
Abstract
Tri-flo cyclone, as a dense-medium separation device, is one of the most typical environmentally friendly industrial techniques in the coal washery plants. Surprisingly, no detailed investigation has been conducted to explore the effectiveness of tri-flo cyclone operating parameters on their representative metallurgical responses (yield and recovery). To fill this gap, this work for the first time in the coal processing sector is going to introduce a type of advanced intelligent method (boosted-neural network “BNN”) which is able to linearly and nonlinearly assess multivariable correlations among all variables, rank them based on their effectiveness and model their produced responses. These assessments and modeling were considered a new concept called “Conscious Laboratory (CL)”. CL can markedly decrease the number of laboratory experiments, reduce cost, save time, remove scaling up risks, expand maintaining processes, and significantly improve our knowledge about the modeled system. In this study, a robust monitoring database from the Tabas coal plant was prepared to cover various conditions for building a CL for coal tri-flo separators. Well-known machine learning methods, random forest, and support vector regression were developed to validate BNN outcomes. The comparisons indicated the accuracy and strength of BNN over the examined traditional modeling methods. In a sentence, generating a novel BNN within the CL concept can apply in various energy and coal processing areas, fill gaps in our knowledge about possible interactions, and open a new window for plants' fully automotive process.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Gravity separation can be considered as the most cost-effective beneficiation method within coal processing plants. This method is relatively simple when compared to other separation processes and has a high potential for fully automatic operation. The heavy medium as a gravity separation process by far is the most efficient process for treating coarse particles (mainly + 0.5–50 mm). Heavy medium separation has several advantages over other coal washing methods. It can sharply separate run of mine materials with close densities, has low capital and operating costs (for coarse coal particle separation, no grinding is needed), and is finally environmentally-friendly (Dodbiba and Fujita 2004; Dehghan and Aghaei 2014; Noori and Dehghan 2020).
Tri-flo, as a multi-stage dynamic heavy medium separator, has been applied satisfactorily for the pretreatment of coal and magnetic ore, chromite, plastic and electronic waste, etc. Tri-flo units, using centrifugal force, can efficiently separate light particles from heavy ones (Mitra and Rao 1992). Separation by tri-flo can be applied at a wide density range where it consumes slight energy and water. A tri-flo separator consists of a cylindrical structure, which installs with a specific angle from the horizontal axial. By axial orifices, the main cylindrical combines with multi consecutive chambers (mainly two). These chambers have involute media inlets and sink discharges. In general, for producing the first sink, the feed was treated by a small quantity of dense medium and entered the first chamber at atmospheric pressure. For feeding the second sink, the first stage float is feeding to the second chamber, which contains a lower density medium (for two chambers tri-flo, it would be called “middling”) (Fig. 1). The same order for other chambers continues until producing the final clean float product (Belardi et al. 2014; Noori and Dehghan 2019).

During the operation of a tri-flo, different parameters such as backpressure, throughput, pulp density, pump speed, tri-flo density, etc., are monitored. However, there are no reported investigations, which explored relationships between these parameters and their representative metallurgical responses (yield and recovery). Thus, there is considerable potential for modeling a tri-flo circuit and straightforwardly develop a system to automate its operation fully. Extending this model based on a robust industrial database and using a powerful artificial intelligent method can build a “Conscious-Laboratory (CL)” model (Tohry et al. 2021). CL has become standard practice in the control and monitoring standpoint in different industries. Generating CL helps modern engineers understand direct and indirect relationships between process variables and wise and intelligent control processes. On the other hand, CL would reduce demands for doing laboratory work because generated models based on available monitored industrial databases can provide an accurate vision by precise predictions about non-examined operation conditions. Since these areas seek sustainable development strategies, modeling and forecasting the possible quality of products based on variations in the operating parameters has been recently started to develop within the coal and fuel processing sector.
Several studies have been done to build accurate models to predict metallurgical responses of various mineral beneficiation techniques using different machine learning methods (Golshani et al. 2013; Jorjani et al. 2008a, b; Chehreh Chelgani and Jorjani 2009; Chelgani et al. 2011a, b). McCoy and Auret (2019) recently reviewed the potential of various machine learning applications in minerals processing. A typical problem in machine learning is the verification of balance through the training dataset. Boosted neural network (BNN) as a new soft computing method could overcome this drawback by combining artificial intelligent models and developing an ensemble of experts in an efficient way. BNN can adaptively improve the probability of sampling data for accurate training experts of prediction models. The Boosting method trains a model based on a wide distribution of inputs and reduces the prediction errors by considering various experts' prediction information (Hadavandi et al. 2015a, b). By using these algorithms, BNN improves learning algorithms' performance (Golshani et al. 2018). Moreover, as an irreplaceable method, BNN is able to explore multivariable correlations among variables and rank them based on their multivariable effectiveness (Golzadeh et al. 2018).
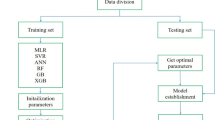
Although the application of BNN has been well developed in different disciplines, it was not implemented for variable importance measurement and modeling within the coal and energy processing sector. This study will fill these gaps and address the issues mentioned above by exploring the relationships between tri-flo operational parameters (monitored in the Tabas coal processing plant for three different tri-flos) and their representative metallurgical responses by BNN for constructing a CL. For validation and comparison purposes, typical models (random forest (RF) and support vector regression (SVR)) also were developed by the same databases, and their outcomes were evaluated based on statistical factors.
2 Materials and methods
2.1 Database
For providing a demanding amount of coking coal from the Esfahan Steel industry, the Parvadeh coalfield (Tabas, Iran) developed a coal washery plant. The plant was designed based on accepting three different size fractions (+ 6–50, + 0.5–6, and − 0.5 mm). The − 0.5 mm size fraction is subjected to processing by column flotation, and coarser particles are fed to the tri-flo circuit (Fig. 2). For treating + 6–50 mm size fraction, a 700 mm tri-flo, and for processing + 0.5–6 mm size fraction, two parallel 500 mm tri-flo are used with different operating conditions (Table 1). Feed rate, pump speeds, and medium density are monitored variables (March 2016 until March 2017-84 records), which are applied for modeling (Table 2). In detail, for the 500 mm tri-flo, variable frequency drive “VFD” pumps, i.e., pump-1000 and 1200, were used for pumping the heavy media into the first and second chamber, respectively. These two pumps were feeding the same heavy media density called “Density-1000” to the tri-flos. The density of slurries, which floated and sunk after each chamber, were monitored and called “Density-Sink” and “Density-float”, respectively. The same procedure can be considered for the tri-flo 700 mm. Pearson correlation and BNN were used for assessing the relationships between operating variables and the prediction of process responses (recovery and yield of tri-flos).

Simplified tri-flo circuits in the Parvardeh coal processing plant
2.2 Modeling
2.2.1 Pearson correlation
Pearson correlation “r” was employed for determining the linear relationships between variables. “r” can measure single (one by one) inter-correlations among inputs and output variables. “r” value varied from − 1 to + 1, its sign shows the magnitude of relationships. The absolute values close to 1 represent the strength of correlations between two variables (Benesty et al. 2009). Since “r” can just assess a linear relationship between two parameters and a substantial curvilinear correlation can result in a non‐significant r, a system that simultaneously can assess linearity and nonlinearity of relationships would be demanded to explore complex relationships.
2.2.2 Boosted neural network
Boosting is a method for the generalization of learning algorithms. Schwenk and Bengio (2000) introduced the boosting neural network as a combination of a simple neural network with boosting techniques. To strengthening weak basic learners (Neural Networks), the number of time boosting trains them via reweighted samples from the training set. For such a process, all samples in the training set initially have equal weight. After that, the heavier samples are predicted with a higher error rate by the last weak learner. Boosted neural network (BNN) conducted these steps to reduce the following objective function, where N is the number of samples in the training dataset, y is the target value and \(\widehat{y}\) is the predicted value by tth, basic learner algorithm. \(\alpha\) is the parameter, which is between 0 and 1. \({W}_{t}\) is the weight vector of tth weak learner in boosting neural network (Chehreh Chelgani et al. 2019):
As a unique capability, BBN models can also consider for multivariable sensitivity analyses (MSA). MSA enables the variation of one or more input features within a pre-defined range to observe the effect of varying values on the target feature in the prediction problem. The MSA analysis can estimate how sensible the target feature is for the given input features. MSA can assist in understanding the multivariate effects of input features on target features. To multi-interactions and their effectiveness on the tri-flo metallurgical responses, the MSA is done by using the Marginal Model Plot of BBN (Fox and Weisberg 2018) that displays a set of plots with a row for each input feature and a column for the target feature. The features are ordered according to the size of their overall total effect importance indices (Carver 2019). For a given input and target feature, the plot displays the target feature's mean response for each input feature value. That means it is taken over all inputs to calculate importance indices (Liu and Motoda 2007; Hadavandi et al. 2017). These BNN model outputs can be used for variable importance measurement (VIM). Calculating VIM is an essential step in data mining, revealing the degree of relevance of a feature to the target concept. As a result, a compelling feature's variation directly affects the model's variability (Liu and Motoda 2007).
2.2.3 Validation
Random forest (RF) and support vector regression (SVR), as typical machine learning methods, have been recently used to model and predict different fuel and energy processing areas. For comparison purposes, these two methods are also considered for the modeling of tri-flo metallurgical responses. One of the most important advantages of these three methods (BNN, RF, and SVR) is that they can successfully be used for modeling based on small databases (when a limited number of records are available (Hadavandi et al. 2017)).
2.2.3.1 Random forest (RF)
Breiman (1996) suggested a new approach to the decision tree base ensembles, which manipulated the learning datasets for each tree by bagging. Bagging decreases correlations between variables by splitting random selection and further exploits the ensemble benefits. This ensemble is called RF. For bagging (Eq. (2)), different bootstrapped samples \({\mathcal{L}}\) (θ) of size n from the training set (\({\mathcal{L}}\)) of size N are adapted from the learning dataset for each new tree. Each predictor tree \({T}_{{\mathcal{L}}(\theta )}\) is dependent on the random vector θ that shows the bagged samples from the original learning set \({\mathcal{L}}\) (Breiman and Cutler 2003; Chehreh Chelgani et al. 2016a, b; Matin et al. 2016). y′η is the predicted response for sample Xη, where K is the size of the ensemble. In other words, each tree through RF modeling develops by various bootstrapped training sets and randomly splits input variables at each node (Matin and Chehreh Chelgani 2016).
2.2.3.2 Support vector regression (SVR)
SVR is an intelligent modeling method is trained by various kernel-based functions to minimize structural risk (MSR) (Drucker et al. 1997). Radial basis function (RBF) is the most popular kernel, capable of transferring the input (x) data into a higher-dimensional space and computing complicated nonlinear problems into linear forms employed for SVR. Specified an input space with n inputs (x1, x2,…, xn), SVR can determine the variable importance (\(VI_{i}\)) by calculating the variance of output error for the testing dataset. This way can put out one input parameter (xi) at a time and check the mean square error (MSEi) of the trained sub-model for the prediction of the targets based on the model performance for the rest of the training dataset (Hadavandi et al. 2019). Classical SVR solves a quadratic optimization problem in the training phase that is computationally extensive (Drucker et al. 1997). Consider a given training dataset \(S\):
where, \(S \subset \Re^{n} \times \Re\) \(X_{i}\) is the input vector with n dimensions of ith sample and \(Y_{i}\) is the target value corresponding to \(X_{i}\). A nonlinear mapping \(\varphi :\Re^{n} \to \Re^{{n_{h} }}\) is defined for mapping input space into a new high-dimensional space. Then, there is a linear function \(f\) (SVR function) in the high dimensional space to formulate a nonlinear relationship between \(X_{i}\) and \(Y_{i}\) as Eq. (4).
\(f(x)\) shows the predicted value and the two parameters \(w \in \Re^{{n_{h} }}\) and \(b \in \Re\) must be adjusted. The formulation of SVR is based on minimizing structural risk and empirical risk (Eq. (5)):
with these constraints:
where, \(\varepsilon\) is a precision parameter representing the radius of the tube located around the regression function (\(\varepsilon\)-insensitive loss function used in standard SVR),\(\zeta^{*}\) and \(\zeta\) are training errors above ɛ and training error below \(- \varepsilon\). C is a trade-off parameter between two terms in the objective function (Drucker et al. 1997). Table 3 summarized some of the applications of these models in various mineral processing methods.
3 Results and discussion
3.1 Correlation assessments
3.1.1 Tri-flo 500 mm
Pearson correlations between operational parameters and their representative metallurgical responses (Fig. 3) indicate these variables for both tri-flo 500 mm have similar magnitudes with their representative metallurgical responses. Within the variables, Density-1000 has the highest positive single linear inter-correlation with the metallurgical responses (r: 0.72). Linear Pearson assessments show by increasing the Pump speed-1000, the metallurgical responses can be decreased (a negative correlation). Other variables illustrate negligible single linear correlations. Nonlinear multivariable correlation assessments by BNN marginal curve (Fig. 4) also show that increasing Density-1000 would increase the metallurgical responses while increasing the pump speed in the first chamber has a negative effect on them. VIM results indicate that Density-1000 is the most influential variable on metallurgical responses, among other monitored operational parameters (Fig. 4). In general, there is a good agreement between “r” and VIM assessment results. These results release that for the processing of fine coal particles, controlling the operational variables of tri-flo 500 mm in the first chamber (density and pump speed) has a critical effect on the process responses.

Pearson correlation between operational parameters of tri-flo 500 m (a, b) and their representative metallurgical responses

BNN marginal curve for tri-flo 500 mm multivariable correlation assessments
3.1.2 Tri-flo 700 mm
Single linear inter-correlation assessments “r” among the variables for the coarse size fraction (Fig. 5) indicate that the feed rate has a significant negative correlation with the metallurgical responses. In other words, by increasing the feed rate, the metallurgical responses extensively would be decreased. Pump speed-1400, Density-1600, and Density Float show moderate linear positive correlations with the metallurgical responses. Exploring nonlinearity multivariable effectiveness assessments of each monitored variable for predicting metallurgical responses by BNN marginal curve indicates (Fig. 6) that Density-1600 and Density Sink 2 have meaningful positive correlations with the metallurgical responses. However, ranking VIM results based on multivariable correlation demonstrate (Fig. 6) that Density-1600 and Pump speed-1400 are the most influential variables for the prediction of recovery and yield prediction, respectively, in the tri-flo 700 m.

Pearson correlation between operational parameters of tri-flo 700 mm and their representative metallurgical responses

BNN variable importance measurement between operational parameters and metallurgical responses for tri-flo 700 mm
3.1.3 Prediction
From the entire databases related to each considered tri-flo, 90% of records are used for training steps, and the rest is applied for the testing stages. A trial and error method is used to obtain a suitable number of experts in the BNN model. The optimum parameters with minimum generalization errors are provided (Table 4). The BNN model experts are a one-layer perceptron neural network with four hidden neurons and a ‘tanh’ activation function. Training of experts is developed by using the back-propagation learning algorithm (Asadi et al. 2012). BBN modeling results (Table 5) indicate that this intelligent method can accurately predict the metallurgical responses based on the operational variables for all the three examined tri-flos. For comparison purposes, the same training and testing sets from each database are employed for RF and SVR modeling. Results show (Table 5) that BNN can present a higher accuracy for different systems than traditional machine learning (RF and SVR). Differences between actual and predicted value in the testing stage supports approved the provided results (Fig. 7). These results indicated that BNN models could be considered as a CL for controlling, maintaining, and predicting the effect of varied operational conditions on the metallurgical responses of tri-flo in the coal processing plants.

Differences between actual and predicted value by different AI models in the testing stage
4 Conclusions
Conscious-Laboratory, potentially as a future trustable lab, can be used for efficient data mining through energy and processing sectors. For example, this investigation explored such a possibility and showed the vast potential for automating tri-flo circuits' operation. Assessment of single linear and multivariable nonlinear relationships between tri-flo operational parameters and their representative metallurgical responses by a powerful new developed ensemble arterial neural net method “boosted neural network” provided valuable information. For fine particles (+ 0.5–6 mm), the density of feeding heavy media and the speed of pumping the media in the first chamber have the highest effect on tri-flo 500 mm' performance. For coarse particles (+ 6–50 mm), the density of heavy media in the second chamber was the most effective parameter on the yield. In contrast, the speed of pumping the heavy media in the first chamber showed the highest importance for modeling recovery. Apart from the particle size, increasing the feeding rate of raw coal would decrease the metallurgical responses, and increasing the density of heavy media could improve the metallurgical responses. BNN modeling results in comparison with popular machine learning methods indicated that the performance of tri-flo could be modeled, and the circuit could be automated based on operational factors quite accurately.
References
Asadi S, Hadavandi E, Mehmanpazir F, Nakhostin MM (2012) Hybridization of evolutionary Levenberg–Marquardt neural networks and data pre-processing for stock market prediction. Knowl Based Syst 35:245–258
Belardi G, Bozano P, Mencinger J, Piller M, Schena G (2014) Numerical simulation of water-air flow pattern in a Tri-Flo™ cylindrical separator. IMPC-XXVII, Santiago-Chile
Benesty J, Chen J, Huang Y, Cohen I (2009) Pearson correlation coefficient. In: Noise reduction in speech processing. Springer, pp 1–4
Breiman L (1996) Bagging predictors. Mach Learn 24:123–140
Breiman L, Cutler A (2003) Manual on setting up, using, and understanding random forests, v4.0. ftp://ftp.stat.berkeley.edu/pub/users/breiman/Using_random_forests_v4.0.pdf
Carver R (2019) Practical data analysis with JMP. SAS Institute
Chehreh Chelgani S, Jorjani E (2009) Artificial neural network prediction of Al2O3 leaching recovery in the Bayer process-Jajarm alumina plant (Iran). Hydrometallurgy 97(1–2):105–110
Chehreh Chelgani S, Hower JC, Hart B (2011a) Estimation of free-swelling index based on coal analysis using multivariable regression and artificial neural network. Fuel Process Technol 92(3):349–355
Chehreh Chelgani S, Hart B, Grady WC, Hower JC (2011b) Study relationship between inorganic and organic coal analysis with gross calorific value by multiple regression and ANFIS. Int J Coal Prep Util 31(1):9–19
Chehreh Chelgani S, Matin SS, Makaremi S (2016a) Modeling of free swelling index based on variable importance measurements of parent coal properties by random forest method. Meas J Int Meas Confed 94:416–422
Chehreh Chelgani S, Matin SS, Hower JC (2016b) Explaining relationships between coke quality index and coal properties by Random Forest method. Fuel 182:754–760
Chehreh Chelgani S, Shahbazi B, Hadavandi E (2018) Support vector regression modeling of coal flotation based on variable importance measurements by mutual information method. Measurement 114:102–108
Chehreh Chelgani S, Hadavandi E, Hower JC (2019) Estimation of heavy and light rare earth elements of coal by intelligent methods. Energy Sources A Recov Util Environ Effects 43:70–79
Dehghan R, Aghaei M (2014) Evaluation of the performance of tri-flo separators in Tabas (Parvadeh) coal washing plant. Res J Appl Sci Eng Technol 7(3):510–514
Diaz P, Salas JC, Cipriano A, Núñez F (2021) Random forest model predictive control for paste thickening. Miner Eng 163:106760
Dodbiba G, Fujita T (2004) Progress in separating plastic materials for recycling. Phys Sep Sci Eng 13(3–4):165–182
Drucker H, Burges CJ, Kaufman L, Smola AJ, Vapnik V (1997) Support vector regression machines. Adv Neural Inf Process Syst 9:155–161
Fox J, Weisberg S (2018) An R companion to applied regression. Sage Publications
Golshani T, Jorjani E, Chehreh Chelgani S, Shafaei SZ, Nafechi YH (2013) Modeling and process optimization for microbial desulfurization of coal by using a two-level full factorial design. Int J Miner Sci Technol 23(2):261–265
Golzadeh M, Hadavandi E, Chehreh Chelgani S (2018) A new Ensemble based multi-agent system for prediction problems: case study of modeling coal free swelling index. Appl Soft Comput 64:109–125
Hadavandi E, Shahrabi J, Hayashi Y (2015a) SPMoE: a novel subspace-projected mixture of experts model for multi-target regression problems. Soft Comput 20:1–19
Hadavandi E, Shahrabi J, Shamshirband S (2015b) A novel Boosted-neural network ensemble for modeling multi-target regression problems. Eng Appl Artif Intell 45:204–219
Hadavandi E, Hower JC, Chehreh Chelgani C (2017) Modeling of gross calorific value based on coal properties by support vector regression method. Model Earth Syst Environ 3(1):37
Jorjani E, Bagherieh AH, Mesroghli Sh, Chehreh Chelgani S (2008a) Prediction of yttrium, lanthanum, cerium, and neodymium leaching recovery from apatite concentrate using artificial neural networks. J Univ Sci Technol Beijing Miner Metall Mater (Eng Ed) 15(4):367–374
Jorjani E, Mesroghli S, Chehreh Chelgani S (2008b) Prediction of operational parameters effect on coal flotation using artificial neural network. J Univ Sci Technol Beijing Miner Metall Mater 15(5):528–533
Liu H, Motoda H (2007) Computational methods of feature selection. CRC Press
Matin SS, Chehreh Chelgani S (2016) Estimation of coal gross calorific value based on various analyses by random forest method. Fuel 177:274–278
Matin SS, Hower JC, Farahzadi L, Chehreh Chelgani S (2016) Explaining relationships among various coal analyses with coal grindability index by Random Forest. Int J Miner Process 155:140–146
McCoy JT, Auret L (2019) Machine learning applications in minerals processing: a review. Miner Eng 132:95–109
Mitra VJ, Rao TC (1992) Analysis of performance of a 76 mm vorsyl separator. Miner Eng 5(1):93–101
Noori M, Dehghan R (2019) Use of density tracers in evaluating performance of Tri-Flo circuits Case study: Tabas (Iran) coal preparation plant. J Min Environ (JME) 10(2):441–450
Noori M, Dehghan R (2020) Toward a better understanding of a Tri-Flo separator using prototyping, central composite design (CCD) and CFD simulation. Int J Coal Prep Util. https://doi.org/10.1080/19392699.2020.1721483
Schwenk H, Bengio Y (2000) Boosting neural networks. Neural Comput 12(8):1869–1887
Shahbazi B, Chehreh Chelgani S, Matin SS (2017) Prediction of froth flotation responses based on various conditioning parameters by Random Forest method. Colloids Surf A Physicochem Eng Asp 529:936–941
Tohry A, Jafari M, Farahani M, Manthouri M, Chehreh Chelgani S (2020a) Variable importance assessments of an innovative industrial-scale magnetic separator for processing of iron ore tailings. Miner Process Extr Metall. https://doi.org/10.1080/25726641.2020.1827674
Tohry A, Chehreh Chelgani S, Matin SS, Noormohammadi M (2020b) Power-draw prediction by random forest based on operating parameters for an industrial ball mill. Adv Powder Technol 31(3):967–972
Tohry A, Yazdani S, Hadavandi E, Mahmudzadeh E, Chehreh Chelgani S (2021) Advanced modeling of HPGR power consumption based on operational parameters by BNN: a “Conscious-Lab” development. Powder Technol 381:280–284
Author information
Authors and Affiliations
Corresponding author
Additional information
Mehdi Alidokht and Chehreh Chelgani are contributed equally to this work.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Alidokht, M., Yazdani, S., Hadavandi, E. et al. Modeling metallurgical responses of coal Tri-Flo separators by a novel BNN: a “Conscious-Lab” development. Int J Coal Sci Technol 8, 1436–1446 (2021). https://doi.org/10.1007/s40789-021-00423-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40789-021-00423-7