
Abstract
Since the traditional ship stability failure probability assessment method has many input parameters and cumbersome intermediate calculation process, this paper proposes a joint multi-model machine learning prediction method based on confidence. The method calculates the confidence of each machine learning model for the current prediction result, selects the top n models among them, and takes the average of their prediction results as the output. The confidence is calculated by a method inspired by semi-supervised learning. To reduce the number of ship features that need to be input for assessment, a sensitivity analysis is used to reject irrelevant features. Eight machine learning models that have good performance and are widely used in other fields, including Radial Basis Function Neural Network, Random Forest, eXtreme Gradient Boosting, and so on, are used as component learners in this study. The hyperparameters of each model are obtained by cross-validation and grid search. The advancedness of the proposed method is verified by comparing it with other models on a small self-built ship stability failure probability dataset. By conducting experiments that simply average the results of the component learners, it is confirmed that simple superposition different models does not necessarily improve the accuracy. At the same time, after pre-processing the input features in different ways, the comparison of the prediction performance was conducted, and the experimental results showed that the proposed method is not affected by the way the input features are preprocessed and therefore has some robustness.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Ships face complex marine environment and harsh sea conditions when sailing at sea. The ship stability is an important measure of whether the ship can navigate safely at sea. At present, the Second Generation Intact Stability Criteria classifies the ship’s stability failure modes into five types [1], including Pure loss of stability, Parametric roll, Dead ship stability, Surf-riding and broaching and Excessive acceleration. Among them, Dead ship stability and Excessive acceleration are two failure modes that tend to occur when the ship is sailing under crosswinds and waves, and have many similarities in terms of phenomena and calculation methods. Therefore, both are studied together in this paper as the focus of research. The ship stability failure probability is the probability of a failure mode occurring when a ship sailing under a range of sea states and wind and wave conditions. The calculation not only takes into account a large number of sea conditions and requires a large number of ship features, but also calculates parameters, such as roll damping coefficient, steady heel angle and resistance, etc. Therefore, this paper is dedicated to build a black-box model by machine learning method to predict the stability failure probability of the ship by inputing a small number of ship features.
For the rapid prediction assessment and intelligent control [2,3,4,5,6], the algorithms of machine learning, for instances, neural networks and support vector machine, are emerging to solve multi-dimensional fitting problems and approximate any nonlinear function applied in intelligent marine systems [7,8,9,10,11,12]. In the field of ship performance assessment, machine learning is widely used to calculate and predict the ship speed and resistance, maneuverability and seakeeping. Regarding to ship speed and resistance prediction, researchers have adopted neural networks to predict various resistances of ships [13,14,15,16]. Yang [16] adopted Radial Basis Function Neural Network (RBFNN) to predict the resistance of container ships and compared with the prediction results of Error Back Propagation Neural Network (BPNN), Support Vector Machine (SVM) and Random Forest (RF). In terms of ship seakeeping, scholars have carried out a lot of research on the rolling motion prediction methods of ships [17, 18], and further extended the roll prediction to multi-degree-of-freedom motions [19,20,21]. Silva conducted related research on the six-degree-of-freedom motion of ships [20]. He [22] established a non-parameterized ship maneuvering motion model based on a fully connected neural network, in the study of ship maneuverability [23]. The prediction method of machine learning has also been widely extended to the prediction of ship engine fuel consumption [24,25,26,27], ship engine state prediction [28], ship positioning [29], ship classification [30] and other studies [31]. Fan [32] used machine learning method to predict ship collision force on bridge. Artificial intelligence technology has also been continuously added to the ship design stage. Cepowski adopted artificial neural network to determine the design formulas for container ships at the preliminary design stage [33].
However, in the field of ship stability, most of the research work conducted the direct calculation and assessment by complying with level criteria of the second generation intact stability [34,35,36]. Some scholars use other methods for stability prediction, in which Duan [37] proposed a domain prediction method of ship nonlinear motion and acceleration response, and Liu [38] adopted Computational Fluid Dynamics (CFD) method on evaluating the pure loss of stability. These are all studies for the ship stability assessment resulted by direct calculations.
In this paper, we try eight machine learning methods including two neural network models RBFNN and BPNN, and six ensemble models RF, Bagging, Extremely randomized trees (Extra-tree), Adaptive Boosting (AdaBoost), Gradient Boosting Decision Tree (GBDT) and eXtreme Gradient Boosting (XGboost) that perform well in other fields, and based on them, proposed a joint multi-model confidence-based method for ship’s stability failure probability prediction. The method is inspired by the idea of co-training in semi-supervised learning and the idea of heterogeneous ensemble in Ensemble learning. The method combines models that have high confidence in the current prediction results, thus avoiding influenced by inferior learners. By testing on a test set, it is verified that the proposed method has a low mean square error compared to other models while maintaining a low mean absolute percentage error, i.e., higher accuracy. Main contributions in this paper are listed as follows:
-
Ship features required for the prediction are obtained by sensitivity analysis. The initial features include various ship parameters, such as principal dimensional, ship form parameters, load parameters, etc. Features that have no effect on different failure modes will be removed as redundant features in the corresponding failure probability prediction.
-
Eight machine learning models were tried, and based on this, proposed a joint multi-model confidence-based method. The core of this method is to add the current prediction results of current model as labels to the training set of other models, and determine the accuracy improvement effect of other models before and after its addition through cross-validation, and use it as the prediction confidence of the current model. Ultimately, only high-confidence models are retained for combination.
-
By conducting experiments that simply average the results of the component learners, it is confirmed that simple superposition different models does not necessarily improve the accuracy, but instead is sometimes very susceptible to poor quality learners. Also in most cases it is accuracy can only be better than the worst and worse than the best.
-
Experiments on various ship features’ pre-processing methods were conducted. By testing on real ship data, it is verified that the proposed method in this paper possesses better accuracy than other models and if not only has a smaller variance in prediction, but also maintains a smaller bias. The method is not susceptible to the perturbation of the input ship features’ processing methods as other models.
The remainder of this article is organized as follows. In section “Ship Stability Failure Mode”, we introduce the principles of the two failure modes studied in this paper. In section “Machine Learning Algorithms for Ship Stability Failure Probability Prediction”, we introduce several commonly used machine learning prediction methods, describe our proposed method, and elaborate its specific implementation steps. In section “Other Details”, some other details are presented, including the search strategy for hyperparameters and the screening method for ship features. Then, We investigate the effects of multiple input feature preprocessing methods on the prediction performance in section “Experiments”. The experimental results under multiple evaluation metrics are provided to demonstrate the superiority of our proposed method. In the final section, a discussion and conclusion of the study are presented. The nomenclature and abbreviations of this paper can be seen in Table 1.
Ship stability failure mode
Currently, the Second Generation Intact Stability Criteria issued by International Maritime Organization (IMO) classifies the stability of a ship into five failure modes, including Dead ship stability, Excessive acceleration, Pure loss of stability, Parametric rolling and Surf-riding/broaching[39]. Among them, Dead ship stability and Excessive acceleration are two failure modes that tend to occur when the ship is sailing under crosswinds and waves. These two failure modes have many similarities in terms of phenomena as well as calculation methods. Therefore, both are studied together in this paper as the focus of the research.
Dead ship stability failure mode
Dead ship stability refers to the stability failure mode in which the ship loses power and maneuvering ability due to mechanical failure while sailing in wind and waves, and resonant rolling (or even capsizing) occurs under free floating conditions[40].

Scenario of stability failure in dead-ship conditions
As shown in Fig. 1, when the ship is rolling to the windward side, it is affected by the sudden wind and constant wind, the ship starts to roll back under the joint action of wind and wave, the speed and reaction force of lateral drift increases. The ship continues to roll to the upwind side, at this time the speed and reaction force of lateral drift continue to increase, providing additional heeling moment, and the ship rolls to the maximum roll angle on the upwind side, at this time the maximum chance of stability failure occurs.
Excessive acceleration failure mode
Excessive acceleration[41] is the phenomenon of excessive rolling acceleration when the ship is sailing in wind and waves, which causes damage to cargo as well as injuries to people.
As shown in Fig. 2, when a ship undergoes rolling, the higher the position(such as the bridge), the greater the distance of transverse movement. For a ship, the period of rolling is the same for each point on the ship, and the greater the distance of transverse movement, the greater the linear velocity it has. So when the direction of the ship’s rolling changes, the point with greater linear velocity will have greater acceleration, and the greater the acceleration, the greater the inertia force. For people and cargo in different positions on the ship, the danger of lateral inertia force is much greater than the danger of vertical inertia force.
Machine learning algorithms for ship stability failure probability prediction
In this section, we introduce the proposed joint multi-model machine learning prediction method, which is used to make predictions of ship stability failure probability. In addition, the specific implementation steps of the method are described in detail.
Artificial neural network prediction models
Artificial neural networks are widely used in the fields of ship resistance forecasting, ship maneuverability forecasting, etc. It has powerful nonlinear fitting capability. In this paper, BPNN and RBFNN are taken as the focus of the research.

Plot of ship excessive acceleration
BPNN [42] is a multilayer feedforward network trained according to the error back propagation algorithm. A typical BP neural network consists of one input layer, one or more hidden layers, and one output layer, and the choice of the number of hidden layers and the number of nodes in the hidden layer of the BP neural network can have a great impact on its prediction accuracy. At the same time, the choice of activation function and optimizer are also influencing factors of the prediction accuracy.In this paper, the activation function is selected as “ReLU” and the optimizer is selected as L-BFGS. The activation function “relu” is calculated as follows:
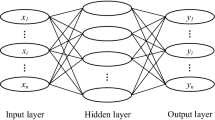
RBFNN is a three-layer feedforward neural network, which can be used to solve the problem of the multi-dimensional fitting. In the forward transmission process, the signal enters the network from the input layer processed by the RBF in the hidden layer, and then the network output is obtained by linearly combining the results of each hidden layer. Figure 5 shows the structure of the RBFNN used to predict ship stability.

Network structure of ship stability prediction
According to the stability failure mode to be predicted, ship parameters as input, are processed by the basis function in the hidden layer. Then, the output results of the hidden layer are linearly superimposed to obtain the failure probability of each failure mode. In Fig. 3, \(f_{1}\),\(f_{2}\),...,\(f_{n}\) are the basis function with different centers and width, \(w_{ij}\) is the weight coefficient from the ith hidden layer to the jth output layer.
In this study, the Gaussian function [43] is used as the basis function, and its calculation formula is as follows:
where r is the distance between the input vector x and the center of the basis function, and \(\sigma \) is the standard deviation.
When using the trained RBFNN to predict the ship stability, the prediction results can be obtained by taking parameters such as ship length, ship width, moulded depth, and speed as input according to the different failure modes selected for prediction. The calculation formula is as follows:
In which, x is the input features, \(w_{p}\) is the weight coefficients from the hidden layer to the output layer, c is the center the Gaussian function.
The performance of RBFNN is affected by the number of center points, the position of center points and the width of basis function. In this paper, we use random search to determine the number of center points, the Particle Swarm Optimization (PSO) algorithm to find the position of center points, and the standard deviation are determined by the following equation:
where \(d_{max}\) is the maximum distance between centers, n is the number of centers.
Ensemble learning prediction models
Ensemble Learning is a class of methods that address supervised machine learning tasks based on the idea of integrating multiple learning algorithms to improve prediction results. By combining multiple learners, Ensemble Learning can often achieve significantly better generalization performance than a single learner. The integration of Ensemble Learning is divided into two types, one is sequential ensemble and the other is parallel ensemble. The algorithms studied in this paper can be divided into two categories, one based on the idea of Bagging and the other based on the idea of Boosting.
Bagging
Bagging [44] algorithm uses a put-back sampling method to generate training data. By randomly sampling the initial training set with multiple rounds of put-back, multiple training sets are generated in parallel, corresponding to multiple base learners can be trained (no strong dependencies between base learners), and then these base learners are combined to build a strong learner. The essence is the introduction of sample perturbation, which achieves the effect of variance reduction by increasing sample randomness.In this paper, a bagging algorithm which uses regression tree as base learner is used (hereinafter referred to as Bagging-tree), and the output results are obtained using the averaging method.
RF (Random Forest) is an ensemble learning algorithm based on decision trees, which introduces random attribute selection based on bagging. RF is very simple, easy to implement, which has very little computational overhead, and shows very impressive performance for both classification and regression. RF was proposed by Breiman [45] and can be used for classification, regression, and multidimensional data processing. The basic unit of RF is a series of decision trees that follow binary rules, also known as classification and regression trees (CART). Compared with the traditional regression model, the RF model can better tolerate noise and outliers, which bears higher computational efficiency, can self-learn multi-dimensional nonlinear mapping, and have a better fitting effect. Figure 4 shows the structure of the RF for predicting ship stability.

Forest structure for ship stability prediction
When combining prediction outputs, RF usually use the voting method for classification tasks and the averaging method for regression tasks. This study is a kind of regression analysis, so the averaging method is used to combine the prediction outputs. Through taking parameters, such as ship length, ship width, moulded depth, and speed as input characteristics, and using different random forests according to different predicted failure modes, the prediction results can be obtained as follows:
where T is the number of CART, \(h_{i}(x)\) is the prediction result of a single regression tree.
Extra-Trees (Extremely randomized trees) [46] are very similar to Random Forests, and are sometimes referred to as Random Forests. The extreme randomness of Extra-Trees compared to Random Forest is manifested in the partitioning of decision tree nodes. Extra-Trees are partitioned directly using a random feature and a random threshold on the random feature.The randomness of each submodel (decision tree) in Extra-Trees becomes greater, and therefore the variability between each submodel (decision tree) is greater. When making predictions, the base regressor combination method of Extra-Trees is exactly the same as RF, as shown in Eq. (5).
Boosting
The training process of Boosting is ladder-like, the training of base models is sequential, each base model will learn on the basis of the previous base model learning, and finally combine the prediction values of all base models to produce the final prediction results, the more comprehensive way used is the weighting method.
AdaBoost (Adaptive Boosting) [47], which is adaptive in the sense that samples that are wrongly classified by the previous base classifier are strengthened, and the weighted whole samples are used again to train the next base classifier. At the same time, a new weak classifier is added in each round until some predefined sufficiently small error rate is reached or a pre-specified maximum number of iterations is reached. In this study, the base learner of adaboost uses regression trees, and the prediction results when Adaboost is used for regression are calculated as follows:
where M is the number of the base regressor, \(a_{m}\) is the weight of the mth regressor, g(x) is the median of all \(a_{m}G_{m}(x)\), i.e., the median of the weighted output results of all weak learners \(G_{m}(x)\).
GBDT (Gradient Boosting Decision Tree) [48] is also an Ensemble Learning algorithm based on the idea of boosting. The core of GBDT is to accumulate the results of all trees as the final result. Each tree of GBDT updates the target value with the residuals obtained from the previous trees, so that the value of each tree is added up to the predicted value of GBDT, which shown as follows:
where k is the number of the base regressor, \(f_{i}(x)\) is the result of ith tree.
XGBoost’s (eXtreme Gradient Boosting) [49] basic idea is the same as GBDT, but with some optimizations, such as second-order derivatives to make the loss function more accurate; regular terms to avoid tree overfitting; Block storage to allow parallel computation, etc. When making predictions, the base regressor combination method of XGBoost is exactly the same as GBDT, as shown in Eq. (7).
Combined strategies for the joint multi-model machine learning prediction method
In this paper, we propose a joint multi-model prediction method to predict the ship stability failure probability. The method is inspired by the idea of co-training in semi-supervised learning [50,51,52,53,54]. When multiple models are used to predict the same failure mode, the models with high prediction confidence are combined, and the models with low prediction confidence are discarded. How to judge the confidence of a model in forecasting the probability of steady failure for a ship that does not enter the training set is key. The idea of cc-training in semi-supervised learning holds that for two learners obtained by using the same training set for training, when a set of features from the test set is input into learner 1 for forecasting, if the prediction result of this learner 1 is used as the label and added to the training set of another learner 2, and training learner 2 with the newly constructed training set can improve its forecasting accuracy, then it is considered that learner 1 s prediction confidence is higher for this test sample. The joint multi-model prediction method proposed in this paper continues this idea.
T different regression models were obtained using the same training set L with different algorithms. Although the training sets of different models are the same, the training set of each model is still denoted as \(L_{i}\) for the convenience of presentation.T regressors are used to predict a test sample \(x_{i}\), and the prediction result of each regressor \(y_{i}\) is denoted as \(y_{i}(x_{i})\). Add \(\{x_{i}, y_{i}(x_{i})\}\) to the training set of all other regressors except \(y_{i}\), retrain each model, and obtain the mean square error \(MSE_{i}\) of each model using cross-validation. Here, a fivefold cross-validation is used in this paper, where four copies are used as the training set and one copy as the validation set each time, while \(\{x_{i}, y_{i}(x_{i})\}\) should be guaranteed to be added to the training set each time. The mean square error of all copies obtained is averaged as \(MSE_{i}\). It should be noted that for different models, the variation of this value may increase or decrease, so the mean value of the mean square error of all models is found to obtain \(\overline{MSE}\):
where T is the number of regressor, \(h_{t}\) is the expective value, \(y_{t}()\) is the tth regressor, \(x_{t}\) is the features of the test sample. After obtaining the \(\overline{MSE}\), the prediction confidence of different models can be calculated as follows:
where \(\overline{MSE}_{before}\) is the average of the mean square error before models retrained, \(\overline{MSE}_{after}\) is the average of the mean square error after models retrained. After obtaining the prediction confidence of each model, the results of the top Z models are selected and averaged as the prediction results of the joint prediction model. In this paper, a simple averaging method as shown in Eq. (10) is used in the combination, which is one of the points that can continue to be improved in the future:
To verify the advancedness of this method, it was compared not only with eight other machine learning prediction models on the test set, but also with a simple averaging method, which averages the results of all models.
The flow chart of the joint multi-model prediction method for ship stability failure probability is shown in Fig. 5.

Flow chart of the joint multi-model prediction method
The pseudocode for this method is shown in Algorithm 1:

Combined algorithm training process
Other details
In this section, we introduce the search strategy for the hyperparameters of each model. In addition, we describe the input features screening method based on sensitivity analysis in detail.
Models hyperparameters searching strategy
The hyperparameters of machine learning have an impact on the performance of the model and therefore usually require manual or automatic tuning to ensure optimal model performance. In this paper, we adopt the idea of grid search and cross-validation for hyperparameters search. When tuning the model hyperparameters, the hyperparameters to be adjusted will be randomly combined within a given range, and then the training set will be divided into five parts, each time four parts will be selected as the training set and one part will be used as the validation set, and it is guaranteed that each part will be used as the validation set once, and the performance of the model under the current hyperparameters will be determined by all the validation sets. Finally, the model with the highest performance will be used to predict the stability failure probability of the ship.The hyperparameters of each model and the search range are shown in Table 2.

Training process of different prediction models
The model evaluation criterion chosen for the hyperparameters search in this paper is the Mean Square Error. The complete models training, hyperparameters search and testing process are shown in Fig. 6. All algorithms and models implemented in this paper are based on python, and random seeds are fixed for easy reproduction.
Selection of ship features for ship stability failure probability prediction
The input features of the machine learning prediction method is generally determined according to the needs of researchers. Very few input characteristics may not be able to make accurate predictions while too many input features will also lead to a long training time. Therefore, to determine the appropriate input features for ship stability prediction, it is necessary to study the influence of ship parameters on each failure mode in the second-generation intact stability, among which the ship parameters with obvious influence are selected as the input features of each prediction model. The ship parameters studied in this paper include: The principal dimensional parameters of the ship include length, breadth, moulded depth and draught; Ship form parameters include block coefficient, waterline coefficient and mid-ship section coefficient; Load parameters include the height of the center of gravity. This features extraction method can filter out irrelevant features, alleviate the dimensionality explosion problem and reduce the difficulty of machine learning tasks.
For the excessive acceleration failure mode(as the results shown in Fig. 7), the changes of moulded depth have little effect on the calculation results of long-term failure probability. Therefore, in this study, ship length (L), ship breath(B), draught (\(T_{m}\)), height of center of gravity (\(Z_{g}\)), block coefficient (\(C_{b}\)), waterline coefficient (\(C_{w}\)), mid-ship section coefficient (\(C_{m}\)) and longitudinal position of the center of buoyancy (\(X_{b}\)) are selected as the input features of each prediction model to predict the probability of this failure mode.

Influence of ship parameters change on long-term failure probability of excessive acceleration
For the dead ship stability failure mode(as the results shown in Fig. 8), in addition to the above-mentioned ship parameters, the effect of flooding angle on the capsizing probability is also taken into the consideration. It is found that the change of the longitudinal position of the center of buoyancy (\(X_{b}\)) has almost no effect on the calculation results. Therefore, in this study, ship length (L), ship breadth (B), moulded depth (D), draught (\(T_{m}\)), height of center of gravity(\(Z_{g}\)), block coefficient (\(C_{b}\)), waterline coefficient (\(C_{w}\)), mid-ship section coefficient (\(C_{m}\)) and flooding angle (\(\varphi _{f}\)) are selected as the input features of each prediction model to predict the probability of this failure mode.

Influence of ship parameters change on dead ship stability failure probability
The ship features of each failure mode when using each machine learning models for prediction are shown in Table 3.
The symbols in Table 3 include: ship length (L), ship width (B), ship depth (D), draught (\(T_{m}\)), the height of center of gravity (\(Z_{g}\)), block coefficient (\(C_{B}\)), waterline coefficient (\(C_{w}\)), mid-ship section coefficient (\(C_{m}\)), flooding angle (\(\varphi _{f}\)), and longitudinal position of the center of buoyancy(\(X_{b}\)).
Experiments
In this section, a series of experiments are executed to evaluate the performance of the proposed model. A fair comparison with other methods is conducted to validate the efficacy of our approach.
Stability failure probability of sample ships
In this study, a series of ships are selected as research objects. The range of each ship features in the ship sample set is shown in Table 4.
The ship stability failure probability is the probability of a failure mode occurring when a ship sailing under a range of sea states and wind and wave conditions. Each sea state corresponds to a short-term failure probability, and the long-term failure probability is a weighted average of these short-term probabilities:
where C is the long-term failure probability; \(W_{i}\) is the weight coefficient under the different sea states which is obtained from North Atlantic Wave Scattering Map shown in Table 5, \(C_{i}\) is the short-term failure probability.
The long-term failure probabilities of each failure mode corresponding to the selected ship samples in this paper are shown in Figs. 9 and 10. It should be noted that the number of sample vessels for the study of each failure mode varies in this paper, with 116 vessels for Dead ship stability and 94 vessels for Excessive acceleration. The images show the failure probabilities of the training samples only. To verify the generalization ability of the algorithm, 8 vessels were randomly selected as test samples for each failure mode.

Dead ship stability failure probability of different ships

Excessive acceleration stability failure probability of different ships
Evaluation metrics of prediction models
In this paper, the performance of the model is evaluated using the Mean Squared Error (MSE), the Mean Absolute Percentage Error (MAPE) and the R-squared (\(R^{2}\)). This is because some models focus on reducing the bias and some focus on reducing the mean squared error, so it is necessary to consider the accuracy of the models from various aspects. The formulas for calculating the three evaluation metrics are as follows:
where N is the number of predicted samples, \(f_{i}\) is the expected value, \(y_{i}\) is the predicted value, and \(\hat{y}\) is the average of the expected value.
The dead ship stability failure probability prediction results
When using machine learning models, it is often necessary to preprocess the input features, and different pre-processing methods can affect the performance of the model. So a total of three data pre-processing approaches are tried to process the input ship features, including standard scaling, max absolute scaling and normalizing.
Table 6 shows the MSE, MAPE and \(R^{2}\) of different ship stability prediction models on the test set of Dead ship stability failure probability. For this failure mode, the hyperparameter Z of the joint prediction model is set to 3. Figure 11 shows the calculated results of the three performance criteria for all models with different ship features processing methods. According to the calculation results of the accuracy criterion of each model, the following conclusions are obtained.

Calculated results of the three performance criteria for each model
-
Different input feature processing can have an impact on the accuracy of the models, especially for RBFNN. Normalizing the input features, regardless of the kind of metric, can adversely affect the performance of all models.
-
Simply averaging the prediction results of all models can reduce MSE and improve \(R^{2}\) to some extent, but MAPE is not reduced, i.e., it can reduce the prediction variance but not effectively reduce the bias.
-
According to the prediction results, it can be seen that not the model with lower MSE has lower MAPE. Without preprocessing, GBDT has the smallest MSE but its MAPE is more than 10%, higher then that of Joint prediction models. After the max absolute scaling, the MSE of the Averaging method is similar to Joint prediction models and is smallest, but its MAPE is twice as large as that of the joint method. After normalization, the MSE of the joint method is the smallest, but its MAPE is more than 20%. After standard scaling the input features, Bagging has the smallest MAPE, but its MSE is still higher than some models.
-
After standard scaling the input features, compared to all other models with all data processing methods,the joint method has the smallest MSE and the largest \(R^{2}\), while the MAPE is only 6.2%.
Among all the models, only the MAPE of RF, Bagging and the joint model is less than 10%, while the MSE of Bagging does not reach the level of the averaging method. The results of the probability of the dead ship stability on test set by RF, Bagging-Tree and the joint model are shown in Figs. 12 and 13. The figure shows that for each prediction sample, the prediction results of the joint model are closer to the expected value.

Prediction results of the Dead ship stability failure probability by RF and joint model

Prediction results of the Dead ship stability failure probability by Bagging-Tree and joint model
The excessive acceleration failure probability prediction results
The results of excessive acceleration failure probability prediction of each model for the ships in test set under different data processing methods are shown in Table 7. For this failure mode, the hyperparameter Z of the joint model is also set to 3. Figure 14 shows the calculated results of the three performance criteria for all models with different ship features processing methods. The following conclusions can be drawn from the prediction results.
-
In the same way as the Dead ship failure mode, the way to pre-processing the ship features is highly impressive for neural network models. For RBFNN and BPNN it is more suitable not to process the ship features. Ensemble models based on the Bagging idea improve their Excessive Acceleration failure probability prediction performance after either standard scaling or max absolute scaling of the ship features. Ensemble models based on the Boosting idea are generally unaffected except for normalization. The joint forecasting model proposed in this paper uses all preprocessing methods can improve the prediction accuracy.
-
Simply averaging the prediction results of each model can only make its accuracy worse than the best and better than the worst, and cannot achieve the purpose of improving the prediction effect.
-
RBFNN has the smallest MSE when the ship features are not processed, but its MAPE is higher than 10%. After max absolute scaling the features, the average result of all models is used as the final prediction result although it can achieve the smallest MSE, but the MAPE still has 10.23%. Only after normalizing the features, the prediction accuracy of RF is comparable to that of the joint model, with an MSE of 1.14E−07 and a MAPE of 4.87%.
-
After standard scaling the input features, compared to all other models with all data processing methods,the joint method has the smallest MSE of 1.05E−07 and the largest \(R^{2}\) of 0.991832, and the lowest MAPE of 4.7%.
In all cases, the joint prediction model not only focuses on reducing the variance, but also significantly reduces the bias of the prediction. Figure 15 shows the prediction results on the Excessive Acceleration failure probability of the RF, which has the highest accuracy among the 8 models, with the joint prediction model on the test set. It can be seen that even with the constant tuning of the hyperparameters and adjustment of the processing of the ship features, the best performing model still has some prediction results that differ significantly from the expected values.

Calculated results of the three performance criteria for each model

Prediction results of the excessive acceleration failure probability by RF and joint model
Combining all the predictions results and the comparison of the errors, the joint multi-model ship stability prediction method proposed in this paper does not combine component learners blindly, but selects top k component learners with high confidence in the current prediction results for combining. Therefore, the method is not susceptible to the perturbation of the input ship features processing methods as other models. Moreover, the method does not care for this and lose that, i.e., the bias or variance will always be higher than the remaining model, but can minimize both the bias and the mean variance in a comprehensive way.
Conclusion
This paper uses eight machine learning models to predict two stability failure probabilities—Dead ship stability and Excessive acceleration—of fishing vessels as well as fishery administration vessels, and based on this, a joint multi-model stability prediction model based on confidence level is proposed. The method is inspired by the idea of co-training in semi-supervised learning and the idea of heterogeneous ensemble in Ensemble learning. By calculating the confidence of the model on the current prediction results, the component learners with high confidence are selected for combination and the low confidence learners are discarded.
The models studied include, artificial neural network models RBFNN and BPNN, Ensemble models Bagging-tree, RF and Extra-tree based on idea of Bagging, and Adaboost, GBDT and XGBoost based on idea of Boosting. The optimal hyperparameters of each model are obtained through grid search strategies. Ship features for input to the model are obtained by sensitivity analysis. And this paper also investigates the effect of different ship feature processing methods on different models. Compared the prediction results of each model on the test set, the following conclusions can be drawn:
-
Regardless of the prediction of the failure probability for either failure mode, the data processing of the ship characteristics can have a significant impact on RBFNN as well as BPNN. These two models are more suitable for prediction without any processing.
-
RF, GBDT and Bagging-Tree have higher accuracy than other Ensemble models when predict ship’s Dead ship stability failure probability. All of the Ensemble models have good accuracy in predicting the ship’s Excessive acceleration failure probability. And the Ensemble models are generally not affected by the data processing method of the input ship features.
-
Simply averaging the results of multiple component learners does not necessarily achieve the expected improvement in accuracy, but instead is sometimes very susceptible to poor quality learners, making MAPE higher.In particular, the MSE of the averaging method is only moderate when predicting the Dead ship stability failure probability, while the MAPE is higher than 10% regardless of the data processing strategy used.
-
The joint multi-model prediction method proposed in this paper has higher accuracy than the other models in predicting both stability failure modes. This method has the lowest mean square error, the highest R-squared and the second lowest MAPE after Bagging-Tree in predicting the ship’s Dead ship stability failure probability. And it can achieve the lowest MAPE while having the lowest mean square error and the highest R-squared in predicting the ship’s excessive acceleration failure probability.
The confidence-based joint multi-model ship stability prediction method can maintain small bias while having small mean square error. In future research, the computational efficiency can be improved by expanding the data set so that the cross-validation process for each confidence level calculation can be discarded. Consider trying more combinations of component learners to continue improving the accuracy of the model. Also, expanding the dataset while adding more scales as well as types of ships allows the method to have a larger range of applications. We may conduct a further research from another perspective by regarding the prediction of ship stability failure probability as a time-series problem. Based on this idea, we may use models such as recurrent neural network (RNN) and long–short term memory (LSTM) that are applicable to time-series problems[56], which may has the potential to improve the prediction accuracy.
Data availability
The data sets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
IMO SDC 8/INF.2 (2021) Physical background and mathematical models for stability failures of the second generation intact stability criteria
Witczak M, Pazera M (2019). In: Escobet T, Bregon A, Pulido B, Puig V (eds) Selected estimation strategies for fault diagnosis of nonlinear systems. Springer, Cham, pp 263–293. https://doi.org/10.1007/978-3-030-17728-7_11
Wang Z, Yang S, Xiang X, Vasilijevic A, Miskovc N, Nad D (2021) Cloud-based mission control of usv fleet: architecture, implementation and experiments. Control Eng Pract 106:104657
Ocampo-Martinez C, Puig V, Cembrano G, Quevedo J (2013) Application of predictive control strategies to the management of complex networks in the urban water cycle [applications of control]. IEEE Control Syst Mag 33(1):15–41
Li J, Xiang X, Yang S (2022) Robust adaptive neural network control for dynamic positioning of marine vessels with prescribed performance under model uncertainties and input saturation. Neurocomputing 484:1–12. https://doi.org/10.1016/j.neucom.2021.03.136
Simani S, Fantuzzi C (2000) Fault diagnosis in power plant using neural networks. Inf Sci 127(3):125–136 (Intelligent Manufacturing and Fault Diagnosis. (II). Soft computing approaches to fault diagnosis)
Formela K, Neumann T, Weintrit A (2019) Overview of definitions of maritime safety, safety at sea, navigational safety and safety in general. TransNav Int J Mar Navig Saf Sea Transp 13(2):285–290
Zhang H, Zhu D, Liu C, Hu Z (2022) Tracking fault-tolerant control based on model predictive control for human occupied vehicle in three-dimensional underwater workspace. Ocean Eng 249:110845. https://doi.org/10.1016/j.oceaneng.2022.110845
Zhang Q, Zhang J, Chemori A, Xiang X (2018) Virtual submerged floating operational system for robotic manipulation. Complexity 2018:9528313. https://doi.org/10.1155/2018/9528313
Prayogo D, Ndori A, Andromeda VF, Kurnianing Sari D, Hartoyo H, Sulistiyowati E (2022) Assessment of factors contributing to the risks of accident. TransNav Int J Mar Navig Saf Sea Transp 16(1):33–37
Xiang G, Xiang X (2021) 3d trajectory optimization of the slender body freely falling through water using cuckoo search algorithm. Ocean Eng 235:109354
Huang Z, Zhu D, Sun B (2016) A multi-auv cooperative hunting method in 3-d underwater environment with obstacle. Eng Appl Artif Intell 50:192–200. https://doi.org/10.1016/j.engappai.2016.01.036
Kim JH, Kim Y, Lu W (2020) Prediction of ice resistance for ice-going ships in level ice using artificial neural network technique. Ocean Eng 217:108031. https://doi.org/10.1016/j.oceaneng.2020.108031
Mittendorf M, Nielsen UD, Bingham HB (2022) Data-driven prediction of added-wave resistance on ships in oblique waves-a comparison between tree-based ensemble methods and artificial neural networks. Appl Ocean Res 118:102964. https://doi.org/10.1016/j.apor.2021.102964
Cepowski T (2020) The prediction of ship added resistance at the preliminary design stage by the use of an artificial neural network. Ocean Eng 195:106657. https://doi.org/10.1016/j.oceaneng.2019.106657
Yang Y, Tu H, Song L, Chen L, Xie D, Sun J (2021) Research on accurate prediction of the container ship resistance by rbfnn and other machine learning algorithms. J Mar Sci Eng 9:376. https://doi.org/10.3390/jmse9040376
Yuchao W, Fanming L, Huixuan F (2012) Ship rolling motion prediction based on wavelet neural network. Appl Mech Mater 190–191:724–728. https://doi.org/10.4028/www.scientific.net/AMM.190-191.724
Yin JC, Zou ZJ, Xu F (2013) On-line prediction of ship roll motion during maneuvering using sequential learning rbf neuralnetworks. Ocean Eng 61:139–147. https://doi.org/10.1016/j.oceaneng.2013.01.005
Khan A, Bil C, Marion KE (2005) Theory and application of artificial neural networks for the real time prediction of ship motion. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 3681 LNAI, 1064–1069. https://doi.org/10.1007/11552413_151
Silva KM, Maki KJ (2022) Data-driven system identification of 6-dof ship motion in waves with neural networks. Appl Ocean Res 125:103222
Chen X, Liu Y, Achuthan K, Zhang X (2020) A ship movement classification based on automatic identification system (ais) data using convolutional neural network. Ocean Eng 218:108182. https://doi.org/10.1016/j.oceaneng.2020.108182
He H-W, Wang Z-H, Zou Z-J, Liu Y (2022) Nonparametric modeling of ship maneuvering motion based on self-designed fully connected neural network. Ocean Eng 251:111113
Xu F, Zou ZJ, Yin JC (2012) On-line modeling of ship maneuvering motion based on support vector machines. Chuan Bo Li Xue/J Ship Mech 16:218–225
Moreira L, Vettor R, Soares CG (2021) Neural network approach for predicting ship speed and fuel consumption. J Mar Sci Eng 9:119. https://doi.org/10.3390/jmse9020119
Gkerekos C, Lazakis I, Theotokatos G (2019) Machine learning models for predicting ship main engine fuel oil consumption: a comparative study. Ocean Eng 188:106282. https://doi.org/10.1016/j.oceaneng.2019.106282
Kim YR, Jung M, Park JB (2021) Development of a fuel consumption prediction model based on machine learning using ship in-service data. J Mar Sci Eng 9:137. https://doi.org/10.3390/jmse9020137
Hu Z, Jin Y, Hu Q, Sen S, Zhou T, Osman MT (2019) Prediction of fuel consumption for enroute ship based on machine learning. IEEE Access 7:119497–119505. https://doi.org/10.1109/ACCESS.2019.2933630
Lazakis I, Raptodimos Y, Varelas T (2018) Predicting ship machinery system condition through analytical reliability tools and artificial neural networks. Ocean Eng 152:404–415. https://doi.org/10.1016/j.oceaneng.2017.11.017
Niu H, Ozanich E, Gerstoft P (2017) Ship localization in Santa Barbara channel using machine learning classifiers. J Acoustical Soc Am 142:455–460. https://doi.org/10.1121/1.5010064
Yang T, Liu Z (2022) Ship type recognition based on ship navigating trajectory and convolutional neural network. J Mar Sci Eng 10:84. https://doi.org/10.3390/jmse10010084
Alvarellos A, Figuero A, Carro H, Costas R, Sande J, Guerra A, Peña E, Rabuñal J (2021) Machine learning based moored ship movement prediction. J Mar Sci Eng 9:800. https://doi.org/10.3390/jmse9080800
Fan W, Yuan WC, Fan QW (2008) Calculation method of ship collision force on bridge using artificial neural network. J Zhejiang Univ Sci A 9:614–623. https://doi.org/10.1631/jzus.A071556
Cepowski T, Chorab P (2021) Determination of design formulas for container ships at the preliminary design stage using artificial neural network and multiple nonlinear regression. Ocean Eng 238:109727. https://doi.org/10.1016/j.oceaneng.2021.109727
Boccadamo G, Rosano G (2019) Excessive acceleration criterion: application to naval ships. J Mar Sci Eng 7:431. https://doi.org/10.3390/JMSE7120431
Kuroda T, Hara S, Houtani H, Ota D (2019) Direct stability assessment for excessive acceleration failure mode and validation by model test. Ocean Eng 187:106137. https://doi.org/10.1016/j.oceaneng.2019.106137
Ma K, Liu F, Li K (2015) Sample calculations and analysis on vulnerability criteria of dead ship stability. Ship Build China 56:106–112
Duan F, Ma N, Gu X, Zhou Y, Wang S (2022) A fast time domain method for predicting of motion and excessive acceleration of a shallow draft ship in beam waves. Ocean Eng 262:112096
Liu L, Feng D, Wang X, Zhang Z, Yu J, Chen M (2022) Study on extreme roll event with capsizing induced by pure loss of stability for the free-running onr tumblehome. Ocean Eng 257:111656
Peters WS, Belenky VI (2022) Second generation intact stability criteria: an overview. SNAME Maritime Convention, vol. Day 2 Wed, September 28, 2022. https://doi.org/10.5957/SMC-2022-049. D021S012R002
Gu M, Lu J, Bu S, Chu J, Zeng K, Wang T (2020) In: Cui W, Fu S, Hu Z (eds.) The second generation intact stability criteria, pp 1–10. Springer, Singapore. https://doi.org/10.1007/978-981-10-6963-5_346-1
IMO MSC.1/Cric.1627 (2020) Interim guidelines on the second generation intact stability criteria
Rumelhart DE, Hinton GE, Williams RJ (1986) Learning representations by back-propagating errors. Nature 323:533–536
Bugmann G (1998) Normalized gaussian radial basis function networks. Neurocomputing 20(1):97–110. https://doi.org/10.1016/S0925-2312(98)00027-7
Breiman L (1996) Bagging predictors. Mach Learn 24:123–140. https://doi.org/10.1023/A:1010933404324
Breiman L (2001) Random forests. Mach Learn 45:5–32. https://doi.org/10.1023/A:1010933404324
Geurts P, Ernst D, Wehenkel L (2006) Extremely randomized trees. Mach Learn 63(1):3–42
Freund Y, Schapire RE (1997) A decision-theoretic generalization of on-line learning and an application to boosting. J Comput Syst Sci 55(1):119–139. https://doi.org/10.1006/jcss.1997.1504
Friedman JH (2001) Greedy function approximation: a gradient boosting machine. Ann Stat 29:1189–1232
Chen T, Guestrin C (2016) Xgboost: A scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. KDD ’16, pp 785–794. Association for Computing Machinery, New York, NY, USA. https://doi.org/10.1145/2939672.2939785
Blum A, Mitchell T (1998) Combining labeled and unlabeled data with co-training. In: Proceedings of the Eleventh Annual Conference on Computational Learning Theory. COLT’ 98, pp 92–100. Association for Computing Machinery, New York, NY, USA. https://doi.org/10.1145/279943.279962
Zhou Z-H, Li M (2005) Semi-supervised regression with co-training. In: International joint conference on artificial intelligence
Zhou Z-H (2009) When semi-supervised learning meets ensemble learning. Front Electr Electron Eng China 6:6–16
Zhou X, Belkin M (2014) Chapter 22 - semi-supervised learning. In: Diniz PSR, Suykens JAK, Chellappa R, Theodoridis S (eds), Academic Press Library in Signal Processing: Volume 1. Academic Press Library in Signal Processing, vol. 1, pp 1239–1269. Elsevier, Amsterdam. https://doi.org/10.1016/B978-0-12-396502-8.00022-X. https://www.sciencedirect.com/science/article/pii/B978012396502800022X
Abdel Hady MF, Schwenker F, Palm G (2009) Semi-supervised learning for regression with co-training by committee. In: Alippi C, Polycarpou M, Panayiotou C, Ellinas G (eds) Artificial Neural Networks - ICANN 2009. Springer, Berlin, Heidelberg, pp 121–130
IMO SDC 6/INF.3 (2019) Information Collected by the Correspondence Group on Intact Stability
Xu W, An J, Xu Y, Huang C, Gan L, Yuen C (2022) Time-varying channel prediction for ris-assisted mu-miso networks via deep learning. IEEE Trans Cognit Commun Netw 8(4):1802–1815. https://doi.org/10.1109/TCCN.2022.3188153
Funding
This work was funded by National Natural Science Foundation of China (Grant 52071153); Hubei Provincial Natural Science Foundation for Innovation Groups (Grant 2021CFA026).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jiang, C., Xiang, X. & Xiang, G. A joint multi-model machine learning prediction approach based on confidence for ship stability. Complex Intell. Syst. 10, 3873–3890 (2024). https://doi.org/10.1007/s40747-024-01363-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-024-01363-w