
Abstract
This study presents an innovative path-following scheme using a new intelligent type-3 fuzzy system for mobile robots. By designing a non-singleton FS and incorporating error measurement signals, this system is able to handle natural disturbances and dynamics uncertainties. To further enhance accuracy, a Boltzmann machine (BM) models tracking errors and predicts compensators. A parallel supervisor is also included in the central controller to ensure robustness. The BM model is trained using contrastive divergence, while adaptive rules extracted from a stability theorem train the NT3FS. Simulation results using chaotic reference signals show that the proposed scheme is accurate and robust, even in the face of unknown dynamics and disturbances. Moreover, a practical implementation on a real-world robot proves the feasibility of the designed controller. To watch a short video of the scheme in action, visit shorturl.at/imoCH.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The control of mobile robots (MR) is an interesting topic because of their wide applications. Wheeled MRs are one of the most popular and widely used types in robot design because they have many benefits, including simple structure, high energy efficiency and speed, low manufacturing cost, and many other valuable features. Wheeled MRs are robots that can quickly move on the ground utilizing wheels that are connected to the motor. The design of wheeled robots is much easier than the robots with legs. At the same time, they are easier to build, program, and control. Disadvantages of wheeled MRs are that obstacles such as uneven terrain, steep drops, or low friction areas cannot be traversed well [1, 2].
Controlling the movement of wheeled MRs and their practical applications is a significant research challenge that has received much attention in recent decades [3, 4]. Various new control methods have been proposed to guide such robots [5]. For example, in [6] a cooperative controller is developed, and designing a kinematic control scheme reaching the desired speed of the robot is investigated. In [7, 8], a sliding mode controller (SMC) is introduced for MRs, and by designing an observer, some disturbances such as wheeled slipping are investigated. In [9], a warehouse MR is reviewed, and by considering the kinematics, a feedback controller is designed, and the tracking of desired velocities is investigated. In [10], a simple PID is intended for wheeled MRs considering the kinematics, and the stability is analyzed. A fault-tolerant controller for autonomous MRs is studied in [11], and the actuator faults are diagnosed. In [12], a fractional SMC is developed, and by deriving some conditions, the stability of MRs in challenging situations is examined. The optimal controller for MRs considering the interchangeable models is studied in [13], and the effect of time-varying constraints on velocity is investigated. In [14], an SMC is designed by iteratively solving quadratic programming, and the optimality of the velocity of MR is analyzed. In [15], an event-triggered controller is intended for MRs, and the estimation of angular and velocity are studied by designing an observer. In [16], a tuned PID by the Grey Wolf algorithm is suggested for MRs, and the stability of MR is studied under forced displacements and noises. Due to the existence of internal restrictions and speed limits in the robot, using model predictive control (MPC) is interesting for researchers. Because, MPC provides an interesting tool to consider all restrictions in designing, such as any limitations for output and control signals [11, 17].
The MPC is a model-based optimal method that uses the prediction of the system output to obtain the control law. The advantages of MPC include simplicity, simple adjustment of controller parameters by changing the definition of the cost function, optimality, simplicity in generalization to multi-input-multi-output systems, usable for non-phase systems and unstable processes, direct use of nonlinear models for prediction delay compensation and the possibility of considering restrictions on input–outputs such as operator restrictions can be mentioned. MPC research on the mobile robot mainly focuses on the problem of stability, optimization, or system modeling. The issue of sustainability has been investigated in many types of research related to robots. Still, it has other analysis methods due to different restrictions on the systems and the type of robot used. In [18], a formation controller based on the concept of MPC is designed, and by examination of the real-life scenarios, the efficacy of the suggested approach is verified. In [19], the effect of friction is considered, an MPC is formulated for three-wheeled MRs, and the impact of constraints on input torque is investigated. In [20], the formation control of MRs is studied, and an MPC is designed considering some limitations on the actuators. MPC can predict the robot’s behavior several steps ahead and optimally operate to control and direct the robot. This method defines the cost function as a sequence of control input and system states. The predictive control model provides the best answer to minimize the cost function by optimizing this sequence. Optimization is done in different ways, some of which are very time-consuming and inefficient because it is necessary to have an answer in the shortest time to continue the control process. In addition, some optimization methods cannot provide solutions in certain conditions. Therefore, further research has been done to achieve the optimal real-time response in MPC. Modeling is a challenging problem in MPC, and it has a substantial impact on the performance of MPC. It should be noted that the accuracy of MPC depends on the accuracy of the model of the plant. Because the model is used for prediction, and the predicted signals are used in the construction of the controller. So, any error in the model directly impacts the prediction efficiency and, subsequently, the controller efficiency. One of the famous practical modeling approaches is the fuzzy logic system (FLSs) [21,22,23,24].
Modeling of moving robots is done in two dynamic and kinematic domains. The relationship between spatial characteristics and time changes with the forces and torques required to create such changes and movements are examined in its equations. In the kinematics of moving robots, the locations and speeds of the robots are considered [24, 25]. In contrast, in the field of dynamics, the forces necessary to create movement in the robots are considered. Some neural-fuzzy controllers have been developed to assess the uncertainties and estimate the dynamics. Using the kinematic model in low-speed robots may be acceptable; however, in high-speed applications, the kinematic model is not an accurate description of the system and does not have the necessary accuracy to describe the system. Using the dynamic model increases the accuracy of the answers and brings the simulation answers closer to the practical solutions. In these approaches, the problem is formulated so that instead of solving two optimization problems on the kinematic model and the dynamic model at each moment, only one optimization problem is needed, which takes less time to perform calculations, and the optimal response is in real-time. Also, in these approaches, the obstacles in the robot’s path are considered so that the proposed algorithm can be evaluated in an environment with a predetermined direction. In these methods, the robot moves in the direction according to the information of the surrounding environment that it receives in each sampling by the camera installed on it. Therefore, at each moment, the position of the robot and obstacles are determined using the information received from the camera, and then the next parts of the robot are determined using the prediction model. In [26], the nonholonomic MRs are studied, and by designing, an MPC is created utilizing the estimation capability of FLSs. In [27], considering the historical data, a T2-FLS based MPC is designed, and by the use of the Stone-Weierstrass approach, the stability is analyzed. In [28], a T2-FLS based controller is developed for MRs, and it is shown that the metaheuristic efficiency is improved using type-2 FLSs. In [29], the backstepping controller is formulated for MRs, and its accuracy is enhanced using T2-FLSs. In [30], the event-triggered controller is developed for MRs using T2-FLSs, and the \(H_\infty \) stability is analyzed. The other challenging problem in fuzzy control is the learning scheme. In [31], an innovative learning method has been devised to facilitate learning in nonlinear systems subject to constraints and perturbation rejection. Specifically, to achieve the targeted output performance and accommodate time-varying state constraints, the learning algorithm will utilize a predetermined performance function and barrier Lyapunov functions. Additionally, the learning approach will integrate a neural network adaptive control coupled with extended state observers to account for internal uncertainties and external disturbances, thereby enabling anticipation and compensation of these factors. In [32], to deal with both matched and mismatched disturbances at the same time, two continuous control algorithms were created for a category of uncertain nonlinear systems to provide asymptotic tracking performance feedback control.

Diagram of control scheme
Ardashir et al. have recently proposed type-3 FLS-based controllers with higher accuracy and robustness for nonlinear problems. T3-FLSs have been used in various issues. For instance, in [33], a controller is suggested for MRs by the use of T3-FLSs, and the Bee colony is developed for optimization. In [34], an MPC controller is designed for MRs using T3-FLSs, and the dynamics of MRs are estimated based on T3-FLSs. In [35] the T3-FLS based observer and controller are designed for nonlinear systems, and the superiority of T3-FLS based controllers is examined on several benchmark systems. In [36], the chaotic financial systems are analyzed using T3-FLSs, and the better accuracy of T3-FLSs is verified. The accurate modeling and forecasting capability of T3-FLSs is shown by applying time series in [37]. In [38] the optimization of T3-FLSs is investigated through evolutionary-based algorithms.
The above literature review shows that most of the MPCs for MRs use conventional models. Also, in many applications of MRs, there are various uncertainties. However, the new strong T3-FLSs have not been developed for MRs. Analyzing the stability of MR is the other topic in this field that needs further study. Regarding the above discussion, a T3-FLS based controller is presented in this paper. The primary objective of the paper is to design a robust path-following scheme in the presence of uncertainties. The main contributions of this study include:
-
A deep learning MPC is designed to enhance the tracking accuracy of MRs, under chaotic references.
-
A T3-FLSs based controller is introduced to improve the resistance of MRs under practical hard situations.
-
The stability and robustness are ensured by new adaptation laws.
-
The feasibility of the designed type-3 fuzzy-based controller is studied, and a practical examination is presented.
Problem description
A general view
A general view of the suggested controller is depicted in Fig. 1. The dynamics of MR are estimated by NT3FSs, and a primary controller is designed. Then, using the Boltzmann machine a nonlinear MPC is designed to improve the accuracy. Finally, by designing a compensator and adjusting the rules of NT3FSs in direction of stability, closed-loop stability is ensured. The NMPC is optimized by Boltzmann machine and NT3FSs are learned by Lyapunov approach.
Kinematic model
In this paper, a 2-wheeled model mobile robot is considered as a case study. The general diagram of 2-wheeled model is depicted in Fig. 2. The velocity equations are written as [39]:
where, v and \(\omega \) are the linear velocities, \({\mathcal {R}}\) denotes the radius, and \(\iota \) denotes the distance of wheels. The rotation equations are [40]:


Diagram of wheeled MR
where, P denotes the rotation angle. By taking into account the angular velocity, one can write:
Dynamics
Using the Lagrange method, the dynamics are give as [41]:
where, \(\theta \left( q \right) \), \(W\left( q\right) \), \({\tau _\vartheta }\), \(\Psi \), and \(\eta \), are inertia, input, disturbance, gravitational and Coriolis matrices, respectively. \(\tau \) and q denote the input vector and the position, respectively. By \(\Psi =0\), we have:
where, the value of all parameters are given in Table 1. Considering the transformation matrix \(\varsigma \) as the null space of Q such that \({\dot{\chi }} = \varsigma \chi \), \(\ddot{\chi }= {\dot{\varsigma }} \chi + \varsigma {\dot{\chi }}\), \(\chi = {\left[ {\begin{array}{*{20}{c}} {{{{\dot{\theta }} }_{\mathcal {R}}}}&{{{{\dot{\theta }} }_\iota }} \end{array}} \right] ^T}\), \({\varsigma ^T}{Q^T} = 0\) ( \(\varsigma \) is the null space of Q), we can write:

Diagram of NT3FS
From (9), by multiplying both side in \({\varsigma ^T}\), defining \({\bar{\theta }} \left( q \right) = {\varsigma ^T}\theta \left( q \right) \varsigma \), and \({\bar{\eta }} \left( {q,\dot{q}} \right) = {\varsigma ^T}\theta \left( q \right) {\dot{\varsigma }} + {\varsigma ^T}\eta \left( {q,\dot{q}} \right) \varsigma \) and \({\bar{W}}\left( q \right) = {\varsigma ^T}W\left( q \right) \) we have:
where,
The following assumptions are considered in developed theorems:
Assumption 1
The dynamics of MR are unknown, and are perturbed by some disturbances.
Assumption 2
The perturbations are bounded.
Assumption 3
The changes of reference trajectory are not too sharp, and it physically can be followed by MR.
Non-singleton T3-FS
The dynamics of MR and also the disturbances are considered to be unknown in this study. The NT3FSs are used as estimators for uncertainties. The general scheme is given in Fig. 3. The computation of NT3FS is explained in detail below.

Suggested type-3 fuzzy set
-
1.
The inputs are \(U_1={\chi _1}\), and \(U_2={\chi _2}\).
-
2.
By the non-singleton fuzzifications the input U is converted \({\bar{U}}\) and \({\underline{U}}\), as follows:
$$\begin{aligned} {{{\bar{U}} }_{i,{{{\bar{\varsigma }} }_j}}}\left( t \right)= & {} \frac{{{U _i}\left( t \right) {\bar{\beta }} _{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}^2 + {o_{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}}{\bar{\beta }} _U ^2}}{{{\bar{\beta }} _{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}^2 + {\bar{\beta }} _U ^2}}, \end{aligned}$$(16)$$\begin{aligned} {{{\bar{U}} }_{i,{{{\underline{\varsigma }} }_j}}}\left( t \right)= & {} \frac{{{U _i}\left( t \right) {\bar{\beta }} _{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}^2 + {o_{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}}{\bar{\beta }} _U ^2}}{{{\bar{\beta }} _{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}^2 + {\bar{\beta }} _U ^2}}, \end{aligned}$$(17)$$\begin{aligned} {{\underline{U}} _{i,{{{\bar{\varsigma }} }_j}}}\left( t \right)= & {} \frac{{{U _i}\left( t \right) {\underline{\beta }} _{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}^2 + {o_{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}}{\bar{\beta }} _U ^2}}{{{\underline{\beta }} _{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}^2 + {\bar{\beta }} _U ^2}}, \end{aligned}$$(18)$$\begin{aligned} {{\underline{U}} _{i,{{{\underline{\varsigma }} }_j}}}\left( t \right)= & {} \frac{{{U _i}\left( t \right) {\underline{\beta }} _{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}^2 + {o_{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}}{\bar{\beta }} _U ^2}}{{{\underline{\beta }} _{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}^2 + {\bar{\beta }} _U ^2}}, \end{aligned}$$(19)where, \({{U _i}\left( t \right) }\) denotes the i-th input of NT3FS, and \({\Lambda _i^h}\) is membership function (MF) (h-th MF for \({{U _i}\left( t \right) }\)). The center of MFs is represented by \({{o_{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}}}\), and other terms \({{\underline{\beta }} _{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}}\), \({{\underline{\beta }} _{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}}\), \({{\bar{\beta }} _{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}}\), \({{\bar{\beta }} _{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}}\) denote the standard divisions of Gaussian MFs. \({{\bar{\beta }} _U }\) denotes the fuzzification level.
-
3.
As shown in Fig. 4, the memberships are computed as:
$$\begin{aligned} {{{\bar{\zeta }} }_{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}}\left( {{U _i}\left( t \right) } \right)= & {} \exp \left( { - \frac{{\left( {{{{\bar{U}} }_{i,{{{\bar{\varsigma }} }_j}}}\left( t \right) - {o_{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}}} \right) }}{{{\bar{\beta }} _{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}^2}}} \right) , \end{aligned}$$(20)$$\begin{aligned} {{{\bar{\zeta }} }_{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}}\left( {{U _i}\left( t \right) } \right)= & {} \exp \left( { - \frac{{\left( {{{{\bar{U}} }_{i,{{{\underline{\varsigma }} }_j}}}\left( t \right) - {o_{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}}} \right) }}{{{\bar{\beta }} _{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}^2}}} \right) , \end{aligned}$$(21)$$\begin{aligned} {{\underline{\zeta }} _{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}}\left( {{U _i}\left( t \right) } \right)= & {} \exp \left( { - \frac{{\left( {{{{\underline{U}} }_{i,{{{\bar{\varsigma }} }_j}}}\left( t \right) - {o_{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}}} \right) }}{{{\underline{\beta }} _{\Lambda _i^h,{{{\bar{\varsigma }} }_j}}^2}}} \right) , \end{aligned}$$(22)$$\begin{aligned} {{\underline{\zeta }} _{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}}\left( {{U _i}\left( t \right) } \right)= & {} \exp \left( { - \frac{{\left( {{{{\underline{U}} }_{i,{{{\underline{\varsigma }} }_j}}}\left( t \right) - {o_{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}}} \right) }}{{{\underline{\beta }} _{\Lambda _i^h,{{{\underline{\varsigma }} }_j}}^2}}} \right) . \end{aligned}$$(23) -
4.
For the rules firing, we have:
$$\begin{aligned} {\bar{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l= & {} {{{\bar{\zeta }} }_{\Lambda _1^{{h_1}},{{{\bar{\varsigma }} }_j}}} \cdot {{{\bar{\zeta }} }_{\Lambda _2^{{h_2}},{{{\bar{\varsigma }} }_j}}} \cdots {{{\bar{\zeta }} }_{\Lambda _n^{{h_n}},{{{\bar{\varsigma }} }_j}}}, \end{aligned}$$(24)$$\begin{aligned} {\bar{\Omega }} _{{{{\underline{\varsigma }} }_j}}^l= & {} {{{\bar{\zeta }} }_{\Lambda _1^{{h_1}},{{{\underline{\varsigma }} }_j}}} \cdot {{{\bar{\zeta }} }_{\Lambda _2^{{h_2}},{{{\underline{\varsigma }} }_j}}} \cdots {{{\bar{\zeta }} }_{\Lambda _n^{{h_n}},{{{\underline{\varsigma }} }_j}}}, \end{aligned}$$(25)$$\begin{aligned} {\underline{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l= & {} {{\underline{\zeta }} _{\Lambda _1^{{h_1}},{{{\bar{\varsigma }} }_j}}} \cdot {{\underline{\zeta }} _{\Lambda _2^{{h_2}},{{{\bar{\varsigma }} }_j}}} \cdots {{\underline{\zeta }} _{\Lambda _n^{{h_n}},{{{\bar{\varsigma }} }_j}}}, \end{aligned}$$(26)$$\begin{aligned} {\underline{\Omega }} _{{{{\underline{\varsigma }} }_j}}^l= & {} {{\underline{\zeta }} _{\Lambda _1^{{h_1}},{{{\underline{\varsigma }} }_j}}} \cdot {{\underline{\zeta }} _{\Lambda _2^{{h_2}},{{{\underline{\varsigma }} }_j}}} \cdots {{\underline{\zeta }} _{\Lambda _n^{{h_n}},{{{\underline{\varsigma }} }_j}}} \end{aligned}$$(27)The form of \(l-th\) rule is give as:
$$\begin{aligned} \begin{array}{*{20}{l}} {\mathrm{{if}}\,\,{\chi _1}\,\mathrm{{is}}\,\Lambda _{1,{\varsigma _j}}^{{h_l}}\,\, \mathrm{{and}}\,\,{\chi _2}\,\mathrm{{is}}\,\Lambda _{2,{\varsigma _j}}^{{h_l}}\,\, \mathrm{{and}}\,\,}\\ {\,\,\,\,\,\,\,{\chi _n}\,\mathrm{{is}}\,\Lambda _{n,{\varsigma _j}}^{{h_l}}\, \, \mathrm{{Then}}\,\,{y_l}\,\in \,\left[ {{{{\underline{\alpha }} }_{l,j}},{{{\bar{\alpha }} }_{l,j}}} \right] ,} \end{array} \end{aligned}$$(28)where, \({{{\underline{\alpha }} }_{l,j}}\) and \({{{\bar{\alpha }} }_{l,j}}\) represent the rule coefficients, and \({{y_l}}\) denotes the output of fuzzy system at l-th rule.
-
5.
The output of NT3FS is written as [42]:
$$\begin{aligned} \begin{array}{l} y = \frac{{\sum \nolimits _{j = 1}^\lambda {} }}{{\sum \nolimits _{j = 1}^\lambda {{{{\bar{\varsigma }} }_j}} }}\left( {\frac{{\sum \nolimits _{l = 1}^r {{{{\bar{\varsigma }} }_j}\left( {{\bar{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l + {\underline{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l} \right) {{{\bar{\alpha }} }_{l,j}}/2} }}{{\sum \nolimits _{l = 1}^r {\left( {{\bar{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l + {\underline{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l} \right) } }} } \right. \\ \left. {\,\,\,\,\,\,\,\,\,\, +\frac{{{{{\underline{\varsigma }} }_j}\sum \nolimits _{l = 1}^r {\left( {{\bar{\Omega }} _{{{{\underline{\varsigma }} }_j}}^l + {\underline{\Omega }} _{{{{\underline{\varsigma }} }_j}}^l} \right) {{{\underline{\alpha }} }_{l,j}}/2} }}{{\sum \nolimits _{l = 1}^r {\left( {{\bar{\Omega }} _{{{{\underline{\varsigma }} }_j}}^l + {\underline{\Omega }} _{{{{\underline{\varsigma }} }_j}}^l} \right) } }}} \right) , \end{array} \end{aligned}$$(29)where, \({{{{\bar{\varsigma }} }_j}}\) and \({{{{\underline{\varsigma }} }_j}}\) are slice levels, \(\lambda \) is the slice number, and r is number of rules. The dynamics of MR are written as:
$$\begin{aligned} {{{\dot{\chi }}}} = {g}\left( {U|{\alpha }} \right) + {u} \end{aligned}$$(30)where U is the input vector, u is control signal, \({g}\left( {U|{\alpha }} \right) \) denote a fuzzy systems and from (29), \({g}\left( {U|{\alpha }} \right) \) is written as:
$$\begin{aligned} {g}\left( {U|{\alpha }} \right) = \alpha ^T{\Phi }, \end{aligned}$$(31)where,
$$\begin{aligned}{} & {} \begin{array}{l} \alpha ^T = \left[ {{{{\underline{\alpha }} }_{1,1}},\ldots ,{{{\underline{\alpha }} }_{1,\lambda }},\ldots ,{{{\underline{\alpha }} }_{r,1}},\ldots ,{{{\underline{\alpha }} }_{r,\lambda }}} \right. ,\\ \left. {\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,{{{\bar{\alpha }} }_{1,1}},\ldots ,{{{\bar{\alpha }} }_{1,\lambda }},\ldots ,{{{\bar{\alpha }} }_{1,1}},\ldots ,{{{\bar{\alpha }} }_{1,\lambda }}} \right] , \end{array} \end{aligned}$$(32)$$\begin{aligned}{} & {} \begin{array}{l} \Phi ^T= \frac{{0.5}}{{\sum \nolimits _{j = 1}^\lambda {{{{\bar{\varsigma }} }_j}} }}\left[ {\frac{{{{{\underline{\varsigma }} }_1}\left( {{\bar{\Omega }} _{{{{\underline{\varsigma }} }_1}}^1 + {\underline{\Omega }} _{{{{\underline{\varsigma }} }_1}}^1} \right) }}{{\sum \nolimits _{l = 1}^r {\left( {{\bar{\Omega }} _{{{{\underline{\varsigma }} }_j}}^1 + {\underline{\Omega }} _{{{{\underline{\varsigma }} }_j}}^1} \right) } }},\ldots ,\frac{{{{{\underline{\varsigma }} }_\lambda }\left( {{\bar{\Omega }} _{{{{\underline{\varsigma }} }_\lambda }}^1 + {\underline{\Omega }} _{{{{\underline{\varsigma }} }_\lambda }}^1} \right) }}{{\sum \nolimits _{l = 1}^r {\left( {{\bar{\Omega }} _{{{{\underline{\varsigma }} }_j}}^1 + {\underline{\Omega }} _{{{{\underline{\varsigma }} }_j}}^1} \right) } }}} \right. ,\\ \,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \frac{{{{{\underline{\varsigma }} }_1}\left( {{\bar{\Omega }} _{{{{\underline{\varsigma }} }_1}}^r + {\underline{\Omega }} _{{{{\underline{\varsigma }} }_1}}^r} \right) }}{{\sum \nolimits _{l = 1}^r {\left( {{\bar{\Omega }} _{{{{\underline{\varsigma }} }_j}}^1 + {\underline{\Omega }} _{{{{\underline{\varsigma }} }_j}}^1} \right) } }},\ldots ,\frac{{{{{\underline{\varsigma }} }_\lambda }\left( {{\bar{\Omega }} _{{{{\underline{\varsigma }} }_\lambda }}^r + {\underline{\Omega }} _{{{{\underline{\varsigma }} }_\lambda }}^r} \right) }}{{\sum \nolimits _{l = 1}^r {\left( {{\bar{\Omega }} _{{{{\underline{\varsigma }} }_j}}^1 + {\underline{\Omega }} _{{{{\underline{\varsigma }} }_j}}^1} \right) } }},\\ \,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,{{{\bar{\varsigma }} }_1}\frac{{\left( {{\bar{\Omega }} _{{{{\bar{\varsigma }} }_1}}^1 + {\underline{\Omega }} _{{{{\bar{\varsigma }} }_1}}^1} \right) }}{{\sum \nolimits _{l = 1}^r {\left( {{\bar{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l + {\underline{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l} \right) } }},\ldots ,{{{\bar{\varsigma }} }_\lambda }\frac{{\left( {{\bar{\Omega }} _{{{{\bar{\varsigma }} }_\lambda }}^1 + {\underline{\Omega }} _{{{{\bar{\varsigma }} }_\lambda }}^1} \right) }}{{\sum \nolimits _{l = 1}^r {\left( {{\bar{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l + {\underline{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l} \right) } }},\\ \left. {\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,{{{\bar{\varsigma }} }_1}\frac{{\left( {{\bar{\Omega }} _{{{{\bar{\varsigma }} }_1}}^r + {\underline{\Omega }} _{{{{\bar{\varsigma }} }_1}}^r} \right) }}{{\sum \nolimits _{l = 1}^r {\left( {{\bar{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l + {\underline{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l} \right) } }},\ldots ,{{{\bar{\varsigma }} }_\lambda }\frac{{\left( {{\bar{\Omega }} _{{{{\bar{\varsigma }} }_\lambda }}^r + {\underline{\Omega }} _{{{{\bar{\varsigma }} }_\lambda }}^r} \right) }}{{\sum \nolimits _{l = 1}^r {\left( {{\bar{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l + {\underline{\Omega }} _{{{{\bar{\varsigma }} }_j}}^l} \right) } }}} \right] , \end{array} \end{aligned}$$(33)
Nonlinear MPC
A predictive controller is one of the most common methods used in various industries. The ability to consider different system constraints is one of the advantages of MPC. The future behavior of the system is estimated according to the assumed model at each sampling time in the determined horizon. In the algorithm, the MPC optimizer is responsible for determining the optimal control input in the predetermined horizon. This work is done based on the defined control strategy and predicted outputs by the prediction block. Optimization has always been one of the most important steps in processing and performing different control methods. In the context of MPC, it is essential to perform calculations in order to achieve an optimal and real-time response. The MPC problem is considered as minimizing the following cost function [43, 44]:
where, \(z=1,2\), \(\pi \) and \(\mu \) denote the constant variables, \({v_{{p_z}}^{}}\) is the z-th predictive controller, \({{n_P}}\) is the prediction horizon, \({\Delta v_{{p_z}}^{}}\) denotes the differential of \({v_{{p_z}}^{}}\), \({\underline{{\hat{\delta }} } _z}\) is written as:
\({{y_{\mathrm{{BM}}}}\left( {{{\underline{{\hat{\delta }} } }_z}|{X _z}} \right) }\) is Boltzmann machine (BM) output (see Fig. 5), and \({X _z}\) includes output and hidden layer weights (\({X _v}\) and \(X _{{z_0}}\)). \({{y_{\mathrm{{BM}}}}\left( {{{\underline{{\hat{\delta }} } }_z}|{X _z}} \right) }\) is written as:

BM block diagram
where,
In (39), \(\eta _1\) is obtained as:
In (38), \(\eta _0\) is written as:
where, \({{\eta _0}}\) denotes input vector of BM, and
\({X _v^{}}\) is optimized by CD training approach [45, 46], such that the cost function (60) is minimized:
where,
Then \(X _v^{}\) is adjusted as:
where \(0 < \gamma \le 1\), and \(X _{{z_0}}\) is adjusted as:
The BM output at steps ahead (j-steps) is:
where,
where, \({\ell _\iota },\,\iota = 0,\ldots ,j - 1\) denote the step responses coefficients, and the estimated step response \(s(t - 1) \) is written as:
where, \(d{v_{{p_z}}}(t)\) denotes the step size, and:
The above-mentioned problem in a matrix form can be written as [45, 46]:
where,
From (60), \(\partial J/\partial \Delta {v_{{p_z}}}\) is written as:
From (61), \(\Delta {v_{{p_z}}}\) is written as:
The controller \({v_{{p_z}}}(t)\) is:
where, \(\Delta {v_{{p_z}}}(t)\) is first element in \(\Delta {v_{{p_z}}}\) in (62).
Stability analysis
By taking into account the optimal NT3FSs, the robot dynamics are written as:
where, \({\omega _i},\,i=1,2\) denote estimation errors. The controllers \(u_1\) and \(u_2\) have three parts: the primary error feedback, predictive signals \(v_p\) (see (63)) and compensators \(v_c\) (see (81) and (82)). As shown in Fig. 1, the controllers are:
where, \(K_1\) and \(K_2\) are constants and \({{\dot{\delta }} }_1\) and \({{\dot{\delta }} }_2\) are errors. Then \({{\dot{\delta }} }_1\) and \({{\dot{\delta }} }_2\) are written as:
From (31), we can write:
From (70)–(71), the equations (68)–(69) are written as:
We consider the Lyapunov function as:
Derivative of (74), results in:
From (72), (73) and (75), \(\dot{V}\) is written as:
Then the tuning rules are written as:
From (77) and (78), the equation (76), becomes:

The designed robot

The designed setup

Implementation performance

Implementation performance: Phase portrait
Regarding the characteristics of MR, we can consider the upper bounds for \(\omega _i\) and \({{ v}_{{p_i}}}\,i=1,2\), then we can write:
From (80), to eliminate the effect of terms \({{{{\bar{\omega }} }_1}\left| {\delta _1^{}} \right| + \left| {\delta _1^{}} \right| {{{\bar{v}}}_{{p_1}}}}\) and \({{{{\bar{\omega }} }_2}\left| {\delta _2^{}} \right| + \left| {\delta _2^{}} \right| {{{\bar{v}}}_{{p_2}}}}\), the compensators are:

The switching modes
Considering (81)-(82), we have:
Then,
Inequality (84), shows that \({\delta _1} \in {\ell ^2}\) and \({\delta _2} \in {\ell ^2}\). Then the asymptotic stability is proved.
Implementation
In this section, the suggested approach is examined on a real robot. The designed robot is depicted in Fig. 6. The robot is communicated by a wireless sensor to a notebook for monitoring. The setup is shown in Fig. 7. The robot has two standard wheels with a 7 cm diameter that are attached to two stepper motors with high accuracy and two idle pins to keep it balanced. The robot includes eight Sharp sensors on each of its four sides and an MPU6050 angle acceleration sensor in its center of mass. The bottom plate of the robot, where the motors are mounted, is made of 1.5 mm aluminum. The precision of two-phase stepper motors is 1.8 degrees per step. The chassis surface is elevated to receive the PCB using four 7 cm spacers. The NRF24L01 radio transmitter module is used for communication between the laptop and the robot.
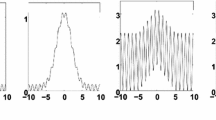
To examine the feasibility, a complicated chaotic path-following is considered. The setup is shown in Fig. 7. The results are shown in Fig. 8. We see that the designed scheme has an accurate performance, even in very noisy conditions. The designed robot well tracks a complicated chaotic path. The suggested predictive approach decreases the tracking error and tackles the natural perturbations. To better see the chaotic behavior the phase portrait is shown in Fig. 9. We see that the robot well follows a chaotic path. The complicated paths can be used in various security applications. For example, the suggested robot can be used in a patrolling application. In this problem, we need that the path of the robot to be secure and unpredictable.

Output signals
Simulations

Control signals

Estimated signals along with the targets

Phase portraits
The reference path is generated by following chaotic system:
The switching modes are shown in Fig. 10. The reference of output signals as shown in Fig. 10 are changed four times. The simulation conditions are depicted in Table 1 and 2. It should be noted that the conditions are considered to be the same for both IT2-FLS and NT3FS (the number of MFs, rules, and values of centers of MFs). The outputs are depicted in Fig. 11. An excellent tacking response is shown in Fig. 11. We see that output signals well track the target signals. In spite of time-varying references and multi-switching between different signals, the robot well tracks the desired path. The controllers are depicted in Fig. 12. The obtained control signals have no high-frequency fluctuations. The estimated signals are given in Fig. 13. The phase portrait is shown in Fig. 14. We see acceptable tracking accuracy. The chaotic path proposes a secure path for robots. Especially considering the fact that the suggested path is suddenly changed from one path to another.

The estimation comparison of FLSs
To give a fair comparison, the effect of the controller is terminated, and the estimation of (15) is considered, without a controller, then we have:
Also, a noise variance/mean of 0.04/0 is added. The RMSEs are provided in Table 3. Also, the comparison phase portrait is depicted in Fig. 15. According to the RMSE values, our designed controller’s performance surpasses that of other related control methods. The proposed controller exhibits improved resistance to switching modes and dynamics uncertainties. Additionally, it showcases significant advancement in performance when operating under highly noisy conditions. Other controllers’ performance drastically declines as measurement noise increases, whereas the accuracy of the proposed scheme remains unaffected by measurement errors. Even as the noise variance increases from 0 to 0.1, the suggested approach’s RMSE only slightly increases. Conversely, other FLSs experience an RMSE increase of over 50%.
Conclusion
This article presents a new innovative approach to controlling MRs. In order to manage nonlinearities of MR dynamics, a novel NT3FS is proposed. Additionally, the dynamics of the tracking error are identified through the development of a BM model. An MPC controller based on the BM model is then designed and stability is scrutinized in the presence of multiple disturbances. Reference signals for the path of the MR are created using a hyperchaotic system comprised of four states. The MR’s desired path is selected from these signals, resulting in sudden changes between four chaotic signals. The proposed intelligent controller is demonstrated to efficiently handle uncertainties, effectively steering the MR along chaotic reference paths. Due to the unpredictable nature of these paths,
this approach proves highly promising for patrol robots. As compared to various FLSs and controllers, the newfound approach is shown to perform with heightened accuracy. The suggested method is found to be 50% better in accuracy as compared to other methods. In future research, the optimality of NT3FSs will be further investigated.
References
Prakash K, Parimala M, Garg H, Riaz M (2022) Lifetime prolongation of a wireless charging sensor network using a mobile robot via linear diophantine fuzzy graph environment. Complex Intell Syst 8(3):2419–2434
Karthikeyan P, Mani P (2020) Applying Dijkstra algorithm for solving spherical fuzzy shortest path problem. Solid State Technol 63(6):10846–10857
Ma Y-M, Hu X-B, Zhou H (2022) A deterministic and nature-inspired algorithm for the fuzzy multi-objective path optimization problem. Complex Intell Syst:1–13
Zhou C-C, Yin G-F, Hu X-B (2009) Multi-objective optimization of material selection for sustainable products: artificial neural networks and genetic algorithm approach. Mater Des 30(4):1209–1215
Li D, Ge SS, Lee TH (2020) Fixed-time-synchronized consensus control of multiagent systems. IEEE Trans Control Netw Syst 8(1):89–98
Shao X, Zhang J, Zhang W (2022) Distributed cooperative surrounding control for mobile robots with uncertainties and aperiodic sampling. IEEE Trans Intell Transp Syst 23(10):18951–18961
Li Z, Zhai J (2022) Super-twisting sliding mode trajectory tracking adaptive control of wheeled mobile robots with disturbance observer. Int J Robust Nonlinear Control 32(18):9869–9881
Chen B, Hu J, Zhao Y, Ghosh BK (2022) Finite-time observer based tracking control of uncertain heterogeneous underwater vehicles using adaptive sliding mode approach. Neurocomputing 481:322–332
Li P, Yang H, Li H, Liang S (2022) Nonlinear eso-based tracking control for warehouse mobile robots with detachable loads. Robot Auton Syst 149:103965
Miranda-Colorado R (2022) Observer-based proportional integral derivative control for trajectory tracking of wheeled mobile robots with kinematic disturbances. Appl Math Comput 432:127372
Hang P, Lou B, Lv C (2022) Nonlinear predictive motion control for autonomous mobile robots considering active fault-tolerant control and regenerative braking. Sensors 22(10):3939
Jiang L, Wang S, Xie Y, Xie SQ, Zheng S, Meng J (2022) Fractional robust finite time control of four-wheel-steering mobile robots subject to serious time-varying perturbations. Mech Mach Theory 169:104634
Kim Y, Singh T (2022) Energy-time optimal control of wheeled mobile robots. J Franklin Inst 359(11):5354–84
Wang D, Wei W, Wang X, Gao Y, Li Y, Yu Q, Fan Z (2022) Formation control of multiple Mecanum-wheeled mobile robots with physical constraints and uncertainties. Appl Intell 52(3):2510–2529
Yang J, Yu H, Xiao F (2022) Hybrid-triggered formation tracking control of mobile robots without velocity measurements. Int J Robust Nonlinear Control 32(3):1796–1827
Singhal K, Kumar V, Rana K (2022) Robust trajectory tracking control of non-holonomic wheeled mobile robots using an adaptive fractional order parallel fuzzy pid controller. J Franklin Inst 359(9):4160–215
Luo R, Peng Z, Hu J (2023) On model identification based optimal control and it’s applications to multi-agent learning and control. Mathematics 11(4):906
Rosenfelder M, Ebel H, Eberhard P (2022) Cooperative distributed nonlinear model predictive control of a formation of differentially-driven mobile robots. Robot Auton Syst 150:103993
Ren C, Li C, Hu L, Li X, Ma S (2022) Adaptive model predictive control for an omnidirectional mobile robot with friction compensation and incremental input constraints. Trans Inst Meas Control 44(4):835–847
Nfaileh N, Alipour K, Tarvirdizadeh B, Hadi A (2022) Formation control of multiple wheeled mobile robots based on model predictive control. Robotica 40:1–36
Zhang X, Shi R, Zhu Z, Quan Y (2022) Adaptive nonsingular fixed-time sliding mode control for manipulator systems’ trajectory tracking. Complex Intell Syst:1–12
Chen Y (2022) Study on non-iterative algorithms for center-of-sets type-reduction of Takagi–Sugeno–Kang type general type-2 fuzzy logic systems. Complex Intell Syst:1–9
Helmy S, Magdy M, Hamdy M (2022) Control in the loop for synchronization of nonlinear chaotic systems via adaptive intuitionistic neuro-fuzzy: a comparative study. Complex Intell Syst 8(4):3437–3450
Xu B, Guo Y (2022) A novel DVL calibration method based on robust invariant extended Kalman filter. IEEE Trans Veh Technol 71(9):9422–9434
Song F, Liu Y, Shen D, Li L, Tan J (2022) Learning control for motion coordination in wafer scanners: toward gain adaptation. IEEE Trans Industr Electron 69(12):13428–13438
Yuan W, Liu Y-H, Su C-Y, Zhao F (2022) Whole-body control of an autonomous mobile manipulator using model predictive control and adaptive fuzzy technique. IEEE Trans Fuzzy Syst
Shui Y, Zhao T, Dian S, Hu Y, Guo R, Li S (2022) Data-driven generalized predictive control for car-like mobile robots using interval type-2 t-s fuzzy neural network. Asian J Control 24(3):1391–1405
Cuevas F, Castillo O, Cortés-Antonio P (2022) Generalized type-2 fuzzy parameter adaptation in the marine predator algorithm for fuzzy controller parameterization in mobile robots. Symmetry 14(5):859
Zou X, Zhao T, Dian S (2022) Finite-time adaptive interval type-2 fuzzy tracking control for Mecanum-wheel mobile robots. Int J Fuzzy Syst 24(3):1570–1585
Ge C, Liu C, Liu Y, Hua C (2022) Interval type-2 fuzzy control for nonlinear system via adaptive memory-event-triggered mechanism. Nonlinear Dyn 111:1–14
Yang G, Yao J, Dong Z (2022) Neuroadaptive learning algorithm for constrained nonlinear systems with disturbance rejection. Int J Robust Nonlinear Control 32(10):6127–6147
Yang G (2023) Asymptotic tracking with novel integral robust schemes for mismatched uncertain nonlinear systems. Int J Robust Nonlinear Control 33(3):1988–2002
Amador-Angulo L, Castillo O, Melin P, Castro JR (2022) Interval type-3 fuzzy adaptation of the bee colony optimization algorithm for optimal fuzzy control of an autonomous mobile robot. Micromachines 13(9):1490
Hua G, Wang F, Zhang J, Alattas KA, Mohammadzadeh A, The VuM (2022) A new type-3 fuzzy predictive approach for mobile robots. Mathematics 10(17):3186
Taghieh A, Mohammadzadeh A, Zhang C, Rathinasamy S, Bekiros S (2022) A novel adaptive interval type-3 neuro-fuzzy robust controller for nonlinear complex dynamical systems with inherent uncertainties. Nonlinear Dyn 111:1–15
Tian M-W, Bouteraa Y, Alattas KA, Yan S-R, Alanazi AK, Mohammadzadeh A, Mobayen S (2022) A type-3 fuzzy approach for stabilization and synchronization of chaotic systems: applicable for financial and physical chaotic systems. Complexity
Castillo O, Castro JR, Melin P (2022) Interval type-3 fuzzy aggregation of neural networks for multiple time series prediction: the case of financial forecasting. Axioms 11(6):251
Peraza C, Ochoa P, Castillo O, Geem ZW (2022) Interval-type 3 fuzzy differential evolution for designing an interval-type 3 fuzzy controller of a unicycle mobile robot, Mathematics. https://doi.org/10.3390/math10193533. https://www.mdpi.com/2227-7390/10/19/3533
Wu Y, Sheng H, Zhang Y, Wang S, Xiong Z, Ke W (2022) Hybrid motion model for multiple object tracking in mobile devices. IEEE Internet Things J 10(6):4735–4748
Liu M, Gu Q, Yang B, Yin Z, Liu S, Yin L, Zheng W (2023) Kinematics model optimization algorithm for six degrees of freedom parallel platform. Appl Sci 13(5):3082
Hou X, Zhang L, Su Y, Gao G, Liu Y, Na Z, Xu Q, Ding T, Xiao L, Li L et al (2023) A space crawling robotic bio-paw (scrbp) enabled by triboelectric sensors for surface identification. Nano Energy 105:108013
Mohammadzadeh A, Sabzalian MH, Zhang W (2019) An interval type-3 fuzzy system and a new online fractional-order learning algorithm: theory and practice. IEEE Trans Fuzzy Syst 28:1940–1950. https://doi.org/10.1109/TFUZZ.2019.2928509
Mohammadzadeh A, Ghaemi S, Kaynak O et al (2019) Robust predictive synchronization of uncertain fractional-order time-delayed chaotic systems. Soft Comput 23(16):6883–6898
Li B, Tan Y, Wu A-G, Duan G-R (2021) A distributionally robust optimization based method for stochastic model predictive control. IEEE Trans Autom Control 67(11):5762–5776
Mohammadzadeh A, Vafaie RH (2021) A deep learned fuzzy control for inertial sensing: Micro electro mechanical systems. Appl Soft Comput 109:107597
Vafaie RH, Mohammadzadeh A, Piran M et al (2021) A new type-3 fuzzy predictive controller for mems gyroscopes. Nonlinear Dyn 106(1):381-403
Acknowledgements
The Deanship of Scientific Research (DSR) at King Abdulaziz University (KAU), Jeddah, Saudi Arabia has funded this Project under grant No. (G: 589-135-1443).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Paper presents
The paper presents no data.
Human participants
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Alkabaa, A.S., Taylan, O., Balubaid, M. et al. A practical type-3 Fuzzy control for mobile robots: predictive and Boltzmann-based learning. Complex Intell. Syst. 9, 6509–6522 (2023). https://doi.org/10.1007/s40747-023-01086-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01086-4