trajectory map regression with temporal priors embedding. In: Proceedings of the ACM International Conference on Multimedia, pp 1377–1386, https://doi.org/10.1145/3474085.3475304
Wang Y, Kitani K, Weng X et al. (2021) Joint object detection and multi-object tracking with graph neural networks. In: Proceedings of the IEEE International Conference on Robotics and Automation, pp 13,708–13,715, https://doi.org/10.1109/ICRA48506.2021.9561110
Wang Z, Zheng L, Liu Y (2020) Towards real-time multi-object tracking. In: Proceedings of the European Conference on Computer Vision, vol. 12356. Springer, pp. 107–122, https://doi.org/10.1007/978-3-030-58621-8_7
Wojke N, Bewley A, Paulus D (2017) Simple online and realtime tracking with a deep association metric. In: Proceedings of the IEEE International Conference on Image Processing, pp. 3645–3649, https://doi.org/10.1109/ICIP.2017.8296962
Wu J, Cao J, Song L (2021) Track to detect and segment: An online multi-object tracker. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 12,352–12,361, https://doi.org/10.1109/CVPR46437.2021.01217
Xu Y, Ban Y, Delorme G (2021) Transcenter: Transformers with dense queries for multiple-object tracking. ArXiv:2103.15145
You S, Yao H, Xu C (2022) Multi-object tracking with spatial-temporal topology-based detector. IEEE Trans Circuit Syst Video Technol 32:3023–3035. https://doi.org/10.1109/TCSVT.2021.3096237
Yu F, Wang D, Darrell T, et al. (2018) Deep layer aggregation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2403–2412, https://doi.org/10.1109/CVPR.2018.00255
Zhang K, Zuo W, Chen Y (2017) Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans Image Process 26:3142–3155. https://doi.org/10.1109/TIP.2017.2662206
Zhang K, Zuo W, Zhang L (2018) Ffdnet: Toward a fast and flexible solution for cnn-based image denoising. IEEE Trans Image Process 27:4608–4622. https://doi.org/10.1109/TIP.2018.2839891
Zhang K, Gool LV, Timofte R et al. (2020) Deep unfolding network for image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 3214–3223, https://doi.org/10.1109/CVPR42600.2020.00328
Zhang K, Li Y, Zuo W (2021) Plug-and-play image restoration with deep denoiser prior. IEEE Trans Patt Anal Mach Intell. https://doi.org/10.1109/TPAMI.2021.3088914
Zhang Y, Sun P, Jiang Y (2021b) Bytetrack: Multi-object tracking by associating every detection box. ArXiv:2110.06864
Zhang Y, Wang C, Wang X et al (2021) Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int J Comput Vis 129:3069–3087. https://doi.org/10.1007/s11263-021-01513-4
Zhou X, Wang D, et al. Krähenbühl P (2019) Objects as points. ArXiv:1904.07850
Zhou X, Koltun V, Krähenbühl P (2020) Tracking objects as points. In: Proceedings of the European Conference on Computer Vision, Vol. 12349. Springer, pp. 474–490, https://doi.org/10.1007/978-3-030-58548-8_28
Funding
The authors gratefully acknowledge support from Major Science and Technology Projects in Yunnan Province (202202AD080013, 202002AB080001-8), the National Natural Science Foundation of China (No. 61971208), Yunnan Reserve Talents of Young and Middle-aged Academic and Technical Leaders (Shen Tao, 2018), Yunnan Young Top Talents of Ten Thousands Plan (Shen Tao, Zhu Yan, Yunren Social Development No. 2018 73), Photonics Fund Class B (20220202, ghfund202202022131). The research work was funded by the Open Foundation of Yunnan Key Laboratory of Computer Technologies Application.
Author information
Authors and Affiliations
Contributions
K.Z.: Data curation, Writing-Original draft, Writing-review & editing.Yujie You: Conceptualization, Methodology, Software, Data curation, Writing-Original draft, Writing-review & editing. T.S.: Conceptualization, Project administration, Funding acquisition, Writing-review & editing. Q.W.: Software, Data curation, Writing-review & editing. Z. T.: Software, Data curation. Z.W.: Software, Data curation. Q.L.: Software, Data curation.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zeng, K., You, Y., Shen, T. et al. NCT:noise-control multi-object tracking. Complex Intell. Syst. 9, 4331–4347 (2023). https://doi.org/10.1007/s40747-022-00946-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00946-9