
Abstract
Many optimization problems suffer from noise, and the noise combined with the large-scale attributes makes the problem complexity explode. Cooperative coevolution (CC) based on divide and conquer decomposes the problems and solves the sub-problems alternately, which is a popular framework for solving large-scale optimization problems (LSOPs). Many studies show that the CC framework is sensitive to decomposition, and the high-accuracy decomposition methods such as differential grouping (DG), DG2, and recursive DG (RDG) are extremely sensitive to sampling accuracy, which will fail to detect the interactions in noisy environments. Therefore, solving LSOPs in noisy environments based on the CC framework faces unprecedented challenges. In this paper, we propose a novel decomposition method named linkage measurement minimization (LMM). We regard the decomposition problem as a combinatorial optimization problem and design the linkage measurement function (LMF) based on Linkage Identification by non-linearity check for real-coded GA (LINC-R). A detailed theoretical analysis explains why our proposal can determine the interactions in noisy environments. In the optimization, we introduce an advanced optimizer named modified differential evolution with distance-based selection (MDE-DS), and the various mutation strategy and distance-based selection endow MDE-DS with strong anti-noise ability. Numerical experiments show that our proposal is competitive with the state-of-the-art decomposition methods in noisy environments, and the introduction of MDE-DS can accelerate the optimization in noisy environments significantly.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Noise widely exists in the fitness evaluation of many problems [1,2,3], which can mislead the direction of optimization. In the past decade, many studies [4, 5] on optimization problems in noisy environments have been published, and some strategies have been introduced to traditional evolutionary algorithms (EAs) to tackle the noise. Examples include explicit averaging [6], implicit averaging [7], Fourier transform [8], fitness estimation [9], and more. Most of the previous research focuses on relatively low-dimensional problems (up to 100-D), and a few studies on noisy problems with large-scale optimization problems (LSOPs) have been published. In fact, many noisy optimization problems are high-dimensional, such as parameters and structures optimization of deep neural networks [10] and subset selection [11].
The LSOPs in noisy environments contain challenges both on the scalability and robustness to noise, which make the difficulties of problem-solving explosive. The main reasons are the following aspects: (1) the complexity of the optimization problem increases, including the increase of dimensionality and the existence of the noise. (2) The search space of LSOPs increases exponentially with the increase of dimensionality, which is known as the curse of dimensionality [12]. (3) The computational cost of building a surrogate model is expensive, and the accuracy is also affected by noise and the curse of dimensionality, which makes some algorithms limited [13, 14].
Many algorithms have been proposed to overcome the challenge of the LSOPs, such as designing optimization operators to adapt the large-scale attributes [15], building surrogate models [16], and decomposing the problem [17], which is known as the cooperative coevolution (CC). In this paper, we apply the CC framework to solve LSOPs in noisy environments. This method is inspired by the divide and conquer, which has achieved great success in solving large-scale continuous [18], combinatorial [19], and constrained [20] problems.
How to decompose the LSOPs is the key to the successful implementation of the CC framework. Many studies [21, 22] show that the CC framework is sensitive to problem decomposition strategies. Taking the linkage identification by non-linearity check for real-coded GA (LINC-R) [23] as a pioneer, many decomposition methods have been proposed. Differential grouping (DG) [24] first extends the identical mechanism of LINC-R to the 1000-D problem. Extend DG (XDG) [25] improves the shortage of DG in dealing with overlaps. DG2 [26] notices the high computational cost in DG and utilizes the transmissibility of separability to save the computational budget. Global DG (GDG) [27] regards the variable interactions matrix as the adjacency matrix of a graph and depth-first search or breadth-first search is applied to identify the interactions and formed the sub-problems. Recursive DG (RDG) [18] further reduces the computational cost by examining the interaction between a pair of sets of variables rather than a pair of variables, and forms the sub-problems recursively. Efficient RDG (ERDG) [28] uses the historical information on interaction identification to save the computational cost in redundant examinations and is more efficient than RDG. These decomposition methods are considered high-accuracy decomposition methods. These methods detect the interaction by determining the difference between fitness difference and threshold. However, they are extremely sensitive to the fidelity of observed objective value and will completely fail to detect the interactions in multiplicative noisy environments. We will explain the reason in the section “Challenges of DG-based decomposition methods in noisy environments”.
In this paper, we propose a novel decomposition method named linkage measurement minimization (LMM), our proposal allows an automatic decomposition that treats the decomposition problem as a combinatorial optimization problem, and we design the linkage measure function (LMF) based on LINC-R as the objective function of combinatorial optimization. In addition, the advanced optimizer: MDE-DS is employed to optimize the sub-problems (MDE-DSCC-LMM). More specifically, the main contributions of this paper are as follows.
-
(1)
Our proposal LMM provides a novel strategy to regard the decomposition problem as a combinatorial optimization problem, and the genetic algorithm is employed to actively search the interactions between decision variables. We mathematically explain the feasibility of LMF and its relationship with LINC-R. Theoretical analysis shows how our proposal detects interactions in noisy environments. In addition, we analyze the time complexity of LMM, and the fitness evaluation times (FEs) consumed in decomposition are controllable. And our proposal can be extended to decompose the higher dimensional, multi-objective, real-world problems with a limited computational budget.
-
(2)
MDE-DS is applied as the optimizer for sub-problems and is well performed on various benchmark functions in noisy environments. The results in this paper further demonstrate that MDE-DS can accelerate cooperative coevolutionary optimization significantly.
-
(3)
Numerical experiments demonstrate that LMM is competitive with some state-of-the-art decomposition methods for LSOPs in noisy environments, and the introduction of MDE-DS is efficient for sub-problems optimization. To the best of our knowledge, not much work has been reported on employing the CC framework to solve LSOPs in noisy environments.
The rest of the paper is organized as follows: the section “Preliminaries and related work” covers preliminaries, MDE-DS, a brief review of the state-of-the-art decomposition method, and reveals the challenges of DG-based decomposition methods in multiplicative noisy environments. The section “Our proposal:MDE-DSCC-LMM” provides a detailed introduction to our proposal, MDE-DSCC-LMM. The section “Numerical experiment and analysis” describes the experiments on CEC2013 LSGO Suite [29] in noisy environments and analyzes the experimental results. The section “Discussion” discusses the direction of our research in the future. Finally, the section “Conclusion” concludes the paper.
Preliminaries and related work
Preliminaries
Large-scale optimization problem
Without loss of generality, an LSOP can be defined as follows:
where \(X=(x_1, x_2, \ldots , x_n)\) is an n-dimensional decision vector, and each \(x_i \ (i \in [1,n])\) is a decision variable. f(X) is the objective function needed to be minimized. In our work, the large-scale optimization problem is a special case of black-box optimization, where the number of decision variables n is large (e.g., \(n \geqslant 1000\)).
Variables’ interaction
The concept of variable interaction is derived from biology. In biology, if a feature at the phenotype level is contributed by two or more genes, then we consider there are interactions between these genes, and the genome composed of these genes is called a linkage set [30]. In the definition of optimization problems. If \(\min f(x_1, x_2, \ldots ,x_n) = (\min \nolimits _{c_1}f_1(...,...), \ldots , \min \nolimits _{c_m}f_m(...,...))\), then f(x) is a partially separable function, and decision variables in identical sub-problem consist of linkage set. There are two extreme cases, when there is no interaction between all variables, which means \(\min \ f(x_{1},x_{2},\ldots ,x_{n})=\min \ \sum _{i=1}^{n}f(x_{i_{1}})\), then we call f(x) is a fully separable function. On the contrary, we call f(x) a completely nonseparable function if all variables have direct or indirect interactions with each other.
Cooperative coevolution
Inspired by divide and conquer, the CC framework was proposed to deal with LSOPs by decomposing the problem into multiple nonseparable sub-problems and optimizing them alternately. A standard CC consists of two stages: decomposition and optimization. Figure 1 shows the main steps of the CC framework.

The flowchart of CC
CC framework first decomposes the LSOPs into k nonseparable sub-problems with a certain strategy. Due to the sub-solution \(i(i \in [1, k])\) cannot form a complete solution for evaluation, all sub-problems maintain a public context vector [31] to construct a complete solution, and after optimization, the latest information updates the context vector. Some studies found that only one context vector may be too greedy for evaluation. Therefore, the adaptive multi-context CC framework [32] is proposed, which employs multiple context vectors to co-evolve subcomponents.
Noise in objective functions
Additive noise [33] and multiplicative noise [34] widely exist in the evaluation of optimization problems. Mathematically, the noisy objective function \(f^N (\textrm{X})\) of a trial solution X is represented by
where f(X) is the real objective function. Equation (1) shows the objective function in addictive noisy environments, \(\eta \) is the amplitude of the addictive noise. Equation (2) reveals the relationship between the real objective function and objective function in multiplicative noisy environments. \(\beta \) is a random noise (such as Gaussian noise).
Anti-noise strategies in EAs
Many optimization problems suffer from noise, and to perform the optimization under the existence of noise, various anti-noise strategies have been proposed in the literature. Following the classification reported in Ref. [35], two categories of noise handling methods for EAs can be mainly classified; each category can be divided into two sub-categories:
-
Methods which require an increase in the computational cost
-
(1)
Explicit averaging methods
-
(2)
Implicit averaging methods.
-
(1)
-
Methods which perform hypotheses about the noise
-
(1)
Averaging through approximated models
-
(2)
Modification of the selection schemes.
-
(1)
Explicit averaging methods consider that re-sampling and re-evaluation can reduce the impact of noise on the fitness landscape. Increasing the re-evaluation times is equivalent to reducing the variance of the estimated fitness. Thus, ideally, an infinite sample size would reduce to 0 uncertainties in the fitness estimations.
Implicit averaging states that a larger population allows the evaluations of neighbor solutions, and thus, the fitness landscape in a particular portion of decision space can be estimated. Paper [36] has shown that a large population size reduces the influence of noise on the optimization process, and paper [37] has proved that a GA with an infinite population size would be noise-insensitive.
Both explicit and implicit averaging methods consume more fitness evaluation times (FEs) to correct the objective value, which is improper or even unacceptable for LSOPs under the FEs’ limitation. To obtain efficient noise filtering without excessive computational cost, various techniques have been proposed in the literature, such as the introduction of the approximated model [38], probability-based selection schemes [39], self-adaptative parameter adjustment [40], and so on.
Modified DE with distance-based selection
Differential evolution algorithm (DE) [41] was first proposed in 1995 and has been wildly applied in data mining [42], pattern recognition [43], artificial neural networks [44], and other fields due to its characteristics, such as easy implementation, fast convergence speed, and strong robustness. MDE-DS [45] is designed for continuous optimization problems in presence of noise with the modification in mutation, crossover, and selection, and the detailed description of MDE-DS is as follows.
Parameter control
The constants F and Cr are unnecessary, as F is randomly sampled from 0.5 to 2 for each mutation operation and Cr is randomly switched between 0.3 and 1 for each target vector. Switching F between two extreme corners of the feasible range is conducive to attaining a balance between exploration and exploitation of the search. And there is a new parameter b (the blending rate) in blending crossover, whose value is also randomly chosen from among three candidates: a low value of 0.1, a medium value of 0.5, and a high value of 0.9. The utility of such a switching scheme has been discussed in paper [46] for solving LSOPs.
Mutation
MDE-DS includes two different mutation strategies and switches them randomly with \(50\%\) probability.
In the population centrality-based mutation, the elite subpopulation (top 50%) is selected and \(\widetilde{\vec {X}}_{{\text {best}}, G}\) is calculated by the arithmetic mean (centroid) of the subpopulation individuals. Eq. (3) is adopted to mutate the ith individual
where \(\vec {X}_{r1, G}\) and \(\vec {X}_{r2, G}\) are two different individuals corresponding to randomly chosen indices r1 and r2. \(\vec {V}_{i, G}\) is the newly generated mutant vector corresponding to the current target vector for present generation G.
In the DMP-based mutation scheme, the best individual \(\vec {X}_{{\text {best}}, G}\) in each generation is selected and the dimension-wise average is implemented for both \(\vec {X}_{{\text {best}}, G}\) and the current target individual \(\vec {X}_{i, G}\). The mutation is generated in the following way:
where \(\Delta _{m}=(X_{{\text {best}}_{\text {dim}}, G}-X_{i_{\text {dim}}, G})\), with \(X_{{\text {best}}_{\text {dim}}, G}=\frac{1}{D}\sum _{k=1}^{D}x_{{\text {best}}_k, G}\) and \(X_{i_{\text {dim}}, G}=\frac{1}{D}\sum _{k=1}^{D}x_{i_k, G}\). \(\frac{\vec {M}_{i, G}}{\Vert \vec {M}_{i, G} \Vert }\) is a unit vector with random direction.
The significance of the population centrality-based mutation scheme is that it balances greediness while still maintaining a certain extent of diversity. For example, it is less greedy than the DE/best/1 scheme, and hence, the probability of the optimization trapped in local optima is less. On the other hand, the DMP-based mutation scheme prefers exploration [47], and thus, in absence of any feedback about the nature of the function, an unbiased combination of these two methods is applied.
Crossover
Crossover plays an important role in generating promising offspring from two or more existing individuals within the function landscape. Blending crossover is employed in MDE-DS and described in Eq. (5)
where \(u_{j,i,G}\) and \(v_{j,i,G}\) are the jth dimensions of the trial and donor vectors, respectively, corresponding to the current index i in generation G and \(x_{j,i,G}\) is the jth dimension of the current population individual \(\vec {X}_{i, G}\). Blending recombination has one parameter b, which is randomly selected from 0.1, 0.5, and 0.9. The concrete analysis can be referred to in Ref. [45].
Selection
The canonical DE selects the offspring based on a simple greedy strategy. However, if the fitness landscape gets corrupted with noise, the greedy selection suffers a lot, because in this case, the original fitness of parent and offspring is unknown and it can be well nigh impossible to infer when an offspring is superior or inferior to its parent. Thus, the design of selection is the key to anti-noise. To handle the presence of noise, a novel distance-based selection mechanism is introduced without any extra parameter. There are three cases of the proposed selection mechanism which are described subsequently
In case 1, when \(\frac{f(\vec {U}_{i,G})}{f(\vec {X}_{i,G})} \le 1\), the offspring replaces the parent and survives to the next generation.
In case 2, although the parent performs better than the offspring, the offspring still can be preserved and survive into the next generation based on a stochastic principle. And the probability is calculated by \({\text {e}}^{-\frac{\Delta f}{{\text {Dis}}}}\), where \(\Delta f=\left.{\&\#Xarrowvert;}f(\vec {U}_{i,G}) - f(\vec {X}_{i,G}) \right.{\&\#Xarrowvert;}\) represents the absolute fitness difference between \(\vec {U}_{i,G}\) and \(\vec {X}_{i,G}\), \({\text {Dis}}=\sum _{k=1}^{D}\left.{\&\#Xarrowvert;}u_{i,k}-x_{i,k} \right.{\&\#Xarrowvert;}\) is the Manhattan distance between those two vectors. Manhattan distance is applied because of its simplicity and computational efficiency, and \(p_s\) is a random number generated from 0 to 1.
In case 3, If the parent significantly outperforms than offspring, then the offspring is removed and the parent persists to the next generation.
This selection process is further illustrated in Fig. 2.

A selection works on fitness landscape in noisy environments
Figure 2 shows a fitness landscape scenario both in noiseless environments and noisy environments, p and \(p^{'}\) represent the parent individual in the original fitness landscape and landscape in noisy environments, o and \(o^{'}\) represent the offspring individual in original fitness landscape and landscape in noisy environments, respectively. The fitness information we can observe is only in noisy environments, so in minimization problems, \(o^{'}\) will be rejected to replace the \(p^{'}\) in the next generation. The objective value of p is better than o in the real fitness landscape, and if we re-evaluate the \(o^{'}\) and \(p^{'}\), the domination may be changed. The mechanism of selection in MDE-DS allows the algorithm to give us some probabilistic flexibility to select worse solutions as in noise-affected landscapes.
In summary, the pseudocode of MDE-DS is shown in Algorithm 1

A brief review of the state-of-the-art decomposition method
Based on the divide and conquer, the CC framework decomposes the LSOPs into multiple nonseparable sub-problems and optimizes them alternately, which is the mainstream framework for solving LSOPs. In this section, we will briefly review the state-of-the-art decomposition method.
Taking the LINC-R [30] as a pioneer, perturbation-based decomposition methods become one of the most popular strategies to collaborate with the CC framework. Equation (7) defines the perturbation in the ith dimension and the jth dimension
LINC-R identifies the interaction between variables based on the fitness difference of perturbation with pre-defined hyperparameter \(\varepsilon \). More specifically
\(\varepsilon \) is the allowable error. DG extends Eq. (8) first to LSOPs up to 1000-D. Due to the FEs’ limitation in LSOPs, the fitness difference from the lower bound of search space to the upper bound can be accepted. The reuse of fitness and negligence of indirect interactions decreases the needed FEs to \(O(\frac{n^2}{m})\), and m is the number of sub-problems. In paper [24], a sensitivity test for threshold \(\epsilon \) is also implemented, the experimental results show that the DG is sensitive to the threshold \(\epsilon \), and \(\epsilon =10^{-3}\) is a recommended value.
Subsequently, the extended DG (XDG) [25] noticed that DG cannot identify the overlapping; thus, it divides all direct and indirect interacting variables into a sub-problem, and then, the overlappings between sub-problems are checked to identify conditional interactions. The needed FEs of XDG are approximately \(n^2\). The complexity of the XDG results in an unsuitable allocation of computational cost between decomposition and optimization and limits the development of XDG to deal with higher dimensional problems.
The high computational cost of decomposition is a critical problem. DG2 [26], a faster and more accurate DG-based decomposition method, was proposed to address this issue. DG2 utilizes the transmissibility of separability to save the FEs. For example, if \(x_1\) interacts with \(x_2\) and \(x_3\), the identification between \(x_2\) and \(x_3\) is unnecessary, as they belong to the same sub-problem, and the computational cost of DG2 is reduced to \(\frac{n^2+n+2}{2}\).
One of the most popular DG-based methods is Recursive DG (RDG) [48]. The RDG examines the interactions between a pair of sub-problems rather than a pair of single variables. For \(f:{\mathbb {R}}^D \rightarrow {\mathbb {R}}\) is an objective function, \(X_1 \subset X\) and \(X_2 \subset X\) are two mutually exclusive subsets of variables: \(X_1 \cap X_2=\emptyset \). If there are two unit vectors \({\textbf {u}}_1 \in U_{X_1}\) and \({\textbf {u}}_2 \in U_{X_2}\), two real numbers \(l_1,l_2>0\) and a solution \({\textbf {x}}^*\) to satisfy Eq. (9)
then there are some interactions between variables in \(X_1\) and \(X_2\); otherwise, \(X_1\) and \(X_2\) are considered as separable sets. If \(X_1\) and \(X_2\) interact with each other, and RDG divides \(X_2\) into two equal-sized and mutually exclusive subsets, then interactions between \(X_1\) and the two subsets are detected. Repeat the above process until RDG finds the variables which interact with \(X_1\). The computational complexity of RDG is \(O(n\log _2n)\), which is better than DG, XDG, and DG2, and more friendly to higher dimensional problems.
The hyperparameter \(\varepsilon \) also plays an important role in interaction identification, and different problems have various fitness landscape characteristics, and the identical threshold may not be suitable for all problems. Inspired by DG2, RDG2 [49] introduces an upper bound of the round-off errors incurred by the calculation of the non-linearity term and applies it as the threshold value. The experimental results in Ref. [49] showed that RDG2 improves the accuracy of RDG in identifying the interactions between variables.
Challenges of DG-based decomposition methods in noisy environments
Additive noise and multiplicative noise are two representative noises. Additive noise is often irrelevant to the fitness landscape, so we can carefully adjust the parameters to overcome the additive noise in the decomposition, although it is not easy [50]. However, multiplicative noise is related to the fitness landscape, so fitness can amplify the noise. Dealing with multiplicative noise is more difficult than additive noise in the decomposition stage. Taking the LINC-R as an example
\(\beta _{i}\) is Gaussian noise. \(|\Delta ^N_{2} - \Delta ^N_{1} |= |\Delta _{2} - \Delta _{1} + f(s_{ij})\beta _3 - f(s_{j})\beta _4 - f(s_{i})\beta _1 + f(s)\beta _2 |\). When the noise \(\beta \sim N(0, \sigma ^2)\), we define the noise term \(\phi _{ij}=f(s_{ij})\beta _3 - f(s_{j})\beta _4 - f(s_{i})\beta _1 + f(s)\beta _2\) which follows the distribution: \(\phi _{ij} \sim N(0, (f^2(s_{ij}) + f^2(s_{j}) + f^2(s_{j}) + f^2(s))\sigma ^2)\). In noisy environments with multiplicative noise, LINC-R cannot identify that the fitness difference is caused by interaction or noise and the probability of \(\phi _{ij}=0\) being satisfied is almost 0 [50]. In practice, the decomposition methods developed on the LINC-R, such as DG, DG2, RDG, etc. will fail in environments with multiplicative noise. We will provide experimental results of decomposition in the section “Performance of LMM”. Therefore, grouping methods that detect interactions by perturbation face severe challenges.
Our proposal: MDE-DSCC-LMM
In this section, we will introduce the details of our proposal. Our proposal consists of two stages: decomposition and optimization. In the decomposition, we divide the decision variables into sub-problems with our proposal: LMM, and in the optimization, MDE-DS is employed as a basic optimizer to optimize the sub-problems. Next, the concrete procedures of decomposition and optimization will be explained.
Decomposition: LMM
First, we provide the flowchart of our proposal in decomposition: LMM. The flowchart is shown in Fig. 3.

The flowchart of decomposition (LMM)
The basic idea is that we regard the decomposition problem as a combinatorial optimization problem and design the LMF based on LINC-R to lead the direction of searching for a better decomposition solution. The specific derivation of LMF is as follows.
The original LINC-R is defined as Eq. (11)
where the size of Pop is m, FEs consumed in a pair of variables based on Pop is 4m, and the interaction between every pair of variables is identified in LINC-R. Thus, in the \(n-\)D problem, the necessary FEs is \(2mn(n+1)\), which is unaffordable for LSOPs. Many studies [18, 24, 51] only detect the interactions by calculating the fitness difference from the lower bound of search space to the upper bound to save the FEs in decomposition, and we adopt the same strategy in our proposal, although it is not so robust and may fail to detect the interactions in trap functions [52].
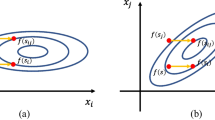
We also notice that the original LINC-R can be transformed into the vector addition form. Equation (12) shows this variant LINC-R
Figure 4 shows how LINC-R and the variant LINC-R work on the separable variables \(x_i\) and \(x_j\). Although the form is different, the mechanisms of LINC-R and variant LINC-R are identical.

a LINC-R works on the separable variables. b Variant LINC-R works on the separable variables
Based on this interesting finding, we derive LINC-R to 3-D and higher dimensions. In 3-D space, the schematic diagram is shown in Fig. 5.

The variant LINC-R works on 3-D space [53]
Here, we define the fitness difference in 3-D
When the variant LINC-R is applied simultaneously to determine the interactions between \(x_i\), \(x_j\), and \(x_k\)
Therefore, we can reasonably infer that when the dimension reaches n
However, when Eq. (15) is not satisfied, we only know that interactions exist in some variables, but we cannot know in which pairs of variables. Taking 3-D space as an example
Therefore, in the n-dimensional space, although it is difficult to detect the interactions between multiple variables through high-dimensional LINC-R directly, we can actively search for the interactions between variables through heuristic algorithms. According to the above description, in the n-dimensional problem, the linkage measurement function (LMF) is defined in Eq. (17)
m is the number of sub-problems. LMF in noisy environments is defined in Eq. (18)
where \(\Delta ^N_{1,2,\ldots ,n} = f^N(s_{1,2,\ldots ,n})-f^N(s)=f(s_{1,2,\ldots ,n})(1+\beta _i)-f(s)(1+\beta _j)\). To optimize the \(\mathrm{LMF^N}(s)\), EGA is employed as the basic optimizer. Figure 6 demonstrates that how to decode from genotype to decomposition.

A demonstration of decoding from genotype to decomposition
The length of a chromosome is LD, L is the genome length, and D is the dimension of the problem.
We decode the binary chromosome to decimal phenotype level and divide the decision variables into corresponding sub-problems, and the decision variables assigned to sub-problem 0 are regarded as separable variables. This procedure of optimization guided by LMF is named linkage measurement minimization (LMM), and the pseudocode of the decomposition is shown in Algorithm 2

As the general process of GA, we first initialize the decomposition solutions randomly in Algorithm 2, from line 2 to 8. The object E saves the best decomposition solution. Then, we repeat the procedure of selection, crossover, mutation, evaluation, and inheritance until the iteration reaches the stop criterion from line 12 to 19. The elitist strategy [54] directly replicates the best individual to the next generation, which can prevent the elite individual from destroying the superior gene and chromosome structure during optimization.
Time complexity analysis
FEs consumed in interaction identification are analyzed in this section. As the structure of an individual in Fig. 6, the best and worst time complexity for evaluating an individual is O(1) and O(D), when all decision variables are identified as nonseparable and separable, respectively. D is the dimension of problems. Suppose that the population size is N, maximum iteration is M. Thus, the best and worst time complexity of our proposal LMM is O(NM) and O(DNM).
Theoretical support for LMM in noisy environments
It is evident that the optimization guided by LMF can identify the interactions in the noiseless environment, because the individuals containing correct linkage information have lower linkage measurement values and higher fitness, which prefer to survive in the selection of EGA. An example we mentioned before is Eq. (16). And an important explanation is why LMM can identify the interactions in noisy environments. Here, we provide theoretical support.
Corollary
Let \(x_i\) and \(x_j\) be separable decision variables, and \(x_m\) and \(x_n\) be nonseparable decision variables. \(I(x_i, x_j)=(f(s_{ij})-f(s_{i}))-(f(s_{j})-f(s))\) and \(I^N(x_i, x_j)=(f^N(s_{ij})-f^N(s_{i}))-(f^N(s_{j})-f^N(s))\) represent the intensity of interaction between \(x_i\) and \(x_j\) in noiseless environment and noisy environments, respectively. In noisy environments, if we prove that the probability \(P(I^N(x_m, x_n)> I^N(x_i, x_j))>0\), which means it is possible that the intensity of the interaction between nonseparable variables can be stronger than separable variables in noisy environments, then the minimization of LMF can guide the direction to search for more interactions.
Proposition
In noisy environments, the probability \(P(I^N(x_m, x_n)> I^N(x_i, x_j))>0\), and individuals containing correct detected interactions have better fitness to survive.
Proof
In noisy environments, the noise \(\beta \sim N(0, \sigma ^2)\). The relationship between \(I^N(\cdot )\) and \(I(\cdot )\) is defined in Eq. (19)
where \(\phi _{ij} = (\beta _1f(s_{ij})-\beta _2f(s_i))-(\beta _3f(s_{j})-\beta _4f(s))\), and \(\phi _{ij}\) follows the distribution:
and \(I^N(x_i,x_j)\) follows the distribution:
Due to \(x_i\) and \(x_j\) are separable variables, \(x_m\) and \(x_n\) are nonseparable variables; similarly
Here, we introduce a distribution \(Y= I^N(x_m,x_n) - I^N(x_i,x_j)\), and the problem is transformed to prove \(P(Y>0)>0\). Y follows the distribution:
The expectation of Y is \(I(x_m,x_n)\), and there are two cases that need to be discussed:
Case 1: \(I(x_m,x_n) > 0\): In this case, \(P(Y>0)>0.5\).
Case 2: \(I(x_m,x_n) < 0\): In this case, \(0<P(Y>0)<0.5\).
In summary, \(P(I^N(x_m, x_n)>I^N(x_i, x_j))>0\) is true, and the optimization of LMF has the probability to detect more interactions in noisy environments, which can be employed as the objective function in our experiment. \(\square \)
Optimization: MDE-DSCC
Figure 7 shows the procedure of optimization.

The flowchart of optimization (MDE-DSCC)
In the optimization, we first introduce the decomposition from Algorithm 2 to divide the decision variables into k sub-problems, and an empty set of the context vector is initialized. For each sub-problem \(i(i \in [1, k])\), we alternately optimize it with MDE-DS. The pseudocode of the whole optimization stage is shown in Algorithm 3.

In Algorithm 3, the initialization of optimization is executed from line 3 to 10. Here, we randomly generate the sub-populations for each sub-problem and update the context vector after evaluating the sub-populations. Then, sub-problems are optimized alternately from line 12 to 20 until all FEs consumed. The context vector is updated after every generation of optimization is finished.
Numerical experiment and analysis
In this section, a set of experiments are implemented to evaluate our proposal, MDE-DSCC-LMM. In the section “Experiment settings”, we introduce the experiment settings, including benchmark functions, comparing methods, and performance indicators. In the section “Performance of our proposal: MDE-DSCC-LMM”, we provide the experimental results of our proposal and comparing methods. Finally, we analyze our proposal both in the decomposition and optimization in the section “Analysis”.
Experiment settings
Benchmark functions
We design 15 test functions in noisy environments based on CEC2013 LSGO Suite, and Eq. (24) defines the benchmark functions in our experiments
\(\beta \sim N(0,0.01)\). Briefly, this benchmark suite consists of 15 test functions with 4 categories.
-
(1)
\(f_1^{N}(x)\) to \(f_3^{N}(x)\): fully separable functions in noisy environments;
-
(2)
\(f_4^{N}(x)\) to \(f_7^{N}(x)\): partially separable functions with 7 none-separable parts in noisy environments;
-
(3)
\(f_8^{N}(x)\) to \(f_{11}^{N}(x)\): partially separable functions with 20 none-separable parts in noisy environments;
-
(4)
\(f_{12}^{N}(x)\) to \(f_{15}^{N}(x)\): functions with overlapping sub-problems in noisy environments; \(f_{13}\) and \(f_{14}\) consist of 905 decision variables, and the rest functions are 1000-D problems.
Comparing methods and parameters
In our experiment design, we compare the decomposition strategy of our proposal with various grouping methods, and the algorithms applied in the comparisons are listed in Tables 1 and 2 shows the parameters of our proposal in the decomposition stage. We also conduct the experiment between MDE-DSCC-LMM and DECC-LMM to show the effect of the introduction of MDE-DS. The maximum FEs including decomposition and optimization are 3,000,000, and the population size of optimization for each sub-problem is set to 30.
Performance indicators
There are two stages of our proposal that need to be evaluated: LMM and MDE-DSCC.
To evaluate the LMM, three metrics are employed: FEs consumed in decomposition, decomposition accuracy (DA), and optimization results. We adopt the calculation method of the DA in [49]. Essentially, DA is the ratio of the number of interacting variables that are correctly grouped to the total number of interacting variables. And to determine the existence of significance, we apply the Kruskal–Wallis test to the fitness at the end of the optimization in 25 trial runs between different decomposition methods. If significance exists, then we apply the p value acquired from the Mann–Whitney U test to do the Holm test. If LMM is significantly better than the second-best algorithm, we mark * (significance level 5%) or ** (significance level 10%) in the convergence curve.
To evaluate the MDE-DS, we apply the Mann–Whitney U test between MDE-DSCC-LMM and DECC-LMM. If MDE-DSCC-LMM is significantly better than DECC-LMM, we mark *(significance level 5%) or **(significance level 10%) at the end of optimization.
Performance of our proposal: MDE-DSCC-LMM
In this section, the performance of MDE-DSCC-LMM is studied, both on the decomposition and optimization. Experiments are conducted on the benchmark functions presented in the section “Benchmark functions”.
Performance of LMM
To verify the analysis in the section “Challenges of DG-based decomposition methods in noisy environments” that DG-based decomposition methods cannot detect the interactions in noisy environments, we apply DG, DG2, and RDG to decompose the benchmark functions. Table 3 shows the decomposition results.
The decomposition results of DG-based methods prove our analysis, all variables are divided into a sub-problem, and interactions failed to be detected completely. Next, we provide the DA and FEs for the decomposition of DG, RDG, DG2, and LMM in Table 4, because the decomposition results of LMM are different in every trial run, the DA and consumed FEs are calculated with the mean of 25 trial runs. The best DA is in bold.
Finally, the optimization results of DECC-D, DECC-G, DECC-DG, DECC-DG2, DECC-RDG, and DECC-LMM are provided in Table 5, and the best solution is in bold.
Performance of MDE-DSCC
The mean and standard deviation of the optimum between DECC-LMM and MDE-DSCC-LMM are shown in Table 6.
And the convergence curve of 25 independent runs of all compared methods is shown in Fig. 8.
Analysis
In this section, we will analyze the performance of LMM and MDE-DS.
LMM in noisy environment
Theoretical analysis in the section “Theoretical support for LMM in noisy environments” shows that LMM has the potential to correctly detect the interactions between decision variables in noisy environments. Experimental results in the section “Performance of LMM” further support this analysis. The identification of interactions in noisy environments is a difficult task, and LMM identifies the decision variables with relatively strong intensity as nonseparable. Although the fitness difference will be affected by noise, the relative intensity of interactions between separable variables and nonseparable variables still has a possible gap, which is the main reason for successful implementation in noisy environments.
However, the optimization of LMF is not an easy task. From the DA in Table 4, the interactions which can be detected by LMM in noisy environments are limited. Although LMF can lead the direction of optimization to search for more correct interactions, a more powerful optimizer will allow LMM to find more interactions.
LMM vs DG-based decomposition methods
DG-based decomposition methods detect the interactions by determining the difference between the fitness difference and a certain parameter \(\epsilon \), and even in fully separable functions, the fitness difference will be amplified by noise and larger than \(\epsilon \) easily, which is the main reason of detection failure in noisy environments, and all decision variables are divided into a sub-problem and optimized directly. Due to the curse of dimensionality, it is difficult for DE to find an acceptable solution with this division. Thus, although the DA of DG-based methods is higher than LMM in \(f_{12}\) and \(f_{15}\), LMM still performed better than DG-based methods in the optimization of these functions, and DG-based methods are the most environmentally sensitive grouping method among the compared methods.
LMM vs D
The schematic diagram of Delta Grouping is shown in Fig. 9.
Delta grouping notices that the difference in coordinates from the initial random population to the optimized population is different in the separable variables and the nonseparable variables. In Fig. 9, when the \(\Delta _{i}\) and \(\Delta _{j}\) has large difference, Delta grouping identify \(x_{i}\) and \(x_{j}\) are separable. This rough estimation is still affected by the noise, because the Delta grouping samples in the fitness landscape and the moving vector will still be influenced by the noise. Thus, Delta grouping is second sensitive in our comparing methods, and experimental results from Table 4 and Fig. 8 all show that our proposed LMM outperforms DECC-D.


The convergence curve of DECC-D, DECC-G, DECC-DG, DECC-DG2, DECC-RDG, DECC-LMM, and MDE-DSCC-LMM. The gap in the initial period is FEs consumed for decomposition
LMM vs random grouping
It is unnecessary to provide any information about the fitness landscape to Random grouping; therefore, Random grouping is the most environmentally insensitive decomposition method. Although paper [56] has proven that Random grouping is efficient and has a high probability to capture some interactions, it cannot detect sufficient interactions and form sub-problems properly, and LMM can detect more corrected interactions, which is the main reason that LMM outperformed than Random grouping.
The efficiency of MDE-DS
Figure 8 and Table 6 all prove that MDE-DS has a strong ability to search for better solutions compared with the canonical DE in most benchmark functions, although canonical DE performs better in \(f_9\) and \(f_{10}\). However, no optimization algorithm can solve all optimization problems perfectly. According to no free lunch theory [57] in optimization, the average performance of any pair of algorithms A and B is identical on all possible problems. Therefore, if an algorithm performs well on a certain class of problems, it must pay for that with performance degradation on the remaining problems, since this is the only way for all algorithms to have the same performance on average across all functions. Thus, although MDE-DS may perform worse than the canonical DE in noiseless functions, it is successful to introduce MDE-DS to solve problems in noisy environments.

a Delta grouping works on the separable function. b Delta grouping works on the nonseparable function
Discussion
The above experimental results and analysis show that our proposal both the LMM and the introduction of MDE-DS have broad prospects to solve LSOPs in noisy environments. However, there are still many aspects for improvement. Here, we list some open topics for potential and future research.
How to improve the LMM
In this paper, we regard the decomposition problem as a combinatorial optimization problem and design the LMF to guide the direction of optimization by EGA. There are two parts of LMM that can be improved: (1). The design of LMF and (2). Optimizer for LMF. For LMF, we notice that it is multi-modal, especially for separable functions. For example, \(f(x)=2x_1 + x_2^2 - 0.5\sqrt{x_3}\), \(((x_1,x_2,x_3)), ((x_1,x_2),x_3)),((x_1,x_3),x_2)) , ((x_1),(x_2,x_3)), ((x_1),(x_2),(x_3))\) are all global optima, and actually, \(((x_1),(x_2),(x_3))\) is our ideal decomposition. Thus, how to design the LMF to avoid this issue is a problem that can be improved in future research. And for the optimizer, this paper employed EGA to optimize the LMF, and parts of correct interactions can be detected in noisy environments. In future research, we will apply various optimizers to optimize the LMF, and the more powerful optimizers are expected to search for more interactions in noisy environments.
Interactions’ identification in noisy environments
Although it is a difficult task to detect interactions in noisy environments, it is necessary to develop an effective interaction identification method to form sub-problems by a proper strategy. Explicit averaging [6] can alleviate the uncertainty of noise by re-evaluation. Let the re-evaluating times for \(f^N(\textrm{X})\) be m and \(f^N_i(X)\)) represents the ith re-evaluation value. Then, we apply the principle of Monte Carlo integration [58], and the mean fitness estimation \(\bar{f}^N(\textrm{X})\), standard deviation \(\sigma (f^N(X))\), and the standard error of the mean fitness \(se(f^N(X))\) are calculated as
Equation (25) shows that sampling an individual’s objective function m times can reduce \(se(\bar{f}^N(X))\) by a factor of m to improve the accuracy in the mean fitness estimation, which means that the accuracy of sampling increases. It is a feasible method to loosen the threshold \(\varepsilon \) in DG-based methods and combine the explicit averaging strategy to identify the interactions, although it will consume lots of FEs.
Conclusion
In this paper, we proposed a novel strategy that regards the decomposition problem as a combinatorial optimization problem and designed the LMF to guide the direction of optimization. Besides, we introduce an advanced optimizer named MDE-DS to tackle optimization problems in noisy environments. Numerical experiments show that LMM can detect some interactions in noisy environments, which is competitive with the compared grouping methods. And MDE-DS has a strong ability to search for better solutions, which can accelerate the optimization in noisy environments.
In future research, we will focus on the improvement of LMM and the development of efficient interaction identification methods in noisy environments.
References
Greiner D, Aznarez JJ, Maeso O, Winter G (2010) Single- and multi-objective shape design of y-noise barriers using evolutionary computation and boundary elements. Adv Eng Softw 41(2):368–378. https://doi.org/10.1016/j.advengsoft.2009.06.007
Hughes EJ (2001) Evolutionary multi-objective ranking with uncertainty and noise. In: International conference on evolutionary multi-criterion optimization. Springer, pp 329–343. https://doi.org/10.1007/3-540-44719-9_23
Li J, Zhou Q, Williams H, Xu H, Du C (2022) Cyber-physical data fusion in surrogate- assisted strength pareto evolutionary algorithm for phev energy management optimization. IEEE Trans Ind Inform 18(6):4107–4117. https://doi.org/10.1109/TII.2021.3121287
Sudholt D (2018) On the robustness of evolutionary algorithms to noise: refined results and an example where noise helps. In: Proceedings of the genetic and evolutionary computation conference, pp 1523–1530. https://doi.org/10.1145/3205455.3205595
Kim J-S, Jeong U-C, Kim D-W, Han S-Y, Oh J-E (2015) Optimization of sirocco fan blade to reduce noise of air purifier using a metamodel and evolutionary algorithm. Appl Acoust 89:254–266. https://doi.org/10.1016/j.apacoust.2014.10.005
Painton L, Diwekar U (1995) Stochastic annealing for synthesis under uncertainty. Eur J Oper Res 83(3):489–502. https://doi.org/10.1016/0377-2217(94)00245-8
Diaz J, Handl J (2015) Implicit and explicit averaging strategies for simulation-based optimization of a real-world production planning problem. Informatica (Slovenia) 39:161–168
Albukhanajer WA, Briffa JA, Jin Y (2014) Evolutionary multiobjective image feature extraction in the presence of noise. IEEE Trans Cybern 45(9):1757–1768. https://doi.org/10.1109/TCYB.2014.2360074
Akimoto Y, Astete-Morales S, Teytaud O (2015) Analysis of runtime of optimization algorithms for noisy functions over discrete codomains. Theor Comput Sci 605:42–50. https://doi.org/10.1016/j.tcs.2015.04.008
Chen Y-W, Song Q, Liu X, Sastry PS, Hu X (2020) On robustness of neural architecture search under label noise. Front Big Data. https://doi.org/10.3389/fdata.2020.00002
Qian C, Shi J-C, Yu Y, Tang K, Zhou Z-H (2017) Subset selection under noise. Adv Neural Inf Process Syst 30
Köppen M (2000) The curse of dimensionality. In: 5th online world conference on soft computing in industrial applications (WSC5), vol 1, pp 4–8
Baluja S (1994) Population-based incremental learning. a method for integrating genetic search based function optimization and competitive learning. Technical report, Carnegie-Mellon University, Pittsburgh, Pa, Department of Computer Science
Pelikan M, Goldberg DE, Lobo FG (2002) A survey of optimization by building and using probabilistic models. Comput Optim Appl 21(1):5–20. https://doi.org/10.1023/A:1013500812258
Moscato P et al. (1989) On evolution, search, optimization, genetic algorithms and martial arts: towards memetic algorithms. Caltech concurrent computation program, C3P report 826, 1989
Li E, Wang H, Ye F (2016) Two-level multi-surrogate assisted optimization method for high dimensional nonlinear problems. Appl Soft Comput 46:26–36. https://doi.org/10.1016/j.asoc.2016.04.035
Potter MA, De Jong KA (1994) A cooperative coevolutionary approach to function optimization. Lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics) 866 LNCS, pp 249–257
Sun Y, Kirley M, Halgamuge SK (2017) A recursive decomposition method for large scale continuous optimization. IEEE Trans Evolut Comput 22(5):647–661. https://doi.org/10.1109/TEVC.2017.2778089
Mei Y, Li X, Yao X (2014) Cooperative coevolution with route distance grouping for large-scale capacitated arc routing problems. IEEE Trans Evolut Comput 18(3):435–449. https://doi.org/10.1109/TEVC.2013.2281503
Sayed E, Essam D, Sarker R, Elsayed S (2015) Decomposition-based evolutionary algorithm for large scale constrained problems. Inf Sci 316:457–486. https://doi.org/10.1016/j.ins.2014.10.035. (nature-inspired algorithms for large scale global optimization)
Omidvar MN, Li X, Yao X (2021) A review of population-based metaheuristics for large-scale black-box global optimization: part a. IEEE Trans Evolut Comput. https://doi.org/10.1109/TEVC.2021.3130838
Nabi Omidvar Mohammad, Xiaodong Li, Xin Yao (2021) A review of population-based metaheuristics for large-scale black-box global optimization: part b. IEEE Trans Evolut Comput. https://doi.org/10.1109/TEVC.2021.3130835
Munetomo M, Goldberg DE (1999) Linkage identification by non-monotonicity detection for overlapping functions. Evol Comput 7(4):377–398. https://doi.org/10.1162/evco.1999.7.4.377
Omidvar MN, Li X, Mei Y, Yao X (2014) Cooperative co-evolution with differential grouping for large scale optimization. IEEE Trans Evolut Comput 18(3):378–393. https://doi.org/10.1109/TEVC.2013.2281543
Sun Y, Kirley M, Halgamuge SK (2015) Extended differential grouping for large scale global optimization with direct and indirect variable interactions. In: Proceedings of the 2015 annual conference on genetic and evolutionary computation. GECCO ’15. Association for Computing Machinery, New York, NY, USA, pp 313–320. https://doi.org/10.1145/2739480.27546661
Omidvar MN, Yang M, Mei Y, Li X, Yao X (2017) DG2: a faster and more accurate differential grouping for large-scale black-box optimization. IEEE Trans Evolut Comput 21(6):929–942. https://doi.org/10.1109/TEVC.2017.2694221
Mei Y, Omidvar MN, Li X, Yao X (2016) A competitive divide-and-conquer algorithm for unconstrained large-scale black-box optimization. ACM Trans Math Softw. https://doi.org/10.1145/2791291
Yang M, Zhou A, Li C, Yao X (2021) An efficient recursive differential grouping for large-scale continuous problems. IEEE Trans Evolut Comput 25(1):159–171. https://doi.org/10.1109/TEVC.2020.3009390
Li X, Tang K, Omidvar MN, Yang Z, Qin K, China H (2013) Benchmark functions for the CEC 2013 special session and competition on large-scale global optimization. Gene 7(33):8
Tezuka M, Munetomo M, Akama K (2004) Linkage identification by nonlinearity check for real-coded genetic algorithms. Lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics), vol 3103, pp 222–233
van den Bergh F, Engelbrecht AP (2004) A cooperative approach to particle swarm optimization. IEEE Trans Evolut Comput 8(3):225–239. https://doi.org/10.1109/TEVC.2004.826069
Tang R-L, Wu Z, Fang Y-J (2017) Adaptive multi-context cooperatively coevolving particle swarm optimization for large-scale problems. Soft Comput 21(16):4735–4754. https://doi.org/10.1007/s00500-016-2081-6
Holmstrom L, Koistinen P (1992) Using additive noise in back-propagation training. IEEE Trans Neural Netw 3(1):24–38. https://doi.org/10.1109/72.105415
Sancho JM, Miguel MS, Katz SL, Gunton JD (1982) Analytical and numerical studies of multiplicative noise. Phys Rev A 26:1589–1609. https://doi.org/10.1103/PhysRevA.26.1589
Jin Y, Branke J (2005) Evolutionary optimization in uncertain environments—a survey. IEEE Trans Evolut Comput 9(3):303–317. https://doi.org/10.1109/TEVC.2005.846356
Fitzpatrick JM, Grefenstette JJ (1988) Genetic algorithms in noisy environments. Mach Learn 3(2):101–120
Miller BL, Goldberg DE (1996) Genetic algorithms, selection schemes, and the varying effects of noise. Evolut Comput 4(2):113–131. https://doi.org/10.1162/evco.1996.4.2.113
Sano Y, Kita H, Kamihira I, Yamaguchi M (2000) Online optimization of an engine controller by means of a genetic algorithm using history of search. In: 2000 26th annual conference of the IEEE Industrial Electronics Society. IECON 2000. 2000 IEEE International conference on industrial electronics, control and instrumentation. 21st century technologies, vol 4, pp 2929–29344. https://doi.org/10.1109/IECON.2000.972463
Iacca G, Neri F, Mininno E (2012) Noise analysis compact differential evolution. Int J Syst Sci IJSySc 43:1248–1267. https://doi.org/10.1080/00207721.2011.598964
Mininno E, Neri F (2010) A memetic differential evolution approach in noisy optimization. Memet Comput 2:111–135. https://doi.org/10.1007/s12293-009-0029-4
Storn R (1996) On the usage of differential evolution for function optimization. In: Proceedings of North American fuzzy information processing, pp 519–523. https://doi.org/10.1109/NAFIPS.1996.534789
He X, Zhang Q, Sun N, Dong Y (2009) Feature selection with discrete binary differential evolution. In: 2009 international conference on artificial intelligence and computational intelligence, vol 4, pp 327–330. https://doi.org/10.1109/AICI.2009.438
Du J-X, Huang D-S, Wang X-F, Gu X (2007) Shape recognition based on neural networks trained by differential evolution algorithm. Neurocomputing 70(4):896–903. https://doi.org/10.1016/j.neucom.2006.10.026. (advanced neurocomputing theory and methodology)
Slowik A, Bialko M (2008) Training of artificial neural networks using differential evolution algorithm. In: 2008 conference on human system interactions, pp 60–65. https://doi.org/10.1109/HSI.2008.4581409
Ghosh A, Das S, Mallipeddi R, Das AK, Dash SS (2017) A modified differential evolution with distance-based selection for continuous optimization in presence of noise. IEEE Access 5:26944–26964. https://doi.org/10.1109/ACCESS.2017.2773825
Ghosh A, Das S, Mullick SS, Mallipeddi R, Das AK (2017) A switched parameter differential evolution with optional blending crossover for scalable numerical optimization. Appl Soft Comput 57:329–352. https://doi.org/10.1016/j.asoc.2017.03.003
Kundu R, Mukherjee R, Das S, Vasilakos AV (2013) Adaptive differential evolution with difference mean based perturbation for dynamic economic dispatch problem. In: 2013 IEEE symposium on differential evolution (SDE), pp 38–45. https://doi.org/10.1109/SDE.2013.6601440
Sun Y, Kirley M, Halgamuge SK (2018) A recursive decomposition method for large scale continuous optimization. IEEE Trans Evolut Comput 22(5):647–661. https://doi.org/10.1109/TEVC.2017.2778089
Sun Y, Omidvar MN, Kirley M, Li X (2018) Adaptive threshold parameter estimation with recursive differential grouping for problem decomposition. In: Proceedings of the genetic and evolutionary computation conference. GECCO ’18. Association for Computing Machinery, New York, NY, USA, pp 889–896. https://doi.org/10.1145/3205455.3205483
Wu Y, Peng X, Wang H, Jin Y, Xu D (2022) Cooperative coevolutionary CMA-ES with landscape-aware grouping in noisy environments. IEEE Trans Evolut Comput. https://doi.org/10.1109/TEVC.2022.3180224
Sun Y, Kirley M, Halgamuge SK (2015) Extended differential grouping for large scale global optimization with direct and indirect variable interactions. In: Proceedings of the 2015 annual conference on genetic and evolutionary computation. GECCO ’15. Association for Computing Machinery, New York, NY, USA, pp 313–320. https://doi.org/10.1145/2739480.2754666
Munetomo M (2002) Linkage identification with epistasis measures considering monotonicity conditions. In: Proceedings of the 4th Asia-Pacific conference on simulated evolution and learning. https://cir.nii.ac.jp/crid/1570009750206806528
Zhong R, Munetomo M (2022) Random population-based decomposition method by linkage identification with non-linearity minimization on graph. In: Transactions on computational science and computational intelligence. Springer
De Jong KA (1975) An analysis of the behavior of a class of genetic adaptive systems. Ph.D. thesis, University of Michigan, USA. AAI7609381
Omidvar MN, Li X, Yao X (2010) Cooperative co-evolution with delta grouping for large scale non-separable function optimization, pp 1–8. https://doi.org/10.1109/CEC.2010.5585979
Yang Z, Tang K, Yao X (2008) Large scale evolutionary optimization using cooperative coevolution. Inf Sci 178(15):2985–2999. https://doi.org/10.1016/j.ins.2008.02.017. (nature inspired problem-solving)
Wolpert DH, Macready WG (1997) No free lunch theorems for optimization. IEEE Trans Evolut Comput 1(1):67–82. https://doi.org/10.1109/4235.585893
Gopalakrishnan G, Minsker BS, Goldberg DE (2001) Optimal sampling in a noisy genetic algorithm for risk-based remediation design. J Hydroinform 5:11–25. https://doi.org/10.1061/40569(2001)94
Acknowledgements
This work was supported by JSPS KAKENHI under Grant No. JP20K11967.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhong, R., Zhang, E. & Munetomo, M. Cooperative coevolutionary differential evolution with linkage measurement minimization for large-scale optimization problems in noisy environments. Complex Intell. Syst. 9, 4439–4456 (2023). https://doi.org/10.1007/s40747-022-00957-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00957-6