
Abstract
Givental’s Lagrangian cone \({\mathscr {L}}_X\) is a Lagrangian submanifold of a symplectic vector space which encodes the genus-zero Gromov–Witten invariants of X. Building on work of Braverman, Coates has obtained the Lagrangian cone as the push-forward of a certain class on the moduli space of stable maps to  . This provides a conceptual description for an otherwise mysterious change of variables called the dilaton shift. We recast this construction in its natural context, namely the moduli space of stable maps to
. This provides a conceptual description for an otherwise mysterious change of variables called the dilaton shift. We recast this construction in its natural context, namely the moduli space of stable maps to  relative the divisor
relative the divisor  . We find that the resulting push-forward is another familiar object, namely the transform of the Lagrangian cone under the action of the fundamental solution matrix. This hints at a generalisation of Givental’s quantisation formalism to the setting of relative invariants. Finally, we use a hidden polynomiality property implied by our construction to obtain a sequence of universal relations for the Gromov–Witten invariants, as well as new proofs of several foundational results concerning both the Lagrangian cone and the fundamental solution matrix.
. We find that the resulting push-forward is another familiar object, namely the transform of the Lagrangian cone under the action of the fundamental solution matrix. This hints at a generalisation of Givental’s quantisation formalism to the setting of relative invariants. Finally, we use a hidden polynomiality property implied by our construction to obtain a sequence of universal relations for the Gromov–Witten invariants, as well as new proofs of several foundational results concerning both the Lagrangian cone and the fundamental solution matrix.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The Gromov–Witten invariants of a smooth projective variety X are defined as certain intersection numbers on moduli spaces of stable maps to X. They can be thought of as counting curves of specified genus and degree passing through specified cycles in X. Their intrinsic interest aside, Gromov–Witten invariants have connections to numerous other areas of mathematics, from representation theory to symplectic topology. In algebraic geometry they have been used in the proofs of classification theorems, as a tool for distinguishing non-deformation-equivalent varieties.
Many results in Gromov–Witten theory are expressed most cleanly via generating functions, that is, formal functions (usually polynomials or power series) whose coefficients are given by Gromov–Witten invariants. Oftentimes, a simple identity involving generating functions is all that is needed to express a relationship which, on the level of individual invariants, is extremely complicated. There is an underlying reason for this: Gromov–Witten theory has deep connections to theoretical physics, through which the aforementioned generating functions appear as the “partition functions” of physical theories. This circle of ideas has been extremely influential for the development of the subject, with the first major result in this direction being the celebrated Mirror Theorem [3, 17, 18].
In keeping with this spirit, Givental describes in [19] a quantisation formalism for Gromov–Witten invariants. In the genus-zero setting (when no “quantisation” is actually required), this amounts to encoding the Gromov–Witten invariants of X in a Lagrangian cone

inside a certain symplectic vector space \({\mathscr {H}}\), now called the Givental space. The data of the cone \({\mathscr {L}}_X\) is equivalent to the data of the generating functions discussed earlier, but it turns out to be a good idea to treat \({\mathscr {L}}_X\) as a geometric object in its own right; many statements in Gromov–Witten theory can then be translated into statements about how \({\mathscr {L}}_X\) transforms under certain symplectomorphisms of \({\mathscr {H}}\).
The benefits of this quantisation formalism are twofold. From a theoretical viewpoint, it can be used to make rigorous sense of a number of deep predictions coming from physics. On the other hand, from a practical point of view, it has proven to be an extremely versatile framework in which to formulate and prove statements about Gromov–Witten invariants. Indeed, there are many results in Gromov–Witten theory which would be difficult to even state without the quantisation formalism: examples include the quantum Riemann–Roch formula [8], the crepant transformation conjecture [10], the Virasoro conjecture and various versions of the “genus zero implies higher genus” principle [20].
Building on work of Braverman [2], Coates shows in [7] that \({\mathscr {L}}_X\) can be obtained as a (\({\mathbb {C}}^*\)-localised) push-forward from the moduli space of stable maps to  (usually called the graph space). This is motivated by Givental’s heuristic description of \({\mathscr {H}}\) as the \(S^1\)-equivariant cohomology of the loop space of X [16], and gives a natural geometric interpretation for a mysterious change of variables, called the “dilaton shift”, which is essential to the quantisation formalism.
(usually called the graph space). This is motivated by Givental’s heuristic description of \({\mathscr {H}}\) as the \(S^1\)-equivariant cohomology of the loop space of X [16], and gives a natural geometric interpretation for a mysterious change of variables, called the “dilaton shift”, which is essential to the quantisation formalism.
Coates’ construction requires restricting to a certain open substack of the moduli space of stable maps to  , before localising to a proper fixed locus (with respect to the natural \({\mathbb {C}}^*\)-action on the moduli space) in order to push forward. With hindsight, this is really the push-forward from one of the \({\mathbb {C}}^*\)-fixed loci in the moduli space of relative stable maps to the pair
, before localising to a proper fixed locus (with respect to the natural \({\mathbb {C}}^*\)-action on the moduli space) in order to push forward. With hindsight, this is really the push-forward from one of the \({\mathbb {C}}^*\)-fixed loci in the moduli space of relative stable maps to the pair  .
.
A natural question to ask is then: what happens if we sum over all the fixed loci? In this article we provide the answer (see Proposition 2.4): the result is the transform of the Lagrangian cone under the action of the fundamental solution matrix. The main tools used in the proof are the relative virtual localisation formula [23, Theorem 3.6], a virtual push-forward theorem for relative stable maps to the non-rigid target [15, Theorem 5.2.7] and a comparison lemma for psi classes, which we prove in Sect. 3.2.
Because we are now summing over all fixed loci, we know that the resulting class must actually belong to the non-localised equivariant cohomology. In practice, this means the following: we push forward and obtain a class which, a priori, looks like a rational function in z; however we know that, after performing suitable cancellations, we must end up with a polynomial (here z denotes the \({\mathbb {C}}^*\)-equivariant parameter). We use this observation to give new and simple proofs of a number of foundational results belonging to the quantisation formalism theory.
Future directions
This construction provides a hint as to how one might obtain a quantisation formalism for relative (or logarithmic) Gromov–Witten invariants; see Remark 2.3. This was in fact the original motivation for this work.
User’s guide
Readers familiar with Gromov–Witten theory and the quantisation formalism may skip straight to Sect. 2.6 where we give the statement of the main result. For the uninitiated, we provide in Sects. 2.1–2.5 a brief introduction to Gromov–Witten invariants, the Lagrangian cone and relative Gromov–Witten theory. The proof of the main result is given in Sect. 3; this is mostly a computation, with the only geometric content being a lemma on psi classes which we prove in Sect. 3.2. Finally in Sect. 4 we provide examples of how the “hidden polynomiality” implied by our construction can be used to obtain universal relations for the Gromov–Witten invariants, as well as new proofs of a number of standard results concerning the Lagrangian cone and the fundamental solution matrix.
2 Background and statement of the main result
2.1 Gromov–Witten invariants
Throughout we fix a smooth projective variety X over the complex numbers. The genus-zero Gromov–Witten invariants of X are defined as certain integrals over moduli spaces of stable maps to X [25]. Fixing a number \(n \geqslant 0\) of marked points and a curve class \(\beta \in \mathrm{H}_2^+(X)\) (where \(\ \mathrm{H}_2^+(X) \subseteq \mathrm{H}_2(X)\) is the submonoid of effective classes, i.e., those which can be represented by algebraic curves), the moduli space of stable maps
parametrises holomorphic maps \(f:C \rightarrow X\) of class \(\beta \), where C is a nodal curve of arithmetic genus zero with n distinct non-singular marked points. There is a stability condition which stipulates that f can only have finitely many automorphisms; this is equivalent to requiring that every component of C which is contracted by f contains at least three special points (either marked points or nodes). The resulting moduli space is a proper Deligne–Mumford stack, with virtual dimension (sometimes also referred to as the expected dimension):

Although it is not in general smooth or even irreducible, and can contain components in excess of the virtual dimension, it admits a virtual fundamental class of pure dimension equal to the virtual dimension: this should be thought of as the fundamental class of some suitably generic perturbation of the moduli space. The Gromov–Witten invariants are then defined as:

In the above formula each  is a class on the target, while each \(\psi _i\) is a class on the moduli space itself which has to do with the complex structure of the source curve near the ith marked point. Ignoring these latter terms (whose geometric interpretation is somewhat more involved [22]) the Gromov–Witten invariant \(\langle \gamma _1,\ldots ,\gamma _n \rangle ^X_{0,n,\beta }\) should be thought of as a “virtual” count of rational curves in X of class \(\beta \) which pass through (representatives of) the classes \(\gamma _1,\ldots ,\gamma _n\). For a more detailed discussion of stable maps and Gromov–Witten invariants, see [14, 11, Section 7], [15, Section 1].
is a class on the target, while each \(\psi _i\) is a class on the moduli space itself which has to do with the complex structure of the source curve near the ith marked point. Ignoring these latter terms (whose geometric interpretation is somewhat more involved [22]) the Gromov–Witten invariant \(\langle \gamma _1,\ldots ,\gamma _n \rangle ^X_{0,n,\beta }\) should be thought of as a “virtual” count of rational curves in X of class \(\beta \) which pass through (representatives of) the classes \(\gamma _1,\ldots ,\gamma _n\). For a more detailed discussion of stable maps and Gromov–Witten invariants, see [14, 11, Section 7], [15, Section 1].
2.2 Givental space
The Lagrangian cone \({\mathscr {L}}_X\) is a geometric object which encodes all the genus-zero Gromov–Witten invariants of X. It can be viewed as the graph of a certain generating function for these invariants. This generating function must keep track, through its formal variables, of both the cohomological insertions \(\gamma _i\) and the exponents \(k_i\) of the classes \(\psi _i\). We begin by defining a vector space \({\mathscr {H}}\) whose co-ordinates will give precisely these formal variables; the Lagrangian cone will then be a submanifold of \({\mathscr {H}}\).
We set  where \(\Lambda \) is some (unspecified) field of characteristic zero; for the moment it is safe to take \(\Lambda ={\mathbb {C}}\), but later we will need to consider larger fields. We assume (for notational simplicity) that X has only even cohomology, and choose a homogeneous basis \(\varphi _0, \ldots , \varphi _N\) such that \(\varphi _0 = \mathbb {1}_X\) is the unit element. We let
where \(\Lambda \) is some (unspecified) field of characteristic zero; for the moment it is safe to take \(\Lambda ={\mathbb {C}}\), but later we will need to consider larger fields. We assume (for notational simplicity) that X has only even cohomology, and choose a homogeneous basis \(\varphi _0, \ldots , \varphi _N\) such that \(\varphi _0 = \mathbb {1}_X\) is the unit element. We let  denote the dual basis with respect to the Poincaré pairing
denote the dual basis with respect to the Poincaré pairing  , so that:
, so that:
The Givental space\({\mathscr {H}}\) is a certain infinite-dimensional symplectic vector space (over \(\Lambda \)) associated to X. It is defined as the space of formal Laurent series in a single variable \(z^{-1}\) with coefficients in  :
:

The notation above is meant to indicate that each series has only finitely many positive powers of z, but can have infinitely many negative powers. The powers of \(z^{-1}\) will keep track of the exponents of the psi classes.
There is a symplectic form \(\Omega \) on \({\mathscr {H}}\) defined as follows:

where  is the Poincaré pairing (extended linearly from
is the Poincaré pairing (extended linearly from  to \({\mathscr {H}}\)), and \(\mathrm{Res}_{z=0}\) simply means that we take the coefficient of \(z^{-1}\) in the resulting Laurent series. A straightforward computation verifies that \(\Omega \) is indeed a symplectic form.
to \({\mathscr {H}}\)), and \(\mathrm{Res}_{z=0}\) simply means that we take the coefficient of \(z^{-1}\) in the resulting Laurent series. A straightforward computation verifies that \(\Omega \) is indeed a symplectic form.
Example 2.1
Take \(X=\text {pt}\) so that  . Then
. Then  and \(\Omega \) is given by:
and \(\Omega \) is given by:

Notice that this sum is finite since the terms which appear must have either k or l non-negative, and there are only finitely many such values for which \(a_k\) and \(b_l\) are both non-zero.
Thus \(({\mathscr {H}},\Omega )\) is an infinite-dimensional symplectic vector space. We will now write down Darboux co-ordinates. It is clear that the following defines a basis for \({\mathscr {H}}\):

It is also easy to see that these give Darboux co-ordinates, i.e. that we have:

Using these canonical co-ordinates we can define linear subspaces \({\mathscr {H}}_+\) and \({\mathscr {H}}_-\) to be the spans, respectively, of the \(A^{k}_\alpha \) and \(B^{\gamma }_l\) inside \({\mathscr {H}}\):

Here, and in what follows, we adopt the Einstein summation convention when dealing with Greek letters, i.e., when summing over cohomology classes \(\varphi _\alpha \) and \(\varphi ^\gamma \). It is clear that both \({\mathscr {H}}_+\) and \({\mathscr {H}}_-\) are Lagrangian subspaces, in the sense that:

Thus we think of \({\mathscr {H}}_+\) and \({\mathscr {H}}_-\) as being “half-dimensional” or “semi-infinite” (since in the finite-dimensional setting a Lagrangian subspace is always half-dimensional). Furthermore this splitting gives an identification of symplectic vector spaces
which means that \({\mathscr {H}}_-\) gets identified with the cotangent fibre; in terms of the co-ordinates \(q^\alpha _k,p_\gamma ^l\) above, the identification is:

2.3 Lagrangian cone
We are now in a position to construct the Lagrangian cone \({\mathscr {L}}_X\). A standard object in Gromov–Witten theory is the genus-zero descendant potential, which is a formal generating function for the genus-zero Gromov–Witten invariants:

Let us explain the notation above. The sum is over all curve classes \(\beta \in \mathrm{H}_2^+(X)\) and non-negative integers \(n \geqslant 0\). The variable Q is a formal variable, called the Novikov variable, which keeps track of the curve class. We make sense of this by taking the ground field \(\Lambda \) to be the Novikov field:
Remember that we defined  for some unspecified field \(\Lambda \); from now on we take \(\Lambda \) to be the Novikov field. The parameter \({\mathbf{t }}(z)\) of the generating function is a formal power series with coefficients in
for some unspecified field \(\Lambda \); from now on we take \(\Lambda \) to be the Novikov field. The parameter \({\mathbf{t }}(z)\) of the generating function is a formal power series with coefficients in 

so that the correlators above are interpreted as

(remember that we are using the Einstein summation convention for the Greek letters). Thus we may rewrite \({\mathscr {F}}^{\,0}_X\) in a more transparent (though less convenient) form as:

We view this as a formal power series in the variables \(t_k^\alpha \) for \(k \geqslant 0\) and \(\alpha = 0,\ldots ,N\). Notice that these co-ordinates are indexed by the same set as the co-ordinates \(q_k^\alpha \) for \({\mathscr {H}}_+\) defined in Sect. 2.2; the two are related by the following change of variables:
called the dilaton shift. In concrete terms this means that \(q_k^\alpha = t_k^\alpha \) unless \((k,\alpha ) = (1,0)\), in which case \(q_1^0 = t_1^0 - 1\). Under this change of variables, we can view \({\mathscr {F}}^{\,0}_X\) as a function

and hence the derivative \(\mathrm{d}{\mathscr {F}}^{\,0}_X\) defines a section of the cotangent bundle \(\mathrm{T}^* {\mathscr {H}}_+\). The Lagrangian cone is defined as the graph of this section:

Thus for every point \({\mathbf{q }}(z) \in {\mathscr {H}}_+\) there is a unique point of \({\mathscr {L}}_X\) lying over \({\mathbf{q }}(z)\). In concrete terms, this is:

The first term \({\mathbf{t }}(z) - z\mathbb {1}_X= {\mathbf{q }}(z)\) specifies the point in the base, while the remaining terms specify the point in the fibre. The meaning of the fractional insertion in the third line is that it should be expanded as a power series in \(z^{-1}\), the result of which is precisely the expression on the second line.
As it has been presented, divorced from its origins in physics, \({\mathscr {L}}_X\) may come across as a mysterious object. Working with it takes some getting used to, but the eventual payoff is significant, and it is now recognised as a fundamental tool in Gromov–Witten theory. To give just a taste of this, we state a few basic facts about the Lagrangian cone.
Theorem 2.2
([8, Proposition 1]) The following basic properties hold:
-
\({\mathscr {L}}_X\) is a cone (it is preserved under scalar multiplication by elements of \(\Lambda \));
-
for
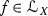 , we have
, we have  ;
; -
the set of all tangent spaces to \({\mathscr {L}}_X\) forms a finite-dimensional family; thus \({\mathscr {L}}_X\) is ruled by a finite-dimensional family of linear subspaces.
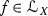 , we have
, we have  ;
;Thus we see that the geometry of \({\mathscr {L}}_X\) is very tightly constrained. The above theorem is actually equivalent [21, Theorem 1] to the following three fundamental results in Gromov–Witten theory: the string equation, the dilaton equation and the topological recursion relations. More generally, the Lagrangian cone can be used to conveniently express statements which would be exceedingly cumbersome to phrase otherwise. For more on this, see [9, 19].
Finally, we note that the dilaton shift \({\mathbf{q }}(z) = {\mathbf{t }}(z) - z\mathbb {1}_X\) is an essential part of the theory; for instance, \({\mathscr {L}}_X\) is not even a cone in the \({\mathbf{t }}(z)\) co-ordinates.
2.4 Fundamental solution matrix
There is one more object in Gromov–Witten theory which we must define. The fundamental solution matrix is a family of symplectic operators on the Givental space \({\mathscr {H}}\) (so named because it encodes a fundamental set of solutions to the quantum differential equations [12]). For our purposes it depends on a parameter \({\mathbf{q }}(z) \!\in \! {\mathscr {H}}_+\), and is given by:

Here the insertion  is expanded linearly in the z and \(\varphi _\alpha \), and \({\mathbf{t }}(z)\) is the dilaton-shifted element corresponding to \({\mathbf{q }}(z)\) (we write \(S_{{\mathbf{t }}(z)}\) instead of \(S_{{\mathbf{q }}(z)}\) to keep our notation compatible with standard usage). As with the Lagrangian cone, the fundamental solution matrix has deep connections to physics, and has been the focus of intense study. We will not attempt to say more than this here; the interested reader should consult [29] and [11, Section 10].
is expanded linearly in the z and \(\varphi _\alpha \), and \({\mathbf{t }}(z)\) is the dilaton-shifted element corresponding to \({\mathbf{q }}(z)\) (we write \(S_{{\mathbf{t }}(z)}\) instead of \(S_{{\mathbf{q }}(z)}\) to keep our notation compatible with standard usage). As with the Lagrangian cone, the fundamental solution matrix has deep connections to physics, and has been the focus of intense study. We will not attempt to say more than this here; the interested reader should consult [29] and [11, Section 10].
In this article we will view S as a single endomorphism of the trivial \({\mathscr {H}}\)-bundle over \({\mathscr {H}}_+\)

where the endomorphism \({\mathscr {H}}\rightarrow {\mathscr {H}}\) over \({\mathbf{q }}(z) \in {\mathscr {H}}_+\) is given by \(S_{{\mathbf{t }}(z)}\). We can also view the Lagrangian cone as a submanifold of  by doubling the base co-ordinate:
by doubling the base co-ordinate:

Thus, we can define the transform  of \({\mathscr {L}}_X\) by S without having to specify a parameter \({\mathbf{q }}(z)\). This will be important for the statement of our main result.
of \({\mathscr {L}}_X\) by S without having to specify a parameter \({\mathbf{q }}(z)\). This will be important for the statement of our main result.
2.5 Relative stable maps
The final ingredient which we need to explain is the theory of relative stable maps. Given a smooth projective variety Z and a smooth hypersurface \(Y \subseteq Z\), the moduli space of relative stable maps parametrises stable maps in Z with fixed tangency orders to Y at the marked points. If there are n marked points then this tangency information is encoded in a vector \(\alpha =(\alpha _1,\ldots ,\alpha _n)\) of non-negative integers. The resulting moduli space
should parametrise stable maps to Z such that the ith marked point has tangency order \(\alpha _i\) to the divisor Y (by convention, \(\alpha _i=0\) means that the marked point is not mapped into the divisor at all, while \(\alpha _i=1\) means it is mapped into the divisor transversely; as such, the map only truly becomes “tangent” to the divisor when \(\alpha _i \geqslant 2\)). This data must satisfy the obvious numerical condition  . The question of how to define these spaces rigorously is a non-trivial one; the problem with the naïve approach described above is that the deformation theory can become extremely wild when there are components of the source curve mapping into Y; this wildness means that the usual construction of the virtual fundamental class no longer works, so these spaces cannot be used to define invariants.
. The question of how to define these spaces rigorously is a non-trivial one; the problem with the naïve approach described above is that the deformation theory can become extremely wild when there are components of the source curve mapping into Y; this wildness means that the usual construction of the virtual fundamental class no longer works, so these spaces cannot be used to define invariants.
The earliest solution to this problem, due to Jun Li and following ideas first developed in symplectic geometry, is to allow the target Z to degenerate into a so-called expanded degeneration  [27, 28]. The space
[27, 28]. The space  is constructed from Z by gluing on a chain of l copies of the projective completion of the normal bundle to Y in Z:
is constructed from Z by gluing on a chain of l copies of the projective completion of the normal bundle to Y in Z:

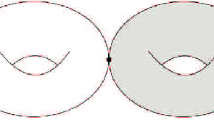
The picture is as follows (which illustrates the case Z[2]):

The idea is that, whenever a component of the source curve starts to fall into the divisor, the target “bubbles” off an extra copy of P, and the internal component is then mapped (transversely) into P.

Two such maps into P are identified if they differ by an element of the group \({\mathbb {C}}^*\) of automorphisms of P given by rescalings of the fibre. As illustrated above, the resulting map to  is transverse in a very strong sense: the only points of the curve which map to the infinity divisor are the markings \(x_i\), and they do so with the correct tangency order \(\alpha _i\). On the other hand, the curve can only map to the singular locus at a finite number of isolated nodal points, and for each node the tangency orders of the two adjacent branches of the curve to the singular locus must be equal. This transversality condition, usually called predeformability, ensures that the resulting moduli space has the correct virtual dimension. An extremely careful analysis of the deformation theory of this new space then shows that a virtual class can be defined [28]. Integrals against this virtual class are called relative Gromov–Witten invariants of (Z, Y). In our applications we will always have
is transverse in a very strong sense: the only points of the curve which map to the infinity divisor are the markings \(x_i\), and they do so with the correct tangency order \(\alpha _i\). On the other hand, the curve can only map to the singular locus at a finite number of isolated nodal points, and for each node the tangency orders of the two adjacent branches of the curve to the singular locus must be equal. This transversality condition, usually called predeformability, ensures that the resulting moduli space has the correct virtual dimension. An extremely careful analysis of the deformation theory of this new space then shows that a virtual class can be defined [28]. Integrals against this virtual class are called relative Gromov–Witten invariants of (Z, Y). In our applications we will always have  and
and  . In this case the normal bundle of Y in Z is trivial, so
. In this case the normal bundle of Y in Z is trivial, so  and thus all the levels of the expanded degeneration, including level 0, are isomorphic.
and thus all the levels of the expanded degeneration, including level 0, are isomorphic.
We will assume that the reader is reasonably familiar with relative stable maps; all the facts which we will use can be found in [23, Sections 2–3], which also serves as a good introduction to relative Gromov–Witten theory.
Remark 2.3
More recently, the theory of logarithmic stable maps, as developed by Abramovich, Chen, Gross and Siebert, has provided an alternative (and significantly more general) approach to relative stable maps [1, 4, 24]. We expect that the computations we carry out here will carry over to the log setting, once a suitable localisation formula has been established for log stable maps. Indeed, log Gromov–Witten theory relative a simple normal crossings divisor seems to be the correct generality in which to apply the construction given in this article.
2.6 Statement of the main result
We are finally in a position to state our main result. Let X be a smooth projective variety. For \(\beta \in \mathrm{H}_2^+(X)\) and \(n \geqslant 0\), consider the moduli space

of relative stable maps to  of class \((\beta ,1)\), where the first n marked points \(x_1,\ldots ,x_n\) have tangency 0 with the divisor, and the last marked point \(x_\infty \) has tangency 1. There is a natural \({\mathbb {C}}^*\)-action on this moduli space induced by the action on the target
of class \((\beta ,1)\), where the first n marked points \(x_1,\ldots ,x_n\) have tangency 0 with the divisor, and the last marked point \(x_\infty \) has tangency 1. There is a natural \({\mathbb {C}}^*\)-action on this moduli space induced by the action on the target  (acting trivially on the first factor and with weight \(-1\) on the second). Consider the following class in the equivariant cohomology of the moduli space:
(acting trivially on the first factor and with weight \(-1\) on the second). Consider the following class in the equivariant cohomology of the moduli space:

where z is the equivariant parameter. Here each \(\mathrm{ev}_i\) is viewed as mapping into X, via the composition:

(Note that this morphism is equivariant with respect to the trivial action on X.) We then have:
Proposition 2.4

where  is the dilaton-shifted co-ordinate corresponding to
is the dilaton-shifted co-ordinate corresponding to  .
.
The proof will be given in Sect. 3; for the moment let us explain the statement. We view \(\mathrm{ev}_\infty \) as a map

so that the target of the push-forward \((\mathrm{ev}_\infty )_*\) is the equivariant cohomology of X with respect to the trivial torus action. But this is just:

On the other hand, \(S({\mathscr {L}}_X)\) naturally lives inside the total space of the trivial bundle  (see the discussion at the end of Sect. 2.4 above); therefore when we write \(S({\mathscr {L}}_X)\) in equation (1), we really mean its projection along
(see the discussion at the end of Sect. 2.4 above); therefore when we write \(S({\mathscr {L}}_X)\) in equation (1), we really mean its projection along  . Another way to say this is that for a fixed \({\mathbf{q }}(z) \in {\mathscr {H}}_+\), with dilaton-shifted co-ordinate \({\mathbf{t }}(z)\), the push-forward of the left-hand side of (1) is equal to \(S_{{\mathbf{t }}(z)}({\mathscr {L}}_X|_{{\mathbf{q }}(z)})\).
. Another way to say this is that for a fixed \({\mathbf{q }}(z) \in {\mathscr {H}}_+\), with dilaton-shifted co-ordinate \({\mathbf{t }}(z)\), the push-forward of the left-hand side of (1) is equal to \(S_{{\mathbf{t }}(z)}({\mathscr {L}}_X|_{{\mathbf{q }}(z)})\).
An immediate corollary of the above result is that  rather than just \({\mathscr {H}}\). For an application of this, as well as a deeper exploration of the “hidden polynomiality” arising from our construction, see Sect. 4.
rather than just \({\mathscr {H}}\). For an application of this, as well as a deeper exploration of the “hidden polynomiality” arising from our construction, see Sect. 4.
Remark 2.5
The total transform \(S({\mathscr {L}}_X)\) has a geometric interpretation as a family of ancestor cones; see [8, Appendix 2].
Remark 2.6
Notice that for any choice of \(\beta \), the curve class \((\beta ,1)\) is non-zero. Hence the sum in Proposition 2.4 is over all\(\beta \) and n. This is in contrast to the sum which appears in the definition of the Lagrangian cone in Sect. 2.3, which is only over the stable range, i.e., excludes the cases \((\beta ,n) = (0,0)\) and (0, 1). This difference will become important during the proof of Proposition 2.4.
3 Proof of the main result
We will assume that the reader is familiar with the space of relative stable maps, and in particular with the torus localisation formula, established in [23] whenever the divisor is fixed pointwise by the action (as is the case for us). We will write \(X_0\) and \(X_\infty \) for  and
and  , viewing them either as divisors in
, viewing them either as divisors in  or in
or in  , as appropriate.
, as appropriate.
3.1 Identifying the fixed loci
The proof proceeds by \({\mathbb {C}}^*\)-localisation. The \({\mathbb {C}}^*\)-fixed loci of the moduli space are indexed by graphs of the following form:

These correspond to splittings of the source curve into three pieces: a piece \(C_0\) which maps to \(X_0\), a piece \(C_\infty \) which maps to \(X_\infty \) (and hence, in general, into the higher levels of the expanded degeneration), and a rational component joining \(C_0\) and \(C_\infty \), which maps isomorphically onto a \({\mathbb {P}}^1\)-fibre of  . The marking \(x_\infty \) always belongs to \(C_\infty \) since it must map to the infinity divisor \(X_\infty \). The other choices—of degrees \(\beta _0\) and \(\beta _\infty \) for the two pieces, and of a partition
. The marking \(x_\infty \) always belongs to \(C_\infty \) since it must map to the infinity divisor \(X_\infty \). The other choices—of degrees \(\beta _0\) and \(\beta _\infty \) for the two pieces, and of a partition  of the non-relative markings—are free. The fixed locus corresponding to this data is isomorphic to
of the non-relative markings—are free. The fixed locus corresponding to this data is isomorphic to

with virtual fundamental class induced by the virtual classes of the two factors; this is part of the statement of the virtual localisation theorem in [23]. Here the second factor

is a moduli space of stable maps to the non-rigid target; see [23, Section 2.4] for a detailed discussion of this space. The notation here is supposed to indicate that there is a set \(A_\infty \) of non-relative markings (so \(\# \,A_\infty =n_\infty \)), a single marking \(q_\infty \) mapping to \(X_0\) with tangency 1, and a single marking \(x_\infty \) mapping to \(X_\infty \) with tangency 1.
The fibre product in (2) is taken with respect to the evaluations at \(q_0\) and \(q_\infty \) on each side. The Euler class of the virtual normal bundle is equal [23, Theorem 3.6 and Example 3.7] to

which obviously splits into a product of classes supported on the two factors. We should briefly explain these:  arises from the deformations of the map on the rational bridge,
arises from the deformations of the map on the rational bridge,  arises from the smoothing of the node connecting the rational bridge to \(C_0\) and \(z-\psi _{q_\infty }\) is a target psi class, which arises from the smoothing of the target singularity connecting the level 0 piece and the level 1 piece of the expanded degeneration. Here we have used the identification of the target psi class with a multiple of the psi class on one of the relative markings [15, Construction 5.1.17]. The term arising from the smoothing of the node connecting the rational bridge to \(C_\infty \) is cancelled out by the local obstruction at that node: see [23, Section 3.8].
arises from the smoothing of the node connecting the rational bridge to \(C_0\) and \(z-\psi _{q_\infty }\) is a target psi class, which arises from the smoothing of the target singularity connecting the level 0 piece and the level 1 piece of the expanded degeneration. Here we have used the identification of the target psi class with a multiple of the psi class on one of the relative markings [15, Construction 5.1.17]. The term arising from the smoothing of the node connecting the rational bridge to \(C_\infty \) is cancelled out by the local obstruction at that node: see [23, Section 3.8].
Note that for certain choices of \((\beta _0, A_0 \, | \, \beta _\infty , A_\infty )\) the moduli spaces which we have written down above do not exist, because the data defining them is not stable. In these degenerate cases, we still have fixed loci; it is simply that one (or both) of the factors becomes trivial. Hence we must deal with these separately. The possible situations are enumerated below.
Case 1: \((\beta ,n)=(0,0)\). This is the maximally degenerate case. The fixed locus is just X, which has virtual codimension 0; there is no virtual normal bundle.
Case 2: \((\beta ,n)=(0,1)\)and\(n_\infty =0\). In this case the fixed locus is again just X, with a single marked point \(x_1\) mapped to \(X_0\) and another marked point \(x_\infty \) mapped to \(X_\infty \) (there is no expansion of the target). The virtual codimension is 1, and the Euler class of the virtual normal bundle is  .
.
Case 3: \(n \geqslant 1\)and\((\beta _0,n_0)=(0,0)\). In this case the fixed locus is a moduli space of relative maps to the non-rigid target, with \(n+2\) marked points. The virtual codimension is 1, and the virtual normal bundle contribution is \(z-\psi _{q_\infty }\).
Case 4: \(n \geqslant 1\)and\((\beta _0,n_0)=(0,1)\). Here the fixed locus is the same as the one in the previous case, but it now has virtual codimension 2 because there is a marked point at the \(X_0\) end of the rational bridge; the Euler class of the virtual normal bundle is  .
.
Case 5: \(n \geqslant 2\)and\((\beta _\infty ,n_\infty )=(0,0)\). In this case the fixed locus is just the moduli space of stable maps to X with \(n+1\) markings. The virtual codimension is 2, and the Euler class of the virtual normal bundle is  .
.
3.2 Comparison lemma for psi classes
We now need to calculate the contributions to the push-forward from each of these fixed loci. A priori this is difficult, because the fixed loci involve moduli spaces of relative stable maps to the non-rigid target, which are in general hard to understand. However, in genus zero, a result of Gathmann says that these moduli spaces are in fact virtually birational to the underlying moduli spaces of stable maps to X. To be more precise: there is a projection map

induced by the collapsing map from the non-rigid target to X, and [15, Theorem 5.2.7] shows that this map respects the virtual classes:

This result goes a long way towards making these invariants computable. However there is still a problem: the map \(\pi \) may contract many components of the source curve, and hence does not in general preserve the psi classes. Consequently, descendant invariants (which certainly appear in our discussion) are still complicated to compute, because one has to keep track of how psi classes pull back. It turns out, however, that  is special in this respect.
is special in this respect.
Lemma 3.1
The map \(\pi \) cannot contract any component of the source curve which contains a marking.
Proof
The components contracted by \(\pi \) are those with two or fewer special points which are mapped into a fibre of  over X. Let \(C^\prime \) be such a component. Since it has two or fewer special points, the map f must be non-constant on \(C^\prime \) (by stability), and hence there is at least one point of \(C^\prime \) which maps to \(X_\infty \) and at least one point which maps to \(X_0\). Thus, \(C^\prime \) contains exactly two special points, which must map to the special divisors of the non-rigid target.
over X. Let \(C^\prime \) be such a component. Since it has two or fewer special points, the map f must be non-constant on \(C^\prime \) (by stability), and hence there is at least one point of \(C^\prime \) which maps to \(X_\infty \) and at least one point which maps to \(X_0\). Thus, \(C^\prime \) contains exactly two special points, which must map to the special divisors of the non-rigid target.
Now suppose for a contradiction that some marking \(x_i\) belongs to \(C^\prime \). If \(x_i\) is a non-relative marking then we immediately arrive at a contradiction, since such a marking cannot map into any special divisor. Otherwise, \(x_i = q_\infty \) or \(x_\infty \) and so is mapped into \(X_0\) or \(X_\infty \), respectively; without loss of generality we may suppose \(x_i = q_\infty \). By the stability condition for relative stable maps, there must exist some other component of the source curve which maps with positive degree into the same level of the non-rigid target as \(C^\prime \). But this would necessarily touch \(X_0\), which is a contradiction since \(q_\infty \) is the only point of the source curve which is allowed to map to \(X_0\) (here we are using the fact that  is a global product; for non-trivial \({\mathbb {P}}^1\)-bundles over X, it is no longer true that a component of the source curve which touches \(X_\infty \) must also touch \(X_0\)). \(\square \)
is a global product; for non-trivial \({\mathbb {P}}^1\)-bundles over X, it is no longer true that a component of the source curve which touches \(X_\infty \) must also touch \(X_0\)). \(\square \)
Corollary 3.2
\(\pi ^* \psi _i = \psi _i\) for any  . Thus, we can identify any non-rigid invariant of
. Thus, we can identify any non-rigid invariant of  with the corresponding invariant of X.
with the corresponding invariant of X.
3.3 Calculating the contributions
We are now in a position to calculate the contributions to the push-forward. We fix \((\beta ,n)\) and look at the fixed loci of the corresponding moduli space. Ignoring the degenerate cases for the moment, we must sum over stable splittings\((\beta _0,A_0 \, | \, \beta _\infty ,A_\infty )\) of \((\beta ,n)\). We may phrase this as summing over splittings \((\beta _0,\beta _\infty )\) of \(\beta \) and \((n_0,n_\infty )\) of n, with a factor of \({n\atopwithdelims ()n_0} = {n \atopwithdelims ()n_\infty }\) introduced to account for the choice of which marked points to put in \(A_0\) and which to put in \(A_\infty \). Thus the contribution

from the non-degenerate loci is equal to:

There are also the contributions from the degenerate fixed loci, enumerated in Sect. 3.1 above. We now calculate these.
Case 1: \((\beta ,n)=(0,0)\). This gives a single contribution, which is

Case 2: \((\beta ,n)=(0,1)\)and \( n_\infty =0\). This also gives a single contribution, which is
here we have used the fact that the psi class \(\psi _1\) restricts to a trivial class on the fixed locus with non-trivial weight z, so the equivariant class \(\psi _1\) gets identified with z.
Case 3: \(n \geqslant 1\)and \((\beta _0,n_0)=(0,0)\). Here we get a contribution for each \((\beta ,n)\) with \(n \geqslant 1\). The contribution is

Case 4: \(n \geqslant 1\)and \((\beta _0,n_0)=(0,1)\). We get a contribution for each \((\beta ,n)\) with \(n \geqslant 1\), and the contribution is

where again we have used the fact that the class \(\psi _0\) restricts to the pure weight class z on the fixed locus.
Case 5: \(n \geqslant 2\)and \((\beta _\infty ,n_\infty )=(0,0)\). Here we get a contribution for each \((\beta ,n)\) with \(n \geqslant 2\), and the contribution is

3.4 Putting everything together
If we sum together all the terms computed in the previous section, we obtain:

Using \({\mathbf{q }}(z) = {\mathbf{t }}(z) - z\mathbb {1}_X\) and grouping the final two terms together, we see that this is equal to:

But this is equal to:

as claimed. This completes the proof of Proposition 2.4.
Remark 3.3
It is perhaps worth comparing our computation to the computation carried out in [7]. There, the moduli space under consideration is the space of ordinary stable maps to  ; Coates restricts to an open substack of this space, consisting of stable maps such that only a single point of the curve is mapped to \(X_\infty \). He then applies torus localisation and pushes forward from the (proper) fixed loci. From our point of view, the loci from which he pushes forward are the degenerate loci which appear as Case 5 in Sect. 3.1 above. The special cases which he calls Case 2 and Case 3 are what we call Case 2 and Case 1, respectively. Our non-special case, which contributes a product of invariants from stable maps to X and stable maps to the non-rigid target, does not appear in his setting; nor do our special Cases 3 and 4.
; Coates restricts to an open substack of this space, consisting of stable maps such that only a single point of the curve is mapped to \(X_\infty \). He then applies torus localisation and pushes forward from the (proper) fixed loci. From our point of view, the loci from which he pushes forward are the degenerate loci which appear as Case 5 in Sect. 3.1 above. The special cases which he calls Case 2 and Case 3 are what we call Case 2 and Case 1, respectively. Our non-special case, which contributes a product of invariants from stable maps to X and stable maps to the non-rigid target, does not appear in his setting; nor do our special Cases 3 and 4.
4 Variants and applications
Since an equivariant push-forward must take values in  , an immediate consequence of Proposition 2.4 is the following:
, an immediate consequence of Proposition 2.4 is the following:
Theorem 4.1
 .
.
This is somewhat surprising, since a priori we only know that \(S({\mathscr {L}}_X) \subseteq {\mathscr {H}}\), and indeed both S and \({\mathscr {L}}_X\) involve many non-positive powers of z. What Theorem 4.1 says is that the coefficients of these non-positive powers cancel out when we take \(S({\mathscr {L}}_X)\); this translates into a sequence of universal relations for the Gromov–Witten invariants. Calculating the coefficients of \(z^{-k}\) explicitly, we obtain for \(k \geqslant 2\) and \({\mathbf{q }}(z) \in {\mathscr {H}}_+\)

where we have used the correlator notation:

These equations appear to be equivalent to the reconstruction relation [26, Equation (2)], combined with the dilaton equation.
Remark 4.2
Theorem 4.1 can be viewed as a generalisation of one of the fundamental results in the quantisation formalism, namely that the J-function is inverse to the fundamental solution matrix; see Remark 4.4 below.
In this section we will now extend the above line of argument, exploiting the “hidden polynomiality” implicit in our construction. We obtain new proofs and generalisations of several foundational results concerning both the fundamental solution matrix and the Lagrangian cone.
4.1 The fundamental solution matrix and its adjoint
Looking at the definition given in Sect. 2.4, we see that we can regard \(S_{{\mathbf{t }}(z)}\) as a power series in \(z^{-1}\) with coefficients in  :
:

We will write \(S_{{\mathbf{t }}(z)}(z)\) to emphasise this point of view. The adjoint \({S_{{\mathbf{t }}(z)}}^*(z)\) is defined by taking the adjoints, term-by-term, of the coefficients of \(S_{{\mathbf{t }}(z)}(z)\) (with respect to the Poincaré pairing on  ). It is easy to check that, for
). It is easy to check that, for  :
:

An important feature of the theory [17] is that when \({\mathbf{t }}(z)=\tau \), the operators \(S_\tau (z)\) and  are inverse to each other; this is in fact equivalent to the statement that \(S_\tau (z)\) is a symplectomorphism [6, Section 3.1]. We now generalise this fact to arbitrary \({\mathbf{t }}(z)\), based on a slight modification of the construction used in Proposition 2.4.
are inverse to each other; this is in fact equivalent to the statement that \(S_\tau (z)\) is a symplectomorphism [6, Section 3.1]. We now generalise this fact to arbitrary \({\mathbf{t }}(z)\), based on a slight modification of the construction used in Proposition 2.4.
Proposition 4.3
 .
.
Proof
We first note that it is sufficient to prove:

Indeed, the operators \(S_{{\mathbf{t }}(z)}(z)\) and  can be viewed as finite-dimensional matrices over the field of Laurent series \(\Lambda ((z^{-1}))\). If (4) holds then both these matrices have maximal rank, and therefore we also have:
can be viewed as finite-dimensional matrices over the field of Laurent series \(\Lambda ((z^{-1}))\). If (4) holds then both these matrices have maximal rank, and therefore we also have:

Thus it remains to show (4). We consider the following moduli space:

which has a single marked point \(x_0\) mapping to \(X_0\), a single marked point \(x_\infty \) mapping to \(X_\infty \), and a collection of other markings \(x_1,\ldots ,x_n\) which carry no tangency conditions.
Since the divisor is now disconnected, we must be slightly careful about what we mean by the space above. For our purposes, the allowed automorphisms act separately on the fibres of the expanded degeneration over \(X_0\) and \(X_\infty \). The stability condition is also imposed separately. As such, each expansion is now indexed by two integers, \(l_0\) and \(l_\infty \), giving the lengths of the expansion over \(X_0\) and \(X_\infty \) respectively. This is close to the approach taken in [13]. One can view this moduli space as the fibre product:

Taking the definition this way ensures that, when we localise, the fixed loci are fibre products of moduli spaces of relative stable maps to the non-rigid target. Furthermore since the stability condition is imposed separately over \(X_0\) and \(X_\infty \), the proof of Lemma 3.1 still applies. An analogous computation to the one given in Sect. 3 then shows that, for  :
:

Since this is an equivariant push-forward, we see that  is a polynomial in z with coefficients in
is a polynomial in z with coefficients in  . On the other hand it is obvious from the definitions that it is also a power series in \(z^{-1}\). Thus
. On the other hand it is obvious from the definitions that it is also a power series in \(z^{-1}\). Thus  is constant in z, and since the constant term is clearly the identity this completes the proof. \(\square \)
is constant in z, and since the constant term is clearly the identity this completes the proof. \(\square \)
Remark 4.4
As noted previously, Proposition 4.3 is a generalisation of the following fundamental fact for  :
:

I would like to thank Mark Shoemaker for pointing out that one can also view Theorem 4.1 as a generalisation of this result. Indeed, when \({\mathbf{t }}(z)=\tau \) we can use the string equation to show that

where \({\mathbf{q }}(z)=\tau -z\). Thus we find:

Our result can be viewed as a generalisation of this to arbitrary \({\mathbf{t }}(z)\). The original proof does not apply in this more general setting, because it relies on an application of the string equation which produces additional unwanted terms when \({\mathbf{t }}(z)\) involves higher powers of z. In particular, the identification (5) no longer holds, which explains why we end up with two different generalisations.
4.2 Properties of the Lagrangian cone
Here we reprove two fundamental facts concerning the Lagrangian cone. First, we modify the previous construction to give a concrete proof that \({\mathscr {L}}_X\) is Lagrangian (though it should be noted that this also follows from the general fact that the graph of any closed 1-form is Lagrangian).
Proposition 4.5
\({\mathscr {L}}_X\) is Lagrangian.
Proof
Let \({\mathbf{q }}(z) \in {\mathscr {H}}_+\) be a point in the base and let \(f = {\mathscr {L}}_X|_{{\mathbf{q }}(z)} \in {\mathscr {H}}\) be the point on the cone lying over \({\mathbf{q }}(z)\). We must show that  is a Lagrangian subspace of \({\mathscr {H}}\). First let us describe the points of
is a Lagrangian subspace of \({\mathscr {H}}\). First let us describe the points of  . Recall that f is given by:
. Recall that f is given by:

Since \({\mathscr {L}}_X\) is the graph of the section \(\mathrm{d}{\mathscr {F}}^{\,0}_X\), the tangent space  is spanned by the partial derivatives of the above expression in the \({\mathscr {H}}_+\)-co-ordinates. Given such a co-ordinate \(q_k^\alpha \) the corresponding derivative is:
is spanned by the partial derivatives of the above expression in the \({\mathscr {H}}_+\)-co-ordinates. Given such a co-ordinate \(q_k^\alpha \) the corresponding derivative is:

Thus the tangent space consists of vectors in \({\mathscr {H}}\) of the form

for \(\mathbf{r }(z) \in {\mathscr {H}}_+\). On the other hand, if we look at the expression (3) given earlier for  , we see that this can be extended in a natural way to give a map
, we see that this can be extended in a natural way to give a map  via
via

(note that this is different from the extension of \(S_{{\mathbf{t }}(z)}(z)\) to an endomorphism of \({\mathscr {H}}\) which we gave in Sect. 2.4, where we treated the insertion \(\mathbf{r }(z)\) formally). Under the above definition, we see that

Fixing \(\mathbf{r }(z), \mathbf{u }(z) \in {\mathscr {H}}_+\), we thus need to show that

which is equivalent to

We take the moduli space

as before and consider the equivariant integral (against the virtual class) of the following class:

Then an analogous computation to the one given in Sect. 3 shows that this integral is equal to

Thus the above pairing is a polynomial in z, and so in particular the coefficient of \(z^{-1}\) vanishes. But this is precisely the residue that we needed to calculate, and the claim follows.\(\square \)
Another fundamental fact about \({\mathscr {L}}_X\), already discussed in Sect. 2.3, is that:

To finish, we will give a direct proof of one important consequence of this fact.
Proposition 4.6
 .
.
Proof
As noted before, an immediate consequence of Proposition 2.4 is that

Applying  to both sides, we find that
to both sides, we find that

where unlike in the proof of Proposition 4.5, the extension of  from
from  to
to  is obtained by expanding linearly in z. A deep fact from the theory now says that, under this definition:
is obtained by expanding linearly in z. A deep fact from the theory now says that, under this definition:

Some care is required here: we also saw this statement in the proof of the previous proposition, but that was for a different extension of  which was not linear in z. Under the new extension used here, which is linear in z, the statement still holds, though it is much less trivial. Using this, we obtain
which was not linear in z. Under the new extension used here, which is linear in z, the statement still holds, though it is much less trivial. Using this, we obtain

as required.\(\square \)
Remark 4.7
The idea of using torus localisation to prove that certain generating functions are polynomials is not new. It was used by Givental in the proof of the Mirror Theorem [17] and by Ciocan-Fontanine and Kim in the proof of the wall-crossing formula for quasimap invariants [5]. The disussion above constitutes a small continuation of this story.
References
Abramovich, D., Chen, Q.: Stable logarithmic maps to Deligne–Faltings pairs II. Asian J. Math. 18(3), 465–488 (2014)
Braverman, A.: Instanton counting via affine Lie algebras. I. Equivariant \(J\)-functions of (affine) flag manifolds and Whittaker vectors. In: Hurtubise, J., Markmann, E. (eds.) Algebraic Structures and Moduli Spaces. CRM Proceedings & Lecture Notes, vol. 38, pp. 113–132. American Mathematical Society, Providence (2004)
Candelas, P., de la Ossa, X.C., Green, P.S., Parkes, L.: A pair of Calabi–Yau manifolds as an exactly soluble superconformal theory. Nuclear Phys. B 359(1), 21–74 (1991)
Chen, Q.: Stable logarithmic maps to Deligne–Faltings pairs I. Ann. Math. 180(2), 455–521 (2014)
Ciocan-Fontanine, I., Kim, B.: Quasimap wall-crossings and mirror symmetry (2016). arXiv:1611.05023
Clader, E., Priddis, N., Shoemaker, M.: Geometric quantization with applications to Gromov–Witten theory (2013). arXiv:1309.1150
Coates, T.: Givental’s Lagrangian cone and \(S^1\)-equivariant Gromov-Witten theory. Math. Res. Lett. 15(1), 15–31 (2008)
Coates, T., Givental, A.: Quantum Riemann–Roch, Lefschetz and Serre. Ann. Math. 165(1), 15–53 (2007)
Coates, T., Iritani, H.: A Fock sheaf for Givental quantization (2014). arXiv:1411.7039
Coates, T., Iritani, H., Jiang, Y.: The crepant transformation conjecture for toric complete intersections. Adv. Math. 329, 1002–1087 (2018)
Cox, D.A., Katz, S.: Mirror Symmetry and Algebraic Geometry. Mathematical Surveys and Monographs, vol. 68. American Mathematical Society, Providence (1999)
Dubrovin, B.: Geometry of \(2\)D topological field theories. In: Francaviglia, M., Greco, S. (eds.) Integrable Systems and Quantum Groups. Lecture Notes in Mathematics, vol. 1620, pp. 120–348. Springer, Berlin (1996)
Faber, C., Pandharipande, R.: Relative maps and tautological classes. J. Eur. Math. Soc. (JEMS) 7(1), 13–49 (2005)
Fulton, W., Pandharipande, R.: Notes on stable maps and quantum cohomology. In: Kollár, J., Lazarsfeld, R., Morrison, D.R. (eds.) Algebraic Geometry—Santa Cruz 1995. Proceedings of Symposia in Pure Mathematics, vol. 62.2, pp. 45–96. American Mathematical Society, Providence (1997)
Gathmann, A.: Gromov–Witten Invariants of Hypersurfaces. Habilitation Thesis. Technischen Universität Kaiserslautern (2003). http://www.mathematik.uni-kl.de/~gathmann/pub/habil.pdf
Givental, A.B.: Homological geometry. I. Projective hypersurfaces. Selecta Math. (N.S.) 1(2), 325–345 (1995)
Givental, A.B.: Equivariant Gromov–Witten invariants. Int. Math. Res. Not. IMRN 1996(13), 613–663 (1996)
Givental, A.B.: A mirror theorem for toric complete intersections. In: Kashiwara, M., et al. (eds.) Topological Field Theory, Primitive Forms and Related Topics. Progress in Mathematics, vol. 160, pp. 141–175. Birkhäuser, Boston (1998)
Givental, A.B.: Gromov–Witten invariants and quantization of quadratic Hamiltonians. Moscow Math. J. 1(4), 551–568, 645 (2001)
Givental, A.B.: Semisimple Frobenius structures at higher genus. Int. Math. Res. Not. IMRN 2001(23), 1265–1286 (2001)
Givental, A.B.: Symplectic geometry of Frobenius structures. In: Hertling, K., Marcolli, M. (eds.) Frobenius Manifolds. Aspects of Mathematics, vol. 36, pp. 91–112. Vieweg, Wiesbaden (2004)
Graber, T., Kock, J., Pandharipande, R.: Descendant invariants and characteristic numbers. Amer. J. Math. 124(3), 611–647 (2002)
Graber, T., Vakil, R.: Relative virtual localization and vanishing of tautological classes on moduli spaces of curves. Duke Math. J. 130(1), 1–37 (2005)
Gross, M., Siebert, B.: Logarithmic Gromov-Witten invariants. J. Amer. Math. Soc. 26(2), 451–510 (2013)
Kontsevich, M.: Enumeration of rational curves via torus actions. In: Dijkgraaf, R.H., Faber, C., van der Geer, G.B.M. (eds.) The Moduli Space of Curves. Progress in Mathematics, vol. 129, pp. 335–368. Birkhäuser, Boston (1995)
Lee, Y.-P., Pandharipande, R.: A reconstruction theorem in quantum cohomology and quantum \(K\)-theory. Amer. J. Math. 126(6), 1367–1379 (2004)
Li, J.: Stable morphisms to singular schemes and relative stable morphisms. J. Differential Geom. 57(3), 509–578 (2001)
Li, J.: A degeneration formula of GW-invariants. J. Differential Geom. 60(2), 199–293 (2002)
Pandharipande, R.: Rational curves on hypersurfaces (after A. Givental). Astérisque 252, Exp. No. 848, 5, 307–340 (1998). Séminaire Bourbaki. Vol. 1997/98
Acknowledgements
I owe a great deal of thanks to Tom Coates, for first suggesting this project, for patiently explaining the quantisation formalism to me and for pointing out some of the applications presented in Sect. 4. I would also like to thank Pierrick Bousseau, Elana Kalashnikov and Mark Shoemaker for useful discussions, and the referee for a number of helpful comments.
Author information
Authors and Affiliations
Corresponding author
Additional information
The author is supported by an EPSRC Standard DTP Scholarship and by the Engineering and Physical Sciences Research Council Grant EP/L015234/1: the EPSRC Centre for Doctoral Training in Geometry and Number Theory at the Interface.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Nabijou, N. The fundamental solution matrix and relative stable maps. European Journal of Mathematics 5, 1067–1089 (2019). https://doi.org/10.1007/s40879-018-0299-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40879-018-0299-9