
Abstract
Low-pressure die cast (LPDC) is widely used in high performance, precision aluminum alloy automobile wheel castings, where defects such as porosity voids are not permitted. The quality of LPDC parts is highly influenced by the casting process conditions. A need exists to optimize the process variables to improve the part quality against difficult defects such as gas and shrinkage porosity. To do this, process variable measurements need to be studied against occurrence rates of defects. In this paper, industry 4.0 cloud-based systems are used to extract data. With these data, supervised machine learning classification models are proposed to identify conditions that predict defectives in a real foundry Aluminum LPDC process. The root cause analysis is difficult, because the rate of defectives in this process occurred in small percentages and against many potential process measurement variables. A model based on the XGBoost classification algorithm was used to map the complex relationship between process conditions and the creation of defective wheel rims. Data were collected from a particular LPDC machine and die mold over three shifts and six continuous days. Porosity defect occurrence rates could be predicted using 36 features from 13 process variables collected from a considerably small sample (1077 wheels) which was highly skewed (62 defectives) with 87% accuracy for good parts and 74% accuracy for parts with porosity defects. This work was helpful in assisting process parameter tuning on new product pre-series production to lower defectives.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Low-pressure die casting (LPDC) is a process broadly used in industries requiring metal cast components with high performance, precision, and volume, such as the production of aluminum alloy wheel rims in the automotive industry. Porosity discontinuities are one of the most frequent defects found in LPDC aluminum products. They can be difficult to avoid and can compromise the integrity and performance of the components. Therefore, the cause and prevention of porosity defects are important considerations in quality control and create a demand to optimize the process variables to improve the part quality. The causes of porosity defects can come from a variety of different factors, such as metal composition, hydrogen content, casting pressures, temperatures, and die thermal management to obtain directional cooling rates.
When such casting defects arise, it is often difficult to diagnose their exact root cause and thus make the correct process parameters changes. A means is needed to monitor and analyze the process settings and deviations which can give rise to porosity defects. An Industry 4.0 quality control data system can associate recorded data from all process measurement points to individual parts complete with its inspection results. With this, machine learning classifier algorithms are utilized to identify the combinations of process settings that give rise to process defects. These can then be used to help tune process control.
LPDC production historically has high defective rates, typically every part in production is inspected using an X-ray machine for porosity defects. While this work can help predict porosity defectives, it cannot replace the X-ray machine for inspection. However, it is helpful for quantifying causes of porosity defects. A typical foundry will have hundreds of different models and dozens of new product models introduced each year. It is critical to quickly tune process settings in pre-series production.
In the first section, challenges to identifying causes of defects during production operation of a LPDC foundry are presented and then related research is discussed. In ‘Industry 4.0 Foundry Data Collection,’ an Industry 4.0 data collection system is presented to means for digitally timestamp and track parts and associated data through the foundry. In ‘LPDC Porosity Defect Prediction,’ casting defects monitored are discussed. Then in ‘Classification Algorithm Model,’ statistical machine learning models are presented that classify process conditions where porosity defects arise.
Challenges in Foundry Quality Control and Root Cause Analysis
Using factory data to construct machine learning models to predict the onset of defective parts is challenging for several reasons. The number of potential causal factors is vast. It can be hard to instrument to collect all these process data. Also features in the time series data must be identified. This can include shifts high and low, or variability too high, or jump in the data versus time. Features are examined that could be associated with a cause of a defect. Furthermore, the process data collected must be associated with the actual part being produced, so that those process conditions can be associated to a pass or a failure indicator on the part. It is not enough just to collect process data, the process data must be tagged to the parts. This means the part must be tracked through the foundry to know what process data to associate to what part. This is one important Industry 4.0 challenge of the Smart Foundry. A foundry operates under harsh conditions, and it is difficult to track and mark each part from the beginning of input material flow to the final casting component.1,2,3
The second challenge is to preprocess the time series data into features for machine learning statistical analysis.4 It is useful not to consider full dataset but rather engineering statistics which are understood by the process engineers. For example, the time series pressure, temperature, and cooling data can be separated into phases and statistics within each phase computed. This might include separating the data into phases such as fill and solidification and computing features such as the mean and variance within the phase. Process engineers wish to understand how mean shifts and higher and lower variability in different phases effect yield.
Lastly, given the features, there are also many alternative classification methods available to associate these features to the defective rate. Overall, research opportunity exists to explore machine learning to better understand the sources of defects and root causes.
Current state foundry process controls are generally inspection-based acceptance procedures. Incoming materials, casting result quality control, and process controls are inspected or monitored for compliance within specified limits. Part defects are defined by visual inspection of X-Ray images for the presence of porosity voids. Problems in operations are defined by when inputs go out of tolerance.
This current state makes defective control difficult. First, the visual inspection and manual control can have substantial repeatability and reproducibility measurement errors.5 Also, this approach can allow for combinations of inputs in tolerance yet unknowingly giving rise to porosity defects. A virtual model of the process is proposed, a so-called “Digital Twin” constructed from machine learning methods to predict passed and failed parts. This digital twin will depend on the marking and tracking of the cast parts through the foundry operations with extensive quality data acquisition. Such Industry 4.0. digital twin models are not widely common today. As introduced by Prucha,6,7 a step-by-step knowledge-based approach will be taken to construct artificial intelligence and data-driven process control of foundry processes for higher quality outcomes.
Challenges in creating an Industry 4.0 smart foundry is applying data science, machine learning, and artificial intelligence methods to the foundry operations. There are barriers of data silos within departments, a plethora of available process measurement points, and a limited set of part inspection points.
The first challenge is the difference in time scales of the data and locations within the foundry where the data are generated and stored. Material data are at the batch level and held within the melt shop. The process data are at a one-second time interval and held within each separate LPDC machine. The inspection data are at the part level and held within the x-ray machine. These datasets are typically siloed within the departments and rarely shared.
Another challenge is the complexity of the data itself. Some records such as material properties are manually entered into excel spread sheets. On the other hand, LPDC machines have gigabytes of time series data per day. The stratified nature of the data record formats creates challenges to data processing into a cohesive dataset.
Finally, as quality improvements are applied, the data structure of passed and fail parts becomes more imbalanced with fewer failed parts. Such imbalanced datasets are more difficult to analyze with machine learning techniques. Further any mistakes in data entry become more sensitive to the accuracy of the machine learning algorithm.
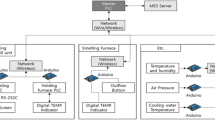
Overall, current state foundry process controls rely on isolated workstation-level compliance measurements, to ensure process and part variables remain within specified tolerances. Here, a new cloud-based Industry 4.0 foundry data collection whereby incoming material inspection, process monitoring, and cast part quality control inspection data are integrated to enable all inspection and process monitoring attributes to be attributed to each produced casting. This thereby enables correlation analysis of defective parts with potential causal incoming material or process conditions.
Related Work
A challenge mentioned was the imbalanced dataset. Extreme gradient boosting (XGBoost) has been developed for such imbalanced datasets and is a supervised machine learning algorithm with a scalable end-to-end tree boosting system.8 This algorithm has been shown to work well with small sample sizes (800 samples).9
The XGBoost algorithm has been applied in various domains of manufacturing, e.g., Machining processes for predicting tool wear of drilling,10 predicting material removal using a robotic grinding process,11 and correlating the input parameters of CNC turning via predicting values of surface roughness and material removal rate of the process.12 It has also been applied to various joining processes, including the prediction of metal active gas (MAG) weld bead geometry,13 prediction of laser welding seam tensile strength,14 and prediction of the geometry of multi-layer and multi-bead wire and arc additive manufacturing (WAAM).15
The XGBoost algorithm has also been applied to material characterization and quality assessment, e.g., predicting the fatigue strength of steels,16 optimizing steel properties by correlating chemical compositions and process parameters with tensile strength and plasticity,17 predicting aluminum alloy ingot quality in casting,18 porosity prediction in oilfield exploration and development,19 and diagnosing wind turbines blade icing.20
Additionally, other works include optimizing die casting process conditions making use of techniques such as experimental robust design,21,22,23 model predictive control,24 and genetic algorithm optimization.25 For example, Guo26 has created classifiers to identify defects in silicon wafers coming from foundry operations. In machining operations, machine learning research has more focused on system health identification and tool wear.27 Wilk-Kolodziejczyk28 studied use of various machine learning classifiers to predict the material property outcomes of austempered ductile iron from varying the chemical compositions.
Another concern is computing the relative contributions of the feature to the classification result. Recently, Shapley values are starting to be used to interpret machine learning models and their predictions29 in management, including profit allocation,30 supply chains,31 and Financial data.32 Shapley indices are used in this study as they give accurate and unbiased estimators of relative feature contribution even with correlated and unbalanced data.
The focus of the work here is metal casting studies. Problem solving methods, numerical simulations (especially computer-based heat flow simulations), and predictive machine learning models have been used to understand the influence of the casting parameters in the occurrence of defects like porosities.
Kittur et al.33 developed equations based on experimental data for high-pressure die casting (HPDC). These equations were used to artificially generate a sufficiently large data for training Neural Networks by selecting the values of the input variables randomly. Rai et al. 34 trained an artificial neural network (ANN) model using data generated by FEM-based flow simulation software. They showed porosity defects were related to input parameters such as melt and mold initial temperatures and first- and second-phase velocities. These model-based input quantities are insufficient to cover all the effects of real LPDC machines, here the complex relations among the process variables are considered with measurement points both from machine and actual sensor values.
In recent sophisticated work, Kooper-Apelian35 studied HPDC mechanical properties of a die cast tensile testing machine bar and the relationship to process features using large dataset spanning many months of production. They compared the regression models of Random Forest, Support Vector Machine (SVM), Neural Network, and XGBoost. Their focus was on large datasets spanning many months of production. They found Random Forest Regression worked best for regression fitting the ultimate tensile strength of produced parts. They also studied classifying good parts and process defectives for HPDC of tensile testing machine bars,36 as well as illustrated machine learning application by a case study using sand cast foundry data.37 The value of applying machine learning to reduce foundry scrap has been studied. Blondheim4 introduced the critical error threshold as the maximum beyond which increased accuracy is not worth the effort.
The studies above were conducted for mostly injection molding and HPDC which is different than LPDC in terms of process parameters, casting physics, and production parts. These works also focused on large dataset and the relationship between features and responses. Our work focuses on LPDC initial production to help set up the process with smaller datasets.
One of the earlier studies on LPDC, Reilly et al.38 used computational process simulation modeling rather than hardware experiments. They studied minimizing various defects in LPDC of aluminum alloy automotive wheels via simulating heat transfer and fluid flow during die casting. These input quantities are quite difficult to measure for real LPDC machines. Rather machine measurement points are used here such as cooling channel’s activation time and silicon content of molten metal. Zhang et al.39 studied an experimental L-shape thin-walled casting with a laboratory LPDC machine to predict and optimize the part quality. This work was early demonstration of using machine learning in LPDC. They made use of artificial neural networks for modeling and genetic algorithms for optimization. Their training data were collected from numerical simulation and tested on an experimental part under laboratory conditions. This work also did not focus on small and imbalanced datasets as studied here typical of actual industrial parts and processes.
The objective here is a method to collect LPDC foundry process data and use machine learning models to correlate the process parameters and tolerances with the occurrence of critical defects that will invalidate a casting part from being used. The method includes machine process data collection, part tracking, and quality inspection of defect data. This study differs as being representative of an industrial foundry with a machine learning application on a small dataset to help establish process settings. LPDC machine and metal related features were utilized to predict porosity defectives of LPDC processing of aluminum alloy high-performance automotive wheels.
Industry 4.0 Foundry Data Collection
Low-Pressure Die Casting Process
LPDC machines consist of a holding furnace, heated electrically, and placed in the lower part of the die casting machine, and two die cavities located above. One cycle of the casting process consists of pressurizing the holding furnace, which contains the molten aluminum that is forced to fill the mold cavity, followed by mold cooling amplified by air and water coming from cooling channels and consequent solidification of the cast.40 In Figure 1, the intersection of the LPDC mold is shown with the cooling channels locations used in this study.

Intersection of a die mold of LPDC machine.
The overall process flow within the foundry includes material loading, melting in a crucible, degassing, and batch transfer to LPDC machine, casting into die mold, directional cooling, X-ray inspection, heat treatment, and further part cleanup and inspections. Of all the foundry steps, the LPDC system is most critical to part quality, and the study focus upon it here. The main process sequence for a LPDC machine is shown in Figure 2.

Low-pressure die casting process cycle.
The casting process of Figure 2 includes three main phases. Phase 1 includes the application of pressure to the molten metal in the fill tube allowing it to be forced up to the runner and Phase 2 is the actual filling of the die mold cavity with the molten metal. There is a threshold that can be adjusted on the duration of these phases. It is important to fill the mold cavity slowly to avoid any turbulence of the liquid metal that would cause entrained air and create porosity defects. On the other hand, if the metal fills too slowly then there will be temperature differences between the metal and the mold that would affect the liquidity and result in cold and hot tearing failures. Phase 3 includes the application of increased feeding pressure and integration of directional solidification by use of cooling channels set into the die mold (Figure 1). These cooling channels can be bubbler style or though passages.
Within the LPDC process many time series data are monitored and saved including pressure and temperatures in the cooling channels used for directional solidification. These measurements are taken on a one-second frequency over a part cycle of around 5 min per rim. An example of time series data is shown in Figure 3 of the molding pressure, where the data shown cover two cycles that created two castings. The dwell time between cycles can vary due to operator and circumstances.

Time series pressure measurement on LPDC machine.
Causes of Porosity Defects in LPDC
There are several casting defects which may occur during the LPDC of aluminum wheel rims. The most common failures include gas and shrinkage porosity, shrinkage, cold shut, and foreign materials.41 In this study, rather than grouping all defects, porosity defects that occur as minute voids are the focus, given that they are one of the most common types of defects. Statistically fitting isolated defects will correlate better to individual process conditions and therefore fit better than trying to fit all defects as one type.4 However, porosity defects mainly arise as two types, gas porosity and shrinkage porosity. The current factory operations have limited ability to distinguish the two so both are considered as one defect.
The wheel rims are 100% inspected using X-ray scanning for porosity void defects which are observed as elongated and round dark spots. The X-ray system used complies with the requirements specified in non-destructive testing standards- DIN EN ISO 19232-142 and DIN EN ISO 19232-5.43 For example, a defective is defined by when the evaluated 20 by 20 mm wheel spoke zone area of the X-ray image has either a flaw size above 3 mm or a when 3% or more of the evaluation field is deemed a void. An example defective wheel rim is shown in Figure 4. Historically, the inspection data were measured, observed, and acted upon locally to the inspection stations and not correlated to the LPDC machine processes other than sequential repeated failures. With this approach it is often hard to associate process deviations with part defects.

X-ray scan of die cast wheel rim with a porosity defect on a spoke.
Porosities occur when there’s poor feeding of the molten metal to compensate the volumetric shrinkage related with the solid-to-liquid transformation. When designing the die and process settings careful consideration is taken to prevent the loss of directional solidification by considering the wall thickness, melting temperature, cooling rate, and cooling temperature, among other process parameters. Other factors that influence macro-porosities are alloy modifications and the hydrogen content.44,45 Therefore, these process parameters should be a focus of monitoring and analysis. The porosity size is dependent on the volume of entrapped liquid metal. Porosities cannot be accepted where they compromise the functionality of the component based on wheel design tolerances and the location. The most critical location is at the intersection between the rim and spoke. These locations on the rims are here a focus for monitoring and analysis as shown in Figure 4.
When porosity defects occur, it traps gases including hydrogen which are released upon solidification. The porosity size and volume are therefore also dependent on initial hydrogen content, solidification conditions, and macro-segregation of alloying elements.46 The porosity defects are often more prone to happen at specific periods of the year, such as summertime with overall higher temperatures and higher humidity levels.40 Therefore, the data shown in this example are from wheel rims manufactured 6 days in a row. The foundry runs for 24 h with three shifts. The measurements were of 5 days of production and a sixth day of one shift only, for a total of sixteen continuous shifts. The first few parts in each batch are clean out parts which are not used and recycled. The result was 1077 kept parts.
Regarding the process parameters, studies have shown that a decrease in melting temperature can reduce the amount and size of the porosity. Further, decrease in holding time and an increase in applied pressure promotes a finer grain size which consequently reduces porosity.47,48,49 In this study, the metal temperature and pressure are included as monitored variables.
Finally, metal properties can also affect the generation of porosity. Therefore, the quality of an aluminum sample ought to be evaluated through the density index (DI), which specifies the weight of a sample hardened in vacuum (free of voids) as opposed to a sample hardened under atmospheric pressure. Jang et al. found that increasing the mold pre-heating temperature increased the DI of an aluminum alloy up to a point after which further temperature increases decreased the DI.50 In this study, the DI is included as monitored variables.
The most frequently used alloying element in aluminum is elemental silicon. The heat of fusion of silicon is about five times that of aluminum and therefore it significantly improves the fluidity. Moreover, silicon expands on solidification and counteracts the solidification shrinkage of aluminum.51,52 Overall, the silicon content is important in porosity failures since it affects the mold filling and solidification shrinkage. In this study, silicon content is included as monitored variable.
Another set of defect causes include directional solidification effects. It is important to ensure that a controlled, non-turbulent fill exists to eliminate air entrapment. To do this, a ready supply of molten metal in the direction of solidification is needed to reduce the shrinkage. The use of a metal die with integral cooling passages allows for controlled cooling of the casting. This can further improve mechanical properties through refinement of the microstructure.53 In this process, there are both water and air cooling channels whose flow rate and activation times are monitored and adjusted according to the most recent X-ray results. This operator-to-operator skill at adjustment compensation of the water and air cooling could be a source of defects or lack of defects. Machine learning can help quantify proper water and air cooling times.
Sui et al.54 also found cooling effects to be important. They implemented a numerical simulation to study the influence of the cooling process of a LPDC on the porosity of an aluminum alloy wheel and concluded that it is difficult to promote sequential solidification and eliminate hot spots.
Fan et al.46 simulated the hydrogen macro-segregation and micro-porosity formation in die casting and found good prediction of pore size range at the but considerable error in predicting the number density of pores. Blondheim et al.55 further discuss the macro-porosity in HPDC and the impact of part shape in porosity.
While the mentioned causes of porosity defects are known, it remains unclear what combination of causes and their extent will give rise to actual onset of porosity defects in the specific parts of wheel rims being cast. This study proposes to associate the collected process data to individual parts and then use the quality inspection result of the parts to establish relationships between process conditions and when porosity defects arise.
Industry 4.0: Measurements Process of the Part Defects
Given these process physics that give a rise to porosity defects as discussed above, these causal process variables need to be monitored and statistically controlled. The foundry process is monitored at several locations such as the metal chemical analysis, LPDC machine, and X-ray.
To complete any statistical analysis of the process inputs for causes of defects, the multiple time series datasets must be associated to the casting. This requires part tracking in the foundry. Most importantly, the time that each part is initiated in the LPDC machine needs to be recorded. This creates a dataset of time and a part identifier with a machine identifier. With this, the subset of recorded LPDC machine process data (e.g., such as pressure shown in Figure 3) can be associated to a part. This similarly holds true for associating batch material from the furnace with parts. This tracking-data collection is an important addition required over and above what most foundry data systems include. This represents more than simple workstation monitoring to remain within process tolerances.
The LPDC machine is setup and adjusted by the machine operators in accordance to process control rules established over time. There are default settings but also inherent flexibility to adjust these by the operator according to the rules and given tolerances. For example, changes are made if the X-ray results indicate a porosity problem over a repeated sample of parts. The operators will change certain settings within limits. Therefore, the actual values of process parameters in the LPDC machine are time series monitored and available for statistical machine learning analysis.
The LPDC machine time series monitors values during serial production include molding pressure, temperature, time, air, and water channel cooling. These values are continuously monitored at one- and two-second intervals to assure they remain within the LPDC machine tolerances. The data itself are stored as time series data with each machine’s identifier, material batch identifier, and the monitored LPDC machine values. This forms the first database of LPDC time series data.
The other set of variables important to porosity are the Aluminum alloy metal batch properties. The LPDC machine is refilled every 17 to 20 parts. To reheat the mold and eliminate mixed material, the first three rims are not used. A sample is taken at the furnace, the time and location are recorded, and the sample sent to a microstructures laboratory for chemical analysis. Among other chemical properties, the analysis includes the batch’s density index and silicon fraction which is causal to porosity defects as discussed in ‘Causes of Porosity Defects in LPDC.’ The data are stored with each batch sample’s time, material batch identifier, and chemical properties. This forms the second database of Aluminum alloy properties, time stamps, and identifiers.
The last set of measurements are the X-ray inspection results of each casting. These results are stored as a dataset of the time of inspection, the part identifier, the X-ray image, and the pass/fail result.
These datasets themselves are insufficient for the machine learning study. Additionally, part tracking data are needed to identify when the X-rayed part was in the LPDC machine. To do this, a part tracking system that tracks when each rim was in the LPDC machine and in the X-Ray is introduced in this study. This database consisted of time as rows and part number at the LPDC machine and a part number at the X-Ray machine. With this, LPDC machine process parameters and Aluminum metal properties with the X-ray results can be associated.
In summary, the result of these data collections are process time series data, batch metal material properties, part level tracking location data, and porosity quality results.
LPDC Porosity Defect Prediction
At this point, we have a dataset composed of part identification numbers, the porosity inspection results, and the sections of the process time series data associated with the identified part. We now seek to characterize the time series data into features of that data to which we can then build statistical prediction models. The data discussed here are as collected from a particular LPDC machine and die mold in the production of automotive wheels castings, at Cevher Wheels Casting Plant, Izmir, Turkey, as supplied to the European automotive market.
Data Preprocessing and Feature Engineering
The focus here is on the casting metal and process variables as likely causal factors of void defects. The initial dataset consisted of 1077 parts in total of which 62 were of porosity failures. The time series process data is taken and partitioned according to the rim tracking data. The result is approximately 300-time increments (seconds) of processing time data points for each of the 1077 rims.
The next step is to take the time series data for each wheel rim and form features that can be used to classify good and defective rims. For example, features might include the average and variance of a pressure over a phase of the casting cycle. Different phases of the pressure cycle are more important than others,56 for instance phase 3 intensification pressure disturbances can affect porosity defects more than other phases, as shown in Figure 5. These disturbances are considered in terms of the standard deviation in this phase as understood by the process operators.

An example of an intensification pressure cycle with high variability.
The pressure and cooling channels machine set points and actual measured point are both captured. However, the machine settings were highly correlated with the mean feature values and therefore not used. The result of the feature extraction is 36 features from the 13 measurement points. There are more features than the measurement points since a single time series measurement might be extracted into multiple phases each with means, standard deviations, and durations.
From this, a dataset for machine learning analysis was prepared. This dataset consists of a 1077 × 37 matrix, where each row represents a production rim casting, and 36 columns of input variable feature data and 1 inspection pass/fail column. The 36 input features are shown in Table 1. Eleven of the acceptable castings had process settings far out of specification as outliers due to maintenance and adjustment. These outliers were removed from the data. The result was a dataset of 1066 parts in total.
Classification Algorithm Model
Next, the approach for fitting the part defect outcome is discussed. This classification is difficult since the dataset is biased to many good parts with few defective parts. This creates an unbalanced dataset in which traditional machine learning methods are not suited. A second challenge is the small quantity of defective datapoints (rims) to train a generalized model. Methods to overcome these obstacles are explored.
Classification Problem Formulation
The aim is to predict which parts have porosity defects, which can be approached as a binary classification problem. When developing machine learning models, the dataset is split into training and testing subsets. Typically, the split uses 70–80% of the data for training and the remaining for model validation testing. However, in this case, leaving 20% for validation leaves too few defectives. Therefore, a 50% split was used for a reasonable number of defectives in the validation dataset which is not included in the model training and hyperparameter optimization. The dataset was split in a random and stratified fashion to ensure an even allocation of the defectives into the training and testing sets.
For fitting models of defectives, multiple evaluation metrics could be used. These include accuracy, precision, recall, and the f1 score given in Eqns. 1, 2, 3, and 4, respectively. Accuracy is the percentage of good and defective parts that model correctly labels out of all the parts, where TP is the number of true positives, FP is the number of false positives, and TN and FN are the number of true negatives and number of false negatives, respectively.
While it would seem accuracy is a good measure, for unbalanced datasets with a high number of good parts over defective parts, total accuracy can be misleading by simply being accurate on the good parts alone and misclassifying many of the defective parts. Two other metrics are precision and recall which indicate the percent of correctly labeled parts and the percent falsely labeled.
These are more informative with respect to the minority class of defective parts. The f1 score is a combination of correct and incorrect labels into an overall model score.
In this paper, all these scores are utilized to ensure a quality model. Machine learning algorithms include hyperparameters that are tuned to fit the best model. This tuning is a crucial task for optimizing performance of the XGBoost algorithm used here. This consists in defining a set of values and searching for a combination that maximizes the classification results. Various approaches can be used for the search from full factorial grid search to random selection.57 Here, an informed automated hyperparameter tuning approach is used, the Bayesian Optimization algorithm from the Hyperopt library58 for model selection and hyperparameter optimization. This method has been proven efficient in terms of computational work and algorithm performance compared to the uninformed hyperparameter searching methods such as grid search.
XGBoost Implementation
In this section, the setup and implementation of the defective classification using XGBoost are presented. First, the repartitioning and resampling of the training data are described to promote a higher concentration of the minority class defective set. Then, the objective function for finding the best fit using hyperopt is described.
A resampling is made with over-sampling to increase and balance the minority defective class in the training data, and with under-sampling to obtain a cleaner space. This is done with Synthetic Over-Sampling (SMOTE)59 and the Edited Nearest Neighbor Rule (ENN) under-sampling.60
For a pass–fail problem, the under-sampling ENN algorithm can be described in the following way: for each wheel rim in the training set, its three nearest neighbors are found. If the wheel rim belongs to the majority class and the classification of its three nearest neighbors do not, then the wheel rim is removed. Similarly, the over-sampling smote algorithm forms new minority class examples by interpolating between several minority class defective wheel rim samples that lie together. The original data had a 16.1 to 1 ratio of good parts to defective parts, in minimizing the training error the oversampled set resulted in a ratio of 0.8 to 1.
Given the resampled training data, the fitting approach must be selected. Here, a Bayesian optimization approach is taken, where initial hyperparameters are estimated and fit, and subsequently that fit is optimized with more trials. The automated hyperparameter tuning library Hyperopt is used. The objective function searches over the selected hyperparameters to minimize the validation error of training set. With informed Bayesian optimization, the next values selected are based on the past evaluation results. The evaluation metric chosen is the area under the curve (AUC) which represents the ability to differentiate between the positive and negative classes (good and defective parts). The fitting algorithm XGBoost’s built in cross validation is utilized for creating validation sets to tune the model on the training data. Cross validation is generally a better approach than a simple single split of the training data since it provides more generalized error. For this study, a 10-fold cross validation was used in a stratified fashion, meaning the hyperparameter set is validated and trained ten times and the mean of these results is the objective function. The testing data remain reserved for validating the machine learning prediction model.
Results and Interpretation
The summary results of the model performance are shown using the confusion matrix in Figure 6. The confusion matrix shows the ability to identify good and defective parts. 440 out of 505 good parts were correctly labeled as good, whereas 65 out of 505 good parts were mislabeled as defective, an 87% recall rate. Similarly, the algorithm was able to correctly identify the defective parts with 23 out of 31 defective parts were correctly labeled as defective, and 8 out of 31 defective parts were mislabeled as good, a 74% recall rate.

Confusion matrix of the XGBoost model for part quality.
The statistical summary report is shown in Table 2. Note that the test data were biased with many good parts (505 of 536, 94%) and only a small fraction of defective parts (31 of 536, 6%) make classification difficult. Also, this sample yield is from the data selected and is not necessarily indicative of the actual foundry yield rates. The results show that the classifier was able to correctly predict a good and defective part using the process and material input data alone.
XGBoost Classification Prediction Model
The predictor equation consisted of a set of 77 separate binary decision tree estimators with maximum depth of four layers. Each tree contributes an increment to the random variable of a logistic distribution function. One such decision tree is shown in Figure 7. Given a set of material and process input values\(\mathop{x}\limits^{\rightharpoonup} \), a decision tree i can be evaluated for that particular set \(\mathop{x}\limits^{\rightharpoonup} \) which can indicate the partial probability of that set passing or failing by the leaf node loaded value \({Z}_{i}\). Repeating this all over 77 trees and adding up summing the resulting leaf nodes of each tree i indicates the logit value for that feature set.

Example binary decision tree estimator.
Then, applying the logit function computes the probability of failure of that feature set.
Interpreting the tree of Figure 7, if the normalized standard deviation value of Air Channel 2 is less than − 0.502 the probability of failure is around 0.37 which is the probability value of the loaded leaf value − 0.5434. Similarly, if the normalized standard deviation value of Air Channel 2 is more than − 0.502 and the normalized value of the Density Index is smaller than 1.106 and the Mean Value of Phase 3 intensification pressure is larger than − 1.284 and the Silicon Content of the metal is smaller than 1.021, then the probability of failure increases to larger than 0.64, which is the probability of the loaded leaf value 0.561. In general, large leaf values in any tree indicate combinations of features give rise to defects.
Feature Importance Scoring
The classifier used 36 input features, some are more important than others to determine whether a part is good or defective. To determine the relative importance of the features, the Shapley index of each feature is computed. The Shapley index is the (weighted) average of marginal contributions of the input feature.61
As a check for feature importance scoring, a random noise variable was added and the analysis with this added variable was rerun. Such a random noise variable will not contribute to prediction accuracy. This resulted in a Shapley index of 0.3 to the insignificant random variable, indicating all features below 0.3 are also insignificant.
The results are shown in Figure 8, with the features ordered according to contribution as shown by the Shapley index. The results show that 15 of 36 features contribute, and the remaining 21 features combined contribute less than a half of the most contributing variable. Note that these contributions do not sum to one since each Shapley index includes interaction effects.

Feature importance order.
Looking at the results shown in Figure 8, three out of the top four contributors are air cooling channel flow rates. The most important contributing feature is the standard deviation of the air flow in the channel closest to the center hub on the bottom mold. The air channel standard deviation varies due to equipment process control during operation of the machine; this analysis shows it indeed has an impact on porosity defects. The second highest contributor was the Melt Silicon Content of the molten metal. This corresponds with known casting physics, where the silicon content of the aluminum effects the fluidity which in turn effects porosity formations.51,52 The third highest contributor is again an air channel flow standard deviation but of the top mold center hub. The Shapley indices indicate that the upper and lower air channels at the center have highest influence on porosity, this corresponds with understood physics since that is the thickest area of the casting as shown in Figure 1.
The fourth contributor is the air channel flow of the top spoke near the center hub. These air channels are located next to the center and are also at a relatively thick location. The fifth highest contributor is the Density Index, which refers to the oxide level in melt quality which is a direct effect on the porosity defects.44,45
Overall, the contributors of the casting defects are improper air channel operations combined with improper variations in material properties. This work quantifies the combinations of the features needed to result in defective wheel rims. That is, a quantified prediction model has been created to predict when porosity will arise on this machine for this wheel.
Tradeoff Between Good and Defective Part Prediction
The hyperparameters were searched to improve the XGBoost model fit. However, the model also includes hyperparameters to tune the tradeoff between the rate of false positives and false negatives. For example, XGBoost implementation includes a hyperparameter scale_pos_weight, which scales the gradient of the minority class of false negatives. We explore a tradeoff curve by varying the model to generate a ratio of true positives to true negatives between 0 and 1. The results are shown in Figure 9. As can be seen, predication of defectives can get above 90% defective part accuracy based on these data and models; however, it would also suffer about 50% accuracy on the good parts. If one were equally concerned on pass and fail accuracy, a reasonable tradeoff value for this dataset would be 80% accuracy on both. For this study, fail accuracy is of more concern.

Model tradeoff between pass and fail accuracy.
Discussion
Use of machine learning on production process data offers the ability to improve statistical quality control. Here, causes of casting defects were identified. The Extreme Boosted Decision Tree (XGBoost) model did well in predicting good parts from defective parts, with 87% accuracy for the good parts and 74% accuracy for the defective parts.
Keeping the data fixed, it is possible to increase the defective part prediction accuracy above 74%, but at the expense of reduced good part prediction accuracy. The cost of a false positive versus the cost of a false negative can be used to determine an appropriate tradeoff point. That is, the cost of calling a percentage of good parts defective and unnecessarily reworking them can be optimized against the cost of calling a percentage of defective parts as good and performing unnecessary downstream steps such as machining and painting. This enables the foundry managers to decide on which classifier has the higher expected benefit.
One critical decision point is how to capture features of the time series data. We chose to consider averages and standard deviations of each phase in a cycle. As pointed out by Blondheim,62 taking averages of time series data can mask patterns in the data. They make use of auto-encoded neural nets to consider the full time series data to detect anomalies. This approach appears promising for increase anomaly detection. We chose here to use the statistics from the process to compare the average with machine set points for the operation and compare the standard deviations with given machine and process tolerances. Future work would include comparing this approach with use of the full time series data and understanding what patterns give rise to defectives.
This work studied porosity defects at all locations across the spoke of the rim to determine a defective. The accuracy could be improved with more refined details of defects. For example, combining multiple defects into a single defective classification can lead to worse performance.5 The porosity failures could be separated by zone of a wheel to enable linking the cooling channels by their locations. This could provide a better understanding of the effects of the mean and standard deviation of the flow rate of the channels as well as the operation times. However, it also requires substantially more data, and therefore would be more suitable for analysis during full production. To enable such high volumes of process and quality inspection data to be analyzed, automated data collection and tracking are needed. Here, we have a semi-automated approach associating the X-Ray and LPDC machine. In future work, a totally automated parts tracking method should be implemented starting from the earliest stages of production. The current laser QR code marking system starts the marking after X-Ray in the middle of the production and is inadequate. Further, the visual inspection system currently used at the X-ray could be automated to isolate the defects to types. More data gathered on failed rims and the coordinates of the failures could be classified and a multiclass classification algorithm applied.
This work made use of the XGBoost classification algorithm. Other methods were explored including Support Vector Machine (SVM) and logistic regression with performance results shown in Table 3. The logistic regression provided poor accuracy on predicting good and defective parts. The SVM provided sufficient accuracy on defective parts but very poor accuracy on predicting good parts. Overall XGBoost did much better.
Beyond the cost of quality, identifying a defective part early reduces the carbon footprint of the foundry by eliminating the unnecessary machining, painting, and recycling. One of the main carbon footprint impacts is the high carbon emission of paint removal when recycling rims. Even with false positives and false negatives, this model approach could possibly be used for predicting porosity failures in the early stages by taking the model predicted and possibly defective parts into quarantine for a deeper quality inspection. Dispositioning into such quarantine parts would not automatically reject the false negatives but rather quarantine them for deeper defect analysis.
This work did not make use of big data. Rather with a small dataset of a thousand units the quality control of new production lines can be formed. While large datasets can provide better and more robust models, practically a LPDC foundry operation needs to make use of early smaller datasets. Foundry operations can use this machine learning methods to predict failures in short time periods. For example, the process optimization can be started immediately to decrease the porosity defect rims for an existing or a new wheel rim production start. The model can be expanded to a more general and robust as more data are gathered. Analysis of small datasets offers a means for foundries to begin to make use of machine learning in their production.
Overall, Industry 4.0 data collection and machine learning worked well to identify causes of casting defects within process data. This required a sophisticated part tracking and data collection in the foundry as well as application of state-of-the-art machine learning algorithm, while it is not sufficiently accurate for dispositioning acceptable versus defective parts in production but is useful for assisting in identifying root causes.
References
T. Uyan, K. Jalava, J. Orkas, K. Otto, Sand casting implementation of two-dimensional digital code direct-part-marking using additively manufactured tags. Int. J. Metalcast. (2021). https://doi.org/10.1007/s40962-021-00680-x
J. Landry, J. Maltais, J.M. Deschênes, M. Petro, X. Godmaire, A. Fraser, Inline integration of shot-blast resistant laser marking in a die cast cell. NADCA Trans 2018, T18–T123 (2018)
A. Fraser, J. Maltais, A. Monroe, M. Hartlieb, X. Godmaire, Important considerations for laser marking an identifier on die casting parts
D. Blondheim Jr., S. Bhowmik, Time-series analysis and anomaly detection of high-pressure die casting shot profiles. NADCA Die Cast. Eng., 14–18 (2019)
D. Blondheim, Improving manufacturing applications of machine learning by understanding defect classification and the critical error threshold. Int. J. Metalcast. (2021). https://doi.org/10.1007/s40962-021-00637-0
T. Prucha, From the editor—big data. Int. J. Met. 9(3), 5 (2015)
T. Prucha, From the editor—AI needs CSI: common sense input. Int. J. Met. 12(3), 425–426 (2018)
T. Chen, C. Guestrin. Xgboost: a scalable tree boosting system. In: Proceedings of the 22nd international conference on knowledge discovery and data mining, pp. 785–794 (2016)
W. Dong, Y. Huang, B. Lehane, G. Ma, XGBoost algorithm-based prediction of concrete electrical resistivity for structural health monitoring. Autom. Construct. 114, 103155 (2020)
M.S. Alajmi, A.M. Almeshal, Predicting the tool wear of a drilling process using novel machine learning XGBoost-SDA. Materials (Basel) 13(21), 1–16 (2020). https://doi.org/10.3390/ma13214952
K. Gao, H. Chen, X. Zhang, X.K. Ren, J. Chen, X. Chen, A novel material removal prediction method based on acoustic sensing and ensemble XGBoost learning algorithm for robotic belt grinding of Inconel 718. Int. J. Adv. Manuf. Technol. 105(1–4), 217–232 (2019). https://doi.org/10.1007/s00170-019-04170-7
S. Chakraborty, S. Bhattacharya, Application of XGBoost algorithm as a predictive tool in a CNC turning process. Reports Mech. Eng. 2(2), 190–201 (2021). https://doi.org/10.31181/rme2001021901b
K. Chen, H. Chen, L. Liu, S. Chen, Prediction of weld bead geometry of MAG welding based on XGBoost algorithm. Int. J. Adv. Manuf. Technol. 101(9–12), 2283–2295 (2019). https://doi.org/10.1007/s00170-018-3083-6
Z. Zhang, Y. Huang, R. Qin, W. Ren, G. Wen, XGBoost-based on-line prediction of seam tensile strength for Al–Li alloy in laser welding: experiment study and modelling. J. Manuf. Process. 64, 30–44 (2021). https://doi.org/10.1016/j.jmapro.2020.12.004
J. Deng, Y. Xu, Z. Zuo, Z. Hou, S. Chen, Bead geometry prediction for multi-layer and multi-bead wire and arc additive manufacturing based on XGBoost. Trans. Intell. Weld. Manuf. (2019). https://doi.org/10.1007/978-981-13-8668-8_7
D.K. Choi, Data-driven materials modeling with XGBoost algorithm and statistical inference analysis for prediction of fatigue strength of steels. Int. J. Precis. Eng. Manuf. 20(1), 129–138 (2019). https://doi.org/10.1007/s12541-019-00048-6
K. Song, F. Yan, T. Ding, L. Gao, S. Lu, A steel property optimization model based on the XGBoost algorithm and improved PSO. Comput. Mater. Sci. (2020). https://doi.org/10.1016/j.commatsci.2019.109472
S. Yan, D. Chen, S. Wang, S. Liu, Quality prediction method for aluminum alloy ingot based on XGBoost. In: Proceedings of the 32nd Chinese Control Decis. Conf. CCDC 2020, pp. 2542–2547, 2020. https://doi.org/10.1109/CCDC49329.2020.9164112
S. Pan, Z. Zheng, Z. Guo, H. Luo, An optimized XGBoost method for predicting reservoir porosity using petrophysical logs. J. Pet. Sci. Eng. 208, 109520 (2022). https://doi.org/10.1016/j.petrol.2021.109520
T. Tao et al., Wind turbine blade icing diagnosis using hybrid features and Stacked-XGBoost algorithm. Renew. Energy 180, 1004–1013 (2021). https://doi.org/10.1016/j.renene.2021.09.008
V.D. Tsoukalas, S.A. Mavrommatis, N.G. Orfanoudakis, A.K. Baldoukas. A study of porosity formation in pressure die casting using the Taguchi approach. In: Proc. Inst. Mech. Eng. Part B J. Eng. Manuf., vol. 218, no. 1, pp. 77–86, 2004. https://doi.org/10.1243/095440504772830228
Q.C. Hsu, A.T. Do, Minimum porosity formation in pressure die casting by taguchi method. Math. Probl. Eng. (2013). https://doi.org/10.1155/2013/920865
W. Ye, W. Shiping, N. Lianjie, X. Xiang, Z. Jianbing, X. Wenfeng, Optimization of low-pressure die casting process parameters for reduction of shrinkage porosity in ZL205A alloy casting using Taguchi method. Proc. Inst. Mech. Eng. 228(11), 1508–1514 (2014). https://doi.org/10.1177/0954405414521065
D.M. Maijer, W.S. Owen, R.A. Vetter, An investigation of predictive control for aluminum wheel casting via a virtual process model. J. Mater. Process. Technol. 209(4), 1965–1979 (2009). https://doi.org/10.1016/J.JMATPROTEC.2008.04.057
V.D. Tsoukalas, Optimization of porosity formation in AlSi9Cu3 pressure die castings using genetic algorithm analysis. Mater. Des. 29(10), 2027–2033 (2008). https://doi.org/10.1016/j.matdes.2008.04.016
Guo, S.M., et al., Inline inspection improvement using machine learning on broadband plasma inspector in an advanced foundry fab. In: Proceedings of the SEMI Advanced Semiconductor Manufacturing Conference (ASMC). IEEE (2019)
Park, S., et al., Prediction of the CNC tool wear using the machine learning technique. . In: Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI)
D. Wilk-Kolodziejczyk, K. Regulski, G. Gumienny, Comparative analysis of the properties of the nodular cast iron with carbides and the austempered ductile iron with use of the machine learning and the support vector machine. Int. J. Adv. Manuf. Technol. 87(1–4), 1077–1093 (2016)
R. Rodríguez-Pérez, J. Bajorath, Interpretation of machine learning models using shapley values: application to compound potency and multi-target activity predictions. J. Comput. Aided. Mol. Des. 34(10), 1013–1026 (2020). https://doi.org/10.1007/s10822-020-00314-0
L. Zaremba, C.S. Zaremba, M. Suchenek, Modification of shapley value and its implementation in decision making. Found. Manag. 9(1), 257–272 (2017). https://doi.org/10.1515/fman-2017-0020]
D.C. Landinez-Lamadrid, D.G. Ramirez-Ríos, D. Neira Rodado, K. Parra Negrete, J.P. Combita Niño, Shapley Value: its algorithms and application to supply chains. INGE CUC 13(1), 61–69 (2017). https://doi.org/10.17981/ingecuc.13.1.2017.06
J. Ohana et al., Shapley values for LightGBM model applied to regime detection. 2021. [Online]. Available: https://hal.archives-ouvertes.fr/hal-03320300
J.K. Kittur, G.C. ManjunathPatel, M.B. Parappagoudar, Modeling of pressure die casting process: an artificial intelligence approach. Int. J. Metalcast. 10(1), 70–87 (2016). https://doi.org/10.1007/s40962-015-0001-7
J.K. Rai, A.M. Lajimi, P. Xirouchakis, An intelligent system for predicting HPDC process variables in interactive environment. J. Mater. Process. Technol. 203(1–3), 72–79 (2008). https://doi.org/10.1016/J.JMATPROTEC.2007.10.011
A. Kopper, R. Karkare, R.C. Paffenroth, D. Apelian, Model selection and evaluation for machine learning: deep learning in materials processing. Integr. Mater. Manuf. Innov. 9(3), 287–300 (2020)
A.E. Kopper, D. Apelian, Predicting quality of castings via supervised learning method. Int. J. Metalcast. (2021). https://doi.org/10.1007/s40962-021-00606-7
N. Sun, A. Kopper, R. Karkare, R.C. Paffenroth, D. Apelian, Machine learning pathway for harnessing knowledge and data in material processing. Int. J. Metalcast. 15(2), 398–410 (2021). https://doi.org/10.1007/s40962-020-00506-2
C. Reilly, J. Duan, L. Yao, D.M. Maijer, S.L. Cockcroft, Process modeling of low-pressure die casting of aluminum alloy automotive wheels. JOM 65(9), 1111–1121 (2013)
L. Zhang, R. Wang, An intelligent system for low-pressure die-cast process parameters optimization. Int. J. Adv. Manuf. Technol. 65(1–4), 517–524 (2013)
B. Zhang, S.L. Cockcroft, D.M. Maijer, J.D. Zhu, A.B. Phillion, Casting defects in low-pressure die-cast aluminum alloy wheels. JOM 57(11), 36–43 (2005). https://doi.org/10.1007/s11837-005-0025-1
ASTM E155-15, Standard reference radiographs for inspection of aluminum and magnesium castings. ASTM International, West Conshohocken, 2015, www.astm.org
ISO 19232-1:2013, Non-destructive testing—image quality of radiographs—Part 1: determination of the image quality value using wire-type image quality indicators
ISO 19232-5:2018, Non-destructive testing—image quality of radiographs—Part 5: determination of the image unsharpness and basic spatial resolution value using duplex wire-type image quality indicators
D. Dispinar, J. Campbell, Porosity, hydrogen and bifilm content in Al alloy castings. Mater. Sci. Eng. A 528(10–11), 3860–3865 (2011). https://doi.org/10.1016/j.msea.2011.01.084
S. Akhtar, L. Arnberg, M. Di Sabatino et al., A comparative study of porosity and pore morphology in a directionally solidified A356 alloy. Int. Metalcast. 3, 39–52 (2009). https://doi.org/10.1007/BF03355440
P. Fan, S.L. Cockcroft, D.M. Maijer, L. Yao, C. Reilly, A.B. Phillion, Porosity prediction in A356 wheel casting. Metall. Mater. Trans. B. Sci. 50, 2421–2425 (2019)
M. Uludağ, R. Çetin, L. Gemi et al., Change in porosity of A356 by holding time and its effect on mechanical properties. J. Mater. Eng. Perform. 27, 5141–5151 (2018). https://doi.org/10.1007/s11665-018-3534-0
S.G. Lee, A.M. Gokhale, G.R. Patel, M. Evans, Effect of process parameters on porosity distributions in high-pressure die-cast AM50 Mg-alloy. Mater. Sci. Eng. A 427(1–2), 99–111 (2006). https://doi.org/10.1016/j.msea.2006.04.082
K.N. Obiekea, S.Y. Aku, D.S. Yawas, Effects of pressure on the mechanical properties and microstructure of die cast aluminum A380 alloy. J. Miner. Mater. Charact. Eng. 02(03), 248–258 (2014). https://doi.org/10.4236/jmmce.2014.23029
H.S. Jang, H.J. Kang, J.Y. Park, Y.S. Choi, S. Shin, Effects of casting conditions for reduced pressure test on melt quality of Al–Si alloy. Metals 10(11), 1422 (2020). https://doi.org/10.3390/MET10111422
M. Di Sabatino, L. Arnberg, Castability of aluminium alloys. Trans. Indian Inst. Met. 62(4), 321–325 (2009)
B. Dybowski, L. Poloczek, A. Kiełbus, The porosity description in hypoeutectic Al-Si alloys. In Proceedings of the Key Engineering Materials (vol. 682, pp. 83–90). Trans Tech Publications Ltd (2016)
G.T. Gridli, P.A. Friedman, J.M. Boileau, Manufacturing processes for light alloys. . In Proceedings of the materials, design and manufacturing for lightweight vehicles, pp. 267-320. Woodhead Publishing (2021)
D. Sui, Z. Cui, R. Wang, S. Hao, Q. Han, Effect of cooling process on porosity in the aluminum alloy automotive wheel during low-pressure die casting. Int. J. Met. 10(1), 32–42 (2016). https://doi.org/10.1007/s40962-015-0008-0
D. Blondheim, A. Monroe, Macro porosity formation: a study in high pressure die casting. Int. J. Metalcast. 16(1), 330–341 (2022). https://doi.org/10.1007/s40962-021-00602-x
T. Prucha, From the editor—signals within signals. Int. J. Met. 9(2), 4 (2015)
D. Krstajic, L.J. Buturovic, D.E. Leahy, S. Thomas, Cross-validation pitfalls when selecting and assessing regression and classification models. J. Cheminform. 6(1), 10 (2014). https://doi.org/10.1186/1758-2946-6-10
J. Bergstra, D. Yamins, D.D. Cox, Making a science of model search: hyperparameter optimization in hundreds of dimensions for vision architectures. To appear in Proc. of the 30th International Conference on Machine Learning (ICML 2013)
G. Lemaître, F. Nogueira, C.K. Aridas, Imbalanced-learn: a python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 18(1), 559–563 (2017)
D.L. Wilson, Asymptotic properties of nearest neighbor rules using edited data. IEEE Trans. Syst. Man Commun. 2(3), 408–421 (1972)
L.S. Shapley, Notes on the N-person Game—I: characteristic-point solutions of the four-person game. Rand Corporation (1951)
D. Blondheim Jr., Utilizing machine learning autoencoders to detect anomalies in time-series data. NADCA Die Casting Engineer (2021)
Acknowledgements
This work was made possible with support from an Academy of Finland, Project Number 310252. The authors would also like to thank Cevher Wheels foundry team for providing the data and field support.
Funding
Open Access funding provided by Aalto University.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Uyan, T.Ç., Otto, K., Silva, M.S. et al. Industry 4.0 Foundry Data Management and Supervised Machine Learning in Low-Pressure Die Casting Quality Improvement. Inter Metalcast 17, 414–429 (2023). https://doi.org/10.1007/s40962-022-00783-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40962-022-00783-z