
Abstract
The focused crawler grabs continuously web pages related to the given topic according to priorities of unvisited hyperlinks. In many previous studies, the focused crawlers predict priorities of unvisited hyperlinks based on the text similarity models. However, the representation terms of the web page ignore the phenomenon of polysemy, and the topic similarity of the text cannot combine the cosine similarity and the semantic similarity effectively. To address these problems, this paper proposes a focused crawler based on semantic disambiguation vector space model (SDVSM). The SDVSM method combines the semantic disambiguation graph (SDG) and the semantic vector space model (SVSM). The SDG is used to remove the ambiguation terms irrelevant to the given topic from representation terms of retrieved web pages. The SVSM is used to calculate the topic similarity of the text by constructing text and topic semantic vectors based on TF × IDF weights of terms and semantic similarities between terms. The experiment results indicate that the SDVSM method can improve the performance of the focused crawler by comparing different evaluation indicators for four focused crawlers. In conclusion, the proposed method can make the focused crawler grab the higher quality and more quantity web pages related to the given topic from the Internet.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Traditional web crawlers start from the initial URLs and obtain the web pages corresponding to these initial URLs. In the crawling process, the traditional web crawlers continuously extract new hyperlinks from the retrieved web pages and put them in the queue including unvisited hyperlinks until the specified conditions are met [1, 2]. But with the rapid growth of web pages in the Internet, web crawlers need to consume more time and space resources. In response to these problems, a topic-oriented web crawler is proposed and a topic-oriented search engine appeared. This topic-oriented web crawler only downloads web pages related to a given topic, and determines the priority of unvisited URLs based on the topic similarities of the retrieved web pages. The topic-oriented web crawler called as focused crawler greatly reduces resources such as storage space and indexing time, and improves the accuracy of retrieval results [3, 4].
The focused crawler uses the initial URLs to predict the priorities of unvisited URLs through the text similarity model. The focused crawler continuously crawls web pages related to a given topic from the Internet according to these priorities in descending order [5, 6]. Firstly, the focused crawler selects web pages related to a given topic through the manual screening or machine recognition, and construct the term vector representing the given topic through the text processing technology [7, 8]. Secondly, the focused crawler downloads web pages corresponding to initial URLs in turn, and extracts the terms and hyperlinks from each web page using the text processing and hyperlink analysis technology [9]. As a result, the term vector and the effective hyperlinks are obtained from the downloaded web page [10]. Then, the text similarity model is used to obtain the similarity between each web page and the given topic, and the similarity value is used to predict the topic similarity of each effective hyperlink in web pages [11]. Effective hyperlinks are added to the queue of unvisited URLs based on their topic similarity values. Finally, the focused crawler downloads web pages corresponding to unvisited hyperlinks from the queue in turn, and adds the web pages to the specified database. The above processes are repeated until a given number of downloaded web pages is reached or the database storage space is full.
The focused crawler utilizes the text contents of web pages or the link structure among web pages to predict the priorities of unvisited URLs [12, 13]. In the focused crawlers based on the text content, the vector space model (VSM) is a classic model that utilizes the text content to obtain the similarity between different texts [14]. In addition, the semantic similarity retrieval model (SSRM) is a semantic model that utilizes the semantic similarity between terms to obtain the similarity between different texts [15]. In the focused crawlers based on the hyperlink analysis, the PageRank algorithm is a classic algorithm that utilizes the link structure to obtain the priorities of unvisited URLs [16]. The above classic algorithm models utilize the text content or the hyperlink structure to make focused crawlers grab web pages related to the given topic. But the text content and the hyperlink structure are not used together to achieve the focused crawler. The focused crawler based on the context graph utilizes the link structure and text contents of the web pages to predict the priorities of unvisited URLs [17]. The crawling strategy guide the focused crawler to retrieve web pages related to the given topic from the Internet.
The focused crawlers based on above methods utilize the text content and the link structure to predict the priorities of the unvisited URLs. These methods can guide the focused crawlers to grab high quality and large number of topic-relevant web pages from the Internet. However, the above topic crawling methods still have some problems and deficiencies in determining representation terms and calculating the text similarity. These problems are described as follows:
-
(1)
The representation terms of the web page ignore the phenomenon of polysemy. The focused crawler utilizes the text processing methods including word segmentation, stem extraction and stop word removal to obtain representation terms of the web page, and compute the TF × IDF weights of representation terms. To achieve the description of the web page, the web page is finally represented as a term vector. However, the phenomenon of polysemous terms is common in the text natural language. For example, the term “apple” can refer to a kind of fruit or a smart phone. The polysemous terms in web pages generally have a specific single semantic. If the specific semantic of the polysemous term in the web page cannot be accurately recognized, this will mislead the focused crawler to grab the web pages. Therefore, the crawling performance of the focused crawler will be reduced.
-
(2)
The topic similarity of the text cannot combine the cosine similarity and the semantic similarity effectively. In the focused crawler based on the VSM, if there are no common terms between the text and the given topic, the topic similarity of the text will be the minimum zero by using the cosine similarity. This makes the focused crawler unable to retrieve web pages that are semantically similar to the given topic. In addition, in the focused crawler based on the SSRM, if the text and topic terms are the same or synonyms and the TF × IDF weights of these terms is very different, the topic similarity of the text will be the maximum one by using the semantic similarity. As a result, the above methods cannot obtain the accurate similarity between the text and the given topic. Therefore, the crawling performance of the focused crawler is also reduced.
To solve the above problems, this paper proposes a focused crawler based on the semantic disambiguation vector space model (SDVSM). The SDVSM method combines the semantic disambiguation graph (SDG) and the semantic vector space model (SVSM). Firstly, the semantic disambiguation graph (SDG) is built to remove the ambiguation terms irrelevant to the given topic in the representation terms of the web pages. Then, the semantic vector space model (SVSM) is utilized to calculate the similarity between the text and the given topic. Finally, the priority of each unvisited hyperlink is predicted based on the topic similarities of full text and anchor text of this unvisited hyperlink. The experiment results demonstrate that the proposed SDVSM Crawler improve the evaluation indicators compared with the BF Crawler, the VSM Crawler and the SSRM Crawler. In conclusion, the proposed method can make the focused crawler to grab the higher quality and more quantity web pages related to the given topic from the Internet.
The contributions of this paper are as follows:
-
(1)
This paper proposes a focused crawler based on the semantic disambiguation vector space model (SDVSM). The SDVSM method combines the semantic disambiguation graph (SDG) and the semantic vector space model (SVSM). This focused crawler utilizes the SDG to remove the ambiguation terms irrelevant to the given topic from representation terms of retrieved web pages. Meanwhile, this focused crawler utilizes the SVSM to calculate the similarity between the text and the given topic to combine the VSM method and the SSRM method.
-
(2)
The experiment has implemented the four focused crawlers including the BF Crawler, the VSM Crawler, the SSRM Crawler and the SDVSM Crawler. The performance of the four focused crawlers is evaluated based on three indicators including the harvest rate, the average topic similarity and the average error.
The remainder of this paper is organized as follows: “Related works” introduces the fuzzy inference model and the concept semantic similarity. In the next section, a focused crawler based on the SDVSM is proposed; experimental results are displayed and analyzed in “Experiment”. The next section puts forward the paper’s conclusions and further research works.
Related works
Fuzzy inference model
The fuzzy inference model transforms the fuzzy input into the clear output based on the fuzzy inference mechanism [18, 19]. In this model, the clear input is firstly fuzzed by the membership function and the corresponding membership degree is obtained. Then, the effective results of fuzzy rules are obtained by using the fuzzy if–then rules which make the membership function values of different input variables implement the T-normal operator operation. The all fuzzy rule results are combined to form the final fuzzy inference result by using the fuzzy inference mechanism. Finally, the inference result is used to produce the clear output based on the defuzzification method. This defuzzification process is the inverse process of the fuzzification.
The Fuzzy Inference Model mainly contain the fuzzification, fuzzy rules, fuzzy inference mechanism and defuzzification. The details are described in the following.
-
(1)
Fuzzification
The fuzzification transforms the clear input variables into the corresponding membership degree values by the membership functions of different language labels. In the fuzzification, the common membership functions include the Trigonometric membership function, Gaussian membership function and Piecewise Linear membership function [20]. In this paper, the Piecewise Linear membership function is used as follows:
$$ \begin{gathered} \hfill \\ \mu \left( x \right) = \left\{ {\begin{array}{*{20}c} 0 & {{\text{or}}} & 1 & {{\kern 1pt} x < a} \\ {\frac{x - a}{{b - a}}} & {{\text{or}}} & {\frac{x - b}{{a - b}}} & {{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} a \le x \le b} \\ 1 & {{\text{or}}} & 0 & {x > b} \\ \end{array} } \right. \hfill \\ \end{gathered} $$(1)where \(\mu (x)\) is the membership degree of a clear input variable \(x\), \(a\) and \(b\) are the parameters corresponding to different language labels.
-
(2)
Fuzzy rules
The fuzzy rules are consisted of if–then language rules. In these rules, the if-part is the conditional statement part of fuzzy rules which includes logical connectives such as ‘and’, ‘or’, and ‘not’, while then-part is the conclusion statement part of fuzzy rules. The fuzzy rules transform essentially membership degree values into the effective fuzzy rule results based on the fuzzy logic operations [21]. The common fuzzy rules include the Mamdani fuzzy rule and Takagi Sugeno Kang fuzzy rule (TSK fuzzy rule) [22]. The Mamdani fuzzy rule has the simple expression, and is often used in the imprecise fuzzy inference model. In this paper, the Mamdani fuzzy rule is used as follows:
$$\begin{aligned} &R_{r} : {\text{IF}}{\kern 1pt} {\kern 1pt} x_{1} {\kern 1pt} {\kern 1pt} {\text{is}}{\kern 1pt} {\kern 1pt} A_{1} {\kern 1pt} {\kern 1pt} {\text{and}}{\kern 1pt} {\kern 1pt} x_{2} {\kern 1pt} {\kern 1pt} {\text{is}}{\kern 1pt} {\kern 1pt} A_{2} {\kern 1pt} {\kern 1pt} {\text{and}}{\kern 1pt} {\kern 1pt} \cdots {\kern 1pt} {\kern 1pt} {\text{and}}{\kern 1pt} {\kern 1pt} x_{n} {\kern 1pt} {\kern 1pt} {\text{is}}{\kern 1pt} {\kern 1pt} A_{n} ,\\ &{\text{THEN}}{\kern 1pt} {\kern 1pt} y_{r} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\text{is}}{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} B{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} r = 1,2, \cdots ,R, \end{aligned} $$(2)where \(R_{r}\) is the r-th fuzzy rule, \(x_{i} (1 \le i \le n)\) is the i-th input variable, \(A_{i} (1 \le i \le n)\) is the i-th fuzzy set of \(x_{i}\), \(n\) is the number of the fuzzy input variables, \(y_{r}\) is the fuzzy variable, \(B\) is the fuzzy set of \(y_{r}\), and \(R\) is the total number of fuzzy rules.
-
(3)
Fuzzy inference mechanism
The fuzzy inference mechanism is used to obtain the fuzzy inference result. The fuzzy inference mechanism transforms the membership degrees of clear inputs into rule results, and then the rule results are combined by the fuzzy logic operations to form the final fuzzy inference result [23]. The common fuzzy inference mechanisms include the Mamdani minimum and Larsen product [24]. In this paper, the Mamdani minimum is used as follows:
$$ \mu_{B} (y) = \mathop {\max }\limits_{r = 1}^{R} \left\{ {\min \, \left( {\mu_{A1} \left( {x_{1} } \right),\mu_{A2} \left( {x_{2} } \right), \cdots \cdots ,\mu_{An} \left( {x_{n} } \right)} \right)} \right\}, $$(3)where \(\mu_{B} (y)\) is the fuzzy inference result, \(B\) is the fuzzy set of \(y\), \(R\) is the total number of fuzzy rules, \(\mu_{Ai} (x_{i} ){\kern 1pt} {\kern 1pt} {\kern 1pt} (1 \le i \le n)\) is the membership degree of the clear input \(x_{i} {\kern 1pt}\), \(A_{i} (1 \le i \le n)\) is the i-th fuzzy set of \(x_{i}\), and \(x_{i} (1 \le i \le n)\) is the i-th input variable.
-
(4)
Defuzzification
The defuzzification transforms the fuzzy inference result formed by the fuzzy inference mechanism into the clear output. The defuzzification can be considered as the inverse process of the fuzzification. In the fuzzy inference model, the defuzzification essentially transforms the fuzzy variable into the clear variable which is used to make the appropriate decision in the fuzzy inference domain [25]. The common defuzzification methods include the maximum membership method, area equipartition method and gravity center method [26]. In this paper, the maximum membership method is used as follows:
$$ \overline{{x_{\max } }} = \frac{1}{N}\sum\limits_{i = 1}^{N} {x_{\max }^{{B_{i} }} } $$(4)where \(\overline{{x_{\max } }}\) is the clear output called as the ambiguity value, \(x_{\max }^{{B_{i} }}\) is the abscissa corresponding to the maximum membership degree for the fuzzy set \(B_{i}\), \(B_{i}\) is the i-th fuzzy set of the ambiguity variable \(x\).
Concept semantic similarity
The concept semantic similarity refers to the semantic similarity of two concepts in the ontology. In addition, the concept semantic similarity needs to consider the contexts and word semantics. The WordNet is widely used in calculating the concept semantic similarity. The concept semantic similarity can be calculated based on the three different methods including path distance method, information content method and attribute feature method in the WordNet [27]. This paper utilizes the information content method to calculate the semantic similarity between concepts. The details are described as follows:
(1) Path distance method
The path distance method calculates the semantic similarity between two concepts through the shortest distance and depths in the relationship tree of two concepts in the WordNet. The path distance method believes that the closer the distance between two concepts is, the higher the semantic similarity between concepts is [28]. The calculation formula is described as follows:
where \({\text{sim}}_{PD} (c_{1} ,c_{2} )\) is the semantic similarity between two concepts \(c_{1}\) and \(c_{2}\), \({\text{len }}(c_{1} ,c_{2} )\) is the shortest path distance of two concepts \(c_{1}\) and \(c_{2}\), \({\text{lso }}(c_{1} ,c_{2} )\) is the deepest common parent node of two concepts \(c_{1}\) and \(c_{2}\), and \({\text{depth }}\left( {{\text{lso}}\left( {c_{1} ,c_{2} } \right)} \right)\) is the depth of the node \({\text{lso }}(c_{1} ,c_{2} )\) in the WordNet. The computational complexity of the path distance method is simple and small.
(2) Information content method
The information content method calculates the semantic similarity between two concepts through the information content (IC) values. The information content method believes that there are common points among concepts, and meanwhile each concept has its own information capacity [29]. The calculation formula is described as follows:
where \({\text{sim}}_{IC} (c_{1} ,c_{2} )\) is the semantic similarity between two concepts \(c_{1}\) and \(c_{2}\) in the WordNet, \({\text{lso }}(c_{1} ,c_{2} )\) is the deepest common parent node of two concepts \(c_{1}\) and \(c_{2}\), \(IC(c_{1} )\) and \(IC(c_{2} )\) are, respectively, the IC values of two concepts \(c_{1}\) and \(c_{2}\), and \(IC({\text{lso }}(c_{1} ,c_{2} ))\) is the IC value of the node \({\text{lso }}(c_{1} ,c_{2} )\). The IC value is calculated as follows:
where \(IC(c)\) is the IC value of the concept \(c\), \({\text{hypo }}(c)\) is the number of all child nodes of the concept \(c\), and \(\max \_{\text{nodes}}\) is the maximum number of concepts contained in the classification tree in the WordNet.
(3) Attribute feature method
The attribute feature method calculates the semantic similarity between two concepts through the attribute features of the two concepts [30]. The calculation formula is described as follows:
where \(sim_{AF} (c_{1} ,c_{2} )\) is the semantic similarity between two concepts \(c_{1}\) and \(c_{2}\) in the WordNet, \(f(c_{1} \cap c_{2} )\) is the number of common attribute features of two concepts \(c_{1}\) and \(c_{2}\), \(f(c_{1} - c_{2} )\) is the number of attribute features that belong to concept \(c_{1}\) and do not belong to concept \(c_{2}\), \(f(c_{2} - c_{1} )\) is the number of attribute features that belong to concept \(c_{2}\) and do not belong to concept \(c_{1}\), \(\gamma\), \(\alpha\) and \(\beta\) are the parameters which, respectively, indicate the influence degrees of the common and non-common attribute features of two concepts \(c_{1}\) and \(c_{2}\).
As mentioned above, there are three kinds of methods to calculate the concept semantic similarity from previous literatures. The three kinds of methods including path distance method, information content method and attribute feature method are visually shown in the following Table 1 from typical literature.
Focused crawler based on SDVSM
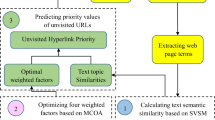
In this section, this paper proposes a focused crawler based on the semantic disambiguation vector space model (SDVSM). The SDVSM method combines the semantic disambiguation graph (SDG) and the semantic vector space model (SVSM). Figure 1 shows the flowchart of the focused crawler based on SDVSM. In Fig. 1, the flowchart of this focused crawler is divided into three main modules: semantic disambiguation graph, semantic vector space model and hyperlink priority prediction. Firstly, the semantic disambiguation graph (SDG) is constructed by using the training web pages related to the given topic. Then, the semantic vector space model (SVSM) combines the cosine similarity in the VSM and the semantic similarity in the SSRM to calculate the similarity between the text and the given topic. Finally, the hyperlink priority prediction obtains the priorities of unvisited hyperlinks to guide the focused crawler to grab web pages related to the given topic based on the SDG and the SVSM. The above three modules are described in the following.

The flowchart of the focused crawler based on SDVSM
Semantic disambiguation graph
The semantic disambiguation graph (SDG) construction is divided into three steps including the topic graph construction, ambiguation term identification and disambiguation term extraction. The SDG is used to remove the ambiguation terms irrelevant to the given topic from the representation terms of retrieved web pages [36]. In short, the SDG further optimizes the representation terms of retrieved web pages.
Topic graph construction
The topic graph is constructed by using the topic terms and co-occurrence degrees between these topic terms. In the topic graph, the topic terms are regarded as nodes, and the co-occurrence degrees between the topic terms are regarded as the weights of the edges in the topic graph. The topic graph cannot only reflect the topic characteristics, but also provide the search range of topic terms for ambiguation term identification and disambiguation term extraction.
The topic terms are extracted from the representation terms of training web pages related to the given topic. The topic terms are determined based on the weights of the representation terms of training web pages. The term weights are calculated based on the TF × IDF [37]. The TF × IDF weights are calculated as follows:
where \(w_{ij}\) is the TF × IDF weight of the term i in the training web page j, \(tf_{ij}\) is the term frequency (TF) of the term i in the training web page j, \(idf_{ij}\) is the inverse term frequency (IDF) of the term i in the training web page j, \(f_{ij}\) is the frequency of the term i in the training web page j, \(f_{\max }^{j}\) is the maximum frequency of all terms in training web page j, \(N_{i}\) is the number of web pages containing the term i in the training web pages, and \(N_{S}\) is the total number of the training web pages.
The co-occurrence degrees express the relationship strengths between topic terms. The co-occurrence degree between two topic terms is the proportion of the number of topic-relevant and co-occurrence web pages to the number of retrieved web pages containing either of two topic terms. The number of retrieved web pages is obtained by inputting either of two topic terms into the general search engine such as Bing, Google. The number of topic-relevant and co-occurrence web pages are the number of retrieved web pages related to the given topic and containing both of two topic terms. The co-occurrence degree between two topic terms is calculated as follows:
where \(cd(k_{1} ,k_{2} )\) is the co-occurrence degree between two topic terms \(k_{1}\) and \(k_{2}\), \(N_{{\text{rel - coo}}} (k_{1} ,k_{2} )\) is the number of topic-relevant and co-occurrence web pages containing both of the topic terms \(k_{1}\) and \(k_{2}\), and \(N(k_{1} ,k_{2} )\) is the total number of retrieved web pages containing either of two topic terms \(k_{1}\) and \(k_{2}\). The certain number of retrieved web pages are randomly selected to simplify the co-occurrence degree calculation because \(N(k_{1} ,k_{2} )\) may be very large in practice.
The topic graph is an undirected graph composed of topic terms and co-occurrence degrees between the topic terms. Figure 2 gives an example of the topic graph construction. In Fig. 2, there are five topic terms \(k_{1}\), \(k_{2}\), \(k_{3}\), \(k_{4}\) and \(k_{5}\). The maximum TF × IDF weight in all nodes is the value 0.62 of the topic term \(k_{3}\), and indicates that the contribution of the topic term \(k_{3}\) to the given topic is the greatest in all topic terms. The values on edges are the weights between nodes corresponding to the co-occurrence degrees between topic terms in Fig. 2. The maximum weight in all edges is the co-occurrence degree 0.86 between two topic terms \(k_{2}\) and \(k_{4}\), and indicates that the relationship strength between two topic terms \(k_{2}\) and \(k_{4}\) is the strongest in all topic term pairs.

An example of the topic graph construction
Ambiguation term identification
The ambiguation term identification obtains ambiguation terms from the topic terms in the topic graph based on the topic indicators and the fuzzy inference model. This identification process is divided into two steps including the indicator calculation and ambiguity resolution. The ambiguation term identification determines the ambiguation terms and further clarifies the search range of topic terms for the disambiguation term extraction. The following will describe the above two steps.
Indicator calculation
The indicator calculation obtains the topic relevance, topic popularity and topic importance of all topic terms to describe the membership degrees of all topic terms with ambiguity. Normally, the higher the three topic indicators of a topic term are, the lower the membership degree of the topic term with ambiguity is. The topic relevance (TR) refers to the relevance of the topic term related to the given topic, and is calculated by the ratio of the occurrence frequencies of the topic term in topic-relevant and topic-irrelevant web pages. The topic popularity (TP) refers to the popularity of the topic term related to the given topic, and is calculated by the ratio of the numbers of topic-relevant and topic-irrelevant web pages containing the topic term. The topic importance (TI) refers to the importance of the topic term related to the given topic, and is calculated by the ratio of the occurrence frequency of the topic term and the total occurrence frequency of other topic terms in training web pages of the topic graph.
The following will describe the calculation method of the three topic indicators of each topic term. The topic item k as a query word is initially inputted into the general search engine to obtain the certain number of retrieved web pages. Then the numbers of topic-relevant and topic-irrelevant web pages are determined by using the VSM. The three topic indicators are calculated as follows:
where \(TR(k)\), \(TP(k)\) and \(TI(k)\) are, respectively, the topic relevance, topic popularity and topic importance of the topic term \(k\), \(RF(k)\) and \(UF(k)\) are, respectively, the occurrence frequencies of the topic term \(k\) in topic-relevant and topic-irrelevant web pages, \(RP(k)\) and \(UP(k)\) are, respectively, the numbers of topic-relevant and topic-irrelevant web pages containing the topic term \(k\), \(C\) is the parameter which is greater than 0 and is equal to 1 in general to ensure that the denominator is not 0, \(N_{k}\) is the occurrence frequency of the topic term k in the training web pages of the topic graph, and \(N_{{{\text{others}}}}\) is the occurrence frequency of other topic terms in the training web pages of the topic graph.
Ambiguity resolution
The ambiguity resolution utilizes the three topic indicators of the topic term to judge whether the topic term is an ambiguation term based on the fuzzy inference model. For example, the term “Amazon” is an ambiguation term and obviously has two different semantics “shopping website” and “tropical rain forest”. The ambiguity resolution contains three processes including the input fuzzification, fuzzy inference engine and output defuzzification. The following will describe the above three processes.
(1) Input fuzzification
The input fuzzification fuzzes the three topic indicators of topic terms by the membership function. The input fuzzification mainly involves language labels and the input membership function. The larger the three topic indicators of the topic term are, the lower the membership degree of the topic term with ambiguity is. In this paper, the language labels include “Low (L)” and “High (H)” which correspond to two different fuzzy sets for the three topic indicators. The Piecewise Linear function is selected as the input membership function for the three topic indicators. The input membership function for the three topic indicators are described as follows:
where \(\mu_{L}^{i} (x)\) and \(\mu_{H}^{i} (x)\) are two input membership functions of the two fuzzy sets “Low” and “High” for the i-th topic indicator, respectively, \(a_{i}\) and \(b_{i}\) are parameters of two input membership functions for the i-th topic indicator, the i-th (\({\kern 1pt} {\kern 1pt} i = 1,2,3\)) topic indicator is the topic relevance, topic popularity and topic importance, respectively.
(2) Fuzzy inference engine
The fuzzy inference engine mainly involves the fuzzy rules and fuzzy inference mechanism. The fuzzy rules are composed of language rules in the form of if–then. The if-part is the conditional part which is composed of language labels of the three topic indicators and the logical conjunction “AND”, while the then-part is the conclusion part which is obtained by performing the fuzzy operations for the membership degrees of the three topic indicators. The fuzzy rules are shown in Table 2. In Table 2, there are eight fuzzy rules for three topic indicators, and L and H are two different fuzzy sets of two language labels “Low” and “High”. For example, for the first fuzzy rule, the if-part is the conditional part “L AND L AND L” for all three topic indicators of a topic term, and the then-part is the conclusion part that the rule result is H for the topic term. Other fuzzy rules are similar to the first fuzzy rule.
The fuzzy inference mechanism converts all rule output results into the final fuzzy inference results. In this paper, the Mamdani minimum inference mechanism is utilized, and the formula is shown as follows:
where \(\mu_{L,k}\) and \(\mu_{H,k}\) are the fuzzy inference results of two fuzzy sets “L” and “H” for the topic term \(k\), respectively, \(R_{L}\) is the fuzzy rule set with the rule result “L” including the fifth, sixth, seventh and eighth fuzzy rules in Table 2, \(R_{H}\) is the fuzzy rule set with the rule result “H” including the first, second, third and fourth fuzzy rules in Table 2, \(r\) refers to a fuzzy rule, \(\mu (TR(k))\) is the membership degree of topic relevance \(TR(k)\) of the topic term \(k\) for the fuzzy set “L” or “H”, \(\mu (TP(k))\) is the membership degree of topic popularity \(TP(k)\) of the topic term \(k\) for the fuzzy set “L” or “H”, and \(\mu (TI(k))\) is the membership degree of topic importance \(TI(k)\) of the topic term \(k\) for the fuzzy set “L” or “H”.
(3) Output defuzzification
The output defuzzification involves the ambiguous membership function and the defuzzification method. The Piecewise Linear function is selected as the ambiguous membership function. The ambiguous membership function is showed as follows:
where \(\mu_{L}^{AV} (av)\) and \(\mu_{H}^{AV} (av)\) are the ambiguous membership functions for two fuzzy sets “L” and “H”, respectively, \(av\) is the ambiguity variable for the two fuzzy sets “L” or “H”, and \(a_{AV}\) and \(b_{AV}\) are the parameters of two membership functions \(\mu_{L}^{AV} (av)\) and \(\mu_{H}^{AV} (av)\) for two fuzzy sets “L” and “H”, respectively.
The defuzzification method converts the fuzzy inference results into a clear output called as the ambiguity value. In this paper, the maximum membership method is utilized. The defuzzification method is shown as follows:
where \(av_{{{\text{output}},k}}\) is the clear output called as the ambiguity value of the topic term \(k\), and \(av_{L,k}\) and \(av_{H,k}\) are the ambiguity values obtained by using the formula (14) and two fuzzy inference results \(\mu_{L,k}\) and \(\mu_{H,k}\) for two fuzzy sets “L” and “H”, respectively. The ambiguity value \(av_{{{\text{output}},k}}\) is used to directly judge whether the topic term \(k\) is an ambiguation term by comparing with an ambiguation threshold value. The ambiguation threshold value is equal to the average of two parameters \(a_{AV}\) and \(b_{AV}\) in the formula (14). If the ambiguity value \(av_{{{\text{output}},k}}\) of the topic term \(k\) is higher than or equal to the ambiguation threshold value, the topic term \(k\) is an ambiguation term. On the contrary, the topic term k is not an ambiguation term.
Figure 3 gives an example of the ambiguation term identification. In Fig. 3, the topic relevance, topic popularity and topic importance of the topic term \(k\) are firstly calculated as 7.1, 3.4 and 5.7, respectively. The table in Fig. 3 indicates the fuzzy inference results for two fuzzy sets “Low” and “High” are, respectively, \(\mu_{L,k} = 0.3\) and \(\mu_{H,k} = 0.575\) by using the formula (13) based on Table 2. The ambiguation threshold value is the average value 15 of two parameters \(a_{AV}\) and \(b_{AV}\). The two ambiguity values \(av_{L,k}\) and \(av_{H,k}\) are calculated based on the formula (14), i.e., \(av_{L,k} = 17\) and \(av_{H,k} = 15.75\). According to the formula (15), the clear output \(av_{{{\text{output}},k}}\) called as the ambiguity value of the topic term \(k\) is the average value 16.375 of two ambiguity values \(av_{L,k}\) and \(av_{H,k}\). Obviously, the ambiguity value \(av_{{{\text{output}},k}}\) of the topic term \(k\) is higher than the ambiguation threshold value. Therefore, the topic term \(k\) is identified as an ambiguation term.

An example of the ambiguation term identification
Disambiguation term extraction
The disambiguation term extraction obtains other topic terms with strong sematic relationships for each ambiguation term from the topic graph. The other topic terms are called disambiguation terms which have the strong semantic relationships with the ambiguation term. The semantic relationship strength can be directly measured by the co-occurrence degrees between topic terms which can be calculated based on the formula (10) in the topic graph. The disambiguation term extraction can be described by the simple formula as follows:
where \(dt(k)\) is the comparison result, \(cd(at,k)\) is the co-occurrence degree between the ambiguation term \(at\) and the topic term \(k\), and \(T_{cd}\) is the given co-occurrence degree threshold which can be equal to the average value of all co-occurrence degrees between the ambiguation term \(at\) and other topic terms. If \(dt(k)\) is equal to 1, the topic term \(k\) is the disambiguation term of the ambiguation term \(at\).
Figure 4 gives an example of the disambiguation term extraction. In Fig. 4, the topic term \(k_{2}\) is an ambiguation term, and the given co-occurrence degree threshold \(T_{cd}\) is set as 0.4. The co-occurrence degrees between topic \(k_{2}\) and other topic terms \(k_{1}\), \(k_{3}\), \(k_{4}\) and \(k_{5}\) are, respectively, 0.36, 0.35, 0.86 and 0.61. According to formula (16), it can judge that disambiguation terms of the ambiguation term \(k_{2}\) include two topic terms \(k_{4}\) and \(k_{5}\).

An example of the disambiguation term extraction
Semantic vector space model
The semantic vector space model (SVSM) utilizes the representation terms of texts optimized based on the SDG to calculate the similarities between these texts and the given topic in this paper. In previous studies, there are two typical text similarity models including the vector space model (VSM) and the semantic similarity retrieval model (SSRM). The SVSM combines the advantages of the VSM and the SSRM. The SVSM constructs the text semantic vector and topic semantic vector, and the cosine value between two semantic vectors is considered as the similarity between the text and the given topic. The VSM, the SSRM and the SVSM are outlined in the following.
-
(1)
VSM
The VSM is the classic text similarity model widely applied to the natural language processing. The VSM constructs the text and topic term vectors based on the TF × IDF weights of terms. Then, the VSM calculates the cosine value between two term vectors to obtain the similarity between the text and the given topic [14]. The VSM formula is shown as follows:
$$ {\text{Sim }}(d,t) = \frac{{\sum\nolimits_{i = 1}^{n} {w_{di} w_{ti} } }}{{\sqrt {\sum\nolimits_{i = 1}^{n} {w_{di}^{2} } } \sqrt {\sum\nolimits_{j = 1}^{n} {w_{tj}^{2} } } }}, $$(17)where \({\text{Sim }}(d,t)\) is the similarity between text d and topic t, \(w_{di}\) and \(w_{tj}\) are the TF × IDF weights of two terms i and j in text d and topic t, respectively, calculated based on the formula (9), and \(n\) is the number of common terms in text d and topic t.
-
(2)
SSRM
The SSRM utilizes the semantic similarity between terms to calculate the similarity between the text and the given topic. The SSRM obtains the TF × IDF weights of terms and the semantic similarities between terms based on the lexical ontology. Then, the SSRM normalizes the sum value of the products among semantic similarities and TF × IDF weights to obtain the similarity between the text and the given topic [15]. The SSRM formula is shown as follows:
$$ {\text{Sim }}(d,t) = \frac{{\sum\nolimits_{i = 1}^{n} {\sum\nolimits_{j = 1}^{m} {{\text{sem}}_{ij} w_{di} w_{tj} } } }}{{\sum\nolimits_{i = 1}^{n} {\sum\nolimits_{j = 1}^{m} {w_{di} w_{tj} } } }}, $$(18)where \({\text{Sim }}(d,t)\) is the similarity between text d and topic t, \({\text{sem}}_{ij}\) is the semantic similarity between two terms i and j in text d and topic t, respectively, calculated based on the formula (6), \(w_{di}\) and \(w_{tj}\) are the TF × IDF weights of two terms i and j in text d and topic t, respectively, and \(n\) and \(m\) are the total numbers of terms in text d and topic t, respectively.
-
(3)
SVSM
The SVSM is an improved semantic text similarity model. The SVSM combines the cosine similarity and the semantic similarity to calculate the similarity between the text and the given topic [38]. The SVSM obtains firstly the TF × IDF weights of terms and the semantic similarities between terms. Secondly, the SVSM constructs the text and topic semantic vectors based on TF × IDF weights of terms and semantic similarities between terms. Finally, the SVSM calculates the cosine value between two semantic vectors to obtain the similarity between the text and the given topic. The SVSM formula is shown as follows:
$$ \begin{aligned} {\text{Sim }}(d,t) & = \overrightarrow {DSV} \cdot \overrightarrow {TSV}\\ & = \frac{{\sum\nolimits_{i = 1}^{m} {\sum\nolimits_{j = 1}^{n} {w_{di} w_{tj} ({\text{sem}}_{ij} )^{2} } } }}{{\sqrt {\sum\nolimits_{i = 1}^{m} {\sum\nolimits_{j = 1}^{n} {(w_{di} {\text{sem}}_{ij} )^{2} } } } \sqrt {\sum\nolimits_{i = 1}^{m} {\sum\nolimits_{j = 1}^{n} {(w_{tj} {\text{sem}}_{ij} )^{2} } } } }}, \end{aligned} $$(19)where \(Sim(d,t)\) is the similarity between text d and topic t, \(\overrightarrow {DSV}\) and \(\overrightarrow {TSV}\) are the text semantic vector and topic semantic vector, respectively, \({\text{sem}}_{ij}\) is the semantic similarity between two terms i and j in text d and topic t, respectively, \(w_{di}\) and \(w_{tj}\) are the TF × IDF weights of two terms i and j in text d and topic t, respectively, and \(n\) and \(m\) are the total numbers of terms in text d and topic t, respectively.
Figure 5 gives an example of the SVSM. In Fig. 5, the text semantic vector \(\overrightarrow {DSV}\) is (0.18, 0.13, 0.3, 0.24, 0.15, 0.03), and the topic semantic vector \(\overrightarrow {TSV}\) is (0.26, 0.16, 0.6, 0.52, 0.28, 0.19). The similarity between text d and topic t is 0.98 based on the SVSM in the formula (19). In summary, the SVSM utilizes the cosine similarity and the semantic similarity to obtain the similarity between the text and the given topic. In the SVSM, the semantic similarity is used to construct the text and topic semantic vector, and the cosine similarity between two semantic vectors is considered as between the text and the given topic. The SVSM combines the advantages of the VSM and the SSRM to obtain the similarity between the text and the given topic more reasonably. Therefore, the SVSM is used to calculate the similarity between the text and the given topic in this paper.

An example of the SVSM
Hyperlink priority prediction
The hyperlink priority prediction utilizes the SDG and the SVSM to predict the priorities of unvisited hyperlinks. The hyperlink priority prediction can be divided into two processes including web term disambiguation and hyperlink priority estimation. The above two processes are described in detail in the following.
Web term disambiguation
The web term disambiguation removes ambiguation terms irrelevant to the given topic to optimize representation terms of web pages based on the SDG. Each ambiguation terms is judged to remove from representation terms of web pages by comparing the average co-occurrence degree between each ambiguation term and its disambiguation terms in web pages with the given threshold parameter. If the average co-occurrence degree is smaller than the given threshold parameter, the ambiguation term is removed from representation terms of web pages. The web term disambiguation can be described by the formula as follows:
where \(P\) is a retrieved web page, \(RT_{P}\) is the representation term set of web page \(P\), \(AT_{SDG}\) is the ambiguation term set in the SDG, \(AT_{P,SDG}\) is the intersection of the ambiguation term set \(AT_{SDG}\) and the representation term set \(RT_{P}\), \(k_{amb}\) is an ambiguation term in the set \(AT_{P,SDG}\), \(DT_{SDG}^{{{\kern 1pt} k_{amb} }}\) is the disambiguation term set of the ambiguation term \(k_{amb}\) in the SDG, \(DT_{P,SDG}^{{{\kern 1pt} k_{amb} }}\) is the intersection of the disambiguation term set \(DT_{SDG}^{{{\kern 1pt} k_{amb} }}\) and the representation term set \(RT_{P}\), \(dt_{i}\) is the i-th disambiguation term in the set \(DT_{P,SDG}^{{{\kern 1pt} k_{amb} }}\), \(cd(dt_{i} ,k_{amb} )\) is the co-occurrence degree between the disambiguation term \(dt_{i}\) and the ambiguation term \(k_{amb}\), \(N\) is the number of disambiguation terms in the set \(DT_{P,SDG}^{{{\kern 1pt} k_{amb} }}\), \(\overline{cd} (k_{amb} )\) is the average co-occurrence degree between all disambiguation terms in the set \(DT_{P,SDG}^{{{\kern 1pt} k_{amb} }}\) and the ambiguation term \(k_{amb}\), \(rt(k_{amb} )\) is the judgment result which is used to judge whether the ambiguation term \(k_{amb}\) is removed from the representation term set \(RT_{P}\), and \(TP\) is the given threshold parameter which is equal to the average co-occurrence degree between the ambiguation term \(k_{amb}\) and its disambiguation terms in the SDG. If \(rt(k_{amb} )\) is equal to 1, i.e., the average co-occurrence degree \(\overline{cd} (k_{amb} )\) is smaller than the given threshold parameter \(TP\), the ambiguation term \(k_{amb}\) is removed from the representation term set \(RT_{P}\) of the web page \(P\).
Hyperlink priority estimation
The hyperlink priority estimation predicts the priorities of unvisited hyperlinks based on the SDG and the SVSM. The SDG is firstly used to remove the ambiguation terms irrelevant to the given topic and optimize the representation terms of web pages. Then, the SVSM is used to calculate the topic similarities of full texts and anchor texts of unvisited hyperlinks. Finally, the topic similarities of full text and anchor text of each unvisited hyperlink are linearly combined as the priority of unvisited hyperlink which determines the visiting order of unvisited hyperlinks in the focused crawler. The priority of each unvisited hyperlink is calculated as follows:
where \(P(l)\) is the priority of the unvisited hyperlink \(l\), \(\lambda\) is a weighted factor, \({\text{Sim }}(f_{l} ,t)\) is the topic similarity of full text \(f_{l}\) of the unvisited hyperlink \(l\), and \({\text{Sim }}(a_{l} ,t)\) is the topic similarity of anchor text \(a_{l}\) of the unvisited hyperlink \(l\).
Figure 6 gives the example of downloading web pages for the proposed focused crawler. In Fig. 6, there are three initial seed URLs including URLs1, URLs2 and URLs3 with the same priorities, and these URLs are added into the queue of unvisited URLs. Firstly, the head URLhead in the queue is selected and visited to download the corresponding web page marked as the i-th web page, and this web page will be added into Web Page Database. In addition, there are p hyperlinks extracted from the i-th web page including URLi1, URLi2, URLip, etc. Meanwhile, there are n terms extracted from the i-th web page including Termi1, Termi2, Termin, etc. Secondly, the web term disambiguation generates m optimized representation terms of the i-th web page including Term’i1, Term’i2 Term’im, etc. Thirdly, for p unvisited hyperlinks in the i-th web page, the SVSM is used to calculate the topic similarities of full text and anchor texts including Sim (fi, t), Sim (ai1, t), Sim (ai2, t), Sim (aip, t), etc. Then, according to the formula (21), the priorities of p unvisited hyperlinks are predicted as P(URLi1), P(URLi2), P(URLip), etc. Finally, according to the priorities, the p unvisited hyperlinks in the i-th web page are added into the queue of unvisited URLs to ensure that hyperlinks with higher priority are in front of the queue. The above processes are repeated until a given number of Web Page Database is reached.

The example of downloading web pages for the proposed focused crawler
Experiment
The experiment system for focused crawlers with different algorithms is constructed to further indicate that the SDVSM method can improve the performance of the focused crawler. The experiment design describes different focused crawlers, provides initial data, and select evaluation indicators to compare the performance of different focused crawlers. The experiment system for focused crawlers will obtain the experimental results of different focused crawlers for the given different topics. The experimental results show that the proposed focused crawler in this paper can grab more and better web pages related to the given topic from the Internet.
Experimental design
The experimental design includes the experimental focused crawlers, the experimental initial data and the experimental evaluation indicators. The following will describe the above three contents in detail.
Experimental focused crawler
The experiment designs focused crawlers with different algorithms and achieves the performance comparison for these focused crawlers. There are four different focused crawlers in this experiment including the BF Crawler, the VSM Crawler, the SSRM Crawler and the SDVSM Crawler. The BF Crawler is the web crawler based on the breadth-first algorithm and does not predict the priorities of unvisited URLs. The VSM Crawler and the SSRM Crawler obtain the topic similarities of full texts and anchor texts of unvisited hyperlinks based on the VSM and the SSRM, respectively. The SDVSM Crawler is proposed based on the SDG and the SVSM in this paper. Specially, the SDVSM Crawler removes the ambiguation terms irrelevant to the given topic in representation terms of retrieved web pages based on the SDG. In addition, the SDVSM Crawler obtains the topic similarities of full texts and anchor texts of unvisited hyperlinks by using the SVSM.
Experimental initial data
The experimental initial data are given for four focused crawlers to comprehensively compare the performance of these focused crawlers. To enhance the experiment persuasion, the four focused crawlers grab ten different topics including fifth-generation mobile networks, artificial neural networks, information retrieval, web search engine, driverless, distributed computing, virtual reality, data mining, data analysis and network security. The experimental initial data mainly contain the topic page set, the initial seed set and the training data set. In addition, the number of crawling web pages is restricted within 5000. The following explains the topic page set, the initial seed set and the training data set.
The topic page set can be used to calculate topic similarities of texts. In order to reduce the time complexity, the topic page set size is set as 20 in this experiment. Firstly, ten different topics are inputted into the general search engine like Bing or Google, respectively. Then, many topic-relevant web pages are retrieved and sorted in the result list for each topic. The top 20 topic-relevant URLs in the result list are recorded into the topic URL file for each topic. Finally, the topic-relevant web pages are downloaded to form the topic page set by using topic-relevant URLs for each topic.
The initial seed set contains the initial URLs of different topics. Table 3 shows the initial URLs of ten different topics, and each topic has three different initial URLs at the start. To comprehensively compare the performance of four focused crawlers, ten different topics are divided into two groups, and each group has five different topics. The first group is composed of the top five topics, and the initial URLs of these topics are relevant to the corresponding topics. The second group is composed of the last five topics, and the initial URLs of these topics are irrelevant to the corresponding topics.
The training data set includes topic terms of different topics and training parameters to construct the SDG. The topic terms are extracted from the topic page set, and each topic page obtains two topic terms with the highest and the second highest TF × IDF weights, respectively. For the training parameters, the number of topic terms is set as 40 to constitute the nodes of the SDG. The number of training web pages is set as 20 to calculate the co-occurrence degrees between topic terms in the SDG.
Experimental evaluation indicator
The experiment obtains three evaluation indicators including the harvest rate, the average topic similarity and the average error to compare four focused crawlers. The three indicators can better measure the performance of each focused crawler [39]. The harvest rate can measure the crawling efficiency of the focused crawler. The average topic similarity can measure the crawling effectiveness of the focused crawler. The average error can measure the crawling accuracy of the focused crawler. These three evaluation indicators are calculated as follows:
where \(HR\) is the harvest rate indicator, \(n_{TR}\) is the number of topic-relevant retrieved web pages, \(n\) is the number of retrieved web pages, \(AS\) is the average topic similarity indicator, \(AS_{i}\) is the topic similarity of the i-th web page obtained based on the VSM, \(T_{tr}\) is the threshold to judge whether a web page is topic relevant, \(AE\) is the average error indicator, and \(P(i)\) is the priority of the i-th hyperlink corresponding to the i-th web page obtained based on the above formula (21).
Experimental crawling results
In the experiment, the above ten topics are divided into two groups based on whether the initial URLs are relevant to the topic. The experiment divides the crawling results into three groups. The crawling results for three groups will be shown in the following tables. In addition, the number of retrieved pages starts with 100 and consecutively increases by 100 until 5000 for each topic in this experiment. Specially, there are no average errors in the crawling results for the BF Crawler because the BF Crawler dose not predict priorities of unvisited hyperlinks.
First group results
The first group results are obtained by crawling the initial URLs of the first five topics for all four focused crawlers. Table 4 displays that the first group results are the average crawling results of the top 5 topics for four focused crawlers. In Table 4, there are three evaluation indicators including the harvest rate (HR), the average topic similarity (AS) and the average error (AE) for the first group results. Figures 7, 8, 9 show the comparison of the three evaluation indicators for all four focused crawlers based on the first group results, respectively.

The comparison of the harvest rate for four focused crawlers based on the first group results

The comparison of the average topic similarity for four focused crawlers based on the first group results

The comparison of the average error for three focused crawlers based on the first group results
Figure 7 shows the comparison of the harvest rate for four focused crawlers based on the first group results. In Fig. 7, when the number of retrieved web pages exceeds 500, the harvest rate for the SDVSM Crawler is significantly higher than for other three focused crawlers. Figure 7 indicates that the SDVSM Crawler can retrieve topic-relevant web pages faster than other three focused crawlers. Figure 8 shows the comparison of the average topic similarity for four focused crawlers based on the first group results. In Fig. 8, when the number of retrieved web pages exceeds 3900, the average topic similarity for the SDVSM Crawler is significantly higher than for other three focused crawlers. Figure 8 indicates that the SDVSM Crawler can retrieve topic-relevant web pages better than other three focused crawlers. Figure 9 shows the comparison of the average error for three focused crawlers based on the first group results. In Fig. 9, for each number of retrieved web pages, the average error for the SDVSM Crawler is significantly smaller than for other two focused crawlers. Figure 9 indicates that the SDVSM Crawler can predict more accurate priorities of unvisited hyperlinks than other two focused crawlers.
Second group results
The second group results are obtained by crawling the initial URLs of the last 5 topics for all four focused crawlers. Table 5 displays that the second group results are the average crawling results of the last five topics for four focused crawlers. In Table 5, there are three evaluation indicators including HR, AS and AE like Table 4 for the second group results. Figures 10, 11, 12 show, respectively, the comparison of the three evaluation indicators for all four focused crawlers based on the second group results.

The comparison of the harvest rate for four focused crawlers based on the second group results

The comparison of the average topic similarity for four focused crawlers based on the second group results

The comparison of the average error for three focused crawlers based on the second group results
Figure 10 shows the comparison of the harvest rate for four focused crawlers based on the second group results. In Fig. 10, when the number of retrieved web pages exceeds 1700, the harvest rate for the SDVSM Crawler is significantly higher than for other three focused crawlers. Figure 10 indicates that the SDVSM Crawler can retrieve topic-relevant web pages faster than other three focused crawlers. Figure 11 shows the comparison of the average topic similarity for four focused crawlers based on the second group results. In Fig. 11, when the number of retrieved web pages exceeds 700, the average topic similarity for the SDVSM Crawler is significantly higher than for other three focused crawlers. Figure 11 indicates that the SDVSM Crawler can retrieve topic-relevant web pages better than other three focused crawlers. Figure 12 shows the comparison of the average error for three focused crawlers based on the second group results. In Fig. 12, for each number of retrieved web pages, the average error for the SDVSM Crawler is significantly smaller than for other two focused crawlers. Figure 12 indicates that the SDVSM Crawler can predict more accurate priorities of unvisited hyperlinks than other two focused crawlers.
Third group results
The third group results are obtained by crawling the initial URLs of all 10 topics for all four focused crawlers. Table 6 displays that the third group results are the average crawling results of all 10 topics for four focused crawlers. In Table 6, there are three evaluation indicators including HR, AS and AE like Table 4 for the third group results. Figures 13, 14, 15 show, respectively, the comparison of the three evaluation indicators for all four focused crawlers based on the third group results.

The comparison of the harvest rate for four focused crawlers based on the third group results

The comparison of the average topic similarity for four focused crawlers based on the third group results

The comparison of the average error for three focused crawlers based on the third group results
Figure 13 shows the comparison of the harvest rate for four focused crawlers based on the third group results. In Fig. 13, when the number of retrieved web pages exceeds 1200, the harvest rate for the SDVSM Crawler is significantly higher than for other three focused crawlers. Figure 13 indicates that the SDVSM Crawler can retrieve topic-relevant web pages faster than other three focused crawlers. Figure 14 shows the comparison of the average topic similarity for four focused crawlers based on the third group results. In Fig. 14, when the number of retrieved web pages exceeds 1500, the average topic similarity for the SDVSM Crawler is significantly higher than for other three focused crawlers. Figure 14 indicates that the SDVSM Crawler can retrieve topic-relevant web pages better than other three focused crawlers. Figure 15 shows the comparison of the average error for three focused crawlers based on the third group results. In Fig. 15, for each number of retrieved web pages, the average error for the SDVSM Crawler is significantly smaller than for other two focused crawlers. Figure 15 indicates that the SDVSM Crawler can predict more accurate priorities of unvisited hyperlinks than other two focused crawlers.
The experiment obtains the crawling results including three evaluation indicators to compare the performance of four focused crawlers. First of all, the experiment results indicate that the SDVSM Crawler can retrieve topic-relevant web pages faster and better than other three focused crawlers including the BF Crawler, the VSM Crawler and the SSRM Crawler from the Internet. In addition, the SDVSM Crawler can predict more accurate priorities of unvisited hyperlinks than other two focused crawlers including the VSM Crawler and the SSRM Crawler. The experiment results indicate that the SDG can acquire the more accurate representation terms of web pages. Meanwhile, the experiment results indicate that the SVSM can acquire the more accurate topic similarity of the text than the VSM and the SSRM. The experiment results indicate that the SDVSM method combining the SDG and SVSM can improve the performance of the focused crawler.
Conclusion and future work
In many previous studies, the representation terms of the web page ignore the phenomenon of polysemy for focused crawlers. In addition, the topic similarity of the text cannot combine the cosine similarity and the semantic similarity effectively. To address these problems, this paper proposes a focused crawler based on the SDVSM method. The SDVSM method combines the SDG and the SVSM. The SDG is used to remove the ambiguation terms irrelevant to the given topic from representation terms of retrieved web pages. The SVSM is used to calculate the topic similarity of the text by constructing the text and topic semantic vectors based on TF × IDF weights of terms and semantic similarities between terms. The experiment results indicate that the SDVSM method can improve the performance of the focused crawler by comparing different evaluation indicators for four focused crawlers. In addition, the experiment results indicate that the SDG can acquire the more accurate representation terms of web pages. Meanwhile, the experiment results indicate that the SVSM can acquire the more accurate topic similarity of the text than the VSM and the SSRM. In conclusion, the proposed method can make the focused crawler retrieve the higher quality and more quantity web pages related to the given topic from the Internet.
In the future, some research works are still worth to further study. First of all, the SDG construction fuzzes three different indicators of topic terms by using the Piecewise Linear membership function in this paper. But the Trigonometric membership function and the Gaussian membership function can be studied to fuzz three different indicators of topic terms. Secondly, the ambiguation term identification is realized by using the fuzzy inference method in this paper. But the supervised approaches and knowledge-based ones can be studied to realize the ambiguation term identification. Thirdly, the semantic similarity between terms is obtained based on thecontent information of concept nodes in WordNet in this paper. But the structure information of these concept nodes can be studied to obtain the semantic similarity between terms. Finally, the topic similarities of texts of unvisited hyperlinks is used to predict priorities of unvisited hyperlinks. But the link structure among unvisited hyperlinks can be studied to predict priorities of unvisited hyperlinks.
References
Wang W, Yu LH (2021) UCrawler: a learning-based web crawler using a URL knowledge base. J Comput Methods Sci Eng 21(2):461–474
Lee JG, Bae D, Kim S et al (2020) An effective approach to enhancing a focused crawler using Google. J Supercomputing 76(10):8175–8192
Prabha KSS, Mahesh C, Raja SP (2021) An enhanced semantic focused web crawler based on hybrid string matching algorithm. Cybern Inf Technol 21(2):105–120
Capuano A, Rinaldi AM, Russo C (2020) An ontology-driven multimedia focused crawler based on linked open data and deep learning techniques. Multimed Tools Appl 79(11–12):7577–7598
Kuze N, Ishikura S, Yagi T et al (2021) Classification of diversified web crawler accesses inspired by biological adaptation. Int J Bio-Inspir Comput 17(3):165–173
Gupta S, Duhan N, Bansal P (2019) An approach for focused crawler to harvest digital academic documents in online digital libraries. Int J Inf Retr Res 9(3):23–47
Rajiv S, Navaneethan C (2021) Keyword weight optimization using gradient strategies in event focused web crawling. Pattern Recogn Lett 142:3–10
Zhou AQ, Zhou YS (2020) Research on the relationship network in customer innovation community based on text mining and social network analysis. Teh Vjesn-Tech Gaz 27(1):58–66
Hernandez J, Marin-Castro HM, Morales-Sandoval M (2020) A semantic focused web crawler based on a knowledge representation schema. Appl Sci-Basel 10(11):3837
Dhanith PRJ, Surendiran B, Raja SP (2021) A word embedding based approach for focused web crawling using the recurrent neural network. Int J Interact Multimed Artif Intell 6(6):122–132
ElAraby ME, Abuelenin SM, Moftah HM et al (2019) A new architecture for improving focused crawling using deep neural network. J Intell Fuzzy Syst 37(1):1233–1245
Bifulco I, Cirillo S, Esposito C et al (2021) An intelligent system for focused crawling from big data sources. Expert Syst Appl 184:115560
Zhao F, Zhou JY, Nie C et al (2016) SmartCrawler: a two-stage crawler for efficiently harvesting deep-web interfaces. IEEE Trans Serv Comput 9(4):608–620
Salton G, Wong A, Yang CS (1975) A vector space model for automatic indexing. Commun Assoc Comput Mach 18(11):613–620
Varelas G, Voutsakis E, Raftopoulou P et al (2005) Semantic similarity methods in WordNet and their application to information retrieval on the web. In: Proceedings of the 7th annual ACM international workshop on Web information and data management, Bremen, Germany, p 10–16.
Brin S, Page L (1998) The anatomy of a large-scale hypertextual web search engine. Comput Netw ISDN Syst 30(1–7):107–117
Diligenti M, Coetzee FM, Lawrence S et al (2000) Focused crawling using context graphs. In: Proceedings of the 26th International Conference on Very Large Database (VLDB), Cairo, Egypt, p 527–534.
Vashishtha S, Susan S (2020) Sentiment cognition from words shortlisted by fuzzy entropy. IEEE Trans Cogn Dev Syst 12(3):541–550
Du Y, Huo H (2020) News text summarization based on multi-feature and fuzzy logic. IEEE Access 8:140261–140272
Takagi T, Sugeno M (1985) Fuzzy identification of systems and its applications to modeling and control. IEEE Trans Syst Man Cybern 15(1):116–132
Goularte FB, Nassar SM, Fileto R et al (2019) A text summarization method based on fuzzy rules and applicable to automated assessment. Expert Syst Appl 115:264–275
Nicolas C, Gil-Lafuente J, Urrutia A et al (2021) Using fuzzy Indicators in customer experience analytics. J Intell Fuzzy Syst 40(2):1983–1996
Wang BK, He WN, Yang Z et al (2020) An unsupervised sentiment classification method based on multi-level fuzzy computing and multi-criteria fusion. IEEE Access 8:145422–145434
He XL, Wei L, She YH (2018) L-fuzzy concept analysis for three-way decisions: basic definitions and fuzzy inference mechanisms. Int J Mach Learn Cybern 9(11):1857–1867
Alvarez D, Fernandez RA, Sanchez L (2017) Fuzzy system for intelligent word recognition using a regular grammar. J Appl Log 24:45–53
Madani Y, Erritali M, Bengourram J et al (2020) A multilingual fuzzy approach for classifying Twitter data using fuzzy logic and semantic similarity. Neural Comput Appl 32(12):8655–8673
Zhao FQ, Zhu ZY, Han P (2021) A novel model for semantic similarity measurement based on wordnet and word embedding. J Intell Fuzzy Syst 40(5):9831–9842
Wu ZB, Palmer M (1994) Verb semantics and lexical selection. In: Proceedings of the 32nd annual meeting on Association for Computational Linguistics, Las Cruces, New Mexico, p 133–138.
Lin D (1998) An information-theoretic definition of similarity. In: Proceedings of the 15th International Conference on Machine Learning, Madison, USA, p 296–304.
Tversky A (1988) Features of Similarity. Psychol Rev 84(2):290–302
Fellbaum C, Miller G (1998) Combining local context and wordnet similarity for word sense identification. WordNet: an electronic lexical database. The MIT Press, Cambridge, pp 265–283
Fellbaum C, Miller G (1998) Lexical chains as representations of context for the detection and correction of malapropisms. WordNet: an electronic lexical database. The MIT Press, Cambridge, pp 305–332
Resnik (1995) Using information content to evaluate semantic similarity in a taxonomy. In: Proceedings of the 14th International Joint Conference on Artificial Intelligence, Montreal, Canada.
Jiang JJ, Conrath DW (1997) Semantic similarity based on corpus statistics and lexical taxonomy. In: Proceedings of the 10th International Conference Research on Computational Linguistics, Taipei, Taiwan, p 1–15.
Xun ED, Yan W (2006) English Word Similarity Calculation Based on Semantic Net. J China Soc Sci Tech Inf 25(1):43–48
Saleh AI, Abulwafa AE, Al Rahmawy MF (2017) A web page distillation strategy for efficient focused crawling based on optimized Naïve bayes (ONB) classifier. Appl Soft Comput 53:181–204
Kim HJ, Baek JW, Chung KY (2020) Optimization of associative knowledge graph using TF-IDF based ranking score. Appl Sci-Basel 10(13):4590
Du YJ, Liu WJ, Lv XJ et al (2015) An improved focused crawler based on semantic similarity vector space model. Appl Soft Comput 36(11):392–407
Liu WJ, Du YJ (2014) A novel focused crawler based on cell-like membrane computing optimization algorithm. Neurocomputing 123(1):266–280
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 61872298), the Science and Technology Department of Sichuan Province (Grant No. 2021YFQ0008), the College Student Innovation and Entrepreneurship Training Project of Sichuan Province (Grant No. S202110650044) and the Education and Teaching Reform Research Project of Xihua University (Grant No. xjjg2019026).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, W., He, Y., Wu, J. et al. A focused crawler based on semantic disambiguation vector space model. Complex Intell. Syst. 9, 345–366 (2023). https://doi.org/10.1007/s40747-022-00707-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00707-8