
Abstract
Inpainting high-resolution images with large holes challenges existing deep learning-based image inpainting methods. We present a novel framework—PyramidFill for high-resolution image inpainting, which explicitly disentangles the task into two sub-tasks: content completion and texture synthesis. PyramidFill attempts to complete the content of unknown regions in a lower-resolution image, and synthesize the textures of unknown regions in a higher-resolution image, progressively. Thus, our model consists of a pyramid of fully convolutional GANs, wherein the content GAN is responsible for completing contents in the lowest-resolution masked image, and each texture GAN is responsible for synthesizing textures in a higher-resolution image. Since completing contents and synthesizing textures demand different abilities from generators, we customize different architectures for the content GAN and texture GAN. Experiments on multiple datasets including CelebA-HQ, Places2 and a new natural scenery dataset (NSHQ) with different resolutions demonstrate that PyramidFill generates higher-quality inpainting results than the state-of-the-art methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Image inpainting, a fundamental low-level vision task, has attracted much attention from academia and industry. A wide range of vision and graphic applications refer to image inpainting, e.g., object removal [1, 2], image restoration [4], manipulation [24], and super-resolution [37]. Image inpainting aims to synthesize alternative contents in the missing regions of an image, which is visually realistic and semantically correct [40].
The existing methods for image inpainting generally fall into two categories: (1) Copying from low-level image features. (2) Generating new contents from high-level semantic features. The former ones attempt to fill holes by matching and copying patches from known regions [1] or external database images [7]. These approaches are effective for easy cases, e.g., uniform textured background inpainting. However, they cannot solve challenge cases where missing regions involve complex textures or nonrepetitive structures, due to the lack of high-level semantic understanding [40]. Since of the great development of advanced deep learning techniques [6, 13, 33,34,35], the approaches of generating new contents learn to capture the context representation of known regions and synthesize the missing contents by using deep Convolutional Neural Networks (CNN) in an end-to-end training manner. Context Encoder [25] is the first CNN-based method to solve the image inpainting task, wherein a deep convolution encoder–decoder architecture is proposed and an adversarial loss [5] is added to generate visually realistic results. The encoder–decoder architecture has been extended by many CNN-based inpainting models to get more reasonable and fine-detailed contents [8, 10, 20, 39,40,41, 44, 45, 47].
However, the end-to-end training encoder–decoder architecture still remains challenging to fill large holes in high-resolution images. As shown in Fig. 1, the results of PConv [20] are obtained from its online demo,Footnote 1 which illustrates that PConv fails to generate reasonable contents for these two cases, due to a lack of the guidance for filling the holes. Because some regions in holes are far away from the surrounding known regions, which causes the generator to produce semantically ambiguous contents or visually artifacts for the holes [16]. In addition, high-resolution images make the discriminator easier to tell the fully recovered images apart from ground truth, thus drastically amplifying the gradient problem [12, 18]. An alternative way is to use two encoder–decoder architectures to separately fill contents and textures for the unknown regions [40]. Even so, only a few methods can process images with resolution smaller than 512 \(\times \) 512, wherein the masked area is generally less than 25% of the whole image [19, 41].

Free-form inpainting results on \(512\times 512\) images by PConv and our model. Zoom-in to see the details
We observe that filling the contents and textures demands quite different abilities from the generator. Content completion relies more on capturing the high-level semantics and the global structure of the image, yet low-level features and local texture statistics of the image is more critical for the texture synthesis. Furthermore, content completion can be regarded as an image generation task [5], and texture synthesis can be treated as an image to image translation task [9].
Motivated by the observation that high-resolution image inpainting could be disentangled into content completion and texture synthesis, we propose a simple yet powerful high-resolution image inpainting framework named PyramidFill, which attempts to fill large holes in images with high resolution reaching to \(1024\times 1024\). Our key insight is that we can fill the contents for the easier low-resolution images and synthesize the textures for the high-resolution progressively, wherein the high-resolution image is formed into a pyramid of different scale images by down-sampling. PyramidFill consists of a pyramid of fully convolutional Generative Adversarial Networks (GANs), wherein the content GAN is responsible for generating contents in the lowest-resolution masked image in image pyramid, and each texture GAN is responsible for synthesizing textures in a higher-resolution image. Unlike the previous inpainting methods, e.g., DeepFill V2 [41] and PEN-Net [42], which complete contents and synthesize textures simultaneously with an encoder–decoder architecture or a pyramid-context encoder, our proposed method fill contents for the masked image before synthesizing textures with different GANs. Under this manner, each GAN can focus on their respective sub-tasks to acquire better results.
Our major contributions can be summarized as follows:
-
we propose a novel framework for high-resolution image inpainting, termed PyramidFill. Our framework disentangles the task of high-resolution image inpainting into two sub-tasks: low-resolution content completion and high-resolution texture synthesis.
-
We design a content GAN architecture for filling contents in the low-resolution masked image, and a texture GAN architecture for synthesizing textures in a high-resolution image progressively.
-
Extensive experiments on CelebA-HQ and Place2 show that PyramidFill outperforms the previous methods on these benchmarks.
-
We introduce a new dataset of natural scenery with high resolution 1920 \(\times \) 1080 for real-image inpainting applications.
Related work
Deep image inpainting
A variety of CNN-based approaches have been proposed for image inpainting. Pathak et al. [25] first introduced an encoder–decoder architecture for the image inpainting task, as well as a pixel-wise reconstruction loss and an adversarial loss. Based on Pathak’s work, Iizuka et al. [8] proposed a fully convolutional GAN model with an extra local discriminator to ensure local image coherency. Yang et al. [36] proposed a multi-scale neural patch synthesis approach based on joint optimization of image content and texture constraints. Based on two-stage encoder–decoder architectures, observing ineffectiveness of CNN in modeling long-term correlations between distant contextual information and the hole regions, Yu et al. [40] presented a novel contextual attention layer to integrate in the second stage, which used the features of known patches as convolutional filters to process the generated patches. The aforementioned approaches were based on vanilla convolutions that treated all input pixels as same valid ones, which is not reasonable for masked holes. To address this limitation, Liu et al. [20] proposed a partial convolutional layer for irregular holes in image inpainting, comprising a masked and re-normalized convolution operation followed by a mask-update step. Partial Convolutions could be viewed as hard-mask convolutional layers, Yu et al. [41] proposed gated convolution to learns a dynamic feature gating mechanism for each channel and each spatial location across all layers, which could be viewed as a soft-mask convolutional layer. Yang et al. [38] proposed a multi-task learning framework to incorporate the image structure knowledge to assist image inpainting, which trained a shared generator to simultaneous complete the masked image and corresponding structures—edge and gradient. Liu et al. [21] proposed a mutual encoder–decoder CNN for joint recovering structures and textures, which used CNN features from the deep and shallow layers of the encoder to represent structures and textures of an input image, respectively.

Pipeline of our high-resolution image inpainting algorithm—PyramidFill. Our model consist of a pyramid of PatchGANs, where training are progressive
High-resolution image inpainting
Most recently, a few works have been presented for high-resolution image inpainting. Instead of directly filling holes in high-resolution images, Yi et al. [39] proposed a contextual residual aggregation mechanism that could produce high-frequency residuals for missing contents by weighted aggregating residuals from contextual patches, thus only requiring a low-resolution prediction from the network. Zeng et al. [43] presented a guided upsampling network to generate high-resolution image inpainting results, by extending the contextual attention module which borrowed high-resolution feature patches in the input image.
Pyramid in image generation
Pyramid has been explored widely in the image generation task. Denton et al. [3] introduced a cascade of CNNs within a Laplacian pyramid framework to generate images in a coarse-to-fine fashion. At each level of the pyramid, a separate generation model was trained using the GAN approach. Shaham et al. [27] introduced SinGAN to learn from a single natural image, which contained a pyramid of fully convolutional GANs, each was responsible for learning the patch distribution at a different scale of the image. Inspired by classical image pyramid representations, Shocher et al. [28] proposed a semantic generation pyramid framework to generate diverse image samples, which utilized the continuum of semantic information encapsulated in deep features, ranging from low-level textural information contained in fine features to high-level semantic information contained in deeper features.
Method
In this section, we first introduce the pipeline of our proposed PyramidFill, and then present the generator and discriminator networks in each level, as well as the loss functions.
Pipeline of PyramidFill
Figure 2 illustrates the pipeline of PyramidFill, which consists of a pyramid of PatchGANs [9, 15]: \(\left\{ G_{i},D_{i}\right\} \), \(i=0,1,2,3,4\). For training, given a high-resolution image x, we sample a binary image mask m at a random location (e.g., center area in Fig. 2). Input image z is masked from the original image as \(z=x\odot (1-m)+m\). The original image, input image, mask are separately downsampled to be the pyramids of images by a factor \(r^{4-i}\) (we choose \(r=2\)): \(x_{i}\), \(z_{i}\), \(m_{i}\) \(i=0,1,2,3,4\). Each Generator \(G_{i}\) is responsible for filling the corresponding-scale masked image \(z_{i}\), trained against the image \(x_{i}\), where \(G_{i}\) learns to fool the discriminator \(D_{i}\).
The filling of a high-resolution image starts with the lowest-scale image \(x_{0}\), wherein \(\left\{ G_0,D_0\right\} \) are trained to complete the contents, and then progressively synthesize the finer textures at the higher-scale image by training \(\left\{ G_i,D_i\right\} \), \(i=1,2,3,4\). The generator \(G_{0}\) takes concatenation of \(z_{0}\) and \(m_{0}\) as input, and output the predicted image \(x^{'}_{0}\) with the same size as input. We then replace the masked region of \(z_{0}\) using the predicted image to get the inpainting result \(y_{0}\),
After training the generator \(G_{0}\), the inpainting result \(y_{0}\) and input image \(z_{1}\) are given to the generator \(G_{1}\) to output the predicted image \(x^{'}_{1}\) with the same size as \(z_{1}\), and it replaces the masked region of \(z_{1}\) to get the inpainting result \(y_{1}\). Training the other PatchGANs is similar to training \(\left\{ G_1,D_1\right\} \), given the corresponding input image \(z_{i}\) and the lower-scale inpainting result \(y_{i-1}\) to get the current-scale inpainting result \(y_{i}\), i.e.,
Generators and discriminators
Since completing contents and synthesizing textures demand quite different abilities from generators, we customize different architectures for \(\left\{ G_0,D_0\right\} \) and \(\left\{ G_i,D_i\right\} \), \(i=1,2,3,4\).
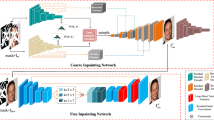
Figure 3 shows the architecture of a PatchGAN for completing contents on the lowest-scale input image \(z_{0}\). For the generator network, we maintain the spatial size of the feature maps since of low-scale input images, instead of the encoder–decoder architecture used in many methods. The input images are first passed through four gated convolutional layers [41], which are then split into two branches along the channel dimension. Four dilated gated convolutional layers are adopted in the upper branch to expand the size of receptive fields for exploring the global structures of input images, four gated convolutional layers are simultaneously adopted in the lower branch for exploiting fine contents. Feature maps from two branches are then concatenated to proceed the last four gated convolutional layers to predict the contents in the masked region. The discriminator network consists of eight convolutional layers, wherein no down-sampling operations are adopted to ensure the spatial size of the output as the same with the input image. It can better capture fine details in the lowest-scale image.

Architecture of a PatchGAN for completing contents
The architecture of a PatchGAN for synthesizing textures is presented in Fig. 4, and \(\left\{ G_1,D_1\right\} \), \(\left\{ G_2,D_2\right\} \), \(\left\{ G_3,D_3\right\} \), \(\left\{ G_4,D_4\right\} \) share this same architecture yet progressively training. There are two stages in the generator, and we call the first stage as the super-resolution network, the second stage as the refinement network. The super-resolution network predicts a higher-resolution image from its lower-resolution counterpart which is taken from the inpainting result of the lower-scale generator. We use the predicted higher-resolution image to replace the masked region of the corresponding-scale input image, which then passes through the refinement network to output a finer result. Inspired by ESRGAN [31] and SRResNet [14], we design a simple yet powerful super-resolution network, wherein all vanilla convolutions in RRDB module [31] are replaced with gated convolutions, and we only adopt two RRDB modules. The upsampling operator uses the sub-pixel layer with the factor 2 to increase the resolution of the input image. In the refinement network, there are only six gated convolutional layers with a shortcut connection within the middle four layers. In the discriminator, we use four strided convolutions with stride 2 to reduce the spatial size of feature maps due to memory cost.

Architecture of a PatchGAN for synthesizing textures
Loss function
To stabilize the training of PatchGANs, the spectral normalization [23] is applied in all discriminators. We use a hinge loss [41] as objective function for all PatchGANs \(\left\{ G_i,D_i\right\} \), \(i=0,1,2,3,4\):
where \(x_{i}\) and \(z_{i}\) represent the real image and the masked input image, respectively. \(D_i\) and \(G_i\) denote the spectral-normalized discriminator and the generator, respectively.
Inspired by U-Net GAN [26], we use a per-pixel consistency regularization technique when training \(D_0\), encouraging the discriminator to focus more on semantic and structural changes between real and fake images. This technique can further enhance the quality of the generated sample \(x^{'}_{0}\). We train the discriminator to provide consistent per-pixel predictions, by introducing the consistency regularization loss term in the discriminator objective function:
where \(\left\| \cdot \right\| \) denotes the \(L^2\) norm. This consistency loss is taken between the per-pixel output of \(D_{0}\) on the composing image \(y_{0}\) and the composite of output of \(D_{0}\) on real and fake images, penalizing the discriminator for inconsistent predictions.
In addition, a pixel reconstruction loss is introduced for training the generators, because the task of generators is not only fool the discriminators but also to generate image being similar to the real image.
where \(N_{x_\textrm{gen}}\) is the number elements in the image \({x_\textrm{gen}}\), which is the predicted image by the generators.
We introduce additional losses for training the texture generators, perceptual loss [11] and style loss [10, 20]. The perceptual loss penalizes results that are not perceptually similar by computing \(L^{1}\) distance between feature maps of a pre-trained network,
where \(N_{q}\) indicates the number of elements in the q-th layer, and \(\phi _{q}\) is the feature map of the q-th layer extracted from the VGG-16 network pre-trained on ImageNet [29], and we choose the feature maps from layers pool1, pool2 and pool3. Style loss compares the content of two images by using Gram matrix. Given feature maps of sizes \(C_{q}\times H_{q}\times W_{q}\), style loss is computed as follows:
where \(G^{\phi }_{q}\) is a \(C_{q}\times C_{q}\) Gram matrix constructed from feature maps \(\phi _{q}\), which are the same with that used in the perceptual loss.
The overall loss functions for training \(\left\{ G_0,D_0\right\} \) are shown as below:
And the whole loss functions for training \(\left\{ G_i,D_i\right\} , i=1,2,3,4\) are as follows:
For our experiments, we empirically set [20] \(\lambda _{a}=0.001\), \(\lambda _{r}=0.1\), \(\lambda _{p}=0.1\) for all generators, and \(\lambda _{s_{1}}=1\), \(\lambda _{s_{2}}=50\), \(\lambda _{s_{3}}=120\), \(\lambda _{s_{4}}=250\) for different generators, respectively.
Experiments
Datasets. We evaluate PyramidFill on three datasets: CelebA-HQ [12], Places2 [46], and our new collected NSHQ dataset. CelebA-HQ contains 30,000 high-quality images at \(1024\times 1024\) resolution focusing on human faces. For Places2, we randomly select 20 categories from the 365 categories to form a subset of 100,000 images. The NSHQ dataset includes 5000 high-quality natural scenery images at \(1920 \times 1080\) or \(1920 \times 1280\) resolution, collecting from the Internet. For Places2 and NSHQ, images are randomly cropped to \(512 \times 512\) and \(1024\times 1024\), respectively. Therefore, there is no \(\left\{ G_4,D_4\right\} \) when training on the Places2 subset. For all datasets, we randomly use 90% of images for training and 10% of images for testing.
Compared methods. We compare PyramidFill with five state-of-the-art approaches: Global & Local [8], DeepFill v1 [40], PConv [20], PEN-Net [42], DeepFill v2 [41].
Evaluation metrics. We perform evaluations using three evaluation metrics: (1) relative L1 loss (mean average error); (2) peak signal-to-noise ratio (PSNR); (3) structural similarity (SSIM) [32]. These metrics are used to compare the low-level differences between the recovered image and the ground truth.
Implementation details. We implement our method in PyTorch. We train the model by the Adam optimizer with \(\beta _{1}=0.5\) and \(\beta _{2}=0.999\), and the learning rate is set to 0.0002 and 0.0008 for the generators and discriminators, respectively. The content GAN (\(\left\{ G_{0},D_{0}\right\} \)) and textures GANs (\(\left\{ G_{i},D_{i}\right\} ,i=1,2,3,4\)) are trained separately, in which the content GAN is trained firstly and the texture GANs are trained sequentially. All networks are trained on 8 NVIDIA V100 GPUs (32 G) with batch size of 8. When training on CelebA-HQ, we use regular masks and random free-form masks [41], wherein the regular masks cover image center with half of image size. Free-form masks are generated automatically by drawing lines and rotating angles during training, and the details can refer to [41]. For Places2 and NSHQ, random free-form masks [41] are employed for training, while irregular masks from PConv [20] are used for testing.
Quantitative evaluation
We conduct quantitative comparisons on CelebA-HQ dataset and Places2 subset. For a fair evaluation, all input images are resized to \(256 \times 256\) and \(512\times 512\), respectively. Because a few compared official pre-trained models are only trained on \(256\times 256\) images. Tables 1 and 2 report the quantitative comparisons on CelebA-HQ testing set with \(256\times 256\) images and \(512\times 512\) images, respectively. The images are masked with center holes. It shows that our PyramidFill outperforms existing state-of-the-art methods with significant advantages. Tables 3 and 4 present the quantitative comparisons on Places2 testing set with \(256\times 256\) images and \(512\times 512\) images masked with irregular masks, respectively. The results are categorized according to the ratios of the hole regions versus the image size. It shows that our PyramidFill performs much better than the state-of-the-art methods, especially for filling large holes in images. We also compare the computational complexity and uptime between our PyramidFill and some SOTA methods. Table 5 shows that PConv has the fewest parameters and FLOPs, which needs 8 ms for processing a \(512\times 512\) image on a single NVIDIA RTX 3090 GPU. DeepFill v2 and our model increase the parameters, which require much more inference time.
Qualitative evaluation
The qualitative comparisons on three datasets are shown in Fig. 5. It shows that Global & Local and DeepFill v1 often generate heavy artifacts, even the holes are not very large. PConv, PEN-Net and DeepFill v2 can generate correct contents for completing faces, yet lacking of detailed textures. By contrast, our model PyramidFill can generate more realistic results on the corrupted faces with finer textures. When dealing with the corrupted images from Places2 and NSHQ, PConv and PEN-Net also produce obvious artifacts. DeepFill v2 and our PyramidFill both can generate reasonable contents and detailed textures. Results obtained from our PyramidFill are closer to the original images than results from DeepFill v2.
Real applications
We study real use cases of image inpainting on high-resolution images using our PyramidFill, e.g., freckles removal, face editing, watermark removal, and general object removal in natural scenery. In the first row of Fig. 6, our model successfully removes the freckles on the face, as well as changing eyes. In the second row, the watermarks on the original image are removed successfully. In the third row, we remove the giraffes on the grassland and recover the background. In the last row, a boat is removed from the river. All inpainting results are realistic and with fine-grained details. Furthermore, our PyramidFill can also be used for more real applications, e.g., removing wrinkles on faces, changing hairstyles, restoring old photos.

Example cases of qualitative comparisons on CelebA-HQ, Places2 and NSHQ testing sets with \(256\times 256\) images

Inpainting results on \(1024\times 1024\) images using our PyramidFill. Zoom-in to see the details. The original images at the first two rows are extracted from CelebA-HQ dataset, and the original images at the last two rows are extracted from NSHQ dataset

Ablation study of refinement network in Texture Generators. From left to right, we show the real image, the masked input, the result with a one-stage network in Texture Generators and our result with a two-stage networks
Ablation study
Consistency regularization loss To demonstrate the effects of consistency regularization loss used in the discriminator \(D_0\), we retrain \(\left\{ G_0,D_0\right\} \) yet without consistency regularization loss on CelebA-HQ dataset masked with center holes. The results are provided in Table 6, which shows that the consistency regularization loss can definitely improve the performance of PyramidFill on completing contents.
Refinement network In Texture Generators, a refinement network is designed as a second-stage for generating a finer result. We provide ablation experiments on CelebA-HQ dataset with \(128\times 128\) images masked with center holes. For fair comparisons, two-stage networks are merged into a one-stage network, wherein the feature maps of the upsampling operator in the super-resolution network are directly inputted to the refinement network, and there is no coarse result to output. As shown in Fig. 7, the two-stage network can generate a more photo-realistic inpainting result.
Discussion
Zooming in Fig. 6, we find that our model works not so well for synthesizing textures of \(1024\times 1024\) images, which is fidelity defect. This illustrates the limitation of our proposed Generator pyramids when processing \(1024\times 1024\) images. Analyzing the architecture of texture Generator \(G_{i},i=1,2,3,4\), we find that this architecture is not available to model long-range dependencies in the whole image, which results in lacking of global visual field. This limitation may be improved by adopting the architecture of visual Transformers [17, 30] to design the generator or using the diffusion model [22] to synthesizing the textures for high-resolution images. This might be an interesting topic for our future work.
Conclusions
We present PyramidFill, a novel framework for the high-resolution image inpainting task. PyramidFill consists of a pyramid of PatchGANs, wherein the content GAN is responsible for generating contents in the lowest-resolution corrupted images, and each texture GAN is responsible for synthesizing textures for higher-resolution images progressively. We customized the generators and discriminators for the content GAN and texture GAN, respectively. Our model is trained on several datasets to evaluate its ability to fill correct contents and realistic textures for high-resolution image inpainting. Quantitative and qualitative results demonstrate the superiority of PyramidFill, comparing with several state-of-the-art methods.
References
Barnes C, Shechtman E, Finkelstein A, Goldman DB (2009) PatchMatch: a randomized correspondence algorithm for structural image editing. ACM Trans Graph 28(3):24
Criminisi A, Perez P, Toyama K (2003) Object removal by exemplar-based inpainting. In: CVPR
Denton E, Chintala S, Szlam A, Fergus RD (2015) generative image models using a Laplacian pyramid of adversarial networks. In: NIPS
Du W, Hu C, Yang H (2020) Learning invariant representation for unsupervised image restoration. In: CVPR
Goodfellow IJ, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. In: NIPS
Guo Y, Liu Y, Oerlemans A, Lao S, Wu S, Lew MS (2016) Deep learning for visual understanding: a review. Neurocomputing 187:27–48
Hays J, Efros AA (2008) Scene completion using millions of photographs. Commun ACM 51:87–94
Iizuka S, Simo-Serra E, Ishikawa H (2017) Globally and locally consistent image completion. ACM Trans Graph 36(4):107
Isola P, Zhu J-Y, Zhou T, Efros AA (2017) Image-to-image translation with conditional adversarial networks. In: CVPR
Jo Y, Park J (2019) SC-FEGAN: face editing generative adversarial network with user’s sketch and color. In: ICCV
Justin J, Alexandre A, Li F-F (2016) Perceptual losses for real-time style transfer and super-resolution. In: ECCV
Karras T, Aila T, Laine S, Lehtinen J (2018) Progressive growing of GANs for improved quality, stability, and variation. In: ICLR
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521(7553):436–444
Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, Aitken A, Tejani A, Totz J, Wang Z, Shi W (2017) Photo-realistic single image super-resolution using a generative adversarial network. In: CVPR
Li C, Wand M (2016) Precomputed real-time texture synthesis with Markovian generative adversarial networks. In: ECCV
Li J, Wang N, Zhang L, Du B, Tao D (2020) Recurrent feature reasoning for image inpainting. In: CVPR
Li W, Lin Z, Zhou K, Qi L, Wang Y, Jia J (2022) MAT: mask-aware transformer for large hole image inpainting. In CVPR, pp 10748–10758
Li X, Guo Q, Lin D, Li P, Feng W, Wang S (2022) MISF: multi-level interactive Siamese filtering for high-fidelity image inpainting. In: CVPR, pp 1859–1868
Liao L, Xiao J, Wang Z, Lin C-W, Satoh S (2021) Image inpainting guided by coherence priors of semantics and textures. In: CVPR, pp 6535–6544
Liu G, Reda FA, Shih KJ, Wang T-C, Tao A, Catanzaro B (2018) Image inpainting for irregular holes using partial convolutions. In: ECCV
Liu H, Jiang B, Song Y, Huang W, Yang C (2020) Rethinking image inpainting via a mutual encoder–decoder with feature equalizations. In: ECCV
Lugmayr A, Danelljan M, Romero A, Yu F, Timofte R, Van Gool L (2022) RePaint: inpainting using denoising diffusion probabilistic models. In: CVPR, pp 11451–11461
Miyato T, Kataoka T, Koyama M, Yoshida Y (2018) Spectral normalization for generative adversarial networks. In: ICLR
Pan X, Zhan X, Dai B, Lin D, Loy CC, Luo P (2020) Exploiting deep generative prior for versatile image restoration and manipulation. In: ECCV
Pathak D, Krähenbühl P, Donahue J, Darrell T, Efros AA (2016) Context encoders: feature learning by inpainting. In: CVPR
Schönfeld E, Schiele B, Khoreva A (2020) A U-Net based discriminator for generative adversarial networks. In: CVPR
Shaham TR, Dekel T, Michaeli T (2019) SinGAN: learning a generative model from a single natural image. In: ICCV
Shocher A, Gandelsman Y, Mosseri I, Yarom M, Irani M, Freeman WT, Dekel T (2020) Semantic pyramid for image generation. In: CVPR
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: ICLR
Wan Z, Zhang J, Chen D, Liao J (2021) High-fidelity pluralistic image completion with transformers. In: ICCV
Wang X, Yu K, Wu S, Gu J, Liu Y, Dong C, Qiao Y, Change Loy C (2018) ESRGAN: enhanced super-resolution generative adversarial networks. In: ECCVW
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13(4):600–612
Xiao Z, Zhang H, Tong H, Xu X (2022) An efficient temporal network with dual self-distillation for electroencephalography signal classification. In: BIBM, pp 1759–1762
Xing H, Xiao Z, Qu R, Zhu Z, Zhao B (2022) An efficient federated distillation learning system for multitask time series classification. IEEE Trans Instrum Meas 71:1–12
Xiao Z, Xu X, Xing H, Song F, Wang X, Zhao B (2021) A federated learning system with enhanced feature extraction for human activity recognition. Knowl-Based Syst 229:107338
Yang C, Lu X, Lin Z, Shechtman E, Wang O, Li H (2017) High-resolution image inpainting using multi-scale neural patch synthesis. In: CVPR
Yang F, Yang H, Fu J, Lu H, Guo B (2020) Learning texture transformer network for image super-resolution. In: CVPR
Yang J, Qi Z, Shi Y (2020) Learning to incorporate structure knowledge for image inpainting. In: AAAI
Yi Z, Tang Q, Azizi S, Jang D, Xu Z (2020) Contextual residual aggregation for ultra high-resolution image inpainting. In: CVPR
Yu J, Lin Z, Yang J, Shen X, Lu X, Huang TS (2018) Generative image inpainting with contextual attention. In: CVPR
Yu J, Lin Z, Yang J, Shen X, Lu X, Huang TS (2019) Free-form image inpainting with gated convolution. In: CVPR
Zeng Y, Fu J, Chao H, Guo B (2019) Learning pyramid-context encoder network for high-quality image inpainting. In: CVPR
Zeng Y, Lin Z, Yang J, Zhang J, Shechtman E, Lu H (2020) High-resolution image inpainting with iterative confidence feedback and guided upsampling. In: ECCV
Zeng Y, Lin Z, Lu H, Patel VM (2021) CR-Fill: generative image inpainting with auxiliary contexutal reconstruction. In: ICCV, pp 14144–14153
Zheng C, Cham T-J, Cai J, Phung D (2022) Bridging global context interactions for high-fidelity image completion. In: CVPR, pp 11512–11522
Zhou B, Lapedriza A, Khosla A, Oliva A, Torralba A (2017) Places: a 10 million image database for scene recognition. IEEE Trans Pattern Anal Mach Intell 40(6):1452–1464
Zhu M, He D, Li X, Li C, Li F, Liu X, Ding E, Zhang Z (2021) Image inpainting by end-to-end cascaded refinement with mask awareness. IEEE Trans Image Process 30:4855–4866
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Leilei Cao did this work when he was with OPPO Research.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cao, L., Yang, T., Wang, Y. et al. Generator pyramid for high-resolution image inpainting. Complex Intell. Syst. 9, 6297–6306 (2023). https://doi.org/10.1007/s40747-023-01080-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01080-w