
Abstract
We consider Fredholm integral equation of the first kind with noisy data and use Landweber-type iterative methods as an iterative solver. We compare regularization property of Tikhonov, truncated singular value decomposition and the iterative methods. Furthermore, we present a necessary and sufficient condition for the convergence analysis of the iterative method. The performance of the iterative method is shown and compared with modulus-based iterative methods for the constrained Tikhonov regularization.
Similar content being viewed by others
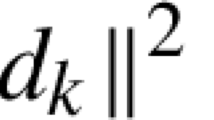

Avoid common mistakes on your manuscript.
Introduction
Integral equations are widely involved in a variety of applications such as potential theory, optimal control, electromagnetic scattering antenna synthesis problem, physics and other applications, see [10, 27, 29, 40, 42]. In many applications in science and engineering such as medical imaging (CT scanning, electrocardiography, etc.), geophysical prospecting (searching for oil, land-mines, etc.), image deblurring (astronomy, crime scene investigations, etc.), spectroscopy, signal processing and image processing [24, 30], the relation between the quantity observed and the quantity to be measured can be formulated as a Fredholm integral equation of the first kind.
Therefore, it should be no surprise that the study of such problems and their solving methods are very substantial literature on applications. We consider the following Fredholm integral equation of the first kind as the generic form
where the functions g (the right-hand side function) and K (the kernel) are known. Here, the function x is the unknown function which must be determined.
In the early twentieth century, Hadamard [19] described the conditions for well-posed problems, that is to say, a problem is well-posed when it satisfied the following three conditions:
-
1.
The problem has a solution.
-
2.
The solution is unique.
-
3.
The solution depends continuously on the data(stability).
If at least one of the above conditions is violated in a problem, it is referred to as the ill-posed problem. The violations of conditions 1 and 2 can often be remedied with a slight re-formulation. The violation of stability is much harder than two other conditions because it implies that a small perturbation in the data leads to a large perturbation in the approximate solution [24].
Fredholm integral equations of the first kind are intrinsically ill-posed [11, 24, 28]; that is to say, the solution is extremely sensitive to small perturbations. After discretizing Eq. (1), the most of classical numerical methods, such as LU, QR and Cholesky factorizations, are failed to compute an appropriate solution for (1), see [20, 23]. These difficulties are inseparably connected with the compactness of the operator which is associated with the kernel K [28]. Several numerical methods have been employed to approximate the solution of (1), see [1, 4, 8, 12, 17, 25, 31, 35, 39].
In many practical applications, which are modeled as (1), the kernel K is given exactly by the underlying mathematical model and the function g typically consists of measured quantities, i.e., g is only known with a certain accuracy and only in a finite set of points [20]. Due to the ill-posedness of the problem, numerical solutions are very sensitive to perturbations and noises. Usually, these kinds of perturbations come from observation, measuring and rounding errors. Therefore, we are interested to consider Eq. (1) with noisy function g. Solving an ill-posed problem with noisy data should be executed by regularization methods [16]. In this paper, we present a self-regularized iterative method and explain that why our method can play as a regularization method.
After discretizing (1), we have the following minimizing problem
where \(A \in {\mathbb {R}}^{n\times n}.\) Note that we consider the minimization problem (2) which is more general than solving linear system \(Ax=b.\) It should be mentioned that a linear system of equations may be consistent with noise-free data whereas using noisy data, which we are interested in, may change it to an inconsistent system. Therefore, considering the minimization problem is more general than the liner system. Eq. (2) is a discrete ill-posed problem in general if the singular values of the matrix A decay gradually to zero and the matrix A be an ill-conditioned (i.e., the condition number of A is large) [23]. Our linear system of equations here is a discrete ill-posed problem. Therefore, the condition number of the matrix A is so large and it increases with the size of the matrix A. As a result, rounding errors prevent the computation of a meaningful solution [20].
When solving a set of linear ill-posed equations by an iterative method typically, the iterates first improve, while at later stages the influence of the noise becomes more and more noticeable. This phenomenon is called semi-convergence by Natterer [32, p. 89].
In this paper, we consider the following Landweber-type method
where \(\lambda _k\) is a relaxation parameter and M is a given symmetric positive definite matrix. Several well-known methods can be written in the form of (3) for appropriate choices of the matrix M. With M equal to the identity, we get the classical Landweber method [29]. Cimmino’s method [9] is obtained with \(M = \frac{1}{m}{\mathrm {diag}}(1/\Vert a_i \Vert ^2)\) where \(a_i\) denotes the ith row of A. The CAV method [7] uses \(M={\mathrm {diag}}(1/\sum _{j=1}^n N_j a_{ij}^2)\) where \(N_j\) is the number of nonzeroes in the jth column of A.
Convergence result and recent extensions, including block versions of (3), can be found in [6, 26]. Their condition is necessary for convergence analysis. Here, we present a necessary and sufficient condition for the convergence analysis of (3) and explain that the iterative method can be a regularization method where the relaxation parameter is constant.
We use the following notation. Let R(A) and \(\Vert x\Vert =\sqrt{x^\mathrm{T} x}\) denote the range of a matrix A and the definition of 2-norm, respectviely. The Moore-Penrose pseudoinverse of A is denoted by \(A^{\dagger }.\) Further for a symmetric positive definite (SPD) matrix M, \(\Vert x\Vert _M=\sqrt{\langle Mx,x\rangle }\) and \(M^{1/2}\) denote a weighted Euclidean norm and the square root of M, respectively. The identity matrix of a proper size is denoted by I.
The paper is organized as follows. In "Popular direct regularization methods" section, we recall direct regularization methods as Tikhonov and truncated singular value decomposition. Furthermore, we remind their filter factors showing how they regularize the ill-posed problems. "Iterative regularization methods" section deals with Landweber-type iterative method and the modulus-based iterative methods. The "Landweber-type methods" section discusses the self-regularization property of Landweber-type iterative method and presents the filter factor of Landweber-type iterative method. Furthermore, we give a necessary and sufficient condition for its convergence analysis. We also reintroduce different strategies of relaxation parameters, which are studied in [13, 14, 34]. We next consider the projected version of Landweber-type iterative method.
We describe the modulus-based iterative methods for constrained Tikhonov regularization [1] in "Modulus-based iterative methods for constrained Tikhonov regularization" section. In the last section, i.e., "Numerical results" section, we present the outcome of numerical experiments using examples taken from [23] for the Fredholm integral equation of the first kind.
Popular direct regularization methods
In this section, we briefly present and discuss the necessity of regularizing discrete ill-posed problems and recall the most popular regularization methods as the truncated SVD (TSVD) and Tikhonov regularization method.
One of the most popular methods for solving (1) or its discrete version, i.e. (2), is the Tikhonov regularization method. The classical way to filter out the high-frequency components associated with the small singular values is to apply regularization to the problem. The regularization method was established by Tikhonov [38, 39] and Phillips [36]. In its original framework, regularization is applied directly to the integral equation (1), see, e.g., [41]. In this presentation, we will restrict our discussion to regularization of (2).
The Tikhonov regularization method replaces (2) by the following minimization problem
where \(\mu\) is referred to the regularization parameter and the matrix L is appropriately chosen. Typically, L is an identity matrix or a discrete approximation of a derivative operator [20]. The normal equations regarding the minimization problem (4) is
Thus, the solution of (4) can be written as
Let \(L=I\) and consider the following additive noise model
where \(\bar{b}\) is the noise-free right-hand side and \(\delta b\) is the noise-component. Using the singular value decomposition (SVD) of the matrix \(A=U \varSigma V^\mathrm{T}\), one easily gets
where \(\{\sigma _i\}_{i=1}^p\) are the singular values of A and \({\hbox {rank}}(A)=p.\) Also \(\{u_i\}_{i=1}^p\) and \(\{v_i\}_{i=1}^p\) denote columns of U and V, respectively. The functions
are called filter factors, see, e.g., [5] and [22, p. 138]. We will discuss the filter factors (8) later.
Similar expression as (7) can be obtained by the truncated SVD (TSVD), see [18, 22] for more information on TSVD. Indeed, the truncated approximate solution of (2) can be written as
for \(k=1,\ldots ,p.\) The filter factors of TSVD method are
Since the singular values of A, i.e., \(\sigma _i,\) decay gradually to zero (the nature of discrete ill-posed problems), the quantity inside the summation (9) goes to infinity. Therefore, we should remark here that using more singular values in (9) leads to get larger norm values for TSVD solution. For that reason, the filter factors of TSVD try to cut off the "unwanted" singular values. But, it is known that \(x_{\mathrm{tsvd}}^{p}=A^{\dag }b\) is the solution of (2) with the minimum norm. After computing the singular values in TSVD method, one may cut off them at some point to get a proper solution for the problem. This contradictory remark shows a proper motivation that the regularization methods must be used for ill-posed problems. However, finding a proper singular value and neglecting the rest of them is a problem which is called finding regularization parameter. We would like to obtain a method which recognizes somehow automatically and cheaply the regularization parameter. The Tikhonov filter factors (8) have somehow such ability. As it is seen, when singular values decay to zero, the filter factors (8) have the same behavior of singular values. But the most important difficulty in Tikhonov regularization parameter is its long computational time (as TSVD) because of SVD’s computational complexity.
Iterative regularization methods
In this section, we recall Landweber-type iterative method and discuss its self-regularization property. Furthermore, we give a necessary and sufficient condition for its convergence analysis. Furthermore, we describe the modulus-based iterative methods for constrained Tikhonov regularization [1].
Landweber-type methods
In order to better understand the mechanism of semi-convergence, we take a closer look at the errors in the regularized solution using the Landweber-type method (3) with a constant relaxation parameter, i.e., \(\lambda _k=\lambda .\)
Let \(x^{*}=\arg \min \Vert A x-\bar{b}\Vert _M\) be the unique weighted least squares solution of minimal 2-norm.
Theorem 1
Let\(\lambda _k=\lambda\)for\(k\ge 0.\)Then, the iterates of (3) converge to a solution (call\(\widehat{x}\)) of (2) if and only if\(0< \lambda < 2/\sigma _1^2\)with\(\sigma _1\)the largest singular value of\(M^{\frac{1}{2}}A.\)If in addition\(x^0\in R(A^{\mathrm{T}})\)then\(\widehat{x}\)is the unique solution with minimal Euclidean norm.
Proof
We assume, without loss of generality, that \({x}^0=0.\) Let
Then using (3), we get
Suppose that
is the singular value decomposition (SVD) of \(M^{\frac{1}{2}}A,\) where \(M^{\frac{1}{2}}\) is the square root of M. Therefore, we can present the matrix B as follows:
where
and rank\((A)=p.\)
Using (10), we get
where
It follows,
Using the SVD one easily finds
where
Also note that if \(|1-\lambda {\sigma }_{i}^2|<1\) for \(i=1,2,\dots ,p\), that is, \(0<\lambda <{\frac{2}{{\sigma }_{1}^2}}\), we get
which completes the proof. \(\square\)
The functions
in (12) are the filter factors of the Landweber-type method (3).
On the other hand, the obtained coefficients [see (12)]
are closed to one where the singular values are small enough. Since the mentioned filter factors try to cancel small singular values in the denominator of (12), we call the iterative method (3) by self-regularized iterative method.
We now recall different strategies of relaxation parameters which are studied in [13, 14, 34]. We first propose the following rules, see [14], for picking relaxation parameters in (3):
where \(\zeta _k\) is the unique root in (0, 1) of
and \(\sigma _1\) is the largest singular value of \(M^{1/2}A.\) As mentioned in [14, Table 3.1], the roots \(\{\zeta _k\}_{k=2}^{\infty }\) can easily be precalculated. The aim of introducing above relaxation parameters was to control (postpone) the semi-convergence phenomenon.
To reduce error in the iterative method (3), the following relaxation parameters are studied by [34]:
where \(r^k=b-Ax^k\) and \(u^k=A^\mathrm{T}Mr^k\) for \(k=0,1,\dots .\)
The use of a priori information (like nonnegativity) when solving an inverse problem is a well-known technique to improve the quality of the reconstruction. An advantage with projection type algorithms is the possibility to adapt them to handle convex constraints. Then usually, the iterates can be shown to converge toward a member of the underlying convex feasibility problem [3]. We next consider the projected version of (3) as follows:
where \(P_{\varOmega }\) denotes the orthogonal projection onto a closed convex set \(\varOmega \in {\mathbb {R}}^n.\) The convergence analysis of (20) is studied by many researchers, see, e.g., [34, section 6] and [15, Theorem 1] for some special cases of (20) and [33, section 4.1] for the general case. As a result of those papers, the iterative method (20) with the relaxation parameters (16–19) converges to a point in \(\varOmega \cap S\) where S is the set of solutions of (2).
Modulus-based iterative methods for constrained Tikhonov regularization
The method is based on modulus-based iterative methods and its application to Tikhonov regularization with nonnegativity constraint. Indeed, modulus-based iterative methods try to find a nonnegative solution for (2). Therefore, using those iterative methods involve the nonnegativity constraints which is useful to improve the quality of the reconstruction.
The idea behind the method is to reduce the computational effort for large-scale problems by using a Krylov subspace method with a fixed Krylov subspace. We briefly explain it, see [1] for more details. In the method, a matrix \(A\in {\mathbb {R}}^{m\times n}\) is reduced to a small bidiagonal matrix by Golub–Kahan bidiagonalization algorithm [18]. Let \(l \ll \min \lbrace m,n \rbrace .\) Applying l steps of Golub–Kahan bidiagonalization on the matrix A with initial vector \(u_{1}=\frac{b}{\Vert b\Vert }\) gives the following decomposition
where U and V have orthonormal columns. Here, B is a lower bidiagonal matrix with positive diagonal and subdiagonal entries. Substituting \(x=V_{l}y\) into (5) (where \(L=I_{n}\) and \(y \in {\mathbb {R}}^{l}\)) and using (21) give equation
where \(T_{l,\mu }=B_{l+1,l}^\mathrm{T}B_{l+1,l}+\mu ^2 I_{l}\) and \(\hat{b}=e_{1}\Vert A^\mathrm{T}b\Vert .\) Here, the vector \(e_{j}\) denotes the j-th column of an identity matrix with appropriate order. If we denote the largest singular value of the matrix \(B_{l+1,l}\) with \(\sigma _{\max },\) the largest eigenvalue of \(T_{l,\mu }\) is \(\sigma _{\max } ^{2}+\mu ^2\) and the smallest eigenvalue is close to \(\mu ^2\) (indeed bounded below by \(\mu ^2\)). This yields the following algorithm and we call it modulus-based iterative (MBI) method
Algorithm 1
MBI method
-
1.
\(y_{0}=V_{l}^{T}x_{0}\)
-
2.
\({\tilde{y}}_{0}=V_{l}^{T}|V_{l}y_{0}|\)
-
3.
For \(k=1,2,3,\dots\)
-
4.
\(\quad y_{k+1}=(\alpha I_{l}+T_{l,\mu })^{-1} \left( (\alpha I_{l}-T_{l,\mu }){\tilde{y}}_{k}+\hat{b})\right)\)
-
5.
\(\quad {\tilde{y}}_{k+1}=V_{l}^\mathrm{T}|V_{l}y_{k+1}|\)
-
6.
End For
-
7.
\(x=V_{l}{\tilde{y}}_{k+1}+|V_{l}{\tilde{y}}_{k+1}|\)
where the relaxation parameter \(\alpha\) is defined as \(\alpha =\sqrt{(\sigma _{\max } ^{2}+\mu ^2)\mu ^2}.\) To see how the regularization parameter \(\mu\) and the starting point \(x_0\) can be calculated, follow [1, Algorithm 2]. Here, the absolute function, i.e., |.|, for vectors is component wise.
Numerical results
In this section, we examine the effectiveness of the strategies (I-IV) (see "Landweber-type methods" section) for the Landweber-type method (20). We present several examples that illustrate the performance of the strategies and justify the accuracy and efficiency of algorithm (20) where \(\varOmega \in {\mathbb {R}}^n\) is the nonnegative orthant. We compare algorithm (20) (using four strategies) with MBI algorithm, i.e., [1, Algorithm 2], and the Tikhonov direct method.
All examples are obtained by discretizing the Fredholm integral equation (1). The discretized version is the discrete ill-posed problem (2). Since, the considered discrete version is a consistent linear system of equations, the minimization problem (2) is replaced by the linear system \(Ax=b.\) We consider noise-free and noisy data with different noise levels \((\frac{\Vert b-\bar{b}\Vert }{\Vert \bar{b}\Vert })\)\(0.01\%, 0.1\%, 1\%, 5\%\) and \(10\%.\) We use additive independent Gaussian noise of mean zero. The examples Phillips [36], Shaw [37], Foxgood [2] and Gravity [21] are produced by Regularization Tools [23]. In all examples of this section, we consider matrix A of dimension \(800\times 800\) and the noise-free right-hand side is calculated by Regularization Tools [23]. The matrix M in (20) is the weight matrix of CAV’s method. The initial iterate is \(x^{0}=0\) in algorithm (20) and for the MBI algorithm we follow the instruction of [1, Algorithm 2]. Furthermore, in MBI algorithm, we let \(\tau =1.01\) and \({ l }=30.\)
In order to analyze the errors, we compute the relative error The numerical examples are compared to each other by computing relative error \((\frac{\Vert x-x^k\Vert }{\Vert x\Vert })\) and elapsed CPU time in seconds. All computations were carried out running the Matlab version R2011b on a laptop computer with an Intel Core i5 and 4 GB of RAM.
We next present our four examples that are based on Fredholm integral equation, i.e., (1). We use Matlab functions of [23] to produce the matrix A, the right-hand side vector b and the vector x which is the discrete version of the solution of (1) for the following examples. In our examples, the exact solutions are nonnegative, i.e., all components of x are nonnegative.
Example 1
(Phillips test) The integral equation is discretized by Galerkin method using the MATLAB function phillips from [23]. It produces the vectors b, x and matrix A. The coefficient matrix A is symmetric and indefinite. The singular values of the matrix decay gradually to zero. The matrix is ill-conditioned, and its condition number is \(k(A)= 1.08 \times 10^{10}.\)
Example 2
(Shaw test) The discretization is carried out by a simple quadrature rule using the function shaw from [23]. It generates the matrix A and vector x. Then, the right-hand side is computed as \(b = Ax.\) The obtained symmetric indefinite matrix A has the condition number \(k(A)=2.40 \times 10^{20}.\) The singular values of A decay fairly quickly to zero.
Example 3
(Foxgood test) This equation was first used by Fox and Goodwin [2]. We use the function foxgood from [23] to determine its discrete version using simple quadrature (midpoint rule). The function foxgood generates A, b and x. This gives a symmetric indefinite matrix A. Its singular values cluster at zero and the computed condition number is \(k(A)=1.09\times 10^{20}.\)
Example 4
(Gravity test) We use the function gravity from [23] to produce the matrix A which is a symmetric Toeplitz matrix. The test has a parameter d which is the depth at which the magnetic deposit is located. The default value for the parameter, see [23], is \(d=0.25\) and we use it in our tests. However, using a larger value for d leads to the faster decay of the singular values. The Matlab function gravity generates the matrix A and vector x. Then, the right-hand side is computed as \(b = Ax.\) The condition number for this matrix is \(k(A)=1.41\times 10^{20}.\)
In our four tests, both strategies II and III give almost the same results for different noise levels. Therefore, we only show the results regarding the strategy III in all Figs. 1, 2, 3 and 4.
Furthermore, the strategies I and IV with low-level noise give almost the same results but the relative error of strategy I oscillates when a large amount of noise is involved in the data. Of course, we expect such behavior for the strategy I because its analysis is based on the consistency of the linear system which may be destroyed by noisy data. However, we only report the strategy IV in all figures.
We also use constant relaxation parameter \(\lambda =1.9\) which gives almost the same results as the strategy IV for all examples except the Foxgood test, see Fig. 3. The constant relaxation parameter for that test produces the stable results, i.e., there is no semi-convergence phenomenon, but it makes slow rate of convergence whereas the strategy IV gives stable and very fast convergence results. Also for the Gravity test with \(10\%\) noise, we get the same conclusion as we get for Foxgood test. However, we only present constant relaxation parameter \(\lambda =1.9\) for Foxgood test.
Based on our numerical results, the strategy IV gives the fastest convergence rate and the most stable results compare to different strategies of the relaxation parameter and MBI algorithm, see Figs. 1, 2, 3 and 4.
The convergence rate of MBI algorithm depends on the amount of noise. Indeed, using more noise in data gives faster convergence rate and reverse. However, in our numerical tests, using \(10\%\) noise gives the best results for the MBI algorithm and they may be comparable with the strategy IV. In Fig. 1f (Phillips test), the strategy IV has faster than MBI algorithm in few first iterations and the strategy does not show semi-convergence phenomenon but the MBI algorithm does. The Fig. 2f (Shaw test) shows that the semi-convergence phenomenon happen neither for strategy IV nor MBI algorithm. However, the strategy IV gives better results than MBI algorithm. We not only get the same conclusion as explained for Fig. 3f but also the strategy IV gives much faster convergence rate than MBI algorithm. In Fig. 4f, we have the same interpretation as Phillips test.

Relative error histories for Phillips test

Relative error histories for Shaw test

Relative error histories for Foxgood test

Relative error histories for Gravity test
All results in Tables 1, 2, 3 and 4 report the average relative errors and CPU times (in seconds) for different methods over 100 runs within 30 iterations and using \(5\%\) noise. We report the results at 30-th iteration where MBI algorithm does not show semi-convergence behavior and that iteration gives the smallest relative error for the method. Furthermore, we use the function discrep from [23], i.e. Discrepancy principle criterion, to compute Tikhonov’s regularization parameter. We also use the exact value of \(\Vert \delta b\Vert\) in the function discrep. Based on the explained results on Figs. 1, 2, 3 and 4, we only report the results of strategy IV, constant relaxation parameter \(\lambda =1.9,\) MBI algorithm and Tikhonov method with \(5\%\) noise.
The Tables 1, 2, 3 and 4 show that the most time-consuming method is Tikhonov and its relative error is larger than the cases strategy IV and the MBI algorithm. The relative error of Tikhonov method is smaller than the case \(\lambda =1.9\) (except the Shaw test, see Table 2). Furthermore, using \(\lambda =1.9\) (within 30 iterations) produces larger relative error than strategy IV and the MBI algorithm whereas it is minimum time-consuming strategy. Therefore, one may only compare two successful cases, i.e., strategy IV and the MBI algorithm. Both cases have almost the same computational times, whereas the relative error of strategy IV is smaller than the MBI algorithm.
Conclusion
We recall Landweber-type iterative method to obtain a solution for the Fredholm integral equation of the first kind with noisy data. We present the self-regularization property of the iterative method and give a necessary and sufficient condition for the convergence analysis of the iterative method with constant relaxation parameter. Our numerical results confirm that Landweber-type iterative method is able to produce accurate and stable results for the integral equation with noisy data. However, MBI algorithm shows proper results as our method, whereas the noise level is enough large.
References
Bai, Z.Z., Buccini, A., Hayami, K., Reichel, L., Yin, J.F., Zheng, N.: Modulus-based iterative methods for constrained Tikhonov regularization. J. Comput. Appl. Math. 319, 1–13 (2017)
Baker, C.T.H.: The Numerical Treatment of Integral Equations. Clarendon Press, Oxford (1977)
Bauschke, H.H., Borwein, J.M.: On projection algorithms for solving convex feasibility problems. SIAM Rev. 38(3), 367–426 (1996). https://doi.org/10.1137/S0036144593251710
Bentbib, A., El Guide, M., Jbilou, K., Reichel, L.: Golub–Kahan bidiagonalization applied to large discrete ill-posed problems. J. Comput. Appl. Math. 322, 46–56 (2017)
Björck, Å., Eldén, L.: Methods in numerical algebra for ill-posed problems. In: Proceedings of the International Symposium on Ill-posed Problems: Theory and Practice, University of Delaware (1979)
Censor, Y., Elfving, T.: Block-iterative algorithms with diagonally scaled oblique projections for the linear feasibility problem. SIAM J. Matrix Anal. Appl. 24(1), 40–58 (2002)
Censor, Y., Gordon, D., Gordon, R.: Component averaging: an efficient iterative parallel algorithm for large and sparse unstructured problems. Parallel Comput. 27(6), 777–808 (2001)
Chen, Z., Xu, Y., Yang, H.: Fast collocation methods for solving ill-posed integral equations of the first kind. Inverse Probl. 24(6), 065007 (2008)
Cimmino, G., delle Ricerche, C.N.: Calcolo approssimato per le soluzioni dei sistemi di equazioni lineari. Istituto per le applicazioni del calcolo, Rome (1938)
Coletsos, J.: A relaxation approach to optimal control of Volterra integral equations. Eur. J. Control 42, 25–31 (2018)
Delves, L.M., Mohamed, J.: Computational Methods for Integral Equations. CUP Archive, Cambridge (1988)
Dykes, L., Noschese, S., Reichel, L.: Rescaling the GSVD with application to ill-posed problems. Numer. Algorithms 68(3), 531–545 (2015)
Elfving, T., Hansen, P.C., Nikazad, T.: Semiconvergence and relaxation parameters for projected SIRT algorithms. SIAM J. Sci. Comput. 34(4), A2000–A2017 (2012)
Elfving, T., Nikazad, T., Hansen, P.C.: Semi-convergence and relaxation parameters for a class of SIRT algorithms. Electron. Trans. Numer. Anal. 37, 321–336 (2010)
Elsner, L., Koltracht, I., Neumann, M.: Convergence of sequential and asynchronous nonlinear paracontractions. Numer. Math. 62(1), 305–319 (1992)
Engl, H.W., Hanke, M., Neubauer, A.: Regularization of Inverse Problems, vol. 375. Springer, Berlin (1996)
Gerth, D., Klann, E., Ramlau, R., Reichel, L.: On fractional Tikhonov regularization. J. Inverse Ill Posed Probl. 23(6), 611–625 (2015)
Golub, G.H., Van Loan, C.F.: Matrix Computations, vol. 3. JHU Press, Baltimore (2012)
Hadamard, J.: Lectures on Cauchy’s Problem in Linear Partial Differential Equations. Yale Univ. Press, New Haven (1923)
Hansen, P.C.: Numerical tools for analysis and solution of Fredholm integral equations of the first kind. Inverse Probl. 8(6), 849–872 (1992)
Hansen, P.C.: Deconvolution and regularization with Toeplitz matrices. Numer. Algorithms 29(4), 323–378 (2002)
Hansen, P.C.: Rank-Deficient and Discrete Ill-Posed Problems: Numerical Aspects of Linear Inversion, vol. 4. SIAM, Philadelphia (2005)
Hansen, P.C.: Regularization tools version 4.0 for matlab 7.3. Numer. Algorithms 46(2), 189–194 (2007)
Hansen, P.C.: Discrete Inverse Problems: Insight and Algorithms, vol. 7. SIAM, Philadelphia (2010)
Hansen, P.C., Sekii, T., Shibahashi, H.: The modified truncated SVD method for regularization in general form. SIAM J. Sci. Stat. Comput. 13(5), 1142–1150 (1992)
Jiang, M., Wang, G.: Convergence studies on iterative algorithms for image reconstruction. IEEE Trans. Med. Imaging 22(5), 569–579 (2003)
Jiang, S., Rokhlin, V.: Second kind integral equations for the classical potential theory on open surfaces II. J. Comput. Phys. 195(1), 1–16 (2004)
Kress, R., Maz’ya, V., Kozlov, V.: Linear Integral Equations, vol. 82. Springer, Berlin (1989)
Landweber, L.: An iteration formula for Fredholm integral equations of the first kind. Am. J, Math. 73(3), 615–624 (1951)
Lu, Y., Shen, L., Xu, Y.: Integral equation models for image restoration: high accuracy methods and fast algorithms. Inverse Probl. 26(4), 045006 (2010)
Mach, T., Reichel, L., Van Barel, M., Vandebril, R.: Adaptive cross approximation for ill-posed problems. J. Comput. Appl. Math. 303, 206–217 (2016)
Natterer, F.: The Mathematics of Computerized Tomography, vol. 32. SIAM, Philadelphia (1986)
Nikazad, T., Abbasi, M.: A unified treatment of some perturbed fixed point iterative methods with an infinite pool of operators. Inverse Probl. 33(4), 044002 (2017)
Nikazad, T., Abbasi, M., Elfving, T.: Error minimizing relaxation strategies in Landweber and Kaczmarz type iterations. J. Inverse Ill Posed Probl. 25(1), 35–56 (2017)
Onunwor, E., Reichel, L.: On the computation of a truncated SVD of a large linear discrete ill-posed problem. Numer. Algorithms 75(2), 359–380 (2017)
Phillips, D.L.: A technique for the numerical solution of certain integral equations of the first kind. J. ACM (JACM) 9(1), 84–97 (1962)
Shaw Jr., C.: Improvement of the resolution of an instrument by numerical solution of an integral equation. J. Math. Anal. Appl. 37(1), 83–112 (1972)
Tikhonov, A.: On the solution of incorrectly posed problem and the method of regularization. Sov. Math. 4, 1035–1038 (1963)
Tikhonov, A.N.: Regularization of incorrectly posed problems. Soviet Math. Doklady 4, 1624–1627 (1963)
Wazwaz, A.M.: Linear and Nonlinear Integral Equations, vol. 639. Springer, Berlin (2011)
Wazwaz, A.M.: The regularization method for Fredholm integral equations of the first kind. Comput. Math. Appl. 61(10), 2981–2986 (2011)
Zhao, R., Huang, Z., Huanga, W.F., Hu, J., Wu, X.: Multiple-traces surface integral equations for electromagnetic scattering from complex microstrip structures. IEEE Trans. Antennas Propag. 66, 3804–3809 (2018)
Acknowledgements
The authors are grateful to the reviewer for his (or her) valuable comments and suggestions that improved the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Mesgarani, H., Azari, Y. Numerical investigation of Fredholm integral equation of the first kind with noisy data. Math Sci 13, 267–278 (2019). https://doi.org/10.1007/s40096-019-00296-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40096-019-00296-7