
Abstract
Knowledge Graphs (KGs) have become an increasingly important part of artificial intelligence, and KGs have been widely used in artificial intelligence fields such as intelligent answering questions and personalized recommendation. Previous knowledge graph completion methods require a large number of samples for each relation. But in fact, in KGs, many relationships are long-tail relationships, and the existing researches on few-shot completion mainly focus on static knowledge graphs. In this paper, we consider few-shot completion in Temporal Knowledge Graphs (TKGs) where the event may only hold for a specific timestamp, and propose a model abbreviated as FTMO based on meta-optimization. In this model, we combine the time-based relational-aware heterogeneous neighbor encoder, the cyclic automatic aggregation network, and the matching network to complete the few-shot temporal knowledge graph. We compare our model with the baseline models, and the experimental results demostrate the performance advantages of our model.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Knowledge Graph (KG) is a new concept proposed by Google, which is used to construct multivariate relational data. In recent years, KGs have been widely used in the artificial intelligence field, such as intelligent answers [28, 43] and social network analysis [45]. However, because of the incompleteness of KGs, the performances of tasks related to knowledge graphs will be affected. Like many KGs, such as WordNet [26], Freebase [1], and Google Knowledge Graph [2], these KGs are static and have no temporal information. In previous studies, researchers have proposed many models, such as TransE [3] and its improved models, to complete KGs. Most of these models embed entities and relationships into low-dimensional space and achieve good performance.
In the past few years, knowledge data usually contain abundant temporal information. In this case, many researchers add timestamps to the traditional knowledge graph triples (s, r, o) as temporal knowledge graph (TKG), which is described as quadruples (s, r, o, t). ICEWS [4] and GDELT [21] are two famous temporal knowledge graphs but they are far from complete. The important task of a TKG is to complete quadruples without correct subject–object entity or relational information. For example, the form of an incomplete quadruple may be (?, r, o, t), (s, r,?, t) or (s, ?, o, t), and we need to infer “?” from the quad we already have. Although KG completion model has achieved remarkable results, it has little effect on TKGs completion model. In this case, the completion of TKGs still has a lot of research space, and it also faces great difficulties. With the development of research, researchers add temporal information processing to the model, such as TTransE [19] and TA-TransE [9]. In addition, some models based on recurrent neural networks have also emerged such as RE-Net [16].
In the previously proposed method, the researchers assumed that each relationship has a sufficient number of entities to train for better performance. However, in fact, in TKGs, a large number of relationships have few entity pairs, which is called the long-tail relationship. For example, for a “s the citizen of” relationship, there may be thousands of entities, but for a “is the president of” relationship, there may be only a few hundred entities. The number of entities corresponding to the two relationships varies greatly, so we should study this situation. The long-tail relationship cannot be ignored in the real world. In this case, several models with few shots, such as GMatching [44], MetaR [5] and FANN [34], were proposed successively. These models are developed for static knowledge graph with few samples, and cannot explain temporal knowledge graph. The encoders they use cannot embed the temporal relation between entities into the models, and the information sharing between fewer entities and the influence of heterogeneous neighborhoods is not considered. After adding temporal information, we propose a relational-aware heterogeneous neighborhood encoder based on temporal information inspired by FSRL [49]. In addition, the one-time learning environment cannot meet the training situation with few samples, so it is necessary to design a new model to realize the interaction between the reference set and temporal information. In addition, we find that the meta-optimizer can be combined with LSTM [12], and LSTM can solve the problem of gradient descent and gradient explosion in training. In addition, combining LSTM update and gradient descent can obtain the optimal parameters of the model better and faster, update the training model through a small number of gradients, realize fast learning of new tasks, and train another neural network classifier through an optimization algorithm in a small number of states.
In this paper, we combine several modules and propose a new model to complete the short shot TKG. The paper makes the following contributions:
-
We propose a few-shot completion model, which addresses few-shot completion in temporal knowledge graphs.
-
We use timestamp information to enhance the representation of task entities and entity pairs by constructing a time-based relationship-aware heterogeneous neighbor encoder.
-
We propose a cyclic automatic encoder aggregation network for TKG.
-
We conduct abundant experiments on two public datasets to demonstrate that FTMO outperforms existing state-of-the-art TKG embedding methods and few-shot completion methods.
The rest of the paper is organized as follows. In “Related work”, we describe related work. In “Our model”, we illustrate the relevant task definitions and the details of the proposed model. Experimental setups and comparative analysis of the experimental results are presented in “Experiments”. In “Conclusion”, we give a conclusion and possible directions for future improvement.
Related work
Static knowledge graph completion methods
There are two types of static knowledge graph completion models: translation models and others.
On one hand, the translation model transforms relationships and entities into vectors, and calculates the dissimilarity of vectors. Bordes et al. propose the famous TransE [3] model, which interprets the relation vector as the semantic translational operation of the entity vector in the vector space. If s + r ≈ o is true, the completion result is correct. However, it only focuses on 1–1 relationship, and is not a good fit for 1–N, N–1 and N–N relationships. To this end, several improved models are taken into account such as TransH [42], TransR [23], and TransD [14], etc. TransH translates subject vector to the front of the object vector by relation and projects the subject vector and object vector onto a plane associated with the current relation. TransR uses the mapping matrix corresponding to the relation to transform entities into different relation semantic spaces to obtain different semantic representations. TransD uses entity-related vectors and relation-related vectors to dynamically obtain the projection matrix of the relation through cross-product computation. On the other hand, one of the most important other models is semantic model, which mainly calculates a similarity score through the latent semantics between entity vector and relation vector, and ranks the completion results according to the calculated similarity score. DistMult [46] proposes a framework, considering entities and relations as low-dimensional vectors and bilinear and/or linear mapping functions. ANALOGY [24] proposes a framework for optimizing the latent representations in the case of the analogical properties of the embedded entities and relations. RESCAL [30] adopts a relation weight matrix to interact the latent features of entities, but its function is too simple, which causes it cannot get efficient vector representations. To have better representations, NTN [36] and HolE [29] are proposed to obtain a better vector representations for improvements. On the other hand, MMKRL [25] can utilize multi-modal knowledge effectively to achieve better link prediction and triple classification by summing different plausibility functions and using specific norm constraints. Wang et al. [41] propose the modeling of complex internal logic by integrating the fusion semantic information, which can make the model converge faster. Huang et al. [13] propose local information fusion to join entities and their adjacencies to obtain multi-relational representations. However, these models cannot be applied to temporal knowledge graph directly.
Temporal knowledge graph completion methods
With the growth of the amount of data information, temporal information has been widely considered. In recent years, temporal stamps have been embedded into low-dimensional space, and three elements (s, r, o) have been extended to four elements (s, r, o, t) to complete TKG. Inspired by TransH [42], Dasgupta et al. propose HyTE [15] model which explicitly combines temporal information in the entity-relationship space by associating each temporal stamp with the corresponding hyperplane. TTransE [19] upgrades TransE by improving the scoring function and learns the temporal representations from the temporal text by a recurrent neural network, so TTransE can complete the temporal knowledge graph and obtain great achievements. García-Durán et al. propose TA-TransE [9] and TA-DistMult [9] adding temporal embeddings into its score function to use temporal information to complete the graph. However, in these models, all static temporal information ignores the relevance of the related quad. In addition, the time dependency also needs to be considered. To make good use of the time dependency, Trivedi et al. present Know-Evolve [38], which is an in-depth assessment of the knowledge semantic network structure. RE-Net [16] chooses to aggregate the neighborhoods of entities and applies the recurrent neural network for time dependence. Chrono-Transation [33] deals with temporal information using rule mining and graph embedding operations. However, these models usually assume that enough training quads are provided for all relationships, and the long tail relationship is not considered, which leads to poor performances in the environment with few samples.
Few-shot knowledge graph completion methods
To obtain good performance, a large amount of data is often used to train the model. But in a real knowledge graph, there are relationships with few entities. Meta-learning methods include metrics-based, model-based and optimization-based methods, aiming at fast learning with a small number of samples.
Because long-tail relations are common in KGs, GMatching [44] learns a matching metric by the learned embeddings and one-hop graph structures and proposes a one-shot relational learning model. By observing a few associative triples. However, GMatching assumes that all local neighbors contribute equally to entity embedding, while heterogeneous neighbors may have different influences. It ignores that the interaction between a few reference instances limits the representation ability of reference sets. MetaR [5] studies few-shot link prediction in KGs. It enables the model to learn faster by considering transferring relation-specific meta information. Xiong et al. [44] propose a metric-based approach to link prediction of long-tail relationships with fewer samples. However, the performance of MetaR is affected by the sparsity of entities and the number of tasks, which affects the performances. FSRL [49] can infer the true entity pairs effectively given the set of few-shot reference entity pairs for every relation, which aims at discovering facts of new relations with few-shot references. FSRL does not consider the importance of timestamp information for the completion of temporal knowledge graph. REFORM [40] studies the problem of error-aware few-shot KG completion to accumulate meta-knowledge across different meta-tasks, and propose neighbor encoder module, cross-relation aggregation module, and error mitigation module in each meta-task. MTransH [31] proposes a few-shot relational learning model with the global stage and the local stage. FAAN [34] proposes an adaptive attentional network for few-shot KG completion, which is predictive for knowledge acquisition. However, these methods are mainly aimed at static knowledge graph, and cannot make good use of the timestamp information in temporal knowledge graph.
Our model
In this section, we design a model called FTMO to complete the missing object entities in the dataset of the few-shot temporal knowledge graph, shown in Fig. 1. FTMO mainly includes the following aspects: entity embedding is generated by a time-based heterogeneous neighbor encoder; a small number of reference entity pairs are aggregated by a time-based cyclic automatic encoder to generate reference set embedding; the similarity score between query pair and reference set is calculated by the matching network, and the candidate entities are sorted to obtain the highest ranked entity. Throughout the paper, the main notations are summarized in Table 1.

The framework of FTMO model
Few-shot completion task
The representation of TKG can be represented as (s, r, o, t), where s and o represent entities, r represents relationships, and t represents timestamps. The TKG tasks mainly include three types: (1) given the subject entity s, the relationship r and the timestamp t to predict the object entity o: (s, r, ?, t); (2) given the relationship r, the object entity o, and the timestamp t to predict the subject entity s: (?, r, o, t); (3) given the subject entity s, the object entity o, and the timestamp t to predict the relationship r: (s, ?, o, t). In this study, the first case is taken into consideration because we want to complete the determination of the missing object entity in the relationship.
Definition 1
Few-shot TKG completion. Given a few-shot TKG, assuming that the relation r and its few-shot reference entity pairs are known, few-shot TKG task is defined as designing a machine learning model. The object candidate entities of each new subject entity s are sorted according to the known content, so that the similarity score of the real object entities of the subject entity s is the highest.
Training task
Our goal is to design a machine learning model to predict the missing object entities in a few-shot TKG. There are two types of training models with few shots. (1) The first is a metric-based method [18, 27, 35, 39], which can learn effective metrics and the corresponding matching functions in a set of training examples. (2) The second method is based on meta-optimization [7, 8, 20, 22, 32, 47]. Its purpose is to quickly optimize model parameters and give gradients on a small number of shot data instances. Here, we use meta-optimization [32] and add LSTM [12] on this basis, which can learn the precise optimization algorithm in a small number of shot states. The task of few-shot knowledge graph completion is described as follows:
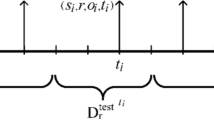
Given a training task, each relationship r ∈ R in the temporal knowledge graph should have a corresponding training dataset called \({D}_{r}^{\mathrm{train}}\), which contains only few-shot entity pairs about the relation r and a testing dataset called \({D}_{r}^{\mathrm{test}}\) contains all entity pairs about the relation r. Therefore, given the test queries (si, r, ti) and a small number of reference pairs in the \({D}_{r}^{\mathrm{train}}\) training, we can sort all the candidate entities and test our model on this basis. In summary, the loss function of r can be defined as \({\mathcal{L}}_{\ominus }\left({s}_{i},{o}_{i},{t}_{i}|{Q}_{{s}_{i},r,{t}_{i}},{D}_{r}^{\mathrm{train}}\right)\), where \(\ominus \) is a collection of all the parameters, and \({Q}_{{s}_{i},r,{t}_{i}}\) represents the remaining candidate entities set.
The process of meta-optimizer is as follows: first, the parameters of meta-learning are initialized, and then n-dimensional learning tasks are cycled. Each task samples \({D}_{r}^{\mathrm{meta-train}}\) and \({D}_{r}^{\mathrm{meta-test}}\) from \({D}_{r}^{\mathrm{train}}\) data set, that is, support set and reference set. For each meta-learning task, T quadruples are extracted from \({D}_{r}^{\mathrm{meta-train}}\) as reference set, one batch is extracted as query set, and then another query set is obtained by processing its query set, and its matching score is calculated, respectively. After calculating its loss function, LSTM network is used for gradient calculation, and meta-learning parameters are updated. After doing the same for \({D}_{r}^{\mathrm{meta-test}}\), update the related parameters of meta-train.
Meta-testing refers to the fact that after sufficient data training, the learning model can be learned spontaneously, and then it can be used to predict the fact that every relationship r ∈ R in TKG. It should be noted that in the self-learning process of a meta-learning model, every relationship is invisible to the outside world. In addition, in the same pattern as mentioned earlier, every relation \({r}^{{\prime}}\) in meta-testing should also have a few-shot training data \({P}_{{r}^{{\prime}}}^{\mathrm{train}}\) that contains only few-shot entity pairs about the relation \({r}^{{\prime}}\) and a few-shot testing data \({P}_{{r}^{{\prime}}}^{\mathrm{test}}\) that contains all entity pairs about the relation \({r}^{{\prime}}\). The objective of model training can be defined as Eq. (1) as follows:
Note that the meta-optimization is performed over the model parameters \(\ominus \), whereas the objective is computed using the updated model parameters \(\ominus \).where \(|{D}_{r}^{\mathrm{test}}|\) is the number of quad (s, r, o, t) in \({D}_{r}^{\mathrm{test}}\). Details on how to calculate each function section and how to modify and optimize the functionality are discussed in subsequent sections.
Time-based relational aware encoding heterogeneous neighbors
In this section, we propose a time-based relationship-aware heterogeneous neighbor encoder. The local coding structure of explicit graphs performs well in relation prediction [37]. In the previous neighborhood encoders, the average of the encoded features between neighbors is used to embed a given entity. Although embedding with the feature vector average can achieve good performance, this method ignores the different influences that heterogeneous neighbors may bring when calculating feature vectors, and this influence will produce differences in the final results [48]. Because of the existence of temporal elements, we design a relational aware heterogeneous neighbor encoder based on time combined with previous work.
Different from FSRL [49], in this process, we upgrade the matrix from three dimensional to four dimensional. In the neighbor coding process, our model first calculates the temporal information and relationship information once and then calculates the temporal information and entity information in a unified and joint way in the subsequent operation. Given a header entity s, the set of time-based relationship neighbors (relationship, entity, time) can be represented as \({\mathcal{N}}_{h}=\left\{\left({r}_{i},{o}_{i},{t}_{i}\right)|\left({s,r}_{i},{o}_{i},{t}_{i}\right)\in G^{\prime}\right\}\), where \(G^{\prime}\) is the background TKG, and \({r}_{i}\), \({o}_{i}\), and \({t}_{i}\) are the \(i\)-th relation, the corresponding object entity, and the current time point \(s\). Therefore, the time-based heterogeneous neighbor encoder can comprehensively consider the different influences of isomorphic and heterogeneous neighbors \(\left({r}_{i},{o}_{i},{t}_{i}\right)\in {\mathcal{N}}_{h}\), and combine entity and temporal information to calculate the feature vector representation of specific entities. On the basis of this, it can encode \({\mathcal{N}}_{h}\) and output a feature representation of \(s\) well. The attention module and formula for embedding \(s\) are defined as follows:
where \(\sigma \) denotes the activation unit, \(\oplus \) represents the concatenation operator, \({e}_{{r}_{i}}\), \({e}_{{o}_{i}}\), and \({e}_{{t}_{i}}\)∈\({\mathbb{R}}\)(d×d×1) are pretrained embeddings of \({r}_{i}\), \({o}_{i}\) and \({t}_{i}\), and \({e}_{{l}_{i}}\) represents the variable of the \({e}_{{r}_{i}}\) and \({e}_{{t}_{i}}\) join operations. In addition, \({\mu }_{ro}\)∈\({\mathbb{R}}\)(d×d×1), \({W}_{\text{ro}}\)∈\({\mathbb{R}}\)(d×d×2d) and \({b}_{rt}\)∈\({\mathbb{R}}\)(d×d×1) (d: pretrained embedding dimension) are learnable parameters.
By leveraging the embeddings of entity \({o}_{i}\), relation \({r}_{i}\) and temporal stamp \({t}_{i}\) to compute \({\alpha }_{i}\) and obtain good use of the attention weight\({\alpha }_{i}\), the formulation of \({f}_{\theta }(s)\) can consider the different impacts of heterogeneous relational neighbors well. The specific details of the time-based relational aware heterogeneous neighbor encoder are shown in Fig. 2. First, the relationship information and temporal information of the quadruple related to the same subject entity are embedded, then the new variable is embedded with the object entity and temporal stamp, and then the weight factor is calculated with the intermediate quantity. Finally, the characteristic representation of the main entity is calculated.

Time-based relation-aware heterogeneous neighbor encoder
Aggregation network of cyclic automatic encoders
In this section, we design an aggregator network consisting of recurrent autoencoder aggregators. \(\left({s}_{k},{o}_{k},{t}_{k}\right)\) can be represented as \({\upepsilon }_{{s}_{k},{o}_{k},{t}_{k}}=\left[{f}_{\theta }\left({s}_{k}\right){\oplus f}_{\theta }\left({o}_{k}\right)\oplus {f}_{\theta }({t}_{k})\right]\) by applying the time-based neighbor encoder \({f}_{\theta }(s)\) to each entity pair \(\left({s}_{k},{o}_{k},{t}_{k}\right)\in {R}_{r}\). The embedding of Rr can be represented as follows [6, 35]:
where \(\mathcal{A}\mathcal{G}\) is an aggregate function for pooling operation and feedforward neural network.
To apply current neural network aggregators in graph embedding [10], we study a cyclic automatic encoder aggregator between a few samples. Specifically, the entity pair embeddings \({\upepsilon }_{{s}_{k},{o}_{k},{t}_{k}}\in {R}_{r}\) are fed into a recurrent autoencoder sequentially by Eq. (7):
where k is the size of the reference set.
In Eq. (7), \({n}_{k}\) denotes encoding and \({d}_{k-1}\) denotes decoding, which are both hidden states of the decoder. \({n}_{k}\) and \({d}_{k-1}\) are calculated as Eqs. (8) and (9):
where RNNencoder represents the recurrent encoder and RNNdecoder describes the decoder.
The reconstruction loss for optimizing the autoencoder can be measured as Eq. (10):
The role of \({\mathcal{L}}_{\text{re}}\) is to merge with relationship-level losses to optimize the representation for each entity pair, thereby improving the model performance.
To embed the reference set, the hidden states of the encoder, residual links [11], and attention weights are aggregated and defined as follows:
where \({\mu }_{R}\in {\mathbb{R}}^{\left(d\times d\times 1\right)}\), \({\mathcal{W}}_{R}\in {\mathbb{R}}^{\left(d\times d\times 2d\right)}\), and \({b}_{R}\in {\mathbb{R}}^{\left(d\times d\times 1\right)}\) (d: pretrained embedding dimension).
Compared with FSRL, our model not only improves temporal information processing and the matrix dimension, but also uses a smaller gradient in combination with LSTM, which makes the result better. The cyclic automatic aggregation network for reference set contains encoder part and decoder part, as shown in Fig. 3. The encoder combines the LSTM aggregation of a small number of reference sets and feature representation vectors of entities to generate relations with small sample embeddings. The decoder aggregates the LSTM and aggregates a small number of reference sets and intermediate amounts of feature representation vectors of entities to compute the loss function.

The cyclic automatic aggregation network for reference set
Matching query and reference set
For matching \({R}_{r}\) with each \(\left({s}_{l},{o}_{l},{t}_{l}\right)\) in r, temporal information is considered in the process of the matching network. According to the previous efforts, there are two types of embedding vectors, which are \({\upepsilon }_{{s}_{l},{o}_{l},{t}_{l}}=\left[{f}_{\theta }({s}_{l}){\oplus f}_{\theta }({o}_{l})\oplus {f}_{\theta }({t}_{l})\right]\) and \({f}_{\epsilon }\left({R}_{r}\right)\). For the recurrent processor, we adopt \({f}_{\mu }\) [11] for multiple step matchings to measure the similarity between these two vectors. The \(t\)-th process step can be represented as follows:
where RNNmatch is the LSTM cell [12], including the hidden state \({g}_{t}\) and the cell state \({c}_{t}\).
The inner product results between \({\upepsilon }_{{s}_{l},{o}_{l},{t}_{l}}\) and \({f}_{\epsilon }({R}_{r})\) are employed as the similarity score. The matching network for query pair and reference set is shown in Fig. 4.

The matching network for query pair and reference set
The query set and LSTM are combined for embedding, then the reference set and LSTM are combined for calculation, and finally the similarity score is obtained. First, the query set and LSTM are combined for embedding. Second, the reference set and LSTM are combined for calculation. Finally, the similarity score can be obtained.
Target mode training
To test the performance of the model in obtaining a reference set Rr for the query relation r, we select randomly a set of few positive (true) entity pairs \(\left\{\left({s}_{k},{o}_{k},{t}_{k}\right)|\left({s}_{k},r,{o}_{k},{t}_{k}\right)\in G\right\}\). After that, the remaining positive (true) entity pairs can be represented as \({\mathcal{P}\upepsilon }_{r}=\left\{\left({s}_{l},{o}_{l},{t}_{l}\right)|\left({s}_{l},r,{o}_{l},{t}_{l}\right)\in G \bigcap \left({s}_{l},{o}_{l},{t}_{l}\right)\notin {R}_{r}\right\}\), where \({\mathcal{P}\upepsilon }_{r}\) is the positive entity pairs. On the other hand, the negative (false) entity pairs \({\mathcal{N}\upepsilon }_{r}=\left\{\left({s}_{l},{o}_{l}^{-},{t}_{l}\right)|\left({s}_{l},r,{o}_{l}^{-},{t}_{l}\right)\notin G\right\}\) are created by polluting the tail entities. The ranking loss can be computed by Eq. (16):
where \({\left[x\right]}_{+}=\mathrm{max}\left[0,x\right]\) is the standard hinge loss, \(\xi \) is the safety margin distance in the model, and \({\mathcal{S}}_{\left({s}_{l},{o}_{l}^{-},{t}_{l}\right)}\) and \({\mathcal{S}}_{\left({s}_{l},{o}_{l},{t}_{l}\right)}\) are the similarity scores between query pairs \(\left({s}_{l},{o}_{l}/{o}_{l}^{-},{t}_{l}\right)\) and reference set Rr.
The final objective function can be formulated as Eq. (17):
where \(\gamma \) is the trade-off factor between \({\mathcal{L}}_{\mathrm{rank}}\) and \({\mathcal{L}}_{\mathrm{re}}\). \(\gamma \) is a hyperparameter because the final joint loss function cannot be computed directly using the sum of the two partial loss functions. In the experiments, we make the loss function of the two parts an order of magnitude by observing the loss function of the two parts and then finally determine the value of \(\gamma \).
To minimize \({\mathcal{L}}_{\mathrm{joint}}\) and optimize the parameters, we deal with each relation as one task and design a batch sampling on the basis of the meta-training. In each training task, few-shot entity pairs and a set of query sets are firstly selected and extracted. Then, a set of negative entity pairs is created by polluting object entities. The feature representation of subject entities, the reconstruction loss for optimizing autoencoder, the challenge and embedding formulation, the ranking loss and the loss function are successively calculated according to the formula proposed in this paper. The optimizer parameters are updated until the task is finished. Finally, an optimal parameter can be returned.
Experiments
Experiment setup
Datasets preprocessing
In the previous knowledge graph completion model, every relation in the existing dataset contained a large number of entity pairs, so it could ensure training accuracy. However, in the real world, there are many relations with a small number of entities. Therefore, to study this kind of relationship called long-tail relationship, each relation should have a small number of entity pairs in a small number of datasets. Therefore, based on the less beat standard [18, 35] and inspired by GMatching [44], we adjust the number of entities in each relationship based on the existing dataset and control the number in a lower range. For example, in a normal TKG dataset, the relationship “is the president of” may have approximately 10,000 entity pairs, but in a few-shot dataset, it may only have 50–500 entity pairs. To test the performance of our model, we should adjust the existing TKG dataset accordingly. Therefore, we keep the number of entities per relationship in the dataset within this range and reduce the number of relationships to less than 100. Details of specific dataset processing are described as follows:
In the experiments, ICEWS [4] and GDELT [21] are used for evaluations. The number of entities for one relation maintains between 50 and 500, and the number of relations is controlled under 100. We divide the dataset into the training set, test set and verification set with a ratio of 70: 15: 7. The statistics of ICEWS and GDELT are listed in Table 2.
Baselines
We perform two kinds of baseline models for comparisons. One kind is the vector representation and relational embedding models such as TransE [3], DistMult [46], TTransE [19], TA-TransE [9] and TA-DistMult [9]. The other kind is neighborhood coding models such as RE-Net [16], GMatching [44], MetaR [5] and FSRL [49].
Parameter settings
For GMatching, MetaR, FSRL, and FTMO, the optimal hyper-parameters are listed in Table 3, where n is the embedding dimension, λ is the learning rate, x is the maximum size of ICEWS and GDELT, h is the hidden dimension, q is the maximum local neighborhood number of the heterogeneous neighborhood encoder species, p is the number of steps, a is the weight attenuation, m is the edge distance, and f is the transaction factor. For the other baselines, the optimal hyper-parameters are listed in Table 4, where n is the latitude of vector embedding, B is the batch size of training data, v is the discard probability. Adam optimizer [17] is selected in the process of updating parameters.
Evaluation index
We use the hit ratio (Hits@1, Hits@5, and Hits@10) and the mean reciprocal rank (MRR) to evaluate the performances.
Experimental results
Comparisons with baselines
In this group of experiments, performance comparisons with baselines on ICEWS-Few and GDELT-Few are presented in Table 5, where the pre/post scores describe experimental results from the validation/test set. In Table 5, the best experimental results are shown in bold, and the best experimental results of the comparative baselines are underlined.
From Table 5, we can make the following conclusions.
-
(1)
In two different comparison models, we can clearly see that the results of the model using graph neighborhood coding are better than those of the relational embedding method, which shows that neighborhood coding can better deal with heterogeneous relational entities, and the method combined with the matching network can better represent and embed entities, thus enhancing the performance of entity completion.
-
(2)
Our model achieves the best performance in all the evaluation parameters, which proves the effectiveness of our model, indicating that preprocessing relational and temporal attributes and the combined use of heterogeneous neighborhood encoder and cyclic autoencoder aggregation network can complete the work of few-shot entities well.
Comparisons over different relations
In this group of experiments, we perform comparative experiments over different relations to evaluate the validity and stability. The comparisons are performed between FSRL and FTMO over ICEWS-Few and GDELT-Few. The experimental results are shown in Tables 6 and 7, where the pre/post scores represent the experimental scores of FSRL and FTMO, respectively.
From Tables 6 and 7, we can make the following conclusions.
-
(1)
From the results, we can see that the variance values of the two models we used are higher in different relationships. This is because in the evaluation process, the size of candidate sets is different for different relationships, so it is normal to have a large variance. As seen in the table, relationships with smaller candidate sets score relatively higher.
-
(2)
It can be observed that our model has strong robustness for different relationships, which shows that our model has strong stability and can handle abnormal situations. The results show that in most cases, our model performs better for most relationships.
Ablation experiments
In this group of experiments, we perform ablation experiments to evaluate the impact of each module in FTMO from three viewpoints: without the time-based relational-aware heterogeneous neighbor encoder (W1), without the cyclic autoencoder (W2), and without the matching network (W3). We replace the relationship-aware heterogeneous neighbor encoder with an embedded average pool layer covering all neighbors in W1. In W2, the cyclic automatic encoder aggregator network is replaced by an average pool operation. In W3, LSTM is canceled and the inner product between the query embedding and reference embedding is used as the similarity score. The evaluations are performed over ICEWS-Few and GDELT-Few. The experimental results are shown in Tables 8 and 9, where the pre/post scores indicate the experimental results from the validation/test set. Different experimental results can be observed from Tables 8 and 9, and the performance differences indicate their impact of different modules in FTMO.
Stability
Impact of few-shot size. The main task of this paper is to investigate TKG completion with small samples, so we study the influence of the size of K. The few-shot size describes the size of K, and K is the size of the hit ratio (Hits@). We conduct experiments on FTMO, FSRL, and GMatching. The evaluations are performed over ICEWS-Few and GDELT-Few, and the experimental results are shown in Figs. 5 and 6. It can be observed that the completion performance of FTMO, FSRL, and GMatching improve with the increase of K value, and the performance of FTMO is always higher than that of FSRL and GMatching. It shows that FTMO has better stability and robustness when completing few-shot TKG, and is more suitable for completing few-shot TKG.

Impact of few-shot size K in dataset ICEWS-Few

Impact of few-shot size K in dataset GDELT-Few
Computational complexity analysis
The time cost of FTMO mainly comes from neighbor encoder, aggregation and matching modules. The computational complexity of neighbor coding is expressed as O(|R||Ε|d), where |R| is the maximum number of neighbor relationships of task relationship r, |Ε| is the number of neighbor entities of task entities involved in the training process, and d is the embedded representation dimension in the experiments. For the aggregation of FTMO, the time cost of updating the entity representation is O(|E|Ld), where L is the number of aggregation layers, d is the embedding dimension. The computational complexity of the matching processor is O(|R|(|E| +|T|), where the embedding representation of the input entity pair is O(|R||Ε|) and |T| is the number of neighbor timestamps of task entities involved in the training process. The computational complexity of timestamp information between entities is O(|R||T|). The initial representation complexity of entity, relationship and timestamp information in the dataset is O(|\(g\)|d), where |\(g\)| is the number of tuples in the training set in the temporal knowledge graph. Because there are N iterations in the training process, the total computational complexity of the model is O(N(|R||E|d +|E|Ld +|R|(|E| +|T|) +|\(g\)|d)). By analyzing the computational complexity of the model in the training process, we found that compared with the baseline, we increase the processing of time information, which leads to an increase in computational complexity. When the number of neighbors facing the task relationship increases, the time complexity is further improved, that is, it takes a lot of time to train large-scale datasets, so the computational efficiency of the model will become lower for training large-scale datasets.
Defects analysis
Our model combines a time-based relational-aware heterogeneous neighbor encoder, cyclic automatic encoder aggregation network, and matching network to complete few-shot TKG. Although FTMO has better stability and is more suitable for completing few-shot TKG, there are several limitations:
-
(1)
Datasets limitations: Although the model achieves good performance on two datasets, our model is suitable for specific temporal datasets with few samples. When applied to other datasets, the dataset needs to be processed into a few-shot temporal dataset with only a few relationships and a few entity pairs.
-
(2)
Method limitation: In the process of time-based relational-aware neighborhood coding, the completeness of temporal knowledge graph is improved by processing relational information and temporal information first. Because the data in the dataset do not necessarily contain temporal information, the embedding ability of entities and relationships is unknown for the data without temporal information, which may have an uncertain impact on the final results.
Conclusion
In this paper, we first extracted few-shot datasets from two common datasets according to the rule of few-shot samples and proposed an innovative small relational model to solve the problem of few-shot TKG completion. The proposed model combines the time-based relational-aware heterogeneous neighbor encoder, cyclic automatic encoder aggregator network and matching network, and obtains good results through experiments. We performed experiments on two few-shot datasets, and the results are superior to those of the existing baseline methods. The completion ability of our model significantly improved in comparative experiments, up to 12% in ICEWS-Few dataset and up to 18% in GDELT-Few dataset. In addition, we also conducted ablation experiments and K-size analysis experiments, and the results show the effectiveness of each module for model performance and the stability of our model for entity completion.
Due to the complex structure of the neural network of FTMO model and the consideration of timestamp information, the tensor in FTMO is higher than that in baselines, which leads to the increase of computational complexity. Although the high tensor increases the complexity, it also makes the effect of entity embedding and aggregation of entity pairs in FTMO model higher than that in baselines, so that the performances of FTMO model with few-shot completion is higher than that of the baselines. In the future, we will consider these issues and make optimizations. In addition, there are other studies on few-shot TKG completion in the future. For example, we can combine entity attributes or text descriptions to improve entity embedding quality, or we can consider the relationship between different timestamps of the same triple when processing temporal information. These improvements may further improve the model performances.
Data availability
The data sets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Bollacker K, Evans C, Paritosh P et al (2008) Freebase: a collaboratively created graph database for structuring human knowledge. In: Proceedings of SIGMOD, 1247–1250
Bordes A, Glorot X, Weston J, Bengio Y (2014) A semantic matching energy function for learning with multi-relational data. Mach Learn 94(2):233–259
Bordes A, Usunier N, Garcia-Duran A et al (2013) Translating embeddings for modeling multi-relational data. In: Proceedings of Neural information processing systems, 2787–2795
Boschee E, Lautenschläger J, O’Brien S et al (2015) Ward MD ICEWS coded event data. Harvard Dataverse 12
Chen M, Zhang W, Zhang W et al (2019) Meta relational learning for few-shot link prediction in knowledge graphs. In: Proceedings of empirical methods in natural language processing & international joint conference on natural language processing, 4216–4225
Conneau A, Kiela D, Schwenk H et al (2017) Supervised learning of universal sentence representations from natural language inference data. In: Proceedings of empirical methods in natural language processing, 670–680
Finn C, Abbeel P, Levine S (2017) Model-agnostic meta-learning for fast adaptation of deep networks. In: Proceedings of international conference on machine learning,1126–1135
Finn C, Xu K, Levine S (2018) Probabilistic model-agnostic meta-learning. In: Proceedings of neural information processing systems, 9537–9548
García-Durán A, Dumančić S, Niepert M (2018) Learning sequence encoders for temporal knowledge graph completion. In: Proceedings of empirical methods in natural language processing, 4816–4821
Hamilton W, Ying Z, Leskovec J (2017) Inductive representation learning on large graphs. In: Proceedings of the 31st International Conference on Neural Information Processing Systems, 1025–1035
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
Huang J, Lu T, Zhu J et al (2022) Multi-relational knowledge graph completion method with local information fusion. Appl Intell 52(7):7985–7994
Ji G, He S, Xu L et al (2015) Knowledge graph embedding via dynamic mapping matrix. In: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 687–696
Jiang T, Liu T, Ge T et al (2016) Encoding temporal information for time-aware link prediction. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 2350–2354
Jin W, Zhang C, Szekely P, Ren X (2019) Recurrent event network for reasoning over temporal knowledge graphs. CoRR, vol. http://arxiv.org/1904.05530
Kingma D, Ba J (2015) Adam: a method for stochastic optimization. In: Proceedings of the international conference on learning representations (ICLR)
Koch G, Zemel R, Salakhutdinov R (2015) Siamese neural networks for one-shot image recognition. In: Proceedings of international conference on machine learning deep learning workshop
Leblay J, Chekol MW (2018) Deriving validity time in knowledge graph. In: Proceedings of the web conference, 1771–1776
Lee Y, Choi S (2018) Gradient-based meta-learning with learned layerwise metric and subspace. In: Proceedings of international conference on machine learning. PMLR, 2927–2936
Leetaru K, Schrodt PA (2013) GDELT: global data on events, location, and tone. In: Proceedings of ISA annual convention, 1–49
Li Z, Zhou F, Chen F et al (2017) Meta-SGD: learning to learn quickly for few shot learning. CoRR. http://arxiv.org/1707.09835
Lin Y, Liu Z, Sun M et al (2015) Learning entity and relation embeddings for knowledge graph completion. In: Proceedings of Twenty-ninth AAAI conference on artificial intelligence, 2181–2187
Liu H, Wu Y, Yang Y (2017) Analogical inference for multi-relational embeddings. In: Proceedings of international conference on machine learning, 2168–2178
Lu X, Wang L, Jiang Z et al (2022) MMKRL: a robust embedding approach for multi-modal knowledge graph representation learning. Appl Intell 52(7):7480–7497
Miller GA (1995) WordNet: a lexical database for English. Commun ACM 38(11):39–41
Mishra N, Rohaninejad M, Chen X et al (2018) A simple neural attentive meta-learner. In: Proceedings of international conference on learning representations (poster), 845–861
Nguyen GH, Lee JB, Rossi RA et al (2018) Continuous-time dynamic network embeddings. In Proceedings of the web conference, 969–976
Nickel M, Rosasco L, Poggio T (2016) Holographic embeddings of knowledge graphs. In: Proceedings of 30th AAAI Conference on Artificial Intelligence, 1955–1961
Nickel M, Tresp V, Kriegel HP (2011) A three-way model for collective learning on multi-relational data. In: Proceedings of international conference on machine learning, 809–816
Niu G, Li Y, Tang C et al (2021) Relational learning with gated and attentive neighbor aggregator for few-shot knowledge graph completion. In: Proceedings of ACM special interest group on information retrieval, 213–222
Ravi S, Larochelle H (2017) Optimization as a model for few-shot learning. In: Proceedings of international conference on learning representations
Sadeghian A, Rodriguez M, Wang DZ et al (2016) Temporal reasoning over event knowledge graphs. In: Proceedings of workshop on knowledge base construction, reasoning and mining, 6669–6683
Sheng J, Guo S, Chen Z et al (2020) Adaptive attentional network for few-shot knowledge graph completion. In: Proceedings of empirical methods in natural language processing, 1681–1691
Snell J, Swersky K, Zemel RS (2017) Prototypical networks for few-shot learning. In: Proceedings of neural information processing systems, 4077–4087
Socher R, Chen D, Manning CD et al (2013) Reasoning with neural tensor networks for knowledge base completion. In: Proceedings of advances in neural information processing systems, 926–934
Sung F, Yang Y, Zhang L et al (2018) Learning to compare: relation network for few-shot learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 1199–1208
Trivedi R, Dai H, Wang Y et al (2017) Know-evolve: deep temporal reasoning for dynamic knowledge graphs. In: Proceedings of International conference on machine learning, 3462–3471
Vinyals O, Blundell C, Lillicrap T et al (2016) Matching networks for one shot learning. In: Proceedings of Neural information processing systems, 3630–3638
Wang S, Huang X, Chen C et al (2021) REFORM: error-aware few-shot knowledge graph completion. In: Proceedings of the 30th ACM International Conference on Information & Knowledge Management, 1979–1988
Wang H, Jiang S, Yu Z (2020) Modeling of complex internal logic for knowledge base completion. Appl Intell 50(10):3336–3349
Wang Z, Zhang J, Feng J et al (2014) Knowledge graph embedding by translating on hyperplanes. In: Proceedings of the AAAI Conference on Artificial Intelligence, 1112–1119
Xiong C, Merity S, Socher R (2016) Dynamic memory networks for visual and textual question answering. In: Proceedings of international conference on machine learning. PMLR, 2397–2406
Xiong W, Yu M, Chang S et al (2018) One-shot relational learning for knowledge graphs. In: Proceedings of Empirical Methods in Natural Language Processing, 1980–1990
Xiong C, Zhong V, Socher R (2017) Dynamic coattention networks for question answering. In: Proceedings of international conference on learning representations (poster)
Yang B, Yih W, He X et al (2015) Embedding entities and relations for learning and inference in knowledge bases. In: Proceedings of international conference on learning representations (poster)
Yao H, Wei Y, Huang J et al (2019) Hierarchically Structured Meta-learning. In: Proceedings of international conference on machine learning. PMLR, 7045–7054
Zhang C, Song D, Huang C et al (2019) Heterogeneous graph neural network. In: Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery and data mining, 793–803
Zhang C, Yao H, Huang C et al (2020) Few-shot knowledge graph completion. In: Proceedings of the AAAI conference on artificial intelligence, 3041–3048
Acknowledgments
The work was supported by the National Natural Science Foundation of China (61402087), the Natural Science Foundation of Hebei Province (F2022501015), and the Fundamental Research Funds for the Central Universities (2023GFYD003).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhu, L., Bai, L., Han, S. et al. Few-shot temporal knowledge graph completion based on meta-optimization. Complex Intell. Syst. 9, 7461–7474 (2023). https://doi.org/10.1007/s40747-023-01146-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01146-9