
Abstract
With huge cheap micro-sensing devices deployed, wireless sensor network (WSN) gathers information from the region and delivers it to the base station (BS) for further decision. The hotspot problem occurs when cluster head (CH) nearer to BS may die prematurely due to uneven energy depletion resulting in partitioning the network. To overcome the issue of hotspot or energy hole, unequal clustering is used where variable size clusters are formed. Motivated from the aforesaid discussion, we propose an enhanced fuzzy unequal clustering and routing protocol (E-FUCA) where vital parameters are considered during CH candidate selection, and intelligent decision using fuzzy logic (FL) is taken by non-CH nodes during the selection of their CH for the formation of clusters. To further extend the lifetime, we have used FL for the next-hop choice for efficient routing. We have conducted the simulation experiments for four scenarios and compared the propound protocol’s performance with recent similar protocols. The experimental results validate the improved performance of E-FUCA with its comparative in respect of better lifetime, protracted stability period, and enhanced average energy.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
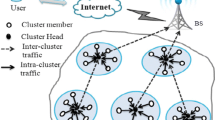
The convergence of massive advancement in embedded computing, wireless communication and diverse sensor technology has fostered the emergence of WSN very swiftly. A WSN consists of enormous tiny devices called sensors to monitor the required field. A simple pictorial representation of WSN is shown in Fig. 1. There are numerous WSN applications, e.g. industrial monitoring, structural monitoring, climatic monitoring, defence, environmental monitoring, and health care [1, 2]. With the miniature size of Sensor Node (SN), there is a restriction of limited energy, storage, communication and computation. WSN has constraints in energy, computation and communication [3, 4]. Battery-operated SN depletes energy because of long-distance transmission to BS and redundant data processing. A single node failure may throw the network into an unreliable state. Thus, reducing energy consumption is a challenging issue that has attracted many researchers. Routing techniques which are capable of reducing energy consumption are highly desirable. Cluster-based routing has proved to be a promising approach [5,6,7]. Election of CH and formation of clusters are crucial parts in dragging out the lifespan of the network.

Representation of WSN
The incorporation of FL helps in efficiently handling the decision-making behaviour of human solving uncertainty. Since there are several overlapping parameters that affect energy consumption, thus, this uncertainty can be driven by FL. Furthermore, FL possesses the potential to deal with imprecision in data and conflicting situations using heuristic human reasoning without requiring a complex mathematical model [8]. Regardless of the evidential advantages of FL by its widespread successful deployment in diverse domains, there is a comparatively limited number of fuzzy-based routing algorithms than fuzzy-based clustering algorithm. Since most of the cluster-based routing protocols require only a simple decision-making process (i.e. single-hop transmission of data from CH to BS), and hence the use of FL is unnecessary. However, for energy-aware clustering and routing demand comprehensive decision-making, FL represents an effective approach [9].
A fuzzy-based system has four primary modules: Fuzzifier maps the crisp input value to fuzzy linguistic value along with the assignment of membership function (MF). Knowledge Base has a set of IF–THEN rules or conditions made by the user, which is considered by Inference Engine while making decisions and inferring or drawing conclusions. A fuzzy set is acquired by the Defuzzifier mapping it into a crisp output value.
Contribution of paper
This paper propounds E-FUCA, which is a distributed protocol for unequal clustering approach for protracting the stability span by balancing the load. The contributions made in this paper are as follows.
-
Maximal clustering protocols are probabilistic and elect CH based on larger residual energy, its aloofness from BS and density of node, which is insufficient for electing the suitable candidate for CH.
-
E-FUCA is an enhancement over the FUCA [10] protocol.
-
FUCA contemplates the remnant power, nearness to BS and node density for calculating rank and competition radius during CH election whereas, in E-FUCA, instead of node density, the average distance to communicating nodes is considered because node density is incapable of giving a complete insight of energy expenditure by CH. Still, average distance can provide a clear idea of communication cost to be carried by CH if selected.
-
In FUCA, during the formation of clusters, non-CH nodes make the greedy decision of choosing the nearest CH without any consideration of CH’s existing load. In contrast, in E-FUCA, non-CH nodes do not make a greedy decision but choose their CH intelligently based on its rank obtained during CH selection, closeness to that CH and number of nodes in its cluster radius obtained during CH selection.
-
FUCA considers BS near/corner of the target field, whereas E-FUCA considers BS’s location at the centre and at far off place.
-
For unequal clustering, we consider FL in the routing of information from CH to BS.
-
We have designed FIS for the selection of next-hop so that energy efficiency can further be enhanced.
-
For gauging the performance of E-FUCA, simulation experiments are performed and obtained results are contrasted with the state of the art approaches such as FUCA [10], LEACH [11] and URBD [12] protocol. Experimental results validate the prolonged stability period, larger average energy with load balancing.
-
The complexity of the proposed E-FUCA in terms of time and message is discussed and computed.
The rest of this paper is summarised as follows: discussion on pertinent work is done in “Pertinent work”. System and Energy model description is provided in “Wireless sensor network model”; the description of the proposed E-FUCA protocol is done in “The proposed approach: E-FUCA”. Simulation experiment and evaluation of performance is shown in “Simulation experiment and result analysis”. Lastly, a summary of the proposed E-FUCA protocol with concluding remarks is discussed in “Conclusion”.
Pertinent work
Energy efficiency is the demanding task of WSN, which can be provided by the clustering approaches. Some of the pertinent unequal clustering approaches are discussed in this section. The literature survey of any cluster-based proposed work is incomplete without the discussion of the LEACH [11] protocol. In the year 2000, Heinzelman et al. propound LEACH, which makes local decisions by adopting a probabilistic method for the selection of CH. For balancing the network load, CHs are rotated in each round as static CH prematurely expires in comparison to non-CH nodes in the network. The data aggregation is done at the CH level to minimise communication cost. Limitations of this protocol are that the CH selection is purely randomised, and crucial factors such as residual energy and aloofness from BS, which affect energy, are not put into consideration.
PRODUCE [13] protocol is proposed for eliminating the hot spot problem makes use of local probabilities for cluster formation of unequal size. CH nearer to BS focuses on inter-cluster communication, whereas CH at a distant place may focus on intra-cluster communication. It successfully balances the network load and prolongs the lifetime. EDUC [14] protocol, which is a distributed algorithm, evades the hot spot problem and energy dissipation in heterogeneous WSN. It involves the energy-driven rotation method of clusters. Every node in this protocol gets an opportunity to be CH in its lifetime. This method is not useful in multi-hop networks. LUCA [15] is based on probability to prevent the hotspot problem. The size of clusters varies with remoteness to BS. GPS is bundled with SN and is location-aware. A backoff timer is there with the randomised initial value. If an SN receives a message form CH, it joins it; else, it will proclaim its candidature. EADUC [16] protocol is designed to gather data periodically in WSN. The weight for CH candidature is based on remnant energy along with the degree of node and exhibits better performance in terms of lifetime. CHEF [17] is a fuzzy-based protocol wherein there are two inputs for FIS: local distance and remnant energy of node. For evaluating the fuzzified inputs and calculating the chance of a node to be chosen as coordinator of the cluster, there are nine fuzzy rules. CHUFL [18] is distributed protocol in which fuzzy inputs are remnant energy, reachability and distance to the BS. The non-CHs choose the nearest CHs to form clusters. A distributive clustering protocol, namely FBECS [19], is proposed, which assigns a pre-defined probability to SN based on distance from BS. It uses FL for the selection of adequate nodes for the role of CH.
An FL-based clustering algorithm is proposed in EAUCF [20], which uses remnant energy and remoteness to BS for electing CH. Nine IF–THEN fuzzy rules are used for selecting tentative CH. Competitive radius is calculated by each tentative CH its candidature. But this proposed work does not anticipate energy exhaustion due to large intra-communication resulting in fading the protocol performance. An improvement over EAUCF is FBUC [21], in which the tentative CHs are selected on a probabilistic method. Competition radius and Chance are computed during the CH election. For cluster formation, the non-CH nodes calculate the chance of each CH on the basis of density and distance to CH. The protocol achieves a better lifetime in comparison to LEACH and EAUCF. The proposed IFUC [22] protocol is capable of reducing energy consumption and lengthening network lifetime. For nominating CHs and computing the range of the cluster, FL is used. The factors considered are remnant energy, closeness to BS and density of nodes. SN with a greater chance is selected as the final CH. DUCF [23] protocol makes load balancing certain by cluster formation using FL. The inputs to the fuzzifier are remoteness to BS, node density and remnant energy. There are two output variables, namely size and chance. The size of the cluster is dependent on the chance obtained. Mamdani method is used for inference.
A distribution independent unequal clustering is propounded in MOFCA [24], which contemplates remnant energy, calculated density and remoteness to BS for clustering. For reducing the intra-cluster relay, the cluster radius is varied as per the remoteness to BS. It successfully addresses the hotspot and energy hole problem. A diverse approach for cluster formation is proposed in MCFL [25]. Those candidates who are most eligible are chosen as CH, and no re-clustering takes place for a few rounds so as to reduce the message exchange for forming clusters. Experimental results exhibit the good performance of the proposed work than its comparatives.
FUCA [10] is a probabilistic approach for unequal clustering. Input variables considered are closeness to BS, remnant energy and density. There are two output variables: rank and competition radius. Higher ranking nodes in the competition radius are elected as CH. It achieves better performance than its counterparts. URBD protocol [12] is another unequal clustering protocol that is based on the density of nodes for clustering. There are two phases in this protocol: CH selection and Member-Join. In this protocol, density and distance parameters are used in collaboration for cluster formation resulting in a longer lifetime.
Tian et al. proposed LEACHEN [26], which introduces a multi-hop clustering cum routing method, which takes into account the fuzzy output as well multipath tree for improving the efficiency of the network. For the routing of information in multipath mode, three input variables are considered, i.e. remaining energy, traffic load and minimum hops. However, in a real-world scenario, other factors should be taken into consideration. AlShawi et al. proposed a routing algorithm [27], which includes FL and an A* algorithm for lifetime enhancement. Remaining energy and Traffic load as the input parameter to the fuzzy system. Leabi and Abdalla [28] proposed a routing protocol using FL and an immune system that contemplates remnant energy and shortest hop for determining a route for communication to sink. This approach improves the efficiency of the network.
Jiang et al. proposed FLEOR [29] for optimised routing. FLEOR considers three factors in the fuzzy-based routing process. The inputs to the inference engine are the degree of closeness to sink (DCS), degree of closeness to the shortest path (DCSP) and degree of energy balance. NORIA [30] is a fuzzy-based routing protocol that considers a fuzzy rule set for parent election and role assignment in routing. The parameters fed to fuzzy systems are the number of hops to the BS and the remaining battery level. A fuzzy-based routing from node to sink is proposed in [28], which contemplates remaining energy and shortest hop as input variables to the fuzzy system for computing edge cost. The simulation results are compared with the Dijkstra routing technique. Haider and Yusuf proposed an energy-optimised approach based on FL [31]. They considered six input variables for the fuzzy system and computed the cost of the same. The simulation results exhibit a reliable and efficient approach, but if the size of the network grows, then the fuzzy system with six input variable will become more complex.
In the aforementioned approaches, a greedy decision is made by the non-CH nodes by choosing the nearest CH candidate for cluster formation, whereas some of these approaches use FL for calculating chance so that non-CH nodes may choose their respective CH based on the chance obtained. Most of these protocols do not consider routing along with clustering, which may limit the performance of the protocol. We have considered FL for all three cases, i.e. CH selection, cluster formation and routing for extending the lifetime of the protocol. Table 1 depicts the summary of the aforementioned approaches.
Wireless sensor network model
Maximising lifetime problem
Designing the architecture of WSN is a very challenging task as the SNs have limited power, computational capability and memory [3]. Energy consumption is the most significant among the three factors as the power source (battery) is irreplaceable. One of the promising solution to achieve energy efficiency is clustering [11]. In the cluster-based routing, deployed SNs are divided into clusters, and one of the SN plays the role of CH. If the CH is inefficient, then the protocol could not maximise energy efficiency [14]. FL has been used in the selection of efficient CHs [32], which has improved the lifetime of the WSN. Even if we select the efficient CHs, then also in most of the protocols, the data are transmitted directly to BS, which limits the performance of the protocol. For maximising lifetime, energy-efficient clustering and routing algorithm have to be in place.
System model
In the proposed protocol, the network has homogeneous nodes with battery level at par, i.e. all the SNs are having the same energy level when they are deployed. The SNs have dispersed arbitrarily over the target field. Once the network gets operational, BS and SNs are immobile, i.e. neither the BS nor the SNs will change their location. There is a continuous power supply to the BS. The radio in SNs is capable of directional communication to conserve energy. The battery of SN is irreplaceable/non-rechargeable as in typical deployment, and the SNs are left unattended once deployed. Once the SNs are deployed, each SN will broadcast a hello_message. The separation distance between the two SNs is computed by the Received Signal Strength Index (RSSI). With RSSI, the SNs can estimate the location of other nearby SNs. SN is presumed to be lifeless only if the battery supply is fully drained. There is no constraint for BS in terms of processing and storage.
Energy consumption model
In E-FUCA, the radio energy model used in FUCA [10] is adapted. The energy of the WSN may get drained in transmission, amplification, reception, sensing, aggregation.
The energy dissipated for transmitting (ETx) and receiving (ERx) s bits over distance d is given by the following equations:
where Eelec is the energy dissipated in electronic circuitry, do is a threshold that determines either free space (\(\varepsilon_{fs}\)) or multipath (\(\varepsilon_{mp}\)) model adopted and it can be calculated by the following equation:
In amplification of the signal, energy (Eamp) dissipated is calculated by the following equation:
For a CH, the amount of energy (ECH) exhausted in a round is computed by the following equation:
where dCM is the distance to cluster members and EDA is the energy exhausted in data aggregation.
For a non-CH node, the energy (EnCH) dissipated is computed by the following equation, in which dCH is the distance from its CH:
Decision variables
Residual energy is considered because a lower energy node is not suitable for CH candidature as it is a resource-intensive task. Residual energy can be calculated by
where Ē is the initial energy level during deployment, and ē is the energy dissipated till now.
Closeness to BS is vital for consideration as CH candidates need to forward the accumulated data. If this distance is too long, then the node will dissipate more energy. The competition radius is inversely proportional to this distance as a closer node will have a larger radius as compared to the node at far off place from BS. The closeness to BS can be calculated as
Average distance is crucial in calculating rank because the intra-cluster communication cost is dependent on the separation distance. The average distance from a node (i) can be computed as
where dk is the distance to communicating nodes, δBS is the remoteness to BS.
Rank determines the candidature weight of an SN to become CH. The higher the rank of SN, the higher will be the probability of the SN to be selected as CH. The rank of each SN can be computed using FL, as shown in Fig. 2.

FIS designed for CH selection in E-FUCA
The closeness to CH is considered because, to reduce the intra-cluster communication cost, cluster members should be closer to CH. It can be calculated by
where node(i).x, node(i).y are x and y coordinates of the node and CHi.x, CHi.y are the coordinates of CH under consideration.
The number of nodes in a cluster radius is useful to determine if the cluster is overcrowded, then it will increase the burden on CH as it has to expend more power in receiving data from a large number of SNs. It can be calculated by
where d() represents the distance between two nodes, and Ḱi is the cluster radius of a node (i).
The distance reduced to BS is considered because we need to ensure that there is a significant reduction of distance after each hop. It can be calculated as
where \(\delta_{BS}\) is the distance to BS, and d() represents the distance between two nodes.
The proposed approach: E-FUCA
The proposed protocol “E-FUCA” is designed to enhance the stability period to make the network more reliable as well as achieving a load-balanced network. E-FUCA is an improvement over the FUCA [10] protocol. The improvements can be enumerated in the following ways: first, In E-FUCA, for computing the rank of a node for CH candidature, the average distance to communicating nodes is calculated as one of the parameters together with remnant energy and aloofness to BS, unlike FUCA which considers node density, residual energy and aloofness from BS. Merely calculating the node density does not fulfil the requirement as the communication cost cannot be calculated only on the basis of node density. Some SNs may be nearer, and some SNs may be at far off place. Thus, to determine the nearest approximation of communication cost, the average distance may serve the purpose instead of node density. Second, in FUCA, during the cluster formation, non-CH nodes select the closest CH without determining the overall load on the CH candidate. In our protocol, the non-CH node will calculate the CH chance to determine which cluster must be joined. This CH chance is calculated on the basis of three parameters; the rank of CH, closeness to that CH and number of nodes in CH competition radius. This chance will help in minimising the extraneous energy dissipation in intra-cluster communication. Third, in FUCA, there is no focus on the routing of data, but in the proposed E-FUCA protocol, the fuzzy-based routing algorithm is designed to further prolong the network's lifetime. The working of the designed protocol is partitioned into rounds. In each round, there are three stages, selection of CH, Cluster formation and Data dissemination stage.
Selection of CH
In this phase, the selection of the CHs is decided on the basis of their characteristics. At the initiation of a round, a random number is generated by every node for becoming tentative CH. The threshold probability (TProb) is compared with the generated number. If the number is less than TProb, then the node becomes a tentative CH. Once the tentative CHs are determined, these nodes calculate their rank using designed FIS, as shown in Fig. 2.
The calculation of rank and competition radius is done using three input variables: remnant energy, the average distance to communicating nodes and closeness to BS.
In FUCA, node density is considered. Node density cannot determine exactly the energy consumption by the CH node for intra-communication. This can be illustrated in Example 1.
Example 1
Suppose there are two nodes N1 and N2, competing for CH candidature. Their current energy level is 0.3 J, and closeness to BS is 150 m with equal node density as 10 (i.e. there are ten neighbouring nodes). FUCA protocol will generate equal rank for both the nodes N1 and N2 as all the values passed on to the FIS are the same because it does not consider the distance to the neighbouring nodes. In the case of the E-FUCA protocol, for N1 and N2, it will compute the average distance to all the communicating nodes. Thus, the rank generated for both the nodes N1 and N2 will be different, which will give a better perspective for CH candidature.
There are two output variables: rank and competition radius. Rank determines the candidature weight of an SN. The higher the rank of SN, the higher will be the probability of the SN to be selected as CH. Competition radius determines the radio range of a node within which it can communicate. It may vary according to the rank obtained by SN as a low energy node ought not to communicate to a longer radio range as it will lead to quicker energy dissipation in intra-cluster communication. The MF plots for input and output variables are shown in Figs. 3 and 4.

MF for input variables in CH selection

MF for output variables in CH selection
We have used Trapezoidal and Triangular MF for boundary and intermediate variables, respectively, because they provide faster calculation and are simpler to implement. Each MF has to satisfy one condition that its degree of membership should range from 0 to 1. There are other MFs that can also be used like Sigmoid, Bell, Gaussian etc. but proposed E-FUCA depicted better results with Triangular and Trapezoidal MF. The linguistic variables which are used are shown in Table 2. The input variables are fed to the designed fuzzy inference system, and IF–THEN rules are applied to calculate rank and competition radius, which are described in Table 3. Here, the Mamdani Inference method [33] is applied, which is most commonly used [19, 34] because of its simplicity and characteristics.
For defuzzification, the centre of area method is used to obtain crisp value from output linguistics variables. After the calculation of rank and competition radius, tentative CH nodes broadcast their candidature within the competition radius, and a higher ranking node is selected as CH. The selection procedure of CH is described in Algorithm 1.

Cluster formation
After the completion of the CH selection procedure, all the nodes which are not selected for the CH role need to make the decision to join the appropriate cluster. In most of the protocols, the non-CH nodes make a greedy decision of joining the nearest CH without determining the load on that CH. In this proposed protocol, the overall load of the CH candidate is already determined by its rank, which is computed during the CH election on the basis of its closeness to BS, its current energy level and average distance to nearby nodes. The decision of choosing the CH by the non-CH node is supported by the designed FIS as shown in Fig. 5, and the MF functions used for the input variables and output variables are presented in Fig. 6 and Fig. 7.

FIS designed for cluster formation in E-FUCA

MF for input variables in cluster formation

MF for output variables in cluster formation
Non-CH nodes calculate the chance of each CH on the basis of IF–THEN rules applied to the inputs: CH_Rank, number of nodes in the competition radius of CH and distance to that CH. Explanation to support this intelligent decision is described in Example 2.
Example 2
Suppose there are two CH nodes C1 and C2. A non-CH node (N1) needs to choose a CH between C1 and C2. Suppose rank of C1 = 2 and rank of C2 = 98. Distance from N1 to C1 is 14 m, and C2 is 16 m. According to FUCA protocol, N1 will take a greedy decision and directly choose C1 as its CH without considering its low rank, which could be due to low energy, a large number of neighbouring nodes and a large distance to BS. If all the nodes make greedy decisions like this, then it could result in more power dissipation as CH responsibility is a resource-intensive task. In the case of the E-FUCA protocol, node N1 will take this decision intelligently by considering the rank of CH, the number of nodes in the competition radius of CH and closeness to CH before choosing its CH. Finally, it will choose C2 as its CH, although C1 is closer to N1. This will result in reducing the load on low-rank CH nodes and balancing the energy dissipation by the CH nodes, thereby contributing an extension of the lifetime of the network.
The linguistic variables used in input and output variables are depicted in Table 4.
The IF–THEN rules applied for determining the chance of CHs are described in Table 5. After the calculation of the chance of each CH node, the non-CH node joins the CH, which is having the highest chance value by transmitting a join request (JOIN_REQ) message. The CH node accepts the request received from all non-CH nodes and forms the cluster. The cluster formation procedure is explained in Algorithm 2.

Data dissemination
Once the clustering process gets completed, the data dissemination stage begins. SNs sense the target area and generate the data on a periodic basis. SNs forward the collected data to their respective CH as per the TDMA slot for preventing loss of data in a collision. Once the CHs collect data from all their cluster members, it compresses the data prior to forwarding it to the BS. In most of the protocols, CHs forward data directly to BS, which depletes a large amount of energy of the CHs. For conserving the energy in forwarding the data from CH to BS, CH will make a decision using a designed FIS, which takes three inputs, namely, next-hop rank, nearness to next-hop and distance reduced to BS as shown in Fig. 8 for computing the cost of next-hop. The next-hop can be one of the chosen CHs or BS. The LV for input and output variables are shown in Table 6. The MF for input and output variables is depicted in Figs. 9 and 10. The CH calculates the eligibility of every other next-hop CH nodes, which are in the direction of BS, using the IF–THEN rules designed for mapping inputs to output which are shown in Table 7.

FIS designed for routing in proposed E-FUCA protocol

MF for input variables in routing

MF for output variables in routing
With an objective to minimise the distance as well as preventing the intermediate CH nodes from overburden during data forwarding, the CH selects the next-hop CH node having maximum eligibility. Once the best next-hop CH node is selected, the current CH checks its remoteness to BS as well as the distance to the next-hop. If the distance to BS is shorter, then it will forward the data to the BS; else, it will forward the data to the next-hop. The process of forwarding the data is elaborated in Algorithm 3.

In this manner, all the CHs forward data to BS for further processing and completes one round of proposed work. For a better understanding of the complete flow of the proposed work, we have drawn a flow chart, as shown in Fig. 11, describing the steps involved in clustering and routing of proposed work.

Flow chart of proposed E-FUCA protocol
Simulation experiment and result analysis
For evaluation of the proposed E-FUCA protocol, simulation experiments are performed extensively for E-FUCA, DEFL [8], URBD [12], FUCA [10] and LEACH [11] under four scenarios in MATLAB, and experimental results are obtained. In scenario-1, the field size is chosen as 200 × 200 m2 with 100 SNs having 1 J of initial energy and the position of BS is kept at a distant position from the field, i.e. (100, 300). In scenario-2, the field size is similar to scenario-1, and the BS is kept at the centre of the field, i.e. (100, 100). There are 200 SNs with an initial energy of 0.5 J. In scenario-3, the field size is 300 × 300 with 300 nodes with 0.5 J. The position of BS is kept at the bottom centre, i.e. (150, 0). In scenario-4, the field size is 500 × 500 with BS located at (0, 500), i.e. at the top-left position of the field. 500 SNs are deployed with 0.5 J of energy. All four scenarios are shown in Fig. 12. The reason behind choosing these four scenarios is that the proposed protocol can be applied to any type of application wherein the position of BS either can be at the centre of the field or beyond the boundaries of the target area at a remote place. The experimental values considered for different parameters are stated in Table 8. For the evaluation and comparison of the E-FUCA with FUCA, LEACH, URBD and DEFL, the performance metrics chosen are Stability period, Total Average Energy, Total Alive nodes, Quarter Node Death (QND) and Half Node Death (HND).

Network scenarios for E-FUCA
Since the objective of WSN is to collect surrounding information, it is necessary that all the SN deployed should be alive so that cent per cent coverage is guaranteed. Reliability, in terms of coverage, is directly proportional to the stability period [35, 36]. Figure 13 exhibits the performance of E-FUCA, FUCA, LEACH, URBD and DEFL protocols in terms of Stability period for four scenarios.

Stability period
The stability period determines the round in which the death of the first node occurred in the network [36]. The larger the stability period, the more the protocol will be reliable because of the complete coverage. We can see that for Scenario-1, the stability period of the E-FUCA protocol is 147.47%, 87.9%, 70.24% and 26.10% better than LEACH, FUCA, URBD and DEFL protocols, respectively. Similarly, for Scenario-2, it is 157.89%, 99.8%, 84.21% and 42.03% enhanced as compared to LEACH, FUCA, URBD and DEFL, respectively. The stability period of E-FUCA over LEACH, FUCA, URBD and DEFL is protracted by 282.50%, 130.94%, 59.38% and 47.12% for scenario-3 and 983.33%, 490.91%, 136.36% and 85.71% for scenario-4, respectively. The proposed E-FUCA has performed tremendously well in terms of stability period because not only the best candidate is chosen for the CH role, but also non-CH nodes take the intelligent decision of selecting the appropriate CH.
In Fig. 14, a graph for QND is plotted for four scenarios. In this graph, an assessment of the performance of the proposed E-FUCA in terms of the first quarter of nodes death can be seen. For scenario-1, E-FUCA has performed 84.33%, 72.15%, 29.38% and 21.19% better than LEACH, FUCA, URBD and DEFL protocols, respectively, and for Scenario-2, it is 79. 96%, 42.92%, 24.28% and 15.10%. Likewise, in scenario-3, E-FUCA has shown improvement of 158.57%, 123.46%, 57.39% and 39.23% over LEACH, FUCA, URBD and DEFL protocols, respectively. Significant enhancement in QND can be seen for scenario-4, where E-FUCA boosted QND by 212.73%, 177.42%, 82.01% and 77.32% over LEACH, FUCA, URBD and DEFL, respectively.

QND for four scenarios
Figure 15 depicts the performance of E-FUCA, LEACH, FUCA, URBD and DEFL protocols in terms of HND. We have contemplated HND only because once half of the nodes are dead; then the complete coverage cannot be guaranteed in most of the cases. In scenario-1, the HND of the proposed E-FUCA protocol is enhanced by 31.81%, 26.03%, 16.95% and 13.11% over LEACH, FUCA, URBD and DEFL protocols, and for Scenario-2, it is extended by 52.21%, 43.20%, 18.66% and 12.27% more than LEACH, FUCA, URBD and DEFL protocols, respectively. In the case of scenario-3, E-FUCA increased HND by 102.56%, 68.09%, 33.90% and 16% over LEACH, FUCA, URBD and DEFL protocols. Similarly, for scenario-4, it is incremented by 176.92%, 144.07%, 35.42% and 22.73% over LEACH, FUCA, URBD and DEFL protocols, respectively.

HND for four scenarios
Figure 16 presents the total average energy of the network for four scenarios. We can observe that the total average energy of the E-FUCA is dissipating at a very slow rate as compared to LEACH and FUCA. It can be clearly observed that the LEACH protocol poorly performed as compared to FUCA, URBD, DEFL and E-FUCA because it does not consider the crucial parameters during CH selection that affect the energy of the network. FUCA protocol has performed better than LEACH but poor in comparison to E-FUCA because it adapts a greedy approach in cluster formation as non-CH nodes choose the closest CH irrespective of considering its existing load. URBD has better performance than FUCA and LEACH because it considers density and distance in cluster formation but has poor performance than E-FUCA because E-FUCA considers average distance instead of node density.

The total energy of the network for four scenarios
In Fig. 17, total alive nodes for different round slices are presented for the four scenarios considered. For scenario-1, we can observe that all nodes are alive in E-FUCA protocol approximately up to 950 rounds, whereas in LEACH and FUCA protocol, the count of the alive node is merely 55%, and for URBD and DEFL protocols, almost 30% of nodes are dead. It can be clearly observed in scenario-2 that E-FUCA performs extremely better than its comparatives. Up to 1500 rounds in E-FUCA protocol, all the nodes are alive, whereas, in the case of LEACH and FUCA, less than 50 per cent of the nodes are alive in the network. In the URBD and DEFL protocols, almost a quarter of nodes are dead in the network, which is poorer as compared to E-FUCA. In scenario-3, almost all the nodes are alive up to 800 rounds in E-FUCA protocol, whereas in case LEACH and FUCA, the network has expired. If we talk about the URBD protocol, less than a quarter of nodes are alive, but in the case of DEFL, one-third of nodes are alive in the network. In scenario-4, at 300 round, LEACH and FUCA lost more than three-fourth of deployed nodes, URBD lost more than three-fifth nodes, and DEFL lost a quarter of nodes, whereas the proposed E-FUCA protocol lost only one-tenth nodes. E-FUCA has shown better performance because it considers influential parameters during the CH election. In addition, at the time of cluster formation, non-CH nodes make an intelligent decision of choosing their CH by determining its existing load.

Total alive nodes for four scenarios
Complexity analysis of E-FUCA
Time complexity
There are total n nodes deployed in the network. For the CH selection, each node will compute its rank and competition radius independently. In the worst case, an SN will make (n − 1) number of comparisons of rank for getting itself elected as CH, as shown in Algorithm 1. Therefore, for n nodes, a total n (n − 1) number of comparisons occur for CH selection. For the formation of the cluster, every non-CH node will calculate the chance of each node in the CH_NODE list. Thus, in the worst case, there will be (n − 1) comparisons. If there are k CHs, then in the case of routing, there will be k comparisons. Therefore, the complexity of the E-FUCA Protocol in terms of BIG-OH will be O(n2).
Message complexity
At the commencement of each round, all the SN generate an RN and if that RN < Tprob, then that SN broadcasts a message (CH_MSG). Let the number of CH be k for each round. Therefore, the total CH_MSG messages will be k. The non-CH nodes will transmit a message (JOIN_REQ) to CH, which will be (n-k). TDMA schedule will be broadcast to cluster members who will be equal to k. Thus, the total number of messages exchanged for a selection of CH and the formation of clusters in a round will be k + (n − k) + k = n + k. In the case of routing, the total messages forwarded will be k. Thus, the message complexity of the proposed protocol will be O(n).
Conclusion
While designing WSN, the proliferation of energy efficiency is a key concern. Distributing the load among all nodes at par may result in a better stability period. E-FUCA is designed to enhance the performance of FUCA protocol by considering remnant energy, closeness to BS and average distance to nearby nodes instead of node density during CH election. In addition, in the E-FUCA protocol, non-CH nodes intelligently determine the prevailing load of CH before making a decision of selecting its CH. Energy-efficient Fuzzy-based next-hop selection is proposed for protracting network lifetime. The experimental evaluation of the propound work is carried out for four different cases wherein the BS position is kept at various places in the area of interest, meeting the requirement of all kinds of applications. The simulation results proclaim remarkable performance of E-FUCA over LEACH, FUCA, URBD and DEFL in all four scenarios in context to stability period, QND, HND, total average energy and total alive nodes.
References
Rawat P, Singh KD, Chaouchi H, Bonnin JM (2014) Wireless sensor networks: a survey on recent developments and potential synergies. J Supercomput 68:1–48. https://doi.org/10.1007/s11227-013-1021-9
Pal R, Yadav S, Karnwal R, Aarti Y (2020) EEWC: energy-efficient weighted clustering method based on genetic algorithm for HWSNs. Complex Intell Syst 6:391–400. https://doi.org/10.1007/s40747-020-00137-4
Yick J, Mukherjee B, Ghosal D (2008) Wireless sensor network survey. Comput Netw 52:2292–2330. https://doi.org/10.1016/J.COMNET.2008.04.002
Bhushan S, Kumar M, Kumar P, Stephan T, Shankar A, Liu P (2021) FAJIT: a fuzzy-based data aggregation technique for energy efficiency in wireless sensor network. Complex Intell Syst. https://doi.org/10.1007/s40747-020-00258-w
Mehra PS, Doja MN, Alam B (2015) Low energy adaptive stable energy efficient (LEASE) protocol for wireless sensor network. Int Conf Futuristic Trends Comput Anal Knowl Manag. https://doi.org/10.1109/ABLAZE.2015.7155044
Afsar MM, Tayarani-N MH (2014) Clustering in sensor networks: a literature survey. J Netw Comput Appl 46:198–226. https://doi.org/10.1016/j.jnca.2014.09.005
Deebak BD, Al-Turjman F (2021) Secure-user sign-in authentication for IoT-based eHealth systems. Complex Intell Syst 1:3. https://doi.org/10.1007/s40747-020-00231-7
Al-Kiyumi RM, Foh CH, Vural S, Chatzimisios P, Tafazolli R (2018) Fuzzy logic-based routing algorithm for lifetime enhancement in heterogeneous wireless sensor networks. IEEE Trans Green Commun Netw 2:517–532. https://doi.org/10.1109/TGCN.2018.2799868
Kulkarni RV, Förster A, Venayagamoorthy GK (2011) Computational intelligence in wireless sensor networks: a survey. IEEE Commun Surv Tutor 13:68–96. https://doi.org/10.1109/SURV.2011.040310.00002
Agrawal D, Pandey S (2018) FUCA: Fuzzy-based unequal clustering algorithm to prolong the lifetime of wireless sensor networks. Int J Commun Syst 31:34–48. https://doi.org/10.1002/dac.3448
Heinzelman WR, Chandrakasan A, Balakrishnan H (2000) Energy-efficient communication protocol for wireless microsensor networks. In: Proceedings of the 33rd Annual Hawaii International Conference on System Sciences. IEEE Computer Society, p 10
Hamidzadeh J, Ghomanjani MH (2018) An unequal cluster-radius approach based on node density in clustering for wireless sensor networks. Wirel Pers Commun 101:1619–1637. https://doi.org/10.1007/s11277-018-5779-1
Kim JH, Chauhdary SH, Yang WC, Kim DS, Park MS (2008) PRODUCE: a probability-driven unequal clustering mechanism for wireless sensor networks. In: 22nd International Conference on Advanced Information Networking and Applications-Workshops (aina workshops 2008). IEEE, pp 928–933
Yu J, Qi Y, Wang G (2011) An energy-driven unequal clustering protocol for heterogeneous wireless sensor networks. J Control Theory Appl 9:133–139. https://doi.org/10.1007/s11768-011-0232-y
Lee S, Choe H, Park B, Song Y, Kim C (2011) LUCA: an energy-efficient unequal clustering algorithm using location information for wireless sensor networks. Wirel Pers Commun 56:715–731. https://doi.org/10.1007/s11277-009-9842-9
Yu J, Qi Y, Wang G, Guo Q, Gu X (2011) An energy-aware distributed unequal clustering protocol for wireless sensor networks. Int J Distrib Sens Netw 7:202145. https://doi.org/10.1155/2011/202145
Kim J, Park S, Han Y, Chung T (2008) CHEF: cluster head election mechanism using fuzzy logic in wireless sensor networks. In: Proceedings of 10th International Conference on Advanced Communication Technology, pp 654–659
Gajjar S, Sarkar M, Dasgupta K (2014) Cluster head selection protocol using fuzzy logic for wireless sensor networks. Int J Comput Appl 97:38–43. https://doi.org/10.5120/17022-7310
Mehra PS, Doja MN, Alam B (2020) Fuzzy based enhanced cluster head selection (FBECS) for WSN. J King Saud Univ Sci 32:390–401. https://doi.org/10.1016/J.JKSUS.2018.04.031
Bagci H, Yazici A (2013) An energy aware fuzzy approach to unequal clustering in wireless sensor networks. Appl Soft Comput 13:1741–1749. https://doi.org/10.1016/J.ASOC.2012.12.029
Logambigai R, Kannan A (2016) Fuzzy logic based unequal clustering for wireless sensor networks. Wirel Netw 22:945–957. https://doi.org/10.1007/s11276-015-1013-1
Mao S, Zhao C, Zhou Z, Ye Y (2013) An improved fuzzy unequal clustering algorithm for wireless sensor network. Mob Netw Appl 18:206–214. https://doi.org/10.1007/s11036-012-0356-4
Baranidharan B, Santhi B (2016) DUCF: Distributed load balancing unequal clustering in wireless sensor networks using fuzzy approach. Appl Soft Comput 40:495–506. https://doi.org/10.1016/J.ASOC.2015.11.044
Sert SA, Bagci H, Yazici A (2015) MOFCA: multi-objective fuzzy clustering algorithm for wireless sensor networks. Appl Soft Comput 30:151–165. https://doi.org/10.1016/J.ASOC.2014.11.063
Mirzaie M, Mazinani SM (2017) MCFL: an energy efficient multi-clustering algorithm using fuzzy logic in wireless sensor network. Wirel Networks. https://doi.org/10.1007/s11276-017-1466-5
Tian Y, Zhou Q, Zhang F, Li J (2017) Multi-hop clustering routing algorithm based on fuzzy inference and multi-path tree. Int J Distrib Sens Netw 13:155014771770789. https://doi.org/10.1177/1550147717707897
AlShawi IS, Yan L, Pan W, Luo B (2012) Lifetime enhancement in wireless sensor networks using fuzzy approach and A-star algorithm. In: IET Conference Publications
Khudair Leabi S, Younis Abdalla T (2015) Energy efficient routing protocol for maximizing lifetime in wireless sensor networks using fuzzy logic. Int J Adv Comput Sci Appl 7(10):95–101. https://doi.org/10.14569/IJACSA.2016.071012
Jiang H, Sun Y, Sun R, Xu H (2013) Fuzzy-logic-based energy optimized routing for wireless sensor networks. Int J Distrib Sens Netw 9:216561. https://doi.org/10.1155/2013/216561
Ortiz AM, Royo F, Olivares T, Castillo JC, Orozco-Barbosa L, Marron PJ (2013) Fuzzy-logic based routing for dense wireless sensor networks. Telecommunication systems. Springer, Berlin, pp 2687–2697
Haider T, Yusuf M (2009) A fuzzy approach to energy optimized routing for wireless sensor networks. Int J Disturb Sens J 9(8):1–8. https://doi.org/10.1155/2013/216561
Dwivedi A, Sharma A, Mehra PS (2020) Energy-aware routing protocols for wireless sensor network based on fuzzy logic: a 10-years analytical review. EAI Endorsed Trans Energy Web. https://doi.org/10.4108/eai.6-10-2020.166548
Mamdani HE (1977) Application of fuzzy logic to approximate reasoning using linguistic synthesis. IEEE Trans Comput C 26:1182–1191. https://doi.org/10.1109/TC.1977.1674779
Al-Quh MAH, Saroit IA, Mohammed Kotb DA (2016) FEQRP: a fuzzy based energy-efficient and QoS routing protocol over WSNs. IOSR J Comput Eng 18:79–89. https://doi.org/10.9790/0661-1804057989
Mehra PS, Doja MN, Alam B (2016) Enhanced stable period for two level and multilevel heterogeneous model for distant base station in wireless sensor network. Advances in intelligent systems and computing. Springer, Berlin, pp 751–759. https://doi.org/10.1007/978-81-322-2517-1_72
Smaragdakis G, Matta I, Bestavros A (2004) SEP: a stable election protocol for clustered heterogeneous wireless sensor networks. Second Int Work Sens Actor Netw Protoc Appl (SANPA). https://doi.org/10.3923/jmcomm.2010.38.42
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
No conflict of interest exists.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mehra, P.S. E-FUCA: enhancement in fuzzy unequal clustering and routing for sustainable wireless sensor network. Complex Intell. Syst. 8, 393–412 (2022). https://doi.org/10.1007/s40747-021-00392-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-021-00392-z