
Abstract
In this paper, a new bivariate discrete distribution is defined and studied in-detail, in the so-called the bivariate exponentiated discrete Weibull distribution. Several of its statistical properties including the joint cumulative distribution function, joint probability mass function, joint hazard rate function, joint moment generating function, mathematical expectation and reliability function for stress–strength model are derived. Its marginals are exponentiated discrete Weibull distributions. Hence, these marginals can be used to analyze the hazard rates in the discrete cases. The model parameters are estimated using the maximum likelihood method. Simulation study is performed to discuss the bias and mean square error of the estimators. Finally, two real data sets are analyzed to illustrate the flexibility of the proposed model.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Weibull (W) distribution is one of the most important and well-recognized continuous probability models in research and also in teaching. It has become important because if you have right-skewed, left-skewed or symmetric data, you can use this distribution to model it. Moreover, the hazard rate of its can be constant, increasing or decreasing. That flexibility of W distribution and its generalizations has made many researchers using it into their data analysis in different fields such as medicine, pharmacy, engineering, reliability, industry, social sciences, economics and environmental. See for example, Mudholkar and Srivastara [41], Bebbington et al. [4], Sarhan and Apaloo [49], El-Gohary et al. [12, 13], El-Bassiouny et al. [9,10,11], El-Morshedy et al. [23, 30], Eliwa et al. [19, 21, 2], El-Morshedy and Eliwa [22], among others.
Sometimes, it is very difficult to measure the life length of a machine on a continuous scale, for example, on-off switching machines, bulb of photocopier device, etc. Thus, several discrete distributions have been derived by discretizing a known continuous distribution. See for example, Nakagawa and Osaki [42], Stein and Dattero [51], Roy [47, 48], Johnson et al. [31], Krishna and Pundir [35], Gomez-Deniz and Calderin-Ojeda [27], Farbod and Gasparian [26], Nekoukhou et al. [43], EL-Bassiouny and El-Morshedy [8, 1], El-Morshedy et al. [24], Eliwa and El-Morshedy [16], Emrah [25], among others.
Unfortunately, we cannot use the previous univariate models for modeling the bivariate data, and therefore, several authors aimed to propose bivariate models to discuss various phenomena in many fields. For bivariate continuous model, see Jose et al. [32], Kundu and Gupta [37], Sarhan et al. [50], Wagner and Artur [52], El- Bassiouny et al. [6], Rasool and Akbar [46], El-Gohary et al. [14], Mohamed et al. [40], Eliwa and El-Morshedy [17, 18], Eliwa et al. [20], among others. Whereas for bivariate discrete models, see Kocherlakota and Kocherlakota [34], Basu and Dhar [3], Kumar [36], Kemp [33], Lee and Cha [39], Nekoukhou and Kundu [44], Kundu and Nekoukhou [38], Eliwa and El-Morshedy [15], El-Bassiouny, et al. [7] among others. Although there are a large number of bivariate discrete models in studies, there still a needing to propose flexible models to analyze different types of data. In this paper, we propose a flexible model, in the so-called the bivariate exponentiated discrete Weibull (BEDsW) distribution. The proposed discrete model can be obtained from three independent exponentiated discrete Weibull (EDsW) distributions by using the maximization method as suggested by Lee and Cha [39].
The BEDsW distribution
Recently, Nekoukhou and Bidram [45] proposed a new three parameters distribution called the exponentiated discrete Weibull (EDsW) distribution. The CDF of the EDsW distribution is given by
where \(\alpha ,\beta >0\), \(0<p<1\) and \( {\mathbb {N}} _{\circ }=\{0,1,2,\ldots \}\). The corresponding PMF of Equation (1) can be written as
For integer values of \(\beta \), Eq. (2) can be represented as
Table 1 presents some discrete distributions which can be obtained as special cases from the EDsW distribution.
Suppose that \(V_{i};\)\(i=1,2,3\) are three independently distributed random variables which \(V_{i}\sim EDsW(\alpha ,p,\beta _{i})\). If \(X_{1}=\max \{V_{1},V_{3}\}\) and \(X_{2}=\max \{V_{2},V_{3}\}\), then the bivariate vector \({\mathbf {X}}=(X_{1},X_{2})\) has the BEDsW distribution with parameter vector \({\boldsymbol{\Omega }}=(\alpha ,p,\beta _{1},\beta _{2},\beta _{3})\). The joint CDF of \({\mathbf {X}}\) is given by
where
and
and \(z=\min \{x_{1},x_{2}\}.\) The marginal CDF of \(X_{i}\), \((i=1,2)\) can be written as
The corresponding marginal probability mass function (PMF) to Equation (5) can be proposed as
The joint PMF of the bivariate vector \({\mathbf {X}}\) can be easily obtained by using the following relation
Thus, the corresponding joint PMF to Eq. (4) can be written as
where
and
with \(p_{1}=[1-p^{(x+1)^{\alpha }}]^{\beta _{1}}\) and \(p_{2}=[1-p^{x^{\alpha } }]^{\beta _{1}+\beta _{3}}\). Figure 1 shows the scatter plot of the joint PMF of the BEDsW distribution for various values of the parameters.

The joint PMF of the BEDsW distribution for different values of \({\boldsymbol{\Omega }}\): a\({\boldsymbol{\Omega }}=(0.9,0.9,0.3,3.3,2)\), b \({\boldsymbol{\Omega }}=(0.5,0.9,0.3,3.3,2)\) and c\({\boldsymbol{\Omega }}=(0.5,0.6,0.3,3.3,2)\)
As expected, the joint PMF of the BEDsW distribution can take various shapes depending on the values of its parameter vector \({\boldsymbol{\Omega }}.\) Suppose \((X_{j1},X_{j2})\)\(\sim \ \)BEDsW\((\alpha ,p,\beta _{j1},\beta _{j2} ,\beta _{j3})\) for \(j=1,\ldots ,n\), and they are independently distributed. If \(Z_{1}=\max \{x_{11},\ldots ,x_{n1}\}\) and \(Z_{2}=\max \{x_{12},\ldots ,x_{n2}\}\), then
The joint survival function (SF) of the random vector \({\mathbf {X}}\) can be defined as
Thus, the joint SF of the BEDsW distribution is given by
where
and
If \({\mathbf {X}}\)\(\sim \) BEDsW\(\left( {\boldsymbol{\Omega }}\right) \), then the stress–strength reliability can be expressed as
The joint hazard rate function (HRF) can be written as
where \(h_{i}(x_{1},x_{2})=\frac{f_{i}(x_{1},x_{2})}{S_{i}(x_{1-1},x_{2} -1)};i=1,2\ \) and \(h_{3}(x)=\frac{f_{3}(x)}{S_{3}(x-1)}\). The scatter plot of the joint HRF of the BEDsW distribution is shown in Fig. 2.

The joint HRF of the BEDsW distribution for different values of \({\boldsymbol{\Omega }}\): a\({\boldsymbol{\Omega }}=(1.5,0.9,0.3,0.3,0.3)\), b\({\boldsymbol{\Omega }}=(1.5,0.5,0.3,0.3,0.3)\) and c\({\boldsymbol{\Omega }}=(1.3,0.5,0.7,0.7,0.7)\)
It is observed that the joint HRF of the proposed model can take various shapes depending on the model parameters which makes this model more flexible to fit different data sets.
Statistical properties
The positive quadrant dependent (PQD) and total positivity of order two (TP2) properties
Assume \({\mathbf {X}}\)\(\sim \) BEDsW\(\left( {\boldsymbol{\Omega }}\right) \), then \(X_{1}\) and \(\ X_{2}\) are PQD for some values of \(x_{1}\) and \(x_{2}\) where
Further, for every pair of increasing functions \(f_{X_{1}}(.)\) and \(f_{X_{2} }(.)\), we get \(Cov\left\{ f_{X_{1}}(X_{1}),f_{X_{2}}(X_{2})\right\} \ge 0\). Let us recall that the function \(\varUpsilon (p,q):R\times R\rightarrow R\) is said to have TP2 property if \(\varUpsilon (p,q)\) satisfies
for all \(p_{1},q_{1},p_{2},q_{2}\in R\). Assume \(x_{11},x_{21},x_{12},x_{22} \in \mathbf { {\mathbb {N}} }_{0}\) and \(x_{11}<x_{21}<x_{12}<x_{22}\) from \({\mathbf {X}}\)\(\sim \) BEDsW\(\left( {\boldsymbol{\Omega }}\right) \), then the joint SF of \({\mathbf {X}}\) satisfies the TP2 property for some values of \(x_{1}\) and \(x_{2}\) where
Similarly, when \(x_{11}=x_{21}<x_{12}<x_{22},\)\(x_{21}<x_{11}<x_{12}<x_{22}\), etc.
The joint probability generating function (PGF)
If \(\ {\mathbf {X}}\thicksim \ \)BEDsW(\({\boldsymbol{\Omega }}\)), then the joint PGF can be expressed as
where \(\left| v\right| <1.\) Hence, different moments and product moments of the BEDsW distribution can be obtained, as infinite series, using the joint PGF.
The conditional expectation (COEX) of \(X_{1}\ \)given \(X_{2}=x_{2}\)
If \(\ {\mathbf {X}}\thicksim \ \hbox {BEDsW}({\boldsymbol{\Omega }}\)), then the conditional PMF of \(\ X_{1}\mid X_{2}=x_{2},\) say \(f_{X_{1}\mid X_{2}=x_{2} }(x_{1}\mid x_{2}),\) is given by
where
and
Therefore, the COEX of \(X_{1}\mid X_{2}=x_{2},\) say \({\mathbf {E}}(X_{1}\mid X_{2}=x_{2}),\) can be expressed as
The conditional probability can be used in various areas, especially, in diagnostic reasoning and decision making. Table 2 lists the COEX for some specific parameter selections.
Maximum likelihood (ML) estimation
In this section, we use the method of the ML to estimate the unknown parameters \(\alpha ,p,\beta _{1},\beta _{2}\) and \(\beta _{3}\) of the BEDsW distribution. Suppose that, we have a sample of size n, of the form \(\left\{ (x_{11},x_{21}),(x_{12},x_{22}),\ldots ,(x_{1n},x_{2n})\right\} \) from the BEDsW distribution. We use the following notations: \(I_{1}=\{x_{1j} <x_{2j}\},\)\(I_{2}=\{x_{2j}<x_{1j}\},\)\(I_{3}=\{x_{1j}=x_{2j}=x_{j}\},\)\(I=I_{1}\cup I_{2}\cup I_{3},\)\(\left| I_{1}\right| =n_{1},\)\(\left| I_{2}\right| =n_{2},\)\(\left| I_{3}\right| =n_{3}\) and \(n=n_{1}+n_{2}+n_{3}.\) Based on the observations, the likelihood function is given by
The log-likelihood function becomes
where \(g_{1}(x;\beta )=[1-p^{(x+1)^{\alpha }}]^{\beta }-[1-p^{x^{\alpha } }]^{\beta }.\) The ML estimation of the parameters \(\alpha ,p,\beta _{1},\beta _{2}\) and \(\beta _{3}\) can be obtained by computing the first partial derivatives of (20) with respect to \(\alpha ,p,\beta _{1},\beta _{2}\) and \(\beta _{3}\), and then putting the results equal zeros. We get the likelihood equations as in the following form
and
where
The ML estimation of the parameters \(\alpha ,\)p, \(\beta _{1},\)\(\beta _{2} \) and \(\beta _{3}\) can be obtained by solving the above system of five nonlinear equations from (21) to (25). The solution of these equations is not easy to solve, so we need a numerical technique to get the ML estimators like the Newton–Raphson method.
Simulation
In this section, we estimate the bias and mean square error (MSE) for the proposed model parameters using simulations under complete sample. The population parameter is generated using software “R” package program. The sampling distributions are obtained for different sample sizes \(n=20,22,24,\ldots ,200\) from \(N=1000\) replications for different values of the model parameters. It is very useful in simulation study for EDsW distribution to know the following relation: If the continuous random variable Y has exponentiated Weibull (EW) distribution, say Y\(\sim EW(\alpha ,\lambda ,\beta ),\)\(\lambda =-\ln (p),\) then \(X=[Y]\sim EDsW(\alpha ,p,\beta ).\) So, to generate a random sample from the EDsW distribution, we first generate a random sample from a continuous EW distribution by using the inverse CDF method, and then by considering \(X=[Y], \) we find the desired random sample. The empirical results are shown in Figures 3 and 4 for BEDsW(0.4, 0.5, 0.8, 0.9, 1.3) and BEDsW(1.1, 0.2, 1.5, 1.5, 0.6), respectively.

The biases and MSEs when \({\boldsymbol{\Omega }}=(0.4,0.5,0.8,0.9,1.3)\)

The biases and MSEs when \({\boldsymbol {\Omega}} =(1.1,0.2,1.5,1.5,0.6)\)
It is clear that the bias and MSE are reduced as the sample size is increased. This shows the consistency of the estimators, and therefore, the ML method is a proper for estimating the model parameters.
Data analysis
In this section, we explain the experimental importance of the BEDsW distribution using two applications to real data sets. The tested distributions are compared using some criteria, namely, the maximized log-likelihood (\(-L\)), Akaike information criterion (AIC) (see [29]), and Hannan–Quinn information criterion (HQIC) (see [28]).
Data set I: football data
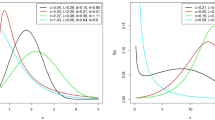
These data are reported in Lee and Cha [39], and it represents a football match score in Italian football match (Serie A) during 1996 to 2011, between ACF Fiorentina(\(X_{1}\)) and Juventus(\(X_{2}\)). We shall compare the fits of BEDsW distribution with some competitive models like BDsE, BDsR, BDsW, bivariate Poisson with minimum operator (BPo\(_{\min }\)), bivariate Poisson with three parameters (BPo-3P), independent bivariate Poisson (IBPo), bivariate discrete inverse exponential (BDsIE) and bivariate discrete inverse Rayleigh (BDsIR) distributions. Before trying to analyze the data by using the BEDsW distribution, we fit at first the marginals \(X_{1}\) and \(X_{2}\) separately and the \(\min (X_{1},X_{2})\) on these data. The ML estimation of the parameters \(\alpha ,p\) and \(\beta \) of the corresponding EDsW distribution for \(X_{1}\), \(X_{2}\) and \(\min (X_{1},X_{2})\) are (0.665, 0.059, 22.543), (1.974, 0.716, 1.673) and (0.722, 0.054, 20.223), respectively. Moreover, the \(-L\) values are 31.224, 31.735 and 28.265, respectively. Figure 5 shows the estimated PMF plots for the marginals \(X_{1} \), \(X_{2}\) and \(\min (X_{1},X_{2})\) by using data set I.

The estimated PMF for the marginals \(X_{1}\), \(X_{2}\) and \(\min (X_{1},X_{2})\) by using football data set
From Figure 5, it is clear that EDsW distribution fits the data for the marginals. Now, we fit BEDsW distribution on these data. The ML estimators (MLEs), \(-L\), AIC and HQIC values for the tested bivariate models are reported in Table 3.
From Table 3, it is clear that BEDsW distribution provides a better fit than the other tested distributions, because it has the smallest values among \(-L\), AIC and HQIC. Figure 6 shows the profiles of the L function, which indicate that the estimators are unique.

The profiles of the L function using football data set
Figure 7 shows the estimated joint PMF for BEDsW, BDsW, BDsR and BDsE distributions by using data set I.

The estimated joint PMFs using football data set
From Fig. 7, it is clear that the BEDsW model is the best among all tested models, which support the results of Table 3.
Data set II: nasal drainage severity score
These data are reported in Davis [5], and it represents the efficacy of steam inhalation in the treatment of common cold symptoms. We shall compare the fits of the BEDsW distribution with some competitive models like bivariate Poisson with four parameters (BPo-4P), IBPo, BDsE, BDsIE and BDsIR distributions. We fit at first the marginals \(X_{1}\) and \(X_{2}\) separately and the \(\min (X_{1},X_{2})\) on these data. The MLEs of the parameters \(\alpha ,p\) and \(\beta \) of the corresponding DsEW distribution for \(X_{1}\), \(X_{2}\) and \(\min (X_{1},X_{2})\) are (4.171, 0.981, 0.570), (1.857, 0.692, 1.658) and (2.906, 0.877, 0.766), respectively. Moreover, the \(-L\) values are 35.868, 37.804 and 34.047, respectively. Figure 8 shows the estimated PMF plots for the marginals \(X_{1}\), \(X_{2}\) and \(\min (X_{1},X_{2})\) by using data set II.

The estimated PMF for the marginals \(X_{1}\), \(X_{2}\) and \(\min (X_{1},X_{2})\) by using nasal drainage severity score
It is clear that the EDsW distribution fits the data for the marginals. Now, we fit BEDsW distribution on these data. The MLEs, \(-L\), AIC and HQIC values for the tested bivariate models are reported in Table 4.
From Table 4, it is clear that BEDsW distribution provides a better fit than the other tested distributions. Figure 9 shows the profiles of the L function.

The profiles of the L function using nasal drainage severity score
Figure 10 shows the estimated joint PMF for BEDsW and BDsE distributions by using these data, which support the results of Table 4.

The estimated joint PMFs using nasal drainage severity score
Conclusions
In this paper, we have introduced a new five parameters bivariate discrete distribution, in the so-called the bivariate exponentiated discrete Weibull distribution. Several of its statistical properties have been studied, and it is found that the marginals are positive quadrant dependent. Moreover, the joint reliability function satisfies the total positivity of order two for some values of \(x_{1}\) and \(x_{2}\). The maximum likelihood method has been used to estimate the model parameters. Simulation has been performed, and it is found that the maximum likelihood method works quite well in estimating the model parameters. Finally, two real data sets have been analyzed, and it is found that the proposed model provides better fit than other well-known discrete distributions like bivariate discrete Weibull, bivariate discrete Rayleigh, bivariate discrete exponential, bivariate Poisson with minimum operator, bivariate Poisson with three parameters, independent bivariate Poisson, bivariate discrete inverse exponential and bivariate discrete inverse Rayleigh distributions.
References
Alamatsaz, M.H., Dey, S., Dey, T., Harandi, S.Shams: Discrete generalized Rayleigh distribution. Pak J Stat 32(1), 1–20 (2016)
Alizadeh, M., Afify, A.Z., Eliwa, M.S., Ali, S.: The odd log-logistic Lindley-G family of distributions: properties, Bayesian and non-Bayesian estimation with applications. Comput. Stat. (2019). https://doi.org/10.1007/s00180-019-00932-9
Basu, A.P., Dhar, S.K.: Bivariate geometric distribution. J. Appl. Stat. Sci. 2, 33–34 (1995)
Bebbington, M., Lai, C.D., Zitikis, R.: A flexible Weibull extension. Reliab. Eng. Syst. Saf. 92, 719–726 (2007)
Davis, C.S.: Statistical Methods for the Analysis of Repeated Measures Data. Springer-Verlag, New York (2002)
El-Bassiouny, A.H., EL-Damcese, M., Abdelfattah, M., Eliwa, M.S.: Bivariate exponentaited generalized Weibull–Gompertz distribution. J. Appl. Probab. Stat. 11(1), 25–46 (2016)
El-Bassiouny, A.H., Tahir, M.H., Elmorshedy, M., Eliwa, M.S.: Univariate and multivariate double slash distribution: properties and application. J. Stat. Appl. Probab. 8(2), 1–14 (2019)
El-Bassiouny, A.H., El-Morshedy, M.: The univarite and multivariate generalized slash student distribution. Int. J. Math. Appl. 3((3–B)), 35–47 (2015)
El-Bassiouny, A.H., EL-Damcese, M., Abdelfattah, M., Eliwa, M.S.: Mixture of exponentiated generalized Weibull–Gompertz distribution and its applications in reliability. J. Stat. Appl. Probab. 5(3), 455–468 (2016)
El-Bassiouny, A.H., Medhat EL-Damcese, Abdelfattah Mustafa, Eliwa, M.S.: Characterization of the generalized Weibull–Gompertz distribution based on the upper record values. Int. J. Math. Appl. 3(3), 13–22 (2015)
El-Bassiouny, A.H., Medhat EL-Damcese, Abdelfattah Mustafa, Eliwa, M.S.: Exponentiated generalized Weibull–Gompertz distribution with application in survival analysis. J. Stat. Appl. Probab. 6(1), 7–16 (2017)
El-Gohary, A., EL-Bassiouny, A.H., El-Morshedy, M.: Exponentiated flexible Weibull extension distribution. Int. J. Math. Appl. 3((A )), 1–12 (2015)
El-Gohary, A., El-Bassiouny, A.H., El-Morshedy, M.: Inverse flexible Weibull extension distribution. Int. J. Comput. Appl. 115, 46–51 (2015)
El-Gohary, A., El-Bassiouny, A.H., El-Morshedy, M.: Bivariate exponentiated modified Weibull extension distribution. J. Stat. Appl. Probab. 5(1), 67–78 (2016)
Eliwa, M.S., El-Morshedy, M.: Bivariate discrete inverse Weibull distribution. (2018). arXiv:1808.07748
Eliwa, M. S., El-Morshedy, M.: Discrete flexible distribution for over-dispersed data: statistical and reliability properties with estimation approaches and applications. J. Appl. Stat. 47, (2020)
Eliwa, M.S., El-Morshedy, M.: Bivariate Gumbel-G family of distributions: statistical properties, Bayesian and non-Bayesian estimation with application. Ann. Data Sci. (2019). https://doi.org/10.1007/s40745-018-00190-4
Eliwa, M. S., El-Morshedy, M.: Bivariate odd Weibull-V family of distributions: properties, Bayesian and non-Bayesian estimation with bootstrap confidence intervals and application. J. Taibah Univ. Sci. 14, (2020)
Eliwa, M. S., El-Morshedy, M., Afify, A.Z.: The odd Chen generator of distributions: properties and estimation methods with applications in medicine and engineering. J. Natl. Sci. Found. Sri Lanka. 48, (2020)
Eliwa, M.S., El-Morshedy, M., El-Damcese, M., Alizadeh, M.: On bivariate Pareto type II distribution. J. Mod. Appl. Stat. Methods. 19(2), (2020)
Eliwa, M.S., El-Morshedy, M., Mohamed, I.: Inverse Gompertz distribution: properties and different estimation methods with application to complete and censored data. Ann. Data Sci. (2018). https://doi.org/10.1007/s40745-018-0173-0
El-Morshedy, M., Eliwa, M.S.: The odd flexible Weibull-H 402 family of distributions: properties and estimation with applications to complete and upper record data. Filomat 33(9), 2635–2652 (2019)
El-Morshedy, M., El-Bassiouny, A.H., El-Gohary, A.: Exponentiated inverse flexible Weibull extension distribution. J. Stat. Appl. Probab. 6(1), 169–183 (2017)
El-Morshedy, M., Eliwa, M.S., Nagy, H.: A new two-parameter exponentiated discrete Lindley distribution: properties, estimation and applications. J. Appl. Stat. (2019). https://doi.org/10.1080/02664763.2019.1638893
Emrah, A.: A new generalization of geometric distribution with properties and applications. Commun. Stat. Simul. Comput. (2019). https://doi.org/10.1080/03610918.2019.1639739
Farbod, D., Gasparian, K.: On the maximum likelihood estimators for some generalized Pareto-like frequency distribution. J. Iran. Stat. Soc. 12(2), 211–234 (2013)
Gomez-Deniz, E., Calderin-Ojeda, E.: The discrete Lindley distribution: properties and applications. J. Stat. Comput. Simul. 81(11), 1405–1416 (2011). https://doi.org/10.1080/00949655.2010.487825
Hannan, E.J., Quinn, B.G.: The determination of the order of an autoregression. J. R. Stat. Soc. B 41, 190–195 (1979)
Hurvich, C.M., Tsai, C.L.: A corrected Akaike information criterion for vector autoregressive model selection. J. Time Ser. Anal. 14, 271–279 (1993)
Jehhan, A., Mohamed, I., Eliwa, M.S., Al-mualim, S., Yousof, H.M.: The two-parameter odd Lindley Weibull lifetime model with properties and applications. Int. J. Stat. Probab. 7(4), 57–68 (2018)
Johnson, N.L., Kemp, A.W., Kotz, S.: Univariate Discrete Distributions. Wiley, New York (2005)
Jose, K.K., Ristic, M.M., Ancy, J.: Marshall–Olkin bivariate Weibull distributions and processes. Stat. Pap. (2009). https://doi.org/10.1007/s00362-009-0287-8
Kemp, A.W.: New discrete appell and humbert distributions with relevance to bivariate accident data. J. Multivar. Anal. 113, 2–6 (2013)
Kocherlakota, S., Kocherlakota, K.: Bivariate Discrete Distributions. Marcel dekker, New York (1992)
Krishna, H., Pundir, P.S.: Discrete Burr and discrete Pareto distributions. Stat. Methodol. 6(2), 177–188 (2009). https://doi.org/10.1016/j.stamet.2008.07.001
Kumar, C.S.: A unified approach to bivariate discrete distributions. Metrika 67, 113–123 (2008)
Kundu, D., Gupta, R.D.: Bivariate generalized exponential distribution. J. Multivar. Anal. 100(4), 581–593 (2009)
Kundu, D., Nekoukhou, V.: On bivariate discrete Weibull distribution. Commun. Stat. Theory Methods (2018). https://doi.org/10.1080/03610926.2018.1476712
Lee, H., Cha, J.H.: On two general classes of discrete bivariate distributions. Am. Stat. 69(3), 221–230 (2015)
Mohamed, I., Eliwa, M.S., El-Morshedy, M.: Bivariate exponentiated generalized linear exponential distribution: properties, inference and applications. J. Appl. Probab. Stat. 14(2), 1–23 (2019)
Mudholkar, G.S., Srivastava, D.K.: Exponentiated Weibull family for analyzing bathtub failure-rate data. IEEE Trans. Reliab. 42, 299–302 (1993)
Nakagawa, T., Osaki, S.: The discrete Weibull distribution. IEEE Trans. Reliab. 24(5), 300–301 (1975)
Nekoukhou, V., Alamatsaz, M.H., Bidram, H.: Discrete generalized exponential distribution of a second type. Statistics 47, 876–887 (2013)
Nekoukhou, V., Kundu, D.: Bivariate discrete generalized exponential distribution. Statistics 51(5), 1143–1158 (2017)
Nekoukhou, V., Bidram, H.: The exponentiated discrete Weibull distribution. SORT 39(1), 127–146 (2015)
Rasool, R., Akbar, A.J.: On bivariate exponentiated extended Weibull family of distributions. Ciênciae natura, santa maria 38(2), 564–576 (2016)
Roy, D.: The discrete normal distribution. Commun. Stat. Theory Methods 32(10), 1871–1883 (2003). https://doi.org/10.1081/sta-120023256
Roy, D.: Discrete Rayleigh distribution. IEEE Trans. Reliab. 53, 255–260 (2004)
Sarhan, A.M., Apaloo, J.: Exponentiated modified Weibull extension distribution. Reliab. Eng. Syst. Saf. 112, 137–144 (2013)
Sarhan, A., Hamilton, D.C., Smith, B., Kundu, D.: The bivariate generalized linear failure rate distribution and its multivariate extension. Comput. Stat. Data Anal. 55(1), 644–654 (2011)
Stein, W.E., Dattero, R.: A new discrete Weibull distribution. IEEE Trans. Reliab. 33(2), 196–197 (1984)
Wagner, B.S., Artur, J.L.: Bivariate Kumaraswamy distribution: properties and a new method to generate bivariate classes. Statistics 47(6), 1321–1342 (2013)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
El- Morshedy, M., Eliwa, M.S., El-Gohary, A. et al. Bivariate exponentiated discrete Weibull distribution: statistical properties, estimation, simulation and applications. Math Sci 14, 29–42 (2020). https://doi.org/10.1007/s40096-019-00313-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40096-019-00313-9