
Abstract
Data-driven decision-making (\(\mathrm {D^3}\)M) is often confronted by the problem of uncertainty or unknown dynamics in streaming data. To provide real-time accurate decision solutions, the systems have to promptly address changes in data distribution in streaming data—a phenomenon known as concept drift. Past data patterns may not be relevant to new data when a data stream experiences significant drift, thus to continue using models based on past data will lead to poor prediction and poor decision outcomes. This position paper discusses the basic framework and prevailing techniques in streaming type big data and concept drift for \(\mathrm {D^3}\)M. The study first establishes a technical framework for real-time \(\mathrm {D^3}\)M under concept drift and details the characteristics of high-volume streaming data. The main methodologies and approaches for detecting concept drift and supporting \(\mathrm {D^3}\)M are highlighted and presented. Lastly, further research directions, related methods and procedures for using streaming data to support decision-making in concept drift environments are identified. We hope the observations in this paper could support researchers and professionals to better understand the fundamentals and research directions of \(\mathrm {D^3}\)M in streamed big data environments.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
Introduction
Organizational decision-making is to find an optimal or the most satisfactory solution for a decision problem. These decision problems have various types, from daily operational decisions to long-term strategy business decisions, from an internal single decision to a multi-level decision or a multi-organizational decision [41]. Different decision-making tasks may have different features and, therefore, are normally modeled in different forms or presented by different methods and solved by different decision-making techniques.
In general, organizational decision problems can be classified by their natures. The classic classification is based on a given problem’s structure, i.e., structured, semi-structured and unstructured [34]. The last two are also called ill-structured. A structured decision problem can be described by classic mathematical models, such as linear programming or statistics methods. The procedure for obtaining the optimal solution is known as standard solution methods. An unstructured decision problem is fuzzy, uncertain and vague, for which there is no standard solution method to get an optimal solution or such an optimal solution does not exist. Semi-structured decision problems fall between structured and unstructured problems, having both structured and unstructured features, and reflecting most real-world situations. Conventional decision support techniques performance well on solving structured decision problems, but cannot solve ill-structured decision problems. Data-driven decision-making (\(\mathrm {D^3}\)M) techniques or called machine-learning-based decision-making techniques are more suitable for an ill-structured decision problem and for decision making in dynamic and complex situations.
Recent years, various data sources (datasets, data warehouses, databases, data streams, etc.) become available to form a Big Data environment. Many decision problems, particularly ill-structured, can be well solved by findings obtained from data through data mining, data analysis and machine learning, that is \(\mathrm {D^3}\)M techniques [41]. Various \(\mathrm {D^3}\)M techniques including models, methods, algorithms and software tools have been developed through learning from big data. As a result, conventional decision-making or decision support systems (DSSs) have evolved in line with the increasing availability of data and computational power. Current \(\mathrm {D^3}\)M techniques are capable to generate decision options through collected data from databases or data warehouses, and to provide queries and management reports according to decision-makers’ requirements. However, they are inadequate for supporting highly dynamic (rapid change) decision situations which require fast responses to the changes. A very recent survey [21] has pointed out that a dynamic environment with uncertainty (concept drift) is an inherent property of big streaming data. These unavoidable rapid changes in decision environments, e.g., new markets, new products and new customer behaviors, inevitably results in changes in the underlying data distribution in data streams. These changes are known as concept drift and may result in poor prediction and poor decision outcomes, as the pattern of past data does not conform to that of newly arrived data. How to maintain the effectiveness of a DSS under concept drift for big streaming data is a challenging research question, and developing a new generation of adaptive DSS for real-time decision-making is an urgent requirement. In other words, self-learning and self-adaptive features are important characteristics for the next generation of \(\mathrm {D^3}\)M and \(\mathrm {D^3}\)M-based DSSs
This paper presents our position on DSSs in the context of big streaming data containing concept drift. We present each challenge and discuss their implications. The rest of the paper is organized as follows. Section 2 summarizes the adaptive decision-making framework. Section 3 highlights the characteristics and the challenges of streamed big data. Section 4 analyzes the existing work on big streaming data and introduces essential work that has not yet been done. Section 5 presents our position on the future directions for real-time decision support under concept drift. Lastly, Sect. 6 presents our summary of this paper.
Adaptive decision-making framework
This section presents the general framework of adaptive decision-making.
Data-driven decision-making
Data-driven decision-making uses a variety of machine learning approaches for data analysis by characterizing a decision problem and ascertaining the connections between the problem variables (input, internal and output variables) without having explicit knowledge of the physical behavior of the decision model.
Adaptive decision-making to address the concept drift problem has gained considerable attention. Concept drift detection and adaptation is an effective strategy for improving the accuracy of decision-making in a dynamic data streaming environment. When a drift is detected, machine learning techniques are applied to adapt decision models to new concepts. The components of an adaptive data-driven decision-making framework are introduced in the next section.
An adaptive data-driven decision-making framework under concept drift

A general framework of adaptive \(\mathrm {D^3}\)M
Data-driven decision support under concept drift in high-volume streaming data has three major components as shown in Fig. 1. The first collects raw data from various sources and reformats them to unify the time frame and feature space, so that they can be applied to modeling and constructing the training data. The second detects and interprets the changes in data streams over time. If the most recently arrived data significantly conflicts with the historical data, a concept drift will be reported and an adaptation process will be triggered. The third component is adaptive decision-making. In this component, DSSs are actively updated according to the results of the drift detection and understanding. The data-driven decision process under this framework is as follows. Drift detection part will detect drift, once a drift is identified, it will notify the system. The drift understanding will be then initialized to target the drift and propose possible drift resolve solutions. To help finding a better solution, the system will interpret the drift from When the drift occurred, How significant the drift is, and Where the drift is located. Drift responses and adaptation are dependent on the types of DSSs. For a model-based DSS, adaptive decision-making could be able to react to drift by, e.g., updating an optimization model’s parameters; for a knowledge-based DSS, adaptive decision-making could be able to react to drift by, e.g., updating a knowledge base. In a data-driven DSS, adaptive decision-making involves, e.g., retraining a prediction model. In this paper, we only focus on data-driven DSSs.
Streamed big data
This section discusses the characteristics of big streaming data and the challenges of learning under big streaming data.
Characteristics of streamed big data
Big data is an outcome of the current information explosion that is relevant to a diverse range of fields in the natural, life, social, and applied science, including physics, biology, medicine, economics and management [26]. Big data has been widely characterized by the three Vs [15]: a hugely increased Volume of data, a Variety of data sources and quality, and the high Velocity at which data is generated or obtained. Big data technology holds incredible promise for improving people’s lives, accelerating scientific discovery and innovation, and instigating positive societal change [7]. Meanwhile, new challenges accompanying the heterogeneity, incompleteness, scale, timeliness, privacy and process complexity of big data, including aspects of data acquisition, data storage, information extraction, and big data analysis, need to be overcome [18]. Further three Vs are now recognized as the development of big data analysis: Veracity, which focuses on the unreliability inherent in data sources; Variability, which refers to variations in data flow rates; and Value, which refers to the issue of low value density [8, 9, 13].
Challenges in streamed big data
Eight big streaming data challenges were discussed in [17], covering the cycle of knowledge discovery from data. We consider these challenges from three aspects: (1) the development of new data mining skills for big streaming data; (2) the development of simpler, self-adaptive machine learning algorithms; and (3) the requirements of privacy and confidentiality for gaining trust of the users and society in the system.
As data evolves over time, the validity and reliability of the historical data are questionable. Decision support for big streaming data has to consider these issues to perform accurate, up-to-date, real-time analysis. For example, the detection of highway flooding [28]. Although data streams, online learning, big data, and adaptation to concept drift have become important research topics during the last decade, a truly autonomous, self-maintaining, adaptive data mining system is still lacking [17]. The short lifespan of data restricts us to storing and accessing all historical data during each processing cycle; however, processing accuracy has been strictly limited by the fact that the data can be accessed only once (one-pass setting). This is critical when concept drift occurs, because good and bad data samples are treated equally when they are used to learn a new concept. Computing resources such as hardware and storage space have been developed to be more efficient and effective, therefore, it is more practical to adopt a limited storage assumption rather than a zero-storage assumption when discussing decision support for high-volume streaming data. In addition, previous decisions are no longer applicable when data evolve and have to be replaced according to the current situation. Therefore, when to make a decision change and how to conduct that change are two unsolved aspects of this problem, which become more difficult when multiple streams are involved.
Concept drift in streamed big data
This section presents the definition of concept drift and how to detect, understand and react it. Related real-world applications are also discussed.
Learning with concept drift
Learning with concept drift is an auxiliary research field of continuous learning, as discussed in [32], and has also been referred to as learning under a dynamic environment [12, 37], or learning in a non-stationary environment [5]. The research objective is to identify whether the model learnt from historical data is the same as that in the hypothesis set, which demonstrates the best performance on current concepts, where a concept is a mapping from input space to labels or target values. Concept drift can be caused by changes in data distribution, or training with misleading samples. Learning with high-volume streaming data requires particular attention to be paid to concept drift.
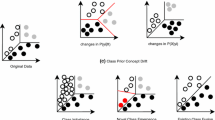
Concept drift can be categorized as sudden/abrupt drift, incremental drift, gradual drift or recurrent drift, according to When, How and Where: (1) When the drift occurs and how long it lasts; (2) How severe the drift is; and (3) Where the drift region is. These three criteria provide a three-dimensional perspective to describe concept drift. Drift adaptation strategies are thus specifically designed and applied to update models experiencing different types of drift.
Early concept drift studies mainly focused on drift point detection, addressing the When criterion by identifying when the empirical error exceeded the upper bound of an established model [2, 11, 29]. Adaptation methods are to relearn the models or to use ensemble algorithms to adapt to new concepts [3, 33, 35]. In recent years, drift point detection has been developed to cover more complicated cases, such as feature selection drift [4, 39], region selection drift [19, 20, 25] and the detection of multi-layer drift [1, 40]. These developments address the Where criterion. Some drift detection techniques have similar objectives as multivariate two-sample tests, which compare the similarity between two distributions according to the available samples [6, 19]. A number of recent publications have considered the test statistics applied in two-sample tests as a measure for quantifying drift severity, addressing the issue of How (How severe the drift is). However, very few have proposed drift adaptation strategies that use the severity information to learn new concepts.
Learning with concept drift has three steps: drift detection, understanding drift, and drift adaptation. We will discuss the challenges of each step in the paragraphs that follow.
Drift detection
A wide range of algorithms for concept drift detection have been developed to identify the inconsistency between historical data and newly available data. False-positive and false-negative criteria are used to evaluate the performance of drift detection algorithms. Type I errors detect drifts with fewer false-positive detections, and Type II errors detect drifts with fewer false-negative detections. In the case of high-volume streaming data, this may be inadequate, since Velocity ensures that data arrives at a very fast pace and there may be insufficient time to collect labels or target values for drift detection. Drift detection algorithms must detect drift with a limited quantity of labeled samples, thus solutions that achieve the desired drift detection accuracy with the least number of samples are preferable. In other words, the convergence rate of algorithms should also be considered as an evaluation metric. Although active learning has been applied to solve this problem [42], solving the issue of Velocity is still an open question.
Drift understanding
Understanding drift is another key stage of learning under concept drift. It refers to retrieving information about the When, How, and Where of concept drift and is used to describe the status of concept drift. This information is learned and integrated after drift has been confirmed by drift detection methods or algorithms and is used as the input for knowledge adaptation. The need to understand drift has increasingly gained attention, as mentioned in [36], but very few concrete methods have been developed to quantify this information.
Drift adaptation
How to update existing learning models according to the characteristics of the drift is critical to achieve consistently high performance [30]. This is called drift adaptation (or knowledge adaptation). Some adaptation methods explicitly rely on drift detection algorithms and adopt a variety of retraining strategies to better handle different types of drift [24]. Others, mainly decision-tree-based methods, may not include a global drift detection procedure but can partially update models according to changes in some leaf node based on the newly available data. Ensemble learning for streaming data with concept drift has also achieved remarkable results [16]; however, integrating concept drift adaptation into incremental learning is still a challenging problem. Making better use of How and Where drift information in high-volume streaming data learning, rather than only When, is the next step in boosting learning performance.
Concept drift applications
Handling concept drift is highly important in real-world practice; for example, in traffic networks, telecommunications, and financial transactions. Machine learning tasks in these systems will inevitably encounter the problem of concept drift, and in some cases, the ability to handle concept drift will be the key factor in improving system performance.
A discussion of concept drift applications in industry can be found in [43]. Drift detection applications in this context refer to the industrial requirement to diagnose significant internal and external environmental changes in industry trends or customer preferences, such as using drift detection technology to identify changes in the news preferences of users [14]. Similar tasks include fraud detection in finance, intrusion detection in computer security, mobile masquerade detection in telecommunications, topic changes in information document organization, and clinical studies in biomedicine. The aim of drift adaptation applications is to maintain a continuously effective evaluation and prediction system for industry. This may also involve using drift detection technologies to achieve greater accuracy. A real case example, in which a credit risk assessment framework for dynamic credit scoring was designed, is represented in [31]. Other real-world drift adaptation applications can be found in transportation traffic management, production and service monitoring, customer recommendation, bankruptcy prediction, and so on.
With the latest developments in technology, data streams have become larger in size and faster. The new challenges posed by high-volume streaming data require the development of more advanced concept drift applications. One such challenge is how to handle concept drift problems in the Internet of Things (IoT) [43], since the huge quantity of streaming data from the IoT requires deeper insight and better understanding of concept drift.
Real-time decision support under concept drift: future directions
This section presents possible future research directions of real-time decision support under concept drift.
Adaptive decision support systems under concept drift
Streaming data are a set of continuous record of events. The volume of data is expanded by its time stamps, which can be infinite in number. Nowadays, streaming data has the capacity to track events for long periods at high frequency from mobile and/or embedded devices (e.g., sensors) [10]. It can thus continuously capture the potential risk of an event by analyzing its data stream. If a potential risk is detected that may result in a significant decision-making failure, the existing decision-making results need to be immediately updated to prevent loss being caused by old decisions. We refer to this as Adaptive Decision Support, and it has application in such environments as the IoT, emergency management, industrial control systems and online decision-making. An example of the applications is situation awareness-based decision support systems which can improve human decision-makers’ performance and reduce error in dynamic environments [27].
Multi-stream decision support under concept drift
Huge amounts of streaming data are now generated by government and industry from multiple sources, such as sensors and marketing activities. They are known as multi-streams. Disruptive technologies and unique user experiences, e.g., new markets and new customer behaviors, have inevitably resulted in changes in the underlying data distribution in almost all streaming data. In addition, high-volume streaming data commonly have undiscovered correlations across data streams, and a drift in one stream may cause drift in other streams. A data-driven decision support system on a single stream could be highly related to decision support systems on other streams, thus efficient learning methods on streaming data, such as identifying correlations between streams and constructing adaptive correlation networks, are urgently needed to support the timely prediction of drift and aid decision-making. In the finance industry, for example, the bid/offer rate in the inter-bank lending market always involves the behaviors of more than two banks. The rate needs to be determined based on the interrelationship between banks to benefit the involved banks; in telecommunications, smartphone producers are competitors between each other. The marketing strategy of one producer affects other producers’ strategies, especially for large companies, such as Samsung and Apple. Therefore, it is import for the Apple company to analyze marketing behaviors of Samsung to make efficient strategies and maximize the profit. How to take advantage of this interrelationship for decision support to benefit these network groups individually or as a whole is a promising future research direction.
Recommender systems under concept drift
Recommender systems have attracted great attention and achieved great success in the last decade [22, 38]. Nevertheless, the dynamic characteristics of high-volume streaming data have not been adequately addressed. Current recommender systems treat user preferences as static, in spite of the fact that preferences change with increased expertise, personal experiences, or social popularity. The performance of recommender systems will be impaired in many aspects, such as accuracy, novelty and diversity, if these dynamic changes in user profiles, item analysis, or user preferences are not considered. Recommendation should consider the consistency of customer behaviors, customer interactions, and changes in customer preferences; adopting concept drift detection and reaction techniques are, therefore, promising directions in recommender system research for both academia and industry.
Data-driven decision-making under uncertainty
A significant challenge of using large quantities of streaming data collected from different sources in different time frames is uncertainty [23]. Uncertainty in high-volume streaming data takes a number of different forms. We consider that four main layers are impacted by uncertainty issues in streaming data-driven decision support: the data layer, the stream layer, the concept drift detection layer, and the decision-making layer. The first two layers correspond to Component I in Fig. 1. Layers three and four correspond, respectively, to Component II and Component III. Uncertainty problems in the data layer concern data insufficiency [33], outdatedness [35], incompletion, and ambiguity [3]. In the stream layer, uncertainty may exist in the relationship between streams, such as whether two streams convey the same information, and may also exist in the correlation of concept drift between streams, such as the likelihood of drift in one stream causing drift in other streams. In the concept drift layer, uncertainty may take the form of noise, false alarms caused by outliers, and new emerging classes. Uncertainty issues also need to be considered in the generation of drift early warning. Lastly, in the decision-making layer, both the model adaptation and decision optimization processes may be subject to uncertainty issues, since there is no universal decision model to fit all situations. The research problem is to develop a general guidance framework for addressing uncertainty issues and to use uncertainty characteristics to aid decision support.
Summary
In this position paper, we propose a framework for adaptive \(\mathrm {D^3}\)M under concept drift in high-volume streaming data environment, elaborate the challenges and opportunities presented by big streaming data, introduce the three steps of learning under concept drift, and discuss future research directions for adaptive decision support.
This paper highlights the issue of real-time \(\mathrm {D^3}\)M and provides some fundamental knowledge and methodologies for researchers and practitioners in decision support system area. We hope it could provide a good guideline on how to apply concept drift handling methodologies to help \(\mathrm {D^3}\)M techniques in big streaming data.
References
Alippi C, Boracchi G, Roveri M (2017) Hierarchical change-detection tests. IEEE Trans Neural Netw Learn Syst 28(2):246–258
Baena-García M, del Campo-Ávila J, Fidalgo R, Bifet A, Gavaldà R, Morales-Bueno R (2006) Early drift detection method. In: ECML/PKDD 2006, proceedings of the 4th international workshop on knowledge discovery from data streams, pp 77–86
Bifet A, Gavalda R, Gavaldà R (2007) Learning from time-changing data with adaptive windowing. In: Proceedings of the 7th SIAM international conference on data mining, pp 443–448
Cavalcante RC, Minku LL, Oliveira ALI (2016) Fedd: feature extraction for explicit concept drift detection in time series. In: Proceedings of the 2016 international joint conference on neural networks, pp 740–747
Ditzler G, Roveri M, Alippi C, Polikar R (2015) Learning in nonstationary environments: a survey. IEEE Comput Intell Magn 10:12–25
Dries A, Rückert U (2009) Adaptive concept drift detection. Stat Anal Data Min ASA Data Sci J 2:311–327
Drosou M, Jagadish HV, Pitoura E, Stoyanovich J (2017) Diversity in big data: a review. Big Data 5(2):73–84
Elgendy N, Elragal A (2014) Big data analytics: a literature review paper. In: Proceedings of the 2014 industrial conference on data mining, Springer, New York, pp 214–227
Fan W, Bifet A (2013) Mining big data: current status, and forecast to the future. ACM SIGKDD Explor Newsl 14(2):1–5
Gaber MM, Gama J, Krishnaswamy S, Gomes JB, Stahl F (2014) Data stream mining in ubiquitous environments: state-of-the-art and current directions. Wiley Interdiscip Rev Data Min Knowl Discov 4:116–138
Gama J, Medas P, Castillo G, Rodrigues P (2004) Learning with drift detection. In: Proceedings of the 17th Brazilian symposium on artificial intelligence, Springer, New York, pp 286–295
Gama J, Žliobaitė I, Bifet A, Pechenizkiy M, Bouchachia A (2014) A survey on concept drift adaptation. ACM Comput Surv 46(4):1–37
Gandomi A, Haider M (2015) Beyond the hype: big data concepts, methods, and analytics. Int J Inf Manag 35(2):137–144
Harel M, Mannor S, El-Yaniv R, Crammer K (2014) Concept drift detection through resampling. In: Proceedings of the 31st international conference on machine learning, pp 1009–1017
Janssen M, Van Der Voort H, Wahyudi A (2017) Factors influencing big data decision-making quality. J Bus Res 70:338–345
Krawczyk B, Minku LL, Gama J, Stefanowski J, Woźniak M (2017) Ensemble learning for data stream analysis: a survey. Inf Fusion 37:132–156
Krempl G, Žliobaite I, Brzeziński D, Hüllermeier E, Last M, Lemaire V, Noack T, Shaker A, Sievi S, Spiliopoulou M, Stefanowski J (2014) Open challenges for data stream mining research. ACM SIGKDD Explor Newsl 16(1):1–10
Labrinidis A, Jagadish HV (2012) Challenges and opportunities with big data. Proc VLDB Endow 5(12):2032–2033
Liu A, Lu J, Liu F, Zhang G (2018) Accumulating regional density dissimilarity for concept drift detection in data streams. Pattern Recogn 76:256–272
Liu A, Song Y, Zhang G, Lu J (2017) Regional concept drift detection and density synchronized drift adaptation. In: Proceedings of the 26th international joint conference on artificial intelligence, pp 2280–2286
Lu J, Liu A, Dong F, Gu F, Gama J, Zhang G (2018) Learning under concept drift: a review. IEEE Trans Knowl Data Eng
Lu J, Wu D, Mao M, Wang W, Zhang G (2015) Recommender system application developments: a survey. Decis Support Syst 74:12–32
Lu J, Zhang G, Ruan D, Wu F (2007) Multi-objective group decision making: methods, software and applications with fuzzy set techniques, vol 6. Imperial College Press, London
Lu N, Lu J, Zhang G, de Mántaras RL (2016) A concept drift-tolerant case-base editing technique. Artif Intell 230:108–133
Lu N, Zhang G, Lu J (2014) Concept drift detection via competence models. Artif Intell 209:11–28
Maass W, Parsons J, Purao S, Rosales A, Storey VC, Woo CC (2017) Big data and theory. Encyclopedia of big data, pp 1–5
Naderpour M, Lu J, Zhang G (2014) An intelligent situation awareness support system for safety-critical environments. Decis Support Syst 59:325–340
Puthal D, Nepal S, Ranjan R, Chen J (2017) Dlsef: a dynamic key-length-based efficient real-time security verification model for big data stream. ACM Trans Embedded Comput Syst (TECS) 16(2):51
Schlimmer JC, Granger RH Jr (1986) Incremental learning from noisy data. Mach Learn 1(3):317–354
Song Y, Lu J, Lu H, Zhang G (2019) Fuzzy clustering-based adaptive regression for drifting data streams. IEEE Trans Fuzzy Syst. https://doi.org/10.1109/TFUZZ.2019.2910714
Sousa MR, Gama J, Brandão E (2016) A new dynamic modeling framework for credit risk assessment. Expert Syst Appl 45:341–351
Stoica I, Song D, Popa RA, Patterson DA, Mahoney MW, Katz RH, Joseph AD, Jordan M, Hellerstein JM, Gonzalez J, Goldberg K, Ghodsi A, Culler DE, Abbeel P (2017) A berkeley view of systems challenges for AI. Report, EECS Department, University of California, Berkeley
Street WN, Kim Y (2001) A streaming ensemble algorithm (SEA) for large-scale classification. In: Proceedings of the 7th ACM international conference on knowledge discovery and data mining, ACM, pp 377–382
Turban E, Rainer RK, Potter RE (2005) Introduction to information technology. Wiley, Amsterdam
Wang H, Fan W, Yu PS, Han J (2003) Mining concept-drifting data streams using ensemble classifiers. In: Proceedings of the 9th international conference on knowledge discovery and data mining, ACM, pp 226–235
Webb GI, Hyde R, Cao H, Nguyen HL, Petitjean F (2016) Characterizing concept drift. Data Min Knowl Disc 30(4):964–994
Widmer G, Kubat M (1993) Effective learning in dynamic environments by explicit context tracking. In: Proceedings of the 1993 European conference on machine learning, Vienna, Springer, pp 227–243
Wu D, Zhang G, Lu J (2015) A fuzzy preference tree-based recommender system for personalized business-to-business e-services. IEEE Trans Fuzzy Syst 23(1):29–43
Yamada M, Kimura A, Naya F, Sawada H (2013) Change-point detection with feature selection in high-dimensional time-series data. In: Proceedings of the 23rd international joint conference on artificial intelligence, pp 1827–1833
Yu S, Abraham Z (2017) Concept drift detection with hierarchical hypothesis testing. In: Proceedings of the 17th SIAM international conference on data mining, SIAM, pp 768–776
Zhang G, Lu J, Gao Y (2015) Multi-level decision making. Springer, New York
Žliobaitė I, Bifet A, Pfahringer B, Holmes G (2014) Active learning with drifting streaming data. IEEE Trans Neural Netw Learn Syst 25(1):27–39
Žliobaitė I, Pechenizkiy M, Gama J (2016) An overview of concept drift applications. Book section Chapter 4, Springer, New York, pp 91–114
Acknowledgements
The work presented in this paper was supported by the Australian Research Council (ARC) under Discovery Grant DP190101733.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Lu, J., Liu, A., Song, Y. et al. Data-driven decision support under concept drift in streamed big data. Complex Intell. Syst. 6, 157–163 (2020). https://doi.org/10.1007/s40747-019-00124-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-019-00124-4