
Abstract
We study the convergence of several natural policy gradient (NPG) methods in infinite-horizon discounted Markov decision processes with regular policy parametrizations. For a variety of NPGs and reward functions we show that the trajectories in state-action space are solutions of gradient flows with respect to Hessian geometries, based on which we obtain global convergence guarantees and convergence rates. In particular, we show linear convergence for unregularized and regularized NPG flows with the metrics proposed by Kakade and Morimura and co-authors by observing that these arise from the Hessian geometries of conditional entropy and entropy respectively. Further, we obtain sublinear convergence rates for Hessian geometries arising from other convex functions like log-barriers. Finally, we interpret the discrete-time NPG methods with regularized rewards as inexact Newton methods if the NPG is defined with respect to the Hessian geometry of the regularizer. This yields local quadratic convergence rates of these methods for step size equal to the inverse penalization strength.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Markov decision processes (MDPs) are an important model for sequential decision making in interaction with an environment and constitute a theoretical framework for modern reinforcement learning (RL). This framework has been successfully applied in recent years to solve increasingly complex tasks from robotics to board and video games [1,2,3,4,5]. In MDPs the goal is to identify a policy \(\pi \), i.e., a procedure to select actions at every time step, which maximizes an expected time-aggregated reward \(R(\pi )\). We will assume that the set of possible states \(\mathcal {S}\) and the set of possible actions \(\mathcal {A}\) are finite, and model the policy \(\pi _\theta \) as a differentiably parametrized element in the polytope \(\Delta _\mathcal {A}^\mathcal {S}\) of conditional probability distributions of actions given states, with \(\pi _\theta (a|s)\) specifying the probability of selecting action \(a\in \mathcal {A}\) when currently in state \(s\in \mathcal {S}\), for the parameter value \(\theta \). We will study gradient-based policy optimization methods and more specifically natural policy gradient (NPG) methods. Inspired by the seminal works of Amari [6, 7], various NPG methods have been proposed [8,9,10]. In general, they take the form
where \(\Delta t>0\) denotes the step size, \(G(\theta )^+\) denotes the Moore–Penrose pseudo inverse and \(G(\theta )_{ij} = g(dP_\theta e_i, dP_\theta e_j)\) is a Gram matrix defined with respect to some Riemannian metric g and some representation \(P(\theta )\) of the parameter. Most of our analysis does not actually depend on the specific choice of the pseudo inverse, but in Sect. 6 we will use the Moore–Penrose pseudo inverse. The most traditional natural gradient method is the special case where \(P(\theta )\) is a probability distribution and g is the Fisher information in the corresponding space of probability distributions. However, the terminology may be used more generally to refer to a Riemannian gradient method where the metric is in some sense natural. Kakade [8] proposed using \(P(\theta ) = \pi _\theta \) and taking for g a product of Fisher metrics weighted by the state probabilities resulting from running the Markov process with policy \(\pi _\theta \). Although this is a natural choice for P, the choice of a Riemannian metric on \(\Delta ^\mathcal {S}_\mathcal {A}\) is a non trivial problem. Peters et al. as well as Bagnell and Schneider [3, 11] offered an interpretation of Kakade’s metric as the limit of Fisher metrics defined on the finite horizon path measures, but other choices of the weights can be motivated by axiomatic approaches to define a Fisher metric of conditional probabilities [12, 13]. From our perspective, a main difficulty is that it is not clear how to choose a Riemannian metric on \(\Delta ^\mathcal {S}_\mathcal {A}\) that interacts nicely with the objective function \(R(\pi )\), which is a non-convex rational function of \(\pi \in \Delta ^\mathcal {S}_\mathcal {A}\). An alternative choice for \(P(\theta )\) is the vector of state-action frequencies \(\eta _\theta \), whose components \(\eta _\theta (s,a)\) are the probabilities of state-action pairs \((s,a)\in \mathcal {S}\times \mathcal {A}\) resulting from running the Markov process with policy \(\pi _\theta \). Morimura et al. [9] proposed using \(P(\theta )=\eta _\theta \) and the Fisher information on the state-action probability simplex \(\Delta _{\mathcal {S}\times \mathcal {A}}\) as a Riemannian metric. We will study both approaches and variants from the perspective of Hessian geometry.
1.1 Contributions
We study the natural policy gradient dynamics inside the polytope \(\mathcal {N}\) of state-action frequencies, which provides a unified treatment of several existing NPG methods. We focus on finite state and action spaces and the expected infinite-horizon discounted reward optimized over the set of memoryless stochastic policies. Our main contributions can be summarized as follows. For an overview of the convergence rates established in this work see Table 1 in Sect. 7.
-
We show that the dynamics of Kakade’s NPG and Morimura’s NPG solve a gradient flow in \(\mathcal N\) with respect to the Hessian geometries of conditional entropic and entropic regularization of the reward (Sects. 4.2 and 4.3 and Proposition 17).
-
Leveraging results on gradient flows in Hessian geometries, we derive linear convergence rates for Kakade’s and Morimura’s NPG flow for the unregularized reward, which is a linear and hence not strictly concave function in state-action space, and also for the regularized reward (Theorems 26 and 27 and Corollaries 31 and 32).
-
Further, for a class of NPG methods which correspond to \(\beta \)-divergences and which generalize Morimura’s NPG, we show sub-linear convergence in the unregularized case and linear convergence in the regularized case (Theorem 27 and Corollary 32, respectively).
-
We complement our theoretical analysis with experimental evaluation, which indicates that the established linear and sub-linear rates for unregularized problems are essentially tight.
-
For discrete-time gradient optimization, our ansatz in state-action space yields an interpretation of the regularized NPG method as an inexact Newton iteration if the step size is equal to the inverse regularization strength. This yields a relatively short proof for the local quadratic convergence of regularized NPG methods with Newton step sizes (Theorem 34). This recovers as a special case the local quadratic convergence of Kakade’s NPG under state-wise entropy regularization previously shown in [14].
1.2 Related work
The application of natural gradients to optimization in MDPs was first proposed by Kakade [8], taking as a metric on \(\Delta ^\mathcal {S}_\mathcal {A} = \prod _{s\in \mathcal S}\Delta _\mathcal A\) the product of Fisher metrics on the individual components \(\Delta ^s_\mathcal {A} \cong \Delta _\mathcal {A}\), \(s\in \mathcal {S}\), weighted by the stationary state distribution. The relation of this metric to finite-horizon Fisher information matrices was studied by Bagnell and Schneider [11] as well as by Peters et al. [3]. Later, Morimura et al. [9] proposed a natural gradient using the Fisher metric on the state-action frequencies, which are probability distributions over states and actions.
There has been a growing number of works studying the convergence properties of policy gradient methods. It is well known that reward optimization in MDPs is a challenging problem, where both the non-convexity of the objective function with respect to the policy and the particular parametrization of the policies can lead to the existence of suboptimal critical points [15]. Global convergence guarantees of gradient methods require assumptions on the parametrization. Most of the existing results are formulated for tabular softmax policies, but more general sufficient criteria have been given in [15,16,17].
Vanilla PGs have been shown to converge sublinearly at rate \(O(t^{-1})\) for the unregularized reward and linearly for entropically regularized reward. For unregularized problems, the convergence rate can be improved to a linear rate by normalization [18, 19]. For continuous state and action spaces, vanilla PG converges linearly for entropic regularization and shallow policy networks in the mean-field regime [20].
For Kakade’s NPG, [21] established sublinear convergence rate \(O(t^{-1})\) for unregularized problems, and the result has been improved to a linear rate of convergence for step sizes found by exact line search [22], constant step sizes [23,24,25], and for geometrically increasing step sizes [26, 27]. For regularized problems, the method converges linearly for small step sizes and locally quadratically for Newton-like step size [14, 28]. These results have been extended to more general frameworks using state-mixtures of Bregman divergences on the policy polytope [27,28,29,30], which however do not include NPG methods defined in state-action space such as Morimura’s NPG. For projected PGs, [21] shows sublinear convergence at a rate \(O(t^{-1/2})\), and the result has been improved to a sublinear rate \(O(t^{-1})\) [26], and to a linear rate for step sizes chosen by exact line search [22]. Apart from the works on convergence rates for policy gradient methods for standard MDPs, a primal-dual NPG method with sublinear global convergence guarantees has been proposed for constrained MDPs [31, 32]. For partially observable systems, a gradient domination property has been established in [33]. NPG methods with dimension-free global convergence guarantees have been studied for multi-agent MDPs and potential games [34]. The sample complexity of a Bregman policy gradient arising from a strongly convex function in parameter space has been studied in [35]. For the linear quadratic regulator, global linear convergence guarantees for vanilla, Gauss–Newton and Kakade’s natural policy gradient methods are provided in [36]; this setting is different to reward optimization in MDPs, where the objective at a fixed time is linear and not quadratic. A lower bound of \(O(\Delta t^{-1}|\mathcal S|^{2^{\Omega ((1-\gamma )^{-1})}})\) on the iteration complexity for softmax PG method with step size \(\Delta t\) has been established in [37].
1.3 Notation
We denote the simplex of probability distributions over a finite set \(\mathcal X\) by \(\Delta _{\mathcal X}\). An element \(\mu \in \Delta _{\mathcal X}\) is a vector with non-negative entries \(\mu _x = \mu (x)\), \(x\in \mathcal {X}\) adding to one, \(\sum _x \mu _x=1\). We denote the set of Markov kernels from a finite set \(\mathcal X\) to another finite set \(\mathcal {Y}\) by \(\Delta _{\mathcal Y}^{\mathcal X}\). An element \(Q\in \Delta _{\mathcal Y}^{\mathcal X}\) is a \(|\mathcal {X}|\times |\mathcal {Y}|\) row stochastic matrix with entries \(Q_{xy} = Q(y|x)\), \(x\in \mathcal {X}\), \(y\in \mathcal {Y}\). Given \(Q^{(1)}\in \Delta _{\mathcal Y}^{\mathcal X}\) and \(Q^{(2)}\in \Delta _{\mathcal Z}^{\mathcal Y}\) we denote their composition into a kernel from \(\mathcal {X}\) to \(\mathcal {Z}\) by \(Q^{(2)}\circ Q^{(1)}\in \Delta _{\mathcal Z}^{\mathcal X}\). Given \(p\in \Delta _{\mathcal {X}}\) and \(Q\in \Delta ^{\mathcal {X}}_{\mathcal {Y}}\) we denote their composition into a joint probability distribution by \(p*Q \in \Delta _{\mathcal {X}\times \mathcal {Y}}\), \((p*Q)(x, y):=p(x)Q(y|x)\). The support of a vector \(v\in \mathbb {R}^\mathcal {X}\) is the set \({\text {supp}}(v) = \{x\in \mathcal {X}:v_x\ne 0\}\).
For a vector \(\mu \in \mathbb R_{\ge 0}^\mathcal X\) we denote its Shannon entropy by
with the usual convention that \(0\log (0):=0\). For \(\mu \in \mathbb R_{\ge 0}^{\mathcal X\times \mathcal Y}\) we denote the X-marginal by \(\mu _X\in \mathbb {R}^\mathcal {X}_{\ge 0}\), where \(\mu _X(x):=\sum _y \mu (x, y)\). Further, we denote the conditional entropy of \(\mu \) conditioned on X by
For any strictly convex function \(\phi :\Omega \rightarrow \mathbb R\) defined on a convex subset \(\Omega \subseteq \mathbb R^d\), the associated Bregman divergence \(D_\phi :\Omega \times \Omega \rightarrow \mathbb R\) is given by \(D_\phi (x, y) :=\phi (x) - \phi (y) - \langle \nabla \phi (y), x-y\rangle \).
Given two smooth manifolds \(\mathcal M\) and \(\mathcal N\) and a smooth function \(f:\mathcal M\rightarrow \mathcal N\), we denote the differential of f at \(p\in \mathcal M\) by \(df_p:T_p\mathcal M\rightarrow T_{f(p)}\mathcal N\). In the Euclidean case, we also write Df(p) for the Jacobian matrix with entries \(Df(p)_{ij} = \partial _j f_i(p)\). We denote the gradient of a smooth function \(f:\mathcal M\rightarrow \mathbb R\) defined on a Riemannian manifold \((\mathcal M, g)\) by \(\nabla ^gf:\mathcal M\rightarrow T\mathcal M\) and denote the values of the vector field by \(\nabla ^g f(p)\in T_p\mathcal M\) for \(p\in \mathcal M\). When the Riemannian metric is unambiguous we drop the superscript.
For \(A\in \mathbb R^{n\times m}\), we denote a pseudo inverse by \(A^+\in \mathbb R^{m\times n}\). Note that for the Moore-Penrose inverse \(AA^+\) is the orthogonal (Euclidean) projection onto \({\text {range}}(A)\) and \(A^+A\) is the orthogonal (Euclidean) projection onto \({\text {ker}}(A)\). We denote the set of symmetric and positive definite matrices by \(\mathbb S_{>0}^{sym}\). Finally, for functions f, g we write \(f(t) = O(g(t))\) for \(t\rightarrow t_0\) if there is a constant \(c>0\) such that \(f(t)\le cg(t)\) for \(t\rightarrow t_0\), where we allow \(t_0=+\infty \).
2 Markov decision processes
A Markov decision process or shortly MDP is a tuple \((\mathcal S, \mathcal A, \alpha , r)\). We assume that \(\mathcal S\) and \(\mathcal A\) are finite sets which we call the state and action space respectively. We fix a Markov kernel \(\alpha \in \Delta _{\mathcal S}^{\mathcal S\times \mathcal A}\) which we call the transition mechanism. Further, we consider an instantaneous reward vector \(r\in \mathbb R^{\mathcal S\times \mathcal A}\). In the case of partially observable MDPs (POMDPs) one also has a fixed kernel \(\beta \in \Delta _{\mathcal O}^{\mathcal S}\) called the observation mechanism. The system is fully observable if \(\beta ={\text {id}}\),Footnote 1 in which case the POMDP simplifies to an MDP.
As policies we consider elements \(\pi \in \Delta _{\mathcal A}^{\mathcal S}\). More generally, in POMDPs we would consider effective policies \(\pi = \pi '\circ \beta \in \Delta _{\mathcal A}^{\mathcal S}\) with \(\pi '\in \Delta ^\mathcal {O}_\mathcal {A}\). We will focus on the MDP case, however. A policy \(\pi \in \Delta _{\mathcal A}^\mathcal S\) induces transition kernels \(P_\pi \in \Delta _{\mathcal S\times \mathcal A}^{\mathcal S\times \mathcal A}\) and \(p_\pi \in \Delta _{\mathcal S}^{\mathcal S}\) by
For any initial state distribution \(\mu \in \Delta _{\mathcal S}\), a policy \(\pi \in \Delta _{\mathcal A}^{\mathcal S}\) defines a Markov process on \(\mathcal S\times \mathcal A\) with transition kernel \(P_\pi \) which we denote by \(\mathbb P^{\pi , \mu }\). For a discount rate \(\gamma \in (0, 1)\) we define
called the expected discounted reward. The expected mean reward is obtained as the limit with \(\gamma \rightarrow 1\) when this exists. We will focus on the discounted case, however. The goal is to maximize R over the policy polytope \(\Delta _\mathcal A^\mathcal S\). For a policy \(\pi \) we define the value function \(V^\pi =V^\pi _\gamma \in \mathbb R^\mathcal S\) via \(V^\pi (s):=R_{\gamma }^{\delta _s}(\pi )\), \(s\in \mathcal {S}\), where \(\delta _s\) is the Dirac distribution concentrated at \(s\).
A short calculation shows that \(R(\pi ) = \sum _{s, a} r(s, a) \eta ^{\pi }(s, a) = \langle r, \eta ^{\pi }\rangle _{\mathcal S\times \mathcal A}\) [38], where
The vector \(\eta ^{\pi }\) is an element of \(\Delta _{\mathcal {S}\times \mathcal {A}}\) called the expected (discounted) state-action frequency [39], or (discounted) visitation/occupancy measure, or on-policy distribution [40]. Denoting the state marginal of \(\eta ^{\pi }\) by \(\rho ^{\pi }\in \Delta _\mathcal S\) we have \(\eta ^{\pi }(s, a) = \rho ^{\pi }(s) \pi (a|s)\). We denote the set of all state-action frequencies in the fully and in the partially observable cases by
Note that the expected cumulative reward function \(R:\Delta _\mathcal A^\mathcal O\rightarrow \mathbb R\) factorizes according to
We recall the following well-known facts.
Proposition 1
(State-action polytope of MDPs, [39]) The set \(\mathcal N\) of state-action frequencies is a polytope given by \(\mathcal N = \Delta _{\mathcal {S}\times \mathcal {A}}\cap \mathcal L = \mathbb R_{\ge 0}^{\mathcal S\times \mathcal A}\cap \mathcal L\), where
and \(\ell _s(\eta ) :=\sum _{a} \eta _{sa} - \gamma \sum _{s',a'} \eta _{s'a'}\alpha (s|s', a') - (1-\gamma ) \mu _s\).
The state-action polytope for a two-state MDP is shown in Fig. 3. We note that in in the case of partially observable MDPs, the set of state-action frequencies \(\mathcal {N}^\beta \) does not form a polytope, but rather a polynomially constrained set involving polynomials of higher degree depending on the properties of the observation kernel [41].
The result above shows that a (fully observable) Markov decision process can be solved by means of linear programming. Indeed, if \(\eta ^*\) is a solution of the linear program \(\langle r,\eta \rangle _{\mathcal {S}\times \mathcal {A}}\) over \(\mathcal {N}\), one can compute the maximizing policy over \(\Delta ^\mathcal {S}_\mathcal {A}\) by conditioning, \(\pi ^*(a|s) = \eta ^*(s,a)/\sum _{a'}\eta ^*(s,a)\). We propose to study the evolution of natural policy gradient methods in state-action space \(\mathcal {N}\subseteq \Delta _{\mathcal {S}\times \mathcal {A}}\). Indeed, we show that the evolution of diverse natural policy gradient algorithms in the state-action polytope solves the gradient flow of a (regularized) linear objective with respect to a Hessian geometry in state-action space. This perspective facilitates relatively short proofs for the global convergence of natural policy gradient methods and can also provide rates. In order to relate Riemannian geometries in the policy space \(\Delta _\mathcal {A}^\mathcal {S}\) to Riemannian geometries in the state-action polytope \(\mathcal N\) we need the following assumption.
Assumption 2
(Positivity) For every \(s\in \mathcal S\) and \(\pi \in \Delta _\mathcal {A}^\mathcal {O}\), we assume that \(\sum _{a} \eta _{sa}^\pi >0\).
Assumption 2 holds in particular if either \(\alpha >0\) and \(\gamma >0\) or \(\gamma <1\) and \(\mu >0\) entrywise [41]. This assumption is standard in linear programming approaches and necessary for the convergence of policy gradient methods in MDPs [18, 42]. With this assumption in place we have the following.
Proposition 3
(Inverse of state-action map, [41]) Under Assumption 2, the mapping \(\Delta _\mathcal {A}^\mathcal {S}\rightarrow \mathcal N, \pi \mapsto \eta \) is rational and bijective with rational inverse given by conditioning \(\mathcal N \rightarrow \Delta _\mathcal {A}^\mathcal {S}, \eta \mapsto \pi \), where \(\pi (a|s) = \frac{\eta _{sa}}{\sum _{a'}\eta _{sa'}}\).
This result shows that the (interior of the) set of policies and the (interior of the) state-action polytope are diffeomorphic. Hence, we can port the Riemannian geometry on any of the two sets to the other by using the pull back along \(\pi \mapsto \eta \) or the conditioning map \(\eta \mapsto \pi \).
3 Natural gradients
In this section we provide some background on the notion of natural gradients.
3.1 Definition and general properties of natural gradients
In many applications, one aims to optimize a model parameter \(\theta \) with respect to an objective function \(\ell \) that is defined on a model space \(\mathcal {M}\), as illustrated in Fig. 1.

Schematic drawing of parametric models with an objective function \(\ell \) and resulting parameter objective function L; note that neither the choice of geometry in the model space nor the factorization or the model space itself is uniquely determined by the objective function L
This general setup, with an objective function that factorizes as \(L(\theta )=\ell (P(\theta ))\), covers parameter estimation and supervised learning cases, and also problems such as the numerical solution of PDEs with neural networks or policy optimization in MDPs and reinforcement learning. Naively, the optimization problem can be approached with first order methods, computing the gradients in parameter space with respect to the Euclidean geometry. However, this neglects the geometry of the parametrized model \(\mathcal M_\Theta = P(\Theta )\), which is often seen as a disadvantage since it may lead to parametrization-dependent plateaus in the optimization landscape. At the same time, the biases that particular parametrizations can introduce into the optimization can be favorable in some cases. This is an active topic of investigation particularly in deep learning, where P is often a highly non-linear function of \(\theta \). At any rate, there is a good motivation to study of the effects of the parametrization and the possible advantages from incorporating the geometry of model space into the optimization procedure in parameter space.
The natural gradient as introduced in [6] is a way to incorporate the geometry of the model space into the optimization procedure and to formulate iterative update directions that are invariant under reparametrizations. Although it has been most commonly applied in the context of parameter estimation under the maximum likelihood criterion, the concept of natural gradient has been formulated for general parametric optimization problems and in combination with arbitrary geometries. In particular, natural gradients have been applied to neural network training [43,44,45,46], policy optimization [3, 8, 9] and inverse problems [47]. Especially in the latter case, different notions of natural gradients have been introduced. A version that incorporates the geometry of the sample space are natural gradients based on an optimal transport geometry in model space [48,49,50]. We shall discuss natural gradients in a way that emphasizes that even for a specific problem there may not be a unique natural gradient. This is because both the factorization \(L(\theta )=\ell (P(\theta ))\) of the objective as well as what should be considered a natural geometry in model space may not be unique.
But what is it that makes a gradient or update direction natural? The general consensus is that it should be invariant under reparametrization to prevent artificial plateaus and provide consistent stopping criteria, and it should (approximately) correspond to a gradient update with respect to the geometry in the model space. We now give the formal definition of the natural gradient with respect to a given factorization and a geometry in model space that we adopt in this work, which can be shown to satisfy the desired properties.
Definition 4
(General natural gradient) Consider the problem of optimizing an objective \(L:\Theta \rightarrow \mathbb R\), where the parameter space \(\Theta \subseteq \mathbb R^p\) is an open subset. Further, assume that the objective factorizes as \(L = \ell \circ P\), where \(P:\Theta \rightarrow \mathcal {M}\) is a model parametrization with \(\mathcal M\) a Riemannian manifold with Riemannian metric g, and \(\ell :\mathcal {M}\rightarrow \mathbb {R}\) is a loss in model space, as shown in Fig. 1. For \(\theta \in \Theta \) we define the Gram matrix \(G(\theta )_{ij}:=g_{P(\theta )}(dP_\theta e_i, dP_\theta e_j)\) and call \(\nabla ^N L(\theta ) :=G(\theta )^+ \nabla L(\theta )\) the natural gradient (NG) of L at \(\theta \) with respect to the factorization \(L = \ell \circ P\) and the metric g.
Natural gradient as best improvement direction. Consider a parametrization \(P:\Theta \rightarrow \mathcal M\) with image \(\mathcal M_\Theta = P(\Theta )\), where \(\mathcal M\) is a Riemannian manifold with metric g. Let us fix a parameter \(\theta \in \Theta \) and set \(p:=P(\theta )\). Moving in the direction \(v\in T_\theta \Theta \) in parameter space results in moving in the direction \(w = dP_\theta v \in T_{p}\mathcal M\) in model space. The space of all directions that can result in this way is the generalized tangent space \(T_\theta \mathcal M_\Theta :={\text {range}}(d_\theta P) \subseteq T_p\mathcal M\). Hence, the best direction one can take on \(\mathcal M_\Theta \) by infinitesimally varying the parameter \(\theta \) is given by
which is equal (up to normalization) to the projection \(\Pi _{T_\theta \mathcal M_\Theta }(\nabla ^g \ell (p))\) of the Riemannian gradient \(\nabla ^g \ell (p)\) onto \(T_\theta \mathcal M_\Theta \). Moving in the direction of the natural gradient in parameter space results in the optimal update direction over the generalized tangent space \(T_\theta \mathcal M_\Theta \) in model space.
Theorem 5
(Natural gradient leads to steepest descent in model space) Consider the settings of Definition 4, where \(\mathcal M\) is a Riemannian manifold with metric g. Let \(\nabla ^NL(\theta ):=G(\theta )^+\nabla _\theta L(\theta )\) denote the natural gradient with respect to this factorization. Then it holds that
For invertible Gram matrices \(G(\theta )\) this result is well known [51, Sect. 12.1.2]; for singular Gram matrices we refer to [52, Theorem 1].
3.2 Choice of a geometry in model space
Invariance axiomatic geometries. A celebrated theorem by Chentsov [53] characterizes the Fisher metric of statistical manifolds with finite sample spaces as the unique metric (up to multiplicative constants) that is invariant with respect to congruent embeddings by Markov mappings. A generalization of Chentsov’s result for arbitrary sample spaces was given by Ay et al. [54].
Given two Riemannian manifolds \((\mathcal {E},g)\), \((\mathcal {E}',g')\) and an embedding \(f:\mathcal {E}\rightarrow \mathcal {E}'\), the metric is said to be invariant if f is an isometry, meaning that
where \(f_*:T_p\mathcal {E}\rightarrow T_{f(p)}\mathcal {E}'\) is the pushforward of f. A congruent Markov mapping is in simple terms a linear map \(p\mapsto M^T p\), where M is a row stochastic partition matrix, i.e., a matrix of non-negative entries with a single non-zero entry per column and entries of each row adding to one. Such a mapping has the natural interpretation of splitting each elementary event into several possible outcomes with fixed conditional probabilities. By Chentsov’s theorem, requiring invariance with respect to these mappings results in a single possible choice for the metric (up to multiplicative constants). We recall that on the interior of the probability simplex \(\Delta _\mathcal {S}\) the Fisher metric is given by
Based on this approach, Campbell [55] characterized the set of invariant metrics on the set of non-normalized positive measures with respect to congruent embeddings by Markov mappings. This results in a family of metrics which restrict to the Fisher metric (up to a multiplicative constant) over the probability simplex. Following this line of ideas, Lebanon [12] characterized a class of invariant metrics of positive matrices that restrict to products of Fisher metrics over stochastic matrices.Footnote 2 The maps considered by Lebanon do not map stochastic matrices to stochastic matrices, which motivated [13] to investigate a natural class of mappings between conditional probabilities. They showed that requiring invariance with respect to their proposed mappings singles out a family of metrics that correspond to products of Fisher metrics on the interior of the conditional probability polytope,
up to multiplicative constants. This work also offered a discussion of metrics on general polytopes and weighted products of Fisher metrics, which correspond to the Fisher metric when the conditional probability polytope is embedded in the joint probability simplex by way of providing a marginal distribution.
Hessian geometries.
Instead of characterizing the geometry of model space \(\mathcal M\) via an invariance axiomatic, one can select a metric based on the optimization problem at hand. For example, it is well known that the Fisher metric is the local Riemannian metric induced by the Hessian of the KL-divergence in the probability simplex. Hence, if the objective function is a KL-divergence, choosing the Fisher metric yields preconditioners that recover the inverse of the Hessian at the optimum, which can yield locally quadratic convergence rates. More generally, if the objective \(\ell :\mathcal M\rightarrow \mathbb R\) has a positive definite Hessian at every point, it induces a Riemannian metric via
in local coordinates, which we call the Hessian geometry induced by \(\ell \) on \(\mathcal {M}\); see [56, 57].
Example 6
(Hessian geometries) The following Riemannian geometries are induced by strictly convex functions.
-
1.
Euclidean geometry: The Euclidean geometry on \(\mathbb R^d\) is induced by the squared Euclidean norm \(x\mapsto \frac{1}{2}\sum _i x_i^2\).
-
2.
Fisher geometry: The Fisher metric on \(\mathbb R_{>0}^{d}\) is induced by the negative entropy \(x\mapsto \sum _i x_i \log (x_i)\).
-
3.
Itakura-Saito: The logarithmic barrier function \(x\mapsto -\sum _i\log (x_i)\) of the positive cone \(\mathbb R_{>0}^d\) yields the Itakura-Saito metric (see the next item).
-
4.
\(\sigma \)-geometries: All of the above examples can be interpreted as special cases of a parametric family of Hessian metrics. More precisely, if we let
$$\begin{aligned} \phi _\sigma (x):={\left\{ \begin{array}{ll} \sum _i x_i\log (x_i) \quad &{} \text {if } \sigma = 1 \\ -\sum _i \log (x_i) \quad &{} \text {if } \sigma = 2 \\ \frac{1}{(2-\sigma )(1-\sigma )}\sum x_i^{2-\sigma } \quad &{} \text {otherwise}, \end{array}\right. } \end{aligned}$$(5)then the resulting Riemannian metric on \(\mathbb R^{d}\) for \(\sigma \in (-\infty , 0]\) and on \(\mathbb R_{>0}^d\) for \(\sigma \in (0, \infty )\) is given by
$$\begin{aligned} g^\sigma _x(v, w) = \sum _{i} \frac{v_i w_i}{x_i^\sigma }. \end{aligned}$$(6)This recovers the Euclidean geometry for \(\sigma =0\), the Fisher metric for \(\sigma =1\), and the Itakura-Saito metric for \(\sigma =2\). Note that these geometries are closely related to the so-called \(\beta \)-divergences [56], which are the Bregman divergences of the functions \(\phi _\sigma \) for \(\beta = 1-\sigma \). We use \(\sigma \) instead of \(\beta \) in order to avoid confusion with our notation for the observation kernel \(\beta \) in a POMDP.
-
5.
Conditional entropy: Given two finite sets \(\mathcal X, \mathcal Y\) and a probability distribution \(\mu \) in \(\Delta _{\mathcal {X}\times \mathcal {Y}}\) we can consider the conditional entropy \(\phi _C(\mu ) :=H(\mu |\mu _X) = H(\mu ) - H(\mu _X)\) from (1). This is a convex function on the simplex \(\Delta _{\mathcal X\times \mathcal Y}\) [58]. The Hessian of the conditional entropy is given by
$$\begin{aligned} \partial _{(x,y)}\partial _{(x',y')} \phi _C(\mu ) = \delta _{xx'}\left( \delta _{yy'} \mu (x,y)^{-1} - \mu _X(x)^{-1} \right) , \end{aligned}$$(7)as can be verified by explicit computation or the chain rule for Hessian matrices (see also proof of Theorem 12). This Hessian does not induce a Riemannian geometry on the entire simplex since it is not positive definite on the tangent space \(T\Delta _{\mathcal X\times \mathcal Y}\), as can be seen by considering the specific choice \(\mathcal X = \mathcal Y = \{1,2\}, \mu _{ij} = 1/4\) for all \(i,j=1, 2\) and the tangent vector \(v\in T_\mu \Delta _{\mathcal X\times \mathcal Y}\) given by \(v_{ij} = (-1)^{i}\). However, when fixing a marginal distribution \(\nu \in \Delta _\mathcal X, \nu >0\), then the conditional entropy \(\phi _C\) induces a Riemannian metric on the interior of \( P = \{\mu \in \Delta _{\mathcal X\times \mathcal Y}: \mu _X = \nu \}\). To see this we consider the diffeomorphism given by conditioning \({\text {int}}(P)\rightarrow {\text {int}}(\Delta _{\mathcal Y}^\mathcal X), \mu \mapsto \mu _{Y|X}\). It can be shown by explicit computation (analogous to the proof of Theorem 12) that the Hessian \(\nabla ^2\phi _C(\mu )\) is the metric tensor of the pull back of the Riemmanian metric
$$\begin{aligned} g:T\Delta _\mathcal Y^\mathcal X\times T\Delta _\mathcal Y^\mathcal X \rightarrow \mathbb R, \quad g_{\mu (\cdot |\cdot )}(v,w) :=\sum _{x} \nu (x) \sum _{y} \frac{v(x,y) w(x,y)}{\mu (y|x)}. \end{aligned}$$This argument can be adapted to sets \(\{\mu \in \Delta _{\mathcal X\times \mathcal X}: \mu _X = \nu (\mu _{Y|X}) \}\), where \(\nu :{\text {int}}(\Delta _\mathcal Y^\mathcal X)\rightarrow {\text {int}}(\Delta _\mathcal X)\) depends smoothly on the conditional \(\mu _{Y|X}\in \Delta _\mathcal Y^\mathcal X\).
We note that the Bregman divergence induced by the conditional entropy is the conditional relative entropy [58],
$$\begin{aligned} D_{\phi _C}(\mu ^{(1)}, \mu ^{(2)})&= D_{KL}(\mu ^{(1)}, \mu ^{(2)}) - D_{KL}(\mu ^{(1)}_X, \mu ^{(2)}_X) \\&= \sum _{x} \mu ^{(1)}_X(x) D_{KL}(\mu ^{(1)}(\cdot |x), \mu ^{(2)}(\cdot |x)). \end{aligned}$$
Local Hessian of Bregman divergences. Let \(\phi \) be a twice differentiable strictly convex function and denote its Bregman divergence with \(D_\phi (x,y) = \phi (x) - \phi (y) - \langle \nabla \phi (y), x-y\rangle \). Then it holds that
To see this, we set \(f(y) :=D_\phi (x,y)\). Then it is straight forward to see that \(\nabla ^2f(y) = \nabla ^2\phi (y)\). Further, one can compute
Hence, we obtain
and hence \(\nabla ^2f(x) = \nabla ^2\phi (x)\).
Connection to Gauss–Newton method. Let \(\phi \) be a twice differentiable strictly convex function. Then the Gram matrix of the Hessian geometry is given by
Hence \(G^{-1}(\theta )\) can be interpreted as a Gauss–Newton preconditioner of the objective function \(\phi \circ P\) [59]. In particular, for the square loss we have \(\phi (x) = \Vert x\Vert _2^2\), in which case \(G(\theta )^{-1} = (DP(\theta )^\top DP(\theta ))^{-1}\) is the usual nonlinear least squares Gauss–Newton preconditioner.
4 Natural policy gradient methods
In this section we give a brief overview of different notions of policy gradient methods that have been proposed in the literature and study their associated geometries in state-action space. Policy gradient methods [60,61,62,63,64] offer a flexible approach to reward optimization. They have been used in robotics [3] and have been combined with deep neural networks [1, 2, 5]. In the context of MDPs there are multiple notions of natural policy gradients. For instance, one may choose to use an optimal transport geometry in model space resulting in Wasserstein natural policy gradients [10]. Most important to our discussion, there are different possible choices for the model space. One obvious candidate is the policy space \(\Delta _\mathcal {A}^\mathcal {S}\), which was used by Kakade [8]. However the objective function \(R(\pi )\) is a rational non-convex function over this space an thus requires a delicate analysis. A second candidate, which was proposed by Morimura et al. [9], is the state-action space \(\mathcal N\subseteq \Delta _{\mathcal {S}\times \mathcal {A}}\), for which the objective becomes a rather simple, linear function. By Proposition 3 the two model spaces \(\Delta ^\mathcal {S}_\mathcal {A}\) and \(\mathcal {N}\) are diffeomorphic under mild assumptions, which allows us to study any NPG method defined with respect to the policy space in state-action space. Because of the simplicity of the objective function in state-action space, we propose to study the evolution of NPG methods in this space. As we will see, this has the added benefit that it allows us to interpret several of the existing NPG methods as being induced by Hessian geometries. Based on this observation we can conduct a relatively simple convergence analysis for these methods. Finally, we propose a class of policy gradients closely related to \(\beta \)-divergences that interpolate between NPG arising from logarithmic barriers, entropic regularization and the Euclidean geometry.
4.1 Policy gradients
Throughout the section, we consider parametric policy models \(P:\Theta \rightarrow \Delta _\mathcal A^\mathcal S\) and write \(\pi _\theta = P(\theta )\in \Delta _\mathcal A^\mathcal S\) for the policy arising from the parameter \(\theta \). We denote the corresponding state-action and state frequencies by \(\eta _\theta \) and \(\rho _\theta \). Finally, in slight abuse of notation we write \(R(\theta )\) for the expected infinite-horizon discounted reward obtained by the policy \(\pi _\theta \). The vanilla policy gradient (vanilla PG) method is given by the iteration
where \(\Delta t>0\) is the step size.
For \(\gamma \in (0,1)\), the reward function \(\pi \mapsto R(\pi )\) is a rational function. Hence, in principle it can be differentiated using any automatic differentiation method. One can use the celebrated policy gradient theorem and use matrix inversion to compute the parameter update.
Theorem 7
(Policy gradient theorem, [21, 62, 63]) Consider an MDP \((\mathcal {S}, \mathcal {A}, \alpha , r), \gamma \in [0,1)\) and a parametrized policy class with differentiable parametrization. It holds that
where \(Q^\pi :=(I-\gamma P_\pi )^{-1}r\in \mathbb R^{\mathcal S\times \mathcal A}\) is the state-action value function.
In a reinforcement learning setup, one does not have direct access to the transition \(\alpha \) and hence to \(P_\pi \) (2) nor \(Q^\pi \), and sometimes even \(\mathcal {S}\) is not known a priori. In this case, one has to estimate the gradient from interactions with the environment [40, 64,65,66]. In this work, however, we study the planning problem in MDPs, i.e., we assume that we have access to exact gradient evaluations.
Policy parametrizations. Many results on the convergence of policy gradient methods have been provided for tabular softmax policies. The tabular softmax parametrization is given by
for \(\theta \in \mathbb R^{\mathcal {S}\times \mathcal {A}}\). One benefit of tabular softmax policies is that they parametrize the interior of the policy polytope \(\Delta _\mathcal {A}^\mathcal {S}\) in a regular way, i.e., such that the Jacobian has full rank everywhere, and the parameter is unconstrained in an affine space.
Definition 8
(Regular policy parametrization) We call a policy parametrization \(\mathbb R^p\rightarrow {\text {int}}(\Delta _{\mathcal A}^\mathcal S), \theta \mapsto \pi _\theta \) regular if it is differentiable, surjective and satisfies
We will focus on regular policy parametrizations, which cover softmax policies as well as escort transformed policies [67]. Nonetheless, we observe that policy optimization with constrained search variables can also be an attractive option and refer to [68] for a discussion in context of POMDPs.
Remark 9
(Partially observable systems) Although we will only consider parametric policies in fully observable MDPs, our discussion covers the case of POMDPs in the following way. Any parametric family of observation-based policies \(\{\pi _\theta :\theta \in \Theta \} \subseteq \Delta _\mathcal {A}^\mathcal {O}\) induces a parametric family of state-based policies \(\{\pi _\theta \circ \beta : \theta \in \Theta \}\subseteq \Delta _\mathcal A^\mathcal S\). Hence, the policy gradient theorem as well as the definitions of natural policy gradients directly extend to the case of partially observable systems. However, the global convergence guarantees in Sects. 5 and 6 do not carry over to POMDPs since they assume regular parametrization of the policies.
Regularization in MDPs. In practice, the reward function is often regularized as
This is often motivated to encourage exploration [60] and has also been shown to lead to fast convergence for strictly convex regularizers \(\psi \) [14, 18]. One popular regularizer is the conditional entropy in state-action space, see [14, 18, 58],
which has also been used to successfully design trust region and proximal methods for reward optimization [69, 70]. It is also possible to take the functions \(\phi _\sigma \) defined in (5) as regularizers. This includes the entropy function, which is studied in state-action space in [58] and logarithmic barriers, which are studied in policy space in [21].
Projected policy gradients. An alternative to using parametrizations with the property that any unconstrained choice of the parameter leads to a policy, is to use constrained parametrizations and projected gradient methods. For instance, one can parametrize policies in \(\Delta ^\mathcal {S}_\mathcal {A}\) by their constrained entries and use the iteration
where \(\Pi _{\Delta _\mathcal {A}^\mathcal {S}}\) is the (Euclidean) projection to \(\Delta _{\mathcal {A}}^\mathcal {S}\). We will not study projected policy gradient methods and refer to [21, 26] for convergence rates of these methods.
4.2 Kakade’s natural policy gradient
Kakade [8] proposed natural policy gradient based on a Riemannian geometry in the policy polytope \(\Delta _\mathcal A^\mathcal S\). We will see that Kakade’s NPG can be interpreted as the NPG induced by the Hessian geometry in state-action space arising from conditional entropy regularization of the linear program associated to MDPs. Kakade’s idea was to mix the Fisher information matrices of the policy over the individual states according to the state frequencies, i.e., to use the following Gram matrix:
Definition 10
(Kakade’s NPG and geometry in policy space) We refer to the natural gradient \(\nabla ^K R(\theta ) :=G_K(\theta )^+ \nabla _\theta R(\pi _\theta )\) as Kakade’s natural policy gradient (K-NPG), where \(G_K\) is defined in (13). Hence, Kakade’s NPG is the NPG induced by the factorization \(\theta \mapsto \pi _\theta \mapsto R(\theta )\) and the Riemannian metric on \({\text {int}}(\Delta _\mathcal A^\mathcal S)\) given by
Due to its popularity, this method is often referred to simply as the natural policy gradient. We will call it Kakade’s NPG in order to distinguish it from other NPGs.
Remark 11
In [8] the definition of \(G_K\) was heuristically motivated by the fact that the reward is also a mix of instantaneous rewards according to the state frequencies, \(R(\pi )=\sum _{s} \rho ^\pi (s) \sum _a \pi (a|s) r(s,a)\). The invariance axiomatic approaches discussed in [12, 13] also yield mixtures of Fisher metrics over individual states, which however do not fully recover Kakade’s metric, since this would require a way to account for the particular process that gives rise to the stationary state distribution \(\rho ^\pi \). The works [3, 11, 71] argued that the Gram matrix \(G_K\) corresponds to the limit of the Fisher information matrices of finite-path probability measures as the path length tends to infinity.
Interpration as Hessian geometry of conditional entropy. The metric \(g^K\) on the conditional probability polytope \(\Delta _{\mathcal A}^\mathcal S\) has been studied in terms of its invariances and its connection to the Fisher metric on finite-horizon path space [3, 11, 13]. We offer a different interpretation of Kakade’s geometry by studying its counterpart in state-action space, which we show to be the Hessian geometry induced by the conditional entropy.
Theorem 12
(Kakade’s geometry as conditional entropy Hessian geometry) Consider an MDP \((\mathcal S, \mathcal A, \alpha )\) and fix \(\mu \in \Delta _\mathcal S\) and \(\gamma \in (0,1)\) such that Assumption 2 holds. Then, Kakade’s geometry on \(\Delta _\mathcal {A}^\mathcal {S}\) is the pull back of the Hessian geometry induced by the conditional entropy on the state-action polytope \(\mathcal N\subseteq \Delta _{\mathcal S\times \mathcal A}\) along \(\pi \mapsto \eta ^\pi \).
Proof
We can pull back the Riemannian metric on the policy polytope proposed by Kakade along the conditioning map to define a corresponding geometry in state-action space. The metric tensor in state-action space is given by
Using \(\partial _{(s,a)} \eta (\tilde{a}|\tilde{s}) = \partial _{(s,a)}( \eta (\tilde{s}, \tilde{a}) \rho (\tilde{s})^{-1}) = \delta _{s\tilde{s}}(\delta _{a\tilde{a}} \rho (\tilde{s})^{-1}- \eta (\tilde{s}, \tilde{a}) \rho (\tilde{s})^{-2})\) we obtain
We aim to show that \(G(\eta ) = \nabla ^2\phi _C(\eta )\), where \(\phi _C(\eta ) = H(\eta ) - H(\rho )\), where \(\rho (s) = \sum _{a}\eta (s,a)\) denotes the state-marginal. Note that \(\nabla ^2\,H(\eta ) = {\text {diag}}(\eta )\), which is the first term appearing in (16). For linear maps \(g_A(x) = Ax\) the chain rule yields the expression
Noting that \(\rho \) is a linear function of \(\eta \) we obtain
which is the second term in (16). Overall this implies \(G(\eta ) = \nabla ^2\phi _C(\eta )\).
The above theorem shows that Kakade’s natural policy gradient is the natural policy gradient induced by the factorization \(\theta \mapsto \eta _\theta \mapsto R(\theta )\) with respect to the conditional entropy Hessian geometry, i.e.,
It is also worth noting that the Bregman divergence of the conditional entropy is the conditional relative entropy and has been studied as a regularizer for the linear program associated to MDPs in [58].
Remark 13
Kakade’s NPG is known to converge at a locally quadratic rate under conditional entropy regularization [14], a regularizer which in policy space takes the form
Note however, by direct calculation, that Kakade’s geometry in policy space \(g^K\) defined in (14) is not the Hessian geometry induced by \(\psi \) in policy space, which would take the form
Instead, the metric proposed by Kakade only considers the contribution of the first term; see (14). As we will see in Sects. 5 and 6, the interpretation of Kakade’s NPG as a Hessian natural gradient induced by the conditional entropic regularization in state-action space allows for a great simplification of its convergence analysis. One can show that Kakade’s metric is not a Hessian metric in policy space. By Schwarz’s theorem the metric tensor of a Hessian Riemannian metric satisfies \(\partial _i g_{jk} = \partial _j g_{ik}\). However, we have
which does not satisfy this symmetry property in general. This shows that the Riemannian metric on the policy polytope \(\Delta _\mathcal A^\mathcal S\) proposed by Kakade does not arise from a Hessian.
4.3 Morimura’s natural policy gradient
In contrast to Kakade’s approach, who proposed a mixture of Fisher metrics to obtain a metric on the conditional probability polytope \(\Delta _\mathcal {A}^\mathcal {S}\), Morimura and co-authors [9] proposed to work with the Fisher metric in state-action space \(\Delta _{\mathcal {S}\times \mathcal {A}}\) to define a natural gradient for reward optimization. The resulting Gram matrix is given by the Fisher information matrix induced by the state-action distributions, that is \(P(\theta )=\eta _\theta \) and
Definition 14
(Morimura’s NPG) We refer to the natural gradient \(\nabla ^M R(\theta ) :=G_M(\theta )^+ \nabla _\theta R(\pi _\theta )\) as Morimura’s natural policy gradient (M-NPG), where \(G_M\) is defined in (18). Hence, Morimura’s NPG is the NPG induced by the factorization \(\theta \mapsto \eta _\theta \mapsto R(\theta )\) and the Fisher metric on \({\text {int}}(\Delta _{\mathcal S\times \mathcal A})\).
By (17) the Gram matrix proposed by Morimura and co-authors and the Gram matrix proposed by Kakade are related to each other by
where \(F_{\rho }(\theta )_{ij} = \sum _{s}\rho _\theta (s) \partial _{\theta _{i}} \log (\rho _\theta (s))\partial _{\theta _{j}} \log (\rho _\theta (s))\) denotes the Fisher information matrix of the state distributions. This relation is reminiscent of the chain rule for the conditional entropy and can be verified by direct computation; see [9]. Where we have seen that Kakade’s geometry in state-action space is the Hessian geometry of conditional entropy, the Fisher metric is known to be the Hessian metric of the entropy function [56]. Hence, we can interpret the Fisher metric as the Hessian geometry of the entropy regularized reward \(\eta \mapsto \langle r, \eta \rangle - H(\eta )\).
4.4 General Hessian natural policy gradient
Generalizing the above definitions, we define general state-action space Hessian NPGs as follows. Consider a twice differentiable function \(\phi :\mathbb R_{>0}^{\mathcal {S}\times \mathcal {A}}\rightarrow \mathbb R\) such that \(\nabla ^2\phi (\eta )\) is positive definite on \(T_\eta \mathcal N = T\mathcal L\subseteq \mathbb R^{\mathcal S\times \mathcal A}\) for every \(\eta \in {\text {int}}(\mathcal N)\). Then we set
which is the Gram matrix with respect to the Hessian geometry in \(\mathbb R_{>0}^{\mathcal {S}\times \mathcal {A}}\).
Definition 15
(Hessian NPG) We refer to the natural gradient \(\nabla ^\phi R(\theta ) := G_\phi (\theta )^+ \nabla _\theta R(\pi _\theta )\) as Hessian natural policy gradient with respect to \(\phi \) or shortly \(\phi \)-natural policy gradient (\(\phi \)-NPG).
Leveraging results on gradient flows in Hessian geometries we will later provide global convergence guarantees including convergence rates for a large class of Hessian NPG flows covering Kakade’s and Morimura’s natural gradients as special cases. Further, we consider the family \(\phi _\sigma \) of strictly convex functions defined in (5). With \(G_\sigma (\theta )\) we denote the Gram matrix associated with the Riemannian metric \(g^\sigma \), i.e.,
Definition 16
(\(\sigma \)-NPG) We refer to the natural gradient \(\nabla ^\sigma R(\theta ) :=G_\sigma (\theta )^+ \nabla _\theta R(\pi _\theta )\) as the \(\sigma \)-natural policy gradient (\(\sigma \)-NPG). Hence, the \(\sigma \)-NPG is the NPG induced by the factorization \(\theta \mapsto \eta _\theta \mapsto R(\theta )\) and the metric \(g^\sigma \) on \({\text {int}}(\Delta _{\mathcal S\times \mathcal A})\) defined in (6).
For \(\sigma =1\) we recover the Fisher geometry and hence Morimura’s NPG; for \(\sigma =2\) we obtain the Itakura-Saito metric; and for \(\sigma =0\) we recover the Euclidean geometry. Later, we show that the Hessian gradient flows exist globally for \(\sigma \in [1, \infty )\) and provide convergence rates depending on \(\sigma \).
5 Convergence of natural policy gradient flows
In this section we study the convergence properties of natural policy gradient flows arising from Hessian geometries in state-action space for fully observable systems and regular parametrizations of the interior of the policy polytope \(\Delta _\mathcal A^\mathcal S\). Leveraging tools from the theory of gradient flows in Hessian geometries established in [72] we show \(O(t^{-1})\) convergence of the objective value for a large class of Hessian geometries and unregularized reward. We strengthen this general result and establish linear convergence for Kakade’s and Morimura’s NPG flows and \(O(t^{-1/(\sigma -1)})\) convergence for \(\sigma \)-NPG flows for \(\sigma \in (1,2)\). We provide empirical evidence that these rates are tight and that the rate \(O(t^{-1/(\sigma -1)})\) also holds for \(\sigma \ge 2\). Under strongly convex penalization, we obtain linear convergence for a large class of Hessian geometries.
Reduction to state-action space. For a solution \(\theta (t)\) of the natural policy gradient flow, the corresponding state-action frequencies \(\eta (t)\) solve the gradient flow with respect to the Riemannian metric. This is made precise in the following result, which shows that it suffices to study Riemannian gradient flows in state-action space in order to study natural policy gradient flows for tabular softmax policies.
Proposition 17
(Evolution in state-action space) Consider an MDP \((\mathcal S, \mathcal A, \alpha )\), a Riemannian metric g on \({\text {int}}(\mathcal {N}) = \mathbb R_{>0}^{\mathcal S\times \mathcal A}\) and an differentiable objective function \(\mathfrak R:{\text {int}}(\Delta _{\mathcal S\times \mathcal A}) \rightarrow \mathbb R\). Consider a regular policy parametrization and the objective \(R(\theta ):=\mathfrak R(\eta _\theta )\) and a solution \(\theta :[0,T]\rightarrow \Theta = \mathbb R^{\mathcal S\times \mathcal A}\) of the natural policy gradient flow
where \(G(\theta )_{ij} = g_\eta (\partial _{\theta _i} \eta _\theta , \partial _{\theta _j} \eta _\theta )\) and \(G(\theta )^+\) denotes some pseudo inverse of \(G(\theta )\). Then, setting \(\eta (t):=\eta _{\theta (t)}\) we have that \(\eta :[0, T] \rightarrow \Delta _{\mathcal S\times \mathcal A}\) is the gradient flow with respect to the metric g and the objective \(\mathfrak R\), i.e., solves
Proof
This is a direct consequence of Theorem 5.
The preceding result covers the commonly studied tabular softmax parametrization. For general parametrizations, the result does not hold. However, if for any two parameters \(\theta , \theta '\) with \(\eta _\theta = \eta _{\theta '}\) it holds that
then a similar result can be established. An important special case of such parametrizations occurs in partially observable problems with memoryless policies parametrized in a regular way, e.g. through the softmax or escort transform; see also Remark 9.
By Proposition 17 it suffices to study solutions \(\eta :[0, T]\rightarrow \mathcal N\) of the gradient flow in state-action space. We have seen before that a large class of natural policy gradients arise from Hessian geometries in state-action space. In particular, this covers the natural policy gradients proposed by Kakade [8] and Morimura et al. [9]. We study the evolution of these flows in state-action space and leverage results on Hessian gradient flows of convex problems in [72, 73] to obtain global convergence rates for different NPG methods.
5.1 Convergence of unregularized Hessian NPG flows
First, we study the case of unregularized reward, i.e., where the state-action objective is linear and given by \(\mathfrak R(\eta ) = \langle r, \eta \rangle \). In this case we obtain global convergence guarantees including rates. In particular, our general result covers the \(\sigma \)-NPGs and thus Morimura’s NPGs as well as Kakade’s NPGs. For the remainder of this section we work under the following assumptions.
Setting 18
Let \((\mathcal S, \mathcal A, \alpha )\) be an MDP, \(\mu \in \Delta _\mathcal S\) and \(r\in \mathbb R^{\mathcal S\times \mathcal A}\) and let the positivity Assumption 2 hold. We denote the state-action polytope by \(\mathcal N = \mathbb R_{\ge 0}^{\mathcal {S}\times \mathcal {A}} \cap \mathcal L\), see Proposition 1, and its (relative) interior and boundary by \({\text {int}}(\mathcal N) = \mathbb R_{>0}^{\mathcal {S}\times \mathcal {A}} \cap \mathcal L\) and \(\partial \mathcal N = \partial \mathbb R_{\ge 0}^{\mathcal {S}\times \mathcal {A}}\cap \mathcal L\) respectively. We consider an objective function \(\mathfrak R:\mathbb R^{\mathcal {S}\times \mathcal {A}}\rightarrow \mathbb R\cup \{-\infty \}\) that is finite, differentiable and concave on \(\mathbb R_{>0}^{\mathcal S\times \mathcal A}\) and continuous on its domain \({\text {dom}}(\mathfrak R) = \{\eta \in \mathbb R^{\mathcal S\times \mathcal A}:\mathfrak R(\eta )\in \mathbb R\}\). Further, we consider a real-valued function \(\phi :\mathbb R^{\mathcal {S}\times \mathcal {A}}\rightarrow \mathbb R\cup \{+\infty \}\), which we assume to be finite and twice continuously differentiable on \(\mathbb R_{>0}^{\mathcal S\times \mathcal A}\) and such that \(\nabla ^2\phi (\eta )\) is positive definite on \(T_\eta \mathcal N = T\mathcal L\subseteq \mathbb R^{\mathcal S\times \mathcal A}\) for every \(\eta \in {\text {int}}(\mathcal N)\) and denote the induced Hessian metric on \({\text {int}}(\mathcal N)\) by g. Further, with \(\eta :[0,T)\rightarrow \mathcal N\) we denote a solution of the Hessian gradient flow
We denoteFootnote 3\(R^*:=\sup _{\eta \in \mathcal N} \mathfrak R(\eta )<\infty \) and by \(\eta ^*\in \mathcal N\), we denote a maximizer – if one exists – of \(\mathfrak R\) over \(\mathcal N\). We denote the policies corresponding to \(\eta _0\) and \(\eta ^*\) by \(\pi _0\) and \(\pi ^*\), see Proposition 3.
We observe that the Hessian of the conditional entropy only defines a Riemannian metric on \({\text {int}}(\mathcal N)\), even if not over all of \(\Delta _{\mathcal {S}\times \mathcal {A}}\). Note that in general \(\eta ^*\) might lie on the boundary and for linear \(\mathfrak R\) corresponding to unregularized reward it necessarily lies on the boundary.
We will repeatedly make use of the following identity
which holds for any \(v\in T\mathcal L\).
Sublinear rates for general case.
We begin by providing a sublinear rate of convergence for general NPG flows, which we then specialize to Kakade and \(\sigma \)-NPGs.
Lemma 19
(Convergence of Hessian natural policy gradient flows) Consider Setting 18 and assume that there exists a solution \(\eta :[0,T)\rightarrow {\text {int}}(\mathcal N)\) of the NPG flow (21) with initial condition \(\eta (0) = \eta _0\). Then for any \(\eta '\in \mathcal N\) and \(t\in [0, T)\) it holds that
where \(D_\phi \) denotes the Bregman divergence of \(\phi \). In particular it holds that \(\mathfrak R(\eta (t))\rightarrow R^*\) as \(T\rightarrow \infty \). Further, this convergence happens at a rate \(O(t^{-1})\) if there is a maximizer \(\eta ^*\in \mathcal N\) of \(\mathfrak R\) with \(\phi (\eta ^*)<\infty \).
Proof
This is precisely the statement of Proposition 4.4 in [72]; note however, that they assume a globally defined objective \(\mathfrak R:\mathbb R^{\mathcal {S}\times \mathcal {A}}\rightarrow \mathbb R\) and hence for completeness we provide a quick argument. It holds that
where we used \(\partial _t\eta (t) = \nabla ^g\mathfrak R(\eta (t))\) as well as (22). Using the concavity of \(\mathfrak R\) we can estimate
which corresponds to Eq. (4.4) in [72], where it is proven under stronger assumption. Integration and the monotonicity of \(t\mapsto \mathfrak R(\eta (t))\) yields the claim.
The previous result is very general and reduces the problem of showing convergence of the natural gradient flow to the problem of well posedness. However, well posedness is not always given, such as for example in the case of an unregularized reward and the Euclidean geometry in state-action space. In this case, the gradient flow in state-action space will reach the boundary of the state-action polytope \(\mathcal N\) in finite time at which point the gradient is not classically defined anymore and the softmax parameters blow up; see Fig. 3. An important class of Hessian geometries that prevent a finite hitting time of the boundary are induced by the class of Legendre-type functions, which curve up towards the boundary.
Definition 20
(Legendre type functions) We call \(\phi :\mathbb R^{\mathcal S\times \mathcal A}\rightarrow \mathbb R\cup \{+\infty \}\) a Legendre type function if it satisfies the following properties:
-
1.
Domain: It holds that \(\mathbb R_{>0}^{\mathcal S\times \mathcal A}\subseteq {\text {dom}}(\phi ) \subseteq \mathbb R_{\ge 0}^{\mathcal S\times \mathcal A} \), where \({\text {dom}}(\phi ) = \{\eta \in \mathbb R^{\mathcal {S}\times \mathcal {A}}:\phi (\eta )<\infty \}\).
-
2.
Smoothness and convexity: We assume \(\phi \) to be continuous on \({\text {dom}}(\phi )\) and twice continuously differentiable on \(\mathbb R_{>0}^{\mathcal S\times \mathcal A}\) and such that \(\nabla ^2\phi (\eta )\) is positive definite on \(T_\eta \mathcal N = T\mathcal L \subseteq \mathbb R^{\mathcal S\times \mathcal A}\) for every \(\eta \in {\text {int}}(\mathcal N)\).
-
3.
Gradient blowup at boundary: For any \((\eta _k)\subseteq {\text {int}}(\mathcal N)\) with \(\eta _k\rightarrow \eta \in \partial \mathcal N\) we have \(\Vert \nabla \phi (\eta _k)\Vert \rightarrow \infty \).
We note that the above definition differs from [72], who consider Legendre functions on arbitrary open sets but work with more restrictive assumptions. More precisely, they require the gradient blowup on the boundary of the entire cone \(\mathbb R_{\ge 0}^{\mathcal {S}\times \mathcal {A}}\) and not only on the boundary of the feasible set \(\mathcal N\) of the optimization problem. However, this relaxation is required to cover the case of the conditional entropy, which corresponds to Kakade’s NPG, as we see now.
Example 21
The class of Legendre type functions covers the functions inducing Kakade’s and Morimura’s NPG via their Hessian geometries. More precisely, the following Legendre type functions will be of great interest in the remainder:
-
1.
The functions \(\phi _\sigma \) defined in (5) used to define the \(\sigma \)-NPG are Legendre type functions for \(\sigma \in [1, \infty )\). Note that this includes the Fisher geometry, corresponding to Morimura’s NPG for \(\sigma =1\) but excludes the Euclidean geometry, which corresponds to \(\sigma =0\).
-
2.
The conditional entropy \(\phi _C\) defined in (12) is a Legendre type function. The Hessian geometry of this function induces Kakade’s NPG. Note that in this case the gradient blowup holds on the boundary \(\mathcal N\) but not on the boundary of \(\Delta _{\mathcal {S}\times \mathcal {A}}\) or even \(\mathbb R_{\ge 0}^{\mathcal {S}\times \mathcal {A}}\).
The definition of a Legendre function with the gradient blowing up at the boundary of the feasible set prevents the gradient flow from reaching the boundary in finite time and thus ensures the global existence of the gradient flow.
Let us now turn towards Kakade’s natural policy gradient, which is the Hessian NPG induced by the conditional entropy \(\phi _C\) defined in (1). The Bregman divergence of the conditional entropy (see [74]) is given by
which has been studied in the context of mirror descent algorithms of the linear programming formulation of MDPs in [58].
Theorem 22
(Convergence of Kakade’s NPG flow for unregularized reward) Consider Setting 18 with \(\phi =\phi _C\) being the conditional entropy defined in (12) and let \(\mathfrak R(\eta ) = \langle r, \eta \rangle \) denote the unregularized reward and fix an element \(\eta _0\in {\text {int}}(\mathcal N)\). Then there exists a unique global solution \(\eta :[0, \infty )\rightarrow {\text {int}}(\mathcal N)\) of Kakade’s NPG flow with initial condition \(\eta (0) = \eta _0\), i.e., of (21) with \(\phi = \phi _C\), and it holds that
where \(D_{\phi _C}\) denotes the conditional relative entropy. In particular, we have \({\text {dist}}(\eta (t), S)\in O(t^{-1})\), where \(S = \{\eta \in \mathcal N:\langle r, \eta \rangle = R^*\}\) denotes the solution set and \({\text {dist}}\) denotes the Euclidean distance.
Proof
The well posedness follows by a similar reasoning as in [72, Theorem 4.1]. Now the result follows directly from Lemma 19.
Now we elaborate the consequences of the general convergence result Lemma 19 for the case of \(\sigma \)-NPG flows. Here, the study is more delicate since for \(\sigma >2\) we typically have \(\phi _\sigma (\eta ^*) = \infty \) since the maximizer \(\eta ^*\) lies at the boundary unless the reward is constant.
Theorem 23
(Convergence of \(\sigma \)-NPG flow for unregularized reward) Consider Setting 18 with \(\phi =\phi _\sigma \) for some \(\sigma \in [1, \infty )\) being defined in (5). Denote the unregularized reward by \(\mathfrak R(\eta ) = \langle r, \eta \rangle \) and fix an element \(\eta _0\in {\text {int}}(\mathcal N)\). Then there exists a unique global solution \(\eta :[0, \infty )\rightarrow {\text {int}}(\mathcal N)\) of the Hessian NPG flow (21) with inital condition \(\eta (0) = \eta _0\) and and there are constants \(c_\sigma >0\) such that
In particular, we have
where \(S = \{\eta \in \mathcal N:\langle r, \eta \rangle = R^*\}\) denotes the solution set and \({\text {dist}}\) denotes the Euclidean distance. This result covers Morimura’s NPG flow as the special case with \(\sigma =1\).
Proof
By the preceding Lemma 19 it suffices to show the well posedness of the \(\sigma \)-NPG flow. The result [72, Theorem 4.1] guarantees the well posedness for Hessian gradient flows for smooth Legendre type functions. Note however that they work with slightly stronger assumptions, which are that the gradient blowup of the Legendre type functions occurs not only on the boundary of \(\mathcal N\) but on the boundary of \(\mathbb R^{\mathcal {S}\times \mathcal {A}}_{\ge 0}\) and that the objective \(\mathfrak R\) is globally defined. Consolidating the proof in [72] reveals that both of these relaxations do not change the validity or proof of the statement.
It is easy to see that for \(\sigma \ge 1\) the functions \(\phi _\sigma \) are of Legendre type and smooth and hence we can apply the preceding Lemma 19. Let \(\eta ^*\) be a maximizer, which necessarily lies at the boundary of \(\mathcal N\) (except for constant reward) and therefore has at least one zero entry. For \(\sigma \in [1, 2)\) we have that \(\phi _\sigma (\eta ^*)<\infty \) and hence we obtain \(R^*-\mathfrak R(\eta (t))\le D_{\phi _\sigma }(\eta ^*, \eta _{0})t^{-1}\). Consider now the case \(\sigma =2\) and pick \(v\in \mathbb R^{\mathcal S\times \mathcal A}\) such that \(\eta _\delta :=\eta ^*+\delta v\in {\text {int}}(\mathcal N)\) for small \(\delta >0\). Then it holds that
Setting \(\delta = t^{-1}\) we obtain \(R^*- \mathfrak R(\eta (t)) = O(t^{-1}) + O((\log (t^{-1}) + 1) t^{-1}) = O(\log (t)t^{-1})\) for \(t\rightarrow \infty \). For \(\sigma \in (2, \infty )\) the calculation follows in analogue fashion. Noting that \({\text {dist}}(\eta (t), S) \sim R^*-\mathfrak R(\eta (t))\) finishes the proof.
Remark 24
Theorems 22 and 23 show global convergence of \(\sigma \)-NPG and Kakade’s NPG flows to a maximizer of the unregularized problem. Note that the reason why this is possible is that one does not work with a regularized objective but rather with a geometry arising from a regularization but with the original linear objective. For \(\sigma <1\) the flow may reach a face of the feasible set in finite time; see Fig. 3. For \(\sigma \ge 3\) Theorem 23 is uninformative since \(\mathfrak R(\eta (t))\) is non increasing. However, by Lemma 19 the flows converge since they are well posed as the functions \(\phi _\sigma \) are Legendre-type functions for \(\sigma \ge 1\); see Example 21. It would be interesting to expand the theoretical analysis to clarify the convergence rate in this particular case. For larger \(\sigma \) the plateau problem becomes more pronounced, as can be seen in Fig. 3.
Furthermore, one can show that the trajectory converges towards the maximizer that is closest to the initial point \(\eta _0\) with respect to the Bregman divergence [72].
Faster rates for \(\varvec{\sigma \in [}\textbf{1,2}\varvec{)}\) and Kakade’s NPG.
Now we obtain improved and even linear convergence rates for Kakade’s and Morimura’s NPG flow for unregularized problems. To this end, we first formulate the following general result.
Lemma 25
(Convergence rates for gradient flow trajectories) Consider Setting 18 and assume that there is a global solution \(\eta :[0, \infty )\rightarrow {\text {int}}(\mathcal N)\) of the Hessian gradient flow (21). Assume that there is \(\eta ^*\in \mathcal N\) such that \(\phi (\eta ^*)<+\infty \) as well as a neighborhood N of \(\eta ^*\) in \(\mathcal N\) and \(\omega \in (0, \infty )\) and \(\tau \in [1, \infty )\) such that
Then there is a constant \(c>0\), possibly depending on \(\eta (0)\), such that
-
1.
if \(\tau =1\), then \(D_\phi (\eta ^*, \eta (t))\le c e^{-\omega t}\),
-
2.
if \(\tau >1\), then \(D_\phi (\eta ^*, \eta (t))\le c t^{-1/(\tau - 1)}\).
The lower bound (25) can be interpreted as a form of strong convexity under which the objective value controls the Bregman divergence and hence convergence in objective value implies convergence of the state-action trajectories in the sense of the Bregman divergence.
Proof
The statement of this result can be found in [72, Proposition 4.9], where however stronger assumptions are made and hence we provide a short proof. First, note (25) implies that \(\eta ^*\) is a strict local maximizer and by concavity of \(\mathfrak R\) the unique global maximizer of \(\mathfrak R\) over \(\mathcal N\). By (24) it holds that \(u(t) :=D_\phi (\eta ^*, \eta (t))\) is strictly decreasing as long as \(\eta (t)\ne \eta ^*\). Note that if \(\eta (t) = \eta ^*\) for some \(t\in [0, \infty )\), we have \(u(t') = 0\) for all \(t'\ge t\) and hence the statement becomes trivial. Therefore, we can assume \(u(t)>0\) for all \(t>0\) and Lemma 19 implies \(\mathfrak R(\eta (t))\rightarrow \mathfrak R(\eta ^*)\). Since \(\mathcal N\) is compact \(\eta (t)\) has at least one accumulation point for \(t\rightarrow \infty \) and by the continuity of \(\mathfrak R\) every accumulation points is a maximizer and hence agrees with \(\eta ^*\), which shows \(\eta (t)\rightarrow \eta ^*\). Hence, \(\eta (t)\in N\) for \(t\ge t_0\). For the statement about the asymptotic behavior we may therefore assume without loss of generality that \(\eta (t) \in N\) for all \(t\ge 0\). Combining (24) and (25) we obtain \(u'(t) \le -\omega u(t)^\tau \). Dividing by the right hand side and integrating the inequality we obtain \(u(t)\le u(0)e^{-\omega t}\) for \(\tau =1\) and \(u(t)\le \omega ^{1/(1-\tau )}(\tau -1)^{1/(1-\tau )}t^{1/(1-\tau )}\).
Theorem 26
(Linear convergence of unregularized Kakade’s NPG flow) Consider Setting 18, where \(\phi = \phi _C\) is the conditional entropy defined in (12) and assume that there is a unique maximizer \(\eta ^*\) of the unregularized reward \(\mathfrak R\). Then \(R^*- \mathfrak R(\eta (t)) \le c_1(\eta _0) e^{-c_2t}\) for some constants \(c_1(\eta _0), c_2>0\).
Proof
Let \(\phi _C\) denote the conditional entropy, so that \(D_{\phi _C}(\eta ^*, \eta ) = D_{KL}(\eta ^*, \eta ) - D_{KL}(\rho ^*, \rho ) \le D_{KL}(\eta ^*, \eta )\). Hence, we obtain just like in the case of \(\sigma \)-NPG flows for \(\sigma =1\) that \(D_{\phi _C}(\eta ^*, \eta ) = O(\mathfrak R(\eta ^*) - \mathfrak R(\eta ))\) for \(\eta \rightarrow \eta ^*\) and hence \(D_{\phi _C}(\eta ^*, \eta (t)) = O(e^{-ct})\) for some \(c>0\) by Lemma 25. Hence, it remains to estimate \(\mathfrak R(\eta ^*) - \mathfrak R(\eta ) = O(\Vert \eta ^*- \eta \Vert _1)\) by the conditional relative entropy \(D_{\phi _C}(\eta ^*, \eta )\). Note that \(\pi ^*\) is a deterministic policy and hence we can write \(\pi ^*(a^*_s|s) = 1\) and estimate
Here, we have used \(\log (t) \le t-1\) as well as
Now we observe that the mapping \(\pi \mapsto \eta \) is L-Lipschitz with constant \(L=O((1-\gamma )^{-1})\). The fact that \(L=O((1-\gamma )^{-1})\) follows from the policy gradient theorem as \(\partial _{\pi (a|s)} \eta ^\pi = \rho ^\pi (s) (I-\gamma P_\pi ^\top )^{-1}e_{(s,a)}\), see also [41, Proposition 48]. In turn, it holds that
Altogether this implies \(R^*- \mathfrak R(\eta (t)) = O(e^{-ct})\), which concludes the proof. The O notation hides constants that scale with the norm of the instantaneous reward vector r, inversely with the minimum state probability, and inversely with \((1-\gamma )\) where \(\gamma \) is the discount rate.
Theorem 27
(Improved convergence rates for \(\sigma \)-NPG flow) Consider Setting 18, where \(\phi = \phi _\sigma \) for some \(\sigma \in [1, 2)\) as defined in (5), and assume that there is a unique maximizer \(\eta ^*\) of the unregularized reward \(\mathfrak R\). Then for suitable constants \(c_1(\eta _0), c_2, c_3(\eta _0)>0\) it holds
where \(\eta :[0, \infty )\rightarrow {\text {int}}(\mathcal N)\) denotes the solution of the \(\sigma \)-NPG flow.
Proof
The key is to show that (25) holds for \(\tau = (2-\sigma )^{-1}\ge 1\). To see that this holds, we first consider the case \(\sigma \in (1, 2)\), where we obtain
We can bound every summand by \(O(|\eta ^*(s,a) - \eta (s,a) |)\) if \(\eta ^*(s,a)>0\) and \(O(|\eta ^*(s,a) - \eta (s,a) |^{2-\sigma })\) if \(\eta ^*(s,a)=0\) for \(\eta \rightarrow \eta ^*\) respectively. Overall, this shows that
where the last estimate holds since \(\eta ^*\) is the unique minimizer of the linear function \(\mathfrak R\) over the polytope \(\mathcal N\). By Lemma 25 we obtain \(D_\sigma (\eta ^*, \eta (t))=O(t^{-1/(\tau -1)}) = O(t^{-(2-\sigma )/(\sigma -1)})\). It remains to estimate the value of \(\mathfrak R\) by means of the Bregman divergence \(D_\sigma \). For this, we note that \(\mathfrak R(\eta ^*) - \mathfrak R(\eta ) = O(\Vert \eta ^*-\eta \Vert _1)\) and estimate the individual terms. First, note that for \(x\rightarrow y\) (with \(x, y\ge 0\)) it holds that
For \(y=0\) this is immediate and for \(y>0\) the local strong convexity of \(x\mapsto x^{2-\sigma }\) around y implies
for \(x\rightarrow y\). Now, Jensen’s inequality yields
Overall, we obtain
The case \(\sigma =1\) can be treated similarly, where one obtains \(D_\sigma (\eta ^*, \eta )=O(\Vert \eta ^*-\eta \Vert )=O(\mathfrak R(\eta ^*) - \mathfrak R(\eta ))\) for \(\eta \rightarrow \eta ^*\). To relate the \(L^1\)-norm to the Bregman divergence one can employ Pinsker’s inequality \(\Vert \eta ^*-\eta \Vert _1\le \sqrt{2 D_{KL}(\eta ^*, \eta )} = \sqrt{2 D_{\sigma }(\eta ^*, \eta )}\).
Compared to Theorem 23 the above Theorem 27 improves the \(O(t^{-1})\) rates for \(\sigma \in [1,2)\). Later, we conduct numerical experiments that indicate that the rates \(O(t^{-1/(\sigma -1)})\) also hold for \(\sigma \ge 2\) and are tight.
Numerical examples.
We use the following example proposed by Kakade [8] and which was also used in [9, 11]. We consider an MDP with two states \(s_1, s_2\) and two actions \(a_1, a_2\), with the transitions and instantaneous rewards shown in Fig. 2.

Transition graph and reward of the MDP example
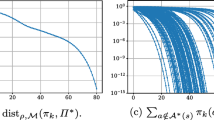
We adopt the initial distribution \(\mu (s_1)=0.2, \mu (s_2) = 0.8\) and work with a discount factor of \(\gamma = 0.9\), whereas Kakade studied the mean reward case. Note however that the experiments can be performed for arbirtrarily large discount factor, where we chose a smaller factor since the correspondence between the policy polytope and the state-action polytope is clearer to see in the illustrations. We consider tabular softmax policies and plot the trajectories of vanilla PG, Kakade’s NPG, and \(\sigma \)-NPG for the values \(\sigma \in \{-0.5, 0, 0.5, 1, 1.5, 2, 3, 4\}\) for 30 random (but the same for every method) initializations. We plot the trajectories in the state-action space (Fig. 3) and in the policy polytope (Fig. 4). In order to put the convergence results from this section into perspective, we plot the evolution of the optimality gap \(R^*-R(\theta (t))\) (Fig. 5). We use an adaptive step size \(\Delta t_k\), which prevents the blowup of the parameters for \(\sigma <1\), and hence we do not consider the number of iterations but rather the sum of the step sizes as a measure for the time, \(t_n = \sum _{k=1}^n \Delta t_k\). For vanilla PG and \(\sigma \in (1, 2)\) we expect a decay at rate \(O(t^{-1})\) [18] and \(O(t^{-1/(\sigma -1)})\) by Theorem 27. Therefore we use a logarithmic (on both scales) plot for vanilla PG and \(\sigma >1\) and also indicate the predicted rate using a dashed gray line. For Kakade’s and Morimuras NPG we expect linear convergence by Theorem 26 and 27 respectively and hence use a semi-logarithmic plot.

State-action trajectories for different PG methods, which are vanilla PG, Kakade’s NPG and \(\sigma \)-NPG, where Morimura’s NPG corresponds to \(\sigma =1\); the state-action polytope is shown in gray inside a three dimensional projection of the the simplex \(\Delta _{\mathcal {S}\times \mathcal {A}}\); shown are trajectories with the same random 30 initial values for every method; the maximizer \(\eta ^*\) is located at the upper left corner of the state-action polytope
First, we note that for \(\sigma \in \{-0.5, 0, 0.5\}\) the trajectories of \(\sigma \)-NPG flow hit the boundary of the state-action polytope \(\mathcal N\), which is depicted in gray inside the simplex \(\Delta _{\mathcal S\times \mathcal {A}}\). This is consistent with our analysis, since the functions \(\phi _\sigma \) are Legendre type functions only for \(\sigma \in [1, \infty )\) and hence only in this case is the NPG flow is guaranteed to exhibit long time solutions. However, we observe finite-time convergence of the trajectories towards the global optimum (see Fig. 5), which we suspect to be due to the error of temporal discretization.
For the other methods, namely vanilla PG, Kakade’s NPG and \(\sigma \)-NPG with \(\sigma \in [1,\infty )\), Theorems 22 and 23 show the global convergence of the gradient flow trajectories, which we also observe both in state-action space and in policy space (see Figs. 3 and 4 respectively). When considering the convergence in objective value we observe that both Kakade’s and Morimura’s NPG exhibit a linear rate of convergence as asserted by Theorems 26 and 27, whereby Kakade’s NPG appears to have more severe plateaus in some examples. For vanilla PG and \(\sigma >1\) we observe a sublinear convergence rate of \(O(t^{-1})\) and \(O(t^{-1/(\sigma -1)})\) respectively, which are shown via dashed gray lines in each case. This confirms the convergence rate \(O(t^{-1})\) for vanilla PG [18] and indicates that the rate \(O(t^{-1/(\sigma -1)})\) shown for \(\sigma \in (1,2)\) is also valid in the regime \(\sigma >2\). Finally, we observe that larger \(\sigma \) appears to lead to more severe plateaus, which is apparent in the convergence in objective and also from the evolution in policy space and in state-action space.

Plots of the trajectories of the individual methods inside the policy polytope \(\Delta _\mathcal {A}^\mathcal {S}\cong [0,1]^2\); additionally, a heatmap of the reward function \(\pi \mapsto R(\pi )\) is shown; the maximizer \(\pi ^*\) is located at the upper left corner of the policy polytope

Plot of the optimality gaps \(R^*-R(\theta (t))\) during optimization; note that for vanilla PG and \(\sigma >1\) these are log-log plots since we expect a decay like \(t^{-1}\) and \(t^{-1/(\sigma -1)}\) respectively, which are shown as a dashed gray line; Kakade’s and Morimura’s NPG are at a log plot since we expect a linear convergence; finally, for \(\sigma <1\) we observe finite time convergence
5.2 Linear convergence of regularized Hessian NPG flows
It is known both empirically and theoretically that strictly convex regularization in state-action space yields linear convergence in reward optimization for vanilla and Kakade’s natural policy gradients [14, 18]. Using Lemma 25 we generalize the result for Kakade’s NPG and provide a result giving the linear convergence for general Hessian NPG.
Theorem 28
(Linear convergence for regularized problems) Consider Setting 18 and let \(\phi \) be a Legendre type function and denote the regularized reward by \(\mathfrak R_\lambda (\eta ) = \langle r, \eta \rangle - \lambda \phi (\eta )\) for some \(\lambda >0\) and fix an \(\eta _0\in {\text {int}}(\mathcal N)\) and assume that the global maximizer \(\eta ^*_\lambda \) of \(\mathfrak R_\lambda \) over \(\mathcal N\) lies in the interior \({\text {int}}(\mathcal N)\). Assume that \(\eta :[0, \infty )\rightarrow {\text {int}}(\mathcal N)\) solves the natural policy gradient flow with respect to the regularized reward \(\mathfrak R_\lambda \) and the Hessian geometry induced by \(\phi \). For any \(c\in (0, \lambda )\) there exists a constant \(K(\eta _0)>0\) such that \(D_\phi (\eta ^*_\lambda , \eta (t)) \le K(\eta _0) e^{-c t}\). In particular, for any \(\kappa \in (\kappa _c, \infty )\) this implies \(R^*_\lambda -\mathfrak R_\lambda (\eta (t))\le \kappa \lambda K(\eta _0) e^{-c t}\), where \(\kappa _c\) denotes the condition number of \(\nabla ^2\phi (\eta ^*_\lambda )\).
Proof
We first recall that by Lemma 19 it holds that \(\mathfrak R(\eta (t))\rightarrow \mathfrak R(\eta ^*)\) and the uniqueness of the maximizer \(\eta (t)\rightarrow \eta ^*\in {\text {int}}(\mathcal N)\). By Lemma 25 it suffices to show that for any \(\omega \in (0,1)\) it holds \(\mathfrak R_\lambda (\eta ^*_\lambda ) - \mathfrak R_\lambda (\eta ) \ge \omega D_\phi (\eta ^*_\lambda ,\eta )\) if \(\eta \) in a neighborhood of \(\eta ^*_\lambda \). Note that
By Lemma 29 it follows that
which shows the linear convergence of the trajectory in the Bregman divergence. For arbitrary \(m, M>0\) such that \(mI \prec \nabla ^2\phi (\eta ^*_\lambda ) \prec MI\) we can estimate
for \(\eta (t)\) close to \(\eta ^*\), where we used that \(\phi \) is m strongly convex in a neighborhood of \(\eta ^*\).
In the proof of the previous theorem we used the following lemma.
Lemma 29
Let \(\phi \) be a strictly convex function defined on an open convex set \(\Omega \subseteq \mathbb R^d\) with unique minimizer \(x^*\). Then for any \(\omega \in (0,1)\) there is a neighborhood \(N_\omega \) of \(x^*\) such that
Proof
Set \(f(x):=D_\phi (x^*, x)\) and \(g(x):=D_\phi (x, x^*)\). It holds that \(f(x^*) = g(x^*) = 0\) and since both functions are non-negative \(\nabla f(x^*) = \nabla g(x^*) = 0\), which implies \(g(x) = \phi (x) - \phi (x^*)\). By (8) we have \(\nabla ^2 f(x^*) = \nabla ^2\,g(x^*) = \nabla ^2\phi (x^*)\) and Taylor extension yields
Hence, for any \(\varepsilon >0\) there is \(\delta >0\) such that for \(x\in B_\delta (x^*)\) it holds that
for any \(m\in (0, \lambda _{{\text {min}}}(\nabla ^2\phi (x^*))\) in a possible smaller neighborhood as \(\phi \) is m-strongly convex in a neighborhood around \(x^*\). Setting \(\omega :=(1+2\varepsilon m^{-1})^{-1}\) yields the claim.
Remark 30
(Location of maximizers) The condition that \(\eta ^*_\lambda \in {\text {int}}(\mathcal N)\) assumed in Theorem 28 is satisfied if the gradient blow-up condition from Definition 20 is slightly strengthened. Indeed, suppose that for any \(\eta \in \partial \mathcal N\) there is a direction v such that \(\eta +tv\in {\text {int}}(\mathcal N)\) for small t and such that \(\partial _v \phi (\eta +tv) = v^\top \nabla \phi (\eta +tv)\rightarrow -\infty \) for \(t\rightarrow 0\). If \(\phi (\eta ) = \infty \), surely \(\eta \ne \eta ^*\). To argue in the case that \(\phi (\eta )<+\infty \), we note that \(\partial _v \mathfrak R_\lambda (\eta +tv)\rightarrow +\infty \) and choose \(t_0>0\) such that \(\partial _v \mathfrak R_\lambda (\eta +t_0v)>0\). Then by the concavity of \(\mathfrak R_\lambda \) and continuity of \(\mathfrak R_\lambda \) we have
and hence \(\eta \ne \eta ^*_\lambda \).
Now we elaborate the consequences of this general convergence result given in Theorem 28 for Kakade and \(\sigma \)-NPG flows.
Corollary 31
(Linear convergence of regularized Kakade’s NPG flow) Assume that \(\eta :[0, \infty )\rightarrow {\text {int}}(\mathcal N)\) solves the natural policy gradient flow with respect to the regularized reward \(\mathfrak R_\lambda = \langle r, \eta \rangle - \lambda \phi _C(\eta )\) and the Hessian geometry induced by \(\phi _C\) where \(\phi _C\) denotes the conditional entropy. Further, denote the maximizer of the regularized reward by \(\eta ^*_\lambda \). For any \(\omega \in (0, \lambda )\) there exists a constant \(K(\eta _0)>0\) such that \(D_\phi (\eta ^*_\lambda , \eta (t)) \le K(\eta _0) e^{-c t}\). In particular, for any \(\kappa \in (\kappa _c, \infty )\) this implies \(R^*_\lambda -\mathfrak R_\lambda (\eta (t))\le \kappa \lambda K(\eta _0) e^{-c t}\), where \(\kappa _c\) denotes the condition number of \(\nabla ^2\phi _C(\eta ^*_\lambda )\).
Proof
We want to use Remark 30. Recall that
where \(\rho (s) = \sum _{a} \eta (s,a)\) is the state marginal. Note that by Assumption 2 it holds that \(\rho (s)>0\). Hence, if \(\eta \in \partial \mathcal N\) we can take any \(v\in \mathbb R^{\mathcal {S}\times \mathcal {A}}\) such that \(\eta _\varepsilon :=\eta +\varepsilon v\in {\text {int}}(\mathcal N)\) for small \(\varepsilon >0\). Writing \(\rho _\varepsilon \) for the associated state marginal, we obtain
for \(\varepsilon \rightarrow 0\) since \(\eta (s',a') = 0\) for some \(s'\in \mathcal {S}, a'\in \mathcal {A}\) and \(\rho _\varepsilon (s)\rightarrow \rho (s)>0\) for all \(s\in \mathcal {S}\).
Corollary 32
(Linear convergence for regularized \(\sigma \)-NPG flow) Consider Setting 18 with \(\phi =\phi _\sigma \) for some \(\sigma \in [1, \infty )\) and denote the regularized reward by \(\mathfrak R_\lambda (\eta ) = \langle r, \eta \rangle - \lambda \phi (\eta )\) and denote the maximizer of \(\mathfrak R_\lambda \) by \(\eta ^*_\lambda \) and fix an element \(\eta _0\in {\text {int}}(\mathcal N)\). Assume that \(\eta :[0, \infty )\rightarrow {\text {int}}(\mathcal N)\) solves the natural policy gradient flow with respect to the regularized reward \(\mathfrak R_\lambda \) and the Hessian geometry induced by \(\phi \). For any \(\omega \in (0, \lambda )\) there exists a constant \(K(\eta _0)>0\) such that \(D_\phi (\eta ^*_\lambda , \eta (t)) \le K(\eta _0) e^{-\omega t}\). In particular, for any \(\kappa \in (\kappa (\eta ^*_\lambda )^\sigma , \infty )\) this implies \(R^*_\lambda -\mathfrak R_\lambda (\eta (t))\le \kappa \lambda K(\eta _0) e^{-\omega t}\), where \(\kappa (\eta ^*_\lambda ) = \frac{\max \eta ^*_\lambda }{\min \eta ^*_\lambda }\).
Proof
Again, we use Remark 30 it is straight forward to see that for the Legendre type functions \(\phi _\sigma \) the unique maximizer \(\eta ^*_\lambda \) of \(\mathfrak R_\lambda \) lies in the interior of \(\mathcal N\). Hence, it remains to compute the condition number, for which we note that \(\nabla ^2\phi _\sigma (\eta ^*_\lambda ) = {\text {diag}}(\eta ^*_\lambda )^{-\sigma }\), which yields the result.
Remark 33
(Regularization error) Introducing a regularizer changes the optimization problem and usually also the optimizer. The difference can be estimated in terms of the regularization strength \(\lambda \). For logarithmic barriers in state-action space, this follows from standard estimates for interior point methods [21, 75]. For entropic regularization in state-action space, this is elaborated in [76], and for the conditional entropy this is done in [14, 18].
The results above do not cover arbitrary combinations of Hessian geometries and regularizers. However, the proof of Theorem 28 can be adapted to this case, where the only part that requires adjustments is (26) that couples the regularized reward to the Bregman divergence. In principle, this can be extended to the case of regularizers that are different from the function inducing the Hessian geometry.
Numerical examples: The \(\varvec{\lambda \rightarrow 0}\) regime. Theorem 28 and its corollaries yield a linear convergence rate of order \(O(e^{-\lambda t})\), where the bound deteriorates when the regularization strength \(\lambda \) is sent to zero, \(\lambda \rightarrow 0\). The bound \(R^*_\lambda - R_{k} = O((1-\lambda \Delta t )^k)\) for entropy regularized NPG descent [14] exhibits a similar degradation for \(\lambda \rightarrow 0\). It is natural to expect that the convergence behavior for \(\lambda \rightarrow 0\) is similar to the convergence behavior for \(\lambda =0\), i.e., the unregularized case. Recall that Theorem 26 and Theorem 27 establish linear rates without regularization for Kakade’s and Morimura’s NPG and a sublinear rate \(O(t^{-1/(\sigma -1)})\) for \(\sigma \in (1,2)\).
To evaluate the convergence behavior for \(\lambda \rightarrow 0\) for a specific NPG method we apply it to a collection of small regularization strengths with 10 different random initializations. Here, we revisit Kakade’s example that was already used in Sect. 5.1 for unregularized problems. For every individual run we estimate the exponent c in the linear convergence rate \(R^*-R(\theta (t))=O(e^{-ct})\) via linear regression after a logarithmic transformation. Here, we take the iterates where the optimality gap \(R^*-R(\theta )\) lies between \(10^{-10}\) and \(10^{-5}\). In Fig. 6 we present the mean of the estimated convergence rates for Kakade’s and Morimura’s NPG as well as for \(\sigma \) NPG for \(\sigma = 1.5\).

Shown are the estimated exponents \(c>0\) when fitting an exponential decay \( O(e^{-ct})\) to the suboptimality gap \(R^*-R(\theta (t))\) for different NPG methods—Kakade, Morimura and \(\sigma = 1.5\)—and for different regularization strengths \(\lambda \)
For both Kakade’s and Morimura’s NPG method we observe that the estimated convergence rates converge to the linear convergence rate of the corresponding unregularized cases. This indicates that the guarantees in Corollary 31 and Corollary 32 for these NPG methods are not tight. In contrast for the \(\sigma \)-NPG with \(\sigma =1.5\) we observe that the convergence rates deteriorate for \(\lambda \rightarrow 0\) which conforms with the sublinear convergence \(O(t^{-2})\) of the unregularized problem. Theorem 28 shows linear convergence based on the strong convexity of the regularizer. The convergence rate of the unregularized NPG methods however is determined by the behavior of the regularizer and hence the metric at the boundary rather than the convexity of the loss. We believe that a theoretical analysis combining these two effects could improve the linear rate in Theorem 28 for small regularization strength.
6 Locally quadratic convergence for regularized problems
It is known that Kakade’s NPG method and more generally quasi-Newton policy gradient methods with suitable regularization and step sizes converge at a locally quadratic rate [14, 28]. Whereas these results regard the NPG method as an inexact Newton method in the parameter space, we regard it as an inexact Newton method in state-action space, which allows us to directly leverage results from the optimization literature and thus formulate relatively short proofs. Our result extends the locally quadratic convergence rate to general Hessian-NPG methods, which include in particular Kakade’s and Morimura’s NPG. Note that the result holds when the step size is equal to the inverse penalization strength, which is reminiscent of Newton’s method converging for step size 1.
Theorem 34
(Locally quadratic convergence of regularized NPG methods) Consider a real-valued function \(\phi :\mathbb R^{\mathcal {S}\times \mathcal {A}}\rightarrow \mathbb R\cup \{+\infty \}\), which we assume to be finite and twice continuously differentiable on \(\mathbb R_{>0}^{\mathcal S\times \mathcal A}\) and such that \(\nabla ^2\phi (\eta )\) is positive definite on \(T_\eta \mathcal N = T\mathcal L\subseteq \mathbb R^{\mathcal S\times \mathcal A}\) for every \(\eta \in {\text {int}}(\mathcal N)\). Further, consider a regular policy parametrization and the regularized reward \(R_\lambda (\theta ) :=R(\theta ) - \lambda \phi (\eta _\theta )\) and assume that \(\eta ^*\in {\text {int}}(\mathcal N)\), i.e., the maximizer lies in the interior of the state-action polytope. Consider the NPG induced by the Hessian geometry of \(\phi \) with step size \(\Delta t = \lambda ^{-1}\), i.e.,
where \(G(\theta _k)^+\) denotes the Moore–Penrose inverse. Assume that \(R_\lambda (\theta _k)\rightarrow R_\lambda ^*\) for \(k\rightarrow \infty \). Then \(\theta _k\rightarrow \theta ^*\) at a (locally) quadratic rate and hence \(R_\lambda (\theta _k)\rightarrow R^*_\lambda \) at a (locally) quadratic rate.
The proof of this result relies on the following convergence result for inexact Newton methods.
Theorem 35
(Theorem 3.3 in [77]) Consider an objective function \(f\in C^2(\mathbb R^d)\) with \(\nabla ^2f(x)\in \mathbb S^{sym}_{>0}\) for any \(x\in \mathbb R^d\) and assume that f admits a minimizer \(x^*\). Let \((x_k)\) be inexact Newton iterates given by
and assume that they converge towards the minimum \(x^*\). If \(\Vert \varepsilon _k \Vert = O(\Vert \nabla f(x_k)\Vert ^{\omega })\), then \(x_k\rightarrow x^*\) at rate \(\omega \), i.e., \(\Vert x_k-x^*\Vert = O(e^{-k^{\omega }})\).
We take this approach and show that the iterates of the regularized NPG method can be interpreted as an inexact Newton method in state-action space. For this, we first make the form of the Newton updates in state-action space explicit.
Lemma 36
(Newton iteration in state-action space) The iterates of Newton’s method in state-action space are given by
where \(\mathfrak R_\lambda (\eta ) = \langle r, \eta \rangle + \lambda \phi (\eta )\) is the regularized reward and \(\Pi _{T\mathcal L}^{E}\) the Euclidean projection onto the tangent space of the affine space L defined in (4).
Proof
The domain of the optimization problem is \(\mathbb R^{\mathcal {S}\times \mathcal {A}}_{\ge 0}\cap \mathcal L\) an hence, we perform Newton’s method on the affine subspace L. Writing \(L = \eta _0 + X\) for a linear subspace X we can equivalently perform Newton’s method on X since the method is affine invariant. We denote the canonical \(\iota :X\hookrightarrow L, x\mapsto x+\eta _0\) and set \(f(x):=\mathfrak R_\lambda (\iota x)\). Then, we obtain the Newton iterates \(x_k\) and \(\eta _k = \iota x_k\) by
Straight up computation yields \(\nabla f(x) \iota ^\top \nabla \mathfrak R_\lambda (\iota x)\) and \(\nabla ^2f(x) = \iota ^\top \nabla ^2\mathfrak R_\lambda (\iota x) \iota \). Hence, we obtain
where we used \(AA^+ = \Pi _{{\text {range}}(A)}\) and \((A^\top )^+A^\top = \Pi _{{\text {ker}}(A^\top )} = \Pi _{{\text {range}}(A)}\).
Lemma 37
Let \((\theta _k)\) be the iterates of a Hessian NPG induced by a stricly convex function \(\phi \) and with step size \(\Delta t\), i.e,
where the Gram matrix is given by \(G(\theta ) = DP(\theta )^\top \nabla ^2 \phi (\eta _\theta ) DP(\theta )\). Then the state-action iterates \(\eta _k:=\eta _{\theta _k}\) satisfy
Proof
Writing P for the mapping \(\theta \mapsto \eta _\theta \) and an application of Taylor’s theorem implies that
The first term is equal to
which again is equal to
since \(DP(\theta _k)DP(\theta _k)^+ = (DP(\theta _k)^\top )^+DP(\theta _k)^\top = \Pi _{{\text {range}}(DP(\theta _k))}\) like before and \({\text {range}}(DP(\theta _k)) = T\mathcal L\).
Proof of Theorem 34
In our case, by the preceding two lemmata, we have
which proves the claim.
Remark 38
A benefit of regarding the iteration as an inexact Newton method in state-action space is that the problem is strongly convex in state-action space. In contrast, in policy space the problem is non-convex, which makes the analysis in that space more delicate. Further, the corresponding Riemannian metric might not be the Hessian metric of the regularizer in policy space (see also Remark 13). In the parameter \(\theta \), the NPG algorithm can be perceived as a generalized Gauss–Newton method; however, the reward function is non-convex in parameter space. Further, for overparametrized policy models, i.e., when \(\text {dim}(\Theta )\ge {\dim }(\Delta _\mathcal A^\mathcal S) = |\mathcal S|(|\mathcal A|-1)\) the Hessian \(\nabla ^2 R(\theta ^*)\) can not be positive definite, which makes the analysis in parameter space less immediate. Note that the tabular softmax policies in (10) are overparametrized since in this case \({\text {dim}}(\Theta ) = |\mathcal S||\mathcal A|\).
Remark 39
(Behavior for\(\Delta t<\lambda ^{-1}\)) Typically, the locally quadratic convergence only holds at exactly the step size \(\Delta t=\lambda ^{-1}\). Consider for example \(f(x)=x^2/2\), where Newton’s method with step size \(\Delta t\in (0,1]\) will produce the iterates \(x_k = (1-\Delta t)^k x_0\). If \(\Delta t\ne 1\), this will only converge linearly at a rate of \(1-\Delta t\) that decreases to 0 for \(\Delta t\rightarrow 1\). Hence, we expect that also for regularized NPG methods the locally quadratic convergence is only achieved for the exact Newton step size \(\Delta t = \lambda ^{-1}\) and linear convergence for \(\Delta t <\lambda ^{-1}\) with a rate decreasing towards 0 for \(\Delta t\rightarrow \lambda ^{-1}\).
7 Discussion
We provide a study of a general class of natural policy gradient methods arising from Hessian geometries in state-action space. This covers, in particular, the notions of NPG due to Kakade and Morimura et al., which are induced by the conditional entropy and entropy respectively. Leveraging results on gradient flows in Hessian geometries we obtain global convergence guarantees of NPG flows for tabular softmax policies and show that both Kakade’s and Morimura’s NPG converge linearly, and obtain sublinear convergence rates for NPG associated with \(\beta \)-divergences. We provide experimental evidence of the tightness of these rates. Finally, we perceive the NPG with respect to the Hessian geometry induced by the regularizer, with step size equal to the inverse regularization strength, as an inexact Newton method in state-action space, which allows for a very compact argument of the locally quadratic convergence of this method. An overview of the established results in relation to existing works is presented in Table 1. Computer code is made available in https://github.com/muellerjohannes/geometry-natural-policy-gradients.
Our convergence analysis currently does not cover the case of general parametric policy classes nor the case of partially observable MDPs, which we consider important future directions. Further, we study only the planning problem, i.e., assume to have access to exact gradients, and hence a combination of our study of NPG methods in state-action space with estimation problems would be a natural extension.
Notes
More generally, the system is fully observable if the supports of \(\{\beta (\cdot |s)\}_{s\in \mathcal S}\) are disjoint subsets of \(\mathcal {O}\).
For Riemannian manifolds \((\mathcal {M}_1,g_1)\) and \((\mathcal {M}_2,g_2)\), the product metric on \(\mathcal {M}_1\times \mathcal {M}_2\) is defined by \(g(u_1+u_2, v_1+v_2)=g_1(u_1,v_1)+g_2(u_2,v_2)\).
Note that \(\mathfrak R\) is bounded over the bounded set \(\mathcal N\) as a concave function.
References
Silver, D., Huang, A., Maddison, C.J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., et al. Mastering the game of go with deep neural networks and tree search. Nature 529(7587), 484–489 (2016)
Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., et al.: Mastering the Game of Go without Human Knowledge. Nature 550(7676), 354–359 (2017)
Peters, J., Vijayakumar, S., Schaal, S.: Reinforcement learning for humanoid robotics. In: Proceedings of the Third IEEE-RAS International Conference on Humanoid Robots, pp. 1–20 (2003)
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., Riedmiller, M.: Playing Atari with deep reinforcement learning. arXiv:1312.5602 (2013)
Shao, K., Tang, Z., Zhu, Y., Li, N., Zhao, D.: A survey of deep reinforcement learning in video games. arXiv:1912.10944 (2019)
Amari, S.: Natural gradient works efficiently in learning. Neural Comput. 10(2), 251–276 (1998)
Amari, S., Douglas, S.C.: Why natural gradient? In: Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP’98 (Cat. No. 98CH36181), vol. 2, pp. 1213–1216 (1998). IEEE
Kakade, S.M.: A natural policy gradient. Adv. Neural Inf. Process. Syst. 14 (2001)
Morimura, T., Uchibe, E., Yoshimoto, J., Doya, K.: A new natural policy gradient by stationary distribution metric. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pp. 82–97 (2008). Springer
Moskovitz, T., Arbel, M., Huszar, F., Gretton, A.: Efficient Wasserstein natural gradients for reinforcement learning. In: International Conference on Learning Representations (2021)
Bagnell, J.A., Schneider, J.G.: Covariant policy search. In: IJCAI, pp. 1019–1024 (2003)
Lebanon, G.: Axiomatic geometry of conditional models. IEEE Trans. Inf. Theory 51, 1283–1294 (2005)
Montúfar, G., Rauh, J., Ay, N.: On the Fisher metric of conditional probability polytopes. Entropy 16(6), 3207–3233 (2014)
Cen, S., Cheng, C., Chen, Y., Wei, Y., Chi, Y.: Fast global convergence of natural policy gradient methods with entropy regularization. Oper. Res. (2021)
Bhandari, J., Russo, D.: Global optimality guarantees for policy gradient methods. arXiv:1906.01786 (2019)
Zhang, K., Koppel, A., Zhu, H., Basar, T.: Global Convergence of Policy Gradient Methods to (Almost) Locally Optimal Policies. SIAM J. Control. Optim. 58(6), 3586–3612 (2020)
Zhang, M.S., Erdogdu, M.A., Garg, A.: Convergence and optimality of policy gradient methods in weakly smooth settings. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 9066–9073 (2022)
Mei, J., Xiao, C., Szepesvari, C., Schuurmans, D.: On the global convergence rates of softmax policy gradient methods. In: International Conference on Machine Learning, pp. 6820–6829 (2020). PMLR
Mei, J., Gao, Y., Dai, B., Szepesvari, C., Schuurmans, D.: Leveraging non-uniformity in first-order non-convex optimization. In: International Conference on Machine Learning, pp. 7555–7564 (2021). PMLR
Leahy, J.-M., Kerimkulov, B., Siska, D., Szpruch, L.: Convergence of policy gradient for entropy regularized MDPs with neural network approximation in the mean-field regime. In: International Conference on Machine Learning, pp. 12222–12252 (2022). PMLR
Agarwal, A., Kakade, S.M., Lee, J.D., Mahajan, G.: On the theory of policy gradient methods: Optimality, approximation, and distribution shift. J. Mach. Learn. Res. 22(98), 1–76 (2021)
Bhandari, J., Russo, D.: On the linear convergence of policy gradient methods for finite MDPs. In: International Conference on Artificial Intelligence and Statistics, pp. 2386–2394 (2021). PMLR
Khodadadian, S., Jhunjhunwala, P.R., Varma, S.M., Maguluri, S.T.: On the linear convergence of natural policy gradient algorithm. In: 2021 60th IEEE Conference on Decision and Control (CDC), pp. 3794–3799 (2021). IEEE
Alfano, C., Rebeschini, P.: Linear convergence for natural policy gradient with log-linear policy parametrization. arXiv preprint arXiv:2209.15382 (2022)
Yuan, R., Du, S.S., Gower, R.M., Lazaric, A., Xiao, L.: Linear convergence of natural policy gradient methods with log-linear policies. arXiv preprint arXiv:2210.01400 (2022)
Xiao, L.: On the convergence rates of policy gradient methods. J. Mach. Learn. Res. 23(282), 1–36 (2022)
Alfano, C., Yuan, R., Rebeschini, P.: A novel framework for policy mirror descent with general parametrization and linear convergence. arXiv preprint arXiv:2301.13139 (2023)
Li, H., Gupta, S., Yu, H., Ying, L., Dhillon, I.: Quasi-Newton policy gradient algorithms. arXiv:2110.02398 (2021)
Lan, G.: Policy mirror descent for reinforcement learning: Linear convergence, new sampling complexity, and generalized problem classes. Mathematical programming, 1–48 (2022)
Zhan, W., Cen, S., Huang, B., Chen, Y., Lee, J.D., Chi, Y.: Policy mirror descent for regularized reinforcement learning: A generalized framework with linear convergence. arXiv:2105.11066 (2021)
Ding, D., Zhang, K., Basar, T., Jovanovic, M.: Natural policy gradient primal-dual method for constrained Markov decision processes. Adv. Neural. Inf. Process. Syst. 33, 8378–8390 (2020)
Ding, D., Zhang, K., Duan, J., Başar, T., Jovanović, M.R.: Convergence and sample complexity of natural policy gradient primal-dual methods for constrained MDPs. arXiv:2206.02346 (2022)
Azizzadenesheli, K., Yue, Y., Anandkumar, A.: Policy gradient in partially observable environments: approximation and convergence. arXiv:1810.07900 (2018)
Alfano, C., Rebeschini, P.: Dimension-Free Rates for Natural Policy Gradient in Multi-Agent Reinforcement Learning. arXiv:2109.11692 (2021)
Huang, F., Gao, S., Huang, H.: Bregman gradient policy optimization. In: International Conference on Learning Representations (2022)
Fazel, M., Ge, R., Kakade, S., Mesbahi, M.: Global convergence of policy gradient methods for the linear quadratic regulator. In: International Conference on Machine Learning, pp. 1467–1476 (2018). PMLR
Li, G., Wei, Y., Chi, Y., Gu, Y., Chen, Y.: Softmax policy gradient methods can take exponential time to converge. In: Conference on Learning Theory, pp. 3107–3110 (2021). PMLR
Zahavy, T., O’Donoghue, B., Desjardins, G., Singh, S.: Reward is enough for convex MDPs. Adv. Neural. Inf. Process. Syst. 34, 25746–25759 (2021)
Derman, C.: Finite State Markovian Decision Processes. Academic Press, New York (1970)
Sutton, R.S., Barto, A.G.: Reinforcement Learning: An Introduction. MIT press, Cambridge, Massachusetts (2018)
Müller, J., Montúfar, G.: The geometry of memoryless stochastic policy optimization in infinite-horizon POMDPs. In: International Conference on Learning Representations (2022)
Kallenberg, L.C.: Survey of linear programming for standard and nonstandard Markovian control problems. Part I: Theory. Zeitschrift für Oper. Res. 40(1), 1–42 (1994)
Park, H., Amari, S., Fukumizu, K.: Adaptive natural gradient learning algorithms for various stochastic models. Neural Netw. 13(7), 755–764 (2000)
Martens, J., Grosse, R.: Optimizing neural networks with Kronecker-factored approximate curvature. In: International Conference on Machine Learning, pp. 2408–2417 (2015). PMLR
Desjardins, G., Simonyan, K., Pascanu, R., et al.: Natural neural networks. Adv. Neural Inf. Process. Syst. 28 (2015)
Izadi, M.R., Fang, Y., Stevenson, R., Lin, L.: Optimization of graph neural networks with natural gradient descent. In: 2020 IEEE International Conference on Big Data (big Data), pp. 171–179 (2020). IEEE
Nurbekyan, L., Lei, W., Yang, Y.: Efficient natural gradient descent methods for large-scale optimization problems. arXiv:2202.06236 (2022)
Li, W., Montúfar, G.: Natural gradient via optimal transport. Inf. Geom. 1(2), 181–214 (2018)
Malagò, L., Montrucchio, L., Pistone, G.: Wasserstein Riemannian geometry of Gaussian densities. Inf. Geom. 1(2), 137–179 (2018)
Arbel, M., Gretton, A., Li, W., Montúfar, G.: Kernelized Wasserstein natural gradient. In: International Conference on Learning Representations (2020)
Amari, S.: Information Geometry and Its Applications, vol. 194. Springer, Japan (2016)
van Oostrum, J., Müller, J., Ay, N.: Invariance properties of the natural gradient in overparametrised systems. Inf. Geom. 1–17 (2022)
Čencov, N.N.: Statistical Decision Rules and Optimal Inference. Translations of Mathematical Monographs, vol. 53, p. 499. American Mathematical Society, Providence, R.I. (1982). Translation from the Russian edited by Lev J. Leifman
Ay, N., Jost, J., Vân Lê, H., Schwachhöfer, L.: Information Geometry. Springer, Cham (2017)
Campbell, L.: An extended Čencov characterization of the information metric. Proc. Am. Math. Soc. 98, 135–141 (1986)
Amari, S., Cichocki, A.: Information geometry of divergence functions. Bulletin of the polish academy of sciences. Tech. Sci. 58(1), 183–195 (2010)
Shima, H.: The Geometry of Hessian Structures. World Scientific, Singapore (2007)
Neu, G., Jonsson, A., Gómez, V.: A unified view of entropy-regularized Markov decision processes. arXiv:1705.07798 (2017)
Martens, J.: New insights and perspectives on the natural gradient method. J. Mach. Learn. Res. 21(1), 5776–5851 (2020)
Williams, R.J.: Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 8(3), 229–256 (1992)
Konda, V., Tsitsiklis, J.: Actor-critic algorithms. Adv. Neural Inf. Process. Syst. 12 (1999)
Sutton, R.S., McAllester, D.A., Singh, S.P., Mansour, Y., et al. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In: NIPS, vol. 99, pp. 1057–1063 (1999). Citeseer
Marbach, P., Tsitsiklis, J.N.: Simulation-based optimization of Markov reward processes. IEEE Trans. Autom. Control 46(2), 191–209 (2001)
Baxter, J., Bartlett, P.L., et al. Reinforcement learning in POMDPs via direct gradient ascent. In: ICML, pp. 41–48 (2000). Citeseer
Baxter, J., Bartlett, P.L.: Infinite-horizon policy-gradient estimation. J. Artif. Intell. Res. 15, 319–350 (2001)
Morimura, T., Uchibe, E., Yoshimoto, J., Peters, J., Doya, K.: Derivatives of logarithmic stationary distributions for policy gradient reinforcement learning. Neural Comput. 22(2), 342–376 (2010)
Mei, J., Xiao, C., Dai, B., Li, L., Szepesvári, C., Schuurmans, D.: Escaping the gravitational pull of softmax. Adv. Neural. Inf. Process. Syst. 33, 21130–21140 (2020)
Müller, J., Montúfar, G.: Solving infinite-horizon POMDPs with memoryless stochastic policies in state-action space. In: The 5th Multidisciplinary Conference on Reinforcement Learning and Decision Making (RLDM 2022) (2022)
Schulman, J., Levine, S., Abbeel, P., Jordan, M., Moritz, P.: Trust region policy optimization. In: International Conference on Machine Learning, pp. 1889–1897 (2015). PMLR
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv:1707.06347 (2017)
Nagaoka, H.: The exponential family of Markov chains and its information geometry. In: 28th Symposium on Information Theory and Its Applications (SITA2005) (2005)
Alvarez, F., Bolte, J., Brahic, O.: Hessian Riemannian gradient flows in convex programming. SIAM J. Control. Optim. 43(2), 477–501 (2004)
Wang, L., Yan, M.: Hessian informed mirror descent. J. Sci. Comput. 92(3), 1–22 (2022)
Polyanskiy, Y., Wu, Y.: Lecture notes on information theory. Lecture Notes for ECE563 (UIUC) and 6(2012–2016), 7 (2014)
Boyd, S., Boyd, S.P., Vandenberghe, L.: Convex Optimization. Cambridge University Press, Cambridge (2004)
Weed, J.: An explicit analysis of the entropic penalty in linear programming. In: Conference On Learning Theory, pp. 1841–1855 (2018). PMLR
Dembo, R.S., Eisenstat, S.C., Steihaug, T.: Inexact Newton methods. SIAM J. Numer. Anal. 19(2), 400–408 (1982)
Acknowledgements
This project has been supported by ERC Starting Grant 757983 and DFG SPP 2298 Grant 464109215. GM has been supported by NSF CAREER Award DMS-2145630. JM acknowledges support from the International Max Planck Research School for Mathematics in the Sciences (IMPRS MiS) and the Evangelisches Studienwerk Villigst e.V.. This work is partly supported by BMBF in DAAD project 57616814 (SECAI) as part of the program Konrad Zuse Schools of Excellence in Artificial Intelligence.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Noboru Murata.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Müller, J., Montúfar, G. Geometry and convergence of natural policy gradient methods. Info. Geo. 7 (Suppl 1), 485–523 (2024). https://doi.org/10.1007/s41884-023-00106-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41884-023-00106-z