
Abstract
Purpose of Review
Deep Learning reconstruction (DLR) is the current state-of-the-art method for CT image formation. Comparisons to existing filter back-projection, iterative, and model-based reconstructions are now available in the literature. This review summarizes the prior reconstruction methods, introduces DLR, and then reviews recent findings from DLR from a physics and clinical perspective.
Recent Findings
DLR has been shown to allow for noise magnitude reductions relative to filtered back-projection without suffering from “plastic” or “blotchy” noise texture that was found objectionable with most iterative and model-based solutions. Clinically, early reader studies have reported increases in subjective quality scores and studies have successfully implemented DLR-enabled dose reductions.
Summary
The future of CT image reconstruction is bright; deep learning methods have only started to tackle problems in this space via addressing noise reduction. Artifact mitigation and spectral applications likely be future candidates for DLR applications.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Turning raw CT projection data into volumetric maps (i.e., images) of patient attenuation has undergone multiple changes from the beginnings of CT in the 1970s [1, 2]. One way to understand the differences between CT reconstruction methods is by what assumptions they make. The first two methods used for CT image reconstruction were algebraic reconstruction (ART) and FBP. Both methods make no assumptions about the absolute value of attenuation of a patient, nor on the frequency content of the patient. In layman’s terms, these methods are incapable of recognizing a relatively “flat” portion of patient anatomy (e.g., a urine-filled bladder) and preferentially reducing noise in this “flat” region. Similarly, ART and FBP cannot recognize regions which should not undergo noise reduction and thereby possibly degrade spatial resolution over patient anatomy with high frequency content (e.g., the inner ear bony anatomy). While ART was used on the first commercial CT scanner, it was quickly replaced by FBP as reconstruction computer hardware and software improved. As of today, FBP is still a standard option available on all CT scanners.
In response to the increasing fear of ionizing radiation due to scientifically debatable applications of the BIER VII report to CT radiation [3, 4] and tissue effects from inappropriately performed brain perfusion exams [5, 6], CT manufacturers developed commercial iterative reconstruction (IR) methods in 2009. IR methods assuaged fears over radiation because they offset the noise increases usually encountered when lowering radiation dose. Today, all major manufacturers and many 3rd-party companies have IR offerings. IR makes assumptions on the imaging object’s signal level and content. In layman’s terms, IR methods can identify the regions of an image which likely are smooth (i.e., a urine-filled bladder) and apply noise reduction processing to those specific regions. Unfortunately, noise reduction is commonly accompanied by spatial resolution degradation and changes to image noise texture. IR methods are therefore capable of identifying regions of high spatial frequency content (i.e., the inner ear bony anatomy) and minimizing the application of any spatial resolution degradation (i.e., noise reduction processes) to those regions. This ability to selectively reconstruct different regions within an image makes IR algorithms powerful noise-reducing methods, but their behavior is highly dependent on CT ionizing radiation dose [7], object size [8], object contrast level [7], and background patient anatomical noise [9]. Furthermore, the noise reduction methods used by the majority of IR algorithms results in suboptimal image texture, often referred to as “plastic” or “blotchy” in the literature [8, 10,11,12,13]. See Fig. 1 for an example of such an objectionable image noise texture.

Image reproduced with permission from Ref. [18]
Axial slices of the abdomen of the same patient at the (left) highest and (right) lowest level of iterative denoising applied. The inset images are zoomed-in views of the kidneys and the surrounding tissue. Note the “plastic” or “blotchy” texture of the image on the left relative to the image on the right.
More advanced forms of IR methods are often referred to as “model-based,” albeit while their performance has been shown to be superior to IR methods for some image quality facets [14], they also suffer from nonlinearities in their performance and noise texture issues [8, 15,16,17].
The latest advancement in the field of CT reconstruction is the focus of this article. Deep learning (DL) approaches also make assumptions about the patient, albeit their assumptions have nothing to do with how or where to apply denoising or edge preservation. DL methods assume the patient is similar in size, attenuation, and frequency content to the data used to train the DL model. If this assumption is valid, then the DL method should produce an image similar to the data used to train the DL model (Table 1).
Issues with Filtered Back-Projection
Filtered back-projection (FBP) makes no assumptions about the imaged object and fails to account for several realities of CT data acquisition [20]. FBP doesn’t account for projection data containing noise, the polychromatic nature of the imaging spectrum, the finite size of the x-ray source, and the size and shape of the detector elements [20,21,22]. A major limiting factor of FBP is that it also fails to account for variable Poisson distributed photon count statistics across an imaging plane, which, in light of these simplifications, means FBP is quite susceptible to noise [22]. Noise increases as the inverse square root of dose or slice thickness with FBP [2, 23]. This fundamental property of CT imaging means large dose increases are needed to lower noise when employing FBP. For example, lowering image noise by a factor of 2 requires 4 times more radiation dose. This explains why dose levels will vary by hundreds of percent over the same body region for the same patient size for different clinical indications. For example, a CT protocol for interpreting the bony detail of the lumbar spine (i.e., an indication that requires relatively low noise) will require several times the dose of a virtual colonoscopy (i.e., an indication that can tolerate a high amount of noise) exam [18]. Clinically speaking, this means that FBP does not allow for potentially meaningful dose reductions unless image noise significantly increases or spatial resolution is degraded [24]. Similarly, photon starvation generated when imaging a morbidly obese patient cannot be overcome without markedly escalating radiation dose [25].
Another undesirable byproduct of FBP is loss of low-contrast lesion detail [26]. Image noise degrades image quality, all of which is accentuated at lower radiation doses [26]. Noise can interfere with the detection of a low-contrast lesion (e.g., hypoenhancing liver metastases) [27, 28]. Unless a certain CT radiation dose threshold is met, low-contrast lesions can be masked by image noise when employing FBP [26].
Issues with Iterative and Model-Based Reconstruction
Iterative (IR) and model-based reconstruction (MBR) algorithms reduce image noise using nonlinear mathematical functions against variable signal intensities within a defined region of interest [19]. The assumptions described in the previous section are performed mathematically using a regularization term. Regularization terms in IR or MBR frameworks are needed to reduce noise and stabilize the solution during iterative noise reduction or image reconstruction. This stabilization essentially limits the space of possible solutions to solutions that match certain assumptions about the object to be reconstructed [29]. As discussed in the introduction, they accomplish noise reduction by assuming that “flat” regions of the patient can be smoothed thereby reducing noise which introduces nonlinearities into the reconstruction process. The degree of “flatness” involves estimating local image value changes (i.e., gradients in CT number) which inherently depend on contrast level and noise magnitude, making IR and MBR method performance depend on contrast level and noise/dose level [7,8,9, 15,16,17]. We can intuitively understand that as dose level decreases noise increases. Increased noise makes it more difficult for the IR and MBR methods to identify uniform versus non-uniform regions; hence, their performance changes for the worse at lower dose levels. Another byproduct of the noise reduction methods employed by IR and MBR methods is that their noise textures tend to peak at lower spatial frequencies (i.e., leftward shift in the noise power spectrum (NPS)), a phenomenon not observed with FBP. The leftward shift in NPS visually translates to an artificially “cartoony” on “plastic” appearing noise texture which is displeasing characteristic for some radiologists as shown in Fig. 1.
The nonlinear behavior of IR and MBR with respect to noise texture is a primary reason why these reconstruction methods exhibit contrast-dependent spatial resolution [26]. Contrast-dependent spatial resolution means that a lesion’s spatial resolution is a function of its contrast with neighboring background tissue [30]. For many low-attenuation diagnostic tasks scanned at clinical doses (e.g., low-attenuation hypovascular metastases), contrast-dependent spatial resolution is not deleterious to a radiologist’s diagnostic accuracy [31]. However, overaggressive dose reductions have shown to be detrimental to the diagnostic accuracy of low-contrast lesion detection tasks [32,33,34]. This effect has been studied in numerous phantom-based and human observer models [32, 33, 35]. Most recent literature shows that IR allows for only modest reductions (e.g., ~ 25%) in radiation dose to preserve low-contrast lesion detection accuracy.
In addition to noise texture changes when IR and MBR methods are applied, the spatial resolution may also change relative to FBP. Several studies have demonstrated the dose/noise and contrast-level dependencies of IR and MBR algorithms. For the majority of IR and MBR methods to date, their performance is better at high-contrast levels and higher doses. This unfortunately is exactly the opposite behavior that is clinically desired. This was demonstrated by Baker et al. who used a liver phantom with lesions decreasing in size and contrast, imaged at decreasing radiation dose, and reconstructed with a variety of IR strengths/techniques [31]. The Baker et al. study showed that at low radiation doses, small low-contrast objects can be invisible regardless of reconstruction technique. Multiple other phantom studies demonstrated similar findings, and these were confirmed in prospective human studies [31, 32, 36, 37]. For example, Pooler et al. showed that very aggressive dose reduction (70% range) led to decreased diagnostic accuracy and confidence in identifying and characterizing metastatic liver lesions regardless of image reconstruction algorithm used [33]. A review of this literature was conducted by Mileto et al. who concluded “Radiologists need to be aware that use of IR can result in a decline of spatial resolution for low-contrast structures and degradation of low-contrast detectability when radiation dose reductions exceed approximately 25%” [35]. We can intuitively understand the degradation of spatial resolution with lower contrast levels as being due to IR and MBR methods being better able to identify higher contrast edges relative to lower contrast edges. Since IR and MBR methods seek to actively preserve edges by not filtering orthogonally to the edge gradients, the higher the edge contrast, the more likely that edge is to receive less noise reduction (i.e., spatial resolution blurring) and therefore a preserved edge detail.
Introduction to Deep Learning CT Image Reconstruction
The known shortcomings of iterative reconstruction discussed above have motivated alternative methods for noise reduction in CT. This section will introduce artificial intelligence (AI)-based methods, built with the goal of preserving the noise reduction features of IR and MBR methods, and mitigating the negative image texture, and nonlinear spatial resolution properties of IR and MBR methods.
While progress was being made in IR for CT, there were parallel efforts which have improved the power AI and its application to an ever-growing set of practical problems. AI most commonly uses neural networks that crudely model the neurons within the brain and the synaptic connections of these neurons [38]. Machine learning (ML) algorithms are a subset of artificial intelligence wherein the algorithm developer must specify a set of features to be included as part of the learning process. Deep learning (DL) offers a framework wherein the algorithm can learn the features throughout the training process. Specifically, one type of deep learning employs convolutional neural networks (CNNs).
Deep learning reconstruction (DLR) has been implemented by multiple CT vendors and third-party software providers [39,40,41]. In each case, the DL neural networks have been trained to reduce noise. In theory, DLR can be used to solve a variety of image reconstruction problems including cone-beam artifacts, motion artifacts, truncation artifacts, and so on. However, the currently available commercial solutions focus on reducing the image noise.
As with any learning process, the network architecture (i.e., the connection of the neurons in the network) is important but even more crucial is the training data used to model the network. Typically, ground truth training data are used to teach the network the properties of a CT image. Then noise is introduced into the data through simulation for instance. In this manner, the network has paired examples of noisy data and clean data and the aim of the network is to learn a method to remove the noise from the data. It has also been shown that denoising can be achieved by training the network with multiple realizations of the same noise pattern in so-called noise2noise training [42]. However, to our knowledge, this method has not yet been implemented clinically.
FBP, IR, and MBIR reconstruction methods require a back-projection operation which maps from the detector space to the image space. The analogous term with DLR is back-propagation. Back-propagation describes the methods used to update the network coefficients during the learning process. The back-propagation step is shown in Fig. 2. Importantly, this step is where the image quality characteristics of the ground truth image are encoded into the network, allowing future sinogram data to pass through the network and inherent the characteristics of the ground truth images used to train the network.

An overview of how a deep neural network is trained to take noisy CT projection data and reconstruct high quality images. In this example, scan data is generated in two pathways, one leading to a “low quality noisy sinogram” and one leading to a “high quality sinogram”. Traditional image reconstruction (i.e., non-DL based) methods are shown here to turn the high quality sinogram data into a ground truth image. This ground truth image is backpropagated through the network to train the network to transform the low quality sinogram data into the high-quality image
In practice, there are choices that can be made for the selection of the “clean” or “target” training data which affect the output of the network. If relatively high-dose FBP images are input to the network, the network output will have noise texture which more closely resembles FBP. On the other hand, if IR is used as the “clean” training data, the noise texture in the images may more closely resemble that of IR [43, 44].
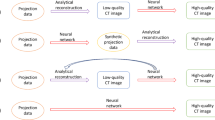
Each CT vendor or third-party denoising vendor performs validation, testing, and quality assurance to ensure their denoising solutions will perform well in practice. After the networks have been tested and ready for clinical implementation, their architecture is saved as a static software instance. Therefore, the networks provide reproducible and stable results when used in the field. Two different workflows for implementation of DLR in the clinic are shown in Fig. 3. The process of using a DL network to reconstruct noisy data is referred to as inference—because we are inferring what the clean data should be from the noisy data. In the future, it may be possible for networks to learn in real time or to make network parameter adjustments tailored to specific patients. But all currently FDA cleared methods use networks with locked weights.

Figure 2 depicts a generalized method for training a DL network to transform noisy projection data into an image. In this figure we depict how one of these networks would be used clinically. In the top row, the network shown in Fig. 2 is used to transform low quality noisy sinogram data into a high-quality image. The bottom row depicts a slightly different network design where the input is a noisy image and the output is higher quality image. The “lock” symbols denote that the networks are fixed, no changes to the weights are performed in the reconstruction process once deployed in the clinical setting
The inferencing step takes advantage of modern graphical processing unit (GPU) hardware solutions which are typically much faster than traditional IR algorithm designs as the inferencing operation does not require any iterations. The major computational hurdle to DLR network design (i.e., defining hyperparameters and network node weights) is cleared during the training stage. This contrasts with computational challenges invoked with MBIR algorithms which are present for every reconstruction. As with IR, DLR typically offers multiple levels of denoising strength to suited to user preferences [39,40,41].
Technical Review of Deep Learning Performance
DLR promises to be fast and produce high-quality images (i.e., lower noise and higher spatial resolution) at lower doses [45]. As with previous generations of nonlinear reconstruction algorithms, the performance of DLR is not adequately quantified using classical image quality metrics such as noise, contrast-to-noise ratio, and signal-to-noise ratio. More advanced metrics such as the noise power spectrum (NPS), the task-based modulation transfer function, and model observer metrics are required [46]. Further, subjective image quality has been essential for characterizing the preferences of radiologists. However, this labor-intensive assessment is now routinely automated with model observer studies and more recently artificial intelligence models have also been proposed toward this goal [47].
The NPSs of DLR images have been shown to be similar to that of FBP [48,49,50,51]. Measuring the mean frequency of DLR images using GE Healthcare’s TrueFidelity (i.e., DLIR reconstruction), a marginal shift was observed across the range of diagnostic dose levels, and only at relatively low-dose levels was a meaningful shift measured for DL relative to FBP [48, 50]. The DLR solution from Canon Medical System, termed Advanced intelligent Clear-IQ Engine (AiCE), showed similar NPS behavior to MBIR [44], but recent changes to the AiCE method have made the texture more FBP like [49]. There is evidence that the strength (or weight) of DLR processing impacts noise texture, with a shift to lower frequencies at high DLR strengths for both on-scanner algorithms currently available [52], albeit that work of Hasegawa et al. that demonstrated this did so at phantom sizes and dose levels not representative of clinical reality. However, there is evidence that this shift is alleviated with newer versions of DLR [46]. In clinical use, DLR images are described as producing a more “natural” image appearance [45, 46, 53]. In summary, DLIR does not suffer from the “plastic” noise texture shown in Fig. 1 given a NPS which does not skew toward low-frequency data.
In the assessment of absolute image noise, DLR achieves the same or higher levels of noise reduction compared to MBIR, with the relative noise increase as dose is lowered muted relative to FBP [48, 49]. Performance evaluation of one commercial product shows DL outperforming all other reconstruction methods at low doses, while it is outperformed only by MBR at higher doses [44, 49]. The noise reduction capabilities of DLIR enables exploring new spatial resolution limits such as deploying detectors with smaller pixels and utilizing shaper kernels with larger image matrices without suffering a noise penalty [44].
DLR similarly exhibits high-contrast spatial resolution that is comparable to MBR methods yielding similar results at the 50% and 10% modulation transfer function (MTF) points [44]. However, as previously reported, spatial resolution can be influenced by both the contrast level of target and the dose levels. More appropriately, a task-based MTF must be considered to fully characterize the performance of a reconstruction algorithm [7]. While there are slight variations in the task-based MTFs across varying levels of tissue contrast with DLR, the variations measured were comparable to measurement-to-measurement variations, and in general, DLR was found to have similar or better MTF values relative to FBP [48]. This is a departure from IR/MBR methods which have been shown across multiple vendor implementations to exhibit lower MTF values relative to FBP, especially for lower contrast tasks [7, 17]. The task-based MTF for DLR was also observed to be robust across a range of doses, with spatial resolution preserved as dose was decreased [48], but with a tendency for a drop off at very low doses and with lower contrast tissues [49, 50]. This behavior is reported to be less of an issue in newer versions of DLR [46]. Vendor neutral, image denoising-based methods have also demonstrated superiority over IR and MBR methods with respect to noise texture performance. Pixelshine from Algomedica has been characterized as providing less central frequency shift in NPS versus IR-based methods from multiple other scanner vendors [51]. In summary, DLR methods characterized to date using phantom data do not appear to suffer from the same MTF degradation at low-contrast levels as do IR and MBR methods.
Going a step further to the task-based detectability index, the performance of all algorithms is related to both tissue contrast and dose level as is expected, with MBR and DLR algorithms significantly outperforming FBP at all dose levels, and with DLR and MBR performance changing relative to each other and to FBP at very low doses [49, 50]. However, the relative differences in performance between DL and MBR as a function of dose and diagnostic task should be considered in context of vendor-specific implementations, and not as indication of the inherent performance of DLR vs. MBR.
CT number accuracy is well preserved with DLR as a function of contrast and dose levels. At routine dose levels, CT numbers of phantom inserts at 340 HU, 120 HU, and -35 HU are within 4 HU of the CT numbers measured at FBP at the same dose level. Even at 25% of the routine dose level, measured CT numbers on DLR images are still within 4 HU of those measured at FBP at routine dose levels [44]. These results are consistent with another study [48] that also evaluated CT number accuracy and found no statistical difference between reconstruction algorithms or reconstructed slice thickness. Additionally, multiple papers looking at nonphantom, (i.e., in vivo) CT number measurements have demonstrated no clinically significant change in CT number with DLR versus FBP and IR/MBR methods [54, 55,56, 57, 58, 59, 60•, 61, 62, 63].
Clinical Review of Deep Learning Performance
Figures 4, 5, and 6 depict clinical DLR cases using three different DLR commercial solutions.

From top left clockwise, ASiR-V 20%, DLIR-low, DLIR-medium, DLIR-High 1.25 mm axial slices (displayed at window width = 380 HU level = 40 HU) reconstructed with a standard kernel. 70-year-old patient with history of cirrhosis presenting with abdominal pain. Contrast enhanced CT of the abdomen and pelvis shows marked cecal wall thickening, new compared to prior exam. Finding was attributed to hepatic congestive colopathy, but a differential for colitis was provided. Image noise standard deviation for these cases (measured in a relatively uniform region of the bowel) was 19, 14, 12, and 8 HU for the ASiR-V 20%, DLIR-low, DLIR-medium, and DLIR-High images respectively

From top left clockwise, FBP (i.e., ASiR-V 0%), PixelShine “S” applied to a FBP (ASiR-V 0%) image, DLIR-low, PixelShine “S” applied to a DLIR-low image. All images are 1.25 mm axial slices (displayed at window width = 355 HU level = 50 HU) reconstructed with a standard kernel. Image noise standard deviation for these cases (measured in a relatively uniform region of the stomach) was 24, 18, 16, and 12 HU for the clockwise from the top left respectively. Note how the noise magnitude is reduced for all images relative to the FBP image, and how the texture is not degraded from a “FBP like” texture of any of the DLR based reconstructions

Images of similar anatomical location reconstructed using FBP (FC 18 kernel), AIDR3D (FC18 kernel, AIDRe Standard) and AiCE (AiCE body sharp standard) from left to right respectively (zoomed in images shown along the bottom row). Notice that the noise texture of the AiCE is not plastic in appearance, while the noise magnitude is markedly reduced compared to the FBP reconstruction. The AIDR3D image does have a lower noise magnitude relative to FBP, but a slightly “patchy” noise texture is apparent. All images at 0.5 mm slice thickness at window width = 380 HU, window level = 340 HU. Images courtesy of Canon Medical Systems USA
Improvements in contrast-to-noise, noise texture, and spatial resolution often correlate with improved subjectively rated radiologist image quality [26]. This is a tried-and-true pattern that typically follows the release of most image reconstruction algorithm launches. However, DL may provide unique opportunities as compared to the generation of IR and MBR given that some phantom studies suggest DLR circumnavigates the limitations of contrast-dependent spatial resolution and overly smoothened noise texture profiles associated with IR and MBR algorithms [48,49,50,51, 54, 55]. Still, it is imperative to show that figure-of-merit improvements augment clinical decision-making and diagnosis. Such findings could further reductions in benchmark CT radiation doses, either by improving or by maintaining diagnostic accuracy.
The majority of published clinical studies assess DLR algorithm performance with subjective image quality scores (IQ) typically assigned by radiologists and contrast-to-noise measurements [54,55,56,57]. For instance, Bernard et al. assessed the performance of AiCE against IR (AIDR 3D) in a CT angiography acute stroke imaging protocol [55]. They concluded that a 40% reduced radiation dose resulted in a 50% increase in IQ scores. Although timely IQ study results are encouraging, their generalizability to diagnostic accuracy is limited. A CT imaging practice should be cautious in reducing exam doses when employing DRL solely based on IQ superiority alone.
Introducing a diagnostic task into the experimental design increases external validity of using DLR in lieu of currently accepted IR methods. For example, Jensen and colleagues compared portal venous phase images reconstructed with IR (ASiR-V 30%) compared to DL (TrueFidelity at low, medium, and high weight) of patients undergoing routine oncologic staging exam of the abdomen [54]. A total of 193 lesions were identified in these patients. Reader assigned lesion diagnostic confidence, conspicuity, and artifact scores all were significantly improved with all DLR weights as compared to IR. Again, such results are encouraging. Another interesting example is a study performed by Benz et al. in which coronary luminal narrowing was evaluated on coronary CT angiography [58]. Images were reconstructed with DLIR (TrueFidelity medium and high strength) and IR (ASiR-V 70%) using standard and high-definition (HD) kernels. They concluded no differences in sensitivity, specificity, or diagnostic accuracy between ASiR-V HD and TrueFidelity high weighting. It should be noted that coronary luminal narrowing is considered a high-contrast task—in which the reader measures the diameter of a contrast-filled coronary artery. However, neither of these examples tests diagnostic confidence at reduced radiation doses.
A more intricate approach to DLR algorithm testing requires a specially tailored experimental design in which a reduced dose CT exam is performed in tandem to a routine clinical dose exam. The reduced dose exam can be reconstructed with various DLR weights and then compared to full-dose images reconstructed with FBP and routine IR strengths. Instead of having radiologist observers only grade image quality, the study design should introduce some predefined diagnostic task such that accuracy can be properly measured. An example task is low-contrast lesion detection.
Assessment of low-contrast metastases is a challenging clinical task and becomes more difficult in the setting of reduced radiation doses. A recent study by Jensen and colleagues prospectively analyzed colorectal low-contrast liver metastases detection, comparing benchmark radiation dose to 65% dose reduction images reconstructed with FBP, IR (ASiR-V 60%), and TrueFidelity medium strength [60•]. They demonstrated that TrueFidelity improved subjective reader image quality and preserved liver metastases detection measuring > 0.5 cm compared to benchmark exposures (lesion accuracy 67.1% versus 80.1% for TrueFidelity and FBP, respectively). All radiologist readers subjectively rated reduced dose DLR images superior to standard-dose FBP images (odds ratio, 1.6; P = 0.02). In a similarly designed study, Singh et al. demonstrated equivalent liver lesion and pulmonary nodule detection using low-dose (83% reduced) AiCE when compared to standard-dose IR (AIDR 3D) and superior detection compared to low-dose FBP and IR (AIDR 3D and FIRST) [62]. The study’s low-dose protocol had a mean volume CT dose index of 2.1 ± 0.8 mGy as compared to 13 ± 4.4 mGy in the standard protocol. This translates to an 83% dose index reduction.
In conclusion, these studies suggest 65–83% dose reductions for low-contrast liver lesion detection; however, only Jensen et al.’s study [60•] specifically evaluates low-contrast liver metastases. More clinical work regarding diagnostic accuracy is needed before radiologists start lowering doses of routine exams.
Conclusion
In summary, the space of CT image reconstruction using deep learning is an active area of research and productization. This chapter outlined the predecessors to DLR (i.e., FBP, IR, and MBR) and reviewed some of the currently available DLR commercial solutions. We expect more solutions to follow. At the time of this writing, Philips has a press release that states they now have AI-enabled image reconstruction on their Incisive platform. Siemens has a product released for MR called “deep resolve,” but nothing at the time of this writing for CT. Other facets of image quality like artifact mitigation and spatial resolution enhancement were not discussed in this chapter (Table 2). They are being developed, however, as shown in Figs. 7 and 8. The future of CT image reconstruction seems bright considering the positive comparisons of DLR to FBP, IR, and MBR made in this chapter. The first photon counting CT scanner release in 2021 [64] will likely also open new avenues for DLR and remains an exciting future prospect for DLR.

Example of deep learning being used for extended field of view reconstruction. In this example, the top row depicts external patient contours, the bottom row axial CT slices. Images are reconstructed out to 50 cm on the left, and 80 cm on the right. The right column was reconstructed using a deep learning-based method from GE Healthcare called “MaxFOV 2”. Note the mitigation of truncation artifacts (i.e., the bright edges) and the accurate patient representation outside of the 50 cm field of view of the deep learning method. Images provided courtesy GE Healthcare

Example of deep learning enabled super spatial resolution [65]. In this clinical example, “normal resolution” data acquired at a spatial resolution of 0.5 mm is fed into a neural network that was trained to transform “normal resolution” data into “super high resolution” 0.25 mm data. Images courtesy Dr. Marcus Chen, NHLBI, National Institutes of Health, USA
References
Recently published papers of particular interest have been highlighted as: • Of importance
Hounsfield GN. Computerized transverse axial scanning (tomography): Part 1. Description of system. Br J Radiol. 1973;46(552):1016–22.
Kak AC, Slaney M. Principles of computerized tomographic imaging. Society for Industrial and Applied Mathematics. 2001.
Brenner DJ, Hall EJ. Computed tomography—an increasing source of radiation exposure. N Engl J Med. 2007;357(22):2277–84.
Siegel JA, Pennington CW, Sacks B. Subjecting radiologic imaging to the linear no-threshold hypothesis: a non sequitur of non-trivial proportion. J Nucl Med. 2017;58(1):1–6.
Wintermark M, Lev MH. FDA investigates the safety of brain perfusion CT. Am J Neuroradiol. 2010;31(1):2.
Lee CS, Lewin JS, Nagy P. Events that have shaped the quality movement in radiology. J Am Coll Radiol. 2012;9(6):437–9.
Richard S, Husarik DB, Yadava G, Murphy SN, Samei E. Towards task-based assessment of CT performance: system and object MTF across different reconstruction algorithms. Med Phys. 2012;39(7Part1):4115–22.
Solomon J, Mileto A, Ramirez-Giraldo JC, Samei E. Diagnostic performance of an advanced modeled iterative reconstruction algorithm for low-contrast detectability with a third-generation dual-source multidetector CT scanner: potential for radiation dose reduction in a multireader study. Radiology. 2015;275(3):735–45.
Solomon J, Samei E. Are uniform phantoms sufficient to characterize the performance of iterative reconstruction in CT?. In: Medical Imaging 2013: Physics of Medical Imaging, vol. 8668. International Society for Optics and Photonics; 2013. p. 86684M
Singh S, Kalra MK, Hsieh J, et al. Abdominal CT: comparison of adaptive statistical iterative and filtered back projection reconstruction techniques. Radiology. 2010;257:373–83.
Hardie AD, Nelson RM, Egbert R, et al. What is the preferred strength setting of the sinogram-affirmed iterative reconstruction algorithm in abdominal CT imaging? Radiol Phys Technol. 2015;8:60–3.
Xu J, Mahesh M, Tsui BM. Is iterative reconstruction ready for MDCT? J Am Coll Radiol. 2009;6:274–6.
Fleischmann D, Boas FE. Computed tomography—old ideas and new technology. Eur Radiol. 2011;21:510–7.
Morsbach F, Desbiolles L, Raupach R, Leschka S, Schmidt B, Alkadhi H. Noise texture deviation: a measure for quantifying artifacts in computed tomography images with iterative reconstructions. Invest Radiol. 2017;52(2):87–94.
Greffier J, Larbi A, Frandon J, Moliner G, Beregi JP, Pereira F. Comparison of noise-magnitude and noise-texture across two generations of iterative reconstruction algorithms from three manufacturers. Diagn Interv Imaging. 2019;100(7–8):401–10.
Li K, Tang J, Chen GH. Statistical model based iterative reconstruction (MBIR) in clinical CT systems: experimental assessment of noise performance. Med Phys. 2014;41(4):041906.
Li K, Garrett J, Ge Y, Chen GH. Statistical model based iterative reconstruction (MBIR) in clinical CT systems. Part II. Experimental assessment of spatial resolution performance. Med Phys. 2014;41(7):071911.
Szczykutowicz TP, The CT. Handbook: optimizing protocols for today’s feature-rich scanners. Madison: Medical Physics Publishing; 2020.
Thibault JB, Sauer KD, Bouman CA, Hsieh J. A three-dimensional statistical approach to improved image quality for multislice helical CT. Med Phys. 2007;34(11):4526–44.
Stiller W. Basics of iterative reconstruction methods in computed tomography: a vendor-independent review. Eur J Radiol. 2018;109:147–54.
Willemink MJ, de John PA, et al. Iterative reconstruction techniques for computed tomography Part 1: Technical principles. Eur J Radiol. 2013;23:1623–31.
Geyer LL, Schoepf J, et al. State of the art: iterative CT reconstruction techniques. Radiology. 2015;276(2):339–57.
Patino M, Fuentes JM, et al. A quantitative comparison of noise reduction across five commercial (hybrid and model-based) iterative reconstruction techniques: an anthropomorphic phantom study. AJR. 2015;204:W176–83.
Ehman EC, Yu L. Methods for clinical evaluation of noise reduction techniques in abdominopelvic CT. Radiographics. 2014;34:849–62.
Qurashi AA, Rainford LA, Alhazmi FH, Alshamrani KM, Sulieman A, Alsharif WM, Foley SJ. Low radiation dose implications in obese abdominal computed tomography imaging. Appl Sci. 2021;11(6):2456.
Mileto A, Guimaraes LS, et al. State of the art in abdominal CT: the limits of iterative reconstruction algorithms. Radiology. 2019;293:491–503.
Goenka A, Herts MR, et al. Image noise, CNR, and detectability of low-contrast, low-attenuation liver lesions in a phantom: effects of radiation exposure, phantom size, integrated circuit detector, and iterative reconstruction. Radiology. 2016;280:475–82.
Fletcher JG, Fidler JL, et al. Observer performance with varying radiation dose and reconstruction methods for detection of hepatic metastases. Radiology. 2018;289(2):455–64.
Fessler JA, Sonka M, Fitzpatrick JM. Statistical image reconstruction methods for transmission tomography. Handb Med Imaging. 2000;2:1–70.
Yu L, Vrieze TJ, Leng S, et al. Technical Note: measuring contrast- and noise-dependent spatial resolution of an iterative reconstruction method in CT using ensemble averaging. Med Phys. 2015;42(5):2261–7.
Baker ME, Dong F, Primak A, et al. Contrast-to-noise ratio and low-contrast object resolution on full- and low-dose MDCT: SAFIRE versus filtered back projection in a low-contrast object phantom and in the liver. AJR. 2012;199(1):8–18.
Fletcher JG, Yu L, Li Z, et al. Observer performance in the detection and classification of malignant hepatic nodules and masses with CT image-space denoising and iterative reconstruction. Radiology. 2015;276(2):465–78.
Pooler BD, Lubner MG, Kim DH, et al. Prospective evaluation of reduced dose computed tomography for the detection of low-contrast liver lesions: direct comparison with concurrent standard dose imaging. Eur Radiol. 2017;27(5):2055–66.
Solomon J, Marin D, et al. Effect of radiation dose reduction and reconstruction algorithm on image noise, contrast, resolution, and detectability of subtle hypoattenuating liver lesions at multidetector CT: filtered back projection versus a commercial model-based iterative reconstruction algorithm. Radiology. 2017;284(3):777–87.
Mileto A, Zamora DA, et al. CT detectability of small low-contrast hypoattenuating focal lesions: iterative reconstructions versus filtered back projection. Radiology. 2018;289(2):443–54.
Dobeli KL, Lewis SJ, Meikle SR, Thiele DL, Brennan PC. Noise-reducing algorithms do not necessarily provide superior dose optimisation for hepatic lesion detection with multidetector CT. Br J Radiol. 2013;86:20120500.
Schindera ST, Odedra D, Raza SA, et al. Iterative reconstruction algorithm for CT: can radiation dose be decreased while low-contrast detectability is preserved? Radiology. 2013;269:511–8.
Topol EJ. High-performance medicine: the convergence of human and artificial intelligence. Nat Med. 2019;25(1):44–56.
Hsieh J, Liu E, Nett B, Tang J, Thibault JB, Sahney S. A new era of image reconstruction: TrueFidelity™. White Paper (JB68676XX), GE Healthcare; 2019.
Boedeker K. AiCE deep learning reconstruction: bringing the power of ultra-high resolution CT to routine imaging. Canon Medical Systems USA. https://global.medical.canon/publication/ct/2019WP_AiCE_Deep_Learning. Accessed 28 Feb 2022.
What’s that noise? How deep learning can elevate CT image quality, reduce dose exposure, and extend the life of older scanners. AlgoMedica https://cdn.b12.io/client_media/MylCrHXR/cd6b3270-78bd-11ec-aeee-0242ac110003-PixelShine_White_Paper_final_1.18.2021.pdf. Accessed 28 Feb 2022.
Wu D, Ren H, Li Q. Self-supervised dynamic CT perfusion image denoising with deep neural networks. IEEE Trans Radiat Plasma Med Sci. 2020;5(3):350–61.
Brady S, et al. Comparison of a deep learning-based CT Reconstruction Algorithm (AiCE) to other reconstruction techniques in a pediatric population. AAPM Virtual Meeting. Brady S. 07/12/20; 301560; BReP-SNAP-I-11 Topic: Multi-detector CT.
Shirasaka T, et al. Image quality improvement with deep learning-based reconstruction on abdominal ultrahigh-resolution CT: a phantom study. J Appl Clin Med Phys. 2021;22(7):286–96. https://doi.org/10.1002/acm2.13318.
McLeavy CM, et al. The future of CT: deep learning reconstruction. Clin Radiol. 2021;76(6):407–15. https://doi.org/10.1016/j.crad.2021.01.010.
Greffier J, et al. Comparison of two versions of a deep learning image reconstruction algorithm on CT image quality and dose reduction: a phantom study. Med Phys. 2021;48(10):5743–55. https://doi.org/10.1002/mp.15180.
Doi Y, et al. Estimating subjective evaluation of low-contrast resolution using convolutional neural networks. Phys Eng Sci Med. 2021;44(4):1285–96. https://doi.org/10.1007/s13246-021-01062-7.
Szczykutowicz TP, et al. Protocol optimization considerations for implementing deep learning CT reconstruction. Am J Roentgenol. 2021;216(6):1668–77. https://doi.org/10.2214/AJR.20.23397.
Higaki T, et al. Deep Learning Reconstruction at CT: Phantom Study of the Image Characteristics. Acad Radiol. 2020;27(1):82–7. https://doi.org/10.1016/j.acra.2019.09.008.
Solomon J, Lyu P, Marin D, Samei E. Noise and spatial resolution properties of a commercially available deep learning-based CT reconstruction algorithm. Med Phys. 2020;47(9):3961–71.
Pan T, Hasegawa A, Luo D, Wu CC, Vikram R. impact on central frequency and noise magnitude ratios by advanced CT image reconstruction techniques. Med Phys. 2020;47(2):480–7.
Hasegawa A, et al. Noise reduction profile: a new method for evaluation of noise reduction techniques in CT. Med Phys. 2021. https://doi.org/10.1002/mp.15382.
Arndt C, et al. Deep learning CT image reconstruction in clinical practice. RöFo - Fortschritte auf dem Gebiet der Röntgenstrahlen und der bildgebenden Verfahren. 2021;193(03):252–61. https://doi.org/10.1055/a-1248-2556.
Jensen CT, Liu X, Tamm EP, et al. Image quality assessment of abdominal CT by use of new deep learning image reconstruction: initial experience. AJR Am J Roentgenol. 2020;215:50–7.
Bernard A, Comby PO, Lemogne B, et al. Deep learning reconstruction versus iterative reconstruction for cardiac CT angiography in a stroke imaging protocol: reduced radiation dose and improved image quality. Quant Imaging Med Surg. 2021;11(1):392–401.
Ichikawa Y, Kanii Y, Yamazaki A, et al. Deep learning image reconstruction for improvement of image quality of abdominal computed tomography: comparison with hybrid iterative reconstruction. Jpn J Radiol. 2021;39(6):598–604.
Kaga T, Noda Y, Fujimoto K, et al. Deep-learning-based image reconstruction in dynamic contrast-enhanced abdominal CT: image quality and lesion detection among reconstruction strength levels. Clin Radiol. 2021. https://doi.org/10.1016/j.crad.2021.03.010.
Benz DC, Benetos G, Rampidis G, et al. Validation of deep-learning image reconstruction for coronary computed tomography angiography: impact on noise, image quality and diagnostic accuracy. J Cardiovasc Comput Tomogr. 2020;14(5):444–51.
Kim JH, Yoon HJ, Lee E, Kim I, Cha YK, Bak SH. Validation of deep-learning image reconstruction for low-dose chest computed tomography scan: emphasis on image quality and noise. Korean J Radiol. 2021;22:131–8.
• Jensen C, Gupta S, Saleh MM, et al. Reduced-dose deep learning reconstruction for abdominal CT of liver metastases. Radiology. 2022;000:1–8. Study on 58 human subject with a direct comparison to the previous state-of-the-art iterative reconstruction methods. It demonstrates the noise reduction and CNR gains in human subjects that other papers previously demonstrated only in phantom models. Important "Effect of a new deep learning image reconstruction algorithm for abdominal computed tomogrpahy imaging on image quality and dose reduction compared with two iterative reconstruction algorithms: a phantom study" Phantom results presented on an FDA cleared and CE marked algorithm demonstrating superiority in noise performance and detectability index over iterative methods.
Li LL, Wang H, Song J, Shang J, Zhao XY, Liu B. A feasibility study of realizing low-dose abdominal CT using deep learning image reconstruction algorithm. J Xray Sci Technol. 2021;29:361–72.
Noda Y, Iritani Y, Kawai N, et al. Deep learning image reconstruction for pancreatic lowdose computed tomography: comparison with hybrid iterative reconstruction. Abdom Radiol. 2021. https://doi.org/10.1007/s00261-021-03111-x.
Singh R, Digumarthy SR, Muse VV, et al. Image quality and lesion detection on deep learning reconstruction and iterative reconstruction of submillisievert chest and abdominal CT. AJR. 2020;214(3):566–73.
Rajendran K, Petersilka M, Henning A, Shanblatt ER, Schmidt B, Flohr TG, McCollough CH. First clinical photon-counting detector CT system: technical evaluation. Radiology. 2021;212579.
Boedeker K. Precision-trained deep learning: redefining cardiac imaging. Canon Medical Systems Corporation 2021. Whitepaper.
Rodrigues MA, Williams MC, Fitzgerald T, et al. Iterative reconstruction can permit the use of lower x-ray tube current in CT coronary artery calcium scoring. Br J Radiol. 2016;89(1064):20150780.
Schindera ST, Odedra D, Mercer D, et al. Hybrid iterative reconstruction technique for abdominal CT protocols in obese patients: assessment of image quality, radiation dose, and low-contrast detectability in a phantom. AJR. 2014;202(2):W14–152.
Juri H, Tsuboyama T, Kumano S, Inada Y, et al. Detection of bladder cancer: comparison of low-dose scans with AIDR 3D and routine-dose scans with FBP on excretory phase in CT urography. Br J Radiol. 2016;89(1058):20150495.
Maamoun I, Khalil MM. Assessment of iterative image reconstruction on kidney and liver donors: potential role of adaptive iterative dose reduction 3D (AIDR 3D) technology. Eur J Radiol. 2018;109:124–9.
Greffier J, Dabli D, Hamard A, et al. Effect of a new deep learning image reconstruction algorithm for abdominal computed tomogrpahy imaging on image quality and dose reduction compared with two iterative reconstruction algorithms: a phantom study. Quant Imaging Med Surg. 2022;12(1):229–43.
Morita S, Ogawa Y, Yamamoto T, et al. Image Quality of early postoperative CT angiography with reduced contrast material and radiation dose using model-based iterative reconstruction for screening of renal pseudoaneurysms after partial nephrectomy. Eur J Radiol. 2020;124:108853.
Tanabe N, Sakamoto R, Kozawa S, et al. Deep learning-based reconstruction of chest ultra-high-resolution computed tomography and quantitative evaluations of smaller airways. Respir Investig. 2022;60(1):167–70.
Pickhardt PJ, Lubner MG, Kim DH, et al. Abdominal CT with model based iterative reconstruction (MBIR): initial results of a prospective trial comparing ultralow-dose with standard-dose imaging. AJR. 2012;199(6):1266–74.
McCollough CH, Yu L, Kofler JM, et al. Degradation of CT low-contrast spatial resolution due to the use of iterative reconstruction and reduced dose levels. Radiology. 2015;276(2):499–506.
Saiprasad G, Filliben J, Peskin A, et al. Evaluation of low-contrast detectability of iterative reconstruction across multiple institutions, CT scanner manufacturers, and radiation exposure levels. Radiology. 2015;277(1):124–33.
Mileto A, Zamora DA, Alessio AM, et al. CT Detectability of small low-contrast hypoattenuating focal lesions: iterative reconstructions versus filtered back projection. Radiology. 2018;289(2):443–54.
Jensen CT, Wagner-Bartak NA, Vu LN, et al. Detection of Colorectal Hepatic Metastasis is superior at standard radiation Dose CT versus Reduced Dose CT. Radiology. 2019;290(2):400–9.
Braenne KR, Flinder LI, Martiniussen MA, et al. A liver phantom study: ct radiation dose reduction and different image reconstruction algorithms affect diagnostic quality. JCAT. 2016;40(5):735–9.
Jensen K, Anderson HK, Tingberg A, et al. Improved Liver Lesion Conspicuity with iterative reconstruction in computed tomography imaging. Curr Probl Diagn Radiol. 2016;45(5):291–6.
Kim JH, Yoon HJ, Lee E, et al. Validation of deep-learning image reconstruction for low-dose chest computed tomography scan: emphasis on image quality and noise. Korean J Radiol. 2021;22(1):131–8.
Park C, Choo KS, Jung Y, et al. CT iterative vs deep learning reconstruction: comparison of noise and sharpness. Eur Radiol. 2021;31(5):3156–64.
Franck C, Zhang G, Deak P, Zanca F. Preserving image texture while reducing radiation dose with a deep learning image reconstruction algorithm in chest CT: a phantom study. Phys Med. 2021;81:86–93.
Khawaja RD, Singh S, Gilman M, et al. Computed Tomography of the chest at less than 1 mSv: an ongoing prospective clinical trial of chest CT at submillisievert radiation doses with iterative reconstruction and iDose4 technique. J Comput Assist Tomogr. 2014;38(4):613–9.
Park CJ, Kim KW, Lee H, et al. Contrast-enhanced CT with knowledge-based iterative model reconstruction for the evaluation of parotid gland tumors: a feasibility study. Korean J Radiol. 2018;19(5):957–64.
Pan Y, Sun M, Wang J, et al. Effect of different reconstruction algorithms on coronary artery calcium scores usin reduced radiation dose protocol: a clinical and phantom study. Quant Imaging Med Surg. 2021;11(4):1504–17.
Bittencourt MS, Schmidt B, Seltmann M, et al. Iterative reconstruction in image space (IRIS) in cardiac computed tomography: initial experience. Int J Cardiovasc Imaging. 2011;27(7):1081–7.
Agostini A, Borgheresi A, Carotti M, et al. Third-generation iterative reconstruction on a dual-source, high-pitch, low-dose chest CT protocol with tin filter for spectral shaping at 100 kV: a study on a small series of COVID-19 patients. Radiol Med. 2021;126(3):388–98.
Fletcher JG, Yu L, Fidler JL, et al. Estimation of observer performance for reduced radiation dose levels in CT: eliminating reduced dose levels that are too low is the first step. Acad Radiol. 2017;24(7):876–90.
Fletcher JG, Fidler JL, Venkatesh SK, et al. Observer performance with varying radiation dose and reconstruction methods for detection of hepatic metastases. Radiology. 2018;289(2):455–64.
Baker ME, Dong F, Primak A, et al. Contrast-to-noise ratio and low-contrast object resolution on full-and low-dose MDCT: SAFIRE versus filtered back projection in a low-contrast object phantom and in the liver. AJR. 2012;199(1):8–18.
Goenka AH, Hert BR, Obuchowski NA, et al. Effect of reduced radiation exposure and iterative reconstruction on detection of low-contrast low-attenuation lesions in an anthropomorphic liver phantom: an 18-reader study. Radiology. 2014;272(1):8–18.
Goenka A, Herts MR, Dong F, Obuchowski NA, Primak AN, Karim W, Maker ME. Image noise, CNR, and detectability of low-contrast, low-attenuation liver lesions in a phantom: effects of radiation exposure, phantom size, integrated circuit detector, and iterative reconstruction. Radiology. 2016;280:475–82.
Solomon J, Marin D, Roy Choudhury K, Patel B, Samei E. Effect of Radiation Dose Reduction and Reconstruction algorithm on image noise, contrast, resolution, and detectability of subtle hypoattenuating liver lesions at multiobserver CT: filtered back projection versus a commercial model-based iterative reconstruction algorithm. Radiology. 2017;284(3):777–87.
Nam JG, Ahn C, Choi H, et al. Image quality of ultralow-dose chest CT using deep learning techniques: potential superiority of vendor-agnostic post-processing over vendor-specific techniques. Eur Radiol. 2021;31:5139–47.
Yeoh H, Hong SH, Ahn C, et al. Deep learning algorithm for simultaneous noise reduction and edge sharpening in low-dose CT images: a pilot study using lumbar spine ct. Korean J Radiol. 2021;22(11):1850–7.
Hong JH, Park EA, Lee W, Ahn C, Kim JH. Incremental Image Noise reduction in coronary CT angiography using a deep-learning-based technique with iterative reconstruction. Korean J Radiol. 2020;21(10):1165–77.
Tian S, Liu A, Liu J, Liu Yi, Pan J. Potential value of the PixelShine deep learning algorithm for increasing quality of 70 kVp+ASiR-V reconstruction pelvic arterial phase CT images. Jpn J Radiol. 2019;37(2):186–90.
Hata A, Yanagawa M, Yoshida Y, Miyata T, Tsbamoto M, et al. Combination of deep learning-based denoising and iterative reconstruction for ultra-low-Dise CT of the chest: image quality and lung-RADS evaluation. Am J Roentgenol. 2020;215:132–1328.
Wisselink HJ, Pelgrim GJ, Rook M, van den Berge M, Slump K, Nagaraj Y, et al. Potential for dose reduction in CT emphysema densitometry with post-scan noise reduction: a phantom study. Br J Radiol. 2020;93:20181019.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
TPS receives research support and is on an advisory board with GE Healthcare. TPS recieves research support from Canon Medical Systems USA. TPS is a consultant to ALARA Imaging, AstoCT LLC, FlowHow.io LLC, AiDoc, and on the advisory board of Imalogix LLC. GVT is a consultant for GE Healthcare.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the Topical collection on Computed Tomography.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Szczykutowicz, T.P., Toia, G.V., Dhanantwari, A. et al. A Review of Deep Learning CT Reconstruction: Concepts, Limitations, and Promise in Clinical Practice. Curr Radiol Rep 10, 101–115 (2022). https://doi.org/10.1007/s40134-022-00399-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40134-022-00399-5