
Abstract
Code-based cryptography is one of the main propositions for the post-quantum cryptographic context, and several protocols of this kind have been submitted on the NIST platform. Among them, BIKE and HQC are part of the five alternate candidates selected in the third round of the NIST standardization process in the KEM category. These two schemes make use of multiplication of large polynomials over binary rings, and due to the polynomial size (from 10,000 to 60,000 bits), this operation is one of the costliest during key generation, encapsulation, or decapsulation mechanisms. In BIKE-2, there is also a polynomial inversion which is time-consuming and this problem has been addressed in Drucker (Fast polynomial inversion for post quantum QC-MDPC cryptography, 2020). In this work, we revisit the different existing constant-time algorithms for arbitrary polynomial multiplication. We explore the different Karatsuba and Toom–Cook constructions in order to determine the best combinations for each polynomial degree range, in the context of AVX2 and AVX512 instruction sets. This leads to different kernels and constructions in each case. In particular, in the context of AVX512, we use the VPCLMULQDQ instruction, which is a vectorized binary polynomial multiplication instruction. This instruction deals with up to four polynomial (of degree up to 63) multiplications, that is four operand pairs of 64-bit words with 128-bit word storing each result, the four results being stored in one single 512-bit word. This allows to divide by roughly 3 the retired instruction number of the operation in comparison with the AVX2 instruction set implementations, while the speedup is up to 39% in terms of processor clock cycles. These results are different than the ones estimated in Drucker (Fast multiplication of binary polynomials with the forthcoming vectorized vpclmulqdq instruction, 2018). To illustrate the benefit of the new VPCLMULQDQ instruction, we used the HQC code to evaluate our approaches. When implemented in the HQC protocol, for the security levels 128, 192, and 256, our approaches provide up to 12% speedup, for key pair generation.

Similar content being viewed by others

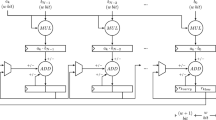

Notes
We do not present in detail our variant karat_mult_1_512 based on the mul128x4, however, we refer the reader to their paper [1] for its presentation.
References
Drucker, N., Gueron, S. and Kostic, D.: Fast polynomial inversion for post quantum QC-MDPC cryptography. In: S Dolev, V Kolesnikov, S Lodha, G Weiss (eds.), Cyber security cryptography and machine learning - fourth international symposium, CSCML 2020, Be’er Sheva, Israel, July 2-3, 2020, Proceedings. volume 12161 of Lecture notes in computer science. pp 110–127. Springer, 2020. https://doi.org/10.1007/978-3-030-49785-9_8
Drucker, N., Gueron, S., Krasnov, V.: Fast multiplication of binary polynomials with the forthcoming vectorized vpclmulqdq instruction. In 2018 IEEE 25th Symposium on Computer Arithmetic (ARITH). pp 115–119, (2018). https://doi.org/10.1109/ARITH.2018.8464777
NIST. Post-Quantum Cryptography, (2019). https://csrc.nist.gov/projects/post-quantum-cryptography, last accessed 15 Sep 2021
McEliece, R.J.: A public-key cryptosystem based on algebraic coding theory. Deep Space Network Prog. Rep. 44, 114–116 (1978)
Berlekamp, E.R., McEliece, R.J., van Tilborg, H.C.A.: On the inherent intractability of certain coding problems (corresp). IEEE Trans. Inf. Theory. 24(3), 384–386 (1978). https://doi.org/10.1109/TIT.1978.1055873
Baldi, M., Barenghi, A., Chiaraluce, F., Pelosi, G., Santini, P.: A finite regime analysis of information set decoding algorithms. Algorithms 12(10), 209 (2019). https://doi.org/10.3390/a12100209
Gaborit, P.: Shorter keys for code-based cryptography. In Proceedings of workshop on codes and cryptography. pp 81–90 (2005). WCC 2005
MacWilliams, F.J., Sloane, N.J.A.: The Theory of Error Correcting Codes. Number ptie. 2 in Mathematical Library. North-Holland Publishing Company, (1977)
Gaborit, P, Girault, M.: Lightweight code-based identification and signature. In IEEE international symposium on information theory, ISIT 2007, Nice, France, June 24–29, 2007. pp 191–195. (2007). https://doi.org/10.1109/ISIT.2007.4557225
Aragon, N., Barreto, P., Bettaieb, S., Bidoux, L., Blazy, O., Deneuville, J.C., Gaborit, P., Gueron, S., Guneysu, T., Melchor, C.A. and Misoczki, R.: Bit flipping key encapsulation (BIKE). In NIST post-quantum cryptography submissions, round 2. NIST, 2019. https://bikesuite.org/, last accessed 15 Sep 2021
Carlos, A-M., Nicolas, A., Slim, B., Loïc, B., Olivier, B., Jean-Christophe, D., Philippe, G., Edoardo, P., Gilles, Z.: Hamming quasi-cyclic (HQC). In NIST Post-Quantum Cryptography submissions, round 2. NIST, (2019). http://pqc-hqc.org/implementation.html, last accessed 15 Sep 2021
Guimarães, A., Aranha, D., Borin, E.: Secure and efficient software implementation of qc-mdpc code-based cryptography. In XX Simpósio em Sistemas Computacionais de Alto Desempenho. pp 116–117, 11 (2019). https://doi.org/10.5753/wscad_estendido.2019.8710
Alagic, G., Alagic, G., Alperin-Sheriff, J., Apon, D., Cooper, D., Dang, Q., Liu, Y.K., Miller, C., Moody, D., Peralta, R., Perlner, R., Robinson, A., Smith-Tone, D.: Status report on the first round of the NIST PQC standardization process (2019). https://nvlpubs.nist.gov/nistpubs/ir/2019/NIST.IR.8240.pdf, last accessed 16 Sep 2021
Karatsuba, A., Ofman, Yu.: Multiplication of many-digital numbers by automatic computers. In Doklady Akad. Nauk SSSR 145, 293–294 (1962)
Bodrato, M.: Towards optimal Toom-Cook multiplication for univariate and multivariate polynomials in characteristic 2 and 0. In: Carlet, C., Sunar, B. (eds.) WAIFI‘07 Proceedings. Springer (2007)
Schönhage, A., Strassen, V.: Schnelle multiplikation großer zahlen. Computing 7(3–4), 281–292 (1971). https://doi.org/10.1007/BF02242355
Fürer, M.: Faster integer multiplication. In Proceedings of the 39th annual ACM symposium on theory of computing, San Diego, California, USA, June 11-13, 2007. pages 57–66, (2007) https://doi.org/10.1145/1250790.1250800
Harvey, D., van der Hoeven, J., Lecerf, G.: Faster polynomial multiplication over finite fields. J. ACM 63(6), 1–23 (2017). https://doi.org/10.1145/3005344
Harvey, D., van der Hoeven, J.: Faster polynomial multiplication over finite fields using cyclotomic coefficient rings. J. Complexity (2019). https://doi.org/10.1016/j.jco.2019.03.004
Ntl: a library for doing number theory. last accessed 21 Sep (2021). https://libntl.org
Inria. gf2x library. In gf2x Library, (2019). https://www.gforge.inria.fr/frs/?group_id=1874, last accessed 15 Sep 2021
Carlos, A.-M., Nicolas, A., Slim, B., Loïc, B., Olivier, B., Jean-Christophe, D., Philippe, G., Edoardo, Persichetti., Jean-Marc, Robert., Pascal, Véron., Gilles, Zémor.: Hamming quasi-cyclic (HQC). In NIST Post-Quantum Cryptography submissions, round 3. NIST, October (2020). http://pqc-hqc.org/, last accessed 15 Sep 2021
Nègre, C., Robert, J-M.: Impact of optimized field operations AB, AC and AB + CD in scalar multiplication over binary elliptic curve. In Progress in Cryptology - AFRICACRYPT, 6th International Conference on Cryptology in Africa, June 22-24., LNCS, pages 279–296, 2013. https://doi.org/10.1007/978-3-642-38553-7_16
Weimerskirch, A., Paar, C.: Generalizations of the Karatsuba algorithm for efficient implementations. Cryptology ePrint Archive, Report 2006/224, (2006). https://eprint.iacr.org/2006/224, last accessed 15 Sep 2021
Intel. IntelR 64 and ia-32 architectures software developer manuals. Intel website, (2021). https://software.intel.com/content/www/us/en/develop/articles/intel-sdm.html, last accessed 15 Sep 2021
Zimmermann, P.: Irred-ntl patch. In ntl Library (2008). https://members.loria.fr/PZimmermann/irred/
Quercia, M., Zimmermann, P.: Irred-ntl patch. In Irred-ntl source code, (2003). https://members.loria.fr/PZimmermann/irred/
Brent, R.P., Gaudry, P., Thomé, E., Zimmermann, P.: Faster multiplication in gf(2)[x]. In Algorithmic number theory, 8th international symposium, ANTS-VIII, Banff, Canada, May 17-22, 2008, Proceedings. pages 153–166, (2008). https://doi.org/10.1007/978-3-540-79456-1_10
Funding
This work has been partially funded by TPM Metropol (AAP2020-IPOCRAS project).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Karatsuba algorithms
We reproduce here the Karatsuba algorithms:
-
Algorithm 1 reproduces the recursive multiplication with a two halves split, from [23];
-
Algorithm 2 shows the three parts split corresponding approach;
-
Algorithm 3 shows the five parts split corresponding approach;



Appendix B Source code for 256-bit operand size multiplication
1.1 B.1 Source code for the \(4\times 4\) 256 bit multiplication of this work based on the schoolbook approach
We present here our schoolbook AVX512 implementation of the 256 bit operand size multiplication, with comments and explanations.

These lines define the constant indexes for the _mm512_permutexvar_epi64 and _mm512_permutex2var_epi64 instructions. These instructions are explained on the fly.

The _mm512_broadcast_i64x4(*A256) instruction duplicates the 256 bits of *A256 in the A512 register, the same for the *B256.
The _mm512_permutexvar_epi64 (idx_b, tmp) spreads the 64 bit words following the index idx_b. This allows to shuffle the 64 bit words of *B256 in the B512 register, in order to prepare the elementary multiplications.
We thus have:
A512 \( \leftarrow \{a_3,a_2,a_1,a_0,a_3,a_2,a_1,a_0\}\)
tmp \( \leftarrow \{b_3,b_2,b_1,b_0,b_3,b_2,b_1,b_0\}\)
B512 \( \leftarrow \{b_1,b_0,b_3,b_2,b_3,b_2,b_1,b_0\}\)

We now compute all the elementary 64 bit multiplications, providing all the 128 bit results as follows:
R0 \( \leftarrow \{a_{2}\times b_{0},a_{0}\times b_{2},a_{2}\times b_{2},a_{0}\times b_{0}\}\)
R1 \( \leftarrow \{a_{2}\times b_{1},a_{0}\times b_{3},a_{2}\times b_{3},a_{0}\times b_{1}\}\)
R2 \( \leftarrow \{a_{3}\times b_{0},a_{1}\times b_{2},a_{3}\times b_{2},a_{1}\times b_{0}\}\)
R3 \( \leftarrow \{\underbrace{a_{3}\times b_{1}}_{128 bits},\underbrace{a_{1}\times b_{3}}_{128 bits},\underbrace{a_{3}\times b_{3}}_{128 bits},\underbrace{a_{1}\times b_{1}}_{128 bits}\}\)

The tmp register now contains all the \(a_i\times b_i\) elementary products coming form the R0_512 and R3_512 registers:
tmp \( \leftarrow \{a_{3}\times b_{3},a_{2}\times b_{2},a_{1}\times b_{1},a_{0}\times b_{0}\}\)
It remains now to compute the middle part of the result to be added to tmp, in order to get the final result.

The middle register now contains the addition (XOR) between R1_512 and R2_512, reordered with the _mm512_permutexvar_epi64:
middle \( \leftarrow \{a_{0} b_{3}\oplus a_{3} b_{0},a_{2} b_{3}\oplus a_{3} b_{2},\)
\(~~~~~a_{1} b_{2}\oplus a_{2} b_{1},a_{1} b_{0}\oplus a_{0} b_{1}\}\)

The tmp register is added (XOR) with the elementary products of the middle register, and nearly contains the result, except some of the products of the middle part:


The remaining products of the middle part to be added with tmp are put in place in the middle register:
middle \( \leftarrow \{\underbrace{0x0UL}_{128 bits},a_{1} b_{3}\oplus a_{3} b_{1},a_{0} b_{2}\oplus a_{2} b_{0},\underbrace{0x0UL}_{128 bits}\}\)

Out gets the final reconstruction :

Appendix C Source code for 512-bit operand size multiplications
We detail now the source code of the karat_mult_1_512_SB procedure.
First, the preamble declares the constant indexes for the _mm512_permutex2var_epi64 and _mm512_permutexvar_epi64 instructions.

Next, we compute the registers al, ah, bl, bh, sa and sb so that they contain the split parts for the 256 bit operands, and the corresponding sums for the Karatsuba 256 bit middle multiplication.

We compute now the three 256 bit multiplications in order to prepare the 512 bit registers cl, ch and cm containing their results.

These lines computes four 128 bit operand size multiplications in parallel, using a schoolbook approach. This procedure acts like the mul128x4 procedure of Drucker et al. [1], which is based on the Karatsuba algorithmFootnote 2.
The 512 bit registers l and h now contains the four elementary 256 bit results.

This is the schoolbook reconstruction for the first 256 bit multiplication. The register cl now contains the 512 bit result of al\(\times \)bl.
We now compute the same the two remaining 256 bit operand size multiplications:

The register ch now contains the 512 bit result of ah\(\times \)bh.
The result cm is directly added (XOR) to the other results cl and ch in order to prepare the final Karatsuba reconstruction, and cm now contains the 512 bit result of (sa\(\times \)sa)\(\oplus \)cl\(\oplus \)ch:

This ends the computation, the final lines stores the result: the 512 least significant bits in the memory place C[0], and the most significant bits in C[1].
Appendix D: Toom–Cook multiplication general algorithm
Several approaches to multiply two arbitrary polynomials over \({\mathbb {F}}_2[X]\) of degree at most \(N-1\), using the Toom–Cook algorithm, have been presented by Bodrato in [15], Brent et al. in [28], and software implementations have been provided by Quercia and Zimmermann, in the context of the ntl and the gf2x library, see [26] and [27]. Let A and B be two binary polynomials of degree at most \(N-1\). These polynomials are packed into an array of 64-bit words, whose size is \(\lceil N/64\rceil \). Let \(t = 3n\) with n a value ensuring \(t \geqslant \lceil N/64\rceil \). Now, A and B are considered as polynomials of degree at most \(64\cdot t-1\). We discuss the value of n in Sect. 3.2.
A and B are split in three parts. One wants now to evaluate the result \(C = A\cdot B\) with
(of maximum degree \(64t-1\), and \(a_i, b_i\) of maximum degree \(64n-1\)) and,
of maximum degree \( 6\cdot 64n-2\).
The “word-aligned” version evaluates the polynomial for the values 0, 1, \(x = X^w\), \(x+1 = X^w +1\), \(\infty \), w being the word size, typically 64 in modern processors. Furthermore, on Intel processors, one can set \(w=256\) to take advantage of the vectorized instruction set AVX-AVX2, and even \(w=512\) (AVX512 extension), at the cost of a slight operand size reduction.
For the evaluation phase, one has:
The implementation of this phase is straightforward, providing that the multiplication \(a_i\cdot b_i\) is either another Toom–Cook or Karatsuba multiplication. Notice that the multiplications by x or \(x^2\) are virtually free word shifts.
For the interpolation phase, one has the following equations:
The matrix associated with this system of equations is given by:
and one has:
Finally, the interpolation phase gives :
Appendix E: experimentation procedure
Measurements were performed on a Dell Inspiron laptop with an Intel Tiger Lake processor.

The compiler is gcc version 10.2.0, the compiler options are as follows:
-O3 -g -march=tigerlake -funroll-all-loops -lm -lgf2x.
We kept the -funroll-all-loops option though it does not provide significant improvements. We follow the same kind of test procedure that the one described in [2] :
-
The Turbo-Boost® is deactivated during the tests;
-
1000 runs are executed in order to “heat” the cache memory;
-
One generates 50 random data sets, and for each data set the minimum of the execution clock cycle numbers over a batch of 1000 runs is recorded;
-
The performance is the average of all these minimums;
-
This procedure is run on console mode, to avoid system perturbations, and obtain the most accurate cycle counts.
The clock cycle counter is rdtsc and the instruction counter is rdpmc with the corresponding selection. The results for the smallest sizes (i.e., 256-bit and 512-bit operand sizes) are not very reliable since rdtsc and rdpmc are not serializing instructions (see [25]). For such sort of small functions, we wanted to avoid the insertion of a costly serializing instruction as cpuid, while the instruction count and the clock cycle number may be less than 20. We chose not to present them. The first size considered is 1024 bits, i.e., binary polynomial of degree at most 1023 operands.
Appendix F: instruction count and performances
1.1 F.1 Instruction count comparison
In Table 13, we provide the comparison between the instruction count of our schoolbook and Karatsuba versions. Moreover, we compare this two approaches with the current state-of-the-art AVX2 reference. Such an AVX2 implementation can be found in the source code of the optimized version of HQC [22]. It uses the AVX2 instruction set and the non vectorized PCLMULQDQ instruction. Finally, we also put in Table 13 the instruction number of the assembly source code for the same multiplication presented by Drucker et al. in [2]. Here are some comments on these results:
-
The best version is our implementation of the schoolbook approach, dividing by more than 2 the instruction number in comparison with the state-of-the-art AVX2 implementation.
-
Our Karatsuba approach presents more instructions but only 3 VPCLMULQDQ instead of 4 for the schoolbook version. Thus, the performance comparison may vary according to the latency and throughput of the instructions.
-
Drucker et al.’s version has 8 VPCLMULQDQ instructions and a larger instruction number (31, instead of 19 for our implementation of the schoolbook approach). This is due to the fact that they only use 2 elementary 64-bit multiplications per VPCLMULQDQ instruction (ymmm version of the instruction), while we use 4. This also implies more XOR’s in their case.
1.2 F.2 Performances for the 256-bit level kernels
We present in Table 14 the performances of the AVX512 Karatsuba multiplications using the 256-bit kernels presented above. We also include the results of the multiplications using our 8x8 SB-512 kernel.
Rights and permissions
About this article

Cite this article
Robert, JM., Véron, P. Faster multiplication over \({\mathbb {F}}_2[X]\) using AVX512 instruction set and VPCLMULQDQ instruction. J Cryptogr Eng 13, 37–55 (2023). https://doi.org/10.1007/s13389-021-00278-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13389-021-00278-3