
Abstract
We propose the tensorizing flow method for estimating high-dimensional probability density functions from observed data. Our method combines the optimization-less feature of the tensor-train with the flexibility of flow-based generative models, providing an accurate and efficient approach for density estimation. Specifically, our method first constructs an approximate density in the tensor-train form by efficiently solving the tensor cores from a linear system based on kernel density estimators of low-dimensional marginals. Subsequently, a continuous-time flow model is trained from this tensor-train density to the observed empirical distribution using maximum likelihood estimation. Numerical results are presented to demonstrate the performance of our method.















Similar content being viewed by others

Data Availability
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Bachmayr, M., Schneider, R., Uschmajew, A.: Tensor networks and hierarchical tensors for the solution of high-dimensional partial differential equations. Found. Comput. Math. 16, 1423–1472 (2016)
Baiardi, A., Reiher, M.: The density matrix renormalization group in chemistry and molecular physics: recent developments and new challenges. J. Chem. Phys. 152, 040903 (2020)
Batchelor, G.K.: An Introduction to Fluid Dynamics. Cambridge University Press, Cambridge (2000)
Behrmann, J., Grathwohl, W., Chen, R.T., Duvenaud, D., Jacobsen, J.-H.: Invertible residual networks. In: International Conference on Machine Learning, PMLR, pp. 573–582 (2019)
Bengio, Y., Ducharme, R., Vincent, P.: A neural probabilistic language model. Adv Neural Inf. Process. Syst. 13 (2000)
Bishop, C.M., Nasrabadi, N.M.: Pattern Recognition and Machine Learning, vol. 4. Springer, Cham (2006)
Blei, D.M., Kucukelbir, A., McAuliffe, J.D.: Variational inference: a review for statisticians. J. Am. Stat. Assoc. 112, 859–877 (2017)
Bond-Taylor, S., Leach, A., Long, Y., Willcocks, C.G.: Deep generative modelling: A comparative review of vaes, gans, normalizing flows, energy-based and autoregressive models, arXiv preprint arXiv:2103.04922 (2021)
Bonnevie, R., Schmidt, M.N.: Matrix product states for inference in discrete probabilistic models, The. J. Mach. Learn. Res. 22, 8396–8443 (2021)
Bradley, T.-D., Stoudenmire, E.M., Terilla, J.: Modeling sequences with quantum states: a look under the hood. Mach. Learn. Sci. Technol. 1, 035008 (2020)
Brandao, F.G., Horodecki, M.: Exponential decay of correlations implies area law. Commun. Math. Phys. 333, 761–798 (2015)
Chan, G.K.-L., Sharma, S.: The density matrix renormalization group in quantum chemistry. Annu. Rev. Phys. Chem. 62, 465–481 (2011)
Chen, C., Li, C., Chen, L., Wang, W., Pu, Y., Duke, L.C.: Continuous-time flows for efficient inference and density estimation. In: International Conference on Machine Learning, PMLR,, pp. 824–833 (2018)
Chen, R.T., Rubanova, Y., Bettencourt, J., Duvenaud, D.K.: Neural ordinary differential equations. Adv. Neural Inf. Process. Syst. 31 (2018)
Cheng, S., Wang, L., Xiang, T., Zhang, P.: Tree tensor networks for generative modeling. Phys. Rev. B 99, 155131 (2019)
Cichocki, A., Zdunek, R., Phan, A.H., Amari, S.-I.: Nonnegative Matrix and Tensor Factorizations: Applications to Exploratory Multi-way Data Analysis and Blind Source Separation. Wiley, London (2009)
De Lathauwer, L., De Moor, B., Vandewalle, J.: A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 21, 1253–1278 (2000)
De Lathauwer, L., De Moor, B., Vandewalle, J.: On the best rank-1 and rank-\((r_1, r_2,\dots, r_n)\) approximation of higher-order tensors. SIAM J. Matrix Anal. Appl. 21, 1324–1342 (2000)
Dinh, L., Krueger, D., Bengio, Y.: Nice: non-linear independent components estimation. arXiv preprint arXiv:1410.8516 (2014)
Dinh, L., Sohl-Dickstein, J., Bengio, S.: Density estimation using real NVP. arXiv preprint arXiv:1605.08803 (2016)
Dolgov, S., Anaya-Izquierdo, K., Fox, C., Scheichl, R.: Approximation and sampling of multivariate probability distributions in the tensor train decomposition. Stat. Comput. 30, 603–625 (2020)
Dolgov, S.V., Khoromskij, B.N., Oseledets, I.V., Savostyanov, D.V.: Computation of extreme eigenvalues in higher dimensions using block tensor train format. Comput. Phys. Commun. 185, 1207–1216 (2014)
Dupont, E., Doucet, A., Teh, Y.W.: Augmented neural odes. Adv. Neural Inf. Process. Syst. 32 (2019)
Durkan, C., Bekasov, A., Murray, I., Papamakarios, G.: Cubic-spline flows, arXiv preprint arXiv:1906.02145 (2019)
Durkan, C., Bekasov, A., Murray, I., Papamakarios, G.: Neural spline flows. Adv. Neural Inf. Process. Syst. 32 (2019)
Ren, W., Vanden-Eijnden, E.: Minimum action method for the study of rare events. Commun. Pure Appl. Math. 57, 637–656 (2004)
Germain, M., Gregor, K., Murray, I., Larochelle, H.: Made: masked autoencoder for distribution estimation. In: International Conference on Machine Learning, PMLR, pp. 881–889 (2015)
Gomez, A.N., Ren, M., Urtasun, R., Grosse, R.B.: The reversible residual network: backpropagation without storing activations. Adv. Neural Inf. Process. Syst. 30 (2017)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Adv. Neural Inf. Process. Syst. 27 (2014)
Grasedyck, L.: Hierarchical singular value decomposition of tensors. SIAM J. Matrix Anal. Appl. 31, 2029–2054 (2010)
Grathwohl, W., Chen, R.T., Bettencourt, J., Sutskever, I., Duvenaud, D.: Ffjord: free-form continuous dynamics for scalable reversible generative models. arXiv preprint arXiv:1810.01367 (2018)
Han, Z.-Y., Wang, J., Fan, H., Wang, L., Zhang, P.: Unsupervised generative modeling using matrix product states. Phys. Rev. X 8, 031012 (2018)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Hinton, G.E.: Training products of experts by minimizing contrastive divergence. Neural Comput. 14, 1771–1800 (2002)
Hinton, G.E., Sejnowski, T.J.: Optimal perceptual inference. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, vol. 448, Citeseer, pp. 448–453 (1983)
Hoffman, M.D., Blei, D.M., Wang, C., Paisley, J.: Stochastic variational inference. J. Mach. Learn. Res. (2013)
Hohenberg, P., Krekhov, A.: An introduction to the Ginzburg-Landau theory of phase transitions and nonequilibrium patterns. Phys. Rep. 572, 1–42 (2015)
Hur, Y., Hoskins, J.G., Lindsey, M., Stoudenmire, E., Khoo, Y.: Generative modeling via tensor train sketching. arXiv preprint arXiv:2202.11788 (2022)
Jacobsen, J.-H., Smeulders, A., Oyallon, E.: i-revnet: deep invertible networks. arXiv preprint arXiv:1802.07088 (2018)
Khoo, Y., Lindsey, M., Zhao, H.: Tensorizing flows: a tool for variational inference. arXiv preprint arXiv:2305.02460 (2023)
Kingma, D.P., Dhariwal, P.: Glow: generative flow with invertible 1x1 convolutions. Adv. Neural Inf. Process. Syst. 31 (2018)
Kingma, D.P., Salimans, T., Jozefowicz, R., Chen, X., Sutskever, I., Welling, M.: Improved variational inference with inverse autoregressive flow. Adv. Neural Inf. Process. Syst. 29 (2016)
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
Kobyzev, I., Prince, S.J., Brubaker, M.A.: Normalizing flows: an introduction and review of current methods. IEEE Trans. Pattern Anal. Mach. Intell. 43, 3964–3979 (2020)
Kressner, D., Uschmajew, A.: On low-rank approximability of solutions to high-dimensional operator equations and eigenvalue problems. Linear Algebra Appl. 493, 556–572 (2016)
Kressner, D., Vandereycken, B., Voorhaar, R.: Streaming tensor train approximation. arXiv preprint arXiv:2208.02600 (2022)
Larochelle, H., Murray, I.: The neural autoregressive distribution estimator. In: Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, pp. 29–37 (2011)
Miao, Y., Yu, L., Blunsom, P.: Neural variational inference for text processing. In: International Conference on Machine Learning, PMLR, pp. 1727–1736 (2016)
Mnih, A., Gregor, K.: Neural variational inference and learning in belief networks. In: International Conference on Machine Learning, PMLR, pp. 1791–1799 (2014)
Novikov, G.S., Panov, M.E., Oseledets, I.V.: Tensor-train density estimation. In: Uncertainty in Artificial Intelligence, PMLR, pp. 1321–1331 (2021)
Oseledets, I., Tyrtyshnikov, E.: Tt-cross approximation for multidimensional arrays. Linear Algebra Appl. 432, 70–88 (2010)
Oseledets, I.V.: Tensor-train decomposition. SIAM J. Sci. Comput. 33, 2295–2317 (2011)
Papamakarios, G., Pavlakou, T., Murray, I.: Masked autoregressive flow for density estimation. Adv. Neural Inf. Process. Syst. 30 (2017)
Penrose, R.: Applications of negative dimensional tensors. Combinat. Math. Appl. 1, 221–244 (1971)
Perez-Garcia, D., Verstraete, F., Wolf, M.M., Cirac, J.I.: Matrix product state representations. arXiv preprint quant-ph/0608197 (2006)
Ranganath, R., Gerrish, S., Blei, D.: Black box variational inference. In: Artificial Intelligence and Statistics, PMLR, pp. 814–822 (2014)
Rezende, D., Mohamed, S.: Variational inference with normalizing flows. In: International Conference on Machine Learning, PMLR, pp. 1530–1538 (2015)
Rezende, D.J., Mohamed, S., Wierstra, D.: Stochastic backpropagation and approximate inference in deep generative models. In: International Conference on Machine Learning, PMLR, pp. 1278–1286 (2014)
Robeva, E., Seigal, A.: Duality of graphical models and tensor networks. Inf. Inference J. IMA 8, 273–288 (2019)
Savostyanov, D., Oseledets, I., Fast adaptive interpolation of multi-dimensional arrays in tensor train format. In: The International Workshop on Multidimensional (ND) Systems. IEEE pp. 1–8 (2011)
Schmidhuber, J.: Generative adversarial networks are special cases of artificial curiosity (1990) and also closely related to predictability minimization (1991). Neural Netw. 127, 58–66 (2020)
Shi, T., Ruth, M., Townsend, A.: Parallel algorithms for computing the tensor-train decomposition. arXiv preprint arXiv:2111.10448 (2021)
Stein, E.M., Shakarchi, R.: Real Analysis: Measure Theory, Integration, and Hilbert Spaces. Princeton University Press, Princeton (2009)
Steinlechner, M.: Riemannian optimization for high-dimensional tensor completion. SIAM J. Sci. Comput. 38, S461–S484 (2016)
Szeg, G.: Orthogonal Polynomials., vol. 23, American Mathematical Society (1939)
Tabak, E.G., Vanden-Eijnden, E.: Density estimation by dual ascent of the log-likelihood. Commun. Math. Sci. 8, 217–233 (2010)
Tang, X., Hur, Y., Khoo, Y., Ying, L.: Generative modeling via tree tensor network states. arXiv preprint arXiv:2209.01341 (2022)
Temme, K., Verstraete, F.: Stochastic matrix product states. Phys. Rev. Lett. 104, 210502 (2010)
Tzen, B., Raginsky, M.: Neural stochastic differential equations: deep latent Gaussian models in the diffusion limit. arXiv preprint arXiv:1905.09883 (2019)
Vieijra, T., Vanderstraeten, L., Verstraete, F.: Generative modeling with projected entangled-pair states. arXiv preprint arXiv:2202.08177 (2022)
Wang, W., Aggarwal, V., Aeron, S.: Tensor train neighborhood preserving embedding. IEEE Trans. Signal Process. 66, 2724–2732 (2018)
White, S.R.: Density-matrix algorithms for quantum renormalization groups. Phys. Rev. B 48, 10345 (1993)
Young, N.: An Introduction to Hilbert Space. Cambridge University Press, Cambridge (1988)
Zhang, L., Wang, L., et al.: Monge-ampère flow for generative modeling. arXiv preprint arXiv:1809.10188 (2018)
Funding
Lexing Ying is partially supported by National Science Foundation under Award No. DMS-2011699. Yuehaw Khoo is partially supported by National Science Foundation under Award No. DMS-2111563 and U.S. Department of Energy, Office of Science under Award No. DE-SC0022232.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
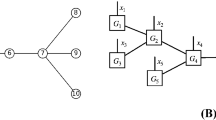
Appendix A. Proof of Proposition 3.3
In this appendix, we prove Proposition 3.3 from Sect. 3.1:
Proof of Proposition 3.3
For \(2\le k\le d\), it suffices for us to consider the k-th equation in (3.1):
By Definition 3.1, there exist orthonormal right singular vectors
of \(p(x_{1:k-1};x_{k:d})\) and
of \(p(x_{1:k};x_{k+1:d})\), and corresponding singular values \(\sigma _{k-1}(1)\ge \cdots \ge \sigma _{k-1}(r_{k-1})\) and \(\sigma _{k}(1)\ge \cdots \ge \sigma _{k}(r_{k})\), satisfying
and
Define \(\Xi _k(x_{k+1:d};\alpha _k)=\sigma _k(\alpha _k)^{-1}\Psi _k(\alpha _k;x_{k+1:d})\). It is easy to check that
Therefore, by contracting \(\Xi _k(x_{k+1:d};\alpha _k)\) to both sides of (A.2), we have
and consequently,
solves equation (A.1).
The uniqueness of the solution is guaranteed by the orthogonality of the functions \(\{\Psi _{k-1}(\alpha _{k-1};x_{k:d})\}_{1\le \alpha _{k-1} \le r_{k-1}}\) by definition. Once \(G_k\) is ready, it is easy to check the validity of (3.2) by plugging the CDE in (3.1) one into the next successively.
Appendix B. Hyperparameters
This section presents the hyperparameters of our tensorizing flow algorithm used for each example in Sect. 4. For simplicity, we choose the internal ranks \(r_k=2\) for \(1\le k\le d-1\), and the number of quadrature points \(l=20\) for all numerical integrations involved. We set the time horizon \(T=0.2\) with step-size \(\tau =0.01\) in the flow model. We choose the bandwidth parameter h in (3.6) to be 5% of the range of the data. We generate N/2 samples separately from the training samples as the test samples. The rest of the hyperparameters are organized in Table 1.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Ren, Y., Zhao, H., Khoo, Y. et al. High-dimensional density estimation with tensorizing flow. Res Math Sci 10, 30 (2023). https://doi.org/10.1007/s40687-023-00395-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40687-023-00395-x