
Abstract
Textile defect recognition is a significant technique in the production processes of the textile industry. However, in the practical processes, it is hard to acquire large amounts of textile defect samples. Meanwhile, the textile samples with correct defect labels are rare. To address these two limitations, in this paper, we propose a novel semi-supervised graph convolutional network for few labeled textile defect recognition. First, we construct the graph convolutional network and convolution neural network to extract spectral features and spatial features. Second, the adaptive convolution structure is proposed to generate adaptive kernels according to their dynamically learned features. Finally, the spatial–spectral adaptive unified learning network (SSA-ULNet) is built for limited labeled defective samples, and graph-based semi-supervised learning is constructed. The textile defect recognition model can extract the textile image features through the image descriptors, enabling the whole network to be end-to-end trainable. To evaluate the proposed method, one public dataset and two unique self-built textile defect datasets are used to textile defect recognition. The evaluation results demonstrate that the proposed SSA-ULNet obviously outperforms existing state-of-the-art deep learning methods.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The textile defect recognition plays a vital role in product quality control in the textile industry. Recently, textile defect recognition still relies on workers’ visual inspection in most textile factories. Due to the low efficiency and high labor intensity, textile defect inspection in automation is an essential process in the textile manufacturing industry.
Currently, there are mainly five categories of methods to solve the problem of textile defect recognition. The first efficient way is the statistical-based algorithms. These methods mainly extract spatial information of image gray value in different ways, e.g., morphology [1]. They can quickly complete the recognition task, but they are easily affected by external interference. The spectral-based methods are the second way, which transform the image from the time domain to the frequency domain, e.g., Fourier Transform [2] and Gabor Transform [3]. The advantage of these algorithms is that they can accurately recognize defects by using frequency domain information, but the disadvantage is that they require a lot of computing resources. The third efficient approach is the learning-based algorithms. These methods extract the feature information of the data, such as neural networks [4, 5] and deep learning [6]. They have good feature representation ability, but the disadvantage is the uninterpretability of the extracted feature information. The structure-based algorithms are the fourth way, which mainly have the texture analysis ability [7]. However, when the textile defects are small with inconspicuous features, the algorithms do not have a good ability to identify the defects. The fifth efficient way is the model-based method, which depicts textile texture patterns by modeling special distributions [8]. The advantage of this method is that textile defects can be identified by adjusting the parameters, but if the appropriate parameters are not selected, the convergence rate of this method will be exceptionally slow. Moreover, with more efficiency and quality requirements, the existing intelligent recognition algorithms can no longer meet these new requirements.
During the recent years, the deep learning methods have achieved an enormous success in image recognition [9], image segmentation [10, 11], and object detection [12, 13]. For instance, Shi et al. [14] presented a multiscale contrastive graph convolutional network for unconstrained face image recognition task. For the visual image question generation task, a radial graph convolutional network [15] was proposed to quickly find the core answer area in an image. In this method, a sparse graph of the radial structure was built to capture the relations between the peripheral nodes and the core node. Meanwhile, due to the powerful feature representation and defect expression ability of deep learning on textile defect images, some textile defect recognition tasks [16] were processed using deep learning algorithms. For example, in order to improve the discrimination of textile defect recognition, Li et al. [17] presented fisher criterion-based stacked denoising autoencoders. In this approach, a fisher criterion-based loss function was designed to improve the detection accuracy when only limited negative samples were available. Mei et al. [18] proposed an unsupervised learning approach for textile defect recognition, which reconstructed image patches with a convolutional denoising autoencoder (CDAE) framework. To detect and localize defects with only defect-free samples, Mei et al. [19] also proposed a multiscale convolutional denoising autoencoder model. Meanwhile, this approach used an inverted pyramid architecture to reconstruct image patches at different resolution scales. However, as most of them are focusing on defect recognition accuracy, deep learning models require deeper networks and large amounts of training data. Thus, the deep structure will lead to higher computational cost.
In the above deep learning methods, supervised learning-based methods are suitable for situations where a large of defect-free and defective samples with reasonable annotations are provided. However, in most cases, there are not enough labeled samples for model training, and the occurrence of defective products is random. The supervised learning-based methods have limitations in such applications. In this paper, we propose a novel semi-supervised spatial-spectral neural network for few labeled textile defect recognition. The spatial-spectral adaptive unified learning network (SSA-ULNet) can obtain both spectral feature information and spatial feature information of the textile image, which has not been widely recognized and studied but is of significant importance. The main contributions of this paper are described as follows.
(1) We propose a new end-to-end framework for textile defect recognition with few labeled data, which can transform the task of textile defect recognition into a task based on semi-supervised method.
(2) We present two feature extraction modules to extract the spectral–spatial features of textile defect images. Moreover, a spatial adaptive kernel is constructed and integrated to learn the correlations of distinctive features.
(3) We build two textile defect benchmark datasets to evaluate the empirical performance of SSA-ULNet. Experimental results show that the textile defect recognition model achieves outstanding performance in a series of textile defect recognition challenges.
The rest of paper is organized as follows. Section 2 summarizes the deep learning-based textile defect recognition methods and the graph convolutional networks. Section 3 presents details of the proposed SSA-ULNet. Section 4 describes extensive experimental results and analyses on one public dataset and two unique self-built textile defect datasets. Section 5 concludes the conclusion and future work.
Related work
Graph convolutional networks
In this section, we describe the spectral-based GCN mathematically. Suppose an input signal \(x \in {R^n}\) is a feature vector of all nodes of a graph, \(U = \left[ {{u_0},{u_1},...,{u_{n - 1}}} \right] \in {R^{n \times n}}\) is the matrix of eigenvectors ordered by eigenvalues. Now, the graph convolution operation in spectral space is defined as
where \(*\) represents the convolution operation, \({\textrm{F}}( \cdot )\) represents graph Fourier transform, \({{\textrm{F}}^{ - 1}}( \cdot )\) represents inverse graph Fourier transform, \(g \in {R^n}\) denotes the weight filter, the superscript T denotes the matrix transpose, \(\odot \) denotes the elementwise product, G denotes the graph. Graph Fourier transform can eigendecompose the Laplacian matrix of a graph into eigenvalues and eigenvectors. Inverse graph Fourier transform can convert the signal in the frequency domain to the spatial domain. Then, a filter \({g_\theta }\) is defined as:
The graph convolution is simplified as
In the GCN, \({g_\theta }\) is a learnable network parameter, \(\theta \in {R^N}\) is the parameter in the Fourier domain. Then, Thomas et al. [20] extended the spectral convolution with Chebyshev polynomials (ChebNet) of the diagonal matrix of eigenvalues, i.e., \({g_\theta }{\mathrm{= }}\sum \nolimits _{i = 0}^K {{\theta _i}{T_i}\left( {{\tilde{\Lambda }} } \right) }\), \(\Lambda \in \left[ {{\mathrm{- }}1,1} \right] \), \({\tilde{\Lambda }} = 2\Lambda /{\lambda _{\max }} - {I_n}\), \({I_n}\) denotes the identity matrix. Furthermore, the Chebyshev polynomials can be expressed as \({T_i}\left( x \right) = 2x{T_{i - 1}}\left( x \right) - {T_{i - 2}}\left( x \right) \). In this mathematical representation, \({T_0}\left( x \right) = 1\), \({T_1}\left( x \right) = x\). Therefore, a graph signal x can be expressed as
When the first-order approximation of ChebNet is introduced into GCN network, Eq. (4) can be expressed in a more concise form. Suppose \(L = 1\) and \({\lambda _{\max }} = 2\), Eq. (4) is simplified as
where A represents adjacency matrix, diagonal matrix D denotes the degrees of A.
To further avoid overfitting and constrain the network parameters, the GCN network assume that \(\theta = {\theta _0} = - {\theta _1}\), graph convolution operation can be converted into the following way:
Meanwhile, Eq. (6) is further modified for multichannel inputs and outputs, which is expressed as follows:
where \(\Theta \) represents the learning parameters, \({\bar{A}} = {I_n} + {D^{ - \frac{1}{2}}}A{D^{ - \frac{1}{2}}}\) and \(f\left( \cdot \right) \) is an activation function. In the training processes of GCN network, the propagation rule is used as follows:
where \({\tilde{A}} = A + I\) and \({{\tilde{D}}_{i,i}} = \sum \nolimits _j {{{{\tilde{A}}}_{i,j}}} \), \(h\left( \cdot \right) \) denote the nonlinear activation function.
Deep learning-based textile defect recognition
Deep learning has achieved state-of-the-art performance in textile defect recognition. At present, there are three types of deep learning-based methods for textile defect recognition and they are summarized as follows.
(1) Supervised learning strategies use convolutional neural network (CNN) to complete the textile defect recognition task. For instance, Jeyaraj et al. [21] used CNN to learn the deep features and constructed an inspection system. Jun et al. [22] presented a two-stage learning-based deep framework for textile defect recognition. This approach used histogram equalization to enhance each image, and a fixed-size slider was used to crop the original image. To solve the data imbalance of textile defect sample, Jing et al. [23] presented a median frequency balancing loss function to overcome the sample imbalance and completed the textile defect recognition. To solve the problem of textile defect recognition in small sample sizes, Wei et al. [6] proposed the CS-CNN method, which was based on compressive sensing and CNN. This approach augmented the small sample data through compressive sampling, and the data features were classified using a CNN model. However, the disadvantage of the above method is that it relies on massive computing power and network depth. To alleviate this problem, Wei et al. [24] presented a biological visual inspired model, where the visual attention mechanism was used to deal with the interference of the texture background. Meanwhile, the visual gain mechanism was used to deal with the classification problem of small textile defects. Furthermore, Wei et al. [25] proposed multi-level multi-attentional deep learning model, aiming to recognize the multi-label textile defect images. In the model, the multi-level structure was constructed to enhance the representation ability of defect features, and the multi-attentional mechanism was incorporated to weaken the features in the foreground regions.
(2) Unsupervised learning methods, e.g., generative adversarial network (GAN) [26] and denoising autoencoders [18], recognize the textile defect when only limited negative samples are available. For instance, Liu et al. [27] proposed a multistage GAN framework for complex-textured fabric defect recognition, in which the multistage GAN was used to synthesize defects of unseen defect-free fabric samples. By combining textile defect features with unsupervised learning, this model can learn existing textile defect samples and automatically adapt to the different textures. Later, Li et al. [17] proposed discriminative representation with denoising autoencoders for patterned texture defect recognition. In this method, the fisher criterion-based SDA framework was used to efficiently inspect defects on periodic pattern and jacquard pattern textiles. Subsequently, Mei et al. [19] proposed a multiscale convolutional denoising autoencoder to detect and localize defects only using defect-free samples for model training. To address the issue that only a small number of defect-free texture samples are available for training, Yang et al. [28] presented unsupervised multiscale feature-clustering-based fully convolutional autoencoder for visual inspection of texture defects. In this approach, in the case of only a small number of defect-free texture samples, the unsupervised model can effectively inspect various types of texture defects by using multiple subnetworks. The advantage of this unsupervised strategy is that it can provide a solution for defect recognition with a small number of defect-free textile samples. However, the unsupervised architecture just completes the clustering of feature information, and does not have robustness for complex texture background.
(3) Semi-supervised learning provides the textile defect recognition method that combines supervised learning with unsupervised learning in a framework. Most importantly, in the practical industrial processes, large amounts of textile defect samples are difficult to obtain, and meanwhile, samples with correct labels are rare. In this case, the semi-supervised learning method can provide a key technical approach to solving these problems. For instance, Zhou et al. [29] attempted to extract feature information and performed density estimation based on a hybrid deep learning method via a semi-supervised strategy. This method can accurately construct defect region boundaries based on Gaussian mixture model and variational autoencoder. Wang et al. [30] introduced a graph guidance mechanism into CNN, which utilized graph guided CNN to extract textile surface defect features. In these approaches, the semi-supervised methods can recognize defects on the basis of both image label and latent space information. However, these approaches do not fully utilize the spatial–spectral information of the data sample. Meanwhile, these methods cannot tune network parameters adaptively during the training process. To cope with these challenges, we propose a novel semi-supervised SSA-ULNet for textile defect image recognition with few labeled data.
The proposed method
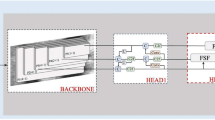
In this section, the overall architecture of SSA-ULNet and its three modules including spectral feature extraction, spatial feature extraction, and adaptive weight refinement are shown in Fig. 1. In this approach, the spectral feature extraction module and spatial feature extraction module extract the features of textile defect image, and the adaptive weight refinement module learns the correlations of distinctive features. The final recognition results are achieved by the full connection layer and softmax function. This section introduces the new model by three modules related to the main sub processes.

Spatial–spectral adaptive unified learning network for textile defect image recognition. Three major components are included in the whole model: spectral feature extraction module, spatial feature extraction module, and adaptive weight refinement module. Spectral feature extraction module aggregates feature information, and spatial feature extraction module extracts the image features. The full connection layer and softmax function are used to obtain the final results
Spectral feature extraction
In our work, we view textile defect image recognition as a semi-supervised graph learning problem. GCN can learn features by gradually aggregating information, which is a novel semi-supervised network. Figure 2 provides the architecture of the spectral feature extraction based on GCN structure. The preprocessed textile defect image \(X \in {R^{n \times d}}\) is taken as inputs. Here, d represents the feature dimension, n represents the number of nodes. Define an undirected graph \(g = \left( {V,E} \right) \) for the following learning process. \(V = \left\{ {{v_i}\left| {i \in \left\{ {1,...,N} \right\} } \right. } \right\} \) and \(E = \left\{ {{e_{i,j}}\left| {\forall i,j \in \left\{ {1,...,N} \right\} } \right. } \right\} \) are the sets of nodes and edges, respectively. \(A \in {R^{n \times n}}\) is defined as the adjacency matrix, and every node in the graph is assumed to be connected to each other. In general, we use the following radial basis function to compute each element in A:
where the parameter \(\delta \) is used to control the width of radial basis function. Vectors \({x_i}\) and \({x_j}\) represent the spectral signatures associated with the vertexes \({v_i}\) and \({v_j}\). Once the adjacency matrix A is given, the graph Laplacian matrix L is constructed as follows:
where D denotes the degrees of A, i.e., \({D_{i,i}} = \sum \nolimits _j {{A_{i,j}}}\) [31] and D is a diagonal matrix. Furthermore, a modified Laplacian matrix, which is called symmetric normalized Laplacian matrix [32], is used to enhance the generalization ability of the graph:
where I is the identity matrix.

The architecture of GCN branch (1). Construct the graph with nodes and edges (2). The graph convolution is applied to update each node from the neighbor (3). The graph-based features are generated by the batch normalization layer
By referring to [32] and Eq. (8), GCN for textile defect image can be finally formulated as:
where \({\tilde{A}} = A + I\) and \({{\tilde{D}}_{i,i}} = \sum \nolimits _j {{{{\tilde{A}}}_{i,j}}}\) are defined as the renormalization terms of A and D, respectively. \(h\left( \cdot \right) \) is the activation function with respect to the weights to be learned \({W^{\left( l \right) }}\) and the biases \({b^{\left( l \right) }}\).
GCN aggregates image features from the neighbors of each node and performs information propagation on a graph. In multilayer GCN, GCN updates all node states based on a weighted sum of the features of their neighbors [33]. For spectral feature learning on a graph, GCN can capture the spectral dependencies among samples through information propagation of adjacent nodes and graph node updates.
Spatial feature extraction
The semi-supervised GCN can learn the spectral features of an input image. The disadvantage of this structure is that the adjacent matrix fails to reveal the effective spatial relationship. To overcome this issue, CNN has the powerful ability of spatial feature extraction, which can further enhance the generalization capability of the model. Given input \(X \in {R^{n \times d}}\), the convolution layer calculates the feature information of the upper layer and generates the feature maps:
where \(x_{cj}^l\) is the feature map, l is the number of the convolutional layer, the subscript j denotes the channel of the convolutional layer, the subscript c denotes the convolution layer parameters, \(u_{cj}^l\) is the activation result of the network, \({M_j}\) is the subset of feature maps, \(k_{ij}^l\) is the convolution kernel, \(b_{cj}^l\) is the bais, "\(*\)" denotes the convolution calculation on the input. The pooling layer computes the feature maps:
where \(down\left( \cdot \right) \) denotes the down sampling function, \(\beta _j^l\) is the weights, the subscript p denotes the pooling layer parameters, \(b_{pj}^l\) denotes the bais, \(u_{pj}^l\) is the output of the pooling layer. In addition, to enhance the feature representation and nonlinear ability, the three convolution layers and nonlinear activation function ReLU are applied in this network.
Adaptive weight refinement
To further learn the correlations among the features, spatial adaptive weight is designed and integrated into the model. For the textile defect recognition task, the adaptive weight refinement can increase its sensitivity to informative features. The adaptive weight refinement (AWR) can be expressed as \(AWR = \left( {{y_s},adaptive\_W} \right) \). \(adaptive\_W\) represent adaptive weight. Similar to the work [34], a learning-based adaptive weighting strategy is used for AWR. Here, we consider two computing operations. First, AWR uses the global average pooling to generate channel-wise statistics. Formally, \({z_s} \in {R^C}\) is generated by shrinking \({y_s}\) through the spatial dimensions \({C_1} \times {C_2}\):
where \({C_1}\) and \({C_2}\) correspond to the length and width of the features; \({z_s}\) is the output of the transformations \({y_s}\), and can be considered as a collection of local descripts. Second, we adopt the global average pooling to aggregate feature information and capture the channel-wise dependencies of feature information. To achieve the goals, the designed function needs to satisfy two criteria: (1) this function must have the ability to learn the nonlinear interaction among channels, which means must be flexible; (2) the function must learn a non-mutually exclusive relationship, thus ensuring that the multiple channel information can be emphasized. Here, similar to the work [35], we use the gating mechanism to complete the desired function:
where \({W_1} \in {R^{\frac{C}{r} \times C}}\), \({W_2} \in {R^{\frac{C}{r} \times C}}\), \(\delta \) refers to the ReLU function, \(\sigma \) is the Sigmoid function, and r is the reduction ratio. The importance of different weights is described as the output \({s_s}\).
Then, the output of AWR can be calculated:
where \(Batch\_Norm\left( \cdot \right) \) is the batch normalization strategy, which can complete the normalization operation of feature information.
Combining the output of GCN and Eq. (18), the final output is obtained:
where H is the spectral feature representation, Y represents the spatial feature representation; \(M\left( \cdot \right) \) is feature fusion operation. Here we use the concatenation to complete the fusion. Thus, the whole model can integrate the spectral features and the spatial features by exploring rich underlying spectral–spatial features.
Learning process of the proposed network
A deep network usually requires many training data to learn the parameters of the model. In this paper, we train the SSA-ULNet model with few labeled textile defect data. Since the optimizer Adam [36] is an extension of stochastic gradient descent, and is widely used in the training process of deep learning models. We use the Adam optimization algorithm to optimize the network. The learning rate is initially set as 0.001. During training the model, the learning rate can be updated dynamically by multiplying by a base learning rate. The L2 loss is used in the training process, which can improve the stabilization of SSA-ULNet learning process. To optimize the proposed model, the model takes the properties of mini-batch fashion [32] into consideration. In the training process, the maximum number of epochs is set to 1,000. The size of each batch of training samples is 128. Batch normalization is adopted with the 0.9 momentum. The training and testing are performed on a Linux workstation with 128GB RAM, and Nvidia Quadro RTX 6000 GPUs (24182 MiB).
Experimental evaluation and discussion
In this section, the performance of proposed SSA-ULNet is tested on one public dataset and two unique self-built textile defect datasets (DHU-Semi1000, Aliyun-Semi10500). Each dataset is divided into two parts for training and testing the proposed model. The content of this section is organized in three subsections below.
(1) We describe the experimental setup, including dataset overview on one public dataset, two unique self-built textile defect datasets and evaluation metrics.
(2) We present experimental results, including performance comparison with three types of learning-based approaches and ablation study in different components of SSA-ULNet.
(3) We present analysis and discussion of the experimental results, including the effect of number of GCN layers and CNN layers, the performance with percentage of missing labels.
Experimental setup
Dataset overview
In our experiments, the public dataset [4] and two self-built datasets (DHU-Semi1000, Aliyun-Semi10500) are used to verify the effectiveness of the proposed method. The former consists of 1000 samples of fabrics. This dataset is artificial generated, but similar to real world and has been widely used for textile defect image recognition. Two self-built datasets are built to evaluate effectiveness of the proposed SSA-ULNet, which are described as follows.
DHU-Semi1000: The original textile defect images captured by CCD camera, which contain interference such as stain and irregular texture. The type of textile products is weaving fabric. The pixels of each original image are \(1280\times 1024\). We perform the transformation, segmentation, and diversification to eliminate the interference of background and the acquisition process. The size of each image used in the training and testing process is \(227\times 227\). DHU-Semi1000 consists of approximately 1000 samples, including 100 defect-free images and 900 defect images. DHU-Semi1000 contains ten categories of textile defects, each with 100 images. Table 1 shows the classes of the DHU-Semi1000 dataset, with the number of training and test samples for each class. Figure 3 shows some defect-free and defect samples in the DHU-Semi1000 dataset.

Defect-free and defect samples: a two defect-free images, and b six defect images
Aliyun-Semi10500: We collect the Aliyun-Semi10500 dataset from the public textile classification competition (TianChi competition [37]). Aliyun-Semi10500 contains 10,500 textile defect images, which fall into seven classes. This dataset contains 9000 textile defect images and 1,500 defect-free textile images. Each image in this dataset is \(224\times 224\) pixels. The seven classes mainly include broken pick, broken end, stain, and felter, hole, crack, and normal (defect-free). Table 2 shows the classes of the Aliyun-Semi10500 dataset, with the number of training and test samples for each class. For training the SSA-ULNet, 30% of the images are used as training samples, and the remaining 70% samples are used as test data in each dataset.
Evaluation metrics
Several quantitative indicators are selected to evaluate the recognition of one public dataset and two self-built datasets, which include error rate [33], accuracy, recall [22], and f1 score [22]. The indicator accuracy is the percentage of all testing samples that are corrected recognized, which can be formulated as:
where TP is true positive rate, FN is false negative rate, TN is true negative rate, FP is the false positive rate. Meanwhile, error rate is another important indicator to measure the recognition performance of the model, which is used to evaluate the learning process.
Experimental results
Performance comparison
The recognition performance of the proposed method is evaluated on one public dataset and two self-built datasets. To comprehensively evaluate the effectiveness of the SSA-ULNet, we compare the method with three types of learning-based approaches. For the supervised learning method, SVM [38], CNN [39], VGG16 [36], Xception [40], VMVI-CNN [4], and VIN-Net [35] are the popular methods used to evaluate the textile defect recognition performance. For semi-supervised learning, GCN [20], Mini-GCN [41], and FuNet-C [32] are compared with the SSA-ULNet in textile defect recognition. For unsupervised learning, GAN [27] is used to compare with our proposed method.
Table 3 shows the recognition results for different methods on the public textile dataset FDI-1000. Testing time represents the total time spent on the testing set. It can be seen from Table 3 that the accuracy of our proposed method can achieve 87.62%, which is the best recognition performance compared to other methods. Meanwhile, comparing the performance indicators recall and F1 score, we can find that the proposed SSA-ULNet also achieves the best image recognition performance. In terms of the time computation, our proposed method requires more testing time than the other ones during the testing processes. Tables 4 and 5 show the recognition results of textile defect images for different methods on two benchmark textile datasets. Compared with all the competitors, it can be seen that SSA-ULNet achieves the best recognition performance. Note that CNN, VGG16, VMVI-CNN, VIN-Net, and Xception exhibit under-fitting as there are not enough labeled samples for training. This shows that when there are a large number of labeled samples for training, the supervised learning method will achieve better recognition performance than the unsupervised learning method. For the unsupervised learning method, the advantage of the algorithm is that it does need not use labeled training samples, but the experiment performance usually cannot be guaranteed. These results show that SSA-ULNet is an effective approach for textile defect recognition with few labeled samples. Meanwhile, we can see that the recognition accuracy of SAA-GCN is 62.82% on Aliyun-Semi10500, which can not achieve better recognition performance possibly due to the following two reasons. Firstly, the background and textures of Aliyun-Semi10500 are more indistinguishable than the DHU-Semi1000 dataset. Secondly, in the Aliyun-Semi10500 dataset, the feature distribution on the training set does not well match the feature distribution on the testing set.
Ablation study
As mentioned in Section III, our proposed SSA-ULNet contains three critical components for textile defect recognition, i.e., spectral feature extraction (GCN), spatial feature extraction (CNN), and adaptive weight refinement. Here, we use two textile datasets to demonstrate the usefulness of these three structures. In the ablation study, we investigate the effectiveness of different components of SSA-ULNet. The recognition performance of SSA-ULNet without GCN, SSA-ULNet without CNN, SSA-ULNet without GCN and adaptive weight, SSA-ULNet without CNN and adaptive weight, and SSA-ULNet without adaptive weight are compared with the SSA-ULNet model.
Tables 6 and 7 show the ablation experiment results on the two textile datasets. Based on the comparison results, it can be concluded that our SSA-ULNet model can obtain the best performance. As shown in Tables 6 and 7, the SSA-ULNet (without CNN) exhibits the effectiveness of the textile defect recognition. This is because SSA-ULNet (without CNN) can learn the semi-supervised spectral features and adaptively weights. Comparing the performance between the SSA-ULNet (without CNN) and SSA-ULNet (without GCN), one can find that GCN structure is more helpful than CNN structure in defect recognition. Furthermore, comparing the performance between SSA-ULNet (without GCN) and SSA-ULNet (without GCN+ adaptive), we find that the adaptive weight refinement is an important component in improving the recognition performance of textile defect images.
Analysis and discussion
Numbers of GCN layers and CNN layers
In this section, we evaluate the performance of SSA-ULNet with different settings of network parameters. The recognition results of the proposed method with different GCN layers and convolutional layers are evaluated on DHU-Semi1000, as shown in Fig. 4.

Recognition performance of different GCN and convolutional layers
Analyzing the curve on Fig. 4, we can see that, the proposed SSA-ULNet is influenced by the number of GCN layers. The performance of the network is improved until it reaches a given optimal point. Meanwhile, analyzing it we can see that SSA-ULNet is also influenced by the number of CNN layers. Our approach is able to achieve state-of-the-art results on three-layer CNN structure. Furthermore, the two-layer GCN structure is sufficient to capture the spectral feature information with few labeled data. This phenomenon can be caused by high-order irrelevant spectral features in the learning process. The irrelevant spectral features of different classes may blur the discrimination of interclass information. Furthermore, the three layers of CNN structures can ensure the best performance of the model.

Trajectories of the six selected weights [a \(\sim \) f] on the DHU-Semi1000

Trajectories of the six selected weights [a\(\sim \)f] on the Aliyun-Semi10500
The performance with the percentage of missing labels
We analyze the impacts of different label rates on recognition performance. Label rate denotes the number of labeled samples that are used for training divided by the total number of samples in each dataset. Table 8 shows the recognition results with different label rates on the DHU-Semi1000 dataset. We find that the defect recognition accuracy is 86.57% when the label rate is 30%. Meanwhile, when the label rate is 10%, the defect image recognition accuracy is 50.13%. It can be concluded that the performance of the proposed approach will decrease significantly when the number of labeled samples is reduced in the dataset. A reasonable explanation for this finding is that the diversity of textile background and textures brings certain difficulties to effective identification.
Training stability of the network
Since the network is trained end-to-end with a semi-supervised learning algorithm via error backpropagation, the training stability of the network is an important indicator of the network performance. During the training processes, we track the changing trend of the initial weights. Here, the six random weights are selected to be tracked, and the trajectories of the selected weights are shown in Figs. 5 and 6. From the Figs. 5 and 6, we can see that the random selected weights can coverage to the stable state on datasets DHU-Semi1000 and Aliyun-Semi10500. The experimental results can further confirm the network stability of the whole network framework.
Conclusions and future work
In this paper, a semi-supervised neural network with few labeled data has been applied to textile defect image recognition. To alleviate the limitations of traditional deep learning models, SSA-ULNet, a novel textile image recognition model is proposed for spectral–spatial-related feature extraction. We use the GCN structure to obtain the spectral feature information of the textile image. Then, the CNN structure is used to address the spatial feature information. Furthermore, the adaptive spatial weight is designed to learn the correlations among the features. Finally, one public dataset and two self-built datasets are used to evaluate effectiveness of the proposed SSA-ULNet model. Experiments confirm that the novel model can achieve good recognition results on different textile images. In the future, we would investigate the online textile defect image recognition problems. Besides, we would like to explore the interpretability and perform the theoretical analysis of the proposed model.
Data availability
Data available on request from the authors.
References
Mak K-L, Peng P, Yiu KFC (2009) Fabric defect detection using morphological filters. Image Vis Comput 27(10):1585–1592
Hu G-H, Wang Q-H, Zhang G-H (2015) Unsupervised defect detection in textiles based on fourier analysis and wavelet shrinkage. Appl Opt 54(10):2963–2980
Bodnarova A, Bennamoun M, Latham S (2002) Optimal gabor filters for textile flaw detection. Pattern Recogn 35(12):2973–2991
Wei B, Hao K, Gao L, Tang X-S, Zhao Y (2020) A biologically inspired visual integrated model for image classification. Neurocomputing 405:103–113
Li J, Li B, Jiang Y, Cai W (2022) Msat-gan: a generative adversarial network based on multi-scale and deep attention mechanism for infrared and visible light image fusion. Complex Intell Syst 1–29
Wei B, Hao K, Tang X-S, Ding Y (2019) A new method using the convolutional neural network with compressive sensing for fabric defect classification based on small sample sizes. Text Res J 89(17):3539–3555
Karasan A, Erdogan M (2021) Creating proactive behavior for the risk assessment by considering expert evaluation: a case of textile manufacturing plant. Complex Intell Syst 7(2):941–959
Susan S, Sharma M (2017) Automatic texture defect detection using gaussian mixture entropy modeling. Neurocomputing 239:232–237
Albattah W, Nawaz M, Javed A, Masood M, Albahli S (2022) A novel deep learning method for detection and classification of plant diseases. Complex Intell Syst 8(1):507–524
Zhang M, Gu S, Shi Y (2022) The use of deep learning methods in low-dose computed tomography image reconstruction: a systematic review. Complex Intell Syst 1–17
You H, Yu L, Tian S, Cai W (2022) Dr-net: dual-rotation network with feature map enhancement for medical image segmentation. Complex Intell Syst 8(eq1):611–623
Zhang Q, Zhang M, Gamanayake C, Yuen C, Geng Z, Jayasekara H, Woo C-W, Low J, Liu X, Guan YL (2022) Deep learning based solder joint defect detection on industrial printed circuit board x-ray images. Complex Intell Syst 8(2):1525–1537
Wang X, Liu J, Liu X, Liu Z, Khalaf OI, Ji J, Ouyang Q (2022) Ship feature recognition methods for deep learning in complex marine environments. Complex Intell Syst 1–17
Shi X, Chai X, Xie J, Sun T (2022) Mc-gcn: a multi-scale contrastive graph convolutional network for unconstrained face recognition with image sets. IEEE Trans Image Process 31:3046–3055
Xu X, Wang T, Yang Y, Hanjalic A, Shen HT (2020) Radial graph convolutional network for visual question generation. IEEE Trans Neural Netw Learn Syst 32(4):1654–1667
Li C, Li J, Li Y, He L, Fu X, Chen J (2021) Fabric defect detection in textile manufacturing: a survey of the state of the art. Secur Commun Netw. https://doi.org/10.1155/2021/9948808
Li Y, Zhao W, Pan J (2016) Deformable patterned fabric defect detection with fisher criterion-based deep learning. IEEE Trans Autom Sci Eng 14(2):1256–1264
Mei S, Wang Y, Wen G (2018) Automatic fabric defect detection with a multi-scale convolutional denoising autoencoder network model. Sensors 18(eq4):1–18
Mei S, Yang H, Yin Z (2018) An unsupervised-learning-based approach for automated defect inspection on textured surfaces. IEEE Trans Instrum Meas 67(6):1266–1277
Kipf TN, Welling M Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907
Jeyaraj PR, Nadar ERS (2020) Effective textile quality processing and an accurate inspection system using the advanced deep learning technique. Text Res J 90(9–10):971–980
Jun X, Wang J, Zhou J, Meng S, Pan R, Gao W (2021) Fabric defect detection based on a deep convolutional neural network using a two-stage strategy. Text Res J 91(1–2):130–142
Jing J, Wang Z, Rätsch M, Zhang H (2022) Mobile-unet: an efficient convolutional neural network for fabric defect detection. Text Res J 92(1–2):30–42
Wei B, Hao K, Gao L, Tang X-S (2020) Bioinspired visual-integrated model for multilabel classification of textile defect images. IEEE Trans Cogn Dev Syst 13(3):503–513
Wei B, Xu B, Hao K, Gao L (2022) Textile defect detection using multilevel and attentional deep learning network (mlma-net). Text Res J. https://doi.org/10.1177/00405175211073773
Hu G, Huang J, Wang Q, Li J, Xu Z, Huang X (2020) Unsupervised fabric defect detection based on a deep convolutional generative adversarial network. Text Res J 90(3–4):247–270
Liu J, Wang C, Su H, Du B, Tao D (2019) Multistage gan for fabric defect detection. IEEE Trans Image Process 29:3388–3400
Yang H, Chen Y, Song K, Yin Z (2019) Multiscale feature-clustering-based fully convolutional autoencoder for fast accurate visual inspection of texture surface defects. IEEE Trans Autom Sci Eng 16(3):1450–1467
Zhou Q, Mei J, Zhang Q, Wang S, Chen G (2021) Semi-supervised fabric defect detection based on image reconstruction and density estimation. Text Res J 91(9–10):962–972
Wang Y, Gao L, Gao Y, Li X, Gao L (2020) Knowledge graph-guided convolutional neural network for surface defect recognition. In: 2020 IEEE 16th international conference on automation science and engineering (CASE), IEEE, pp 594–599
Hong D, Yokoya N, Chanussot J, Zhu XX (2019) Cospace: common subspace learning from hyperspectral-multispectral correspondences. IEEE Trans Geosci Remote Sens 57(7):4349–4359
Hong D, Gao L, Yao J, Zhang B, Plaza A, Chanussot J (2020) Graph convolutional networks for hyperspectral image classification. IEEE Trans Geosci Remote Sens 59(7):5966–5978
Liang J, Deng Y, Zeng D (2020) A deep neural network combined cnn and gcn for remote sensing scene classification. IEEE J Select Top Appl Earth Observ Remote Sens 13:4325–4338
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7132–7141
Wei B, He H, Hao K, Gao L, Tang X-S (2020) Visual interaction networks: a novel bio-inspired computational model for image classification. Neural Netw 130:100–110
Simonyan K, Zisserman A Very deep convolutional networks for large-scale image recognition, arXiv preprint arXiv:1409.1556
Fabirc defect dataset of aliyun tianchi competition, [Online]. Available: https://tianchi.aliyun.com/competition/entrance/231666/information
Shi Q, Zhang H (2020) Fault diagnosis of an autonomous vehicle with an improved svm algorithm subject to unbalanced datasets. IEEE Trans Industr Electron 68(7):6248–6256
Krizhevsky A, Sutskever I, Hinton GE (2013) Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst 25:1097–1105
Chollet F (2017) Xception: eep learning with depthwise separable convolutions, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1251–1258
Chen J, Jiao L, Liu X, Li L, Liu F, Yang S (2021) Automatic graph learning convolutional networks for hyperspectral image classification. IEEE Trans Geosci Remote Sens. https://doi.org/10.1109/TGRS.2021.3135084
Acknowledgements
This work was supported in part by the Fundamental Research Funds for the Central Universities (2232021D-32,2232021A-10), Shanghai Sailing Program (No. 22YF1401300), National Natural Science Foundation of China (Nos. 61806051, 61903078), Natural Science Foundation of Shanghai (20ZR1400400), Shanghai Pujiang Program (22PJ1423400), and the Key Research Projects of China Telecom (No. P-2022-06).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, Y., Han, T., Wei, B. et al. A spatial–spectral adaptive learning model for textile defect images recognition with few labeled data. Complex Intell. Syst. 9, 6359–6371 (2023). https://doi.org/10.1007/s40747-023-01070-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01070-y