
Abstract
Metal powder bed fusion (MPBF) is not a standalone process, and other manufacturing technologies, such as heat treatment and surface finishing operations, are often required to achieve a high-quality component. To optimise each individual process for a given component, its progression through the full process chain must be considered and understood, which can be achieved through the use of validated models. This article aims to provide an overview of the various modelling techniques that can be utilised in the development of a digital twin for MPBF process chains, including methods for data transfer between physical and digital entities and uncertainty evaluation. An assessment of the current maturity of modelling techniques through the use of technology readiness levels is conducted to understand their maturity. Summary remarks highlighting the advantages and disadvantages in physics-based modelling techniques used in MPBF research domains (i.e. prediction of: powder distortion; temperature; material properties; distortion; residual stresses; as well as topology optimisation), post-processing (i.e. modelling of: machining; heat treatment; and surface engineering), and digital twins (i.e. simulation of manufacturing process chains; interoperability; and computational performance) are provided. Future perspectives for the challenges in these MPBF research domains are also discussed and summarised.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The capability of metal powder bed fusion (MPBF) to produce complex structural components in a wide range of materials has the potential to remove traditional manufacturing constraints from product design. This can enable greater product performance to be achieved through the creation of more functional shapes, the reduction of weight, and the consolidation of multi-part assemblies into single components.
MPBF is not without its drawbacks where key challenges such as poor surface finish, uncertainty and standardisation in part quality and certification, high processing costs, and process variability must be overcome [1]. In many cases, existing technologies can be employed to do this, such as post-processing methods for improving material properties, and digital tools for planning and optimising operations. By linking all of these physical and digital components together, it is possible to create a “digital twin”, a digital replica of a physical asset, process, or system that uses associated real data streams to communicate with and optimise its physical counterpart [2, 3].
Digital twins have become increasingly common in the industry over the last decade, with prime examples being digital twins for asset monitoring [4, 5]. It will ultimately be desirable to create a digital twin of the entire MPBF process chain, whereby data is passed from one process simulation to the next, models are updated according to machine and inspection data from physical sensors, and components and production plans are updated and optimised accordingly via data analytics and artificial intelligence. This would enable designs and processes to be optimised for a particular part with less reliance on costly and time-consuming physical trials, increasing productivity and reducing the barriers to new product introduction [3]. Work on digital twins in additive manufacturing has shown conceptual developments that can be the basis to deliver industrial impact [6,7,8,9], however, further work in the development of digital twins would help to fully realise all of the benefits of additive manufacturing in the industrial production environments while maximising productivity and cost-efficiency.
This paper reviews the state of the art for modelling the physics of manufacturing processes involved in MPBF process chains, with a view to support the realisation of future digital twins. Areas of focus are the process models themselves and methods for passing data between simulations according to the physical process chain, as well as how this affects confidence in the results of the models and the propagation of uncertainty. This allows the maturity of the various modelling methods and data transfer technologies to be assessed through the use of Technology Readiness Levels (TRLs) so that roadmaps of their predicted development can be generated in the near future.
2 Digital twin and process chain concepts in MPBF
2.1 Overview of a digital twin concept
A digital twin can be described as an organised collection of physics-based methods and advanced analytics that is used to model the present state of every asset [3, 10]. By additionally considering the data streams of these assets and communicating with them, it can be considered as a digital counterpart to physical reality. Wherever a physical tool services a need (for example moving people from one place to another, electricity provision, manufacturing a product, etc.), a virtual counterpart can be created to plan, optimise, and control it. For MBPF, a process chain digital twin would provide accurate predictions of component properties, greatly reducing the amount of trial-and-error physical experimentation that is required when developing new parts.
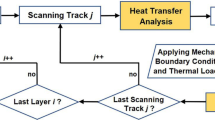
To describe the role of the simulation models in a digital twin, Fig. 1 shows an example of a digital twin concept for product and process development in MPBF. Alongside the digital twin is the physical environment, as well as middleware that facilitates connectivity and the transfer and storage of data, information, and knowledge. This can all be accessed by people with the necessary knowledge to act upon it, for example by deciding the next step of the product and process development. Information from the digital twin could also be used to inform other decisions, such as optimising the layout of a facility and production schedules, developing cost models, or adapting the post-processing route to help combat the variable nature of MBPF production.

An example of a digital twin for product and process development
The first step in the development of a product is the design work, which can include simulation and other analyses to optimise design performance. Once an initial design has been created, the product undergoes design for manufacture. This includes simulating the manufacturing process chain to determine the geometric and material changes that will arise when the material is subject to mechanical and/or thermal energy inputs. The steps shown in Fig. 1 include an additive manufacturing (AM) build process, followed by heat treatment (HT), machining operations (MO), and surface engineering (SE). The simulation of this chain can generate useful knowledge for product and process development, such as the optimal parameters for a particular process and potential regions of risk in the design geometry. Following this, the part performance analyses can be conducted again to assess the impact of any geometry and material changes that may arise during manufacture.
Once there is sufficient confidence that the design meets the requirements for functionality and performance, physical manufacturing trials can be executed. The test parts may be inspected for dimensional accuracy, surface quality, material characteristics, and internal defects at each stage of the manufacturing process, and this data is passed back to the simulations so that they can be updated, validated, and identify solutions to any potential problems that may arise during manufacture. The relevant experts then decide whether more improvements or iterations are needed and where such changes are required. An example problem could be an excessive distortion of the part in some locations, which could be addressed through further stiffening of the geometry in that area or by applying distortion compensation based on inspection or simulation results [11,12,13].
The final step is physical testing of the MPBF parts using test rigs representing in-service conditions. Further development iterations may be needed if the functionality of the parts does not meet the requirements or if further quality improvements or cost reductions can be achieved. Once the designed MPBF parts and the associated processes have been developed, inspected and tested, the designs can be prototyped and further progressed for production.
The presented example shows that physics-based modelling and simulation could potentially provide more benefits in the process and product development stage if they are integrated in a digital twin.
2.2 Overview of process chain simulation concept
Physics-based simulation is typically used in design and manufacture to reduce the need for costly experimental work, for example by examining variables in a manufacturing process or a test that the final product will undergo. These simulations typically require material properties that are heavily dependent on temperature and strain rate, as well as they can undergo phase changes during use. For instance, physics-based simulations have been applied to manufacturing processes, such as: forming and forging [14,15,16,17,18], casting [19,20,21], welding [22,23,24], metal cutting [25,26,27], non-conventional machining [28, 29], additive manufacturing [30,31,32,33], shot-peening [34, 35] and heat treatment [36,37,38]. A new vision, in which micro-structural simulations, multi-scale process and material models, and manufacturing process chain simulations can be integrated into a single workflow, would enable material properties to be predicted and propagated from simulation to simulation.
Figure 2 shows a suggested manufacturing process chain simulation workflow. The vertical direction shows a multiscale materials computational approach, the objective of which is to (i) predict the microscale mechanical fields characterising the mesoscale based on local microstructure information and (ii) derive the component-level properties from the mesoscale behaviour. Challenges in this direction include the development of efficient and accurate macroscale continuum models that implicitly simulate the influence of process-induced microstructure variations on the process, and characterisation and classification of micro-structural simulation outputs into multi-scale models representing material behaviour. This needs to be accomplished without significantly compromising accuracy and also needs to be capable of coping with numerical discontinuities, so that the multi-scale build models can be used to inform subsequent process models.

MPBF process chain simulation concept
The challenges in the horizontal direction regard data transfer between different micro-structural simulations, material models, and process simulations. This must be accomplished to predict the micro-structural defects, residual stresses, geometric distortion, fatigue life, and mechanical properties of parts passing through the process chain.
The simulation workflow shown in Fig. 2 aims to reduce the amount of physical testing required to obtain the material properties that are necessary for manufacturing process simulations. Although doing so would not completely replace the need for obtaining physical material property data, building on the results of process-specific micro-scale models should enable more effective simulation of emerging materials and applications.
3 Laser powder bed fusion (LPBF)
The multiscale nature of the LPBF process means that behaviour over a range of length and time scales needs to be addressed if an entire process chain is to be realised. At the lowest level, interactions between the heat source and the powder particles are fundamental in the development of the melt-pool and resulting thermal fields. The solidified microstructures are composed of grains (of the order of tens of microns), fine precipitates (of a few nanometres) and voids (ranging from nanometres to microns in size). These factors will then influence the mechanical response of the material at the mesoscale, characterised as length scales of ~ 100 μm. In general, the resulting micromechanical fields will be non-uniform at these length scales.
3.1 Micro and meso scale models
Physical modelling of the powder melting process is extremely challenging. To arrive at accurate results, a representative statistical distribution of the powder particles within the layer of interest must first be obtained. Powder size distribution impacts the packing density of the powder bed which has been linked with the formation of lack-of-fusion voids [39]. The relationship between the powder size distribution and the packing density is shown in Fig. 3.

Packing density (f) reaches a maximum (f*) when the particle size distribution includes a mixture of small (s) and large (L) particles. Image sourced from [40]
One method used for generating a powder bed is the rain model [41], whereby a falling particle searches for a local minimum in potential energy. The falling particle rotates as necessary when coming into contact with another particle, ultimately either settling in place at the local minimum or falling until reaching the global minimum. Variations of this method have been employed by a range of authors [42,43,44] to generate distinct powder packing characteristics based on experimentally measured particle size distributions. An alternate technique is the use of the discrete element method to simulate the raking of powder particles into position on the bed [45,46,47,48]. In this approach, the motion of the individual particles and their effects on one another are computed by considering the various forces that act on each particle, such as friction and gravity. Most of these approaches currently consider spherical particles.
In addition to the powder bed, the laser beam power, point distance, and scan speed all have significant impacts on the melt-pool dynamics, spatter pattern, and sublimation of particles, and therefore the resulting porosity and surface roughness of the part [49]. The heat source can be described using a variety of techniques, such as Gaussian expressions [50, 51] or ray tracing that describes the absorption and reflection of the laser by the powder and substrate [52].
One of the main purposes of meso-scale modelling is to predict porosity and the cooling rates that dictate microstructural evolution, and thus component properties. The meso-scale describes phase transitions during laser melting, capturing the molten pool dynamics as a function of the powder, process parameters, and material [43].
The melting and solidification are achieved by scanning a laser beam over a randomly distributed powder bed, which in turn is situated over a preplaced powder layer or previously solidified powder layer in a multilayer scanning strategy. The development of porosity has been correlated experimentally with both top sample surface structures and the melt pool and flow behaviour [53], and this behaviour has been further explained through numerical modelling [54]. Recent experimental analysis into the transient dynamics of powder spattering in LPBF has provided information on the various powder melting stages that dictate local flow dynamics as well as the effect of environmental pressure on spatter [55].
Given the stochastic nature of the process being simulated, confidence in the output of powder melting models may be improved through running multiple simulations with different powder bed morphologies. Doing so enables the construction of probabilistic functions, for example of porosity against energy density, layer thickness, and beam scanning speeds. The output of these meso-scale models is a thermal history that can be used for the calculation of microstructure evolution and the prediction of effective material properties. In particular, homogenisation of microscale fields defined within a representative volume element (RVE) or unit cell provides a method for calculating the mechanical and thermal properties of an additively manufactured material [56]. The advantage of such simulations is that details of the process-induced microstructure are explicitly accounted for. Such methods also enable the exploration of the sensitivity of the effective properties to the presence of voids and unmelted particulates [57], ensuring that the effects of variable build quality can be considered at component level. For an additively manufactured material, it is likely properties would be orthotropic or anisotropic [58, 59] since build direction will potentially have an effect on properties. For a material with some random factors in its microstructure, such as porosity or grain orientation, many randomly generated RVEs should be analysed to capture the statistical variability correctly, leading to a corresponding statistical description of the component level properties.
Many parts have elaborated internal geometry with cellular, lattice or beam structures providing high performance to weight ratio, and homogenisation methods can evaluate the effective properties of these substructures to simplify simulations at component level [60, 61]. Homogenization methods have also been used in conjunction with topology optimisation methods to define effective properties for topological designs created using density-based methods [62]. Some software vendors are already building RVE-type tools into their engineering simulation packages to facilitate the use of these approaches. Other homogenisation methods are limited to regular or nearly periodic geometries, but they can be useful for porous materials with medium to low porosity levels and widely separated pores. The simplest of these is Maxwell’s method [63] which can be used to calculate effective mechanical and thermal properties for materials with spheroidal pores and inclusions.
Microstructural evolution models can be grouped into interface tracking methods (such as phase field and level-set) [64,65,66,67], cellular automata (CA) [68, 69] and kinetic Monte Carlo (kMC) [70]. The interface tracking methods have shown a realistic modelling of dendritic structures while accounting for the solute segregation, however the higher computational requirements often limit the application over a large number of grain-aggregates. On the other side, kMC based on the Potts model captures the general characteristics of solidification of grains over a large number of grain aggregates, however, it cannot predict the range of solidification structures observed during LPBF such as cellular and dendritic domains. The CA methods based on finite element or finite difference schemes provide a half-way solution between interface tracking and kMC methods. They can deal with a range of computational domain sizes and are able to simulate cellular, dendritic and large-scale grain structures. The CA-FD (cellular automata finite difference) approach has recently been extended by Panwisawas et al. [43] to take into account local curvature effects as well as strain energy contributions and mass transport.
Despite these advances, it is still a challenge to numerically model the complexity of the LPBF over multiple scales. This challenge is increased by statistical variation and a lack of material data in the literature. The accurate prediction of surface roughness, mechanical and physical properties, fatigue life, melt-pool dynamics, and porosity remains a distant goal.
3.2 Component scale models
At present, macro-scale models tend to be based on empirical data (commonly using an eigenstrain formulation) and as such are relatively computationally efficient and have been demonstrated to be effective in simulating trends for the development of residual stresses and topological deformations accompanying the LPBF process [71]. However, such models do not explicitly consider the powder particles and their interactions with the heat source, and neglect the important meso-micro scale fluid dynamics [72]. The biggest challenge in modelling the build of an entire component at the micro and meso scales is excessive computational time, which arises due to the large number of finite elements needed to represent the additive layers. To reduce computational time, some researchers have adopted the “classical welding” approach for modelling the melt pool and assume that the powder can be modelled as a continuous solid. Although this is a significant simplification, such models can produce representative results after calibration against measured data [73]. Even with this assumption, the classical welding approach still requires large computational times unless additional approaches are utilised. For example, dynamic adaptive meshing techniques to maintain mesh refinement around the heat source while coarsening it elsewhere have been used [74, 75]. This technique requires temperature data to be mapped between dissimilar meshes, introducing further computational effort and sources of error.
Analytical formulations have been used to predict the thermal history of a moving laser [76]. Similar approaches have been used in modelling the welding process [77]. The method is extremely fast and can deliver quick solutions, meaning it has the potential to be used at the component scale. The disadvantages are that it cannot consider temperature-dependent thermal properties and lacks the ability to incorporate realistic boundary conditions. Since the heat source beam is very small compared to the component and surrounding powder, the analytical thermal model is similar to conduction in an infinite body. Terry et al. [78] demonstrated that the use of an analytical thermal model to predict temperature evolution in an industrial impeller is feasible for both single and multiple laser systems. Figure 4 is sourced from this work, and it shows the predicted temperature at the top three layers of an impeller made of In718. The computational time required to provide this prediction was reported to be less than a minute. Terry et al. [78] also demonstrated the integration of a machine toolpath generated by a Computer-Aided Manufacturing (CAM) system into their model.

Prediction of thermal history of IN718 impeller using a multi-layer analytical thermal model integrated with a gCode reader [78]
Another challenge in modelling the melt pool at the component scale is the selection of an appropriate heat source model (surface or volumetric heat source). It is well known in welding modelling that volumetric heat source models more realistically represent the melt pool generated by laser melting. Surface heat sources, such as a 2D Gaussian heat source, lack the ability to quickly transfer energy into the material, which results in shallower melt pools. A common technique used in welding is to calibrate the heat source model to match the melt pool dimensions [79]. This suggests that a calibration step is essential to gain confidence in LPBF models thermal models.
At the component scale, temperature predictions are vital for simulating the thermal expansion and the generation of thermal stresses and distortion. Due to the aforementioned challenges in calculating temperature, predicting the residual stresses and distortion using conventional coupled thermo-mechanical approaches has proven to be challenging. This has led to the development of different techniques for predicting mechanical behaviour. For example, researchers have assumed that a number of layers can be lumped together and assigned a given temperature, before being allowed to cool [80]. Other researchers applied a heat flux based on the energy equilibrium, rather than an initial temperature [81]. In both approaches, the prescribed temperature field does not represent the actual temperature during the process. Analytical temperature fields have also been used to induce thermal strains and stresses [11, 82]. This methodology has been validated using a radially and vertically varying temperature field [82, 83]. Other researchers have adopted the inherent strain approach [83,84,85], which treats the residual strains in the material as a source for calculating the residual stresses with Hooke’s law. In the finite element model, the plastic strains represent the residual strains. Some researchers have therefore solved the thermo-mechanical problem at the micro scale to predict the plastic strains, before imposing them in a component scale model. It is typically assumed that the strains are uniformly distributed in a single layer. While the inherent strain method is usually based on the theory of elasticity, some researchers have found that considering plasticity improves distortion predictions [83].
Figure 5 shows a comparison of fast methods for predicting distortion in LPBF [83]. It can be seen that the accuracy depends on the selected method. The inherent strain method using elastic plastic material properties shows the most accurate prediction of distortion distribution and magnitude of an impeller made of In718. The difference of the maximum predicted and measured surface deviation in the buckled blade was approximately 11%. Such predictions can be used to assess the likelihood of build failures due to recoater collision or support failures, and can also help with selecting appropriate support strategies. Distortion predictions can also be inverted and used to pre-distort the initial geometry, so that the built part distorts into the correct shape, rather than out of it. This concept has been demonstrated to be feasible and implementable on industrial parts [11, 86]. The main challenge is the requirement for an accurate initial distortion prediction; however, it has been demonstrated that pre-distorting the geometry using experimentally measured data from a test component can deliver distortion compensation of approximately 75% using one iteration for an impeller and a blade [12], and a manifold [13]. Figure 6 shows an example of a distortion compensation of an impeller where the distorion was reduced from approximately ± 300 μm to approximately ± 65 μm.

Comparison of calculated surface deviations obtained using various fast predictive methods and experimentally measured data, all aligned to the nominal geometry using the same alignment method [83]. Units in mm

The effect of compensation on the distortion of two otherwise identical experimental In718 Impellers [12]. The surface deviation vs. nominal geometry is plotted and was measured using a structured light scanner. Dimensions in mm
Modelling residual stress at the component scale is another challenge. Most of the validations of LPBF models are based on distortion comparisons, although there are a number of studies comparing predicted and experimentally measured residual stresses. For example, Yaghi et al. [83] compared residual stresses obtained with fast finite element predictive methods against experimentally measured stresses obtained by the neutron diffraction method for a component made of In718 as shown in Fig. 7. The fast-predictive methods were: (i) inherent strain method with elastics material model; (ii) inherent strain method with elastic–plastic material model; and (iii) analytical thermal field using temperature dependant elastic–plastic material properties [11]. It can be seen that the three methods capture the overall behaviour of the residual stress distribution (tensile at the surface and compressive inside). The analytical temperature field method predicted the residual stresses most closely to the experimentally measured results where the difference of predicted and measured peak compressive stress was approximately 9.5%. Also, Yaghi et al. [87] compared predicted stainless steel 316 residual stresses against data that was obtained using the contour and hole drilling methods. A comparison between the contour and finite element methods are shown in Fig. 8. It was reported that the FE predicted and experimentally measured residual stresses demonstrate reasonable agreement except at the bottom right corner, where the predicted stresses are lower. This could be due to the fact that the predicted residuals stresses from the process models are based on a 3D geometrically circumferential model of the impeller, whereas the calculated stresses in the contour method are based on distortion measurement of a cross section applied into a plane strain FE model to calculate the residual stresses using the Hooke’s low [87].

Comparison of FE and experimentally predicted stresses for In718 [83]

Comparison of FE and experimentally predicted residual stresses for stainless steel 316 [87]
4 Electron beam powder bed fusion (EBPBF)
Similar approaches to modelling LPBF are often used in the modelling of EBPBF, with considerations given to the different physics of the two process. In EBPBF, the primary energy source for powder melting is the kinetic energy of electrons travelling at around 0.1–0.4 times the speed of light [88]. Upon collision with a powder particle, some of this kinetic energy is converted to heat. With a sufficient number of collisions, the heat generated is easily capable of melting the metal.
A recent review of EBPBF modelling techniques highlighted three main approaches for modelling the EBPBF process [88]:
-
Uncoupled thermal models, which simplify the physics and reduce the computational resources required by only considering the main heat transfer phenomena. These consist of conduction between the powder particles, conduction between the powder bed and substrate, and radiation from the powder into the chamber. Heat dissipated by viscous forces and convection in the melt pool are ignored [89, 90].
-
Thermal-fluid models, which include the effects of flow convection on the temperature distributions and melt pool geometry [91, 92].
-
Thermomechanical models, which incorporate mechanical properties to predict the residual stresses induced in the material by the EBPBF process. This results in more informative models at the cost of longer run times [93].
Models can also be split according to how they treat the powder; some consider individual powder particles, while others treat the powder as a continuum. Examples of thermal-fluid models include using a lattice Boltzmann approach to model the melting of a randomly generated powder bed with an electron beam [94]. Different approaches are used in the modelling of the heat source as well, for example simulating the impact of electrons on the powder bed using a Monte Carlo method to predict the heat flux distribution across the beam diameter [90].
At the component scale, EBPBF models also need to consider the effect of the semi-sintered powder on the stress and distortion of the part, as this can affect the heat transfer from a component as well as the mechanical loads on it. A compact model of the EBPBF processes to predict shrinkage was developed in [95]. The model assumes that the thermal stresses can be neglected because they are low due to the elevated temperature in the build machine, and that the creep rates at temperatures above 1000 °C are significant, leading to quick stress relief of the parts. Considering this assumption, the EBPBF process model can be simplified by assuming an initial temperature of the part equivalent to the temperature in the build machine and allowing it to cool down to room temperature using natural convection. Figure 9 shows a comparison between experimental and predicted distortion for Ti64 part produced on the Arcam Q20 [96]. The results show a very similar distribution between predicted and measured distortion by comparing the surface deviations. It was reported that the maximum surface deviations were less than 8% between predicted and measured surface deviations. It needs to be noted that creep deformations due to gravity loads have not been modelled. However, the proposed model showed that it can predict the overall distortion and it can be used for distortion compensation instead of using global or Cartesian scaling factors.

Comparison of experimental data with FE predictions for EBPBF shrinkage of a Ti64 component [95]
5 Topology optimisation models
The topology optimisation can be tracked back to over a hundred years ago where criteria for least-weighted layout of trusses was developed. In the seventies, analytical solutions were developed for grid-type structures. With the emergence of the finite element method, the topology optimisation started its rapid development along with the development of computational capabilities. The following methods emerged since then, including in chronological order: density-based methods, evolutionary procedures, bubble method, topological derivative, level-set methods and phase field methods [97, 98]. Those methods have been incorporated in commercial finite element solvers to tackle structural topology optimisations, particularly light weighting of structures. Choe et al. [99] benchmarked commercially available software and the results showed that the topology optimisation methods subject to mechanical loads are mature enough to be applied to industrial designs. Dbouk [100] reviewed the research work conducted in the last 20 years in the topology optimisation of heat transfer and fluid flow systems. They concluded that despite the advanced developments and advanced work in the field, the topology optimisation is not a robust numerical design technique for finding optimal designs of thermal systems. Therefore, further work is required to mature and validated the numerical techniques before they are adopted in industry. Topology optimisation methods have been applied in electro-magnetisms, but those methods have not been widely adopted in industry despite the promising results published in the literature [101]. Computation fluid dynamics methods using gradient-based algorithms, stochastic algorithms and metamodeling have been applied to aerodynamics shape optimisation applications [102].
Topology optimisation algorithms that consider manufacturing constraints have been developed for minimum member size, minimum hole size, symmetry, pattern repetition, casting, milling, turning, forging, extrusion and rolling [103]. The inclusion of manufacturing constraints modifies the solution resulting in greater material volume/mass for the design. In additive manufacturing, particularly powder bed technologies, supports are used for build angles lower than 45°. The implementation of overhang-free topological designs has been demonstrated for different topology optimisation methods [104]. For additive manufacturing design application, where the use of supports is unavoidable for some geometries, topology optimisation methods can be used to generate the supports. For example, a validated process model for a build simulation was used to predict the forces acting at the overhang structures in [95] based on the model presented in [11] where the support structures are modelled with spring elements to represent the stuffiness of the support structures in the three directions of the Cartisian coordinate system. The predicted forces were then applied to a topology optimisation model to obtain the support structures (see Fig. 10). It was found that the topology optimised supports were 50% lighter than conventionly generated supports using commercially available tools [95].

Topology optimised supports based on predicted forces from a process model [95]
Additive manufacturing induces material anisotropy which is unavoidable despite the efforts made to be reduced. The material anisotropy constraint has been implemented by the implemented anisotropic constitutive material model in the finite element solution or by changing the plasticity criteria [104]. Furthermore, topology optimisation techniques for multi-materials, microstructure control and lattices have been reviewed and presented as future development opportunities towards their maturation [104, 105].
In additive manufacturing process chains, post-processing steps (heat treatment, surface finishing, surface hardening, and inspection techniques) can be required to deliver the functional requirements of designs. Therefore, considering topology optimisation for additive manufacturing process chains can introduce further complexity due to an increased number of manufacturing constraints. To the best knowledge of the authors, the inclusion of manufacturing constraints considering the full additive manufacturing process chain has not been addressed by the research community which presents an opportunity for future research.
6 Post-processing operations
6.1 Heat treatment
Heat treatment is an important step for most MPBF components, and it can deliver improved performance through aging and residual stress relief. The latter is typically conducted for a relatively short period of time (i.e. a couple of hours, depending on the material and thermal mass of the part). Depending on the material performance that needs to be achieved (for example large grains for better creep performance or fine grains for better fatigue performance), the aging time can be significantly greater.
Modelling both processes requires the prediction of the thermal history in the furnace. Many furnaces operate under a vacuum, meaning heat is primarily transferred from the heating elements to the parts through radiation. Reflection at the part needs to be considered when modelling this radiation, which can be accomplished using view factor calculations [38]. These models can accurately predict the thermal history of the parts, and can therefore provide practical benefits. These include optimising the power in the heating elements to control thermal gradients, or identifying how to position the parts in the furnace to avoid shading and cold spots [106]. The predicted thermal history can also be used to calculate the evolution of the microstructure and support the development of the most appropriate thermal cycle [36]. One of the challenges in this type of modelling is determining the surface emissivity, which depends on the surface oxidation and surface roughness. The emissivity can vary over a wide range, suggesting that validation using experimentally measured temperatures should be used to gain confidence in the values used [107].
Post-build stress relief modelling requires the thermal history from the heat treatment process and residual stresses in the component from the MBPF build process. Stress relief or relaxation is typically simulated with a creep model, which is generally empirical and describes the material response to temperature and stress as a time-dependent process. Creep models are based on material data gathered from tests conducted at either constant load/stress or constant elongation/strain. The strain rates for each of the creep tests at constant stress are obtained at the secondary creep region.
There is limited creep data for materials manufactured using powder bed fusion in the literature. What is available is often for different temperatures than those of the stress relief thermal cycle used for additive manufacturing. For example, Read et al. [108] conducted creep tests at constant stress for AlSi10Mg at 180 °C, while the typical stress relief thermal cycle for AlSi10Mg is heating up to 300 °C, holding for 2 h and cooling down to room temperature.
The Norton creep law is commonly used to simulate stress relaxation. O’Brien et al. [109] conducted a study where the Norton creep constants for In718 at 980 °C were obtained using a reverse engineering approach. The manufacture of a cantilever beam specimen that was built on a Renishaw AM250 and heat treated (by heating to 980 °C, holding for 2.5 h at 980 °C, and cooling down to room temperature) was simulated using a validated LPBF build model and the Norton creep law approach. Figure 11 compares measurements from the physical parts with simulated distortion predictions for both the as-built and stress relieved parts, demonstrating the validity of the Norton creep law approach for simulating stress relief. O’Brien et al. [109] reported that the maximum measured and predicted vertical distortions after cutting the double cantilever beam from the baseplate after LPBF were between 0.84 mm and 0.87 mm respectively, which is less than 4% difference. They also reported that the vertical displacements were less than 0.04 mm for both the predicted and measured vertical displacements after the stress relief step.

Results from a study comparing measured and predicted vertical distortion for an as-built and stress relieved cantilever beam for In718 [109]
6.2 Machining operations
A disadvantage of powder bed fusion technologies is an inability to produce quality surface finishes without further processing, particularly on overhanging structures [110]. The typical average surface roughness (Ra) for LPBF is in the vicinity of 20 µm, depending on the material, laser system, powder characteristics, and build angle [110, 111]. Yaghi et al. [87] conducted milling on an LPBF manufactured stainless steel 316 impeller to demonstrate the improved surface finish that can be achieved. Milling can also induce compressive residual stresses at the surface, which can be beneficial for fatigue life [112]. Grinding is another process that can be employed for improving the surface finish and surface integrity [113].
The modelling of conventional material removal processes is typically done by deactivating elements of the finite element stiffness matrix [27, 114]. The element deactivation technique does not take into account the effect of the tool-workpiece interaction on the surface stresses, meaning potential contributions to residual stress, distortion, and component fatigue life are neglected. Yaghi et al. [87] consider the surface stresses in their work by combining the bulk material removal process and the tool-workpiece interaction. This was achieved by imposing surface stresses obtained from experimental measurements, although simulation-based surfaces stresses could also be imposed if desired.
Conventional machining processes can only be conducted once a build is complete, and it can therefore only be applied to external surfaces and any internal features that can be accessed by the machine tools. Given the complex geometries powder bed fusion permits, conventional machining processes may not be capable of providing a quality surface finish on all surfaces of an AM part. Hybrid LPBF combined with micro-milling can overcome this limitation by machining the internal and external surfaces as the layers are built up. Little research has been conducted into modelling hybrid LPBF and micro-milling. Afazov et al. [115] used the inherent strain approach for modelling LPBF and further developed the inclusion of the micro-milling process. The material removal process was modelled by deactivating elements form the stiffness matrix, in a similar fashion to the modelling of conventional machining. A comparison of predicted and experimental distortion for a hybrid LPBF component is shown in Fig. 12 where it can be seen that the predicted and experimentally measured distortion have similar overall distribution. In addition, the peak distortion deviations have the same location and pattern. The authors used the model to optimise a nozzle design by incorporating two additional applied stiffeners at the outlet where the distortion was alleviated by approximately 60% at the bottom of the nozzle, with the entire nozzle being within the application specified tolerance of ± 0.2 mm.

Modelling of hybrid LPBF for a stainless steel 316 component. The figure shows a comparison of experimentally measured surface deviation from the nominal geometry and that predicted numerically [115]. Units in mm
6.3 Surface engineering
Treating the surface of LPBF parts is essential for improving the surface finish and/or surface integrity. A high-quality surface finish (with low surface roughness) improves the fatigue life [116], while surface treatment can also be used to improve surface functionality by creating an appropriate surface texture [117]. The most widely used technologies for improving the surface quality of LPBF parts are sand blasting, laser polishing, linishing and mass finishing. Fatigue life improvements can also be achieved by applying surface hardening processes, such as shot-peening and laser shock peening.
The numerical modelling of some of the surface engineering processes can be challenging, and it may require the use of alternative analytical solutions. For example, the modelling of sand blasting can be very computationally expensive, since there is a need to calculate multiple particle impacts over large surfaces. Developing a material model capable of accurately capturing the abrasive phenomena involved in sand blasting is another challenge [118]. Linishing and mass finishing processes present similar challenges, and so analytical and empirical solutions are often utilised for prediction and optimisation purposes [119].
Laser polishing can be numerically modelled by applying a volumetric heat source that produces the required melt pool shape [120]. This type of model can predict temperature distribution and residual stresses, however, the prediction of surface roughness after melting can be very challenging. The surface roughness is therefore typically predicted using empirical equations, which can be developed using techniques such as regression or artificial neural networks [118]. Regression functions have also been utilised in mass finishing for the prediction of surface roughness [121].
Shot-peening has been modelled at the micro scale, including the impact of a number of shots on a small surface. This type of modelling can give an understanding of the effect of ball diameter, momentum, impact angle, and surface coverage on the induced residual stresses. The main challenge in modelling shot-peening is developing a material model to account for the cyclic hardening caused by multiple shot impacts. Previous reviews of these models have shown that the combined use of kinematic and isotropic hardening can produce good predictions [35]. Unfortunately, micro scale modelling cannot be applied at the component scale due to the large computational requirements that would arise. To overcome this, micro-to-macro mathematical models have been developed to map residual stress profiles to the component level [122]. The mapping techniques have been successfully applied to aerospace components [123].
In a similar fashion to modelling shot-peening, laser shock peening modelling is conducted at the micro scale. The laser shockwave is represented by a moving pressure distribution that follows the toolpath of the laser. The pressure distribution is calculated from the laser pulse and the laser power using empirical methods. Laser shock peening is very quick, with the laser pulse for a single shock usually less than 100 ns. This requires the use of strain rate-dependent models such as the Johnson–Cook model and an explicit dynamic finite element solver [124]. The challenge in laser shock peening is obtaining the residual stresses after the explicit dynamic simulation. The stresses oscillate after each shock and cannot reach equilibrium, despite the use of infinite elements that have been used in the modelling of shot-peening to minimise the dilatational and shear wave energy reflected back into the finite element mesh. The use of the inherent strain approach has proven that the modelling of laser shock peening is possible [125]. This approach consists of a dynamic model predicting the plastic strains induced by the laser shockwaves. The plastic strains are then used as inherent strains in an implicit finite element solver to predict the residual stresses. Figure 13 shows a comparison between predicted and measured residual stresses for In718, which can then be mapped to the component level using a micro-to-macro scale mathematical model using the formulations from [122]. The results show that the model can predict peaks of the residual stresses while the experimentally measured residual stresses represent an average representation of the area. Therefore, it is difficult to quantify the accuracy of the model.

Prediction of residual stresses using eigenstrain modelling and experimental data for In718 [126]
6.4 Inspection
Inspection is discussed briefly as this is the means by which experimental data is obtained for use in and validation of models. Inspection here relates to integrity assessment of parts (typically by non-destructive testing means), dimensional conformance analysis (deviations from nominal, etc.) and surface topology measurement. Such inspection may be conducted at multiple stages in the LPBF process chain, including during the build itself, and may be applied to feedstock, test coupons, full components or sectioned regions (destructive cut-ups). From the perspective of inspection providing an input/target output for a model of part of the LPBF process chain, it is important to be aware of the limitations of inspection techniques (both in terms of what cannot be inspected, and what the likely uncertainty is) and the format of inspection output (given data transfer challenges).
The three groups of techniques most relevant to metal powder bed part inspection are structured light and laser line scanning, optical surface topography methods such as focus variation, and X-ray Computed Tomography (XCT). The first group relates to optical means of capturing a component’s dimensions, which means that it requires line of sight access to the sample surface, and is affected by surface reflectivity. The output format is a point cloud, which may be converted to a (generally non-watertight) surface mesh. Optical surface topology methods are similarly limited by line of sight access constraints and affected by surface reflectivity. The output generally is a surface height map, which can then be processed to obtain surface roughness metrics. XCT is a radiographic method for obtaining a volumetric model of a sample by acquiring many X-ray transmission images. Whilst this technique provides a fully volumetric inspection that can be used for integrity, dimensional and topology inspections, it has numerous other limitations, including on the size/density of components that can be inspected [127]. The inspection output is a volume (of greyscale voxels, equivalent to 3D pixels), which can then be processed to obtain a surface mesh. For all these techniques estimating inspection uncertainty is challenging and an active area of research.
Additionally, it is worth noting that modelling techniques may be applied to the inspection process itself, as a means of technique development, inspection planning and optimisation, uncertainty estimation and improving data analysis [128,129,130]. Such modelling could potentially also be linked into the product manufacturing process chain digital twin, for example with predictions on likely regions of porosity being fed into inspection planning models, to enable optimal inspections [131]. The relevant modelling techniques here are raycasting, for computing optical wavelength inspection coverage as well as the primary (simply absorbed) radiation in X-ray transmission images, and Monte Carlo photon propagation, for modelling more complex matter interactions [132]. Whilst these models are well established, the latter type is generally slow, and producing high fidelity predictions of sensor outputs following photon interaction with real surfaces remains a subject of research [133].
7 Data acquisition and transfer in manufacturing process chain simulation
In the digital twin and the manufacturing process chain, data needs to be transferred between different models that may have been created in different software packages. Physical data will also be required for boundary conditions, material properties, and geometric information, either as inputs or for validation. In general, one model will require more than one set of data, and a single set of data may be used more than once, either because the data is common across multiple parts (e.g. the material powder used is all from the same batch), or because the model that uses the data is being used for multiple predictive scenarios.
7.1 Data acquisition
In order for the data to be used correctly, context about how the data was gathered must be stored with it. This contextual information is called metadata, and it could include all information that would enable users to be sure that the use of the data is appropriate. Metadata could include time and date, sensor type, last date of calibration, operator name (if not automated), identification of the object or material being measured, and measurement uncertainty, amongst other categories. Collection and transfer of metadata are particularly important for data reuse.
Many of the models in the process chains are transient, and so much of the data gathered will be a time series. If multiple time-dependent data sets are being used in the same model, it is important to ensure that the sensors are synchronised. This is particularly important for data that are gathered often where the quantities being measured change rapidly. Calibration of sensors is vital to the digital twin approach: if the data are gathered from an uncalibrated sensor the results cannot be relied upon. This aspect is particularly important in an industrial environment because the sensors are generally being used in an uncontrolled environment, meaning factors like thermal drift, humidity, and vibration are more likely to affect sensor performance. Similarly (as is discussed in more detail in Sect. 8) uncertainties associated with measurement data affect the reliability of the decisions made based on the digital twin, and a good understanding of the uncertainty associated with the data is required for reliable decision-making.
It is also important to draw a distinction between data to be used for input into models, data to be used for parameter-fitting for models, and data to be used for validation of models. The validation data cannot be used for inputs or for parameter determination, otherwise the model will effectively become a self-fulfilling prophecy. This requirement is necessary even if the data has been used in a sub-model of the model being validated. For instance, if a phase change in a material has been observed, a micro-scale model of that phase change has been developed based on the observations, and the micro-scale model has been fed into a macro-scale model of the process that produced the phase change, then observation of the phase change in the macro scale model cannot be regarded as validation.
7.2 Data transfer
All data transfer within the digital twin may require conversion from one data format to another, as well as the interpolation of data between different models and meshes. For example, an MPBF process model will likely require a large mesh to capture the layers of the build, which may not be appropriate for simulating heat treatment if the furnace and the associated thermal cycles are modelled in detail. This is because modelling the vacuum furnace requires considerable memory to solve the radiation problem. For this type of analysis, the large number of surface elements required is still a limitation. Less refined meshes at the surfaces are therefore desirable for complex geometries, especially when multiple components are placed in the furnace. Further down the chain, different meshes may be needed. For example, surface engineering processes that affect the surface and sub-surface integrity of the component require very fine meshes at the surface. As a result, interpolation of simulation data from the previous meshes will be needed.
There are several tools available that can transfer and interpolate finite element data between different meshes and solvers, but it must be stated that errors can accumulate during interpolation [134, 135]. The interpolation methods themselves will induce some errors, while the type of data that needs to be interpolated may also have an effect. Values computed at the nodal points of the mesh (such as displacement and temperature) will introduce less error during interpolation because they can be mapped directly. Data that is calculated at integration/Gaussian points (e.g. strains and stresses) will likely generate more errors during data transfer, due to averaging that occurs as they are mapped from a refined mesh to a coarse one.
For example, if data needs to be transferred from an MPBF build process model into a heat treatment model, the predicted strains and stresses of the build model will need to be mapped to the integration nodes of the heat treatment model to be used as an initial condition. If the element shape function is used for the interpolation, the stress and strain values of the additive model will need to be at the nodal points, requiring extrapolation from the integration points. This is done by averaging and smoothing the data, which can introduce errors. If the mesh of the MPBF build process model is more refined than the heat treatment model, and the peak stresses are at the surface, then the integration points of the heat treatment model might be too far from the peak stresses of the build model to accurately capture them. Mapping between processes further down the chain would involve similar steps, and it could therefore generate more errors [123]. Another source of error is the potential use of different material properties for the different models, which could cause rebalancing of the mapped stresses at the beginning of the numerical analyses when computational stress equilibrium is first obtained.
Mapping stress and strain tensors from very refined to very coarse meshes should therefore be avoided. For the case of a heat treatment model where a coarser mesh may be required, it could be good practice to use a coarse mesh for the thermal analyses and a more refined mesh for the mechanical analyses. This would require mapping of temperature data from the nodal points of the coarse mesh into the nodal points of the refined mesh, which should introduce a lower level of error. Errors due to the use of different material properties can be mitigated using the multi-scale approach discussed in Sect. 3. This would prevent the use of material data from test specimens that do not adequately represent the actual material behaviour of the component, such as tensile data from a forged specimen being used to represent the properties of an MPBF part.
Apart from developing accurate process and material models, and data transfer strategies in the manufacturing process chains, attention should be paid to data storage, traceability, and reuse. This could be achieved by using an open, non-proprietary file format that permits data visualisation [123]. Such a file format would allow data to be passed more readily between different commercial software tools, be easily visualised and analysed when desired, and ensure long-term access to data. This is particularly important for manufacturing areas with strict data retention requirements, such as aerospace.
Figure 14 shows the simulation of two additive manufacturing process chains using data transfer and mapping techniques detailed in [109]. The first manufacturing process chain consists of AM (or LPBF) followed by HT (or stress relief) and shot-peening (SP). The second processes chain applies laser shock peening (LSP) after the stress relief operation instead of SP. The residual stress distribution from both manufacturing routes has been used for the selection of manufacturing routes in the development of new additive manufacturing components and processes. Similar approach for LPBF manufacturing process chain of an aero-casing was used and demonstrated in [134]. In both research works [109, 136], validated process models have been applied to demonstrate the simulation of a manufacturing process chain, but the validation on the process chain has been highlighted as a future research.

Predicted principal residual stresses in the LPBF process chain of an impeller [109]. Units in MPa
8 Uncertainties in modelling, validation and data transfer
8.1 General overview
The evaluation of the uncertainties associated with model results provides increased confidence in those results and supports reliable decision-making. Uncertainty evaluation, and an understanding of associated sensitivity coefficients, can also drive process improvements by identifying the parameters that need to be most tightly controlled to improve product quality. These aspects are particularly important for techniques such as additive manufacturing where a complex process is used to create load-bearing, and potentially safety critical, structural parts.
Uncertainty quantification is also key to model validation: if model results are to be compared to measured values, the uncertainties should be included in the comparison to make the agreement quantitative and meaningful. For instance, if the uncertainties associated with the model results are 100 times bigger than those associated with the measurements, it is highly debatable whether the model is telling you anything useful even if its predictions agree exactly with the measurements.
A lot of the work on uncertainty evaluation in AM processes to date has focussed on assessing process variability by measuring the finished product and considering this as uncertainty [137,138,139]. Whilst this approach does not generally return enough information or understanding to know how to improve a process, it can provide information of the sort needed to validate models in a statistically meaningful way.
Uncertainty evaluation for model results has three main stages [140]:
-
Identification of uncertain input quantities and quantification via appropriate probability density functions (PDFs);
-
Propagation of the PDFs through the model;
-
Summarising the results statistically.
A further step that is useful in many cases is sensitivity analysis, which quantifies the effects of the model inputs on the model outputs and can therefore enable prioritisation. The identification and propagation steps will be discussed in more detail with reference to LPBF and EBPBF below.
The approach above considers only the uncertainties associated with the model inputs (i.e. the parameters and numerical values used to define a specific instance of the model). An additional source of uncertainty that is more difficult to quantify is model uncertainty. This source includes not only errors associated with discretisation and time stepping, which can usually be reduced if more computational resources are available, but also the effects of the various assumptions made in the model development. The effects of the assumptions are generally very difficult to quantify for a physically derived model and are usually reduced as far as possible through validation and improvement.
The main circumstances where model uncertainty should be considered in more detail are when a simplified model is used for reasons of computational cost. This approach is particularly common in MPBF simulations, where complex multi-physics multi-scale processes need to be simplified in order to be made solvable. Here the information used to validate the simplified model can be used to estimate the model uncertainty, which can then be treated as an additional source of uncertainty in the propagation step, using a statistical model of the error based on the results of the validation. This approach has been used in AM applications to evaluate uncertainty associated with the use of a multiscale model [141, 142].
Hu and Mahadevan [143] provide a thorough overview of the current state of the art regarding uncertainty evaluation for AM, including identifying the uncertain and poorly-known aspects of each stage of the manufacturing process. The same authors [144] also provided a similar analysis of the various approaches associated with material property prediction.
8.2 Input parameters and assigning distributions
The problem of turning knowledge about a quantity into a suitable probability density function is one of the more difficult aspects of uncertainty evaluation. Generally, the available knowledge will be some combination of measured values, experience and expertise, and results of smaller-scale simulations.
MPBF techniques have a very wide range of inherently variable input parameters. The powder will have an associated size distribution, which may change as a powder gets recycled, and the powder material properties (thermophysical and optical) are likely to vary from sample to sample, from particle to particle, and as recycling occurs. The laser power may be known as an average value, but the laser spot size and the spatial distribution of the power across the spot are likely to be more difficult to obtain.
Jacob et al. [145] have begun to assess the uncertainty associated with measurements of some of these quantities. Others researchers have used smaller-scale models to calculate effective properties and associated uncertainties for input to bulk-scale models [146, 147]. Obtaining appropriate uncertainties for these variations is likely to be one of the key challenges of reliable uncertainty evaluation and hence reliable process control for MPBF.
Most MPBF models have more than one input quantity. The existence of multiple-input quantities raises the question of whether there is correlation between the quantities. Some uncertainty evaluation methods require independence of input quantities, so it is important to identify, and if possible eliminate, any correlations. If it is possible to express two input quantities in terms of a set of independent quantities about which information can be gathered, this is often preferable to the use of correlated quantities.
Some quantities exhibit random behaviour that cannot be described using a single PDF. An example is a material property such as porosity that typically varies randomly in space and has a correlation length associated with its variation. A commonly accepted approach to describe such quantities is the use of random fields [148]. This approach captures the randomness and the correlation in a way that can be used within a sampling method or another method for the solution of stochastic equations.
The aim of assigning a PDF to a quantity is to encapsulate all available information about the quantity without imposing further constraints on the quantity. The two most useful tools in the assignation process are Bayes' theorem and the principle of maximum entropy, but other approaches can be used if their use can be justified. For instance, a quantity may have been measured so many times that construction of a reliable PDF directly from the measured values is possible, although care should be taken to check the values for drift or other dependencies.
Bayes' theorem is a law of conditional probability that also applies to continuous random variables described by PDFs. The significance here is that it enables a PDF that encapsulates existing information about a quantity to be updated in the light of new information, and in particular it allows a PDF to be assigned based on measurements or other evaluations of the quantity, under certain fairly widely applicable assumptions. The book “Bayesian Data Analysis” by Gelman et al. [149] provided a comprehensive introduction to the use of Bayes’ theorem for practical analysis.
The principle of maximum entropy is useful for assigning distributions when information that can be expressed as a statement about the PDF is available. Examples include knowledge of the mean value or other percentiles, knowledge of the standard deviation, and knowledge (including inexact knowledge) of limits on the value of the quantity. Application of the principle of maximum entropy can be mathematically challenging, but it has already been carried out for many commonly available types of information. An extensive list of cases for which solutions have been found is available in Section 6.4 of the first supplement to the Guide to the expression of Uncertainty in Measurement (GUM) [140], including a description of how to sample from each PDF, but some of the most common cases are listed in Table 1 below.
8.3 Uncertainty propagation and sensitivity
Different methods of uncertainty propagation are suitable for different models. For models that are linear in their uncertain quantities, and if the uncertainties are not dominated by the contribution of one input that does not have a Gaussian distribution, the method described in the GUM is likely to give a reliable value quickly and easily [150]. This approach expands the model function as a Taylor series about its mean value, truncates the series after the linear terms, and uses the results to derive an analytical expression for the uncertainty associated with the model output.
Many models are not linear in their uncertain input quantities, meaning this simple approach is not suitable. Further, the approach requires the user to be able to obtain the partial derivative of the model result with respect to the input quantity (called the sensitivity coefficient). For many models, this information is not available, either because the model has been constructed using “black box” software such as a finite element solver, or because the equations linking the inputs and the outputs are too complicated for this derivative to be obtained.
For nonlinear and “black box” models, sampling methods are preferable. These methods take samples from the PDFs of the uncertain inputs, evaluate the model at the resulting values, and construct a PDF for the output quantities from the evaluated results. The simplest sampling method is random, or Monte Carlo sampling [140]. This method can be analysed to calculate how many samples, M, and hence how many model evaluations, are required for a given level of accuracy in the uncertainty estimate. A value of M = 106 can often be expected to deliver a 95% coverage interval for the output quantity such that this length of this interval is correct to one or two significant decimal digits.
This number of samples is manageable if the model takes a fraction of a second to run (a million seconds is about 11.5 days), and has been applied to simple models of laser powder bed fusion processes [151]. Most complex models of thermal processes take significantly longer than this to solve. There has been much research into uncertainty evaluation using fewer samples. The available methods can broadly be split into smart sampling methods and surrogate models.
Smart sampling methods use non-random methods of selecting sampling points from the PDFs of the input quantities to obtain improved accuracy for a small number of samples. Latin hypercube sampling [152] is widely used and comparatively simple to implement: the approach subdivides the input PDF into regions of equal probability and samples once within each region, thus ensuring that the sample spans the full range of each input quantity. Approaches such as importance sampling [153] use knowledge of the model to ensure that the sample focusses on the region of the input quantities that causes the greatest variability in the output quantity. Space-filling sequences can be created by adding random small perturbations to low discrepancy sequences, which are structured sequences that have similar distribution properties to uniformly distributed random variables.
Surrogate models, also known as metamodels, similarly take samples from the inputs and evaluate the model, but they then use various approaches to create a model that is quick to solve, accurately reproduces the results at the points where the full model has been evaluated, and is expected to be a good approximation to the full model in regions where the full model has not been solved [154]. These models can vary in complexity from simple polynomial expressions to more mathematically challenging approaches such as Gaussian processes (often known as kriging) and polynomial chaos.
Gaussian process surrogate models [155] approximate the model output as a weighted sum of random functions, parameterised by a variance and a set of correlation lengths, are chosen so that the values of a function at two points are more strongly correlated the closer they are together. The surrogate model is generally a smooth interpolant of the known model results, and the use of random functions means that an estimate of the interpolation error at intermediate points is immediately available, so that areas where the error is large can easily be identified and further model runs can be carried out to reduce the error. Kriging approaches have been applied to AM models by several authors [156,157,158], who have provided guidance on methods for the selection of input values to build a reliable surrogate model.
Polynomial chaos uses the link between different families of orthogonal polynomials and specific PDFs, identified by Wiener [159], to construct an approximation to the model as a polynomial of the random variables representing the model input quantities. In many models with only a few inputs, an accurate surrogate can be constructed using a small number of model evaluations. Careful choice of input points is key to efficient implementation for models with a lot of inputs. Polynomial chaos has been applied to AM models for a small number of input parameters [146], focussing on the laser beam diameter and the material emissivity as these quantities are generally poorly known and difficult to control.
An alternative method of reducing the computational complexity of an uncertainty evaluation problem is to reduce the number of uncertain inputs. This can be achieved by focussing only on those inputs whose uncertainties have the most effect on the uncertainty associated with the output quantities. The identification of the most important inputs is effectively a process of sensitivity analysis. Another approach is to reduce problem dimensionality through principal component analysis, which identifies linear combinations of inputs that have the most effect on the output. Assigning a distribution to these combinations would need to be done numerically, but the problem complexity would be reduced.
The simplest approach to sensitivity analysis is to evaluate, either analytically or numerically, the partial derivative of the model output with respect to the model input, as suggested by the GUM [140]. In general, this gives a single point value, which is only informative if the model is linear. Other approaches use a set of local numerical estimates of the partial derivative to calculate indices that rate not only the sensitivity of the model to each input variable, but also the sensitivity of the model results to combinations of more than one input variable. Sobol indices [160], which give a large amount of information about the input quantities but require multiple model evaluations, have been applied to AM models using a Gaussian process surrogate model [156].
8.4 Uncertainties in data transfer
Transferring data from one model to another is effectively altering the data through a “transfer model”. In some cases, this transfer model is as simple as extracting a single value from one model to use as an input in another model, for instance if a detailed model of a multi-phase material has been used to calculate the effective properties of that material. In such cases, the results of the first model should be treated as an uncertain input to the second model, and the methods discussed above should be used.
In other cases, the transformation of the results of one model are more complicated and so need more careful consideration. One of the most common processes is transferring the results of one type of finite element model to the inputs of another type of finite element model. This task generally includes several potential sources of uncertainty and error:
-
change of formats between different software packages;
-
change of physics;
-
change of geometry or spatial distribution;
-
change of time distribution;
The change of format is described in Sect. 7.2. Beyond the challenge of transferring between data formats, common sources of error include consistency of units and coordinate systems (local and global); consistency of tensor notation, particularly when considering stresses and strains; and consistency of definition of signs on stresses and effective stress measures.
Changing physics often generates problems associated with geometry. Models that are constructed to simulate different physics on the same object are likely to have different levels of detail, for instance the key heat flow paths in an object are not necessarily the key load-bearing paths. Further, some objects that are insignificant and hence neglected in one physics model may be crucial to another. An example is the use of plastic supports for some AM geometries: the plastic is an insulator so can be neglected in thermal analysis, which is a key part of stress analyses. These kinds of transfer problems can be reduced via care when planning the analysis and ensuring good communication between different domain experts.
Change of geometry is probably the most common problem when transferring data between models, and it has been discussed in Sect. 7. Change of time step causes similar interpolation issues, with the added complication of stability limitations. In many cases, an error bound for interpolations in time and space can be estimated, either as a constant over the entire model or as a map over the model geometry. The error could then be treated as an additional source of uncertainty uniformly distributed over the interval [− C, + C] where C is the error bound.
9 Maturation of MPBF modelling technologies
Technology Readiness Levels (TRLs) have proven to be an effective tool to communicate, design, and launch new products and technologies, adopt new processes, assess internal and external capabilities, and define technology road maps [161,162,163]. For this work, the TRL scale has been used to determine the maturity of MPBF modelling domains. First, a methodology with 5 questions (as shown in Fig. 15) was developed to determine the TRL of different simulation domains. The aim of the methodology was to provide representative guidance for identifying where different modelling domains are positioned on the TRL scale.

Methodology for determining the TRL rating of different simulations
A workshop was conducted to determine the TRL of various MPBF simulation domains by following the proposed methodology. These domains were considered individually, i.e. without concerns about data transfer from one to another. The investigated domains were:
-
Mechanical properties: prediction of properties that govern the mechanical behaviour of the part, such as the Young’s modulus.
-
Physical properties: prediction of properties that govern the non-mechanical behaviour of the part, for example thermal, electrical conductivity or density.
-
Micro-cracks: the ability to predict small cracks that form and propagate at the micro and meso scales.
-
Surface roughness/texture: the surface finish quality of an MPBF component following a build.
-
Micro-structure: the microscopic structure of the material, including grains and precipitates, that evolves as it cools and solidifies.
-
Porosity: the ability to predict the amount of non-material space in the part, such as gas pores or other voids.
-
Powder distribution/raking: the morphology and distribution of metal powder as it is spread over the build chamber bed.
-
Melt pool temperature: the variation in the temperature of the molten material in the melt pool with time.
-
Lack of fusion: areas of the part where the powder has failed to fully melt.
-
Overheating: the temperature of a component and the risk of it becoming too high during a build.
-
Geometric distortion: the deviation of the part geometry from that which is intended due to stresses and strains that arise during the build process.
-
Recoater collision: the risk of the powder recoating blade within the machine hitting the part due to geometric distortion.
-
Residual stresses: stresses remaining in the part following manufacture that arose as a result of the manufacturing process.
The results from this exercise are summarised by Fig. 16, which shows that component scale predictions of geometric distortion, recoater collision, and component scale residual stresses are currently amongst the more developed aspects of MPBF simulation. A variety of commercial tools provide capability in this area, and results around component scale distortion are relatively easy to validate. On the other hand, simulations of micro and meso-scale phenomena, such as the micro-structure, porosity, and physical and mechanical properties, were found to be at the lower end of the TRL scale. There is promising early-stage research in these areas, however, significant investment, research, and development is needed in these domains if the full potential of simulating MPBF is to be realised.

Summary of results from TRL mapping workshop. Note that the numbers 0–9 indicate the TRL in the spider diagram. The zero indicates that no work has been done in that domain. Applications—Strengths and Weaknesses
10 Conclusions
An overview of modelling techniques for powder bed fusion process chain has been presented, with a view to identifying the work required to realise future digital twins. This has been achieved through a review of the various computational modelling techniques from micro-scale simulations of powder behaviour to simulations of subsequent process steps such as heat treatment and surface finishing. In addition, methods for transferring data between different models have been discussed, alongside uncertainties involved in modelling the process chain. Finally, a discussion on the current maturity of powder bed fusion-specific modelling domains, such as the prediction of residual stresses, has been presented. Table 2 summarises the key conclusions and it provides future perspectives.
Abbreviations
- AM:
-
Additive manufacturing
- CA:
-
Cellular automata
- CA-FD:
-
Cellular automata finite difference
- CAD:
-
Computer-aided design
- CAM:
-
Compute aided manufacturing
- EBPBF:
-
Electron beam powder bed fusion
- FE:
-
Finite element
- GUM:
-
Guide to the expression of uncertainty in measurement
- HT:
-
Heat treatment
- kMC:
-
Kinetic Monte Carlo
- LPBF:
-
Laser powder bed fusion
- LSP:
-
Laser shock peening
- MO:
-
Machining operation
- MPBF:
-
Metal powder bed fusion
- PDF:
-
Probability density function
- RVE:
-
Representative volume element
- SE:
-
Surface engineering
- SP:
-
Shot peening
- TRL:
-
Technology readiness level
- XCT:
-
X-ray computed tomography
References
Additive Manufacturing UK, “National Strategy 2018 - 25,” 26 September 2017. [Online]. Available: https://am-uk.org/additive-manufacturing-national-strategy-sets-establish-uk-world-leader/. Accessed 22 June 2021
A. Parrott and L. Warshaw, “Industry 4.0 and the digital twin,” 12 May 2017. [Online]. Available: https://www2.deloitte.com/content/dam/Deloitte/cn/Documents/cip/deloitte-cn-cip-industry-4-0-digital-twin-technology-en-171215.pdf. Accessed 22 June 2021
High Value Manufacturing Catapult, “Feasibility of an immersive digital twin: The definition of a digital twin and discussions around the benefit of immersion,” September 2018. [Online]. Available: https://www.amrc.co.uk/files/document/219/1536919984_HVM_CATAPULT_DIGITAL_TWIN_DL.pdf. Accessed 11 Mar 2019
Soothill C (2016) Analytics challenge for GE power. In: NAFEMS Conference for Engineering Simulation: The Future Begins Today, Telford, UK
Liao M, Renaud G, Bombardier Y (2020) Airframe digital twin technology adaptability assessment and technology demonstration. Eng Fract Mech 225:106793
DebRoy T, Zhang W, Turner J, Babu S (2017) Building digital twins of 3D printing machines. Scripta Mater 135:119–124
Manadolla C, Petruzzelli AM, Percoco G, Urbinati A (2019) Building a digital twin for additive manufacturing thriugh the exploitation of blockchain: a case analysis of the aircraft industry. Comput Ind 109:134–152
Mukherjee T, DebRoy T (2019) A digital twin for rapid qualification of 3D printed metallic components. Appl Mater Today 14:59–65
Tao F, Zhang H, Liu A, Nee AY (2018) Digital twin in industry: state-of-the-art. IEEE Trans Indus Info 15(4):2405–2415
GE Power Digital Solutions, “GE Digital Twin,” 2016. [Online]. Available: https://www.ge.com/digital/sites/default/files/download_assets/Digital-Twin-for-the-digital-power-plant-.pdf. Accessed 24 June 2020
Afazov S, Denmark W, Lazaro Toralles B, Holloway A, Yaghi A (2017) Distortion prediction and compensation in selective laser melting”. Addit Manufac 17:15–22
Afazov S, Okioga A, Holloway A, Denmark W, Triantaphyllou A, Smith S-A, Bradley-Smith L (2017) A methodology for precision additive manufacturing through compensation. Precis Eng 50:269–274
Afazov S, Semerdzhieva E, Scrimieri D, Serjouei A, Kairoshev B, Derguti F (2021) An improved distortion compensation approach for additive manufacturing using optically scanned data. Virtual Phys Prototyp 16:1–13
Karbasian H, Tekkaya E (2010) A review on hot stamping. J Mater Process Technol 210:2103–2118
Music O, Allwood JM, Kawai K (2021) A review of the mechanics of metal spinning. J Mater Process Technol 210:3–23
Psyk V, Risch D, Kinsey BL, Tekkaya E, Kleiner M (2011) Electromagnetic forming—a review. J Mater Process Technol 211:787–829
Polyblank JA, Allwood JM, Duncan SR (2014) Closed-loop control of product properties in metal forming: a review and prospectus. J Mater Process Technol 214:2333–2348
Mouta K, Azevedo L, Fernandes MG, Fonseca EMM (2017) Sheet metal forming by numerical simulations: 2D and 3D axisymmetric deformation of a cylindrical piece. In: 7th International Conference on Mechanics and Materials in Design, Proceedings M2D2017, pp 157–166. ISBN: 978-989-98832-7-7
Collot J (2001) Review of new process technologies in the aluminium die-casting industry. Mater Manuf Process 16:595–617
Pattnaik S, Karunakar DB, Jha PK (2012) Developments in investment casting process—a review. J Mater Process Technol 212:2332–2348
Pattnaik S, Jha PK, Karunakar DB (2014) A review of rapid prototyping integrated investment casting processes. J Mater Design Appl 228:249–277
Lindgren L (2007) Computational welding mechanics. Woodhead, Cambridge
Uday MB, Fauzi MN, Zuhailawati H, Ismail AB (2010) Advances in friction welding process: a review. Sci Technol Welding Joining 15:534–558
He X, Gu F, Ball A (2014) A review of numerical analysis of friction stir welding. Prog Mater Sci 65:1–66
Jawahir IS, Brinksmeier E, M’Saoubi R, Aspinwall DK, Outeiro JC, Meyer D, Umbrello D, Jayal AD (2011) Surface integrity in material removal processes: recent advances. CIRP Annals—Manuf Technol 60:03–626
Quintatana G, Ciurana J (2011) Chatter in machining processes: a review. Int J Mach Tools Manuf 51:363–376
Arrazola PJ, Ozel T, Umbrello D, Davies M, Jawahir IS (2013) Resent advances in modelling of metal machining processes. CIRP Annals Manuf Technol 62:695–718
Abbas NM, Solomon DG, Bahari MF (2007) A review on current research trends in electrical discharge machining (EDM). Int J Mach Tools Manuf 47:1214–1228
Parandoush P, Hossain A (2014) A Review of modelling and simulation of laser beam machining. Int J Mach Tools Manuf 85:135–145
Frazier WE (2014) Metal additive manufacturing: a review. J Mater Eng Perform 23:1917–1928
Gong X, Anderson T, Chou K (2014) Review on powder-based electron beam additive manufacturing technology. Manuf Rev 1:1–12
Fernandes MG, Alves JL, Fonseca EMM (2016) Diaphyseal femoral fracture: 3D biomodel and intramedullary nail created by additive manufacturing. Int J Mater Eng Innov 7:130–142
Dilip JJS, Zhang S, Teng C, Zeng K, Robinson C, Pal D, Stucker B (2017) Influence of processing parameters on the evolution of melt pool, porosity, and microstructures in Ti-6Al-4V alloy parts fabricated by selective laser melting. Prog Addit Manuf 2:157–167
Bagheri S, Guagliano M (2008) Review of shot peening processes to obtain nanocrystalline surface in metal alloys. Surf Eng 25:3–14
Zimmermann M, Klemenz M, Schulze V (2010) Literature review on shot peening simulation. Int J Comput Mater Sci Surf Eng 3:289–310
Asta M, Beckermann C, Karma A, Kurz W, Napolitano R, Plapp M, Purdy G, Rappaz M, Trivedi R (2009) Solidification microstructures and solid-state parallels: recent developments, future directions. Acta Mater 57(4):941–971
Mishin Y, Sta M, Li J (2010) Atomistic modelling of interfaces and their impact on microstructure and properties. Acta Mater 58:1117–1151
Warnken N, Larsson H, Reed RC (2009) Coupled modelling of solidification and solution heat treatment of advanced single crystal nickel bas superalloy. Mater Sci Technol 25:179–185
Tan JH, Wong WLE, Dalgarno KW (2017) An overview of powder granulometry on feedstock and part performance in the selective laser melting process. Addit Manuf 18:228–255
Huck-Jones D, Langley C (2017) Beyond particle size: exploring the influence of particle shape on metal powder performance. Metal Addit Manuf 3(4):99–103
Meakin P, Juillien R (1987) Restructuring effects in the rain model for random deposition. J de Physique 48:1651–1662
Körner C, Attar E, Heinl P (2011) Mesoscopic simulation of selective beam melting processes. J Mater Process Technol 211:978–987
Panwisawas C, Qiu C, Anderson MJ, Sovani Y, Turner RP, Atallah MM, Brooks JW, Basoalto HC (2017) Mesoscale modelling of selective laser melting: thermal fluid dynamics and microstructural evolution. Comput Mater Sci 126:479–490
Zhou J, Zhang Y, Chen J (2009) Numerical simulation of random packing of spherical particles for powder-based additive manufacturing. J Manuf Sci Eng 131(3):031004
Zielinski J, Vervoort S, Mindt H-W, Megahed M (2017) Influence of powder bed characteristics on material quality in additive manufacturing. BHM 162(5):192–198
Leitz K-H, Grohs C, Singer P, Tabernig B, Plankensteiner A, Kestler H, Sigl L (2018) Fundamental analysis of the influence of powder characteristics in Selective Laser Melting of molybdenum based on a multi-physical simulation model. Int J Refractory Metals Hard Mater 72:1–8
Parteli EJ, Pöschel T (2016) Particle-based simulation of powder application in additive manufacturing. Powder Technol 288:96–102
Sun Y, Aindow M, Hebert RJ (2018) Comparison of virgin Ti-6Al-4V powders for additive manufacturing. Addit Manuf 21:544–555
Cherry J, Davies H, Mehmood S, Lavery N, Brown S, Sienz J (2015) Investigation into the effect of process parameters on microstructural and physical properties of 316L stainless steel parts by selective laser melting. Int J Adv Manuf Technol 76:869–879
Rahul VY, Patil B (2007) Finite element analysis of temperature distribution in single metallic powder layer during metal laser sintering. Int J Mach Tools Manuf 47:1069–1080
Roberts IA, Wang CJ, Esterlein R, Standford M, Mynors DJ (2009) A three-dimensional finite element analysis of the temperature field during laser melting of metal powders in additive layer manufacturing. Int J Mach Tools Manuf 49(12):916–923
Jin X, Cheng Y, Zeng L, Zou Y, Zhang H (2012) Multiple reflections and Fresnel absorption of Gaussian laser beam in an actual 3D keyhole during deep-penetration laser welding. Int J Optics 2012:361818
Qiu C, Panwisawas C, Ward M, Basoalto H, Brooks J, Attallah M (2015) On the role of melt flow into the surface structure and porosity development during selective laser melting. Acta Mater 96:72–79
Panwisawas C, Qiu C, Sovani Y, Brooks J, Attallah M, Basoalto H (2015) On the role of thermal fluid dynamics into the evolution of porosity during selective laser melting. Scripta Mater 105:14–17
Guo Q, Zhao C, Escano L, Young Z, Xiong L, Fezzaa K, Everhart W, Brown B, Sun T, Chen L (2018) Transient dynamics of powder spattering in laser powder bed fusion additive manufacturing process revealed by in-situ high-speed high-energy x-ray imaging. Acta Mater 151:169–180
Liu X, Shapiro V (2016) Homogenization of material properties in additively manufactured parts. Comput Aided Des 78:71–82
Moustafa AR, Dinwiddie RB, Pawlowski AE, Spliter DA, Shyam A, Cordero ZC (2018) Mesostructure and porosity effects on the thermal conductivity of additively manufactured interpenetrating phase composites. Addit Manuf 22:223–229
Xin H, Sun W, Fish J (2017) A surrogate modelling approach for additive-manufactured materials. Int J Multiscale Comput Eng 15(6):525–543
Xu S, Shen J, Zhou S, Huang X, Xie Y (2016) Design of lattice structures with controlled anisotropy. Mater Des 93:443–447
Tabatabaei M, Le D, Atluri SN (2017) Nearly exact and highly efficient elastic-plastic homogenization and/or direct numerical simulation of low-mass metallic systems with architected cellular microstructure. J Mech Mater Struct 12(5):633–665
Tang TLE, Liu Y, Lu D, Arisoy EB, Musuvathy S (2017) Lattice structure design advisor for additive manufacturing using Gaussian process. In: ASME International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Ohio, USA
Robbins V, Owen S, Clark B, Voth T (2016) An efficient and scalable approach for generating topologically optimized cellular structures for additive manufacturing. Addit Manufact 12B:296–304
McCartney L (2010) Maxwell’s far-field methodology predicting elastic properties of multi-phase composites reinforced with aligned transverse isotropic spheroids. Phil Mag 90(31–32):4175–4207
Elder N (2010) Phase-field methods in materials science and engineering. Wiley-VCH, Weinheim, Germany
Wang J (2010) Phase field modeling of defects and deformation. Acta Mater 58(4):1212–1235
Hallberg H (2013) A modified level set approach to 2D modeling of dynamic recrystallization. Model Simul Mater Sci Eng 21:085012
Hallberg H (2014) Influence of anisotropic grain boundary properties on the evolution of grain boundary character distribution during grain growth—a 2D level set study. Model Simul Mater Sci Eng 22:085005
Rauch L, Madej L, Spytkowski P, Golab R (2015) Development of the cellular automata framework dedicated for metallic materials microstructure evolution models. Arch Civil Mech Eng 15(1):48–61
Rai C (2017) Simulation of grain structure evolution during powder bed based additive manufacturing. Addit Manuf 13:124
Tikare MV (2006) An experimental validation of a 3D kinetic, Monte Carlo model for microstructural evolution during sintering. Adv Sci Technol 45:522–529
Hajializadeh F, Ince A (2019) Short review on modeling approaches for metal additive manufacturing process. Mater Design Process Commun 2(2):e56
Markl M, Körner C (2016) Multiscale modeling of powder bed–based additive manufacturing. Annu Rev Mater Res 46:93–123
Chiumenti M, Lin X, Cervera M, Wei L, Zheng Y, Huang W (2017) Numerical simulation and experimental calibration of additive manufacturing by blown powder technology. Part I: thermal analysis. Rapid Prototyp J 23:448–463
Martukanitz R, Michaleris P, Palmer T, Debroy T, Liu Z-K, Otis R, Heo T, Chen L-Q (2014) Toward an integrated computational system for describing the additive manufacturing process for metallic materials. Addit Manuf 1–4:52–63
Patil N, Pal D, Rafi H, Zeng K, Moreland A, Hicks A, Beeler D, Stucker B (2015) A generalised feed forward dynamic adaptive mesh refinement and derefinement finite element framework for metal laser sintering - Part I: formulation and algorithm development. J Manuf Sci Eng Trans ASME 137(2):041001
Yang Y, Knol M, Van Keulen F, Ayas C (2018) A semi-analytical thermal modelling approach for selective laser melting. Addit Manuf 21:284–297
Parkitny R, Winczek J (2013) Analytical solution of temporary temperature field in half-infinite body caused by moving tilted volumetric heat source. Int J Heat Mass Transf 60:469–479
Terry H, Afazov S, Frame J (2019) Ultrafast modelling of temperature and microstructure in the additive manufacturing process. In Fourth ASTM Symposium on Structural Integrity of Additive Manufactured Materials and Parts, Washington DC, USA
Villa M (2016) Metallurgical and mechanical modelling of Ti-6Al-4V for welding applications. PhD Thesis, University of Birmingham
Luo Z, Zhao Y (2018) A survery of finite element analysis of temperature and thermal stress fields in powder bed fusion additive manufacture. Addit Manuf 21:318–332
Bikas H, Stavrapoulos P, Chryssolouris G (2016) Additive manufacturing methods and modelling approaches: a critical review. Int J Adv Manuf Technol 89:389–405
Afazov S, Yaghi A, Holloway A, Denmark W, Lazaro Toralles B, Okioga A (2017) Methodology and validation of rapid prediction of distortion for powder-bed additive layer manufacture. In NAFEMS World Congress - 3rd International Conference on Simulation Process and Data Management, Stockholm, Sweden
Yaghi A, Afazov S, Holloway A, Denmark W (2017) Comparison of fast finite element modelling techniques for prediction of distortion and residual stresses in laser powder bed fusion. In Design and Manufacturing Simulation of Additive Manufacturing Components, NAFEMS Seminar, Coventry, UK
Pursell (2016) On the creation of a new finite element simulation environment for additive manufacturing. In: NAFEMS Americas Conference: Session reviews, Session 7/1D, Seattle, USA
Keller N, Ploshikhin V (2014) New method for fast predictions of residual stress and distortion of AM parts. In Annual International Solid Freeform Fabrication Symposium—An Additive Manufacturing Conference, The University of Texas in Austin, USA
Peter N, Pitts Z, Thompson S, Saharan A (2020) Benchmarking build simulation software for laser powder bed fusion of metals. Addit Manuf 36:101531
Yaghi A, Ayvar-Soberanis S, Moturu S, Bilkhu R, Afazov A (2019) Design against distortion for additive manufacturing. Addit Manuf 27:224–235
Galati M, Iuliano L (2018) A literature review of powder-based electron beam melting focusing on numerical simulations. Addit Manuf 19:1–20
Shen N, Chou K (2012a) Thermal modeling of electron beam additive manufacturing process: powder sintering effects. In ASME 2012 International Manufacturing Science and Engineering Conference, pp 287–295
Galati M, Iuliano L, Salmi A, Atzenni E (2017) Modelling energy source and powder properties for the development of a thermal FE model of the EBM additive manufacturing process. Addit Manuf 14:49–59
Jamshidinia M, Kong F, Kovacevic R (2013) Numerical modelling of heat distribution in the electron beam melting of Ti-6Al-4V. J Manuf Sci Eng 135(6):061010
Jamshidinia M, Kong F, Kovacevic R (2013a) The Coupled CFD-FEM model of electron beam melting (EBM). Mech Eng Res, 4
Shen N, Chou K (2012b) Simulations of thermo-mechanical characteristics in electron beam additive manufacturing. In: Proceedings of the ASME 2012 international mechanical engineering congress and exposition. vol 3. Design, Materials and Manufacturing, Parts A, B, and C, Houston, Texas, USA. pp 67–74
Ammer R, Markl M, Ljungblad U, Körner C, Rüde U (2014) Simulating fast electron beam melting with a parallel thermal free surface lattice Boltzmann method. Comput Math Appl 67(2):318–330
MTC (2017) 11289 – Quality data framework for additive layer manufacturing – Deliverable 3: Use Cases and Demonstrations,” MTC, Coventry
AMamble consortium, “Motorbike Fork as a sample use case for AMable,” 2018. [Online]. Available: https://www.amable.eu/cases/motorbike-fork. Accessed 24 June 2021
Rozvany G (2009) A critical review of established methods of structural topology optimisation. Struct Multidiscip Optim 37:217–237
Xia L, Xia Q, Huang X, Xie Y (2018) ”Bi-directional evolutionary structural optimization on advanced structures and materials: a comprehensive review. Arch Comput Methods Eng 25:437–478
Choi WH, Kim JM, Park GJ (2016) Comparison study of some commercial structural optimisation software systems. Struct Multidisc Optim 54:685–699
Dbouk T (2017) A review about engineering design of optimal transfer systems using topology optimisation. Appl Therm Eng 112:841–854
Campelo F, Ramirez J, Igarashi H (2010) A survey of topology optimization in electromagnetics: considerations and current trends. Academia 46:2010
Skinner S, Zare-Behtash H (2018) State-of-the-art in aerodynamic shape optimisation methods. Appl Soft Comput 62:933–962
Vatanabe S, Lippi T, Lima C, Paulino G, Silva E (2016) Topology optimisation with manufacturing constrains: a unified projection-based approach. Adv Eng Softw 100:97–112
Liu J, Caynor A, Chen S, Kang Z, Suresh K, Takezawa A, Lai L, Kato J, Tang J, Wang C, Cheng L, Liang X, To A (2018) Current and future trends in topology optimisation for additive manufacturing”. Struct Multidisc Optim 57:2457–2483
Brackett D, Ashcroft I, Hague R (2011) Topology optimisation for additive manufacturing. In 22nd Proceedings of the SFF Symposium, Austin, TX
Kang J, Rong Y (2006) Modeling and simulation of load heating in heat treatment furnaces. J Mater Process Technol 174(1–3):109–114
King J, Jo H, Tirawat R, Blomstrand K, Sridharan K (2017) Effects of surface roughness, oxidation, and temperature on the emissivity of reactor pressure vessel alloys. Nucl Technol 200(1):1–14
Read N, Wang W, Essa K, Attallah M (2015) Selective laser melting of AlSi10Mg alloy: process optimisation and mechanical properties development. Mater Design 65:417–424
O’Brien JM, Montgomery S, Yaghi A, Afazov SM (2021) Process chain simulation of laser powder bed fusion including heat treatment and surface hardening. CIRP J Manuf Sci Technol 32:266–276
Fox J, Moylan S, Lane B (2016) Effect of process parameters on the surface roughness of overhanging structures in laser powder bed fusion additive manufacturing. Procedia CIRP 45:131–134
Townsend A, Senin N, Blunt L, Leach R, Taylor J (2016) Surface texture metrology for metal additive manufacturing: a review. Precis Eng 46:34–47
Xu Z, Dunleavey J, Antar M, Hood R, Soo S, Kucukturk G, Hyde C, Clare A (2018) The influence of shot peening on the fatigue response of Ti-6Al-4V surfaces subject to different machining processes. Int J Fatigue 111:196–207
Yang Z, Zhang M, Zhang Z, Liu A, Yang R, Liu S (2016) A study on the diamond grinding wheels with regular grain distribution using additive manufacturing (AM) technology. Mater Des 104:292–297
Ulutan D, Ozel T (2011) Machining induced surface integrity in titanium and nickel alloys: a review. Int J Mach Tools Manuf 51(3):250–280
Afazov S, Ceesay L, Larkin O, Berglind L, Denmark W, Ozturk E (2021) A methodology for precision manufacture of a nozzle using hybrid laser powder-bed fusion: a case study. IMechE, Part B: J Eng Manuf 235:751–760
Greitemeier D, Dalle Donne C, Syassen F, Eufinger J, Melz T (2016) Effect of surface roughness on fatigue performance of additive manufactured Ti–6Al–4V. Mater Sci Technol 32(7):629–634
Triantaphyllou A, Giusca C, Macaulay G, Roerig F, Hoebel M, Leach R, Tomita B, Milne K (2015) Surface texture measurement for additive manufacturing. Surf Topography: Metrol Prop 3(2):024002
Ciampini D, Spelt J, Papini M (2003) Simulation of interference effects in particle streams following impact with a flat surface: Part I. Theory and analysis. Wear 254(3–4):237–249
Jamal M, Morgan M, Peavoy D (2017) A digital process optimization, process design and process informatics system for high-energy abrasive mass finishing. Int J Adv Manuf Technol 92(1–4):303–319
Marimuthu S, Triantaphyllou A, Antar M, Wimpenny D, Morton H, Beard M (2015) Laser polishing of selective laser melted components. Int J Mach Tools Manuf 95:97–104
Benardos P, Vosniakos G (2003) Predicting surface roughness in machining: a review. Int J Mach Tools Manuf 43(8):833–844
Afazov S, Becker A, Hyde T (2012) Mathematical modeling and implementation of residual stress mapping from microscale to macroscale finite element models. J Manuf Sci Eng 134(2):021001
Afazov S (2013) Modelling and simulation of manufacturing process chains. CIRP J Manuf Sci Technol 6(1):70–77
Keller S, Chupakhin S, Staron P, Maawad E, Kashaev N, Klusemann B (2018) Experimental and numerical investigation of residual stresses in laser shock peened AA2198. J Mater Process Technol 255:294–307
Achintha M, Nowell D (2011) Eigenstrain modelling of residual stresses generated by laser shock peening. J Mater Process Technol 211:1091–1101
Xu S, Huang S, Meng X, Sheng J, Zhang H, Zhou J (2017) Thermal evolution of residual stress in IN718 alloy subjected to laser peening. Opt Lasers Eng 94:70–75
De Chiffre L, Carmignato S, Kruth J-P, Schmitt R, Weckenmann A (2014) Industrial applications of computed tomography. CIRP Ann 63(2):655–677
Marinovszki A, De Beenhouwer J, Sijbers J (2018) An efficient CAD projector for X-ray projection based 3D inspection with the ASTRA Toolbox. In 8th Conference on Industrial Computed Tomography, Wels, Austria
Heinzl C, Kastner J, Amirkhamov A, Gröller E, Gusenbauer C (2012) Optimal specimen placement in cone beam X-ray computed tomography. NDT E Int 50:42–49
Maier J, Leinweber C, Sawall S, Stoschus H, Ballach F, Müller T, Hammer M, Christoph R, Kachelrieß M (2016) Simulation-based metal artifact reduction for computed tomography of multi-material components. In 6th Conference on Industrial Computed Tomography, Wels, Austria
Brierley N, Bellon C, Lazaro Toralles B (2018) Optimized multi-shot imaging inspection design. Proc R Soc A Math Phys Eng Sci 474(2216):20170319
Bellon C, Deresch A, Gollwitzer C, Jaenisch G (2012) Radiographic simulator aRTist: version 2. In 18th World Conference on Nondestructive Testing, Durban, South Africa
Hodgson J, Kinnell P, Justham L, Jackson M (2015) Characterizing the influence of surface roughness and inclination on 3D vision sensor performance. In Proceedings Volume 9875, Eighth International Conference on Machine Vision (ICMV 2015), Barcelona, Spain
Afazov S, Becker A, Hyde T (2012) Finite element data exchange system for simulation of manufacturing process chains. Adv Eng Softw 47:104–113
Scrimieri D, Afazov S, Becker A, Ratchev S (2014) Fast mapping of finite element field variables between meshes with different densities and element types. Adv Eng Softw 67:90–98
Afazov S, Frame J, Ankalkhope U, Bidare P, Liu Y, Vesga W, Dutton B (2020) Prediction of residual stress evolution for end-to-end process chain of laser powder bed fusion process and determination of fatigue S-N curves. In: Shamsaei N, Seifi M (eds) Structural integrity of additive manufactured materials and parts. West Conshohocken, PA, ASTM International, pp 165–175
Reed H, Vinci R, Robeck C, Verdonik T, Pires M, Castro M, Misiolek W, Haden C (2017) Statistically-substantiated density characterizations of additively manufactured steel alloys through verification, validation, and uncertainty quantification. In Big Data (Big Data), 2017 IEEE International Conference on
Hermanek P, Simone C (2017) Establishment of metrological traceability in porosity measurements by X-ray computed tomography. Developments in X-Ray Tomography XI. https://doi.org/10.1117/12.2276942
Greitemeier D, Dalle Donne C, Schoberth A, Jurgens M, Eufinger J, Melz T (2015) Uncertainty of additive manufactured Ti-6Al-4V: chemistry, microstructure and mechanical properties. Appl Mech Mater 807:169–180
JCGM 101 (2008) Evaluation of measurement data – supplement 1 to the ‘guide to the expression of uncertainty in measurement’ – propagation of distributions using a Monte Carlo method
Choi S, Gorguluarslan R, Park S, Stone T, Moon J, Rosen D (2015) Simulation-based uncertainty quantification for additively manufactured cellular structures. J Electron Mater 44(10):4035–4041
Gholaminezhad I, Assimi H, Jamali A, Vajari D (2016) Uncertainty quantification and robust modeling of selective laser melting process using stochastic multi-objective approach. Int J Adv Manuf Technol 86(5–8):1425–1441
Hu Z, Mahadevan S (2017) Uncertainty quantification and management in additive manufacturing: current status, needs, and opportunities. Int J Adv Manuf Technol 93(5–8):2855–2874
Hu Z, Mahadevan S (2017) Uncertainty quantification in prediction of material properties during additive manufacturing. Scripta Mater 135:135–140
Jacob G, Donmez A, Slotwinski J, Moylan S (2016) Measurement of powder bed density in powder bed fusion additive manufacturing processes. Measure Sci Technol 27(11):115601
Moser D, Yuksel A, Cullinan M, Murthy J (2018) Use of detailed particle melt modeling to calculate effective melt properties for powders. J Heat Transfer 140(5):052301
Moser D, Pannala S, Murthy J (2015) Computation of effective radiative properties of powders for selective laser sintering simulations. JOM 67(5):1194–1202
Lord G, Powell C, Shardlow T (2014) An introduction to computational stochastic PDEs (No. 5). Cambridge University Press, Cambridge
Gelman A, Stern H, Carlin J, Dunson D, Vehtari A, Rubin D (2013) Bayesian data analysis. Chapman and Hall CRC
Rasmussen K, Kondrup J, Allard A, Demeyer S, Fischer N, Barton E, Partridge D, Wright L, Bär M, Fiebach A, Gross H, Heidenreich S, Henn M-A, Model R, Schmelter S, KG, Pelevic N (2015) Best practice guide to uncertainty evaluation for computationally expensive models
Lopez F, Witherell P, Lane B (2016) Identifying uncertainty in laser powder bed fusion models. In: Proceedings of the ASME 2016 11th international manufacturing science and engineering conference. vol 3. Joint MSEC-NAMRC Symposia. Blacksburg, Virginia, USA. V003T08A005
McKay M, Beckman R, Conover W (2000) A comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics 42(1):55–61
Owen A, Zhou Y (2000) Safe and effective importance sampling. J Am Stat Assoc 95(449):135–143
Forrester AI, Keane A (2009) Recent advances in surrogate-based optimization. Prog Aerosp Sci 45(1–3):50–79
Rasmussen C, Williams C (2006) Gaussian process for machine learning. MIT Press, Cambridge, Massachussetts, USA
Nath P, Hu Z, Mahadevan S (2018) Modeling and uncertainty quantification of material properties in additive manufacturing. In 2018 AIAA Non-Deterministic Approaches Conference
Yang Z, Eddy D, Krishnamurty S, Grosse I, Denno V, Lopez F (2016) Investigating predictive metamodelling for additive manufacturing. In: Proceedings of the ASME 2016 international design engineering technical conferences and computers and information in engineering conference. 36th computers and information in engineering conference, Charlotte, North Carolina, USA, vol 1A
Kamath C (2016) Data mining and statistical inference in selective laser melting. Int J Adv Manuf Technol 86(5–8):1659–1677
Wiener N (1938) The homogeneous chaos. Am J Math 60(4):897–936
Sobol I (1993) Sensitivity estimates for nonlinear mathematical models. Math Modell Comput Exp 1(4):407–414
Clay R, Marburger S, Trucano T, Shneider M (2006) Modeling and simulation technology readiness levels. United States Department of Energy
Oberkampf W, Pilch M, Trucano T (2007) “Predictive capability maturity model for computational modelling & simulation. Sandia National Laboratories, Albuquerque, New Mexico, USA
NASA (2008) NASA-STD-7009 Standard for Models and Simulations. In: National Aeronautics and Space Administration (NASA), Washington, USA
Acknowledgements
The authors wish to acknowledge Innovate UK, the Aerospace Technology Institute, and the High-Value Manufacturing Catapult for financially supporting the DRAMA (Digital Reconfigurable Additive Manufacturing facilities for Aerospace) project that has resulted in this work.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Afazov, S., Roberts, A., Wright, L. et al. Metal powder bed fusion process chains: an overview of modelling techniques. Prog Addit Manuf 7, 289–314 (2022). https://doi.org/10.1007/s40964-021-00230-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40964-021-00230-1