
Abstract
In this work, we propose an inertial extragradient method for solving strongly pseudomonotone equilibrium problems utilizing a novel self-adaptive stepsize approach. We establish the R-linear convergence rate of the proposed method without prior knowledge of the Lipschitz-type constants associated with the bifunction. We also discuss the application of the obtained results to variational inequality problems involving strongly pseudomonotone and Lipschitz continuous mapping. Numerical examples are presented to illustrate the efficiency of the proposed method.
Similar content being viewed by others
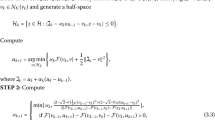


Avoid common mistakes on your manuscript.
1 Introduction
Let C be a nonempty closed and convex subset of a real Hilbert space H. Let \(f: H\times H\rightarrow {\mathbb {R}}\) be a bifunction with \(f(x,x)=0\) for all \(x\in C\). The equilibrium problem of the bifunction f on C, denoted by EP(f, C), is stated as follows:
Equilibrium problem is also called the Ky Fan inequality due to his contribution to this field (Fan 1972). Mathematically, EP(f, C) is a generalization of various important mathematical models including variational inequality problems, optimization problems and fixed point problems, see (Blum and Oettli 1994; Konnov 2000, 2007; Muu and Oettli 1992; Quoc and Muu 2012; Vuong and Strodiot 2020). EPs have been considered by many authors in recent years, e.g., see (Combettes and Hirstoaga 2005; Hieu et al. 2018; Iusem et al. 2009; Lyashko et al. 2011; Lyashko and Semenov 2016; Moudafi 2003; Nguyen et al. 2014; Strodiot et al. 2016; Tran et al. 2008; Vinh and Muu 2019; Vuong et al. 2015, 2012) and the references therein. Some notable methods for EPs have been proposed such proximal point methods (PPM) (Flam and Antipin 1997; Moudafi 1999), auxiliary problem principle methods (Mastroeni 2000) and gap function method (Mastroeni 2003). For an excellent collection of equilibrium modelling and applications, solutions existence as well as solution methods for EPs, we refer the readers to a recent monograph (Bigi et al. 2019).
The PPM is often used for solving monotone EPs, in which a regularized equilibrium problem is formed at each iteration. This sub-problem is strongly monotone, hence the solution is unique and can be computed more easily than solutions of the original problem. Solution approximations generated by the PPM will converge finitely or asymptotically to some solution of the original EPs (Flam and Antipin 1997; Moudafi 1999).
For solving pseudomonotone EPs, a powerful algorithm is the extragradient methods (EGM) studied originally by Korpelevich (1976) for variational inequalities and saddle point problems. This algorithm was extended to EPs in Tran et al. (2008) where the equilibrium bifunctions are pseudomonotone and satisfy a Lipschitz-type assumption. Under suitable conditions imposed on parameters and bifunctions, the iterative sequences generated by the EGM are proved to be convergent to some solution of EP(f, C). In recent years, the extragradient methods have received great attention from the many authors, see, e.g., Censor et al. (2011); Nguyen et al. (2014); Vuong et al. (2015). The advantage of the extragradient method (Vinh and Muu 2019) is that the sub-problems are easier to solve than the PPM. Moreover, it can be applied to the more general class of bifunctions.
The main drawback of EGM is that the chosen step-size depends on the Lipschitz-type constants of the bifunctions (Dang 2017; Lyashko et al. 2011; Lyashko and Semenov 2016; Moudafi 1999). This fact can make some restrictions in applications because the Lipschitz-type constants are often unknown or difficult to estimate. In this work, we propose a new inertial extragradient method for solving strongly pseudo-monotone equilibrium problem. Note that, an extragradient method with inertial effect for solving EPs can be found in Vinh and Muu (2019) where the inertial parameters were chosen depending on the iteration gap and a summable sequence. In addition, no convergence rate was obtained in Vinh and Muu (2019).
The EGM variant proposed in this paper uses a new step-size rule which does not require the knowledge of the Lipschitz-type constants of the bifunction as in Vinh and Muu (2019). Moreover, the inertial parameter can be chosen independently to the iterations. Under suitable conditions on the parameters, we establish the linear convergence of the iterations to the unique solution of the EPs. As a consequence, we provide a linear convergence rate of a modified extragradient method for solving variational inequality problems in Hilbert spaces.
This paper is organized as follows: in Sect. 2, we collect some definitions and preliminary results for further use. Section 3 deals with analyzing the convergence of the proposed algorithm. Finally, we discuss the applications to variational inequalities in Sect. 4, following with some numerical examples in Sect. 5.
2 Preliminaries
Let C be a nonempty closed convex subset of H. We begin with some concepts of monotonicity of a bifunction (Blum and Oettli 1994; Muu and Oettli 1992). A bifunction \(f:H\times H\rightarrow {\mathbb {R}}\) is said to be:
(i) strongly monotone on C if there exists a constant \(\gamma >0\) such that
(ii) strongly pseudomonotone on C if there exists a constant \(\gamma >0\) such that
(iii) satisfied Lipschitz-type condition on C if there exist two positive constants \(c_1,c_2\) such that
From the definitions above, it is obvious that \(\mathrm (i) \Longrightarrow (ii)\).
The normal cone \(N_C\) to C at a point \(x\in C\) is defined by
For every \(x\in H\), the metric projection \({ P_C(x)}\) of x onto C is defined by
Since C is nonempty, closed and convex, \({ P_C(x)}\) exists and is unique.
For each \(x,z\in H,\) by \(\partial f(z,x),\) we denote the subdifferential of convex function \(f(z,\cdot )\) at x, i.e.,
In particular,
For proving the convergence of the algorithm, we need the following lemma.
Lemma 2.1
(Peypouquet 2015, Proposition 3.61) Let C be a nonempty closed convex subset of H and \(g:H\rightarrow {\mathbb {R}}\cup \{+\infty \}\) be a proper, convex and lower semicontinuous function on H. Assume either that g is continuous at some point of C, or that there is an interior point of C where g is finite. Then, \(x^*\) is a solution to the following convex problem \( \min \left\{ g(x):x\in C\right\} \) if and only if \(0\in \partial g(x^*)+N_C(x^*)\), where \(\partial g(\cdot )\) denotes the subdifferential of g and \(N_C(x^*)\) is the normal cone of C at \(x^*\).
Definition 2.1
(Ortega and Rheinboldt 1970) Let \(\{x_n\}\) be a sequence in H.
(i) \(\{x_n\}\) is said to converge R-linearly to \(x^*\) with rate \(\rho \in [0, 1)\) if there is a constant \(c>0\) such that
(ii) \(\{x_n\}\) is said to converge Q-linearly to \(x^*\) with rate \(\rho \in [0, 1)\) if
3 Convergence analysis
Now, we are in a position to present a modified version of inertial extragradient method in Vinh and Muu (2019) for solving equilibrium problems.

Remark 3.1
The self-adaptive stepsizes \(\{\lambda _n\}\) chosen as in (2) is allowed to increase from iteration to iteration showing that the self-adaptive stepsize in this work is different from the studied self-adaptive stepsize in the literature (Hieu et al. 2018; Dang 2017; Muu and Quoc 2009; Tran et al. 2008; Vinh and Muu 2019). The initial stepsize \(\lambda _1\) chosen in (2) could be arbitrary large allowing fast convergence from the beginning of the iterations. In particular, (Vinh and Muu 2019, Algorithm 1) proposed an inertial extragradient method for solving pseudo-monotone EPs with fixed stepsize and inertial parameters were chosen along the course of iterations depending on a summable series, which were different from Algorithm (3.1). In addition, the linear convergence rate was not investigated in (Vinh and Muu 2019).
In order to establish the convergence of Algorithm 3.1, we assume that bifunction \(f:H\times H\rightarrow {\mathbb {R}}\) satisfies the following conditions.
Condition 1
(A1) f is \(\gamma \)-strongly pseudomonotone on C.
(A2) f satisfies Lipschitz-type condition on H with two constants \(c_1\) and \(c_2\).
(A3) \(f(x,\cdot )\) is convex and lower semicontinuous on H for every fixed \(x\in H.\)
(A4) Either \(int C \ne \emptyset \) or \(f (x,\cdot )\) is continuous at some point in C for every \(x \in H\).
Remark 3.2
From the condtions (A1) and (A2) we get \(f(x,x)=0\) for all \(x\in C.\) It is also known that under Condition 1, the problem EP(f,C) has unique solution (Muu and Quy 2015). It is easy to see that the uniqueness of solution is guaranteed by the strong pseudomonotonicity of the bifunction f. For generic conditions of solution existence and their relaxations, we refer the readers to an excellent survey (Bigi et al. 2013, Section 2). In particular, the most simplest conditions for solution existence are: C is a bounded and convex set; \(f(x, \cdot )\) is convex for each \(x\in C\) and \(f(\cdot , y)\) is continuous for each \(y\in C\).
Next, we will establish the convergence rate of Algorithm 3.1. We start with the following lemmas which play an important role in proving the convergence of the proposed algorithm.
Lemma 3.1
(Yang 2020) Let Condition 1 be satisfied. Let \(\{\lambda _n\}\) be a sequence generated by Algorithm 3.1. Then
where \(\tau =\sum _{n=1}^\infty \tau _n.\)
Lemma 3.2
For any \(\lambda > 0\) and \(x,t \in H\), let
then
Proof
Since z is the unique solution of the strongly convex minimization problem (3). The optimality condition (Lemma 2.1) implies that there exists \(s \in { \partial f(x, z)}\) such that
Hence, by definition of this cone, we obtain that
On the other hand, since \(s \in { \partial f(x, z)}\), we have
Combining (4) and (5), we obtain
Lemma 3.3
Let C be a nonempty, closed and convex subset of H and \(f:H\times H \rightarrow {\mathbb {R}}\) be a bifunction satisfying Condition 1. Let u be the unique solution of EP(f, C). Then the following inequality holds
Proof
From
by Lemma 3.2, we get
Substituting \(y:=u \in C\), we obtain
Since u is the unique solution of EP(f, C) and \(v_n\in C\), we have \(f(u,v_n)\ge 0\). By the strong pseudomonotonicity assumption of f, we obtain \(f(v_n,u)\le -\gamma \Vert v_n-u\Vert ^2.\) It implies from (7) that
Again, since
Lemma 3.2 implies
This implies that
On the other hand, from the definition of the sequence \(\lambda _n\) we get
Substituting (10) into (11) we obtain
In the following theorem we will show that the sequence \(\{u_n\}\) generated by Algorithm 3.1 converges strongly to the unique solution u with a R-linear rate.
Theorem 3.1
Let C be a nonempty closed convex subset of H. Let \(f: H \times H \rightarrow {\mathbb {R}}\) be a bifunction satisfying Condition 1. Let \(\theta \in (0,1)\) be arbitrary and \(\rho \) be a real number such that
where \(\omega :=1-\min \bigg \{\dfrac{(1-\mu )\theta }{ 4},\dfrac{\gamma \lambda }{2} \bigg \}\) and \(\epsilon :=\dfrac{1}{ 2}(1-\mu )(1-\theta )\theta \). Then the sequence \(\{u_n\}\) generated by Algorithm 3.1 converges in norm to the unique solution u of the problem EP(f,C) with a R-linear rate.
Proof
First, we show that there exists \(N_1\in {\mathbb {N}}\) such that
Indeed, it follows from Lemma 3.1 that \(\lim _{n \rightarrow \infty } \lambda _n = \lambda > 0\) and since \({ \mu < 1}\), there exists \(N>0\) such that
Thanks to (6) and \(\theta \in (0,1)\), we have for all \(n\ge N\) that
where we have used the Cauchy–Schwartz inequality in the last estimation. Moreover, we get
Using the definition of the limit, there exists \(N_1\in {\mathbb {N}}\) and \(N_1\ge N\), such that for all \(n\ge N_1\)
and
Using (14) we obtain for all \(n\ge N_1\) that
Next, we show that the sequence \(\{u_n\}\) converges strongly to the unique solution u of the problem EP(f, C). Indeed, we have
and
Combining these inequalities with (13) we obtain
or equivalently
Setting
since \(\omega \in (0,1)\), we can write
We show that
Indeed, from (12) we get \(\rho \in [0,1)\), thus we obtain \(1+ \rho \le 2\) and \(\rho (1-\rho )\le \rho \), hence
Therefore
Next, we show that \(\Sigma _n\ge 0\) for all n. From (12) we deduce
which implies \(\rho \le \frac{\epsilon (1-\rho )}{2}\). Using this fact, we obtain
Hence
which means that \(\left\{ u_n \right\} \) converges R-linearly to u.
Remark 3.3
Using the similar technique in Vinh and Muu (2019); Yang (2020), one can obtain the weak convergence of Algorithm 3.1 under conditions: f is pseudomonotone on C; \(f(\cdot ,y)\) is weakly upper semicontinuous on C, (A2), (A3), (A4) and the solution set \(EP(f,C)\ne \emptyset \). We omit the proof here.
4 Application to variational inequalities
In this Section, we discuss the applications of the main result obtained in Sect. 3 for solving variational inequality problems in Hilbert spaces. Let \( f(x, y) = \langle { F(x)}, y- x\rangle , \ \forall x, y \in C\), where \(F: H \rightarrow H\) is a continuous mapping. Then the equilibrium problems (1) becomes the variational inequality problem, i.e., find \(x^*\in C\) such that
The solution set of (15) is denoted by Sol(F, C). Moreover, we have
We recall that the mapping F is \(\delta \)-strongly pseudomonotone on C if there exists a constant \(\delta >0\) such that
If F is L-Lipschitz continuous and strongly pseudomonotone, then the conditions (A1)-(A4) hold for f with \(c_1 = c_2 = \dfrac{L}{2}\). Note that, under these assumption, Sol(F, C) is nonempty and singleton (Kim et al. 2016). For solving variational inequality, we propose the following algorithm.

The following result is a direct consequence of Theorem 3.1.
Theorem 4.1
Assume that \(F: H\rightarrow H\) is L-Lipschitz continuous on H and \(\delta \)-strongly pseudomonotone on C. Let \(\theta \in (0,1)\) be arbitrary and \(\rho \) be a real number such that
where \(\omega :=1-\min \bigg \{\dfrac{(1-\mu )\theta }{4}, \dfrac{\gamma \lambda }{2}\bigg \}\) and \(\epsilon :=\dfrac{1}{{ 2}}(1-\mu )(1-\theta )\theta \). Then the sequence \(\{u_n\}\) generated by Algorithm 4.1 converges in norm to the unique solution \(u \in \mathrm{Sol(F,C)}\) with a R-linear rate.
Remark 4.1
As a consequence of Remark 3.3 we can also obtain the weak convergence of Algorithm 4.1 under conditions: F is pseudomonotone on H; F is L-Lipschitz continuous on H; F is sequentially weakly continuous on C and the solution set \(Sol(F,C)\ne \emptyset \).
5 Numerical Illustrations
In this section, we consider some numerical results to illustrate the linear convergence of Algorithm 3.1 and compare its performance with the relaxed projection algorithm (Vuong and Strodiot 2020) and the inertial extragradient algorithm proposed by Vinh and Muu (2019). The codes are implemented in MATLAB.
Example 1: The bifunction f of the equilibrium problem comes from the Cournot-Nash equilibrium model considered by Quoc and Muu (2012). It is defined for each \(x,y \in {\mathbb {R}}^5\), by
where \(r \in {\mathbb {R}}^5\), and P and Q are two square matrices of order 5 such that \(P-Q\) is symmetric positive definite. It was proved by Quoc and Muu (2012) that the function f is strongly pseudo-monotone with modulus \(\gamma =\lambda _{min}(P-Q)\), the smallest eigenvalue of \(P-Q\) and f satisfies the Lipschitz-type condition with modulus \(c_1 = c_2 = \frac{1}{2}\Vert P-Q\Vert \). As in Quoc and Muu (2012), in our test, the vector r and the matrices P and Q are chosen as follows:
The constraint set of this problem is defined by
and its solution \(x^*\) is given by
In this example, \(\gamma =\lambda _{min}(P-Q)=0.7192\) and \(L = \Vert P-Q\Vert ,\) \(c_1 =c_2 = \frac{1}{2}\Vert P-Q\Vert = 1.45 \). The stopping condition is ErrorBound = \(\Vert u_{n+1}-u_n\Vert \le 10^{-5}\).
For the projection type algorithms in Vuong and Strodiot (2020), we choose \(\lambda = 1.9 * \gamma /L^2\) with the non-relaxed parameter (\(\alpha = 1\), red curve in Fig. 1) and \(\lambda = \gamma /L^2\) with the over-relaxed parameter (\(\alpha _{max} = 1.014\), black curve in Fig. 1). Moreover, the blue curve in Fig. 1 presents the inertial extragradient algorithm in Vinh and Muu (2019) with the stepsize \(\lambda = \frac{1}{2c_2}, \delta = 0.6\) and \(\epsilon _n=\frac{1}{n^2}, n=1,2,....\). Figure 1 presents the comparisons of the performance of these methods with \(u_0= u_1= (2,1,4,-1,-2)^T\) and the stopping condition \(10^{-5}\). It is clear that Algorithm 3.1 (green curve in Fig. 1) outperforms the others thanks to the very large initial stepsize (\(\lambda _1=5000\)) and inertial effect even though it is quite small (\(\rho = 0.003\)). The sequence \(\{\tau _n\}\) is chosen the same as \(\{\epsilon _n\}\). It is also noticed that the error estimates in Algorithm 3.1 has some oscillation phenomenon, which is well understood in algorithms with inertial effects for solving optimization problems. We believe that this is also the case for algorithms with inertial effects for solving EPs.

Performance of different algorithms when \(u_0=u_1=(2,1,4,-1,-2)^T\)
Example 2: Similar to Krawczyk and Uryasev (2000); Quoc and Muu (2012), in this example, we consider the problem of River basin pollution game. There are three players \(j =1,2,3\) located along a river. Each agent is engaged in an economic activity (paper pulp producing) at a chosen level \(x_j\), but the players must meet the environmental condition set by a local authority. Pollutants may be expelled into the river, where they disperse. Two monitoring stations are located along the river, at which the local authority has set maximum pollutant concentration levels. The revenue and the expenditure for player j are
and
respectively, where the parameters \(a_1=3.0, a_2=0.01, b_{1j}=0.1, 0.12, 0.15,\) and \(c_{2j}=0.01, 0.05, 0.01\) for \(j=1, 2, 3\), respectively. The profit of player j is
The constraint on emission imposed by the local authority at location is
where \(u_j=0.5, 0.25, 0.75, v_{1j}=6.5, 5.0, 5.5\) and \(v_{2j}=4.583, 6.25, 3.75\) for \(j =1,2,3\), respectively. The level \(x_j\) is nonnegative for \(j = 1,2,3\). Players try to maximize their profit \(K_j(x)\) satisfying the condition \(q_i(x) \le 100, i = 1,2\) and \(x \ge 0.\)
This problem can be reformulated as the equilibrium problem, where
and \(r=\left[ \begin{array}{r}b_{11}-a_1\\ b_{12}-a_1\\ b_{13}-a_1\end{array}\right] .\) Note that since \(P-Q\) is not positive definite, this linear equilibrium problem is not strongly monotone. However, since \(P+Q\) and Q are positive definite, we can choose matrix \(T=0.1\times \textrm{diag}(b_{21},b_{22},b_{23})\) such that this problem is equivalent to a strongly monotone linear equilibrium problem as in Example 1 when \(P_1 = P+T, Q_1 = Q-T\) and \(r_1 = r\) (see Quoc and Muu (2012) for more details). For this choice, the corresponding parameters are \(\gamma = \lambda _{min}(P_1-Q_1) = 0.019\) and \(L = \frac{1}{2}\Vert P_1-Q_1\Vert = 0.055.\) The other parameters are similar to Example 1 except \(\alpha _{max} = 1.5\). We also compare the performance of four algorithms with \(u_0= u_1= (0,0,0)^T\) and the stopping condition ErrorBound\(=\Vert u_{n+1}-u_n\Vert \le 10^{-5}\) in Fig. 2. Once again, Algorithm 3.1 demonstrates its effectiveness thanks to the large initial stepsize (\(\lambda _1 =5000\)) and inertial effects.

Performance of different algorithms when \(u_0=u_1=(0,0,0)^T\)
Example 3: We continue with a very interesting model namely the Nash-Cournot oligopolistic equilibrium models of electricity markets introduced by Contreras et al. (2004). This model was reformulated as a strongly monotone equilibrium problem in Muu and Quy (2015); Quoc et al. (2012). Consider a Nash-Cournot oligopolistic equilibrium model arising in electricity markets with \(n^c \) \((n^c = 3)\) generating companies and each company i \((i=1,2,3)\) (com. #) possesses several generating units \(n_i^c \,(gen. \, \#)\). The quantities x and \(x^c\) are the power generation of a unit and a company, respectively. The lower and upper bounds of the power generation of the generating units and companies are given in Table 1. The parameters of the cost function are pointed out in Table 2.
The cost of a generating unit j (\(j=1,\dots ,6\)) is determined as follows
where
It turns out that the cost of the generating unit j does not depend on other generating units. Let us denote \(n^g\) by the number of generating units of all companies (i.e. \(n^g = \sum _{i=1}^{n^c} n_i^c\)) and \(I_i\) by the index set of all generating units of the company i.
If the selling price of a unit of electricity is fixed at \(378.4 - 2 \sum _{l=1}^{n^g} x_l \) then the profit of the company i that owns \(n_i^c\) generating units will be defined by
where \((x_{min}^g)_j \le x_j \le (x_{max}^g)_j \, (j=1,\dots , n^g)\).
For each \(i=1,\dots ,n^c\), let us define
The Nikaido-Isoda function is defined as

Performance of different algorithms when \(u_0=u_1=(0,0,0,0,0,0)^T\)
Since each company intends to maximize their profit, the oligopolistic equilibrium model of electricity markets can be reformulated as an equilibrium problem of finding \(x^*\in C^g\) such that
where \(C^g\) is the feasible set given by
To figure out the properties of the bifunction f, first let us introduce two vectors \(q^i = (q_1^i,q_2^i, \dots , q_{n^g}^i)^T\) and \({\bar{q}}^i = ({\bar{q}}^i_1,\dots ,{\bar{q}}^i_{n^g})^T\) in which
and \({\bar{q}}^i_j=1-q^i_j \, (j=1,\dots ,n^g)\). By (Quoc et al. 2012, Lemma 7), the equilibrium problem being solved can be formulated as
where the two matrices A, B, the vector a, and the cost function are identified as follows
It is worth knowing that since c is a nonsmooth convex function and B is symmetric positive semidefinite, f is continuous on \(C^g \times C^g\) and \(f(x,\cdot )\) is convex but not smooth for all \(x\in C^g\). In addition, the function f is only monotone but it can be transformed equivalently to a strongly monotone equilibrium problem by considering the following bifunction (see (Muu and Quy 2015, Lemma 4)).
We test the Algorithm 3.1 with \(u_0=u_1=(0,0,0,0,0,0)^T,\) the initial stepsize \(\lambda _1 = 100\), the stopping condition ErrorBound=\(\Vert u_{n+1}-u_n\Vert \le 10^{-3}\) and small inertial effect (\(\rho = 0.003\)). For the other three algorithms, since the Lipschitz constants are not available, we select a positive stepsize so that the algorithms converge. We choose \(\lambda = 0.02\) for the projection algorithm and \(\lambda = 0.03, \alpha = 0.5\) for the relaxed projection algorithm. The inertial extragradient also uses the same stepsize with the relaxed projection. The sequences \(\{\tau _n\}\) and \(\{\epsilon _n\}\) are similar to Example 1. The results are reported in Fig. 3. We realize that the Algorithm 3.1 is still effective for this problem. We also notice that Algorithm 3.1 converges even faster with larger inertial effect, for example \(\rho =0.5\), but in this case condition (12) is not guaranteed.
References
Bigi G, Castellani M, Pappalardo M, Passacantando M (2013) Existence and solution methods for equilibria. Eur J Oper Res 227:1–11
Bigi G, Castellani M, Pappalardo M, Passacantando M (2019) Nonlinear programming techniques for equilibria. Springer, Berlin
Blum E, Oettli W (1994) From optimization and variational inequalities to equilibrium problems. Math Student 63:123–145
Censor Y, Gibali A, Reich S (2011) Strong convergence of subgradient extragradient methods for the variational inequality problem in Hilbert space. Optim Methods Softw 26:827–845
Combettes PL, Hirstoaga SA (2005) Equilibrium programming in Hilbert spaces. J Nonlinear Convex Anal 6:117–136
Contreras J, Klusch M, Krawczyk JB (2004) Numerical solutions to Nash-Cournot equilibria in coupled constraint electricity markets. IEEE Trans Power Syst 19(1):195–206
Dang VH (2017) Halpern subgradient extragradient method extended to equilibrium problems. RACSAM 111:823–840
Fan K (1972) A minimax inequality and applications, inequalities III. Academic Press, New York, pp 103–113
Flam SD, Antipin AS (1997) Equilibrium programming and proximal-like algorithms. Math Program 78:29–41
Hieu DV, Cho YJ, Xiao Y-B (2018) Modified extragradient algorithms for solving equilibrium problems. Optimization 67:2003–2029
Iusem AN, Kassay G, Sosa W (2009) On certain conditions for the existence of solutions of equilibrium problems. Math Program Ser B 116:259–273
Kim DS, Vuong PT, Khanh PD (2016) Qualitative properties of strongly pseudomonotone variational inequalities. Optim Lett 10:1669–1679
Konnov IV (2000) Combined relaxation methods for variational inequalities. Springer, Berlin
Konnov IV (2007) Equilibrium models and variational inequalities. Elsevier, Amsterdam
Korpelevich GM (1976) The extragradient method for finding saddle points and other problems. Ekonomikai Matematicheskie Metody 12:747–756
Krawczyk JB, Uryasev S (2000) Relaxation algorithms to find Nash equilibria with economic applications. Environ Model Assess 5:63–73
Lyashko SI, Semenov VV (2016) A new two-step proximal algorithm of solving the problem of equilibrium programming. In: Goldengorin B (ed) Optimization and its applications in control and data sciences. Springer optimization and its applications, vol 115. Springer, Cham, pp 315–325
Lyashko SI, Semenov VV, Voitova TA (2011) Low-cost modification of Korpelevich’s methods for monotone equilibrium problems. Cybern Syst Anal 47:631–640
Mastroeni G (2000) On auxiliary principle for equilibrium problems. Publicatione del Dipartimento di Mathematica dell, Universita di Pisa. 3:1244–1258
Mastroeni G (2003) Gap function for equilibrium problems. J Glob Optim 27:411–426
Moudafi A (1999) Proximal point algorithm extended to equilibrium problem. J Nat Geom 15:91–100
Moudafi A (2003) Second-order differential proximal methods for equilibrium problems. J Inequal Pure Appl Math 4:Article 18
Muu LD, Oettli W (1992) Convergence of an adaptive penalty scheme for finding constraint equilibria. Nonlinear Anal Theory Methods Appl 18:1159–1166
Muu LD, Quoc TD (2009) Regularization algorithms for solving monotone Ky Fan inequalities with application to a Nash–Cournot equilibria model. J Optim Theory Appl 142:185–204
Muu LD, Quy NV (2015) On existence and solution methods for strongly pseudomonotone equilibrium problems. Vietnam J Math 43:229–238
Nguyen TTV, Strodiot JJ, Nguyen VH (2014) Hybrid methods for solving simultaneously an equilibrium problem and countably many fixed point problems in a Hilbert space. J Optim Theory Appl 160:809–831
Ortega JM, Rheinboldt WC (1970) Iterative solution of nonlinear equations in several variables. Academic Press, New York
Peypouquet J (2015) Convex optimization in normed spaces: theory, methods and examples. Springer, Berlin
Quoc TD, Muu LD (2012) Iterative methods for solving monotone equilibrium problems via dua gap functions. Comput Optim Appl 51:709–728
Quoc TD, Anh PN, Muu LD (2012) Dual extragradient algorithms extended to equilibrium problems. J Glob Optim 52:139–159
Strodiot JJ, Vuong PT, Nguyen TTV (2016) A class of shrinking projection extragradient methods for solving non-monotone equilibrium problems in Hilbert spaces. J Glob Optim 64:159–178
Tran DQ, Dung ML, Nguyen VH (2008) Extragradient algorithms extended to equilibrium problems. Optimization 57:749–776
Vinh NT, Muu LD (2019) Inertial extragradient algorithms for solving equilibrium problems. Acta Math Vietnam 44:639–663
Vuong PT, Strodiot JJ (2020) A dynamical system for strongly pseudo-monotone equilibrium problems. J Optim Theory Appl 185:767–784
Vuong PT, Strodiot JJ, Nguyen VH (2012) Extragradient methods and linesearch algorithms for solving Ky Fan inequalities and fixed point problems. J Optim Theory Appl 155:605–627
Vuong PT, Strodiot JJ, Nguyen VH (2015) On extragradient-viscosity methods for solving equilibrium and fixed point problems in a Hilbert space. Optimization 64:429–451
Yang J (2020) The iterative methods for solving pseudomontone equilibrium problems. J Sci Comput 84:50. https://doi.org/10.1007/s10915-020-01298-7
Acknowledgements
The authors thank the two anonymous referees for their constructive comments, which help improving significantly the presentation of the paper.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Dedicate to Professor Le Dung Muu (Institute of Mathematics, VAST, Vietnam) on the occasion of his 75th birthday.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Le, T.T.H., Duong, V.T. & Phan, T.V. An inertial extragradient method for solving strongly pseudomonotone equilibrium problems in Hilbert spaces. Comp. Appl. Math. 43, 363 (2024). https://doi.org/10.1007/s40314-024-02840-1
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40314-024-02840-1