
Abstract
Many real-world optimization problems have complex features, such as bias, multimodel, etc. Existing evolutionary algorithms mainly utilize solutions’ current performance to decide their survivals, which are not comprehensive enough to describe the evolving trend, and may misguide the evolve decision. In this paper, a novel robust performance evaluation approach for evolutionary multiobjective optimization algorithm is proposed. Here, the robustness refers to the performance fluctuation degree among several generations, which can be expressed by interval values in respect to the decision and objective spaces. Based on the robust performance evaluation, solutions can be selected and preserved considering their historical performance, and thus, the exploration strength in convergence potential areas can be maintained. Meanwhile, to construct an evolutionary algorithm that embeds robustness evaluation, a robust elite managerial method and a learning-based updating strategy are also designed. Experiments on multiobjective benchmark problems and a real-world optimization in a robotic manipulation system have proved the superiority of the proposed approach.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Multiobjective optimization problems (MOPs) widely exist in real-world applications, such as community extraction [17], trajectory planning [13], network configuration [39], mechanism design [29], and so on. In the past 2 decades, a large number of algorithms have been designed to obtain an accurate and well-distributed approximation of the true optimal front, most of which adopt the population-based metaheuristic mechanism that can provide multiple solutions at one time [42]. In this mechanism, individuals update according to competition or cooperation principles, thus building the approximate front. Here, the definition and preservation of the elite solution are essential, since they will affect the searching preference as well as the final performance. Up to now, the static definition that bases on the current fitness values has been fully studied.
Dominance relation, crowding estimation, and aggregation cost function are the most commonly used strategies in handling elite definition and preservation [22]. Dominance relation is the primary consideration in most studies. The nondominated sorting technique has provided efficient convergence strength in MOPs with less than three objectives [7]. To guarantee selection pressure under high-dimensional problem, modified dominance relations have been studied [1]. Crowding estimation is usually required as the secondary criterion to maintain the searching diversity, where Minkowski distance and cosine distance have been studied under different problem dimensions [31]. Two approaches are commonly used to preserve solution based on the crowding estimation. The first one calculates the neighboring distance from the same nondominated front, and then selects solutions with larger distance to fill the elite archive [7]. The second one calculates the distance between the nonselected solution and its closest selected solution, and then moves the most distant solution to the selected archive one at a time until the archive’s capacity limit is reached [20]. Finally, aggregation cost function is mostly designed based on reference vectors in the objective space; therefore, it has advantages in controlling the search direction and maintaining the diversity performance. This strategy is always adopted in the decomposition-based algorithm MOEA/D and its variants [21], and also in dominance-based mechanism as a secondary criterion to guarantee the diversity performance [41]. Moreover, indicator-based methods and preference-based weightings have also been widely studied in recent years [32].
Meanwhile, the above strategies can also work in a cooperative manner. Through introducing multi-stage and multi-archive approaches, solutions under different standards are selected as elite ones to balance the searching performance. A few works introduced multiple stages focusing on convergence or diversity controls, where aggregated convergence measure and distance-based diversity estimation are, respectively, adopted in updating the approximate Pareto front. For example, Tian et al. updated the population by different selection schemes in different stages [28], while Chen et al. introduced different grouping schemes in different stages [3]. Similarly, studies adopting multiple archives also assign different elite handling methods to different archives [35]. These archives update in parallel and store elite records separately. Defining preferences in different times and archives has greatly improved the performance in many-objective optimization problems [25].
The population’s update approach is another essential process which determines the exploration and exploitation behaviors [30, 33]. To inherit from the previous generation, the existing update mechanisms can be classified into two categories, elimination-based and learning-based, respectively. Elimination-based mechanism mainly refers to the genetic and differential evolution operators, where offsprings are generated through crossover and mutation, and then, all the individuals participate in the competition following the rule of “survival of the fittest” according to the elite definition strategy [34]. Under these mechanisms, individuals are memoryless; thus, they have a rapid response for exploitation in local regions, yet it is difficult for them to fulfill the exploration based on historical information. On the other hand, the learning-based mechanisms, such as particle swarm operator, competitive swam operator, etc., are less greedy and have continuous dynamic model; thus, they have advantages in exploring the global optima [26]. However, the individual association for learning behaviors under multiple elites environment will significantly affect the optimization efficiency [38].
In conclusion, the existing studies mainly utilize the solution’s current objective values to conduct elite preservation and updating, which are not comprehensive enough to describe the searching trends. For instance, facing complex Pareto set including bias, scattered, and multimodel proprieties, estimation based on the current performance may lead to premature decision, causing diversity loss and misguided exploitation direction. Meanwhile, to enhance convergence strength and restrict computing expenses, most algorithms do not consider diversity control in the decision space, thus good alternative solutions may not be found. Since historical conditions and learning-based mechanisms show advantages in exploring the global optima, and utilizing historical evaluations does not bring additional computational costs, it makes sense to record and utilize individuals’ representative information during evolution. The information may contribute to choosing the right leader as well as preserving promising directions for evolution. Based on the above assumptions, this work attempts to define elite solutions based on their performance intervals in several historical generations. The performance includes convergence and diversity assessments, and the diversity considers the sparsity from both the objective space and the decision space. This novel idea is denoted as the robust performance evaluation (RPE). Based on the RPE, a multiobjective optimization framework with a robust archive is established.
The contributions of this paper are summarized in the following three aspects. First, a robust performance evaluation approach is introduced to define elite solutions according to the historical performance. Second, an external robust archive is established and its preservation strategy is designed. Third, a learning-based updating strategy is proposed for individuals in the external robust archive. The proposed RPE-based framework has proved to have competitive performance compared to several well-known evolutionary algorithms for solving MOPs.
The remainder of this paper is organized as follows. The preliminaries of related definitions and studies on interval dominance relation are introduced in the section “Related definitions”. The proposed robust performance evaluation and the RPE-based algorithm are detailed in the section “The proposed algorithm”. Then, the experiments on several benchmark instances and a parameter sensitivity study are presented in the section “Experiments”. Finally, the section “Discussions” presents the conclusions.
Related definitions
In this section, some basic knowledge in MOP study will be presented first. Then, a brief introduction of the interval dominance relation is given.
Multiobjective optimization problem
An MOP can be mathematically formulated as
where \(\Omega =\prod _{i=1}^{D}[a_{i},b_{i}]\subseteq {\mathbb {R}}^{D}\) is the D-dimensional decision space, and \(a_{i}\) and \(b_{i}\) are the lower and upper bound of the ith dimension respectively. \({\textbf{x}}=(x_{1},x_{2},\ldots ,x_{D})^{\textrm{T}}\in \Omega \) is a candidate solution, and \({\textbf{f}}\in {\mathbb {R}}^{M}\) constitutes M objective functions.
When adopting the population-based searching mechanism to solve MOP, the position of each individual represents a candidate solution. The Pareto dominance is used to make comparison between individuals.
Definition 1
(Zhou et al. [40]) Given two individual \(p_1\) and \(p_2\), \(p_1\) Pareto dominates \(p_2\) is defined as
\(p_1\) and \(p_2\) are incomparable when they are nondominated with each other. These nondominated individuals provide the so-called trade-off solutions, which form the Pareto set (PS) in the decision space and map to the Pareto front (PF) in the objective space.
Interval comparison
Interval values have been introduced in studying optimization problems with environmental uncertainty or time-varying optima [10, 12, 23, 36]. Among these studies, on comparing interval values, several relations have been presented. The following relation is the most commonly adopted [18].
Definition 2
Given two intervals \(a=[\underline{a},\overline{a}]\) and \(b=[\underline{b},\overline{b}]\), relation \(<_{\textrm{IN}}\) is defined as
By taking both the lower and upper boundaries into consideration, this relation is reasonable in handing interval comparison. When intervals are incomparable, it is denoted as \(a\Vert b\).
When solving an optimization through metaheuristic approaches, disturbance to the individual will provide a group of solutions and generate multiple objective values accordingly. Therefore, the individuals can be compared based on the generated objective interval, which is defined as follows.
Definition 3
Given a solution set \(\{{\textbf{x}}_1,\ldots ,{\textbf{x}}_n\}\), the jth objective interval is denoted as
In single-objective optimization, individuals with one-dimensional objective interval \(f^I\) can be compared according to Definition 2. When dealing with multiobjective optimization, individuals with multi-dimensional objective interval \({\textbf{f}}^I = (f_1^I,f_2^I,\ldots ,f_M^I)\) should be compared according to the interval Pareto dominance relation.
Definition 4
(Sun et al. [24]) Given two individuals \(p_1, p_2\) each related to a solution set, the jth objective interval is denoted as \(p_1. f_j^I\) and \(p_2. f_j^I\), respectively. The interval Pareto dominance relation \(\prec _{IF}\) is defined as
The interval dominance relation will be adopted in our work to utilize historical performance for robust elite definition.
The proposed algorithm
In this part, the concept of the robust performance evaluation over time will be introduced, and then, the selecting and updating details in building the robust archive will be described. In the end, the framework of the proposed RPE-based algorithm is given.
Robust performance evaluation
In multiobjective metaheuristic algorithm, solutions eliminated in an elite competition must not provide guidance for subsequent generations. However, considering the multimodal, deceptive situations, or the diversity estimation affected by the whole distribution, the elite definition principle is not absolutely correct and can lead to premature situations. Therefore, the RPE technique is presented to define the suboptimal solutions according to the individuals’ states in a time window.
The individuals’ historical states include position information and objective values. The historical states over a time interval are recorded as follows. At time t, the historical positions in the last K generations are denoted as \(\{{\textbf{x}}_{t-k}\mid k=0,\ldots ,K-1\}\). According to Definition 3, for an individual p, the objective interval over time window K is \( p.f_j^I \triangleq [ \underline{f_j}({\textbf{x}}_{t-K+1:t}), \overline{f_j}({\textbf{x}}_{t-K+1:t}) ]\), \( j=1,2,\ldots ,M\). These historical states can demonstrate the stability and evolving trend of the individual.
For high-dimensional space, the selection pressure provided by the interval Pareto dominance relation is not enough; therefore, instead of comparing the objective values directly, two metrics to establish comparison during the robust evaluation are adopted. The two metrics, respectively, focus on evaluating convergence and evaluating diversity. They are defined according to the states of the individual to be evaluated relative to an elite solution set.
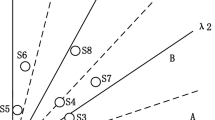
The convergence evaluation metric is denoted as \(\hbox {EC}\), and it is defined as the distance between an individual and an existing elite solution set. Here, the two kinds of distance are plotted in Fig. 1a.

Diagrams of basic concepts in RPE. a \(\hbox {EC}\): the distance between an individual and a solution set. b Intervals in the objective space and the decision space over time
The first one is the Euclidean distance from the individual to the ideal point of the solution set in a normalized objective space. Although this distance has been adopted in several studies for convergence measure, it is not quite reasonable for MOP with concave PF. For instance, in Fig. 1a (left), compared to individual \(p_1\), \(p_2\) looks closer to the approximate PF, yet its advantage cannot be reflected. The second distance is calculated by adding a scaling procedure and transforming the PF to the convex shape. The scaling ratio is the length of the normalized objective vector closest to the individual. Assume \({\mathcal {X}}\) is an elite solution set, for individual p, \(\hbox {EC}\) using the second distance is calculated as follows:
where \(z^{id}_j = \min _{{\textbf{x}} \in {\mathcal {X}}} f_j({\textbf{x}}), j\in \{1,2,\ldots ,M\} \) represents the jth dimension of the ideal point, and \(z_j^{na}\) represents the nadir value. \({\textbf{f}}'\) is the normalized objective vector. Through this \(\hbox {EC}\) metric, the individuals can be distinguished (Fig. 1a (right)).
The diversity evaluation metric is denoted as \(\hbox {ED}\). In this work, \(\hbox {ED}\) has two forms: one evaluates crowding degree in the objective space, termed as \(\hbox {ED}^o\); the other preforms in the decision space, termed as \(\hbox {ED}^d\). In each form, the diversity evaluation for one individual follows two steps, association and quantification. Given an elite set \({\varepsilon }\) and population \({\mathcal {P}}_e\) to be evaluated. First, each individual \(p\in {\mathcal {P}}_e\) is associated with one closet elite in \({\varepsilon }\). Second, the diversity metric is quantified as follows:
where, for \(\hbox {ED}^o\), \(\hbox {dist}\) represents one minus the cosine of the included angle between the normalized objective vectors; for \(\hbox {ED}^d\), \(\hbox {dist}\) represents Euclidean distance in the normalized decision space. \(\alpha \) is a penalty factor, \(\alpha \in [0,1]\); c is the index after sorting individual associated with a same elite in descending order with respect to their \(\hbox {dist}\) values.
Based on the above definition, the RPE mechanism transforms a individual’ historical states to the metric intervals over time window K, denoted as \(p.\hbox {EC}^I \triangleq [\underline{\hbox {EC}}({\textbf{x}}_{t-K+1:t}),\overline{\hbox {EC}}({\textbf{x}}_{t-K+1:t})]\), \(p.\hbox {ED}^I \triangleq [\underline{\hbox {ED}}({\textbf{x}}_{t-K+1:t}),\overline{\hbox {ED}}({\textbf{x}}_{t-K+1:t})]\). The diagram of the intervals is displayed in Fig. 1b. The following sections will introduce the RPE-based elite preservation.
Robust performance evaluation-based preservation
This section bases on the RPE metrics in the section “Robust performance evaluation” and the interval Pareto dominance relation in Definition 4.
To incorporate RPE into metaheuristic algorithms, a robust archive (RA) is established to preserve individuals with advantageous intervals in the objective or the decision spaces. These individuals are selected considering convergence as well as diversity performance. Hence, RA consists of two segments with equal capacity, which, respectively, evaluated by interval \([\hbox {EC}^I,-\hbox {ED}^{oI}]\) and interval \([\hbox {EC}^I,-\hbox {ED}^{dI}]\). The intervals are displayed in Fig. 2a. The cylinders represent the convergence intervals quantified by \(\hbox {EC}^I\), and the arcs represent the diversity fluctuation quantified by \(\hbox {ED}^I\). Based on the interval Pareto relation, in the decision space, \(p_1 \prec _{\textrm{IN}} p2\); in the objective space, \(p_3 \prec _{\textrm{IN}} p4\).

Diagrams of a performance intervals in decision space and objective space for individual comparison; b evolving trends corresponding to different \(\varphi \) values: (left) small \(\varphi \); (right) large \(\varphi \)
During RA selection, individuals with nondominated intervals have higher preserve priorities; individuals on the same interval nondominated level are selected according to their current convergence degree \(\hbox {EC}_t\). This procedure is described in Algorithm 1.

Learning-based local search
Solutions selected by RPE metric have strong robustness, which indicate potential convergence areas. However, since interval evaluation has less selection pressure, these solutions are suboptimal and always lag behind the converging process on the basis of the current fitness evaluation, they cannot directly contribute to the approximate Pareto front. Therefore, the utilization of these solutions is to conduct local search that enhances the exploration performance in subregions. The local search is realized by updating the position of individuals in RA.
A learning-based local search (LBLS) is proposed for this purpose. LBLS takes into account the robust solutions’ current state, historical states, and information from the current optimal solutions. It consists of two steps: individual selection and learning-based update.
-
(1)
Select individuals from RA and current optimal population separately. For example, in genetic algorithm (GA), the current population is the optimal population, which is updated by environmental selection strategy. The tournament selection mechanism is adopted to determine the mating parents. First, two sets of individuals, \({\mathcal {R}}_1\) and \({\mathcal {R}}_2\), are selected from RA. The individuals’ interval nondominated levels and the maximum crowding distances of the interval in the objective space (for \({\mathcal {R}}_1\)) as well as the decision space (for \({\mathcal {R}}_2\)) determine the selection result. Second, select individuals from the current optimal population \({\mathcal {P}}\). The nondominated levels and the closest distance to the selected robust individuals are considered during the selection. To be noted, the number of selected individuals for LBLS is designed to be adaptive to maintain diversity at the beginning and stability at the end, that is
$$\begin{aligned} \mid {\mathcal {R}}_1\mid= & {} \left\lceil \frac{N_A}{4}\times \frac{\hbox {Eval}-\hbox {Evaluated}}{\hbox {Eval}} \right\rceil \nonumber \\ \mid {\mathcal {R}}_1\mid= & {} \mid {\mathcal {R}}_2\mid , \quad \mid {\mathcal {P}}\mid = \mid {\mathcal {R}}_1\mid +\mid {\mathcal {R}}_2\mid . \end{aligned}$$(8) -
(2)
Update the individuals in RA. LBLS strategy is inspired from PSO [5] and CSO [4] operators. The individual from the elite archive is seen as a leader, and its position is denoted as \({\textbf{x}}_{e}\). Denote at time t, the position and velocity of individuals from robust archive are denoted as \({\textbf{x}}_{r,t}\) and \({\textbf{v}}_{r,t}\). The update formulation is as follows:
$$\begin{aligned} {\textbf{v}}_{r,t+1}= & {} {\textbf{r}}1\times {\textbf{v}}_{r,t}\nonumber \\{} & {} +{\textbf{r}}2\times ({\textbf{x}}_{e}-{\textbf{x}}_{r,t}) +{\textbf{r}}3\times \varphi \times (\overline{{\textbf{x}}}_{r,T} -{\textbf{x}}_{r,t})\nonumber \\ {\textbf{x}}_{r,t+1}= & {} {\textbf{x}}_{r,t}+{\textbf{v}}_{r,t+1}. \end{aligned}$$(9)Here, \({\textbf{r}}_1\), \({\textbf{r}}_2\), \({\textbf{r}}_3 \in [0,1]^D\) are randomly generated vectors, \(\overline{{\textbf{x}}}_{r,T}\) is the mean value of the individual’s historical position over time interval T, and \(\varphi \in [0,1]\) is a parameter to control the proportion of the historical information and the elite information. When \(\varphi \) is small, the update operator presents higher convergence strength guided by the elite information; otherwise, when \(\varphi \) is large, the updated individual receives backward strength, remaining exploration in local areas. Trajectories under these two conditions are illustrated in Fig. 2b. To control the influence of local search to the main searching process, \(\varphi \) can be designed adaptive to fit different evolution stages.
Main framework
The main framework of MOEA-RPE is illustrated in Algorithm 2. In the framework, “GA” represents the general evolutionary algorithm including tournament selection, simulated binary crossover, and polynomial mutation. The “EnvironmentalSelection” can refer to any existing selection technique in multiobjective research, such as metric-based sorting, one-by-one selection, etc. Individuals eliminated by “EnvironmentalSelection” are denoted as \({\mathcal {P}}^r\). These individuals will be further evaluated and selected to update RA. At the same time, optimal solutions found by RA will update the population in MOEA.
It can be seen that the proposed framework is a modification of traditional MOEA that appends an external production–selection process to discover robust noninferior solutions. The external process will contribute to the diversity preservation in the objective space and the decision space, as well as enhancing exploration in local regions. The update diagram of the population in MOEA and the external RA is displayed in Fig. 3.

The update diagram of the population and the robust archive in MOEA-RPE

Experiments
In this section, the experiments are arranged to validate the effectiveness of the robust performance evaluation. Problems with complex properties are selected as the test instances, respectively. Several appropriate optimization algorithms for these kinds of problems are selected to compare with the proposed method.
Experiments on problems with biased decision space
Experiment setting
For optimization problems, complexity in the decision space mainly refers to the biased searching space [15]. Bias means that the slopes of objectives are large in the vicinities of some Pareto solutions, that is, a small variation will cause significant deterioration. Therefore, the bias feature presents difficulty in the balance between exploitation and exploration, results in premature during optimization, and also challenges the diversity performance. Benchmarks have been built considering this complexity. Typical benchmark suite is BT [16].
The complexity in decision space challenges the evolution operator. Therefore, in this experiment, MOP methods with different operators are selected, namely genetic operator, particle swarm optimizer, and differential optimizer. Since this part of experiment does not focus on the high dimension in the objective space, the performance of traditional algorithms, such as NSGAII [7], MOPSO [5], and MOEADDE [15], is similar to that of the current new algorithms. Thus, these traditional algorithms are selected as comparisons. Moreover, two algorithms with local search mechanisms are selected, namely, MOEADCMA [16] and NSLS [2]. These algorithms have advantages in dealing with complexity in the decision space. The comparison algorithms are provided by PlatEMO [27].
Elite definition has great influence on the optimization performance. For fair competition, the proposed MOEA-RPE adopts the same environmental selection methods as NSGAII (Algorithm 2, Line 7). The population size N and the maximal number of fitness evaluations are set to be 100 and 1e5 in all runs.
The inverted generational distance (IGD) is used as the performance assess indicators, which is a combinational metric for both convergence and diversity. IGD is the average distance from a uniformly distributed set selected from the true PF to the obtained solution set. The size of the uniform set for calculating IGD is set to be 5000.
Experimental results
The best, medium, and worst IGD values of each algorithm on test instances BT1-5 from 30 independent runs are presented in Table 1. The best IGD value in each row is marked in black. The Wilcoxon’s rank sum test with the significance level 0.05 is performed to show the statistically significant differences between the results; the symbols “\(+\)”, “−”, and “=” in the table, respectively, indicate that the results obtained by the reference algorithms are significantly better than, worse than or equal to the ones obtained by the proposed MOEA-RPE. Also, the Pareto optimal solutions of all runs are plotted in Fig. 4, where the true PFs are marked in red. From the IGD values and the position of the best solutions, it can be observed that MOEA-RPE have achieved most of the best performance. For BTs that have distance-related bias, the convergence difficulty is raised. Here, MOPSO, MOEADDE, MOEADCMA, and NSLS cannot converge to the true PF; NSGAII and MOEA-RPE have competitive performance, while MOEA-RPE shows smaller converge distance and better stability. BT3 and BT4 also have position-related bias. In these cases, compared to the approximate PF of NSGAII, the shape of MOEA-RPE is closer to the true PF. Considering that NSGAII and MOEA-RPE adopt the same environmental selection method, it can be concluded that MOEA-RPE has better exploration ability. The IGD curves within 1e5 fitness evaluations are given in Fig. 5. Compared to NSGAII, MOEA-RPE can further improve the optimization performance. This can be explained by the robust performance evaluation approach that can reserve potential good solutions, thus improving the exploration ability of MOEA.

The obtained solutions from 30 independent runs on BTs

The IGD curves with respect to the fitness evaluation times on BT1, BT2, and BT5
Experiments on many-objective problems
Experiment setting
Complexity in objective space mainly refers to high-dimensionality, degeneration, and so on. For many-objective optimization, diversity control is essential in objective space as well as decision space. The popular many-objective benchmark test suite MaF is selected as the optimization problem in this section. MaF includes diverse properties in separability, variable linkage, modality, and front geometry. In MaF, the nonlinearity simulated by several transformation functions can examine the convergence ability of the optimization methods. In this section, the objective dimension in MaF suite M is set to be 5.
MaF8 is a multi-point distance minimization problem (MPDMP), which can visually examine the elite distribution in decision space [14]. The difficulty of MaF8 has been raised, and another 3 MPDMPs with disconnected PS, local optima, and shift transformation have been built. These new instances are described in Table 2, where the penalty area \(\Omega _p\) is built in decision space to complicate the fitness landscape; shift transformation in MPDMP4 makes the problem deceptive and multimodal. All these changes require algorithm to have better exploration ability. In MPDMP experiments, the objective dimension M is set to be 10.
For many-objective problems, both evolution operator and environmental selection method are important. Therefore, many-objective algorithms using different operators are selected as the comparison, namely, NSGAIII [6], MyODEMR [8], and NMPSO [19]. The operators adopted are GA, DE, and PSO, respectively. Also, an algorithm for MaOP considering history information, NSGAIII-F1 [11], is also selected, which introduces an information feedback model in updating population. And a newly proposed decomposition-based algorithm MOEA/D-UR [9] is included. All methods adopt the reference-based method and the truncation approach in environmental selection. In this experiment, to adjust the proposed RPE-based method for solving many-objective problem, during the environmental selection (Algorithm 2, Line 7), extreme solution on each objective is first selected; the rest solutions are selected by the truncation approach according to the minimum distance to the neighboring solutions [37]. The population size N is set to be 150 (for NSGAIII, \(N=126\)), and the maximal number of fitness evaluations is 1e5.
Experiment result
The IGD performance from 30 independent runs on MaF1-8 and MPDMP2-4 is displayed in Table 3. It can be observed from the IGD values that MOEA-RPE has an obvious advantage on MaF1,2,5,6. For instances with multimodal modality, MOEA-RPE has poor performance on MaF3, which has a large number of local fronts. However, it is competitive on MaF4. It can be concluded that although the robust performance evaluation has the ability to handle local optima, it may not suitable for highly multimodal situation. This limitation can be explained by the leader matching mechanism in LBLS, which can cause fluctuations in exploiting an objective direction. Therefore, the highly multimodal complexity remains a challenge for MOEA-RPE. On MPDMP2-4, MOEA-RPE has achieved the best IGD scores. To observe the effectiveness of integrating historical information, attention should be paid to NSGAIII-F1 and MOEA-RPE. Compared to NSGAIII, NSGAIII-F1 has advantage in solving a few instances, such as MaF8 and MPDMP2, while MOEA-RPE has advantage in most of the instances, except MaF3. Therefore, the robust-based approach has better effectiveness and stability to utilize the historical information.
To study the distribution of the obtained solutions, the solutions with medium performance are given in the parallel coordinates in Fig. 6. It can be seen that MOEA-RPE has advantageous convergence and diversity performance in MaF1,2,4-8; and both NMPSO and MOEA-RPE have competitive performance in MPDMPs. For MaF8 and MPDMPs, the distributions in decision space can reflect the performance visually, which are given in Fig. 7. Since the robust performance evaluation consider the solutions’ historical position in both objective space and decision space, MOEA-RPE can achieve better distribution compared to the other algorithms, including NMPSO and NSGAIII-F1. That is to say, MOEA-RPE can provide more diverse solutions for the decision maker.

Solutions with medium performance on MaFs and MPDMPs

The distribution of solutions with medium performance on MPDMPs
In summary, according to the experiments, the proposed method has advantages in dealing with bias in the decision space, and is competitive in maintaining a uniform distribution in high-dimensional objective space. Since many real-world problems, such as the path planning and crashworthiness optimizations, have the bias characteristics, the proposed mechanism is suitable for solving these cases. To further demonstrate this point, a robotic path planning experiment will be performed in the section “Application on a path planning problem in robotic manipulation system”.
Discussions
In this section, the effectiveness analysis of the applied strategies and the sensitivity analysis of the main parameters are included, followed by a computational complexity analysis of the proposed framework.
Strategy effectiveness analysis
The proposed MOEA-RPE algorithm includes two main operations, RA selection and LBLS. The effectiveness of these two operations is discussed in this section.
Since the LBLS update requires individuals’ historical performance, it cannot work alone without RPE in RA selection. The effectiveness of the combination of LBLS and RA selection will be first discussed. When MOEA-RPE employs the same environmental selection approach as NSGAII, the comparative study between MOEA-RPE and NSGAII will illustrate the differences. The bi-objective benchmark suite BT is selected as the optimization problem. The optimization results are displayed in Table 4, MOEA-RPE is represented by “NSGAII\(+\)RA\(+\)LBLS”, which is significantly better than NSGAII on 2 of the 5 test instances, and has better average performance on 4 instances. This demonstrates that the utilization of historical performance is meaningful.
Moreover, to analyze the effectiveness of LBLS separately, an altered algorithm “NSGAII\(+\)RA\(+\)GA” is generated which adopts GA operation instead of LBLS. Results show that without LBLS, the performance of four instances would be degraded. The phenomenon can beŁ explained by the advantages of the learning-based mechanisms in balancing global exploration and local search.
Sensitivity study on the robust archive capacity
In the proposed method, the robust archive capacity \(N_A\) determines the extent of its influence on MOEA. In previous experiment, \(N_A\) is equal to the population size N. In this section, MOEA-RPE with different \(N_A\) values will be examined and analyzed.
Let \(P=N_A/N\), the IGD performance of \(P \in \{0.2,0.4,0.6,0.8,1.0\}\) from 10 independent runs are plotted in the box diagram Fig. 8. It can be seen that, compared to the performance of NSGAII and NMPSO, the fluctuation in P has no significant impact on MOEA-RPE. In previous experiment, MOEA-RPE has presented better performance on BT1-5, MaF1-2, and MaF5; in this section, the advantage still exists when the proportion of robust solutions is reduced. However, on MaF3 and MaF4, the performance deteriorates when the proportion P is increased. Generally, the performance has better stability when the proportion P is in range [0.2, 0.8]. Thus, \(P=0.6\) is recommended when using the proposed MOEA-RPE.

Sensitivity study on the robust archive capacity
Computational complexity analysis
Compared with traditional MOEAs which hold an average time complexity of \(O(MN^2)\), the complexity of MOEA-RPE is mainly increased in processing the RPE-based preservation. In RPE, the number of comparison operation used to obtain a metric interval is equal to the length of time window K, and thus, the complexity in handling historical information is O(KN). The complexity of an interval nondominated sorting operation is \(O(2MN^2)\). Since the sorting operation performs twice in the two-metric-based selection process (according to Algorithm 1), the time consumption will be doubled. Taking all the above considerations and computations into account, the worst-case complexity is \(O(5MN^2)\). When the constant coefficient is not considered, the time complexity becomes \(O(MN^2)\). Meanwhile, since each noninferior individual maintains K historical metrics, the space complexity would increase. In the worst case, it needs K times more memory space than algorithms with no historical records. To be concluded, although the proposed algorithm has the same time complexity as most MOEAs, it requires more sorting operations and read–write operations, so the optimization process will take more time. Figure 9 shows the average runtime of experiments in Table 3. The hardware platform contains an Intel i7-9700K CPU and a memory of 16 GB. The software platform is Matlab. \(K=5\) is adopted in these experiments.

Runtimes on MaFs and MPDMPs

The performance of robotic manipulation path planning optimization problem
Application on a path planning problem in robotic manipulation system
In this section, the proposed algorithm is adopted and tested in a robotic manipulation scenario. Industrial robots work in environments with many obstacles. In addition to completing a task without collision with obstacles or other manipulators, safety and energy costs should also be considered. Therefore, a multiobjective path planning optimization problem can be built. A manipulator can be described in two spaces, a 6-dimensional task-space illustrating the manipulator’s location and orientation; and a \(N_d\)-dimensional joint-space to record the joint angles of the manipulator motors, where \(N_d\) is the dimension of freedom (DOF). The optimized solution is a trajectory which consists of multiple points in the task-space or the joint-space. Since a small change on the joint angle will cause a significant change in the task-space, the optimizations of the moving safety and the trajectory length have bias features, which present difficulties for evolutionary algorithms.
The manipulator path planning problem under environment with obstacles is defined as follows. The working environment includes a 6-DOF manipulator and a spherical obstacle. The task is to move the manipulator tip from initial position to target position through the stationary obstacle without collision. To optimize the moving path, some points in the path are selected as the control points. During optimization, these control points are first determined by the optimization algorithm, and then, the other points in the path can be determined by interpolation between adjacent control points and endpoints. Each point in the path has two positions, position in the task-space \({\textbf{x}}_{\textrm{op}}\) and position in the joint-space \({\textbf{x}}_{\textrm{jt}}\), respectively.
During path optimization, three objectives are considered. The first objective is the manipulator end-effector/tip travelling length in the task-space. The distance is the summation of the displacements between adjacent points in the task-space. The second objective is the safe distance. It is defined as the minimal distance from the obstacle to the manipulator. The manipulator is simplified as six cylinders, the minimal distance from each cylinder to the obstacle is denoted as \(D_{\textrm{cy}}\). The larger safe distance is, the safer while operating the task. The third objective is the energy cost in the joint-space. It is the summation of angle increments on all joint motors. The objective functions are formulated as follows. To formulate a minimization MOP, a minus sign is added to the safe distance
Here, the number of control points is set to be 10. Thus the dimension of the decision variable is \(10\times N_d\). \(N_p\) is the number of points in the path after interpolation, and the points include start point and target point.
To compare the optimization performance, four algorithms are adopted in this section. The Pareto optimal solutions from 10 independent runs are plotted in Fig. 10. To compare the convergence performance more clearly, the PFs are plotted in the 2D space illustrating the trajectory length (\(f_1\)) and the angle increment (\(f_3\)), and the safe distance (\(-f_2\)) is displayed by the color bar.
It can be seen from the figures that the convergence performance of MOEA-RPE has significant advantage. NSGAIII comes second. From the enlarged views, compared to NSGAIII, the multiple fronts obtained by MOEA-RPE have a similar distribution, which means that MOEA-RPE has better stability in different runs. Therefore, the path planning problem proved that the proposed method has good performance in biased practical problems.
Conclusion
This paper presents a robust performance evaluation approach for multiobjective optimization. Based on this approach, a robust archive has been established to preserve potential solutions for evolution, and an RPE-based MOEA framework has been designed. Experiments have been carried out to examine the effectiveness of the proposed method. Since the RPE considers solutions’ historical performance in decision space and objective space, the RPE-based algorithm can achieve well-distributed solutions with better convergence performance in most test problems. Meanwhile, the proposed method is deeply analyzed in respect of strategy effectiveness and parameter sensitivity, and a recommended range for the robust solution proportion has been given. Finally, the proposed method has been applied to a robotic manipulation system to obtain the optimal path. In conclusion, the RPE approach is a novel and promising technique for multiobjective optimization. However, it still has limitations in highly multimodal environment. In future, the learning-based mechanism will be further studied for multimodal problems, and the RPE-based mechanism will be applied in other complex practical applications.
References
Abdel-Basset M, Mohamed R, Mirjalili S et al (2021) Moeoeed, a multi-objective equilibrium optimizer with exploration exploitation dominance strategy. Knowl Based Syst 214:106717. https://doi.org/10.1016/j.knosys.2020.106717
Chen B, Zeng W, Lin Y et al (2015) A new local search-based multiobjective optimization algorithm. IEEE Trans Evolut Comput 19(1):50–73. https://doi.org/10.1109/TEVC.2014.2301794
Chen H, Cheng R, Pedrycz W et al (2019) Solving many-objective optimization problems via multistage evolutionary search. IEEE Trans Syst Man Cybern Syst. https://doi.org/10.1109/TSMC.2019.2930737
Cheng R, Jin Y (2015) A competitive swarm optimizer for large scale optimization. IEEE Trans Cybern 45(2):191–204. https://doi.org/10.1109/TCYB.2014.2322602
Coello CAC, Pulido GT, Lechuga MS (2004) Handling multiple objectives with particle swarm optimization. IEEE Trans Evolut Comput 8(3):256–279. https://doi.org/10.1109/tevc.2004.826067
Deb K, Jain H (2014) An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: solving problems with box constraints. IEEE Trans Evolut Comput 18(4):577–601
Deb K, Pratap A, Agarwal S et al (2002) A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans Evolut Comput 6(2):182–197. https://doi.org/10.1109/4235.996017
Denysiuk R, CostaL, Santo IE (2013) Manyobjective optimization using differential evolution with variable-wise mutation restriction. In: Proceedings of the 15th annual conference on genetic and evolutionary computation (GECCO’13). Association for Computing Machinery, New York, NY, USA, 591–598. https://doi.org/10.1145/2463372.2463445
de Farias LRC, Araújo AFR (2022) A decomposition-based many-objective evolutionary algorithm updating weights when required. Swarm Evolut Comput 68:100980. https://doi.org/10.1016/j.swevo.2021.100980
Gong D, Xu B, Zhang Y et al (2020) A similarity-based cooperative co-evolutionary algorithm for dynamic interval multiobjective optimization problems. IEEE Trans Evolut Comput 24(1):142–156. https://doi.org/10.1109/tevc.2019.2912204
Gu Z, Wang G (2020) Improving NSGA-III algorithms with information feedback models for large-scale many-objective optimization. Future Gener Comput Syst 107:49–69. https://doi.org/10.1016/j.future.2020.01.048
Guo Y, Yang H, Chen M et al (2019) Ensemble prediction-based dynamic robust multi-objective optimization methods. Swarm Evolut Comput 48:156–171. https://doi.org/10.1016/j.swevo.2019.03.015
Huang W, Wu M, Hu J et al (2022) A multi-objective optimisation algorithm for a drilling trajectory constrained to wellbore stability. Int J Syst Sci 53:154–167. https://doi.org/10.1080/00207721.2021.1941396
Ishibuchi H, Hitotsuyanagi Y, Tsukamoto N, Nojima Y (2010) Many-objective Test problems to visually examine the behavior of multiobjective evolution in a decision space. In: Schaefer R, Cotta C, Kolodziej J, Rudolph G (eds) Parallel problem solving from nature,PPSN XI. PPSN 2010. Lecture Notes in Computer Science, vol 6239. Springer, Berlin,Heidelberg. https://doi.org/10.1007/978-3-642-15871-1_10
Li H, Zhang Q (2009) Multiobjective optimization problems with complicated Pareto sets, MOEA/D and NSGA-II. IEEE Trans Evolut Comput 13(2):284–302. https://doi.org/10.1109/tevc.2008.925798
Li H, Zhang Q, Deng J (2017) Biased multiobjective optimization and decomposition algorithm. IEEE Trans Cybern 47(1):52–66. https://doi.org/10.1109/TCYB.2015.2507366
Li Q, Cao Z, Ding W et al (2020) A multi-objective adaptive evolutionary algorithm to extract communities in networks. Swarm Evolut Comput. https://doi.org/10.1016/j.swevo.2019.100629
Limbourg P, Aponte DES (2005) An optimization algorithm for imprecise multi-objective problem functions. In: 2005 IEEE Congress on evolutionary computation, vol 1, pp 459–466. https://doi.org/10.1109/CEC.2005.1554719
Lin Q, Liu S, Zhu Q et al (2018) Particle swarm optimization with a balanceable fitness estimation for many-objective optimization problems. IEEE Trans Evolut Comput 22(1):32–46. https://doi.org/10.1109/tevc.2016.2631279
Liu Y, Gong D, Sun J et al (2017) A many-objective evolutionary algorithm using a one-by-one selection strategy. IEEE Trans Cybern 47(9):2689–2702
Ma X, Yu Y, Li X et al (2020) A survey of weight vector adjustment methods for decomposition-based multiobjective evolutionary algorithms. IEEE Trans Evolut Comput 24(4):634–649. https://doi.org/10.1109/TEVC.2020.2978158
Palakonda V, Mallipeddi R, Suganthan PN (2021) An ensemble approach with external archive for multi- and many-objective optimization with adaptive mating mechanism and two-level environmental selection. Inf Sci 555:164–197. https://doi.org/10.1016/j.ins.2020.11.040
Sengupta A, Pal TK (2000) On comparing interval numbers. Eur J Oper Res 127(1):28–43. https://doi.org/10.1016/S0377-2217(99)00319-7
Sun J, Miao Z, Gong D et al (2020) Interval multiobjective optimization with memetic algorithms. IEEE Trans Cybern 50(8):3444–3457. https://doi.org/10.1109/tcyb.2019.2908485
Sun Y, Xue B, Zhang M et al (2019) A new two-stage evolutionary algorithm for many-objective optimization. IEEE Trans Evolut Comput 23(5):748–761. https://doi.org/10.1109/TEVC.2018.2882166
Tao X, Guo W, Li Q et al (2020) Multiple scale self-adaptive cooperation mutation strategy-based particle swarm optimization. Appl Soft Comput 89:106,124. https://doi.org/10.1016/j.asoc.2020.106124
Tian Y, Cheng R, Zhang X et al (2017) PlatEMO: a MATLAB platform for evolutionary multi-objective optimization [educational forum]. IEEE Comput Intell Mag 12(4):73–87
Tian Y, Cheng H, Cheng R et al (2021) A Multistage evolutionary algorithm for better diversity preservation in multiobjective Optimization. IEEE Trans Syst Man Cybern Syst 51(9):5880–5894. https://doi.org/10.1109/TSMC.2019.2956288
Villarreal-Cervantes MG, Pantoja-García JS, Rodríguez-Molina A et al (2021) Pareto optimal synthesis of eight-bar mechanism using meta-heuristic multi-objective search approaches: application to bipedal gait generation. Int J Syst Sci 52:671–693. https://doi.org/10.1080/00207721.2020.1837991
Wang C, Xu R, Qiu J et al (2020) AdaBoost-inspired multi-operator ensemble strategy for multi-objective evolutionary algorithms. Neurocomputing 384:243–255. https://doi.org/10.1016/j.neucom.2019.12.048
Wang H, Jiao L, Yao X (2015) Two Arch2: an improved two-archive algorithm for many-objective optimization. IEEE Trans Evolut Comput 19(4):524–541. https://doi.org/10.1109/tevc.2014.2350987
Wu HC (2022) Solving multiobjective optimisation problems using genetic algorithms and solutions concepts of cooperative games. Int J Syst Sci. https://doi.org/10.1080/00207721.2022.2070793
Xu B, Zhang H, Zhang M et al (2019) Differential evolution using cooperative ranking-based mutation operators for constrained optimization. Swarm Evolut Comput 49:206–219. https://doi.org/10.1016/j.swevo.2019.06.007
Yi JH, Xing LN, Wang GG et al (2020) Behavior of crossover operators in NSGA-III for large-scale optimization problems. Inf Sci 509:470–487
Zhang K, Shen C, Yen GG et al (2021) Two-stage double niched evolution strategy for multimodal multiobjective optimization. IEEE Trans Evolut Comput 25(4):754–768. https://doi.org/10.1109/TEVC.2021.3064508
Zhang L, Wang S, Zhang K et al (2019) Cooperative artificial bee colony algorithm with multiple populations for interval multiobjective optimization problems. IEEE Trans Fuzzy Syst 27(5):1052–1065. https://doi.org/10.1109/tfuzz.2018.2872125
Zhang X, Tian Y, Cheng R et al (2018) A decision variable clustering-based evolutionary algorithm for large-scale many-objective optimization. IEEE Trans Evolut Comput 22(1):97–112
Zhang X, Zheng X, Cheng R et al (2018) A competitive mechanism based multi-objective particle swarm optimizer with fast convergence. Inf Sci 427:63–76. https://doi.org/10.1016/j.ins.2017.10.037
Zhang X, Zhan ZH, Fang W et al (2021) Multi population ant colony system with knowledge based local searches for multiobjective supply chain configuration. IEEE Trans Evolut Comput. https://doi.org/10.1109/TEVC.2021.3097339
Zhou A, Qu BY, Li H et al (2011) Multiobjective evolutionary algorithms: a survey of the state of the art. Swarm Evolut Comput 1(1):32–49
Zhou Y, Chen Z, Huang Z et al (2020) A multiobjective evolutionary algorithm based on objective-space localization selection. IEEE Trans Cybern. https://doi.org/10.1109/TCYB.2020.3016426
Zhu S, Xu L, Goodman ED et al (2021) A new many-objective evolutionary algorithm based on generalized Pareto dominance. IEEE Trans Cybern. https://doi.org/10.1109/TCYB.2021.3051078
Acknowledgements
This work was supported in part by the Shanghai Sailing Program (21YF1401400), the National Natural Science Foundation of China (62273088, 52078356), and the Fundamental Research Funds for the Central Universities (2232020D-49).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pan, A., Wang, C., Shen, B. et al. A robust performance evaluation approach for solution preservation in multiobjective optimization. Complex Intell. Syst. 9, 1913–1927 (2023). https://doi.org/10.1007/s40747-022-00889-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00889-1