
Abstract
We analyze the information geometric structure of time reversibility for parametric families of irreducible transition kernels of Markov chains. We define and characterize reversible exponential families of Markov kernels, and show that irreducible and reversible Markov kernels form both a mixture family and, perhaps surprisingly, an exponential family in the set of all stochastic kernels. We propose a parametrization of the entire manifold of reversible kernels, and inspect reversible geodesics. We define information projections onto the reversible manifold, and derive closed-form expressions for the e-projection and m-projection, along with Pythagorean identities with respect to information divergence, leading to some new notion of reversiblization of Markov kernels. We show the family of edge measures pertaining to irreducible and reversible kernels also forms an exponential family among distributions over pairs. We further explore geometric properties of the reversible family, by comparing them with other remarkable families of stochastic matrices. Finally, we show that reversible kernels are, in a sense we define, the minimal exponential family generated by the m-family of symmetric kernels, and the smallest mixture family that comprises the e-family of memoryless kernels.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Time reversibility is a fundamental property of many statistical laws of nature. Inspired by Schrödinger [1], Kolmogorov was the first [2], in his celebrated work [3, 4], to investigate this notion in the context of Markov chains and diffusion processes. Reversible chains also find numerous applications in computer science, for instance in queuing networks [5] or Markov Chain Monte Carlo sampling algorithms [6]. For instance, a random walk over a weighted network corresponds to a reversible Markov chains [7, Section 3.2].
Reversible Markov operators enjoy a considerably richer mathematical structure than their non-reversible counterparts, enabling a wide range of analytical tools and techniques. Indeed, the significance of reversibility spans across surprisingly many areas of mathematics, from spectral theory [8, Chapter 12] to abstract algebra [9]. For instance, the mixing time of a reversible Markov chain, i.e. the time to guarantee closeness to stationarity, is controlled up to logarithmic factors by its absolute spectral gap (the difference of its two largest eigenvalues in magnitude). The diversity of the existing tools and analyses prompts our first question of whether reversibility can also be treated from an information geometry perspective.
Through the lens of information geometry, the manifold of all irreducible Markov kernels forms both an exponential family (e-family) and a mixture family (m-family). Our natural second question is whether we can find subfamilies of irreducible kernels that enjoy similar geometric properties, or in other words, can we find submanifolds that are autoparallel with respect to affine connections of interest? For instance, the set of doubly-stochastic matrices is known to form an m-family [10], while a tree model is an e-family of Markov kernels, if and only if it is an FSMX model [11].
In this article, we will answer these two questions, see that reversible irreducible Markov chains enjoy the structure of both exponential and mixture families, and explore their geometric properties.
1.1 Related work
The concept of exponential tilting of stochastic matrices using Perron-Frobenius (PF) theory can be traced back to the work of Miller [12]. The large deviation theory for Markov chains, whose crown achievement is showing that the convex conjugate of the log-PF root of the tilted kernel essentially controls the large deviation rate was further developed by Donsker and Varadhan [13], Gärtner [14], Dembo and Zeitouni [15]. Csiszár et al. [16] seem to be the first to recognize the exponential structure of the set of irreducible Markov kernels, in the context of information projections. Independently, Ito and Amari [17] implicitly introduced the notion of asymptotic exponential families, and exhibited irreducible Markov kernels as an example. Takeuchi and Barron [18] later formalized this definition (see also Takeuchi and Kawabata [19]), and Takeuchi and Nagaoka [20] subsequently proved that exponential families and their asymptotic counterparts are equivalent. Nakagawa and Kanaya [21] formally defined the exponential family of irreducible Markov chains and Nagaoka [22] later gave a full treatment in the language of information geometry, proving its dually flat structure. A notable collection of works has also explored the implications of this geometric structure for problems related to parameter estimation [10], hypothesis testing [21, 23], large deviation theory [24], and hidden Markov models [25, 26].
We refer the reader to Levin et al. [8] and Amari and Nagaoka [27] for thorough treatments of the theory of Markov chains and information geometry.
1.2 Outline and main results
In Section 2, we begin with a primer on reversible Markov chains, define exponential and mixture families, and briefly discuss the importance of affine structures for our analysis of exponential families. In Section 3, we define a time-reversal operation on parametric families, and show in Proposition 1 that both m-families and e-families are closed under this transformation. In Section 4 we introduce the concept of a reversible e-family, and provide a characterization (Theorem 2) of such family in terms of its carrier kernel and set of generator functions. Adapting the Kolmogorov criterion, we show that the necessary and sufficient conditions can be verified in a time that depends polynomially on the number of states. In Section 5, we prove that the set of all reversible and irreducible transition kernels is both an m-family, and an e-family (Theorem 3), construct a basis (Theorem 4), and derive a parametrization (Theorem 5) of the entire set of reversible kernels. In Section 6, we investigate information projections of an irreducible Markov chain onto its reversible submanifold. We show that the projections verify Pythagorean identities, and obtain closed-form expressions (Theorem 7). Additionally, we prove that the projections are always equidistant from an irreducible Markov kernel and its time-reversal (bisection property, Proposition 2). In Section 7, we show that reversible edge measures also form an e-family in distributions over pairs (Theorem 8). In Section 8, we briefly compare the geometric properties of reversible chains with several other natural families of Markov kernels. Finally, in Section 9, we characterize the reversible family as both the smallest exponential family that comprises symmetric kernels (Theorem 9), and the smallest mixture family that contains memoryless Markov kernels (Theorem 10).
2 Preliminaries
For \(m \in {\mathbb {N}}\) we write \([m] = \left\{ 1, 2, \dots , m \right\} \). Let \({\mathcal {X}}\) be a set such that \(\left| {\mathcal {X}} \right| = m < \infty \), identified with [m], where to avoid trivialities, we also assume that \(m > 1\). We denote \({\mathcal {P}}({\mathcal {X}})\) the probability simplex over \({\mathcal {X}}\), and \({\mathcal {P}}_{+}({\mathcal {X}}) = \left\{ \mu \in {\mathcal {P}}({\mathcal {X}}) :\forall x \in {\mathcal {X}}, \mu (x) > 0 \right\} \). All vectors will be written as row-vectors, unless otherwise stated. For some real matrices A and B, \(\rho (A)\) is the spectral radius of A, f[A] for \(f :{\mathbb {R}}\rightarrow {\mathbb {R}}\) is the entry-wise application of f to A; \(A \circ B\) is the Hadamard product of A and B, \(A > 0\) (resp. \(A \ge 0\)) means that A is an entry-wise positive (resp. non-negative) matrix. We will routinely identify a function \(f :{\mathcal {X}}^2 \rightarrow {\mathbb {R}}\) with the linear operator \(f :{\mathbb {R}}^ {\mathcal {X}} \rightarrow {\mathbb {R}}^{\mathcal {X}}\).
2.1 Irreducible Markov chains
We let \(({\mathcal {X}}, {\mathcal {E}})\) be a strongly connected directed graph, where \({\mathcal {X}}\) is the set of vertices, and \({\mathcal {E}} \subset {\mathcal {X}}^2\) the set of edges. Let \({\mathcal {F}}({\mathcal {X}}, {\mathcal {E}})\) be the set of all real functions over the set \({\mathcal {E}}\), identified with the totality of functions over \({\mathcal {X}}^2\) that are null outside of \({\mathcal {E}}\), and let \({\mathcal {F}}_+({\mathcal {X}}, {\mathcal {E}}) \subset {\mathcal {F}}({\mathcal {X}}, {\mathcal {E}})\) be the subset of positive functions over \({\mathcal {E}}\). Similarly, we define \({\mathcal {P}}({\mathcal {E}}) = {\mathcal {P}}({\mathcal {X}}^2) \cap {\mathcal {F}}_+({\mathcal {X}}, {\mathcal {E}})\), the set of distributions whose mass is concentrated on the edge set \({\mathcal {E}}\). We write \({\mathcal {W}}({\mathcal {X}})\) for the set of row-stochastic transition kernels over the state space \({\mathcal {X}}\), and \({\mathcal {W}}({\mathcal {X}}, {\mathcal {E}})\) for the subset of irreducible kernels whose support is \({\mathcal {E}}\), i.e.
and where \(P(x,x')\) corresponds to the transition probability from state x to state \(x'\)Footnote 1. For \(P \in {\mathcal {W}}({\mathcal {X}}, {\mathcal {E}})\), there exists a unique \(\pi \in {\mathcal {P}}_+({\mathcal {X}})\), such that \(\pi P =\pi \) [8, Corollary 1.17], which we call the stationary distribution of P. When \({\mathcal {E}} = {\mathcal {X}}^2\) and if there is no ambiguity about the space under consideration, we may write more simply \({\mathcal {F}}, {\mathcal {F}}_+\) instead of \({\mathcal {F}}({\mathcal {X}}, {\mathcal {X}}^2), {\mathcal {F}}_+({\mathcal {X}}, {\mathcal {X}}^2)\) (a similar notation will apply to all subsequently defined spaces).
2.2 Reversibility
For an irreducible kernel P, we write \(Q = {{\,\mathrm{diag}\,}}(\pi ) P\) for the edge measure matrix, [8, (7.5)], which corresponds to stationary pair-probabilities of P, i.e. \(Q(x, x') = {\mathbb {P}}_{\pi }\left( X_t = x, X_{t+1} = x' \right) \), and denote the set of irreducible edge measures by
Note that this definition is equivalent to
We further denote \(P^\star \) for the uniquely defined time-reversal of P, that verifies \(P^\star (x, x') = \pi (x') P(x', x) / \pi (x)\), and write \(Q^\star = Q ^\intercal \) for its corresponding edge measure, where \(^\intercal \) denotes matrix transposition. When Q is symmetric (i.e. \(Q^\star = Q \)), the chain verifies the detailed balance equation,
i.e. \(P^\star = P\), and we say that the Markov chain is reversible. Observe that in this case, for P irreducible over \({\mathcal {E}}\), the edge set must also be symmetric (\({\mathcal {E}} = {\mathcal {E}}^\star \), where \({\mathcal {E}}^\star \triangleq \left\{ (x, x') \in {\mathcal {X}}^2 :(x' , x) \in {\mathcal {E}} \right\} \)). We write  for the set of all reversible kernels that are irreducible over \(({\mathcal {X}}, {\mathcal {E}})\). For \(f, g \in {\mathbb {R}}^{\mathcal {X}}\), \(\langle f, g \rangle _\pi \triangleq \sum _{x \in {\mathcal {X}}} f(x) g(x) \pi (x)\) defines an inner product. We call \(\ell _2(\pi )\) the corresponding Hilbert space. The time-reversal is the adjoint operator of P in \(\ell _2(\pi )\), i.e. the unique linear operator that verifies \(\langle P f, g \rangle _\pi = \langle f, P^\star g \rangle _\pi , \forall f,g \in {\mathbb {R}}^{\mathcal {X}}\) (represented here as column vectors). As a consequence, when P is reversible, it is also self-adjoint in \(\ell _2(\pi )\), and the spectrum of P is real.
for the set of all reversible kernels that are irreducible over \(({\mathcal {X}}, {\mathcal {E}})\). For \(f, g \in {\mathbb {R}}^{\mathcal {X}}\), \(\langle f, g \rangle _\pi \triangleq \sum _{x \in {\mathcal {X}}} f(x) g(x) \pi (x)\) defines an inner product. We call \(\ell _2(\pi )\) the corresponding Hilbert space. The time-reversal is the adjoint operator of P in \(\ell _2(\pi )\), i.e. the unique linear operator that verifies \(\langle P f, g \rangle _\pi = \langle f, P^\star g \rangle _\pi , \forall f,g \in {\mathbb {R}}^{\mathcal {X}}\) (represented here as column vectors). As a consequence, when P is reversible, it is also self-adjoint in \(\ell _2(\pi )\), and the spectrum of P is real.
2.3 Mixture family and exponential family
For later convenience we consider the following three equivalent definitions of a mixture family.
Definition 1
(m-family of transition kernels) We say that a family of irreducible transition kernels \({\mathcal {V}}_m\) is a mixture family (m-family) of irreducible transition kernels on \(({\mathcal {X}}, {\mathcal {E}})\) when one of the following (equivalent) statements (i), (ii), (iii) holds.
-
(i)
[28] There exist affinely independent \(Q_0, Q_1, \dots , Q_d \in {\mathcal {Q}}({\mathcal {X}}, {\mathcal {E}})\) such that
$$\begin{aligned} {\mathcal {V}}_m = \left\{ P_\xi \in {\mathcal {W}}({\mathcal {X}}, {\mathcal {E}}) :Q_\xi = \sum _{i = 1}^{d} \xi ^i Q_i + (1 - \sum _{i=1}^{d}\xi ^i) Q_0, \xi \in \varXi \right\} , \end{aligned}$$where \(\varXi = \left\{ \xi \in {\mathbb {R}}^d :Q_\xi (x,x') > 0, \forall (x,x') \in {\mathcal {E}} \right\} \), and \(Q_\xi \) is the edge measure that pertains to \(P_\xi \).
-
(ii)
[27, 2.35] There exists \(C, F_1, \dots , F_d \in {\mathcal {F}}({\mathcal {X}}, {\mathcal {E}})\), such that \(C, C + F_1, \dots , C + F_d\) are affinely independent,
$$\begin{aligned} \sum _{x,x'} C(x,x') = 1, \qquad \sum _{x,x'} F_i(x,x') = 0, \forall i \in [d], \end{aligned}$$and
$$\begin{aligned} {\mathcal {V}}_m = \left\{ P_\xi \in {\mathcal {W}}({\mathcal {X}}, {\mathcal {E}}) :Q_\xi = C + \sum _{i =1}^{d} \xi ^i F_i, \xi \in \varXi \right\} \end{aligned}$$where \(\varXi = \left\{ \xi \in {\mathbb {R}}^d:Q_\xi (x,x') > 0, \forall (x,x') \in {\mathcal {E}} \right\} \), and \(Q_\xi \) is the edge measure that pertains to \(P_\xi \).
-
(iii)
[10, Section 4.2] There exist \(k \in {\mathbb {N}}, g_1, \dots , g_k \in {\mathcal {F}}({\mathcal {X}}, {\mathcal {E}})\) and \(c_1, \dots , c_k \in {\mathbb {R}}\), such that
$$\begin{aligned} {\mathcal {V}}_m = \left\{ P \in {\mathcal {W}}({\mathcal {X}}, {\mathcal {E}}) :\sum _{x,x'} Q(x,x') g_i(x,x') = c_i, \forall i \in [k] \right\} . \end{aligned}$$
Note that \(\varXi \) is an open set, \(\xi \) is called the mixture parameter and d is the dimension of the family \({\mathcal {V}}_m\).
Definition 2
(e-family of transition kernels) Let \(\varTheta \subset {\mathbb {R}}^d\), be some connected parameter space that contains an open ball centered at 0. We say that the parametric family of irreducible transition kernels
is an exponential family (e-family) of transition kernels on \(({\mathcal {X}}, {\mathcal {E}})\) with natural parameter \(\theta \), whenever
-
(i)
For all \(\theta \in \varTheta \), \(P_\theta \in {\mathcal {W}}({\mathcal {X}}, {\mathcal {E}})\) .
-
(ii)
There exist functions
$$\begin{aligned} \begin{aligned} K :{\mathcal {X}} \times {\mathcal {X}}&\rightarrow {\mathbb {R}}, \\ R :\varTheta \times {\mathcal {X}}&\rightarrow {\mathbb {R}}, \\ g_1, \dots , g_d :{\mathcal {X}} \times {\mathcal {X}}&\rightarrow {\mathbb {R}}, \\ \psi :\varTheta&\rightarrow {\mathbb {R}}, \end{aligned} \end{aligned}$$such that \(\forall (x,x', \theta ) \in {\mathcal {X}}^2 \times \varTheta \),
$$\begin{aligned} \log P_\theta (x, x') = K(x, x') + \sum _{i = 1}^{d} \theta ^i g_i(x, x') + R(\theta , x') - R(\theta , x) - \psi (\theta ),\qquad \end{aligned}$$(2)when \((x, x') \in {\mathcal {E}}\), and \(P_\theta (x, x') = 0\) otherwise.
When fixing some \(\theta \in \varTheta \), we may later write for convenience \(\psi _\theta \) for \(\psi (\theta )\) and \(R_\theta \) for \(R(\theta , \cdot ) \in {\mathbb {R}}^{\mathcal {X}}\). The carrier kernel K, the collection of generator functions \(g_1, \dots , g_d\) and the parameter range \(\varTheta \) define the family entirely. The remaining functions \(R_\theta \) and \(\psi _\theta \) will be determined uniquely by PF theory, from the constraint of \(P_\theta \) being row-stochastic (see for example the proof of Proposition 1). In fact, we can define the mapping \({\mathfrak {s}}\) that constructs a proper irreducible stochastic matrix from any linear operator defined by an irreducible matrix over \(({\mathcal {X}}, {\mathcal {E}})\).
where \(\rho ({\widetilde{P}})\) and v are respectively the PF root and right PF eigenvector of \({\widetilde{P}}\).
Remark 1
In Feigin et al. [29], Küchler and Sørensen [30], Hudson [31], Stefanov [32], Küchler and Sørensen [33], Sørensen [34], an exponential family of transition kernels has the form
for some function \(\phi :\varTheta \times {\mathcal {X}} \rightarrow {\mathbb {R}}\). Our Definition 2 however follows the one of Nagaoka [22], Hayashi and Watanabe [10], Watanabe and Hayashi [23], that is endowed with a more compelling geometrical structure [10, Remark 3].
Following the information geometry philosophy [27], we view the e-families or m-families that we defined, as d-dimensional submanifolds of \({\mathcal {W}}({\mathcal {X}}, {\mathcal {E}})\) with corresponding chart maps \(\theta , \xi :{\mathcal {W}}({\mathcal {X}}, {\mathcal {E}}) \rightarrow {\mathbb {R}}^d\). We can give more geometrical, parametrization-free definitions of e-families and m-families of irreducible transition kernel over \(({\mathcal {X}}, {\mathcal {E}})\), as autoparallel submanifolds of \({\mathcal {W}}({\mathcal {X}}, {\mathcal {E}})\) with respect to the e-connection and m-connection [22, Section 6]. We will prefer, however, to mostly cast our analysis in the language of linear algebra, and defer analysis of the relationship with differential geometry concepts to Section 5.3. This choice is motivated by the existence of a known correspondence between affine functions over \({\mathcal {E}}\) and the manifold \({\mathcal {W}}({\mathcal {X}}, {\mathcal {E}})\) [22] that we now describe. Denote,
Then \({\mathcal {F}}({\mathcal {X}}, {\mathcal {E}})\) defines a \(\left| {\mathcal {E}} \right| \)-dimension vector space, while \({\mathcal {N}}({\mathcal {X}}, {\mathcal {E}})\) is an \(\left| {\mathcal {X}} \right| \)-dimensional vector space [22, Section 3]. Introducing the mapping,
we see from the expression at (3) that \(\varDelta \) gives a diffeomorphism from the quotient linear space
to \({\mathcal {W}}({\mathcal {X}}, {\mathcal {E}})\) and a subset \({\mathcal {V}}\) of \({\mathcal {W}}({\mathcal {X}}, {\mathcal {E}})\) is an e-family if and only if there exists an affine subspace \({\mathcal {A}}\) of the quotient space \({\mathcal {G}}({\mathcal {X}}, {\mathcal {E}})\) such that \({\mathcal {V}} = \varDelta ({\mathcal {A}})\) (we identify a coset with a representative function in that coset). In this case, the correspondence is one-to-one, and the dimension of the affine space and the submanifold coincide [22, Theorem 2]. In particular, this entails that \(\dim {\mathcal {W}}({\mathcal {X}}, {\mathcal {E}}) = \left| {\mathcal {E}} \right| - \left| {\mathcal {X}} \right| \) Nagaoka [22, Corollary 1].
Remark 2
For Definition 2, unless stated otherwise, we will henceforth assume that the \(g_i\) form an independent family in \({\mathcal {G}}({\mathcal {X}}, {\mathcal {E}})\). This will ensure that the family is well-behaved in the sense of Hayashi and Watanabe [10, Lemma 4.1].
3 Time-reversal of parametric families
We begin by extending the definition of a time-reversal to families of Markov chains.
Definition 3
(Time-reversal family) We say that the family of irreducible transition kernels \({\mathcal {V}}^\star \) is the time-reversal of the family of irreducible transition kernels \({\mathcal {V}}\) when \({\mathcal {V}}^\star = \left\{ P^\star :P \in {\mathcal {V}} \right\} \), where \(P^\star \) denotes the time-reversal of P.
We now state the fundamental fact that the quality of being an e-family or an m-family of transition kernels is closed under this time-reversal operation.
Proposition 1
The following statements hold.
Time reversal of m-family: Let \({\mathcal {V}}_m\) be an m-family over \(({\mathcal {X}}, {\mathcal {E}})\), then \({\mathcal {V}}_m^\star \) is an m-family over \(({\mathcal {X}}, {\mathcal {E}}^\star )\). Furthermore, if \({\mathcal {V}}_m\) is the m-family generated by \(Q_1, \dots , Q_d \in {\mathcal {Q}}({\mathcal {X}}, {\mathcal {E}})\) (following the notation at Definition 1-(i)), then the time-reversal m-family is given by
where \(Q_\xi \) pertains to \(P_\xi \) and with
Time reversal of e-family: Let \({\mathcal {V}}_e\) be an e-family over \(({\mathcal {X}}, {\mathcal {E}})\), then \({\mathcal {V}}_e^\star \) is an e-family over \(({\mathcal {X}}, {\mathcal {E}}^\star )\). Furthermore, if \({\mathcal {V}}_e\) is the e-family generated by K and \(g_1, \dots , g_d\) (following the notation at Definition 2), then the time-reversal e-family is given by \({\mathcal {V}}^\star = \left\{ P^\star _\theta : \theta \in \varTheta \right\} \) such that
when \((x, x') \in {\mathcal {E}}^\star \), \(P_\theta ^\star (x, x') = 0\) otherwise, and where \(L_\theta \) is the left PF eigenvector of the non-negative irreducible matrix
Proof
Since the edge measure \(Q^\star _\xi \) of the time-reversal \(P^\star _\xi \) is the transpose of \(Q_\xi \) corresponding to \(P_\xi \), it is easy to obtain the expression of the time-reversal, and to see that \({\mathcal {V}}_m^\star \) is a mixture family. It remains to show that this also holds true for e-families. From the definition of an exponential family (2), and the requirement that \(P_\theta \) be row-stochastic, it must be that for any \(x \in {\mathcal {X}}\),
or more concisely, writing \({\widetilde{P}}_\theta (x,x') = \exp (K(x, x') + \sum _{i = 1}^{d}\theta ^i g_i(x, x'))\) for \(x, x' \in {\mathcal {E}}\) and \({\widetilde{P}}_\theta (x,x') = 0\) otherwise, \({\widetilde{P}}_\theta \exp [R_\theta ] = e^{\psi _\theta } \exp [R_\theta ]\). By positivity of the exponential function, the vector \(\exp [R_\theta ] \in {\mathbb {R}}^{{\mathcal {X}}}\) is positive. Thus, from the PF theorem, \(e^{\psi _\theta }\) corresponds to the spectral radius of \({\widetilde{P}}_\theta \), and \(\exp [R_\theta ]\) its (right) associated eigenvector. There must therefore also exist a left positive eigenvector, which we denote by \(\exp [L_\theta ]\), such that
Defining the positive normalized measure
it is easily verified that \(\pi _\theta \) is the stationary distribution of \(P_\theta \). Notice that \(\theta \), K and \(g_i\) determine uniquely \(L_\theta , R_\theta , \psi _\theta \) and \(\pi _\theta \) by the PF theorem. Recall that the adjoint of a transition kernel P can be written \(P^\star (x, x') = \pi (x')P(x', x)/\pi (x)\), thus we can compute the time-reversal as
when \((x', x) \in {\mathcal {E}}\), and 0 for \((x', x) \not \in {\mathcal {E}}\). The requirements of Definition 2 for an e-family are all fulfilled, which concludes the proof. \(\square \)
Remark 3
Recall that for a distribution \(\mu \in {\mathcal {P}}({\mathcal {X}})\), we can by exponential change of measure – also known as exponential tilting – construct the natural exponential family of \(\mu \):
where \(A(\theta )\) is a normalization function that ensures \(\mu _\theta \in {\mathcal {P}}({\mathcal {X}})\) for all \(\theta \in {\mathbb {R}}\). The idea of exponential change of measure for distributions can be traced back to Chernoff [35], and was later termed tilting [36, 37]. Similarly, given some function \(g :{\mathcal {X}}^2 \rightarrow {\mathbb {R}}\) we can tilt an irreducible kernel P (e.g. Miller [12]), by first constructing \({\tilde{P}}_\theta (x,x') = P(x,x') e^{\theta g(x,x')}\), and then rescaling the newly obtained irreducible matrixFootnote 2 with the mapping \({\mathfrak {s}}\). When \(\theta = 0\), notice that we recover the original P. But while in our definition,
denotes the kernel tilted involving the right PF eigenvector \(v_\theta \), we could alternatively define the Markov kernel \(P'_\theta \) by tilting P with the left PF eigenvector \(u_\theta \):
Observe that the right and left tilted versions of P with identical \(\theta \) share the same stationary distribution \(\pi _\theta \propto u_\theta \circ v_\theta \) (6) and that they are in fact each other’s time-reversal (\(P'_\theta = P^\star _\theta \)), i.e. they form a pair of adjoint linear operators over the space \(\ell _2(\pi _\theta )\).
4 Reversible exponential families
The previous section extended the time-reversal operation to parametric families of transition kernels. It seems then natural to investigate fixed points, i.e. parametric families that remain invariant under this transformation. We say that an irreducible e-family \({\mathcal {V}}({\mathcal {X}}, {\mathcal {E}})\) is reversible when P is reversible \(\forall P \in {\mathcal {V}}({\mathcal {X}}, {\mathcal {E}})\). In this case, \({\mathcal {E}}\) coincides with \({\mathcal {E}}^\star \) and \({\mathcal {V}}^\star ({\mathcal {X}}, {\mathcal {E}}^\star )\) with \({\mathcal {V}}({\mathcal {X}}, {\mathcal {E}})\). Observe first that an e-family obtained from tilting a reversible P is not generally reversible, making it clear that the reversible nature of the family cannot be determined solely by the properties of the carrier kernel K. It is however easy to see that an e-family is reversible when K and all the generator functions \(g_1, \dots , g_d\) are symmetric. Moreover, for a state space \({\mathcal {X}}\) of size 2, any exponential family would be reversible regardless of symmetry, showing that this condition is not always necessary. In this section, we give a complete characterization of this invariant set. Additionally, we explore the algorithmic cost of checking whether this property is verified from the description of the carrier kernel and generators of a given e-family. Before diving into the general theory of reversible e-families, let us consider the following simple examples.
Example 1
(Lazy random walk on the m-cycle) For \(\mathcal{X}=[m]\), and
let
where \(\psi (\theta )=\log \big ( e^{\theta _1}+e^{\theta _2} + e^{-\theta _2}\big )\) and \(\delta _{m+1}=\delta _1\). This e-family \(\{P_\theta \}_{\theta \in {\mathbb {R}}^2}\) corresponds to the set of biased lazy random walks on the m-cycle given by
Observe that \(P^\star _{(\theta _1, \theta _2)} = P_{(\theta _1, - \theta _2)}\), and thus \(P_\theta \) is not a reversible e-family. The subfamily \(\{ P_\theta : \theta _1 \in {\mathbb {R}}, \theta _2=0 \}\), however, i.e. unbiased lazy random walks on the m-cycle, form a a reversible e-family.
Example 2
(Birth-and-death chains) For \(\mathcal{X}=[m]\) and \(\mathcal{E}_{\mathsf {bd}}=\{ (i,j) : |i-j| \le 1\}\), a Markov kernel having its support on \(\mathcal{E}_{\mathsf {bd}}\) is referred to as a birth-and-death chain. Since every birth-and-death chain is reversible [8, Section 2.5], \(\mathcal{W}(\mathcal{X},\mathcal{E}_{\mathsf {bd}})\) is a reversible e-family.
We first recall Kolmogorov’s characterization of reversibility, which will be instrumental in our argument. For \({\mathcal {E}} \subset {\mathcal {X}}^2\) such that \(({\mathcal {X}}, {\mathcal {E}})\) is a strongly connected directed graph, we write \(\varGamma ({\mathcal {X}}, {\mathcal {E}})\) for the set of finite directed closed paths in the graph \(({\mathcal {X}}, {\mathcal {E}})\). Formally, we treat \(\gamma \) as a map \([n] \rightarrow {\mathcal {E}}\) such that \(\gamma (t) = (x_t, x_{t+1})\) with \(x_{n+1} = x_1\) and we write \(\left| \gamma \right| = n\) for the length of the path. For each \(\gamma \in \varGamma ({\mathcal {X}}, {\mathcal {E}})\), we also introduce the reverse closed path \(\gamma ^\star \in \varGamma ({\mathcal {X}}, {\mathcal {E}}^\star )\) given by \(\gamma ^\star (t) = (x_{t+1}, x_t)\). Namely, if \(\gamma \in \varGamma ({\mathcal {X}}, {\mathcal {E}})\), we can write \(\gamma \) informally as a succession of edges such that the starting and finishing states agree (i.e. as an element of \({\mathcal {E}}^n\)).
Note that \(\gamma \) is not necessarily a cycle, i.e. in our definition, multiple occurrences of the same point of the space are allowed.
Theorem 1
(Kolmogorov’s criterion [3]) Let P irreducible over \(({\mathcal {X}}, {\mathcal {E}})\). P is reversible if and only if for all \(\gamma \in \varGamma ({\mathcal {X}}, {\mathcal {E}})\),
Example 3
When \(\left| {\mathcal {X}} \right| = 2\), all chains are reversible. For \(\left| {\mathcal {X}} \right| = 3\), only one equation needs to be verified for P to be reversible:
We now extend the definition of reversibility to arbitrary irreducible functions \({\mathcal {F}}_+({\mathcal {X}}, {\mathcal {E}})\) (non-negative on \({\mathcal {X}}^2\) and positive exactly on \({\mathcal {E}}\)) based on Kolmogorov’s criterion, and further introduce the concept of log-reversibility for \({\mathcal {F}}({\mathcal {X}}, {\mathcal {E}})\), that considers sums instead of products.
Definition 4
(Reversible and log-reversible functions) Let \({\mathcal {E}} \subset {\mathcal {X}}^2\) such that \({\mathcal {E}} = {\mathcal {E}}^\star \).
-
reversible: A function \(h \in {\mathcal {F}}_+({\mathcal {X}}, {\mathcal {E}})\) is reversible whenever it satisfies that,
$$\begin{aligned} \prod _{t = 1 }^{\left| \gamma \right| } h(\gamma (t)) = \prod _{t = 1}^{\left| \gamma \right| } h(\gamma ^\star (t)). \end{aligned}$$for all finite directed closed paths \(\gamma \in \varGamma ({\mathcal {X}}, {\mathcal {E}})\).
-
log-reversible: A function \(h \in {\mathcal {F}}({\mathcal {X}}, {\mathcal {E}})\) is log-reversible whenever it satisfies that,
$$\begin{aligned} \sum _{t = 1 }^{\left| \gamma \right| } h(\gamma (t)) = \sum _{t = 1}^{\left| \gamma \right| } h(\gamma ^\star (t)). \end{aligned}$$for all finite directed closed paths \(\gamma \in \varGamma ({\mathcal {X}}, {\mathcal {E}})\).
Remark These definitions do not rely on connectedness properties of \({\mathcal {E}}\) per se, but we will assume irreducibility nonetheless. Observe that when h is represented by an irreducible row-stochastic matrix, the definition of reversibility of h as a function and as a Markov operator coincide by Kolmogorov’s criterion (Theorem 1). Clearly, for \(h \in {\mathcal {F}}({\mathcal {X}}, {\mathcal {E}})\), \(\exp [h]\) being reversible is equivalent to h being log-reversible. We could endow the set of positive reversible functions on \({\mathcal {E}}\) with a group structure by considering the standard multiplicative operation on functions. We will choose however (Lemma 4), to rather construct and focus on the vector space of log-reversible functions.
Lemma 1
Let \(h \in {\mathcal {F}}_+(\mathcal X, {\mathcal {E}})\) such that \({{\,\mathrm{rank}\,}}(h) = 1\). Then h is a reversible function.
Proof
Consider a closed path \(\gamma \in \varGamma ({\mathcal {X}}, {\mathcal {E}})\). Writing \(h = u_h ^\intercal v_h\), we successively have that
\(\square \)
Theorem 2
(Characterization of reversible e-family) Let \({\mathcal {V}}({\mathcal {X}}, {\mathcal {E}})\) be an irreducible e-family of Markov chains, with natural parametrization \(\theta \), generated by K and \((g_i)_{i \in [d]}\). The following two statements are equivalent.
-
(i)
\({\mathcal {V}}({\mathcal {X}}, {\mathcal {E}})\) is reversible.
-
(ii)
\({\mathcal {E}} = {\mathcal {E}}^\star \) and \({\mathcal {V}}({\mathcal {X}}, {\mathcal {E}})\) is such that the carrier kernel K and generator functions \(g_i, \forall i \in [d]\) are all log-reversible functions.
Proof
We apply Kolmogorov’s criterion to some arbitrary family member. Let \(\gamma \) be some finite closed path in \(({\mathcal {X}}, {\mathcal {E}})\),
Rewriting the left-hand side,
Proceeding in a similar way with the right-hand side, we obtain
When K and the \(g_i\) are log-reversible, this equality is verified for any closed path, and every member of the family is therefore reversible. Taking \(\theta = 0\) yields the reversibility requirement for K. Further taking \(\theta ^i = \delta _{i}(j)\) for \(j \in [d]\) similarly yields the requirement for \(g_j\). \(\square \)
This path checking approach, although mathematically convenient, is not algorithmically efficient. In order to determine whether a full-support kernel –or function– is reversible, the number of distinct Kolmogorov equations that must be checked is
which corresponds to the maximal number of cycles (i.e. closed paths such that the only repeated vertices are the first and last one) in a complete graph over \(\left| {\mathcal {X}} \right| \) nodes. Such testing algorithm becomes rapidly intractable as \(\left| {\mathcal {X}} \right| \) increases. However for Markov kernels, we know that this is equivalent to verifying the detailed balance equation, which can be achieved in (at most) polynomial time \({\mathcal {O}}(\left| {\mathcal {X}} \right| ^3)\), by solving a linear system in order to find \(\pi \). We show that this idea naturally extends to verifying reversibility of functions, enabling us to design an algorithm of time complexity \({\mathcal {O}}(\left| {\mathcal {X}} \right| ^3)\).
Lemma 2
Let \(h \in {\mathcal {F}}_+({\mathcal {X}}, {\mathcal {E}})\) irreducible. h is reversible if and only if \(\varPi _h \circ h ^\intercal \) is a symmetric matrix, with \(\varPi _h = v_h ^\intercal u_h\) the PF projection of h, where \(u_h \) and \(v_h\) are respectively the left and right PF eigenvectors of h, normalized such that \(u_h v_h ^\intercal = 1\).
Proof
Treat h as the linear operator \(h :{\mathbb {R}}^{{\mathcal {X}}} \rightarrow {\mathbb {R}}^{{\mathcal {X}}}\). Suppose first that h is reversible. We apply PF theory, which guarantees that the following Cesàro averages converge [39, Example 8.3.2] to some positive projection,
Fix \((x, x') \in {\mathcal {X}}^2\) such that \(h(x, x') \ne 0\). For \(k \in {\mathbb {N}}\), we write \(\varGamma _k(x,x') \subset \varGamma ({\mathcal {X}}, {\mathcal {E}})\) the set of all directed closed paths \(\gamma \) with \((x_1, x_2, \dots , x_k) \in {\mathcal {X}}^k\) such that
For any such cycle, it holds (perhaps vacuously if \(\varGamma _k(x,x') = \emptyset \)) that
Summing this equality over all possible paths in \(\varGamma _k(x, x')\) (i.e. summing over all \((x_1, \dots , x_k) \in {\mathcal {X}}^k\), with the assumption that \(h(x,x') = 0\) whenever \((x,x') \not \in {\mathcal {E}}\)), we obtain
In the case where \(h(x, x') = 0\), the above equation holds by symmetry of \({\mathcal {E}}\). For \(n \in {\mathbb {N}}\), appropriately rescaling on both sides with the PF root, summing over all \(k \in \left\{ 0, \dots ,n \right\} \) and taking the limit at \(n \rightarrow \infty \), (7) yields detailed balance equations with respect to the projection \(\varPi _h\),
or in other words, reversibility of h implies symmetry of \(\varPi _h \circ h ^\intercal \).
To prove necessity, we suppose now that this symmetry holds, with \(\varPi _h\) the PF projection of h. We know that \({{\,\mathrm{rank}\,}}(\varPi _h) = {{\,\mathrm{rank}\,}}(v_h ^\intercal u_h) = 1\), and that \(\varPi _h\) is positive. Consider some finite directed closed path \(\gamma \). Rearranging products yields
but the first factor on the right-hand side vanishes, from the fact that rank one functions are always reversible (Lemma 1). This concludes the proof of the lemma. \(\square \)
Notice that we can define \(\pi _h(x) \triangleq u_h(x)/v_h(x)\) the positive entry-wise ratio of the PF eigenvectors. We can then restate Lemma 2 in terms of the familiar detailed balance equation \(\pi _h(x) h(x, x') = \pi _h(x') h(x', x)\).
Corollary 1
Let \(h \in {\mathcal {F}}({\mathcal {X}}, {\mathcal {E}})\) some irreducible function. h is log-reversible if and only if there exists \(f \in {\mathbb {R}}^{\mathcal {X}}\) such that \(\forall x, x' \in {\mathcal {X}}\), \(h(x, x') = h(x', x) + f(x') - f(x)\).
Remark: when h is known to be reversible, one can compute \(\pi _h\) in \({\mathcal {O}}(\left| {\mathcal {X}} \right| )\), by adapting the technique of [40]; unfortunately, it is not possible to check for reversibility using this method. If the space becomes large, the reader can consider iterative (power) methods to compute the PF projector, potentially further reducing the verification time cost. We end this section with a technical lemma that will allow us in later sections to swiftly compute expectations of functions under certain reversibility or skew-symmetricity properties.
Lemma 3
Let P irreducible with associated edge measure matrix Q. For a function \(g :{\mathcal {X}}^2 \rightarrow {\mathbb {R}}\), we write \(Q[g] = \sum _{x, x' \in {\mathcal {X}}} Q(x, x') g(x, x')\).
-
(i)
If g is log-reversible, \(Q[g] = Q^\star [g]\).
-
(ii)
If g is skew-symmetric and P is reversible, \(Q[g] = 0\).
-
(iii)
If there exists \(f \in {\mathbb {R}}^{\mathcal {X}}\) such that for all \(x, x' \in {\mathcal {X}}\), \(g(x,x') = f(x') - f(x)\), \(Q[g] = 0\) (regardless of P being reversible).
Proof
Claim (iii) follows by property of edge measure Q.
From Corollary 1, claim (iii), and re-indexing,
which yields (i). To prove (ii), consider g such that \(g(x', x) = - g(x, x')\). Then by re-indexing and symmetry of Q,
\(\square \)
5 The e-family of reversible Markov kernels
In Section 5.1, we begin by analyzing the affine structure of the space of log-reversible functions, derive its dimension, construct a basis, and deduce that the manifold of all irreducible reversible Markov kernels forms an exponential family. The dimension of this family confirms the well-known fact that the number of free parameters for a reversible kernel is only about half of what is required for the general case, hence that reversible chains serve in a sense as a “natural intermediate” [41, Section 5] in terms of model complexity. In Section 5.2, we proceed to derive a systematic parametrization of the manifold \({\mathcal {W}}({\mathcal {X}}, {\mathcal {E}})\), similar in spirit to the one given in Ito and Amari [17], and in Nagaoka [22, Example 1]. In Section 5.3, we connect our results to general differential geometry, and point out that reversible kernels  form a doubly autoparallel submanifold in \({\mathcal {W}} ({\mathcal {X}}, {\mathcal {E}})\). Finally, we conclude with a brief discussion on reversible geodesics (Section 5.4).
form a doubly autoparallel submanifold in \({\mathcal {W}} ({\mathcal {X}}, {\mathcal {E}})\). Finally, we conclude with a brief discussion on reversible geodesics (Section 5.4).
5.1 Affine structures
Identifying \({\mathcal {X}}\) with [m], we can endow the set with the natural order induced from \({\mathbb {N}}\). In this section, we will henceforth assume that \({\mathcal {E}}\) is symmetric, and consider the following subsets of \({\mathcal {E}}\),
and
We immediately observe that the following cardinality relations hold
and that from irreducibility, \(x^\star \ne m\). The last expression in (8) highlights the fact that \(\left| T({\mathcal {E}}) \right| \) is independent of any ordering of elements of \({\mathcal {X}}\). Note also that the element \((m, x_\star )\) in the definition of \(T({\mathcal {E}})\) plays no special role, and could be replaced with any other element of \(T_0({\mathcal {E}}) \cup T_+({\mathcal {E}})\). We define the sets of symmetric and log-reversible functions (Definition 4) over the graph \(({\mathcal {X}}, {\mathcal {E}})\), respectively by
We note that \({\mathcal {F}} _{\mathsf {sym}}({\mathcal {X}}, {\mathcal {E}})\) is isomorphic to the vector space of symmetric matrices whose entries are null outside of \({\mathcal {E}}\), thus \(\dim {\mathcal {F}} _{\mathsf {sym}}({\mathcal {X}}, {\mathcal {E}}) = \left| T_+({\mathcal {E}}) \right| + \left| T_0({\mathcal {E}}) \right| \). We now show that  is also a vector space, and that it contains \({\mathcal {N}} ({\mathcal {X}}, {\mathcal {E}})\) defined at (4).
is also a vector space, and that it contains \({\mathcal {N}} ({\mathcal {X}}, {\mathcal {E}})\) defined at (4).
Lemma 4
The following vector subspace inclusions hold:
Proof
To verify (ii), we argue that  is closed by linear combinations from properties of the sum. The fact that the null function is trivially reversible concludes this claim. For (i), consider an element \(h \in {\mathcal {N}}({\mathcal {X}}, {\mathcal {E}})\), such that \(h(x, x') = f(x') - f(x) + c\). Then \(h(x, x') = h(x', x) + 2f(x') - 2f(x)\), and from Corollary 1,
is closed by linear combinations from properties of the sum. The fact that the null function is trivially reversible concludes this claim. For (i), consider an element \(h \in {\mathcal {N}}({\mathcal {X}}, {\mathcal {E}})\), such that \(h(x, x') = f(x') - f(x) + c\). Then \(h(x, x') = h(x', x) + 2f(x') - 2f(x)\), and from Corollary 1,  , thus the inclusion holds. The set is closed by linear combinations by properties of sums again, and taking \(f = 0, c =0\) is allowed, whence claim (i). \(\square \)
, thus the inclusion holds. The set is closed by linear combinations by properties of sums again, and taking \(f = 0, c =0\) is allowed, whence claim (i). \(\square \)
Remark 4
In fact, defining
Corollary 1 implies that  .
.
It is then possible to further define the quotient space of reversible generator functions
Theorem 3
The following statements hold.
-
(i)
The set of reversible generators
 can be endowed with a \(\left| T({\mathcal {E}}) \right| \)-dimensional vector space structure.
can be endowed with a \(\left| T({\mathcal {E}}) \right| \)-dimensional vector space structure. -
(ii)
The set
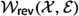 of irreducible and reversible Markov kernels over \(({\mathcal {X}}, {\mathcal {E}})\) forms an e-family of dimension
of irreducible and reversible Markov kernels over \(({\mathcal {X}}, {\mathcal {E}})\) forms an e-family of dimension  .
.
 can be endowed with a
can be endowed with a  of irreducible and reversible Markov kernels over
of irreducible and reversible Markov kernels over  .
.Proof
Let g be a log-reversible function over \(({\mathcal {X}},{\mathcal {E}})\). From Corollary 1, there exists \(f \in {\mathbb {R}}^{\mathcal {X}}\) such that \(g(x, x') = g(x', x) + f(x') - f(x)\), or writing \(h(x, x') = g(x, x') + {\tilde{f}}(x) - {\tilde{f}}(x')\) with \({\tilde{f}} = f/2\) (i.e. \(h = (g + g ^\intercal )/2\)), it holds that \(h(x, x') = h(x', x)\), i.e. h is symmetric.  thus also corresponds to the alternative quotient space
thus also corresponds to the alternative quotient space
and as a consequence  . This concludes the proof of (i). Let
. This concludes the proof of (i). Let  , and recall the definition (5) of the diffeomorphism \(\varDelta \). By Theorem 2,
, and recall the definition (5) of the diffeomorphism \(\varDelta \). By Theorem 2,  . Conversely, let \(P \in {\mathcal {W}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\). Then by the Kolmogorov criterion (Theorem 1), \(\log [P] \in {\mathcal {F}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\), and there exist \((g, f, c) \in {\mathcal {G}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}}) \times {\mathbb {R}}^{\mathcal {X}} \times {\mathbb {R}}\) such that for any \(x, x' \in {\mathcal {X}}, \log P(x,x') = g(x,x') + f(x') - f(x) + c\) (where c is unique, f is unique up to an additive constant, and both can be recovered from PF theory). In other words, there exists \(g \in {\mathcal {G}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\), with \(P = {\mathfrak {s}}\circ \exp [g]\), hence \(P \in \varDelta ({\mathcal {G}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}}))\), proving that
. Conversely, let \(P \in {\mathcal {W}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\). Then by the Kolmogorov criterion (Theorem 1), \(\log [P] \in {\mathcal {F}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\), and there exist \((g, f, c) \in {\mathcal {G}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}}) \times {\mathbb {R}}^{\mathcal {X}} \times {\mathbb {R}}\) such that for any \(x, x' \in {\mathcal {X}}, \log P(x,x') = g(x,x') + f(x') - f(x) + c\) (where c is unique, f is unique up to an additive constant, and both can be recovered from PF theory). In other words, there exists \(g \in {\mathcal {G}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\), with \(P = {\mathfrak {s}}\circ \exp [g]\), hence \(P \in \varDelta ({\mathcal {G}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}}))\), proving that
Claim (ii) then follows from Nagaoka [22, Theorem 2], as discussed at the end of Section 2. \(\square \)
Corollary 2
For the set of positive Markov kernel, \(\left| T_0({\mathcal {E}}) \right| = \left| {\mathcal {X}} \right| \) and \(\left| {\mathcal {E}} \right| = \left| {\mathcal {X}} \right| ^2\), thus \(\dim {\mathcal {W}}_{\mathsf {rev} }({\mathcal {X}}, {\mathcal {X}}^2) = \left| {\mathcal {X}} \right| (\left| {\mathcal {X}} \right| +1)/2 - 1\). This is in line with the known number of degrees of freedom of reversible Markov chains [9, 41].
Theorem 4
The family of functions \(g_{i j} = \delta _i ^\intercal \delta _j + \delta _j ^\intercal \delta _i\), for \((i,j) \in T({\mathcal {E}})\), forms a basis of \({\mathcal {G}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\).
Proof
We begin by proving the independence of the family in the quotient space \({\mathcal {G}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\). Since \(g_{ij}\) is symmetric in the sense that \(g_{ij} = g_{ij} ^\intercal \), it trivially verifies the log-reversibility property, thus belongs to \({\mathcal {G}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\). Let now \(g \in {\mathcal {G}}_{\mathsf {rev} }({\mathcal {X}}, {\mathcal {E}})\) be such that
with \(\alpha _{ij} \in {\mathbb {R}}\), for any \((i,j) \in T({\mathcal {E}})\), and suppose that \(g = 0_{{\mathcal {G}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})}\). Our first step is to observe that necessarily \(g = 0_{{\mathcal {F}} ({\mathcal {X}},{\mathcal {E}} )}\), i.e. g must be the null vector in the ambient space. Let us suppose for contradiction that there exist \((f, c) \in ({\mathbb {R}}^{\mathcal {X}}, {\mathbb {R}})\) such that \(g(x, x') = f(x') - f(x) + c\) and either \(c \ne 0\) or f is not constant over \({\mathcal {X}}\). Since by definition, \((m, x_\star ), (x_\star , m) \not \in T({\mathcal {E}})\),
therefore summing the latter equalities yields \(c = 0\), thus f cannot be constant. But then, g is both symmetric and skew-symmetric, which leads to a contradiction, and \(g = 0_{{\mathcal {F}}({\mathcal {X}}, {\mathcal {E}})}\). Since the family \(\left\{ g_{ij} :(i,j) \in T({\mathcal {E}}) \right\} \) is independent in the ambient space \({\mathcal {F}}({\mathcal {X}}, {\mathcal {E}})\), the coefficients \(\alpha _{ij}, (i,j) \in T({\mathcal {E}})\) must be null, and as result, the family is also linearly independent in \({\mathcal {G}}_{\mathsf {rev} }({\mathcal {X}}, {\mathcal {E}})\). Finally, since from Theorem 3, \(\left| T({\mathcal {E}}) \right| = \dim {\mathcal {G}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\), the family is maximally independent, hence constitutes a basis of the quotient vector space. \(\square \)
Remark 5
An alternative way of showing the linear independence of the family \(\left\{ g_{ij} :(i,j) \in T({\mathcal {E}}) \right\} \) in Theorem 4 consists in verifying that (i) the family is independent in \({\mathcal {F}}_{\mathsf {sym}}\), (ii) \({\mathbb {R}}\ \not \subset {{\,\mathrm{span}\,}}\left\{ g_{ij} :(i,j) \in T({\mathcal {E}}) \right\} \), and then invoking (10).
5.2 Parametrization of the manifold of reversible kernels
Recall that from [22, Example 1], in the complete graph case (\({\mathcal {E}} = {\mathcal {X}}^2\)), we can find an explicit parametrization for \({\mathcal {W}}({\mathcal {X}}, {\mathcal {X}}^2)\). Indeed, picking any \(x_\star \in {\mathcal {X}}\), we can easily verify that for the two cases where \(x'= x_\star \) and \(x' \ne x_\star \),
In the remainder of this section, we show how to derive a similar parametrization for \({\mathcal {W}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\). We start by recalling the definition of the expectation parameter of an exponential family of kernels. For an e-family \({\mathcal {V}}_e\), following the notation of Definition 2, we define
and call \(\eta = (\eta _1, \dots , \eta _d)\) the expectation parameter of the family. We will first derive \(\eta \) and later convert to the natural parameter \(\theta \) using the following lemma.
Lemma 5
For a given exponential family, we can express the chart transition maps between the expectation and natural parameters \(\theta \circ \eta ^{-1}\) and \(\eta \circ \theta ^{-1}\). Extending the notation at Lemma 3,
-
(i)
$$\begin{aligned}\eta _i(\theta ) = Q_\theta [g_i] = \sum _{x, x' \in {\mathcal {X}}} Q_\theta (x,x') g_i(x,x') .\end{aligned}$$
-
(ii)
$$\begin{aligned} \begin{aligned} \theta ^i(\eta )&= \left( \frac{\partial }{\partial \eta _i} Q_\eta \right) \left[ \log P_\eta - K \right] \\&= \sum _{x, x' \in {\mathcal {X}}} \left( \frac{\partial }{\partial \eta _i} Q_\eta (x, x') \right) \left( \log P_\eta (x, x') - K(x, x') \right) . \end{aligned} \end{aligned}$$
In particular, when the carrier kernel verifies \(K = 0\), we more simply have
$$\begin{aligned} \theta ^i(\eta ) = \left( \frac{\partial }{\partial \eta _i} Q_\eta \right) \left[ \log P_\eta \right] . \end{aligned}$$
Proof
It is well-known that \(\eta _i(\theta ) = \frac{\partial }{\partial \theta ^i} \psi _\theta = Q_\theta [g_i]\) [10, Lemma 5.1], [22, Theorem 4], [21, (28)], therefore we only need to show (ii). Let \(g_1, g_2, \dots , g_d\) be a collection of independent functions of \({\mathcal {G}} ({\mathcal {X}}, {\mathcal {E}})\). Consider the exponential family as in Definition 2. Recall that for two transition kernels \(P_1, P_2\) respectively irreducible over \(({\mathcal {X}}, {\mathcal {E}}_1)\) and \(({\mathcal {X}}, {\mathcal {E}}_2)\), and with stationary distributions \(\pi _1\) and \(\pi _2\), the information divergence of \(P_1\) from \(P_2\) is given by
Writing \(P_0\) for \(P_\theta \) when \(\theta = 0\),
where for the last equality we used (i) of the present lemma and Lemma 3-(iii). Moreover, by a direct computation,
Thus, the potential function is given by
By taking the derivative, we recover \(\frac{\partial }{\partial \eta _i} \varphi (\eta ) = \theta ^i(\eta )\) [22, (17)]. Moreover, from (12), we have that
where for the last equality, we used the fact that \(Q_\eta [ \partial K / \partial \eta _i] = 0\), and that from \(P_\eta \) being stochastic,
This finishes proving (ii) of the lemma. \(\square \)
Theorem 5
Let \(P \in {\mathcal {W}}_{\mathsf {rev} }({\mathcal {X}}, {\mathcal {E}})\), with stationary distribution \(\pi \). Using the basis \(g_{ij} = \delta _i ^\intercal \delta _j + \delta _j ^\intercal \delta _i\), we can write Q, the edge measure matrix associated with P, as a member of the m-family of reversible kernels,
where \(g_\star = \delta _{m} ^\intercal \delta _{x_\star } + \delta _{x_\star } ^\intercal \delta _{m}\), and we can write P as a member of the e-family,
when \((x,x') \in {\mathcal {E}}\), \(P(x,x') = 0\) otherwise, and where \(x_\star = {{\,\mathrm{\hbox {arg min}}\,}}_{x \in {\mathcal {X}}} \left\{ (m, x) \in {\mathcal {E}} \right\} \).
Proof
Let us consider the basis
and taking \(K = 0\), we are looking for a parametrization of the type
where \(\exp \psi _\theta \) and \(\exp [R_\theta ]\) are respectively the PF root and right PF eigenvector of \({\widetilde{P}}_\theta \). We first derive a parametrization of the edge measure \(Q_\eta \) as a member of an m-family (following Definition 1-(ii) with respect to the expectation parameter \(\eta \)). For \((i, j) \in {\mathcal {X}}^2\), by Lemma 5-(i),
and thus, from symmetry of \(Q_\eta \) and since \(Q_\eta \in {\mathcal {P}}({\mathcal {X}}^2)\),
and more compactly, for \((x, x') \in {\mathcal {X}}^2\),
where \(g_\star \) is defined as in the statement of the theorem. We differentiate by \(\eta _{i j}\) for \((i,j) \in T({\mathcal {E}})\), to obtain
Invoking (ii) of Lemma 5, we convert the expectation parametrization to a natural one,
so that
Notice that \({\widetilde{P}}_\theta = {\widetilde{P}}_\theta ^\intercal \), hence the right and left PF eigenvector are identical, i.e. \(R_\theta = L_\theta \) and as is known (see (6)), the stationary distribution is given by \(\pi _\theta = \exp [2 R_\theta ]/\sum _{x \in {\mathcal {X}}} \exp (2 R_\theta (x))\). In fact, we can easily verify that the right PF eigenvector is given by \(\exp [R_\theta ] = \sqrt{\pi }\), and that the PF root is
Indeed, letting \(x \in {\mathcal {X}}\), from detailed balance of P, we have
\(\square \)
5.3 The doubly autoparallel submanifold of reversible kernels
Recall that we can view \({\mathcal {W}} = {\mathcal {W}}({\mathcal {X}}, {\mathcal {E}})\) as a smooth manifold of dimension \(d = \dim {\mathcal {W}} = \left| {\mathcal {E}} \right| - \left| {\mathcal {X}} \right| \). For each \(P \in {\mathcal {W}}\), we can then consider the tangent plane \(T_P\) at P, endowed with a d-dimensional vector space structure. Together with the manifold, we define an information geometric structure consisting of a Riemannian metric, called the Fisher information metric \({\mathfrak {g}}\), and a pair of torsion-free affine connections \(\nabla ^{(e)}\) and \(\nabla ^{(m)}\) respectively called e-connection and m-connection, that are dual with respect to \({\mathfrak {g}}\), i.e. for any vector fields \(X, Y, Z \in \varGamma (T{\mathcal {W}})\),
where \(\varGamma (T {\mathcal {W}})\) is the set of all sections over the tangent bundle. We now review an explicit construction for \({\mathfrak {g}}, \nabla ^{(m)}, \nabla ^{(e)}\).
Construction in the natural chart map.
Consider a parametric family \({\mathcal {V}} = \left\{ P_\theta :\theta \in \varTheta \right\} \) with \(\varTheta \) open subset of \({\mathbb {R}}^d\). For any \(n \in {\mathbb {N}}\), we define the path measure \(Q_\theta ^{(n)} \in {\mathcal {P}}({\mathcal {X}}^n)\) induced from the kernel \(P_\theta \).
Nagaoka [22] defines the Fisher metric as
and the dual affine e/m-connections of \(\left\{ P_\theta :\theta \in \varTheta \right\} \) by their Christoffel symbols,
where \({\mathfrak {g}}_{ij}^{n}(\theta ), \varGamma ^{(e), n}_{ij, k}(\theta ), \varGamma ^{(m), n}_{ij, k}(\theta )\) are the Fisher metric, and Christoffel symbols of the e/m-connections that pertain to the distribution family \(\left\{ Q_\theta ^{(n) } \right\} _{\theta \in \varTheta }\).
Autoparallelity.
Connections allow us to talk about covariant derivatives and parallelity of vectors fields.
Definition 5
A submanifold \({\mathcal {V}}\) is called autoparallel in \({\mathcal {W}}\) with respect to a connection \(\nabla \), when for any vector fields \(\forall X, Y \in \varGamma (T {\mathcal {V}})\), it holds that
A submanifold \({\mathcal {V}}\) of \({\mathcal {W}}\) is then an e-family (resp. m-family) if and only if it is autoparallel with respect to \(\nabla ^{(e)}\) (resp. \(\nabla ^{(m)}\)) [22, Theorem 6]. As the manifold of reversible kernels is both an e-family and an m-family, it is called doubly autoparallel [42, Definition 1].
Theorem 6
The manifold \({\mathcal {W}}_{\mathsf {rev} }({\mathcal {X}}, {\mathcal {E}})\) of irreducible and reversible Markov chains over \(({\mathcal {X}}, {\mathcal {E}})\) is a doubly autoparallel submanifold in \({\mathcal {W}}({\mathcal {X}}, {\mathcal {E}})\) with dimension
where \(T_0({\mathcal {E}}) = \left\{ (x,x') \in {\mathcal {E}} :x = x' \right\} \).
Proof
The set of reversible Markov chains is an e-family (Theorem 3), and an m-family (Theorem 5). \(\square \)
5.4 Reversible geodesics
In this section, we let two irreducible reversible kernels \(P_0\) and \(P_1\) over \(({\mathcal {X}}, {\mathcal {E}})\), and discuss the geodesics that connect them with respect to \(\nabla ^{(e)}\) and \(\nabla ^{(m)}\). Although already guaranteed (see for example Ohara and Ishi [42, Proposition 1]), we offer alternative elementary proofs that any kernel lying on either e/m-geodesic is irreducible and reversible.
m-geodesics.
By irreducibility, there exist unique \(Q_0, Q_1, \in {\mathcal {Q}}({\mathcal {X}}, {\mathcal {E}})\) corresponding to \(P_0, P_1\). Moreover, by reversibility \(Q_0\) and \(Q_1\) are symmetric. We let
be the m-geodesic (auto-parallel curve with respect to the m-connection) connecting \(P_0\) and \(P_1\). Then \(G_m(P_0, P_1)\) forms an m-family of dimension 1. For any \(\xi \in [0,1]\), the matrix \(Q_\xi \) is symmetric as convex combination of two symmetric matrices. \(Q_\xi \) takes value 0 exactly when \(Q_0, Q_1\), i.e. \(P_0, P_1\) take value 0. Furthermore, writing \(\pi _0\) (resp. \(\pi _1\)) the unique stationary distribution of \(P_0\) (resp. \(P_1\)),
thus \(Q_\xi \) always defines a proper associated stochastic irreducible stochastic \(P_\xi \).
e-geodesics.
We consider the auto-parallel curve with respect to the e-connection that connect \(P_0\) and \(P_1\),
The set \(G_e(P_0, P_1)\) forms an e-family of dimension 1. Indeed, from Theorem 2, and since \(P_0\) and \(P_1\) are reversible by hypothesis, it suffices to verify that \((x, x') \mapsto P_1(x, x') / P_0(x, x')\) is a reversible function over \(({\mathcal {X}}, {\mathcal {E}})\). This follows from a simple application of the Kolmogorov criterion (Theorem 1).
6 Reversible information projections
Reversible Markov kernels, as self-adjoint linear operators, enjoy a set of powerful yet brittle spectral properties. The eigenvalues are real, the second largest in magnitude controls the time to stationarity of the Markov process [8, Chapter 12], and all are stable under perturbation and estimation [43]. However, any deviation from reversibility carries steep consequences, as the spectrum can suddenly become complex, and partially loses control over the mixing time. Furthermore, eigenvalue perturbation results that were dimensionless [44, Corollary 4.10 (Weyl’s inequality)] now come at a cost possibly exponential in the dimension [44, Theorem 1.4 (Ostrowski-Elsner)]. For some irreducible P with stationary distribution \(\pi \), it is therefore interesting to find the closest representative that is reversible, so as to enable Hilbert space techniques. Computing the closest reversible transition kernel with respect to a norm induced from an inner product was considered in Nielsen and Weber [45], who showed that the problem reduces to solving a convex minimization problem with a unique solution.
In this section, we examine this problem under a different notion of distance. We consider information projections onto the reversible family of transition kernels \({\mathcal {W}}_{\mathsf {rev} }({\mathcal {X}}, {\mathcal {E}})\), for some symmetric edge set \({\mathcal {E}}\). We define the m-projection and the e-projection of P onto the set of reversible transition kernels \({\mathcal {W}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\) respectively as
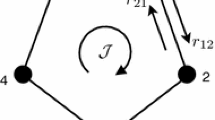
where \(D\left( \cdot \parallel \cdot \right) \) is the informational divergence, that was defined at (11). These two generally distinct projections (D is not symmetric in its arguments) correspond to the closest reversible chains when considering information divergence as a measure of distance. Under a careful choice of the connection graph of the reversible family, we derive closed-form expressions for \(P_m\) and \(P_e\), along with Pythagorean identities, as illustrated in Figure 1.
Theorem 7
Let P be irreducible over \(({\mathcal {X}}, {\mathcal {E}})\).
m-projection.

The m-projection \(P_m\) of P onto \({\mathcal {W}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}} \cup {\mathcal {E}}^\star )\) is given by
Moreover, for any \({\bar{P}} \in {\mathcal {W}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}} \cup {\mathcal {E}}^\star )\), \(P_m\) satisfies the following Pythagorean identity.
e-projection. When \({\mathcal {E}} \cap {\mathcal {E}}^\star \) is a strongly connected directed graph, the e-projection \(P_e\) of P onto \({\mathcal {W}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}} \cap {\mathcal {E}}^\star )\) is given by
and where \({\mathfrak {s}}\) is the stochastic rescaling mapping defined at (3). Moreover, for any \({\bar{P}} \in {\mathcal {W}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}} \cap {\mathcal {E}}^\star )\), \(P_e\) satisfies the following Pythagorean identity.
Proof
Our first order of business is to show that \(P_m\) and \(P_e\) belong respectively to \({\mathcal {W}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}} \cup {\mathcal {E}}^\star )\) and \({\mathcal {W}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}} \cap {\mathcal {E}}^\star )\). It is easy to see that \(P_m(x, x') > 0\) exactly when \((x, x')\) or \((x', x)\) belongs to \({\mathcal {E}}\), hence \(P_m \in {\mathcal {W}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}} \cup {\mathcal {E}} ^\star )\), and that \(P_e(x, x') > 0\) whenever \((x, x')\) belongs to both \({\mathcal {E}}\) and \({\mathcal {E}}^\star \). Moreover, since the time-reversal operation preserves the stationary distribution of an irreducible chain, \(P_m\) has the same stationary distribution \(\pi _m = \pi \), and a straightforward computation shows that \(P_m\) satisfies the detailed balance equation. To prove reversibility of \(P_e\), we rewrite
From Corollary 1, \(\log [P_e] \in {\mathcal {F}}_{\mathsf {rev} }({\mathcal {X}},{\mathcal {E}})\), thus \(P_e \in {\mathcal {W}}_{\mathsf {rev} }({\mathcal {X}},{\mathcal {E}})\).
To prove optimality of \(P_m\), it suffices to verify the following Pythagorean identity
Writing \(Q_m = {{\,\mathrm{diag}\,}}(\pi ) P_m\), notice that \(P_m = (P + P^\star )/2\) is equivalent to \(Q_m = (Q + Q^\star )/2\). We then have
where the last equality stems from (i) of Lemma 3 and reversibility of \(P_m\) and \({\bar{P}}\). Similarly, to prove optimality of \(P_e\), it suffices to verify that
By reorganizing terms
From the definition of \(P_e(x,x')\),
The first three terms being skew-symmetric, reversibility of \({\bar{P}}\) and (ii) of Lemma 3 yield that
By a similar argument, \(Q_e \left[ \log ( P /P_e) \right] = \log \rho ({\widetilde{P}}_e)\), which concludes the proof. \(\square \)
In other words, the m-projection is given by the natural additive reversiblization [46, (2.4)] of P, while the e-projection is achieved by some newly defined exponential reversiblization of P.
The difference between the m-projection and the e-projection is illustrated in the following example.
Example 4
Let us consider the family of biased lazy random walks \(P_\theta = P_{(\theta _1, \theta _2)}\), given in Example 1. Note that \({\mathcal {E}}={\mathcal {E}}^\star \). The m-projection \(P_m\) of \(P_\theta \) onto \({\mathcal {W}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\) is the unbiased lazy random walk given by \(P_m = P_{(\theta ', 0)}\) with \(\theta ' = \theta _1 - \log \cosh \theta _2\), i.e.
On the other hand, the e-projection \(P_e\) of \(P_\theta \) onto \({\mathcal {W}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {E}})\) is the unbiased lazy random walk given by \(P_e = P_{(\theta _1, 0)}\), i.e.
Remark 6
We observe that, although the m-projection preserves the stationary distribution, this is not true for \(P_e\), which exhibits a stationary distribution \(\pi _e\) generally different from \(\pi \). Furthermore, while the solution for the m-projection is always properly defined by taking union of the edge sets, our expression for the e-projection requires additional constraints on the connection graph of P. Indeed, taking the intersection \({\mathcal {E}} \cap {\mathcal {E}}^\star \), we always obtain a symmetric set, but can lose strong connectedness. We note but do not pursue the fact that reversibility can be defined for the less well-behaved set of reducible chains. In this case, \(\pi \) need not be unique, or could take null values, and the kernel could have a complex spectrum.
Finally, we show that for any irreducible P, both its reversible projections \(P_m\) and \(P_e\) are equidistant from P and its time-reversal \(P^\star \) (see also Fig. 1).
Proposition 2
(Bisection property) Let P irreducible, and let \(P_m\) (resp. \(P_e\)) the m-projection (resp. e-projection) of P onto \({\mathcal {W}}_{\mathsf {rev} }({\mathcal {X}}, {\mathcal {E}})\).
Proof
For \(P_1\) irreducible over \(({\mathcal {X}}, {\mathcal {E}}_1)\) and \(P_2\) irreducible over \(({\mathcal {X}}, {\mathcal {E}}_2)\), it is easy to see that
Then take \(P_2 = P_m\) for the first equality, and \(P_1 = P_e\) for the second. \(\square \)
7 The e-family of reversible edge measures
Recall that \({\mathcal {P}}({\mathcal {X}}^2)\), the set of all distributions over \({\mathcal {X}}^2\), forms an e-family [27, Example 2.8]. For some e-family of irreducible transition kernels \({\mathcal {V}}_e { \subset } {\mathcal {W}}({\mathcal {X}}, {\mathcal {X}}^2)\), one may wonder whether the corresponding family of edge measures also forms an e-family of distributions in \({\mathcal {P}}({\mathcal {X}}^2)\). We begin by illustrating that this holds in particular for the e-family obtained by tilting a memoryless Markov kernel.
Example 5
Consider the degenerate Markov kernel corresponding to an iid process \(P(x, x') = \pi (x')\) for \(\pi \in {\mathcal {P}}({\mathcal {X}})\). For a given function \(g :{\mathcal {X}} \rightarrow {\mathbb {R}}\), and \(\theta \in {\mathbb {R}}\), construct \({\widetilde{P}}_\theta (x, x') = P(x, x') e^{\theta g(x')} = \pi (x') e^{\theta g(x')}\). Then \(v_\theta = {\varvec{1}}\) is right eigenvector of \({\widetilde{P}}_\theta \) with eigenvalue \(\rho (\theta ) = \sum _{x' \in {\mathcal {X}}} \pi (x') e^{\theta g(x')}\). Letting \(\pi _\theta (x) = \pi (x) e^{\theta g(x)}/\rho (\theta )\), we see that \(\pi _\theta \) is the left PF eigenvector of \({\widetilde{P}}_\theta \), and the stationary distribution of the rescaled \(P_\theta \). We can therefore write,
thus \(\left\{ Q_\theta \right\} _{\theta \in \varTheta }\) forms an exponential family of distributions over \({\mathcal {X}}^2\). This fact can be further understood in the following manner. An e-family of distributions \(\left\{ \pi _\theta \right\} _{\theta }\) induces an e-family of memoryless Markov kernels \(\left\{ P_\theta \right\} _\theta \) with \(P_\theta (x,x') = \pi _\theta (x')\) (see Lemma 7 for a proof of this fact for the set of all memoryless kernels), and thus with edge measures \(Q_\theta (x,x') = \pi _\theta (x) \pi _\theta (x')\). Since the 2-iid extension \(\left\{ \pi _\theta (x)\pi _\theta (x') \right\} _\theta \) of the e-family \(\left\{ \pi _\theta \right\} _\theta \) is also an e-family, it follows that \(\left\{ Q_\theta (x,x') \right\} _\theta \) forms an e-family.
In the remainder of this section, we show that the subset of positive reversible edge measures \({\mathcal {Q}}_{\mathsf {rev} } = {\mathcal {Q}}_{\mathsf {rev} } ({\mathcal {X}}, {\mathcal {X}}^2)\), induced from the e-family of reversible positive kernels, forms a submanifold of \({\mathcal {P}}({\mathcal {X}}^2)\) that is autoparallel with respect to the e-connection, i.e. \({\mathcal {Q}}_{\mathsf {rev} }\) is an e-family of distribution of over pairs. Our proof will rely on the definition of a Markov map.
Definition 6
(e.g. Nagaoka [47]) We say that \(M :{\mathcal {P}}({\mathcal {X}}) \rightarrow {\mathcal {P}}({\mathcal {Y}})\) is a Markov map, when there exists a transition kernel \(P_M\) from \({\mathcal {X}}\) to \({\mathcal {Y}}\) (also called a channel) such that for any \(\mu \in {\mathcal {P}}({\mathcal {X}})\),
Let \({\mathcal {U}}\) and \({\mathcal {V}}\) be smooth submanifolds (statistical models) of \({\mathcal {P}}({\mathcal {X}})\) and \( {\mathcal {P}}({\mathcal {Y}})\) respectively. When there exists a pair of Markov maps \(M :{\mathcal {P}}({\mathcal {X}}) \rightarrow {\mathcal {P}}({\mathcal {Y}})\), \(N :{\mathcal {P}}({\mathcal {Y}}) \rightarrow {\mathcal {P}}({\mathcal {X}})\) such that their restrictions \(M|_{\mathcal {U}}\), \(N|_{\mathcal {V}}\) are bijections between \({\mathcal {U}}\) and \({\mathcal {V}}\), and are the inverse mappings of each other, we say that \({\mathcal {U}}\) and \({\mathcal {V}}\) are Markov equivalent, and write \({\mathcal {U}} \cong {\mathcal {V}}\).
Lemma 6
It holds that
Proof
Identify \({\mathcal {X}} = [m]\), and consider \(Q \in {\mathcal {Q}}_{\mathsf {rev} }\) such that
and where \(\eta _{mm} = 1 - \sum _{i \le j, (i,j) \ne (m, m)} \eta _{ij}\). We flatten the definition of Q.
Let the matrix E with \(m(m-1)/2\) columns and \(m(m-1)\) rows be such that,
Block matrix multiplication yields
and further observing that for \(F = \frac{1}{2} E ^\intercal \), it holds that \(FE = I_{m(m-1)/2}\). Thus the mappings defined by \(\begin{pmatrix} I_m &{} 0 \\ 0 &{} E \end{pmatrix}\) and \(\begin{pmatrix} I_m &{} 0 \\ 0 &{} \frac{1}{2}E ^\intercal \end{pmatrix}\) are Markov maps and verify \(\begin{pmatrix} I_m &{} 0 \\ 0 &{} \frac{1}{2}E ^\intercal \end{pmatrix} \begin{pmatrix} I_m &{} 0 \\ 0 &{} E \end{pmatrix} = I_{m(m+1)/2}\). This finishes proving the claim. \(\square \)
Theorem 8
The set \({\mathcal {Q}}_{\mathsf {rev} } \) forms an e-family and an m-family of \({\mathcal {P}}({\mathcal {X}}^2)\) with dimension \(\left| {\mathcal {X}} \right| (\left| {\mathcal {X}} \right| + 1)/2 - 1\). Moreover, \({\mathcal {Q}}\) does not form an e-family in \({\mathcal {P}}({\mathcal {X}}^2)\) (except when \(\left| {\mathcal {X}} \right| = 2\)).
Proof
Since \({\mathcal {Q}}_{\mathsf {rev} } { \subset } {\mathcal {P}}({\mathcal {X}}^2)\), the claim stems from the equivalence between (i) and (ii) of Nagaoka [47, Theorem 1], and application of Lemma 6, and the fact that \(\dim {\mathcal {P}} \left( \left[ \frac{\left| {\mathcal {X}} \right| (\left| {\mathcal {X}} \right| + 1)}{2} \right] \right) = \frac{\left| {\mathcal {X}} \right| (\left| {\mathcal {X}} \right| + 1)}{2} - 1\). In order to prove that \({\mathcal {Q}}\) is not an e-family in \({\mathcal {P}}({\mathcal {X}}^2)\), we first construct the following family of edge measures over three states.
Computing the point on the e-geodesic in \({\mathcal {P}}({\mathcal {X}}^2)\) at parameter value 1/2, yields
which does not belong to \({\mathcal {Q}}\). We can readily expand the above example to general state space size, \(m > 3\), by considering the one-padded versions of the above \(Q_i^{(m)} \propto \begin{pmatrix} Q_i^{(3)} &{} {\varvec{1}}_3 ^\intercal {\varvec{1}}_{m - 3} \\ {\varvec{1}}_{m - 3} ^\intercal {\varvec{1}}_{3} &{} {\varvec{1}}_{m - 3} ^\intercal {\varvec{1}}_{m - 3} \end{pmatrix}\), for \(i \in \left\{ 0, 1 \right\} \). \(\square \)
Remark 7
-
(i)
Nagaoka [47, Theorem 1-(iv)], actually proves the stronger result that \({\mathcal {Q}}_{\mathsf {rev} }\) forms an \(\alpha \)-family in \({\mathcal {P}}({\mathcal {X}}^2)\), for any \(\alpha \in {\mathbb {R}}\) (see Amari and Nagaoka [27, Section 2.6] for a definition of \(\alpha \)-families).
-
(ii)
We note but do not pursue here the fact that a more refined treatment over some irreducible edge set \({\mathcal {E}} \subsetneq {\mathcal {X}}^2\) is possible.
8 Comparison of remarkable families of Markov chains
We briefly compare the geometric properties of reversible kernels with that of several other remarkable families of Markov chains, and compile a summary in Table 1.
Family of all kernels irreducible over \(({\mathcal {X}}, {\mathcal {E}})\): \({\mathcal {W}}({\mathcal {X}}, {\mathcal {E}})\).This family is known to form both an e-family and an m-family of dimension \(\left| {\mathcal {E}} \right| - \left| {\mathcal {X}} \right| \) [22, Corollary 1].
Family of all reversible kernels irreducible over  . We show in Theorem 3 and Theorem 6 that
. We show in Theorem 3 and Theorem 6 that  is both an e-family and m-family or dimension \(T({\mathcal {E}})\), where
is both an e-family and m-family or dimension \(T({\mathcal {E}})\), where
with \(T_0({\mathcal {E}}) = \left\{ (x,x') \in {\mathcal {E}} :x = x' \right\} \).
Family of positive memoryless (iid) kernels: \({\mathcal {W}} _{\mathsf {iid}}({\mathcal {X}}, {\mathcal {X}}^2)\). This family comprises degenerate irreducible kernels that correspond to iid processes, i.e. where all rows are equal to the stationary distribution. Notice that for \(P \in {\mathcal {W}} _{\mathsf {iid}}\), irreducibility forces P to be positive. We show that \({\mathcal {W}} _{\mathsf {iid}}\) is an e-family of dimension \(\left| {\mathcal {X}} \right| - 1\) (Lemma 7), but not an m-family (Lemma 8).
Lemma 7
\({\mathcal {W}}_{\mathsf {iid} }\) forms an e-family of dimension \(\left| {\mathcal {X}} \right| - 1\).
Proof
For \({\mathcal {X}} = [m]\), let us consider the following parametrization proposed by Ito and Amari [17]:
This corresponds to the basis
with parameters
Let P irreducible with stationary distribution \(\pi \). Suppose first that P is memoryless, i.e. for all \(x, x' \in {\mathcal {X}}\), \(P(x,x') = \pi (x')\). In this case, for all \(i,j \in [m - 1]\), the coefficient \(\theta ^{ij}\) vanishes, and for all \(i \in [m - 1]\), it holds that \(\theta ^i = \pi (i)/\pi (m)\), so that we can write more simply
Conversely, now suppose that \(\theta ^{i j} = 0\) for any \(i,j \in [m - 1]\). Then the matrix
has rank one, the right PF eigenvector is constant, and P is memoryless. As a result, \({\mathcal {W}} _{\mathsf {iid}}\) is an e-family of \({\mathcal {W}}\) such that \(\theta ^{ij} = 0\) for every \(i,j \in [m - 1]\). \(\square \)
Lemma 8
\({\mathcal {W}}_{\mathsf {iid} }\) does not form an m-family.
Proof
We prove the case \(\left| {\mathcal {X}} \right| = 2\) and \(p \ne 1/2\),
Computing the corresponding edge measures,
But then if we let
we see that the stationary distribution is \(\pi _{1/2} = {\varvec{1}}/ 2\), and
But for \(p \ne 0\), \(P_{1/2}\) does not belong to \({\mathcal {W}} _{\mathsf {iid}}\), hence the family is not an m-family. The proof can be extended to the more general \({\mathcal {X}} = [m], m >2 \) by considering instead the two kernels defined by \(\pi _{p} = ( p, 1 - p, 1, \dots , 1 )/(m - 1)\) and \(\pi _{1 - p}\) for \(p \in (0, 1), p \ne 1/2\). \(\square \)
For simplicity, in the remainder of this section, we mostly consider the full support case.
Family of positive doubly-stochastic kernel: \({\mathcal {W}} _{\mathsf {bis}}({\mathcal {X}}, {\mathcal {X}}^2)\). Recall that a kernel P is said to be doubly-stochastic, or bi-stochastic, when P and \(P ^\intercal \) are both stochastic matrices. In this case, the stationary distribution is always uniform. It is known that the set of doubly stochastic Markov chains forms an m-family of dimension \((\left| {\mathcal {X}} \right| - 1)^2\) [10, Example 4]. However, as a consequence of Lemma 10, it does not form an e-family (except when \(\left| {\mathcal {X}} \right| = 2\)).
Family of positive symmetric kernel: \({\mathcal {W}} _{\mathsf {sym}}({\mathcal {X}}, {\mathcal {X}}^2)\). A Markov kernel is symmetric, when \(P = P ^\intercal \), hence this family lies at the intersection between reversible and doubly-stochastic families of Markov kernels, which are both m-families. This implies that symmetric kernels also form an m-family. In fact, Lemma 9 shows that the dimension of this family is \(\left| {\mathcal {X}} \right| (\left| {\mathcal {X}} \right| - 1)/2\). Lemma 10, however, shows that \({\mathcal {W}} _{\mathsf {sym}}\) only forms an e-family for \(\left| {\mathcal {X}} \right| = 2\).
Lemma 9
\({\mathcal {W}}_{\mathsf {sym} }\) forms an m-family of dimension \(\left| {\mathcal {X}} \right| (\left| {\mathcal {X}} \right| - 1)/2\).
Proof
To prove the claim, we will rely on Definition 1-(ii) of a mixture family. Consider the functions \(s_0 :{\mathcal {X}}^2 \rightarrow {\mathbb {R}}\) and \(s_{ij} :{\mathcal {X}}^2 \rightarrow {\mathbb {R}}\) for \(i,j \in {\mathcal {X}}, i > j\) such that for any \(x,x' \in {\mathcal {X}}\), \(s_0(x,x') = \delta _x(x')/\left| {\mathcal {X}} \right| \) and \(s_{ij} = \delta _i ^\intercal \delta _j + \delta _j ^\intercal \delta _i - 2 \delta _i ^\intercal \delta _i\). Let \(Q \in {\mathcal {Q}}\), we verify that for any \(x,x' \in {\mathcal {X}}\),
and moreover
It remains to show that the \(s_0, s_0 + s_{ij}\), for \(i > j\), are affinely independent, or equivalently, that the \(s_{ij}\), for \(i > j\), are linearly independent. Let \(s = \sum _{i > j} \alpha _{ij} s_{ij}\) with \(\alpha _{ij} \in {\mathbb {R}}\), for any \(i > j\), be such that \(s = 0\). For any \(i > j\), taking \(x = i, x'=j\) yields \(\alpha _{ij} = 0\), thus the family is independent, hence constitutes a basis, and the dimension is \(\left| \left\{ i,j \in {\mathcal {X}} :i > j \right\} \right| = \left| {\mathcal {X}} \right| (\left| {\mathcal {X}} \right| - 1) / 2\). \(\square \)
Lemma 10
For \(\left| {\mathcal {X}} \right| \ge 2\),
-
(i)
The set \({\mathcal {W}} _{\mathsf {sym}}\) does not form an e-family, unless \(\left| {\mathcal {X}} \right| = 2\).
-
(ii)
The set \({\mathcal {W}} _{\mathsf {bis}}\) does not form an e-family, unless \(\left| {\mathcal {X}} \right| = 2\).
Proof
We first treat the case \(\left| {\mathcal {X}} \right| = 2\) for (i) and (ii). Notice that
for \(\theta \in {\mathbb {R}}\) satisfies \(P_\theta \in {\mathcal {W}}_{\mathsf {sym}}\), and that the latter expression exhausts all irreducible symmetric chains. We can therefore write
which follows the defintion at (2) of an e-family with carrier kernel \(K = 0\), generator \(g(x,x') = \delta _x(x')\), natural parameter \(\theta \), \(R_\theta = 0\) and potential function \(\psi _\theta = \log (e^\theta + 1)\). Furthermore, for \(\left| {\mathcal {X}} \right| = 2\), it is easy to see that symmetric and doubly-stochastic families coincide, hence \({\mathcal {W}} _{\mathsf {bis}}\) is also an e-family.
We now prove (i) for \(\left| {\mathcal {X}} \right| = 3\). We will consider two positive symmetric Markov kernels \(P_0\) and \(P_1\), and look at the e-geodesic
where the map \({\mathfrak {s}}\), defined in (3), enforces stochasticity. The matrix \(P_\theta (x, x') = {\mathfrak {s}}({\widetilde{P}}_\theta )\) is symmetric, if and only if the right eigenvector of \({\widetilde{P}}_\theta \) is constant. This, in turn, is equivalent to the rows of \({\widetilde{P}}_\theta \) being all equal. Consider the two symmetric kernels
with free parameter \(\alpha \ne 1/3\), and let us inspect the curve at parameter \(\theta = 1/2\). For \(P_{1/2}\) to be symmetric, it is necessary that
whose unique solution is precisely \(\alpha = 1/3\). Invoking Nagaoka [22, Corollary 3] finishes proving (i) for \(\left| {\mathcal {X}} \right| = 3\). We extend the proof to \(\left| {\mathcal {X}} \right| \ge 4\) using the padding argument of Theorem 8, considering \(\frac{1}{m}\begin{pmatrix} 3 P_i &{} {\varvec{1}}^\intercal {\varvec{1}}\\ {\varvec{1}}^\intercal {\varvec{1}}&{} {\varvec{1}}^\intercal {\varvec{1}}\end{pmatrix}\). Suppose for contradiction that (ii) is false, i.e. bi-stochastic matrices form an e-family. Take then any e-geodesic between two arbitrary symmetric kernels. The latter operators being reversible, so is the geodesic. But then this curve must also be composed entirely of symmetric matrices, hence the geodesic is symmetric, which contradicts (i). \(\square \)
Remark 8
For \(\left| {\mathcal {X}} \right| \ge 3\), the following hierarchies hold:
9 Generation of the reversible family
In this final section, we consider the family of positive Markov kernels \({\mathcal {W}} = {\mathcal {W}}({\mathcal {X}},{\mathcal {X}}^2)\) i.e. where the support \({\mathcal {E}} = {\mathcal {X}}^2\). We first show that  is in a sense the smallest exponential family that contains \({\mathcal {W}} _{\mathsf {sym}}\), the family of symmetric Markov kernels. Our notion of minimality relies on the following definition of the exponential hull of some submanifold of \({\mathcal {W}}\).
is in a sense the smallest exponential family that contains \({\mathcal {W}} _{\mathsf {sym}}\), the family of symmetric Markov kernels. Our notion of minimality relies on the following definition of the exponential hull of some submanifold of \({\mathcal {W}}\).
Definition 7
(Exponential hull) Let \({\mathcal {V}} { \subset } {\mathcal {W}}\).
where \({\mathfrak {s}}\) is defined in (3).
Remark: When \(U = \frac{1}{\left| {\mathcal {X}} \right| } {\varvec{1}}^\intercal {\varvec{1}}\in {\mathcal {V}}\), the constraint \(\sum _{i = 1}^{k} \alpha _i = 1\) is redundant. Indeed, since U corresponds to the origin in e-coordinates, the linear hull and affine hull coincide in this case.
By (10), the reversible family is generated by symmetric functions. Even though not all symmetric functions correspond to symmetric kernels, the reversible family is spanned by the symmetric kernels as follows.
Theorem 9
For \(\left| {\mathcal {X}} \right| \ge 3\), it holds that
Proof
We begin by proving the inclusion  . Let \(P \in {{\,\mathrm{e-hull}\,}}({\mathcal {W}} _{\mathsf {sym}})\), then there exist a positive \({\widetilde{P}} \in {\mathcal {F}}_+\), and \(k \in {\mathbb {N}}, \alpha _1, \dots , \alpha _k \in {\mathbb {R}}, P_1, \dots , P_k \in {\mathcal {W}} _{\mathsf {sym}}\) such that \(\log {\widetilde{P}}(x,x') = \sum _{i = 1}^{k} \alpha _i \log P_i(x,x')\). Observe that the function \(\sum _{i = 1}^{k} \alpha _i \log P_i(x,x')\) is symmetric in x and \(x'\), thus \(\log {\widetilde{P}}(x,x')\) is log-reversible, and P is reversible.
. Let \(P \in {{\,\mathrm{e-hull}\,}}({\mathcal {W}} _{\mathsf {sym}})\), then there exist a positive \({\widetilde{P}} \in {\mathcal {F}}_+\), and \(k \in {\mathbb {N}}, \alpha _1, \dots , \alpha _k \in {\mathbb {R}}, P_1, \dots , P_k \in {\mathcal {W}} _{\mathsf {sym}}\) such that \(\log {\widetilde{P}}(x,x') = \sum _{i = 1}^{k} \alpha _i \log P_i(x,x')\). Observe that the function \(\sum _{i = 1}^{k} \alpha _i \log P_i(x,x')\) is symmetric in x and \(x'\), thus \(\log {\widetilde{P}}(x,x')\) is log-reversible, and P is reversible.
We now prove the second inclusion  . We let
. We let
Recall from Theorem 4 that the functions \(g_{ij} = \delta _i ^\intercal \delta _j + \delta _j ^\intercal \delta _i\) , for \((i,j) \in T({\mathcal {X}}^2)\), form a basis of the quotient space  . It suffices therefore to show that \(\left\{ g_{ij} :(i, j) \in T({\mathcal {X}}^2) \right\} { \subset } {\mathcal {H}}\). Introduce a free parameter \(t \in (0, 1), t \ne 1/2\), and let us fix \((i,j) \in T_+({\mathcal {X}})\). Consider \(P_{ij,t} \in {\mathcal {W}} _{\mathsf {sym}}\) defined as follows
. It suffices therefore to show that \(\left\{ g_{ij} :(i, j) \in T({\mathcal {X}}^2) \right\} { \subset } {\mathcal {H}}\). Introduce a free parameter \(t \in (0, 1), t \ne 1/2\), and let us fix \((i,j) \in T_+({\mathcal {X}})\). Consider \(P_{ij,t} \in {\mathcal {W}} _{\mathsf {sym}}\) defined as follows
and the functions \({\hat{h}}_{ij}, {\tilde{h}}_{ij}\)
where for simplicity we wrote \(a = \log 2(1 - t)\) and \(b = \log 2t \ne a\). Since the function \(((x, x') \mapsto \log \left| {\mathcal {X}} \right| ) \in {\mathcal {N}}\), we have \({\hat{h}}_{ij}, {\tilde{h}}_{ij} \in {\mathcal {H}}\). Notice that we can write
hence also \(g_{ij} \in {\mathcal {H}}\). Introduce the function
and observe that we can rewrite the identity \(I = {\varvec{1}}^\intercal {\varvec{1}}- \sum _{(i,j) \in T_+({\mathcal {X}}^2)} g_{ij}\) with \({\varvec{1}}^\intercal {\varvec{1}}\) being a constant function. It follows that \(I \in {\mathcal {H}}\), and for any \(j \in {\mathcal {X}}\), we can express
As a result, \(\left\{ g_{ij} :(i,j) \in T({\mathcal {X}}^2) \right\} { \subset } {\mathcal {H}}\), and the theorem follows. \(\square \)
Remark 9
Observe that in the above proof, it is crucial that \(\left| {\mathcal {X}} \right| \ge 3\). For \(\left| {\mathcal {X}} \right| =2 \), we can only have \(h_{21} = \begin{pmatrix} 1 &{} 0 \\ 0 &{} 1 \end{pmatrix}\), and cannot construct \(g_{11} = \begin{pmatrix} 1 &{} 0 \\ 0 &{} 0 \end{pmatrix}\) nor \(g_{22} = \begin{pmatrix} 0 &{} 0 \\ 0 &{} 1 \end{pmatrix}\). This is consistent with the observation that  for \(\left| {\mathcal {X}} \right| =2 \).
for \(\left| {\mathcal {X}} \right| =2 \).
Secondly, we show that  is also the smallest mixture family that contains \({\mathcal {W}} _{\mathsf {iid}}\), the family of Markov kernels that correspond to iid processes. For this, we define minimality in terms of a mixture hull.
is also the smallest mixture family that contains \({\mathcal {W}} _{\mathsf {iid}}\), the family of Markov kernels that correspond to iid processes. For this, we define minimality in terms of a mixture hull.
Definition 8
(Mixture hull) Let \({\mathcal {V}} { \subset } {\mathcal {W}}\).
where Q (resp. \(Q_i\)) pertains to P (resp. \(P_i\)).
Theorem 10
It holds that
Proof
Let \(P \in {{\,\mathrm{m-hull}\,}}({\mathcal {W}} _{\mathsf {iid}})\), then the corresponding edge measure can be expressed as a linear combination \(\sum _{i = 1}^{k} \alpha _i Q_i\), with \(k \in {\mathbb {N}}, \alpha _1, \dots , \alpha _k \in {\mathbb {R}}\), and where the \(Q_i\) pertain to some degenerate iid kernel \(P_i = {\varvec{1}}^\intercal \pi _i\). This implies that \(Q_i(x,x') = \pi _i(x) \pi _i(x')\), hence \(Q_i\) is symmetric. In turn, Q is symmetric, i.e. P is reversible, and .
For \((i,j) \in {\mathcal {X}}^2\), \(i \ge j\), and \(\varepsilon \in [0, 1]\), consider the mixture distribution
A direct computation yields that the pair probabilities of the iid process can be written as
We first show that \(\left\{ Q_{ij,0} :i \ge j \right\} \) forms a basis of \({\mathcal {F}}_{\mathsf {sym}}\). Let \(\left\{ \alpha _{ij} \in {\mathbb {R}}:i \ge j \right\} \) be such that \(\sum _{i \ge j} \alpha _{ij} Q_{ij, 0} = 0\). Consider first \(x, x' \in {\mathcal {X}}\) such that \(x > x'\).
By a similar argument for the case \(x < x'\), we obtain that \(\alpha _{xx'} = 0\) for any \(x \ne x'\). Inspecting now the diagonal for \(x \in {\mathcal {X}}\),
This implies that the family \(\left\{ Q_{ij, 0} :i \ge j \right\} \) is independent. Since \(\dim {\mathcal {F}} _{\mathsf {sym}}= \left| {\mathcal {X}} \right| (\left| {\mathcal {X}} \right| + 1) /2 = \left| \left\{ Q_{ij, 0} :i \ge j \right\} \right| \), it is maximally so, thus forms a basis. However, the basis elements are not in \({\mathcal {W}} _{\mathsf {iid}}\). We therefore examine the case \(\varepsilon > 0\), and leverage the property that in normed vector spaces, finite linearly independent systems are stable under small perturbations (see Lemma 11 reported below for convenience) in order to show existence of a basis in \({\mathcal {W}} _{\mathsf {iid}}\).
Lemma 11
(Costara and Popa [48, p.9, Exercise 35]) Let \(n \in {\mathbb {N}}\), X is a normed vector space and \(x_1, \dots , x_n\) are n linearly independent elements in X. Then there exists \(\eta > 0\) such that if \(y_1, y_2, \dots , y_n\) are such that \(\left\| y_i \right\| < \eta \) for \(i = 1, \dots , n\), then \(x_1 + y_1, x_2 + y_2, \dots , x_n + y_n\) are also n linearly independent elements in X.
Let us consider \(({\mathcal {F}} _{\mathsf {sym}}, \left\| \cdot \right\| _{1,1})\), the space of real symmetric matrices equipped with the entry-wise \(\ell _1\) norm. For any \(i \ge j\) and for any \(\varepsilon \in (0, 1)\),
thus
Let \(\eta \) as defined in Lemma 11, with respect to the basis \(\left\{ Q_{ij,0} :i \ge j \right\} \), and choose \(0< \varepsilon < \frac{\eta }{5 \left| {\mathcal {X}} \right| ^2}\). Then \(\left\| Q_{ij, \varepsilon } - Q_{ij, 0} \right\| _{1,1} < \eta \), thus the family \(\left\{ Q_{ij, \varepsilon :i \ge j} \right\} \) is a also basis for \({\mathcal {F}} _{\mathsf {sym}}\) that lies in \({\mathcal {W}} _{\mathsf {iid}}\), whence the theorem. \(\square \)
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analysed during the current study.
Notes
We note that in information theory, \(P(x,x')\) is often denoted by \(P(x'|x)\). Our choice follows the applied probability literature (see e.g. Levin et al. [8]), and allows us to extend the notation seamlessly to general functions over \({\mathcal {X}}^2\).
Interestingly, the large deviation rate of g is given by the convex conjugate of the log-PF root of \({\tilde{P}}_\theta \) [15, Chapter 3].
References
Schrödinger, E.: Über die umkehrung der naturgesetze. Sitzungsberichte der preussischen Akademie der Wissenschaften, physikalische mathematische Klasse 8(N9), 144–153 (1931)
Dobrushin, R.L., Sukhov, Y.M., Fritz, J.: A.N. Kolmogorov - the founder of the theory of reversible Markov processes. Russian Math. Surv. 43(6), 157–182 (1988)
Kolmogorov, A.: Zur theorie der Markoffschen ketten. Math. Ann. 112(1), 155–160 (1936)
Kolmogorov, A.: Zur umkehrbarkeit der statistischen naturgesetze. Math. Ann. 113(1), 766–772 (1937)
Kelly, F.P.: Reversibility and stochastic networks. Cambridge University Press, Cambridge (2011)
Brooks, S., Gelman, A., Jones, G., Meng, X.L.: Handbook of Markov Chain Monte Carlo. CRC Press, Boca Raton (2011)
Aldous, D., Fill, J.: Reversible Markov chains and random walks on graphs (2002)
Levin, D.A., Peres, Y., Wilmer, E.L.: Markov chains and mixing times, second edition. American Mathematical Soc (2009)
Pistone, G., Rogantin, M.P.: The algebra of reversible Markov chains. Ann. Inst. Stat. Math. 65(2), 269–293 (2013)
Hayashi, M., Watanabe, S.: Information geometry approach to parameter estimation in Markov chains. Ann. Stat. 44(4), 1495–1535 (2016). https://doi.org/10.1214/15-AOS1420
Takeuchi, J., Nagaoka, H.: Information geometry of the family of Markov kernels defined by a context tree. In: 2017 IEEE Information Theory Workshop (ITW), IEEE, pp 429–433 (2017)
Miller, H.: A convexity property in the theory of random variables defined on a finite Markov chain. The Annals of mathematical statistics pp 1260–1270 (1961)
Donsker, M.D., Varadhan, S.S.: Asymptotic evaluation of certain Markov process expectations for large time, i. Commun. Pure Appl. Math. 28(1), 1–47 (1975)
Gärtner, J.: On large deviations from the invariant measure. Theory Probab. Applic. 22(1), 24–39 (1977)
Dembo, A., Zeitouni, O.: Large deviations techniques and applications, vol 38 (1998)
Csiszár, I., Cover, T., Choi, B.S.: Conditional limit theorems under Markov conditioning. IEEE Trans. Inform. Theory 33(6), 788–801 (1987)
Ito, H., Amari, S.i.: Geometry of information sources. In: Proceedings of the 11th Symposium on Information Theory and Its Applications (SITA ’88), pp 57–60 (1988)
Takeuchi, J.i., Barron, A.R.: Asymptotically minimax regret by Bayes mixtures. In: Proceedings. 1998 IEEE International Symposium on Information Theory (Cat. No. 98CH36252), IEEE, p 318 (1998)
Takeuchi, J., Kawabata, T.: Exponential curvature of Markov models. In: 2007 IEEE International Symposium on Information Theory, IEEE, pp 2891–2895 (2007)
Takeuchi, J., Nagaoka, H.: On asymptotic exponential family of Markov sources and exponential family of Markov kernels (2017)
Nakagawa, K., Kanaya, F.: On the converse theorem in statistical hypothesis testing for Markov chains. IEEE Trans. Inform. Theory 39(2), 629–633 (1993)
Nagaoka, H.: The exponential family of Markov chains and its information geometry. In: The proceedings of the Symposium on Information Theory and Its Applications, vol 28, pp 601–604, (2005) (available on arXiv:1701.06119)
Watanabe, S., Hayashi, M.: Finite-length analysis on tail probability for Markov chain and application to simple hypothesis testing. Ann. Appl. Probab. 27(2), 811–845 (2017). https://doi.org/10.1214/16-AAP1216
Moulos, V., Anantharam, V.: Optimal Chernoff and Hoeffding bounds for finite state Markov chains. arXiv preprint arXiv:1907.04467 (2019)
Hayashi, M.: Local equivalence problem in hidden Markov model. Inform. Geom. 2(1), 1–42 (2019)
Hayashi, M.: Information geometry approach to parameter estimation in hidden Markov model. Bernoulli to appear (2021+)
Amari, Si., Nagaoka, H.: Methods of information geometry, vol 191. American Mathematical Soc (2007)
Fujiwara, A.: Foundations of information geometry. Makino Shoten (2015)
Feigin, P.D., et al.: Conditional exponential families and a representation theorem for asympotic inference. Ann. Statist. 9(3), 597–603 (1981)
Küchler, U., Sørensen, M.: On exponential families of Markov processes. J. Statist. Plann. Infer 66(1), 3–19 (1998)
Hudson, I.L.: Large sample inference for Markovian exponential families with application to branching processes with immigration. Australian J. Stat. 24(1), 98–112 (1982)
Stefanov, VT.: Explicit limit results for minimal sufficient statistics and maximum likelihood estimators in some Markov processes: exponential families approach. Ann. Stat. 1073–1101 (1995)
Küchler, U., Sørensen, M.: Exponential families of stochastic processes: A unifying semimartingale approach. International Statistical Review/Revue Internationale de Statistique pp 123–144 (1989)
Sørensen, M.: On sequential maximum likelihood estimation for exponential families of stochastic processes. International Statistical Review/Revue Internationale de Statistique pp 191–210 (1986)
Chernoff, H.: A measure of asymptotic efficiency for tests of a hypothesis based on the sum of observations. Ann. Math. Stat. pp 493–507 (1952)
Gallager, R.G.: Information theory and reliable communication, vol. 2. Springer, Berlin (1968)
Van Campenhout, J., Cover, T.: Maximum entropy and conditional probability. IEEE Trans. Inform. Theory 27(4), 483–489 (1981)
Brill, P., Hlynka, M., Jiang, Q., et al.: Reversibility checking for Markov chains. Commun. Stochastic Anal. 12(2), 2 (2018)
Meyer, CD.: Matrix analysis and applied linear algebra, vol 71. Siam (2000)
Suomela, P.: Invariant measures of time-reversible Markov chains. J. Appl. Prob. pp 226–229 (1979)
Diaconis, P., Rolles, S.W., et al.: Bayesian analysis for reversible Markov chains. Ann. Stat. 34(3), 1270–1292 (2006)
Ohara, A., Ishi, H.: Doubly autoparallel structure on the probability simplex. In: Information Geometry and its Applications IV, Springer pp 323–334 (2016)
Hsu, D., Kontorovich, A., Levin, D.A., Peres, Y., Szepesvári, C., Wolfer, G.: Mixing time estimation in reversible markov chains from a single sample path. Ann. App. Probab. 29(4), 2439–2480 (2019). https://doi.org/10.1214/18-AAP1457
Stewart, G.W.: Matrix perturbation theory. Academic Press, Boston (1990)
Nielsen, A., Weber, M.: Computing the nearest reversible Markov chain. Numer. Linear Algebra Appl. 22(3), 483–499 (2015)
Fill, J.A.: Eigenvalue bounds on convergence to stationarity for nonreversible Markov chains, with an application to the exclusion process. The annals of applied probability pp 62–87 (1991)
Nagaoka, H.: Information-geometrical characterization of statistical models which are statistically equivalent to probability simplexes. In: 2017 IEEE International Symposium on Information Theory (ISIT), IEEE, pp 1346–1350 (2017)
Costara, C., Popa, D.: Exercises in functional analysis, vol. 26. Springer Science & Business Media, Berlin (2013)
Acknowledgements
Many thanks to the anonymous referees for the helpful comments, which helped us to improve the presentation of this manuscript. We also thank Hiroshi Nagaoka for an enlightening discussion, and constructive remarks, as well as Alexander Yu. Mitrophanov for commenting on a previous version of this manuscript.
Open Access
This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The first author is supported by the Japan Society for the Promotion of Science (International Research Fellow, and under KAKENHI Grant 21F20378). The second author is supported in part by Japan Society for the Promotion of Science KAKENHI under Grant 20H02144.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wolfer, G., Watanabe, S. Information Geometry of Reversible Markov Chains. Info. Geo. 4, 393–433 (2021). https://doi.org/10.1007/s41884-021-00061-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41884-021-00061-7