
Abstract
The increasing dissemination of JSON as exchange and storage format through its popularity in business and analytical applications requires efficient storage and processing of JSON documents. Consequently, this led to the development of specialized JSON document stores and the extension of existing relational stores, while no JSON-specific benchmarks were available to assess these systems.
In this work, we assess currently available JSON document store benchmarks and select the recently developed DeepBench benchmark to experimentally study important dimensions like analytical querying capabilities, object nesting and array unnesting. To make the computational complexity of array unnesting more tractable, we introduce an improvement that we evaluate within a commercial system as part of the common, performance-oriented development process in practice.
We conclude our evaluation of well-known document stores with DeepBench and give new insights into strengths and potential weaknesses of those systems that were not found by existing, non-JSON benchmarking practices. In particular the algebraic optimization of JSON query processing is still limited despite prior work on hierarchical data models in the XML context.










Similar content being viewed by others


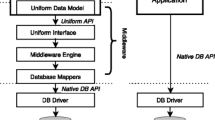
Change history
07 December 2022
An Erratum to this paper has been published: https://doi.org/10.1007/s13222-022-00434-x
Notes
TPC, visited 9/22: http://tpc.org/.
Performance is given in relative terms due to [19].
No order by index, visited 9/22: https://bit.ly/3va3oyB.
Workload Isolation, visited 9/22: https://bit.ly/3t5JEt7.
References
Abiteboul S, Arenas M, Barceló P, Bienvenu M, Calvanese D, David C, Hull R, Hüllermeier E, Kimelfeld B, Libkin L, Martens W, Milo T, Murlak F, Neven F, Ortiz M, Schwentick T, Stoyanovich J, Su J, Suciu D, Vianu V, Yi K (2018) Research directions for principles of data management (dagstuhl perspectives workshop 16151). Dagstuhl Manif 7(1):1–29
Belloni S, Ritter D, Schröder M, Rörup N (2022) Deepbench: Benchmarking JSON document stores. In: DBTest@SIGMOD. ACM, pp 1–9 https://doi.org/10.1145/3531348.3532176
Bray T et al (2014) The javascript object notation (json) data interchange format
Chen Y, Qin X, Bian H, Chen J, Dong Z, Du X, Gao Y, Liu D, Lu J, Zhang H (2014) A study of sql-on-hadoop systems. In: BPOE. LNCS, vol 8807. Springer, pp 154–166
Codd E (1998) A relational model of data for large shared data banks. 1970. MD Comput 15(3):162–166
Cole RL, Funke F, Giakoumakis L, Guy W, Kemper A, Krompass S, Kuno HA, Nambiar RO, Neumann T, Poess M, Sattler K, Seibold M, Simon E, Waas F (2011) The mixed workload ch-benchmark. In: DBTest. ACM, p 8
Cooper BF, Silberstein A, Tam E, Ramakrishnan R, Sears R (2010) Benchmarking cloud serving systems with YCSB. In: SoCC. ACM, pp 143–154
Daly D (2021) Creating a virtuous cycle in performance testing at mongodb. In: ICPE. ACM, pp 33–41
Daly D, Brown W, Ingo H, O’Leary J, Bradford D (2020) The use of change point detection to identify software performance regressions in a continuous integration system. In: ICPE. ACM, pp 67–75
Dann J, Ritter D, Fröning H (2022) Non-relational databases on FPGAs: survey, design decisions, challenges. ACM Computing Surveys. https://doi.org/10.1145/3568990
Dann J, Wagner R, Ritter D, Faerber C, Fröning H (2022) Pipejson: Parsing JSON at line speed on fpgas. In: DaMoN. ACM, pp 3:1–3:7
Durner D, Leis V, Neumann T (2021) JSON tiles: Fast analytics on semi-structured data. In: SIGMOD. ACM, pp 445–458
Erling O, Averbuch A, Larriba-Pey JL, Chafi H, Gubichev A, Prat-Pérez A, Pham M, Boncz PA (2015) The LDBC social network benchmark: Interactive workload. In: SIGMOD. ACM, pp 619–630
Galvizo G, Carey MJ (2022) On multi-valued indexing in asterixdb. In: DOLAP. CEUR workshop proceedings, vol 3130. CEUR-WS.org, pp 11–20
Ingo H, Daly D (2020) Automated system performance testing at mongodb. In: DBTest@SIGMOD, pp 3:1–3:6
Jahangiri S (2021) Wisconsin benchmark data generator: To JSON and beyond. In: SIGMOD. ACM, pp 2887–2889
Kamsky A (2019) Adapting TPC‑C benchmark to measure performance of multi-document transactions in mongodb. Proc VLDB Endow 12(12):2254–2262
May N, Helmer S, Moerkotte G (2004) Nested queries and quantifiers in an ordered context. In: Proceedings. 20th International Conference on Data Engineering. IEEE, pp 239–250
Read AG (2006) Dewitt clauses: Can we protect purchasers without hurting microsoft. Rev Litig 25:387
Ritter D, May N, Sachs K, Rinderle-Ma S (2016) Benchmarking integration pattern implementations. In: DEBS. ACM, pp 125–136
Ritter D, Dell’Aquila L, Lomakin A, Tagliaferri E (2021) Orientdb: A nosql, open source MMDMS. In: BICOD. CEUR workshop proceedings, vol 3163. CEUR-WS.org, pp 10–19
Seltenreich A, Tang B, Mullender S (2016) Sqlsmith. https://github.com/anse1/sqlsmith. Accessed: September 2022
Vogelsgesang A, Haubenschild M, Finis J, Kemper A, Leis V, Mühlbauer T, Neumann T, Then M (2018) Get real: How benchmarks fail to represent the real world. In: DBTest@SIGMOD. ACM, pp 1:1–1:6
Author information
Authors and Affiliations
Corresponding author
Additional information
The authors contributed equally to this work.
The original online version of this article was revised. The following reference was missing: Jonas Dann, Daniel Ritter, and Holger Fröning. Non-Relational Databases on FPGAs: Survey, Design Decisions, Challenges. In: ACM Computing Surveys (2022). https://doi.org/10.1145/3568990. Furthermore a text passage was missing after Example 4, starting with “The complexity of an UNNEST operation […]” until the end of Sect. 3. The section title of Sect. 4 was also missing: “4 Experiments” as well as the complete first paragraph before Subsection 4.1 “Setup”.
Rights and permissions
Springer Nature oder sein Lizenzgeber (z.B. eine Gesellschaft oder ein*e andere*r Vertragspartner*in) hält die ausschließlichen Nutzungsrechte an diesem Artikel kraft eines Verlagsvertrags mit dem/den Autor*in(nen) oder anderen Rechteinhaber*in(nen); die Selbstarchivierung der akzeptierten Manuskriptversion dieses Artikels durch Autor*in(nen) unterliegt ausschließlich den Bedingungen dieses Verlagsvertrags und dem geltenden Recht.
About this article

Cite this article
Belloni, S., Ritter, D. Benchmarking JSON Document Stores in Practice. Datenbank Spektrum 22, 217–226 (2022). https://doi.org/10.1007/s13222-022-00425-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13222-022-00425-y